1 Lecture 1 Introduction Advanced High Performance Computing Fall 2014

Lecture 1 Introduction
Jan 01, 2016
Lecture 1 Introduction. Advanced High Performance Computing Fall 2014. Contents. Acknowledgments for today’s lecture • Jack Dongarra (U. Tennessee) --- CS 594 slides from Spring 2008 — http://www.cs.utk.edu/%7Edongarra/WEB-PAGES/cs594-2008.htm - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Lecture 1 Introduction
Advanced High Performance ComputingFall 2014

2
Contents Acknowledgments for today’s lecture• Jack Dongarra (U. Tennessee) --- CS 594 slides from Spring
2008 —http://www.cs.utk.edu/%7Edongarra/WEB-PAGES/cs594-2008.htm
• Kathy Yelick (UC Berkeley) --- CS 267 slides from Spring 2007 — http://www.eecs.berkeley.edu/~yelick/cs267_sp07/lectures
• Slides accompanying course textbook —http://www-users.cs.umn.edu/~karypis/parbook/
• Vivek Sarkar(Rice University) – http://www.owlnet.rice.edu/~comp422/lecture-notes/comp422-lec1-s08-v1.pdf
• Alexandros Gerbessiotis (New Jersey Institute of Technology)
3
Why parallel computing? – computational modeling and simulation
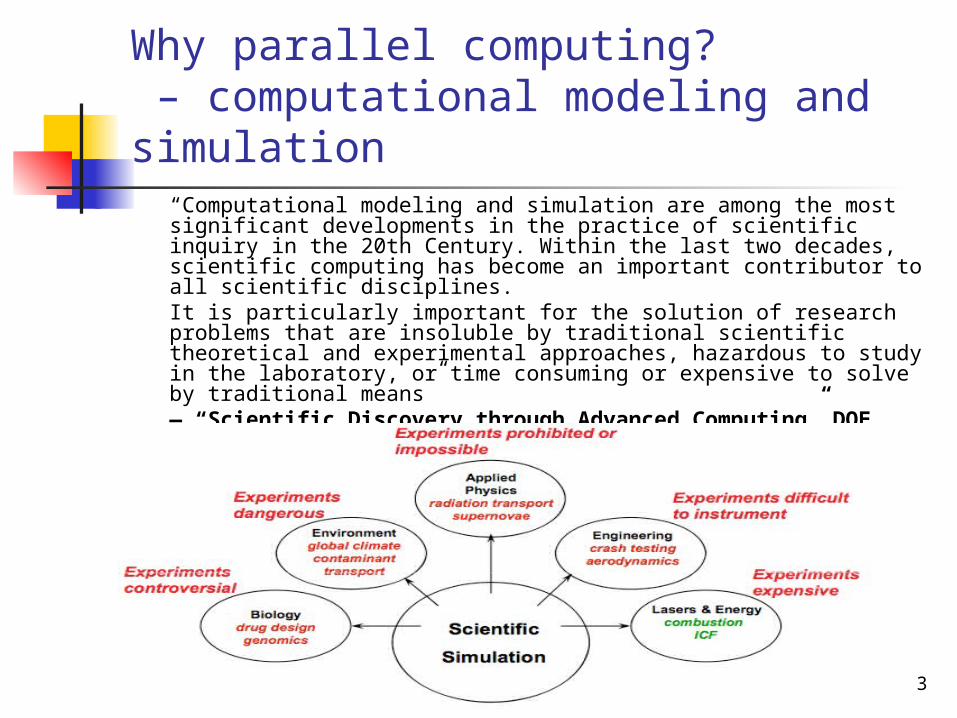
“Computational modeling and simulation are among the most significant developments in the practice of scientific inquiry in the 20th Century. Within the last two decades, scientific computing has become an important contributor to all scientific disciplines. It is particularly important for the solution of research problems that are insoluble by traditional scientific theoretical and experimental approaches, hazardous to study in the laboratory, or time consuming or expensive to solve by traditional means” — “Scientific Discovery through Advanced Computing” DOE Office of Science, 2000

4
Simulation: The Third Pillar of Science
• Traditional scientific and engineering paradigm:1)Do theory or paper design.2) Perform experiments or build system.
• Limitations:—Too difficult -- build large wind tunnels.—Too expensive -- build a throw-away passenger jet.—Too slow -- wait for climate or galactic evolution.—Too dangerous -- weapons, drug design, climate
experimentation.
• Computational science paradigm:3) Use high performance computer systems to simulate the
phenomenon– Base on known physical laws and efficient numerical
methods.

