Funk et al. BMC Bioinformatics 2014, 15:59 http://www.biomedcentral.com/1471-2105/15/59 RESEARCH ARTICLE Open Access Large-scale biomedical concept recognition: an evaluation of current automatic annotators and their parameters Christopher Funk 1* , William Baumgartner Jr 1 , Benjamin Garcia 1,2 , Christophe Roeder 1 , Michael Bada 1 , K Bretonnel Cohen 1 , Lawrence E Hunter 1 and Karin Verspoor 3,4* Abstract Background: Ontological concepts are useful for many different biomedical tasks. Concepts are difficult to recognize in text due to a disconnect between what is captured in an ontology and how the concepts are expressed in text. There are many recognizers for specific ontologies, but a general approach for concept recognition is an open problem. Results: Three dictionary-based systems (MetaMap, NCBO Annotator, and ConceptMapper) are evaluated on eight biomedical ontologies in the Colorado Richly Annotated Full-Text (CRAFT) Corpus. Over 1,000 parameter combinations are examined, and best-performing parameters for each system-ontology pair are presented. Conclusions: Baselines for concept recognition by three systems on eight biomedical ontologies are established (F-measures range from 0.14–0.83). Out of the three systems we tested, ConceptMapper is generally the best-performing system; it produces the highest F-measure of seven out of eight ontologies. Default parameters are not ideal for most systems on most ontologies; by changing parameters F-measure can be increased by up to 0.4. Not only are best performing parameters presented, but suggestions for choosing the best parameters based on ontology characteristics are presented. Background Ontologies have grown to be one of the great enabling technologies of modern bioinformatics, particularly in areas like model organism database curation, where they have facilitated large-scale linking of genomic data across organisms, but also in fields like analysis of high- throughput data [1] and protein function prediction [2,3]. Ontologies have also played an important role in the development of natural language processing systems in the biomedical domain, which can use ontologies both as terminological resources and as resources that pro- vide important semantic constraints on biological enti- ties and events [4]. Ontologies provide such systems with a target conceptual representation that abstracts over variations in the surface realization of terms. This *Correspondence: [email protected]; [email protected] 1 Computational Bioscience Program, U. of Colorado School of Medicine, Aurora, CO 80045, USA 3 Victoria Research Lab, National ICT Australia, Melbourne 3010, Australia Full list of author information is available at the end of the article conceptual representation of the content of documents in turn enables development of sophisticated informa- tion retrieval tools that organize documents based on categories of information in the documents [5-7]. Finally, ontologies themselves can benefit from concept recognition in text. Yao et al. [8] propose new ontology quality metrics that are based on the goodness of fit of an ontology with a domain-relevant corpus. They note that a limitation of their approach is the dependency on tools that establish linkages between ontology concepts and their textual representations. However, a general approach to recognition of terms from any ontology in text remains a very open research problem. While there exist sophisticated named entity recognition tools that address specific categories of terms, such as genes or gene products [9], protein mutations [10], or diseases [11,12], these tools require targeted training material and cannot generically be applied to recognize arbitrary terms from large, fine-grained vocabularies [6]. Furthermore, as Brewster et al. [13] point out, there is © 2014 Funk et al.; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly credited.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Funk et al BMC Bioinformatics 2014 1559httpwwwbiomedcentralcom1471-21051559
RESEARCH ARTICLE Open Access
Large-scale biomedical concept recognitionan evaluation of current automatic annotatorsand their parametersChristopher Funk1 William Baumgartner Jr1 Benjamin Garcia12 Christophe Roeder1 Michael Bada1K Bretonnel Cohen1 Lawrence E Hunter1 and Karin Verspoor34
Abstract
Background Ontological concepts are useful for many different biomedical tasks Concepts are difficult to recognizein text due to a disconnect between what is captured in an ontology and how the concepts are expressed in text Thereare many recognizers for specific ontologies but a general approach for concept recognition is an open problem
Results Three dictionary-based systems (MetaMap NCBO Annotator and ConceptMapper) are evaluated on eightbiomedical ontologies in the Colorado Richly Annotated Full-Text (CRAFT) Corpus Over 1000 parametercombinations are examined and best-performing parameters for each system-ontology pair are presented
Conclusions Baselines for concept recognition by three systems on eight biomedical ontologies are established(F-measures range from 014ndash083) Out of the three systems we tested ConceptMapper is generally thebest-performing system it produces the highest F-measure of seven out of eight ontologies Default parameters arenot ideal for most systems on most ontologies by changing parameters F-measure can be increased by up to 04 Notonly are best performing parameters presented but suggestions for choosing the best parameters based on ontologycharacteristics are presented
BackgroundOntologies have grown to be one of the great enablingtechnologies of modern bioinformatics particularly inareas like model organism database curation wherethey have facilitated large-scale linking of genomic dataacross organisms but also in fields like analysis of high-throughput data [1] and protein function prediction [23]Ontologies have also played an important role in thedevelopment of natural language processing systems inthe biomedical domain which can use ontologies bothas terminological resources and as resources that pro-vide important semantic constraints on biological enti-ties and events [4] Ontologies provide such systemswith a target conceptual representation that abstractsover variations in the surface realization of terms This
Correspondence christopherfunkucdenvereduKarinVerspoornictacomau1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA3Victoria Research Lab National ICT Australia Melbourne 3010 AustraliaFull list of author information is available at the end of the article
conceptual representation of the content of documentsin turn enables development of sophisticated informa-tion retrieval tools that organize documents based oncategories of information in the documents [5-7]Finally ontologies themselves can benefit from concept
recognition in text Yao et al [8] propose new ontologyquality metrics that are based on the goodness of fit ofan ontology with a domain-relevant corpus They notethat a limitation of their approach is the dependency ontools that establish linkages between ontology conceptsand their textual representationsHowever a general approach to recognition of terms
from any ontology in text remains a very open researchproblem While there exist sophisticated named entityrecognition tools that address specific categories of termssuch as genes or gene products [9] proteinmutations [10]or diseases [1112] these tools require targeted trainingmaterial and cannot generically be applied to recognizearbitrary terms from large fine-grained vocabularies [6]Furthermore as Brewster et al [13] point out there is
copy 2014 Funk et al licensee BioMed Central Ltd This is an Open Access article distributed under the terms of the CreativeCommons Attribution License (httpcreativecommonsorglicensesby20) which permits unrestricted use distribution andreproduction in any medium provided the original work is properly credited
Funk et al BMC Bioinformatics 2014 1559 Page 2 of 29httpwwwbiomedcentralcom1471-21051559
often a disconnect between what is captured in an ontol-ogy and what can be expected to be explicitly stated intext This is particularly true for relations among conceptsbut it is also the case that concepts themselves can beexpressed in text with a huge amount of variability andpotentially ambiguity and underspecification [1415]The work reported here aims to advance the state of
the art in recognizing terms from ontologies with a widevariety of differences in both the structure and content ofthe ontologies and in the surface characteristics of termsassociated with concepts in the ontology In the course ofthe work reported in this paper we evaluate a number ofhypotheses related to the general task of finding referencesto concepts from widely varying ontologies in text Theseinclude the following
bull Not all concept recognition systems perform equallyon natural language texts
bull The best concept recognition system varies fromontology to ontology
bull Parameter settings for a concept recognition systemcan be optimized to improve performance on a givenontology
bull Linguistic analysis in particular morphologicalanalysis affects the performance of conceptrecognition systems
To test these hypotheses we apply a variety ofdictionary-based tools for recognizing concepts in text toa corpus in which nearly all of the concepts from a varietyof ontologies have been manually annotated We performan exhaustive exploration of the parameter spaces for eachof these tools and report the performance of thousands ofcombinations of parameter settings We experiment withthe addition of tools for linguistic analysis in particularmorphological analysis Along with reporting quantita-tive results we give the results of manual error analysisfor each combination of concept recognition system andontologyThe gold standard used is the Colorado Richly Anno-
tated Full-Text (CRAFT) Corpus [1617] The full CRAFTcorpus consists of 97 completely annotated biomedi-cal journal articles while the ldquopublic releaserdquo set whichconsists of 67 documents was used for this evaluationCRAFT includes over 100000 concept annotations fromeight different biomedical ontologies Without CRAFTthis large-scale evaluation of concept annotation wouldnot have been possible due to lack of corpora annotatedwith a large number of concepts frommultiple ontologies
RelatedworkA number of tools and strategies have been proposed forconcept annotation in text These include both tools thatare generally applicable to a wide range of terminology
resources and strategies that have been designed specif-ically for one or a few terminologies The two mostwidely used generic tools are the National Library ofMedicinersquos MetaMap [18] and NBCOrsquos Open Biomedi-cal Annotator (NCBO Annotator) [19] based on a toolfrom the University of Michigan called mgrep Othertools including Whatizit [20] KnowledgeMap [2122]CONANN [23] IndexFinder [2425] Terminizer [26] andPeregrine [2728] have been created but are not pub-licly available or appear not to be in widespread useWe therefore focus our analysis in this paper on theNCBO Annotator and MetaMap In addition we includeConceptMapper [2930] a tool that was not specificallydeveloped for biomedical term recognition but rather forflexible look up of terms from a dictionary or controlledvocabularyThe tools mgrep and MetaMap have been directly
compared on several term recognition tasks [1931]These studies indicate that mgrep outperforms Meta-Map in terms of precision of matching Both studies alsonote that MetaMap returns many more annotations thanmgrep Recall is not calculated in either study becausethe document collections used as input were not fullyannotated By using a completely annotated corpus suchas CRAFT we are able to generate not only precision butrecall which gives a complete picture of the performanceof the systemThe Gene Ontology [32] has been the target of several
customized methods that take advantage of the specificstructure and characteristics of that ontology to facilitaterecognition of its constituent terms in text [233-36] Inthis work we will not specifically compare these methodsto the more generic tools identified above as they are notapplicable to the full range of ontologies that are reflectedin the CRAFT annotationsThe CRAFT corpus has been utilized previously in the
context of evaluating the recognition of specific cate-gories of terms Verspoor et al [16] provide a detailedassessment of named entity recognition tool performancefor recognition of genes and gene products As with thework mentionned in the previous paragraph these arespecialized tools with a more targeted approach thanwe explore in this work typically requiring substan-tial amounts of training material tailored to the specificnamed entity category We do not repeat those exper-iments here as they are not relevant to the generalproblem of recognition of terms from large controlledvocabularies
A note on ldquoconceptsrdquoWe are aware of the controversies associated with the useof the word ldquoconceptrdquo with respect to biomedical ontolo-gies but the content of the paper is not affected by theconflicting positions on this issue we use theword to refer
Funk et al BMC Bioinformatics 2014 1559 Page 3 of 29httpwwwbiomedcentralcom1471-21051559
to the tuple of namespace identifier term(s) definitionsynonym(s) and metadata that make up an entry in anontology
MethodsCorpusWe used version 10 released October 19 2012 of theColorado Richly Annotated Full Text Corpus (CRAFT)data set [1617] The full corpus consists of 97 full-text documents selected from the PubMed Central OpenAccess subset Each document in the collection serves asevidence for at least one mouse functional annotationFor this paper we used the ldquopublic releaserdquo subsectionwhich consists of 21000 sentences from 67 articles Thereare over 100000 concept annotations from eight differentbiomedical ontologies in this public subset Each anno-tation specifies the identifier of the concept from therespective ontology along with the beginning and endpoints of the text span(s) of the annotationTo fully understand the results presented it is impor-
tant to understand how CRAFT was annotated [17] Herewe present three guidelines First the text associated witheach annotation in CRAFT must be semantically equiv-alent to the term from the ontology with which it isannotated In other words the text in its context hasthe same meaning as the concept used to annotate itSecond annotations are made to a specific ontology andnot to a domain that is annotations are created onlyfor concepts explicitly represented in the given ontologyand not to concepts that ldquoshouldrdquo be in the ontology butare not explicitly represented For example if the ontol-ogy contains a concept representing vesicles but nothingmore specific a mention of ldquomicrovesiclesrdquo would not beannotated Even though it is a type of vesicle it is notannotated because microvesicles are not explicitly rep-resented in the ontology and annotating this text withthe more general vesicle concept would not be seman-tically equivalent ie information would be lost Thirdonly text directly corresponding to a concept is taggedfor example if the text ldquomutant vesiclesrdquo is seen ldquovesi-clesrdquo is tagged by itself (ie without ldquomutantrdquo) with thevesicle concept Because only the most specific conceptis annotated there are no subsuming annotations thatis given an annotation of a text span with a particu-lar concept no annotations are made within this textspan(s) with a more general concept even if they appearin the term For an example from the Cell Type Ontologygiven the text ldquomesenchymal cellrdquo this phrase is annotatedwith ldquoCL0000134 - mesenchymal cellrdquo but the nestedldquocellrdquo is not additionally annotated with ldquoCL0000000 -cellrdquo as the latter is an ancestor of the former andtherefore redundant There are very specific guidelinesas to what text is included in an annotation set out inBada et al [37]
OntologiesThe annotations of eight ontologies representing awide variety of biomedical terminology were used forthis evaluation 1ndash3) The three sub-ontologies of theGene Ontology (Biological Process Molecular FunctionCellular Component) [32] 4) the Cell Type Ontology[38] 5) Chemical Entities of Biological Interest Ontol-ogy [39] 6) the NCBI Taxonomy [40] 7) the SequenceOntology [41] and 8) the Protein Ontology [42] Ver-sions of ontologies used along with descriptive statisticscan be seen in Table 1 CRAFT also contains EntrezGene annotations but these were analyzed in previ-ous work [16] The Gene Ontology (GO) aims to stan-dardize the representation of gene and gene productattributes it consists of three distinct sub-ontologieswhich are evaluated separately Molecular Function Bio-logical Process and Cellular Component The Cell TypeOntology (CL) provides a structured vocabulary for celltypes Chemical Entities of Biological Interest (ChEBI) isfocused on molecular entities molecular parts atomssubatomic particles and biochemical roles and appli-cations NCBI Taxonomy (NCBITaxon) provides classi-fication and nomenclature of all organisms and typesof biological taxa in the public sequence database TheSequence Ontology (SO) aims to describe the featuresand attributes of biological sequences The Protein Ontol-ogy (PRO) provides a representation of protein-relatedentities
Structure of ontology entriesThe ontologies used are from the Open BiomedicalOntologies (OBO) [43] flat file format To help to under-stand the structure of the file an entry of a concept fromCL is shown below The only parts of an entry used inour systems are the id name and synonym rows Alter-native ways to refer to terms are expressed as synonymsthere are many types of synonyms that can be specifiedwith different levels of relatedness to the concept (exactbroad narrow and related) An ontology contain a hier-archy among its terms these are expressed in the ldquois_ardquoentry Terms described as ldquoancestorsrdquo ldquoless specificrdquo orldquomore generalrdquo lie above the specified concept in the hier-archy while terms described as ldquomore specificrdquo are belowthe specified concept
id CL0000560name band form neutrophildef ldquoA late neutrophilic metamyelocyte in which thenucleus is in the form of a curved or coiled band not hav-ing acquired the typical multi lobar shape of the matureneutrophilrdquosynonym ldquoband cellrdquo EXACTsynonym ldquorod neutrophilrdquo EXACTsynonym ldquobandrdquo NARROW
Funk et al BMC Bioinformatics 2014 1559 Page 4 of 29httpwwwbiomedcentralcom1471-21051559
Table 1 Characteristics of ontologies evaluated
Ontology Version Concepts Avg term Avg words Avg Have Have Havelength in term synonyms punctuation numerals stop words
Cell type 25052007 838 200 plusmn 95 30 plusmn 14 05 plusmn 11 116 48 33
Sequence 30032009 1610 216 plusmn 133 31 plusmn 10 14 plusmn 1 919 66 93
ChEBI 28052008 19633 255 plusmn 242 43 plusmn 48 20 plusmn 25 548 413 0
NCBITaxon 12072011 789538 246 plusmn 102 36 plusmn 20 NA 537 560 03
GO-MF 28112007 7984 391 plusmn 154 46 plusmn 22 28 plusmn 46 528 266 27
GO-BP 28112007 14306 401 plusmn 190 50 plusmn 27 21 plusmn 25 235 70 457
GO-CC 28112007 2047 266 plusmn 142 36 plusmn 17 01 plusmn 09 295 144 68
Protein 22042011 26807 384 plusmn 185 55 plusmn 25 31 plusmn 32 684 748 43
is_a CL0000776 immature neutrophilrelationship develops_from CL0000582 neutrophilicmetamyelocyte
A note on obsolete termsOntologies are ever changing new terms are added modi-fications aremade to others and others aremade obsoleteThis poses a problem because obsolete terms are notremoved from the ontology but only marked as obsoletein the obo flat file The dictionary-based methods used inour analysis do not distinguish between valid or obsoleteterms when creating their dictionaries so obsolete termsmay be returned by the systems A filter was incorpo-rated to remove obsolete terms returned (discussed morebelow) Not filtering obsolete terms introduces many falsepositives For example the terms ldquoGO0005574 - DNArdquoand ldquoGO0003675 - proteinrdquo are both obsolete in the cellu-lar component branch of the Gene Ontology and are men-tioned very frequently within the biomedical literature
Concept recognition systemsWe evaluated three concept recognition systems NCBOAnnotator (NCBO Annotator) [44] MetaMap [18] andConceptMapper [2930] All three systems are publiclyavailable and able to produce annotations for many dif-ferent ontologies but differ in their underlying implemen-tation and amount of configurable parameters The fullevaluation results are available for download at httpbionlpsourceforgenetNCBO Annotator is a web service provided by the
National Center for Biomedical Ontology (NCBO) thatannotates textual data with ontology terms from theUMLS and BioPortal ontologies The input text is fedinto a concept recognition tool (mgrep) and annotationsare produced A wrapper [45] programmatically convertsannotations produced by NCBO into xml which is thenimported into our evaluation pipeline The evaluationsfrom NCBO Annotator were performed in October andNovember 2012
MetaMap (MM) is a highly configurable program cre-ated to map biomedical text to the UMLS MetathesaurusMM parses input text into noun phrases and generatesvariants (alternate spellings abbreviations synonymsinflections and derivations) from these A candidate setof Metathesaurus terms containing one of the variantsis formed and scores are computed on the strength ofmapping from the variants to each candidate term Incontrast to a Web service MM runs locally we installedMM v2011 on a local Linux server MM natively workswith UMLS ontologies but not all ontologies that we haveevaluated are a part of the UMLS The optional data filebuilder [46] allowsMM to use any ontology as long as theycan be formatted as UMLS database tables therefore aPerl script was written to convert the ontology obo filesto UMLS database tables following the specification in thedata file builder overviewConceptMapper (CM) is part of the Apache UIMA
[47] Sandbox and is available at httpuimaapacheorgduima-addons-currentConceptMapper Version 231 wasused for these experiments CM is a highly configurabledictionary lookup tool implemented as a UIMA compo-nent Ontologies are mapped to the appropriate dictio-nary format required by ConceptMapper The input textis processed as tokens all tokens within a span (sen-tence) are looked up in the dictionary using a configurablelookup algorithm
Parameter explorationEach systemrsquos parameters were examined and config-urable parameters were chosen Table 2 gives a list ofeach systemwith the chosen parameters along with a briefdescription and possible values The list of stop wordsused is provided in Additional file 1
Evaluation pipelineAn evaluation pipeline for each system was constructedand run in UIMA [49] MM produces annotations sep-arate from the evaluation pipeline UIMA components
Funk et al BMC Bioinformatics 2014 1559 Page 5 of 29httpwwwbiomedcentralcom1471-21051559
Table 2 System parameter description and values
NCBO Annotator parameters
Parameter Description and possible values
wholeWordOnly Term recognition must match whole words - (YES NO)
filterNumber Specifies whether the entity recognition step should filter numbers - (YES NO)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
stopWordsCaseSensitive Whether stop words are case sensitive - (YES NO)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
withSynonyms Whether to include synonyms in matching - (YES NO)
MetaMap parameters
Parameter Description and possible values
model Determines which data model is used - (STRICT - lexical manual and syntactic filtering are applied RELAXED - lexicaland manual filtering are used)
gaps Specifies how to handle gaps in terms when matching - (ALLOW NONE)
wordOrder Specifies how to handle word order when matching - (ORDER MATTERS IGNORE)
acronymAbb Determines which generated acronym or abbreviations are used - (NONE DEFAULT UNIQUE - restricts variants toonly those with unique expansions)
derivationalVars Specifies which type of derivational variants will be used - (NONE ALL ONLY ADJ NOUN)
scoreFilter MetaMap reports a score from 0ndash1000 for every match with 1000 being the highest those matches with scores lewill be returned - (0 600 800 1000)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
ConceptMapper parameters
Parameter Description and possible values
searchStrategy Specifies the dictionary lookup strategy - (CONTIGUOUS - longest match of contiguous tokens SKIP ANY - returnslongest match of not-necessarily contiguous tokens and next lookup begin in next span SKIP ANY ALLOWOVERLAP -returns longest match of not-necessarily contiguous tokens in the span and next lookup begin after next token)
caseMatch Specifies the case folding mode to use - (IGNORE - fold everything to lower case INSENSITIVE - fold only tokens withinitial caps to lowercase SENSITIVE - no folding FOLD DIGIT - fold only tokens with digits to lower case)
stemmer Name of the stemmer to use before matching - (Porter - classic stemmer that removes common morphological andinflectional endings from Engish words BioLemmatizer - domain specific lemmatization tool for the morphologicalanalysis of biomedical literature presented in Liu et al [48] NONE)
orderIndependentLookup Specifies if ordering of tokens within a span can be ignored - (TRUE FALSE)
findAllMatches Specifies if all matches will be returned - (TRUE FALSE - only the longest match will be returned)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
synonyms Specifies which synonyms will be included when creating the dictionary - (EXACT ONLY ALL)
Parameters that were evaluated for each system along with a description and possible values are listed in all capital letters For the most part parameters areself-explanatory but for more information see documentation for each system CM [29] NCBO Annotator [44] MM [18]
were created to load the annotations before evaluationNCBOAnnotator is able to produce annotations and eval-uate themwithin the same pipeline but NCBO Annotatorannotations were cached to avoid hitting the Web servicecontinually Like MM a separate analysis engine was cre-ated to load annotations before evaluation CM producesannotations and evaluates them in a single pipelineEvaluation pipelines for each system have a similar
structure First the gold standard is loaded then the sys-temrsquos annotations are loaded obsolete annotations are
removed and finally a comparison is made CRAFT wasnot annotated with obsolete terms so the obsolete termsfiltered out are those that are obsolete in the version of theontology used to annotate CRAFTCM andMMdictionaries were created with the versions
of the ontologies that were used to annotate CRAFT SinceNCBOAnnotator is aWeb service we do not have controlover the versions of ontologies used it uses newer versionswithmore terms To remove spurious terms not present inthe ontologies used to annotate CRAFT a filter was added
Funk et al BMC Bioinformatics 2014 1559 Page 6 of 29httpwwwbiomedcentralcom1471-21051559
to the NCBO Annotator evaluation pipeline The NCBOAnnotator specific filter removes terms not present inthe version used to annotate CRAFT and ensures thatthe term is not obsolete in the version used to annotateCRAFT Because the versions of the ontologies used inCRAFT are older it may be the case that some termsannotated in CRAFT are obsolete in the current versionsAll systems were restricted to only using valid terms fromthe versions of the ontology used to annotate CRAFTAll comparisons were performed using a STRICT com-
parator which means that ontology ID and span(s) of agiven annotation must match the gold-standard annota-tion exactly to be counted correct A STRICT comparatorwas chosen because it was our desire to see how wellautomated methods can recreate exact human annota-tions A pitfall of the using a STRICT comparator is thata distinction cannot be made between erroneous termsvs those along the same hierarchical lineage both arecounted as fully incorrect in our analysis For exampleif the gold standard annotation is ldquoGO0005515 - proteinbindingrdquo and ldquoGO0005488 - bindingrdquo is returned by asystem partial credit should be given because ldquobindingrdquois an ancestor of ldquoprotein bindingrdquo Future comparisonscould address this limitation by accounting for the hierar-chical relationship in the ontology by counting those lessspecific terms as partially correct by using hierarchicalprecisionrecallF-measure as seen in Verspoor et al [50]The output is a text file for each parameter combination
listing true positives (TP) false positives (FP) and falsenegatives (FN) for each document as well as precision (P)recall (R) and F-measure (F) (Calculations of P R and Fcan be seen in formulas 1 2 and 3) Precision recall andF-measure are calculated over all annotations across alldocuments in CRAFT ie as amicro-average
P = TPTP + FP
(1)
R = TPTP + FN
(2)
F = 2 lowast P lowast RP + R
(3)
Statistical analysisThe Kruskal-Wallis statistical method was chosen to testsignificance for all our comparisons because it is a non-parametric test that identifies differences between rankedgroup of variables It is appropriate for our experimentsbecause we do not assume our data follows any partic-ular distribution and desire to determine if the distribu-tion of scores from a particular experimental conditionsuch as tool or parameters are different from the othersThe implementation built into R was used (kruskaltest)Kruskal-Wallis was applied in three different ways
1 For each ontology Kruskal-Wallis was used todetermine if there is a significant difference inF-measure performance between tools The meanand variance was computed across all parametercombinations for a given tool calculated at thecorpus level using the micro-average F-measure andprovided as input to Kruskal-Wallis
2 For each tool Kruskal-Wallis was used to determineif there is a difference in performance betweenparameter values for each parameter The mean andvariance was computed across all parameter valuesfor a given parameter calculated at the corpus levelusing the micro-average F-measure
