Fast optimal instruction scheduling for single-issue processors with arbitrary latencies Peter van Beek, University of Waterloo Kent Wilken, University of California, Davis CP 2001 · Paphos, Cyprus November 2001

Local instruction scheduling
Dec 31, 2015
Fast optimal instruction scheduling for single-issue processors with arbitrary latencies Peter van Beek, University of Waterloo Kent Wilken, University of California, Davis CP 2001 · Paphos, Cyprus November 2001. Local instruction scheduling. Schedule basic-block - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Fast optimal instruction scheduling for single-issue processors with arbitrary latencies
Peter van Beek, University of WaterlooKent Wilken, University of California, DavisCP 2001 · Paphos, CyprusNovember 2001

2
Local instruction scheduling
Schedule basic-block·straight-line sequence of code with single entry, single exit
Single-issue pipelined processors·single instruction can begin execution each clock cycle·delay or latency before result is available
Classic problem·lots of attention in literature
Remains important·single-issue RISC processors used in embedded systems
3
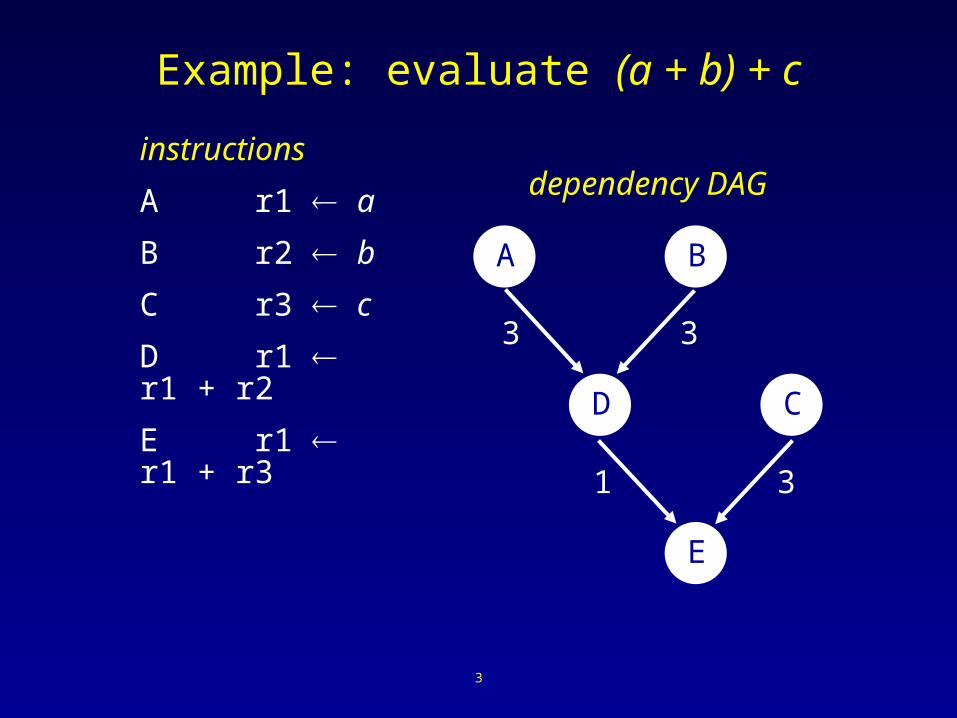
Example: evaluate (a + b) + c
instructions
A r1 a
B r2 b
C r3 c
D r1 r1 + r2
E r1 r1 + r3
3 3
31
A B
D C
E
dependency DAG

4
Example: evaluate (a + b) + c
non-optimal schedule
A r1 aB r2 b
nopnop
D r1 r1 + r2C r3 c
nopnop
E r1 r1 + r3
A B
D C
E
3 3
31
dependency DAG

5
Example: evaluate (a + b) + c
optimal schedule
A r1 aB r2 bC r3 c
nopD r1 r1 + r2E r1 r1 + r3
A B
D C
E
3 3
31
dependency DAG

6
Local instruction scheduling problem
Given a labeled dependency DAG G = (N, E) for a basic block, find a schedule S that specifies a start time S( i ) for each instruction such that
S( i ) S( j ), i, j N, i j,
and
S( j ) S( i ) + latency( i, j ), ( i, j ) E,
and
max{ S( i ) | i N } is minimized.