5
Some Particularly Challenging Computations• Science—Global climate modeling—Biology: genomics; protein folding; drug design—Astrophysical modeling—Computational Chemistry—Computational Material Sciences and Nanosciences• Engineering—Semiconductor design—Earthquake and structural modeling—Computation fluid dynamics (airplane design)—Combustion (engine design)—Crash simulation• Business—Financial and economic modeling—Transaction processing, web services and search engines• Defense—Nuclear weapons -- test by simulations—Cryptography
6
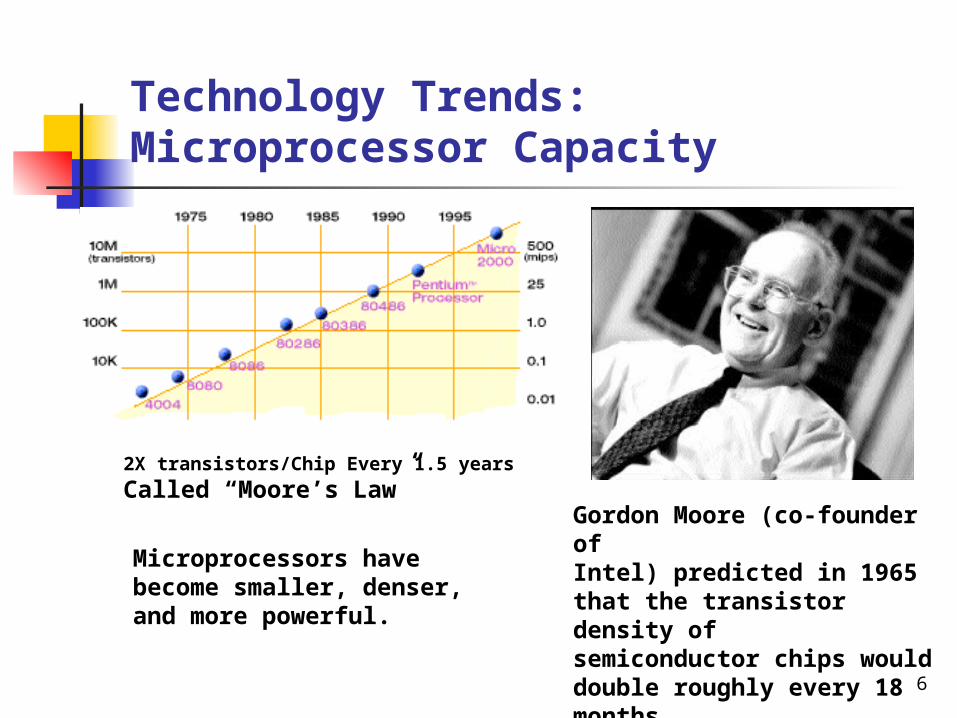
Technology Trends: Microprocessor Capacity
2X transistors/Chip Every 1.5 years
Called “Moore’s Law”
Microprocessors havebecome smaller, denser,and more powerful.
Gordon Moore (co-founder ofIntel) predicted in 1965 that the transistor density ofsemiconductor chips woulddouble roughly every 18months.Slide source: Jack Dongarra

