1 TM-Kuliah 3 From Textual Information to Numerical Vectors

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
TM-Kuliah 3 From Textual
Information to Numerical Vectors

Contents• Introduction• Collecting Documents• Document Standardization• Basic indexing pipeline• Sparse Vectors• [Vector Space Model]
2

Introduction
3

• 4
Introduction• To Mine Text we need to
process it in a form that Data Mining procedures use.
• Spreadsheet Model is embodiment of representation that is supportive of predictive modeling.
• Text mining is unstructured because very far from the spreadsheet model that we need to process data for prediction.

• 5
Introduction• Transformation of data to spreadsheet model is methodical and carefully organized procedure to fill in cells in a spread sheet.
• We have to determine nature of column in spread sheet.

Collecting Documents
6

• 7
Collecting Documents• Text Mining is collect data• If documents are identified, then they can be obtained- main issue – cleanse the samples and ensure high quality
• Web application compromising a number of autonomous Websites, one may deploy s/w tool such as WebCrawler to collect the documents

• 8
Collecting Documents• For R&D work of Text Mining -
we need generic data. – Corpus
• Accompanying Software is Reuter which is called Reuter’s corpus(RV1)
• Early days (1960’s and 1970’s)1 million works was considered –size of collection of size of collection Brown corpus consist of 500 samples for 2000 words of American English test

• 9
Collecting Documents• European corpus was modeled on Brown corpus – British English– 1970’s 0r 80’s more resource
were available- govt sponsored.– Some widely used corpora –Penn
Tree Bank (collection manually parsed sentences from Journal)
o Resource is World Wide Web. Web crawlers can build collections of pages from a particular sit such as yahoo. Give n size of web, collections require cleaning before use

Document Standardization
10

• 11
Document Standardization
• When Documents are collected, you can have them in different formats
• To process these documents we have to convert them to standard formats
• Standard Format –XML• XML is Extensible Markup
Language

• 12
Document Standardization-XML
• Standard way to insert tags onto text to identify it’s parts.
• Each Document is markedoff from corpus through XML
• XML will have tags – <Date> – <Subject> – <Topic>– <Text> – <Body>– <Header>

• 13
XML – An Example<?xml version="1.0" encoding="ISO-8859-1"?>
- <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body>
</note>

• 14
XML• Selected document is
concatenated into strings- separated by tags
• Document Standardization- • Advantage of data standardization
is mining tools can be applied without having to consider the pedigree of document.

Basic Index Pipeline
15
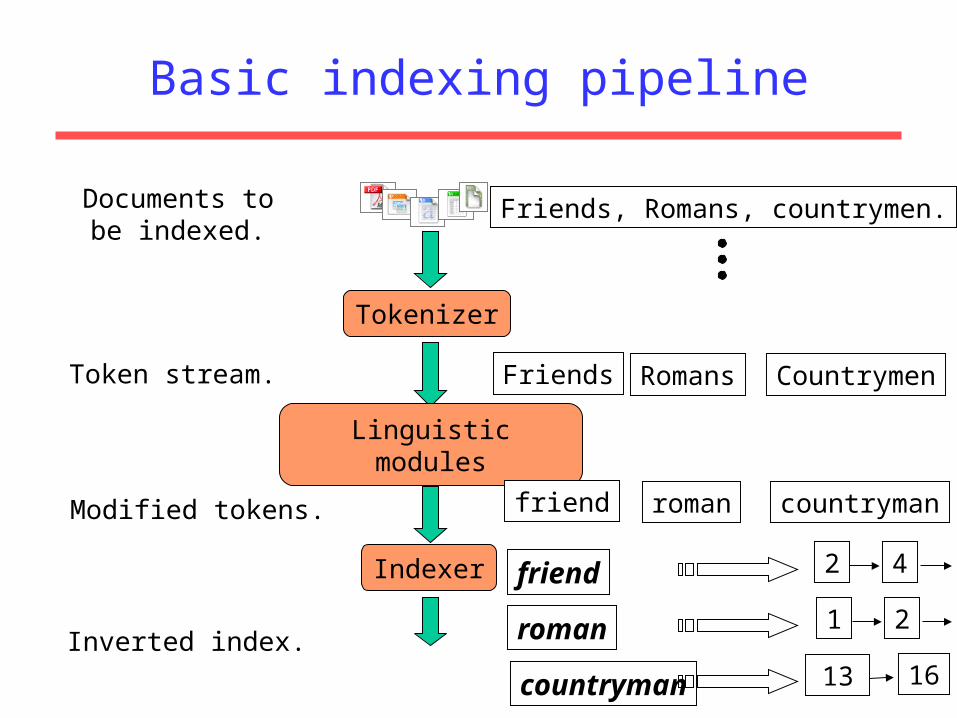
Basic indexing pipeline
Tokenizer
Token stream. Friends Romans Countrymen
Linguistic modules
Modified tokens. friend roman countryman
Indexer
Inverted index.
friend
roman
countryman
2 4
2
13 16
1
Documents tobe indexed.
Friends, Romans, countrymen.

