Mon-3-Mar, 11:15am, Mathieu Poirier LCA14-104: GTS- A solution to support ARM’s big.LITTLE technology

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Mon-3-Mar, 11:15am, Mathieu Poirier
LCA14-104: GTS- A solution to support ARM’s big.LITTLE technology

• Things to know about Global Task Scheduling (GTS).
• MP patchset description and how the solution works.
• Configuration parameters at various levels.
• Continuous integration at Linaro.
Today’s Presentation:

• This presentation is the lighter version of two presentation Linaro has on GTS.
• The other runs for about 75 minutes and goes much deeper in the solution.
• If you are interested in the in-depth version please contact Joe Bates: [email protected]
Other Presentations on GTS:

• A set of patches enacting Global Task Scheduling(GTS).• Developed by ARM Ltd. • GTS modifies the Linux scheduler in order to place tasks
on the best possible CPU.
• Advantages:• Take full advantage of the asynchronous nature of b.L architecture.
• Maximum performance• Minimum power consumption
• Better benchmark scores for thread-intensive benchmarks.• Increased responsiveness by spinning off new tasks on big CPUs.• Decreases power consumption, specifically with small-task packing.
What is the MP Patchset?
• In a tarball from the release page:• Always look for the latest “vexpress-lsk” release on release.linaro.org
- ex. for January:
http://releases.linaro.org/14.01/android/vexpress-lsk• February should look like:
http://releases.linaro.org/14.02/android/vexpress-lsk
• In the Linaro Stable Kernel:https://git.linaro.org/gitweb?p=kernel/linux-linaro-stable.git;a=summary
Where to get it

• In the ARM big LITTLE MP tree:https://git.linaro.org/gitweb?p=arm/big.LITTLE/mp.git;a=summary
** Linaro doesn’t rebase the MP patchset on other kernels than the Linaro Stable Kernel.
Where to get it (continued)

• General Overview:• The Linux kernel builds a hierarchy of scheduling domains at boot
time. The order is (Linux convention):• Sibling (for Hyperthreading)• MC - multi-core• CPU - between clusters• NUMA
• To understand how the kernel does this:• Enable CONFIG_SCHED_DEBUG and • set “sched_debug=1” on the kernel cmd line
• In a pure SMP context load balancing is done by spreading tasks evenly among all processors.• Maximisation of CPU resources• Run-to-completion model
MP Patchset Description

Domain Load Balancing - no GTS
CPU0 CPU1
CPU2
CFS (MC level)
CPU3 CPU4CFS
(MC level)
CFS (CPU level)
CFS (CPU level)
Vexpress (A7x3 + A15x2)

