IN DEGREE PROJECT TECHNOLOGY, FIRST CYCLE, 15 CREDITS , STOCKHOLM SWEDEN 2019 Labeling Moods of Movies by Processing Subtitles PETER SVENSSON YOUSSEF TAOUDI KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

IN DEGREE PROJECT TECHNOLOGY,FIRST CYCLE, 15 CREDITS
, STOCKHOLM SWEDEN 2019
Labeling Moods of Movies by Processing Subtitles
PETER SVENSSON
YOUSSEF TAOUDI
KTH ROYAL INSTITUTE OF TECHNOLOGYSCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE

i
AbstractLabeling movies by moods is a feature that is useful for recommendation en-gines in modern movie streaming applications. Movie recommendation basedon moods is a feature that could improve user experience for movie stream-ing platforms by recommending more relevant movies to users. This thesisdescribes the development of a mood labeling feature that labels movies byprocessing movie subtitles through Natural Language Processing. Movies areprocessed by analysing subtitles to predict the mood of a movie through com-putational methods. The prototype utilizes movies pre-labeled with moodsto construct a lexicon that contains information of the defining attributes formoods in movie subtitles. Using the constructed lexicon, the similarities be-tween a movie subtitle and a lexicon can be compared to calculate the prob-ability that a movie belongs to a specific mood. Four moods were chosen foranalysis in the prototype: fear, sadness, joy, and surprise.
The Naive Bayes method was chosen as the classifier for the prototype. ANaive Bayes classifier observes each occurring word in a movie without con-sideration to the context of the word in a text or sentence. The results showedthat the classifier had trouble distinguishing between the moods. However, forall configurations of the prototype, the classifier showed higher precision forthe mood fear compared to the other moods. Overall the classifier performedpoorly and did not produce a reliable result.
Keywords - Mood Labeling, Natural Language Processing, Navie Bayes, TextClassification

ii
SammanfattningKlassificering av filmer via stämning är en funktion som är användbar för re-kommendationsmotorer i moderna filmströmmingsprogram. Filmrekommen-dation baserad på stämning är en funktion som kan förbättra användarupple-velsen på filmströmmande plattformar genom att rekommendera mer relevan-ta filmer till användarna. Denna uppsats beskriver utvecklingen av en prototypför att klassificera filmer efter deras stämning genom att bearbeta filmens un-dertexter med hjälp av metoder inom språkteknologi. Filmer bearbetas genomatt analysera undertexter för att avgöra stämningen hos en film. Prototypen an-vänder filmer som är fördefinierade med stämning för att konstruera ett lexikonsom innehåller information om de definierande egenskaperna för en stämningi filmtexter. Med hjälp av ett konstruerat lexikon kan likheterna mellan en film-textning och ett lexikon jämföras för att beräkna sannolikheten för att en filmtillhör en viss stämning. Fyra stämningar valdes för analys i prototypen: räds-la, sorg, glädje och överraskning.
Navie Bayes-metoden valdes som klassificeringsmedel för prototypen. En Na-ive Bayes-klassificerare observerar varje förekommande ord utan hänsyn tillordets sammanhang i en mening eller text. Resultaten visade att klassificering-en hade problem att skilja mellan stämningarna. För samtliga konfigurationerav prototypen visade klassificeringsenheten dock högre precision för rädslajämfört med de andra stämningarna. Sammantaget presterade klassificerarendåligt och gav inte ett tillförlitligt resultat.
Nyckelord - Stämningsklassificering, språktekonolgi, Navie Bayes, textklas-sificering

Contents
1 Introduction 11.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Purpose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.5 Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.6 Stakeholders . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.7 Delimitations . . . . . . . . . . . . . . . . . . . . . . . . . . 41.8 Benefits, Ethics and Sustainability . . . . . . . . . . . . . . . 41.9 Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Moods and Natural Language Processing 72.1 Moods and Emotions . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Basic Emotions . . . . . . . . . . . . . . . . . . . . . 82.1.2 Moods in Film . . . . . . . . . . . . . . . . . . . . . 9
2.2 Natural Language Processing . . . . . . . . . . . . . . . . . . 102.2.1 Word Sense Disambiguation . . . . . . . . . . . . . . 112.2.2 Phases of Corpus Processing . . . . . . . . . . . . . . 122.2.3 Natural Language Levels . . . . . . . . . . . . . . . . 132.2.4 Similarity Measurement . . . . . . . . . . . . . . . . 152.2.5 Naive Bayes . . . . . . . . . . . . . . . . . . . . . . . 162.2.6 Accuracy, Precision and Recall . . . . . . . . . . . . . 20
2.3 Database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . 212.5 Software and Frameworks . . . . . . . . . . . . . . . . . . . 23
2.5.1 Python . . . . . . . . . . . . . . . . . . . . . . . . . 232.5.2 Natural Language toolkit . . . . . . . . . . . . . . . . 242.5.3 Beautiful Soup . . . . . . . . . . . . . . . . . . . . . 242.5.4 MySQL . . . . . . . . . . . . . . . . . . . . . . . . . 24
iii

iv CONTENTS
3 Methodology and Methods 263.1 Research Methods . . . . . . . . . . . . . . . . . . . . . . . . 263.2 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.1 Literature Study . . . . . . . . . . . . . . . . . . . . 273.2.2 Interview . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3 Data Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . 293.4 Research Quality Assurance . . . . . . . . . . . . . . . . . . 303.5 Software Quality Assurance . . . . . . . . . . . . . . . . . . 303.6 Software Process Model . . . . . . . . . . . . . . . . . . . . 31
3.6.1 Reuse Model . . . . . . . . . . . . . . . . . . . . . . 313.6.2 Waterfall Model . . . . . . . . . . . . . . . . . . . . 323.6.3 Incremental Model . . . . . . . . . . . . . . . . . . . 34
4 Development Process 364.1 Prerequisites . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.2 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . 374.3 Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5 Prerequisites 395.1 Interview . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395.2 Selecting Moods for Prototype . . . . . . . . . . . . . . . . . 405.3 Selecting Sample Movies . . . . . . . . . . . . . . . . . . . . 40
6 Implementation of Prototype 426.1 Text Processing . . . . . . . . . . . . . . . . . . . . . . . . . 43
6.1.1 Removing Noise . . . . . . . . . . . . . . . . . . . . 436.1.2 Stop Words . . . . . . . . . . . . . . . . . . . . . . . 436.1.3 Stemming . . . . . . . . . . . . . . . . . . . . . . . . 456.1.4 Term Frequency . . . . . . . . . . . . . . . . . . . . 46
6.2 Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 466.3 Classification . . . . . . . . . . . . . . . . . . . . . . . . . . 47
7 Testing and Results 50
8 Conclusion and Future Work 558.1 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 558.2 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . 568.3 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
A Training and Test Movies 58

CONTENTS v
B Stop Words 63
C Interview with the Swedish Film Institute 64
D Implementation 65
Bibliography 66

List of Figures
2.1 Figure illustrating the Bag of Words method . . . . . . . . . . 132.2 Illustration of the conditional probability for the eventsH and
E in Bayes theorem . . . . . . . . . . . . . . . . . . . . . . . 172.3 A figure representing the structure of the attributes, A with
regards to a class node (C) in the Naive Bayes classifier . . . . 18
3.1 Figure illustrating the flowchart of the methods applied for lit-erature study . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2 Figure illustrating the waterfall model . . . . . . . . . . . . . 333.3 Figure illustrating a sprint in the Scrum model . . . . . . . . . 34
4.1 Figure illustrating the development process of the prototype . . 36
6.1 Figure illustrating the processes of the prototype . . . . . . . . 426.2 A subtitle formatted as HTML. . . . . . . . . . . . . . . . . . 436.3 Figure illustrating stemming . . . . . . . . . . . . . . . . . . 45
7.1 Results with stemming, with stop words removed . . . . . . . 517.2 Results without stemming, with stop words removed . . . . . . 527.3 Results without stemming, without stop words removed . . . . 527.4 Results with stemming, without stop words removed . . . . . . 53
vi

List of Tables
6.1 A table displaying the frequency for the ten most occurringwords in movies for the moods ’Joy’ (left table) and ’Fear’(right table) without removing stop words . . . . . . . . . . . 44
6.2 A table displaying the frequency for the ten most occurringwords in movies for the moods ’Joy’ (left table) and ’Fear’(right table) after removing stop words . . . . . . . . . . . . . 45
6.3 Table illustrating structure of lexicon . . . . . . . . . . . . . . 46
7.1 Table displaying the accuracy of the prototype for differentconfigurations . . . . . . . . . . . . . . . . . . . . . . . . . . 51

Chapter 1
Introduction
Natural language has developed and evolved as a method of communicationbetween humans[1]. The field of Natural Language Processing centers aroundhow computers can be used to understand and manipulate natural language intext or speech. The goal of the research within this field is to develop tech-niques for machines to understand and handle the natural language to performtasks [2, p. 51]. The applications can be machine translation, natural text pro-cessing, user interfaces, speech recognition and artificial intelligence[2]. Inthis project, Natural Language Processing techniques are used to develop aprototype that labels movies by moods through processing movie subtitles.
Moods and emotions have a very a close relation even though they are separa-ble from each-other[3]. What sets a mood apart from an emotion is that moodsare longer-lasting, while emotions exist in a very short time frame. Emotionsare often related to a specific event or person while moods can exist withoutattachment to any particular event or person. Moods also tend to be less in-tense than emotions[3]. Emotions can be categorized into basic emotions asdescribed by Ekman[4, pp. 45-60] and Plutchik[5]. Ekman [4] lists six ba-sic emotions: happiness, sadness, anger, fear, disgust, surprise. Plutchik [5]lists eight basic emotions: ecstasy, grief, vigilance, amazement, terror, rage,loathing and admiration. The characteristics of basic emotions are that they areprimal and hard-wired in our brains which humans respond quickly to, help-ing survive and avoiding dangerous situations[5]. The distinction between amood and an emotion is minimal and the terms are thus used interchangeablyin this thesis.
1

2 CHAPTER 1. INTRODUCTION
1.1 BackgroundSentiment Analysis, within Natural Language Processing, is the process ofcomputationally analysing a piece of text to identify or categorize a reader orwriter’s sentiment or opinion[6]. Usually Sentiment Analysis is used to spec-ify the positive or negative polarity of a piece of text [7]. Sentiment Analysisfor multiple categories can also be done[8]. In the case of this thesis, Senti-ment Analysis is used to determine the moods of different movies by analyzingtheir movie subtitles.
Sentiment Analysis uses Text Classification to categorize sentiments and opin-ions[8, p. 24]. Text classification is the method of classifying texts of differenttopics or categories [8]. Text classification is done by observing patterns intext, such as the structure of words and sentences or the word frequencies inmovies of different moods [9]. An algorithm that classifies text is called aclassifier.
1.2 ProblemA problem in sentiment analysis and text classification is that pre-labeled textmust be collected before any classification can be done [9]. Generally, classi-fication can not be done before the patterns in text for the different categorieshas been observed. A pattern could for example be a word structure or wordfrequency that coincide with a specific class[9, p. 221]. To find patterns foreach category, a classifier must rely on knowledge from previously analyzeddata, called a training set [9]. Movies and their Swedish subtitles for themoodshad to be collected before implementing the classifier.
There are many obstacles and difficulties in extracting sentiments and patternsfrom text. The human language is subjective and the same word or sentencecan be ambiguous or give different impressions when used in different con-texts. The ambiguity can be problematic when trying to identify underlyingmoods in aword or sentence because theymay vary from context to context[10,p. 180].
This can be summed up with the following problem statement:
How can a system label the mood of a movie by analysing the movie subtitles?

CHAPTER 1. INTRODUCTION 3
1.3 PurposeThe purpose of this thesis is to present the development of a prototype for la-beling moods of movies with Swedish subtitles. The functionality of beingable to correctly label movies by their mood could be useful for recommen-dation engines in movie streaming platforms. Mood labeling could be used torecommend more relevant movies for a user based on the moods of the moviesin the user’s history. An effective recommendation engine could increase userexperience and increase user watch-time on a movie streaming platform.
1.4 GoalThe goal of this project is to develop and present a prototype for labelingmoods of movies through processing movies subtitles by applying NaturalLanguage Processing techniques.
1.5 MethodsThere are two method categories when performing research, Qualitative andQuantitative[11]. Qualitative researchmethods involve gaining an understand-ing of underlying reasons, opinions and motivations. The understanding canbe reached by performing observations, interviews and reading literature re-lated to the work that the research is carried out for. The Quantitative researchmethods focuses on objective measurements and/or mathematical analysis ofcollected data. The Quantitative research methods rely on large sets of datacollected through surveys, case studies or experiments to ensure a valid out-come.
Research methods of qualitative character were the main focus in this project.The data collection involved defining moods for the chosen movies whichrequired understanding the characteristics that define a particular mood inSwedish text. Although qualitative research methods were used, the projectstill involved processing a rather large data-set. If proper qualitative researchregarding the moods of movies was not performed, it would have rendered theoutcome of the data useless or invalid.

4 CHAPTER 1. INTRODUCTION
1.6 StakeholdersSF Studios[12] is a Swedish movie production and distribution company. Forthe distribution to their private customers, SF studios has a platform called SFAnytime[13]. On this platform, customers can rent movies and series on de-mand. The platform is available via a web page, smartphone application andTV-application.
SF Anytime expressed a desire of a mood labeling feature for movies on theirplatform. The feature is desired to improve their recommendation system.
1.7 DelimitationsDue to the complex nature of moods, which is subjective to an observer, theproject and the prototype covered four moods: fear, joy, sadness and surprise.
Since the project focused on the technical aspect of developing a prototype,there was no consideration to philosophical questions regarding the properdefinition of what a mood is.
The subtitles were analysed word by word, meaning that the context of a wordand the structure or the grammar of a sentence was not taken into account inclassification and analysis.
The prototype is only compatible with Swedish subtitles, due to the databaseof SF Anytime[13] only consisting of subtitles for the Scandinavian countries.
Time performance and speed optimization were not prioritized in the devel-opment of the prototype.
1.8 Benefits, Ethics and SustainabilityA benefit of integrating the prototype with a movie recommendation enginecould be that it would increase the user experience of the end user. Moviesrecommended to a user could have a higher relevance and keep the user activelonger. A more active user would generate more income for the owner of the

CHAPTER 1. INTRODUCTION 5
platform.
Since the intended use of the prototype is to create movie recommendationsby moods, the platform that integrates the prototype could be able to constructa mood profile of a user based on the mood labels derived from the watchedmovies of a user. An ethical issue might arise since the information could pro-vide personal information about a users mental state and provide informationfor targeted advertising.
Sustainability refers to the concept of Sustainable Development[14] which isused to identify development that meets the needs of the present world withoutcompromising the ability of future generations to meet their needs[14]. Sus-tainable development is divided into three different areas: ecological, social,and economic sustainability.
Ecological sustainability relates to the function of the biochemical system ofthe Earth[15]. Services and products that are produced must take consid-eration to the water, air, land, biodiversity, and ecological services of theEarth[15]. The production of services and goods must not overload the ca-pacity of the ecosystem and make sure that nature is given time to regenerateresources of the ecosystem[15]. The prototype has no effect in this aspect.
Social sustainability concerns the psychological and physical needs of the in-dividual[16]. This includes human rights, justice, and quality of life for eachindividual. The prototype has no effect in this area.
There are two major definitions of economical sustainability[17]. The firstdefinition is from an ecological and a social sustainability perspective. Theincrease in economical growth must not have a negative impact on the envi-ronment or social sustainability. The second definition of economical sustain-ability is from an economical perspective where economical growth is desired.The second definition allows for economical growth on the expense of naturalresources and welfare[17]. The prototype might have an impact in this area. Ifthe prototype is integrated in amovie recommendation system it could increasethe amount of money a user would spend on the platform by recommendingmore relevant movies to the user. A user might spend more money on theplatform than they intended and have a negative on the personal economy of aindividual.

6 CHAPTER 1. INTRODUCTION
1.9 OutlineChapter two of this thesis, Theoretical Background, discusses emotions, moodsas labels and which emotions that are identifiable in movies. Furthermore, thechapter introduces the topic of Natural Language Processing and discusses dif-ferent problems and techniques in the area of analyzing the human languagerelevant to the project.
In chapter 3,Methods and Methodology, the methods and methodologies usedin the project will be discussed. This includes software development-, research-, data collecting- and analysis methods.
The development process for the prototype is presented in chapter 4, Devel-opment Process. This chapter discusses the three phases of the developmentprocess, Prerequisites , Implementation and Testing.
The first of the three phases in the development process is described in chapter5, Prerequisites. The chapter describes the data collection process of develop-ment.
Chapter 6 describes the Implementation phase of the development process. Inthis chapter, all functionality of the prototype is explained along with the ap-plication of Natural Language Processing methods for classifying the mood ofa movie.
The 7th chapter of the thesis, Testing and Results, presents the estimated pre-cision and accuracy of the classifier for the different moods. The chapter alsodiscusses how the prediction tests were constructed.
Chapter 8, Conclusion and Future Work discusses the validity and accuracyof the results and any improvements that could be made to the final prototype.