Tokenization• Issues in tokenization:
– Finland’s capital Finland? Finlands? Finland’s?– Hewlett-Packard Hewlett and Packard as two tokens?• State-of-the-art: break up hyphenated sequence.
• co-education ?• the hold-him-back-and-drag-him-away-maneuver ?• It’s effective to get the user to put in possible hyphens
– San Francisco: one token or two? How do you decide it is one token?
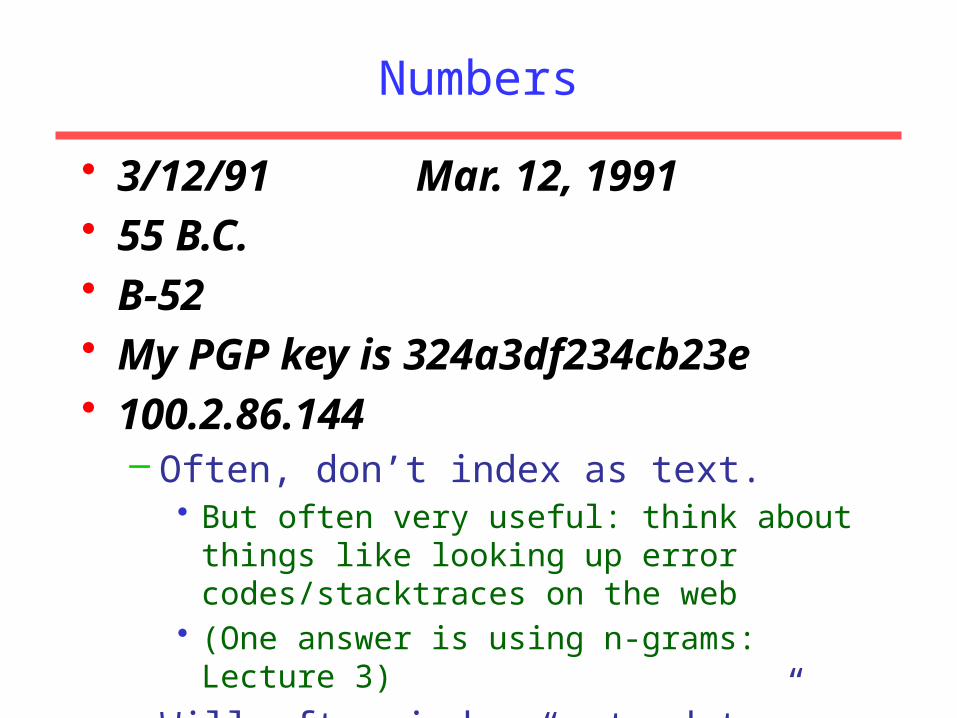
Numbers• 3/12/91 Mar. 12, 1991• 55 B.C.• B-52• My PGP key is 324a3df234cb23e• 100.2.86.144
– Often, don’t index as text.• But often very useful: think about things like looking up error codes/stacktraces on the web
• (One answer is using n-grams: Lecture 3)
– Will often index “meta-data” separately• Creation date, format, etc.