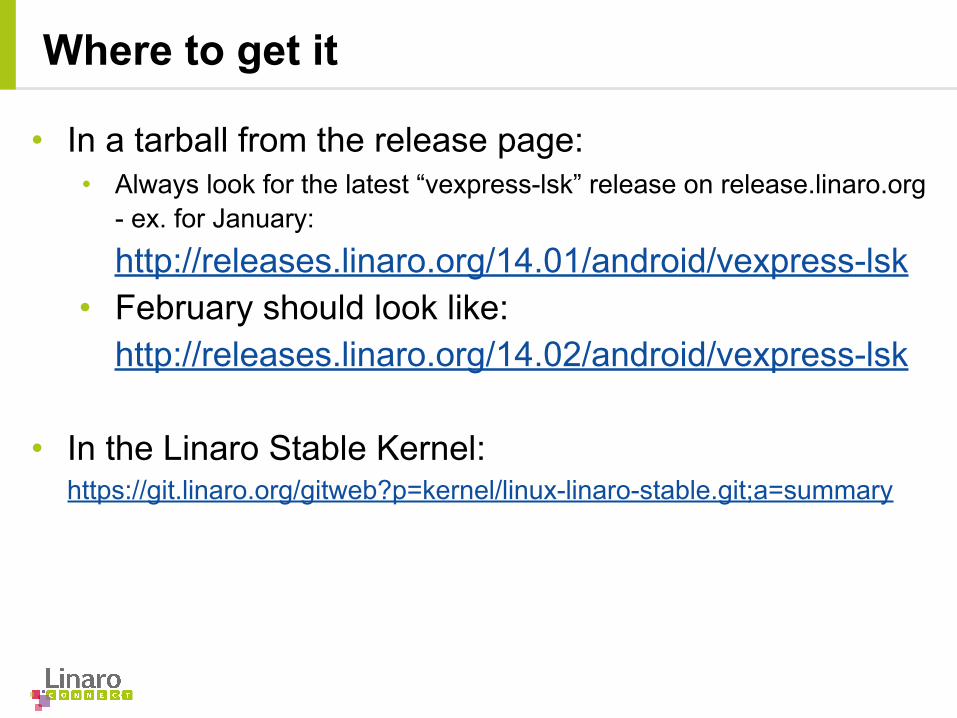
• Classic load balancing between CPU domains (i.e big and LITTLE) is disabled.
• A derivative of Paul Turner’s “load_avg_contrib” metric is used to decide if a task should be moved to another HMP domain.
Paul’s work: http://lwn.net/Articles/513135/
• Migration of tasks among the CPU domains is done by comparing their loads with migration thresholds.
• By default, all new user tasks are placed on the big cluster.
How MP Works
Domain Load Balancing - with GTS
CPU0 CPU1
CPU2
CFS (MC level)
CPU3 CPU4CFS
(MC level)
CFS (CPU level)
CFS (CPU level)
Vexpress (A7x3 + A15x2)
GTS
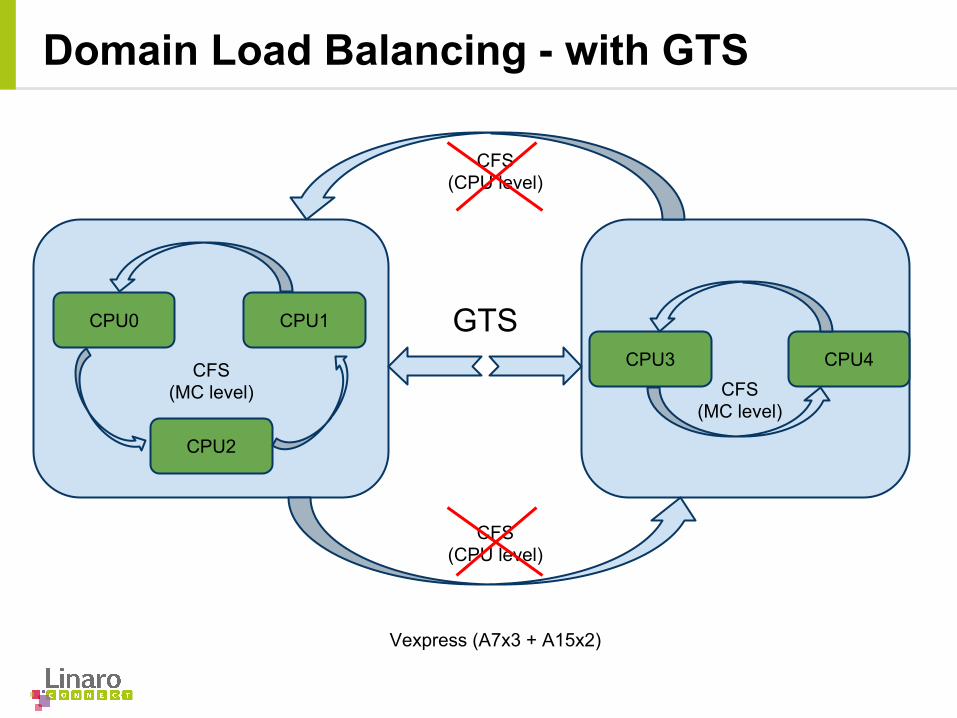
Load Average Contribution and Decay
Plotting of the “runnable_avg_sum” metric introduced by Paul Turner

• Paul Turner introduced the load average contribution metric in his work on per-entity load tracking:
load_avg_contrib = task->weight * runnable_averagewhere runnable_average is:
runnable_average = runnable_avg_sum / runnable_avg_period
• runnable_avg_sum and runnable_avg_period are geometric series.
• load_avg_contrib is good for scheduling decisions but bad for task migration i.e, weight scaling doesn’t reflect the true time spent by a task in the runnable state.
Per Entity Load Tracking

• The MP patchset introduces the load average ratio:load_avg_ratio = NICE_0_LOAD * runnable_average
• The load average ratio allows for the comparison of tasks without their weight factor, giving the same perspective for all of them.
• At migration time the load average ratio is compared against two thresholds:• hmp_up_threashold• hmp_down_threashold
Load Average Ratio

UP and Down Migration thresholds
A task’s load is compared to the up and down migration threshold during the MP domain balancing process.
* Source: ARM Ltd.

• The Linux scheduler will separate CPUs into domains.• Tasks are spread out among the domains as equally as
possible.• For GTS load balancing at the CPU domain level is
disabled.• GTS will move tasks between CPU domains using a
derivative of the load average contribution and a couple of thresholds.
• But when is GTS moving tasks between the CPU domains?
What We’ve Learned So Far

• 4 task migration points:• When tasks are created (fork migration).
• At wakeup time (wakeup migration).
• With every scheduler tick (forced migration).
• When a CPU is about to become idle (idle pull).
Task Migration Points

• When tasks are created (fork migration):
• Done by setting the task’s load statistics to their maximum value.
• Tasks are placed on big CPUs unless they are:• Kernel Threads• Forked from init i.e, Android services.
• Android apps are forked from Zygote, hence go on big CPUs.
• Tasks are eventually migrated down if they aren’t heavy enough.
Fork Migration

