AOSP Mini-Conference Linaro

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

AOSP Mini-ConferenceLinaro

ENGINEERS AND DEVICES
WORKING TOGETHER
Welcome● Main difference between the miniconference and regular
Connect talks: Let’s be more interactive!
● One additional purpose of the miniconference: Bring
together the various groups inside Linaro that work on the
AOSP codebase:○ LMG -- probably the most obvious use of AOSP
○ LHG -- Android TV
○ Potentially LITE -- Brillo
○ Kernel, Toolchain, … -- need to support both regular Linux and AOSP use
○ Are there other groups (member engineering teams, maybe) here? What is your use of the AOSP code base?


ENGINEERS AND DEVICESWORKING TOGETHER
File System analysis● Filesystems investigated: ext4, btrfs, f2fs, nilfs, squashfs
● Variants: encryption enabled/disabled, compression off/zlib/lz4
● File system analysis briefing (ongoing changes)
○ https://docs.google.com/a/linaro.org/document/d/1jam-PlV9iefnOqujzYWZoY8U9d9GnmPwda3MItxsPsU/edit?usp=sharing
● Challenges○ Fixed build support for f2fs image generation (core.mk & image size alignment to 4096)
○ Fixed sparse raw image generation issue
■ Need to use for btrfs and nilfs
○ Image generation for btrfs, nilfs, squashfs etc..
○ Benchmark porting - bonnie, iozone
○ Partition overload scripts and long run impact scripts
ENGINEERS AND DEVICESWORKING TOGETHER
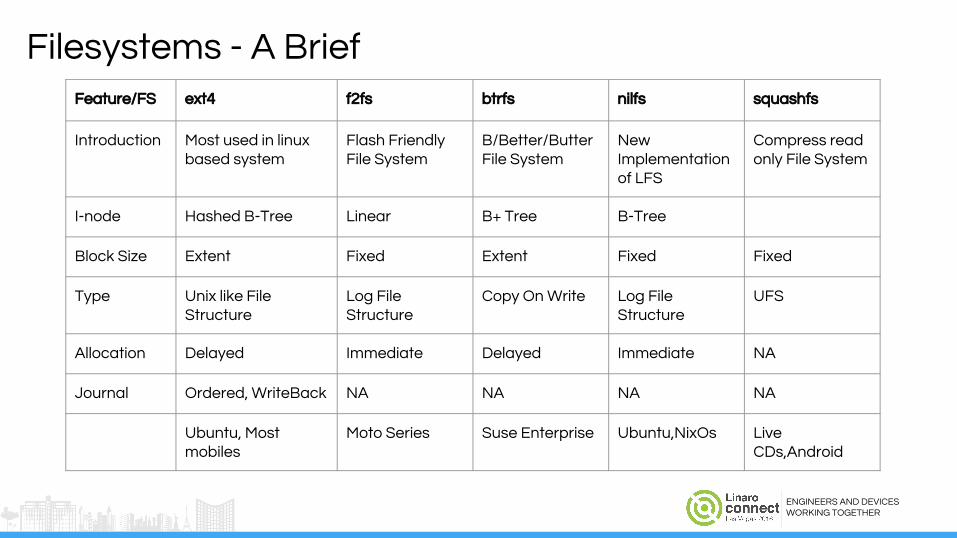
Filesystems - A Brief Feature/FS ext4 f2fs btrfs nilfs squashfs
Introduction Most used in linux based system
Flash Friendly File System
B/Better/Butter File System
New Implementation of LFS
Compress read only File System
I-node Hashed B-Tree Linear B+ Tree B-Tree
Block Size Extent Fixed Extent Fixed Fixed
Type Unix like File Structure
Log File Structure
Copy On Write Log File Structure
UFS
Allocation Delayed Immediate Delayed Immediate NA
Journal Ordered, WriteBack NA NA NA NA
Ubuntu, Most mobiles
Moto Series Suse Enterprise Ubuntu,NixOs Live CDs,Android

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - A Traditional Layer
WebKit
Memory Management
Logical File System(ext4, f2fs, btrfs etc..)
Basic File System
Device Driver 1 Device Driver 2 Device Driver n
Storage 1 Storage 2 Storage n
Application
OS
- file access- dir operations- file indexing and management- security operations
- data operation on physical device- buffering if required- no management
Video/ImageSqlite
ENGINEERS AND DEVICESWORKING TOGETHER
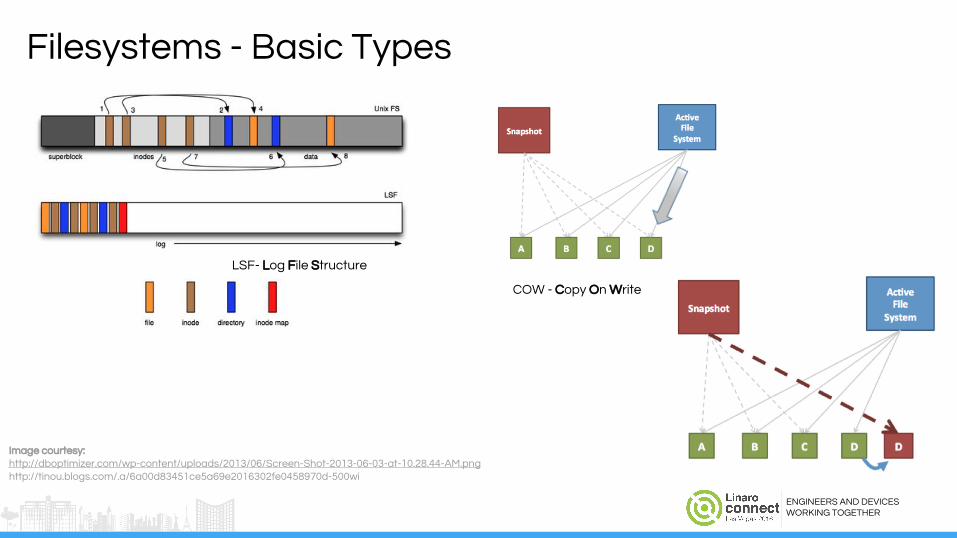
Filesystems - Basic Types
Image courtesy: http://dboptimizer.com/wp-content/uploads/2013/06/Screen-Shot-2013-06-03-at-10.28.44-AM.pnghttp://tinou.blogs.com/.a/6a00d83451ce5a69e2016302fe0458970d-500wi
COW - Copy On Write
LSF- Log File Structure

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - Test Environment● Hikey - 96Board
○ 1GB RAM
○ Cortex-A53 Octa Core
○ eMMC
■ Popular on embedded Device
■ Cheap & Flexible
■ Fast read & random seek
■ Domains - navigation, eReaders, smartphones, industrial loggers, entertainment devices etc..
● AOSP + Linaro PatchSet (branch : r55, kernel 4.4)
● F2FS, Ext4, Squashfs, btrfs, nilfs
● Benchmarks○ Vellamo, RL bench, androbench
○ Bonnie (ported for Android)
○ Iozone (ported for Android)
○ Overload and long run test - in progress!!
http://www.96boards.org/product/hikey/

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - Challenges
● Fixed build support for f2fs image generation (core.mk & image size alignment
to 4096)
● Fixed sparse raw image generation issue
● Need to use for btrfs and nilfs
● Image generation for btrfs, nilfs, squashfs etc. (raw -> format -> sparse)
● Benchmark porting - bonnie, iozone
● Partition overload scripts and long run impact scripts

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - Results• Given ranking based on performance for each benchmark and test
– Average rank for iozone test (span over various record length)
• Few more points to consider
– Performance impact as filesystem ages
– CPU utilization
• O_SYNC (-+r option iozone) : requires that any write operations block until all data and all metadata have been written to persistent storage. This ensure file integrity (rather than data integrity with O_DSYNC flag)
ENGINEERS AND DEVICESWORKING TOGETHER
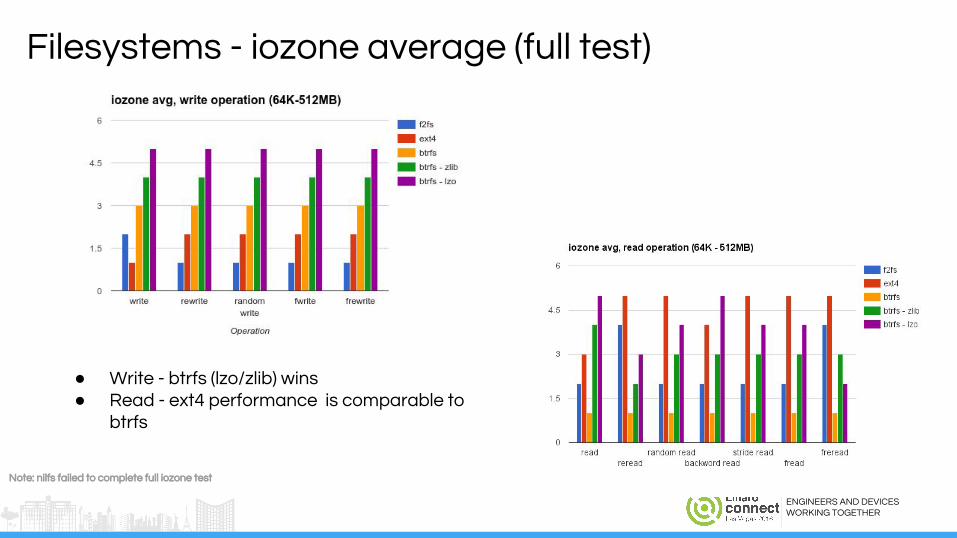
Filesystems - iozone average (full test)
● Write - btrfs (lzo/zlib) wins● Read - ext4 performance is comparable to
btrfs
Note: nilfs failed to complete full iozone test
ENGINEERS AND DEVICESWORKING TOGETHER
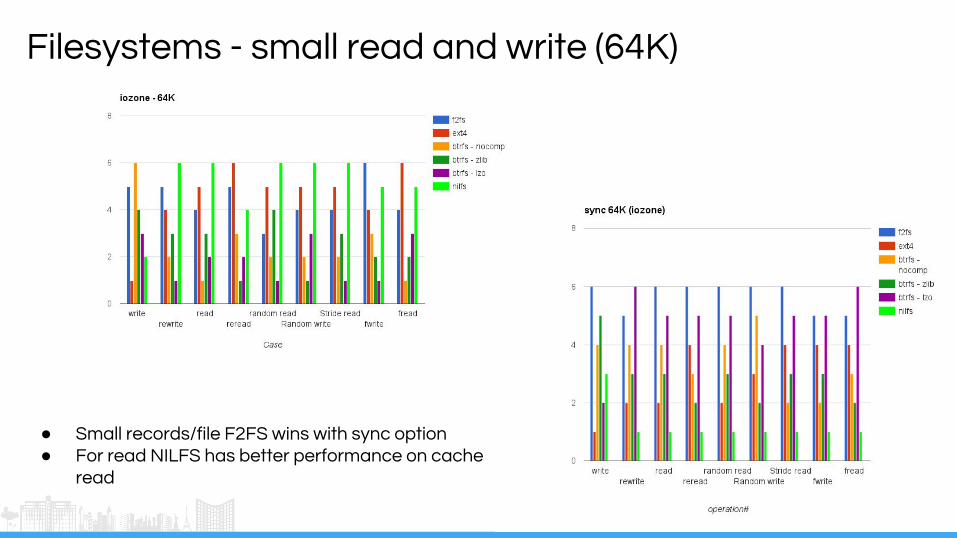
Filesystems - small read and write (64K)
● Small records/file F2FS wins with sync option● For read NILFS has better performance on cache
read
ENGINEERS AND DEVICESWORKING TOGETHER
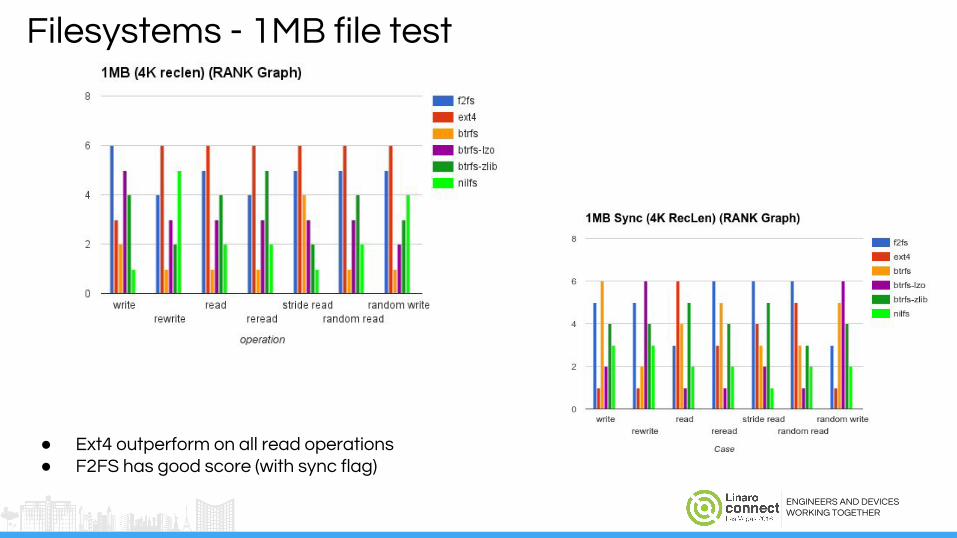
Filesystems - 1MB file test
● Ext4 outperform on all read operations● F2FS has good score (with sync flag)