7
More Limits: How fast can a serial computer be?
Consider the 1 Tflop/s sequential machine: Data must travel some distance, r, to get from
memory to CPU. To get 1 data element per cycle, this means
1012times per second at the speed of light, c = 3x108 m/s. Thus r < c/1012 = 0.3 mm.
Now put 1 Tbyte of storage in a 0.3 mm x 0.3 mm area:
Each bit occupies about 1 square Angstrom, or thesize of a small atom.
No choice but parallelism
1 Tflop/s, 1Tbyte sequentialmachine
r = 0.3mm
8
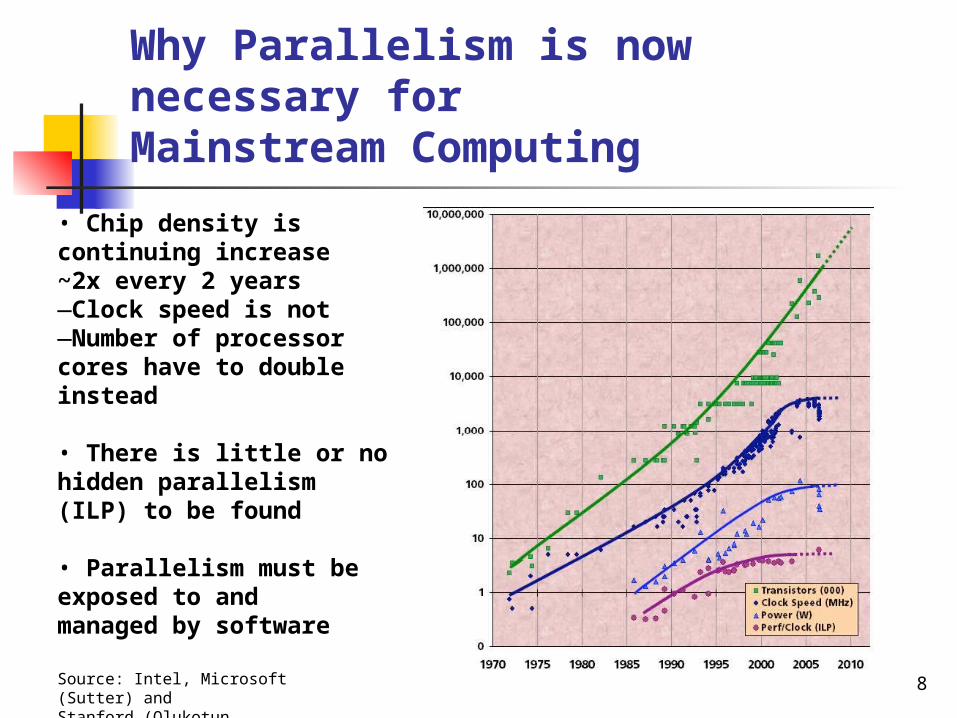
Why Parallelism is now necessary forMainstream Computing
• Chip density is continuing increase~2x every 2 years —Clock speed is not—Number of processor cores have to double instead
• There is little or no hidden parallelism (ILP) to be found
• Parallelism must be exposed to andmanaged by software
Source: Intel, Microsoft (Sutter) andStanford (Olukotun, Hammond)

9
Fundamental limits on Serial Computing: Three “Walls”
• Power Wall—Increasingly, microprocessor performance is limited byachievable power dissipation rather than by the number of available integrated-circuit resources (transistors and wires). Thus, the only way to significantly increase the performance of microprocessors is to improve power efficiency at about the same rate as the performance increase.
• Frequency Wall—Conventional processors require increasingly deeper instruction pipelines to achieve higher operating frequencies. This technique has reached a point of diminishing returns, and even negative returns if power is taken into account.
• Memory Wall—On multi-gigahertz symmetric processors --- even those with integrated memory controllers --- latency to DRAM memory is currently approaching 1,000 cycles. As a result, program performance is dominated by the activity of moving data between main storage (the effective-address space that includes main memory) and the processor.

10
What is Parallel computing? Parallel computing involves performing
parallel tasks using more than one computer.
Example in real life with related principles -- book shelving in a library Single worker P workers with each worker stacking n/p
books, but with arbitration problem(many workers try to stack the next book in the same shelf.)
P workers with each worker stacking n/p books, but without arbitration problem (each worker work on a different set of shelves)

11
Important Issues in parallel computing Task/Program Partitioning.
How to split a single task among the processors so that each processor performs the same amount of work, and all processors work collectively to complete the task.
Data Partitioning. How to split the data evenly among the
processors in such a way that processor interaction is minimized.
Communication/Arbitration. How we allow communication among
different processors and how we arbitrate communication related conflicts.

12
Challenges
1. Design of parallel computers so that we resolve the above issues.
2. Design, analysis and evaluation of parallel algorithms run on these machines.
3. Portability and scalability issues related to parallel programs and algorithms
4. Tools and libraries used in such systems.

