InfoSphere BigInsights Analytics power for Hadoop – field experience Wilfried Hoge IT Architect Big Data @wilfriedhoge [email protected]

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

InfoSphere BigInsights Analytics power for Hadoop – field experience
Wilfried Hoge IT Architect Big Data
@wilfriedhoge

© 2015 International Business Machines Corporation 2
Open Data Platform Initiative Why is IBM involved? • Strong history of leadership in open source &
standards • Supports our commitment to open source currency in
all future releases • Accelerates our innovation within Hadoop &
surrounding applications
Open Data Platform (ODP) and Apache Software Foundation (ASF) • ODP supports the ASF mission • ASF provides a governance model around individual
projects without looking at ecosystem • ODP aims to provide a vendor-led consistent
packaging model for core Apache components as an ecosystem
All Standard Apache Open Source Components
HDFS
YARN
MapReduce
Ambari HBase
Spark
Flume
Hive Pig
Sqoop
HCatalog
Solr/Lucene
ODP

© 2015 International Business Machines Corporation 3
Text Analytics
POSIX Distributed Filesystem Multi-workload, Multi-tenant scheduling IBM BigInsights Enterprise Management
System ML on Big R
Distributed R
Business Analyst
Data Scientist
IBM Open Platform with Apache Hadoop
Developer
Administrator
IBM BigInsights Data Scientist
IBM BigInsights Analyst
Big SQL
Big Sheets
Big SQL
BigSheets
IBM BigInsights for Apache Hadoop
IBM BigInsights for Apache Hadoop Three new user-centric modules founded on an Open Data Platform

© 2015 International Business Machines Corporation 4
Field experience – analyzing binary data The challenge
• Use case – Enable users to analyze data that is provided in binary format without the
need to run scripts
• Challenges – Binary to csv transformation – Access csv data on HDFS to directly analyze content – Access csv data from BI tools through SQL
– Possibility to analyze the data for technical business users – Flexible automation capabilities (scheduling)

© 2015 International Business Machines Corporation 5
Field experience – analyzing binary data The binary file – direct analysis not possible

© 2015 International Business Machines Corporation 6
Running Applications on Big Data
• Browse available applications • Deploy published applications
(administrators only) • Launch (or schedule for launch) a
deployed application • Monitor job (application) execution
status
• Predefined applications • Import & Export Data
• Database & Files • Web and Social
• Analyze and Query • Predictive Analytics • Text Analytics • SQL/Hive, Jaql, Pig, Hbase
• Accelerators

© 2015 International Business Machines Corporation 7
7
Editors • A workflow editor that greatly simplifies the
creation of complex Oozie workflows with a consumable interface
• A Pig/Jaql Editor with content assist and syntax highlighting that enables users to create and execute new applications using Pig or Jaql in local or cluster mode from the Eclipse IDE
Application development & deployment • Enablement of BigSheets macro
and BigSheets reader development • Text Analytics development,
including support for modular rule sets
• Publish new application: BigSheets Macro, BigSheets Reader, AQL module, Jaql module
Tools for Developers 1. Sample your
Data 2. Develop your application using BigInsights tools
3. Test your application
4. Package and publish your application
5. Deploy your application on the cluster

© 2015 International Business Machines Corporation 8
Field experience – analyzing binary data Developing and publishing a transformation application

© 2015 International Business Machines Corporation 9
Field experience – analyzing binary data The transformation application – user can convert binary data to csv

© 2015 International Business Machines Corporation 10
Field experience – analyzing binary data The csv file – BigSheets offers easy analysis

© 2015 International Business Machines Corporation 11
1 2
3 1
2
3
Load data with reader in a schema-on-read fashion
Analyze data as easy as in a spreadsheet application
Visualize data and create dashboards
Explorative Analytics with BigSheets

© 2015 International Business Machines Corporation 12
Field experience – analyzing binary data An analytical result with BigSheets

© 2015 International Business Machines Corporation 13
Field experience – analyzing binary data The loader application – create tables for analysis