7
Previous work
NP-Complete if arbitrary latencies (Hennessy & Gross, 1983; Palem & Simons,
1993)
Polynomial special cases(Bernstein & Gertner, 1989; Palem & Simons,
1993; Wu et al., 2000)
Optimal algorithms·dynamic programming (e.g., Kessler, 1998)·integer linear programming (e.g., Wilken et al., 2000)·constraint programming (e.g., Ertl & Krall, 1991)

8
Minimal constraint model
variables A, B, C, D, E
domains {1, …, m}
constraints D A + 3D B + 3E C + 3E D + 1all-diff(A, B, C, D, E)
A B
D C
E
3 3
31
dependency DAG

9
Bounds consistency
[1, 3]
[4, 6]
variable ABCDE
domain [1, 6][1, 6][1, 6][1, 6][1, 6]
D A + 3constraints
D B + 3 E C + 3 E D + 1 all-diff(A, B, C, D, E)
[4, 5] [3, 3]
[6, 6]
[1, 2] [1, 2]
For each constraint C and for each variable x in C, min has a support in C and max has a support in C

10
Three improvements to minimal model
1. Initial distance constraints •defined over nodes which define regions
2. Improved distance constraints for small regions
3. Predecessor and successor constraints•defined over nodes with multiple predecessors
or multiple successors

11
Three improvements to minimal model
1. Initial distance constraints •defined over nodes which define regions
2. Improved distance constraints for small regions
3. Predecessor and successor constraints•defined over nodes with multiple predecessors
or multiple successors

12
Distance constraints: RegionsA pair of nodes i, j define a region in a DAG G if:
(i) there is more than one path from i to j, and
(ii) not all paths from i to j go through some node k distinct from i and j.

13
Distance constraints: Initial estimate
A
B
ED
H
F G
C
1
1
1
33
1
3
1
3

14
Distance constraints: Initial estimate
A
B
ED
H
F G
C
1
1
1
33
1
3
1
3j j+1j+2j+3j+4j+5
5
A F

15
Distance constraints: Initial estimate
A
B
ED
H
F G
C
1
1
1
33
1
3
1
3j j+1j+2j+3j+4j+5
E H
5

16
Distance constraints: Initial estimate
A
B
ED
H
F G
C
1
1
1
33
1
3
1
3
9
A
j j+1j+2j+3j+4j+5
j+6j+7j+8j+9
H

17
Three improvements to minimal model
1. Initial distance constraints •defined over nodes which define regions
2. Improved distance constraints for small regions
3. Predecessor and successor constraints•defined over nodes with multiple predecessors
or multiple successors
18
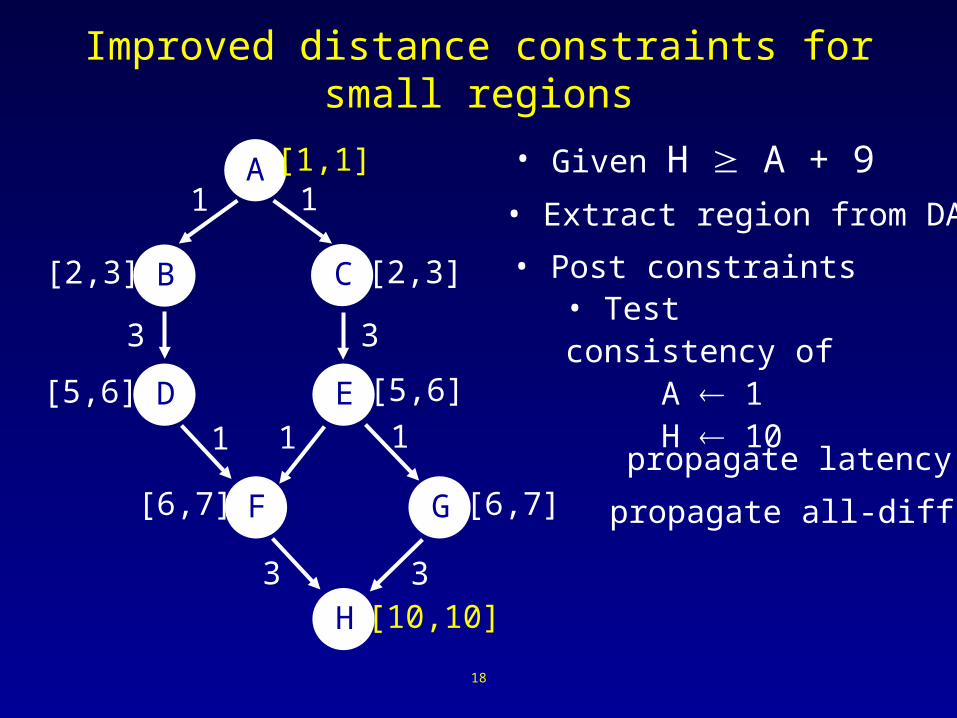
Improved distance constraints for small regions
A
B
ED
H
F G
C
1
1
1
33
1
3
1
3
[1,1]
[10,10]
[2,3]
[5,6] [5,6]
[6,7] [6,7]
[2,3]
propagate latency
propagate all-diff
• Extract region from DAG
• Post constraints
• Test consistency of A 1
H 10
• Given H A + 9

