LOGO Discussion Zhang Gang 2012/11/8

LOGO Discussion Zhang Gang 2012/11/8. Discussion Progress on HBase 1 Cassandra or HBase 2.
Dec 31, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

LOGO
Discussion Zhang Gang
2012/11/8

Discussion
Progress on HBase1
Cassandra or HBase2

HBase Sechma Design
HBase reference guide How to design a good HBase schema.
– row key– column family

HBase Sechma Design
row key– monotonically increasing keys or timeseries
keys may cause a pile-up on a single region.– randomize the input records to not be in
sorted order can mitigate the situation. So its best to avoid using a timestamp or a sequence as the row key.
– at present, I use the startTime(a timestamp) as the row key, in future I will explore if there has a better replacement.

HBase Sechma Design
column famliy:– I was wrong about the schema with two
column families. – HBase currently does not do well with
anything above two or three column families.– Try to make do with one column family if you
can in your schemas.– If you have thousands or even millions
column, you can consider have more than one column family. We only have 21 columns, so one is enough and the best choice.

HBase Sechma Design
Optimization(minimize row and column sizes)– in HBase, values are always as a cell value that
accompanied by its row, column name, and timestamp. So if row and column name is long, it will waste a large size.(see behind)
– column family: keep the name as short as possible.
– row key length: keep them as short as is reasonable such that they can still be useful for required data access.

Sqoop
Have successfully configured the sqoop in my PC. On farm, have a Exception--”access denied for user ‘zhang’, but it seems successfully transfer the data.
Command:– Sqoop import –connect jdbc:

Sqoop
sqoop on my PC:– test: 81,280 records, 45.1613s– test: 215,500 records, 73.2617s– test: 1,539,763 records,310s– then:35,427,339 records, 1235060s/about
3.43h– the HBase table size: about 35G, compare
mysql table(5G), the size is bigger. So design a good schema is very necessary.
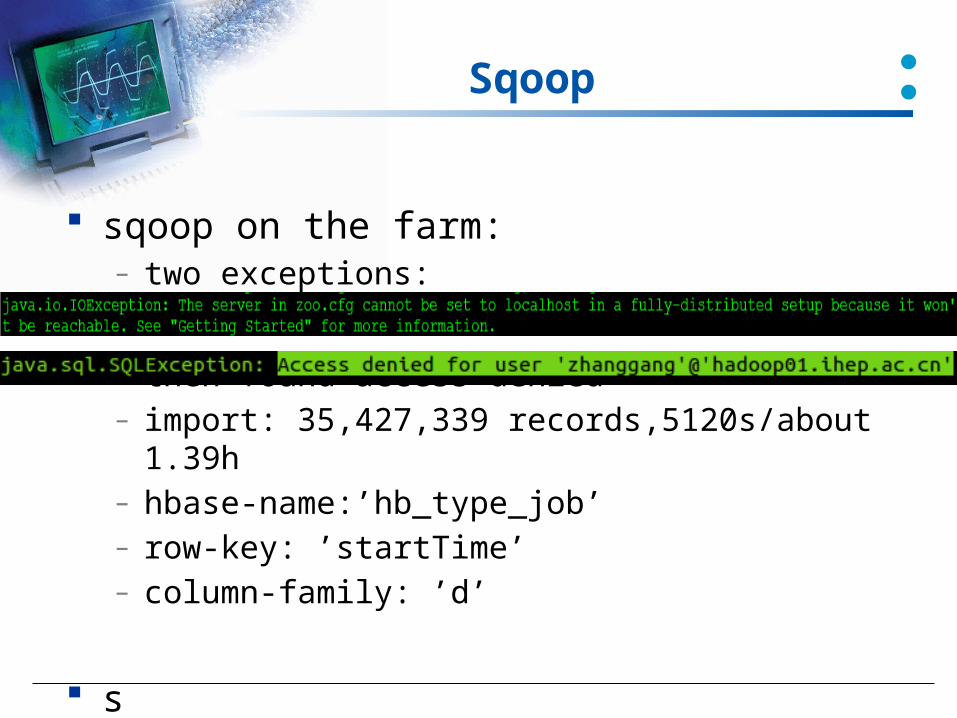
Sqoop
sqoop on the farm:– two exceptions:
– then found access denied– import: 35,427,339 records,5120s/about
1.39h– hbase-name:’hb_type_job’– row-key: ’startTime’– column-family: ’d’
s

Sqoop

Cassandra or HBase

Cassandra or HBase
review our requirement:– big data: now 5G, increases 1.5 GB per year,
not very big.– high scalability: we want the database we
choice has a better scalability.(many candidates have the feature.
– write/read: we read more than we write.(One of the reasons we choose HBase before)

Cassandra or HBase
Written in: Java Main point: Best of BigTable and Dynamo Tunable trade-offs for distribution and replication (N, R, W) Querying by column, range of keys BigTable-like features: columns, column families Has secondary indices Writes are much faster than reads (!) Map/reduce possible with Apache Hadoop All nodes are similar, as opposed to Hadoop/Hbase Gossip protocol, multi data center, no single point of failure

Cassandra or HBase
C has only one type of nodes, all nodes are similar . H consists of several different types of nodes (Muster/RegionServer).
H must deployed over the HDFS, compare this C is much more simple
Data consistency of C is tunable(N,W,R). H better support map/reduce H provides the developer with row locking facilities whereas
Cassandra can not. C just use timestamp. C has better I/O performance and better scalability but not
good at range scan. CAP:C focus on AC and H focus on CP H has an SQL compatibility interface(Hive),so H support SQL

Cassandra or HBase
The structure of C is simple ,deploy and maintenance is simple, compare C(save money, save time) ,H is much more complex deploy or maintenance.
H maybe more suitable for data warehousing, and large scale data processing and analysis. And C being more suitable for real time transaction processing and the serving of interactive data.

Cassandra or HBase
How do I incorporate my logo to a slide that will apply to all the other slides?– bb
Aa– bb
Aa– On

Cassandra or HBase
the possibility we start to explore Cassandra– more simple than Hadoop HBase.– written by Java.(same as HBase)– pycassa:It is a python client library for Apache
Cassandra.
problem: seem doesn’t have a ready-made tool for transfer the data from mysql to Cassandra.

LOGO
Your Company Slogan
Related Documents