Chapter 2
Moods andNatural LanguagePro-cessing
This chapter discusses the theoretical background that was used in develop-ment of the prototype. The chapter is divided into five sections. The firstsection, section 2.1, describes moods and emotions on a human level, the con-cept of basic emotions and the use of moods in film. Section 2.1 also givesan insight to which moods were suitable as classes for text classification in theprototype. The ability to classify text into categories was crucial to the func-tionality of the prototype. Movie subtitles had to be classified into moods,therefore, section 2.2 aims to explain how Natural Language Processing tech-niques can be used to classify texts into categories. Section 2.3 presents howthe movie data were collected. Section 2.4 presents related work in this field.Section 2.5 discusses the use of programming languages and frameworks forthe development.
2.1 Moods and EmotionsVery often the two terms, mood and emotion, are confused with each-otheror used in the wrong context[18]. David Watson[19] defines moods as “tran-sient episodes of feeling or affect”[19], which in it self, proves a strong rela-tion between moods and emotions. The duration of the emotion is the mostsignificant characteristic which sets moods and emotions apart. An emotion issomething that is usually intense and the duration is very short as a result of anencounter with meaningful stimuli that requires quick adaptation in behaviorand response[18]. The nature of this reaction is sometimes argued to be a rem-nant of our primal instincts, a trigger of the basic “fight or flight behavior”[5].
7

8 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
Emotions can be seen as reactions or a response to a specific event and do notarise randomly and for no reason[19]. In contrast a mood is something thatis much longer in duration, from a few hours to a couple of days. Moods canalso arise from internal processes and they do not need a clear external iden-tifiable object as a cause for the specific mood. Moods are not as strong asemotions but they are, as mentioned, very strongly related. Being in a "good"mood makes the person more prone to experiencing positive emotions, whilebeing in a "bad" mood makes a person more inclined to experiencing negativeemotions[3].
2.1.1 Basic EmotionsThere is a close relationship between moods and emotions and the theoreti-cal background will be based on research with regards to emotions rather thanmoods. A major reason for using the term emotion is because of the theory ofbasic emotions.
Plutchik[5] has developed a model for representing human emotions[5]. Inthis model Plutchik has placed the primary, or basic, emotions in the centerof the model. The argument for this architecture is that other emotions aremixtures of the eight basic emotions[20]. In the original model the proposedbasic emotions were; joy, sorrow, anger, fear, acceptance, disgust, surpriseand expectancy. These emotions were selected since they polarize each-otherin pairs. Naturally, over the years, there have been other suggestions for basicemotions and the number of basic emotions. The basic emotions of the modeltoday are; ecstasy, grief, vigilance, amazement, terror, rage, loathing, and ad-miration[5].
Ekman[21] has conducted extensive research concerning the relation betweenemotions and facial expressions. Through this research Ekman found that fa-cial expressions of certain emotion appeared to be universal[22]. These emo-tions can be identified as separate, discrete states. The strongest evidence fordistinguishing one emotion from another comes from research of facial expres-sions and through this method Ekman recognizes six different basic emotions;happiness, sadness, anger, fear, disgust, surprise[21]. Ekman also argues thatthere is no need to take an evolutionary view of the emotions to be able tosuccessfully identify them. Social-learning is seen as a major contributor tothese basic emotions, regardless of culture.

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 9
2.1.2 Moods in FilmDespite its neglect in film-philosophy and film theory, mood has long beenrecognized as important to the films aesthetics. One term that often has beenused in movie context for referring to the mood of a film, is the German wordStimmung[23], meaning mood or atmosphere. Moods contribute to the com-position of the universe where the film takes place. The mood of a certaincinematographic universe sets the baseline for what events, actions and situa-tions the viewer might find interesting, odd, disturbing or otherwise emotion-ally significant. Moods can also serve as tools to mold or disturb the narrativeflow of a film or aid in a transition of narrative[23].
Greg M. Smith[24] claims that the "...primary emotive effect of film is to cre-ate mood.”[24]. Movies can invoke both emotions andmoods. A viewer mightbecome angry for a brief moment during one scene, but the movie in its en-tirety invokes a mood of happiness. In this context the issue of art moodsversus human moods arises. Saying that a movie is sad is metaphorical, sincea human mood is a discrete mental state and a movie cannot posses a mentalstate[25]. A movie can be used to invoke different moods in viewers but itcannot have human moods itself. In film and literature, the mood of a work isthe emotional character or tone. The mood of a film can be seen as a combina-tion of all the small elements of the film, that together characterize the overallexperience of the film. A sad film might fail to invoke sadness and a happyfilm might fail to invoke happiness, but the film extends an invitation to “feel”.It is up to the viewer to accept or reject the invitation[23].
The Swedish Film Institute[26] conducted a research, in the fall of 2018, tomapwhat moods the Swedish film audience wished to experience whenwatch-ing a film[27]. The research done by the Swedish Film Institute focused on fourbasic moods; excitement/surprise, happiness/laughter, emotional/cry, fear/dis-comfort. The research showed that the majority of the film audience wished tofeel excitement/surprise when watching a film. The results were most promi-nent among audience in the age category of 40 to 54, living in rural area andof low income. Among women the wish to fell happiness/laughter was partic-ularly popular[27].
When asked about what evokes the mood of excitement/surprise in the filmaudience, the result showed a strong correlation between a mood and certaingenres. Particularly strong correlation was evident with excitement/surprise

10 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
and the genres action, criminal and thriller. Answers from the research alsoshowed a strong correlation between the mood of happiness/laughter and thegenre comedy[27].
2.2 Natural Language ProcessingNatural Language Processing is a field in computer science concerning howto manipulate natural language in the form of text or speech through compu-tational methods [2]. One field in Natural Language Processing, text classifi-cation, is particularly important for this degree project. Text classification is aproblem of determining which category a body of text belongs to. Bodies oftext in Natural Language Processing applications are represented as corpora,which is the plural of corpus.
A corpus is a body of text [28, p. 6] that is used to perform statistical analysis[29]. Corpora serve as building blocks of data that are used to build up largelexicons [9]. Analysing corpora is done by statistically probing and manip-ulating text. Some corpora contain noise, that must be filtered out for betterresults[29]. One type of noise in corpora is markup [28, p. 475] which is anannotation in a document that explains the structure or format of a text [28,p. 123]. Another type of noise that occurs in written corpora are functionwords. Function words are short grammatical words, such as it, in and for,that generally dominate the word population in text that may need to be ac-counted for when processing a corpus[28, pp. 20-23].
There are many different types of corpora that can be used for Natural Lan-guage Processing applications. The leading platform for building python pro-grams with human language data, Natural Language toolkit (NLTK) [30], usesfour different types of corpora: Isolate Corpus, Categorized Corpus, Overlap-ping Corpus and Temporal Corpus[9].
The simplest type of corpus used by NLTK, the isolated corpus, is a standardcollection of text without any categorization. If a corpus is grouped into dif-ferent types of categories, it is called a categorized corpus. An overlappingcorpus is a categorized corpus with overlapping categories. The final type ofcorpus that is used by NLTK is called a temporal corpus. A temporal corpusis a collection of usages of text for a specific period in time [9].
Another representation of text that is particularly useful for text classification

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 11
are lexicons[31, p. 19]. A lexicon is a collection of information about wordsthat belong to a specific category [32]. Each set in a lexicon is called a lexicalentry. Each lexical entry contains a word and information about the particularword in the lexicon [32]. Lexicons can be used to store information concern-ing word frequency for a given category which is needed in text classification[33]. Information needed for probabilistic approaches in large lexicons shouldalways be collected computationally as it is infeasible to do manually. Lexicalentries are collected by analysing adequate corpus data [33].
Text classification can be done using a Corpus-Based Approach. A corpus-based classifier approach relies on using corpora to build specific lexiconscategories that can be used for analysis [8, p. 95]. There is however one ma-jor problem with a corpus-based text classification approach, the Word SenseDisambiguation problem.
2.2.1 Word Sense DisambiguationWord Sense Disambiguation is a classification problem for determining whichsense or meaning of a specific word is activated in a specific context. Thereare three classes of Word Sense Disambiguation methods used in the field ofartificial intelligence: Supervised-, Unsupervised and Knowledge-Based Dis-ambiguation [34].
Supervised disambiguation is based on learning and makes use of annotatedcorpora to learn. The input data are marked with the classes or categories theybelong in to further build on a lexicon [35]. The corpora can also be anno-tated with the weight of how much the text data reflects the importance of thecorpus for a certain category [36]. Supervised learning is generally used as aclassification task [28].
As opposed to supervised disambiguation, unsupervised disambiguation onlyuses raw corpora for learning. Unsupervised learning will often start by mak-ing use of knowledgeable sources that it can improve further. Unsupervisedalgorithms often use a technique called clustering. Clustering is a way ofanalysing corpora by grouping similar objects into the same category [28].
The final technique, the Knowledge-Based technique relies primarily on dic-tionaries or lexicon bases [36]. Knowledge-based methods are usually basedon already developed and well established lexicons. The problem with using

12 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
knowledge-based methods is that they only perform well for very large dic-tionaries. These are often general and may not be suitable to use for nicheprojects [35]. A knowledge-based approach is sometimes called dictionary-based approach[8, p. 91].
2.2.2 Phases of Corpus ProcessingThemethod for processing a corpus consists of three phases: Text Pre-processing,Text Representation and Knowledge Discovery[37, pp. 388-390].The first phase, the text pre-processing phase, is the process of filtering outnoise from text [38]. Corpora scraped from the web can for example be anno-tated with markup. Markup is a type of noise must be taken into account whendata mining on the web [9]. A popular format for web pages is HTML, whichis a markup language [39], meaning it has tags and markings that explains anddenotes the structure of a document [40]. Another, more common, type ofnoise are function words [28] or stop words [38]. Stop words can be removedby using a stop word dictionary [38]. It is important that words in a corpus areall in the same letter case. If a word is in the beginning of a sentence, it startswith an uppercase letter and will not be seen as the same word in the eyes of acomputer as the lowercase word [29, p. 71].
Stemming is an important term in text pre-processing. "Stemming is the pro-cess of removing affixes from a word in order to obtain its stem, and a stemmeris an algorithm that performs this process " [41]. The complexity for stemmersvary from language to language. Languages such asArabic wheremany affixescan be used on words are more difficult than languages such as English [41].Stemmers can become quite complex and may become difficult to implementor may require a large amount of data. There are many stemmers available inEnglish, but not very many exist in Swedish. Stemming is particularly usefulfor smaller entities of text. A similar technique called Lemmatization can beused instead to convert words into their grammatical base [41].
The second phase of corpus processing is defining data structures for text rep-resentation. Text can be represented as corpora or lexical entities. The data-structure of corpora and lexical entries is an important choice for text analysis.The simplest model is called the Bag of Words model [9, p. 50] where eachword is one entry in the data set. The data set is unordered and the only infor-mation stored about a word in the bag is the frequency in which it appears in acorpus [42, p. 65]. Figure 2.1 illustrates how raw text can be transformed into

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 13
a Bag of Words data-structure that contains the frequency of each word in thetext.
Figure 2.1: Figure illustrating the Bag of Words method. Figure inspired byManning [28]
Another model could be used is the Vector Space Model. In the Vector SpaceModel, a document is represented as a count vector. Each entry in the vector iscalled a feature and it represents one entry in the document vector [28]. Whilethe two are similar, a document vector generally contains more informationthan a Bag of Words.
The third and final phase is called Knowledge Discovery. Knowledge Discov-ery means to extract knowledge from data [43]. It is in this phase where thedata from the text representation phase is actually used through machine learn-ing or data mining methods [37, p. 390] such as the Naive Bayes [44, p. 20]classifier. For example, the Bag ofWords could be used to create or build uponlexical entries in a lexicon.
2.2.3 Natural Language LevelsBefore processing a corpus, one must first decide which parts of natural lan-guage to analyse. Natural Language Processing is a broad field that concerns

14 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
processing many different levels of texts. Extracting and processing text canbe done in six different levels: morphological-, lexical, syntactic, semantic,discourse and pragmatic levels [2, p. 56]. Different techniques should be useddepending on the level a corpus will be processed on.
The morphological level deals with the smallest parts of words such as pre-fixes and suffixes [2, p. 56]. A big focus in the morphological level is wordformation. The same words can appear in different forms depending on theinflection of the word [28]. Examples of techniques in the scope of morphol-ogy are Stemming and Lemmatization [45] that are used in text pre-processing.
Following the morphological level is the lexical level. In this level, analysisis applied in the scope of words [2, p. 56]. This level focuses on which partof speech a particular word is used for. Part of speech can be seen as a gram-matical category for words [28]. The technique used for labeling words aftertheir grammatical category is called Part-of-Speech Tagging (POS-tagging)[46]. Stockholm University [47] has a part-of-speech tagger for Swedish textavailable called Stagger [48] that is available in open source.
The syntactic level in Natural Language Processing deals with the structure ofsentences [2, p. 56]. A syntax in linguistics is a rule in a language that con-cerns the form of sentences [32]. The form of a sentence should not be con-fused with morphological structures as they only concern words. As the formof sentences can be structured in different ways, it is not feasible to capture allpossible patterns for a sentence manually. Instead computational approachesmust be taken. One approach is to construct syntactic N-Trees [49] which aretree data-structures with n-tuples that can be used to store the structures ofsentences.
The semantic level covers the meaning of words and sentences [2, p. 56]. Thislevel focuses on the meaning of a word or sentence without taking the outsidecontext into account [32]. Lexical semantics can be studied through two differ-ent approaches. The first approach is to study themeaning of individual words.The second approach is to study how the meaning of words are related to eachother and howmultiple words can be combined into meaning of sentences [28,pp. 109-110]. Examples of applications in this level are identifying words withsimilar meanings (synonyms), words with opposite meanings (antonyms) andmeanings of ambiguous words [28, p. 110].

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 15
The discourse level concerns the relationships between sentences in a text. Theanalysis in this level mainly focuses on analysing anaphors [28]. Anaphors areexpressions that refer back to previous expressions in the same text [32]. Forexample, a person that has previously been introduced in a text may be referredto as ’He’ or ’the Man’. For a program to know who ’He’ or ’the Man’ may bereferring to, it must be able to identify the person in the context of the text. If’He’ and ’the Man’ were referring to the same person, they would be anaphor-ically related [28].
Pragmatics is the study of how knowledge about the world interacts with theliteral meaning of text. Due to the difficulty of modeling the complexity of theworld and the lack of data, this area of Natural Language Processing has notreceived a lot of attention.[28]. The semantic representation, or logical form,of an utterance is distinct from its pragmatic interpretation[50]. Pragmaticsconsiders language as an instrument of communication, what people actuallymean when they use language and how a listener interprets it. According toJenny Thomas[51], pragmatics consider the negotiation of meaning betweenspeaker and listener, the context of the utterance, and the meaning potential ofan utterance[51]. This can be illustrated by this simple example.
Utterance: “Do you know what time it is?”
Pragmatic meaning: Why are you late? Response: Explanation or apology.
Literal meaning: What time is it? Response: A time
The above example supports the notion of ambiguity in the natural languagealong with the difficulty of modeling the real world when performing NaturalLanguage Processing.
2.2.4 Similarity MeasurementSimilarity measurement is the means of determining how well a particularcorpus or vector fits a certain pattern or category by quantifying the relation-ship between different features [52]. Similarity measurement is useful whentesting supervised dictionary algorithms or when learning unsupervised dic-tionary algorithms. [34, p. 57].
If both the input document and the lexicon are represented as vectors in the

16 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
same term space, a measure of the similarity between them can be computed.Similarity can be calculated as the probability that a certain query belongsto a certain category. Similarity can only be measured through probabilisticmodels if there is quantifiable data available. To get quantifiable data, theremust be some form of weighting in the proposed data-structures of a lexicon.The most optimal weighting principle for documents is based estimating therelevancy of a query to a certain document or lexicon [44].
2.2.5 Naive BayesThe Naive Bayes is a probabilistic classifier that is useful for text classifica-tion. A classifier is an algorithm that implements classification by mappinginput data to a category. Naive Bayes applies Bayes theorem[53] which is amathematical formula for calculating conditional probabilities and is mainlyused in statistical mathematics. Conditional probability is the probability ofone event occurring, given that another event has already occurred[54].
P (H|E) =P (E|H)× P (H)
P (E)(2.1)
In Bayes theorem, presented in formula 2.1, P (H|E) is the likelihood of eventH given that E is true. In the same way, P (E|H) is the likelihood of event Egiven thatH is true. The probabilityP (H) is the likelihood of eventH withoutany knowledge ofE and P (E) is the likelihood of eventE without any knowl-edge of H . P (E|H)× P (H) can be written as P (H ∩ E) which is the prob-ability of both H and E being true. P (H ∩E) also equals P (H|E)× P (E).Figure 2.2 illustrates the probability of the events as two intersecting circles ina Venn diagram. The diagram displays the denominator P (E) in formula 2.1as the right circle, P (H) as the left circle and the numerator, P (E|H)×P (H)
is illustrated as intersection of the two circles. In the Venn diagram, the proba-bility of P (H|E) would thus be the size of the intersection divided by the sizeof the right circle.