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - 512MB, 4MB
● Write - btrfs (lZO), with sync flag ZLIB wins the race - not sure why?
● 4MB file read EXT4

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - bonnie results
Low the better
● Btrfs (lzo, zlib) gives good number but.. ○ At the cost of CPU eating.. ○ No of kworker threads are more. Coming up next
● F2FS/Ext4 has fair amount of CPU usage on read/write● F2FS outperform on char operation - do we have usecase ?
ENGINEERS AND DEVICESWORKING TOGETHER
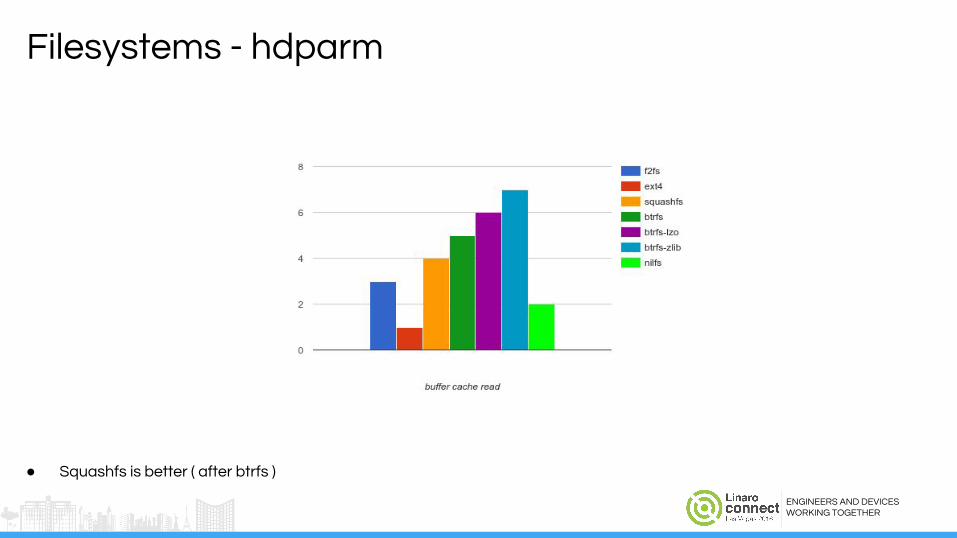
Filesystems - hdparm
● Squashfs is better ( after btrfs )
ENGINEERS AND DEVICESWORKING TOGETHER
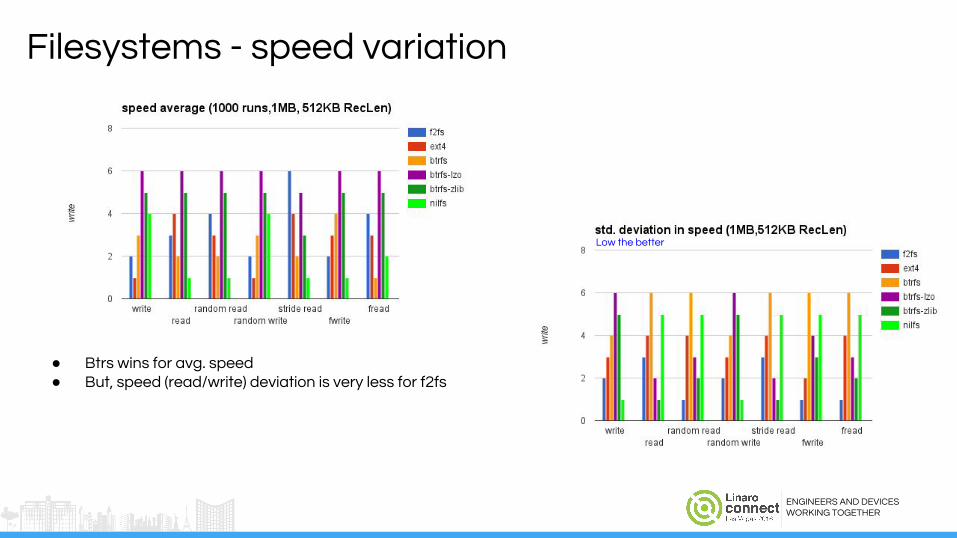
Filesystems - speed variation
● Btrs wins for avg. speed● But, speed (read/write) deviation is very less for f2fs
Low the better

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - disk access
● Disk reads are more for f2fs ( use of less buffered i/o)● Nilfs disk read are less● More writes for btrfs ( might be due background write
activities, for snapshot handling)● High disk utilization in case of nilfs ● NilFS if we do not run gc - 1000 runs, system went to
out of disk space

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - btrfs low lights
Though BTRFS has good performance
• High CPU Utilization: More kernel threads
• For small data (<1MB), btrfs under perform over f2fs and ext4. Not recommended where small i/o transaction with sync is expected. E.g. frequent calls to DB entries.
• Btrfs does not force all dirty data to disk on every fsync or O_SYNC operation ( risk on power/crash recovery)
• Yet to test effect on long run test ??

ENGINEERS AND DEVICESWORKING TOGETHER
File System analysis - Summary● All relative rank graphs is available at
○ https://docs.google.com/a/linaro.org/spreadsheets/d/1ctknBBVWUjrIZwS8OQcb5L8gCdCLuzktJgx-K_CMgt0/edit?usp=sharing
● F2FS/Ext4 Wins for○ Small File Access (4K-1MB) + DB Access with disk data integrity
○ Potential use case: Industrial monitoring system, Consumer Phone, Health monitoring system
● NilFS outperforms for SQLite operations
○ Only cache here is, metadata/data gets updated later once get written to log file ( kind of extended version of fdatasync over fsync)
○ Can be useful for power backed system and continuous log recording of small data (upto 4K) but with good amount of storage
○ It quickly fill up the space if GC is not called in between. On 5GB space, it just went out of space for 1000 runs of iozone test. Do not recommended for “Embedded System”
● SquashFS : Good buffered I/O read○ Can be used for read only partitions ( system libraries and ro database)

ENGINEERS AND DEVICESWORKING TOGETHER
File System analysis - Summary● BTRFS : Large file + large RAM
○ LZO - Outperforms for block write/read operations ( > 4MB)○ Potential use case:
■ In flight entertainment system ( mostly for movies/songs/images etc..)■ Portable streaming & recording devices ( should be power backed up)
○ Low lights:■ High cpu utilization ( more no# of threads)■ Not recommended where small i/o transaction with sync is expected■ Risk on power failure recovery (Not high, but sometimes corrupt itsself)
● Hybrid use of different file systems on multiple partitions can improve overall
performance e.g.○ large read/write (movies, extra download) on BTRFS partition ○ All small read/write (docs, images) on f2fs/ext4 partition○ All database access insert/update/delete on f2fs/nilfs partition
● Note: Yet to perform impact on file system as it ages

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - Todo List
● Perform long run test (3-4 days, with various operations) and measure the impact
● Partition overload testing - impact on low disk availability
● Encryption impact
● Overhead of overlayfs etc. if we need to add drivers, HALs etc. for a specific piece of hardware to /system when otherwise using a common /system with HAL consolidation
● Any other ?

ENGINEERS AND DEVICESWORKING TOGETHER
Filesystems - Some points of discussion
• Any other filesystems (out-of-tree, perhaps) we should look into?
• Impact of storage technology (devices might start using NVMe)
• Best way to measure filesystem longevity



ENGINEERS AND DEVICESWORKING TOGETHER
HAL Consolidation - one build, many devices● Goal is one Android build/filesystem per cpu architecture while maintaining
configurability for device specific builds: http://tinyurl.com/zscbbrx
● A directory per feature for features more than just a config variable
● KConfig based configuration for features
● Supporting DB410c, HiKey, Nexus 7, QEMU, RaspberryPi 3
● Tablet/phone or TV targets
● Next platforms or targets to add?
● Possible next config features:○ Anything the next device needs
○ Any feature Linaro is working on
○ Custom compiler and compiler flags
○ Kernel build integration
○ malloc selection
○ f2fs filesystem

ENGINEERS AND DEVICESWORKING TOGETHER
HAL Consolidation - Graphics (Done)● CI job for Mesa Android builds
● GBM based gralloc implementation - GBM map/unmap support
● Mali (HiKey flavor) support in build
● YUV planar support○ GBM allocation and EGL import
○ CSC conversion in GPU shader for gallium - Thanks Rob Clark
● Initial vc4 support - still some issues
● Supporting running Android under Xen and KVM on arm64
● Various driver and build fixes

ENGINEERS AND DEVICESWORKING TOGETHER
HAL Consolidation - Graphics (ToDo)● drm_hwcomposer and HWC2
○ WIP drm_composer HWC2 support
from Google: https://chromium-review.googlesource.com/#/c/385505
■ HWC2 necessary for upstream explicit
sync support
■ Being worked on by Collabra
○ Overlay and YUV plane support
● Mesa
○ DRM Explicit fence and
EGL_ANDROID_native_fence_sync support
○ software rendering support
●
● gbm_gralloc
○ Support scanout buffer alloc from KMS node
○ Gralloc 1.0 support
○ miniGBM support
● Video playback w/ V4L2 h/w codec
○ Not many h/w choices with mainline (or mainline ABI) support
○ Needs an OpenMax to V4L2 layer
○ Probably some buffer allocation issues and more YUV formats
● Mali (blob) and Mesa co-existence -
do we care?