3 Results from Kruskal-Wallis only determine if thereis a difference between the groups but does notprovide insight into how many differences orbetween which groups a difference exists When asignificant difference was seen between three or moregroups Kruskal-Wallis was used between a post hoctest to identify the significantly different group(s)
Significance is determined at a 99 level α = 001because there are multiple comparisons a Bonferroni cor-rection was used and the new significance level is α =000036
Analysis of results filesFor each ontology-system pair an analysis was performedon the maximum F-measure parameter combination Wedid not analyze every annotation produced by all sys-tems but made sure to account for sim70ndash80 of themBy performing the analysis this way we are concentratingon the general errors and terms missed rather than rareerrorsFor each maximum F-measure parameter combination
file the top 50ndash150 (grouped by ontology ID and rankedby number of annotations for each ID) of each true pos-itive (TP) false positive (FP) and false negative (FN)were analyzed by separating them into groups of likeannotations For example the types of bins that FPs fallinto are ldquoerrors from variantsrdquo ldquoerrors from ambigu-ous synonymsrdquo ldquoerrors due to identifying less specificconceptsrdquo etc and are different than the bins into whichTPs or FNs are categorizedBecause we evaluated all parameter combinations we
were able to examine the impact of single param-eters by holding all other parameters constant Themaximum F-measure producing parameter combina-tion result file and the complementary result file withvaried parameter were run through a graphical differ-ence program DiffMerge to examine the annotationsfoundlost by varying the parameter Examples men-tioned in the Results and discussion are from thiscomparison
Funk et al BMC Bioinformatics 2014 1559 Page 7 of 29httpwwwbiomedcentralcom1471-21051559
Results and discussionResults and discussion are broken down by ontology andthen by tool For each ontology we present three differentlevels of analysis
1 At the ontology level This provides a synopsis ofoverall performance for each system with commentsabout common terms correct (TPs) errors (FPs) andcategories missed (FNs) Specific examples are takenfrom the top-performing highest F-measureparameter combination
2 A high-level parameter analysis performed over allparameter combinations This allows for observationabout impact on performance seen by manipulatingparameter values presented as ranges of impact(Presented in Additional file 2)
3 A low-level analysis obtained from examiningindividual result files gives insight into specific termsor categories of terms that are affected bymanipulating parameters (Presented in Additionalfile 2)
Within a particular ontology each systemrsquos performanceis described The most impactful parameters are exploredfurther and examples from variations on maximumF-measure combination are provided to show the effectthey have on matching Results presented as numbersof annotations are of this type of analysis We end theResults and discussion Section with overall parameteranalysis and suggestions for parameters on any ontologyThe best-performing result for each system-ontology
pair is presented in Figure 1 There is a wide range of F-measures for all ontologies from lt 010 to 083 Not onlyis there a wide range when looking at all ontologies but awide range can be seen within each ontology Two of ourhypotheses are supported by this analysis we can see thatnot all concept recognition systems perform equally andthe best concept recognition system varies from ontologyto ontology
Best parametersBased on analysis the suggested parameters for maximumperformance for each ontology-system pair can be seen inTables 3 and 4
Cell Type OntologyThe Cell Type Ontology (CL) was designed to providea controlled vocabulary for cell types from many differ-ent prokaryotic fungal and eukaryotic organisms Outof all ontologies annotated in CRAFT it is the smallestterms are the simplest and there are very few synonyms(Table 1) The highest F-measure seen on any ontologyis on CL CM is the top performer (F = 083) MM per-forms second best (F = 069) and NCBO Annotator is the
worst performer (F = 032) Statistics for the best scorescan be seen in Table 5 All parameter combinations foreach system on CL can be seen in Figure 2Annotations from CL in CRAFT are heavily weighted
towards the root node ldquoCL0000000 - cellrdquo it is annotatedover 2500 times and makes up sim44 of all annota-tions To test whether annotations of ldquocellrdquo introduced abias all annotations of CL0000000 were removed and re-evaluated (Results not shown here) We see a decrease inF-measure of 008 for all systems and are able to identifysimilar trends in the effect of parameters when ldquocellrdquo is notincluded We can conclude that ldquocellrdquo annotations do notintroduce any biasPrecision on CL is good overall the highest being CM
(088) and the lowest beingMM (060) withNCBOAnno-tator in the middle (076) Most of the FPs found are dueto partial term matching ldquoCL0000000 - cellrdquo makes upmore than 50 of total FPs because it is contained inmany terms and is mistakenly annotated when a morespecific term cannot be found Besides ldquocellrdquo terms rec-ognized that are less specific than the gold standard areldquoCL0000066 - epithelial cellrdquo instead of ldquoCL0000082 -lung epithelial cellrdquo and ldquoCL0000081 - blood cellrdquo insteadof ldquoCL0000232 - red blood cellrdquo MM finds more FPs thanthe other systems many of these due to abbreviations Forexample MM incorrectly annotates the span ldquoES cellsrdquowith ldquoCL0000352 - epiblast cellrdquo and ldquoCL0000034 stemcellrdquo By utilizing abbreviations MM correctly annotatesldquoNCCrdquo with ldquoCL0000333 - neural crest cellrdquo which theother two systems do not findRecall for CM andMM are over 08 while NCBO Anno-
tator is 02 The low recall seen from NCBO Annotatoris due to the fact that it is unable to recognize pluralsof terms unless they are explicitly stated in the ontol-ogy it correctly finds ldquomelanocyterdquo but does not recognizeldquomelanocytesrdquo for example Because CL is small and itsterms are quite simple there are only two main categoriesof termsmissed missing synonyms and conjunctions Thebiggest category is insufficient synonyms We find ldquoconerdquoand ldquocone photoreceptorrdquo annotated with ldquoCL0000573 -retinal cone cellrdquo and ldquophotoreceptor(s)rdquo annotated withldquoCL0000210 - photoreceptor cellrdquo these two examplesmake up 33 (400 out of 1200) of annotations missed byall systems No systems found any annotations that con-tained conjunctions For example for the text span ldquoretinalbipolar ganglion and rod cellsrdquo three cell types are anno-tated in CRAFT ldquoCL0000748 - retinal bipolar neuronrdquoldquoCL0000740 - retinal ganglion cellrdquo and ldquoCL0000604 -retinal rod cellrdquo
Gene Ontology - Cellular ComponentThe cellular component branch of the Gene Ontologydescribes locations at the levels of subcellular structuresandmacromolecular complexes It is useful for annotating
Funk et al BMC Bioinformatics 2014 1559 Page 8 of 29httpwwwbiomedcentralcom1471-21051559
Best performance for all tools on all ontologies
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Ontologies
GO_CCGO_MFGO_BPSOCLPRNCBITAXONCHEBI
Figure 1Maximum F-measure for each system-ontology pair A wide range of maximum scores is seen for each system within each ontology
where gene products have been found to be localizedGO_CC is similar to CL in that it is a smaller ontologyand contains very few synonyms but the terms are slightlylonger and more complex than CL (Table 1) Performancefrom CM (F = 077) is the best with MM (F = 070)second and NCBO Annotator (F = 040) third (Table 5)All parameter combinations for each system on GO_CCcan be seen in Figure 3Just as in CL there are many annotations to
ldquoGO0005623 - cellrdquo 3647 or 44 of all 8354 annotationsWe removed annotations of ldquocellrdquo and saw a decreasein performance Unlike CL removal of these annota-tions does not affect all systems consistently CM sees alarge decrease in F-measure (02) while MM and NCBOAnnotator see decreases of 008 and 002 respectivelyPrecision for all parameter combinations of CM and
MM are over 050 with the highest being CM at 092NCBO Annotator widely varies from lt 01 to 085Because precision is high there are very few FPs that arefound The FPs in common by all systems are due to lessspecific terms being found and ambiguous terms NCBOAnnotator also finds FPs from broad synonyms and MMspecific errors are from abbreviations Most of the com-mon FPs are mentions that are less specific than thegold standard due to higher-level terms contained withinlower-level ones For instance ldquoGO0016020 - membranerdquo
is found instead of a more specific type of membranesuch as ldquovesicle membranerdquo ldquoplasma membranerdquo or ldquocel-lular membranerdquo All systems find sim20 annotations ofldquoGO0042603 - capsulerdquo when none are seen in CRAFTthis is due to overloaded terms from different biomedicaldomains Because NCBO Annotator is a Web service wehave no control over versions of ontologies used so itused a newer version of the ontology than that whichwas used to annotate CRAFT and as inputted into CMand MM sim42 of NCBO Annotator FPs were becauseldquoGO0019814 - immunoglobulin complex circulatingrdquo hasa broad synonym ldquoantibodyrdquo added Because MM gen-erates variants and incorporates synonyms we see aninteresting error produced from MM ldquohair(s)rdquo get anno-tated with ldquoGO0009289 - pilusrdquo It is not understandablewhy MM would assume this because ldquohairrdquo is not a syn-onym but in the GO definition pilus is described as aldquohair-like appendagerdquoMM achieves the highest recall of 073 with CM slightly
lower at 066 and NCBO Annotator the lowest (027)NCBO Annotatorrsquos inability to recognize plurals andgenerate variants significantly hurts recall NCBO Anno-tator can annotate neither ldquovesiclesrdquo with ldquoGO0031982 -vesiclerdquo nor ldquoautosomalrdquo with ldquoGO0030849 - autosomerdquowhich both CM and MM correctly annotate Thelargest category of missed annotations represents other
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 2 of 29httpwwwbiomedcentralcom1471-21051559
often a disconnect between what is captured in an ontol-ogy and what can be expected to be explicitly stated intext This is particularly true for relations among conceptsbut it is also the case that concepts themselves can beexpressed in text with a huge amount of variability andpotentially ambiguity and underspecification [1415]The work reported here aims to advance the state of
the art in recognizing terms from ontologies with a widevariety of differences in both the structure and content ofthe ontologies and in the surface characteristics of termsassociated with concepts in the ontology In the course ofthe work reported in this paper we evaluate a number ofhypotheses related to the general task of finding referencesto concepts from widely varying ontologies in text Theseinclude the following
bull Not all concept recognition systems perform equallyon natural language texts
bull The best concept recognition system varies fromontology to ontology
bull Parameter settings for a concept recognition systemcan be optimized to improve performance on a givenontology
bull Linguistic analysis in particular morphologicalanalysis affects the performance of conceptrecognition systems
To test these hypotheses we apply a variety ofdictionary-based tools for recognizing concepts in text toa corpus in which nearly all of the concepts from a varietyof ontologies have been manually annotated We performan exhaustive exploration of the parameter spaces for eachof these tools and report the performance of thousands ofcombinations of parameter settings We experiment withthe addition of tools for linguistic analysis in particularmorphological analysis Along with reporting quantita-tive results we give the results of manual error analysisfor each combination of concept recognition system andontologyThe gold standard used is the Colorado Richly Anno-
tated Full-Text (CRAFT) Corpus [1617] The full CRAFTcorpus consists of 97 completely annotated biomedi-cal journal articles while the ldquopublic releaserdquo set whichconsists of 67 documents was used for this evaluationCRAFT includes over 100000 concept annotations fromeight different biomedical ontologies Without CRAFTthis large-scale evaluation of concept annotation wouldnot have been possible due to lack of corpora annotatedwith a large number of concepts frommultiple ontologies
RelatedworkA number of tools and strategies have been proposed forconcept annotation in text These include both tools thatare generally applicable to a wide range of terminology
resources and strategies that have been designed specif-ically for one or a few terminologies The two mostwidely used generic tools are the National Library ofMedicinersquos MetaMap [18] and NBCOrsquos Open Biomedi-cal Annotator (NCBO Annotator) [19] based on a toolfrom the University of Michigan called mgrep Othertools including Whatizit [20] KnowledgeMap [2122]CONANN [23] IndexFinder [2425] Terminizer [26] andPeregrine [2728] have been created but are not pub-licly available or appear not to be in widespread useWe therefore focus our analysis in this paper on theNCBO Annotator and MetaMap In addition we includeConceptMapper [2930] a tool that was not specificallydeveloped for biomedical term recognition but rather forflexible look up of terms from a dictionary or controlledvocabularyThe tools mgrep and MetaMap have been directly
compared on several term recognition tasks [1931]These studies indicate that mgrep outperforms Meta-Map in terms of precision of matching Both studies alsonote that MetaMap returns many more annotations thanmgrep Recall is not calculated in either study becausethe document collections used as input were not fullyannotated By using a completely annotated corpus suchas CRAFT we are able to generate not only precision butrecall which gives a complete picture of the performanceof the systemThe Gene Ontology [32] has been the target of several
customized methods that take advantage of the specificstructure and characteristics of that ontology to facilitaterecognition of its constituent terms in text [233-36] Inthis work we will not specifically compare these methodsto the more generic tools identified above as they are notapplicable to the full range of ontologies that are reflectedin the CRAFT annotationsThe CRAFT corpus has been utilized previously in the
context of evaluating the recognition of specific cate-gories of terms Verspoor et al [16] provide a detailedassessment of named entity recognition tool performancefor recognition of genes and gene products As with thework mentionned in the previous paragraph these arespecialized tools with a more targeted approach thanwe explore in this work typically requiring substan-tial amounts of training material tailored to the specificnamed entity category We do not repeat those exper-iments here as they are not relevant to the generalproblem of recognition of terms from large controlledvocabularies
A note on ldquoconceptsrdquoWe are aware of the controversies associated with the useof the word ldquoconceptrdquo with respect to biomedical ontolo-gies but the content of the paper is not affected by theconflicting positions on this issue we use theword to refer
Funk et al BMC Bioinformatics 2014 1559 Page 3 of 29httpwwwbiomedcentralcom1471-21051559
to the tuple of namespace identifier term(s) definitionsynonym(s) and metadata that make up an entry in anontology
MethodsCorpusWe used version 10 released October 19 2012 of theColorado Richly Annotated Full Text Corpus (CRAFT)data set [1617] The full corpus consists of 97 full-text documents selected from the PubMed Central OpenAccess subset Each document in the collection serves asevidence for at least one mouse functional annotationFor this paper we used the ldquopublic releaserdquo subsectionwhich consists of 21000 sentences from 67 articles Thereare over 100000 concept annotations from eight differentbiomedical ontologies in this public subset Each anno-tation specifies the identifier of the concept from therespective ontology along with the beginning and endpoints of the text span(s) of the annotationTo fully understand the results presented it is impor-
tant to understand how CRAFT was annotated [17] Herewe present three guidelines First the text associated witheach annotation in CRAFT must be semantically equiv-alent to the term from the ontology with which it isannotated In other words the text in its context hasthe same meaning as the concept used to annotate itSecond annotations are made to a specific ontology andnot to a domain that is annotations are created onlyfor concepts explicitly represented in the given ontologyand not to concepts that ldquoshouldrdquo be in the ontology butare not explicitly represented For example if the ontol-ogy contains a concept representing vesicles but nothingmore specific a mention of ldquomicrovesiclesrdquo would not beannotated Even though it is a type of vesicle it is notannotated because microvesicles are not explicitly rep-resented in the ontology and annotating this text withthe more general vesicle concept would not be seman-tically equivalent ie information would be lost Thirdonly text directly corresponding to a concept is taggedfor example if the text ldquomutant vesiclesrdquo is seen ldquovesi-clesrdquo is tagged by itself (ie without ldquomutantrdquo) with thevesicle concept Because only the most specific conceptis annotated there are no subsuming annotations thatis given an annotation of a text span with a particu-lar concept no annotations are made within this textspan(s) with a more general concept even if they appearin the term For an example from the Cell Type Ontologygiven the text ldquomesenchymal cellrdquo this phrase is annotatedwith ldquoCL0000134 - mesenchymal cellrdquo but the nestedldquocellrdquo is not additionally annotated with ldquoCL0000000 -cellrdquo as the latter is an ancestor of the former andtherefore redundant There are very specific guidelinesas to what text is included in an annotation set out inBada et al [37]
OntologiesThe annotations of eight ontologies representing awide variety of biomedical terminology were used forthis evaluation 1ndash3) The three sub-ontologies of theGene Ontology (Biological Process Molecular FunctionCellular Component) [32] 4) the Cell Type Ontology[38] 5) Chemical Entities of Biological Interest Ontol-ogy [39] 6) the NCBI Taxonomy [40] 7) the SequenceOntology [41] and 8) the Protein Ontology [42] Ver-sions of ontologies used along with descriptive statisticscan be seen in Table 1 CRAFT also contains EntrezGene annotations but these were analyzed in previ-ous work [16] The Gene Ontology (GO) aims to stan-dardize the representation of gene and gene productattributes it consists of three distinct sub-ontologieswhich are evaluated separately Molecular Function Bio-logical Process and Cellular Component The Cell TypeOntology (CL) provides a structured vocabulary for celltypes Chemical Entities of Biological Interest (ChEBI) isfocused on molecular entities molecular parts atomssubatomic particles and biochemical roles and appli-cations NCBI Taxonomy (NCBITaxon) provides classi-fication and nomenclature of all organisms and typesof biological taxa in the public sequence database TheSequence Ontology (SO) aims to describe the featuresand attributes of biological sequences The Protein Ontol-ogy (PRO) provides a representation of protein-relatedentities
Structure of ontology entriesThe ontologies used are from the Open BiomedicalOntologies (OBO) [43] flat file format To help to under-stand the structure of the file an entry of a concept fromCL is shown below The only parts of an entry used inour systems are the id name and synonym rows Alter-native ways to refer to terms are expressed as synonymsthere are many types of synonyms that can be specifiedwith different levels of relatedness to the concept (exactbroad narrow and related) An ontology contain a hier-archy among its terms these are expressed in the ldquois_ardquoentry Terms described as ldquoancestorsrdquo ldquoless specificrdquo orldquomore generalrdquo lie above the specified concept in the hier-archy while terms described as ldquomore specificrdquo are belowthe specified concept
id CL0000560name band form neutrophildef ldquoA late neutrophilic metamyelocyte in which thenucleus is in the form of a curved or coiled band not hav-ing acquired the typical multi lobar shape of the matureneutrophilrdquosynonym ldquoband cellrdquo EXACTsynonym ldquorod neutrophilrdquo EXACTsynonym ldquobandrdquo NARROW
Funk et al BMC Bioinformatics 2014 1559 Page 4 of 29httpwwwbiomedcentralcom1471-21051559
Table 1 Characteristics of ontologies evaluated
Ontology Version Concepts Avg term Avg words Avg Have Have Havelength in term synonyms punctuation numerals stop words
Cell type 25052007 838 200 plusmn 95 30 plusmn 14 05 plusmn 11 116 48 33
Sequence 30032009 1610 216 plusmn 133 31 plusmn 10 14 plusmn 1 919 66 93
ChEBI 28052008 19633 255 plusmn 242 43 plusmn 48 20 plusmn 25 548 413 0
NCBITaxon 12072011 789538 246 plusmn 102 36 plusmn 20 NA 537 560 03
GO-MF 28112007 7984 391 plusmn 154 46 plusmn 22 28 plusmn 46 528 266 27
GO-BP 28112007 14306 401 plusmn 190 50 plusmn 27 21 plusmn 25 235 70 457
GO-CC 28112007 2047 266 plusmn 142 36 plusmn 17 01 plusmn 09 295 144 68
Protein 22042011 26807 384 plusmn 185 55 plusmn 25 31 plusmn 32 684 748 43
is_a CL0000776 immature neutrophilrelationship develops_from CL0000582 neutrophilicmetamyelocyte
A note on obsolete termsOntologies are ever changing new terms are added modi-fications aremade to others and others aremade obsoleteThis poses a problem because obsolete terms are notremoved from the ontology but only marked as obsoletein the obo flat file The dictionary-based methods used inour analysis do not distinguish between valid or obsoleteterms when creating their dictionaries so obsolete termsmay be returned by the systems A filter was incorpo-rated to remove obsolete terms returned (discussed morebelow) Not filtering obsolete terms introduces many falsepositives For example the terms ldquoGO0005574 - DNArdquoand ldquoGO0003675 - proteinrdquo are both obsolete in the cellu-lar component branch of the Gene Ontology and are men-tioned very frequently within the biomedical literature
Concept recognition systemsWe evaluated three concept recognition systems NCBOAnnotator (NCBO Annotator) [44] MetaMap [18] andConceptMapper [2930] All three systems are publiclyavailable and able to produce annotations for many dif-ferent ontologies but differ in their underlying implemen-tation and amount of configurable parameters The fullevaluation results are available for download at httpbionlpsourceforgenetNCBO Annotator is a web service provided by the
National Center for Biomedical Ontology (NCBO) thatannotates textual data with ontology terms from theUMLS and BioPortal ontologies The input text is fedinto a concept recognition tool (mgrep) and annotationsare produced A wrapper [45] programmatically convertsannotations produced by NCBO into xml which is thenimported into our evaluation pipeline The evaluationsfrom NCBO Annotator were performed in October andNovember 2012
MetaMap (MM) is a highly configurable program cre-ated to map biomedical text to the UMLS MetathesaurusMM parses input text into noun phrases and generatesvariants (alternate spellings abbreviations synonymsinflections and derivations) from these A candidate setof Metathesaurus terms containing one of the variantsis formed and scores are computed on the strength ofmapping from the variants to each candidate term Incontrast to a Web service MM runs locally we installedMM v2011 on a local Linux server MM natively workswith UMLS ontologies but not all ontologies that we haveevaluated are a part of the UMLS The optional data filebuilder [46] allowsMM to use any ontology as long as theycan be formatted as UMLS database tables therefore aPerl script was written to convert the ontology obo filesto UMLS database tables following the specification in thedata file builder overviewConceptMapper (CM) is part of the Apache UIMA
[47] Sandbox and is available at httpuimaapacheorgduima-addons-currentConceptMapper Version 231 wasused for these experiments CM is a highly configurabledictionary lookup tool implemented as a UIMA compo-nent Ontologies are mapped to the appropriate dictio-nary format required by ConceptMapper The input textis processed as tokens all tokens within a span (sen-tence) are looked up in the dictionary using a configurablelookup algorithm
Parameter explorationEach systemrsquos parameters were examined and config-urable parameters were chosen Table 2 gives a list ofeach systemwith the chosen parameters along with a briefdescription and possible values The list of stop wordsused is provided in Additional file 1
Evaluation pipelineAn evaluation pipeline for each system was constructedand run in UIMA [49] MM produces annotations sep-arate from the evaluation pipeline UIMA components
Funk et al BMC Bioinformatics 2014 1559 Page 5 of 29httpwwwbiomedcentralcom1471-21051559
Table 2 System parameter description and values
NCBO Annotator parameters
Parameter Description and possible values
wholeWordOnly Term recognition must match whole words - (YES NO)
filterNumber Specifies whether the entity recognition step should filter numbers - (YES NO)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
stopWordsCaseSensitive Whether stop words are case sensitive - (YES NO)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
withSynonyms Whether to include synonyms in matching - (YES NO)
MetaMap parameters
Parameter Description and possible values
model Determines which data model is used - (STRICT - lexical manual and syntactic filtering are applied RELAXED - lexicaland manual filtering are used)
gaps Specifies how to handle gaps in terms when matching - (ALLOW NONE)
wordOrder Specifies how to handle word order when matching - (ORDER MATTERS IGNORE)
acronymAbb Determines which generated acronym or abbreviations are used - (NONE DEFAULT UNIQUE - restricts variants toonly those with unique expansions)
derivationalVars Specifies which type of derivational variants will be used - (NONE ALL ONLY ADJ NOUN)
scoreFilter MetaMap reports a score from 0ndash1000 for every match with 1000 being the highest those matches with scores lewill be returned - (0 600 800 1000)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
ConceptMapper parameters
Parameter Description and possible values
searchStrategy Specifies the dictionary lookup strategy - (CONTIGUOUS - longest match of contiguous tokens SKIP ANY - returnslongest match of not-necessarily contiguous tokens and next lookup begin in next span SKIP ANY ALLOWOVERLAP -returns longest match of not-necessarily contiguous tokens in the span and next lookup begin after next token)
caseMatch Specifies the case folding mode to use - (IGNORE - fold everything to lower case INSENSITIVE - fold only tokens withinitial caps to lowercase SENSITIVE - no folding FOLD DIGIT - fold only tokens with digits to lower case)
stemmer Name of the stemmer to use before matching - (Porter - classic stemmer that removes common morphological andinflectional endings from Engish words BioLemmatizer - domain specific lemmatization tool for the morphologicalanalysis of biomedical literature presented in Liu et al [48] NONE)
orderIndependentLookup Specifies if ordering of tokens within a span can be ignored - (TRUE FALSE)
findAllMatches Specifies if all matches will be returned - (TRUE FALSE - only the longest match will be returned)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
synonyms Specifies which synonyms will be included when creating the dictionary - (EXACT ONLY ALL)
Parameters that were evaluated for each system along with a description and possible values are listed in all capital letters For the most part parameters areself-explanatory but for more information see documentation for each system CM [29] NCBO Annotator [44] MM [18]
were created to load the annotations before evaluationNCBOAnnotator is able to produce annotations and eval-uate themwithin the same pipeline but NCBO Annotatorannotations were cached to avoid hitting the Web servicecontinually Like MM a separate analysis engine was cre-ated to load annotations before evaluation CM producesannotations and evaluates them in a single pipelineEvaluation pipelines for each system have a similar
structure First the gold standard is loaded then the sys-temrsquos annotations are loaded obsolete annotations are
removed and finally a comparison is made CRAFT wasnot annotated with obsolete terms so the obsolete termsfiltered out are those that are obsolete in the version of theontology used to annotate CRAFTCM andMMdictionaries were created with the versions
of the ontologies that were used to annotate CRAFT SinceNCBOAnnotator is aWeb service we do not have controlover the versions of ontologies used it uses newer versionswithmore terms To remove spurious terms not present inthe ontologies used to annotate CRAFT a filter was added
Funk et al BMC Bioinformatics 2014 1559 Page 6 of 29httpwwwbiomedcentralcom1471-21051559
to the NCBO Annotator evaluation pipeline The NCBOAnnotator specific filter removes terms not present inthe version used to annotate CRAFT and ensures thatthe term is not obsolete in the version used to annotateCRAFT Because the versions of the ontologies used inCRAFT are older it may be the case that some termsannotated in CRAFT are obsolete in the current versionsAll systems were restricted to only using valid terms fromthe versions of the ontology used to annotate CRAFTAll comparisons were performed using a STRICT com-