13
Units of Measure in HPC
• High Performance Computing (HPC) units are:—Flop: floating point operation—Flops/s: floating point operations per second—Bytes: size of data (a double precision floating point number
is 8)• Typical sizes are millions, billions, trillions…Mega Mflop/s = 106 flop/sec Mbyte = 220 = 1048576 ~ 106
bytesGiga Gflop/s = 109 flop/sec Gbyte = 230 ~ 109 bytesTera Tflop/s = 1012 flop/sec Tbyte = 240 ~ 1012 bytesPeta Pflop/s = 1015 flop/sec Pbyte = 250 ~ 1015 bytesExa Eflop/s = 1018 flop/sec Ebyte = 260 ~ 1018 bytesZetta Zflop/s = 1021 flop/sec Zbyte = 270 ~ 1021 bytesYotta Yflop/s = 1024 flop/sec Ybyte = 280 ~ 1024 bytes• See www.top500.org for current list of fastest machines

14
What is a parallel computer? A parallel computer is a collection of
processors that cooperatively solve computationally intensive problems faster than other computers.
Parallel algorithms allow the efficient programming of parallel computers.
This way the waste of computational resources can be avoided.
Parallel computer v.s. Supercomputer supercomputer refers to a general-purpose computer
that can solve computational intensive problems faster than traditional computers.
A supercomputer may or may not be a parallel computer.

15
Parallel Computers: Past and Present
1980’s Cray supercomputer was 20-100 times faster than other computers(main frames, minicomputers) in use. (The price of supercomputer is 10 times other computers – worth it)
1990’s “Cray”-like CPU is 2-4 times as fast as a microprocessor. (The price of supercomputer is 10-20 times a microcomputer – make no sense)
The solution to the need for computational power is a massively parallel computers, where tens to hundreds of commercial off-the-shelf processors are used to build a machine whose performance is much greater than that of a single processor.
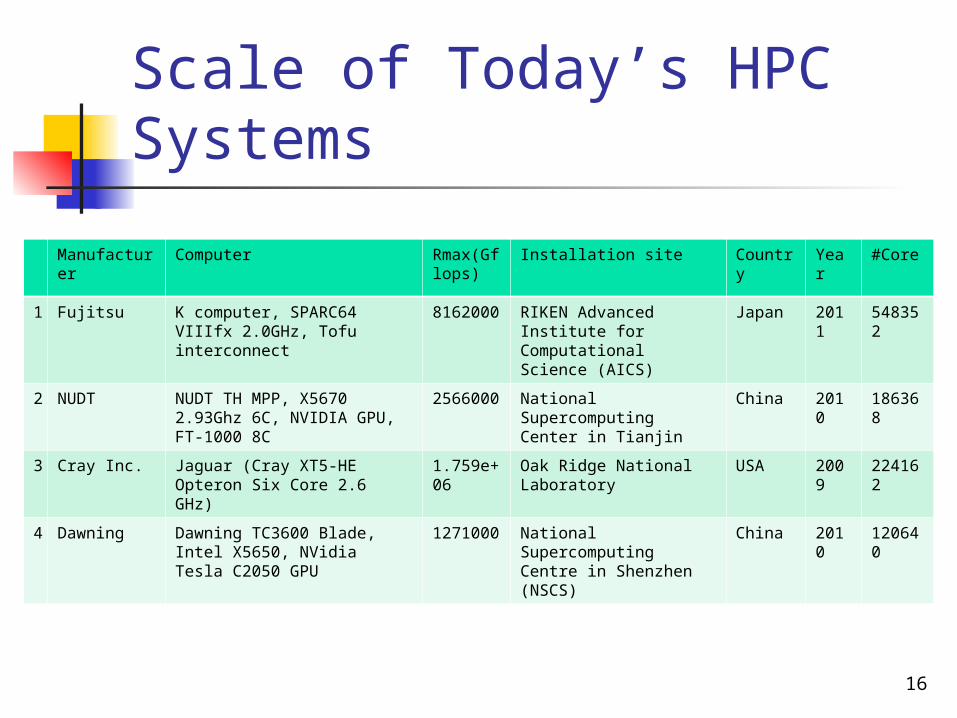
Scale of Today’s HPC Systems
16
Manufacturer
Computer Rmax(Gflops)
Installation site Country
Year #Core
1 Fujitsu K computer, SPARC64 VIIIfx 2.0GHz, Tofu interconnect
8162000
RIKEN Advanced Institute for Computational Science (AICS)
Japan 2011
548352
2 NUDT NUDT TH MPP, X5670 2.93Ghz 6C, NVIDIA GPU, FT-1000 8C
2566000
National Supercomputing Center in Tianjin
China 2010
186368
3 Cray Inc. Jaguar (Cray XT5-HE Opteron Six Core 2.6 GHz)
1.759e+06
Oak Ridge National Laboratory
USA 2009
224162
4 Dawning Dawning TC3600 Blade, Intel X5650, NVidia Tesla C2050 GPU
1271000
National Supercomputing Centre in Shenzhen (NSCS)
China 2010
120640

