Implementing a Hybrid SRAM / eDRAM NUCA Architecture Javier Lira (UPC, Spain) Carlos Molina (URV, Spain) [email protected] [email protected] David Brooks (Harvard, USA) Antonio González (Intel-UPC, Spain) [email protected] [email protected] HiPC 2011, Bangalore (India) – December 21, 2011

Javier Lira (UPC, Spain)Carlos Molina (URV, Spain) [email protected]@urv.net David Brooks (Harvard, USA)Antonio González (Intel-UPC,
Dec 11, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Implementing a HybridSRAM / eDRAM NUCA
ArchitectureJavier Lira (UPC, Spain) Carlos Molina (URV, Spain)[email protected] [email protected]
David Brooks (Harvard, USA) Antonio González (Intel-UPC, Spain)
[email protected] [email protected]
HiPC 2011, Bangalore (India) – December 21, 2011
2
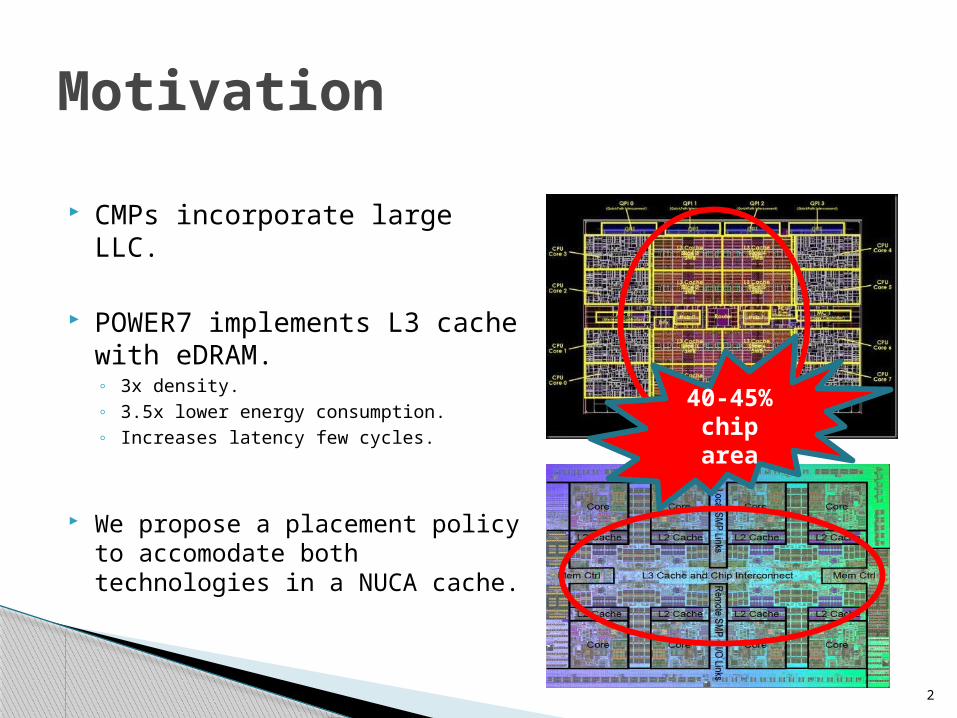
CMPs incorporate large LLC.
POWER7 implements L3 cache with eDRAM.◦ 3x density.◦ 3.5x lower energy consumption.◦ Increases latency few cycles.
We propose a placement policy to accomodate both technologies in a NUCA cache.
Motivation
40-45% chip area
3
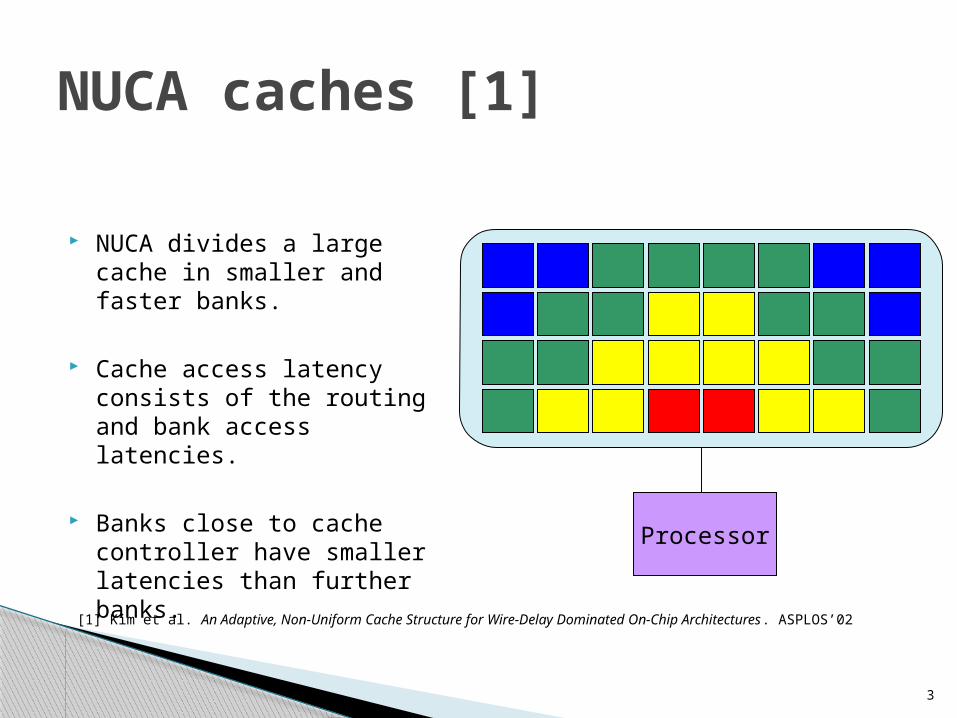
NUCA divides a large cache in smaller and faster banks.
Cache access latency consists of the routing and bank access latencies.
Banks close to cache controller have smaller latencies than further banks.
NUCA caches [1]
Processor
[1] Kim et al. An Adaptive, Non-Uniform Cache Structure for Wire-Delay Dominated On-Chip Architectures. ASPLOS’02