ENGINEERS AND DEVICESWORKING TOGETHER
HAL Consolidation - WiFi/BT● Integrated “generic” and QCom WiFi into build
○ Investigate moving QCom WiFi specifics into kernel
○ Needs more testing with different devices (e.g. USB WiFi)
○ How to handle firmware? Include linux-firmware?
● UART attached device kernel support (https://lwn.net/Articles/700489/)○ Treat UART attached devices the same as any other bus (USB, PCI, SDIO, SPI, etc.)
○ Moves the userspace device management (firmware load, serial config, PM, etc.) to kernel
○ Move serio framework out of drivers/input/
○ Extend serio from character at a time to buffer at a time API
○ Make tty_port usable for in-kernel drivers (i.e. serio host driver)
○ Help needed to test devices

ENGINEERS AND DEVICESWORKING TOGETHER
New developments with AOSP and the kernel● AOSP EAS (Energy Aware Scheduler) Integration
● Sync API Changes in 4.6+
● Arm64 KASLR and hardened user copy backport from upstream


ENGINEERS AND DEVICESWORKING TOGETHER
EAS: A common topic at ConnectLAS16-TR04: Using tracing to tune and optimize EAS
LAS16-410: Window Based Load Tracking (WALT) versus PELT utilization
LAS16-307: Benchmarking Schedutil in Android
LAS16-105: Walkthrough of the EAS kernel adaptation to the Android Common Kernel
BKK16-317: How to generate power models for EAS and IPA (x2)
BKK16-311: EAS core – upstreaming strategy
BKK16-208: EAS
SFO15-411: Energy Aware Scheduling: Power vs. Performance policy (x2)
SFO15-302: EAS Policy
LCU14-507: Chromebook2 EAS Enablement
LCU14-410: How to build an Energy Model for your SoC
LCU14-406: A QuIC Take on Energy-Aware Scheduling
LCU14-402: Energy Aware Scheduling: Kernel summit update
LCA14-109: Path to Energy Efficient Scheduler
LCU13 Power-efficient scheduling, and the latest news from the kernel summit
LCE13: Why all this sudden attention on the Linux Scheduler?
http://connect.linaro.org/resource/lcu13/lcu13-power-efficient-scheduling-latest-news-kernel-summit/

We’ve heard quite a bit about EAS
Now, how does one use it with Android?

ENGINEERS AND DEVICES
WORKING TOGETHER
Kernel side
● Need the EAS patchset○ Currently v5.2○ Already in common/android-3.18 and
common/android-4.4
● Includes:○ EAS core○ Schedfreq (cpufreq gov)○ Schedtune (boosting mechanism)○ WALT (PELT load-tracking replacement)
● Need energy model for board○ Not going to cover this

ENGINEERS AND DEVICES
WORKING TOGETHER
Kernel Config
CONFIG_CPU_FREQ_DEFAULT_GOV_SCHED=y
CONFIG_CPU_FREQ_GOV_SCHED=y
CONFIG_CGROUP_SCHEDTUNE=y
CONFIG_SCHED_TUNE=y
CONFIG_SCHED_WALT=y
CONFIG_WQ_POWER_EFFICIENT_DEFAULT=y
CONFIG_DEFAULT_USE_ENERGY_AWARE=y

ENGINEERS AND DEVICES
WORKING TOGETHER
AOSP Integration Components
● Basic concepts
● Three components:○ ActivityManager & Schedpolicy
○ Init setup○ powerHAL

ENGINEERS AND DEVICES
WORKING TOGETHER
Conceptual Android task typesTOP_APP
FOREGROUND
BACKGROUND
SYSTEM
AUDIO_APP
AUDIO_SYS

ENGINEERS AND DEVICES
WORKING TOGETHER
Activity Manager & Schedpolicy
● Activity manager○ Tracks foreground and background tasks
○ Adjusts things like timerslack
● Schedpolicy○ Handles moving tasks between cgroups,
lower-level interfaces

ENGINEERS AND DEVICES
WORKING TOGETHER
Multiple approaches usedBase scheduler behavior
Cpusets
Cpuctl
Schedtune boosting
Interactive touch-boosting

ENGINEERS AND DEVICES
WORKING TOGETHER
Device BoardConfig.mkENABLE_CPUSETS := true
ENABLE_SCHEDBOOST := true
ENABLE_SCHED_BOOST := false
(Deprecated foreground boosting for big.LITTLE
HMP scheduler)

ENGINEERS AND DEVICES
WORKING TOGETHER
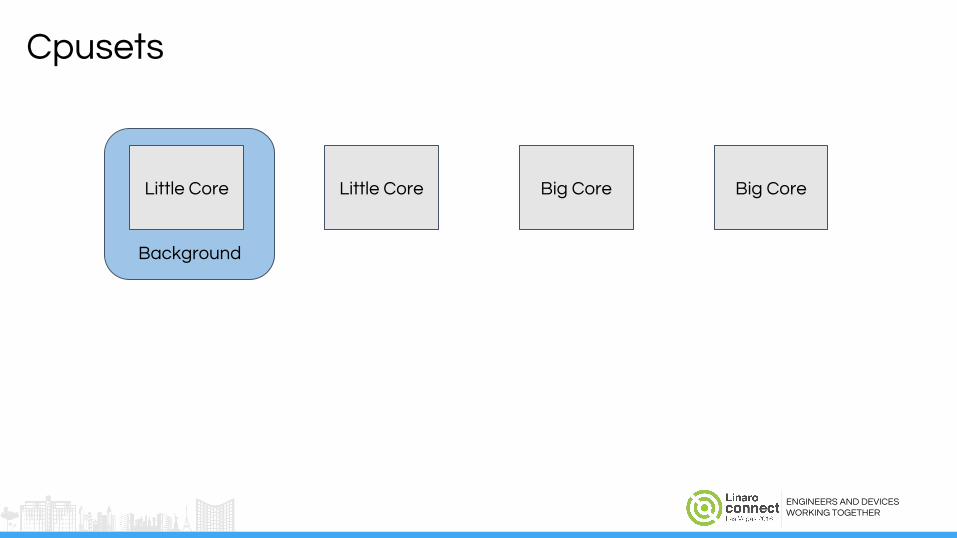
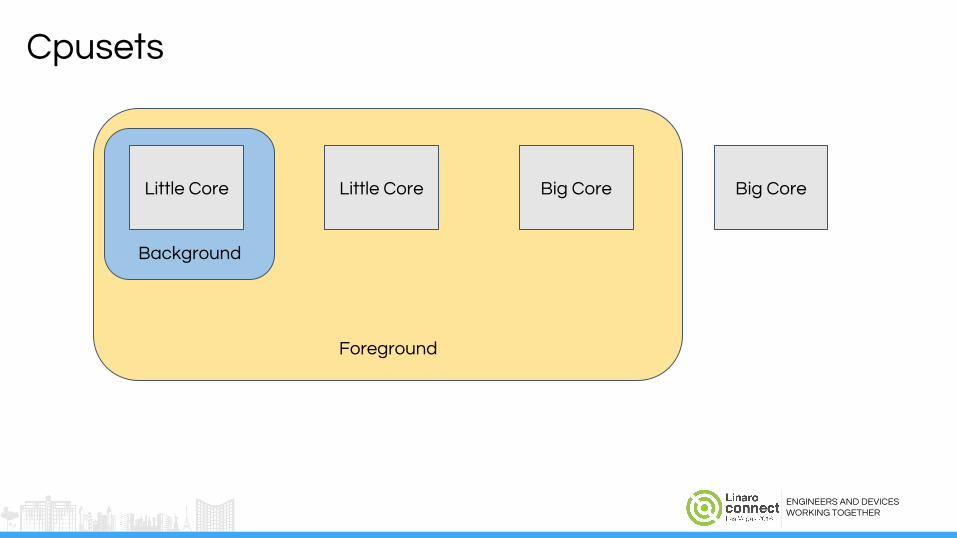
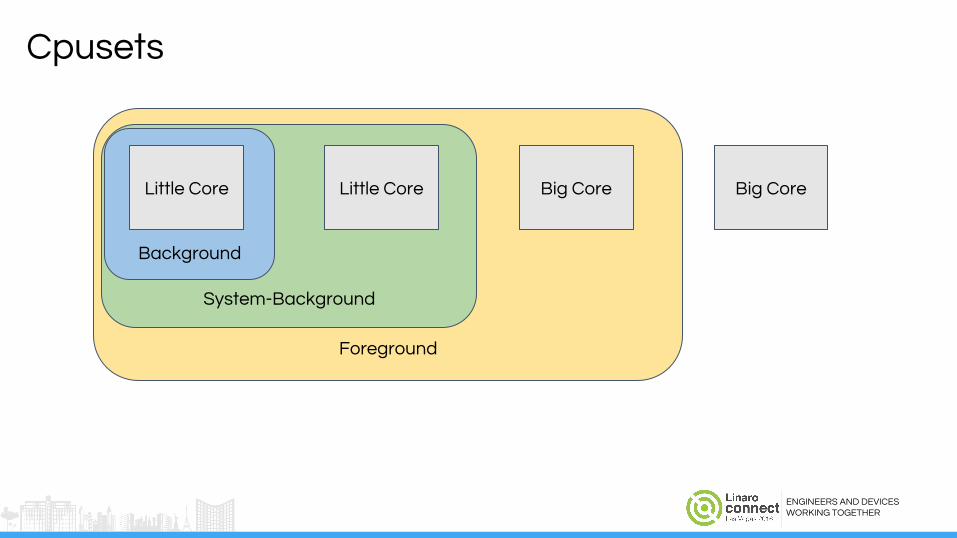
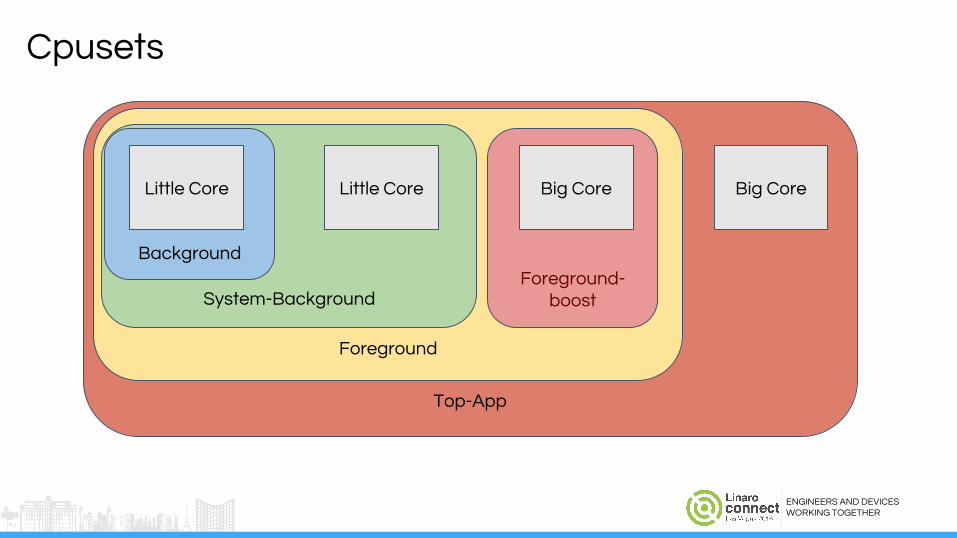
Cpusets: Limit what runs whereTop-app
Foreground
Background
System-background
Foreground-boost (Deprecated!)
ENGINEERS AND DEVICESWORKING TOGETHER
Cpusets
Big Core Big CoreLittle CoreLittle Core
ENGINEERS AND DEVICESWORKING TOGETHER
Cpusets
Big Core
Background
Big CoreLittle CoreLittle Core
ENGINEERS AND DEVICESWORKING TOGETHER
Foreground
Cpusets
Big Core
Background
Big CoreLittle CoreLittle Core
ENGINEERS AND DEVICESWORKING TOGETHER
Foreground
System-Background
Cpusets
Big Core
Background
Big CoreLittle CoreLittle Core