parator which means that ontology ID and span(s) of agiven annotation must match the gold-standard annota-tion exactly to be counted correct A STRICT comparatorwas chosen because it was our desire to see how wellautomated methods can recreate exact human annota-tions A pitfall of the using a STRICT comparator is thata distinction cannot be made between erroneous termsvs those along the same hierarchical lineage both arecounted as fully incorrect in our analysis For exampleif the gold standard annotation is ldquoGO0005515 - proteinbindingrdquo and ldquoGO0005488 - bindingrdquo is returned by asystem partial credit should be given because ldquobindingrdquois an ancestor of ldquoprotein bindingrdquo Future comparisonscould address this limitation by accounting for the hierar-chical relationship in the ontology by counting those lessspecific terms as partially correct by using hierarchicalprecisionrecallF-measure as seen in Verspoor et al [50]The output is a text file for each parameter combination
listing true positives (TP) false positives (FP) and falsenegatives (FN) for each document as well as precision (P)recall (R) and F-measure (F) (Calculations of P R and Fcan be seen in formulas 1 2 and 3) Precision recall andF-measure are calculated over all annotations across alldocuments in CRAFT ie as amicro-average
P = TPTP + FP
(1)
R = TPTP + FN
(2)
F = 2 lowast P lowast RP + R
(3)
Statistical analysisThe Kruskal-Wallis statistical method was chosen to testsignificance for all our comparisons because it is a non-parametric test that identifies differences between rankedgroup of variables It is appropriate for our experimentsbecause we do not assume our data follows any partic-ular distribution and desire to determine if the distribu-tion of scores from a particular experimental conditionsuch as tool or parameters are different from the othersThe implementation built into R was used (kruskaltest)Kruskal-Wallis was applied in three different ways
1 For each ontology Kruskal-Wallis was used todetermine if there is a significant difference inF-measure performance between tools The meanand variance was computed across all parametercombinations for a given tool calculated at thecorpus level using the micro-average F-measure andprovided as input to Kruskal-Wallis
2 For each tool Kruskal-Wallis was used to determineif there is a difference in performance betweenparameter values for each parameter The mean andvariance was computed across all parameter valuesfor a given parameter calculated at the corpus levelusing the micro-average F-measure
3 Results from Kruskal-Wallis only determine if thereis a difference between the groups but does notprovide insight into how many differences orbetween which groups a difference exists When asignificant difference was seen between three or moregroups Kruskal-Wallis was used between a post hoctest to identify the significantly different group(s)
Significance is determined at a 99 level α = 001because there are multiple comparisons a Bonferroni cor-rection was used and the new significance level is α =000036
Analysis of results filesFor each ontology-system pair an analysis was performedon the maximum F-measure parameter combination Wedid not analyze every annotation produced by all sys-tems but made sure to account for sim70ndash80 of themBy performing the analysis this way we are concentratingon the general errors and terms missed rather than rareerrorsFor each maximum F-measure parameter combination
file the top 50ndash150 (grouped by ontology ID and rankedby number of annotations for each ID) of each true pos-itive (TP) false positive (FP) and false negative (FN)were analyzed by separating them into groups of likeannotations For example the types of bins that FPs fallinto are ldquoerrors from variantsrdquo ldquoerrors from ambigu-ous synonymsrdquo ldquoerrors due to identifying less specificconceptsrdquo etc and are different than the bins into whichTPs or FNs are categorizedBecause we evaluated all parameter combinations we
were able to examine the impact of single param-eters by holding all other parameters constant Themaximum F-measure producing parameter combina-tion result file and the complementary result file withvaried parameter were run through a graphical differ-ence program DiffMerge to examine the annotationsfoundlost by varying the parameter Examples men-tioned in the Results and discussion are from thiscomparison
Funk et al BMC Bioinformatics 2014 1559 Page 7 of 29httpwwwbiomedcentralcom1471-21051559
Results and discussionResults and discussion are broken down by ontology andthen by tool For each ontology we present three differentlevels of analysis
1 At the ontology level This provides a synopsis ofoverall performance for each system with commentsabout common terms correct (TPs) errors (FPs) andcategories missed (FNs) Specific examples are takenfrom the top-performing highest F-measureparameter combination
2 A high-level parameter analysis performed over allparameter combinations This allows for observationabout impact on performance seen by manipulatingparameter values presented as ranges of impact(Presented in Additional file 2)
3 A low-level analysis obtained from examiningindividual result files gives insight into specific termsor categories of terms that are affected bymanipulating parameters (Presented in Additionalfile 2)
Within a particular ontology each systemrsquos performanceis described The most impactful parameters are exploredfurther and examples from variations on maximumF-measure combination are provided to show the effectthey have on matching Results presented as numbersof annotations are of this type of analysis We end theResults and discussion Section with overall parameteranalysis and suggestions for parameters on any ontologyThe best-performing result for each system-ontology
pair is presented in Figure 1 There is a wide range of F-measures for all ontologies from lt 010 to 083 Not onlyis there a wide range when looking at all ontologies but awide range can be seen within each ontology Two of ourhypotheses are supported by this analysis we can see thatnot all concept recognition systems perform equally andthe best concept recognition system varies from ontologyto ontology
Best parametersBased on analysis the suggested parameters for maximumperformance for each ontology-system pair can be seen inTables 3 and 4
Cell Type OntologyThe Cell Type Ontology (CL) was designed to providea controlled vocabulary for cell types from many differ-ent prokaryotic fungal and eukaryotic organisms Outof all ontologies annotated in CRAFT it is the smallestterms are the simplest and there are very few synonyms(Table 1) The highest F-measure seen on any ontologyis on CL CM is the top performer (F = 083) MM per-forms second best (F = 069) and NCBO Annotator is the
worst performer (F = 032) Statistics for the best scorescan be seen in Table 5 All parameter combinations foreach system on CL can be seen in Figure 2Annotations from CL in CRAFT are heavily weighted
towards the root node ldquoCL0000000 - cellrdquo it is annotatedover 2500 times and makes up sim44 of all annota-tions To test whether annotations of ldquocellrdquo introduced abias all annotations of CL0000000 were removed and re-evaluated (Results not shown here) We see a decrease inF-measure of 008 for all systems and are able to identifysimilar trends in the effect of parameters when ldquocellrdquo is notincluded We can conclude that ldquocellrdquo annotations do notintroduce any biasPrecision on CL is good overall the highest being CM
(088) and the lowest beingMM (060) withNCBOAnno-tator in the middle (076) Most of the FPs found are dueto partial term matching ldquoCL0000000 - cellrdquo makes upmore than 50 of total FPs because it is contained inmany terms and is mistakenly annotated when a morespecific term cannot be found Besides ldquocellrdquo terms rec-ognized that are less specific than the gold standard areldquoCL0000066 - epithelial cellrdquo instead of ldquoCL0000082 -lung epithelial cellrdquo and ldquoCL0000081 - blood cellrdquo insteadof ldquoCL0000232 - red blood cellrdquo MM finds more FPs thanthe other systems many of these due to abbreviations Forexample MM incorrectly annotates the span ldquoES cellsrdquowith ldquoCL0000352 - epiblast cellrdquo and ldquoCL0000034 stemcellrdquo By utilizing abbreviations MM correctly annotatesldquoNCCrdquo with ldquoCL0000333 - neural crest cellrdquo which theother two systems do not findRecall for CM andMM are over 08 while NCBO Anno-
tator is 02 The low recall seen from NCBO Annotatoris due to the fact that it is unable to recognize pluralsof terms unless they are explicitly stated in the ontol-ogy it correctly finds ldquomelanocyterdquo but does not recognizeldquomelanocytesrdquo for example Because CL is small and itsterms are quite simple there are only two main categoriesof termsmissed missing synonyms and conjunctions Thebiggest category is insufficient synonyms We find ldquoconerdquoand ldquocone photoreceptorrdquo annotated with ldquoCL0000573 -retinal cone cellrdquo and ldquophotoreceptor(s)rdquo annotated withldquoCL0000210 - photoreceptor cellrdquo these two examplesmake up 33 (400 out of 1200) of annotations missed byall systems No systems found any annotations that con-tained conjunctions For example for the text span ldquoretinalbipolar ganglion and rod cellsrdquo three cell types are anno-tated in CRAFT ldquoCL0000748 - retinal bipolar neuronrdquoldquoCL0000740 - retinal ganglion cellrdquo and ldquoCL0000604 -retinal rod cellrdquo
Gene Ontology - Cellular ComponentThe cellular component branch of the Gene Ontologydescribes locations at the levels of subcellular structuresandmacromolecular complexes It is useful for annotating
Funk et al BMC Bioinformatics 2014 1559 Page 8 of 29httpwwwbiomedcentralcom1471-21051559
Best performance for all tools on all ontologies
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Ontologies
GO_CCGO_MFGO_BPSOCLPRNCBITAXONCHEBI
Figure 1Maximum F-measure for each system-ontology pair A wide range of maximum scores is seen for each system within each ontology
where gene products have been found to be localizedGO_CC is similar to CL in that it is a smaller ontologyand contains very few synonyms but the terms are slightlylonger and more complex than CL (Table 1) Performancefrom CM (F = 077) is the best with MM (F = 070)second and NCBO Annotator (F = 040) third (Table 5)All parameter combinations for each system on GO_CCcan be seen in Figure 3Just as in CL there are many annotations to
ldquoGO0005623 - cellrdquo 3647 or 44 of all 8354 annotationsWe removed annotations of ldquocellrdquo and saw a decreasein performance Unlike CL removal of these annota-tions does not affect all systems consistently CM sees alarge decrease in F-measure (02) while MM and NCBOAnnotator see decreases of 008 and 002 respectivelyPrecision for all parameter combinations of CM and
MM are over 050 with the highest being CM at 092NCBO Annotator widely varies from lt 01 to 085Because precision is high there are very few FPs that arefound The FPs in common by all systems are due to lessspecific terms being found and ambiguous terms NCBOAnnotator also finds FPs from broad synonyms and MMspecific errors are from abbreviations Most of the com-mon FPs are mentions that are less specific than thegold standard due to higher-level terms contained withinlower-level ones For instance ldquoGO0016020 - membranerdquo
is found instead of a more specific type of membranesuch as ldquovesicle membranerdquo ldquoplasma membranerdquo or ldquocel-lular membranerdquo All systems find sim20 annotations ofldquoGO0042603 - capsulerdquo when none are seen in CRAFTthis is due to overloaded terms from different biomedicaldomains Because NCBO Annotator is a Web service wehave no control over versions of ontologies used so itused a newer version of the ontology than that whichwas used to annotate CRAFT and as inputted into CMand MM sim42 of NCBO Annotator FPs were becauseldquoGO0019814 - immunoglobulin complex circulatingrdquo hasa broad synonym ldquoantibodyrdquo added Because MM gen-erates variants and incorporates synonyms we see aninteresting error produced from MM ldquohair(s)rdquo get anno-tated with ldquoGO0009289 - pilusrdquo It is not understandablewhy MM would assume this because ldquohairrdquo is not a syn-onym but in the GO definition pilus is described as aldquohair-like appendagerdquoMM achieves the highest recall of 073 with CM slightly
lower at 066 and NCBO Annotator the lowest (027)NCBO Annotatorrsquos inability to recognize plurals andgenerate variants significantly hurts recall NCBO Anno-tator can annotate neither ldquovesiclesrdquo with ldquoGO0031982 -vesiclerdquo nor ldquoautosomalrdquo with ldquoGO0030849 - autosomerdquowhich both CM and MM correctly annotate Thelargest category of missed annotations represents other
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 3 of 29httpwwwbiomedcentralcom1471-21051559
to the tuple of namespace identifier term(s) definitionsynonym(s) and metadata that make up an entry in anontology
MethodsCorpusWe used version 10 released October 19 2012 of theColorado Richly Annotated Full Text Corpus (CRAFT)data set [1617] The full corpus consists of 97 full-text documents selected from the PubMed Central OpenAccess subset Each document in the collection serves asevidence for at least one mouse functional annotationFor this paper we used the ldquopublic releaserdquo subsectionwhich consists of 21000 sentences from 67 articles Thereare over 100000 concept annotations from eight differentbiomedical ontologies in this public subset Each anno-tation specifies the identifier of the concept from therespective ontology along with the beginning and endpoints of the text span(s) of the annotationTo fully understand the results presented it is impor-
tant to understand how CRAFT was annotated [17] Herewe present three guidelines First the text associated witheach annotation in CRAFT must be semantically equiv-alent to the term from the ontology with which it isannotated In other words the text in its context hasthe same meaning as the concept used to annotate itSecond annotations are made to a specific ontology andnot to a domain that is annotations are created onlyfor concepts explicitly represented in the given ontologyand not to concepts that ldquoshouldrdquo be in the ontology butare not explicitly represented For example if the ontol-ogy contains a concept representing vesicles but nothingmore specific a mention of ldquomicrovesiclesrdquo would not beannotated Even though it is a type of vesicle it is notannotated because microvesicles are not explicitly rep-resented in the ontology and annotating this text withthe more general vesicle concept would not be seman-tically equivalent ie information would be lost Thirdonly text directly corresponding to a concept is taggedfor example if the text ldquomutant vesiclesrdquo is seen ldquovesi-clesrdquo is tagged by itself (ie without ldquomutantrdquo) with thevesicle concept Because only the most specific conceptis annotated there are no subsuming annotations thatis given an annotation of a text span with a particu-lar concept no annotations are made within this textspan(s) with a more general concept even if they appearin the term For an example from the Cell Type Ontologygiven the text ldquomesenchymal cellrdquo this phrase is annotatedwith ldquoCL0000134 - mesenchymal cellrdquo but the nestedldquocellrdquo is not additionally annotated with ldquoCL0000000 -cellrdquo as the latter is an ancestor of the former andtherefore redundant There are very specific guidelinesas to what text is included in an annotation set out inBada et al [37]
OntologiesThe annotations of eight ontologies representing awide variety of biomedical terminology were used forthis evaluation 1ndash3) The three sub-ontologies of theGene Ontology (Biological Process Molecular FunctionCellular Component) [32] 4) the Cell Type Ontology[38] 5) Chemical Entities of Biological Interest Ontol-ogy [39] 6) the NCBI Taxonomy [40] 7) the SequenceOntology [41] and 8) the Protein Ontology [42] Ver-sions of ontologies used along with descriptive statisticscan be seen in Table 1 CRAFT also contains EntrezGene annotations but these were analyzed in previ-ous work [16] The Gene Ontology (GO) aims to stan-dardize the representation of gene and gene productattributes it consists of three distinct sub-ontologieswhich are evaluated separately Molecular Function Bio-logical Process and Cellular Component The Cell TypeOntology (CL) provides a structured vocabulary for celltypes Chemical Entities of Biological Interest (ChEBI) isfocused on molecular entities molecular parts atomssubatomic particles and biochemical roles and appli-cations NCBI Taxonomy (NCBITaxon) provides classi-fication and nomenclature of all organisms and typesof biological taxa in the public sequence database TheSequence Ontology (SO) aims to describe the featuresand attributes of biological sequences The Protein Ontol-ogy (PRO) provides a representation of protein-relatedentities
Structure of ontology entriesThe ontologies used are from the Open BiomedicalOntologies (OBO) [43] flat file format To help to under-stand the structure of the file an entry of a concept fromCL is shown below The only parts of an entry used inour systems are the id name and synonym rows Alter-native ways to refer to terms are expressed as synonymsthere are many types of synonyms that can be specifiedwith different levels of relatedness to the concept (exactbroad narrow and related) An ontology contain a hier-archy among its terms these are expressed in the ldquois_ardquoentry Terms described as ldquoancestorsrdquo ldquoless specificrdquo orldquomore generalrdquo lie above the specified concept in the hier-archy while terms described as ldquomore specificrdquo are belowthe specified concept
id CL0000560name band form neutrophildef ldquoA late neutrophilic metamyelocyte in which thenucleus is in the form of a curved or coiled band not hav-ing acquired the typical multi lobar shape of the matureneutrophilrdquosynonym ldquoband cellrdquo EXACTsynonym ldquorod neutrophilrdquo EXACTsynonym ldquobandrdquo NARROW
Funk et al BMC Bioinformatics 2014 1559 Page 4 of 29httpwwwbiomedcentralcom1471-21051559
Table 1 Characteristics of ontologies evaluated
Ontology Version Concepts Avg term Avg words Avg Have Have Havelength in term synonyms punctuation numerals stop words
Cell type 25052007 838 200 plusmn 95 30 plusmn 14 05 plusmn 11 116 48 33
Sequence 30032009 1610 216 plusmn 133 31 plusmn 10 14 plusmn 1 919 66 93
ChEBI 28052008 19633 255 plusmn 242 43 plusmn 48 20 plusmn 25 548 413 0
NCBITaxon 12072011 789538 246 plusmn 102 36 plusmn 20 NA 537 560 03
GO-MF 28112007 7984 391 plusmn 154 46 plusmn 22 28 plusmn 46 528 266 27
GO-BP 28112007 14306 401 plusmn 190 50 plusmn 27 21 plusmn 25 235 70 457
GO-CC 28112007 2047 266 plusmn 142 36 plusmn 17 01 plusmn 09 295 144 68
Protein 22042011 26807 384 plusmn 185 55 plusmn 25 31 plusmn 32 684 748 43
is_a CL0000776 immature neutrophilrelationship develops_from CL0000582 neutrophilicmetamyelocyte
A note on obsolete termsOntologies are ever changing new terms are added modi-fications aremade to others and others aremade obsoleteThis poses a problem because obsolete terms are notremoved from the ontology but only marked as obsoletein the obo flat file The dictionary-based methods used inour analysis do not distinguish between valid or obsoleteterms when creating their dictionaries so obsolete termsmay be returned by the systems A filter was incorpo-rated to remove obsolete terms returned (discussed morebelow) Not filtering obsolete terms introduces many falsepositives For example the terms ldquoGO0005574 - DNArdquoand ldquoGO0003675 - proteinrdquo are both obsolete in the cellu-lar component branch of the Gene Ontology and are men-tioned very frequently within the biomedical literature
Concept recognition systemsWe evaluated three concept recognition systems NCBOAnnotator (NCBO Annotator) [44] MetaMap [18] andConceptMapper [2930] All three systems are publiclyavailable and able to produce annotations for many dif-ferent ontologies but differ in their underlying implemen-tation and amount of configurable parameters The fullevaluation results are available for download at httpbionlpsourceforgenetNCBO Annotator is a web service provided by the
National Center for Biomedical Ontology (NCBO) thatannotates textual data with ontology terms from theUMLS and BioPortal ontologies The input text is fedinto a concept recognition tool (mgrep) and annotationsare produced A wrapper [45] programmatically convertsannotations produced by NCBO into xml which is thenimported into our evaluation pipeline The evaluationsfrom NCBO Annotator were performed in October andNovember 2012
MetaMap (MM) is a highly configurable program cre-ated to map biomedical text to the UMLS MetathesaurusMM parses input text into noun phrases and generatesvariants (alternate spellings abbreviations synonymsinflections and derivations) from these A candidate setof Metathesaurus terms containing one of the variantsis formed and scores are computed on the strength ofmapping from the variants to each candidate term Incontrast to a Web service MM runs locally we installedMM v2011 on a local Linux server MM natively workswith UMLS ontologies but not all ontologies that we haveevaluated are a part of the UMLS The optional data filebuilder [46] allowsMM to use any ontology as long as theycan be formatted as UMLS database tables therefore aPerl script was written to convert the ontology obo filesto UMLS database tables following the specification in thedata file builder overviewConceptMapper (CM) is part of the Apache UIMA
[47] Sandbox and is available at httpuimaapacheorgduima-addons-currentConceptMapper Version 231 wasused for these experiments CM is a highly configurabledictionary lookup tool implemented as a UIMA compo-nent Ontologies are mapped to the appropriate dictio-nary format required by ConceptMapper The input textis processed as tokens all tokens within a span (sen-tence) are looked up in the dictionary using a configurablelookup algorithm
Parameter explorationEach systemrsquos parameters were examined and config-urable parameters were chosen Table 2 gives a list ofeach systemwith the chosen parameters along with a briefdescription and possible values The list of stop wordsused is provided in Additional file 1
Evaluation pipelineAn evaluation pipeline for each system was constructedand run in UIMA [49] MM produces annotations sep-arate from the evaluation pipeline UIMA components
Funk et al BMC Bioinformatics 2014 1559 Page 5 of 29httpwwwbiomedcentralcom1471-21051559
Table 2 System parameter description and values
NCBO Annotator parameters
Parameter Description and possible values
wholeWordOnly Term recognition must match whole words - (YES NO)
filterNumber Specifies whether the entity recognition step should filter numbers - (YES NO)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
stopWordsCaseSensitive Whether stop words are case sensitive - (YES NO)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
withSynonyms Whether to include synonyms in matching - (YES NO)
MetaMap parameters
Parameter Description and possible values
model Determines which data model is used - (STRICT - lexical manual and syntactic filtering are applied RELAXED - lexicaland manual filtering are used)
gaps Specifies how to handle gaps in terms when matching - (ALLOW NONE)
wordOrder Specifies how to handle word order when matching - (ORDER MATTERS IGNORE)
acronymAbb Determines which generated acronym or abbreviations are used - (NONE DEFAULT UNIQUE - restricts variants toonly those with unique expansions)
derivationalVars Specifies which type of derivational variants will be used - (NONE ALL ONLY ADJ NOUN)
scoreFilter MetaMap reports a score from 0ndash1000 for every match with 1000 being the highest those matches with scores lewill be returned - (0 600 800 1000)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
ConceptMapper parameters
Parameter Description and possible values
searchStrategy Specifies the dictionary lookup strategy - (CONTIGUOUS - longest match of contiguous tokens SKIP ANY - returnslongest match of not-necessarily contiguous tokens and next lookup begin in next span SKIP ANY ALLOWOVERLAP -returns longest match of not-necessarily contiguous tokens in the span and next lookup begin after next token)
caseMatch Specifies the case folding mode to use - (IGNORE - fold everything to lower case INSENSITIVE - fold only tokens withinitial caps to lowercase SENSITIVE - no folding FOLD DIGIT - fold only tokens with digits to lower case)
stemmer Name of the stemmer to use before matching - (Porter - classic stemmer that removes common morphological andinflectional endings from Engish words BioLemmatizer - domain specific lemmatization tool for the morphologicalanalysis of biomedical literature presented in Liu et al [48] NONE)
orderIndependentLookup Specifies if ordering of tokens within a span can be ignored - (TRUE FALSE)
findAllMatches Specifies if all matches will be returned - (TRUE FALSE - only the longest match will be returned)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
synonyms Specifies which synonyms will be included when creating the dictionary - (EXACT ONLY ALL)
Parameters that were evaluated for each system along with a description and possible values are listed in all capital letters For the most part parameters areself-explanatory but for more information see documentation for each system CM [29] NCBO Annotator [44] MM [18]
were created to load the annotations before evaluationNCBOAnnotator is able to produce annotations and eval-uate themwithin the same pipeline but NCBO Annotatorannotations were cached to avoid hitting the Web servicecontinually Like MM a separate analysis engine was cre-ated to load annotations before evaluation CM producesannotations and evaluates them in a single pipelineEvaluation pipelines for each system have a similar
structure First the gold standard is loaded then the sys-temrsquos annotations are loaded obsolete annotations are
removed and finally a comparison is made CRAFT wasnot annotated with obsolete terms so the obsolete termsfiltered out are those that are obsolete in the version of theontology used to annotate CRAFTCM andMMdictionaries were created with the versions
of the ontologies that were used to annotate CRAFT SinceNCBOAnnotator is aWeb service we do not have controlover the versions of ontologies used it uses newer versionswithmore terms To remove spurious terms not present inthe ontologies used to annotate CRAFT a filter was added
Funk et al BMC Bioinformatics 2014 1559 Page 6 of 29httpwwwbiomedcentralcom1471-21051559
to the NCBO Annotator evaluation pipeline The NCBOAnnotator specific filter removes terms not present inthe version used to annotate CRAFT and ensures thatthe term is not obsolete in the version used to annotateCRAFT Because the versions of the ontologies used inCRAFT are older it may be the case that some termsannotated in CRAFT are obsolete in the current versionsAll systems were restricted to only using valid terms fromthe versions of the ontology used to annotate CRAFTAll comparisons were performed using a STRICT com-
parator which means that ontology ID and span(s) of agiven annotation must match the gold-standard annota-tion exactly to be counted correct A STRICT comparatorwas chosen because it was our desire to see how wellautomated methods can recreate exact human annota-tions A pitfall of the using a STRICT comparator is thata distinction cannot be made between erroneous termsvs those along the same hierarchical lineage both arecounted as fully incorrect in our analysis For exampleif the gold standard annotation is ldquoGO0005515 - proteinbindingrdquo and ldquoGO0005488 - bindingrdquo is returned by asystem partial credit should be given because ldquobindingrdquois an ancestor of ldquoprotein bindingrdquo Future comparisonscould address this limitation by accounting for the hierar-chical relationship in the ontology by counting those lessspecific terms as partially correct by using hierarchicalprecisionrecallF-measure as seen in Verspoor et al [50]The output is a text file for each parameter combination
listing true positives (TP) false positives (FP) and falsenegatives (FN) for each document as well as precision (P)recall (R) and F-measure (F) (Calculations of P R and Fcan be seen in formulas 1 2 and 3) Precision recall andF-measure are calculated over all annotations across alldocuments in CRAFT ie as amicro-average
P = TPTP + FP
(1)
R = TPTP + FN
(2)
F = 2 lowast P lowast RP + R
(3)
Statistical analysisThe Kruskal-Wallis statistical method was chosen to testsignificance for all our comparisons because it is a non-parametric test that identifies differences between rankedgroup of variables It is appropriate for our experimentsbecause we do not assume our data follows any partic-ular distribution and desire to determine if the distribu-tion of scores from a particular experimental conditionsuch as tool or parameters are different from the othersThe implementation built into R was used (kruskaltest)Kruskal-Wallis was applied in three different ways
1 For each ontology Kruskal-Wallis was used todetermine if there is a significant difference inF-measure performance between tools The meanand variance was computed across all parametercombinations for a given tool calculated at thecorpus level using the micro-average F-measure andprovided as input to Kruskal-Wallis
2 For each tool Kruskal-Wallis was used to determineif there is a difference in performance betweenparameter values for each parameter The mean andvariance was computed across all parameter valuesfor a given parameter calculated at the corpus levelusing the micro-average F-measure
3 Results from Kruskal-Wallis only determine if thereis a difference between the groups but does notprovide insight into how many differences orbetween which groups a difference exists When asignificant difference was seen between three or moregroups Kruskal-Wallis was used between a post hoctest to identify the significantly different group(s)
Significance is determined at a 99 level α = 001because there are multiple comparisons a Bonferroni cor-rection was used and the new significance level is α =000036
Analysis of results filesFor each ontology-system pair an analysis was performedon the maximum F-measure parameter combination Wedid not analyze every annotation produced by all sys-tems but made sure to account for sim70ndash80 of themBy performing the analysis this way we are concentratingon the general errors and terms missed rather than rareerrorsFor each maximum F-measure parameter combination