• At wakeup time (wakeup migration):• When a task is to be placed on a CPU, the scheduler will normally
prefer:• The previous CPU the task ran on• Or one in the same package.
• For GTS, the decision is based on the load a task had before it was suspended:
• if load(task) > hmp_up_threshold, select more potent HMP domain• if load(task) < hmp_down_threshold, select less powerful HMP
domain
• What happened in the past is likely to happen again.
Wakeup Migration

• With every scheduler tick (forced migration):• Every CPU in the system has a scheduler tick.
• With each tick (minimum interval of 1 jiffies) a CPU’s runqueue is rebalanced if event due.
• Each time the load balancer runs, the MP code will inspect the runqueue of all CPUs in the system:
• If LITTLE CPU → can a task be moved to big cluster?• if ((big CPU ) && (CPU overloaded)) → offload lightest task.• When offloading, always select an idle CPU to ensure CPU availability
for the task.• So that tasks can be migrated as quickly as possible as domains can
stay balanced for a long time.
Forced Migration

• When a CPU is about to become idle(idle pull):
• When a CPU is about to go idle the scheduler will attempt to pull tasks away from other CPUs in the same domain.
• Happens only if the CPU average idle time is more than the estimated migration cost.
• Balancing within a domain is left to normal scheduler operation.
• If the scheduler didn’t find any task to pull and CPU is in big cluster:• Go through the runqueues of all online CPUs in the LITTLE cluster. • If a task’s load is above threshold, move it to a CPU in the big cluster. • When moving a task, always look for the least loaded CPU.
Idle Pull

MP Migration Types
* Source: ARM Ltd.

• Scheduler will try to fit as many small task on a single CPU as possible.
• A small task is =< 90% of NICE_0_LOAD, i,e 921• Done on the LITTLE cluster only to make sure tasks on
the big cluster have all the CPU time they need.• Takes place when a task is waking up:
• Using the tracked load of CPU runqueues and tasks.• Saturation threshold to make sure tasks offloaded from
the big domain can keep being serviced.
• Effects of enabling small task packing:• CPU operating point may increase → CPUfreq governor will kick in.• Wakeup latency of task may increase → more tasks to run.
Small Task Packing

• Load balancing at the CPU domain level is disabled to favour the GTS scheme.
• GTS works by comparing a task’s runnable load ratio and migrating it to a different HMP domain if need be.
• There are 4 migration points:• At creation time.• At wakeup time.• Every rebalance.• When a CPU is about to become idle.
• Small task packing when CPU gating is possible.
Key Things to Remember

• GTS doesn’t hotplug CPUs and is not concerned at all with hotplugging
• When hotplugging:• It takes too long to bring a CPU in and out of service
• All smpboot threads need to be stopped.• “stop_machine” threads suspend interrupts on all online CPUs.• IRQs on the swapped CPU are diverted to another CPU.• All processes in swapped CPU’s runqueue are migrated.• CPU is taken out of coherency.
• More CPUs means longer hotplug time per CPU.• Very expensive to make a CPU coherent with the domain hierarchy
again.• The system needs intelligence to determine when CPUs will be
swapped in and out.
One Last Remark

• The GTS solution itself has a number of parameters that can be tuned. Examples:
• From /sys/kernel/hmp:• up_threshold, down_threshold for task migration limits• load_avg_period_ms and frequency_invariant_load_scale
• From the code:• runqueue saturation when doing small task packing• Amount of task on a runqueue to search when force migrating between
domains
GTS Tuning

• Linaro and ARM have been using the “interactive” governor in their testing of the solution. • Any governor can be used.• b.L CPUfreq driver makes the architecture seamless to the governor.
• Example of interactive governor tuneables:• hispeed_freq and go_hispeed_load• target_loads• timer_rate and min_sample_time• above_hispeed_delay
• Governors will have tuneable parameters.• Regardless of the governor used, there are parameters to adjust in
order to yield the right behavior• Default values are usually not what you want
CPUFreq Governor Tuning

• As Linaro assimilate MP patches in the LSK, continuous integration testing is done daily to catch possible regressions.
• We run bbench with an audio track in the background - good average test case.• exercises both big and LITTLE clusters
• All automated in our LAVA environment and results verified each day.
• Full WA regression tests with each monthly release.• TC2 is the only b.L platform being tested at Linaro - we’d
welcome other platforms.
MP Testing at Linaro

Question and Acknowledgements
Special thanks to:Chris Redpath (ARM) Robin Randhawa (ARM)Vincent Guittot (Linaro)

More about Linaro Connect: http://connect.linaro.orgMore about Linaro: http://www.linaro.org/about/
More about Linaro engineering: http://www.linaro.org/engineering/Linaro members: www.linaro.org/members
Related Documents