March 25, 2022 Computation Products Group 1 AMD Opteron Architecture and AMD Opteron Architecture and Software Infrastructure Software Infrastructure Tim Wilkens Ph.D. Tim Wilkens Ph.D. Member of Technical Staff Member of Technical Staff [email protected] [email protected]

June 1, 2015Computation Products Group1 AMD Opteron Architecture and Software Infrastructure Tim Wilkens Ph.D. Member of Technical Staff [email protected].
Dec 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

April 18, 2023 Computation Products Group 1
AMD Opteron Architecture andAMD Opteron Architecture andSoftware InfrastructureSoftware Infrastructure
Tim Wilkens Ph.D.Tim Wilkens Ph.D.Member of Technical StaffMember of Technical Staff
[email protected]@amd.com

April 18, 2023 Computation Products Group 2
AgendaAgenda
Architecture – Opteron, Itanium, XeonEMTArchitecture – Opteron, Itanium, XeonEMT
ACML – AMD’s superior equivalent of MKLACML – AMD’s superior equivalent of MKL
Compilers – PGI performance enhancementsCompilers – PGI performance enhancements
Performance – delivering on the promisePerformance – delivering on the promise
Summary and Closing PointsSummary and Closing Points

April 18, 2023 Computation Products Group 3
FADDFADD FMULFMUL
MULTMULT
FSTFSTALUALU
AGUAGU
ALUALU
AGUAGU
ALUALU
AGUAGU
Instruction Control Unit (72 entries)Instruction Control Unit (72 entries)
FastpathFastpath μμ code Engine code Engine
FetchFetch BranchBranchPredictionPrediction
Scan/AlignScan/Align
Int Decode & RenameInt Decode & Rename FP Decode & RenameFP Decode & Rename
36-entry scheduler36-entry schedulerResRes ResRes ResRes
Architecture AgendaArchitecture AgendaOpteron = Execution + Memory Access + IOOpteron = Execution + Memory Access + IO
L2L2CacheCache
L1L1DataData
CacheCache64KB64KB
L1L1InstructionInstruction
CacheCache64KB64KB
4444entryentryLoadLoadStoreStoreQueueQueue
SystemSystemRequestRequestQueueQueue
CPU 0CPU 0CPU 1CPU 1
DDR MemoryDDR Memory
IO HT LinkIO HT Link
CrossbarCrossbar
CPU-CPU HT LinkCPU-CPU HT Link
CPU-CPU HT LinkCPU-CPU HT Link
FADDFADD FMULFMUL
MULTMULT
FSTFSTALUALU
AGUAGU
ALUALU
AGUAGU
ALUALU
AGUAGU
SystemSystemRequestRequestQueueQueue
CPU 0CPU 0CPU 1CPU 1
DDR MemoryDDR Memory
IO HT LinkIO HT Link
CrossbarCrossbar
CPU-CPU HT LinkCPU-CPU HT Link
CPU-CPU HT LinkCPU-CPU HT Link
Customer Centric 64-bit ComputingCustomer Centric 64-bit Computing Instruction Decoding Processors with Artificial Intelligence
Not all X86 Processors are created =Not all X86 Processors are created = RISC Cores – scrupulous instruction preference
Scalable Memory Bandwidth and IOScalable Memory Bandwidth and IO physical memory scales with CPU # memory bandwidth scales with CPU # increased single threaded memory bandwidth memory latency does not scale with CPU # dramatically lower memory latency
Instruction Control Unit (72 entries)Instruction Control Unit (72 entries)
FastpathFastpath μμ code Engine code Engine
FetchFetch BranchBranchPredictionPrediction
Scan/AlignScan/Align
Int Decode & RenameInt Decode & Rename FP Decode & RenameFP Decode & Rename
36-entry scheduler36-entry schedulerResRes ResRes ResRes

April 18, 2023 Computation Products Group 4
Customer Centric 64-bit ComputingCustomer Centric 64-bit ComputingOpteron vs ItaniumOpteron vs Itanium
Instruction Control Unit (72 entries)Instruction Control Unit (72 entries)
FastpathFastpath μμ code Engine code Engine
FetchFetch BranchBranchPredictionPrediction
Scan/AlignScan/Align
Int Decode & RenameInt Decode & Rename FP Decode & RenameFP Decode & Rename
36-entry scheduler36-entry schedulerResRes ResRes ResRes
Progressive 64-bit approach: Progressive 64-bit approach: 32-bit instruction + prefix byte32-bit instruction + prefix byte
leverages x86 compiler technology – leverages x86 compiler technology – reliable compilers, port easilyreliable compilers, port easily
code size increase is minimal (~5%) – code size increase is minimal (~5%) – large caches not requiredlarge caches not required
x86 CPUs = RISC cores + CISCx86 CPUs = RISC cores + CISCRISC instruction decodersRISC instruction decoders
provides x86 processors provides x86 processors high clock frequencyhigh clock frequency and and legacy compatibilitylegacy compatibility
processor not compiler manages RISC core - processor not compiler manages RISC core - recompile rarelyrecompile rarely
Itanium is a slave to the compiler - Itanium is a slave to the compiler - recompile oftenrecompile often
out-of-order execution and register renamingout-of-order execution and register renaming
Opteron manages it’s registers intelligently – Opteron manages it’s registers intelligently – less compiler reliantless compiler reliant
Itanium requires the compiler to think for it – Itanium requires the compiler to think for it – strong compiler reliancestrong compiler reliance
Both Both OpteronOpteron and and ItaniumItanium are RISC, but Opteron doesn’t require are RISC, but Opteron doesn’t require reinventing compilersreinventing compilers, , large caches large caches & & a mint to purchacea mint to purchace

April 18, 2023 Computation Products Group 5
All X86 RISC Cores aren’t created = All X86 RISC Cores aren’t created =
Opteron vs Xeon EMTOpteron vs Xeon EMT
FADDFADD FMULFMUL
MULTMULT
FSTFSTALUALU
AGUAGU
ALUALU
AGUAGU
ALUALU
AGUAGU
OpteronOpteron: : INT and FP Execution UnitsINT and FP Execution Units
FADDFADD FMULFMUL
Xeon EMTXeon EMT: : FP Execution UnitsFP Execution Units
80-bits80-bits
128-bits128-bits
8080-bit x -bit x 33 = = 240240-bit bandwidth-bit bandwidth
128128-bits x -bits x 11 = = 128128-bit -bit bandwidthbandwidthconstriction limits performanceconstriction limits performance
8080-bit x -bit x 22 = = 160160 bits bits
1212 pipelinepipelinestagesstages
3131 pipelinepipelinestagesstages
# of int pipes and pipeline depth impact integer throughput# of int pipes and pipeline depth impact integer throughput
Opteron has 3 integer pipes – Opteron has 3 integer pipes – +50% reg,reg move thoughput+50% reg,reg move thoughput
Opteron has 3 Opteron has 3 ALUALU//AGUAGU units – units – +50% +,-,logical, shift throughput+50% +,-,logical, shift throughput
# pipeline stages differs – # pipeline stages differs – shorter instruction execution latencyshorter instruction execution latency
Different Register File Sizes (Opteron 80-bit, Xeon 128-bit)Different Register File Sizes (Opteron 80-bit, Xeon 128-bit)
size dictates # size dictates # RISCRISC ops an x86 instruction decodes into ops an x86 instruction decodes into
instruction selection preference is different for Opteron and Xeon64instruction selection preference is different for Opteron and Xeon64
Design of FPU and issue bandwidth from FP schedulerDesign of FPU and issue bandwidth from FP scheduler
Opteron has 240 bits per clock SIMD throughput, Xeon has 128 bitsOpteron has 240 bits per clock SIMD throughput, Xeon has 128 bits
Coupled with register file size, Opteron is a more robust engineCoupled with register file size, Opteron is a more robust engine
Though Xeon64 and Opteron are instruction compatible, OpteronThough Xeon64 and Opteron are instruction compatible, Opterondoesn’t require extensive compiler tuning to perform welldoesn’t require extensive compiler tuning to perform well

