Learning Bayesian Networks CSE 473

Learning Bayesian Networks CSE 473. © Daniel S. Weld 2 Last Time Basic notions Bayesian networks Statistical learning Parameter learning (MAP, ML, Bayesian.
Dec 21, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Learning Bayesian Networks
CSE 473

© Daniel S. Weld 2
Last Time• Basic notions• Bayesian networks• Statistical learning
Parameter learning (MAP, ML, Bayesian L) Naïve Bayes
•Issues Structure Learning Expectation Maximization (EM)
• Dynamic Bayesian networks (DBNs)• Markov decision processes (MDPs)

© Daniel S. Weld 3
Simple Spam Model
Spam
Nigeria NudeSex …Naïve Bayes assumes attributes independent Given class of parent Correct?

© Daniel S. Weld 4
Naïve Bayes Incorrect, but Easy!
• P(spam | X1 … Xn) = P(spam | Xi)
• How compute P(spam | Xi)?
• How compute P(Xi | spam)?
i

Smooth
with a Prior
• Note that if m = 10 in the above, it is like saying “I have seen 10 samples that make me believe that P(Xi | S) = p”
• Hence, m is referred to as the
equivalent sample size
# + # # + mp
+ mP(Xi | S) =

Probabilities: I
mportant
Detail!
Is there any potential problem here?
• P(spam | X1 … Xn) = P(spam | Xi)i
• We are multiplying lots of small numbers Danger of underflow! 0.557 = 7 E -18
• Solution? Use logs and add! p1 * p2 = e log(p1)+log(p2)
Always keep in log form

© Daniel S. Weld 7
P(S | X)• Easy to compute from data if X discrete
Instance X Spam?
1 T F
2 T F
3 F T
4 T T
5 T F
• P(S | X) = ¼ ignoring smoothing…
© Daniel S. Weld 8
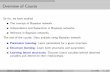
P(S | X)• What if X is real valued?
Instance X Spam?
1 0.01 F
2 0.01 F
3 0.02 F
4 0.03 T
5 0.05 T
• What now?
----- <T
----- <T
----- <T
----- >T
----- >T

© Daniel S. Weld 9
Anything Else?# X S?1 0.0
1
F
2 0.01
F
3 0.02
F
4 0.03
T
5 0.05
T
.01 .02 .03 .04 .05
3
2
1
0
P(S|.04)?
© Daniel S. Weld 10
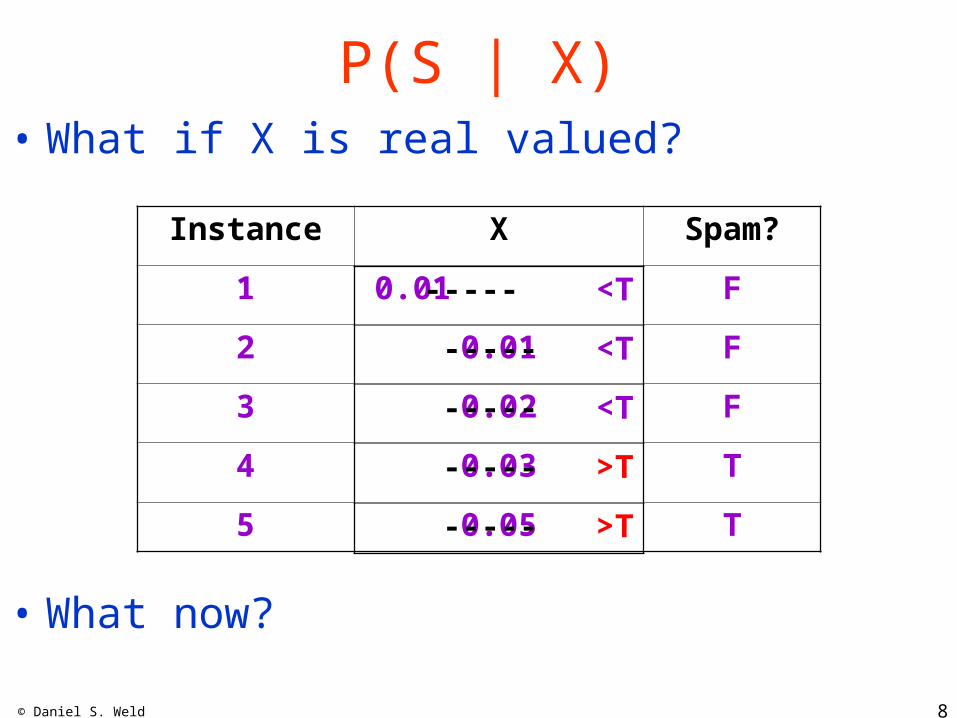
Smooth with Gaussianthen sum
“Kernel Density Estimation”
# X S?1 0.0
1
F
2 0.01
F
3 0.02
F
4 0.03
T
5 0.05
T
.01 .02 .03 .04 .05
3
2
1
0