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 17
Figure 2.2: Illustration of the conditional probability for the events H and E.Figure by the authors.
The Naive Bayes classifier assigns a class to a corpus, given its vector repre-senting the occurrence of words, also referred to as features or attributes, ina specific corpus. A classifier is constructed by using a collection of labeledtraining corpora to estimate the parameters for each class. Classification canthen be performed by assigning a new corpus to the class that is most likely tohave generated that specific corpus[55]. The Naive Bayes classifier is a veryeffective and is one of the simpler classifier among the Bayesian classifiers.The Naive Bayes classifier assumes that all attributes of a vector are indepen-dent of each-other, also called conditional independence[56]. In reality, theassumption is far from correct since there is a strong correlation between theoccurrences of words in a corpus, but regardless of this, the Naive Bayes clas-sifier generally performs well. Since the attributes are seen as non-related theycan be learned separately hence simplifying learning when a large number ofattributes are involved, which is often the case when working with corpora. InNaive Bayes each attribute has no parent node, except the class node as shownin 2.3[56].
There are two models of how occurrences of attributes in a corpus can be rep-resented before the Naive Bayes assumption is performed[55]. In both modelsthe order of words are lost, thus both can be seen as a Bag of Words[9]. In thefirst model a corpus is represented as a vector of binary attributes indicatingwhich words occur or do not occur in the corpus. The number of occurrencesof a word is not represented in the vector. When calculating the probabilityof a corpus, multiplication of the probability of all attribute values, including

18 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
Figure 2.3: A figure representing the structure of the attributes, An, with re-gards to a class node, C, in the Naive Bayes classifier. Figure inspired by H.Zhang[56]
non-occurrence, is performed. In the second model, a corpus is represented bythe set of word occurrences in the document, along with the number of occur-rences for that particular word. When calculating probability for a corpus inthe second model, multiplication with the probability of the occurring wordsis performed[55]. An example is to calculate the probability of a documentbelonging to a class through multiplying the conditional probabilities of thefeatures in the corpus [34, p. 11] as illustrated through the formula 2.2 wherethe features are words. In formula 2.2, P (wordi|class) is the probability of aword belonging to a class and P (corpus|class) is the probability of the entiretext belonging to a class. When classifying a corpus, the probability that thecorpus belongs to each possible class must be calculated. The class that givesgives the highest probability is the most likely class that the corpus is catego-rized into.
P (corpus|class) =a∏
i=1
P (wordi|class) (2.2)
The Naive Bayes classifier encounters a problem when the number of wordsin a corpus grows large. The probability for a word belonging to a class willbe represented by a value between one and zero. Since the probability fac-tors for each word in the corpus are multiplied with each other, the overallproduct will be very small. This number can be so small that computer com-pilers cannot represent them as floating point data and thus assumes them aszero[57]. This would result in the introduction of invalid zero probabilities in

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 19
the calculations. A common way of overcoming this issue is to represent theprobabilities as log-probabilities[57]. The transformation to logarithm workswell because the logarithm of a product is the sum of the logarithms. Theformula 2.3 shows how the formula 2.2 is logarithmized to calculate the log-arithmic probability Plogarithmic(corpus|class), which is the probability of acorpus in a specific class. The logarithm of a product is calculated as the sumof the logarithms. Therefore, the probabilities P (wordi|class) in 2.3 will besummed instead of multiplied. This will result in more manageable numbersbut since the logarithm is taken for values between zero and one the final prob-ability will be a negative number.
Plogarithmic(corpus|class) =a∑
i=1
lnP (wordi|class) (2.3)
Another obstacle in the Naive Bayes implementation is when the classifier en-counters a word that was not in the training corpora, meaning that the worddoes not exist in the lexicon of the classifier. This will result in the classi-fier calculating the probability for a word missing in the lexicon as zero. Theclassifier calculates the probability of a corpus belonging to a specific classthrough multiplication of the probability of each word belonging to the class.An introduced zero will result in a zero product and zero probability for thatcorpus belonging to a class[9]. This can have dramatic effect due to the prob-ability being calculated to zero even though all words but one matched to acertain class lexicon. This, however, can be solved by using a statistical tech-nique called Smoothing[58], where the classifier assumes that all words havebeen seen one more time than they actually have. Smoothing leads to a priorlyunseen word being handled as it was included in the training corpora one time.This will remove any unwanted zero probabilities from the final probabilitycalculation. This technique is sometimes referred to as Laplace estimator orAdditive Smoothing[58] due to the minimum one occurrence approach for allwords.
Psmoothing(word|class) =occ(word, class) + 1∑
i=1 occ(wordi, class) + |V |(2.4)

20 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
2.4 is the formula for calculating the conditional probability of a word given aspecific class with additive smoothing. The function occ(word, class) is theamount of occurrences of theword for a specific classwhile
∑i=1 occ(wordi, class)
is the amount of occurrences of all words in the class. |V | is the length of alexical vector or in other words, the amount of words in a lexicon or dictio-nary. Adding one to the occurrence of a word for a specific class guaranteesnon-zero probability and adding the size of the vector to the divisor means thatwords that do not occur for a class are not very significant.
2.2.6 Accuracy, Precision and RecallWhen evaluating a classifier there are three different methods: accuracy, pre-cision and recall[28]. The simplest method is accuracy, which measures thepercentage of provided inputs that the classifier correctly labeled. To receivethe accuracy metric the number of correctly labeled inputs is divided with thetotal number of inputs. This metric can be misleading since it does not accountfor the number inputs not being relevant to a specific class[28].
Precision is howmany of the items that were identified were relevant and recallis how many of the relevant items that were identified. To calculate precisionand recall four metrics needs to be identified:
True positive, TP, relevant items labeled correctly
True negative, TN, irrelevant items labeled incorrectly
False positive, FP, irrelevant items labeled correctly
False negative, FN, relevant items labeled incorrectly
Precision =TP
TP + FPRecall =
TP
TP + FN(2.5)
When calculating precision and recall account is taken to the fact that, in infor-mation retrieval, the number of irrelevant inputs outweigh the relevant inputsfor a class[9].
When evaluating the accuracy of a classifier, the test set can not consist of datathat was used for learning or training. The evaluation of the results from theclassifier must be with regards to previously unseen data[28].

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 21
2.3 DatabaseSf Anytime [13] provided a database with movies and their movie subtitles.The subtitles from SF Anytime were formatted as HTML meaning markupnoise had to be removed from subtitles. The SF Anytime database did not haveany information about the mood of the movies in the database. Movies thatwere pre-labeled with moods were available through the Internet Movie Data-Base, IMDB[59] and TiVo[60]. IMDB is an online database for informationabout movies. The movies on the IMDB website are tagged with the moodof the movies. TiVo is a company that is involved in creating and licensingproperty related to television. TiVo has a large database [61] with informationabout movies and tv-series that include a mood tag. TiVo has an API that canbe used to fetch information about the movies in the database.
2.4 Related WorkRelated work covers published work in the same problem domain as the de-gree project. The purpose of exploring related work is to compare techniquesand methods and to find out how well certain methods solve the problem. Ex-ploring related work also gives a good understanding of what limitations thereare for solving a problem.
IBM [62] has an AI platform called Watson[63]. The platform provides API’sconcerning many different fields in artificial intelligence and machine learn-ing [63]. One API, called Tone Analyzer, is particularly interesting to discuss.The Tone Analyzer is an API that allows a user to input a corpus and receivethe emotional tone of the corpus as return value. The tone analyzer analysestext on a discourse level by identifying anaphors in conversation, on a syntac-tic level through the use of n-trees and on a lexical level through the use ofdictionaries [64]. IBMWatson makes use of an alternative to the Naive Bayesclassifier called a Support Vector Machine [64]. A Support Vector Machineclassifier transforms training data into a high-dimensional space and tries tofind a plane in the space that separates the training data in a way that all pointsof a category are on one side of the plane and all points of another categoryare on another side of the plane [35, p. 27]. While the tone analyzer was notspecific to movie subtitles, the research made by IBM shows that it is possibleto identify emotions from text with decent precision.

22 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
In an article by Tarvainen and Laaksonen [65], it is described how film moodscan be identified through analysis of movie scenes. The article describes anal-ysis of movie scenes through visual and auditory style. For the visual analysis,the focus was on brightness and color features, pixel motion and face emotion.The audio analysis on the other hand consisted of analysing loudness, musicand dialogue [65]. The dialogue was analysed using IBM’s Watson tone an-alyzer [62]. In the results, the authors discussed the influence of each fieldof analysis to the result. The results of the influence analysis showed thatspeech or dialogue was fairly influential in the prediction of moods in non-music scenes. In the scenes where there was music, dialogue did not influencethe prediction of moods [65]. The results in the article indicate that analysingmoods through dialogues and narration is possible for scenes without musicwhen analysing audio.
Wietreck, 2018[66], investigates the possibility of implementing a movie rec-ommendation system based on emotions. A 10-item Positive Affect - NegativeAffect Scale, PANA-Scale, is used to reflect a specific mood state. The rec-ommendation system was based on a Random Forest which is a set of train-able decision trees. A decision tree is a data structure that employs a top-down divide-and-conquer strategy that partitions a given set of objects intosmaller and smaller subsets with the growth of the tree[67]. Decision trees arespecially effective with small data sets[66]. To aid the decision making andweighting of the system, input knowledge was collected from the user suchas age, gender, and current mood, trough a questionnaire. The mood of theuser is determined with help of the PANA-Scale, ten positive and ten negativeaffect questions. As a source for the output the Internet Movie Data Base[59]was used for selecting movie sets, based on genre, that is believed to matchthe user. After the questionnaire, the user is presented with a set of movietitles from a genre that has the highest probability of matching the user. Twoversions of the system were constructed, one which uses arbitrary recommen-dation and one that utilizes on the mood of the user for recommendations. Therecommendations were then compared against each other for relevance to theuser. The results show a favor for the recommendation system based on theusers mood[66]. The author summarizes that it is possible to build a recom-mendation system based on moods.
Wakil, Ali, Bakhtyar and Alaadin, 2015[68], developed a movie recommenda-tion system based on emotions of the user. The recommendation system con-sisted of Collaborative Filtering, where content was presented to the user based

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 23
on the content of similar user profiles and Content-Based Filtering, where con-tent was compared to the users profile and then presented. The system con-sisted of five steps: user registration, user rating, hybrid recommendation sys-tem, prediction, and a list of recommendation movies. In the first step the userregistered and choose three colors to represent the emotion state. In the secondstep the system calculated initial rating and allowed the user to rate movies,from a scale of one to five. The third step was where the system calculated thesimilarity between users and items. In the fourth step, the system predicted theusers rating and in the last step a list of recommended movies was shown to theuser. The result showed that the recommendation system based on emotionshad much better accuracy when presenting recommendations.
Blackstock and Spitz, 2008[69], classifies movies scripts by genre using Max-imum Entropy Markov Model and Natural Language Processing-based fea-tures. Movies scripts were run through the Stanford Named Entity Recog-nizer[70] and Part-of-Speech Tagger[71] systems for generating output files.Out of 399 movies scripts, 359 were used for training the system, and 40 wereused for testing the system. The result showed that the system could accuratelylabel the genre of a movie, by analyzing the movies scripts, in 55 % of the testcases.
2.5 Software and FrameworksThe prototype uses supervised disambiguation to build a lexicon in the formof a vector using the Vector Space Model. The lexicon contains informationabout the probability of a mood each word in the collection. Through a NaiveBayes Classifier, input corpora can be compared to the lexical entries in thelexicon to measure the probability that a movie is of a certain mood.
2.5.1 PythonThe prototype was developed in Python[72]. Python is a high-level object-oriented open source programming language[72]. Python is sometimes re-ferred to as a object-oriented scripting language. A script is a small programthat runs in the shell of a operating system and handles simple tasks[73].Python provides fast development speed due to the high-level nature of thelanguage. The Python interpreter handles details which would have had tobeen explicitly coded for in a low-level language[73]. Type declarations, mem-ory management and build procedures are not present in the Python language,

24 CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING
which gives the developer freedom to focus on the task of the developed pro-gram. Python is suitable for Natural Language Processing because of its string-handling functionality and transparent syntax and semantics[9]. There aremany useful Natural Language Processing libraries in Python, some of whichwere used in the development of the prototype.
2.5.2 Natural Language toolkitOne of the frameworks that was used in development of the prototype was theNatural Language toolkit (NLTK)[30] which is a platform with useful toolsto handle human language data. It provided an easy to use API for Python.NLTK was one of the few platforms that provided stemming in Swedish. TheNatural Language toolkit had multiple stemmers available for use but the onlyone that provided stemming for Swedish was their snowball stemmer library[74]. The toolkit also had a library for removing stop words in Swedish.
nltk.stem.snowball.SwedishStemmer was a NLTK class that wasused for stemming Swedish text. The class provided a method for stemmingtext named stem(text). The stemming method took the text that was to bestemmed as an argument in the form of a string and returned the stemmed textas a string [74].
2.5.3 Beautiful SoupAnother Python framework that was used in development of the prototype wasBeautiful Soup[75]. Beautiful Soup is a python framework that was used forextracting data from markup [75]. The framework was useful for parsing un-structured data to raw text.
find_all(tag) was a Beautiful Soup[75] method which extracted textfrom inside all tags specified by the argument tag[75]. The method is gener-ally used to extract text from markup languages such as HTML.
2.5.4 MySQLMySQL[76] is an open source client/server relational database managementsystem using Structured Query Language (SQL). Structure Query Language(SQL)[77] is a database access language created by IBM[43] for writing rou-tines to query databases [77]. Examples of queries for SQL are the INSERT

CHAPTER 2. MOODS AND NATURAL LANGUAGE PROCESSING 25
query that adds new data to a collection [78] and the SELECT query whichreads data from a collection [79]. MySQL includes an SQL server, client pro-grams for accessing the server, administrative tools, and a programming inter-face for writing your own programs. MySQL was developed in Sweden as aresult of a company requiring a faster management system that could handletheir large tables[76].