ENGINEERS AND DEVICESWORKING TOGETHER
Foreground
System-BackgroundForeground-
boost
Cpusets
Big Core
Background
Big CoreLittle CoreLittle Core
ENGINEERS AND DEVICESWORKING TOGETHER
Top-App
Foreground
System-BackgroundForeground-
boost
Cpusets
Big Core
Background
Big CoreLittle CoreLittle Core

ENGINEERS AND DEVICES
WORKING TOGETHER
Init cpuset config (init.hikey.rc)# Foreground should contain most cores
write /dev/cpuset/foreground/cpus 0-6
# top-app gets all cores (7 is reserved for top-app)
write /dev/cpuset/top-app/cpus 0-7
#background contains a small subset (generally one little core)
write /dev/cpuset/background/cpus 0
# add system-background cpuset, a new cpuset for system services
# that should not run on larger cores
# system-background is for system tasks that should only run on
# little cores, not on bigs to be used only by init
write /dev/cpuset/system-background/cpus 0-3

ENGINEERS AND DEVICES
WORKING TOGETHER
Init cpuset config (init.bullhead.rc)# foreground gets all CPUs except CPU 3
# CPU 3 is reserved for the top app
write /dev/cpuset/foreground/cpus 0-2,4-5
write /dev/cpuset/foreground/boost/cpus 4-5
write /dev/cpuset/background/cpus 0
write /dev/cpuset/system-background/cpus 0-2
write /dev/cpuset/top-app/cpus 0-5

ENGINEERS AND DEVICES
WORKING TOGETHER
Cpuctl: Restrict cputime● bg_non_interactive cgroup
● Keeps background tasks to only small portion
of little core
ENGINEERS AND DEVICES
WORKING TOGETHER
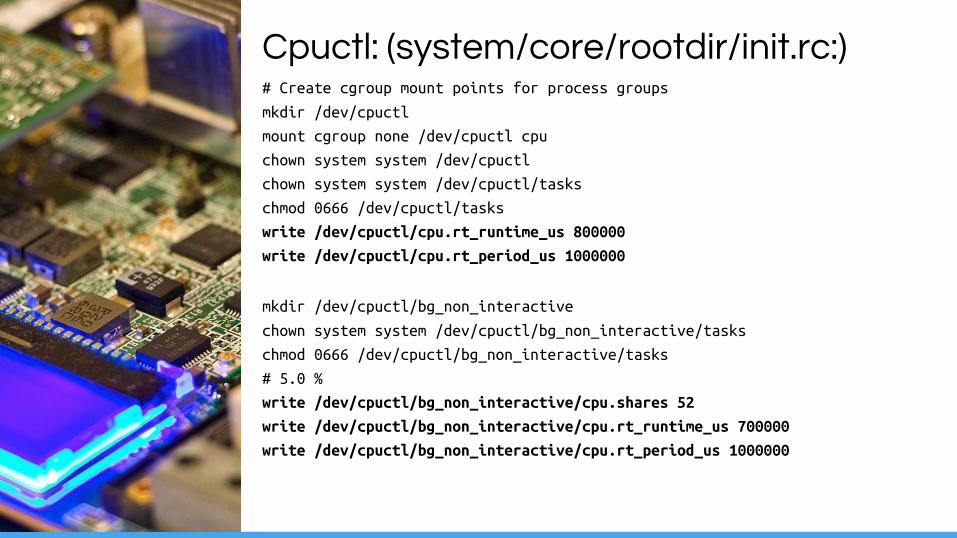
Cpuctl: (system/core/rootdir/init.rc:)# Create cgroup mount points for process groups
mkdir /dev/cpuctl
mount cgroup none /dev/cpuctl cpu
chown system system /dev/cpuctl
chown system system /dev/cpuctl/tasks
chmod 0666 /dev/cpuctl/tasks
write /dev/cpuctl/cpu.rt_runtime_us 800000
write /dev/cpuctl/cpu.rt_period_us 1000000
mkdir /dev/cpuctl/bg_non_interactive
chown system system /dev/cpuctl/bg_non_interactive/tasks
chmod 0666 /dev/cpuctl/bg_non_interactive/tasks
# 5.0 %
write /dev/cpuctl/bg_non_interactive/cpu.shares 52
write /dev/cpuctl/bg_non_interactive/cpu.rt_runtime_us 700000
write /dev/cpuctl/bg_non_interactive/cpu.rt_period_us 1000000

ENGINEERS AND DEVICESWORKING TOGETHER
Schedtune: Runtime Boost-Knob
System wide: sched_cfs_boost
Per-cgroup : schedtune.boost
Adds a “margin” to load-tracking
accounting, making scheduler
think there is more work to be
done, which likely raises the
cpufreq
Image from: http://www.linaro.org/blog/core-dump/energy-aware-scheduling-eas-progress-update/

ENGINEERS AND DEVICES
WORKING TOGETHER
Schedtune: Default BoostingForeground
(everything else)

ENGINEERS AND DEVICES
WORKING TOGETHER
Init stune config (init.hikey.rc)#
# EAS stune boosting interfaces
#
chown system system /dev/stune/foreground/schedtune.boost
chown system system /dev/stune/foreground/schedtune.prefer_idle
chown system system /dev/stune/schedtune.boost
write /dev/stune/foreground/schedtune.boost 10
write /dev/stune/foreground/schedtune.prefer_idle 1
write /dev/stune/schedtune.boost 0

ENGINEERS AND DEVICES
WORKING TOGETHER
Android PowerHAL
Provides interactivity signals from userspace
POWER_HINT_INTERACTION
POWER_HINT_VSYNC
POWER_HINT_LOW_POWER
POWER_HINT_SUSTAINED_PERFORMANCE
POWER_HINT_VR_MODE
Deprecated?:
POWER_HINT_VIDEO_ENCODE
POWER_HINT_VIDEO_DECODE

ENGINEERS AND DEVICES
WORKING TOGETHER
For old interactive cpufreq govSet the boostpulse_duration on init:# boost for 1sec
echo 1000000 > \
/sys/devices/system/cpu/cpufreq/interactive/boostpulse_duration
On POWER_HINT_INTERACTION:
echo 1 > /sys/devices/system/cpu/cpufreq/interactive/boostpulse

ENGINEERS AND DEVICES
WORKING TOGETHER
For EAS w/ schedtuneThe kernel doesn’t do deboosting!
On POWER_HINT_INTERACTION:
echo 40 > /dev/stune/foreground/schedtune.boost
Wait some time… then:
echo 10 > /dev/stune/foreground/schedtune.boost

ENGINEERS AND DEVICESWORKING TOGETHER
static void schedtune_power_init(struct hikey_power_module *hikey)
{
hikey->deboost_time = 0;
sem_init(&hikey->signal_lock, 0, 1);
pthread_create(&tid, NULL, schedtune_deboost_thread, hikey);
}
static int schedtune_boost(struct hikey_power_module *hikey)
{
long long now;
pthread_mutex_lock(&hikey->lock);
now = gettime_ns();
if (!hikey->deboost_time) {
schedtune_sysfs_boost(hikey, SCHEDTUNE_BOOST_INTERACTIVE);
sem_post(&hikey->signal_lock);
}
hikey->deboost_time = now + SCHEDTUNE_BOOST_TIME_NS;
pthread_mutex_unlock(&hikey->lock);
return 0;
}
Example touch-boost implementationstatic void* schedtune_deboost_thread(void* arg)
{
struct hikey_power_module *hikey = (struct hikey_power_module *)arg;
while(1) {
sem_wait(&hikey->signal_lock);
while(1) {
long long now, sleeptime = 0;
pthread_mutex_lock(&hikey->lock);
now = gettime_ns();
if (hikey->deboost_time > now) {
sleeptime = hikey->deboost_time - now;
pthread_mutex_unlock(&hikey->lock);
nanosleep_ns(sleeptime);
continue;
}
schedtune_sysfs_boost(hikey, SCHEDTUNE_BOOST_NORM);
hikey->deboost_time = 0;
pthread_mutex_unlock(&hikey->lock);
break;
}
}
return NULL;
}See full source here: https://android.googlesource.com/device/linaro/hikey/+/master/power/power_hikey.c

ENGINEERS AND DEVICES
WORKING TOGETHER
Other conceptual complicationsNegative boosting:
● Use schedtune to further reduce cpufreq for
background or other groups
schedboost.prefer_idle:
● Prefer to place tasks on idle cpus.
● Gives a bit more responsiveness but costs
some power.
● Consider for foreground tasks



ENGINEERS AND DEVICES
WORKING TOGETHER
Sync API changes in 4.6+
Android Sync API in staging has been
refactored and pulled mostly out of
staging into the DRM fences and
sync_file code.
Major credit to Gustavo Padovan
for this work!

Good News!Proper sync/fence api in upstream kernel!
One less Android specific kernel feature!

Bad News!Your out-of-tree vendor graphics driver
is now terribly, terribly broken!

