Oct 19, 2015 Roberto Innocente [email protected] 1 ipv6 ● History and motivations ● Introduction to ipv6 : addressing and prefixes ● Proposal for gradual deployment ● Transition technologies: tunnels (6to4, teredo) ● Multicast, Control protocols : ICMPv6 ( ND, RD) ● Booting (SLAAC/DHCPv6), naming (DNSv6, mDNS) ● Routing : RIPng, OSPFv3, IS-IS, BGP4+

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Oct 19, 2015 Roberto Innocente [email protected] 1
ipv6
● History and motivations● Introduction to ipv6 : addressing and prefixes● Proposal for gradual deployment● Transition technologies: tunnels (6to4, teredo)● Multicast, Control protocols : ICMPv6 ( ND, RD)● Booting (SLAAC/DHCPv6), naming (DNSv6,
mDNS)● Routing : RIPng, OSPFv3, IS-IS, BGP4+

Oct 19, 2015 Roberto Innocente [email protected] 2
IPv6 history
● Well , probably all of you know that since the '90 the Internet governing bodies thought about a technical way out from the foreseeable moment of IPv4 address consumption.
● First named IPng and then IPv6 a new protocol was finalized between '94 and 2000.● The main feature of it was ( impressive at that time) the increase of the address size from 32
bits(up to 2^32 ~ 10^10 addresses) to 128 bits (4 times more bits up to 2^128 ~ 10^40 addresses). Explanation for physicists : 30 orders of magnitude more, Millions of Avogadro's number IPv4 address spaces ( sic! )
● Don't be astonished. Many think that if it would be developed now the address would be at least 256 bits.
● In fact there was before IPv6 an ISO protocol that to be smart implemented variable length addresses (up to 20 bytes, 160 bits) ISO 8473/1998 CLNP (Connectionless Network Protocol RFC1162). Their supporters proposed to solve the IPv4 problem by the substitution of IP by CLNP with a solution called TUBA (TCP and UDP with Bigger Addresses RFC1437)
● The NSFNET backbone in US and some GARR parts( bologna – trieste) supported CLNP for some time from 1990 to 1993. The nsfnet together with ip, ts-bo encapsulating ip in clnp (“routing pass like ships in the night”).
● Soon it was realized that Variable Length Addresses were a really bad idea from the point of view of routing and switching efficiency. This was of course also giving variable offsets to options : a nightmare for hardware switching.

Oct 19, 2015 Roberto Innocente [email protected] 3
CLNP address
Variable Length Address till 20 bytes, for TUBA 20 bytes

Oct 19, 2015 Roberto Innocente [email protected] 4
Why ? Why now ?
The IPv4 address prefixes are finished at IANA (Internet Assigned Numbers Authority) and at ARIN (Canada, USA registry ) some remain in the hands of ISPs.Therefore soon some islands of IPv6 only will appear and it will be necessary to speak IPv6 to reach them.The vision that is behind the Internet Of Things (IOT) is pushing hard to have an IP address for everything :● Washing machines, dish-washers, fridges, ovens .. smartphones, TV top boxes, ..Mobile 4G (LTE) provides voice as the service Voice over IP.In the orig 3GPP spec it was only requested to be available and IPv4 optional, but most operators now use IPv6 for this.There is another difficult problem that afflicts today IPv4 Internet at large: the routing prefix explosion (now routers in the Default Free Zone have over 500.000 prefixes). With IPv6 there is the hope to aggregate prefixes by LIR/ISP , RIRs. Last but not least IPv6 will give to people now constrained behind a NAT, End-to-End Transparency (some nonetheless consider this a threat ) : RFC2775 Internet Transparency, RFC4924 Reflexions on Internet Transparency.

Oct 19, 2015 Roberto Innocente [email protected] 5
We want to avoid the chaos :Dagen H (hå), 5 am. Stockholm 1967
when traffic switched from left to right
Benjamin Edelman,Running out of numbershttp://www.benedelman.org/publications/runningout-draft.pdf


Oct 19, 2015 Roberto Innocente [email protected] 7
Routing explosion IPv6 prefixes announced over the DFZ IPv4 prefix explosion : prefixes announced
over the Default-Free Zone DFZ
From apnic.net
NB. Instabilities on DFZ routing due to reaching the 512K prefix limit of some routersRFC4984 “routing scalability is the most important problem facing the Internet today and must be solved”

Oct 19, 2015 Roberto Innocente [email protected] 8
End-to-End transparencyRFC4924
It is not often cited as a motive for the adoption of IPv6, but the new protocol will give back to the current Internet and the forthcoming Internet of Things (IOT) end-to-end transparency.This at the same time is a threat for some and an essential tool for others.
“Two ports Internet” Today Internet is filtered and NATted everywhere, except for the web ports. Therefore whoever today is developing new things doesn't care to use new ports and register them, but uses exclusively :● Port 80 http● Port 443 https

Oct 19, 2015 Roberto Innocente [email protected] 9
Ipv6 adoptionAmsterdam traffic Exchange amsix ipv6 traffic :
Adoption by operator(percentage of requests to akamai servers made over IPv6):

Oct 19, 2015 Roberto Innocente [email protected] 10
Distribution of
addressesMin
AllocatedTo LIR /32
Minimum AllocatedTo EndUsers /64
Universities usually /48
eg RIPE
eg GARR
eg SISSA
IANA
RIR RIR
NIR
ISP/LIRISP/LIR
EU EU EU End Users
Local Internet Registries(LIR,ISP..)
National Internet Registries
(APNIC region)
Regional Internet Registries
(ARIN,RIPE,APNIC..)


Oct 19, 2015 Roberto Innocente [email protected] 12
PI (Provider Independent)PA (Provider Assigned) prefixes
There have been lots of discussion about ipv6 addresses deployment. 3 methods were proposed :● PA provider assigned or aggregatable : specified in the RFC's, usually
universities in italy got their ipv6 /48 prefix from GARR. These addresses will stay with provider and if you change provider you have to change addresses.
● PI provider independent : these addresses will be announced independently over the whole Internet and will stay with you. Registries are now providing also these
● GeographicallyIn 2009 RIPE accepted a policy proposal on this topic :● RIPE will assign directly to organization PI prefixes that should be at least /48 or /32.
The request can be addressed directly to RIPE or trough a sponsoring LIR● This will make possible for an organization to move to another provider without
renumbering● On the other side this poses a burden on global routing because it blocks the
possibility of an efficient route aggregation.

Oct 19, 2015 Roberto Innocente [email protected] 13
Sparsest address allocation usingbit-reversal permutation
How to assign from a finite number of ordered adjacent boxes in the sparsest way ? Such that you leave the max free space among the occupied boxes ? ( RFC3531 sparse allocation)Using as you can see on the right a bit-reversal involution ( involution f(f(x)) = x ). It is one of the damn parts of the FFT algorithm especially for its trashing effects on the cache.
001 → 100 = 4
010 → 010 = 2
011 → 110 = 6
100 → 001 = 1
101 → 101 = 5
110 → 011 = 3
It is used for address allocation by registries to permit to give new allocations adjacent to the old ones given to the same requestor.
000 → 000 = 0
1 2 3 4 5 6 70

Oct 19, 2015 Roberto Innocente [email protected] 14
IPv6 address textual representation● IPv4 address textual representation is the well known quad decimal dotted
representation : 147.122.24.71 a decimal number (0-255) for each byte of the address, separated by dots. The address representation becomes from 7 to 15 characters.
● In IPv6 this is not possible because with 128 bits(16 bytes) the length would be from 31 to 63 characters.
● It was chosen to use half of the punctuation (one colon every 4 hex digits: 2 bytes) and to use 2 hex digits to represent a byte. Still the representation is long : from 15 to 39 characters. You can compress it omitting leading zeroes in each quad hex, replacing at most once multiple 0 quadhexes with :: .
● Curiosity : trying to obtain a compact representation someone proposed a base85 representation (there are 94 ASCII characters utilizable for the representation, in
base84, 21 chars would be required, in base85 to 94 only 20 characters because 8520
> 2128 ! ) RFC1924 (A compact representation of IPv6 addresses)Eg. 1080:0:0:0:8:800:200C:417AIn decimal : 21932261930451111902915077091070067066Remainders dividing by 85 : 51, 34, 65, 57, 58, 0, 75, 53, 37, 4, 19, 61, 31, 63, 12, 66, 46, 70, 68, 4Therefore in base 85 it is : 4-68-70-46-66-12-63-31-61-19-4-37-53-75-0-58-57-65-34-51
That becomes : 4)+k&C#VzJ4br>0wv%Yp

Oct 19, 2015 Roberto Innocente [email protected] 15
IPv6 address representation :compressed quadhex
128 bits :
1111110100000000000000000000000000000000000000110000000000000010
0000000000000000000000000000000000000000000000000000000000000001
32 hex digits:
FD000000000300020000000000000001
8 quadhex colon separated :
FD00:0000:0003:0002:0000:0000:0000:0001
FD00:0:3:2:0:0:0:1
FD00:0:3:2::1
Replace every nibble (4 bits) with an hex digit
Take the left most sequence of multiple 0s quad-hexes and replace it with a double colon ::
In each quad-hex cancel leading 0s
Every 4 hex digits insert a colon

Oct 19, 2015 Roberto Innocente [email protected] 16
IPv6 prefix text representation
RFC4291 Text Representation of Address Prefixes
The text representation of IPv6 address prefixes is similar to the way IPv4 address prefixes are written in Classless Inter-Domain Routing (CIDR) notation [CIDR]. An IPv6 address prefix is represented by the notation: ipv6-address/prefix-length where ipv6-address is an IPv6 address in any of the notations listed in Section 2.2. prefix-length is a decimal value specifying how many of the leftmost contiguous bits of the address comprise the prefix. For example, the following are legal representations of the 60-bit prefix 20010DB80000CD3 (hexadecimal): 2001:0DB8:0000:CD30:0000:0000:0000:0000/60 2001:0DB8::CD30:0:0:0:0/60 2001:0DB8:0:CD30::/60 The following are NOT legal representations of the above prefix: 2001:0DB8:0:CD3/60 may drop leading zeros, but not trailing zeros, within any 16-bit chunk of the address 2001:0DB8::CD30/60 address to left of "/" expands to 2001:0DB8:0000:0000:0000:0000:0000:CD30 2001:0DB8::CD3/60 address to left of "/" expands to 2001:0DB8:0000:0000:0000:0000:0000:0CD3

Oct 19, 2015 Roberto Innocente [email protected] 17
IPv6 Variable Length Prefix
● Full address : 128 bits● Global prefix : n bits , Subnet ID : m bits● Interface ID : (128 – n - m) bits
But .. many following specs require intID at 64 bits
Subnet ID Interface ID
128 bits
Global prefix
n bits m bits 128 – n - m bits
1st three bits have special meaning :000 no constraint on IID001 currently assigned global unicast prefixes….. unassigned111 multicast etc.
It should be clear from this that most of the space remains unallocated : 5/8 of it is unallocated
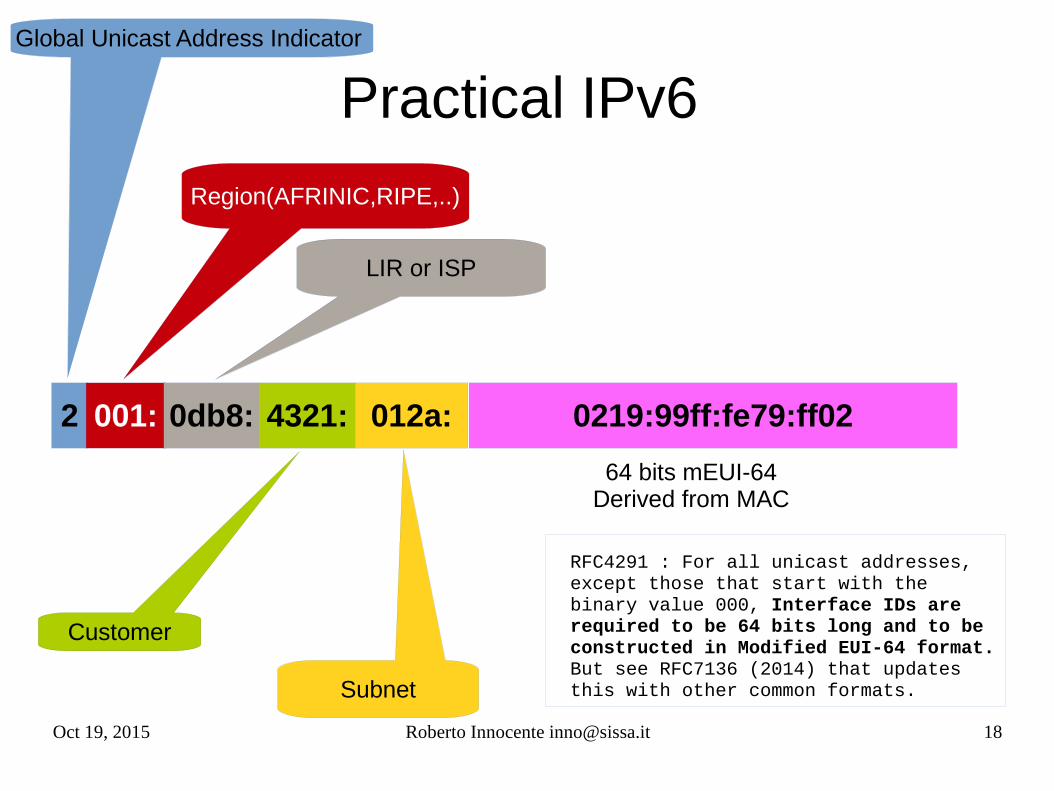
Oct 19, 2015 Roberto Innocente [email protected] 18
Practical IPv6
Global Unicast Address Indicator
Region(AFRINIC,RIPE,..)
LIR or ISP
Customer
Subnet
2 001: 0db8: 4321: 012a: 0219:99ff:fe79:ff02
64 bits mEUI-64Derived from MAC
RFC4291 : For all unicast addresses, except those that start with the binary value 000, Interface IDs are required to be 64 bits long and to be constructed in Modified EUI-64 format.But see RFC7136 (2014) that updates this with other common formats.

Oct 19, 2015 Roberto Innocente [email protected] 19
Put out of your mind ..
the idea that one of the things to know for a subnet plan is the possible number of hosts !!e.g. We were used to think that if maybe 300/400 hosts would at the end populate a subnet then we had to give to this subnet a /22 subnet address and a coupled netmask of 255.255.252.0.Using 8 bytes for the interface identifier there will never be problems with this part of the address : it allows 264 ~ 1020 different hosts !

Oct 19, 2015 Roberto Innocente [email protected] 20
Ipv6 address types
IPv6 addresses types– Unicast, single interface on single node. Pkt sent to it is delivered to that interface.
● Global Unicast 2000::/3● Link Local fe80::/10● Loopback ::1/128● Unspecified ::/128● Unique Local fc00::/7● Embedded Ipv4 ::/80 (deprecated)● Compatible Ipv4 ::fff0:x.y.z.w/96
– Multicast: multitude of interfaces on a multitude of nodes. Pkt sent to it is sent to all these interfaces.
● Assigned ff00::/8● Solicited Node ff02::1:ff00:0000/104
– Anycast : a set of interfaces usually on different nodes. Pkt sent to it is sent only to the nearest interface with that address.
● Any Unicast can be used as anycast● Reserved : Subnet-router anycast

Oct 19, 2015 Roberto Innocente [email protected] 21
IPv6 scoped addresses/1
Interface local : ::1/128scope
Global scope : 2000::/3
Link-Local : fe80::/10scope
Site-local : fec0::/10 deprecated by rfc3879Unique-LocalAddress(ULA): fd00::/8 replaces site-local.In RFC4193 ,ULA globalID is agenerated pseudorandomnumber, subnetID is assignedadministratevely, L=1 makingprefix fd00::/8.
fe80 0 Interface ID
1111 1110 10
fe80::/10
1111 110 L global ID subnet ID Interface ID
1 locally assigned0 globally assigned
7 bits 1 40bits 16bits 64bits
Link-local address LLAfe80::/10
Unique Local Address ULAfd00::/8
RFC4007 IPv6 Scoped address
10 bits 54 bits 64 bits
x

Oct 19, 2015 Roberto Innocente [email protected] 22
IPv6 scoped addresses/2
Interface local scope
Link-Local scope
Site-local
Unique-Local-Address(ULA)
Global scope
x
::1/128
fec0::/10
fd00::/8
2000::/3
fe80::/10

Oct 19, 2015 Roberto Innocente [email protected] 23
IPv6 address scopes or simply zones
● The address tells you the scope : interface, link-local, site-local, global:– ::1/128, fe80::/64, fd00::/8,2000::/3
● A zone is a concrete instance of a scope.● fe80::2 tells you the scope : Link Local, but not the zone.● 2100:760::2 tells you the scope : Global, and the zone : Internet.● Zone : a connected region of a given scope.● Global scope has only 1 zone : all Internet● There are as many Link-local zones as linksWhen an app needs to communicate with lower layers about a link-local address, it has to communicate a zone identifier (on linux an interface name or index on windows an interface index), this zone identifier has only local meaning. RFC4007 prescribes to use the percent % sign to add the zone to the address :
fe80::1%eth0 fe80::2%4● In linux fe80::2%eth0 tells you the scope link-local and the zone : eth0 of the node.In windows use: netsh interface ipv6 show interfaceAlso ipconfig shows zoneid of linklocal addresses.In linux use : ip -6 linkRFC4007 Ipv6 Scoped address

Oct 19, 2015 Roberto Innocente [email protected] 24
Ipv6 anycast - RFC3513
● Anycast are explicitly contemplated by IPv6.● An anycast address is taken from the unicast addresses and assigned to multiple
interfaces (RFC4921), it has the same scope as the unicast family from which is taken. The node to which an anycast is assigned should be explicitly configured to recognize the address.
● The routing infrastructure, that should be aware of it, will deliver a packet having as destination an anycast address to the nearest of the instances of that address.
● Usage examples :– TLD anycast dns servers
– Reserve Subnet-router anycast address (RFC4291)
– 6to4 relay anycast address RFC3068
This is accomplished trough the propagation of host routes for the anycasts in all the parts of the network that can't summarize the anycast with a route prefix.There is a longest prefix P that is common to the region of all these interfaces … in the worst case this prefix P can be null and the region be then the whole Internet.In this case the host route should be maintained over all Internet.