file the top 50ndash150 (grouped by ontology ID and rankedby number of annotations for each ID) of each true pos-itive (TP) false positive (FP) and false negative (FN)were analyzed by separating them into groups of likeannotations For example the types of bins that FPs fallinto are ldquoerrors from variantsrdquo ldquoerrors from ambigu-ous synonymsrdquo ldquoerrors due to identifying less specificconceptsrdquo etc and are different than the bins into whichTPs or FNs are categorizedBecause we evaluated all parameter combinations we
were able to examine the impact of single param-eters by holding all other parameters constant Themaximum F-measure producing parameter combina-tion result file and the complementary result file withvaried parameter were run through a graphical differ-ence program DiffMerge to examine the annotationsfoundlost by varying the parameter Examples men-tioned in the Results and discussion are from thiscomparison
Funk et al BMC Bioinformatics 2014 1559 Page 7 of 29httpwwwbiomedcentralcom1471-21051559
Results and discussionResults and discussion are broken down by ontology andthen by tool For each ontology we present three differentlevels of analysis
1 At the ontology level This provides a synopsis ofoverall performance for each system with commentsabout common terms correct (TPs) errors (FPs) andcategories missed (FNs) Specific examples are takenfrom the top-performing highest F-measureparameter combination
2 A high-level parameter analysis performed over allparameter combinations This allows for observationabout impact on performance seen by manipulatingparameter values presented as ranges of impact(Presented in Additional file 2)
3 A low-level analysis obtained from examiningindividual result files gives insight into specific termsor categories of terms that are affected bymanipulating parameters (Presented in Additionalfile 2)
Within a particular ontology each systemrsquos performanceis described The most impactful parameters are exploredfurther and examples from variations on maximumF-measure combination are provided to show the effectthey have on matching Results presented as numbersof annotations are of this type of analysis We end theResults and discussion Section with overall parameteranalysis and suggestions for parameters on any ontologyThe best-performing result for each system-ontology
pair is presented in Figure 1 There is a wide range of F-measures for all ontologies from lt 010 to 083 Not onlyis there a wide range when looking at all ontologies but awide range can be seen within each ontology Two of ourhypotheses are supported by this analysis we can see thatnot all concept recognition systems perform equally andthe best concept recognition system varies from ontologyto ontology
Best parametersBased on analysis the suggested parameters for maximumperformance for each ontology-system pair can be seen inTables 3 and 4
Cell Type OntologyThe Cell Type Ontology (CL) was designed to providea controlled vocabulary for cell types from many differ-ent prokaryotic fungal and eukaryotic organisms Outof all ontologies annotated in CRAFT it is the smallestterms are the simplest and there are very few synonyms(Table 1) The highest F-measure seen on any ontologyis on CL CM is the top performer (F = 083) MM per-forms second best (F = 069) and NCBO Annotator is the
worst performer (F = 032) Statistics for the best scorescan be seen in Table 5 All parameter combinations foreach system on CL can be seen in Figure 2Annotations from CL in CRAFT are heavily weighted
towards the root node ldquoCL0000000 - cellrdquo it is annotatedover 2500 times and makes up sim44 of all annota-tions To test whether annotations of ldquocellrdquo introduced abias all annotations of CL0000000 were removed and re-evaluated (Results not shown here) We see a decrease inF-measure of 008 for all systems and are able to identifysimilar trends in the effect of parameters when ldquocellrdquo is notincluded We can conclude that ldquocellrdquo annotations do notintroduce any biasPrecision on CL is good overall the highest being CM
(088) and the lowest beingMM (060) withNCBOAnno-tator in the middle (076) Most of the FPs found are dueto partial term matching ldquoCL0000000 - cellrdquo makes upmore than 50 of total FPs because it is contained inmany terms and is mistakenly annotated when a morespecific term cannot be found Besides ldquocellrdquo terms rec-ognized that are less specific than the gold standard areldquoCL0000066 - epithelial cellrdquo instead of ldquoCL0000082 -lung epithelial cellrdquo and ldquoCL0000081 - blood cellrdquo insteadof ldquoCL0000232 - red blood cellrdquo MM finds more FPs thanthe other systems many of these due to abbreviations Forexample MM incorrectly annotates the span ldquoES cellsrdquowith ldquoCL0000352 - epiblast cellrdquo and ldquoCL0000034 stemcellrdquo By utilizing abbreviations MM correctly annotatesldquoNCCrdquo with ldquoCL0000333 - neural crest cellrdquo which theother two systems do not findRecall for CM andMM are over 08 while NCBO Anno-
tator is 02 The low recall seen from NCBO Annotatoris due to the fact that it is unable to recognize pluralsof terms unless they are explicitly stated in the ontol-ogy it correctly finds ldquomelanocyterdquo but does not recognizeldquomelanocytesrdquo for example Because CL is small and itsterms are quite simple there are only two main categoriesof termsmissed missing synonyms and conjunctions Thebiggest category is insufficient synonyms We find ldquoconerdquoand ldquocone photoreceptorrdquo annotated with ldquoCL0000573 -retinal cone cellrdquo and ldquophotoreceptor(s)rdquo annotated withldquoCL0000210 - photoreceptor cellrdquo these two examplesmake up 33 (400 out of 1200) of annotations missed byall systems No systems found any annotations that con-tained conjunctions For example for the text span ldquoretinalbipolar ganglion and rod cellsrdquo three cell types are anno-tated in CRAFT ldquoCL0000748 - retinal bipolar neuronrdquoldquoCL0000740 - retinal ganglion cellrdquo and ldquoCL0000604 -retinal rod cellrdquo
Gene Ontology - Cellular ComponentThe cellular component branch of the Gene Ontologydescribes locations at the levels of subcellular structuresandmacromolecular complexes It is useful for annotating
Funk et al BMC Bioinformatics 2014 1559 Page 8 of 29httpwwwbiomedcentralcom1471-21051559
Best performance for all tools on all ontologies
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Ontologies
GO_CCGO_MFGO_BPSOCLPRNCBITAXONCHEBI
Figure 1Maximum F-measure for each system-ontology pair A wide range of maximum scores is seen for each system within each ontology
where gene products have been found to be localizedGO_CC is similar to CL in that it is a smaller ontologyand contains very few synonyms but the terms are slightlylonger and more complex than CL (Table 1) Performancefrom CM (F = 077) is the best with MM (F = 070)second and NCBO Annotator (F = 040) third (Table 5)All parameter combinations for each system on GO_CCcan be seen in Figure 3Just as in CL there are many annotations to
ldquoGO0005623 - cellrdquo 3647 or 44 of all 8354 annotationsWe removed annotations of ldquocellrdquo and saw a decreasein performance Unlike CL removal of these annota-tions does not affect all systems consistently CM sees alarge decrease in F-measure (02) while MM and NCBOAnnotator see decreases of 008 and 002 respectivelyPrecision for all parameter combinations of CM and
MM are over 050 with the highest being CM at 092NCBO Annotator widely varies from lt 01 to 085Because precision is high there are very few FPs that arefound The FPs in common by all systems are due to lessspecific terms being found and ambiguous terms NCBOAnnotator also finds FPs from broad synonyms and MMspecific errors are from abbreviations Most of the com-mon FPs are mentions that are less specific than thegold standard due to higher-level terms contained withinlower-level ones For instance ldquoGO0016020 - membranerdquo
is found instead of a more specific type of membranesuch as ldquovesicle membranerdquo ldquoplasma membranerdquo or ldquocel-lular membranerdquo All systems find sim20 annotations ofldquoGO0042603 - capsulerdquo when none are seen in CRAFTthis is due to overloaded terms from different biomedicaldomains Because NCBO Annotator is a Web service wehave no control over versions of ontologies used so itused a newer version of the ontology than that whichwas used to annotate CRAFT and as inputted into CMand MM sim42 of NCBO Annotator FPs were becauseldquoGO0019814 - immunoglobulin complex circulatingrdquo hasa broad synonym ldquoantibodyrdquo added Because MM gen-erates variants and incorporates synonyms we see aninteresting error produced from MM ldquohair(s)rdquo get anno-tated with ldquoGO0009289 - pilusrdquo It is not understandablewhy MM would assume this because ldquohairrdquo is not a syn-onym but in the GO definition pilus is described as aldquohair-like appendagerdquoMM achieves the highest recall of 073 with CM slightly
lower at 066 and NCBO Annotator the lowest (027)NCBO Annotatorrsquos inability to recognize plurals andgenerate variants significantly hurts recall NCBO Anno-tator can annotate neither ldquovesiclesrdquo with ldquoGO0031982 -vesiclerdquo nor ldquoautosomalrdquo with ldquoGO0030849 - autosomerdquowhich both CM and MM correctly annotate Thelargest category of missed annotations represents other
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 4 of 29httpwwwbiomedcentralcom1471-21051559
Table 1 Characteristics of ontologies evaluated
Ontology Version Concepts Avg term Avg words Avg Have Have Havelength in term synonyms punctuation numerals stop words
Cell type 25052007 838 200 plusmn 95 30 plusmn 14 05 plusmn 11 116 48 33
Sequence 30032009 1610 216 plusmn 133 31 plusmn 10 14 plusmn 1 919 66 93
ChEBI 28052008 19633 255 plusmn 242 43 plusmn 48 20 plusmn 25 548 413 0
NCBITaxon 12072011 789538 246 plusmn 102 36 plusmn 20 NA 537 560 03
GO-MF 28112007 7984 391 plusmn 154 46 plusmn 22 28 plusmn 46 528 266 27
GO-BP 28112007 14306 401 plusmn 190 50 plusmn 27 21 plusmn 25 235 70 457
GO-CC 28112007 2047 266 plusmn 142 36 plusmn 17 01 plusmn 09 295 144 68
Protein 22042011 26807 384 plusmn 185 55 plusmn 25 31 plusmn 32 684 748 43
is_a CL0000776 immature neutrophilrelationship develops_from CL0000582 neutrophilicmetamyelocyte
A note on obsolete termsOntologies are ever changing new terms are added modi-fications aremade to others and others aremade obsoleteThis poses a problem because obsolete terms are notremoved from the ontology but only marked as obsoletein the obo flat file The dictionary-based methods used inour analysis do not distinguish between valid or obsoleteterms when creating their dictionaries so obsolete termsmay be returned by the systems A filter was incorpo-rated to remove obsolete terms returned (discussed morebelow) Not filtering obsolete terms introduces many falsepositives For example the terms ldquoGO0005574 - DNArdquoand ldquoGO0003675 - proteinrdquo are both obsolete in the cellu-lar component branch of the Gene Ontology and are men-tioned very frequently within the biomedical literature
Concept recognition systemsWe evaluated three concept recognition systems NCBOAnnotator (NCBO Annotator) [44] MetaMap [18] andConceptMapper [2930] All three systems are publiclyavailable and able to produce annotations for many dif-ferent ontologies but differ in their underlying implemen-tation and amount of configurable parameters The fullevaluation results are available for download at httpbionlpsourceforgenetNCBO Annotator is a web service provided by the
National Center for Biomedical Ontology (NCBO) thatannotates textual data with ontology terms from theUMLS and BioPortal ontologies The input text is fedinto a concept recognition tool (mgrep) and annotationsare produced A wrapper [45] programmatically convertsannotations produced by NCBO into xml which is thenimported into our evaluation pipeline The evaluationsfrom NCBO Annotator were performed in October andNovember 2012
MetaMap (MM) is a highly configurable program cre-ated to map biomedical text to the UMLS MetathesaurusMM parses input text into noun phrases and generatesvariants (alternate spellings abbreviations synonymsinflections and derivations) from these A candidate setof Metathesaurus terms containing one of the variantsis formed and scores are computed on the strength ofmapping from the variants to each candidate term Incontrast to a Web service MM runs locally we installedMM v2011 on a local Linux server MM natively workswith UMLS ontologies but not all ontologies that we haveevaluated are a part of the UMLS The optional data filebuilder [46] allowsMM to use any ontology as long as theycan be formatted as UMLS database tables therefore aPerl script was written to convert the ontology obo filesto UMLS database tables following the specification in thedata file builder overviewConceptMapper (CM) is part of the Apache UIMA
[47] Sandbox and is available at httpuimaapacheorgduima-addons-currentConceptMapper Version 231 wasused for these experiments CM is a highly configurabledictionary lookup tool implemented as a UIMA compo-nent Ontologies are mapped to the appropriate dictio-nary format required by ConceptMapper The input textis processed as tokens all tokens within a span (sen-tence) are looked up in the dictionary using a configurablelookup algorithm
Parameter explorationEach systemrsquos parameters were examined and config-urable parameters were chosen Table 2 gives a list ofeach systemwith the chosen parameters along with a briefdescription and possible values The list of stop wordsused is provided in Additional file 1
Evaluation pipelineAn evaluation pipeline for each system was constructedand run in UIMA [49] MM produces annotations sep-arate from the evaluation pipeline UIMA components
Funk et al BMC Bioinformatics 2014 1559 Page 5 of 29httpwwwbiomedcentralcom1471-21051559
Table 2 System parameter description and values
NCBO Annotator parameters
Parameter Description and possible values
wholeWordOnly Term recognition must match whole words - (YES NO)
filterNumber Specifies whether the entity recognition step should filter numbers - (YES NO)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
stopWordsCaseSensitive Whether stop words are case sensitive - (YES NO)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
withSynonyms Whether to include synonyms in matching - (YES NO)
MetaMap parameters
Parameter Description and possible values
model Determines which data model is used - (STRICT - lexical manual and syntactic filtering are applied RELAXED - lexicaland manual filtering are used)
gaps Specifies how to handle gaps in terms when matching - (ALLOW NONE)
wordOrder Specifies how to handle word order when matching - (ORDER MATTERS IGNORE)
acronymAbb Determines which generated acronym or abbreviations are used - (NONE DEFAULT UNIQUE - restricts variants toonly those with unique expansions)
derivationalVars Specifies which type of derivational variants will be used - (NONE ALL ONLY ADJ NOUN)
scoreFilter MetaMap reports a score from 0ndash1000 for every match with 1000 being the highest those matches with scores lewill be returned - (0 600 800 1000)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
ConceptMapper parameters
Parameter Description and possible values
searchStrategy Specifies the dictionary lookup strategy - (CONTIGUOUS - longest match of contiguous tokens SKIP ANY - returnslongest match of not-necessarily contiguous tokens and next lookup begin in next span SKIP ANY ALLOWOVERLAP -returns longest match of not-necessarily contiguous tokens in the span and next lookup begin after next token)
caseMatch Specifies the case folding mode to use - (IGNORE - fold everything to lower case INSENSITIVE - fold only tokens withinitial caps to lowercase SENSITIVE - no folding FOLD DIGIT - fold only tokens with digits to lower case)
stemmer Name of the stemmer to use before matching - (Porter - classic stemmer that removes common morphological andinflectional endings from Engish words BioLemmatizer - domain specific lemmatization tool for the morphologicalanalysis of biomedical literature presented in Liu et al [48] NONE)
orderIndependentLookup Specifies if ordering of tokens within a span can be ignored - (TRUE FALSE)
findAllMatches Specifies if all matches will be returned - (TRUE FALSE - only the longest match will be returned)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
synonyms Specifies which synonyms will be included when creating the dictionary - (EXACT ONLY ALL)
Parameters that were evaluated for each system along with a description and possible values are listed in all capital letters For the most part parameters areself-explanatory but for more information see documentation for each system CM [29] NCBO Annotator [44] MM [18]
were created to load the annotations before evaluationNCBOAnnotator is able to produce annotations and eval-uate themwithin the same pipeline but NCBO Annotatorannotations were cached to avoid hitting the Web servicecontinually Like MM a separate analysis engine was cre-ated to load annotations before evaluation CM producesannotations and evaluates them in a single pipelineEvaluation pipelines for each system have a similar
structure First the gold standard is loaded then the sys-temrsquos annotations are loaded obsolete annotations are
removed and finally a comparison is made CRAFT wasnot annotated with obsolete terms so the obsolete termsfiltered out are those that are obsolete in the version of theontology used to annotate CRAFTCM andMMdictionaries were created with the versions
of the ontologies that were used to annotate CRAFT SinceNCBOAnnotator is aWeb service we do not have controlover the versions of ontologies used it uses newer versionswithmore terms To remove spurious terms not present inthe ontologies used to annotate CRAFT a filter was added
Funk et al BMC Bioinformatics 2014 1559 Page 6 of 29httpwwwbiomedcentralcom1471-21051559
to the NCBO Annotator evaluation pipeline The NCBOAnnotator specific filter removes terms not present inthe version used to annotate CRAFT and ensures thatthe term is not obsolete in the version used to annotateCRAFT Because the versions of the ontologies used inCRAFT are older it may be the case that some termsannotated in CRAFT are obsolete in the current versionsAll systems were restricted to only using valid terms fromthe versions of the ontology used to annotate CRAFTAll comparisons were performed using a STRICT com-
parator which means that ontology ID and span(s) of agiven annotation must match the gold-standard annota-tion exactly to be counted correct A STRICT comparatorwas chosen because it was our desire to see how wellautomated methods can recreate exact human annota-tions A pitfall of the using a STRICT comparator is thata distinction cannot be made between erroneous termsvs those along the same hierarchical lineage both arecounted as fully incorrect in our analysis For exampleif the gold standard annotation is ldquoGO0005515 - proteinbindingrdquo and ldquoGO0005488 - bindingrdquo is returned by asystem partial credit should be given because ldquobindingrdquois an ancestor of ldquoprotein bindingrdquo Future comparisonscould address this limitation by accounting for the hierar-chical relationship in the ontology by counting those lessspecific terms as partially correct by using hierarchicalprecisionrecallF-measure as seen in Verspoor et al [50]The output is a text file for each parameter combination
listing true positives (TP) false positives (FP) and falsenegatives (FN) for each document as well as precision (P)recall (R) and F-measure (F) (Calculations of P R and Fcan be seen in formulas 1 2 and 3) Precision recall andF-measure are calculated over all annotations across alldocuments in CRAFT ie as amicro-average
P = TPTP + FP
(1)
R = TPTP + FN
(2)
F = 2 lowast P lowast RP + R
(3)
Statistical analysisThe Kruskal-Wallis statistical method was chosen to testsignificance for all our comparisons because it is a non-parametric test that identifies differences between rankedgroup of variables It is appropriate for our experimentsbecause we do not assume our data follows any partic-ular distribution and desire to determine if the distribu-tion of scores from a particular experimental conditionsuch as tool or parameters are different from the othersThe implementation built into R was used (kruskaltest)Kruskal-Wallis was applied in three different ways
1 For each ontology Kruskal-Wallis was used todetermine if there is a significant difference inF-measure performance between tools The meanand variance was computed across all parametercombinations for a given tool calculated at thecorpus level using the micro-average F-measure andprovided as input to Kruskal-Wallis
2 For each tool Kruskal-Wallis was used to determineif there is a difference in performance betweenparameter values for each parameter The mean andvariance was computed across all parameter valuesfor a given parameter calculated at the corpus levelusing the micro-average F-measure
3 Results from Kruskal-Wallis only determine if thereis a difference between the groups but does notprovide insight into how many differences orbetween which groups a difference exists When asignificant difference was seen between three or moregroups Kruskal-Wallis was used between a post hoctest to identify the significantly different group(s)
Significance is determined at a 99 level α = 001because there are multiple comparisons a Bonferroni cor-rection was used and the new significance level is α =000036
Analysis of results filesFor each ontology-system pair an analysis was performedon the maximum F-measure parameter combination Wedid not analyze every annotation produced by all sys-tems but made sure to account for sim70ndash80 of themBy performing the analysis this way we are concentratingon the general errors and terms missed rather than rareerrorsFor each maximum F-measure parameter combination
file the top 50ndash150 (grouped by ontology ID and rankedby number of annotations for each ID) of each true pos-itive (TP) false positive (FP) and false negative (FN)were analyzed by separating them into groups of likeannotations For example the types of bins that FPs fallinto are ldquoerrors from variantsrdquo ldquoerrors from ambigu-ous synonymsrdquo ldquoerrors due to identifying less specificconceptsrdquo etc and are different than the bins into whichTPs or FNs are categorizedBecause we evaluated all parameter combinations we
were able to examine the impact of single param-eters by holding all other parameters constant Themaximum F-measure producing parameter combina-tion result file and the complementary result file withvaried parameter were run through a graphical differ-ence program DiffMerge to examine the annotationsfoundlost by varying the parameter Examples men-tioned in the Results and discussion are from thiscomparison
Funk et al BMC Bioinformatics 2014 1559 Page 7 of 29httpwwwbiomedcentralcom1471-21051559
Results and discussionResults and discussion are broken down by ontology andthen by tool For each ontology we present three differentlevels of analysis
1 At the ontology level This provides a synopsis ofoverall performance for each system with commentsabout common terms correct (TPs) errors (FPs) andcategories missed (FNs) Specific examples are takenfrom the top-performing highest F-measureparameter combination
2 A high-level parameter analysis performed over allparameter combinations This allows for observationabout impact on performance seen by manipulatingparameter values presented as ranges of impact(Presented in Additional file 2)
3 A low-level analysis obtained from examiningindividual result files gives insight into specific termsor categories of terms that are affected bymanipulating parameters (Presented in Additionalfile 2)
Within a particular ontology each systemrsquos performanceis described The most impactful parameters are exploredfurther and examples from variations on maximumF-measure combination are provided to show the effectthey have on matching Results presented as numbersof annotations are of this type of analysis We end theResults and discussion Section with overall parameteranalysis and suggestions for parameters on any ontologyThe best-performing result for each system-ontology
pair is presented in Figure 1 There is a wide range of F-measures for all ontologies from lt 010 to 083 Not onlyis there a wide range when looking at all ontologies but awide range can be seen within each ontology Two of ourhypotheses are supported by this analysis we can see thatnot all concept recognition systems perform equally andthe best concept recognition system varies from ontologyto ontology
Best parametersBased on analysis the suggested parameters for maximumperformance for each ontology-system pair can be seen inTables 3 and 4
Cell Type OntologyThe Cell Type Ontology (CL) was designed to providea controlled vocabulary for cell types from many differ-ent prokaryotic fungal and eukaryotic organisms Outof all ontologies annotated in CRAFT it is the smallestterms are the simplest and there are very few synonyms(Table 1) The highest F-measure seen on any ontologyis on CL CM is the top performer (F = 083) MM per-forms second best (F = 069) and NCBO Annotator is the
worst performer (F = 032) Statistics for the best scorescan be seen in Table 5 All parameter combinations foreach system on CL can be seen in Figure 2Annotations from CL in CRAFT are heavily weighted
towards the root node ldquoCL0000000 - cellrdquo it is annotatedover 2500 times and makes up sim44 of all annota-tions To test whether annotations of ldquocellrdquo introduced abias all annotations of CL0000000 were removed and re-evaluated (Results not shown here) We see a decrease inF-measure of 008 for all systems and are able to identifysimilar trends in the effect of parameters when ldquocellrdquo is notincluded We can conclude that ldquocellrdquo annotations do notintroduce any biasPrecision on CL is good overall the highest being CM
(088) and the lowest beingMM (060) withNCBOAnno-tator in the middle (076) Most of the FPs found are dueto partial term matching ldquoCL0000000 - cellrdquo makes upmore than 50 of total FPs because it is contained inmany terms and is mistakenly annotated when a morespecific term cannot be found Besides ldquocellrdquo terms rec-ognized that are less specific than the gold standard areldquoCL0000066 - epithelial cellrdquo instead of ldquoCL0000082 -lung epithelial cellrdquo and ldquoCL0000081 - blood cellrdquo insteadof ldquoCL0000232 - red blood cellrdquo MM finds more FPs thanthe other systems many of these due to abbreviations Forexample MM incorrectly annotates the span ldquoES cellsrdquowith ldquoCL0000352 - epiblast cellrdquo and ldquoCL0000034 stemcellrdquo By utilizing abbreviations MM correctly annotatesldquoNCCrdquo with ldquoCL0000333 - neural crest cellrdquo which theother two systems do not findRecall for CM andMM are over 08 while NCBO Anno-
tator is 02 The low recall seen from NCBO Annotatoris due to the fact that it is unable to recognize pluralsof terms unless they are explicitly stated in the ontol-ogy it correctly finds ldquomelanocyterdquo but does not recognizeldquomelanocytesrdquo for example Because CL is small and itsterms are quite simple there are only two main categoriesof termsmissed missing synonyms and conjunctions Thebiggest category is insufficient synonyms We find ldquoconerdquoand ldquocone photoreceptorrdquo annotated with ldquoCL0000573 -retinal cone cellrdquo and ldquophotoreceptor(s)rdquo annotated withldquoCL0000210 - photoreceptor cellrdquo these two examplesmake up 33 (400 out of 1200) of annotations missed byall systems No systems found any annotations that con-tained conjunctions For example for the text span ldquoretinalbipolar ganglion and rod cellsrdquo three cell types are anno-tated in CRAFT ldquoCL0000748 - retinal bipolar neuronrdquoldquoCL0000740 - retinal ganglion cellrdquo and ldquoCL0000604 -retinal rod cellrdquo
Gene Ontology - Cellular ComponentThe cellular component branch of the Gene Ontologydescribes locations at the levels of subcellular structuresandmacromolecular complexes It is useful for annotating
Funk et al BMC Bioinformatics 2014 1559 Page 8 of 29httpwwwbiomedcentralcom1471-21051559
Best performance for all tools on all ontologies
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Ontologies
GO_CCGO_MFGO_BPSOCLPRNCBITAXONCHEBI
Figure 1Maximum F-measure for each system-ontology pair A wide range of maximum scores is seen for each system within each ontology
where gene products have been found to be localizedGO_CC is similar to CL in that it is a smaller ontologyand contains very few synonyms but the terms are slightlylonger and more complex than CL (Table 1) Performancefrom CM (F = 077) is the best with MM (F = 070)second and NCBO Annotator (F = 040) third (Table 5)All parameter combinations for each system on GO_CCcan be seen in Figure 3Just as in CL there are many annotations to
ldquoGO0005623 - cellrdquo 3647 or 44 of all 8354 annotationsWe removed annotations of ldquocellrdquo and saw a decreasein performance Unlike CL removal of these annota-tions does not affect all systems consistently CM sees alarge decrease in F-measure (02) while MM and NCBOAnnotator see decreases of 008 and 002 respectivelyPrecision for all parameter combinations of CM and
MM are over 050 with the highest being CM at 092NCBO Annotator widely varies from lt 01 to 085Because precision is high there are very few FPs that arefound The FPs in common by all systems are due to lessspecific terms being found and ambiguous terms NCBOAnnotator also finds FPs from broad synonyms and MMspecific errors are from abbreviations Most of the com-mon FPs are mentions that are less specific than thegold standard due to higher-level terms contained withinlower-level ones For instance ldquoGO0016020 - membranerdquo