ENGINEERS AND DEVICESWORKING TOGETHER
Old Android Sync Concept
1 2 3 ... ... ... 16 17 18 19
sync_timeline:
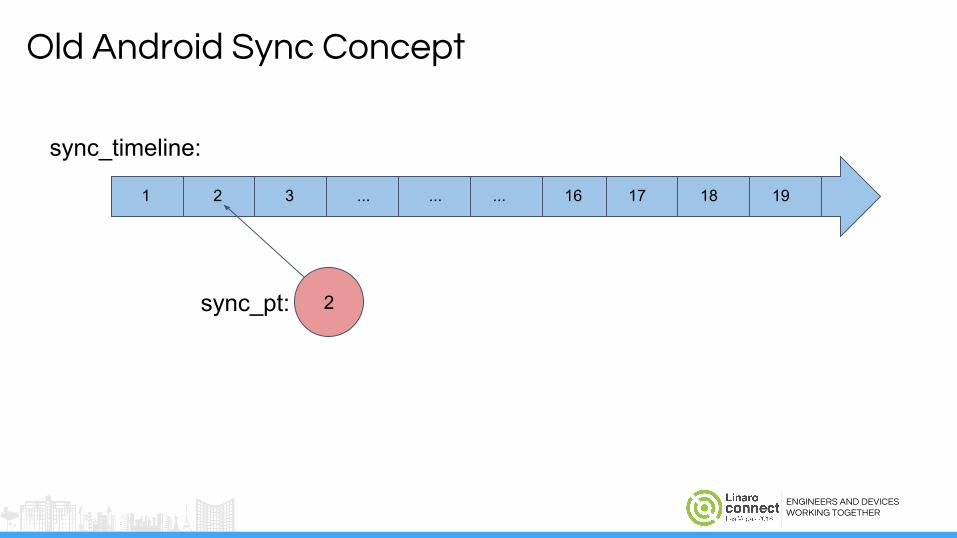
ENGINEERS AND DEVICESWORKING TOGETHER
sync_pt:
Old Android Sync Concept
1 2 3 ... ... ... 16 17 18 19
2
sync_timeline:
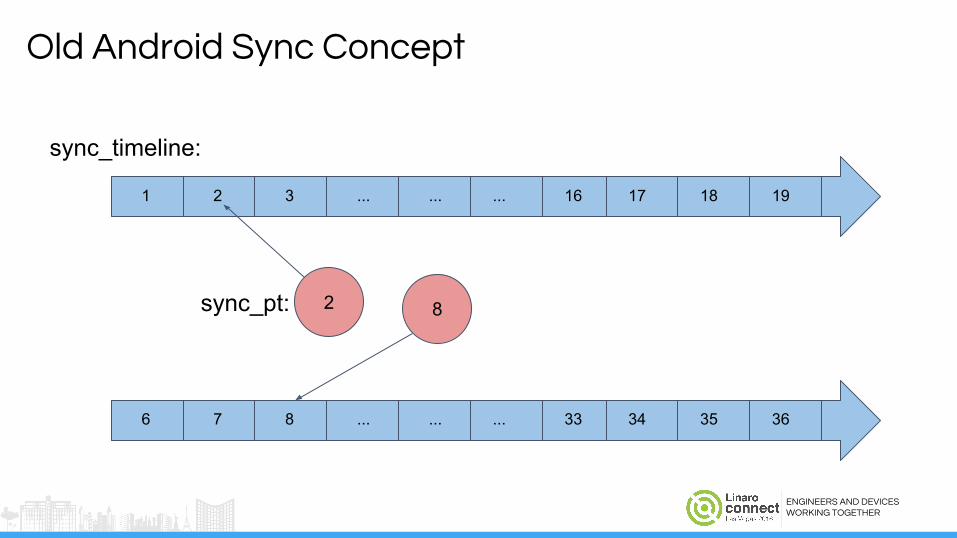
ENGINEERS AND DEVICESWORKING TOGETHER
sync_pt:
Old Android Sync Concept
1 2 3 ... ... ... 16 17 18 19
6 7 8 ... ... ... 33 34 35 36
2 8
sync_timeline:
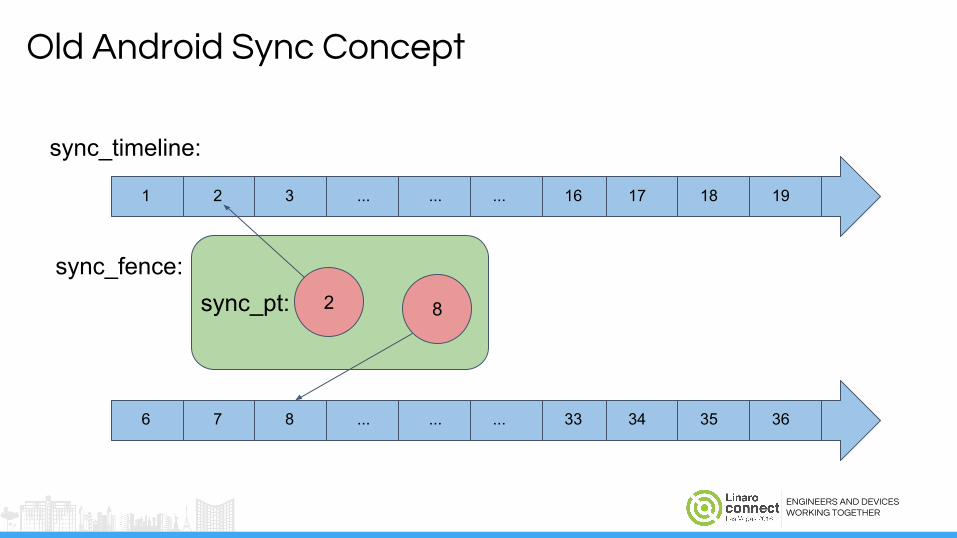
ENGINEERS AND DEVICESWORKING TOGETHER
sync_pt:
Old Android Sync Concept
1 2 3 ... ... ... 16 17 18 19
6 7 8 ... ... ... 33 34 35 36
2 8
sync_timeline:
sync_fence:
ENGINEERS AND DEVICESWORKING TOGETHER
fence:
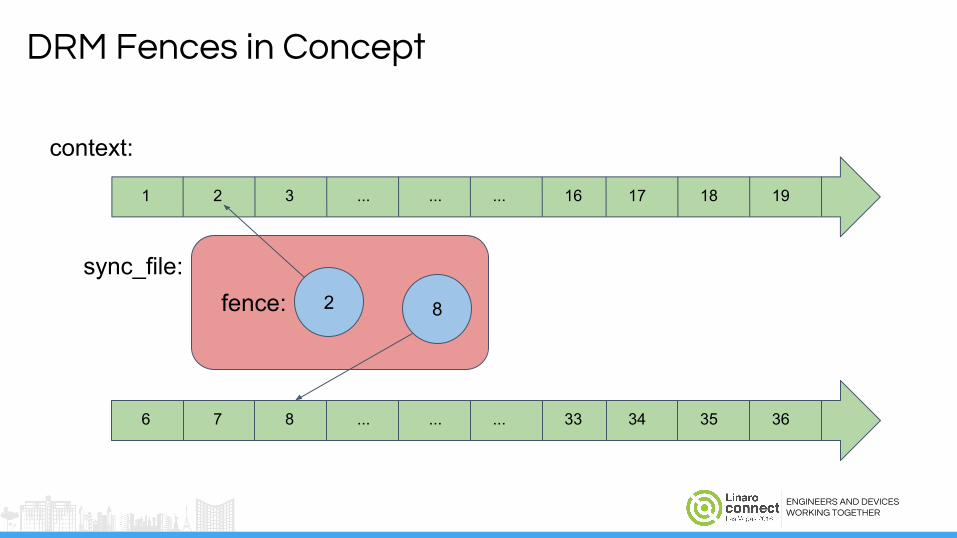
DRM Fences in Concept
1 2 3 ... ... ... 16 17 18 19
6 7 8 ... ... ... 33 34 35 36
2 8
context:
sync_file:

ENGINEERS AND DEVICES
WORKING TOGETHER
Kernel transition from old API
Old API New API
CONFIG_SYNC
struct sync_fencestruct sync_pt
sync_fence_put()sync_fence_fdget()
sync_fence_wait_async()sync_fence_cancel_async()
sync_timeline_create()sync_timeline_signal()
sync_pt_create()
sync_timeline_ops
CONFIG_SYNC_FILE
struct sync_filestruct fence
fput(fence->file)sync_file_get_fence()
fence_add_callback()fence_remove_callback()
fence_context_alloc()fence_signal()
fence_init()
fence_ops
ENGINEERS AND DEVICESWORKING TOGETHER

No exact matches
Async waits were previously done on sync_fences
- Which are closest to sync_files
Now async callbacks are done on fences
- Which were analogous to sync_pts
sync_timelines were objects
contexts are just a unique 64-bit id
Drivers have to manage their own context objects

ENGINEERS AND DEVICESWORKING TOGETHER
In addition...
Most graphics drivers have their own higher-level
meta-infrastructure that overlaps functionality:
struct mali_timeline
struct mali_timeline_point
struct mali_timeline_fence
What do you do with something like:
mali_timeline_sync_fence_create_and_add_tracker()

Bonus!Some changes for DRM fences are still in flight

Good luck rewriting your driver.
It wouldn’t be so bad if your driver was upstream.



ENGINEERS AND DEVICES
WORKING TOGETHER
Userspace libsync changesGustavo’s libsync tree:
https://git.collabora.com/cgit/user/padovan/android-system-core.git
Rob Herring’s DRM HWC changes:
https://github.com/robherring/drm_hwcomposer/commits/android-m

ENGINEERS AND DEVICESWORKING TOGETHER
ReferencesEric Gilling’s LPC13 talk:
https://www.youtube.com/watch?v=rhNRItGn4-M
Riley Andrew’s LPC14 talk:https://linuxplumbersconf.org/2014/ocw/system/presentations/2355/original/03%20-%20sync%20&%20dma-fence.pdf
Gustavo’s LinuxCon16 talk:
http://padovan.org/pub/GustavoPadovan-Explicit-Fencing_Talk.pdf
Gustavo’s Blog post:
http://padovan.org/blog/2016/09/mainline-explicit-fencing-part-1/


ENGINEERS AND DEVICESWORKING TOGETHER
ION● Who is using Ion? Who wants to use Ion on mainline?
● What are you using Ion for?
● Do you need kernel APIs?
● What out of tree Ion features are you missing? What help do you need?
● Can you help with testing?