Oct 19, 2015 Roberto Innocente [email protected] 25
128 – n Bitsn bits
Required anycast :Subnet-Router anycast
From rfc4291, required. It is built from prefix of a subnet zeroing remaining bits. All routers attached to a subnet need to listen to this anycast that is used to communicate with the nearest router.
NB. use of /127 prefix on pt to pt links was discouraged (rfc3627) and deprecated because of conflict with special use addresses like this. Look RFC6164 for a discussion about it, but is still recommended to use /64 for pt-to-pt links even if this raises security issues (ping pong issue on SDN that don't use ND). /126 is recommended by rfc3627 so that the 2 interfaces don't need to use the 0 suffix (reserved for subnet router anycast)
Subnet Prefix 000...000

Oct 19, 2015 Roberto Innocente [email protected] 26
IPv6 addresses
Multicast AnycastUnicastUnicast
Unique Localfc00::/7
Assignedff00::/8
Global Unicast2000::/3
Link Localfe80::/10
Loopback::1/128
Embedded IPv4::/80
Unspecified address::/0
Assigned unicast
Subnet Anycast
Subnet::0
Solicited nodeff02::1:ff00:0:0/104

Oct 19, 2015 Roberto Innocente [email protected] 27
Ipv4-ipv6 correspondenceIPv4 IPv6
Multicast address(224.0.0.0/4) Multicast address (ff00::/8)
Loopback (127.0.0.1) Loopback (::1)
Unspecified address (0.0.0.0) Unspecified address (::)
Broadcast address Not applicable in IPv6
Public Ipv4 address Global Unicast Address (2000::/3)
Private IP address(10.0.0.0/8, 172.16.0.0/12,192.168.0.0/16)
Unique Local Address (fd00::/8)
APIPA address(169.254.0.0/16)Automatic Private IP addressing
Link Local address (fe80::/64)

Oct 19, 2015 Roberto Innocente [email protected] 28
IPv6 prefixes assigned
byIANA
● 2001:0000::/23 IANA● 2001:0200::/23 APNIC 1999-07-01 whois.apnic.net https://rdap.apnic.net/ ALLOCATED ● 2001:0400::/23 ARIN 1999-07-01 whois.arin.net https://rdap.arin.net/registry● 2001:0600::/23 RIPE NCC 1999-07-01 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:0800::/23 RIPE NCC 2002-05-02 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:0a00::/23 RIPE NCC 2002-11-02 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:0c00::/23 APNIC 2002-05-02 whois.apnic.net https://rdap.apnic.net/ ALLOCATED ● 2001:0e00::/23 APNIC 2003-01-01 whois.apnic.net https://rdap.apnic.net/ ALLOCATED ● 2001:1200::/23 LACNIC 2002-11-01 whois.lacnic.net https://rdap.lacnic.net/rdap/ ALLOCATED ● 2001:1400::/23 RIPE NCC 2003-02-01 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:1600::/23 RIPE NCC 2003-07-01 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:1800::/23 ARIN 2003-04-01 whois.arin.net https://rdap.arin.net/registry● 2001:1a00::/23 RIPE NCC 2004-01-01 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:1c00::/22 RIPE NCC 2004-05-04 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:2000::/20 RIPE NCC 2004-05-04 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:3000::/21 RIPE NCC 2004-05-04 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:3800::/22 RIPE NCC 2004-05-04 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:4000::/23 RIPE NCC 2004-06-11 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:4200::/23 AFRINIC 2004-06-01 whois.afrinic.net https://rdap.afrinic.net/rdap/ ● 2001:4400::/23 APNIC 2004-06-11 whois.apnic.net https://rdap.apnic.net/ ALLOCATED ● 2001:4600::/23 RIPE NCC 2004-08-17 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:4800::/23 ARIN 2004-08-24 whois.arin.net https://rdap.arin.net/registry● 2001:4a00::/23 RIPE NCC 2004-10-15 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:4c00::/23 RIPE NCC 2004-12-17 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:5000::/20 RIPE NCC 2004-09-10 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2001:8000::/19 APNIC 2004-11-30 whois.apnic.net https://rdap.apnic.net/ ALLOCATED ● 2001:a000::/20 APNIC 2004-11-30 whois.apnic.net https://rdap.apnic.net/ ALLOCATED ● 2001:b000::/20 APNIC 2006-03-08 whois.apnic.net https://rdap.apnic.net/ ALLOCATED ● 2003:0000::/18 RIPE NCC 2005-01-12 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2400:0000::/12 APNIC 2006-10-03 whois.apnic.net https://rdap.apnic.net/ ALLOCATED ● 2600:0000::/12 ARIN 2006-10-03 whois.arin.net https://rdap.arin.net/registry.● 2a00:0000::/12 RIPE NCC 2006-10-03 whois.ripe.net https://rdap.db.ripe.net/ ALLOCATED ● 2c00:0000::/12 AFRINIC 2006-10-03 whois.afrinic.net https://rdap.afrinic.net/rdap●
●
●

Oct 19, 2015 Roberto Innocente [email protected] 29
RIPE prefixes Prefix obtained Will be given away with nets of prefix ...2001:600::/23 /64 /482001:800::/23 /322001:a00::/23 /322001:1400::/23 /322001:1600::/23 /322001:1a00::/23 /322001:1c00::/22 /322001:2000::/20 /322001:3000::/21 /322001:3800::/22 /322001:4000::/23 /322001:4600::/23 /322001:4a00::/23 /322001:4c00::/23 /322001:5000::/20 /322003::/18 /32
2a00::/12 /32

Oct 19, 2015 Roberto Innocente [email protected] 30
GARR IPv6 assignements
● /40 for each POP eg :– 2001:760:0::/40 POP Roma– 2001:760:200::/40 POP Bologna
● Backbone links and networks use 2001:760:ffff::/48 addresses– /64 for each router from the /56 of principal POP eg:
● ts.garr.net 2001:760:ffff:1200::/56● router 2001:760:1200::/64
– /48 for each customer of the /40 of the POP : Pop trieste 2001:760:2800::/40
Uni Pavia 2001:760:2000::/48– /128 for loopback interfaces
– /127 for point to point links● Naming :
– Loopback interface : pop_name.6net.garr.net●
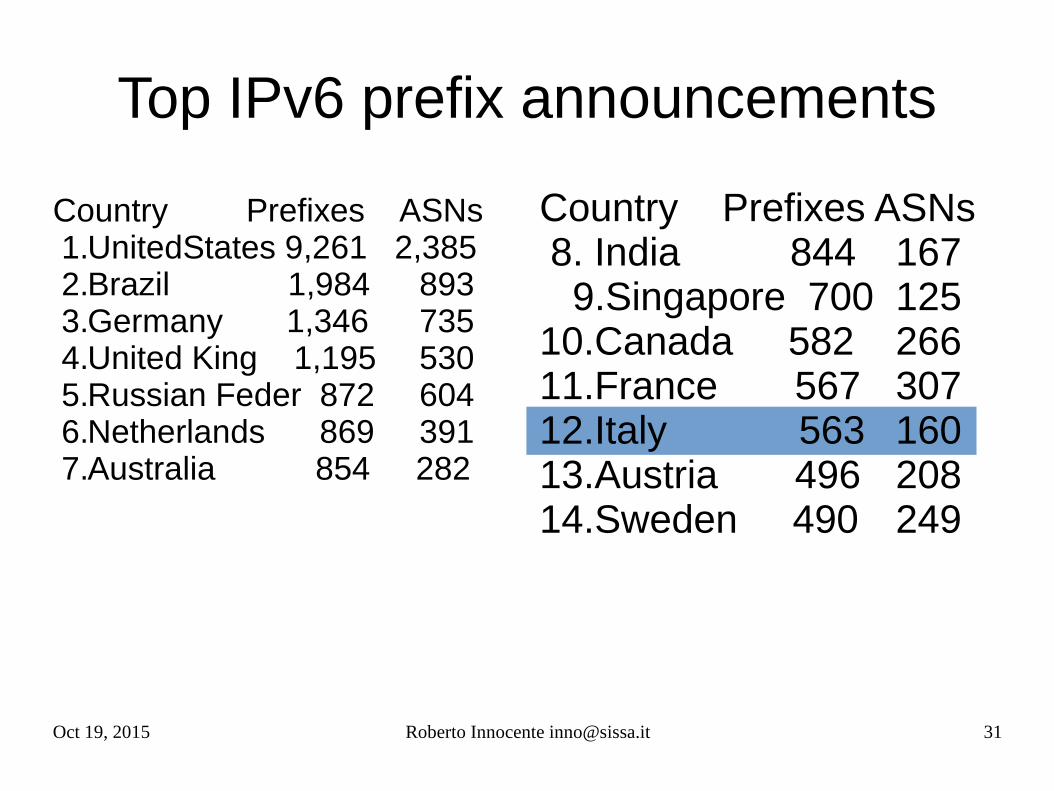
Oct 19, 2015 Roberto Innocente [email protected] 31
Country Prefixes ASNs 1.UnitedStates 9,261 2,385 2.Brazil 1,984 893 3.Germany 1,346 735 4.United King 1,195 530 5.Russian Feder 872 604 6.Netherlands 869 391 7.Australia 854 282
Top IPv6 prefix announcements
Country Prefixes ASNs 8. India 844 167 9.Singapore 700 125 10.Canada 582 266 11.France 567 307 12.Italy 563 160 13.Austria 496 208 14.Sweden 490 249

Oct 19, 2015 Roberto Innocente [email protected] 32
● ARIN 2001:0400::/23● Columbia 2001:0468:0904::/48● University of Nebraska 2607:f320::/32● LuisianaUniversity 2620:105:B000::/40 ● Internet2 2001:468::/16● TIM 2a03:8980::/32 ● Wind Italia 2a02:b000::/23● MessageNet 2a01:9300::/32● SeeWeb 2001:4b78::/29● GARR LIR 2001:760::/32
– Caspur 2001:760:2::/48
– Roma Tre 2001:760:4::/48
– Univ.Bologna 2001:760:202::/48
– PoliTo 2001:760:400::/48
– Universita' di trieste 2001:760:2e03::/48
Some prefixes
● Vodafone italia 2a01:820::/32 2a01:827::/32 2a01:8d0::/32
● Telecomitalia 2a01:2000::/20● CNR 2a00:1620::/32

Oct 19, 2015 Roberto Innocente [email protected] 33
Ipv6 special addresses
Prefix Length Description
2001:db8:: /32 Addresses to be used for Documentation
2001:: /32 Teredo
2002:: /16 6to4
5f00:: /8 6bone
3ffe:: /16 6bone
fc00:: /7 Unique Local Address ULA
fe80:: /16 Link Local unicast addresses
::1 /128 Loopback

Oct 19, 2015 Roberto Innocente [email protected] 34
Improper / Martian IPv6 routes
These are routes that some governing body has declared reserved for special purposes and that should not be globally routed on the IPv6 internet.
Prefix::/0 Unspecified address, default
::/96 Unspecified address, IPv4 compatible
::/128 Unspecified address
::1/128 Loopback address
::224.0.0.0/100 Compatible ipv4 multicast
::127.0.0.0/104 Compatible ipv4 loopback
::0.0.0.0/104 Ipv4 compatbile default
::255.0.0.0/104 Ipv4 comp. broadcast
0000::/8 Pool used for unspec and embedded addr
0200::/7 OSI NSAP deprecated
3ffe::/16 Former 6bone decommissioned
2001:db8::/32 Reserved IANA for doc
Prefix2002:e000::/20 Invalid 6to4
2002:7f00::/24 Invalid 6to4
2002:0a00::/24 Invalid 6to4
2002:ac10::/28 Invalid 6to4
2002:c0a8::/32 Ipv4 compatible default
fc00::/7 Unicast Unique local address rfc4193
fe80::/10 Link local addresses
fec0::/10 Site local unicast addresses
ff00::/8 Multicast range

Oct 19, 2015 Roberto Innocente [email protected] 35
Bogon routes
Probably you know already the meaning of the word : in hacker's jargon it is the quantum of bogosity (the property of being bogus : fake).
They are net prefixes not yet allocated by IANA and that therefore should never be announced.
# last updated 1443512101 (Tue Sep 29 07:35:01 2015 GMT)::/8100::/8200::/7400::/6800::/51000::/42000::/162001:201::/322001:202::/312001:204::/302001:209::/322001:20a::/312001:20c::/302001:210:2000::/352001:210:4000::/342001:210:8000::/332001:211::/322001:212::/312001:214::/302001:219::/322001:21a::/312001:21c::/302001:221::/322001:222::/312001:224::/302001:228:2000::/352001:228:4000::/342001:228:8000::/332001:229::/322001:22a::/312001:22c::/302001:231::/322001:232::/312001:234::/302001:239::/322001:23a::/312001:23c::/302001:241::/322001:242::/312001:244::/302001:248:2000::/352001:248:4000::/342001:248:8000::/33.
2001:249::/322001:24a::/312001:24c::/302001:253::/322001:255::/322001:257::/322001:259::/322001:25a::/312001:25c::/302001:261::/322001:262::/312001:264::/302001:269::/322001:26a::/312001:26c::/302001:271::/322001:272::/312001:274::/302001:279::/322001:27a::/312001:27c::/302001:281::/322001:282::/312001:284::/302001:289::/322001:28a::/312001:28c::/302001:291::/322001:292::/312001:294::/302001:299::/322001:29a::/312001:29c::/302001:2a1::/322001:2a2::/312001:2a4::/302001:2a9::/322001:2aa::/312001:2ac::/302001:2b1::/322001:2b2::/312001:2b4::/302001:2b9::/322001:2ba::/312001:2bc::/302001:2c1::/322001:2c2::/312001:2c4::/302001:2c9::/322001:2ca::/312001:2cc::/30.....
2001:2d0:2000::/352001:2d0:4000::/342001:2d0:8000::/332001:2d1::/322001:2d2::/312001:2d4::/302001:2d9::/322001:2da::/312001:2dc::/302001:2e1::/322001:2e2::/312001:2e4::/302001:2e9::/322001:2ea::/312001:2ec::/302001:2f1::/322001:2f2::/312001:2f4::/302001:2f9::/322001:2fa::/312001:2fc::/302001:301::/322001:302::/312001:304::/302001:309::/322001:30a::/312001:30c::/302001:311::/322001:312::/312001:314::/302001:319::/322001:31a::/312001:31c::/302001:321::/322001:322::/312001:324::/302001:329::/322001:32a::/312001:32c::/302001:331::/322001:332::/312001:334::/302001:339::/322001:33a::/312001:33c::/302001:341::/322001:342::/312001:344::/302001:349::/322001:34a::/312001:34c::/30..
.
.
.
.
.
.
.
.
( available at http://www.team-cymru.org/Services/Bogons/fullbogons-ipv6.txt )

Oct 19, 2015 Roberto Innocente [email protected] 36
Measuring IPv6 address consumption RFC3194
HD=log (NumberOfAllocatedObjects )
log (NumberOfAllocatableObjects )
To recognize the reason for an allocation larger than a /56 often is required to have a 75% HD :Eg. out of the 256 subnets you can have you should already have 64 :HD = log2(64)/log2(256)=6/8= 0.75eg. if you are given a 48 with a 2^16 subnet space , your HD will require new allocation when you have allocated 2^12=4096 subnets :HD = log2(4096)/log2(65536)=12/16=0.75
HD(US 10 digits telephone) = log(10^8) / log(10^10) = 0.8 = 80%HD(SPAN/HEPNET decnet IV ) = log(15000) / log(2^16) =0.867 = 86.7 % !!!!!!!!!!!!
A measure often employed in measuring IPv6 address consumption is Durand-Huitema Host Density :
HD is a real number between 0 and 1, often expressed as a percentage 0% to 100%. Using log
2 or log
10 or ln
is indifferent cause : log
10(x) =log
2(x)*log
10(2)
From experience : 80% is reasonable, 85% painful, 86% very painful, 87% maximum.