Tokenization: Language issues
• L'ensemble one token or two?– L ? L’ ? Le ?– Want l’ensemble to match with un
ensemble
• German noun compounds are not segmented– Lebensversicherungsgesellschaftsangestellter– ‘life insurance company employee’

Tokenization: language issues
• Chinese and Japanese have no spaces between words:– 莎莎莎莎莎莎莎莎莎莎莎莎莎莎莎莎莎莎莎。– Not always guaranteed a unique tokenization
• Further complicated in Japanese, with multiple alphabets intermingled– Dates/amounts in multiple formats
フフフフフフ 500 フフフフフフフフフフフフフ $500K( フ 6,000 フフ )
Katakana Hiragana Kanji Romaji
End-user can express query entirely in hiragana!

Tokenization: language issues
• Arabic (or Hebrew) is basically written right to left, but with certain items like numbers written left to right
• Words are separated, but letter forms within a word form complex ligatures
• ة� ي� س�ن� ر ف� ائ�� لت� ال�ج�ز� ق� عد 1962اس�ت� سي�132 ب�� لال ال�ف�زن � . ع�ام�ا م�ن* الاح�ت�• ← → ← → ← start
• ‘Algeria achieved its independence in 1962 after 132 years of French occupation.’
• With Unicode, the surface presentation is complex, but the stored form is straightforward

Normalization• Need to “normalize” terms in indexed text as well as query terms into the same form– We want to match U.S.A. and USA
• We most commonly implicitly define equivalence classes of terms– e.g., by deleting periods in a term
• Alternative is to do asymmetric expansion:– Enter: window Search: window, windows– Enter: windows Search: Windows, windows– Enter: Windows Search: Windows
• Potentially more powerful, but less efficient

Normalization: other languages
• Accents: résumé vs. resume.• Most important criterion:
– How are your users like to write their queries for these words?
• Even in languages that standardly have accents, users often may not type them
• German: Tuebingen vs. Tübingen– Should be equivalent

Normalization: other languages
• Need to “normalize” indexed text as well as query terms into the same form
• Character-level alphabet detection and conversion– Tokenization not separable from this.
– Sometimes ambiguous:
7 月 30 月 vs. 7/30
Morgen will ich in MIT … Is this
German “mit”?

Case folding• Reduce all letters to lower case– exception: upper case (in mid-sentence?)• e.g., General Motors• Fed vs. fed• SAIL vs. sail
– Often best to lower case everything, since users will use lowercase regardless of ‘correct’ capitalization…

Stop words
• With a stop list, you exclude from dictionary entirely the commonest words. Intuition:– They have little semantic content: the, a, and, to,
be– They take a lot of space: ~30% of postings for top 30
• But the trend is away from doing this:– Good compression techniques (lecture 5) means the space for including stopwords in a system is very small
– Good query optimization techniques mean you pay little at query time for including stop words.
– You need them for:• Phrase queries: “King of Denmark”• Various song titles, etc.: “Let it be”, “To be or not to be”
• “Relational” queries: “flights to London”

Thesauri and soundex• Handle synonyms and homonyms
– Hand-constructed equivalence classes• e.g., car = automobile• color = colour
• Rewrite to form equivalence classes
• Index such equivalences– When the document contains
automobile, index it under car as well (usually, also vice-versa)
• Or expand query?– When the query contains
automobile, look under car as well

Soundex• Traditional class of heuristics to expand a query into phonetic equivalents– Language specific – mainly for names
– E.g., chebyshev tchebycheff• More on this later ...