4
SRAM provides high-performance.
eDRAM provides low power and high density.
SRAM eDRAM
Latency X 1.5x
Density X 3x
Leakage 2x X
Dynamic energy
1.5x X
Need refresh?
No Yes
SRAM vs. eDRAM

5
Introduction
Methodology
Implementing a hybrid NUCA cache
Analysis of our design
Exploiting architectural benefits
Conclusions
Outline

6
Baseline architecture [2]
Migration
Placement Access
Replacement
Placement Access
Migration Replacement
Core 0 Core 1 Core 2 Core 3
Core 4 Core 5 Core 6 Core 7
16 positions per data
Partitioned multicast
Gradual promotionLRU + Zero-copy
Core 0
[2] Beckmann and Wood. Managing Wire Delay in Large Chip-Multiprocessor Caches. MICRO’04

7
Number of cores 8 – UltraSPARC IIIi
Frequency 1.5 GHz
Main Memory Size 4 Gbytes
Memory Bandwidth 512 Bytes/cycle
Private L1 caches 8 x 32 Kbytes, 2-way
Shared L2 NUCA cache
8 MBytes, 128 Banks
NUCA Bank 64 KBytes, 8-way
L1 cache latency 3 cycles
NUCA bank latency 4 cycles
Router delay 1 cycle
On-chip wire delay 1 cycle
Main memory latency
250 cycles (from core)
Experimental framework
GEMS
Simics
Solaris 10
PARSECSPEC
CPU2006
8 x UltraSPARC IIIi
Ruby Garnet Orion

8
Introduction
Methodology
Implementing a hybrid NUCA cache
Analysis of our design
Exploiting architectural benefits
Conclusions
Outline