April 18, 2023 Computation Products Group 6
AMD OpteronAMD OpteronTMTM,Pentium,Pentium®®4 4 (FPU analysis)(FPU analysis) Throughput of SSE, SSE2, x87 OperationsThroughput of SSE, SSE2, x87 Operations
OperationOperation SSESSE Scalar Scalar SSESSE vector vector SSE2SSE2 scalar scalar SSE2SSE2 vector vector X87X87
AddAdd 1 / cycle1 / cycle 2 / cycle2 / cycle 1 / cycle1 / cycle 1 / cycle1 / cycle 1 / cycle1 / cycle
MultiplyMultiply 1 / cycle1 / cycle 2 / cycle2 / cycle 1 / cycle1 / cycle 1 / cycle1 / cycle 1 / cycle1 / cycle
Add & Add & MultiplyMultiply
2 / cycle2 / cycle 4 / cycle4 / cycle 2 / cycle2 / cycle 2 / cycle2 / cycle 2 / cycle2 / cycle
OperationOperation SSESSE Scalar Scalar SSESSE vector vector SSE2SSE2 scalar scalar SSE2SSE2 vector vector X87X87
AddAdd 1 / 2 cycles1 / 2 cycles 2 / cycle2 / cycle 1 / 2 cycles1 / 2 cycles 1 / cycle1 / cycle 1 / cycle1 / cycle
MultiplyMultiply 1 / 2 cycles1 / 2 cycles 2 / cycle2 / cycle 1 / 2 cycles1 / 2 cycles 1 / cycle1 / cycle 1 / 1 /
2 cycles2 cycles
Add & Add & MultiplyMultiply
1 / cycle1 / cycle 4 / cycle4 / cycle 1 / cycle1 / cycle 2 / cycle2 / cycle 1 / cycle1 / cycle

April 18, 2023 Computation Products Group 7
AMD OpteronAMD OpteronTMTM,Pentium,Pentium®®4 4 (ALU Analysis)(ALU Analysis)
Throughput and Latency ComparisonThroughput and Latency Comparison
OperationOperation 32-bit32-bit 64-bit64-bit
ADD/SUB 3 / cycle3 / cycle 3 / cycle3 / cycle
MULsignedsigned1 / cycle1 / cycle
4 cycle latency4 cycle latency
1 / 2 cycles1 / 2 cycles
MUL unsignedsigned1 / cycle1 / cycle
4 cycle latency4 cycle latency
1 / 2 cycles1 / 2 cycles
MOVmem,regmem,reg2 / cycle2 / cycle 2 / cycle2 / cycle
MOVreg,regreg,reg3 / cycle3 / cycle 3 / cycle3 / cycle
XOR/AND/OR 3 / cycle3 / cycle 3 / cycle3 / cycle
Shift/Rotate 3 / cycle3 / cycle 3 / cycle3 / cycle
DIV signedsigned42 cycle latency42 cycle latency
DIV unsignedunsigned39 cycle latency39 cycle latency
LEA 3 / cycle3 / cycle 3 / cycle3 / cycle
OperationOperation 32-bit32-bit 64-bit64-bit
ADD/SUB 2 / cycle2 / cycle NANA
MULsignedsigned1 / cycle1 / cycle
18 cycle latency18 cycle latency
NANA
MUL unsignedsigned1 / cycle1 / cycle
10 cycle latency10 cycle latency
NANA
MOVmem,regmem,reg2 / cycle2 / cycle NANA
MOVreg,regreg,reg2 / cycle2 / cycle NANA
XOR/AND/OR 2 / cycle2 / cycle NANA
Shift/Rotate 2 / cycle2 / cycle NANA
DIV signedsigned80 cycle latency80 cycle latency NANA
DIV unsignedunsigned80 cycle latency80 cycle latency NANA
LEA (2–0.5) / cycle(2–0.5) / cycle NANA