is found instead of a more specific type of membranesuch as ldquovesicle membranerdquo ldquoplasma membranerdquo or ldquocel-lular membranerdquo All systems find sim20 annotations ofldquoGO0042603 - capsulerdquo when none are seen in CRAFTthis is due to overloaded terms from different biomedicaldomains Because NCBO Annotator is a Web service wehave no control over versions of ontologies used so itused a newer version of the ontology than that whichwas used to annotate CRAFT and as inputted into CMand MM sim42 of NCBO Annotator FPs were becauseldquoGO0019814 - immunoglobulin complex circulatingrdquo hasa broad synonym ldquoantibodyrdquo added Because MM gen-erates variants and incorporates synonyms we see aninteresting error produced from MM ldquohair(s)rdquo get anno-tated with ldquoGO0009289 - pilusrdquo It is not understandablewhy MM would assume this because ldquohairrdquo is not a syn-onym but in the GO definition pilus is described as aldquohair-like appendagerdquoMM achieves the highest recall of 073 with CM slightly
lower at 066 and NCBO Annotator the lowest (027)NCBO Annotatorrsquos inability to recognize plurals andgenerate variants significantly hurts recall NCBO Anno-tator can annotate neither ldquovesiclesrdquo with ldquoGO0031982 -vesiclerdquo nor ldquoautosomalrdquo with ldquoGO0030849 - autosomerdquowhich both CM and MM correctly annotate Thelargest category of missed annotations represents other
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
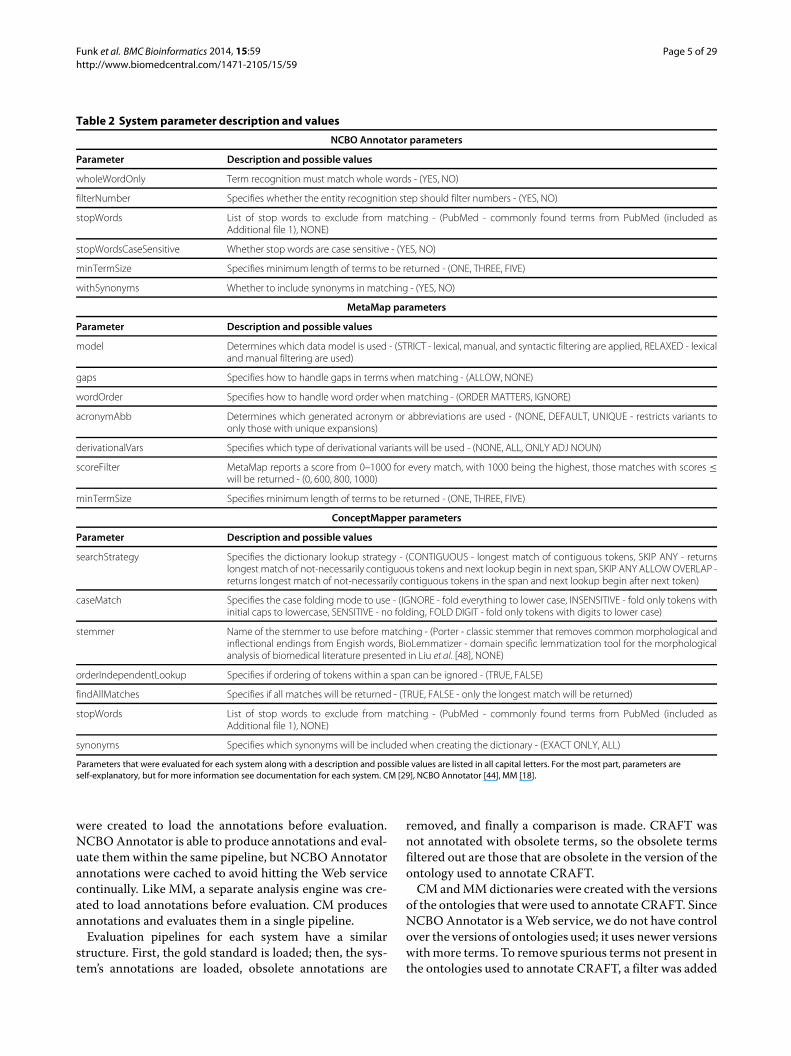
Funk et al BMC Bioinformatics 2014 1559 Page 5 of 29httpwwwbiomedcentralcom1471-21051559
Table 2 System parameter description and values
NCBO Annotator parameters
Parameter Description and possible values
wholeWordOnly Term recognition must match whole words - (YES NO)
filterNumber Specifies whether the entity recognition step should filter numbers - (YES NO)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
stopWordsCaseSensitive Whether stop words are case sensitive - (YES NO)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
withSynonyms Whether to include synonyms in matching - (YES NO)
MetaMap parameters
Parameter Description and possible values
model Determines which data model is used - (STRICT - lexical manual and syntactic filtering are applied RELAXED - lexicaland manual filtering are used)
gaps Specifies how to handle gaps in terms when matching - (ALLOW NONE)
wordOrder Specifies how to handle word order when matching - (ORDER MATTERS IGNORE)
acronymAbb Determines which generated acronym or abbreviations are used - (NONE DEFAULT UNIQUE - restricts variants toonly those with unique expansions)
derivationalVars Specifies which type of derivational variants will be used - (NONE ALL ONLY ADJ NOUN)
scoreFilter MetaMap reports a score from 0ndash1000 for every match with 1000 being the highest those matches with scores lewill be returned - (0 600 800 1000)
minTermSize Specifies minimum length of terms to be returned - (ONE THREE FIVE)
ConceptMapper parameters
Parameter Description and possible values
searchStrategy Specifies the dictionary lookup strategy - (CONTIGUOUS - longest match of contiguous tokens SKIP ANY - returnslongest match of not-necessarily contiguous tokens and next lookup begin in next span SKIP ANY ALLOWOVERLAP -returns longest match of not-necessarily contiguous tokens in the span and next lookup begin after next token)
caseMatch Specifies the case folding mode to use - (IGNORE - fold everything to lower case INSENSITIVE - fold only tokens withinitial caps to lowercase SENSITIVE - no folding FOLD DIGIT - fold only tokens with digits to lower case)
stemmer Name of the stemmer to use before matching - (Porter - classic stemmer that removes common morphological andinflectional endings from Engish words BioLemmatizer - domain specific lemmatization tool for the morphologicalanalysis of biomedical literature presented in Liu et al [48] NONE)
orderIndependentLookup Specifies if ordering of tokens within a span can be ignored - (TRUE FALSE)
findAllMatches Specifies if all matches will be returned - (TRUE FALSE - only the longest match will be returned)
stopWords List of stop words to exclude from matching - (PubMed - commonly found terms from PubMed (included asAdditional file 1) NONE)
synonyms Specifies which synonyms will be included when creating the dictionary - (EXACT ONLY ALL)
Parameters that were evaluated for each system along with a description and possible values are listed in all capital letters For the most part parameters areself-explanatory but for more information see documentation for each system CM [29] NCBO Annotator [44] MM [18]
were created to load the annotations before evaluationNCBOAnnotator is able to produce annotations and eval-uate themwithin the same pipeline but NCBO Annotatorannotations were cached to avoid hitting the Web servicecontinually Like MM a separate analysis engine was cre-ated to load annotations before evaluation CM producesannotations and evaluates them in a single pipelineEvaluation pipelines for each system have a similar
structure First the gold standard is loaded then the sys-temrsquos annotations are loaded obsolete annotations are
removed and finally a comparison is made CRAFT wasnot annotated with obsolete terms so the obsolete termsfiltered out are those that are obsolete in the version of theontology used to annotate CRAFTCM andMMdictionaries were created with the versions
of the ontologies that were used to annotate CRAFT SinceNCBOAnnotator is aWeb service we do not have controlover the versions of ontologies used it uses newer versionswithmore terms To remove spurious terms not present inthe ontologies used to annotate CRAFT a filter was added
Funk et al BMC Bioinformatics 2014 1559 Page 6 of 29httpwwwbiomedcentralcom1471-21051559
to the NCBO Annotator evaluation pipeline The NCBOAnnotator specific filter removes terms not present inthe version used to annotate CRAFT and ensures thatthe term is not obsolete in the version used to annotateCRAFT Because the versions of the ontologies used inCRAFT are older it may be the case that some termsannotated in CRAFT are obsolete in the current versionsAll systems were restricted to only using valid terms fromthe versions of the ontology used to annotate CRAFTAll comparisons were performed using a STRICT com-
parator which means that ontology ID and span(s) of agiven annotation must match the gold-standard annota-tion exactly to be counted correct A STRICT comparatorwas chosen because it was our desire to see how wellautomated methods can recreate exact human annota-tions A pitfall of the using a STRICT comparator is thata distinction cannot be made between erroneous termsvs those along the same hierarchical lineage both arecounted as fully incorrect in our analysis For exampleif the gold standard annotation is ldquoGO0005515 - proteinbindingrdquo and ldquoGO0005488 - bindingrdquo is returned by asystem partial credit should be given because ldquobindingrdquois an ancestor of ldquoprotein bindingrdquo Future comparisonscould address this limitation by accounting for the hierar-chical relationship in the ontology by counting those lessspecific terms as partially correct by using hierarchicalprecisionrecallF-measure as seen in Verspoor et al [50]The output is a text file for each parameter combination
listing true positives (TP) false positives (FP) and falsenegatives (FN) for each document as well as precision (P)recall (R) and F-measure (F) (Calculations of P R and Fcan be seen in formulas 1 2 and 3) Precision recall andF-measure are calculated over all annotations across alldocuments in CRAFT ie as amicro-average
P = TPTP + FP
(1)
R = TPTP + FN
(2)
F = 2 lowast P lowast RP + R
(3)
Statistical analysisThe Kruskal-Wallis statistical method was chosen to testsignificance for all our comparisons because it is a non-parametric test that identifies differences between rankedgroup of variables It is appropriate for our experimentsbecause we do not assume our data follows any partic-ular distribution and desire to determine if the distribu-tion of scores from a particular experimental conditionsuch as tool or parameters are different from the othersThe implementation built into R was used (kruskaltest)Kruskal-Wallis was applied in three different ways
1 For each ontology Kruskal-Wallis was used todetermine if there is a significant difference inF-measure performance between tools The meanand variance was computed across all parametercombinations for a given tool calculated at thecorpus level using the micro-average F-measure andprovided as input to Kruskal-Wallis
2 For each tool Kruskal-Wallis was used to determineif there is a difference in performance betweenparameter values for each parameter The mean andvariance was computed across all parameter valuesfor a given parameter calculated at the corpus levelusing the micro-average F-measure
3 Results from Kruskal-Wallis only determine if thereis a difference between the groups but does notprovide insight into how many differences orbetween which groups a difference exists When asignificant difference was seen between three or moregroups Kruskal-Wallis was used between a post hoctest to identify the significantly different group(s)
Significance is determined at a 99 level α = 001because there are multiple comparisons a Bonferroni cor-rection was used and the new significance level is α =000036
Analysis of results filesFor each ontology-system pair an analysis was performedon the maximum F-measure parameter combination Wedid not analyze every annotation produced by all sys-tems but made sure to account for sim70ndash80 of themBy performing the analysis this way we are concentratingon the general errors and terms missed rather than rareerrorsFor each maximum F-measure parameter combination
file the top 50ndash150 (grouped by ontology ID and rankedby number of annotations for each ID) of each true pos-itive (TP) false positive (FP) and false negative (FN)were analyzed by separating them into groups of likeannotations For example the types of bins that FPs fallinto are ldquoerrors from variantsrdquo ldquoerrors from ambigu-ous synonymsrdquo ldquoerrors due to identifying less specificconceptsrdquo etc and are different than the bins into whichTPs or FNs are categorizedBecause we evaluated all parameter combinations we
were able to examine the impact of single param-eters by holding all other parameters constant Themaximum F-measure producing parameter combina-tion result file and the complementary result file withvaried parameter were run through a graphical differ-ence program DiffMerge to examine the annotationsfoundlost by varying the parameter Examples men-tioned in the Results and discussion are from thiscomparison
Funk et al BMC Bioinformatics 2014 1559 Page 7 of 29httpwwwbiomedcentralcom1471-21051559
Results and discussionResults and discussion are broken down by ontology andthen by tool For each ontology we present three differentlevels of analysis
1 At the ontology level This provides a synopsis ofoverall performance for each system with commentsabout common terms correct (TPs) errors (FPs) andcategories missed (FNs) Specific examples are takenfrom the top-performing highest F-measureparameter combination
2 A high-level parameter analysis performed over allparameter combinations This allows for observationabout impact on performance seen by manipulatingparameter values presented as ranges of impact(Presented in Additional file 2)
3 A low-level analysis obtained from examiningindividual result files gives insight into specific termsor categories of terms that are affected bymanipulating parameters (Presented in Additionalfile 2)
Within a particular ontology each systemrsquos performanceis described The most impactful parameters are exploredfurther and examples from variations on maximumF-measure combination are provided to show the effectthey have on matching Results presented as numbersof annotations are of this type of analysis We end theResults and discussion Section with overall parameteranalysis and suggestions for parameters on any ontologyThe best-performing result for each system-ontology
pair is presented in Figure 1 There is a wide range of F-measures for all ontologies from lt 010 to 083 Not onlyis there a wide range when looking at all ontologies but awide range can be seen within each ontology Two of ourhypotheses are supported by this analysis we can see thatnot all concept recognition systems perform equally andthe best concept recognition system varies from ontologyto ontology
Best parametersBased on analysis the suggested parameters for maximumperformance for each ontology-system pair can be seen inTables 3 and 4
Cell Type OntologyThe Cell Type Ontology (CL) was designed to providea controlled vocabulary for cell types from many differ-ent prokaryotic fungal and eukaryotic organisms Outof all ontologies annotated in CRAFT it is the smallestterms are the simplest and there are very few synonyms(Table 1) The highest F-measure seen on any ontologyis on CL CM is the top performer (F = 083) MM per-forms second best (F = 069) and NCBO Annotator is the
worst performer (F = 032) Statistics for the best scorescan be seen in Table 5 All parameter combinations foreach system on CL can be seen in Figure 2Annotations from CL in CRAFT are heavily weighted
towards the root node ldquoCL0000000 - cellrdquo it is annotatedover 2500 times and makes up sim44 of all annota-tions To test whether annotations of ldquocellrdquo introduced abias all annotations of CL0000000 were removed and re-evaluated (Results not shown here) We see a decrease inF-measure of 008 for all systems and are able to identifysimilar trends in the effect of parameters when ldquocellrdquo is notincluded We can conclude that ldquocellrdquo annotations do notintroduce any biasPrecision on CL is good overall the highest being CM
(088) and the lowest beingMM (060) withNCBOAnno-tator in the middle (076) Most of the FPs found are dueto partial term matching ldquoCL0000000 - cellrdquo makes upmore than 50 of total FPs because it is contained inmany terms and is mistakenly annotated when a morespecific term cannot be found Besides ldquocellrdquo terms rec-ognized that are less specific than the gold standard areldquoCL0000066 - epithelial cellrdquo instead of ldquoCL0000082 -lung epithelial cellrdquo and ldquoCL0000081 - blood cellrdquo insteadof ldquoCL0000232 - red blood cellrdquo MM finds more FPs thanthe other systems many of these due to abbreviations Forexample MM incorrectly annotates the span ldquoES cellsrdquowith ldquoCL0000352 - epiblast cellrdquo and ldquoCL0000034 stemcellrdquo By utilizing abbreviations MM correctly annotatesldquoNCCrdquo with ldquoCL0000333 - neural crest cellrdquo which theother two systems do not findRecall for CM andMM are over 08 while NCBO Anno-
tator is 02 The low recall seen from NCBO Annotatoris due to the fact that it is unable to recognize pluralsof terms unless they are explicitly stated in the ontol-ogy it correctly finds ldquomelanocyterdquo but does not recognizeldquomelanocytesrdquo for example Because CL is small and itsterms are quite simple there are only two main categoriesof termsmissed missing synonyms and conjunctions Thebiggest category is insufficient synonyms We find ldquoconerdquoand ldquocone photoreceptorrdquo annotated with ldquoCL0000573 -retinal cone cellrdquo and ldquophotoreceptor(s)rdquo annotated withldquoCL0000210 - photoreceptor cellrdquo these two examplesmake up 33 (400 out of 1200) of annotations missed byall systems No systems found any annotations that con-tained conjunctions For example for the text span ldquoretinalbipolar ganglion and rod cellsrdquo three cell types are anno-tated in CRAFT ldquoCL0000748 - retinal bipolar neuronrdquoldquoCL0000740 - retinal ganglion cellrdquo and ldquoCL0000604 -retinal rod cellrdquo
Gene Ontology - Cellular ComponentThe cellular component branch of the Gene Ontologydescribes locations at the levels of subcellular structuresandmacromolecular complexes It is useful for annotating
Funk et al BMC Bioinformatics 2014 1559 Page 8 of 29httpwwwbiomedcentralcom1471-21051559
Best performance for all tools on all ontologies
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Ontologies
GO_CCGO_MFGO_BPSOCLPRNCBITAXONCHEBI
Figure 1Maximum F-measure for each system-ontology pair A wide range of maximum scores is seen for each system within each ontology
where gene products have been found to be localizedGO_CC is similar to CL in that it is a smaller ontologyand contains very few synonyms but the terms are slightlylonger and more complex than CL (Table 1) Performancefrom CM (F = 077) is the best with MM (F = 070)second and NCBO Annotator (F = 040) third (Table 5)All parameter combinations for each system on GO_CCcan be seen in Figure 3Just as in CL there are many annotations to
ldquoGO0005623 - cellrdquo 3647 or 44 of all 8354 annotationsWe removed annotations of ldquocellrdquo and saw a decreasein performance Unlike CL removal of these annota-tions does not affect all systems consistently CM sees alarge decrease in F-measure (02) while MM and NCBOAnnotator see decreases of 008 and 002 respectivelyPrecision for all parameter combinations of CM and
MM are over 050 with the highest being CM at 092NCBO Annotator widely varies from lt 01 to 085Because precision is high there are very few FPs that arefound The FPs in common by all systems are due to lessspecific terms being found and ambiguous terms NCBOAnnotator also finds FPs from broad synonyms and MMspecific errors are from abbreviations Most of the com-mon FPs are mentions that are less specific than thegold standard due to higher-level terms contained withinlower-level ones For instance ldquoGO0016020 - membranerdquo
is found instead of a more specific type of membranesuch as ldquovesicle membranerdquo ldquoplasma membranerdquo or ldquocel-lular membranerdquo All systems find sim20 annotations ofldquoGO0042603 - capsulerdquo when none are seen in CRAFTthis is due to overloaded terms from different biomedicaldomains Because NCBO Annotator is a Web service wehave no control over versions of ontologies used so itused a newer version of the ontology than that whichwas used to annotate CRAFT and as inputted into CMand MM sim42 of NCBO Annotator FPs were becauseldquoGO0019814 - immunoglobulin complex circulatingrdquo hasa broad synonym ldquoantibodyrdquo added Because MM gen-erates variants and incorporates synonyms we see aninteresting error produced from MM ldquohair(s)rdquo get anno-tated with ldquoGO0009289 - pilusrdquo It is not understandablewhy MM would assume this because ldquohairrdquo is not a syn-onym but in the GO definition pilus is described as aldquohair-like appendagerdquoMM achieves the highest recall of 073 with CM slightly
lower at 066 and NCBO Annotator the lowest (027)NCBO Annotatorrsquos inability to recognize plurals andgenerate variants significantly hurts recall NCBO Anno-tator can annotate neither ldquovesiclesrdquo with ldquoGO0031982 -vesiclerdquo nor ldquoautosomalrdquo with ldquoGO0030849 - autosomerdquowhich both CM and MM correctly annotate Thelargest category of missed annotations represents other
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 6 of 29httpwwwbiomedcentralcom1471-21051559
to the NCBO Annotator evaluation pipeline The NCBOAnnotator specific filter removes terms not present inthe version used to annotate CRAFT and ensures thatthe term is not obsolete in the version used to annotateCRAFT Because the versions of the ontologies used inCRAFT are older it may be the case that some termsannotated in CRAFT are obsolete in the current versionsAll systems were restricted to only using valid terms fromthe versions of the ontology used to annotate CRAFTAll comparisons were performed using a STRICT com-
parator which means that ontology ID and span(s) of agiven annotation must match the gold-standard annota-tion exactly to be counted correct A STRICT comparatorwas chosen because it was our desire to see how wellautomated methods can recreate exact human annota-tions A pitfall of the using a STRICT comparator is thata distinction cannot be made between erroneous termsvs those along the same hierarchical lineage both arecounted as fully incorrect in our analysis For exampleif the gold standard annotation is ldquoGO0005515 - proteinbindingrdquo and ldquoGO0005488 - bindingrdquo is returned by asystem partial credit should be given because ldquobindingrdquois an ancestor of ldquoprotein bindingrdquo Future comparisonscould address this limitation by accounting for the hierar-chical relationship in the ontology by counting those lessspecific terms as partially correct by using hierarchicalprecisionrecallF-measure as seen in Verspoor et al [50]The output is a text file for each parameter combination
listing true positives (TP) false positives (FP) and falsenegatives (FN) for each document as well as precision (P)recall (R) and F-measure (F) (Calculations of P R and Fcan be seen in formulas 1 2 and 3) Precision recall andF-measure are calculated over all annotations across alldocuments in CRAFT ie as amicro-average
P = TPTP + FP
(1)
R = TPTP + FN
(2)
F = 2 lowast P lowast RP + R
(3)
Statistical analysisThe Kruskal-Wallis statistical method was chosen to testsignificance for all our comparisons because it is a non-parametric test that identifies differences between rankedgroup of variables It is appropriate for our experimentsbecause we do not assume our data follows any partic-ular distribution and desire to determine if the distribu-tion of scores from a particular experimental conditionsuch as tool or parameters are different from the othersThe implementation built into R was used (kruskaltest)Kruskal-Wallis was applied in three different ways
1 For each ontology Kruskal-Wallis was used todetermine if there is a significant difference inF-measure performance between tools The meanand variance was computed across all parametercombinations for a given tool calculated at thecorpus level using the micro-average F-measure andprovided as input to Kruskal-Wallis
2 For each tool Kruskal-Wallis was used to determineif there is a difference in performance betweenparameter values for each parameter The mean andvariance was computed across all parameter valuesfor a given parameter calculated at the corpus levelusing the micro-average F-measure
3 Results from Kruskal-Wallis only determine if thereis a difference between the groups but does notprovide insight into how many differences orbetween which groups a difference exists When asignificant difference was seen between three or moregroups Kruskal-Wallis was used between a post hoctest to identify the significantly different group(s)
Significance is determined at a 99 level α = 001because there are multiple comparisons a Bonferroni cor-rection was used and the new significance level is α =000036
Analysis of results filesFor each ontology-system pair an analysis was performedon the maximum F-measure parameter combination Wedid not analyze every annotation produced by all sys-tems but made sure to account for sim70ndash80 of themBy performing the analysis this way we are concentratingon the general errors and terms missed rather than rareerrorsFor each maximum F-measure parameter combination
file the top 50ndash150 (grouped by ontology ID and rankedby number of annotations for each ID) of each true pos-itive (TP) false positive (FP) and false negative (FN)were analyzed by separating them into groups of likeannotations For example the types of bins that FPs fallinto are ldquoerrors from variantsrdquo ldquoerrors from ambigu-ous synonymsrdquo ldquoerrors due to identifying less specificconceptsrdquo etc and are different than the bins into whichTPs or FNs are categorizedBecause we evaluated all parameter combinations we
were able to examine the impact of single param-eters by holding all other parameters constant Themaximum F-measure producing parameter combina-tion result file and the complementary result file withvaried parameter were run through a graphical differ-ence program DiffMerge to examine the annotationsfoundlost by varying the parameter Examples men-tioned in the Results and discussion are from thiscomparison
Funk et al BMC Bioinformatics 2014 1559 Page 7 of 29httpwwwbiomedcentralcom1471-21051559
Results and discussionResults and discussion are broken down by ontology andthen by tool For each ontology we present three differentlevels of analysis
1 At the ontology level This provides a synopsis ofoverall performance for each system with commentsabout common terms correct (TPs) errors (FPs) andcategories missed (FNs) Specific examples are takenfrom the top-performing highest F-measureparameter combination
2 A high-level parameter analysis performed over allparameter combinations This allows for observationabout impact on performance seen by manipulatingparameter values presented as ranges of impact(Presented in Additional file 2)
3 A low-level analysis obtained from examiningindividual result files gives insight into specific termsor categories of terms that are affected bymanipulating parameters (Presented in Additionalfile 2)
Within a particular ontology each systemrsquos performanceis described The most impactful parameters are exploredfurther and examples from variations on maximumF-measure combination are provided to show the effectthey have on matching Results presented as numbersof annotations are of this type of analysis We end theResults and discussion Section with overall parameteranalysis and suggestions for parameters on any ontologyThe best-performing result for each system-ontology
pair is presented in Figure 1 There is a wide range of F-measures for all ontologies from lt 010 to 083 Not onlyis there a wide range when looking at all ontologies but awide range can be seen within each ontology Two of ourhypotheses are supported by this analysis we can see thatnot all concept recognition systems perform equally andthe best concept recognition system varies from ontologyto ontology
Best parametersBased on analysis the suggested parameters for maximumperformance for each ontology-system pair can be seen inTables 3 and 4
Cell Type OntologyThe Cell Type Ontology (CL) was designed to providea controlled vocabulary for cell types from many differ-ent prokaryotic fungal and eukaryotic organisms Outof all ontologies annotated in CRAFT it is the smallestterms are the simplest and there are very few synonyms(Table 1) The highest F-measure seen on any ontologyis on CL CM is the top performer (F = 083) MM per-forms second best (F = 069) and NCBO Annotator is the
worst performer (F = 032) Statistics for the best scorescan be seen in Table 5 All parameter combinations foreach system on CL can be seen in Figure 2Annotations from CL in CRAFT are heavily weighted
towards the root node ldquoCL0000000 - cellrdquo it is annotatedover 2500 times and makes up sim44 of all annota-tions To test whether annotations of ldquocellrdquo introduced abias all annotations of CL0000000 were removed and re-evaluated (Results not shown here) We see a decrease inF-measure of 008 for all systems and are able to identifysimilar trends in the effect of parameters when ldquocellrdquo is notincluded We can conclude that ldquocellrdquo annotations do notintroduce any biasPrecision on CL is good overall the highest being CM
(088) and the lowest beingMM (060) withNCBOAnno-tator in the middle (076) Most of the FPs found are dueto partial term matching ldquoCL0000000 - cellrdquo makes upmore than 50 of total FPs because it is contained inmany terms and is mistakenly annotated when a morespecific term cannot be found Besides ldquocellrdquo terms rec-ognized that are less specific than the gold standard areldquoCL0000066 - epithelial cellrdquo instead of ldquoCL0000082 -lung epithelial cellrdquo and ldquoCL0000081 - blood cellrdquo insteadof ldquoCL0000232 - red blood cellrdquo MM finds more FPs thanthe other systems many of these due to abbreviations Forexample MM incorrectly annotates the span ldquoES cellsrdquowith ldquoCL0000352 - epiblast cellrdquo and ldquoCL0000034 stemcellrdquo By utilizing abbreviations MM correctly annotatesldquoNCCrdquo with ldquoCL0000333 - neural crest cellrdquo which theother two systems do not findRecall for CM andMM are over 08 while NCBO Anno-
tator is 02 The low recall seen from NCBO Annotatoris due to the fact that it is unable to recognize pluralsof terms unless they are explicitly stated in the ontol-ogy it correctly finds ldquomelanocyterdquo but does not recognizeldquomelanocytesrdquo for example Because CL is small and itsterms are quite simple there are only two main categoriesof termsmissed missing synonyms and conjunctions Thebiggest category is insufficient synonyms We find ldquoconerdquoand ldquocone photoreceptorrdquo annotated with ldquoCL0000573 -retinal cone cellrdquo and ldquophotoreceptor(s)rdquo annotated withldquoCL0000210 - photoreceptor cellrdquo these two examplesmake up 33 (400 out of 1200) of annotations missed byall systems No systems found any annotations that con-tained conjunctions For example for the text span ldquoretinalbipolar ganglion and rod cellsrdquo three cell types are anno-tated in CRAFT ldquoCL0000748 - retinal bipolar neuronrdquoldquoCL0000740 - retinal ganglion cellrdquo and ldquoCL0000604 -retinal rod cellrdquo
Gene Ontology - Cellular ComponentThe cellular component branch of the Gene Ontologydescribes locations at the levels of subcellular structuresandmacromolecular complexes It is useful for annotating
Funk et al BMC Bioinformatics 2014 1559 Page 8 of 29httpwwwbiomedcentralcom1471-21051559
Best performance for all tools on all ontologies
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Ontologies
GO_CCGO_MFGO_BPSOCLPRNCBITAXONCHEBI
Figure 1Maximum F-measure for each system-ontology pair A wide range of maximum scores is seen for each system within each ontology
where gene products have been found to be localizedGO_CC is similar to CL in that it is a smaller ontologyand contains very few synonyms but the terms are slightlylonger and more complex than CL (Table 1) Performancefrom CM (F = 077) is the best with MM (F = 070)second and NCBO Annotator (F = 040) third (Table 5)All parameter combinations for each system on GO_CCcan be seen in Figure 3Just as in CL there are many annotations to
ldquoGO0005623 - cellrdquo 3647 or 44 of all 8354 annotationsWe removed annotations of ldquocellrdquo and saw a decreasein performance Unlike CL removal of these annota-tions does not affect all systems consistently CM sees alarge decrease in F-measure (02) while MM and NCBOAnnotator see decreases of 008 and 002 respectivelyPrecision for all parameter combinations of CM and