ENGINEERS AND DEVICESWORKING TOGETHER
Reducing bootup time● AOSP is increasingly being used in non-phone environments, where boot times
matter much more (e.g. automotive).
● What can we do to improve boot times?
Some measuring to help us decide, run on
● HiKey 2GB Ram version from LeMaker
● Android Nougat 7.0.0_r6
● Kernel AOSP android-hikey-linaro-4.4
● HDMI, Micro-USB, Serial Console connected
● Soft boot with reboot command for 2nd boot
ENGINEERS AND DEVICESWORKING TOGETHER
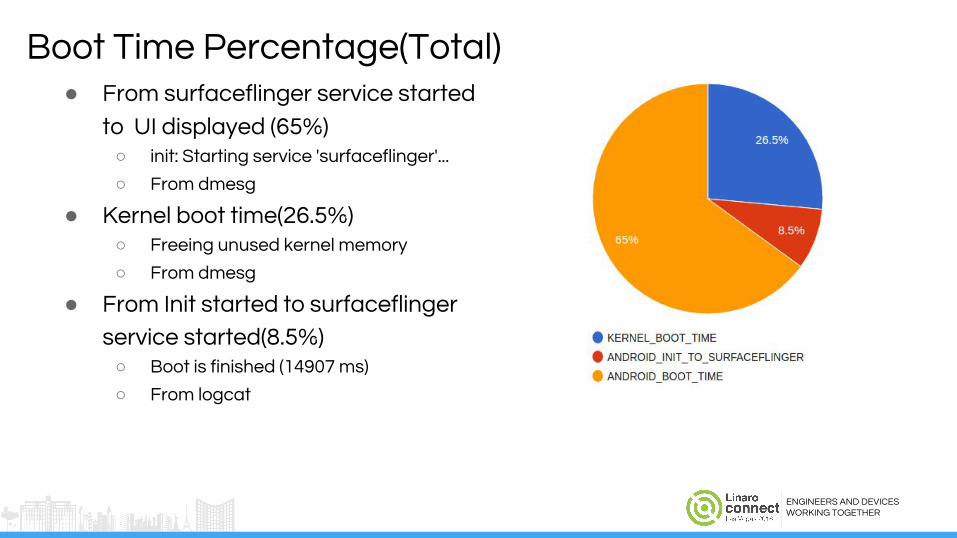
Boot Time Percentage(Total)● From surfaceflinger service started
to UI displayed (65%)○ init: Starting service 'surfaceflinger'...
○ From dmesg
● Kernel boot time(26.5%)○ Freeing unused kernel memory
○ From dmesg
● From Init started to surfaceflinger
service started(8.5%)○ Boot is finished (14907 ms)
○ From logcat

ENGINEERS AND DEVICESWORKING TOGETHER
Boot Time Percentage(Boot Progress)
● From preload_start to preload_end(23.4%)
● From pms_system_scan_start to
pms_data_scan_start(15%)
● From boot_progress_start to
preload_start(14.9%)
● From pms_ready to ams_ready(13.2%)
● From ams_ready to enable_screen(11.2%)
The top 5 take 77.7% in total

ENGINEERS AND DEVICESWORKING TOGETHER
Measurements
Target Method Comments
Kernel boot time ❏ Information from dmesg
● Can not measure time for bootloader automatically
● Need extra tools for accurate measurements
Android boot time before surfaceflinger service started
❏ Information from dmesg
❏ bootchart
● Services like vold, debuggerd are started here
Android boot time from surfaceflinger service started to Launcher displayed
❏ Information from logcat(including the events buffer)
❏ bootchart
● Timestamp in dmesg and logcat are not the same for the same message
Others like Application start time, web site loading time, media app start time.
? ● What others we want to check as well?

ENGINEERS AND DEVICESWORKING TOGETHER
Reducing bootup time● What can we do to improve boot times?
○ Suspend to disk instead of complete shutdown?
○ Parallel init?
○ Launch extra services after UI is up?
○ Better file system type for system/userdata/cache partitions?
○ … ???

ENGINEERS AND DEVICESWORKING TOGETHER
Out of tree AOSP userspace patches● Keeping a number of out of tree patches can become more problematic than it
already is - with the move to more frequent security updates and the
appearance of Android One-style devices, maintaining extra patches becomes
more work.
● Upstreaming more important than ever…○ Will try hard to upstream Linaro patches
○ Do members need/want help upstreaming patches from their vendor trees/BSPs? Is licensing sorted out?
● Do we keep some patches Members-First?
● What can we do about patches getting stuck in the upstream review queue?
● How will we handle out-of-tree patches that can’t go upstream (e.g. rejected
patches that still matter to a member) in the future?
● Patchset scripts vs. committing to git repositories?

ENGINEERS AND DEVICESWORKING TOGETHER
AOSP transition to clang● As of AOSP N, AOSP’s primary toolchain is clang - based on a recent 4.0
snapshot.
● Being able to build all of AOSP with clang was largely Linaro’s work
● gcc is still used to build some HALs for old devices and the kernel
● We can build the HiKey kernel with clang now - with a few patches and a few
ugly workarounds that need to be fixed
● Resulting system works, but has some stability issues that need to be
debugged
● Point of discussion: Do we need to patch support for building with gcc back in?

ENGINEERS AND DEVICESWORKING TOGETHER
AOSP with upstream clang (especially TOT)● Primary reasons for this work
○ Clang in AOSP toolchain is 5+ months behind compared to tot upstream clang○ Enable monitoring the impact of upstream clang on AOSP (mainly for performance)○ Enable safe landing of clang's latest code onto AOSP when time is come
● Linaro's current efforts○ Downstream patches of AOSP clang now all upstreamed (thanks to Renato and Google folks)○ AOSP master can be built with upstream clang (at July) successfully
■ Not have been tested for boot-up yet (See Future work for CI)
○ Monitoring compilation of AOSP master with tot upstream clang■ 3 clang bugs reported (1 fixed 2 open)■ 1 AOSP bionic patch upstreamed
● Future work○ CI for building AOSP master with upstream clang is in progress for boot-up and benchmark tests○ Continuously finding and fixing problems that prevent successful compilation
■ e.g. new warning (-address-of-packed-member ) added in tot clang causes compilation failure.

VIXL: A Programmatic Assembler and Disassembler for AArch32
Anton KirilovLinaro ART team

ENGINEERS AND DEVICESWORKING TOGETHER
Agenda● What is VIXL?
● Assembler
● Disassembler
● VIXL in the Android Runtime
91

ENGINEERS AND DEVICESWORKING TOGETHER
What is VIXL?● A programmatic assembler and disassembler
○ Does not process text files
● Originally designed for JIT compilers
● Supports AArch32 (both A32 and T32) and AArch64
● Written in C++
● Uses the modified BSD license
● Used by the Android Runtime, QEMU, HHVM, etc.
● Also, simulator and debugger for AArch64
● This presentation will concentrate on AArch32
92
ENGINEERS AND DEVICESWORKING TOGETHER
Useful links● Download:
git clone https://review.linaro.org/arm/vixl
● For AArch64 refer to the SFO15 500 presentation VIXL:
http://connect.linaro.org/resource/sfo15/sfo15-500-vixl/
93

ENGINEERS AND DEVICESWORKING TOGETHER
Assembler● The basic low-level interface is the Assembler class
● Provides full control over code generation (e.g. the exact encoding used)
● Declared in aarch32/assembler-aarch32.h
● Generates A32 code by default, but can be changed:○ By the constructor
○ On-the-fly, e.g. by the UseA32()/UseT32() methods
■ Possible to mix A32 and T32 instructions in the generated code
94

ENGINEERS AND DEVICESWORKING TOGETHER
The Assembler class● Let’s start with a simple factorial:
unsigned factorial(unsigned x) {
unsigned r = 1;
while (x) {
r *= x--;
}
return r;
}
● In T32 assembly:
factorial:
movs r1, r0
mov r0, #1
it eq
bxeq lr
loop:
mul r0, r0, r1
subs r1, #1
it ne
bne loop
bx lr
95

ENGINEERS AND DEVICESWORKING TOGETHER
The Assembler class● With VIXL:
Assembler as(T32);
Label factorial;
Label loop;
as.bind(&factorial);
as.movs(r1, r0);
as.mov(r0, 1);
as.it(eq);
as.bx(lr);
(continued from the left)
as.bind(&loop);
as.mul(r0, r0, r1);
as.subs(r1, r1, 1);
as.it(ne);
as.b(&loop);
as.bx(lr);
as.FinalizeCode();
96

ENGINEERS AND DEVICESWORKING TOGETHER
The Assembler class limitations● No code buffer overflow check
○ The caller is responsible
● No automatic generation of large constants○ Immediate operands of instructions such as MOV, etc.
○ Branch offsets
○ The Assembler methods will print an error message if a large constant is passed
● Consequence of being a low-level interface
97

ENGINEERS AND DEVICESWORKING TOGETHER
Macro assembler● Implemented by the MacroAssembler class
● Declared in aarch32/macro-assembler-aarch32.h
● Uses the assembler internally
● The interface is mostly the same
● The macro assembler-specific method names are capitalized
● Provides some extra features that make programming easier and safer○ Veneers for branch offsets that can’t be encoded
○ Literal pools
○ Further examples follow
● It is the expected end-user interface
98

ENGINEERS AND DEVICESWORKING TOGETHER
Macro assembler example● Source code:
MacroAssembler masm(T32);
masm.Add(r0, r0, 0x12345678);
masm.FinalizeCode();
● Generated code:
mov ip, #22136
movt ip, #4660
add r0, ip
99

ENGINEERS AND DEVICESWORKING TOGETHER
Further macro assembler example● Performs simple optimizations:
MacroAssembler masm(T32);
masm.Mov(r0, 0xFFFFFF00);
masm.FinalizeCode();
● Generated code:
mvn r0, #255
100

ENGINEERS AND DEVICESWORKING TOGETHER
The UseScratchRegisterScope class● Structured way to deal with scratch registers
● The IP register (R12) in particular should not be used directly
● Follows a standard C++ idiom:
MacroAssembler as(T32);
{
UseScratchRegisterScope temps(&as);
Register temporary = temps.Acquire();
as.Mov(temporary, 0x12345678);
as.Add(r0, temporary, temporary);
}
101

ENGINEERS AND DEVICESWORKING TOGETHER
Macro assembler pitfalls● Consider the following situation
(assuming we could access the IT
instruction in the macro assembler):
MacroAssembler masm(T32);
masm.It(eq, 0x8);
masm.Add(r1, r0, 0x12345678);
masm.FinalizeCode();
● Generated code:
it eq
moveq r1, #22136
movt r1, #4660
add r1, r0, r1
102

ENGINEERS AND DEVICESWORKING TOGETHER
The AssemblerAccurateScope class● Helps to control the number of generated instructions
● Prevents the assembler from emitting veneers and literal pools
● In fact, in situations like these the assembler must be used
● Provides bounds checking for the assembler
● Note that the constructor uses a size in bytes, not number of instructions
103

ENGINEERS AND DEVICESWORKING TOGETHER
AssemblerAccurateScope exampleMacroAssembler masm(T32);
{
AssemblerAccurateScope aas(&masm,
4 * k32BitT32InstructionSizeInBytes,
CodeBufferCheckScope::kMaximumSize);
masm.ittt(eq);
masm.mov(r1, 22136);
masm.movt(r1, 4660);
masm.add(r1, r0, r1);
}
masm.FinalizeCode();
104

ENGINEERS AND DEVICESWORKING TOGETHER
Assembler vs. MacroAssembler● The following table summarizes the differences:
105
Assembler MacroAssembler
Control over the generated code precise relaxed
Code simplifications no yes
Convenience no yes

ENGINEERS AND DEVICESWORKING TOGETHER
Disassembler● Implemented in the Disassembler class
● Declared in aarch32/disasm-aarch32.h
● Strives for strict ARMv8 compliance
● The main entry points are the DecodeA32() and DecodeT32() methods
● A little bit low-level for most use cases, especially when dealing with the
variable-length T32 instructions
106

ENGINEERS AND DEVICESWORKING TOGETHER
The PrintDisassembler class● Provides a more convenient interface
● Most applications will probably use it instead of directly the disassembler
● Provides methods to disassemble a whole buffer of instructions:
DisassembleA32Buffer()
DisassembleT32Buffer()
● Also, a way to process a single instruction more conveniently (particularly for
T32):
DecodeA32At()
DecodeT32At()
107