April 18, 2023 Computation Products Group 8
Scalable Memory Bandwidth and IOScalable Memory Bandwidth and IOOpteron’s on die IO controllerOpteron’s on die IO controller
SystemSystemRequestRequestQueueQueue
CPU 0CPU 0CPU 1CPU 1
DDR MemoryDDR Memory
IO HT LinkIO HT Link
CrossbarCrossbar
CPU-CPU HT LinkCPU-CPU HT Link
CPU-CPU HT LinkCPU-CPU HT Link6.46.4 GB/sGB/s
6.46.4 GB/sGB/s
6.4 – 8.06.4 – 8.0 GB/sGB/s
6.4 – 8.06.4 – 8.0 GB/sGB/s
25.6 – 28.825.6 – 28.8GB/sGB/s
1.6 – 2.0 1.6 – 2.0 GT/sGT/s coherentcoherent
1.6 1.6 GT/sGT/s non-coherentnon-coherent
Dual channelsDual channelsto DDR Memoryto DDR Memory
AMD Opteron™ Processor ServerAMD Opteron™ Processor Server Intel Xeon MP Processor ServerIntel Xeon MP Processor Server
KeyMemory TrafficI/O TrafficIPC Traffic
KeyMemory TrafficI/O TrafficIPC Traffic
HyperTransport™ Technology Buses HyperTransport™ Technology Buses for Glueless I/O or CPU Expansionfor Glueless I/O or CPU Expansion
HyperTransport™ Technology HyperTransport™ Technology Buses Enable Glueless Buses Enable Glueless Expansion for up to 8-way Expansion for up to 8-way ServersServers
Separate Memory andSeparate Memory andI/O Paths Eliminates Most I/O Paths Eliminates Most Bus ContentionBus Contention
HyperTransportHyperTransportLink Has Ample Link Has Ample Bandwidth For Bandwidth For I/O DevicesI/O Devices
Memory CapacityMemory CapacityScales w/ NumberScales w/ Numberof Processorsof Processors
PCI-XBridge *
PCI-XBridge *
PCI-X
OtherBridge
OtherBridge
OtherI/O
AMDOpteron™Processor
AMDOpteron™Processor
AMDOpteron
Processor
AMDOpteron
Processor
DDR144-bit144-bit
AMDOpteron
Processor
AMDOpteron
Processor
AMDOpteron
Processor
AMDOpteron
Processor
PCI-XBridge
PCI-XBridge
I/OHub**
I/OHub**
IDE, USB,LPC, Etc.
FSB Bus Bandwidth Shared Across FSB Bus Bandwidth Shared Across All Four ProcessorsAll Four Processors
I/O & Memory Share FSBI/O & Memory Share FSB
Bandwidth Bottlenecks:Bandwidth Bottlenecks:Link Bandwidth < I/O Bridge Link Bandwidth < I/O Bridge BandwidthBandwidth
IntelXeon
Processor
IntelXeon
Processor
IntelXeon
Processor
IntelXeon
Processor
IntelXeon
Processor
IntelXeon
ProcessorIntelXeon
Processor
IntelXeon
Processor
I/OHub3
I/OHub3
PCIIDE, FDC,USB, Etc.
PCI-XPCI-XPCI-XBridgeBridge22
PCI-XPCI-XBridgeBridge22
MemoryMemoryCtlr HubCtlr Hub(MCH)(MCH)
MemoryMemoryCtlr HubCtlr Hub(MCH)(MCH)
PCI-XPCI-XPCI-XBridgeBridge
PCI-XPCI-XBridgeBridge
PCI-XPCI-XPCI-XBridgeBridge
PCI-XPCI-XBridgeBridge
MemoryMemoryAddressAddressBufferBuffer
MemoryMemoryAddressAddressBufferBuffer
Maximum of Four Processors Maximum of Four Processors per Memory Controller Hubper Memory Controller Hub
Maximum of Three Maximum of Three PCI-X Bridges per PCI-X Bridges per Memory Controller Memory Controller HubHub
Limited Memory Limited Memory Bandwidth Bandwidth Shared by Shared by AllAllMemoryMemory
MemoryMemoryAddressAddressBufferBuffer
MemoryMemoryAddressAddressBufferBuffer
MemoryMemoryAddressAddressBufferBuffer
MemoryMemoryAddressAddressBufferBuffer
MemoryAddressBuffer
MemoryAddressBuffer
DDR144-bit144-bit
DDR144-bit144-bit
DDR144-bit144-bit
DDR144-bit144-bit
DDR144-bit144-bit
DDR144-bit144-bit
DDR144-bit144-bit
4 Separate IO Channels per CPU – 4 Separate IO Channels per CPU – Scalable SMP BandwidthScalable SMP Bandwidth
HyptertransportHyptertransportTMTM Interconnect – Interconnect – low SMP memory latencylow SMP memory latency
Commodity/High Performance SMP SolutionCommodity/High Performance SMP Solution
presently dual core ready – SRQ controller has port for 2presently dual core ready – SRQ controller has port for 2ndnd core core
fewer # of chips required for MP chipsets – lowering cost of SMP systemsfewer # of chips required for MP chipsets – lowering cost of SMP systems
6.4 GB/s6.4 GB/s6.4 GB/sXeonEMT
115.2 GB/s41.6 GB/s12.8 GB/sOpteron
4P2P1PArchitectureArchitecture
> 200 ns~200 ns80 nsXeonEMT
110 ns75 ns50 nsOpteron
4P2P1PArchitectureArchitecture

April 18, 2023 Computation Products Group 9
ACML 2.1 AgendaACML 2.1 Agenda
FeaturesFeatures
BLAS, LAPACK, FFT PerformanceBLAS, LAPACK, FFT Performance
Open MP PerformanceOpen MP Performance
ACML 2.5 Snap Shot – Soon to be releasedACML 2.5 Snap Shot – Soon to be released

April 18, 2023 Computation Products Group 10
Work carried out in collaboration with the NNumerical AAlgorithms GGroup (NAGNAG). Below is a list of contributors for each facet of ACML.
NAG Project ManagerNAG Project Manager: Mick Pont
AMD Compiler/OS SupportAMD Compiler/OS Support: Chip Freitag
BLAS/LAPACK Arch/OptimizationBLAS/LAPACK Arch/Optimization: Ed SmythEd Smyth
Tim Wilkens
FFT Arch/OptimizationFFT Arch/Optimization: Lawrence Mulholland Tim Wilkens Themos Tsikas
AcknowledgmentsAcknowledgments

April 18, 2023 Computation Products Group 11
Components of ACMLComponents of ACMLBLAS, LAPACK, FFTsBLAS, LAPACK, FFTs
Linear Algebra (LA)Linear Algebra (LA) BBasic asic LLinear inear AAlgebra lgebra SSubroutinesubroutines ((BLASBLAS))
o Level 1Level 1 (vector-vector operations) (vector-vector operations)o Level 2Level 2 (matrix-vector operations) (matrix-vector operations)o Level 3Level 3 (matrix-matrix operations) (matrix-matrix operations)o Routines involving sparse vectorsRoutines involving sparse vectors
LLinear inear AAlgebra lgebra PACKPACKageage (LAPACK) (LAPACK)o leverage BLAS to perform complex operationsleverage BLAS to perform complex operationso 28 Threaded LAPACK routines28 Threaded LAPACK routines
Fast Fourier TransformsFast Fourier Transforms ( (FFTsFFTs)) 1D, 2D, single, double, r-r, r-c, c-r, c-c support1D, 2D, single, double, r-r, r-c, c-r, c-c support
C and Fortran interfacesC and Fortran interfaces