Lemmatization• Reduce inflectional/variant forms to base form
• E.g.,– am, are, is be– car, cars, car's, cars' car
• the boy's cars are different colors the boy car be different color
• Lemmatization implies doing “proper” reduction to dictionary headword form

Stemming• Reduce terms to their “roots” before indexing
• “Stemming” suggest crude affix chopping– language dependent– e.g., automate(s), automatic,
automation all reduced to automat.for example compressed
and compression are both accepted as equivalent to
compress.
for exampl compress andcompress ar both acceptas equival to compress

Porter’s algorithm• Commonest algorithm for stemming English– Results suggest at least as good as other stemming options
• Conventions + 5 phases of reductions– phases applied sequentially– each phase consists of a set of commands
– sample convention: Of the rules in a compound command, select the one that applies to the longest suffix.

Litle Task 1• Find the other stemming algorithm especially of stemming Indonesian language.
32

Sparse Vectors
33

34
Sparse Vectors• Vocabulary and therefore dimensionality of vectors can be very large, ~104 .
• However, most documents and queries do not contain most words, so vectors are sparse (i.e. most entries are 0).
• Need efficient methods for storing and computing with sparse vectors.

35
Sparse Vectors as Lists• Store vectors as linked lists of non-zero-weight tokens paired with a weight.– Space proportional to number of unique tokens (n) in document.
– Requires linear search of the list to find (or change) the weight of a specific token.
– Requires quadratic time in worst case to compute vector for a document:
)(2)1( 2
1nOnni
n
i

36
Sparse Vectors as Trees• Index tokens in a document in a balanced binary tree or trie with weights stored with tokens at the leaves.
memory<
< <
film variable
variable2
memory1
film1
bit2
Balanced Binary Tree

37
Sparse Vectors as Trees (cont.)
• Space overhead for tree structure: ~2n nodes.
• O(log n) time to find or update weight of a specific token.
• O(n log n) time to construct vector.
• Need software package to support such data structures.

38
Sparse Vectors as HashTables
• Store tokens in hashtable, with token string as key and weight as value.– Storage overhead for hashtable ~1.5n.
– Table must fit in main memory.– Constant time to find or update weight of a specific token (ignoring collisions).
– O(n) time to construct vector (ignoring collisions).

39
Sparse Vectors in VSR• Uses the hashtable approach called a HashMapVector.
• The hashMapVector() method of a Document computes and returns a HashMapVector for the document.
• hashMapVector() only works once after initial Document creation (i.e. Document object does not store it internally for later reuse).

40
Implementation Based on Inverted Files
• In practice, document vectors are not stored directly; an inverted organization provides much better efficiency.
• The keyword-to-document index can be implemented as a hash table, a sorted array, or a tree-based data structure (trie, B-tree).
• Critical issue is logarithmic or constant-time access to token information.

41
Inverted Index
system
computerdatabase
science D2, 4
D5, 2
D1, 3D7, 4
Index terms df
3
2
41
Dj, tfj
Index file Postings lists

42
VSR Inverted Index
HashMaptokenHash
Stringtoken
TokenInfodoubleidf
ArrayListoccList
TokenOccurenceDocumentReference
docRefint
countFilefile
doublelength
TokenOccurenceDocumentReference
docRefint
countFilefile
doublelength
…

43
Creating an Inverted IndexCreate an empty HashMap, H;For each document, D, (i.e. file in an input directory):
Create a HashMapVector,V, for D; For each (non-zero) token, T, in V: If T is not already in H, create an empty
TokenInfo for T and insert it into H;
Create a TokenOccurence for T in D and
add it to the occList in the TokenInfo for T;
Compute IDF for all tokens in H;Compute vector lengths for all documents in H;

Litle Task 2• Improve Inverted index for a special purpose case that expressed in class.
• Discuss.. 1. Kembangkan inverted indek untuk
mencatat kemunculan term ke-i selain di body juga di judul.
2. Misalkan Hashmap dimaksudkan untuk mencatat data pada satu dokumen saja. Susun struktur data hashmap untuk mencatat kemunculan term di paragraph dan catat berada pada kalimat mana dalam paragraph tersebut.
44

Litle Task 3• Kembangkan program (copy) untuk menyimpan infomasi term vektor pada beberapa dokumen masukan, meliputi antara lain :– Preposesing (tokenisasi, filtering, [stemming]) bisa menggunakan lib. Lucene atau VSR.
– dokumen masukan dibaca daru satu direktori tertentu.
– Direktori menyatakan katagori dari dokumen terebut.
45