© 2015 International Business Machines Corporation 14
Big SQL– Architected for Performance
• Leverage IBM's rich SQL heritage, expertise, and technology – Modern SQL:2011 capabilities – DB2 compatible SQL PL support
• SQL bodied functions and stored procedures • Application logic/security encapsulation
• Architected from the ground up for performance
– low latency and high throughput
• MapReduce replaced with a modern MPP architecture – Compiler and runtime are native code (not java) – Big SQL worker daemons live directly on cluster – Continuously running (no startup latency) – Processing happens locally at the data
• Operations occur in memory with the ability
to spill to disk – Supports aggregations and sorts larger than available RAM
• Integration with BigSheets (source & target)
InfoSphere BigInsights
Big SQL SQL MPP Runtime
Data Sources
Parquet CSV Seq RC
Avro ORC JSON Custom
SQL-based Application
IBM Data Server Client

© 2015 International Business Machines Corporation 15
Big SQL – Features
Data shared with Hadoop ecosystem Comprehensive file format support
Superior enablement of IBM software Enhanced by Third Party software
Modern MPP runtime Powerful SQL query rewriter
Cost based optimizer Optimized for concurrent user throughput
Results not constrained by memory
Distributed requests to multiple data sources within a single SQL statement
Main data sources supported: DB2 LUW, DB2/z, Teradata, Oracle, Netezza
Advanced security/auditing Resource and workload management
Self tuning memory management Comprehensive monitoring
Comprehensive SQL Support IBM SQL PL compatibility
Application Portability & Integration
Federation
Performance
Enterprise Features
Rich SQL

© 2015 International Business Machines Corporation 16
Field experience – analyzing binary data Run complex SQL on generated tables
INSERT INTO Sites (Counter,Tested,Site1,Site_num1,Number_of_xxxx_tested, XA1,Percentage_of_xxxx_per_yyyy, Counter_plus_one,Pass,Site2,Site_num2,Number_of_pass_xxxx, ZB2,xxxxx_of_site_num,xxxx_file_name) SELECT 12000 + ROW_NUMBER() OVER () * 10,'Tested','Site’,tab1.Site_num,
(SELECT sum(tab2.piece_count) FROM tab2 WHERE tab2.site_num=tab1.site_num) as num_xxxx_tested, 'PA',(SELECT sum(tab2.piece_count) FROM tab2 WHERE tab2.site_num=tab1.site_num and tab2.head_num=255), 34000 + ROW_NUMBER() OVER () * 10 + 1,'Pass','Site',tab1.site_num, (SELECT COUNT(*) FROM tab1 as tab12 WHERE tab1.site_num=tab12.site_num and tab1.piece_Flg=0) as num_xxxx_passed, 'PA',((SELECT sum(tab2.piece_count) FROM tab2 WHERE tab2.site_num=tab1.site_num) / NULLIF(0.001,(SELECT COUNT(*) FROM tab1 as tab12 WHERE tab1.site_num=tab12.site_num and tab1.piece_Flg=0))), tab1.xxxx_file_name
FROM tab1 as tab1, tab2 as tab2 GROUP BY tab1.site_num, tab1.piece_Flg, tab1.xxxx_file_name;
rank function
subselects

© 2015 International Business Machines Corporation 17
Field experience – analyzing binary data What was achieved 1/2
– Conversion from binary to csv (Transformation App) • Customer provided Java classes that read binary file and produced csv output • Developer embedded java code in an BigInsights application • User can provide source and target path • User can provide filters if not the whole data set should be extracted • User can schedule the application (with parameters) • Application automatically has a REST interface for external scheduling • Application uses map/reduce for scaling if larger number of files have to be
transformed
– User can analyze the csv files with BigSheets