April 18, 2023 Computation Products Group 12
Structural AnalysisStructural Analysis
GE, Raytheon, Boeing, Lockheed, Motorola, Fiat, Toyota, Pratt &
Whitney, Dupont, Rolls Royce, Corning,
General Dynamics, GTE
Structural AnalysisStructural Analysis
GE, Raytheon, Boeing, Lockheed, Motorola, Fiat, Toyota, Pratt &
Whitney, Dupont, Rolls Royce, Corning,
General Dynamics, GTE
Driving Enterprise BusinessDriving Enterprise BusinessMarket Segment Use of HPC Math LibrariesMarket Segment Use of HPC Math Libraries
Oil and GasOil and Gas
Shell, BP, Total, Petrobras,
Halliburton, ChevronTexaco,
ExxonMobil,Aramco
EducationEducationDefenseDefense
PNNL, LANL, LLNL, ORNL,
NCSA, ANL, SNL, BNL, FNAL, NERSC
ComputationalComputationalFluid DynamicsFluid Dynamics
Boeing, Ferrari, Raytheon, Lockheed,
Daimler, Morton Thiokol, AMD,Martin Marietta, Ducati, Renault
Crash AnalysisCrash Analysis
NASA, Boeing, Volvo, Mitsubishi,
Ferrari, Volkswagen, Airbus, GM, Ford,
Daimler, Honda
Digital SignalDigital SignalProcessingProcessing
NSA, DEA, CIA, Texas
Instruments, AT&T, Sprint,
MCI
Materials ScienceMaterials ScienceBiologyBiology
Eli Lilly, Bristol Meyers, Dow Chemical, DuPont, Union Carbide, Pfizer, Genentech, Genencor,
Accelrys, Incyte Genomics
Oil and GasOil and Gas
Shell, BP, Total, Petrobras,
Halliburton, ChevronTexaco,
ExxonMobil, Aramco
EducationEducationDefenseDefense
PNNL, LANL, LLNL, ORNL,
NCSA, ANL, SNL, BNL, FNAL, NERSC
Materials ScienceMaterials ScienceBiologyBiology
Eli Lilly, Bristol Meyers, Dow Chemical, DuPont, Union Carbide, Pfizer, Genentech, Genencor,
Accelrys, Incyte Genomics
Financial AnalysisFinancial Analysis
NumeriX, Palisade, MathWorks, Wolfram
Research, Goldman Sachs, Morgan Stanley, JP Morgan,
Salomon Brothers
EducationEducationDefenseDefense
PNNL, LANL, LLNL, ORNL,
NCSA, ANL, SNL, BNL, FNAL, NERSC
Materials ScienceMaterials ScienceBiologyBiology
Eli Lilly, Bristol Meyers, Dow Chemical, DuPont, Union Carbide, Pfizer, Genentech, Genencor,
Accelrys, Incyte Genomics
Financial AnalysisFinancial Analysis
NumeriX, Palisade, MathWorks, Wolfram
Research, Goldman Sachs, Morgan Stanley, JP Morgan,
Salomon Brothers
Digital SignalDigital SignalProcessingProcessing
NSA, DEA, CIA, Texas
Instruments, AT&T, Sprint,
MCI

April 18, 2023 Computation Products Group 13
Gaming – Real World RealismGaming – Real World Realism water surfaces, physics gaming engineswater surfaces, physics gaming engines
Rendered MoviesRendered Movies modeling real clothing surfaces (PDEs)modeling real clothing surfaces (PDEs)
Medical ProceduresMedical Procedures CATCAT scan imaging, Cancer Radiation Therapy scan imaging, Cancer Radiation Therapy
Airline Flight SchedulesAirline Flight Schedules minimizing equations of constraint (fuel, food, time, etc)minimizing equations of constraint (fuel, food, time, etc)
National SecurityNational Security voice analysis and authentication, weapons simulationvoice analysis and authentication, weapons simulation
Connecting HPC and youConnecting HPC and youHow HPC impacts our daily livesHow HPC impacts our daily lives

April 18, 2023 Computation Products Group 14
AMD Core Math LibraryAMD Core Math Library ( (ACMLACML))Assembly Optimizations and AccuracyAssembly Optimizations and Accuracy
single precisionsingle precision
double precisiondouble precisionSSESSE
SSE2SSE2
SSESSE
X87X87
AMD OpteronAMD OpteronTMTM ProcessorProcessor32-bit32-bit
AMD Opteron AMD Opteron ProcessorProcessor
AMD Athlon AMD Athlon MP and XP MP and XP ProcessorProcessor
AMD AthlonAMD AthlonTMTM ProcessorProcessor
Processors Supported
SSESSE
SSE2SSE2
SSESSE
X87X87
X87X87
X87X87
BLAS Assembly Support
SSESSE
SSE2SSE2
SSESSE
X87X87
X87X87
X87X87
FFT Assembly Support
64-bit64-bit
32-bit32-bit
32-bit32-bit
Address Space
Supported
1,,0
110
11
221
0
ti
NeNd
ddddx
i
ett
-
exponent
mantissa
Floating-point Numbers are represented in many formats specified by a set of parameters:
The IEEE standard sets to 2 to for beneficial reasons
t and N are dictated by the precision of the number being represented
FP OperationFP Operation tt NN
SSESSE 24 127
SSE2SSE2 53 1,023
X87X87 64 32,767
3 3 ACMLACML 32-bit binaries 32-bit binaries• supports AMD processors with/without SSE & SSE2
1 1 ACMLACML 64-bit binary 64-bit binary• supports AMD Athlon 64 and AMD Opteron

April 18, 2023 Computation Products Group 15
64-bit BLAS Performance64-bit BLAS PerformanceDGEMM (DGEMM (Double Precision General Matrix MultiplyDouble Precision General Matrix Multiply))
DGEMM Performance
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
0 250 500 750 1000 1250 1500 1750 2000
N=M
Effi
ciency
ACML 2.0 ACML 1.5 MKL 6.1 MKL 5.2 ACML Fortran (G77) MKL 6.1 on Pentium® 4

April 18, 2023 Computation Products Group 16
64-bit BLAS Performance64-bit BLAS PerformanceDSYMM (DSYMM (Double Precision Symmetric Matrix MultiplyDouble Precision Symmetric Matrix Multiply))
DSYMM Performance
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
0 250 500 750 1000 1250 1500 1750 2000
N=M
Effi
ciency
ACML 2.0 ACML 1.5 MKL 6.1 MKL 5.2 ACML Fortran (G77) MKL 6.1 on Pentium® 4

April 18, 2023 Computation Products Group 17
64-bit LAPACK Performance64-bit LAPACK PerformanceDGETRF (DGETRF (Double Precision LU FactorizationDouble Precision LU Factorization))
LU Factorize
0.40
0.45
0.50
0.55
0.60
0.65
0.70
0.75
0.80
0.85
200 450 700 950 1200 1450 1700 1950 2200 2450 2700 2950
N=M
Effi
ciency
ACML 2.0 ACML 1.5 MKL 6.1 MKL 5.2 ACML Fortran (G77) MKL 6.1 on Pentium® 4

April 18, 2023 Computation Products Group 18
64-bit LAPACK Performance64-bit LAPACK PerformanceDGETRS (DGETRS (Double Precision LU SolveDouble Precision LU Solve))
LU Solve
0.40
0.45
0.50
0.55
0.60
0.65
0.70
0.75
0.80
0.85
0.90
200 400 600 800 1000 1200 1400 1600 1800 2000
N=M
Effi
ciency
ACML 2.0 ACML 1.5 MKL 6.1 MKL 5.2 ACML Fortran (G77) MKL 6.1 on Pentium® 4

April 18, 2023 Computation Products Group 19
64-bit LAPACK Performance64-bit LAPACK PerformanceDPOTRF (DPOTRF (Double Precision Cholesky FactorizationDouble Precision Cholesky Factorization))
Cholesky Factorize
0.40
0.45
0.50
0.55
0.60
0.65
0.70
0.75
400 650 900 1150 1400 1650 1900 2150 2400 2650 2900
N=M
Effi
ciency
ACML 2.0 ACML 1.5 MKL 6.1 MKL 5.2 ACML Fortran (G77) MKL 6.1 on Pentium® 4