Chapter 3
Methodology and Methods
This chapter discusses the relevant research methods in the project, relevantsoftware engineering methods and techniques for the development of the pro-totype. This chapter also explains the use of the methods and methodologiesas well as the motivation for choosing the methods. Section 3.1 discusses thecharacteristics of qualitative and quantitative research methodologies. Section3.2 discusses the research methods that were used to collect data. Section 3.3discusses relevant analysis methods used to solve the problem at hand. Section3.4 explains quality assurance from the perspective of research and softwaredevelopment. The final section of the chapter, section 3.5, discusses suitablesoftware process models that could be used for development of the prototype.
3.1 Research MethodsResearchmethods can be split up into two different methodologies, Qualitativeand Quantitative methods. The Qualitative methods are based on case studies,field studies, document studies, interviews and observational studies[11][80]and uses smaller data sets. When working with Qualitative methods when per-forming research, the goal is to understand meanings, opinions and behaviors.This can also be referred to as the verstehen approach, where the name derivesfrom the German word for understanding[80]. Quantitative research methodsfall under the category of empirical studies[81], to some, or statistical stud-ies, according to other[80]. The Quantitative research methods requires largedata sets, on which experiments and tests are conducted. Data in Quantita-tive research is coded according to a prior operational and standardized def-initions[80]. The hypothesis must be formulated in such a way that it can beverified or discarded by the result of the Quantitative research[11].
26

CHAPTER 3. METHODOLOGY AND METHODS 27
3.2 Data CollectionThe data collection methods used as a base for the development of the pro-totype were carried out before initial implementation of the prototype began.The reason for this was to ensure that the first iteration of the prototype wasimplemented and operated in a manner that ensured as valid of a result as pos-sible. The two data collection methods that were used were literature studyand interviews.
3.2.1 Literature StudyLiterature study can be described as an objective, thorough summary and crit-ical analysis of the relevant available research and non-research literature onthe topic being studied [82]. Literature study is also essential for identifyingwhat has been written on a specific subject determining the extent of which aspecific research area reveals any interpretable trends or patterns, aggregatingempirical findings related to a narrow research question to support evidence-based practice and identifying topics or questions requiring more investiga-tion[83]. The purpose of performing a literature study is to bring the readerup to speed with what work has been conducted within a certain topic or field.It can also identify the gaps and inconsistencies in the knowledge collectedduring the literature study[84]. A literature study can also provide a theoreti-cal foundation for a study and motivate the methods applied and choices madein a study[83].
As proposed by Templier and Paré[85], when conducting the literature studythe following methods were applied as shown in figure 3.1: formulating theresearch question(s) and objective(s), searching the extant literature, screeningfor inclusion, assessing the quality of the primary studies, extracting data andanalyzing data. By first formulating a good research question the need and ob-jective of the research could be motivated. This resulted in a more well definedand fine-grained search of literature which gave a smaller but more suitable re-search results for use in the project. After the material was identified they wereall screened at a more detailed level to determine if the information they con-tained was applicable or relevant in this project. Material gathered at this stagewas also screened by the other group member to ensure that the material wasrelevant. Once this was done, the quality of the material had to be assessed,

28 CHAPTER 3. METHODOLOGY AND METHODS
Figure 3.1: Figure illustrating the flowchart of the methods applied for litera-ture study. Figure by the authors.
which included confirming that the source and/or author were reliable and thatthe material had references to its claims or presented facts. When the mate-rial had been verified as being a reliable source of information, the relevantinformation in the material could be extracted from each of the sources. In-formation about how, when and where a study in a source had been conductedcould also be collected. After this, the gathered information was summarized,organized, compared and presented in a meaningful way.
The twomain sources for thematerial wasKTH’s online library[86] andGoogleScholar[87].
3.2.2 InterviewInterviews falls within the Qualitative research method and is used as a pri-mary data gathering method[88]. Interviews can give a more in-depth un-derstanding of a certain problem by tapping into the expert knowledge of anindividual. Interviews can can be conducted and structured in three differ-ent ways: unstructured, semi-structured, and structured[11]. A structured in-terview only consists of predefined questions, compared to an unstructuredinterview, that can be compared to a conversation about a topic or issue, rep-resenting the interviewers control of the interview. Interviews are a good wayto resolve conflicting information since the researcher has the opportunity to

CHAPTER 3. METHODOLOGY AND METHODS 29
directly ask about a specific topic, whereas data from a survey can be moregeneralized[88]. Interviews are also a good way of exploring the more fine-grained aspects of a topic with follow-up questions.
3.3 Data AnalysisData Analysis in qualitative research is comprised of reducing raw data tothemes through qualitative analysis methods and then representing that datain the form of figures, tables or text [89, p. 188]. Commonly used meth-ods in qualitative data analysis analysis include Coding, Analytic Induction,Grounded Theory, Narrative Analysis, Hermeneutic and Semiotic [11]. Onlytwo of the data analysis methods are relevant in text and document analysis:Coding and Grounded Theorising [90].
Grounded Theory is an approach to conduct data collection and analysis simul-taneously through iterations [91]. Coding on the other hand is a strategy thatallows for quick retrieval and collection for all text and data that correspondsto an identified theme. Simply put, coding is a process of labeling a passageof text or piece of data [92]. The grounded theory strategy had to be discardedfor the project as large amount of data had already been collected before theanalysis phase. Since the prototype concerned labeling text by moods, it onlyseemed natural that the coding strategy was the most suitable choice.
The data that was analysed in this thesis was movies, or more specifically,movie subtitles. According toMikos [93], there are four types of activities thatcan be analysed through qualitative data analysis in films: cognitive activities,emotional activities, habitual activities and social-communicative activities.This thesis will focus purely on emotional activities of films. The object offilm analysis is the textual structure of films [93].
Data analysis was thus done by reducing the raw movie subtitles into moresuitable data-structures that could used for mood labeling through the codingstrategy.

30 CHAPTER 3. METHODOLOGY AND METHODS
3.4 Research Quality AssuranceQuality assurance is the validation and verification of research material[11].Methods for verification of the researchmaterial can be divided into two strate-gies: ensuring the quality of the data and the quality of the analysis[94]. Thereare different concepts that can be applied to the gathered research material de-pending on how it has been collected. In this thesis the qualitative researchmethod has been used hence concepts for verification with aspects to thismethod are best applied, which are: credibility, transferability, dependability,confirmability and authenticity[95].
Credibility - is the researcher or the source of the data reliable?
Transferability - is the findings applicable in other context?
Dependability - would similar findings be produced if someone else per-formed the research?
Confirmability - is the data a product of a researchers biases, motiva-tions, interests, or perspective?
Authenticity - does the research represent a fair rage of viewpoints onthe topic?
The presented concepts for improving validity of the collected data must beapplied with judgement on the part of the researcher[96].
3.5 Software Quality AssuranceThe Institute of Electrical and Electronics Engineers (IEEE)[97] define qualityassurance as the following[98].
1. A planned and systematic pattern of all actions necessary to provide ad-equate confidence that an item or product conforms to established tech-nical requirements.
2. A set of activities designed to evaluate the process by which the productsare developed or manufactured.
This definition describes the processes and standards that should be in place,throughout a development process, that leads to a high-quality software prod-uct. This can sometimes also include the phase after the software product has

CHAPTER 3. METHODOLOGY AND METHODS 31
been handed over by developers, including verification, validation and config-uration management. There are two types of standards for software develop-ment[99].
1. Product standards applies to the software being developed. They in-clude document standards, documentation standards, and coding stan-dards.
2. Process standards defines the process that should be followed duringsoftware development. They should encapsulate good development prac-tice. Process standards may include specification, design and validationprocesses, and documentation processes.
Software quality assurance should not be limited to technical aspects of de-velopment. The main goal of software quality assurance is to minimize thecost of guaranteeing quality by applying processes throughout development,including scheduling and budget. There is a close relationship between meet-ing requirements, budget and time failure[98].
3.6 Software Process ModelSoftware Process Models [99, p. 27] or Software Development Methods [100]as they are referred to in some academia, provide guidance for planning anddevelopment by dividing large processes into smaller processes and activities[100]. A software process is a set of activities that form the production of asoftware product [99, p. 28]. Most software processes can be generalized intoone of three generic software process models: Waterfall Models, Incrementaldevelopment models and Reuse-Oriented Models [99, pp. 29-30].
3.6.1 Reuse ModelThe reuse model concept is based on reusing existing developed software innew applications. A reusable asset can be either reusable software or softwareknowledge. Reusability is a property that indicates the probability of an assetto be reused[101].The overall cost and time of developing software is corre-lated with the amount of new code written[102]. By implementing the reusemodel and integrating existing software assets into the development of newsoftware systems, less code has to be created and the development cost andtime can be reduced. Using existing assets also has the advantage of the codealready having been rigorously tested. Reuse can also improve the quality of

32 CHAPTER 3. METHODOLOGY AND METHODS
existing assets by being tested again after integration with the developed soft-ware system[103]. Assets are also likely to be highly portable to further aidthe reuse of that particular asset. The reuse model general process is made upof four steps: component analysis, requirements modification, system designwith reuse and development/integration [99].
1. Component analysis A search is made for existing assets that fit the re-quirements specification of the software being development
2. Requirements modification Requirements are analyzed using the infor-mation about the assets discovered. The requirements are then modifiedto fit the available assets
3. System design with reuse A framework of the system is designed andorganized to fit the assets to be reused
4. Development and integration New code is developed, assets and devel-oped code are integrated to create the new system.
The initial requirement specification stage and validation stage of the develop-ment process are identical with other development processes.
While there were a few frameworks that were used or could be used in theproject, they were not enough to warrant the reuse model. The reason for notchoosing the reuse model was because the frameworks only covered a smallpart of the product functionality.
3.6.2 Waterfall ModelThe waterfall model is a sequential approach to software development wherethe project is divided into five processes that each represent one step of theproduction process [104, p. 39]. The first phase, the requirements phase, in-volves defining behavior, performance, functional and non-functional require-ments for the product [105, p. 164]. The second and third phases, planning andmodeling, emphasize scheduling, planning and documenting the project anddesigning the software that is to be developed. The final two phases are the im-plementation phase and deployment phase [104, p. 39]. Some academia men-tion a sixth step to the waterfall model, the maintenance phase [106, p. 270].
The waterfall method provides a lot of overhead in the form of design and plan-ning [99, pp. 30-32]. Brooks’[108] rule of thumb estimates that one third of

CHAPTER 3. METHODOLOGY AND METHODS 33
Figure 3.2: Figure illustrating the waterfall model. Figure inspired by[107]
the production goes to planning, one sixth to coding and half to testing [108,p. 265]. The overhead in the form of planning and testing is generally onlyjustifiable for large teams working on a particular project for a long time [99,p. 58]. Another fallacy for the model is that it assumes that the project onlygoes through a process once and that the architecture is easy to use and im-plement. In reality, a project may need to be flexible for any future changesor mistakes. Repairs using the waterfall model may not always be smoothlyinterspersed or easily fixable [99, pp. 30-32].
The structure and functionality of the project was prone to changes. If a featureimpacted the test results of the prototype negatively, it was either changed ordropped completely from the requirement specification. By virtue of the flex-ibility that was needed in the development of the project, the waterfall modelwas not an appropriate choice. Another factor for not choosing the waterfallmodel was because the project team only consisted of two members whereasthe waterfall model was designed for larger teams [99, p. 58].

34 CHAPTER 3. METHODOLOGY AND METHODS
3.6.3 Incremental ModelIncremental development models are based on the idea of first developing acore product [104, p. 41] and then evolving it through several iterations untila final product has been developed[99, pp. 32-33]. The most commonly usedincremental models in software development follow agile development meth-ods[99, p. 59]. Agile development methods rely on incremental approaches todeliver and implement software and are best suited for projects where systemrequirements change frequently[99, p. 59]. There are many agile developmentmethods that have been introduced to the field of software development, butthe Scrum [109] model has become the most dominant standard agile processmodel in the software industry [110, p. 11].
Figure 3.3: Figure illustrating a sprint in the Scrum model. Figure inspired byI. Sommerville[99]
With the Scrum model, each iteration of development, called a sprint[109],is divided into five stages, similar to the waterfall model but in the scope ofa single iteration. The five stages are: requirement, analysis, design, evolu-tion and delivery. The duration of a sprint is defined before the sprint hascommenced and should generally not be very long. Project requirements orproduct functionality are stored in a backlog. Before each sprint, the most

CHAPTER 3. METHODOLOGY AND METHODS 35
prioritized features or requirements are chosen from the backlog to be imple-mented. This way, development is highly flexible because requirements maybe dropped, changed or added from the backlog quite easily [104, pp. 82-83].When a sprint has commenced, short Scrum meetings should be held dailyto discuss the daily progress, obstacles and goals for the next meeting. Themeetings are useful for showing the exact progress of the sprint [106, p. 314].
The prototype was developed by using different methods and using differentfeatures until it could label movies with adequate accuracy. Due to the inherentflexibility needed in development of the prototype, an incremental method wasthe best software processmodel of choice. By using Scrum, new features couldeasily be added or changed depending on how they affected test results.

Chapter 4
Development Process
This chapter describes the development process for the prototype. The pro-cess for development followed the Scrum methodology where the prototypewas developed incrementally in sprints. The development of the prototypewas divided into three sprints, prerequisites, implementation, and testing, asillustrated in the figure 4.1. Each sprint encapsulates more fine-grained pro-cesses that together make up one sprint. The three sprints were identified bythe requirements specification. The individual sprints are introduced in sec-tions 4.1, 4.2, and 4.3.
Figure 4.1: Figure illustrating the development process of the prototype. Fig-ure by the authors
36

CHAPTER 4. DEVELOPMENT PROCESS 37
4.1 PrerequisitesThe prerequisites sprint of the development process consisted of selectingmoods and selecting sample movie data. The selection was done by defin-ing the delimitations of the prototype and gathering the requirements and datawhich was vital for the prototype when performing classification. The collec-tion included selecting and motivating which moods would be used as classesin the classifier. It also included mapping and collecting data for constructingthe lexicon used by the classifier in the prototype. The data for the prototypeconsisted of subtitles of movies that belonged to one of the chosen moods forthe prototype.
4.2 ImplementationThe implementation sprint of the development process consisted of three dif-ferent tasks: Text Processing, Learning, and Classification. These tasks wereidentified as requirements specifications of the prototype. The requirementsspecifications were derived by the functionality expressed by the stakeholderat an initial meeting and could be summarized by the following:
Text Processing - The prototype must be able to handle input as Swedishsubtitles from the SF Anytime video streaming platform.
Learning - The prototype must be able to learn to differentiate betweendifferent moods.
Classification - The prototype must be able to classify a movie by mood.
The Text Processing task of the implementation sprint encapsulated all thefunctionality of handling text in the requirement specification of the prototype.This included collecting text as unprocessed data from a provided source andconverting it so that it could be utilized by the prototype when performingclassification. The conversion of the text was performed by removing noise,stop words, stemming and identifying term frequency. The prototype also hadto be able to handle exclusively Swedish words.
The Learning task of the implementation sprint consisted of providing func-tionality for the prototype to be able to differentiate between different moodsin movie subtitles. This was accomplished by running pre-labeled sample datain the prototype and storing information about occurrence words for different

38 CHAPTER 4. DEVELOPMENT PROCESS
moods in a lexicon. Words were stored in the mood which correlated to theprovided label at input.
The Classification task of the second sprint was where the classification func-tionality of the prototype was implemented. The prototype receives an inputof un-labeled text data related to a movie, processes that data and performsclassification on that text data. Classification of movies was based on com-parison of words occurring in a movie text data with the words in the lexiconusing Bayes theorem for probability. The classifier produces a mood label fora movie by choosing the mood with the highest probability for the queriedmovie.
4.3 TestingThe Testing sprint of the development process consisted of running collectedtext data through the prototype, storing the results of the classification andevaluating the results. The text data that was used in testing the prototype hadto be pre-labeled with moods that the prototype was configured to recognize.This was essential for any measurable results to be produced by the prototype.The results of the tests was measured for accuracy, precision and recall.

Chapter 5
Prerequisites
This chapter describes why and how the prerequisites where gathered. Section5.1 presents the interview that was conducted with the Swedish Film Instituteand the results of that interview. Section 5.2 describes how the moods for theprototypewere chosen and section 5.3 concerns how sample data was collectedfor the lexicon of the prototype.
5.1 InterviewSince the prototype processes Swedish subtitles, consideration to the Swedishlanguage ergo the Swedish movie audience had to be considered, hence re-search based on English speaking audience could not be taken into account. Toanswer these questions an employee at the Swedish Film Institute (Swe. Sven-ska Filminstitutet), was contacted and interviewed. The questions that wereasked were comprised during the literature study phase to cover any questionsthat were left unanswered by the academic literature that was collected. Thequestions addressed the relations between emotions and movies, the feasibilityof deriving a mood from a movie and the perception of a certain mood in amovie. The interview was conducted over telephone and in a semi-structuredformat to allow for information probing which allowed for clarification of in-teresting aspects of the topic. The question guide for the interview is presentedin appendix C. The interviewee referred to articles related research conductedby the Swedish Film Institute. The Swedish Film Institute had conducted aquantitative research using questionnaires to question Swedish movie atten-ders about emotions in regards to movies. The result of the research that hadbeen performed by the Swedish Film Institute showed a clear correlation be-tween the genre and the mood of the movie. The Swedish Film Institute’s
39

40 CHAPTER 5. PREREQUISITES
research also provided a foundation to base the development of the prototypeon. The Swedish Film Institute’s research resulted in the identification of fourbasic moods to base the prototype on.
5.2 Selecting Moods for PrototypeBased on the result of the qualitative research performed concerning basicmoods and the interview, a choice was made to only include four of the basicmoods in the development of the prototype. Due to the fact that the prototypeprocesses the corpora at a lexical level, choosing moods that were polarizedwould make it easier for the prototype to assign a given movie a correct class.This is because the prototype looks at each individual word without consider-ation to the context of which a word is used. Choosing polarized moods alsoaids the prototype in classifying movies correctly since the basic emotions arenot discrete. The basic moods tend to overlap with each other and in an effortto avoid overlapping, moods that were as separable from each other as possiblewere chosen.
The four moods that were chosen for the prototype were: joy, sadness, fear,and surprise. The motivation for choosing these four emotions was that thereis a clear distinction between them and that they do not overlap with eachother. Another reason for choosing joy, fear, sadness, and surprise as moodsfor the prototype was the quantitative research that had been conducted bythe Swedish Film Institute. The Swedish Film Institute’s quantitative researchused the same four correlating moods when movie audience classified movies.This indicates that the four chosen basic emotions are identifiable in movies.
5.3 Selecting Sample MoviesIn order to construct the lexicon of the prototype, pre-labeled data had to becollected. This data consisted of categorized corpus in the form of subtitlesfrom movies that had already been categorized as belonging to one of the fourdifferent basic mood selected for the prototype. Movies to be included in thetraining data set were chosen using the IMDB online search function and theTiVo API. Search filters with moods were applied in the search and that pro-duced a result of movies that fitted that specific mood. The movies from thesearch result were then crossed checked to confirm that they existed in SF Any-

CHAPTER 5. PREREQUISITES 41
time’s database and that Swedish subtitles were provided for that title. Full listof movies used as data is presented in appendix A. When selecting moviesfor each category, titles from as wide of a range of genres as possible wereselected in an effort to try to deviate from the apparent genre/mood relation.As an example, exclusively obvious comedies for the joy mood data set wereavoided since a mood is not necessarily genre specific, even though there existsa strong correlation between the two.