Oct 19, 2015 Roberto Innocente [email protected] 37
Using HD to plan an IPv6 net
2 levels : Sites, vlansSites < 8 = 2^3 => all at least 2^4 = 1 hex HD=0.75Vlans < 256= 2^8 => all at least 2^11 = 3 hex HD=0.66
● 2001:760:xxxx::/48 assigned● 2001:760:xxxx:y000::/52 sites● 2001:760:xxxx:yzzz::/64 vlans
23

Oct 19, 2015 Roberto Innocente [email protected] 38
48 bits of Site Prefix
IPv6 has variable mask lengths and so there is no predetermined division between subnets like in CIDR IPv4.● 3 bits assigned by IETF : 2000::/3 to mean global
unicast● 9 bits assigned by IANA : e.g. 2620::/12 assigned to the
RIR ARIN, 2a00::/12 to RIPE(12 bits are 3 hex digits)● 12-20 RIR ● 16-24 RIR or ISP● Universities are often assigned a /48 prefix, leaving
them a 16 bits subnet field to be used for the internal topology
12+24 = 36 bits20+16 = 36 bits

Oct 19, 2015 Roberto Innocente [email protected] 39
Gradual deployment. How ?
● First : it will be given to the IT personnel the possibility to browse IPv6 trough a tunnel to create appropriate skills
● Second : an IPv6 island will be configured on the router interface for the IT personnel vlan or the DMZ
● Third : it will be configured on all routers and switches and given to the users

Oct 19, 2015 Roberto Innocente [email protected] 40
Transition technologies
Tunnels (poor men IPv6) :● 6to4 doesn't work behind our fw,
encapsulates IPv6 pkt in IPv4 pkt using IPv6-in-IPv4 protocol type
● ISATAP● Teredo encapsulates Ipv6 in IPv4 UDP● ...

Oct 19, 2015 Roberto Innocente [email protected] 41
Teredo tunnel
Ipv6Internet
IPv4Internet
IPv4 Teredo serverMiredo...mucip.net
Ipv4 UDP3545
Ipv4 UDP 3544
Ipv4/ipv6 Teredo Relay
…. .he.net
Ipv6 onlyhost
Ipv6
Ipv6
Teredo ClientIpv6/ipv4
IPv4 UDP

Oct 19, 2015 Roberto Innocente [email protected] 42
Teredo address and data packets
Teredo prefix2001 : 0000
Teredo Server IPv4address
ObscuredExternal Address
Flags ObscuredExternal Port
32 bits 32 bits 16bits 16bits 32 bits 2001:0::/32 83.170.6.76 RFC4380 teredo.remlab.net
IPv4 header UDP header IPv6 payload IPv6 header
Client address :
Data Packet :
Client address :
Teredo bubble Packet : Data packet with an IPv6 packet without payload. Sent regularly to keep warm the connection (usually the NAT association).

Oct 19, 2015 Roberto Innocente [email protected] 43
Teredo generated traffic
root@geist:~# tcpdump port 3544 or port 3545tcpdump: verbose output suppressed, use -v or -vv for full protocol decodelistening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
12:49:13.679161 IP geist.local.3545 > miredo.svr01.mucip.net.3544: UDP, length 6112:49:13.701575 IP miredo.svr01.mucip.net.3544 > geist.local.3545: UDP, length 11712:49:13.727435 IP geist.local.3545 > miredo.svr01.mucip.net.3544: UDP, length 6612:49:13.772224 IP miredo.svr01.mucip.net.3544 > geist.local.3545: UDP, length 48
12:49:13.772313 IP geist.local.3545 > 6to4.lon1.he.net.60298: UDP, length 4012:49:13.804079 IP 6to4.lon1.he.net.60298 > geist.local.3545: UDP, length 6612:49:13.804134 IP geist.local.3545 > 6to4.lon1.he.net.60298: UDP, length 8212:49:13.804144 IP geist.local.3545 > 6to4.lon1.he.net.60298: UDP, length 8212:49:13.847535 IP 6to4.lon1.he.net.60298 > geist.local.3545: UDP, length 11412:49:13.847617 IP 6to4.lon1.he.net.60298 > geist.local.3545: UDP, length 14312:49:13.848351 IP geist.local.3545 > 6to4.lon1.he.net.60298: UDP, length 8212:49:13.848364 IP geist.local.3545 > 6to4.lon1.he.net.60298: UDP, length 82
ExchangeWith Teredo server
Exchange withTeredo Relay

Oct 19, 2015 Roberto Innocente [email protected] 44
Configure Teredo on Linux
$sudo aptget install miredo$sudo echo “InterfaceName teredoServerAddress teredodebian.remlab.net” >/etc/miredo.conf$sudo /etc/init.d/miredo restart #or usingsystemdCode from Rémi Denis-Courmont (remlab.net), relays courtesy of Hurricane Electric (a wholsesale provider) that distributed around the world 14 teredo relays. The microsoft relay since long is not in operation anymore.

Oct 19, 2015 Roberto Innocente [email protected] 45
Configure Teredo on Windows
Run as administrator at the command prompt :
C:\> netsh interface teredoNetsh>interface>teredo> show all..Netsh>interface>teredo> set servername=teredo.remlab.net..

Oct 19, 2015 Roberto Innocente [email protected] 46
Ipv6-test.com after teredo from firefox
Score 18/20 = teredo tunneled ipv6 / no hostname in dns

Oct 19, 2015 Roberto Innocente [email protected] 47
Ipv6-test.com after teredo with konqueror
Score 15/20 because konqueror doesnt fast-fallback on ipv4 (red : -3) !

Oct 19, 2015 Roberto Innocente [email protected] 48
Ipv6 test sites
● ipv6.google.com● ipv6-test.com● test-ipv6.com● [2001:200:dff:fff1:216:3eff:feb1:44d7]
(www.kame.net : turtle swimms if your reach the site using ipv6)
● http://ip.bieringer.de/

Oct 19, 2015 Roberto Innocente [email protected] 49
Questions/1
● How many bits in an IPv6 address ? How many bits in the interface part ?– 128, 64
● Protocol with longer addresses ?– ISO CLNP (Connectionless protocol) addresses up to 160 bits
● Chain of control for IPv6 addresses ?– IANA, RIRs, ISPs/LIRs
● In which case end users should renumber if they change provider ?– Provider aggregatable address
● How long will be normally the IPv6 prefix assigned to an institution or a company ? How many bits for the site topology will remain ?– /48, 16
● Algorithm for assigning addresses in the sparsest way, an example ?– Bit reversal, 0 8 4 12 2 10 6 14 1 9 5 7 3 11 7 15
● Objective measure of being “short of addresses” ? – Host density = log(allocated)/log(allocateable) > 0.75, hd=log(23)/log(24)=3/4=0.75
● Prefix for Link local addresses ? Unique Local ? Teredo ?– Fe80::/10, fd00::/8, 2001:0::/32
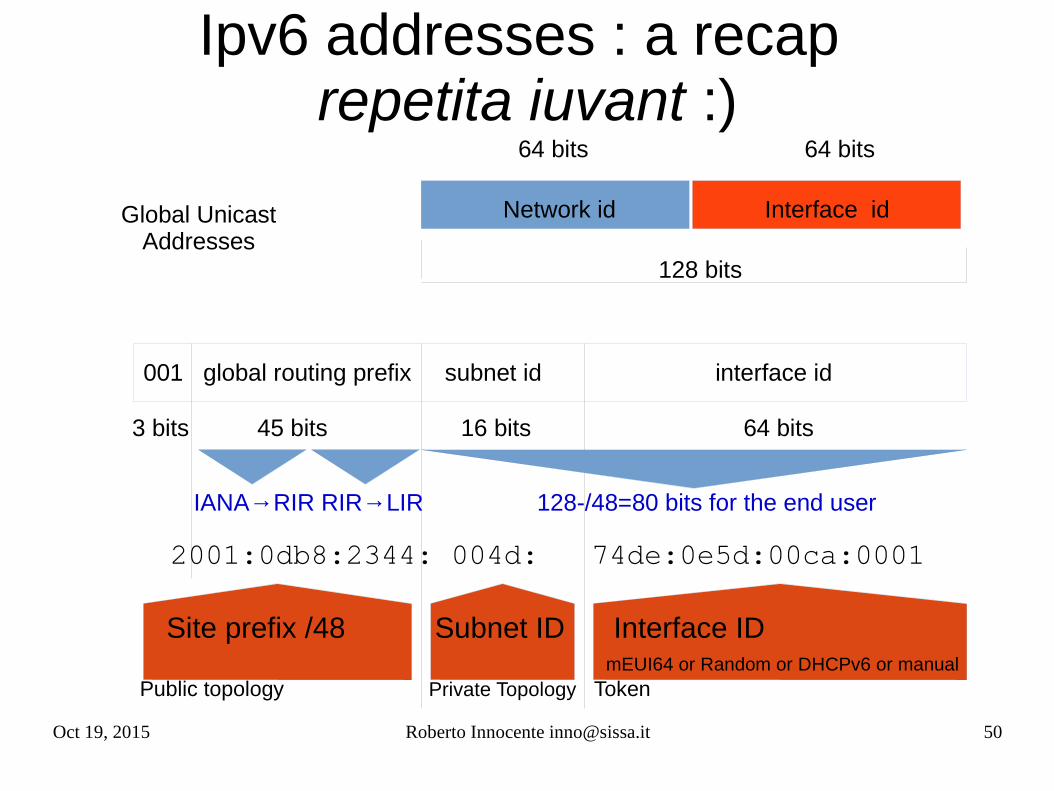
Oct 19, 2015 Roberto Innocente [email protected] 50
Ipv6 addresses : a recap repetita iuvant :)
64 bits 64 bits
Interface idNetwork id
128 bits
001 global routing prefix subnet id interface id
45 bits3 bits 16 bits 64 bits
IANA→RIR RIR→LIR 128-/48=80 bits for the end user
2001:0db8:2344: 004d: 74de:0e5d:00ca:0001
Site prefix /48 Subnet ID Interface ID mEUI64 or Random or DHCPv6 or manual Public topology Private Topology Token
Global UnicastAddresses

Oct 19, 2015 Roberto Innocente [email protected] 51
How to use a numeric IPv6 addressin a URL ?
For reasons that you'll understand , often if you access this site with its name the turtle will not swimm. Use : nslookup www.kame.net to get the address.NB. firefox in previous release supported the IPv6 zone id: %eth0 or %7, in later releases it does'nt anymore. There is a clash with the use of characters in hex : %20.

Oct 19, 2015 Roberto Innocente [email protected] 52
aptget
You are using a tunnel technology and apt- get over IPv6 is a snail ?1. Valid for the single command , add the option :aptget install log4cplus o Acquire::ForceIPv4=true
2. Valid forever, create/etc/apt/apt.conf.d/99forceipv4 and put in it the line :Acquire::ForceIPv4 “true”;

Oct 19, 2015 Roberto Innocente [email protected] 53
ping
There is a separate version for pinging on ipv6 on linux : ping6, on Windows use ping -6
inno@geist:~$ ping6 google.comPING google.com(mia07s24inx0e.1e100.net) 56 data bytes64 bytes from mia07s24inx0e.1e100.net: icmp_seq=1 ttl=57 time=367 ms64 bytes from mia07s24inx0e.1e100.net: icmp_seq=2 ttl=57 time=126 msLink local addresses should be specified together with interface :inno@geist:~$ ping6 I eth0 ghost.localPING ghost.local(ghost.local) from fe80::219:99ff:fe79:ff0 eth0: 56 data bytes64 bytes from ghost.local: icmp_seq=1 ttl=64 time=0.460 ms64 bytes from ghost.local: icmp_seq=2 ttl=64 time=0.458 ms
Ping6 consults the neighbour cache to find the LinkLayer Address (MAC) of the next-hop address and if it is there and still valid then it sends an ICMPv6 EchoRequest = 128 to the node and waits to receive an ICMPv6 EchoReply = 129. If the entry doesnt exists or it is expired then the kernel itself sends an ICMPv6 NeighborSolicitation = 135 packet and waits for an ICMPv6 NeighborAdvertisement = 136 from the other node.NeighborSolicitation usually happens every 60 seconds.

Oct 19, 2015 Roberto Innocente [email protected] 54
IPv6 Node Information
● Rfc4620 (experimental)● NIC (Node Information Query)● Implemented in the original KAME on bsd :
ping6 as client and ninfod as server.● On Ubuntu Linux ping6 implements the client,
but no server (daemon) for it (security concerns)
● A server ninfod exists in the iputils of the USAGI/WIDE project, in fedora iputils-ninfod

Oct 19, 2015 Roberto Innocente [email protected] 55
Ping as rfc4620/NIQclient
ping N ...In this case ping will send a Network Information query (rfc4620).
Flag Description
-N X Sends a Node Addresses query. X can be the following character.
help – show help for NI
name – query for node names
ipv6 – query addresses
ipv6-global query global scope unicast addresses
ipv6-sitelocal query site-local addressses
ipv6-linklocal query link local addresses
ipv6-all query all addresses
ipv4 query ipv4 addresses
ipv4-all on all interfaces
subject-ipv6=ipv6addr
subject-ipv4=ipv4addr
subject-name=nodename
subject-fqdn=fullyqualifieddomainname

Oct 19, 2015 Roberto Innocente [email protected] 56
ssh to link local ipv6 address
inno@geist:~$ avahi-resolve -6n ghost.localghost.local fe80::b6b6:76ff:fe60:588cinno@geist:~$ ssh -6 inno@fe80::b6b6:76ff:fe60:588c%eth0 #doesn't work with .local%eth0Welcome to Ubuntu 15.04 (GNU/Linux 3.19.3-031903-generic x86_64) * Documentation: https://help.ubuntu.com/Last login: Thu Sep 17 09:59:42 2015 from fe80::219:99ff:fe79:ff0%eth0inno@ghost:~$ tail /var/log/auth.logSep 17 10:05:55 ghost sshd[4245]: Address fe80::219:99ff:fe79:ff0%eth0 maps to geist.local, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!Sep 17 10:05:55 ghost sshd[4245]: Accepted publickey for inno from fe80::219:99ff:fe79:ff0%eth0 port 59205 ssh2: RSA fe:6b:ef:53:f7:78:fe:55:5e:b8:b8:60:d1:d2:90:ab

Oct 19, 2015 Roberto Innocente [email protected] 57
cccccc0g|cccccccc|mmmmmmmm|mmmmmmmm|mmmmmmmm
Generation of modified EUI64 Extended Unique ID(64 bits suffix)
1. Get 48 bit MAC of interface 00:19:99:79:0f:f02. Split into 2 24bit groups 001999 790ff03. Insert 0xfffe in the middle 001999fffe790ff04. Flip 7th bit of 1st byte 021999fffe790ff05. Represent it as an Ipv6 ::219:99ff:fe79:ff0 suffixTo get the LinkLocal EUI64 address, prefix it with 0xfe80 : LinkLocal Address: fe80::219:99ff:fe79:ff0An IPv6 node can be configured to get an EUI64 or a Randomized LinkLocal Address.7th bit of 1st byte is U/L (Universally/Locally assigned) MAC address bit.If the MAC was Universally assigned =1, then the modified EUI64 is a Locally assigned =0 address.
48 bits MAC address details 14 bits manufacturer code : c0=universally assignedg individual/group bit24 bits assigned by manufacturer : m..