April 18, 2023 Computation Products Group 20
64-bit LAPACK Performance64-bit LAPACK PerformanceDGEQRF (DGEQRF (Double Precision QR FactorizationDouble Precision QR Factorization))
QR Factorize
0.30
0.35
0.40
0.45
0.50
0.55
0.60
0.65
0.70
200 400 600 800 1000 1200 1400 1600 1800 2000
N=M
Effi
ciency
ACML 2.0 ACML 1.5 MKL 6.1 MKL 5.2 ACML Fortran (G77) MKL 6.1 on Pentium® 4

April 18, 2023 Computation Products Group 21
64-bit FFT Performance 64-bit FFT Performance (non-power of 2)(non-power of 2)MKL vs ACML on 2.2 Ghz OpteronMKL vs ACML on 2.2 Ghz Opteron
Performance Ratio of 64-bit ACML 2.1 to 32-bit MKL 7.0 upon 2.2 Ghz Opteron
0%
50%
100%
150%
200%
250%
300%
350%
400%
450%
0 2000 4000 6000 8000 10000 12000 14000 16000 18000 20000
1D FFT Order (N)
Perf
orm
ance R
ati
o

April 18, 2023 Computation Products Group 22
64-bit FFT Performance 64-bit FFT Performance (non-power of 2)(non-power of 2)2.2 Ghz Opteron vs 3.2 Ghz XeonEMT2.2 Ghz Opteron vs 3.2 Ghz XeonEMT
Performance Ratio of 64-bit ACML 2.1 to 32-bit MKL 7.0 upon 3.2 Ghz XeonEMT
0%
50%
100%
150%
200%
250%
300%
350%
400%
0 2000 4000 6000 8000 10000 12000 14000 16000 18000 20000
1D FFT Order (N)
Perf
orm
ance R
ati
o
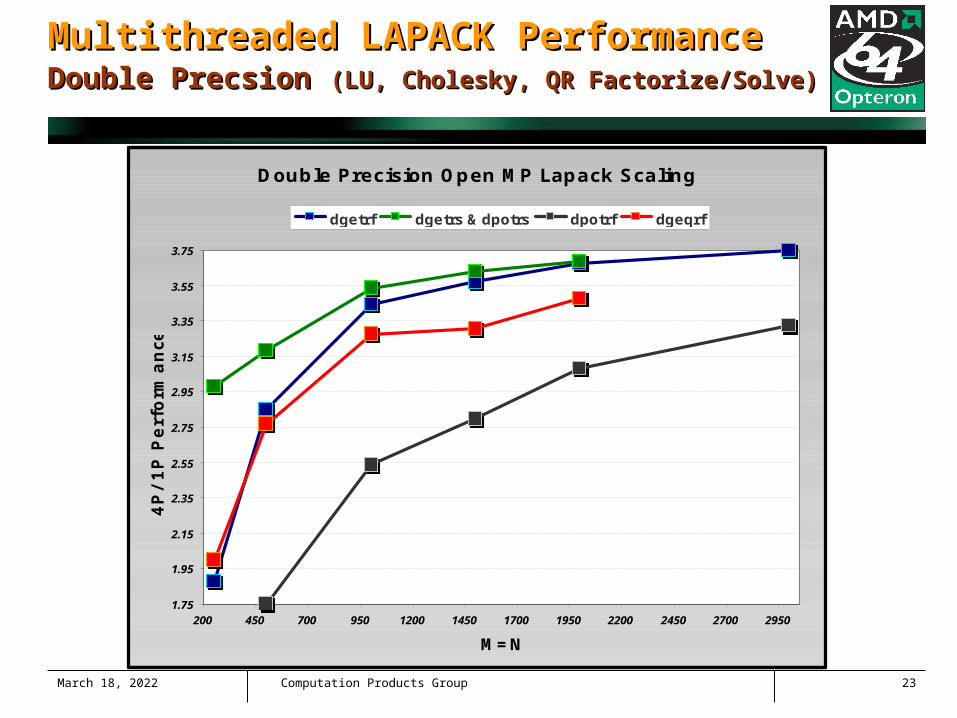
April 18, 2023 Computation Products Group 23
Multithreaded LAPACK PerformanceMultithreaded LAPACK PerformanceDouble PrecsionDouble Precsion (LU, Cholesky, QR Factorize/Solve)(LU, Cholesky, QR Factorize/Solve)
Double Precision Open MP Lapack Scaling
1.75
1.95
2.15
2.35
2.55
2.75
2.95
3.15
3.35
3.55
3.75
200 450 700 950 1200 1450 1700 1950 2200 2450 2700 2950
M=N
4P
/1P
Perf
orm
ance
dgetrf dgetrs & dpotrs dpotrf dgeqrf

April 18, 2023 Computation Products Group 24
ACML 64 5.051.171.211.251.121.331.321.131.201.311.041.201.232.041.301.081.141.141.1512.561.541.061.541.781.551.541.521.543.831.641.611.141.541.141.22
ACML 325.241.031.131.031.031.001.031.071.161.221.001.171.182.111.221.010.861.050.888.251.331.041.271.701.291.271.261.262.531.421.361.101.291.131.04
RoutineCbdsqrCfft1dCgemmCgemvCgeqrfCgercCgeruCgetrfCgetrsChemmCpotrfCpotrsCsfftCsteqrCsymmCtrmmCtrmvCtrsmCtrsvDbdsqrDgemmDgemvDgeqrfDgerDgetrfDgetrsDpotrfDpotrsDsteqrDsymmDtrmmDtrmvDtrsmDtrsvDzfft
ACML 64 6.721.281.321.761.292.761.241.381.181.371.861.461.291.651.301.677.911.391.151.221.251.201.271.361.231.361.251.081.373.361.251.141.381.251.18
ACML 32 5.191.121.191.411.052.231.001.130.981.121.451.310.991.321.031.347.211.290.931.171.241.161.131.191.171.331.201.051.343.161.211.131.191.251.26
RoutineSbdsqrScfftSgemmSgemvSgeqrfSgerSgetrfSgetrsSpotrfSpotrsSsteqrSsymmStrmmStrmvStrsmStrsvZbdsqrZdfftZfft1dZgemmZgemvZgeqrfZgercZgeruZgetrfZgetrsZhemmZpotrfZpotrsZsteqrZsymmZtrmmZtrmvZtrsmZtrsv
Conclusion and Closing PointsConclusion and Closing Points
How good is our performance?Averaging over 70 BLAS/LAPACK/FFT routinesAveraging over 70 BLAS/LAPACK/FFT routines
Computation weighted averageComputation weighted average
All measurements performed on an All measurements performed on an 4P AMD Opteron4P AMD OpteronTMTM 844 Quartet Server 844 Quartet Server
ACML 32-bit ACML 32-bit isis 55% faster 55% faster thanthan MKL 6.1 MKL 6.1
April 18, 2023 Computation Products Group 24
ACML 64-bit ACML 64-bit isis 80% faster 80% faster thanthan MKL 6.1 MKL 6.1
““Give me a long lever and a place upon which Give me a long lever and a place upon which to stand and I will move the world ” Archimedes circa 250 B.Cto stand and I will move the world ” Archimedes circa 250 B.C