© Daniel S. Weld 11
Spam?# X S?1 0.0
1
F
2 0.01
F
3 0.02
F
4 0.03
T
5 0.05
T
.01 .02 .03 .04 .05
3
2
1
0
P(S| X=.023)
P(S| X=.023)
What’s with the shape?

© Daniel S. Weld 12
Analysis
Attribute value

© Daniel S. Weld 13
Recap
• Given a BN structure (with discrete or continuous variables), we can learn the parameters of the conditional prop tables.
Spam
Nigeria NudeSex
Earthqk Burgl
Alarm
N2N1

What if we don’t know structure?

© Daniel S. Weld 15
Outline
• Statistical learning Parameter learning (MAP, ML, Bayesian L) Naïve Bayes
•Issues Structure Learning Expectation Maximization (EM)
• Dynamic Bayesian networks (DBNs)• Markov decision processes (MDPs)

Learning The Structure
of
Bayesian
Networks
• Search thru the space of possible network structures! (for now, assume we observe all variables)
• For each structure, learn parameters• Pick the one that fits observed data best
Caveat – won’t we end up fully connected?
????
• When scoring, add a penalty model complexity

Learning The Structure
of
Bayesian
Networks
• Search thru the space • For each structure, learn parameters• Pick the one that fits observed data best
• Problem? Exponential number of networks! And we need to learn parameters for each! Exhaustive search out of the question!
• So what now?

Learning The Structure
of
Bayesian
Networks
Local search! Start with some network
structure Try to make a change (add or delete or reverse
edge) See if the new network is any
better
What should be the initial state?

Initial
Network Structure?
• Uniform prior over random networks?
• Network which reflects expert knowledge?

© Daniel S. Weld 20
Learning BN Structure

The
Big Picture
• We described how to do MAP (and ML) learning of a Bayes net (including structure)
• How would Bayesian learning (of BNs) differ?
• Find all possible networks
• Calculate their posteriors
• When doing inference, return weighed combination of predictions from all networks!

© Daniel S. Weld 22
Outline
• Statistical learning Parameter learning (MAP, ML, Bayesian L) Naïve Bayes
•Issues Structure Learning Expectation Maximization (EM)
• Dynamic Bayesian networks (DBNs)• Markov decision processes (MDPs)

© Daniel S. Weld 23
Hidden Variables
• But we can’t observe the disease variable• Can’t we learn without it?
© Daniel S. Weld 24
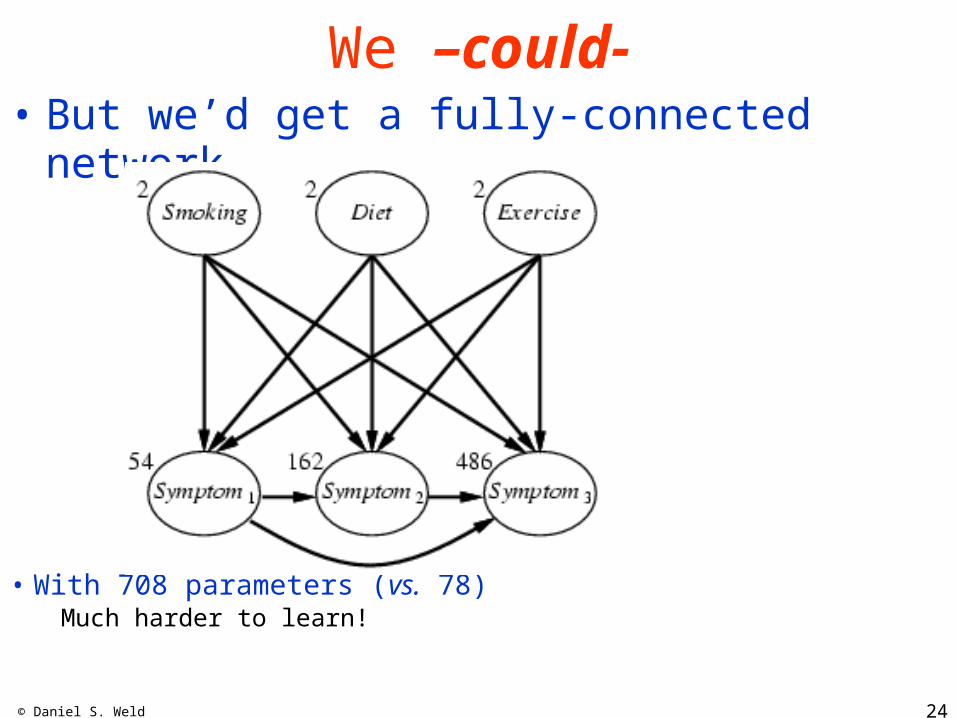
We –could-• But we’d get a fully-connected network
• With 708 parameters (vs. 78) Much harder to learn!