Fast SRAM banks are located close to the cores.
Slower eDRAM banks in the center of the NUCA cache.
PROBLEM: Migration tends to concentrate shared data in central banks.
9
Homogeneous approachCore 0 Core 1 Core 2 Core 3
Core 4 Core 5 Core 6 Core 7
eDRAM
SRAM
10
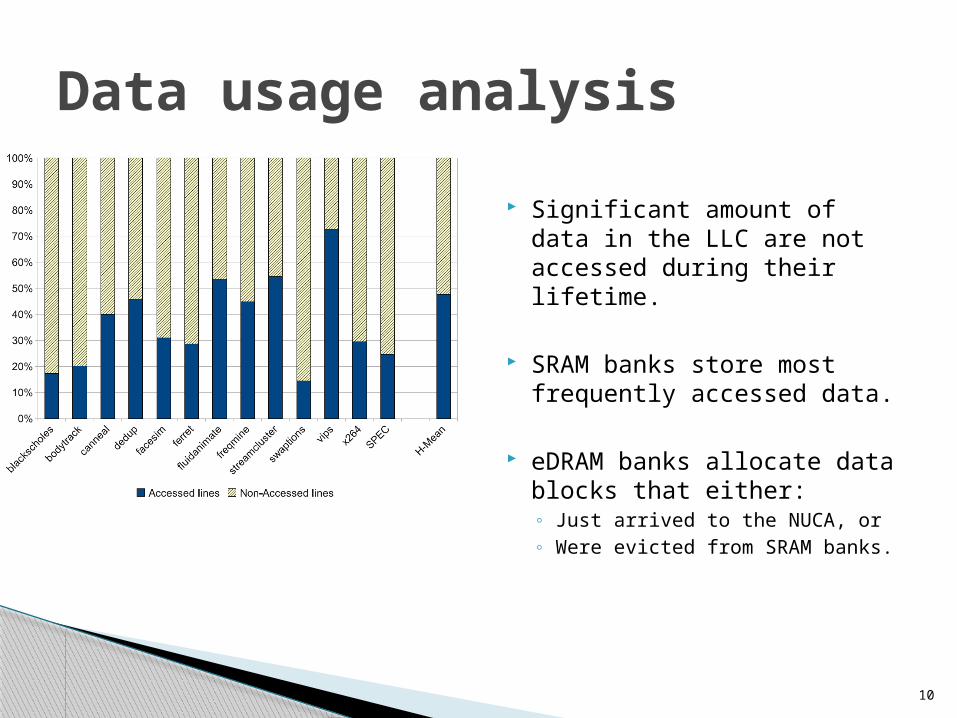
Significant amount of data in the LLC are not accessed during their lifetime.
SRAM banks store most frequently accessed data.
eDRAM banks allocate data blocks that either:◦ Just arrived to the NUCA, or◦ Were evicted from SRAM banks.
Data usage analysis

11
First goes to an eDRAM.
If accessed, it moves to SRAM.
Features:◦ Migration between SRAM banks.◦ Lack of communication in eDRAM.◦ No eviction from SRAM banks.◦ eDRAM is extra storage for SRAM.
PROBLEM: Access scheme must search to the double number of banks.
Heterogeneous approach
eDRAM
SRAM
Core 0 Core 1 Core 2 Core 3
Core 4 Core 5 Core 6 Core 7

12
Tag Directory Array (TDA) stores tags of eDRAM banks.
Using TDA, the access scheme looks up to 17 banks.
TDA requires 512 Kbytes for an 8 Mbyte (4S-4D) hybrid NUCA cache.
TDA

Heterogeneous + TDA outperforms the other hybrid alternatives.
13
Performance results
We use Heterogeneous + TDA as hybrid NUCA cache in further analysis.

14
Introduction
Methodology
Implementing a hybrid NUCA cache
Analysis of our design
Exploiting architectural benefits
Conclusions
Outline

15
Well-balanced configurations achieve similar performance as all-SRAM NUCA cache.
The majority of hits are in SRAM banks.
Performance

16
Hybrid NUCA pays for TDA.
The less SRAM the hybrid NUCA uses, the better.
Power and Area
All SRAM
7S-1D 6S-2D 5S-3D 4S-4D 3S-5D 2S-6D 1S-7D All DRAM
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Dyn. Network Dyn. Cache Sta. NetworkSta. SRAM Sta. eDRAM Sta. TDA

17
Similar performance results as all-SRAM. Reduces power consumption by 10%. Occupies 15% less area than all-SRAM.
The best configuration
4S-4D

18
Introduction
Methodology
Implementing a hybrid NUCA cache
Analysis of our design
Exploiting architectural benefits
Conclusions
Outline

19
New configurations
all SRAM banksSRAM: 4MBytes
eDRAM: 4MBytes
15% reduction on area
+1MByte in SRAM banks
+2MBytes in eDRAM banks
5S-4D
4S-6D
SRAM
eDRAM

20
And do not increase power consumption.
Both configurations increases performance by 4%.
Exploiting benefits
All SRAM 4S-4D 5S-4D 4S-6D0%
20%
40%
60%
80%
100%
Sta. TDASta. eDRAMSta. SRAMSta. NetworkDyn. CacheDyn. Network

21
Introduction
Methodology
Implementing a hybrid NUCA cache
Analysis of our design
Exploiting architectural benefits
Conclusions
Outline

22
IBM® integrates eDRAM in its latest general-purpose processor.
We implement a hybrid NUCA cache, that effectively combines SRAM and eDRAM technologies.
Our placement policy succeeds in concentrating most accesses to the SRAM banks.
Well-balanced hybrid cache achieves similar performance as all-SRAM configuration, but occupies 15% less area and dissipates 10% less power.
Exploiting architectural benefits we achieve up to 10% performance improvement, and by 4%, on average.
Conclusions

Implementing a HybridSRAM / eDRAM NUCA
Architecture
Questions?
HiPC 2011, Bangalore (India) – December 21, 2011
Related Documents