April 18, 2023 Computation Products Group 25
64-ACML 2.5 Snapshot64-ACML 2.5 SnapshotSmall Dgemm EnhancementsSmall Dgemm Enhancements
DGEMM: Small Square Matrix Timings of ACML 2.0, 2.1 and 2.5 on 2Ghz Opteron
400
800
1200
1600
2000
2400
2800
3200
3600
4 14 24 34 44 54 64 74 84 94
Square Matrix Size (Order)
MFL
OP
S
ACML 2.0 ACML 2.1 ACML 2.5

April 18, 2023 Computation Products Group 26
Compiler EcosystemCompiler Ecosystem
PGIPGI , , Pathscale , GNU , , GNU , AbsoftIntel, Microsoft and SUN

April 18, 2023 Computation Products Group 27
Compiler Comparisons TableCompiler Comparisons TableCritical Features Supported by x86 CompilersCritical Features Supported by x86 Compilers
VectorVector
SIMDSIMD
SupportSupport
PeelsPeels
VectorVector
LoopsLoops
GlobalGlobal
IPAIPA
OpenOpen
MPMP
LinksLinks
ACMLACMLLibrariesLibraries
Profile Profile
GuidedGuided
FeedbackFeedback
AlignsAligns
VectorVector
LoopsLoops
ParallelParallel
DebuggersDebuggers
Large Large Array Array
SupportSupport
Medium Medium Memory Memory ModelModel
PGIPGI
GNUGNU
IntelIntel
PathscalePathscale
AbsoftAbsoft
SUNSUN
MicrosoftMicrosoft

April 18, 2023 Computation Products Group 28
Tuning Performance with CompilersTuning Performance with CompilersMaintaining Stability while OptimizingMaintaining Stability while Optimizing
STEP 0: Build application using the following procedure:STEP 0: Build application using the following procedure:
compile all files with the most aggressive optimization flags below:compile all files with the most aggressive optimization flags below:
-tp k8-64 –fastsse-tp k8-64 –fastsse
if compilation fails or the application doesn’t run properly, turn off if compilation fails or the application doesn’t run properly, turn off vectorization:vectorization:
-tp k8-64 –fast –Mscalarsse-tp k8-64 –fast –Mscalarsse
if problems persist compile at Optimization level 1:if problems persist compile at Optimization level 1:
-tp k8-64 –O0-tp k8-64 –O0
STEP 1: Profile binary and determine performance critical STEP 1: Profile binary and determine performance critical routinesroutines
STEP 2: Repeat STEP 0 on performance critical functions, one STEP 2: Repeat STEP 0 on performance critical functions, one at a time, and run binary after each step to check stabilityat a time, and run binary after each step to check stability

April 18, 2023 Computation Products Group 29
Tuning Memory IO BandwidthTuning Memory IO BandwidthOptimizing large streaming operationsOptimizing large streaming operations
2 Methods of writing to memory in x86/x86-64:2 Methods of writing to memory in x86/x86-64:
traditional memory stores cause write allocates to cachetraditional memory stores cause write allocates to cache
Mov %rax,[%rdi] movsd %xmm0,[%rdi] movapd %xmm0,[%rdi]Mov %rax,[%rdi] movsd %xmm0,[%rdi] movapd %xmm0,[%rdi]
1.1. page to be modified is read into cachepage to be modified is read into cache
2.2. cache is modified, written to memory when new memory page loadedcache is modified, written to memory when new memory page loaded
3.3. to write N bytes, 2N bytes of bandwidth generatedto write N bytes, 2N bytes of bandwidth generated
non-temporal stores bypass cache and write directly to memorynon-temporal stores bypass cache and write directly to memory
1.1. no write allocate to cacheno write allocate to cache, to write N bytes, , to write N bytes, N bytes of bandwidth generatedN bytes of bandwidth generated
2.2. data is not backed up into cache, do not use with often reused datadata is not backed up into cache, do not use with often reused data
Use only on functions which write L2/2 > bytes of data or Use only on functions which write L2/2 > bytes of data or more, normally would assure little cache reuse valuemore, normally would assure little cache reuse value
Group all eligible routines into a common file to as toGroup all eligible routines into a common file to as tosimplifysimplify the compilation procedure. Enable non-temporal storesthe compilation procedure. Enable non-temporal stores
in PGIin PGI compiler with the –Mnontemporal compiler optioncompiler with the –Mnontemporal compiler option

April 18, 2023 Computation Products Group 30
PGI Compiler FlagsPGI Compiler FlagsOptimization FlagsOptimization Flags
Below are 3 different sets of recommended PGI compiler Below are 3 different sets of recommended PGI compiler flags for flag mining application source bases:flags for flag mining application source bases:
Most aggressive: -tp k8-64 –fastsse –Mipa=fastMost aggressive: -tp k8-64 –fastsse –Mipa=fast
enables instruction level tuning for Opteron, O2 level optimizations, sse scalar and vector code generation, inter-procedural analysis, LRE optimizations and unrolling
strongly recommended for any single precision source codestrongly recommended for any single precision source code
Middle of the ground: -tp k8-64 –fast –MscalarsseMiddle of the ground: -tp k8-64 –fast –Mscalarsse
enables all of the most aggressive except vector code generation, which can reorder loops and generate slightly different results
in double precision source bases a good substitute since Opteron has the in double precision source bases a good substitute since Opteron has the same throughput on both scalar and vector codesame throughput on both scalar and vector code
Least aggressive: -tp k8-64 –O0 (or –O1)Least aggressive: -tp k8-64 –O0 (or –O1)

April 18, 2023 Computation Products Group 31
PGI Compiler FlagsPGI Compiler FlagsFunctionality FlagsFunctionality Flags
-mcmodel=medium-mcmodel=medium
use if your application statically allocates a net sum of data structures greater than 2GB
-Mlarge_arrays-Mlarge_arrays
use if any array in your application is greater than 2GB
-KPIC -KPIC
use when linking to shared object (dynamically linked) libraries
-mp -mp
process OpenMPOpenMP/SGISGI directives/pragmas (build multi-threaded code)
-Mconcur-Mconcur
attempt auto-parallelization of your code on SMP system with OpenMP

April 18, 2023 Computation Products Group 32
Absoft Compiler FlagsAbsoft Compiler FlagsOptimization FlagsOptimization Flags
Below are 3 different sets of recommended PGI compiler Below are 3 different sets of recommended PGI compiler flags for flag mining application source bases:flags for flag mining application source bases:
Most aggressive: -O3Most aggressive: -O3
loop transformations, instruction preference tuning, cache tiling, & SIMD code generation (CG). Generally provides the best performance but may cause compilation failure or slow performance in some cases
strongly recommended for any single precision source codestrongly recommended for any single precision source code
Middle of the ground: -O2Middle of the ground: -O2
enables most options by –O3, including SIMD CG, instruction preferences, common sub-expression elimination, & pipelining and unrolling.
in double precision source bases a good substitute since Opteron has the in double precision source bases a good substitute since Opteron has the same throughput on both scalar and vector codesame throughput on both scalar and vector code
Least aggressive: -O1Least aggressive: -O1