MM are over 050 with the highest being CM at 092NCBO Annotator widely varies from lt 01 to 085Because precision is high there are very few FPs that arefound The FPs in common by all systems are due to lessspecific terms being found and ambiguous terms NCBOAnnotator also finds FPs from broad synonyms and MMspecific errors are from abbreviations Most of the com-mon FPs are mentions that are less specific than thegold standard due to higher-level terms contained withinlower-level ones For instance ldquoGO0016020 - membranerdquo
is found instead of a more specific type of membranesuch as ldquovesicle membranerdquo ldquoplasma membranerdquo or ldquocel-lular membranerdquo All systems find sim20 annotations ofldquoGO0042603 - capsulerdquo when none are seen in CRAFTthis is due to overloaded terms from different biomedicaldomains Because NCBO Annotator is a Web service wehave no control over versions of ontologies used so itused a newer version of the ontology than that whichwas used to annotate CRAFT and as inputted into CMand MM sim42 of NCBO Annotator FPs were becauseldquoGO0019814 - immunoglobulin complex circulatingrdquo hasa broad synonym ldquoantibodyrdquo added Because MM gen-erates variants and incorporates synonyms we see aninteresting error produced from MM ldquohair(s)rdquo get anno-tated with ldquoGO0009289 - pilusrdquo It is not understandablewhy MM would assume this because ldquohairrdquo is not a syn-onym but in the GO definition pilus is described as aldquohair-like appendagerdquoMM achieves the highest recall of 073 with CM slightly
lower at 066 and NCBO Annotator the lowest (027)NCBO Annotatorrsquos inability to recognize plurals andgenerate variants significantly hurts recall NCBO Anno-tator can annotate neither ldquovesiclesrdquo with ldquoGO0031982 -vesiclerdquo nor ldquoautosomalrdquo with ldquoGO0030849 - autosomerdquowhich both CM and MM correctly annotate Thelargest category of missed annotations represents other
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 7 of 29httpwwwbiomedcentralcom1471-21051559
Results and discussionResults and discussion are broken down by ontology andthen by tool For each ontology we present three differentlevels of analysis
1 At the ontology level This provides a synopsis ofoverall performance for each system with commentsabout common terms correct (TPs) errors (FPs) andcategories missed (FNs) Specific examples are takenfrom the top-performing highest F-measureparameter combination
2 A high-level parameter analysis performed over allparameter combinations This allows for observationabout impact on performance seen by manipulatingparameter values presented as ranges of impact(Presented in Additional file 2)
3 A low-level analysis obtained from examiningindividual result files gives insight into specific termsor categories of terms that are affected bymanipulating parameters (Presented in Additionalfile 2)
Within a particular ontology each systemrsquos performanceis described The most impactful parameters are exploredfurther and examples from variations on maximumF-measure combination are provided to show the effectthey have on matching Results presented as numbersof annotations are of this type of analysis We end theResults and discussion Section with overall parameteranalysis and suggestions for parameters on any ontologyThe best-performing result for each system-ontology
pair is presented in Figure 1 There is a wide range of F-measures for all ontologies from lt 010 to 083 Not onlyis there a wide range when looking at all ontologies but awide range can be seen within each ontology Two of ourhypotheses are supported by this analysis we can see thatnot all concept recognition systems perform equally andthe best concept recognition system varies from ontologyto ontology
Best parametersBased on analysis the suggested parameters for maximumperformance for each ontology-system pair can be seen inTables 3 and 4
Cell Type OntologyThe Cell Type Ontology (CL) was designed to providea controlled vocabulary for cell types from many differ-ent prokaryotic fungal and eukaryotic organisms Outof all ontologies annotated in CRAFT it is the smallestterms are the simplest and there are very few synonyms(Table 1) The highest F-measure seen on any ontologyis on CL CM is the top performer (F = 083) MM per-forms second best (F = 069) and NCBO Annotator is the
worst performer (F = 032) Statistics for the best scorescan be seen in Table 5 All parameter combinations foreach system on CL can be seen in Figure 2Annotations from CL in CRAFT are heavily weighted
towards the root node ldquoCL0000000 - cellrdquo it is annotatedover 2500 times and makes up sim44 of all annota-tions To test whether annotations of ldquocellrdquo introduced abias all annotations of CL0000000 were removed and re-evaluated (Results not shown here) We see a decrease inF-measure of 008 for all systems and are able to identifysimilar trends in the effect of parameters when ldquocellrdquo is notincluded We can conclude that ldquocellrdquo annotations do notintroduce any biasPrecision on CL is good overall the highest being CM
(088) and the lowest beingMM (060) withNCBOAnno-tator in the middle (076) Most of the FPs found are dueto partial term matching ldquoCL0000000 - cellrdquo makes upmore than 50 of total FPs because it is contained inmany terms and is mistakenly annotated when a morespecific term cannot be found Besides ldquocellrdquo terms rec-ognized that are less specific than the gold standard areldquoCL0000066 - epithelial cellrdquo instead of ldquoCL0000082 -lung epithelial cellrdquo and ldquoCL0000081 - blood cellrdquo insteadof ldquoCL0000232 - red blood cellrdquo MM finds more FPs thanthe other systems many of these due to abbreviations Forexample MM incorrectly annotates the span ldquoES cellsrdquowith ldquoCL0000352 - epiblast cellrdquo and ldquoCL0000034 stemcellrdquo By utilizing abbreviations MM correctly annotatesldquoNCCrdquo with ldquoCL0000333 - neural crest cellrdquo which theother two systems do not findRecall for CM andMM are over 08 while NCBO Anno-
tator is 02 The low recall seen from NCBO Annotatoris due to the fact that it is unable to recognize pluralsof terms unless they are explicitly stated in the ontol-ogy it correctly finds ldquomelanocyterdquo but does not recognizeldquomelanocytesrdquo for example Because CL is small and itsterms are quite simple there are only two main categoriesof termsmissed missing synonyms and conjunctions Thebiggest category is insufficient synonyms We find ldquoconerdquoand ldquocone photoreceptorrdquo annotated with ldquoCL0000573 -retinal cone cellrdquo and ldquophotoreceptor(s)rdquo annotated withldquoCL0000210 - photoreceptor cellrdquo these two examplesmake up 33 (400 out of 1200) of annotations missed byall systems No systems found any annotations that con-tained conjunctions For example for the text span ldquoretinalbipolar ganglion and rod cellsrdquo three cell types are anno-tated in CRAFT ldquoCL0000748 - retinal bipolar neuronrdquoldquoCL0000740 - retinal ganglion cellrdquo and ldquoCL0000604 -retinal rod cellrdquo
Gene Ontology - Cellular ComponentThe cellular component branch of the Gene Ontologydescribes locations at the levels of subcellular structuresandmacromolecular complexes It is useful for annotating
Funk et al BMC Bioinformatics 2014 1559 Page 8 of 29httpwwwbiomedcentralcom1471-21051559
Best performance for all tools on all ontologies
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Ontologies
GO_CCGO_MFGO_BPSOCLPRNCBITAXONCHEBI
Figure 1Maximum F-measure for each system-ontology pair A wide range of maximum scores is seen for each system within each ontology
where gene products have been found to be localizedGO_CC is similar to CL in that it is a smaller ontologyand contains very few synonyms but the terms are slightlylonger and more complex than CL (Table 1) Performancefrom CM (F = 077) is the best with MM (F = 070)second and NCBO Annotator (F = 040) third (Table 5)All parameter combinations for each system on GO_CCcan be seen in Figure 3Just as in CL there are many annotations to
ldquoGO0005623 - cellrdquo 3647 or 44 of all 8354 annotationsWe removed annotations of ldquocellrdquo and saw a decreasein performance Unlike CL removal of these annota-tions does not affect all systems consistently CM sees alarge decrease in F-measure (02) while MM and NCBOAnnotator see decreases of 008 and 002 respectivelyPrecision for all parameter combinations of CM and
MM are over 050 with the highest being CM at 092NCBO Annotator widely varies from lt 01 to 085Because precision is high there are very few FPs that arefound The FPs in common by all systems are due to lessspecific terms being found and ambiguous terms NCBOAnnotator also finds FPs from broad synonyms and MMspecific errors are from abbreviations Most of the com-mon FPs are mentions that are less specific than thegold standard due to higher-level terms contained withinlower-level ones For instance ldquoGO0016020 - membranerdquo
is found instead of a more specific type of membranesuch as ldquovesicle membranerdquo ldquoplasma membranerdquo or ldquocel-lular membranerdquo All systems find sim20 annotations ofldquoGO0042603 - capsulerdquo when none are seen in CRAFTthis is due to overloaded terms from different biomedicaldomains Because NCBO Annotator is a Web service wehave no control over versions of ontologies used so itused a newer version of the ontology than that whichwas used to annotate CRAFT and as inputted into CMand MM sim42 of NCBO Annotator FPs were becauseldquoGO0019814 - immunoglobulin complex circulatingrdquo hasa broad synonym ldquoantibodyrdquo added Because MM gen-erates variants and incorporates synonyms we see aninteresting error produced from MM ldquohair(s)rdquo get anno-tated with ldquoGO0009289 - pilusrdquo It is not understandablewhy MM would assume this because ldquohairrdquo is not a syn-onym but in the GO definition pilus is described as aldquohair-like appendagerdquoMM achieves the highest recall of 073 with CM slightly
lower at 066 and NCBO Annotator the lowest (027)NCBO Annotatorrsquos inability to recognize plurals andgenerate variants significantly hurts recall NCBO Anno-tator can annotate neither ldquovesiclesrdquo with ldquoGO0031982 -vesiclerdquo nor ldquoautosomalrdquo with ldquoGO0030849 - autosomerdquowhich both CM and MM correctly annotate Thelargest category of missed annotations represents other
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
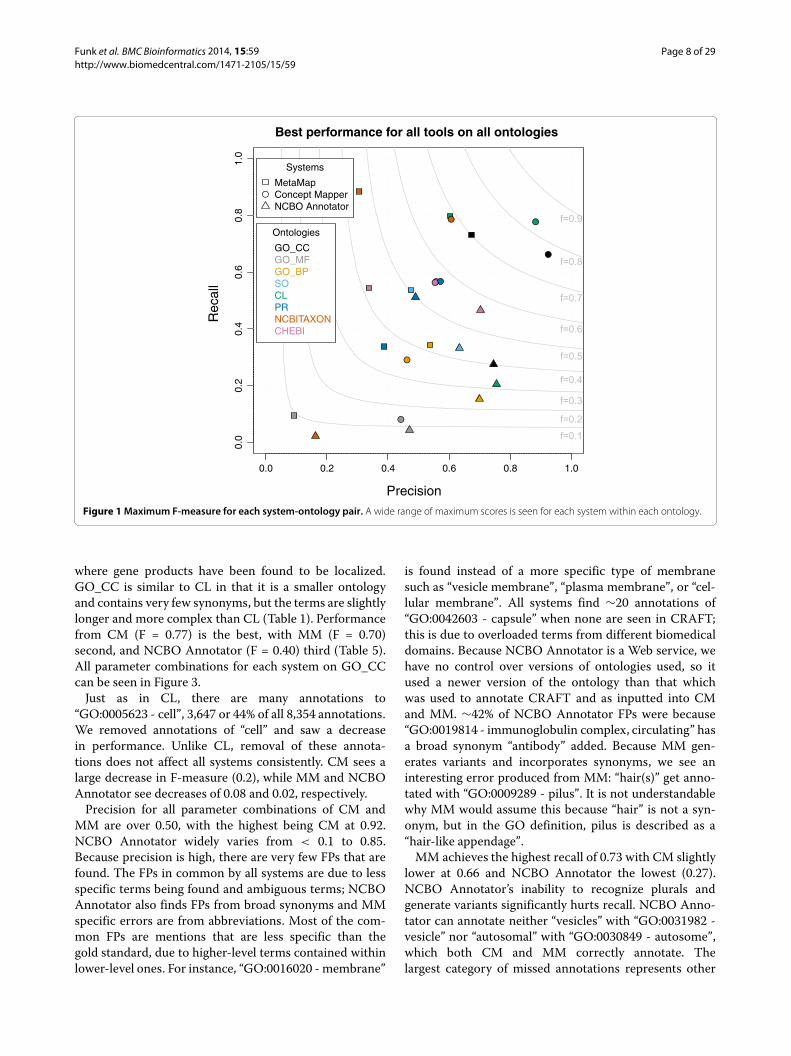
Funk et al BMC Bioinformatics 2014 1559 Page 8 of 29httpwwwbiomedcentralcom1471-21051559
Best performance for all tools on all ontologies
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Ontologies
GO_CCGO_MFGO_BPSOCLPRNCBITAXONCHEBI
Figure 1Maximum F-measure for each system-ontology pair A wide range of maximum scores is seen for each system within each ontology
where gene products have been found to be localizedGO_CC is similar to CL in that it is a smaller ontologyand contains very few synonyms but the terms are slightlylonger and more complex than CL (Table 1) Performancefrom CM (F = 077) is the best with MM (F = 070)second and NCBO Annotator (F = 040) third (Table 5)All parameter combinations for each system on GO_CCcan be seen in Figure 3Just as in CL there are many annotations to
ldquoGO0005623 - cellrdquo 3647 or 44 of all 8354 annotationsWe removed annotations of ldquocellrdquo and saw a decreasein performance Unlike CL removal of these annota-tions does not affect all systems consistently CM sees alarge decrease in F-measure (02) while MM and NCBOAnnotator see decreases of 008 and 002 respectivelyPrecision for all parameter combinations of CM and
MM are over 050 with the highest being CM at 092NCBO Annotator widely varies from lt 01 to 085Because precision is high there are very few FPs that arefound The FPs in common by all systems are due to lessspecific terms being found and ambiguous terms NCBOAnnotator also finds FPs from broad synonyms and MMspecific errors are from abbreviations Most of the com-mon FPs are mentions that are less specific than thegold standard due to higher-level terms contained withinlower-level ones For instance ldquoGO0016020 - membranerdquo
is found instead of a more specific type of membranesuch as ldquovesicle membranerdquo ldquoplasma membranerdquo or ldquocel-lular membranerdquo All systems find sim20 annotations ofldquoGO0042603 - capsulerdquo when none are seen in CRAFTthis is due to overloaded terms from different biomedicaldomains Because NCBO Annotator is a Web service wehave no control over versions of ontologies used so itused a newer version of the ontology than that whichwas used to annotate CRAFT and as inputted into CMand MM sim42 of NCBO Annotator FPs were becauseldquoGO0019814 - immunoglobulin complex circulatingrdquo hasa broad synonym ldquoantibodyrdquo added Because MM gen-erates variants and incorporates synonyms we see aninteresting error produced from MM ldquohair(s)rdquo get anno-tated with ldquoGO0009289 - pilusrdquo It is not understandablewhy MM would assume this because ldquohairrdquo is not a syn-onym but in the GO definition pilus is described as aldquohair-like appendagerdquoMM achieves the highest recall of 073 with CM slightly
lower at 066 and NCBO Annotator the lowest (027)NCBO Annotatorrsquos inability to recognize plurals andgenerate variants significantly hurts recall NCBO Anno-tator can annotate neither ldquovesiclesrdquo with ldquoGO0031982 -vesiclerdquo nor ldquoautosomalrdquo with ldquoGO0030849 - autosomerdquowhich both CM and MM correctly annotate Thelargest category of missed annotations represents other
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
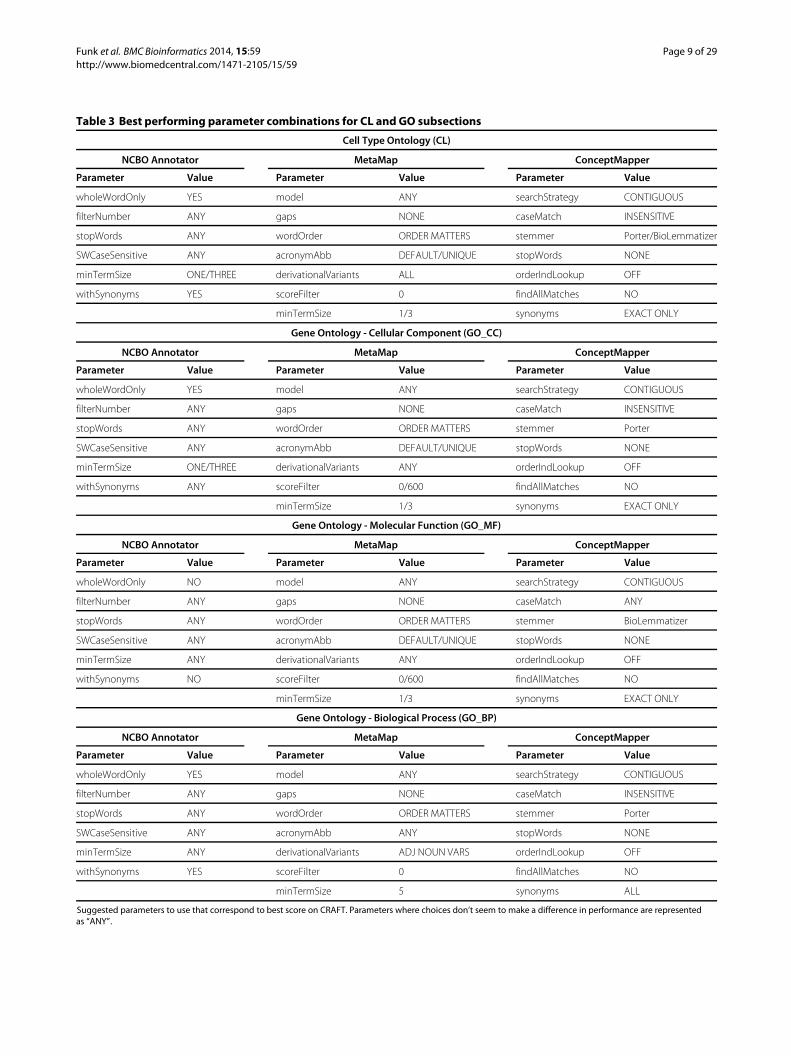
Funk et al BMC Bioinformatics 2014 1559 Page 9 of 29httpwwwbiomedcentralcom1471-21051559
Table 3 Best performing parameter combinations for CL and GO subsections
Cell Type Ontology (CL)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ALL orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Cellular Component (GO_CC)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants ANY orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Molecular Function (GO_MF)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ANY derivationalVariants ANY orderIndLookup OFF
withSynonyms NO scoreFilter 0600 findAllMatches NO
minTermSize 13 synonyms EXACT ONLY
Gene Ontology - Biological Process (GO_BP)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer Porter
SWCaseSensitive ANY acronymAbb ANY stopWords NONE
minTermSize ANY derivationalVariants ADJ NOUN VARS orderIndLookup OFF
withSynonyms YES scoreFilter 0 findAllMatches NO
minTermSize 5 synonyms ALL
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
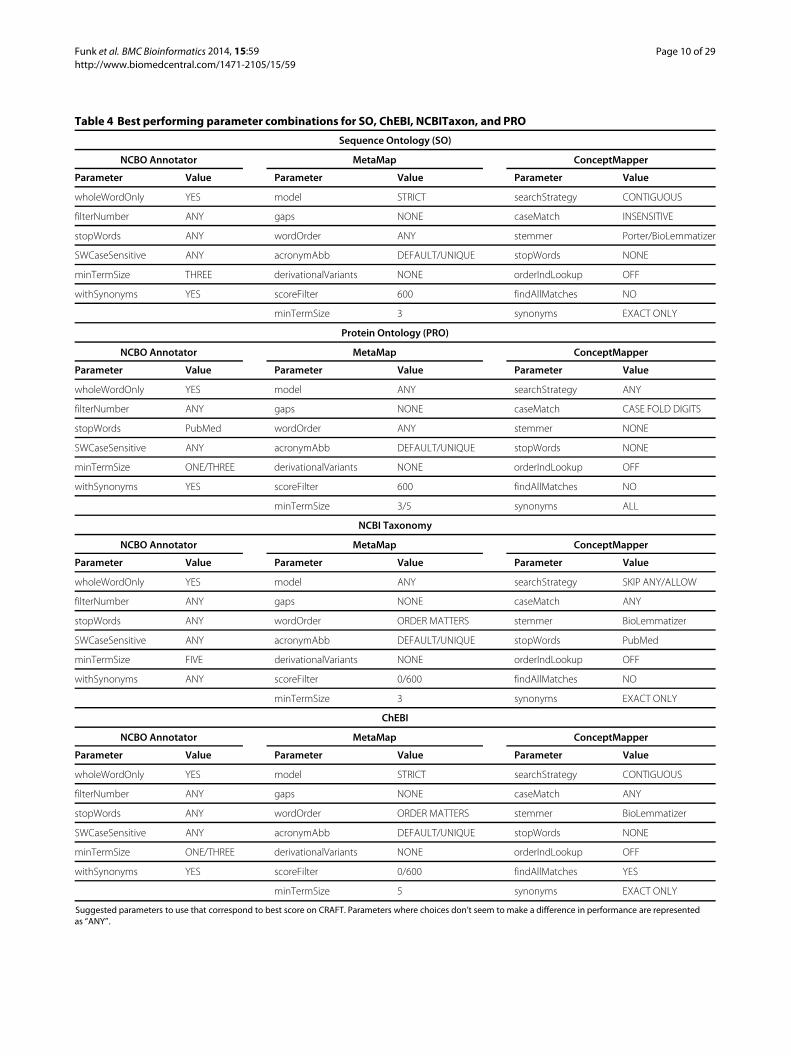
Funk et al BMC Bioinformatics 2014 1559 Page 10 of 29httpwwwbiomedcentralcom1471-21051559
Table 4 Best performing parameter combinations for SO ChEBI NCBITaxon and PRO
Sequence Ontology (SO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch INSENSITIVE
stopWords ANY wordOrder ANY stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
Protein Ontology (PRO)
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy ANY
filterNumber ANY gaps NONE caseMatch CASE FOLD DIGITS
stopWords PubMed wordOrder ANY stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 600 findAllMatches NO
minTermSize 35 synonyms ALL
NCBI Taxonomy
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model ANY searchStrategy SKIP ANYALLOW
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords PubMed
minTermSize FIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms ANY scoreFilter 0600 findAllMatches NO
minTermSize 3 synonyms EXACT ONLY
ChEBI
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch ANY
stopWords ANY wordOrder ORDER MATTERS stemmer BioLemmatizer
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize ONETHREE derivationalVariants NONE orderIndLookup OFF
withSynonyms YES scoreFilter 0600 findAllMatches YES
minTermSize 5 synonyms EXACT ONLY
Suggested parameters to use that correspond to best score on CRAFT Parameters where choices donrsquot seem to make a difference in performance are representedas ldquoANYrdquo
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
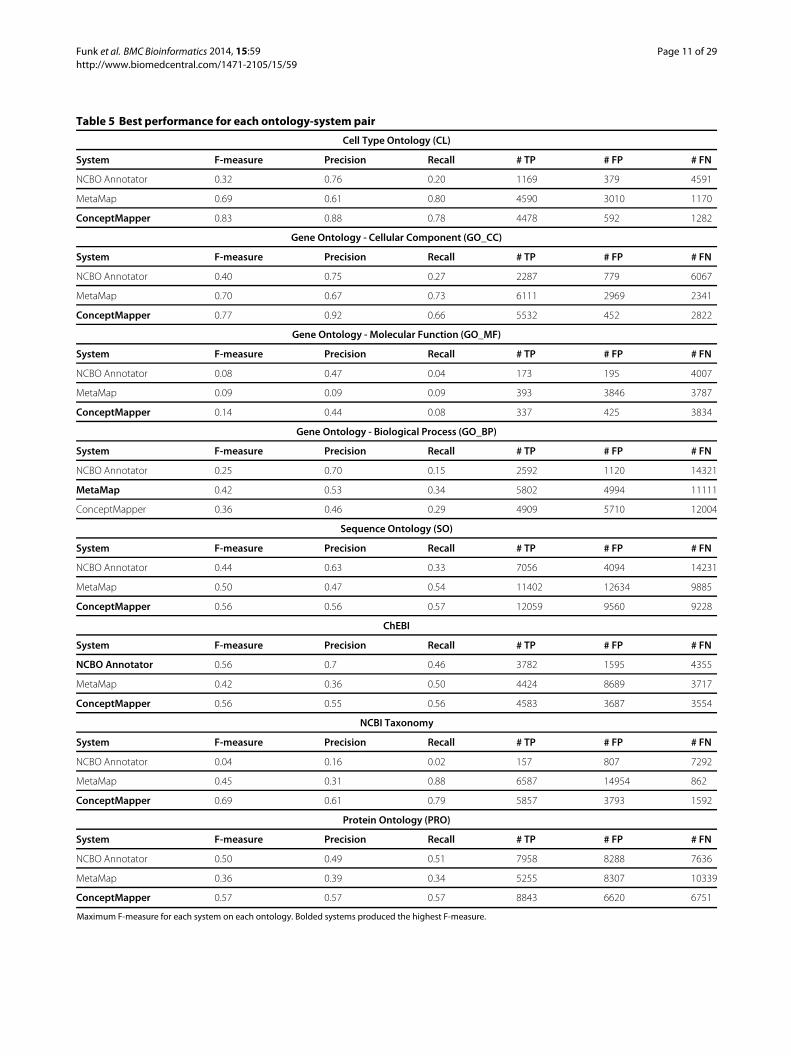
Funk et al BMC Bioinformatics 2014 1559 Page 11 of 29httpwwwbiomedcentralcom1471-21051559
Table 5 Best performance for each ontology-system pair
Cell Type Ontology (CL)
System F-measure Precision Recall TP FP FN
NCBO Annotator 032 076 020 1169 379 4591
MetaMap 069 061 080 4590 3010 1170
ConceptMapper 083 088 078 4478 592 1282
Gene Ontology - Cellular Component (GO_CC)
System F-measure Precision Recall TP FP FN
NCBO Annotator 040 075 027 2287 779 6067
MetaMap 070 067 073 6111 2969 2341
ConceptMapper 077 092 066 5532 452 2822
Gene Ontology - Molecular Function (GO_MF)
System F-measure Precision Recall TP FP FN
NCBO Annotator 008 047 004 173 195 4007
MetaMap 009 009 009 393 3846 3787
ConceptMapper 014 044 008 337 425 3834
Gene Ontology - Biological Process (GO_BP)
System F-measure Precision Recall TP FP FN
NCBO Annotator 025 070 015 2592 1120 14321
MetaMap 042 053 034 5802 4994 11111
ConceptMapper 036 046 029 4909 5710 12004
Sequence Ontology (SO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 044 063 033 7056 4094 14231
MetaMap 050 047 054 11402 12634 9885
ConceptMapper 056 056 057 12059 9560 9228
ChEBI
System F-measure Precision Recall TP FP FN
NCBO Annotator 056 07 046 3782 1595 4355
MetaMap 042 036 050 4424 8689 3717
ConceptMapper 056 055 056 4583 3687 3554
NCBI Taxonomy
System F-measure Precision Recall TP FP FN
NCBO Annotator 004 016 002 157 807 7292
MetaMap 045 031 088 6587 14954 862
ConceptMapper 069 061 079 5857 3793 1592
Protein Ontology (PRO)
System F-measure Precision Recall TP FP FN
NCBO Annotator 050 049 051 7958 8288 7636
MetaMap 036 039 034 5255 8307 10339
ConceptMapper 057 057 057 8843 6620 6751
Maximum F-measure for each system on each ontology Bolded systems produced the highest F-measure
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
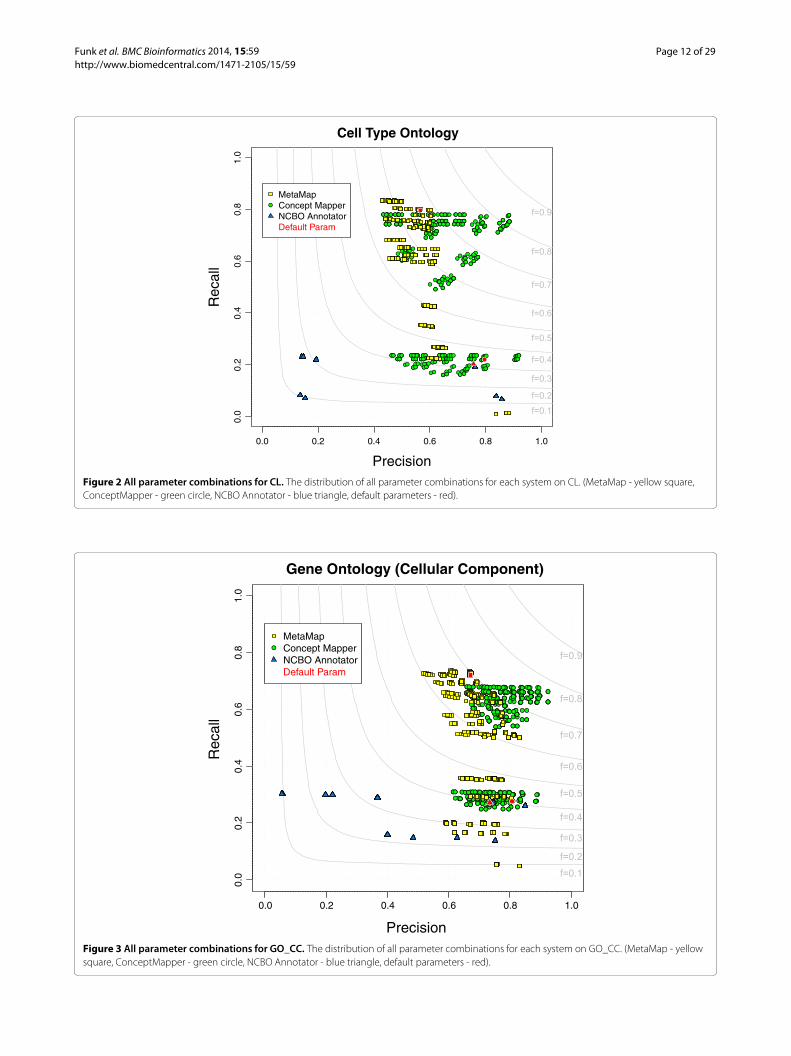
Funk et al BMC Bioinformatics 2014 1559 Page 12 of 29httpwwwbiomedcentralcom1471-21051559
Cell Type Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 2 All parameter combinations for CL The distribution of all parameter combinations for each system on CL (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Gene Ontology (Cellular Component)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 3 All parameter combinations for GO_CC The distribution of all parameter combinations for each system on GO_CC (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 13 of 29httpwwwbiomedcentralcom1471-21051559
ways to refer to terms not in the synonym list InCRAFT ldquocomplex(es)rdquo is annotated with ldquoGO0032991 -macromolecular complexrdquo and ldquoantibodyrdquo ldquoantibodiesrdquoldquoimmune complexrdquo and ldquoimmunoglobulinrdquo are all anno-tated with ldquoGO0019814 - immunoglobulin complexrdquo butno systems are able to identify these annotations becausethese synonyms do not exist in the ontologyMM achieveshighest recall because it identifies abbreviations that othersystems are unable to find For example ldquochrrdquo is correctlyannotated with ldquoGO0005694 - chromosomerdquo ldquoERrdquo withldquoGO0005783 - endoplasmic reticulumrdquo and ldquoECMrdquo withldquoGO0031012 - extracellular matrixrdquo
Gene Ontology - Biological ProcessTerms from GO_BP are complex they have the longestaverage length contain many words and almost half con-tain stop words (Table 1) The longest annotations fromGO_BP in CRAFT contain five tokens Distribution ofannotations broken down by number of words along withperformance can be seen in Table 6 When dealing withlonger and more complex terms it is unlikely to see themexpressed exactly in text as they are seen in the ontologyFor these reasons none of the systems performed verywell The maximum F-measures seen by each system canbe seen in Table 5 All parameter combinations for eachsystem on GO_BP can be seen in Figure 4 Examiningmean F-measures for all parameter combinations there isno difference in performance between CM (F = 037) andMM (F = 042) but considering only the top 25 of combi-nations there is a difference between the two A statisticaldifference exists between NCBO Annotator (F = 025) andall others under all comparison conditionsPerformance by all parameter combinations for all sys-
tems are grouped tightly along the dimension of recallPrecision for all systems is in the range of 02ndash08with NCBO Annotator situated on the extremes of therange and CMMM distributed throughout Commoncategories of FPs encountered by all three systems arerecognizing parts of longermore specific terms and hav-ing different annotation guidelines As seen in the pre-vious ontologies high-level terms are seen in lowerlevel terms which introduces errors in systems thatfind all matches For example we see NCBO Annotator
Table 6 Word length in GO - Biological Process
Words CRAFT Found Found Foundin term annotations by CM byMM by NCBO
5 7 143 143 143
4 109 174 37 92
3 317 372 334 350
2 2077 490 507 433
1 13574 276 342 116
incorrectly annotate ldquoGO001625 - deathrdquo within ldquocelldeathrdquo and both CM and MM annotate ldquodevelopmentrdquowith ldquoGO00032502 - developmental processrdquo within thespan ldquolimb developmentrdquo Different annotation guidelinesalso cause errors to be introduced eg all systems anno-tate ldquoformationrdquo with ldquoGO0009058 - biosynthetic pro-cessrdquo because it has a synonym ldquoformationrdquo but in CRAFTldquoformationrdquo may be annotated with ldquoGO0032502 - devel-opmental processrdquo ldquoGO0009058 - biosynthetic processrdquoor ldquoGO0022607 - cellular component assemblyrdquo depend-ing on the context Most of the FPs common toboth CM and MM are due to variant generation forexample CM annotates ldquoregion(s)rdquo with ldquoGO003002 -regionalizationrdquo and MM annotates ldquoregularrdquo and ldquoreg-ulator(s)rdquo with ldquoGO0065007 - biological regulationrdquoEven though we see errors introduced through gen-erating variants many more correct annotations areproducedIn the grouping of all systems performance recall lies
between 01ndash04 which is low in comparison to mostall other ontologies More than sim7000 (gt 50ndash60) ofthe FNs are due to different ways to refer to termsnot in the synonym list The most missed annotationwith over 2200 mentions are those of ldquoGO0010467 -gene expressionrdquo different surface variants seen in textare ldquoexpressedrdquo ldquoexpressrdquo ldquoexpressingrdquo and ldquoexpressionrdquoThere are sim800 discontiguous annotations that no sys-tems are able to find An example of a discontiguousannotation is seen in the following span the textitd textfrom ldquolocalization of the Ptdsr proteinrdquo gets annotatedwith ldquoGO0008104 - protein localizationrdquo Many of theannotations in CRAFT cannot be identified using theontology alone so improvements in recall can be made byanalyzing disparities between term name and the way theyare expressed in text
Gene Ontology - Molecular FunctionThe molecular function branch of the Gene Ontologydescribes molecular-level functionalities that gene prod-ucts possess It is useful in the protein function predictionfield and serves as the standard way to describe functionsof gene products Like GO_BP terms from GO_MF arecomplex long and contain numerous words with 528containing punctuation and 266 containing numerals(Table 1) All parameter combinations for each system onGO_MF can be seen in Figure 5 Performance on GO_MFis poor the highest F-measure seen is 014 Besides termsbeing complex another nuance of GO_MF that makestheir recognition in text difficult is the fact that nearly allterms with the primary exception of binding terms endin ldquoactivityrdquo This was done to differentiate the activity ofa gene product from the gene product itself for exampleldquonuclease activityrdquo versus ldquonucleaserdquo However the largemajority of GO_MF annotations of terms other than those
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
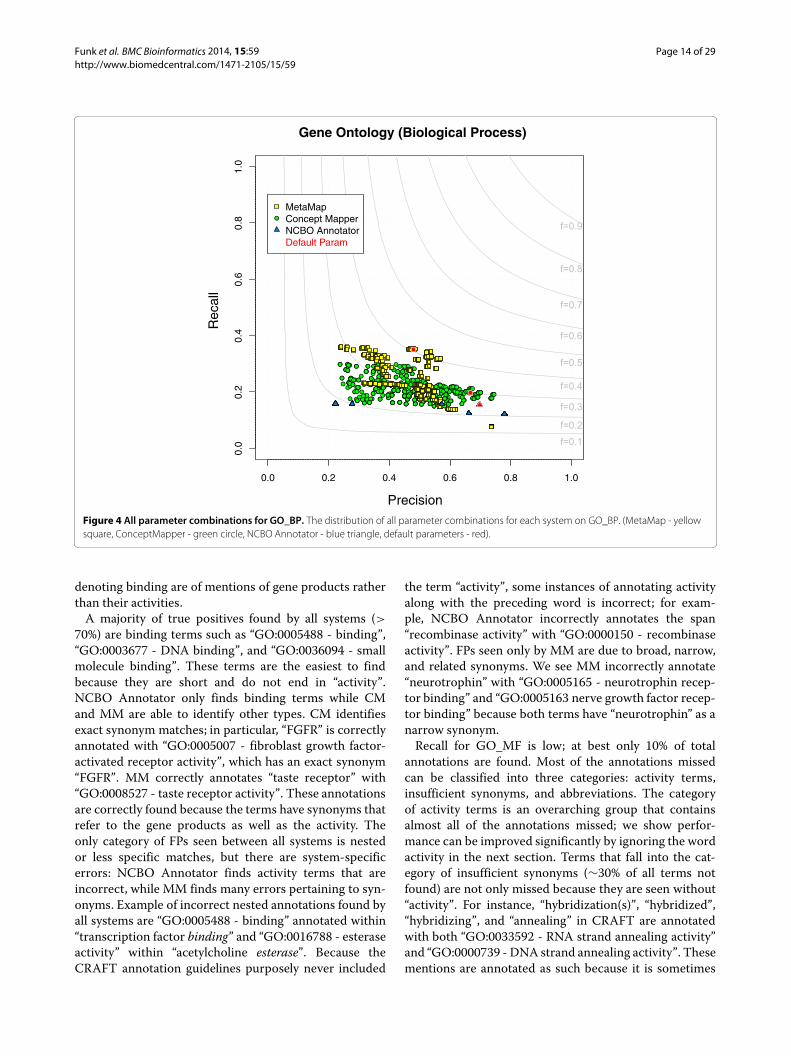
Funk et al BMC Bioinformatics 2014 1559 Page 14 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Biological Process)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 4 All parameter combinations for GO_BP The distribution of all parameter combinations for each system on GO_BP (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
denoting binding are of mentions of gene products ratherthan their activitiesA majority of true positives found by all systems (gt
70) are binding terms such as ldquoGO0005488 - bindingrdquoldquoGO0003677 - DNA bindingrdquo and ldquoGO0036094 - smallmolecule bindingrdquo These terms are the easiest to findbecause they are short and do not end in ldquoactivityrdquoNCBO Annotator only finds binding terms while CMand MM are able to identify other types CM identifiesexact synonym matches in particular ldquoFGFRrdquo is correctlyannotated with ldquoGO0005007 - fibroblast growth factor-activated receptor activityrdquo which has an exact synonymldquoFGFRrdquo MM correctly annotates ldquotaste receptorrdquo withldquoGO0008527 - taste receptor activityrdquo These annotationsare correctly found because the terms have synonyms thatrefer to the gene products as well as the activity Theonly category of FPs seen between all systems is nestedor less specific matches but there are system-specificerrors NCBO Annotator finds activity terms that areincorrect while MM finds many errors pertaining to syn-onyms Example of incorrect nested annotations found byall systems are ldquoGO0005488 - bindingrdquo annotated withinldquotranscription factor bindingrdquo and ldquoGO0016788 - esteraseactivityrdquo within ldquoacetylcholine esteraserdquo Because theCRAFT annotation guidelines purposely never included
the term ldquoactivityrdquo some instances of annotating activityalong with the preceding word is incorrect for exam-ple NCBO Annotator incorrectly annotates the spanldquorecombinase activityrdquo with ldquoGO0000150 - recombinaseactivityrdquo FPs seen only by MM are due to broad narrowand related synonyms We see MM incorrectly annotateldquoneurotrophinrdquo with ldquoGO0005165 - neurotrophin recep-tor bindingrdquo and ldquoGO0005163 nerve growth factor recep-tor bindingrdquo because both terms have ldquoneurotrophinrdquo as anarrow synonymRecall for GO_MF is low at best only 10 of total
annotations are found Most of the annotations missedcan be classified into three categories activity termsinsufficient synonyms and abbreviations The categoryof activity terms is an overarching group that containsalmost all of the annotations missed we show perfor-mance can be improved significantly by ignoring the wordactivity in the next section Terms that fall into the cat-egory of insufficient synonyms (sim30 of all terms notfound) are not only missed because they are seen withoutldquoactivityrdquo For instance ldquohybridization(s)rdquo ldquohybridizedrdquoldquohybridizingrdquo and ldquoannealingrdquo in CRAFT are annotatedwith both ldquoGO0033592 - RNA strand annealing activityrdquoand ldquoGO0000739 - DNA strand annealing activityrdquo Thesementions are annotated as such because it is sometimes
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
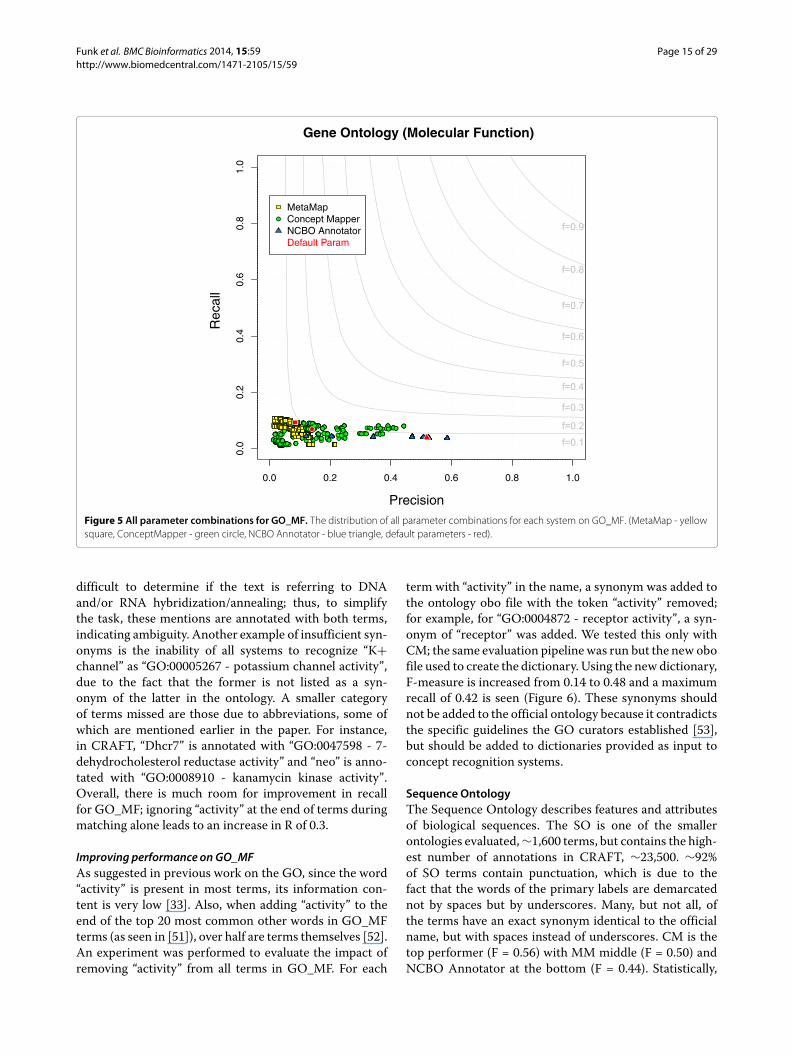
Funk et al BMC Bioinformatics 2014 1559 Page 15 of 29httpwwwbiomedcentralcom1471-21051559
Gene Ontology (Molecular Function)
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 5 All parameter combinations for GO_MF The distribution of all parameter combinations for each system on GO_MF (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
difficult to determine if the text is referring to DNAandor RNA hybridizationannealing thus to simplifythe task these mentions are annotated with both termsindicating ambiguity Another example of insufficient syn-onyms is the inability of all systems to recognize ldquoK+channelrdquo as ldquoGO00005267 - potassium channel activityrdquodue to the fact that the former is not listed as a syn-onym of the latter in the ontology A smaller categoryof terms missed are those due to abbreviations some ofwhich are mentioned earlier in the paper For instancein CRAFT ldquoDhcr7rdquo is annotated with ldquoGO0047598 - 7-dehydrocholesterol reductase activityrdquo and ldquoneordquo is anno-tated with ldquoGO0008910 - kanamycin kinase activityrdquoOverall there is much room for improvement in recallfor GO_MF ignoring ldquoactivityrdquo at the end of terms duringmatching alone leads to an increase in R of 03
Improving performance on GO_MFAs suggested in previous work on the GO since the wordldquoactivityrdquo is present in most terms its information con-tent is very low [33] Also when adding ldquoactivityrdquo to theend of the top 20 most common other words in GO_MFterms (as seen in [51]) over half are terms themselves [52]An experiment was performed to evaluate the impact ofremoving ldquoactivityrdquo from all terms in GO_MF For each
term with ldquoactivityrdquo in the name a synonym was added tothe ontology obo file with the token ldquoactivityrdquo removedfor example for ldquoGO0004872 - receptor activityrdquo a syn-onym of ldquoreceptorrdquo was added We tested this only withCM the same evaluation pipeline was run but the new obofile used to create the dictionary Using the new dictionaryF-measure is increased from 014 to 048 and a maximumrecall of 042 is seen (Figure 6) These synonyms shouldnot be added to the official ontology because it contradictsthe specific guidelines the GO curators established [53]but should be added to dictionaries provided as input toconcept recognition systems
Sequence OntologyThe Sequence Ontology describes features and attributesof biological sequences The SO is one of the smallerontologies evaluatedsim1600 terms but contains the high-est number of annotations in CRAFT sim23500 sim92of SO terms contain punctuation which is due to thefact that the words of the primary labels are demarcatednot by spaces but by underscores Many but not all ofthe terms have an exact synonym identical to the officialname but with spaces instead of underscores CM is thetop performer (F = 056) with MM middle (F = 050) andNCBO Annotator at the bottom (F = 044) Statistically