Contoh Program
46

Vector Space Model
47

Term Vector Theory
Where :– tfi = term frequency (term counts) or
number of times a term i occurs in a document.
– dfi = document frequency or number of documents containing term I
– D = number of documents in the database.48

Vector Space Model
49

Salton's Vector Space Model
• IR systems assign weights to terms by considering1. local information from individual documents
2. global information from collection of documents
50

Term Vector Theory
51

Self-Similarity Elements• Note that collections consist of documents, documents consist of passages and passages consist of sentences.
• Thus, for a term i in a document j we can talk in terms of : – collection frequencies (Cf),– term frequencies (tf), – passage frequencies (Pf) – and sentence frequencies (Sf)
52

Vector Space Example• To simplify, let assume we deal with a basic term vector model in which we :1. do not take into account WHERE
the terms occur in documents.2. use all terms, including very
common terms and stopwords.3. do not reduce terms to root
terms (stemming).4. use raw frequecies for terms
and queries (unnormalized data).
53

Vector Space Example• Suppose we query an IR system for the query "gold silver truck".
• The database collection consists of three documents (D = 3) with the following content– D1: "Shipment of gold damaged in a fire"
– D2: "Delivery of silver arrived in a silver truck"
– D3: "Shipment of gold arrived in a truck"
54the following example are from courtesy of Professors David Grossman and Ophir
Frieder (Illinois Institute of Technology)
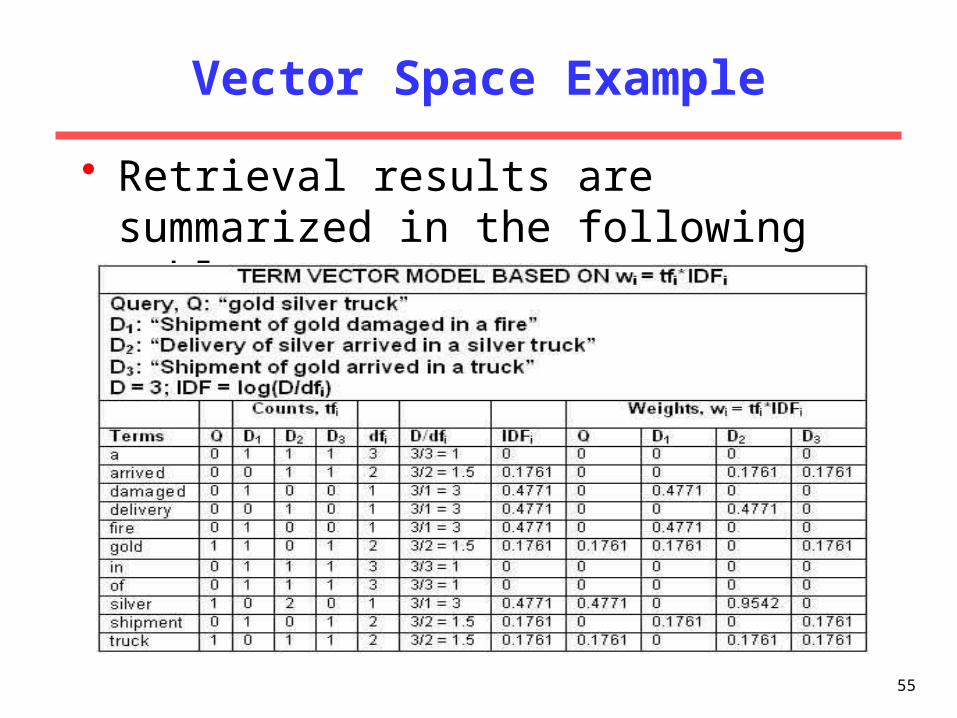
Vector Space Example• Retrieval results are summarized in the following table.
55