Oct 19, 2015 Roberto Innocente [email protected] 58
mEUI64 modified EUI64
00 f00f799919
19 0f79feff99 f000
19 0f79feff99 f002
00000000
00000010
MAC 48 bits
mEUI64 bits
EUI 64 bits
The 7th bit of 1st byte is the Universal(=0), Local(=1) bit. In this way the Universal MAC assigned by the producer, becomes a Locally assigned 64 bits mEUI.
48 bits
64 bits
64 bits

Oct 19, 2015 Roberto Innocente [email protected] 59
IPv4 header
Version IHL Type of Service
Identification (Fragment ID)
Total Lenght
MF
DF Fragment offset
ProtocolTime-To-Live Header Checksum
0
4
8
12
16
20
20 b
ytes
| 0 3 | 4 7 | 8 15 | 16 31 |
32 bits
In IPv4 the header is common to all protcols. There is no IP only packet, but ICMPv4, TCP, UDP and IPSEC are top level entities at same level (signalled by the Protocol field) :
1 ICMPv4 Internet Control Message Protocol for IPv4 (RFC 792) 2 IGMP Internet Group Management Protocol (RFCs 1112, 2236 and 3376)4 IPv4 IPv4 in IPv4 encapsulation, "IP in IP" tunneling (RFC 2003) 6 TCP Transmission Control Protocol (RFC 793) 8 EGP Exterior Gatgeway Protocol (RFC 888)
Pic CourtesyG. Radeka
17 UDP User Datagram Protocol (RFC 768) 41 IPv6 IPv6 tunneled over IPv4, "6in4" tunneling (RFC 2473)50 IPSec ESP Header (RFC 2406) 51 IPSec AH Header (RFC 2402)89 OSPF Open Shortest Path First routing (RFC 1583) 132 SCTP Streams Control Transmission Protocol (RFC 4960)

Oct 19, 2015 Roberto Innocente [email protected] 60
Header checksum, Upper Layer Checksum
● A major decision for IPv6 was to eliminate the header checksum : it was due to the fact that most of the errors revealed were due to the memory of routers when this checksum is in any case recalculated and so it was not of any help.
● UDP and TCP provide a checksum by themselves that covers not the real header (that changes along the way [ think about the HopLimit] and would require expensive recalculations, but a pseudo header (that doesn't change, same strategy as IPv4) that will be checked only by the destination.
Source address16 bytes
Destination address16 bytes
Upper layer packet-length (4 bytes)Zeroes (3 bytes) Next Header
0 31
IPv6pseudo-header

Oct 19, 2015 Roberto Innocente [email protected] 61
IPv6 header
In IPv6:● IPv4 IHL is missing. Header is always 40 bytes
(quite more efficient for routers on the path)● IPv4 TotalLength is replaced by IPv6
PayloadLength● IPv4 Fragment ID, Fragment offset, DF, MF
are part of a special fragment header: only sending node can fragment in IPv6
● Header checksum is missing : most errors happen in memory when headers are recalculated
● IPv4 options are missing : header is fixed length, eventually Next Header field can specify a list of other headers
● IPv6 flowlabel is new and gives the possibility to give a label to the flow. Label that will be processed by routers on the way
● IPv4 TTL is now more properly called Hop Limit
Version Traffic Class Flow Label (20 bits)
Payload Length Next Header Hop Limit
Source Address (128 bits)
Destination Address (128 bits)
|0 3| 11| 15|16 31|
40 bytes
0 4 8 12 1 6 20 24 28 32 36

Oct 19, 2015 Roberto Innocente [email protected] 62
IPv6 Next Header
NextHeader codes :A new Hop-by-Hop extension header is defined in RFC 2675, "IP Jumbograms", August 1999. If this extension header is present, it overrides the Payload Length field with a 32 bit value. This allows the payload length to be up to 4 gigabytes.They can be found mixed with IPv4 analogous protocol values in /etc/protocols.
0 Hop-by-Hop extension header 6 TCP - Transmission Control Protocol (RFC 793) 17 UDP - User Datagram Protocol (RFC 768) 43 Routing Extension Header : ipv6-route 44 Fragment Extension Header : ipv6-frag 50 IPSec ESP Header (RFC 2406) : esp 51 IPSec AH Header (RFC 2402) : ah 58 ICMPv6 (Internet Control Message Protocol for IPv6 (RFC 4443) : ipv6-icmp 59 No next header (packet ends after this header or extension header): ipv6-nonxt 60 Destination Options extension header: ipv6-opts 89 OSPF - Open Shortest Path First routing (RFC 1583): ospf132 SCTP - Streams Control Transmission Protocol (RFC 4960): sctp

Oct 19, 2015 Roberto Innocente [email protected] 63
IPv6 header chains
Header chains in IPv6 :
IPv6TCP
TCPHeader Data
IPv6ICMPv6
ICMPv6Header Data
IPv6Rout Hdr
Routing Extension hdr Data
IPv6FragmentHeader 1st fragment
Data
TCPHeader
Routing Extension hdr
Frag H TCPRout Hdr
TCPHeader
TCP
NoNxt
Next Header Labels
RFC2460 order of hdrs :- Hop-by-Hop- Destination Opt hdr- Routing Header- Fragment Header- Auth hdr- ESP hdr- UpperLayer protocol hdr

Oct 19, 2015 Roberto Innocente [email protected] 64
IPv6 fragmentation/1
● Routers can't perform fragmentation along the path like in IPv4
● Only the source node,after performing PathMTU discovery or receving a Packet Too Big ICMPv6 error msg, can fragment the packets (How can this happen ?)
Fragment Header :
NextHeader: 8 bits header type of the payloadReserved : 8 bitsFragment offset : 13 bits unsigned, offset into fragmentable part in multiples of 8 bytes. Therefore can indicate an offset up to 8191*8 = 65,528. You can't use it for jumbograms. Res : 2 bitsM : 1=more frags, 0=last fragmentIdentification : 32 bits unique integer
Next Hdr Reserved Fragment Offset Res M
Identification
8 bits 8 bits 13 bits 2 1
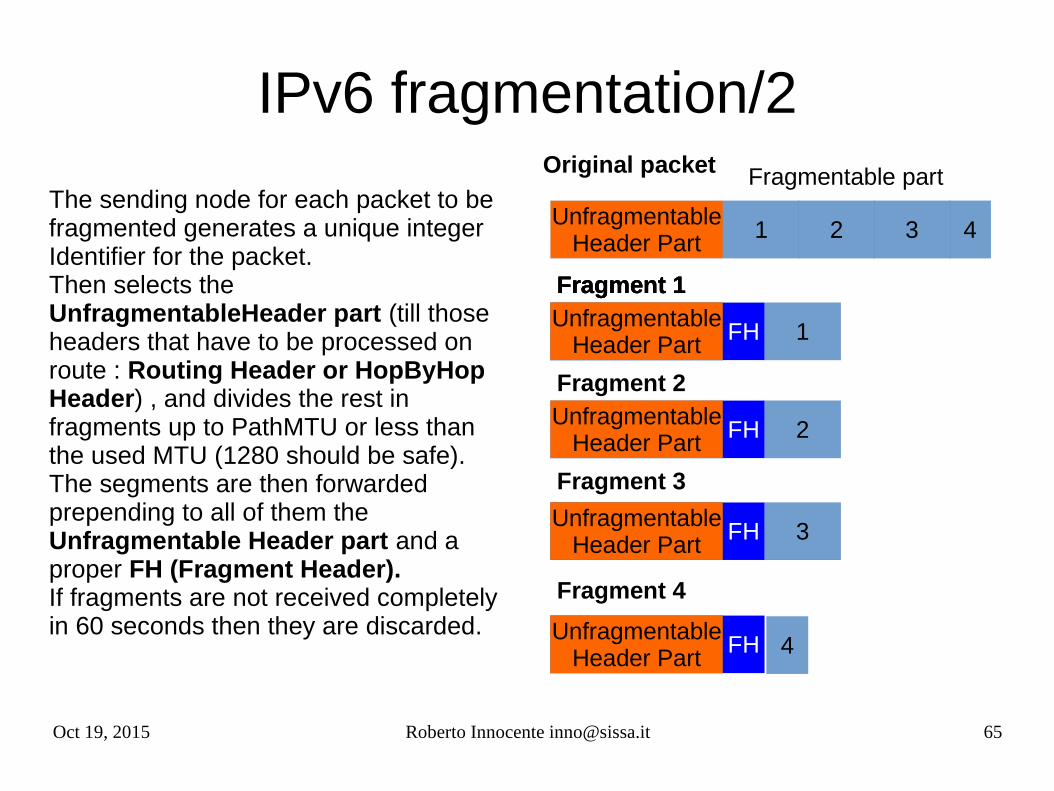
Oct 19, 2015 Roberto Innocente [email protected] 65
IPv6 fragmentation/2
The sending node for each packet to be fragmented generates a unique integer Identifier for the packet.Then selects the UnfragmentableHeader part (till those headers that have to be processed on route : Routing Header or HopByHop Header) , and divides the rest in fragments up to PathMTU or less than the used MTU (1280 should be safe).The segments are then forwarded prepending to all of them the Unfragmentable Header part and a proper FH (Fragment Header).If fragments are not received completely in 60 seconds then they are discarded.
UnfragmentableHeader Part
1
Fragmentable part
432
UnfragmentableHeader Part
3
4
Original packet
UnfragmentableHeader Part
UnfragmentableHeader Part
UnfragmentableHeader Part 2
Fragment 1Fragment 1Fragment 1
Fragment 2
UnfragmentableHeader Part
UnfragmentableHeader Part
UnfragmentableHeader Part
UnfragmentableHeader Part 1
UnfragmentableHeader Part
UnfragmentableHeader Part
Fragment 4
Fragment 3
UnfragmentableHeader Part
FH
FH
FH
FH

Oct 19, 2015 Roberto Innocente [email protected] 66
IPv6 fragmentation/3
Security risk :With fragments the upper layer protocol can finish in next packets, hidden in the fragmentable part :● Extension headers tricks : reorder, long chains,
overlapping fragments (forbidden recently by RFC5722)
● Impossible to filter without stateful firewallOnly possible stateless remedy (eg on Cisco) :● deny ipv6 any any log undetermined transport

Oct 19, 2015 Roberto Innocente [email protected] 67
IPv6 jumbograms (RFC2675)
● The Hop-by-Hop header is used to specify delivery parameters for hops on the path (it is specified by a previous next-header=0)
Next Hdr Hdr Ext length Options ….
1 byte 1 byteNumber
of 8 bytes groupsother than 1st
Options in TLV format and padding to 8x
Option type Option length Data
Jumbo payload opt
=194
4 4 bytesJumbo payload length
Up to 232 -1
Hop-by-hopExt Header
Jumbogramoption
NB. This is an IPv6 jumbogram (that in principle can cross the whole Internet), not a “jumbogram frame”, those used on Ethernet with an MTU of just 9000. Rumors : “terrible academic idea” :)

Oct 19, 2015 Roberto Innocente [email protected] 68
Routing extension header/1
Next header Segments leftRouting typeHdr ext len
0 24168 31
type specific data
Type 0 : evil. Provides the same loose route mechanism as in IPv4. Should be filtered. Type 1 : unused now. Defined by the Nimrod project for ipng. Should be filtered also.Type 2 : used by mobile MIPv6 and understood only by mobile stacks. Inoffensive. Should be allowed.
OS host router deactivateLinux >2.6.20 drop process no
MacOS X >10.4.10drop process No
Cisco IOS N/a process yes
Windows >Vista drop N/a N/a
What OS do withsource route type 0Headers ?

Oct 19, 2015 Roberto Innocente [email protected] 69
Routing extension type 0/2
Next header Segments leftRouting type=0Hdr ext len = N
0 24168 31
Address 1 (16 bytes)
Reserved 32 bits (4 bytes)
Address N/2 (16 bytes)
.
.
.
RH0 security threat : with an MTU of 1500 you can inject packets with up to 90 waypoints (it means traversing all internet for 45 times back and forth), because the waypoints don't need to be contiguous. With a 2 mbit/s connection you amplificate your DoS attack till 180 mbit/s. That's why processing of RH0 headers should by default be avoided. (RFC5722)

Oct 19, 2015 Roberto Innocente [email protected] 70
Routing extension type 0/3Packet Initial Src : fd00:18::1:0 and Dst : fd00:18:3:5
fd00:18::1:0 fd00:18::4:2fd00:18::3:5fd00:18::1:1
Dst: fd00:18::1:1 Dst: fd00:18::6:4Dst: fd00:18::4:2Dst: fd00:18::3:5

Oct 19, 2015 Roberto Innocente [email protected] 71
Cisco and RH0
#conf t
(config)#no ipv6 sourceroute
All source route packets can be blocked in this way, but this would also block RH2 required by MIPv6(Mobile Ipv6). To avoid this we need to apply on each interface :(config)#ipv6 accesslist denysourcerouted
(configipv6acl)#deny ipv6 any any routingtype 0
(configipv6acl)#permit ipv6 any any
(configipv6acl)#int gi0/0
(configif)#ipv6 sourceroute
(configif)#ipv6 trafficfilter denysourcerouted in

Oct 19, 2015 Roberto Innocente [email protected] 72
IPv6 on Ethernet
Max size of ethernet frames was since the beginning established in 1518 bytes.IPv4 was encapsulated on Ethernet II using a 16 bits ether-type of 0x0800 (look at /etc/ethertypes).NB. IPv4 Arp uses a different ethertype of 0x0806.IPv6 uses the 0x86dd ethertype for all its functions ICMPv6, Neighbor Discovery, Router Discovery, …08:44:54.554797 f0:79:59:62:02:42 (oui Unknown) > 00:19:99:79:0f:f0 (oui Unknown), ethertype IPv6 (0x86dd), length 118: (hlim 64, nextheader ICMPv6 (58) payload length: 64) linux.local > geist.local: [icmp6 sum ok] ICMP6, echo reply, seq 1
Ethernet II header = 14 bytes + 4 bytes FrameCheckSequence = RFC894 encapsulation 18 bytesIPv6 packets sent over Ethernet II have a maximum transmission unit of 1500 (9000 for ethernet jumbograms) and a minimum size of 46 (to comply with the minimum ethernet frame size of 64 bytes: eventually should be padded to 46 bytes).Ethernet 802.3 header = 14 bytes + 8 bytes LLC/SNAP hdr + 4 bytes FCS = RFC1042 encapsulation 26 bytesIPv6 over 802.3 Ethernet (very rare now) and LLC/SNAP encapsulation has an MTU of 1492 bytes due to the 8 bytes of the LLC/SNAP header.IEEE 802.11 Wireless has an MTU of 2312 bytesFDDI has an MTU of 4352 bytes With the large diffusion of VLANs use the max size of Ethernet frames has been increased for the purpose of including the VLAN tag (4 bytes) to 1522 bytes, Leaving the MTU to 1500 and 1492.

Oct 19, 2015 Roberto Innocente [email protected] 73
Transition addresses
● IPv4-compatible address : used by IPv4/6 nodes that are communicating in IPv6 over an IPv4 structure 0.0.0.0.0.0.w.x.y.z or ::w.x.y.z for the IPv4 address in dotted decimal notation w.x.y.z, deprecated in RFC4291
● IPv4-mapped address: used to represent an IPv4 address as an IPv6 address (same socket6 address struct) ::ffff:x.y.w.z. Should not be seen on a wire. Appears if you program in an ip-agnostic way and the connection is from an ipv4 node.
● 6to4 address : a 2002:wwxx:yyzz:subnetID:interfaceID for the IPv4 node in hex notation ww.xx.yy.zz
● ISATAP address● Teredo address : 2001:0::/32●

Oct 19, 2015 Roberto Innocente [email protected] 74
Network programming/1
Is it possible to build network programs that can work transparently with ipv4 or ipv6 ?● The latest socket API can support transparently IPv4
and IPv6 together.● The oldest gethostbyname() has been replaced by
getaddrinfo() with which to query DNS servers and get indifferently ipv4 or ipv6 address structures.
● inet_addr() and inet_toa() are replaced by : – inet_pton() : convert ipv4/6 text to binary for both stacks
– inet_ntop() : convert ipv4/6 binary addr to text for both stacks