19
Improved distance constraints for small regions
• Repeat with H A + 10
• Extract region from DAG
• Post constraints
A
B
ED
H
F G
C
1
1
1
33
1
3
1
3
[1,1]
[10,10]
[2,3]
[5,6] [5,6]
[6,7] [6,7]
[2,3]
propagate latency
• Test consistency of A 1
H 10
• Given H A + 9
propagate all-diff
inconsistent

20
Three improvements to minimal model
1. Initial distance constraints •defined over nodes which define regions
2. Improved distance constraints for small regions
3. Predecessor and successor constraints•defined over nodes with multiple predecessors
or multiple successors

21
Predecessor constraints
[4, ]
3
1A
B
DC E
H
F G
3 3
22
11
1
[ ,14]
[5,9]
[8,12][9,12]
[5,9][6,9]
[5,8]
7
11

22
Predecessor constraints
D E
G
A
B
C
H
F
[4, ]
11
3
1
2
1
2[ ,14]
3 3
[5,9]
[8,12][9,12]
[5,9][6,9]
[5,8]
7
11
[9,12]
5 6 7 8 9

23
Predecessor constraints
[4, ]
3
1A
B
DC E
H
F G
3 3
22
11
1
[ ,14]
[5,9]
[8,12][9,12]
[5,9][6,9]
[5,8]
7
11
[9,12]
[12,14]
9 10 11 12

24
Successor constraints
[4, ]
3
1A
B
DC E
H
F G
3 3
22
11
1
[ ,14]
[5,9]
[8,12][9,12]
[5,9][6,9]
[5,8]
7
11
[9,12]
[12,14]
[4,6]
6 7 8 9

25
Solving instances of the model
Use constraints to establish:·lower bound on length m of optimal schedule·lower and upper bounds of variables
Backtracking search·maintains bounds consistency
Puget’s (1998) all-diff propagator and optimizationsLeconte’s (1996) optimizations
·branches on lower(x), lower(x)+1, …
If no solution found, increment m and repeat search

26
Experimental results
Embedded in Gnu Compiler Collection (GCC)
Compared with:·GCC’s critical path list scheduling·ILP scheduler (Wilken et al., 2000)
SPEC95 floating point benchmarks·compiled using highest level of optimization (-O3)
Target processor:·single-issue·latency of 3 for loads, 2 for floating point, 1 for integer ops

27
Experimental results: SPEC95 floating point benchmarks
Total basic blocks (BB)
BB passed to CSP scheduler
BB solved optimally by CSP scheduler
BB with improved schedule
Static cycles improved
Total benchmark cycles
CSP scheduling time (sec.)
Baseline compile time (sec.)
7,402
517
517
29
66
107,245
4.5
708

28
Scheduling time for CSP and ILP schedulers

29
Quantifying contributions ofthree model improvements
0 5 10 15
full constraint model
mm + improved distance
mm + initial distance
mm + pred + succ
mm = latency + alldiff
10
100
1000
Problems solved (/15)

30
Conclusions
CP approach to local instruction scheduling·single-issue processors·arbitrary latencies
Optimal and fast on very large, real problems
·experimental evaluation on SPEC95 benchmarks·20-fold improvement over previous best approach
Key was an improved constraint model

31
Good ideas not included
Cycle cutsets (e.g., Dechter, 1990)·most larger problems had small cutsets (2 to 20 nodes) that split problem into equal-sized independent subproblems
Singleton consistency (e.g., Prosser et al., 2000)·often reduced domains dramatically prior to search
Symmetry breaking constraints·many symmetric (non) schedules
Related Documents