Documents as vectors• Each doc d can now be viewed as a vector of tfIDF values, one component for each term
• So we have a vector space– terms are axes– docs live in this space– even with stemming, may have 50,000+ dimensions

Why turn docs into vectors?• First application: Query-by-example– Given a doc d, find others “like” it.
• Now that d is a vector, find vectors (docs) “near” it.
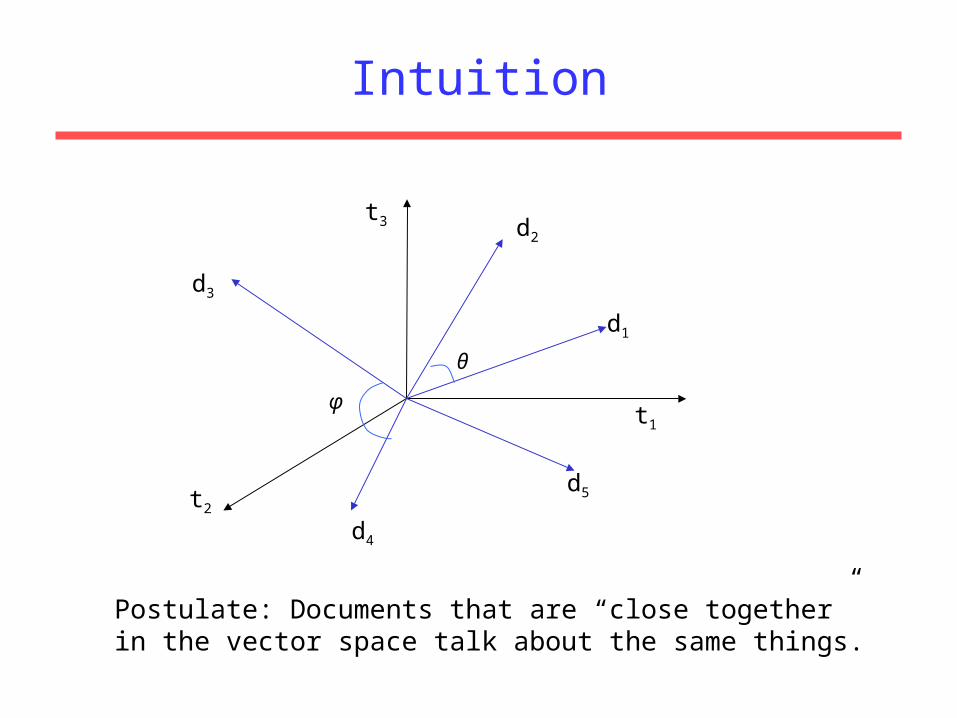
Intuition
Postulate: Documents that are “close together” in the vector space talk about the same things.
t1
d2
d1
d3
d4
d5
t3
t2
θ
φ

Desiderata for proximity• If d1 is near d2, then d2 is near d1.
• If d1 near d2, and d2 near d3, then d1 is not far from d3.
• No doc is closer to d than d itself.

First cut• Idea: Distance between d1 and
d2 is the length of the vector |d1 – d2|.– Euclidean distance
• Why is this not a great idea?• We still haven’t dealt with the issue of length normalization– Short documents would be more similar to each other by virtue of length, not topic
• However, we can implicitly normalize by looking at angles instead

Cosine similarity• Distance between vectors d1 and d2 captured by the cosine of the angle x between them.
• Note – this is similarity, not distance– No triangle inequality for similarity.
t 1
d
2
d 1
t 3
t 2
θ

Cosine similarity• A vector can be normalized (given a length of 1) by dividing each of its components by its length – here we use the L2 norm
• This maps vectors onto the unit sphere:
• Then, • Longer documents don’t get more weight
11 ,
ni jij wd
i ix22x

Cosine similarity
• Cosine of angle between two vectors
• The denominator involves the lengths of the vectors.
ni ki
ni ji
ni kiji
kj
kjkj
ww
wwdddd
ddsim1
2,1
2,
1 ,,),(
Normalization

Normalized vectors• For normalized vectors, the cosine is simply the dot product:
kjkj dddd
),cos(