Chapter 6
Implementation of Prototype
The prototype is implemented according to the requirement specification: TextProcessing, Learning and Classification. Each section describes the imple-mentation of the respective requirement.
Figure 6.1: Figure illustrating the processes of the prototype. With kind per-mission from the authors[111]. Image has been modified.
The prototype that was developed consisted of two separate processes, as il-lustrated by figure 6.1. The process for learning in the prototype was onlyconcerned with processing the movie text data that would be used for con-structing the lexicon. The figure 6.1 illustrates that a label was attached withthe input. Attaching a label to the input was required for storing the resultingBag of Words for the corresponding mood in the lexicon. The classification
42

CHAPTER 6. IMPLEMENTATION OF PROTOTYPE 43
<p begin="00:01:07.320" end="00:01:09.640"region="bottom" style="default">
"utan vind och utan strömmar,<br/>ska de ändå mötas en dag."
</p>
Figure 6.2: Subtitle kindly provided by SF Anytime[13]
process consisted of input for the movie that was going to be labeled by theprototype. When classifying, the mood of the input corpus was unknown anda label was produced by the prototype.
6.1 Text ProcessingThe text processing for the prototype was the process of transforming the sub-titles of a movie into a Bag of Words containing the term frequency for eachword in the text. The transformation was done by processing the words in thesubtitles of a movie in iterations by removing noise, such as HTML tags andstop words, calculating word frequency and stemming.
6.1.1 Removing NoiseThe subtitles that were provided by SF Anytime were not raw text. They wereformatted as HTML with extra information about the text. The first step in thetext processing stage was thus to convert the subtitles into raw text by removingall HTML tags and irrelevant information for classification.Figure 6.2 displays a subtitle from a movie as HTML. In order to use the sub-title, the text had to be extracted from the markup. Using Beautiful Soup,the text was extracted from the <p> tags. Punctuation marks and break-lineHTML tags were then removed using regex, leaving only raw text to process.Regex is a sequence of characters that define patterns in text.
6.1.2 Stop WordsThe occurrence of function words or generally common words should not beused by the classifier as they are not distinctive for any particular mood. For

44 CHAPTER 6. IMPLEMENTATION OF PROTOTYPE
example, in table 6.1, the highest occurring words in the sample movies withstop words and the average frequency in which the words appeared in a movieare displayed for the moods ’Joy’ and ’Fear’. The same 10 words are highestoccurring in both moods, meaning they were not useful for similarity measure-ment since they were featured almost equally as much for all movies. Thus,words like this were treated as stop words.
Word Frequencyjag 213.0är 174.7det 170.6du 146.1inte 97.8att 73.7och 70.7vi 69.7en 68.4har 63.8
Word Frequencyjag 193.5det 175.0är 154.0du 136.7inte 98.4att 75.8en 70.5har 62.4och 55.4vi 54.8
Table 6.1: A table displaying the frequency for the ten most occurring wordsin movies for the moods ’Joy’ and ’Fear’ without removing stop words.
To remove these types of stop words from raw text, the toolkit for natural lan-guage, NLTK, was used. NLTK had a stop word list that included mostlyfunction words such as the Swedish words att, och and en (eng. to, and, one).A custom stop word list was also created to remove very frequent words thatwere not covered by NLTK. The words for the custom stop word list wereidentified as words that occurred more than 20 times on average per moviefor each possible mood. Full list of stop words is presented in appendix B.By only processing words that were not in the NLTK stop word list and thecustom made stop word list, the most frequent words for the different moodsdiffered significantly more as shown in table 6.2, making the lexicon better forsimilarity measurement. Table 6.2 shows the highest occurring words in thesample movies without stop words. The frequency (occurrences per movie)for which a word appeared in all sample movies are displayed for the mood’Joy’ in the left-hand table and ’Fear’ in the right-hand table.

CHAPTER 6. IMPLEMENTATION OF PROTOTYPE 45
Word Frequencyhej 12.9pappa 6.6vänta 5.6mr 5.3låt 5.2mamma 5.2nog 5.0titta 5.0dag 4.9tillbaka 4.9
Word Frequencyfan 7.8hej 6.6ner 5.6gjorde 5.3mamma 5.1mer 5.1hit 4.9känner 4.8vänta 4.6va 4.6
Table 6.2: A table displaying the frequency for the ten most occurring wordsin movies for the moods ’Joy’ and ’Fear’ after removing stop words.
6.1.3 StemmingThe dataset of movies used in the prototype was relatively small which meantthat all affixes of certain words were not covered in the lexicon. To combatthe problem, stemming was used. Stemming makes it more likely to find cor-responding words in a dataset. A consequence of Stemming is that it leadsto loss of precision since words of different meaning can share stem and be-cause affixes of the same base word can provide different meanings to a word.The words in the movie subtitles for the movie samples were stemmed usingNLTK’s snowball stemmer API.
Figure 6.3: Figure illustrating stemming. Figure inspired by [112]

46 CHAPTER 6. IMPLEMENTATION OF PROTOTYPE
Figure 6.3 illustrates how the three inflections of the Swedishword lyssna (eng.listen) would be transformed into the same stem using the NLTK stemmer.In this case, even if the word lyssnat (eng. listening) had never occurred inany movie, it would be calculated as having 17 occurrences because the othervariations of the word had previously occurred. Note that the figure 6.3 is onlyan example and does not illustrate the actual data in the lexicon.
6.1.4 Term FrequencyWhen iterating through each word in the subtitles, each word was added onto aBag of Words data-structure. If a word occurred for the first time, a new entrywas added in the Bag of Words along with a counter set to one. Whenever aword occurred more than once, the counter was incremented by one for thecorresponding word. The term frequency was collected to be used for similar-ity measurement in the Bayes classifier. Figure 2.1 illustrates the bags of wordmodel.
6.2 LearningThe learning requirement concerned storing the term frequency of processedmovie subtitles in a lexicon. The prototype used supervised disambiguation,meaning the movies that were used for learning had to be annotated with themood of the movie. The learning stage of the prototype was done by filling upa lexicon in the form of a SQL table with words and the total word occurrencefor specificmoods using Bag ofWords as input. The structure for the lexicon isillustrated in figure 6.3. In the figure, occ(word,mood)means the occurrenceof a word for a certain mood in the lexicon. There was one column for eachpossible mood where the occurrences of words in the processed movies foreach of the respective moods were stored.
Word Joy Surprise Sadness Fearword occ(word , joy) occ(word , surprise) occ(word , sadness) occ(word , fear)
älsk 186 131 132 78lyssn 39 64 48 40vän 90 81 73 54tunn 2 1 5 9
Table 6.3: Table illustrating structure of lexicon

CHAPTER 6. IMPLEMENTATION OF PROTOTYPE 47
All words that were stemmed into älsk in figure 6.3 were all inflections of theSwedish verb älska (eng. love) and the Swedish noun älskare (eng. lover).The words that were stemmed into lyssn were all inflections of the Swedishverb lyssna (eng. listen). The stem vän, on the other hand was representedby inflections of the four different words vän (eng. friend), vänlighet (eng.kindness), vänlig (eng. kind) and vänligen (eng. kindly). While the wordsthat were stemmed into the vän had different meanings, they were very closelyrelated. The words that were stemmed into the stem tun in figure 6.3 wereinflections of the Swedish words tunna (eng. barrel) and tunn (eng. thin). Inthe case of the stem tun, the two base words tunn and tunna have completelydifferent meanings, meaning the stem leads to a loss of accuracy.
The input parameters for updating a lexicon was a Bag of Words and a mood.Each word in the bag was iterated and the term frequency in the bag was addedon top of the occurrences for the respective word in the lexicon for the specifiedmood. If a word in the Bag of Words did not exist in the lexicon, a new entryfor the lexicon was created for the word with zero occurrences across the othermoods.
6.3 ClassificationThe classification requirement concerned implementing a Naive Bayes clas-sifier that selected the most suitable mood for labeling a movie based on themovie subtitles. This was done by calculating the probability of a movie givena each mood in the lexicon using Bayes theorem. The mood with the highestprobability given the queried movie was chosen as label. The probability for amood conditioned to the queried movie (P (mood|movie)) was calculated asshown in equation 6.1.
When classifying, the probability for each possible mood for a movie wascalculated, and the mood with the highest probability was chosen as a labelfor the movie. The probability of a mood in a movie was the conditionalprobability P (mood|movie). According to Bayes theorem, the probabilityP (mood|movie) is calculated as shown in equation 6.1.
P (mood|movie) =P (movie|mood)× P (mood)
P (movie)(6.1)

48 CHAPTER 6. IMPLEMENTATION OF PROTOTYPE
P (movie) in the equation 6.1 was a constant since the probability of a moviein the sample set was the same for all movies and could thus be removed fromthe equation. The equation could therefore be written as shown in 6.2.
P (mood|movie) = P (movie|mood)× P (mood) (6.2)
The probability that a movie belonged to a mood was represented by the termP (movie|mood) in equation 6.2. The factor P (movie|mood) was calculatedas the probability that the subtitles of the movie belongs to a mood. Assum-ing that the words in the movie were independent, P (movie|mood) could becalculated by multiplying the probability that all words in the movie subtitlebelonged to the mood as shown in equation 6.3.
P (movie|mood) =a∏
i=1
P (wordi|mood) (6.3)
In the equation 6.3, P (wordi|mood) was the probability that the i:th word be-longed to the mood, meaning
∏ai=1 P (wordi|mood) was the probability for all
words combined for the mood. The variable a was the amount of words in themovie subtitles and b was the amount of words in the lexicon.
The probability that a word belonged to a mood was calculated using the datastored in the lexicon through the equation 6.4. The conditional probability of aword in a mood was calculated by dividing occ(word,mood) (the total occur-rence of a word for amood) with
∑bj=1 occ(wordj,mood) (the total occurrence
of all words in the lexicon for the same mood). To avoid zero probabilities, theequation was smoothed using additive smoothing where |V | was the amountof words stored in the lexicon.
P (word|mood) =occ(word,mood) + 1
|V |+∑bj=1 occ(wordj,mood)
(6.4)
The term P (mood) in equation 6.1 was the probability of a mood, calculatedusing the information about the words that are stored in the lexicon. The proba-bility was calculated as occ(mood) divided by
∑ck=1 occ(moodk). In equation
6.5, occ(mood) was the total occurrence of all words for a specified moodwhile
∑ck=1 occ(moodk) was the total occurrence of all words for all possible
moods and c was the amount of moods in the lexicon.
P (mood) =occ(mood)∑c
k=1 occ(moodk)(6.5)

CHAPTER 6. IMPLEMENTATION OF PROTOTYPE 49
The formula 6.6was derived by replacing the variablesP (mood) andP (movie|mood)
in 6.2 with the equations 6.5 and 6.6 respectively.
P (mood|movie) =occ(mood)∑c
k=1 occ(moodk)×
a∏i=1
(occ(wordi,mood) + 1
|V |+∑bj=1 occ(wordj,mood)
)
(6.6)
Amovie subtitle generally had thousands of words whichmeant that thousandsof probabilities could be multiplied. The multiplication meant that the proba-bilities would become too small for the Python interpreter to handle. To avoidthis problem, the values were instead logarithmized so that the probabilitieswere added onto each other instead. A logarithmized function of 6.6 was il-lustrated in 6.7. As showcased by the equation, the products were transformedinto sums when logarithmizing.
P (mood|movie) = lnocc(moodk)∑ck=1 occ(moodk)
+a∑
i=1
ln(occ(wordi,mood) + 1
|V |+∑bj=1 occ(wordj,mood)
)
(6.7)
To summarize, when a movie was queried to be classified, the logarithmicprobability of each word in the Bag of Words for the movie was calculatediteratively and was added onto a counter. The probability for each word wascalculated by collecting values from the lexicon using SQL and applying thosevalues as described in 6.4. The resulting logarithmic probability was thenadded onto the probability of the mood, P (mood) which was calculated bycollecting the values for the moods in the lexicon and applying them as de-scribed in 6.5. When classifying P (mood|movie) was calculated for each ofthe four moods and the one with the highest probability was chosen as thepredicted label.