© 2015 International Business Machines Corporation 18
Field experience – analyzing binary data What was achieved 2/2
– Create SQL tables from csv (Loader App) • Developer embedded necessary SQL in App • User can create tables from csv files
– User can run complex SQL on tables with preferred Front-End tool
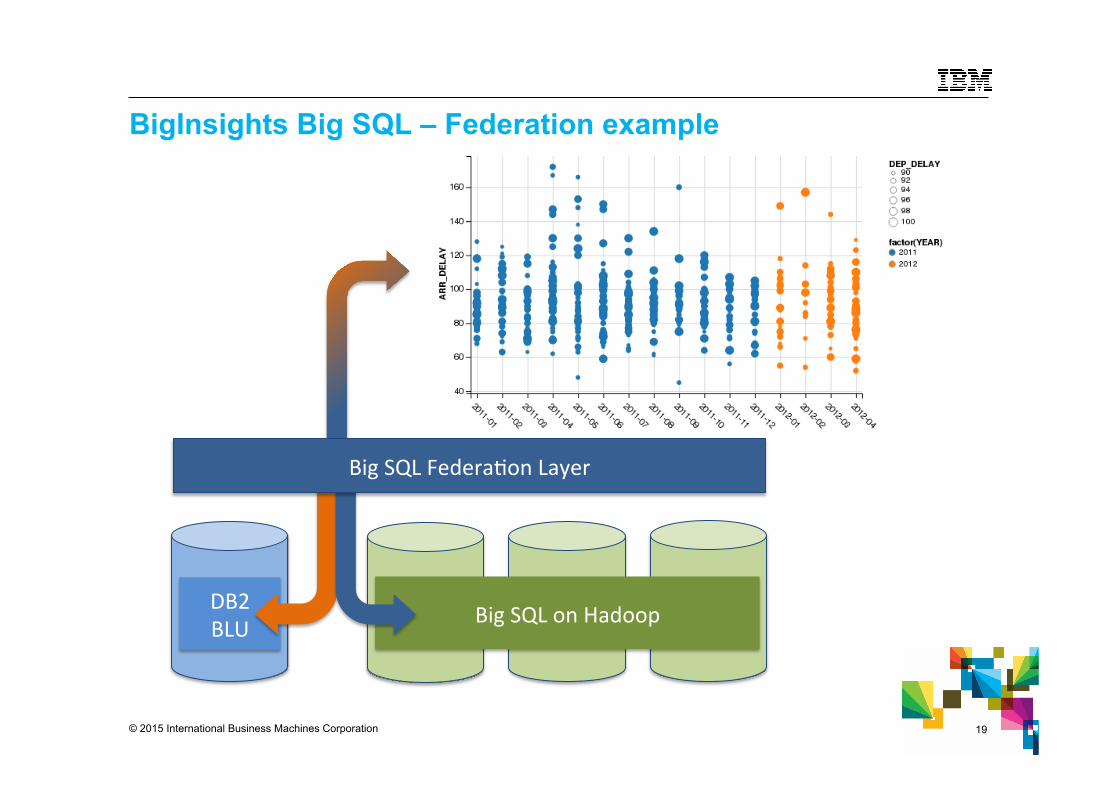
© 2015 International Business Machines Corporation 19
BigInsights Big SQL – Federation example
DB2 BLU Big SQL on Hadoop
Big SQL Federa4on Layer