© Daniel S. Weld 25
Chicken & Egg Problem
• If we knew that a training instance (patient) had the disease… It would be easy to learn P(symptom |
disease) But we can’t observe disease, so we don’t.
• If we knew params, e.g. P(symptom | disease) then it’d be easy to estimate if the patient had the disease. But we don’t know these parameters.

© Daniel S. Weld 26
Expectation Maximization (EM)(high-level version)
• Pretend we do know the parameters Initialize randomly
• [E step] Compute probability of instance having each possible value of the hidden variable
• [M step] Treating each instance as fractionally having both values compute the new parameter values
• Iterate until convergence!

© Daniel S. Weld 27
Candy Problem
• Given a bowl of mixed candies• Can we learn contents of each bag, and• What percentage of each is in bowl?
+
© Daniel S. Weld 28
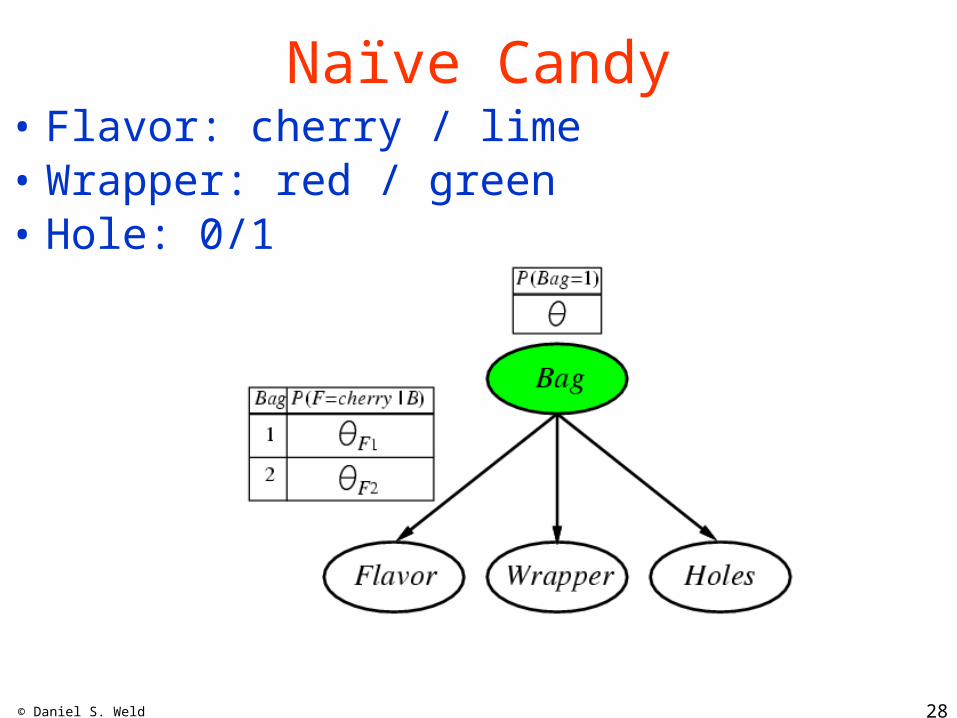
Naïve Candy• Flavor: cherry / lime• Wrapper: red / green• Hole: 0/1
© Daniel S. Weld 29
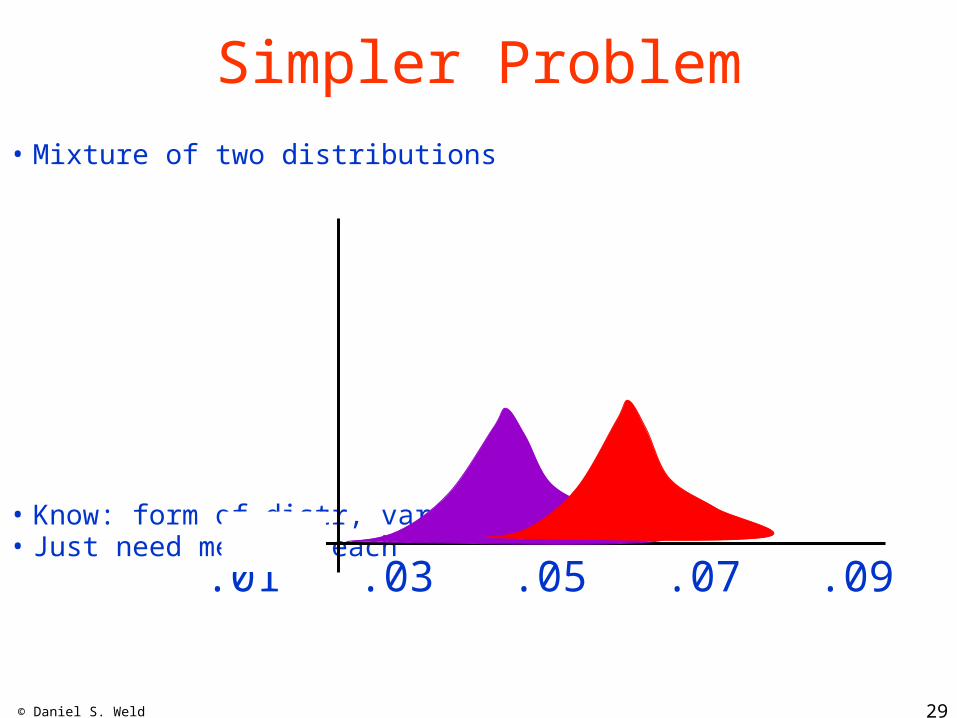
Simpler Problem• Mixture of two distributions
• Know: form of distr, variance, % =5• Just need mean of each.01 .03 .05 .07 .09
© Daniel S. Weld 30
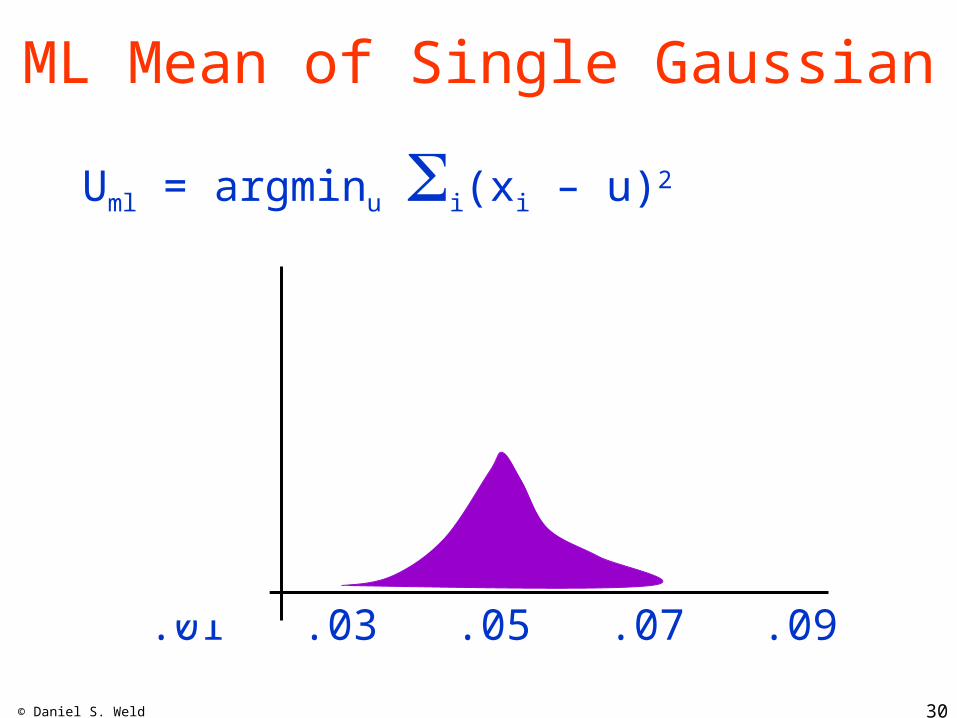
ML Mean of Single Gaussian
Uml = argminu i(xi – u)2
.01 .03 .05 .07 .09
Related Documents