Oct 19, 2015 Roberto Innocente [email protected] 75
socketsstruct in_addr { __be32 s_addr;};#define __SOCK_SIZE__ 16/* sizeof(structsockaddr)*/
struct sockaddr_in { __kernel_sa_family_tsin_family; /*Addressfamily*/ __be16 sin_port;/* Port number */
struct in_addrsin_addr; /*Internet address*/ /* Pad to size of `struct sockaddr'. */ unsigned char __pad[__SOCK_SIZE__ sizeof(short int)sizeof(unsigned short int) sizeof(struct in_addr)];};
struct sockaddr_in6 { sa_family_t sin6_family; /*AF_INET6 */ in_port_t sin6_port; /*port number*/ uint32_t sin6_flowinfo; /*IPv6 flow */
struct in6_addr sin6_addr; /*IPv6 address*/ uint32_t sin6_scope_id; /*Scope ID*/};struct in6_addr { unsigned char s6_addr[16]; /* IPv6 address*/};
struct addrinfo { int ai_flags; int ai_family; int ai_socktype; int ai_protocol; socklen_t ai_addrlen; struct sockaddr *ai_addr; char *ai_canonname; struct addrinfo *ai_next;};
family
flags
*next
*addr
addrlen
type
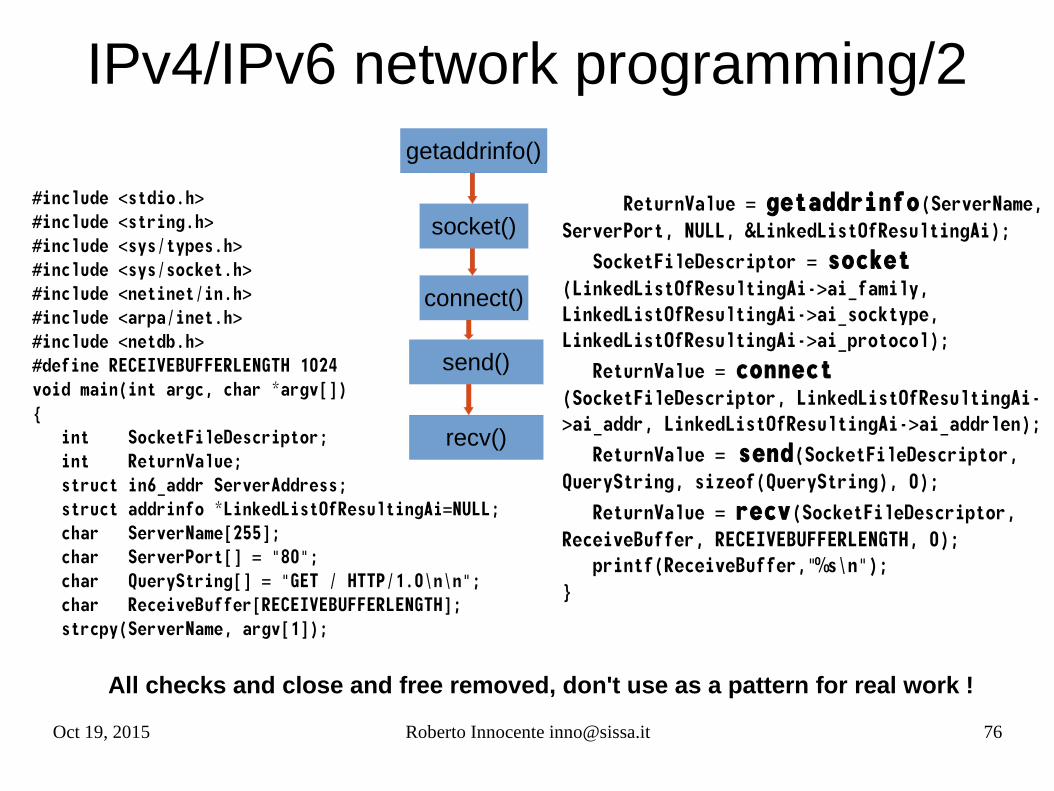
Oct 19, 2015 Roberto Innocente [email protected] 76
IPv4/IPv6 network programming/2
#include <stdio.h>#include <string.h>#include <sys/types.h>#include <sys/socket.h>#include <netinet/in.h>#include <arpa/inet.h>#include <netdb.h>#define RECEIVEBUFFERLENGTH 1024void main(int argc, char *argv[]){ int SocketFileDescriptor; int ReturnValue; struct in6_addr ServerAddress; struct addrinfo *LinkedListOfResultingAi=NULL; char ServerName[255]; char ServerPort[] = "80"; char QueryString[] = "GET / HTTP/1.0\n\n"; char ReceiveBuffer[RECEIVEBUFFERLENGTH]; strcpy(ServerName, argv[1]);
ReturnValue = getaddrinfo(ServerName, ServerPort, NULL, &LinkedListOfResultingAi); SocketFileDescriptor = socket (LinkedListOfResultingAi->ai_family, LinkedListOfResultingAi->ai_socktype, LinkedListOfResultingAi->ai_protocol); ReturnValue = connect (SocketFileDescriptor, LinkedListOfResultingAi->ai_addr, LinkedListOfResultingAi->ai_addrlen); ReturnValue = send(SocketFileDescriptor, QueryString, sizeof(QueryString), 0); ReturnValue = recv(SocketFileDescriptor, ReceiveBuffer, RECEIVEBUFFERLENGTH, 0); printf(ReceiveBuffer,"%s\n");}
All checks and close and free removed, don't use as a pattern for real work !
getaddrinfo()
recv()
send()
connect()
socket()
Oct 19, 2015 Roberto Innocente [email protected] 77
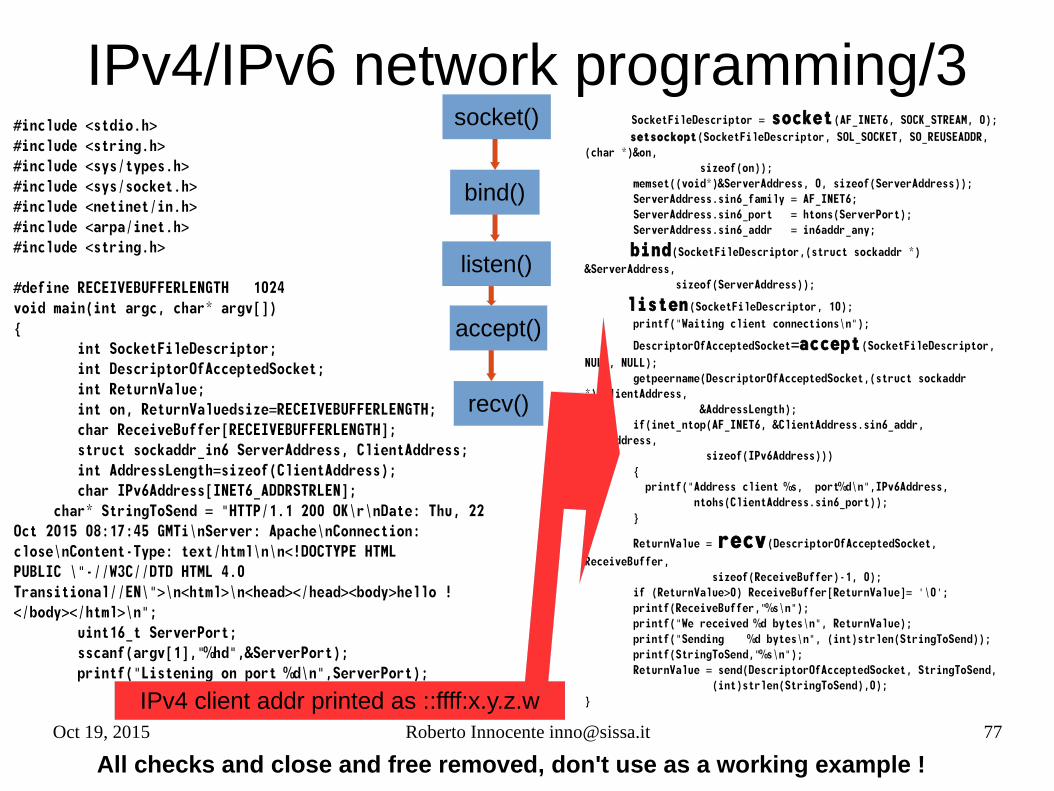
IPv4/IPv6 network programming/3#include <stdio.h>#include <string.h>#include <sys/types.h>#include <sys/socket.h>#include <netinet/in.h>#include <arpa/inet.h>#include <string.h>
#define RECEIVEBUFFERLENGTH 1024void main(int argc, char* argv[]){ int SocketFileDescriptor; int DescriptorOfAcceptedSocket; int ReturnValue; int on, ReturnValuedsize=RECEIVEBUFFERLENGTH; char ReceiveBuffer[RECEIVEBUFFERLENGTH]; struct sockaddr_in6 ServerAddress, ClientAddress; int AddressLength=sizeof(ClientAddress); char IPv6Address[INET6_ADDRSTRLEN]; char* StringToSend = "HTTP/1.1 200 OK\r\nDate: Thu, 22 Oct 2015 08:17:45 GMTi\nServer: Apache\nConnection: close\nContent-Type: text/html\n\n<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0 Transitional//EN\">\n<html>\n<head></head><body>hello !</body></html>\n"; uint16_t ServerPort; sscanf(argv[1],"%hd",&ServerPort); printf("Listening on port %d\n",ServerPort);
SocketFileDescriptor = socket(AF_INET6, SOCK_STREAM, 0); setsockopt(SocketFileDescriptor, SOL_SOCKET, SO_REUSEADDR,(char *)&on, sizeof(on)); memset((void*)&ServerAddress, 0, sizeof(ServerAddress)); ServerAddress.sin6_family = AF_INET6; ServerAddress.sin6_port = htons(ServerPort); ServerAddress.sin6_addr = in6addr_any;
bind(SocketFileDescriptor,(struct sockaddr *) &ServerAddress, sizeof(ServerAddress));
listen(SocketFileDescriptor, 10); printf("Waiting client connections\n");
DescriptorOfAcceptedSocket=accept(SocketFileDescriptor, NULL, NULL); getpeername(DescriptorOfAcceptedSocket,(struct sockaddr *)&ClientAddress, &AddressLength); if(inet_ntop(AF_INET6, &ClientAddress.sin6_addr, IPv6Address, sizeof(IPv6Address))) { printf("Address client %s, port%d\n",IPv6Address, ntohs(ClientAddress.sin6_port)); }
ReturnValue = recv(DescriptorOfAcceptedSocket, ReceiveBuffer, sizeof(ReceiveBuffer)-1, 0); if (ReturnValue>0) ReceiveBuffer[ReturnValue]= '\0'; printf(ReceiveBuffer,"%s\n"); printf("We received %d bytes\n", ReturnValue); printf("Sending %d bytes\n", (int)strlen(StringToSend)); printf(StringToSend,"%s\n"); ReturnValue = send(DescriptorOfAcceptedSocket, StringToSend, (int)strlen(StringToSend),0);}
All checks and close and free removed, don't use as a working example !
socket()
recv()
accept()
listen()
bind()
IPv4 client addr printed as ::ffff:x.y.z.w

Oct 19, 2015 Roberto Innocente [email protected] 78
IPv6 Multicast addressesand their Ethernet mapping
Group ID
8 bits
4 bits
4 bits
112 bits
Scope Flag0xff
Multicast IPv6 addresses have the prefix ff00::/8.Flag:0 Permanent well know address By IANA1 Transient, dynamic multicast address, RendezVous2 Without prefix info, take it by net3 Transient, dynamic. Assigned Ethernet destination addresses for IPv6 multicasts :33-33+last 32 bits of Group IDe.g. ff02::101 all ntp servers on LAN ff08::101 all ntp servers in organizationEthernet dest equivalent : 33-33-00-00-01-01..
Scope :• 0: Reserved• 1: Interface-Local scope• 2: Link-Local scope• 3: IPv4 local scope • 4: Admin-Local scope• 5: Site-Local scope• 6: Unassigned• 7: Rendezvous Point flag• 8: Organization-Local scope• E: Global Scope
IPv4 multicasts were instead mapped to the ethernet destinations :● 01:00:5E:00:00:00 – 01:00:5E:7F:FF:FF (23 bits
available for Group ID)

Oct 19, 2015 Roberto Innocente [email protected] 79
Multicast ScopesInternet
E - GlobalE - Global
1 – Interface Local
2 – Link Local
5 – Site Local
8 – Organization Local

Oct 19, 2015 Roberto Innocente [email protected] 80
Multicast groups
IPv6 tries to be minimal in resources it consumes so it replaced broadcast messages (as used by IPv4 : eg. arp) with multicast messages. There are 2 well known groups (that can be usually used with literals because they appear in /etc/hosts ) :● ff02::1 ip6-allnodes ● ff02::2 ip6-allrouters E.g. : ping6 -I eth0 ip6-allnodes ping6 -I eth0 ip6-allroutersAll nodes should be listen on the ip6-allnodes multicast address and all routers should be listen to the ip6-allrouters address. Therefore a node can easily discover its neighbours nodes, and the routers in its broadcast domain.

Oct 19, 2015 Roberto Innocente [email protected] 81
Multicast groups/2well known
Well known multicast groups :● ff02::1 All nodes on the local network segment● ff02::2 All routers on the local network segment● ff02::5 OSPFv3 All SPF routers● ff02::6 OSPFv3 All DR routers ● ff02::8 IS-IS for IPv6 routers● ff02::9 RIP routers● ff02::a EIGRP routers● ff02::d PIM routers● ff02::16 MLDv2 reports (defined in RFC 3810)● ff02::1:2 All DHCP servers and relay agents on the local network segment (defined in RFC 3315)● ff02::1:3 All LLMNR hosts on the local network segment (defined in RFC 4795)● ff05::1:3 All DHCP servers on the local network site (defined in RFC 3315)● ff0x::c Simple Service Discovery Protocol● ff0x::fb Multicast DNS● ff0x::101 Network Time Protocol● ff0x::108 Network Information Service● ff0x::181 Precision Time Protocol (PTP) version 2 messages ● ff02::6b Precision Time Protocol (PTP) version 2 peer delay measurement messages

Oct 19, 2015 Roberto Innocente [email protected] 82
RFC 2464 IPv6 Solicited-Node Multicast Address
In adddition to all unicast addresses assigned to an interface, a device will have an IPv6 Solicited-Node Multicast Address (remember that IPv6 doesn't use broadcasts ) created mapping the device unicast addr with the special multicast prefix :
So the device having :● LL address : fe80::374:12f8:8a7e:54d2/64● Global Unicast address: 2001:db8:bb:10:374:12f8:8a7e:54d2
Will listen also to ff02:0:0:0:0:1:ff7e:54d2 multicast address formed adding to the well known prefix the last 3 bytes of the IPv6 unicast address.
Copy 24 bits(3 bytes)
ff02::1:ff00:0/104Ff02:0:0:0:0:1:ff00:0/104

Oct 19, 2015 Roberto Innocente [email protected] 83
IPv4-IPv6 control protocols
IPv4 control protocols:● ARP● ICMPv4● IGMPv4
Parts of ICMPv4 and IGMPv4 are not required to be implemented. IGMP is part of IP multicast and is not usually available.
IPv6 control protocols :● Only ICMPv6
ICMPv6 needs to be fully implemented and every node needs to implement multicast.

Oct 19, 2015 Roberto Innocente [email protected] 84
ICMPv6
ICMPv6 is not just the transposition of ICMP to IPv6, but it collects in itself many different functionalities :● NDP (Network Discovery Protocol, RFC 4861), it
replaces arp of IPv4● MRD (Multicast Router Discovery, RFC4286)● MLD2 (Multicast Listener Discovery, RFC3810)● SEND (Secure Network Discovery Protocol,
RFC3971) an extension of NDPNextHeader type for ICMPv6 is 58.

Oct 19, 2015 Roberto Innocente [email protected] 85
ICMPv6/21 Destination Unreachable
2 Packet Too Big
3 Time Exceeded
4 Parameter Problem
128 Echo Request
129 Echo Reply
130 Multicast Listener Query
131 Multicast Listener Report
132 Multicast Listener Done
133 Router Solicitation (NDP)
134 Router Advertisement (NDP)
135 Neighbor Solicitation (NDP)
136 Neighbor Advertisement (NDP)
137 Redirect Message (NDP)
138 Router Renumbering
139 ICMP Node Information Query
140 ICMP Node Information Response
141 Inverse Neighbor Discovery Solicitation Message
142 Inverse Neighbor Discovery Advertisement Message
143 Multicast Listener Discovery (MLDv2) reports (RFC 3810)
144 Home Agent Address Discovery Request Message
145 Home Agent Address Discovery Reply Message
146 Mobile Prefix Solicitation
147 Mobile Prefix Advertisement
148 Certification Path Solicitation (SEND)
149 Certification Path Advertisement (SEND)
151 Multicast Router Advertisement (MRD)
152 Multicast Router Solicitation (MRD)
153 Multicast Router Termination (MRD)
155 RPL Control Message
58 = ICMPv6PING
ROUTER
PING
NEIGHBOR
MULTICAST
Bit offset 0-7 8-15 16-310 Type Code checksum
32 Message Body
Version4 bits
Traffic Class8 bits Flow Label (20 bits)
Payload Length(16bits)Next Header
8 bitsHop Limit
8 bits
Source Address (128 bits)
Destination Address (128 bits)
|0 3| 11| 15|16 31|
40 bytes
0 4 8 12 1 6 20 24 28 32 36
ICM
P m
sg T
ypes
ERRORS

Oct 19, 2015 Roberto Innocente [email protected] 86
ICMPv6/3
NDP (RFC4861) Network Discovery Protocol ( replaces arp), discovers LinkLayer addresses :● Show neighbours in neighbour
cache (NC) : ip -6 neighYou can populate the cache with a ping to ip-allnodesping6 -I eth0 ip-allnodes● Add a neighbour in NC :
Ip -6 neigh add fe80::be5f:f4ff:fecb:742f dev eth0 lladdr bc:5f:f4:cb:74:2f ● Delete a neighbour in NC :
Ip -6 neigh dele fe80::be5f:f4ff:fecb:742f dev eth0 lladdr bc:5f:f4:cb:74:2f● You can use ndisc6 to manually
perform network discovery of nodes :ndisc6 fe80::be5f:f4ff:fecb:742f eth0
ND is usually done automatically by the kernel when entries do not exist or are expired. To see it at work :1.Launch in a window ndpmon2.Launch in another window a
ping6 to a LinkLocal node fe80::...
3.You will see every minute or so that the kernel refreshes the entry in the NC sending a NeighborSolicitation and receiving a NeighborAdvertisement

Oct 19, 2015 Roberto Innocente [email protected] 87
ICMPv6/4
Routers on the LAN are discovered with simply a different ICMPv6 type : RouterSolicitation = 133 and RouterAdvertisement = 134 :● Show routes in tables :
ip -6 routeYou can populate the table with a ping to ip-allroutersping6 -I eth0 ip-allrouters● Add a route :
Ip -6 route add fe80::/64 dev eth0 proto kernel metric 256 ● Delete a route :
Ip -6 neigh dele fe80::/64 dev eth0 proto kernel metric 256● Discover manually :
rdisc6● You can list ipv6 routes also with :
netstat -6r
ndpmon monitors also Router Solicitation / Advertisement traffic. Routers are supposed to send an advertisement every 60 seconds to the multicast address ff02::2 (ip6-allrouters) in this way all nodes learn about the routers on the LAN and create their dispatch table. When nodes start ipv6 on an interface they try to solicit a router advertisement after 1 second and they try for 3 times every 4 seconds (default timers in net.ipv6.conf.... )In linux the router advertisement is done by the service radvd (Router Advertisement Daemon) configured by the file /etc/radvd.conf.Should not be activated on end nodes : in fact the daemon dies if it is not configured to send RA.On routers the router advertisement is activated by default when you assign an interface an ipv6 address.