17
CSI’s High Performance CenterNeptune. (neptune.csi.cuny.edu)
– a gateway or interface system for CUNY users that are not within local area network at the College of Staten Island.
– As a single, two socket, 2 x 4 = 8 core head-like node, Neptune's 8 Intel Clovertown cores run at 3.16 GHz. Neptune has a total of 16 Gbytes of memory or 2 Gbytes per core.
– Neptune is not generally to be used for numerically intensive calculation, but as a secure jumping-off point to access the larger cluster systems described below.
– Neptune can also be used as an access point to submit jobs using some applications (MATLAB for instance) to the batch schedulers on the others systems.
– It can also be used to run a number of serial applications for which a GUI is required or convenient.
Athena (athena.csi.cuny.edu)– 97 node Dell PowerEdge Cluster (1 headnode and 96 compute nodes)
• 1 Gbit ethernet internal network– 96 Compute nodes (PowerEdge 1850)
• Two Intel Xeon dual processor chips operating at 2.8 GHz• 8 Gbytes of memory
– 1 Head node (PowerEdge 2850)• Two Intel Xeon dual processor chips operating at 2.8 GHz• 4 Gbytes of memory

CSI’s High Performance Center
• Zeus– supporting users running Gaussian03, and now also, the development of CPU-GPU applications –11 node Dell PowerEdge Cluster
• 1 Gbit ethernet internal network– 10 Compute nodes (PowerEdge 1850) – Compute nodes 0-7
• two sockets with Intel 2.66 GHz quad-core Harpertown processors• • providing a total of eight cores per node
• 8 Harpertown nodes have 2 Gbytes of memory per core for a total of 16 Gbytes per node
• Each Harpertown node also has a 1 TByte disk drive (/state/partition1) for storing Gaussian scratch files. – Compute nodes 8-9
• two sockets with Intel 2.27 GHz Woodcrest dual-core processors • • a total of 6 Gbytes of memory
• each attached to their own NVIDIA Tesla S1070, 1U, 4-way GPU array via dual PCI-Express 2.0 cables to support integrated CPU-GPU computing.
• Each GPU (4 per 1U Tesla node) has 240, 32-bit floating-pointing units with a peak performance of 1 teraflop (there are 30 64-bit units).• Each GPU also has 4 Gbytes of GPU-local memory
– 1 Head node (PowerEdge 1850)• 2 x 4 cores running at 1.86 GHz
18