Chapter 7
Testing and Results
This chapter discusses the testing and the results collected when estimatingprecision, recall and accuracy of the prototype for the different moods. 24movies were used as training data, six for every mood label that the prototypecould classify for. The purpose for testing the prototype was to estimate howwell it predicted the mood of a movie through the recall, precision and accu-racy estimation methods. Two benchmark scripts were used to estimate thethree methods, one for measuring accuracy and one for measuring recall andprecision for all moods.
Accuracy =correctpredictions
totalpredictions(7.1)
The accuracy was tested by calculating the total amount of correct predictionsby the prototype divided by the total amount of guesses, as shown in equa-tion7.1. The results from the tests of the prototype with and without stem-ming and stop words are displayed in table 7.1. The results were very similarin accuracy for all combinations of stemming and stop words but the high-est accuracy (29%) was achieved when not removing stop words no matter ifstemming was used or not. The problem with using accuracy as an estimationmethod is that it does not represent how well the classifier classifies each ofthe four moods. Instead, precision and recall could be used to measure howwell the classifier predicts each of the possible moods.
50
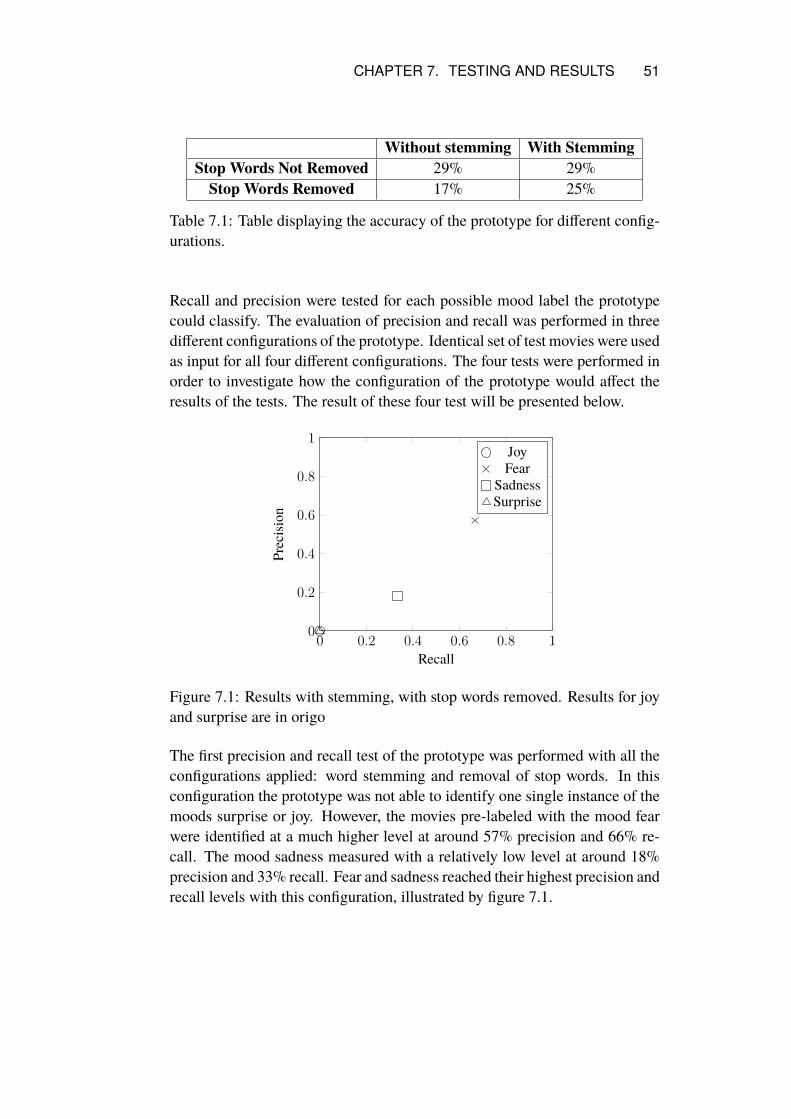
CHAPTER 7. TESTING AND RESULTS 51
Without stemming With StemmingStop Words Not Removed 29% 29%
Stop Words Removed 17% 25%
Table 7.1: Table displaying the accuracy of the prototype for different config-urations.
Recall and precision were tested for each possible mood label the prototypecould classify. The evaluation of precision and recall was performed in threedifferent configurations of the prototype. Identical set of test movies were usedas input for all four different configurations. The four tests were performed inorder to investigate how the configuration of the prototype would affect theresults of the tests. The result of these four test will be presented below.
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
Recall
Precision
JoyFear
SadnessSurprise
Figure 7.1: Results with stemming, with stop words removed. Results for joyand surprise are in origo
The first precision and recall test of the prototype was performed with all theconfigurations applied: word stemming and removal of stop words. In thisconfiguration the prototype was not able to identify one single instance of themoods surprise or joy. However, the movies pre-labeled with the mood fearwere identified at a much higher level at around 57% precision and 66% re-call. The mood sadness measured with a relatively low level at around 18%precision and 33% recall. Fear and sadness reached their highest precision andrecall levels with this configuration, illustrated by figure 7.1.
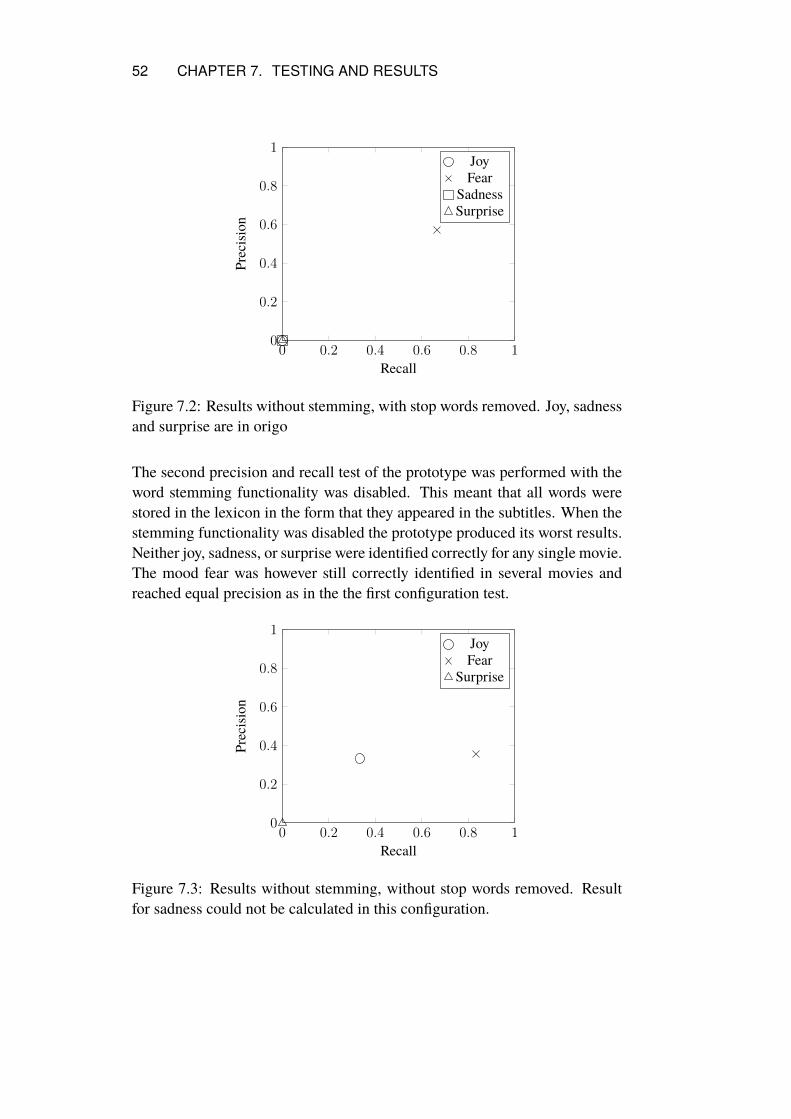
52 CHAPTER 7. TESTING AND RESULTS
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
Recall
Precision
JoyFear
SadnessSurprise
Figure 7.2: Results without stemming, with stop words removed. Joy, sadnessand surprise are in origo
The second precision and recall test of the prototype was performed with theword stemming functionality was disabled. This meant that all words werestored in the lexicon in the form that they appeared in the subtitles. When thestemming functionality was disabled the prototype produced its worst results.Neither joy, sadness, or surprise were identified correctly for any single movie.The mood fear was however still correctly identified in several movies andreached equal precision as in the the first configuration test.
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
Recall
Precision
JoyFear
Surprise
Figure 7.3: Results without stemming, without stop words removed. Resultfor sadness could not be calculated in this configuration.
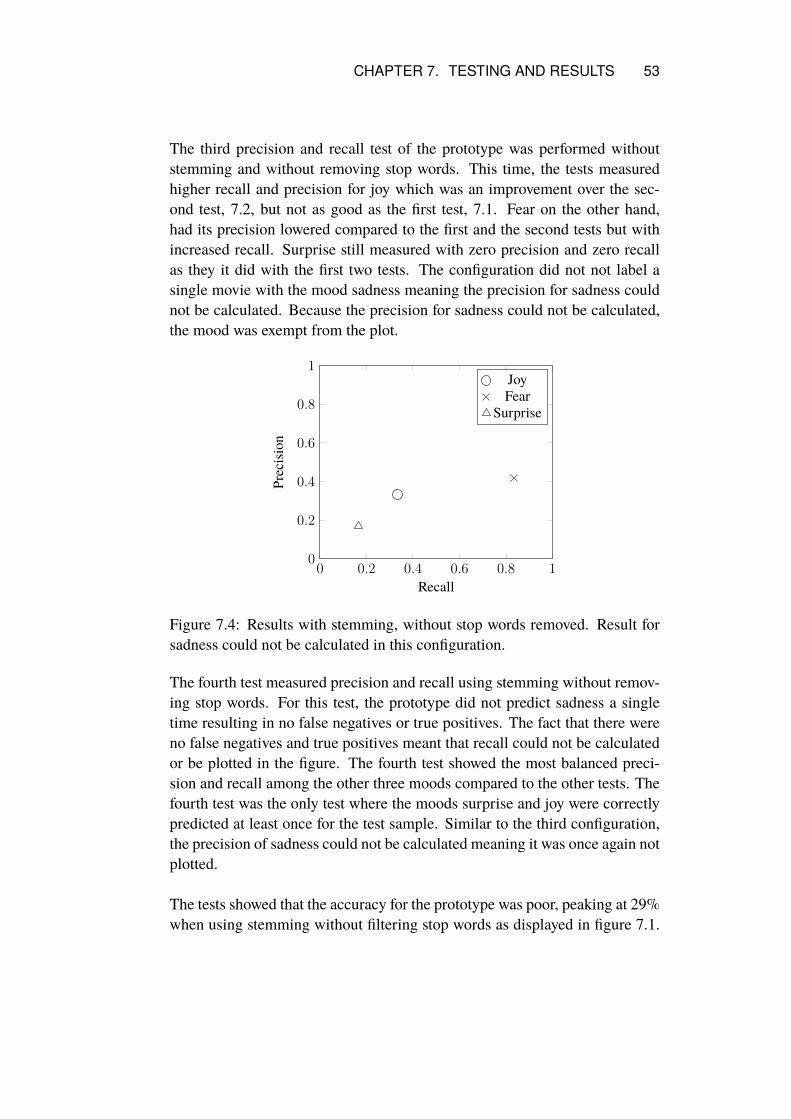
CHAPTER 7. TESTING AND RESULTS 53
The third precision and recall test of the prototype was performed withoutstemming and without removing stop words. This time, the tests measuredhigher recall and precision for joy which was an improvement over the sec-ond test, 7.2, but not as good as the first test, 7.1. Fear on the other hand,had its precision lowered compared to the first and the second tests but withincreased recall. Surprise still measured with zero precision and zero recallas they it did with the first two tests. The configuration did not not label asingle movie with the mood sadness meaning the precision for sadness couldnot be calculated. Because the precision for sadness could not be calculated,the mood was exempt from the plot.
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
Recall
Precision
JoyFear
Surprise
Figure 7.4: Results with stemming, without stop words removed. Result forsadness could not be calculated in this configuration.
The fourth test measured precision and recall using stemming without remov-ing stop words. For this test, the prototype did not predict sadness a singletime resulting in no false negatives or true positives. The fact that there wereno false negatives and true positives meant that recall could not be calculatedor be plotted in the figure. The fourth test showed the most balanced preci-sion and recall among the other three moods compared to the other tests. Thefourth test was the only test where the moods surprise and joy were correctlypredicted at least once for the test sample. Similar to the third configuration,the precision of sadness could not be calculated meaning it was once again notplotted.
The tests showed that the accuracy for the prototype was poor, peaking at 29%when using stemming without filtering stop words as displayed in figure 7.1.

54 CHAPTER 7. TESTING AND RESULTS
Considering that the average accuracy when choosing a mood randomly was25%, the classifier had very poor accuracy. The prototype generally performedeven worse for precision and recall. The prototype frequently estimated with0% recall and precision rate for the moods sadness, joy and surprise (7.3, 7.2,7.1) while the precision and recall for the mood fear was significantly higher.The recall for fear peaked at 83% in 7.4 and 7.3 where stop words were notfiltered and precision for fear peaked at 57% in 7.2 and 7.1 where stop wordswere filtered. The highest average precision and recall among the four moodswas estimated in the configuration with stemming but without stopword filter-ing as displayed in figure 7.4 where the precision averaged to 33% and recallto 23%. The downside of the configuration was that it did not register a singleinstance where the classifier labeled a movie by sadness. To summarize, allconfigurations of the prototype were poor in terms of accuracy, precision andrecall.

Chapter 8
Conclusion and Future Work
This chapter concludes this thesis by discussing the challenges and difficultiesin the development process of the prototype and future work that could be doneto improve the results.
8.1 DiscussionThe classifier implemented in the prototype was naive and performed classi-fication based on processing words at a morphological level. At the morpho-logical level, the context of a word in sentence or document was not takeninto account which could have had a high impact on the performance of theclassifier. Words are ambiguous and the same words used in different contextscan have completely different meaning. The context of a word was somethingthe classifier could not determine. The words in the lexicon for the mood joycould appear in a sad context in a movie and the classifier would classify themovie as joyful, unaware of the context.
Movies make use of more than the dialogue to convey a mood to the audience.Moods can also be conveyed using for example music, color theme, facial ex-pression, the location of a scene, the time of day for a scene or through charac-ter interactions. This information was not accessible to the classifier throughthe subtitles and hence could not be accounted for in the classification of themovie but could be features to look at for future work.
The prototype assumed that each movie conveyed one single mood but in re-ality the mood of a movie could vary throughout the duration of the movie.This could have led to labeling words that were used in a sad scene as joyful
55

56 CHAPTER 8. CONCLUSION AND FUTURE WORK
because the scene was from a joyful movie. Handling the text in this mannercould have introduced false data when constructing the lexicon of the proto-type resulting in a joy lexicon consisting of keywords for the mood sadness.The assumption could have been a reason to why the prototype did not performwell in terms of precision, accuracy and recall. The assumption also made itdifficult to label a movie to one specific mood in the data collection phase.
Finding training data for the prototype proved difficult due to the lack of infor-mation concerningmovies of certain types ofmoods. The information that wasavailable was in the form of lists in articles and blog posts that were not basedon scientific research. There had not been any extensive quantitative researchperformed concerningmoods inmovies that could be applied in this study. Theevaluation performed by the Swedish Film Institute handled a small sample ofmovies, too small to use as training data for the classifier. The Swedish FilmInstitute’s evaluation also measured the moods fear, sadness, joy and surpriseof the movies by using questionnaires to movie watchers. The results of theSwedish Film Institute’s evaluation showed that each movie in the question-naire had multiple different moods which could be a reason that the classifierdid poorly since the sample movies used for the prototype were only annotatedwith one mood each. Another point to note, was that the annotated moods inthe IMDB and TiVo databases did not follow the basic emotions of Plutchnikand Ekdal andwere for that reason not entirely suitable for use in the prototype.
The number of movies used to construct the lexicons of the prototype was lim-ited due to the lack of information regarding the mood of the movie. A largermovie data sample would perhaps have improved the results of the classifierdue to a wider range of movies from each mood being stored in the lexicons ofthe prototype. Furthermore, having a larger number of movies as test sampleswould have lead to a more reflective result of the actual accuracy, precisionand recall of the classifier.
8.2 ConclusionIn conclusion, developing an accurate Naive Bayes classifier for classifyingmoods in movies by analysing term frequency in movie subtitles proved to beineffective in terms of accuracy, precision and recall.

CHAPTER 8. CONCLUSION AND FUTURE WORK 57
8.3 Future WorkTo further improve the prototype, an extensive quantitative data collectioncould be done to collect more sample movies to use by the classifier. Other fu-ture improvements to the prototype could be to analyze text on higher naturallanguage such as the semantic level where the meaning of words and sentencesare taken into account and the syntactic level where the structures of sentencesare analyzed. Furthermore, there are many other classifiers that could havebeen used such as the Support Vector Machine or Maximum Entropy classi-fiers that might have performed better than Naive Bayes.
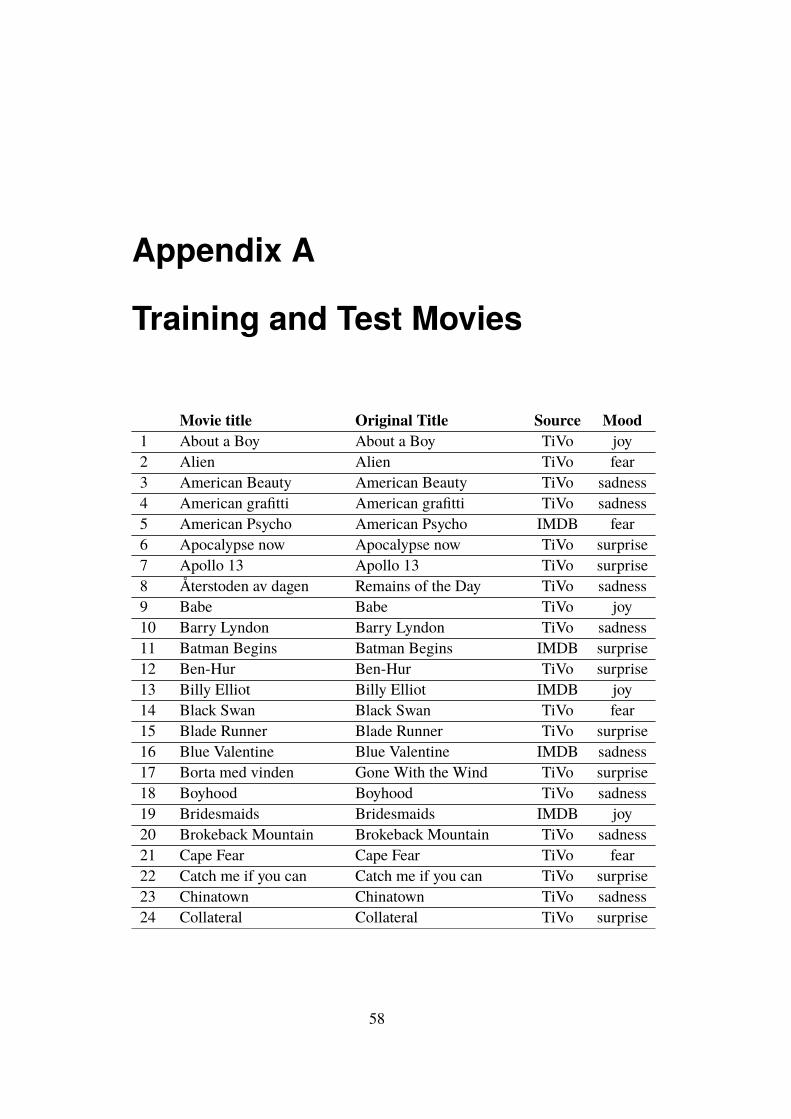
Appendix A
Training and Test Movies
Movie title Original Title Source Mood1 About a Boy About a Boy TiVo joy2 Alien Alien TiVo fear3 American Beauty American Beauty TiVo sadness4 American grafitti American grafitti TiVo sadness5 American Psycho American Psycho IMDB fear6 Apocalypse now Apocalypse now TiVo surprise7 Apollo 13 Apollo 13 TiVo surprise8 Återstoden av dagen Remains of the Day TiVo sadness9 Babe Babe TiVo joy10 Barry Lyndon Barry Lyndon TiVo sadness11 Batman Begins Batman Begins IMDB surprise12 Ben-Hur Ben-Hur TiVo surprise13 Billy Elliot Billy Elliot IMDB joy14 Black Swan Black Swan TiVo fear15 Blade Runner Blade Runner TiVo surprise16 Blue Valentine Blue Valentine IMDB sadness17 Borta med vinden Gone With the Wind TiVo surprise18 Boyhood Boyhood TiVo sadness19 Bridesmaids Bridesmaids IMDB joy20 Brokeback Mountain Brokeback Mountain TiVo sadness21 Cape Fear Cape Fear TiVo fear22 Catch me if you can Catch me if you can TiVo surprise23 Chinatown Chinatown TiVo sadness24 Collateral Collateral TiVo surprise
58
APPENDIX A. TRAINING AND TEST MOVIES 59
25 De hänsynslösa Reservoir Dogs TiVo surprise26 De skoningslösa Unforgiven TiVo sadness27 Den gröna milen The Green Mile IMDB sadness29 Den tunna röda linjen The Thin Red Line TiVo sadness30 Det våras för Hitler The Producers TiVo joy31 Die Hard Die Hard TiVo surprise32 District 9 District 9 TiVo fear33 Dom i Nürnberg Judgment at Nuremberg TiVo sadness34 Elle Elle TiVo fear35 En fisk som heter Wanda A fish called Wanda TiVo joy36 En oväntad vänskap Intouchables IMDB joy37 Ex Machina Ex Machina IMDB fear38 Exorsisten The Exorsist TiVo fear39 Familjen Savage The Savages TiVo sadness40 Familjetrippen Were the Millers IMDB joy41 Farväl Las Vegas Leaving Las Vegas TiVo sadness42 Firman The Firm TiVo surprise
43 Född den fjärde juli Born on thefourth of July TiVo sadness
44 Fönstret mot gården Rear Window TiVo surprise45 Frozen River Frozen River TiVo sadness46 Get Out Get Out IMDB fear47 Ghost Ghost TiVo joy48 Gravity Gravity TiVo surprise49 Grease Grease TiVo joy50 Gudfadern The God Father TiVo sadness51 Gudfadern 2 The God father part 2 TiVo sadness52 Hajen Jaws TiVo fear53 Halloween Halloween TiVo fear
54 Harry Potter och denflammande bägare
Harry Potter and thegoblet of fire IMDB surprise
55 Hemkomsten Coming Home TiVo joy56 Hitta Nemo Finding Nemo TiVo joy57 Hunger Hunger TiVo sadness
58 Indiana Jones ochde fördömdas Tempel
Indiana Jones andthe Temple of Doom TiVo surprise
59 Inglourious Basterds Inglourious Basterds TiVo surprise
60 APPENDIX A. TRAINING AND TEST MOVIES
60 Insidan Ut Indise out TiVo joy61 It It TiVo fear62 Jagad The Fugitive TiVo surprise63 Juno Juno TiVo joy64 Jurassic Park Jurassic Park TiVo fear65 Kärlek på italienska Sono Amore TiVo fear66 La la land La la land TiVo sadness67 Lawrence av Arabien Lawrence of Arabia TiVo surprise68 Let Me In Let Me In TiVo fear69 Lion Lion IMDB sadness70 Livet är Underbart It’s Wonderful Life TiVo joy71 Maffiabröder Good Fellas TiVo surprise72 Mångalen Moonstruck TiVo joy73 Midnight Cowboy Midnight Cowboy TiVo sadness74 Mystic River Mystic River TiVo sadness75 När Harr mötte Sally When Harry met Sally TiVo joy76 När lammen tysnar Silence of the Lambs TiVo fear77 No Country for Old Men No Country for Old Men TiVo sadness
78 Nyckeln till firhet The ShawshankRedemption TiVo joy
79 Out of Sight Out of Sight TiVo surprise80 Pans labyrint El laberinto del fauno TiVo fear
81 Paraplyerna iCherboug
The Umbrellasof Cherbourg TiVo joy
82 Pianot The Piano TiVo sadness83 Prinsessa på Vift Roman Holiday TiVo joy84 Prometheus Prometheus TiVo fear85 Psycho Psycho TiVo fear86 Pulp Fiction Pulp Fiction TiVo surprise87 Purpusfärgen The Color Purple TiVo joy88 Rädda menige Ryan Saving Private Ryan TiVo surprise89 Reolutionary Road Reolutionary Road TiVo sadness90 Rocky Rocky TiVo surprise91 Rovdjuret Predator TiVo fear
92 Sagan om konungensåterkomst
LOTR:Return of the King TiVo surprise
93 Schindler’s list Schindlers’s List TiVo sadness