Oct 19, 2015 Roberto Innocente [email protected] 88
ICMPv6 Router Advertisement pkt/1Current Hop Limit :The value the routersuggests hosts on the LANto use as Hop LimitRouter Lifetime :expiration lifetime inseconds for the routerbeing used as defaultrouter only, 0 means don'tuse this router as defaultrouterRechable Time :Tells hosts how long in msthey should considerreachable a neighbor aftera reachable msgRetransmission timer :The time in ms a hostshould wait to retxmit aNeighbor SolicitationmessageOptions :MTUPrefix
Reserved
ICMPv6 Options
Reachable Time
Retransmission Timer
Autoconfig Flags Router LifetimeCurrent Hop Limit
Code=0 ChecksumType=134
0 8 16 32
M managd
Addr conf
OOtherconf

Oct 19, 2015 Roberto Innocente [email protected] 89
ICMPv6 Router Advertisement pkt/2
Type Length Value...Options TLV format :
Source/Target LL Address (contains the LL address of source or target)
Type Length Value...
1=Source LL2=Target LL Length LL address
3=prefix info 0-128 bitsOf prefix
Prefix information L A Reserved 1
Valid Lifetime in sec for on-link
Preferred lifetime in sec for validity of derived addresses
Reserved1 must be =0
Prefix
L = on-link flag : this prefix can be used for on-link determinationA = autonomous address configuration flag : when set indicates that this prefix can be used for stateless address configuration

Oct 19, 2015 Roberto Innocente [email protected] 90
ICMPv6 Router Advertisement pkt/3
Type Length Value...Options TLV format : Type Length Value...
5=MTU1 x
8 bytes ...
5=MTU 1 x8 bytes
Reserved 1set to 0
MTU 32 bits
MTU (Maximum Transmission Unit)
The MTU option is sent in Router Advertisement to be sure that all nodes on a link use the same MTU.

Oct 19, 2015 Roberto Innocente [email protected] 91
RA flags
An host can perform dynamic address configuration in a stateful or stateless manner. Both are indipendent and can also be used together.1) Stateless :
● Using prefix discovery SLAAC● Using DHCPv6 stateless● Manually
2) Stateful :– Using DHCPv6 stateful
The A flag (Autonomous Address Configuration) in RA tells if the prefix advertised in the Router Advertisement can be used in SLAAC, by default is set to 1=yes.
IPv6 host behaviour Depends on 2 flags the router sets in its Route Advertisement messages:● M flag or Managed Address Configuration flag● O flag or Other Stateful Configuration flag
M,O are 0,0 : net w/o DHCPv6 server, host configures address from RA, other parameters are set manuallyM,O are 1,1 : DHCPv6 is used for addresses and other parameters (DHCP stateful)M,O are 0,1 : hosts get node addresses from RAs, DHCPv6 is used to get other conf parameters (DHCPv6 stateless)M,O are 1,0 : DHCPv6 is used for address configuration but not for other settings (unlikely because hosts need other parameters like DNS servers)
I

Oct 19, 2015 Roberto Innocente [email protected] 92
Questions 2● How do you use a numeric address in an URL ?
– [2001:760:……]
● Length of IPv4 header ? Length of IPv6 header ?– Variable 20.. , fixed 40 bytes
● Why header checksum was abandoned in IPv6 ?– Because errors were mostly caused by bad memory in routers were header checksum is in any case recalculated
● Is there any remnant of fragment management in the IPv6 header ?– No, it is part of an extension header
● If in an extension header the next header field =TCP , what will be the nextheader field in the TCP header ?– Tcp header is just the normal tcp header, it is not an ipv6 extension header and has no next header field
● Components of ICMPv6 ?– ND neighbour discovery, RD router discovery , MLD multicast listener discovery
● Fragmentation can manage packets up to how many bytes ? – 64 K
● What is a jumbogram in IPv6 lingo ? how many bytes in it ?– A packet with the jumbo payload option in an icmpv6 header, up to 232 -1 bytes
● Important flags of Router Advertisement packets ?– Managed stateful flag, Other stateful flag . Options of prefixes : On-link prefix, Autonomous Address configuration prefix

Oct 19, 2015 Roberto Innocente [email protected] 93
IPv6 DAD Duplicate Address Detection
A device uses Duplicate Address Detection(DAD) to discover if an address that it wants to use is already used by some other device on the LAN.RFC4861 recommends that DAD be performed for every unicast address : link local or global, manually assigned or assigned by SLAAC or DHCPv6. If a duplicate address is discovered it cannot be used by the device.
1. A device builts its own LinkLocal address using the modified EUI64 algorithm : fe80::219:99ff:fe79:ff0
2. It sends an ICMPv4 Neighbor Solicitation Message source mac its MAC address, destination mac the (ipv6-mapped multicast) 33-33-fe-79-0f-f0, source ipv6 unspecified(::), dest ipv6 fe80::219:99ff:fe79:ff0
3. The device waits for some seconds for a Neighbor Advertisement answer. If no answer it uses the address calculated.

Oct 19, 2015 Roberto Innocente [email protected] 94
IPv6 NUD Neighbor Unreachability DetectionRFC4861
Devices monitor the reachability of neighbors to which they are sending traffic. The reachability is confirmed by a response to a Neighbor Solicitation or an ACK in a TCP connection for instance.When a path seems to be failing :1. If the neighbor is the ultimate destination : address resolution should
be performed again : 1. Send a NeighborSolicitation msg
2. Wait for a NeighborAdvertisement msg
2. If the neighbor is a router try to use a different default gateway
NUD, of course, is performed only for neighbors to which unicast packets are sent

Oct 19, 2015 Roberto Innocente [email protected] 95
IPv6 MLDv2 (RFC3810) Multicast Listener Discovery
Based on IGMPv3, compatible with MLDv1 extends MLDv1 with support of Source Specific Multicast (SSM).

Oct 19, 2015 Roberto Innocente [email protected] 96
IPv6 MLDv2/2
● Multicast Listener Query type=130– General Query
– Multicast-Address-specific query
● Multicast Listener Report type=131
● Multicast Listener Done type=132
With these messages the routers on the LAN learn which channels (multicast addresses) should be re-txmitted on the LAN.
1. The router priodically sends a General Query to the ip6-allnodes multicast address
2. A host member of the multicast group ff3e:0060:2002:0DB8:ccc:1:0000:2222 receives the query, waits a random amount of time and if it doesn't hear another host to report for the same group, it sends a Multicast Listener Report for it to the multicast address all MLDv2 capable router ff02::16
3. Another host member of a different group waits also a rnd amount of time and sends its Multicast Listener Report also to ff02::16
4. When a host wants to stop listening to a multicast address it sends a Multicast Listener Done msg to the ff02::16
5. The router doesn't maintain a list of nodes listening on an address so when it receives the Done message it needs to send a Multicast-Address-specific query to the multicast address of the group to see if there are nodes still listening to the address and if not to clear it from the listened mcast addresses on the LAN

Oct 19, 2015 Roberto Innocente [email protected] 97
Path MTU
In IPv4 routers can fragment a packet along the path. These fragments pose some security risks and usually security appliances will re-assemble them. In IPv6 only the sender can fragment a packet, routers do not fragment it. For this reason it is recommended to discover the maximum Path MTU to have a more efficient transmission.IPv6 dictates that all links support an MTU of at least 1280 bytes, in IPv4 this was 64 bytes.
Path MTU discoveryThe sender supposes the path has a PathMTU equal to the one of the first hop and tries to send a packet of that size. If the packet is ack then it sets that as the PMTU, otherwise a router will refuse to forward the pkt and sends back an ICMPv6 Error Message : Packet too big that contains a supported smaller MTU that the sender will now try to use. This is one of the reasons why ICMPv6 should not be blocked. They are essential for normal behaviour.

Oct 19, 2015 Roberto Innocente [email protected] 98
Multihoming in IPv6
To deploy a fault tolerant connection to the Internet many connect to 2 different ISPs. In this case the idea of the IPv6 Provider Aggregatable addresses does'nt work well.
The initial answer from IPv6 specs was that the company should get a different prefix from both providers and its host should configure in both networks. In reality today, despite the initial aims, companies that want to be multihomed get a Provider Independent prefix from RIRs. It is hoped that before an IPv6 route explosion something different will be devised (~20.000 IPv6 prefixes announced as of today).

Oct 19, 2015 Roberto Innocente [email protected] 99
RFCs
More than 100 RFCs are available for IPv6. In the Rfcs Node is a host or router.Therefore rfc6434 applies to both.● Rfc2460 Internet Protocol, Version6, Specification● Rfc6434 IPv6 node requirements● Rfc6204 Basic requirements for IPv6 customer edge routers● RIPE-554 Requirements for IPv6 in ICT equipment● Rfc4291 IPv6 addressing architecture● Rfc4007 IPv6 scoped address architecture● Rfc3879 Deprecating Site-Local addresses● Rfc4193 Unique Local IPv6 unicast addresses● Rfc5942 IPv6 subnet model : the relationship between subnet and link
prefixes● Rfc4941 Privacy extension for stateless address autoconfiguration in IPv6● Rfc3971 Secure Neighbor Discovery (SEND)

Oct 19, 2015 Roberto Innocente [email protected] 100
Linux tools for ipv6/1
● ifconfig● ip -6 route● Ip -6 addr● ip -6 maddr● iip -6 neigh● ip -6 ntable● ip -6 neigh show nup all

Oct 19, 2015 Roberto Innocente [email protected] 101
Linux tools for ipv6/2
● ipv6calc● ipv6loganon● ipv6logconv● ipv6logstats

Oct 19, 2015 Roberto Innocente [email protected] 102
Linux tools for ipv6/3
●ndisc6 ICMPv6 Neighbour Discovery tool● rdisc6 ICMPv6 Route Discovery tool● tracepath6 Trace path using UDP and discovering path MTU● ip6tables ipv6 version of iptables ● traceroute6 / tcptraceroute6 Equivalent to : traceroute -6●
● Install with : sudo apt-get install ndisc6
inno@geist:~$ traceroute6 google.comtraceroute to 2607:f8b0:4008:804::200e (2607:f8b0:4008:804::200e) from 2001:0:53aa:64c:3422:f226:6c85:e7b5, 30 hops max, 60 bytes packets 1 2001:0:53aa:64c:2ccf:708d:27bd:bf75 (2001:0:53aa:64c:2ccf:708d:27bd:bf75) 234.680 ms 101.461 ms 100.401 ms 2 gigabitethernet5-2.core1.ash1.he.net (2001:470:0:136::1) 209.740 ms 100.546 ms 108.117 ms 3 * * * 4 2001:4860::1:0:9ff (2001:4860::1:0:9ff) 212.682 ms 113.411 ms 107.457 ms 5 2001:4860::8:0:6374 (2001:4860::8:0:6374) 210.626 ms 103.878 ms 235.942 ms 6 2001:4860::8:0:5b13 (2001:4860::8:0:5b13) 263.756 ms 246.549 ms 117.172 ms 7 2001:4860::1:0:245b (2001:4860::1:0:245b) 398.464 ms 139.171 ms 126.571 ms 8 2001:4860:0:1::f3 (2001:4860:0:1::f3) 268.305 ms 126.539 ms 126.867 ms 9 mia07s24-in-x0e.1e100.net (2607:f8b0:4008:804::200e) 126.467 ms 125.864 ms 125.758 ms

Oct 19, 2015 Roberto Innocente [email protected] 103
ifconfig
inno@ghost:~/ipv6$ ifconfig eth0eth0 Link encap:Ethernet HWaddr b4:b6:76:60:58:8c inet addr:147.122.24.71 Bcast:147.122.24.255 Mask:255.255.255.0
inet6 addr: fe80::b6b6:76ff:fe60:588c/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:12862876 errors:0 dropped:0 overruns:0 frame:0 TX packets:19512845 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:11451349683 (11.4 GB) TX bytes:26499471613 (26.4 GB)
inno@ghost:~/ipv6$ ifconfig teredoteredo Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet6 addr: 2001:0:53aa:64c:38a9:399e:6c85:e7b8/32 Scope:Global inet6 addr: fe80::ffff:ffff:ffff/64 Scope:Link UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1280 Metric:1 RX packets:48992 errors:0 dropped:0 overruns:0 frame:0 TX packets:41757 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:500 RX bytes:19399443 (19.3 MB) TX bytes:8271112 (8.2 MB)
inno@ghost:~/ipv6$ sudo ifconfig eth0 add 2001:db8:0204::1 inno@ghost:~/ipv6$ sudo ifconfig eth0 del 2001:db8:0205::1
Adding and deleting an Unicast Global address from an interface

Oct 19, 2015 Roberto Innocente [email protected] 104
Windows commands for IPv6
● Netsh inter ipv6 show address● Netsh inter ipv6 show neighbor● Netsh inter ipv6 show route● Netsh inter ipv6 show dnsserv● Netsh inter ipv6 show global● Netsh inter ipv6 show interf● Netsh inter ipv6 show privacy● Netsh inter ipv6 show siteprefix● Netsh inter ipv6 add address● Netsh inter ipv6 del address● Netsh inter ipv6 show joins

Oct 19, 2015 Roberto Innocente [email protected] 105
Linux/Windows commands
Linux WindowsPing6 ip6-localhost Ping -6 ::1
Ping6 -I eth0 ip6-allnodes Ping -6 fe02::1%7
Ping6 -I eth0 ip6-allrouters Ping -6 fe02::1%7
Ip -6 addr Netsh inter ipv6 show addr
Ip -6 maddr Netsh inter ipv6 show joins
Ip -6 neigh Netsh inter ipv6 show neigh
Ip -6 route Netsh inter ipv6 show route
For windows add the literal names in c:\windows\system32\drivers\etc\hosts

Oct 19, 2015 Roberto Innocente [email protected] 106
Multicast and unicast addresses
in practice/1
C:\>netsh inter ipv6 show joinsInterface 21: Wi-FiScope References Last Address---------- ---------- ---- --------------------------0 0 Yes ff01::10 0 Yes ff02::10 4 Yes ff02::c0 1 Yes ff02::fb0 1 Yes ff02::1:30 1 Yes ff02::1:ff52:8f8cInterface 1: Loopback Pseudo-Interface 1Scope References Last Address---------- ---------- ---- ------------------------0 4 Yes ff02::cInterface 19: Teredo Tunneling Pseudo-InterfaceScope Ref Last Address---------- ------ ---- ---------0 0 Yes ff01::10 0 Yes ff02::10 2 Yes ff02::1:ff02:45Interface 7: EthernetScope Ref Last Address---------- ----- ---- -----------0 0 Yes ff01::10 0 Yes ff02::10 1 Yes ff02::1:ff7f:c528
C:>netsh inter ipv6 show addr
Interface 21: Wi-Fi
Addr Type DAD State Valid Life Pref. Life Address
--------- ----------- ---------- ---------- --------------------
Other Preferred infinite infinite fe80::517c:baca:1852:8f8c%21
Interface 1: Loopback Pseudo-Interface 1
Addr Type DAD State Valid Life Pref. Life Address
--------- ----------- ---------- ---------- ------------------------
Other Preferred infinite infinite ::1
Interface 19: Teredo Tunneling Pseudo-Interface
Addr Type DAD State Valid Life Pref. Life Address
--------- ----------- ---------- ---------- ------------------------
Public Preferred infinite infinite 2001:0:53aa:64c:a5:8bbe:a402:45
Other Preferred infinite infinite fe80::a5:8bbe:a402:45%19
Interface 7: Ethernet
Addr Type DAD State Valid Life Pref. Life Address
--------- ----------- ---------- ---------- ------------------------
Other Deprecated infinite infinitefe80::e12f:2f9a:a07f:c528%7