CSI’s High Performance Center
Bob– named in honor of Dr. Robert E. Kahn, an alumnus of the City College of New York who, along with Vinton G. Cerf, invented the TCP/IP protocol– a Dell PowerEdge system consisting of one head node and thirty compute nodes
• both a standard 1 Gbit Ethernet interconnect and a low-latency, Infiniband SDR (10 Gbit/second) interconnect
– 30 Compute nodes • the same type providing a total of 30 x 8 = 240 cores.
• • Each compute node has 16 Gbytes of memory or 2 Gbytes of memory per core– 1 Head node (PowerEdge 1850)
• two sockets of AMD Shanghai native quad-core processors running at 2.3 GHz Andy
– named in honor of Dr. Andrew S. Grove, an alumnus of the City College of New York and one of the founders of Intel– an SGI ICE system consisting of several head and service nodes, and 45 dual-socket, compute nodes
• The interconnect network is a dual DDR Infiniband (20 Gbit/second) network in which one rail is used for storage and the other for processor communication– 30 Compute nodes
• each with Intel 2.93 GHz quad-core Intel Core 7 (Nehalem) processors providing a total of 360 compute cores
• • Each compute node has 24 Gbytes of memory or 3 Gbytes of memory per core – has a Lustre parallel file system with 24 Tbytes of useable storage 19
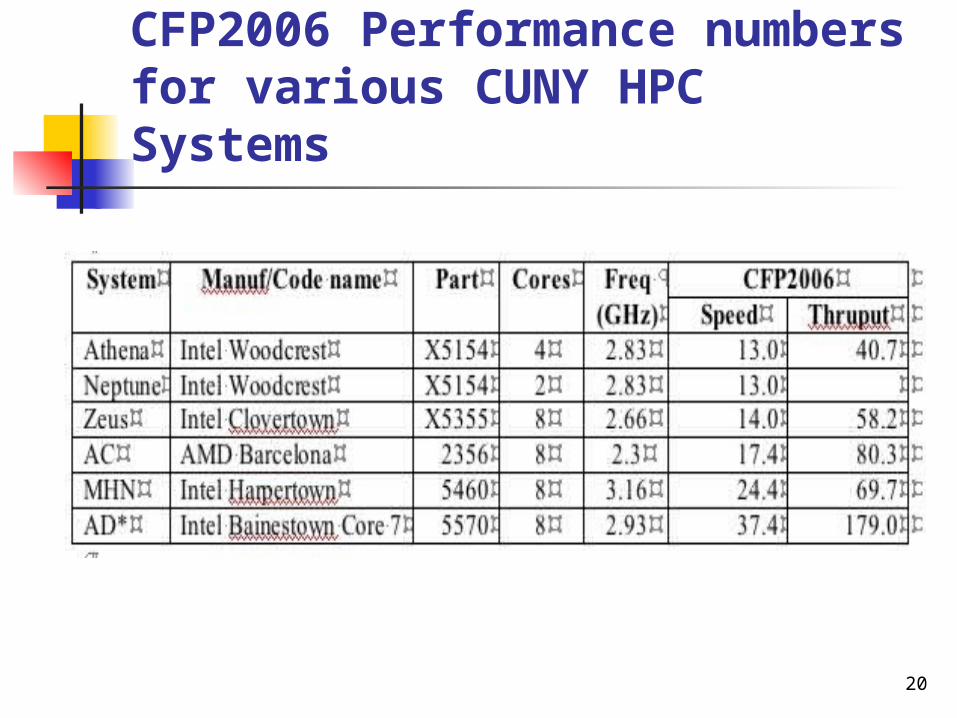
CFP2006 Performance numbers for various CUNY HPC Systems
20

21
Applications of Parallel Computing
Astrophysics(explore the evoluation of galaxies, analysis of extremely large datasets from telescope).
Material sciences (eg superconductivity). Biology, biochemistry, gene sequencing. Medicine and human organ modeling (eg. to study the
effects and dynamics of a heart attack, developing new drugs and cures for diseases).
Global weather prediction. Visualization (eg movie industry, 3D animation). Data Mining (optimizing business and marketing
decisions). Computational-Fluid Dynamics (CFD) for aircraft and
automotive vehicle design. Computer security, cryptography

22
Global Climate Modeling Problem
Problem is to compute:f(latitude, longitude, elevation, time) ->
temperature, pressure, humidity, wind velocity Approach:
—Discretize the domain, e.g., a measurement point every 10 km—Devise an algorithm to predict weather at time t+δt given t
Uses:- Predict major events,e.g., El Nino- Use in setting airemissions standards
Source: http://www.epm.ornl.gov/chammp/chammp.html

23
Global Climate Modeling Computation
• One piece is modeling the fluid flow in the atmosphere—Solve Navier-Stokes equations– Roughly 100 Flops per grid point with 1 minute timestep
• Computational requirements:—To match real-time, need 5 x 1011 flops in 60 seconds = 8 Gflop/s—Weather prediction (7 days in 24 hours) -> 56 Gflop/s—Climate prediction (50 years in 30 days) -> 4.8 Tflop/s—To use in policy negotiations (50 years in 12 hours) -> 288 Tflop/s
• To double the grid resolution, computation is 8x to 16x• State of the art models require integration of
atmosphere,ocean, sea-ice, land models, plus possibly carbon cycle,geochemistry and more
• Current models are coarser than this

24
What is a parallel algorithm? A parallel algorithm is an algorithm
designed for a parallel computer.

25
Questions when combining processor power
How does one combine processors efficiently?
Do processors work independently? Do they cooperate? If they cooperate
how do they interact with each other? How are the processors interconnected? How can we make programs portable? How does one program such machines so
that programs run efficiently and do not waster resourses?

26
End of lecture 1
Thank you!
Related Documents