APPENDIX A. TRAINING AND TEST MOVIES 61
94 School of Rock School of Rock IMDB joy95 Seven Seven TiVo fear96 Sideways Sideways TiVo sadness97 Sin City Sin City TiVo fear98 Singin’ in the Rain Singin’ in the Rain TiVo joy
99 Snövit och desju dvärgarna
Snowhite andthe seven dwarfs TiVo joy
100 Solens rike Empire of the Sun TiVo sadness
101 Star Wars:The Empire Strikes Back
Star Wars:The Empire Strikes Back TiVo surprise
102 Supehjältarna 2 Incredibles 2 TiVo joy103 Taxi driver Taxi driver TiVo fear
104 Terminator 2:Domedagen
Terminator 2:Judgement Day TiVo surprise
105 Skönheten och odjuret The Beauty and the Beast TiVo joy106 The Blind Side The Blind Side IMDB joy108 The Blues Brothers The Blues Brothers IMDB joy109 The Deer Hunter The Deer Hunter TiVo surprise110 The Departed The Departed TiVo surprise111 The Fighter The Fighter TiVo sadness112 The Hateful Eight The Hateful Eight TiVo fear113 The Hurt Locker The Hurt Locker TiVo fear114 The Insider The Insider TiVo surprise
115 The ManchurianCandidate
The ManchurianCandidate TiVo surprise
116 The Matrix The Matrix TiVo surprise117 The Pianist The Pianist TiVo sadness
118 The Possesionof Hanna Grace
The Possesionof Hanna Grace TiVo fear
119 The Ring The Ring TiVo fear120 The Shape of Water The Shape of Water TiVo fear121 The Shining The Shining IMDB fear122 The sound of music The sounds of music TiVo joy123 The Wrestler The Wrestler TiVo sadness124 Titta vi flyger Airplane TiVo joy125 Toy Story Toy Story TiVo joy126 Trollkarlen från Oz The wizard from Oz TiVo joy
62 APPENDIX A. TRAINING AND TEST MOVIES
127 Tully Tully TiVo joy128 Ubåten Das Boot TiVo surprise129 Venom Venom IMDB fear
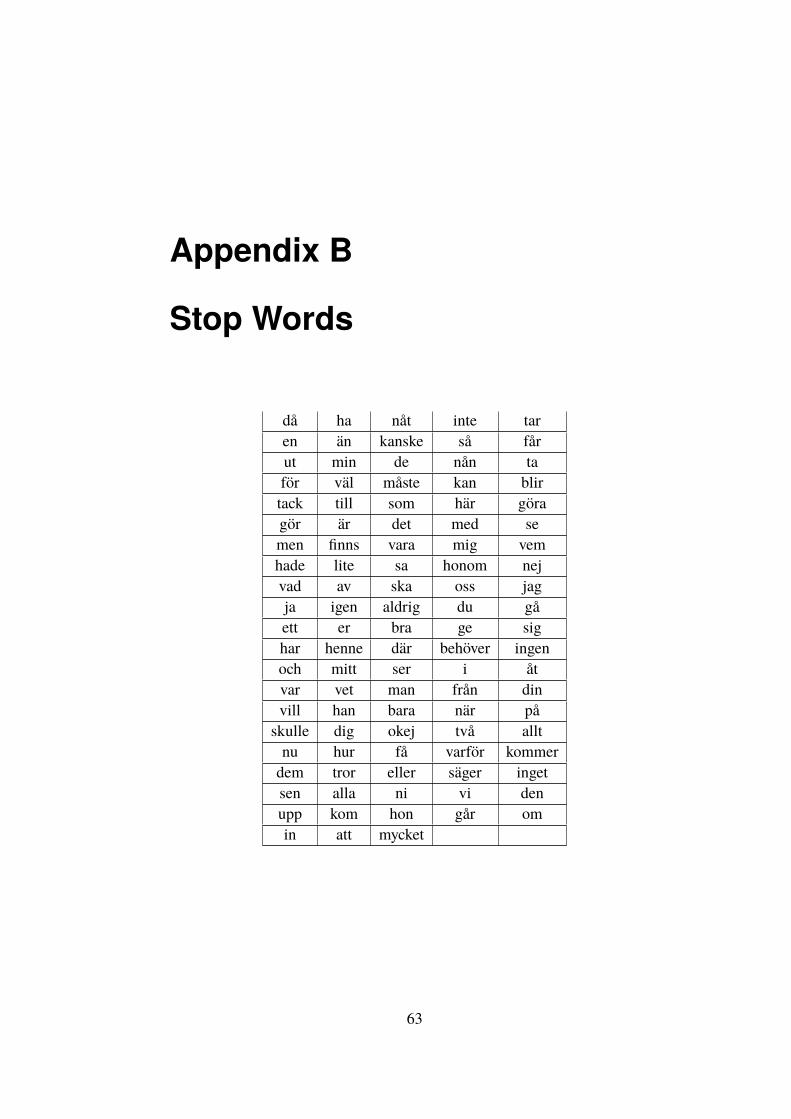
Appendix B
Stop Words
då ha nåt inte taren än kanske så fårut min de nån taför väl måste kan blirtack till som här göragör är det med semen finns vara mig vemhade lite sa honom nejvad av ska oss jagja igen aldrig du gåett er bra ge sighar henne där behöver ingenoch mitt ser i åtvar vet man från dinvill han bara när på
skulle dig okej två alltnu hur få varför kommerdem tror eller säger ingetsen alla ni vi denupp kom hon går omin att mycket
63

Appendix C
Interview with the Swedish FilmInstitute
Here the guide questions, which were used at the semi-structured interviewthat was performed with an employee at the Swedish Film Institute, are pre-sented.
Can you point to any research conducted concerning moods and movies?
Are there accepted and established moods, similar to genres, within the movieindustry?
What would be the major mood-themes within the movie industry?
How big of a role does the dialogue within a movie contribute to the mood ofthe movie compared to music, color, and set?
What other attributes contribute to conveying a mood with in a movie?
Do you believe that it is possible to determine the mood of a movie from justthe information in the subtitles?
64

Appendix D
Implementation
The implementation of the prototype can be found on GitHub through the pro-vided URL: https://github.com/moodlabeler/mood-labeling-movies.
65


Bibliography
[1] NATURAL LANGUAGE | meaning in the Cambridge English Dictio-nary. en. url: https : / / dictionary . cambridge . org /dictionary/english/natural-language (visited on 04/01/2019).
[2] Gobinda G. Chowdhury. “Natural language processing”. en. In: An-nual Review of Information Science and Technology 37.1 (Jan. 2003),pp. 51–89. issn: 1550-8382. (Visited on 03/27/2019).
[3] What AreMoods? en-US.url:https://www.psychologytoday.com/blog/hot-thought/201805/what-are-moods (vis-ited on 04/01/2019).
[4] Tim Dalgleish and Mick Power.Handbook of Cognition and Emotion.en. John Wiley & Sons, 2000. isbn: 978-0-470-84221-8.
[5] Robert Plutchik. “The Nature of Emotions”. en. In: American Scientist89.4 (Aug. 2001), pp. 344–350. url:https://www.jstor.org/stable/27857503.
[6] Eric Cambria Soujanya Poria Amir Hussein. Mulitmodal SentimentAnalysis. Springer, 2018. isbn: 978-3-319-95020-4.
[7] Vadim Kagan, Edward Rossini, and Demetrios Sapounas. SentimentAnalysis for PTSD Signals. en. SpringerBriefs in Computer Science.New York, NY: Springer New York, 2013. isbn: 978-1-4614-3096-4.
[8] Bing Liu. Sentiment Analysis andOpinionMining. en.Morgan&Clay-pool, 2012. isbn: 9781608458851.
[9] Steven Bird. “Natural Language Processing with Python”. en. In: (),p. 504.
[10] AlexanderMehler BerlinHeidelberg. Text mining: from ontology learn-ing to automated text processing applications. Springer, 2014. isbn:978-3-319-12654-8.
66

BIBLIOGRAPHY 67
[11] Anne Håkansson. “Portal of ResearchMethods andMethodologies forResearch Projects andDegree Projects”. en. In:Computer Engineering(2013), p. 8.
[12] SF Studios. url: http : / / www . sfstudios . se / Om - oss/(visited on 03/20/2019).
[13] SFAnytime.url:http://www.sfstudios.se/sf-anytime/(visited on 03/20/2019).
[14] Hållbar utveckling. sv-SE. url: https://www.kth.se/om/miljo-hallbar-utveckling/utbildning-miljo-hallbar-utveckling/verktygslada/sustainable-development/hallbar-utveckling-1.350579 (visited on 05/17/2019).
[15] Ekologisk hållbarhet. sv-SE. url: https : / / www . kth . se /om/miljo-hallbar-utveckling/utbildning-miljo-hallbar - utveckling / verktygslada / sustainable -development/ekologisk- hallbarhet- 1.432074 (vis-ited on 05/17/2019).
[16] Social hållbarhet. sv-SE. url: https : / / www . kth . se / om /miljo-hallbar-utveckling/utbildning-miljo-hallbar-utveckling/verktygslada/sustainable-development/social-hallbarhet-1.373774 (visited on 05/17/2019).
[17] Ekonomisk hållbarhet. sv-SE. url: https : / / www . kth . se /om/miljo-hallbar-utveckling/utbildning-miljo-hallbar - utveckling / verktygslada / sustainable -development/ekonomisk- hallbarhet- 1.431976 (vis-ited on 05/17/2019).
[18] Jonathan Rottenberg. “Mood and Emotion in Major Depression”. In:Current Directions in Psychological Science 14.3 (2005), pp. 167–170. eprint: https://doi.org/10.1111/j.0963-7214.2005.00354.x. url: https://doi.org/10.1111/j.0963-7214.2005.00354.x.
[19] David Watson. Mood and Temperament. en. Google-Books-ID: iPF-boulhcQcC. Guilford Press, Jan. 2000. isbn: 978-1-57230-526-7.
[20] Robert Plutchik. “A GENERAL PSYCHOEVOLUTIONARY THE-ORY OF EMOTION”. en. In: Theories of Emotion. Elsevier, 1980,pp. 3–33. isbn: 978-0-12-558701-3.url:https://linkinghub.elsevier.com/retrieve/pii/B9780125587013500077(visited on 04/08/2019).

68 BIBLIOGRAPHY
[21] Paul Ekman. “An argument for basic emotions”. en. In: Cognition andEmotion 6.3-4 (May 1992), pp. 169–200. issn: 0269-9931, 1464-0600.url: https://www.tandfonline.com/doi/full/10.1080/02699939208411068 (visited on 04/08/2019).
[22] Wagner Hugh andMansteadAntony.Handbook of Social Psychophys-iology. en. John Wiley & Sons, 1989. isbn: 0-471-91156-9.
[23] R. Sinnerbrink. “Stimmung: exploring the aesthetics of mood”. en. In:Screen 53.2 (June 2012), pp. 148–163. issn: 0036-9543, 1460-2474.(Visited on 04/10/2019).
[24] Greg M. Smith. Film Structure and the Emotion System. en. Cam-bridge University Press, Oct. 2003. isbn: 978-1-139-43831-5.
[25] Carl Plantinga. “Art Moods and HumanMoods in Narrative Cinema”.In: New Literary History 43.3 (2012), pp. 455–475. issn: 00286087,1080661X.url:http://www.jstor.org/stable/23358875.
[26] Svenska Filminstitutet, Verksamhet & Organisation. sv. url: https://www.filminstitutet.se/sv/om-oss/vart-uppdrag/verksamhet--organisation/ (visited on 03/25/2019).
[27] Känslorna publiken vill uppleva när de ser film. sv. url: https://www.filminstitutet.se/sv/nyheter/2019/kanslorna-publiken-vill-uppleva-nar-de-ser-film/ (visited on04/08/2019).
[28] Christopher D Manning and Hinrich Schiitze. Foundations of Statisti-cal Natural Language Processing. en. Massachusetts Institute of Tech-nology, 1999, p. 704.
[29] Jalaj Thanaki. Python Natural Language Processing. en. 2017. url:https://app.knovel.com/hotlink/toc/id:kpPNLP000H/python-natural-language/python-natural-language(visited on 04/08/2019).
[30] Natural Language ToolKit. url: https://www.nltk.org/ (vis-ited on 04/08/2019).
[31] Khaled Shaalan, Aboul Ella Hassanien, and Fahmy Tolba, eds. In-telligent Natural Language Processing: Trends and Applications. en.Vol. 740. Studies in Computational Intelligence. Cham: Springer In-ternational Publishing, 2018. isbn: 978-3-319-67055-3.