April 18, 2023 Computation Products Group 33
Absoft Compiler FlagsAbsoft Compiler FlagsFunctionality FlagsFunctionality Flags
-mcmodel=medium-mcmodel=medium
use if your application statically allocates a net sum of data structures greater than 2GB
-g77-g77
enables full compatibility with g77 produced objects and libraries
((must use this option to link to GNU ACML librariesmust use this option to link to GNU ACML libraries))
-fpic-fpic
use when linking to shared object (dynamically linked) libraries
-safefp -safefp
performs certain floating point operations in a slower manner that avoids overflow, underflow and assures proper handling of NaNs

April 18, 2023 Computation Products Group 34
Pathscale Compiler FlagsPathscale Compiler FlagsOptimization FlagsOptimization Flags
Most aggressive: -OfastMost aggressive: -Ofast
Equivalent to –O3 –ipa –OPT:Ofast –fno-math-errno
Aggressive : -O3Aggressive : -O3
optimizations for highest quality code enabled at cost of compile time
Some generally beneficial optimization included may hurt performance
Reasonable: -O2Reasonable: -O2
Extensive conservative optimizations
Optimizations almost always beneficial
Faster compile time
Avoids changes which affect floating point accuracy.

April 18, 2023 Computation Products Group 35
Pathscale Compiler FlagsPathscale Compiler FlagsFunctionality FlagsFunctionality Flags
-mcmodel=medium-mcmodel=medium use if static data structures are greater than 2GB
-ffortran-bounds-check -ffortran-bounds-check (fortran) check array bounds
-shared-shared generate position independent code for calling shared object libraries
Feedback Directed OptimizationFeedback Directed Optimization STEP 0: Compile binary with -fb_create_fbdata
STEP 1: Run code collect data
STEP 2: Recompile binary with -fb_opt fbdata
-march=(opteron|athlon64|athlon64fx)-march=(opteron|athlon64|athlon64fx) Optimize code for selected platform (Opteron is default)

April 18, 2023 Computation Products Group 36
Microsoft Compiler FlagsMicrosoft Compiler FlagsOptimization FlagsOptimization Flags
Recommended Flags : /O2 /Ob2 /GL /fp:fastRecommended Flags : /O2 /Ob2 /GL /fp:fast
/O2 turns on several general optimization & /O2 enable inline expansion
/GL enables inter-procedural optimizations /fp:fast allows the compiler to use a fast floating point model
Feedback Directed OptimizationFeedback Directed Optimization
STEP 0: Compile binary with /LTCG:PGI
STEP 1: Run code collect data
STEP 2: Recompile binary with /LTCG:PGO
Turn off Buffer Over Run CheckingTurn off Buffer Over Run Checking
The compiler by default runs on /GS to check for buffer overruns. Turning off checking by specifying /GS- may result in additional performance

April 18, 2023 Computation Products Group 37
Microsoft Compiler FlagsMicrosoft Compiler FlagsFunctionality FlagsFunctionality Flags
/GT/GT
enables run-time information
/Wp64 /Wp64
supports fiber safety for data allocated using static thread-local storage
/LD/LD
detects most 64-bit portability problems
/Oa/Oa
creates a dynamic-link library
/Ow/Ow
assumes aliasing across function calls but not inside functions

April 18, 2023 Computation Products Group 38
64-Bit Operating Systems64-Bit Operating SystemsRecommendations and StatusRecommendations and Status
SUSESUSE SLES 9 with latest Service Pack available SLES 9 with latest Service Pack available Has technology for supporting latest AMD processor featuresHas technology for supporting latest AMD processor features
Widest breadth of NUMA support and enabled by defaultWidest breadth of NUMA support and enabled by default
Oprofile system profiler installable as an RPM and modularizedOprofile system profiler installable as an RPM and modularized
complete support for static & dynamically linked 32-bit binariescomplete support for static & dynamically linked 32-bit binaries
Red Hat Enterprise Server 3.0 Service Pack 2 or laterRed Hat Enterprise Server 3.0 Service Pack 2 or later NUMA features support not as complete as that of NUMA features support not as complete as that of SUSE SLES 9SUSE SLES 9
Oprofile installable as an RPM but installation is not modularized Oprofile installable as an RPM but installation is not modularized and may require a kernel rebuild if RPM version isn’t satisfactoryand may require a kernel rebuild if RPM version isn’t satisfactory
only SP 2 or later has complete 32-bit shared object library only SP 2 or later has complete 32-bit shared object library support (a requirement to run all 32-bit binaries in 64-bit)support (a requirement to run all 32-bit binaries in 64-bit)
Posix-threading library changed between 2.1 and 3.0, may Posix-threading library changed between 2.1 and 3.0, may require users to rebuild applicationsrequire users to rebuild applications

April 18, 2023 Computation Products Group 39
AMD64 ISV PerformanceAMD64 ISV Performance
Fluent, LS-DYNA, STAR-CD, AnsysFluent, LS-DYNA, STAR-CD, Ansys

April 18, 2023 Computation Products Group 40
64-bit Fluent v6.1.2564-bit Fluent v6.1.25Serial Performance ComparisonSerial Performance Comparison
0
500
1000
1500
2000
2500
Score
FL5S1 FL5S2 FL5S3 FL5M1 FL5M2 FL5M3 FL5L1 FL5L2 FL5L3
Benchmark
Serial Fluent Performance
Dell Powerledge 1750 - Xeon 3.06 Ghz HP RX5670 - Itanium 2 1.5 Ghz IBM RS6000 Pseries 655 - Power4+ 1.7 Ghz
64-bit 4P Celestica - AMD Opteron 2.2 Ghz 64-bit 2P Linux Networks - AMD Opteron 2.2 Ghz

April 18, 2023 Computation Products Group 41
64-bit Fluent v6.1.2564-bit Fluent v6.1.25Serial Performance ComparisonSerial Performance Comparison
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Perf
orm
an
ce R
ela
tive t
o I
tan
ium
2
FL5S1 FL5S2 FL5S3 FL5M1 FL5M2 FL5M3 FL5L1 FL5L2 FL5L3
Benchmark
Serial Fluent Performance Relative to I tanium 2
Dell Powerledge 1750 - Xeon 3.06 Ghz HP RX5670 - Itanium 2 1.5 Ghz IBM RS6000 Pseries 655 - Power4+ 1.7 Ghz
64-bit 4P Celestica - AMD Opteron 2.2 Ghz 64-bit 2P Linux Networks - AMD Opteron 2.2 Ghz