ENGINEERS AND DEVICESWORKING TOGETHER
PrintDisassembler example● Continuing our assembler example:
Assembler as(T32);
…as.bind(&factorial);
as.movs(r1, r0);
…PrintDisassembler disasm(std::cout);
disasm.DisassembleT32Buffer(
as.GetStartAddress<uint16_t *>(),
as.GetSizeOfCodeGenerated());
● Output:
0x00000000 0001 movs r1, r0
0x00000002 f04f0001 mov r0, #1
0x00000006 bf08 it eq
0x00000008 4770 bxeq lr
0x0000000a fb00f001 mul r0, r0, r1
0x0000000e 1e49 subs r1, #1
0x00000010 bf18 it ne
0x00000012 e7fa bne 0x0000000a
0x00000014 4770 bx lr
108

ENGINEERS AND DEVICESWORKING TOGETHER
The DisassemblerStream class● The main approach to customize the disassembler output
● Used internally by the disassembler
● Each instruction is broken down into components by the disassembler, e.g.:○ Register
○ MemOperand
○ etc.
● The DisassemblerStream defines operators for processing each component
● Override the operator of interest to change the output
109

ENGINEERS AND DEVICESWORKING TOGETHER
DisassemblerStream example● Assigning a special name to a register:
class RegisterPrettyPrinter : public DisassemblerStream {
…DisassemblerStream& operator<<(const Register reg) override {
if (reg.Is(r9)) {
os() << "tr";
return *this;
} else {
return DisassemblerStream::operator<<(reg);
}
}
…};
110

ENGINEERS AND DEVICESWORKING TOGETHER
More examples and documentation● Look into the examples/aarch32 directory in the VIXL source tree
● An excellent starting point for a beginner:
doc/getting-started-aarch32.md
111

ENGINEERS AND DEVICESWORKING TOGETHER
VIXL in the Android Runtime● The ART team has been working on integrating VIXL into the AArch32 backend
● Lead to a safer and more extensible code base
● Mechanisms such as the UseScratchRegisterScope class provide better
detection of mistakes
● The majority of the assembler and disassembler are automatically generated -
it should be much easier to support future ISA additions
● Much more extensive testing
112

Thank You
#LAS16For further information: www.linaro.org
LAS16 keynotes and videos on: connect.linaro.org

Android Runtime Performance AnalysisArtem Serov
Linaro ART team
114

ENGINEERS AND DEVICES
WORKING TOGETHER
Agenda● Introduction
● Performance measurement
● Performance analysis
115

ENGINEERS AND DEVICESWORKING TOGETHER
Linaro ART Team● Android Runtime (ART)
○ The managed runtime used by Java applications (Dex bytecode) and some system services on Android
○ https://source.android.com/devices/tech/dalvik/
○ Android 6.0 or 7.0 Hybrid Mode (AOT)
○ ART JIT in Android N by Xueliang ZHONG
● Linaro ART team○ Working on Android Runtime - improving the performance and stability
○ Members and assignees from ARM, Spreadtrum, Mediatek
116

ENGINEERS AND DEVICESWORKING TOGETHER
Art-testing● Art-testing repository
● Benchmarks○ Recognized benchmarks:
■ Caffeinemark■ Benchmarksgame■ Stanford■ Richards■ Deltablue■ etc
○ Microbenchmarks■ New features■ Catch regressions
● Framework○ $ ./run.py --target --iterations 10○ Host and target○ Statistics○ Perf tools
117
Analyzable and flexible CHECKED!
Embeddable CHECKED!
Stable and reproducible CHECKED!
Recognized CHECKED!
ENGINEERS AND DEVICESWORKING TOGETHER
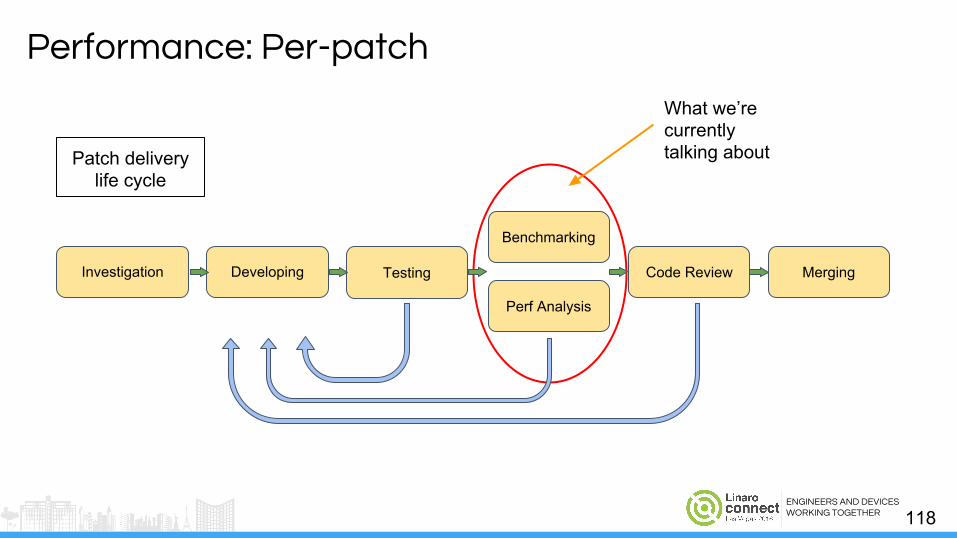
Performance: Per-patch
Code Review Merging
Benchmarking
Perf Analysis
Developing TestingInvestigation
What we’re currently talking about
118
Patch delivery life cycle

ENGINEERS AND DEVICESWORKING TOGETHER
Performance Tracking● Per-patch
○ Performance comparing before and after
○ We want to make sure that patches improve performance and don’t bring unexpected degradation
● Continuous tracking○ Regressions and anomalies whenever they happen○ Upstream changes○ Linaro patches tracking (double checking)
119

ENGINEERS AND DEVICES
WORKING TOGETHER
Agenda● Introduction
● Performance measurement
● Performance analysis
120

ENGINEERS AND DEVICESWORKING TOGETHER
Performance: Continuous Tracking
121

ENGINEERS AND DEVICESWORKING TOGETHER
Build-scripts● Automated process to run benchmarks: building, configuring, running
○ ./scripts/benchmarks/benchmarks_run_target.sh --mode 32 --cpu little --iterations 10
● “Android root”○ “chroot” like (/system -> /data/local/tmp/system)○ Do not depend on other AOSP projects and GUI environment
● Device configuration: CPU frequencies and clusters (big/little)○ Stable results○ CPU pinning○ Overheating
● Running the benchmarks
122
ENGINEERS AND DEVICESWORKING TOGETHER
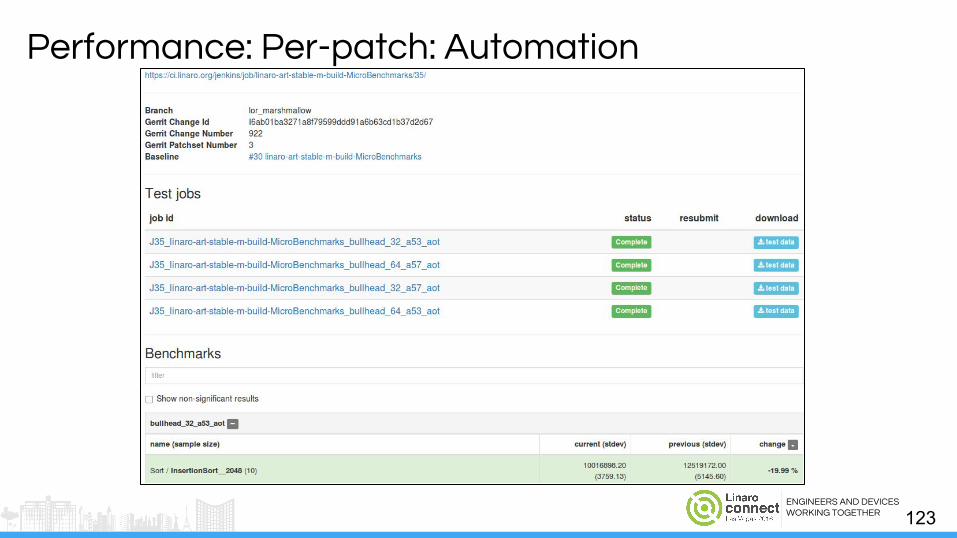
Performance: Per-patch: Automation
123

ENGINEERS AND DEVICESWORKING TOGETHER
Performance: Manual Check geomean diff (%) geomean error 1 (%) geomean error 2 (%)
---------------------- ---------------- ------------------- -------------------
...
caffeinemark/LoopAtom -24.423 0.017 0.258
...
--- Summary ----------------------------------------------------------------------
intrinsics -5.436 0.266 0.443
micro -3.536 0.122 0.145
benchmarksgame -2.745 0.495 0.616
algorithm -12.280 0.214 0.205
stanford -7.553 0.269 0.167
math -0.392 0.490 0.210
caffeinemark -5.639 0.315 0.372
OVERALL -4.762 0.099 0.116
-----------------------------------------------------------------------------------
124
● We measure time that’s why negative numbers mean improvement

ENGINEERS AND DEVICES
WORKING TOGETHER
Agenda● Introduction
● Performance measurement
● Performance analysis
125

ENGINEERS AND DEVICESWORKING TOGETHER
Performance Analysis: Example● caffeinemark/LoopAtom.java: - 24.4% reduction of execution time
(improvement)
● Task: Investigate the reason for performance difference
● Run perf-tools to collect data for A (before) and B (after) builds for
caffeinemark/LoopAtom.java
126

ENGINEERS AND DEVICESWORKING TOGETHER
Performance Analysis: Hotspots● Hotspots - sections of code that get most of execution time
○ Typically there are few hotspots which determine overall performance
● Generic naive algorithm
● Find hotspots: Profiling○ Method level○ Loop level○ Instruction level
● Analyze hotspots○ Source code○ Binary code○ Tools
127
Find hotspots
Analyze hotspots
PROFIT!
...