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
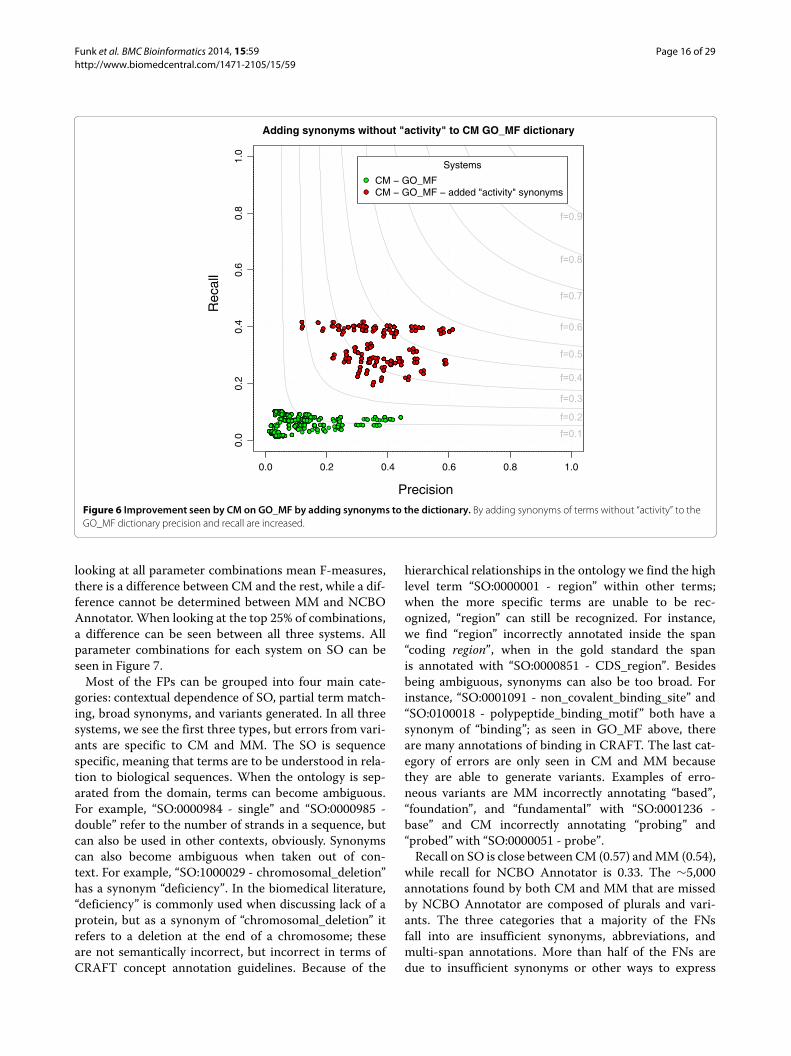
Funk et al BMC Bioinformatics 2014 1559 Page 16 of 29httpwwwbiomedcentralcom1471-21051559
Adding synonyms without activity to CM GO_MF dictionary
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
CM minus GO_MFCM minus GO_MF minus added activity synonyms
Figure 6 Improvement seen by CM on GO_MF by adding synonyms to the dictionary By adding synonyms of terms without ldquoactivityrdquo to theGO_MF dictionary precision and recall are increased
looking at all parameter combinations mean F-measuresthere is a difference between CM and the rest while a dif-ference cannot be determined between MM and NCBOAnnotator When looking at the top 25 of combinationsa difference can be seen between all three systems Allparameter combinations for each system on SO can beseen in Figure 7Most of the FPs can be grouped into four main cate-
gories contextual dependence of SO partial term match-ing broad synonyms and variants generated In all threesystems we see the first three types but errors from vari-ants are specific to CM and MM The SO is sequencespecific meaning that terms are to be understood in rela-tion to biological sequences When the ontology is sep-arated from the domain terms can become ambiguousFor example ldquoSO0000984 - singlerdquo and ldquoSO0000985 -doublerdquo refer to the number of strands in a sequence butcan also be used in other contexts obviously Synonymscan also become ambiguous when taken out of con-text For example ldquoSO1000029 - chromosomal_deletionrdquohas a synonym ldquodeficiencyrdquo In the biomedical literatureldquodeficiencyrdquo is commonly used when discussing lack of aprotein but as a synonym of ldquochromosomal_deletionrdquo itrefers to a deletion at the end of a chromosome theseare not semantically incorrect but incorrect in terms ofCRAFT concept annotation guidelines Because of the
hierarchical relationships in the ontology we find the highlevel term ldquoSO0000001 - regionrdquo within other termswhen the more specific terms are unable to be rec-ognized ldquoregionrdquo can still be recognized For instancewe find ldquoregionrdquo incorrectly annotated inside the spanldquocoding regionrdquo when in the gold standard the spanis annotated with ldquoSO0000851 - CDS_regionrdquo Besidesbeing ambiguous synonyms can also be too broad Forinstance ldquoSO0001091 - non_covalent_binding_siterdquo andldquoSO0100018 - polypeptide_binding_motifrdquo both have asynonym of ldquobindingrdquo as seen in GO_MF above thereare many annotations of binding in CRAFT The last cat-egory of errors are only seen in CM and MM becausethey are able to generate variants Examples of erro-neous variants are MM incorrectly annotating ldquobasedrdquoldquofoundationrdquo and ldquofundamentalrdquo with ldquoSO0001236 -baserdquo and CM incorrectly annotating ldquoprobingrdquo andldquoprobedrdquo with ldquoSO0000051 - proberdquoRecall on SO is close between CM (057) andMM (054)
while recall for NCBO Annotator is 033 The sim5000annotations found by both CM and MM that are missedby NCBO Annotator are composed of plurals and vari-ants The three categories that a majority of the FNsfall into are insufficient synonyms abbreviations andmulti-span annotations More than half of the FNs aredue to insufficient synonyms or other ways to express
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
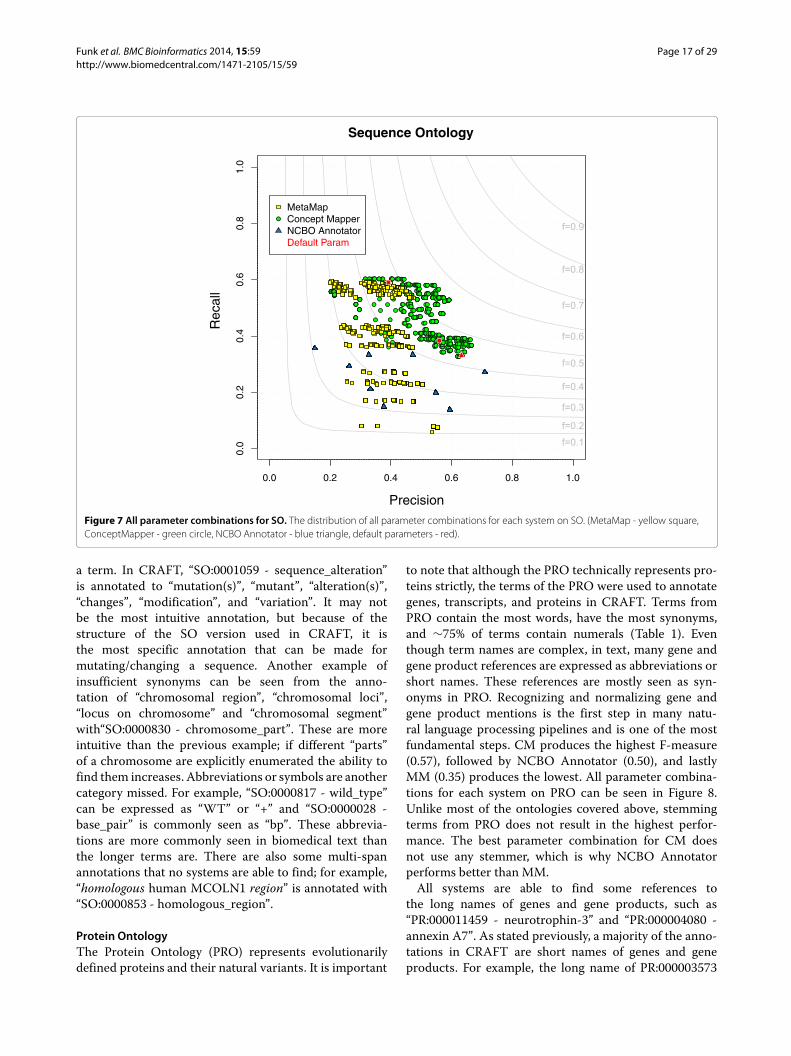
Funk et al BMC Bioinformatics 2014 1559 Page 17 of 29httpwwwbiomedcentralcom1471-21051559
Sequence Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 7 All parameter combinations for SO The distribution of all parameter combinations for each system on SO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
a term In CRAFT ldquoSO0001059 - sequence_alterationrdquois annotated to ldquomutation(s)rdquo ldquomutantrdquo ldquoalteration(s)rdquoldquochangesrdquo ldquomodificationrdquo and ldquovariationrdquo It may notbe the most intuitive annotation but because of thestructure of the SO version used in CRAFT it isthe most specific annotation that can be made formutatingchanging a sequence Another example ofinsufficient synonyms can be seen from the anno-tation of ldquochromosomal regionrdquo ldquochromosomal locirdquoldquolocus on chromosomerdquo and ldquochromosomal segmentrdquowithldquoSO0000830 - chromosome_partrdquo These are moreintuitive than the previous example if different ldquopartsrdquoof a chromosome are explicitly enumerated the ability tofind them increases Abbreviations or symbols are anothercategory missed For example ldquoSO0000817 - wild_typerdquocan be expressed as ldquoWTrdquo or ldquo+rdquo and ldquoSO0000028 -base_pairrdquo is commonly seen as ldquobprdquo These abbrevia-tions are more commonly seen in biomedical text thanthe longer terms are There are also some multi-spanannotations that no systems are able to find for exampleldquohomologous human MCOLN1 regionrdquo is annotated withldquoSO0000853 - homologous_regionrdquo
Protein OntologyThe Protein Ontology (PRO) represents evolutionarilydefined proteins and their natural variants It is important
to note that although the PRO technically represents pro-teins strictly the terms of the PRO were used to annotategenes transcripts and proteins in CRAFT Terms fromPRO contain the most words have the most synonymsand sim75 of terms contain numerals (Table 1) Eventhough term names are complex in text many gene andgene product references are expressed as abbreviations orshort names These references are mostly seen as syn-onyms in PRO Recognizing and normalizing gene andgene product mentions is the first step in many natu-ral language processing pipelines and is one of the mostfundamental steps CM produces the highest F-measure(057) followed by NCBO Annotator (050) and lastlyMM (035) produces the lowest All parameter combina-tions for each system on PRO can be seen in Figure 8Unlike most of the ontologies covered above stemmingterms from PRO does not result in the highest perfor-mance The best parameter combination for CM doesnot use any stemmer which is why NCBO Annotatorperforms better than MMAll systems are able to find some references to
the long names of genes and gene products such asldquoPR000011459 - neurotrophin-3rdquo and ldquoPR000004080 -annexin A7rdquo As stated previously a majority of the anno-tations in CRAFT are short names of genes and geneproducts For example the long name of PR000003573
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
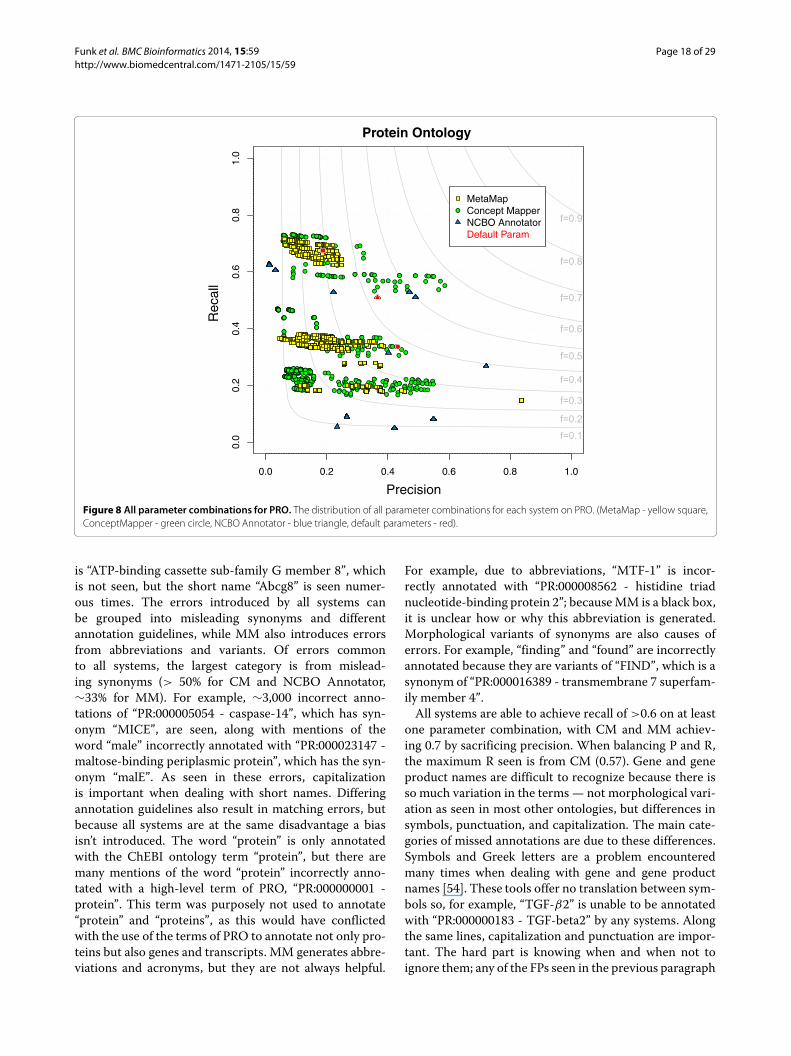
Funk et al BMC Bioinformatics 2014 1559 Page 18 of 29httpwwwbiomedcentralcom1471-21051559
Protein Ontology
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 8 All parameter combinations for PRO The distribution of all parameter combinations for each system on PRO (MetaMap - yellow squareConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
is ldquoATP-binding cassette sub-family G member 8rdquo whichis not seen but the short name ldquoAbcg8rdquo is seen numer-ous times The errors introduced by all systems canbe grouped into misleading synonyms and differentannotation guidelines while MM also introduces errorsfrom abbreviations and variants Of errors commonto all systems the largest category is from mislead-ing synonyms (gt 50 for CM and NCBO Annotatorsim33 for MM) For example sim3000 incorrect anno-tations of ldquoPR000005054 - caspase-14rdquo which has syn-onym ldquoMICErdquo are seen along with mentions of theword ldquomalerdquo incorrectly annotated with ldquoPR000023147 -maltose-binding periplasmic proteinrdquo which has the syn-onym ldquomalErdquo As seen in these errors capitalizationis important when dealing with short names Differingannotation guidelines also result in matching errors butbecause all systems are at the same disadvantage a biasisnrsquot introduced The word ldquoproteinrdquo is only annotatedwith the ChEBI ontology term ldquoproteinrdquo but there aremany mentions of the word ldquoproteinrdquo incorrectly anno-tated with a high-level term of PRO ldquoPR000000001 -proteinrdquo This term was purposely not used to annotateldquoproteinrdquo and ldquoproteinsrdquo as this would have conflictedwith the use of the terms of PRO to annotate not only pro-teins but also genes and transcripts MM generates abbre-viations and acronyms but they are not always helpful
For example due to abbreviations ldquoMTF-1rdquo is incor-rectly annotated with ldquoPR000008562 - histidine triadnucleotide-binding protein 2rdquo becauseMM is a black boxit is unclear how or why this abbreviation is generatedMorphological variants of synonyms are also causes oferrors For example ldquofindingrdquo and ldquofoundrdquo are incorrectlyannotated because they are variants of ldquoFINDrdquo which is asynonym of ldquoPR000016389 - transmembrane 7 superfam-ily member 4rdquoAll systems are able to achieve recall of gt06 on at least
one parameter combination with CM and MM achiev-ing 07 by sacrificing precision When balancing P and Rthe maximum R seen is from CM (057) Gene and geneproduct names are difficult to recognize because there isso much variation in the terms mdash not morphological vari-ation as seen in most other ontologies but differences insymbols punctuation and capitalization The main cate-gories of missed annotations are due to these differencesSymbols and Greek letters are a problem encounteredmany times when dealing with gene and gene productnames [54] These tools offer no translation between sym-bols so for example ldquoTGF-β2rdquo is unable to be annotatedwith ldquoPR000000183 - TGF-beta2rdquo by any systems Alongthe same lines capitalization and punctuation are impor-tant The hard part is knowing when and when not toignore them any of the FPs seen in the previous paragraph
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
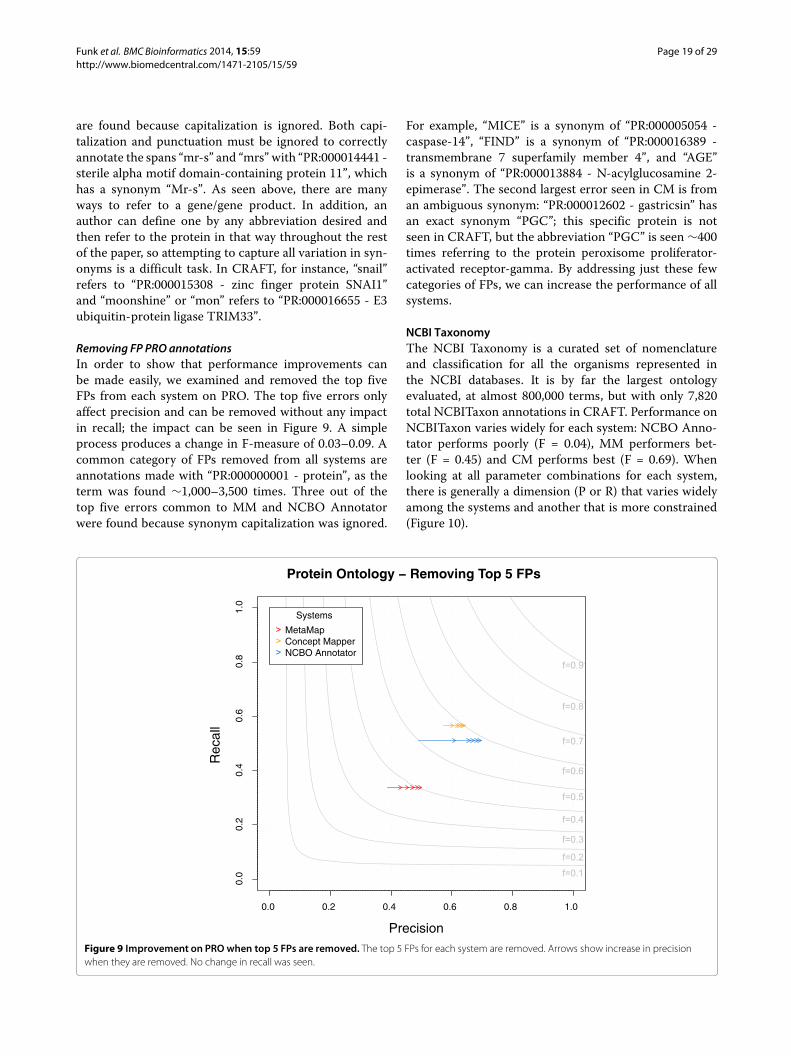
Funk et al BMC Bioinformatics 2014 1559 Page 19 of 29httpwwwbiomedcentralcom1471-21051559
are found because capitalization is ignored Both capi-talization and punctuation must be ignored to correctlyannotate the spans ldquomr-srdquo and ldquomrsrdquo with ldquoPR000014441 -sterile alpha motif domain-containing protein 11rdquo whichhas a synonym ldquoMr-srdquo As seen above there are manyways to refer to a genegene product In addition anauthor can define one by any abbreviation desired andthen refer to the protein in that way throughout the restof the paper so attempting to capture all variation in syn-onyms is a difficult task In CRAFT for instance ldquosnailrdquorefers to ldquoPR000015308 - zinc finger protein SNAI1rdquoand ldquomoonshinerdquo or ldquomonrdquo refers to ldquoPR000016655 - E3ubiquitin-protein ligase TRIM33rdquo
Removing FP PROannotationsIn order to show that performance improvements canbe made easily we examined and removed the top fiveFPs from each system on PRO The top five errors onlyaffect precision and can be removed without any impactin recall the impact can be seen in Figure 9 A simpleprocess produces a change in F-measure of 003ndash009 Acommon category of FPs removed from all systems areannotations made with ldquoPR000000001 - proteinrdquo as theterm was found sim1000ndash3500 times Three out of thetop five errors common to MM and NCBO Annotatorwere found because synonym capitalization was ignored
For example ldquoMICErdquo is a synonym of ldquoPR000005054 -caspase-14rdquo ldquoFINDrdquo is a synonym of ldquoPR000016389 -transmembrane 7 superfamily member 4rdquo and ldquoAGErdquois a synonym of ldquoPR000013884 - N-acylglucosamine 2-epimeraserdquo The second largest error seen in CM is froman ambiguous synonym ldquoPR000012602 - gastricsinrdquo hasan exact synonym ldquoPGCrdquo this specific protein is notseen in CRAFT but the abbreviation ldquoPGCrdquo is seen sim400times referring to the protein peroxisome proliferator-activated receptor-gamma By addressing just these fewcategories of FPs we can increase the performance of allsystems
NCBI TaxonomyThe NCBI Taxonomy is a curated set of nomenclatureand classification for all the organisms represented inthe NCBI databases It is by far the largest ontologyevaluated at almost 800000 terms but with only 7820total NCBITaxon annotations in CRAFT Performance onNCBITaxon varies widely for each system NCBO Anno-tator performs poorly (F = 004) MM performers bet-ter (F = 045) and CM performs best (F = 069) Whenlooking at all parameter combinations for each systemthere is generally a dimension (P or R) that varies widelyamong the systems and another that is more constrained(Figure 10)
Protein Ontology minus Removing Top 5 FPs
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Systems
MetaMapConcept MapperNCBO Annotator
Figure 9 Improvement on PRO when top 5 FPs are removed The top 5 FPs for each system are removed Arrows show increase in precisionwhen they are removed No change in recall was seen
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
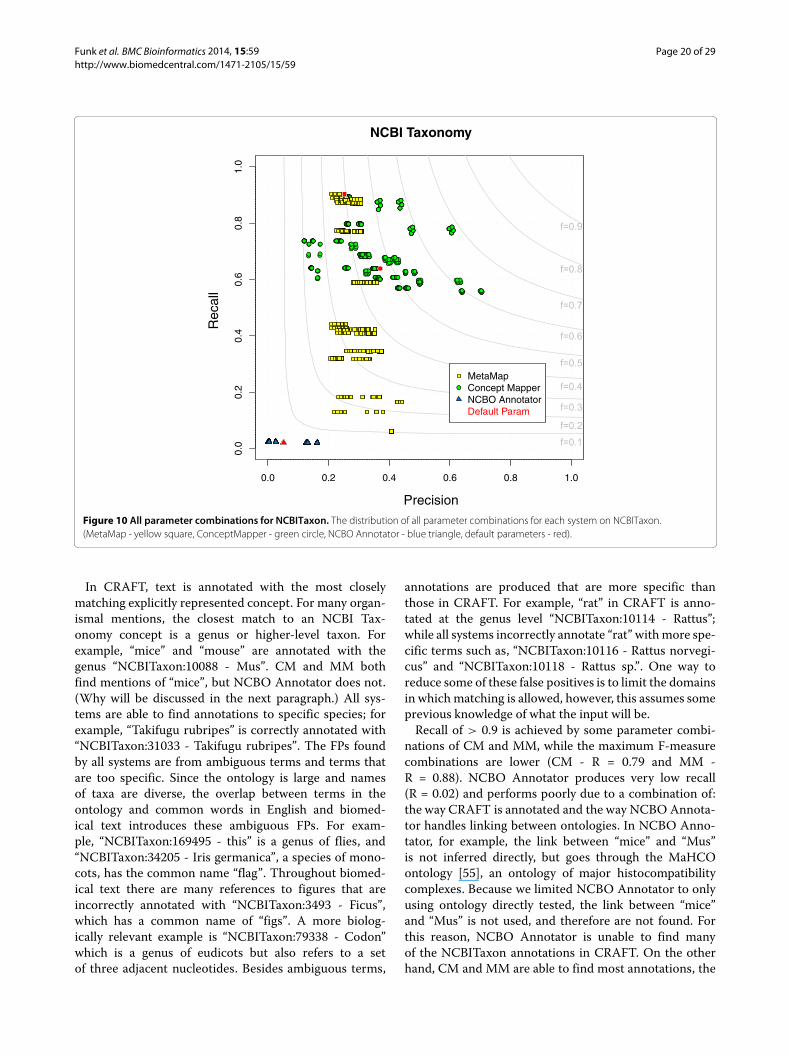
Funk et al BMC Bioinformatics 2014 1559 Page 20 of 29httpwwwbiomedcentralcom1471-21051559
NCBI Taxonomy
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 10 All parameter combinations for NCBITaxon The distribution of all parameter combinations for each system on NCBITaxon(MetaMap - yellow square ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
In CRAFT text is annotated with the most closelymatching explicitly represented concept For many organ-ismal mentions the closest match to an NCBI Tax-onomy concept is a genus or higher-level taxon Forexample ldquomicerdquo and ldquomouserdquo are annotated with thegenus ldquoNCBITaxon10088 - Musrdquo CM and MM bothfind mentions of ldquomicerdquo but NCBO Annotator does not(Why will be discussed in the next paragraph) All sys-tems are able to find annotations to specific species forexample ldquoTakifugu rubripesrdquo is correctly annotated withldquoNCBITaxon31033 - Takifugu rubripesrdquo The FPs foundby all systems are from ambiguous terms and terms thatare too specific Since the ontology is large and namesof taxa are diverse the overlap between terms in theontology and common words in English and biomed-ical text introduces these ambiguous FPs For exam-ple ldquoNCBITaxon169495 - thisrdquo is a genus of flies andldquoNCBITaxon34205 - Iris germanicardquo a species of mono-cots has the common name ldquoflagrdquo Throughout biomed-ical text there are many references to figures that areincorrectly annotated with ldquoNCBITaxon3493 - Ficusrdquowhich has a common name of ldquofigsrdquo A more biolog-ically relevant example is ldquoNCBITaxon79338 - Codonrdquowhich is a genus of eudicots but also refers to a setof three adjacent nucleotides Besides ambiguous terms
annotations are produced that are more specific thanthose in CRAFT For example ldquoratrdquo in CRAFT is anno-tated at the genus level ldquoNCBITaxon10114 - Rattusrdquowhile all systems incorrectly annotate ldquoratrdquo withmore spe-cific terms such as ldquoNCBITaxon10116 - Rattus norvegi-cusrdquo and ldquoNCBITaxon10118 - Rattus sprdquo One way toreduce some of these false positives is to limit the domainsin whichmatching is allowed however this assumes someprevious knowledge of what the input will beRecall of gt 09 is achieved by some parameter combi-
nations of CM and MM while the maximum F-measurecombinations are lower (CM - R = 079 and MM -R = 088) NCBO Annotator produces very low recall(R = 002) and performs poorly due to a combination ofthe way CRAFT is annotated and the way NCBO Annota-tor handles linking between ontologies In NCBO Anno-tator for example the link between ldquomicerdquo and ldquoMusrdquois not inferred directly but goes through the MaHCOontology [55] an ontology of major histocompatibilitycomplexes Because we limited NCBO Annotator to onlyusing ontology directly tested the link between ldquomicerdquoand ldquoMusrdquo is not used and therefore are not found Forthis reason NCBO Annotator is unable to find manyof the NCBITaxon annotations in CRAFT On the otherhand CM and MM are able to find most annotations the
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
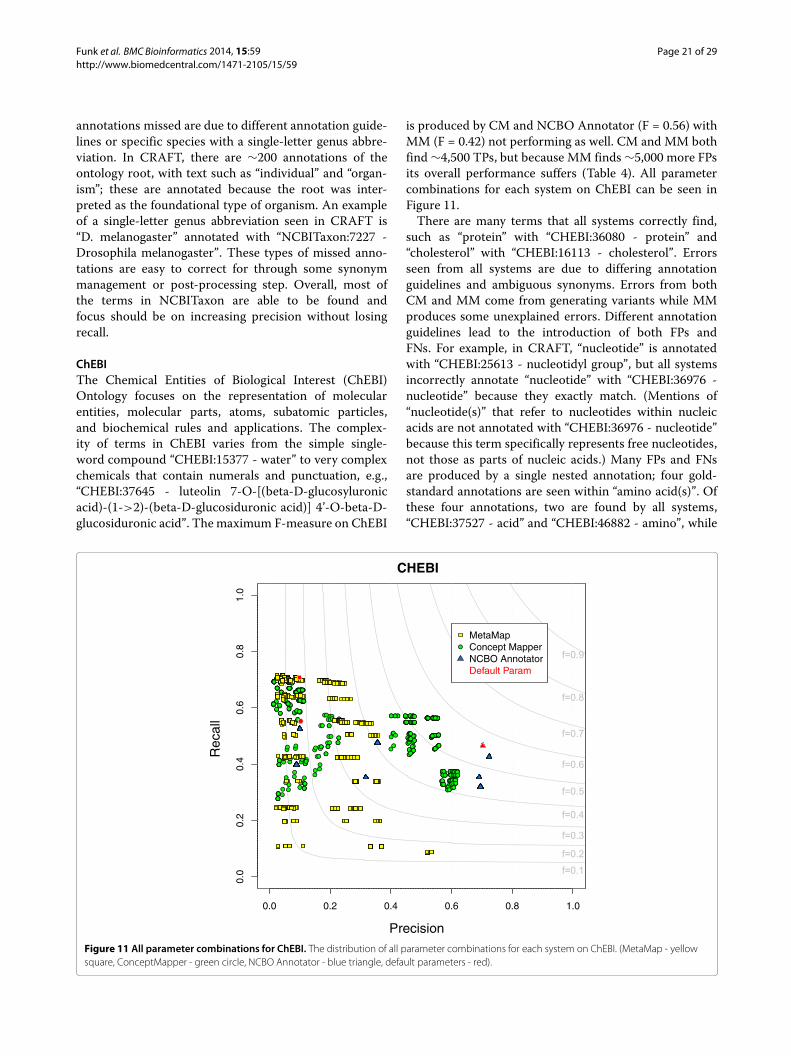
Funk et al BMC Bioinformatics 2014 1559 Page 21 of 29httpwwwbiomedcentralcom1471-21051559
annotations missed are due to different annotation guide-lines or specific species with a single-letter genus abbre-viation In CRAFT there are sim200 annotations of theontology root with text such as ldquoindividualrdquo and ldquoorgan-ismrdquo these are annotated because the root was inter-preted as the foundational type of organism An exampleof a single-letter genus abbreviation seen in CRAFT isldquoD melanogasterrdquo annotated with ldquoNCBITaxon7227 -Drosophila melanogasterrdquo These types of missed anno-tations are easy to correct for through some synonymmanagement or post-processing step Overall most ofthe terms in NCBITaxon are able to be found andfocus should be on increasing precision without losingrecall
ChEBIThe Chemical Entities of Biological Interest (ChEBI)Ontology focuses on the representation of molecularentities molecular parts atoms subatomic particlesand biochemical rules and applications The complex-ity of terms in ChEBI varies from the simple single-word compound ldquoCHEBI15377 - waterrdquo to very complexchemicals that contain numerals and punctuation egldquoCHEBI37645 - luteolin 7-O-[(beta-D-glucosyluronicacid)-(1-gt2)-(beta-D-glucosiduronic acid)] 4rsquo-O-beta-D-glucosiduronic acidrdquo Themaximum F-measure on ChEBI
is produced by CM and NCBO Annotator (F = 056) withMM (F = 042) not performing as well CM and MM bothfind sim4500 TPs but because MM finds sim5000 more FPsits overall performance suffers (Table 4) All parametercombinations for each system on ChEBI can be seen inFigure 11There are many terms that all systems correctly find
such as ldquoproteinrdquo with ldquoCHEBI36080 - proteinrdquo andldquocholesterolrdquo with ldquoCHEBI16113 - cholesterolrdquo Errorsseen from all systems are due to differing annotationguidelines and ambiguous synonyms Errors from bothCM and MM come from generating variants while MMproduces some unexplained errors Different annotationguidelines lead to the introduction of both FPs andFNs For example in CRAFT ldquonucleotiderdquo is annotatedwith ldquoCHEBI25613 - nucleotidyl grouprdquo but all systemsincorrectly annotate ldquonucleotiderdquo with ldquoCHEBI36976 -nucleotiderdquo because they exactly match (Mentions ofldquonucleotide(s)rdquo that refer to nucleotides within nucleicacids are not annotated with ldquoCHEBI36976 - nucleotiderdquobecause this term specifically represents free nucleotidesnot those as parts of nucleic acids) Many FPs and FNsare produced by a single nested annotation four gold-standard annotations are seen within ldquoamino acid(s)rdquo Ofthese four annotations two are found by all systemsldquoCHEBI37527 - acidrdquo and ldquoCHEBI46882 - aminordquo while
CHEBI
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
MetaMapConcept MapperNCBO AnnotatorDefault Param
Figure 11 All parameter combinations for ChEBI The distribution of all parameter combinations for each system on ChEBI (MetaMap - yellowsquare ConceptMapper - green circle NCBO Annotator - blue triangle default parameters - red)
Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 22 of 29httpwwwbiomedcentralcom1471-21051559
one introduces a FP ldquoCHEBI33709 - amino acidrdquo incor-rectly annotated instead of ldquoCHEBI33708 - amino-acidresiduerdquo while ldquoCHEBI32952 - aminerdquo is not found byany system Ambiguous synonyms also lead to errors forexample ldquoleadrdquo is a common verb but also a synonymof ldquoCHEBI25016 - lead atomrdquo and ldquoCHEBI27889 -lead(0)rdquo Variants generated by CM and MM do notalways carry the same semantic meaning as the originalterm such as ldquobasedrdquo and ldquobasisrdquo from ldquoCHEBI22695 -baserdquo MM also produces some interesting unexplainableerrors For example ldquodiseaserdquo is incorrectly annotatedwith ldquoCHEBI25121 - maleoyl grouprdquo ldquoCHEBI25122 -(Z)-3-carboxyprop-2-enoyl grouprdquo and ldquoCHEBI15595 -malate(2-)rdquo all three terms have a synonym of ldquoMalrdquo butwe could find no further explanationsRecall for maximum F-measure combinations are in a
similar range 046ndash056 The two most common cate-gories of annotations missed by all systems are abbrevi-ations and a difference between terms and the way theyare expressed in text Many terms in ChEBI are morecommonly seen as abbreviations or symbols For instanceldquoCHEBI29108 - calcium(2+)rdquo is more commonly seen asldquoCa2+rdquo even though it is a related synonym the sys-tems evaluated are unable to find it A more complicatedexample can be seen when talking about the chemicalsthat lie on the ends of amino acid chains In CRAFTldquoCrdquo from ldquoC-terminusrdquo is annotated with ldquoCHEBI46883 -carboxyl grouprdquo and ldquoCHEBI18245 - carboxylato grouprdquo(the double annotation indicating ambiguity amongthese) which all systems are unable to find The sameprinciple also applies for the N-terminus One simpleannotation that should be easy to get is ldquomRNArdquo anno-tated with ldquoCHEBI33699 - messenger RNArdquo but CMand NCBO Annotator miss it There is not always anoverlap between the term names and their expression intext For instance the term ldquoCHEBI36357 - polyatomicentityrdquo was chosen to annotate general ldquosubstancerdquo wordslike ldquomolecule(s)rdquo ldquosubstancesrdquo and ldquocompoundsrdquo andldquoCHEBI33708 - amino-acid residuerdquo is often expressed asldquoamino acid(s)rdquo and ldquoresiduerdquoAn additional comparison between CM and ChemSpot
[56] a ChEBI-specific named entity recognizer withmachine learning components on CRAFT can be seen inAdditional file 3 The results of this comparison show thatperformance between both systems is similar and smallchanges to stop word lists and dictionaries can have a bigimpact of F-measure It also explores FPs of ChemSpotwhich could represent a potential missed annotation inCRAFT or lack of a ChEBI term for a chemical
Overall parameter analysisHere we present overall trends seen from aggregating allparameter data over all ontologies and explore param-eters that interact Suggestions for parameters for any
ontology based upon its characteristics are given Theseobservations are made from observing which param-eter values and combinations produce the highest F-measures and not from statistical differences in meanF-measures
NCBO AnnotatorOf the six NCBO Annotator parameters evaluated onlythree impact performance of the system wholeWord-sOnly withSynonyms and minTermSize Two parametersfilterNumber and stopWordsCaseSensitive did not impactrecognition of any terms while removing stop words onlymade a difference for one ontology (PRO)A general rule for NCBO Annotator is that only whole
words should be matched matching whole words pro-duced the highest F-measure on seven out of eight ontolo-gies and on the eighth the difference was negligibleAllowing NCBO Annotator to find terms that are notwhole words greatly decreases precision while minimallyif at all increasing recallUsing synonyms of terms makes a significant differ-
ence in five ontologies Synonyms are useful because theyincrease recall by introducing other ways to express con-cepts It is generally better to use synonyms as onlyone ontology performed better when not using synonyms(GO_MF)minTermSize does not effect the matching of terms
but acts as a filter to remove matches of less than acertain length A safe value ofminTermSize for any ontol-ogy would be one or three because only very smallwords (lt 2 characters) are removed Filtering termsless than length five is useful not so much for find-ing desired terms but for removing undesired termsUndesired terms less than five characters can be intro-duced either through synonyms or small ambiguous termsthat are commonly seen and should be removed toincrease performance (eg ldquoNCBITaxon3863 - Lensrdquo andldquoNCBITaxon169495 - Thisrdquo)
Interacting parameters - NCBO AnnotatorBecause half of NCBO Annotatorrsquos parameters do notaffect performance we only see interaction between twoparameters wholeWordsOnly and synonyms The inter-actions between these parameters come from mixingwholeWordsOnly = no and synonyms = yes As notedin the discussion of ontologies above using this combi-nation of parameters introduces anywhere from 1000 to41000 FPs depending on the test scenario and ontologyThese errors are introduced because small synonyms orabbreviations are found within other words
MetaMapWe evaluated seven MM parameters The only parametervalue that remained constant between all ontologies was
Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 23 of 29httpwwwbiomedcentralcom1471-21051559
gaps we have come to the consensus that gaps betweentokens should not be allowed whenmatching By insertinggaps precision is decreased with no or slight increase inrecallThemodel parameter determines which type of filtering
is applied to the terms The difference between the twovalues for model is that strict performs an extra filter-ing step on the ontology terms Performing this filteringincreases precision with no change in recall for ChEBI andNCBITaxon with no differences between the parametervalues on the other ontologies Because it is best perform-ing on two ontologies and inMMdocumentation is said toproduce the highest level of accuracy the strict modelshould be used for best performanceOne simple way to recognize more complex terms is to
allow the reordering of tokens in the terms Reorderingtokens in terms helpsMM to identify terms as long as theyare syntactically or semantically the same For exampleldquoGO0000805 - X chromosomerdquo is equal to ldquochromosomeXrdquo Practically the previous example is an exception asmost reorderings are not syntactically or semanticallysimilar by ignoring token order precision is decreasedwithout an increase in recall Retaining the order of tokensproduces highest F-measure on six out of eight ontolo-gies while there was no difference on the other two Weconclude for best performance it is best to retain tokenorderOne unique feature of MM is that it is able to com-
pute acronym and abbreviation variants when map-ping text to the ontology MM allows the use of allacronymabbreviations (-a) only those with uniqueexpressions (-u) and the default (no flags) For allontologies there is no difference between using thedefault or only those with unique expressions butboth are better than using all Using all acronymsand abbreviations introduces many erroneous matchesprecision is decreased without an increase in recall Forbest performance use default or unique values ofacronyms and abbreviationsGenerating derivational variants helps to identify dif-
ferent forms of terms The goal of generating variants isto increase recall without introducing ambiguous termsThis parameter produces the most varied results Thereare three parameter values (all none and adj nounonly ) and each of them produces the highest F-measureon at least one ontology Generating variants hurts theperformance on half of the ontologies Of these ontolo-gies variants of terms from PRO and ChEBI do not makesense because they do not follow typical English languagerules while variants of terms in NCBITaxon and SO intro-duce many more errors than correct matches all vari-ants produce highest F-measure on CL while adj nounonly variants are best-performing on GO_BP Thereis no difference between the three values for GO_CC
and GO_MF With these varied results one can decidewhich type of variants to use by examining the way theyexpect terms in their ontology to be expressed If mostof the terms do not follow traditional English rules likegeneprotein names chemicals and taxa it is best to notuse any variants For ontologies where terms could beexpressed as nouns or verbs a good choicewould be to usethe default value and generate adj noun only variantsThis is suggested because it generates the most commontypes of variants those between adjectives and nounsThe parameters minTermSize and scoreFilter do not
affect matching but act as a post-processing filter onannotations returned minTermSize specifies the mini-mum length in characters of annotated text text shorterthan this is filtered out This parameter acts exactly likethat of the NCBO Annotator parameter with the samename presented above MM produces scores in the rangeof 0 to 1000 with 1000 being the most confident For allontologies a score of 1000 produces the highest P and thelowest R while a score of 0 returns all matches and has thehighest R with the lowest P with 600 and 800 somewherebetween Performance is best on all ontologies when usingmost of the annotations found by MM so a score of 0 or600 is suggested As input to MM we provided the entiredocument it is possible that different scores are producedwhen providing a phrase sentence or paragraph as inputThe scores are not as important as the understanding thatmost of the annotations returned by MM are used
ConceptMapperWe evaluated seven CM parameters When examiningbest performance all parameter values vary but oneorderIndependentLookup = off which does not allow thereordering of tokens when matching is set in the highestF-measure parameter combination for all ontologies Asfor MM it is best to retain ordering of tokenssearchStrategy affects the way dictionary lookup is per-
formed contiguous matching returns the longest spanof contiguous tokens while the other two values (skipany match and skip any allow overlap) canskip tokens and differ on where the next lookup beginsPerformance on six out of eight ontologies is best whenonly contiguous tokens are returned On NCBITaxon thebehavior of searchStrategy is unclear and unintuitive Byreturning non contiguous tokens precision is increasedwithout loss of recall For most ontologies only selectingcontiguous tokens produces the best performanceThe caseMatch parameter tells CM how to handle cap-