April 18, 2023 Computation Products Group 42
64-bit Fluent v6.1.2564-bit Fluent v6.1.252P Performance Comparison2P Performance Comparison
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Perf
orm
an
ce R
ela
tive t
o I
tan
ium
2
FL5S1 FL5S2 FL5S3 FL5M1 FL5M2 FL5M3 FL5L1 FL5L2 FL5L3
Benchmark
2P Fluent Performance Relative to I tanium 2
Dell Powerledge 1750 - Xeon 3.06 Ghz HP RX5670 - Itanium 2 1.5 Ghz IBM RS6000 Pseries 655 - Power4+ 1.7 Ghz
64-bit 4P Celestica - AMD Opteron 2.2 Ghz 64-bit 2P Linux Networks - AMD Opteron 2.2 Ghz

April 18, 2023 Computation Products Group 43
64-bit Fluent v6.1.2564-bit Fluent v6.1.254P Performance Comparison4P Performance Comparison
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
Perf
orm
an
ce R
ela
tive t
o I
tan
ium
2
FL5S1 FL5S2 FL5S3 FL5M1 FL5M2 FL5M3 FL5L1 FL5L2 FL5L3
Benchmark
4P Fluent Performance Relative to I tanium 2
Dell Powerledge 1750 - Xeon 3.06 Ghz HP RX5670 - Itanium 2 1.5 Ghz IBM RS6000 Pseries 655 - Power4+ 1.7 Ghz
64-bit 4P Celestica - AMD Opteron 2.2 Ghz 64-bit 2P Linux Networks - AMD Opteron 2.2 Ghz

April 18, 2023 Computation Products Group 44
64-bit Fluent v6.1.2564-bit Fluent v6.1.258P Performance Comparison8P Performance Comparison
0
0.5
1
1.5
2
2.5
3
Perf
orm
an
ce R
ela
tive t
o I
tan
ium
2
FL5S1 FL5S2 FL5S3 FL5M1 FL5M2 FL5M3 FL5L1 FL5L2 FL5L3
Benchmark
8P Fluent Performance Relative to I tanium 2
Dell Powerledge 1750 - Xeon 3.06 Ghz HP RX2600 GIGE - Itanium 2 1.5 Ghz
IBM RS6000 Pseries 655 - Power4+ 1.7 Ghz 64-bit 4P HP DL585 - AMD Opteron 2.2 Ghz
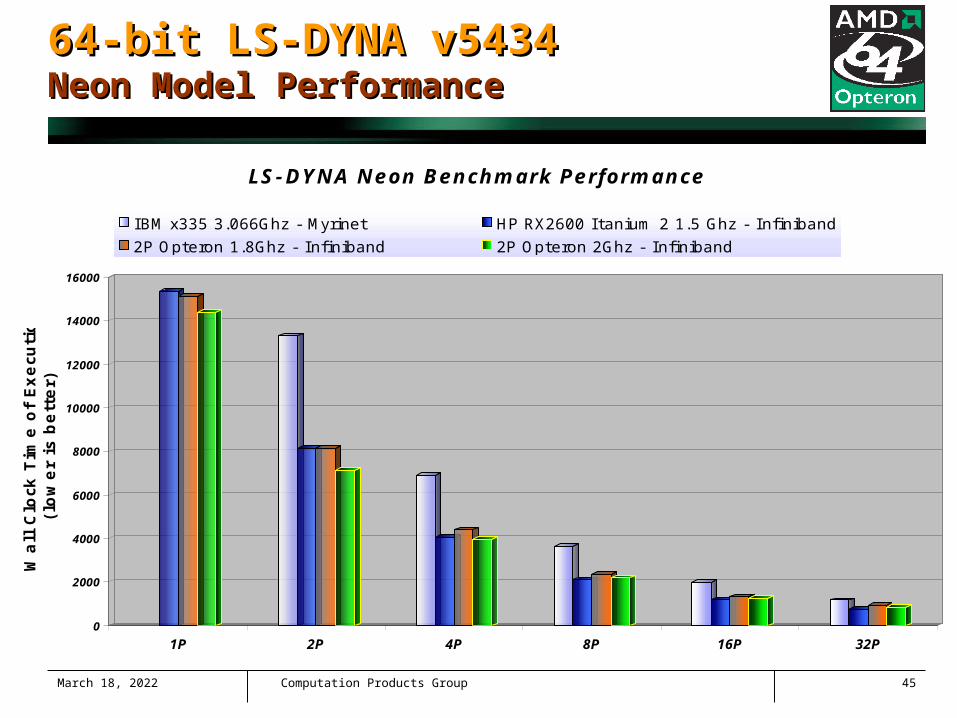
April 18, 2023 Computation Products Group 45
64-bit LS-DYNA v543464-bit LS-DYNA v5434Neon Model PerformanceNeon Model Performance
0
2000
4000
6000
8000
10000
12000
14000
16000
Wall
Clo
ck T
ime o
f Execu
tion
(low
er
is b
ett
er)
1P 2P 4P 8P 16P 32P
LS-DYNA Neon Benchmark Performance
IBM x335 3.066Ghz - Myrinet HP RX2600 I tanium 2 1.5 Ghz - Infiniband
2P Opteron 1.8Ghz - Infiniband 2P Opteron 2Ghz - Infiniband

April 18, 2023 Computation Products Group 46
64-bit LS-DYNA v543464-bit LS-DYNA v5434Neon Model PerformanceNeon Model Performance
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1.10
1.20
Perf
orm
ance
Rela
tive t
o I
taniu
m 2
1P 2P 4P 8P 16P 32P
LS-DYNA Neon Benchmark Performance Relative to I tanium 2
IBM x335 3.066Ghz - Myrinet HP RX2600 I tanium 2 1.5 Ghz - Infiniband
2P Opteron 1.8Ghz - Infiniband 2P Opteron 2Ghz - Infiniband

April 18, 2023 Computation Products Group 47
64-bit LS-DYNA v543464-bit LS-DYNA v54343-Car Model Performance3-Car Model Performance
0
10000
20000
30000
40000
50000
60000
Wall
Clo
ck T
ime o
f Execu
tion
(low
er
is b
ett
er)
8P 16P 32P 64P
LS-DYNA 3-Car Benchmark Performance
IBM x335 2.8Ghz - Gigabit HP RX2600 I tanium 2 1.5 Ghz - Infiniband 2P Opteron 2Ghz - Infiniband

April 18, 2023 Computation Products Group 48
64-bit LS-DYNA v543464-bit LS-DYNA v54343-Car Model Performance3-Car Model Performance
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1.10
1.20
1.30
1.40
1.50
1.60
Perf
orm
ance
Rela
tive t
o I
taniu
m 2
8P 16P 32P 64P
LS-DYNA 3-car Benchmark Performance Relative to I tanium 2
IBM x335 2.8Ghz - Gigabit HP RX2600 I tanium 2 1.5 Ghz - Infiniband 2P Opteron 2Ghz - Infiniband

April 18, 2023 Computation Products Group 49
AMD, the AMD Arrow Logo, AMD Opteron and combinations thereof are trademarks of Advanced Micro Devices, Inc. HyperTransport is a licensed trademark of the HyperTransport Technology Consortium. Other product names used in this presentation are for identification purposes only and may be trademarks of their respective companies.
Trademark AttributionTrademark Attribution
Related Documents