Queries in the vector space model
Central idea: the query as a vector:
• We regard the query as short document
• We return the documents ranked by the closeness of their vectors to the query, also represented as a vector.
• Note that dq is very sparse!
ni qi
ni ji
ni qiji
qj
qjqj
ww
wwdddd
ddsim1
2,1
2,
1 ,,),(

Similarity Analysis• From Vector Spave example, first for each document and query, we compute all vector lengths (zero terms ignored)
66

Similarity Analysis
67

Similarity Analysis• Finally we sort and rank the documents in descending order according to the similarity values– Rank 1: Doc 2 = 0.8246– Rank 2: Doc 3 = 0.3271– Rank 3: Doc 1 = 0.0801
68

69
Computing IDFLet N be the total number of Documents;
For each token, T, in H: Determine the total number of documents, M,
in which T occurs (the length of T’s occList);
Set the IDF for T to log(N/M);
Note this requires a second pass through all the tokens after all documents have been
indexed.

70
Document Vector Length• Remember that the length of a document vector is the square-root of sum of the squares of the weights of its tokens.
• Remember the weight of a token is:
TF * IDF• Therefore, must wait until IDF’s are known (and therefore until all documents are indexed) before document lengths can be determined.

71
Computing Document LengthsAssume the length of all document vectors (stored in the DocumentReference) are initialized to 0.0;
For each token T in H: Let, I, be the IDF weight of T; For each TokenOccurence of T in document D
Let, C, be the count of T in D;
Increment the length of D by (I*C)2;
For each document D in H: Set the length of D to be the square-root of the
current stored length;

72
Minimizing Iterations Through Tokens
• To avoid iterating though all tokens twice (after all documents are already indexed), computing IDF’s and vector lengths are combined in one iteration in VSR.

73
Time Complexity of Indexing• Complexity of creating vector and indexing a document of n tokens is O(n).
• So indexing m such documents is O(m n).
• Computing token IDFs for a vocabularly V is O(|V|).
• Computing vector lengths is also O(m n).
• Since |V| m n, complete process is O(m n), which is also the complexity of just reading in the corpus.

74
Retrieval with an Inverted Index
• Tokens that are not in both the query and the document do not effect cosine similarity.– Product of token weights is zero and does not contribute to the dot product.
• Usually the query is fairly short, and therefore its vector is extremely sparse.
• Use inverted index to find the limited set of documents that contain at least one of the query words.

75
Inverted Query Retrieval Efficiency
• Assume that, on average, a query word appears in B documents:
• Then retrieval time is O(|Q| B), which is typically, much better than naïve retrieval that examines all N documents, O(|V| N), because |Q| << |V| and B << N.
Q = q1 q2 … qn
D11…D1B D21…D2B Dn1…DnB

76
Processing the Query• Incrementally compute cosine similarity of each indexed document as query words are processed one by one.
• To accumulate a total score for each retrieved document, store retrieved documents in a hashtable, where DocumentReference is the key and the partial accumulated score is the value.

77
Inverted-Index Retrieval Algorithm
Create a HashMapVector, Q, for the query.Create empty HashMap, R, to store retrieved documents with scores.
For each token, T, in Q: Let I be the IDF of T, and K be the count of T in Q;
Set the weight of T in Q: W = K * I; Let L be the list of TokenOccurences of T from H;
For each TokenOccurence, O, in L: Let D be the document of O, and C be the count of O (tf of T in D); If D is not already in R (D was not previously retrieved)
Then add D to R and initialize score to 0.0;
Increment D’s score by W * I * C; (product of T-weight in Q and D)

78
Retrieval Algorithm (cont)Compute the length, L, of the vector Q (square-root of the sum of the squares of its weights).
For each retrieved document D in R: Let S be the current accumulated score of D;
(S is the dot-product of D and Q) Let Y be the length of D as stored in its DocumentReference;
Normalize D’s final score to S/(L * Y);
Sort retrieved documents in R by final score and return results in an array.

Exercise
79
Related Documents