italization The best performance on four out of eightontologies uses insensitive case matching while thereis no difference between the values of caseMatch onthree ontologies There is no difference on those threebecause the best parameter combination utilizes theBioLemmatizer which automatically ignores case Thus
Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 24 of 29httpwwwbiomedcentralcom1471-21051559
best performance on seven out of eight ontologies ignorescase PRO is the exception its best-performing combina-tion only ignores case on those tokens containing digitsFor most ontologies it is best to use insensitive match-ingStemming and lemmatization allow matching of mor-
phological term variants Performance on only oneontology PRO is best when no morphological variantsare used this is the case because PRO terms annotatedin CRAFT are mostly short names which do not behaveand have the properties of normal English words Thebest-performing combination on all other ontologies useeither the Porter stemmer or the BioLemmatizer Forsome ontologies there is a difference between the twovariant generators and for others there was not Evenontologies like ChEBI and NCBITaxon perform best withmorphological variants because they are needed for CMto identify inflectional variants such as plurals For mostontologies morphological variants should be usedCM can take a list of stop words to be ignored when
matching Performance on seven out of eight ontologies isbetter when stop words are not ignored Ignoring PubMedstop words from these ontologies introduces errors with-out an increase in recall An example of one error seenis the span ldquoproteins that targetrdquo incorrectly annotatedwith ldquoGO0006605 - protein targetingrdquo The one ontologyNCBITaxon where ignoring stop words results in bestperformance is due to a specific term ldquoNCBITaxon169495 - thisrdquo By ignoring the word ldquothisrdquosim1800 FPs areprevented If there is not a specific reason to ignore stopwords such as the terms seen in NCBITaxon we suggestnot ignoring stop words for any ontologyBy default CM only returns the longest match all
matches can be returned by setting findAllMatches totrue Seven out of eight ontologies perform better whenonly the longest match is returned Returning all matchesfor these ontologies introduces errors because higher-level terms are found within lower-level ones and theCRAFT concept annotation guidelines specifically pro-hibit these types of nested annotations CHEBI performsbest when all matches are returned because it containssuch nested annotations If the goal is to find all possibleannotations or it is known that there are nested anno-tations we suggest to set findAllMatches to true butfor most ontologies only the longest match should bereturnedThere are many different types of synonyms in ontolo-
gies When creating the dictionary with the value allall synonyms (exact broad narrow related etc) areused the value exact creates dictionaries with only theexact synonyms The best performance on six out ofeight ontologies uses only exact synonyms On theseontologies using only exact instead of all synonymsincreases precision with no loss of recall use of broad
related and narrow synonyms mostly introduce errorsPerformance on PRO and GO_BP is best when using allsynonyms On these two ontologies the other types ofsynonyms are useful for recognition and increase recallFor most ontologies using only exact synonyms producesthe best performance
Interacting parameters - ConceptMapperWe see the most interaction between parameters in CMThere are two different interactions that are apparent incertain ontologies 1) stemmer and synonyms and 2) stop-Words and synonyms The first interaction found is inChEBI We find the synonyms parameter partitions thedata into two distinct groups Within each group thestemmer parameter has two completely different patterns(Figure 12) When only exact synonyms are used allthree stemmers are clustered with BioLemmatizer per-forming best but when all synonyms are used it is hardto find any difference between the three stemmers Thesecond interaction found is between the stopWords andsynonyms parameters In GO_MF several terms have syn-onyms that contain two words with one being in thePubMed stop word list For example all mentions ofldquoactivityrdquo are incorrectly annotated with ldquoGO0050501 -hyaluronan synthase activityrdquo which has a broad synonymldquoHAS activityrdquo ldquohasrdquo is contained in the stop word list andtherefore is ignoredNot only do we find interactions within CM but some
parameters also mask the effect of other parameters It isalready known and stated in the CM guidelines that thesearchStrategy values skip any match and skip anyallow overlap imply that orderIndependentLookupis set to true Analyzing the data it was also discov-ered that BioLemmatizer converts all tokens to lower casewhen lemmas are created so the parameter caseMatch iseffectively set to ignore For these reasons it is impor-tant to not only consider interactions but also the maskingeffect that a specific parameter value can have on anotherparameter
Substringmatching and stemmingThrough our analysis we have shown that accounting formorphology of ontological terms has an important impacton the performance of concept annotation in text Nor-malizing morphological variants is one way to increaserecall by reducing the variation between terms in anontology and their natural expression in biomedical textIn NCBO Annotator morphology can only be accom-modated in the very rough manner of either requiringthat ontology terms match whole (space or punctuation-delimited) words in the running text or allowing anysubstring of the text whatsoever to match an ontologyterm This leads to overall poorer performance by NCBOAnnotator for most ontologies through the introduction
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
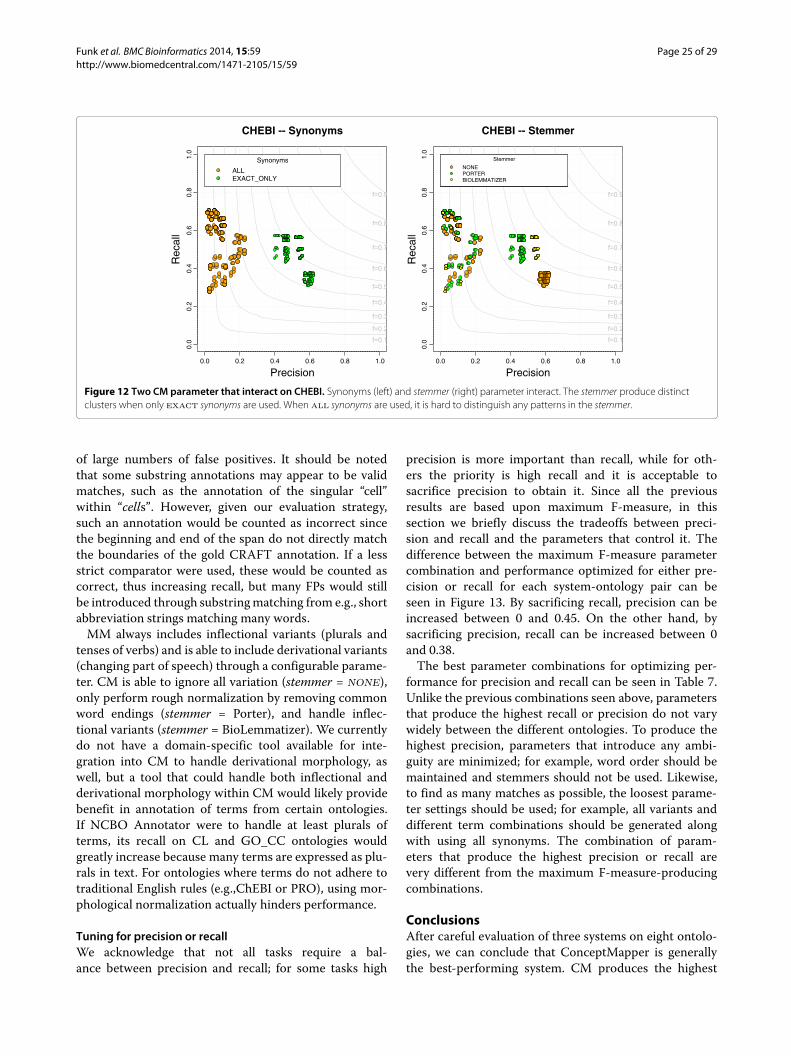
Funk et al BMC Bioinformatics 2014 1559 Page 25 of 29httpwwwbiomedcentralcom1471-21051559
CHEBI -- Synonyms
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Synonyms
ALLEXACT_ONLY
CHEBI -- Stemmer
Precision
Rec
all
00 02 04 06 08 10
00
02
04
06
08
10
Stemmer
NONEPORTERBIOLEMMATIZER
Figure 12 Two CM parameter that interact on CHEBI Synonyms (left) and stemmer (right) parameter interact The stemmer produce distinctclusters when only exact synonyms are used When all synonyms are used it is hard to distinguish any patterns in the stemmer
of large numbers of false positives It should be notedthat some substring annotations may appear to be validmatches such as the annotation of the singular ldquocellrdquowithin ldquocellsrdquo However given our evaluation strategysuch an annotation would be counted as incorrect sincethe beginning and end of the span do not directly matchthe boundaries of the gold CRAFT annotation If a lessstrict comparator were used these would be counted ascorrect thus increasing recall but many FPs would stillbe introduced through substringmatching from eg shortabbreviation strings matching many wordsMM always includes inflectional variants (plurals and
tenses of verbs) and is able to include derivational variants(changing part of speech) through a configurable parame-ter CM is able to ignore all variation (stemmer = none)only perform rough normalization by removing commonword endings (stemmer = Porter) and handle inflec-tional variants (stemmer = BioLemmatizer) We currentlydo not have a domain-specific tool available for inte-gration into CM to handle derivational morphology aswell but a tool that could handle both inflectional andderivational morphology within CM would likely providebenefit in annotation of terms from certain ontologiesIf NCBO Annotator were to handle at least plurals ofterms its recall on CL and GO_CC ontologies wouldgreatly increase because many terms are expressed as plu-rals in text For ontologies where terms do not adhere totraditional English rules (egChEBI or PRO) using mor-phological normalization actually hinders performance
Tuning for precision or recallWe acknowledge that not all tasks require a bal-ance between precision and recall for some tasks high
precision is more important than recall while for oth-ers the priority is high recall and it is acceptable tosacrifice precision to obtain it Since all the previousresults are based upon maximum F-measure in thissection we briefly discuss the tradeoffs between preci-sion and recall and the parameters that control it Thedifference between the maximum F-measure parametercombination and performance optimized for either pre-cision or recall for each system-ontology pair can beseen in Figure 13 By sacrificing recall precision can beincreased between 0 and 045 On the other hand bysacrificing precision recall can be increased between 0and 038The best parameter combinations for optimizing per-
formance for precision and recall can be seen in Table 7Unlike the previous combinations seen above parametersthat produce the highest recall or precision do not varywidely between the different ontologies To produce thehighest precision parameters that introduce any ambi-guity are minimized for example word order should bemaintained and stemmers should not be used Likewiseto find as many matches as possible the loosest parame-ter settings should be used for example all variants anddifferent term combinations should be generated alongwith using all synonyms The combination of param-eters that produce the highest precision or recall arevery different from the maximum F-measure-producingcombinations
ConclusionsAfter careful evaluation of three systems on eight ontolo-gies we can conclude that ConceptMapper is generallythe best-performing system CM produces the highest
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
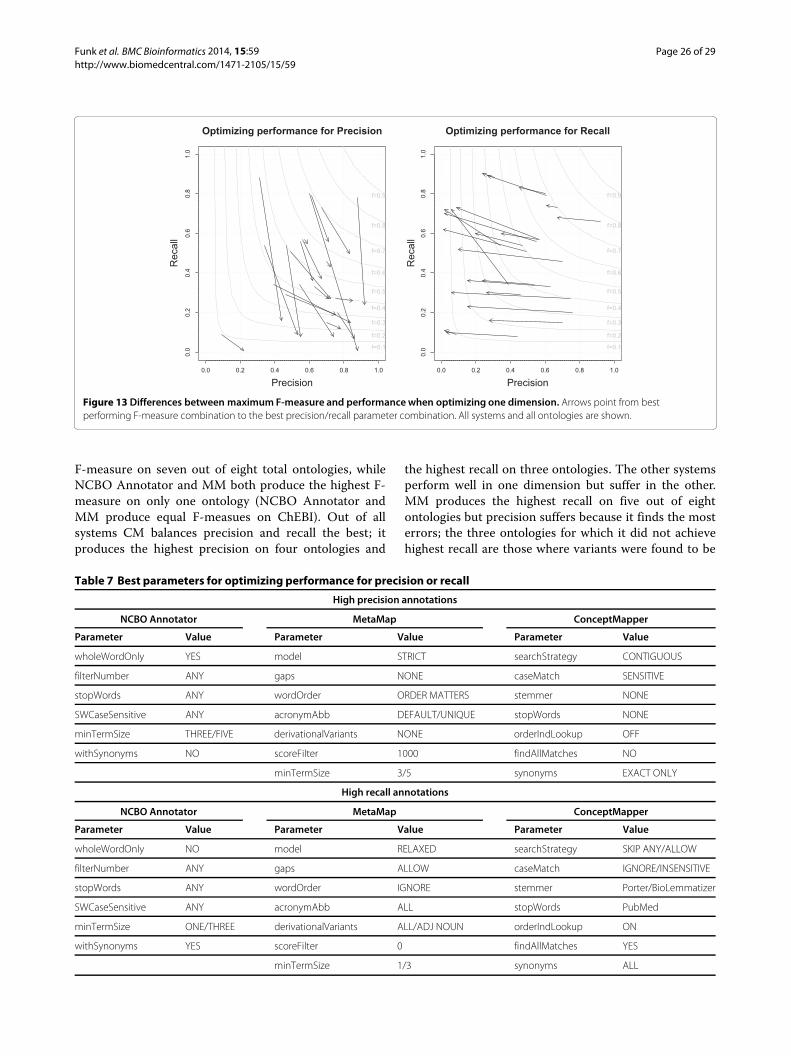
Funk et al BMC Bioinformatics 2014 1559 Page 26 of 29httpwwwbiomedcentralcom1471-21051559
Optimizing performance for Precision
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Optimizing performance for Recall
Precision
Recall
00 02 04 06 08 10
00
02
04
06
08
10
f=01
f=02
f=03
f=04
f=05
f=06
f=07
f=08
f=09
Figure 13 Differences between maximum F-measure and performancewhen optimizing one dimension Arrows point from bestperforming F-measure combination to the best precisionrecall parameter combination All systems and all ontologies are shown
F-measure on seven out of eight total ontologies whileNCBO Annotator and MM both produce the highest F-measure on only one ontology (NCBO Annotator andMM produce equal F-measues on ChEBI) Out of allsystems CM balances precision and recall the best itproduces the highest precision on four ontologies and
the highest recall on three ontologies The other systemsperform well in one dimension but suffer in the otherMM produces the highest recall on five out of eightontologies but precision suffers because it finds the mosterrors the three ontologies for which it did not achievehighest recall are those where variants were found to be
Table 7 Best parameters for optimizing performance for precision or recall
High precision annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly YES model STRICT searchStrategy CONTIGUOUS
filterNumber ANY gaps NONE caseMatch SENSITIVE
stopWords ANY wordOrder ORDER MATTERS stemmer NONE
SWCaseSensitive ANY acronymAbb DEFAULTUNIQUE stopWords NONE
minTermSize THREEFIVE derivationalVariants NONE orderIndLookup OFF
withSynonyms NO scoreFilter 1000 findAllMatches NO
minTermSize 35 synonyms EXACT ONLY
High recall annotations
NCBO Annotator MetaMap ConceptMapper
Parameter Value Parameter Value Parameter Value
wholeWordOnly NO model RELAXED searchStrategy SKIP ANYALLOW
filterNumber ANY gaps ALLOW caseMatch IGNOREINSENSITIVE
stopWords ANY wordOrder IGNORE stemmer PorterBioLemmatizer
SWCaseSensitive ANY acronymAbb ALL stopWords PubMed
minTermSize ONETHREE derivationalVariants ALLADJ NOUN orderIndLookup ON
withSynonyms YES scoreFilter 0 findAllMatches YES
minTermSize 13 synonyms ALL
Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 27 of 29httpwwwbiomedcentralcom1471-21051559
detrimental (SO ChEBI and PRO) On the other handNCBO Annotator produces the highest precision for fourontologies but falls behind in recall because it is unableto recognize plurals or variants of terms Overall CMperforms best out of all systems evaluated on the conceptnormalization taskBesides performance another important thing to con-
sider when using a tool is the ease of use In order touse CM one must adopt the UIMA framework Trans-forming any ontology for matching is easy with CM witha simple tool that converts any OBO ontology file to adictionary MM is a standalone tool that works only withUMLS ontologies natively getting it to work with anyarbitrary ontology can be done but is not straightforwardMM is the most like a black box of all the systems whichresults in some annotations that are unintuitive and can-not be traced to their source NCBO Annotator is theeasiest to use as it is provided as a Web service withlarge retrieval occurring through a REST service NCBOAnnotator currently works with any of the 330+ BioPor-tal ontologies Drawbacks of NCBO Annotator are due toit being provided as a Web service they include changesin the underlying implementation resulting in differentannotations returned over time there is also no controlover the version of the ontologies used or the ability to addan ontologyUsing the default parameters for any tool is a com-
mon practice but as seen here the defaults often do notproduce the best results We have discovered that someparameters do not impact performance while othersgreatly increase performance when compared to defaultsAs seen in the Results and discussion Section we haveprovided parameter suggestions for not only the ontolo-gies evaluated but also provide general suggestions thatcan be applied to any ontology We can also concludethat parameters cannot be optimized individually If wedidnrsquot generate all parameter combinations and insteadexamined parameters individually we would be unable tosee these interacting parameters and could have chosen anon-optimal parameter combination as the bestComplex multi-token terms are seen in many ontolo-
gies and are more difficult to normalize than thesimpler one- or two-token terms Inserting gaps skip-ping tokens and reordering tokens are simple methodscurrently implemented in bothCM andMM Thesemeth-ods provide a simple heuristic but do not always pro-duce valid syntactic structures or retain the semanticmeaning of the original term From our analysis abovewe can conclude that more sophisticated syntacticallyvalid methods need to be implemented to recognizecomplex terms seen in ontologies such as GO_MF andGO_BPOur results demonstrate the important role of linguistic
processing in particular morphological normalization
of terms during matching Several of the highest-performing sets of parameters take advantage of stem-ming or handling of morphological variants though theexact best tool for this job is not yet entirely clear Insome cases there is also an important interaction betweenthis functionality and other system parameters leadingto some spurious results It appears that these problemscould be addressed in some cases through more carefulintegration of the tools and in others through simpleadaptation of the tools to avoid some common errors thathave occurredIn this paper we established baselines for performance
of three publicly available dictionary-based tools on eightbiomedical ontologies analyzed the impact of parame-ters for each system and made suggestions for param-eter use on any ontology We can conclude that of thetested tools the generic ConceptMapper tool generallyprovides the best performance on the concept normaliza-tion task despite not being specifically designed for use inthe biomedical domain The flexibility it provides in con-trolling precisely how terms are matched in text makesit possible to adapt it to the varying characteristics ofdifferent ontologies
Additional files
Additional file 1 Stop words list Text file that contains a list of stopwords used It consists of the PubMed stop words available at httpwwwncbinlmnihgovbooksNBK3827tablepubmedhelpT43 along with theaddition of the conjunction ldquoorrdquo
Additional file 2 Detailed analysis of parameters for each system-ontology pair Here we present a detailed analysis of the statisticallysignificant parameters for each system-ontology pair Many interestingexamples are given to show the impact of changing a single parameter
Additional file 3 Comparison of CM to ChemSpot Comparisonbetween ConceptMapper and ChemSpot a ChEBI specific named entityrecognition tool It was performed and written up as a lab rotation byBenjamin Garcia
AbbreviationsCM ConceptMapper MM MetaMap NCBO Annotator NCBO OpenBiomedical Annotator TP True positive FP False positive FN False negativeP Precision R Recall F F-measure GS Gold standard CL Cell Type OntologyGO_MF Gene Ontology Molecular Function GO_CC Gene Ontology CellularComponent GO_BP Gene Ontology Biological Process ChEBI ChemicalEntities of Biological Interest NCBITaxon NCBI Taxonomy SO SequenceOntology PRO Protein Ontology Param Parameter(s)
Competing interestsThe authors declare that they have no competing interests
Authorsrsquo contributionsKV and LEH initiated the project and defined the overall research questionsKV KBC and CF planned the experiments CF WBJ and CR constructedevaluation piplines and ran the experiments CF and BG performed data anderror analysis CF wrote the first version of Methods Results and discussionand Conclusions Sections of the manuscript KV KBC and CF wrote theBackground and Introduction MB contributed ontology expertise to themanuscript KV KBC and LEH supervised all aspects of the work All authorsread and approved the final manuscript
Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 28 of 29httpwwwbiomedcentralcom1471-21051559
AcknowledgementsThis work was supported by NIH grant 2T15LM009451 to LEH and NSF grantDBI-0965616 to KV KV was also supported by National ICT Australia (NICTA)NICTA is funded by the Australian Government as represented by theDepartment of Broadband Communications and the Digital Economy and theAustralian Research Council through the ICT Centre of Excellence programWe would like to acknowledge Helen Johnson and Ceacutesar Mejia Muntildeoz forexecuting early versions of these experiments We also appreciate WillieRogers from NLM with help getting MetaMap to work with ontologies otherthan those in the UMLS
Author details1Computational Bioscience Program U of Colorado School of MedicineAurora CO 80045 USA 2Center for Genes Environment and Health NationalJewish Health Denver CO 80206 USA 3Victoria Research Lab National ICTAustralia Melbourne 3010 Australia 4Computing and Information SystemsDepartment University of Melbourne Melbourne 3010 Australia
Received 22 April 2013 Accepted 24 January 2014Published 26 February 2014
References
1 Khatri P Draghici S Ontological analysis of gene expression datacurrent tools limitations and open problems Bioinformatics 200521(18)3587ndash3595 [httpbioinformaticsoxfordjournalsorgcontent21183587abstract]
2 Krallinger M Padron M Valencia A A sentence sliding windowapproach to extract protein annotations from biomedical articlesBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S19]
3 Sokolov A Funk C Graim K Verspoor K Ben-Hur A Combiningheterogeneous data sources for accurate functional annotation ofproteins BMC Bioinformatics 2013 14(Suppl 3)S10[httpwwwbiomedcentralcom1471-210514S3S10]
4 Hunter L Lu Z Firby J Baumgartner WA Johnson HL Ogren PV CohenKBOpenDMAP an open source ontology-driven concept analysisengine with applications to capturing knowledge regardingprotein transport protein interactions and cell-type-specific geneexpression BMC Bioinformatics 2008 978 [httpdxdoiorg1011861471-2105-9-78]
5 Muller HM Kenny EE Sternberg PW Textpresso an ontology-basedinformation retrieval and extraction system for biological literaturePLoS Biol 2004 2(11) [httpdxdoiorg101371journalpbio0020309]
6 Doms A Schroeder M GoPubMed exploring PubMedwith the GeneOntology Nucleic Acids Res 2005 33783ndash786 [httpdxdoiorg101093nargki470]
7 Van Landeghem S Hakala K Roumlnnqvist S Salakoski T Van de Peer YGinter F Exploring biomolecular literature with EVEX connectinggenes through events homology and indirect associations AdvBioinformatics 2012 Special issue Literature-Mining Solutions for LifeScience Research ID 582765 [httpdxdoiorg1011552012582765]
8 Yao L Divoli A Mayzus I Evans JA Rzhetsky A Benchmarkingontologies bigger or better PLoS Comput Biol 2011 7e1001055[httpdxdoiorg101371journalpcbi1001055]
9 Settles B ABNER an open source tool for automatically tagginggenes proteins and other entity names in text Bioinformatics 200521(14)3191ndash3192 [httpdxdoiorgdoi101093bioinformaticsbti475]
10 Caporaso JG Baumgartner WA Jr Randolph DA Cohen KB Hunter LMutationFinder a high-performance system for extracting pointmutationmentions from text Bioinformatics 2007 231862ndash1865[httpdxdoiorg101093bioinformaticsbtm235]
11 Jimeno A Assessment of disease named entity recognition on acorpus of annotated sentences BMC Bioinformatics 2008 9(Suppl 3)S3[httpdxdoiorg1011861471-2105-9-S3-S3]
12 Leaman R Gonzalez G BANNER an executable survey of advances inbiomedical named entity recognition Pac Symp Biocomput 200813652ndash663
13 Brewster C Alani H Dasmahapatra S Wilks Y Data-driven ontologyevaluation In 4th International Conference on Language Resource andEvaluation (LRECrsquo04) 2004
14 Verspoor C Joslyn C Papcun G The Gene Ontology as a source oflexical semantic knowledge for a biological natural languageprocessing application In Proceedings of the SIGIRrsquo03 Workshopon Text Analysis and Search for Bioinformatics Toronto CA 2003[httpcompbioucdenvereduHunter_labVerspoorPublications_filesLAUR_03-4480pdf]
15 Cohen KB Palmer M Hunter L Nominalization and alternations inbiomedical language PLoS ONE 2008 3(9) [httpdxdoiorg101371journalpone0003158]
16 Verspoor K Cohen KB Lanfranchi A Warner C Johnson HL Roeder CChoi JD Funk C Malenkiy Y Eckert M Xue N Baumgartner WA Jr Bada MPalmer M Hunter LE A corpus of full-text journal articles is a robustevaluation tool for revealing differences in performance ofbiomedical natural language processing tools BMC Bioinformatics2012 13(207) [httpdxdoiorg1011861471-2105-13-207]
17 Bada M Eckert M Evans D Garcia K Shipley K Sitnikov D Baumgartner JrWA Cohen KB Verspoor K Blake JA Hunter LE Concept annotation inthe CRAFT corpus BMC Bioinformatics 2012 13(161) [httpdxdoiorg1011861471-2105-13-161]
18 Aronson A Effective mapping of biomedical text to the UMLSMetathesaurus the MetaMap program In Proc AMIA 2001 200117ndash21[httpciteseerxistpsueduviewdocsummarydoi=10112369]
19 Shah N Bhatia N Jonquet C Rubin D Chiang A Musen M Comparisonof concept recognizers for building the Open Biomedical AnnotatorBMC Bioinformatics 2009 10(Suppl 9)S14[httpdxdoiorg1011861471-2105-10-S9-S14]
20 Rebholz-Schuhmann D Text processing throughWeb servicescallingWhatizit Bioinformatics 2008 24(2)296ndash298[httpdxdoiorg101093bioinformaticsbtm557]
21 Denny JC Smithers JD Miller RA Spickard A Understanding medicalschool curriculum content using KnowledgeMap J AmMed InformAssoc 2003 10(4)351ndash362 [httpdxdoiorg101197jamiaM1176]
22 Denny JC Spickard A III Miller RA Schildcrout J Darbar D Rosenbloom STPeterson JF Identifying UMLS concepts from ECG Impressions usingKnowledgeMap In AMIA Annual Symposium Proceedings Volume 2005American Medical Informatics Association 2005196ndash200
23 Reeve L Han H CONANN an online biomedical concept annotator InData Integration in the Life Sciences Springer 2007264ndash279 [httpdxdoiorg101007978-3-540-73255-6_21]
24 Zou Q Chu WW Morioka C Leazer GH Kangarloo H IndexFinder amethod of extracting key concepts from clinical texts for indexingIn AMIA Annual Symposium Proceedings Volume 2003 American MedicalInformatics Association 2003763
25 Chu WW Liu Z Mao W Zou Q KMeX A knowledge-based digitallibrary for retrieving scenario-specific medical text documents InBiomedical Information Technology Edited by Feng D BurlingtonAcademic Press 2008325ndash340
26 Hancock D Morrison N Velarde G Field D Terminizerndashassistingmark-up of text using ontological terms 2009[httpdxdoiorg101038npre200931281]
27 Schuemie MJ Jelier R Kors JA Peregrine Lightweight gene namenormalization by dictionary lookup Proc Biocreative 2007 223ndash25
28 Kang N Singh B Afzal Z van Mulligen EM Kors JA Using rule-basednatural language processing to improve disease normalization inbiomedical text J AmMed Inform Assoc 2012 20876ndash884
29 ConceptMapper Annotator Documentation httpuimaapacheorgdownloadssandboxConceptMapperAnnotatorUserGuideConceptMapperAnnotatorUserGuidehtml
30 Tanenblatt M Coden A Sominsky I The ConceptMapper approach tonamed entity recognition In Proceedings of Seventh InternationalConference on Language Resources and Evaluation (LRECrsquo10) 2010
31 Stewart SA von Maltzahn ME Abidi SSR ComparingMetamap toMGrep as a tool for mapping free text to formal medical lexicons InProceedings of the 1st International Workshop on Knowledge Extraction andConsolidation from Social Media (KECSM2012) 2012
32 The Gene Ontology Consortium Gene Ontology tool for theunification of biology Nat Genet 2000 2525ndash29 [httpdxdoiorg10103875556]
33 Verspoor K Cohn J Joslyn C Mniszewski S Rechtsteiner A Rocha LMSimas T Protein annotation as term categorization in the gene
Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit

Funk et al BMC Bioinformatics 2014 1559 Page 29 of 29httpwwwbiomedcentralcom1471-21051559
ontology using word proximity networks BMC Bioinformatics 2005 6Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S20]
34 Ray S Craven M Learning statistical models for annotating proteinswith function information using biomedical textBMC Bioinformatics 2005 6 Suppl 1 [httpdxdoiorg1011861471-2105-6-S1-S18]
35 Couto FM Silva MJ Coutinho PM Finding genomic ontology terms intext using evidence content BMC Bioinformatics 2005 6(Suppl 1)[httpdxdoiorg1011861471-2105-6-S1-S21] [1471-2105]
36 Koike A Niwa Y Takagi T Automatic extraction of geneproteinbiological functions from biomedical text Bioinformatics 200521(7)1227ndash1236 [httpdxdoiorg101093bioinformaticsbti084]
37 Bada M Hunter LE Eckert M Palmer M An overview of the CRAFTconcept annotation guidelines In Proceedings of the Fourth LinguisticAnnotation Workshop Association for Computational Linguistics2010207ndash211
38 Bard J Rhee SY Ashburner M An ontology for cell types Genome Biol2005 6(2) [httpdxdoiorg101186gb-2005-6-2-r21]
39 Degtyarenko K Chemical vocabularies and ontologies forbioinformatics In Proceedings of the 2003 International ChemicalInformation Conference 2003
40 Wheeler DL Barrett T Benson DA Bryant SH Canese K Chetvernin VChurch DM DiCuccio M Edgar R Federhen S Geer LY Helmberg WKapustin Y Kenton DL Khovayko O Lipman DJ Madden TL Maglott DROstell J Pruitt KD Schuler GD Schriml LM Sequeira E Sherry ST Sirotkin KSouvorov A Starchenko G Suzek TO Tatusov R Tatusova TA et alDatabase resources of the National Center for BiotechnologyInformation Nucleic Acids Res 2006 34(Database issue)D5ndashD12[httpdxdoiorg101093nargkl1031] [1362-4962]
41 Eilbeck K Lewis SE Mungall CJ Yandell M Stein L Durbin R Ashburner MThe Sequence Ontology a tool for the unification of genomeannotations Genome Biol 2005 6(5) [httpdxdoiorg101186gb-2005-6-5-r44]
42 Natale DA Arighi CN Barker WC Blake JA Bult CJ Caudy M Drabkin HJDrsquoEustachio P Evsikov AV Huang H et al The Protein Ontology astructured representation of protein forms and complexes Nucleicacids research 2011 39(suppl 1)D539ndashD545 [httpdxdoiorg101093nargkl1031]
43 Open biomedical ontologies (OBO) httpwwwobofoundryorg44 Jonquet C Shah NH Musen MA The open biomedical annotator
Summit Transl Bioinformatics 2009 20095645 Roeder C Jonquet C Shah NH Baumgartner WA Jr Verspoor K Hunter L
A UIMAwrapper for the NCBO annotator Bioinformatics 201026(14)1800ndash1801 [httpdxdoiorg101093bioinformaticsbtq250]
46 MetaMap Data File Builder httpmetamapnlmnihgovDocsdatafilebuilderpdf
47 Ferrucci D Lally A Building an example applicationwith theunstructured information management architecture IBM Syst J 200443(3)455ndash475
48 Liu H Christiansen T Baumgartner Jr WA Verspoor K BioLemmatizer alemmatization tool formorphological processing of biomedical textJ Biomed Semantics 212 3(3) [httpdxdoiorg1011862041-1480-3-3]
49 IBM UIMA Java Framework 2009 httpuima-frameworksourceforgenet
50 Verspoor K Cohn J Mniszewski S Joslyn C A categorization approachto automated ontological function annotation Protein Sci 200615(6)1544ndash1549 [httpdxdoiorg101110ps062184006]
51 McCray AT Browne AC Bodenreider O The lexical properties of thegene ontology Proc AMIA Symp 2002 2002504ndash508
52 Ogren PV Cohen KB Acquaah-Mensah GK Eberlein J Hunter L Thecompositional structure of Gene Ontology terms Pac SympBiocomputing 2004 2004214ndash225
53 Verspoor K Dvorkin D Cohen KB Hunter LOntology quality assurancethrough analysis of term transformations Bioinformatics 200925(12)77ndash84 [httpdxdoiorg101093bioinformaticsbtp195]
54 Yu H Hatzivassiloglou V Friedman C Rzhetsky A Wilbur WJ Automaticextraction of gene and protein synonyms from MEDLINE andjournal articles In Proceedings of the AMIA Symposium American MedicalInformatics Association 2002919
55 DeLuca DS Beisswanger E Wermter J Horn PA Hahn U Blasczyk RMaHCO an ontology of the major histocompatibility complex forimmunoinformatic applications and text mining Bioinformatics 200925(16)2064ndash2070 [httpdxdoiorg101093bioinformaticsbtp306]
56 Rocktaschel T Weidlich M Leser U ChemSpot a hybrid system forchemical named entity recognition Bioinformatics 2012[httpdxdoiorg101093bioinformaticsbts183]
doi1011861471-2105-15-59Cite this article as Funk et al Large-scale biomedical concept recognitionan evaluation of current automatic annotators and their parameters BMCBioinformatics 2014 1559
Submit your next manuscript to BioMed Centraland take full advantage of
bull Convenient online submission
bull Thorough peer review
bull No space constraints or color figure charges
bull Immediate publication on acceptance
bull Inclusion in PubMed CAS Scopus and Google Scholar
bull Research which is freely available for redistribution
Submit your manuscript at wwwbiomedcentralcomsubmit
Related Documents