Oct 19, 2015 Roberto Innocente [email protected] 107
Multicast and unicast
addresses in practice/2
cisco@onepk:~$ ip -6 addr1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000 inet6 fe80::a00:27ff:fe25:ce0a/64 scope link valid_lft forever preferred_lft forever3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000 inet6 fe80::a00:27ff:fe09:d95a/64 scope link valid_lft forever preferred_lft forever9: teredo: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1280 qlen 500 inet6 2001:0:53aa:64c:499:88fb:a402:45/32 scope global valid_lft forever preferred_lft forever inet6 fe80::ffff:ffff:ffff/64 scope link valid_lft forever preferred_lft forevercisco@onepk:~$
cisco@onepk:~$ ip -6 maddr1: lo inet6 ff02::12: eth0 inet6 ff02::fb inet6 ff02::1:ff25:ce0a inet6 ff02::13: eth1 inet6 ff02::fb inet6 ff02::1:ff09:d95a inet6 ff02::15: virbr0 inet6 ff02::17: teredo inet6 ff02::1cisco@onepk:~$

Oct 19, 2015 Roberto Innocente [email protected] 108
ndisc6Neighbor discovery :root@geist:~# ndisc6 hawx.local eth0Soliciting hawx.local (fe80::219:99ff:fe7b:feab) on eth0...Target linklayer address: 00:19:99:7B:FE:AB from fe80::219:99ff:fe7b:feabTrace of it :root@geist:~# tcpdump i eth0 e ip6tcpdump: verbose output suppressed, use v or vv for full protocol decodelistening on eth0, linktype EN10MB (Ethernet), capture size 262144 bytes11:27:27.847150 00:19:99:79:0f:f0 (oui Unknown) > 33:33:00:00:00:fb (oui Unknown), ethertype IPv6 (0x86dd), length 90: geist.local.mdns > ff02::fb.mdns: 0 AAAA (QM)? hawx.local. (28)11:27:27.847541 00:19:99:7b:fe:ab (oui Unknown) > 33:33:00:00:00:fb (oui Unknown), ethertype IPv6 (0x86dd), length 112: hawx.local.mdns > ff02::fb.mdns: 0* [0q] 1/0/0 (Cache flush) AAAA fe80::219:99ff:fe7b:feab (50)11:27:27.848084 00:19:99:79:0f:f0 (oui Unknown) > 33:33:ff:7b:fe:ab (oui Unknown), ethertype IPv6 (0x86dd), length 86: geist.local > ff02::1:ff7b:feab: ICMP6, neighbor solicitation, who has hawx.local, length 3211:27:27.848337 00:19:99:7b:fe:ab (oui Unknown) > 00:19:99:79:0f:f0 (oui Unknown), ethertype IPv6 (0x86dd), length 86: hawx.local > geist.local: ICMP6, neighbor advertisement, tgt is hawx.local, length 3211:27:28.922283 00:19:99:79:0f:f0 (oui Unknown) > 33:33:00:00:00:fb (oui Unknown), ethertype IPv6 (0x86dd), length 152: geist.local.mdns > ff02::fb.mdns: 0 PTR (QM)? 0.f.f.0.9.7.e.f.f.f.9.9.9.1.2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.e.f.ip6.arpa. (90)11:27:28.922514 00:19:99:79:0f:f0 (oui Unknown) > 33:33:00:00:00:fb (oui Unknown), ethertype IPv6 (0x86dd), length 171: geist.local.mdns > ff02::fb.mdns: 0* [0q] 1/0/0 (Cache flush) PTR geist.local. (109)11:27:29.023351 00:19:99:79:0f:f0 (oui Unknown) > 33:33:00:00:00:fb (oui Unknown), ethertype IPv6 (0x86dd), length 152: geist.local.mdns > ff02::fb.mdns: 0 PTR (QM)? b.a.e.f.b.7.e.f.f.f.9.9.9.1.2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.e.f.ip6.arpa. (90)11:27:29.023796 00:19:99:7b:fe:ab (oui Unknown) > 33:33:00:00:00:fb (oui Unknown), ethertype IPv6 (0x86dd), length 170: hawx.local.mdns > ff02::fb.mdns: 0* [0q] 1/0/0 (Cache flush) PTR hawx.local. (108)11:27:32.853122 00:19:99:7b:fe:ab (oui Unknown) > 00:19:99:79:0f:f0 (oui Unknown), ethertype IPv6 (0x86dd), length 86: hawx.local > geist.local: ICMP6, neighbor solicitation, who has geist.local, length 3211:27:32.853163 00:19:99:79:0f:f0 (oui Unknown) > 00:19:99:7b:fe:ab (oui Unknown), ethertype IPv6 (0x86dd), length 78: geist.local > hawx.local: ICMP6, neighbor advertisement, tgt is geist.local, length 24
Solicited-node-multicast address

Oct 19, 2015 Roberto Innocente [email protected] 109
rdisc6Discover routers on the LAN :root@geist:~# rdisc6 m eth0
Soliciting ff02::2 (ff02::2) on eth0...
Hop limit : 64 ( 0x40)Stateful address conf. : NoStateful other conf. : NoRouter preference : mediumRouter lifetime : 1800 (0x00000708) secondsReachable time : unspecified (0x00000000)Retransmit time : unspecified (0x00000000) Prefix : fd00:b3:18::/64 Valid time : 86400 (0x00015180) seconds Pref. time : 14400 (0x00003840) seconds MTU : 1280 bytes (valid) Source linklayer address: 00:19:99:79:0F:F0 from fe80::219:99ff:fe79:ff0Trace of it :root@geist:~# tcpdump e i eth0 ip6tcpdump: verbose output suppressed, use v or vv for full protocol decodelistening on eth0, linktype EN10MB (Ethernet), capture size 262144 bytes12:57:17.164777 00:19:99:79:0f:f0 (oui Unknown) > 33:33:00:00:00:02 (oui Unknown), ethertype IPv6 (0x86dd), length 62: geist.local > ip6allrouters: ICMP6, router solicitation, length 812:57:17.164996 00:19:99:79:0f:f0 (oui Unknown) > 33:33:00:00:00:01 (oui Unknown), ethertype IPv6 (0x86dd), length 118: geist.local > ip6allnodes: ICMP6, router advertisement, length 6412:57:18.247996 00:19:99:79:0f:f0 (oui Unknown) > 33:33:00:00:00:fb (oui Unknown), ethertype IPv6 (0x86dd), length 152: geist.local.mdns > ff02::fb.mdns: 0 PTR (QM)? 0.f.f.0.9.7.e.f.f.f.9.9.9.1.2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.e.f.ip6.arpa. (90)12:57:18.248221 00:19:99:79:0f:f0 (oui Unknown) > 33:33:00:00:00:fb (oui Unknown), ethertype IPv6 (0x86dd), length 171: geist.local.mdns > ff02::fb.mdns: 0* [0q] 1/0/0 (Cache flush) PTR geist.local. (109)
Router Advertisement Flags :M=0, O=0 no dhcpv6
ip6-allrouters multicast

Oct 19, 2015 Roberto Innocente [email protected] 110
tracepath6
Discovers hops and Path MTU :root@geist:~# tracepath6 b www.tudelft.nl 1?: [LOCALHOST] 0.058ms pmtu 1280 1: miredo.surfnet.nl (2001:610:168:a:145:220:0:46) 101.349ms 1: miredo.surfnet.nl (2001:610:168:a:145:220:0:46) 32.535ms 2: onweer.as1101.net (2001:610:168:a::1) 77.222ms 3: XE116.JNR01.Asd001A.surf.net (2001:610:f01:8152::153) 77.039ms 4: AE0.500.JNR01.Asd002A.surf.net (2001:610:e08:80::81) 67.500ms 5: 2001:610:f02:6096::98 (2001:610:f02:6096::98) 70.445ms 6: 2001:610:908:112:131:180:77:102 (2001:610:908:112:131:180:77:102) 34.837ms reached Resume: pmtu 1280 hops 6 back 6

Oct 19, 2015 Roberto Innocente [email protected] 111
tracert6/traceroute6/tcptraceroute6traceroute6 by default sends UDP packets while increasing their Hop Limit (similar to what traceroute does for IPv4), it can also send ICMPv6 Echo Request like the windows implementation does (tracert6 does this). tcptraceroute6 uses tcp packets (SYN/ACK).root@geist:~# tracert6 ipv6.google.com
traceroute to ipv6.l.google.com (2a00:1450:4002:803::1000) from 2001:0:53aa:64c:86f:f226:6c85:e7b5, 30 hops max, 60 bytes packets
1 6to4.fra1.he.net (2001:470:0:150::2) 99.130 ms 17.012 ms 16.992 ms
2 10gigabitethernet6.switch2.fra1.he.net (2001:470:0:150::1) 98.886 ms 22.923 ms 26.685 ms
3 de-cix10.net.google.com (2001:7f8::3b41:0:1) 5046.514 ms 41.821 ms 17.838 ms
4 2001:4860::1:0:abf5 (2001:4860::1:0:abf5) 155.991 ms 42.605 ms 23.773 ms
5 2001:4860::8:0:5038 (2001:4860::8:0:5038) 42.525 ms 18.071 ms 18.040 ms
6 2001:4860::1:0:ab33 (2001:4860::1:0:ab33) 599.687 ms 42.877 ms *
7 2001:4860:0:1::207 (2001:4860:0:1::207) 91.442 ms 33.767 ms 33.954 ms
8 mil02s05-in-x00.1e100.net (2a00:1450:4002:803::1000) 27.220 ms 27.124 ms 26.911 ms
root@geist:~# traceroute6 www.tudelft.nl
traceroute to www.tudelft.nl (2001:610:908:112:131:180:77:102) from 2001:0:53aa:64c:86f:f226:6c85:e7b5, port 33434, from port 55020, 30 hops max, 60 bytes packets
1 miredo.surfnet.nl (2001:610:168:a:145:220:0:46) 134.457 ms 32.323 ms 32.379 ms
2 onweer.as1101.net (2001:610:168:a::1) 84.721 ms 32.683 ms 32.503 ms
3 XE1-1-6.JNR01.Asd001A.surf.net (2001:610:f01:8152::153) 84.171 ms 33.115 ms 32.701 ms
4 AE0.500.JNR01.Asd002A.surf.net (2001:610:e08:80::81) 71.039 ms 32.797 ms 32.673 ms
5 2001:610:f02:6096::98 (2001:610:f02:6096::98) 69.960 ms * *
6 2001:610:908:112:131:180:77:102 (2001:610:908:112:131:180:77:102) 34.390 ms 34.608 ms 34.257 ms
root@geist:~# tcptraceroute6 www.tudelft.nl
traceroute to www.tudelft.nl (2001:610:908:112:131:180:77:102) from 2001:0:53aa:64c:86f:f226:6c85:e7b5, port 80, from port 54914, 30 hops max, 60 bytes packets
1 * * miredo.surfnet.nl (2001:610:168:a:145:220:0:46) 65.961 ms
2 onweer.as1101.net (2001:610:168:a::1) 101.656 ms 32.520 ms 32.738 ms
3 XE1-1-6.JNR01.Asd001A.surf.net (2001:610:f01:8152::153) 90.450 ms 43.507 ms 32.813 ms
4 AE0.500.JNR01.Asd002A.surf.net (2001:610:e08:80::81) 32.800 ms 40.499 ms 33.255 ms 5

Oct 19, 2015 Roberto Innocente [email protected] 112
Conceptual model of a host/1rfc4861
Data structures :Neighbor cache : on-link unicast address, LL address, R/H, neighbor reachability, unanswered probes, next scheduled NUDDestination cache : includes both on-link and off-link destinations. It maps the IPv6 address to the next-hop neighbor (an entry in the neighbor cache). This cache is update by ICMPv6 redirects. It can contain PMTU and RTT informations.Prefix list : a list of the prefixes received in Router Advertisements with the on-link flag on. The link local (fe80::) prefix is considered to be on the list with an infinite validity timer.Default Router List : a list of routers to which packets can be send. Entries can be added manually, trough router advertisements, or DHCPv6.
Neighbor cache reachability state :INCOMPLETE address resolution in progressREACHABLE it is know it was reachableSTALE it is not known anymore, but nothing will be done till new pkts sent DELAY is no longer known to be reachable, pkt were sent not long ago, waiting for an ULP confirmationPROBE is no longer known to be reachable and NS packets are sent to verify

Oct 19, 2015 Roberto Innocente [email protected] 113
Conceptual model of a host/2
Next hop determination:1. Longest prefix match against Prefix List, if
found determine if it is on-link or not, otherwise is off-link.
2. If dest on-link then next-hop=destination, otherwise next-hop is a router choosen from Default Router List. Next-hop for efficiency is not performed for every packet but its results are stored in the Destination Cache. Next time 1st the destination cache will be searched for next-hop and only if not found the normal prefix search will be started.
3. When the next-hop is known it will be searched in the Neighbor Cache and if no entry exist an Address Resolution (Neighbor Solicitation) will be performed entering the next-hop in the cache as an entry in state INCOMPLETE.
For multicast pkts :The destination is considered the same multicast address and supposed on-link. The pkt is simply sent to the multicast address on the interface. The LL destination address is computed from the IPv6 multicast address.

Oct 19, 2015 Roberto Innocente [email protected] 114
DestinationCache
Next hop determination
NeighbourCache
(2)Longest prefix
match. On-link ?
(3)Search next-hop in NC.If onlink, next-hop = destination. If not found initiates Address Resolution.
(1)Search Destination Cache, if found don't perform next-hop determination
(4)Destination OffLink,Select a router
Next hop determination
DefaultRouter List
Next-hop determination is not performed for every connection, but only when there is no entry in the Destionation Cache. After next-hop determination the entry is inserted in the Destination Cache.

Oct 19, 2015 Roberto Innocente [email protected] 115
NDP functions
1.Router discovery:host discover router that are on an attached link
2.Prefix discovery: nodes discover which prefixes denote nodes on-link
3.Parameter discovery: nodes learn about MTU, hop limits, etc ..
4.Address autoconfiguration: nodes discover prefixes to be used for address autoconfiguation
5.Address resolution: node discover the Link Layer address (like ARP)
6.Next hop determination: node determine next hop
7.Neighbor Unreachability Detection(NUD): node can determine if a node is still reachable
8.Duplicate Address Detection(DAD): node can determine if an address is in use
9.Redirect : routers can tell nodes a better next-hop for a destination

Oct 19, 2015 Roberto Innocente [email protected] 116
Different subnet model: RFC5942
IPv6 has a subnet model that is slightly different from IPv4 in subtle ways and this resulted in some implementations not able to interoperate. The most important difference is that an IPv6 address isn't automatically related to an on-link prefix ! .In IPv4 an interface is assigned an address and a netmask. Based on that info nodes decide which addresses are on-link and should be contacted directly.In IPv6 address assignement and on-link determination are separate :● A host can have IPv6 addresses not related to any on-
link prefix, or without knowing on-link prefixes (think about anycasts).
● A host can have IPv6 prefixes not related to any other address it has.
By default only the Linklocal fe80::/16 prefix is treated as on-link.The reception of a Prefix Information Option (PIO) (rfc4861 on RD) with the L bit (on-Link bit) set and with a nonzero lifetime creates an entry in the Prefix List of a node for that interface. The same the manual configuration of an on-link prefix (can be a /128 : host route).
All prefixes on a Prefix List of a node are considered on-link by that node. Pkt for destinations that are considered on-link by sender, trigger name resolution, pkt for other destinations are forwarded to a default router (if the Default Router List is empty then an ICMPv6 dest unreachable is sent back).In this way Non-Broadcast Multi-Access (NBMA) is supported.A link can have multiple prefixes, a prefix can be assigned to multiple links.Host rule :If a host gets an address trough one of the many methods, it should not suppose a prefix derived arbitrarily from it be treated as on-link. E.g. : a link is assigned 2 prefixes by 2 different routers. 2 nodes can use the different prefixes for SLAAC : in IPv4 those nodes would not speak each other, in IPv6 yes, using their link-local addresses.
.