ENGINEERS AND DEVICESWORKING TOGETHER
Art-testing Perf Tools● Performance analysis of code generated by ART
○ Not kernel○ Not native libraries
● Scripts based on linux-perf-tools○ Linux profiling with performance counters○ Statistical profiling
● Features○ Profiling - hotspots identification○ .cfg (IR + assembly) files generation○ Perf events collection○ All of the above in one click!
128

ENGINEERS AND DEVICESWORKING TOGETHER
Identifying Hotspots: Methods● Java methods
○ benchmark.oat○ boot.oat
● Native methods○ Kernel○ Libart○ Others
|%-------|Events-----|----|DSO---------------------------------|k?--|method------------------------------------------|
+ 89.37% 10768209032 main data@local@[email protected]@classes.dex [.] int benchmarks.caffeinemark.LoopAtom.execute()
+ 3.30% 397223644 main linker [.] __dl__ZNK6soinfo10gnu_lookupER10SymbolName...
+ 1.03% 123764181 main [kernel.kallsyms] [k] 0xffffffc0002896c0
+ 0.92% 110683861 main linker [.] __dl__ZNK6soinfo19find_symbol_by_nameER10S...
+ 0.80% 96237748 main linker [.] __dl__ZN10SymbolName8gnu_hashEv
129

ENGINEERS AND DEVICESWORKING TOGETHER
Hotspot: .CFG File● c1visualizer - tool to visualize ART intermediate
representation (IR)○ Control flow graph (CFG)○ IR○ Assembly
● For each method before and after each optimization
130
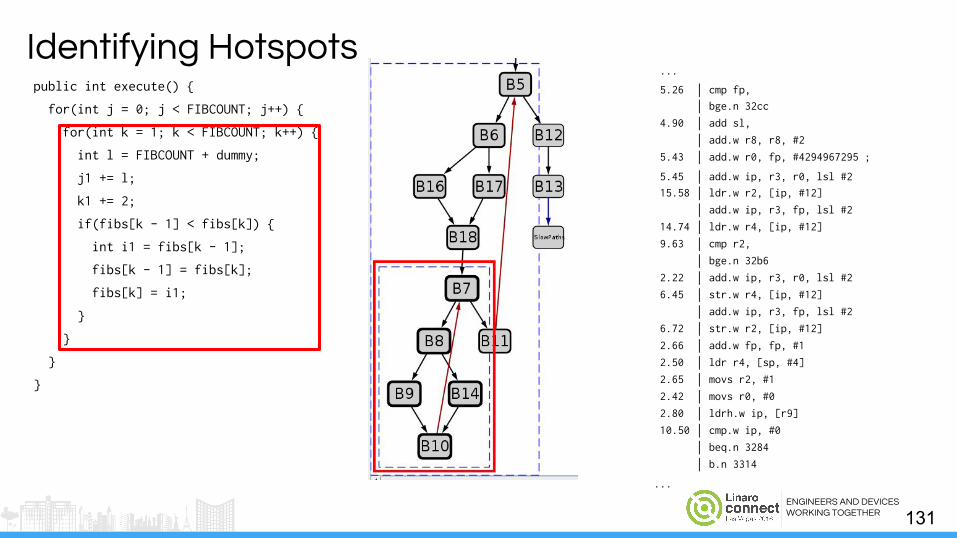
ENGINEERS AND DEVICESWORKING TOGETHER
Identifying Hotspots
131
...
5.26 │ cmp fp, │ bge.n 32cc 4.90 │ add sl, │ add.w r8, r8, #2 5.43 │ add.w r0, fp, #4294967295 ;
5.45 │ add.w ip, r3, r0, lsl #2 15.58 │ ldr.w r2, [ip, #12] │ add.w ip, r3, fp, lsl #2 14.74 │ ldr.w r4, [ip, #12] 9.63 │ cmp r2, │ bge.n 32b6 2.22 │ add.w ip, r3, r0, lsl #2 6.45 │ str.w r4, [ip, #12] │ add.w ip, r3, fp, lsl #2 6.72 │ str.w r2, [ip, #12] 2.66 │ add.w fp, fp, #1 2.50 │ ldr r4, [sp, #4] 2.65 │ movs r2, #1 2.42 │ movs r0, #0 2.80 │ ldrh.w ip, [r9] 10.50 │ cmp.w ip, #0 │ beq.n 3284 │ b.n 3314
...
public int execute() {
for(int j = 0; j < FIBCOUNT; j++) {
for(int k = 1; k < FIBCOUNT; k++) {
int l = FIBCOUNT + dummy;
j1 += l;
k1 += 2;
if(fibs[k - 1] < fibs[k]) {
int i1 = fibs[k - 1];
fibs[k - 1] = fibs[k];
fibs[k] = i1;
}
}
}
}
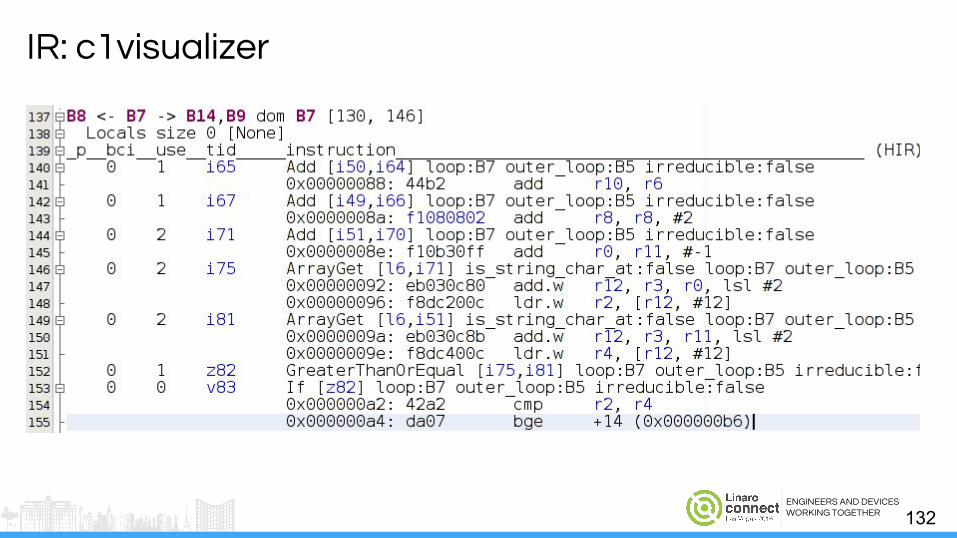
ENGINEERS AND DEVICESWORKING TOGETHER
IR: c1visualizer
132

ENGINEERS AND DEVICESWORKING TOGETHER
IR: c1visualizer
133

ENGINEERS AND DEVICESWORKING TOGETHER
Analyzing Hotspot: .CFG File
134
IR A (before the patch) IR B (after the patch)
i75 ArrayGet [l6,i71]
add.w r12, r3, r0, lsl #2
ldr.w r2, [r12, #12]
i81 ArrayGet [l6,i51]
add.w r12, r3, r11, lsl #2
ldr.w r4, [r12, #12]
l18 IntermediateAddress [l6,i184]
add r4, r3, #12
i75 ArrayGet [l185,i71]
ldr.w r5, [r4, r2, lsl #2]
i81 ArrayGet [l185,i51]
ldr.w r6, [r4, r0, lsl #2]

ENGINEERS AND DEVICESWORKING TOGETHER 135
Event Descriptions Total events A
Total events B
Diff EPI A EPI B
cycles Hardware event 4565192341 3433910203 -24.78% 1024 812
instructions Hardware event 4456377599 4229550675 -5.09% 1000 1000
0x14 L1 Instruction cache access 2142888354 1698883460 -20.72% 481 402
0xE5 load/store instruction waiting for data to calculate the
address in the AGU.
1330740047 225172166 -83.08% 299 53
Perf Events● PMU counters - look into ARM Infocenter
● EPI - event per 1000 instructions
● IPC - instructions per cycle - increased from 0.97 to 1.23
● Events are sorted by EPI A

ENGINEERS AND DEVICESWORKING TOGETHER
DS-5: Streamline Performance Analyzer● ARM DS-5 Streamline - system-wide performance analysis tool
● Features:○ PMU counters○ Timeline○ Filter by processes and threads○ Multicore, multicluster and big.LITTLE™○ Add custom annotations○ Overlay charts and customize expressions○ Mali GPU Optimization
● Supports Linux, Android○ For Android use the tutorial
136

ENGINEERS AND DEVICESWORKING TOGETHER
Streamline: Diagram Example
137

ENGINEERS AND DEVICESWORKING TOGETHER
Useful Links1. https://source.android.com/ - Android Open Source Project
2. https://source.android.com/devices/tech/dalvik/ - Android Runtime
3. https://android-git.linaro.org/gitweb/linaro/art-testing.git/tree - Linaro
benchmarks and tools repository
4. https://java.net/projects/c1visualizer/ - tool to visualizer ART intermediate
representation
5. https://perf.wiki.kernel.org/index.php/Main_Page - Linux profiling with
performance counters
6. https://developer.arm.com/products/software-development-tools/ds-5-develo
pment-studio/streamline - ARM Streamline Performance Analyzer
7. http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0500f/BIIDBA
FB.html - Cortex-A53 Performance Monitor Unit Events
138

Thank You
#LAS16For further information: www.linaro.org
LAS16 keynotes and videos on: connect.linaro.org
139

ENGINEERS AND DEVICESWORKING TOGETHER
Android Runtime: Metrics● Compilation
○ How long it takes to compile the app
○ How much RAM is consumed during app compilation
● Memory footprint○ Static: How much storage is required for the app binary
○ Dynamic: How much RAM is consumed when the app is running
● Run-time performance○ The quality of the generated code
● From this point performance = run-time performance
140

ENGINEERS AND DEVICESWORKING TOGETHER
Backup: Identifying hotspots1. Check performance difference (in %)
2. Skim over the bench sources
3. Run perf with ‘cycles’ event
4. Identify the hotspots using perf reporta. Single very hot java leaf methodb. Non-leaf java method not from boot.oatc. Native methodd. Java method from boot.oat
5. Examine the hotspota. Validate that this particular hotspot determines the difference in total performance
b. Split and alter big methods
141

ENGINEERS AND DEVICESWORKING TOGETHER
Backup: Analyzing Hotspots1. Get .cfg file for the method
2. Identify the exact piece of hot codea. Loopsb. Perf-annotate
3. Compare the corresponding IR (c1visualizer)a. find the compiler phase where difference occur
4. Compare the corresponding assembly (c1visualizer)
5. Use static binary built from assembly for performance difference validation
6. Run perf scripts will all PMU eventsa. Total-period optionb. CPI – Cycle per instruction – reflect the performance
c. ${Counter} / instructions * 1000 reflect counter’s impact
142

ENGINEERS AND DEVICESWORKING TOGETHER
O and on: What’s in AOSP’s future and how can we help?●● New partition layout, A/B updates
● What else would we LIKE to see in AOSP’s future?
● … and how can we help bring it about?

ENGINEERS AND DEVICESWORKING TOGETHER
Anything else?● Did the topics of the microconference bring up another topic we should be
talking about?
● Did we omit an important topic?
● Feel free to talk about anything AOSP related now...

Thank You
#LAS16For further information: www.linaro.org
LAS16 keynotes and videos on: connect.linaro.org

ENGINEERS AND DEVICESWORKING TOGETHER
Memory allocator analysis● Primary focus: Reduce memory usage on low-memory devices
● Malloc implementations investigated: jemalloc, dlmalloc, nedmalloc, tcmalloc,
musl malloc, TLSF, lockless allocator
● Memory analysis briefing
○ https://docs.google.com/document/d/15ycUEuplwZs0LPXMVc6yKRaLOnflY8QE2mA7kkEoa_o/edit#heading=h.z9n368sk0eai
● Challenges○ Porting of atomic routines for ARM 64-bit platform
○ name mangling issues
○ C99 warnings
○ Wrapper/dummy calls for bionic integration (e.g. malloc_usable_size, malloc_disable, mallinfo etc.)
○ Other runtime issues
○ Benchmark porting - (tlsf-test, t-test)
○ Fragmentation analysis script

ENGINEERS AND DEVICESWORKING TOGETHER
Memory allocator analysis
Summary● tcmalloc, jemalloc wins for multi-threaded apps and run time
performance (good amount of small pages available at runtime)
● static size reduction for libc is improved with nedmalloc and tlsf
● jemalloc-svelte does not have good stand compare to jemalloc & tcmalloc
● Support issue with nedmalloc - no more support.● Lockless allocator - under private license
Note: Rank graph is generated based on relative performance. For real numbers kindly refer to memory analysis document
Related Documents