BIBLIOGRAPHY 69
[32] The Natural Language Processing Dictionary. url: http://www.cse.unsw.edu.au/~billw/nlpdict.html#corpus (vis-ited on 04/08/2019).
[33] Anna Korhonen, Yuval Krymolowski, and Ted Briscoe. “A Large Sub-categorization Lexicon forNatural Language ProcessingApplications”.en. In: (), p. 6.
[34] Florentina T. Hristea. The Naïve Bayes model for unsupervised wordsense disambiguation: aspects concerning feature selection. en. Springer-Briefs in statistics. OCLC: ocn826900512. Berlin ; London: Springer,2013. isbn: 978-3-642-33692-8.
[35] Basant Agarwal and Namita Mittal. Prominent Feature Extraction forSentiment Analysis. en. Socio-Affective Computing. Cham: SpringerInternational Publishing, 2016. isbn: 978-3-319-25341-1 978-3-319-25343-5. url: http://link.springer.com/10.1007/978-3-319-25343-5 (visited on 04/01/2019).
[36] Eneko Agirre Philip Admond. Word Sense Disambiguation - Algo-rithms and Applications. en. Springer, 2007. isbn: 978-1-4020-4809-2.
[37] ChengXiang Zhai Charu C. Aggarwal.Mining Text Date. en. Springer-Briefs in statistics. Berlin ; London: Springer, 2012. isbn: 978-1-4614-3223-4.
[38] Dhanashri Chafale and Amit Pimpalkar. “Review on Developing Cor-pora for Sentiment Analysis Using Plutchik’s Wheel of Emotions withFuzzy Logic”. en. In: 2 (2014), p. 5.
[39] DanielW.Connolly <[email protected]>.HypertextMarkup Language- 2.0. en. url: https://tools.ietf.org/html/rfc1866#page-18 (visited on 05/15/2019).
[40] Definition of MARKUP LANGUAGE. en. url: https : / / www .merriam-webster.com/dictionary/markup+language(visited on 05/15/2019).
[41] C. D. Paice. “Stemming”. In: Encyclopedia of Language & Linguistics(Second Edition). Ed. by Keith Brown. Oxford: Elsevier, Jan. 2006,pp. 149–150. isbn: 978-0-08-044854-1.url:http://www.sciencedirect.com/science/article/pii/B0080448542009512 (vis-ited on 04/08/2019).

70 BIBLIOGRAPHY
[42] Daniel Jurafski and James H. Martinr. Speech and Language Process-ing. en. Draft of September 23. Springer-Verlag New York Inc, 2018.
[43] KnowledgeDiscovery andDataMining - IBM. en-US.url:undefined(visited on 04/08/2019).
[44] David. A Grossman and Ophir Frieder. Information Retrieval Algo-rithms and Heuristics. en. Springer-Verlag New York Inc, 2013. isbn:978-1-4615-5539-1.
[45] Stemming and lemmatization. url: https://nlp.stanford.edu / IR - book / html / htmledition / stemming - and -lemmatization-1.html (visited on 04/09/2019).
[46] Angel R. Martinez. “Part-of-speech tagging”. en. In: Wiley Interdis-ciplinary Reviews: Computational Statistics 4.1 (2012), pp. 107–113.issn: 1939-0068. url: http://onlinelibrary.wiley.com/doi/abs/10.1002/wics.195 (visited on 04/09/2019).
[47] Stockholm University. url: https://www.su.se/english/(visited on 04/09/2019).
[48] Robert Östling. “Stagger: an Open-Source Part of Speech Tagger forSwedish”. In: Northern European Journal of Language Technology3 (Sept. 2013), pp. 1–18. issn: 20001533. url: http : / / www .nejlt.ep.liu.se/2013/v3/a01/ (visited on 04/09/2019).
[49] Vlado Keselj et al. “N-GRAM-BASED AUTHOR PROFILES FORAUTHORSHIP ATTRIBUTION”. en. In: (), p. 10.
[50] Geoffrey N. Leech.Principles of Pragmatics. en. Longman, July 1983.isbn: 9780582551107.
[51] J. Thomas. “Cross-Cultural Pragmatic Failure”. en. In: Applied Lin-guistics 4.2 (Feb. 1983), pp. 91–112. issn: 0142-6001, 1477-450X.url: https://academic.oup.com/applij/article-lookup/doi/10.1093/applin/4.2.91 (visited on 04/10/2019).
[52] Sanghamitra Bandyopadhyay and Sriparna Saha. “SimilarityMeasures”.en. In: Unsupervised Classification: Similarity Measures, Classicaland Metaheuristic Approaches, and Applications. Ed. by Sanghami-tra Bandyopadhyay and Sriparna Saha. Berlin, Heidelberg: SpringerBerlin Heidelberg, 2013, pp. 59–73. isbn: 978-3-642-32451-2. url:https://doi.org/10.1007/978-3-642-32451-2_3(visited on 04/08/2019).

BIBLIOGRAPHY 71
[53] Bayes’ theorem. en. Page Version ID: 891530484. Apr. 2019. url:https://en.wikipedia.org/w/index.php?title=Bayes % 5C % 27 _ theorem & oldid = 891530484 (visited on04/17/2019).
[54] James Joyce. “Bayes’ Theorem”. In: (June 2003). url: https://stanford.library.sydney.edu.au/entries/bayes-theorem/ (visited on 04/17/2019).
[55] AndrewMcCallum and Kamal Nigam. “A Comparison of Event Mod-els for Naive Bayes Text Classication”. en. In: (), p. 8.
[56] Harry Zhang. “The Optimality of Naive Bayes”. en. In: (), p. 6.
[57] Using log-probabilities for Naive Bayes. url: http://www.cs.rhodes.edu/~kirlinp/courses/ai/f18/projects/proj3/naive-bayes-log-probs.pdf (visited on 04/30/2019).
[58] Amir Hazem and Emmanuel Morin. “A Comparison of SmoothingTechniques for Bilingual Lexicon Extraction from Comparable Cor-pora”. en. In: (), p. 10.
[59] Ratings and Reviews for New Movies and TV Shows. url: http ://www.imdb.com/ (visited on 04/22/2019).
[60] Digital Entertainment Technology | TiVo.url:https://business.tivo.com/ (visited on 04/30/2019).
[61] Metadata Cloud Services Documentation. url: https://tivo.api-docs.io/v2/movie/data_movie (visited on 04/23/2019).
[62] IBM. url: https://www.ibm.com/ (visited on ).
[63] IBMWatsonDocumentation.url:https://console.bluemix.net/developer/watson/documentation (visited on ).
[64] The science behind the service. url: https : / / cloud . ibm .com/docs/services/tone- analyzer?topic=tone-analyzer-ssbts#ssbts (visited on 04/22/2019).
[65] Jussi Tarvainen, Jorma Laaksonen, and Tapio Takala. “Film mood andits quantitative determinants in different types of scenes”. en. In: IEEETransactions on Affective Computing (2018), pp. 1–1. issn: 1949-3045.url:http://ieeexplore.ieee.org/document/8252762/(visited on 04/22/2019).
[66] Niklas Wietreck. “Towards a new generation of movie recommendersystems: A mood based approach”. en. In: (), p. 71.

72 BIBLIOGRAPHY
[67] J. R. Quinlan. “Decision trees and decision-making”. In: IEEE Trans-actions on Systems, Man, and Cybernetics 20.2 (Mar. 1990), pp. 339–346. issn: 0018-9472.
[68] Karzan Wakil et al. “Improving Web Movie Recommender SystemBased on Emotions”. en. In: International Journal of Advanced Com-puter Science and Applications 6.2 (2015). issn: 21565570, 2158107X.(Visited on 04/22/2019).
[69] Alex Blackstock and Matt Spitz. “Classifying Movie Scripts by Genrewith a MEMM Using NLP-Based Features”. en. In: (), p. 23.
[70] The Stanford Natural Language Processing Group. url: https://nlp.stanford.edu/software/CRF-NER.html (visited on04/23/2019).
[71] The Stanford Natural Language Processing Group. url: https://nlp.stanford.edu/software/tagger.shtml (visited on04/23/2019).
[72] Wesly J. Chun. Core Python Programming, Volume 1. en. PrenticeHall PTR, 2001. isbn: 0-13-026036-3.
[73] Mark Lutz. Programming Python, Second Edition. en. O’Reily Asso-ciates, 2001. isbn: 0-596-0085-5.
[74] nltk.stem package — NLTK 3.4.1 documentation. url: https://www . nltk . org / api / nltk . stem . html # nltk . stem .snowball.SnowballStemmer (visited on 04/23/2019).
[75] Beautiful Soup Documentation — Beautiful Soup 4.4.0 documenta-tion.url:https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (visited on 04/29/2019).
[76] Paul DuBois. MySQL, Fourth Edition. en. Pearson Education, 2008.isbn: 0132704641.
[77] Nicholas Enticknap. “SQL”. In: Computer Jargon Explained. Ed. byNicholas Enticknap. Elsevier, Jan. 1989, pp. 105–106. isbn: 978-1-4831-3553-3. doi: 10.1016/B978-1-4831-3553-3.50054-2. url: http : / / www . sciencedirect . com / science /article/pii/B9781483135533500542 (visited on 05/15/2019).
[78] MySQL :: MySQL 8.0 Reference Manual 13.2.6. url: https://dev.mysql.com/doc/refman/8.0/en/insert.html(visited on 05/15/2019).

BIBLIOGRAPHY 73
[79] MySQL :: MySQL 8.0 Reference Manual 13.2.10. url: https://dev.mysql.com/doc/refman/8.0/en/select.html(visited on 05/15/2019).
[80] Isadore Newman, Carolyn R. Benz, and Professor Carolyn S. Ride-nour. Qualitative-quantitative Research Methodology: Exploring theInteractive Continuum. en. SIU Press, 1998. isbn: 978-0-8093-2150-6.
[81] empirical | Definition of empirical in English by Oxford Dictionaries.url:https://en.oxforddictionaries.com/definition/empirical (visited on 04/03/2019).
[82] Chris Hart. Doing a Literature Review: Releasing the Research Imag-ination. en. SAGE, Feb. 2018. isbn: 978-1-5264-2314-6.
[83] Guy Paré and Spyros Kitsiou. Chapter 9 Methods for Literature Re-views. en. University of Victoria, Feb. 2017. url: https://www.ncbi.nlm.nih.gov/books/NBK481583/ (visited on 04/04/2019).
[84] Michel Coughlan Patricia Cronin Frances Ryan. “Undertaking a liter-ature review: a step-by-step approach”. en. In: British Journal of Nurs-ing (2008), p. 147.
[85] Mathieu Templier and Guy Paré. “A Framework for Guiding and Eval-uating Literature Reviews”. en. In:Communications of the Associationfor Information Systems 37 (2015). issn: 15293181. url: https ://aisel.aisnet.org/cais/vol37/iss1/6/ (visited on04/08/2019).
[86] KTHBiblioteket. sv-SE.url:https://www.kth.se/biblioteket(visited on 04/08/2019).
[87] Google Scholar. url: https://scholar.google.se/ (visitedon 04/08/2019).
[88] Margaret C Harrell and Melissa A Bradley. “Data Collection Meth-ods. Semi-Structured Interviews and Focus Groups”. en. In: RANDNATIONAL DEFENSE RESEARCH INST SANTA MONICA CA (Jan.2009), p. 147.
[89] Jeong-Hee Kim. Understanding Narrative Inquiry: The Crafting andAnalysis of Stories as Research. en. SAGE Publications, Mar. 2015.isbn: 978-1-4833-2469-2.

74 BIBLIOGRAPHY
[90] Amanda Coffey. Analysing Documents, In: The SAGE Handbook ofQualitative Data Analysis. en. SAGE Publications Ltd, 2014. isbn:978-1-4462-0898-4 978-1-4462-8224-3.
[91] Robert Thornberg and Kathy Charmaz. Grounded Theory and The-oretical Coding, In: The SAGE Handbook of Qualitative Data Anal-ysis. en. 1 Oliver’s Yard, 55 City Road, London EC1Y 1SP UnitedKingdom: SAGE Publications Ltd, 2014. isbn: 978-1-4462-0898-4978-1-4462-8224-3. url: http://methods.sagepub.com/book/the- sage- handbook- of- qualitative- data-analysis (visited on 04/07/2019).
[92] Graham Gibbs. Using Software in Qualitative Analysis, In: The SAGEHandbook of Qualitative Data Analysis. en. 1 Oliver’s Yard, 55 CityRoad, London EC1Y 1SP United Kingdom: SAGE Publications Ltd,2014. isbn: 978-1-4462-0898-4 978-1-4462-8224-3. url: http://methods.sagepub.com/book/the- sage- handbook-of-qualitative-data-analysis (visited on 04/07/2019).
[93] Mikos Lothar. Analysis of Film, In: The SAGE Handbook of Quali-tative Data Analysis. en. SAGE Publications Ltd, 2014. isbn: 978-1-4462-0898-4 978-1-4462-8224-3.
[94] Joan Sargeant. “Qualitative Research Part II: Participants, Analysis,and Quality Assurance”. In: Journal of Graduate Medical Education4.1 (Mar. 2012), pp. 1–3. issn: 1949-8349. url: https://www.jgme.org/doi/full/10.4300/JGME-D-11-00307.1(visited on 04/22/2019).
[95] Gareth Treharne and Damien Riggs. “Ensuring Quality in QualitativeResearch”. In: Jan. 2015, pp. 57–73. isbn: 978-1-137-29104-2.
[96] Nicholas Mays and Catherine Pope. “Assessing quality in qualitativeresearch”. In: BMJ : British Medical Journal 320.7226 (Jan. 2000),pp. 50–52. issn: 0959-8138. url: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1117321/ (visited on 04/22/2019).
[97] IEEE - The world’s largest technical professional organization dedi-cated to advancing technology for the benefit of humanity.url:https://www.ieee.org/ (visited on 04/22/2019).
[98] Daniel Galin. Software quality assurance. en. Harlow, England ; NewYork: Pearson Education Limited, 2004. isbn: 978-0-201-70945-2.
[99] Ian Sommerville. Software engineering. en. 9th ed. Boston: Pearson,2011. isbn: 978-0-13-705346-9.

BIBLIOGRAPHY 75
[100] S. A. Licorish et al. “Adoption and Suitability of Software Develop-mentMethods and Practices”. In: 2016 23rd Asia-Pacific Software En-gineering Conference (APSEC). Dec. 2016, pp. 369–372.
[101] W.B. Frakes and Kyo Kang. “Software reuse research: status and fu-ture”. en. In: IEEE Transactions on Software Engineering 31.7 (July2005), pp. 529–536. issn: 0098-5589.url:http://ieeexplore.ieee.org/document/1492369/ (visited on 04/18/2019).
[102] M. L. Griss. “Software reuse: From library to factory”. en. In: IBMSystems Journal 32.4 (1993), pp. 548–566. issn: 0018-8670.url:http://ieeexplore.ieee.org/document/5387334/ (visitedon 04/18/2019).
[103] Yongbeom Kim and Edward A. Stohr. “Software Reuse: Survey andResearchDirections”. en. In: Journal ofManagement Information Sys-tems 14.4 (Mar. 1998), pp. 113–147. issn: 0742-1222, 1557-928X.url: https://www.tandfonline.com/doi/full/10.1080/07421222.1998.11518188 (visited on 04/18/2019).
[104] Roger S. Pressman. Software engineering: a practitioner’s approach.en. 7th ed. New York: McGraw-Hill Higher Education, 2010. isbn:978-0-07-337597-7.
[105] Mohammad Ayoub Khan et al., eds. Embedded and Real Time SystemDevelopment: A Software Engineering Perspective. en. Vol. 520. Stud-ies in Computational Intelligence. Berlin, Heidelberg: Springer BerlinHeidelberg, 2014. isbn: 978-3-642-40888-5. url: http://link.springer.com/10.1007/978-3-642-40888-5 (visited on04/03/2019).
[106] Rod Stephens.Beginning software engineering. en. OCLC: ocn889736021.Indianapolis, IN: JohnWiley & Sons, 2015. isbn: 978-1-118-96914-4.
[107] Vattenfallsmodellen. sv. Page Version ID: 42422653. Feb. 2018. url:https://sv.wikipedia.org/w/index.php?title=Vattenfallsmodellen&oldid=42422653 (visited on 05/17/2019).
[108] Frederick P. Brooks. The mythical man-month: essays on software en-gineering. en. Anniversary ed. Reading, Mass: Addison-Wesley Pub.Co, 1995. isbn: 978-0-201-83595-3.
[109] Homepage | Scrum.org. url: https://www.scrum.org/ (vis-ited on 04/04/2019).

[110] Andreas Opelt et al. Agile contracts: creating and managing success-ful projects with Scrum. en. Hoboken, New Jersey: JohnWiley & SonsInc, 2013. isbn: 978-1-118-64012-8 978-1-118-64010-4.
[111] 6. Learning to Classify Text. url: https://www.nltk.org/book/ch06.html (visited on 05/06/2019).
[112] Figure 2: Stemming process Algorithms of stemming methods are di-vided... en.url:https://www.researchgate.net/figure/Stemming-process-Algorithms-of-stemming-methods-are-divided-into-three-parts-mixed_fig2_324685008(visited on 05/17/2019).

TRITA-EECS-EX-2019:207
www.kth.se
Related Documents