© 2015 International Business Machines Corporation 20
A Bluemix sample - start from Dashboard
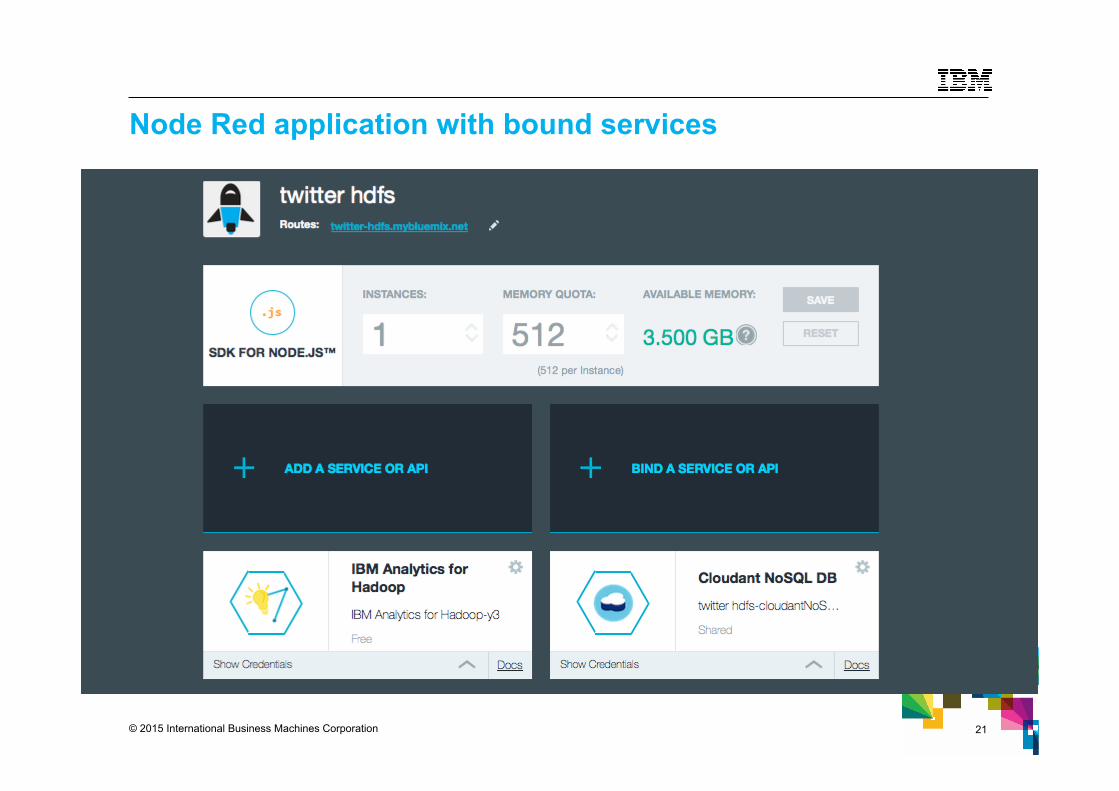
© 2015 International Business Machines Corporation 21
Node Red application with bound services

© 2015 International Business Machines Corporation 22
Node Red: Collect Twitter data and write to HDFS

© 2015 International Business Machines Corporation 23
Find written Tweets in HDFS – JSON format

© 2015 International Business Machines Corporation 24
Bring schema on-read to the data

© 2015 International Business Machines Corporation 25
Add sentiment with text analytics in BigSheets

© 2015 International Business Machines Corporation 26
Twitter data with sentiment in BigSheets

© 2015 International Business Machines Corporation 27 * Requires Service Engagement
ISV Partner Solution Type
BigInsight Version Certified
ISV Partner Solution Type
BigInsight Version Certified
Data Integration
2.1 (3.0 in process 4Q) Reporting 2.1 & 3.0
Data Security 2.1.2 Customer Analytics 2.1.2
Cluster Mgt 3.0 Analytics 2.1.2 (3.0 in
process)
Data Vis 2.1 (3.0 in process)
Visual Reporting 2.1 & 3.0 Data Virtual-
ization 2.1.2 & 3.0
TDHC 3.0 Analytics 2.1.2&3.0
Aster 3.0 *
Data Integration
2.1 (3.0 in process 3Q)
Backup & Recovery 2.1.2
IBM Product Solution Type
BigInsight Version Certified
IBM Product Solution Type
BigInsight Version Certified
Business Intelligence
2.1.2 (3.0 end of Nov’14)
Predictive Analytics
2.1.2 (3.0 mid4Q)
InfoSphere InformationServer v11.3
Data Integration 3.0
SPSS v10.2.1 AS v1.0.1
BigInsights Certifications

© 2015 International Business Machines Corporation 28
lHelium SW
BigInsights ISV Partner Ecosystem

© 2015 International Business Machines Corporation 29
Get started with BigInsights
• Hadoop Dev: links to videos, white papers, lab, . . . . http://developer.ibm.com/hadoop/ • BigInsights Trials http://ibm.com/software/data/infosphere/hadoop/trials.html

IBM big data • IBM big data • IBM big data
IBM big data • IBM big data • IBM big data
IBM
big
dat
a
• IB
M b
ig d
ata
IBM
big data • IBM
big data
THINK
Related Documents