Oct 19, 2015 Roberto Innocente [email protected] 117
IPv6 addreses for a ...
Router : ● Unicast addresses
– A link-local address for each interface
– Additional global or ULA for each interface
– The loopback address ::1 for the loopback interface
● Anycast addresses– A subnet router anycast for each subnet
– Additional optional anycast
● Multicast addresses – Interface-local scope multicast all-nodes ff01::1
– Interface-local scope multicast all-routers ff01::2
– Link-local scope multicast all-nodes ff02::1
– Link-local scope multicast all-routers ff02::2
– Site-local scope multicast all-routers ff05::2
Host:● Unicast addresses
– A link-local address for each interface
– Additional global or ULA for each interface
– The loopback ::1 for the loopback interface
● Anycast addresses– Any anycast address assigned to the node
● Multicast addresses– Interface-local scope multicast all-nodes
ff01::1
– Link-local scope multicast all-nodes ff02::1
– The solicited node multicast for each unicast address
– The multicast groups to which the node subscribed

Oct 19, 2015 Roberto Innocente [email protected] 118
Happy eyeballs algorithmaka FastFallback RFC6555
During the passage to IPv6, tunnels, not reliable IPv6 connections, etc can prejudicate user experience. Therefore an algorithm was devised to mitigate the drawbacks of dual stack users.
DNS Server Client Server | | | 1. |<--www.example.com A?-----| | 2. |<--www.example.com AAAA?--| | 3. |---192.0.2.1------------->| | 4. |---2001:db8::1----------->| | 5. | | | 6. | |==TCP SYN, IPv6===>X | 7. | |==TCP SYN, IPv6===>X | 8. | |==TCP SYN, IPv6===>X | 9. | | | 10. | |--TCP SYN, IPv4------->| 11. | |<-TCP SYN+ACK, IPv4----| 12. | |--TCP ACK, IPv4------->|
Figure 1: Existing Behavior Message Flow
Typical browser behaviour pre rfc6555 : many seconds wasted to try IPv6 SYNs repeatedly. NB. konqueror works this way. At least the one now in ubuntu 15.04

Oct 19, 2015 Roberto Innocente [email protected] 119
Happy eyeballs/2
DNS Server Client Server | | | 1. |<--www.example.com A?-----| | 2. |<--www.example.com AAAA?--| | 3. |---192.0.2.1------------->| | 4. |---2001:db8::1----------->| | 5. | | | 6. | |==TCP SYN, IPv6===>X | 7. | |--TCP SYN, IPv4------->| 8. | |<-TCP SYN+ACK, IPv4----| 9. | |--TCP ACK, IPv4------->| 10. | |==TCP SYN, IPv6===>X |
Figure 2: Happy Eyeballs Flow 1, IPv6 BrokenSolution : try both addresses at SYN time and take IPv4 if IPv6 broken :Firefox 13, MacOSX Lion, Chrome implement it

Oct 19, 2015 Roberto Innocente [email protected] 120
Happy eyeballs/3
DNS Server Client Server | | | 1. |<--www.example.com A?-----| | 2. |<--www.example.com AAAA?--| | 3. |---192.0.2.1------------->| | 4. |---2001:db8::1----------->| | 5. | | | 6. | |==TCP SYN, IPv6=======>| 7. | |--TCP SYN, IPv4------->| 8. | |<=TCP SYN+ACK, IPv6====| 9. | |<-TCP SYN+ACK, IPv4----| 10. | |==TCP ACK, IPv6=======>| 11. | |--TCP ACK, IPv4------->| 12. | |--TCP RST, IPv4------->|
Figure 3: Happy Eyeballs Flow 2, IPv6 WorkingTry both : prefer IPv6 if it works and reset IPv4 connection
NB. On firefox you can disable the algorithm with : Enter about:config, unset
network.http.fast-fallback-to-IPv4

Oct 19, 2015 Roberto Innocente [email protected] 121
Coexistence of IPv4/IPv6 in DNS
This is the standard way to declare a double stack host :ghost IN A 147.122.24.71 IN AAAA 2001:db8:12::213:45ea:3aef Unfortunately there are many broken resolvers out there that despite not being able to reach the Ipv6 Internet at large would try to contact only the IPv6 address without falling back to the IPv4.In the past many used the trick to put the ipv6 under a different name or domain :ghost IN A 147.122.24.71ghost.ipv6 IN AAAA 2001:db8:12::213:45ea:3aef

Oct 19, 2015 Roberto Innocente [email protected] 122
IPv6 routing
Routing on the LAN :● Is done using Router Advertisement instead of a routing protocol
– Router Discovery
– Prefix discovery

Oct 19, 2015 Roberto Innocente [email protected] 123
Router Advertisement
IPv6 routers send regularly avertisements and they reply to Router solicitations. On linux this is done by the service daemon : radvd. It is configured by the file : /etc/radvd.conf. If the file doesn't exist the daemon dies. # /etc/radvd.conf example on eth0 advertise the prefixfd00:b3:18::/64 interface eth0{ AdvSendAdvert on; # send RA AdvLinkMTU 1500; # optional prefix 2001:db8:0:18::/64 # Unique Local Address Space, not routable { AdvOnLink on; AdvAutonomous on; # this prefix can be used for autonomous # address configuration AdvRouterAddr on; };After creating the configuration file you can start the service with /etc/init.d/radvd start or with systemd .radvd will die out if ipv6 forwarding is not enabled : sysctl net.ipv6.conf.all.forwarding=1 sysctl net.ipv6.conf.default.forwarding=1

Oct 19, 2015 Roberto Innocente [email protected] 124
/etc/radvd.conf
By default radvd would read all interface routable addresses and would advertise their prefixes.Anyway the behaviour can be controlled per interface.Therefore its configurations is made by one or more interface definitions :interface eth0 { List of interface opt List of prefix List of clients List of routes List of RDNSS List of DNSSL};prefix prefix/length { List of prefix opt}; route prefix/length { List of route opt};RDNSS ip [ip] [ip] { List of rdnss opt};DNSSL suffix [suffix] [suffix]{ List of dnssl opt};
INTERFACE OPTIONSIgnoreIfMissing on|offAdvSendAdvert on|offUnicastOnly on|offMaxRtrAdvInterval secondsMinRtrAdvInterval secondsMinDelayBetweenRAs secondsAdvManagedFlag on|offAdvOtherConfigFlag on|offAdvLinkMTU integerAdvReachableTime millisecondsAdvRetransTimer millisecondsAdvCurHopLimit integerAdvDefaultLifetime secondsAdvDefaultPreference low|medium|highAdvSourceLLAddress on|offAdvHomeAgentFlag on|offAdvHomeAgentInfo on|offHomeAgentLifetime secondsHomeAgentPreference integerAdvMobRtrSupportFlag on|offAdvIntervalOpt on|off
PREFIX OPTIONSAdvOnLink on|offAdvAutonomous on|offAdvRouterAddr on|offAdvValidLifetime seconds|infinityAdvPreferredLifetime seconds|infinityDeprecatePrefix on|offDecrementLifetimes on|offBase6Interface nameBase6to4Interface nameROUTE OPTIONSAdvRouteLifetime seconds|infinityAdvRoutePreference low|medium|highRemoveRoute on|offRDNSS, DNSSL OPTIONSAdvRDNSSLifetime seconds|infinityFlushRDNSS on|offAdvDNSSLLifetime seconds|infinity;FlushDNSSL on|off

Oct 19, 2015 Roberto Innocente [email protected] 125
IPv6 node configuration
IPv6 addresses are made up of 2 parts : interface ID and network ID.● Interface ID :
– manual
– auto (stateful or stateless)
● Network ID :– manual
– auto (stateful or stateless)
– predefined well known prefix like link local : fe80::/10

Oct 19, 2015 Roberto Innocente [email protected] 126
Ubuntu/etc/network/interfaces
Auto method:● privext (0off,1=on,2=prefer)
● accept_ra int (0=off, 1=on,2=on+fwd)
● dhcp int (0=off,1=stateless dhcp)
Static method:address address Address (colon delimited/netmask) requirednetmask mask Netmask (number of bits, eg 64)gateway address Default gateway (colon delimited), requiredmedia type Medium type, driver dependenthwaddress address Hardware addressmtu size MTU sizeaccept_ra int Accept router advertisements (0=off, 1=on, 2=on+forwarding)autoconf (0=off,1=on) stateless autoconfprivext int Privacy extensions (RFC3041) (0=off, 1=assign, 2=prefer)
scope Address validity scope. Possible values: global, site, link, hostpreferredlifetime int Time that address remains preferred dadattempts Number of attempts to settle DAD (0 to disable). Default value: "60"dadinterval DAD state polling interval in seconds. Default value: "0.1"
Manual method : hwaddress address Hardware addressmtu sizeMTU sizeDhcp method :hwaddress addraccept_ra intautoconf int
iface eth? inet6 [ auto | static | manual | dhcp ]

Oct 19, 2015 Roberto Innocente [email protected] 127
Zeroconf
Zero Configuration Networking is whatever set of technologies that automatically creates a working and usable computer network when machines are interconnected. A group of the same name was created inside the IETF in 1999, to organize the efforts in this direction :● Address selection : autoconfiguration● Name resolution● Service discoveryApple since its AppleTalk had this kind of technologies, that now form a suite called Bonjour (previously Rendezvous).IPv6 made strong efforts to reach a similar goal.

Oct 19, 2015 Roberto Innocente [email protected] 128
SLAACStateLess Address AutoConfiguration
IPv6 was devised to allow nodes to autoconfigure, copying ideas from the Zero Configuration architectures like Bonjour/RendezVous. In IPv6 a node can autoconfigure in any case at least a Link Local Address to be used to communicate with nodes on the same broadcast domain. In this case the network ID is set to the well known Link Local prefix fe80:0::/10 and the interface ID is created by the OS in 2 possible ways :
– Using a modified EUI64 suffix from the interface 48 bits MAC
– Using a randomized suffix

Oct 19, 2015 Roberto Innocente [email protected] 129
Simple Service Discovery ProtocolSSDP
It is a text protocol that uses HTTPU (Http over UDP), the proposal was described in an internet draft in 1999 that expired, it was then used by UpnP and appears in their docs, used by windows.Services are announced by hosts sending the announcements, UDP port 1800 , to the following addresses: 239.255.255.250 (IPv4 site-local address) [FF02::C] (IPv6 link-local) [FF05::C] (IPv6 site-local) [FF08::C] (IPv6 organization-local) [FF0E::C] (IPv6 global)Microsoft implements it in MediaPlayer and Server using the link-local address, using port 2869.
IPv6 ff0x::c

Oct 19, 2015 Roberto Innocente [email protected] 130
LLMNR and the battle with Bonjour
● LLMNR (Link Local Multicast Name Resolution) is a protocol used by Windows from Vista on and proposed by Msoft to the IETF as RFC 4795 pretending it was a better solution than Bonjour. It allows computers on the same LAN to perform name resolution (both IPv4 and IPv6) without the help of a DNS server using multicasting. It performs part of the job of mDNS, but is not compatible with it. LLMNR sends a mcast query to ipv6: ff02::1:3 udp port 5355. Messages use DNS format.
● Therefore IETF after long discussion in which they asked msoft to make it compatible with the existing Bonjour, moved RFC4795 to the Informational state and asked Apple to submit rfcs for their protocols : RFC6762 about mDNS was then moved to the state of proposed standard.

Oct 19, 2015 Roberto Innocente [email protected] 131
Multicast DNS mDNS (zeroconf-dnsext groups)
Finds DNS names or addresses for local nodes without a server.mDNS at work:1. Sends a mcast query to MAC 33:33:00:00:00:fb ipv6: ff02::fb udp port 53532. If the node is on the LAN it answers with a mcast packet with its addresses
Happens when you ping a .local node.
RFC6762 specifies how to make DNS request over IP multicast for small networks where there is no DNS server. It forms the basis of the easy-to-use Apple Bonjour from 2002, together with DNS - service discovery (RFC6763 DNS/SD).It uses the same API as the normal DNS in this way avoiding the necessity to rewrite applications : it can use normal DNS at large and mDNS locally.By default mDNS resolves only names of the .local domain (conflict with DNS specs).mDNS sends queries to the multicast :The mDNS Ethernet frame is a multicast UDP packet to:
MAC address 01:00:5E:00:00:FB (for IPv4) or 33:33:00:00:00:FB (for IPv6) IPv4 address 224.0.0.251 or IPv6 address FF02::FB UDP port 5353Its payloads have essentially the DNS packet format .

Oct 19, 2015 Roberto Innocente [email protected] 132
DNS Service Discovery (DNS-SD)/1
It discovers services in a way compatible with regular DNS : its queries and replies are based on standard dns SRV and TXT records. A client queries for a service making an inverse query : a PTR record to _ipp._tcp for instance or _ssh._tcp . $ dig ptr _ipp._tcp.sissa.it._ipp._tcp.sissa.it. 0 IN PTR “SISSA ps3rc._ipp._tcp.sissa.it.”_ipp._tcp.sissa.it. 0 IN PTR “SISSA ps7lc._ipp._tcp.sissa.it.”_ipp._tcp.sissa.it. 0 IN PTR “SISSA ps2r._ipp._tcp.sissa.it.”...It receives an answer of zero or more <service>.<domain> record pointers.$ dig any “SISSA ps1r._ipp._tcp.sissa.it”“SISSA ps1r._ipp._tcp.sissa.it.” 0 IN TXT "txtvers=1" "rp=printers/ps1r" "ty=Xerox Phaser 5550DT" "Product=(Phaser 5550DT)" "note=Level 1 East Wing" "qtotal=1" "Color=F" "Duplex=T" "Transparent=T" "Copies=T" "pdl=application/postscript" "PaperMax=legalA4" "adminurl=http://ipp.sissa.it:631/printers/ps1r"“SISSA ps1r._ipp._tcp.sissa.it.” 0 IN SRV 0 0 631 ipp.sissa.it.Then the client gets SRV and TXT records for the pointed service : in the service SRV record there is the port and the host to contact for it : ipp.sissa.it:631 .Service types are now managed by IANA together with SRV record types :It can work together with mDNS on a LAN using multicast or with DNS using unicasts.RFC 6763 DNS-based Service Discovery

Oct 19, 2015 Roberto Innocente [email protected] 133
DNS-SD srv records/2
A service (SRV) record has the form:
_service._proto.name. TTL class SRV priority weight port target. service: the symbolic name of the desired service(_http,_ssh,_afpovertcp,_workstation,_vnc...) . proto: the transport protocol of the desired service; this is usually either TCP or UDP. name: the domain name for which this record is valid, ending in a dot. TTL: standard DNS time to live field. class: standard DNS class field (this is always IN). priority: the priority of the target host, lower value means more preferred. weight: A relative weight for records with the same priority, higher value means more preferred. port: the TCP or UDP port on which the service is to be found. target: the canonical hostname of the machine providing the service, ending in a dot.An example SRV record in textual form that might be found in a zone file might be the following:
_sip._tcp.example.com. 86400 IN SRV 0 5 5060 sipserver.example.com.This points to a server named sipserver.example.com listening on TCP port 5060 for Session Initiation Protocol (SIP) protocol services. The priority given here is 0, and the weight is 5.

Oct 19, 2015 Roberto Innocente [email protected] 134
DNS-SD /3
$ dig -t PTR _services._dns-sd._udp.dns-sd.org _services._dns-sd._udp.dns-sd.org. 60 IN PTR _http._tcp.dns-sd.org._services._dns-sd._udp.dns-sd.org. 60 IN PTR _afpovertcp._tcp.dns-sd.org._services._dns-sd._udp.dns-sd.org. 60 IN PTR _ftp._tcp.dns-sd.org._services._dns-sd._udp.dns-sd.org. 60 IN PTR _printer._tcp.dns-sd.org._services._dns-sd._udp.dns-sd.org. 60 IN PTR _pdl-datastream._tcp.dns-sd.org._services._dns-sd._udp.dns-sd.org. 60 IN PTR _ipp._tcp.dns-sd.org._services._dns-sd._udp.dns-sd.org. 60 IN PTR _ssh._tcp.dns-sd.org.
$ avahi-browse -a -d dns-sd.orghttp://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xhtml?&page=2 _http - web service _ftp - file transfer service _ldap - LDAP service _imap - IMAP mail service _PKIXREP - PKIX Repository (X.509 certificates) _printer

Oct 19, 2015 Roberto Innocente [email protected] 135
DNS-SD/4
When a computer starts it is given a default domain like (eg sissa.it ). DNS-SD searches for the ptr records :$dig ptr b._udp.sissa.it. ;browsing
$dig ptr lb._udp.sissa.it. ;legacy browsingThis is a suggestion for the compter to use widearea DNS-SD to browse (or legacy browse) the domain for obtaining a list of services available.

Oct 19, 2015 Roberto Innocente [email protected] 136
Bonjour/Zeroconf/Avahi/1
Avahi is an implementation of mDNS and DNS-SD for Zeroconf Networking.Look at http://www.enterprisenetworkingplanet.com/netos/article.php/3618026/Run-Zeroconf-for-Linux-in-a-Snap.htm This service registers ipv4/ipv6 addresses and services according to Apple's zero configuration architecture. Very popular among MacOS users it's not frequently used by linux users despite it is quite useful. In particular even without any network connection let the nodes to work on the local LAN/VLAN. When it starts or when it finds that interfaces are up but don't have a routable IPv4 ( in IPv6 this is part of the protocol IPv6: stateless address autoconfiguration SLAAC ) address, it tries to assigns to them a pseudorandom private IPv4 address (RFC3927) from the range 168.254.0.0/16 and checks if there is no duplicate for it. It then goes on using such address and transmits the service it offers trough multicast to well know multicast addresses on which the other nodes part of the group are all listening.It's very useful because even with no network connection (no DHCP, no DNS, ..) all the nodes running it can autoconfigure and cooperate on a LAN. Main components are the multicast DNS (mDNS) and the DNS/SD Service Discovery by DNS service.
The most commonly used implementation in Linux is avahi :- avahi-daemon , avahi-autoipd, avahi-dnsconfd- avahi-resolve- avahi-browse- avahi-discover- avahi-publish- avahi-set-host-nameAvahi sends to the mcast IPv6 addr ff02::1:3 udp port 5353 and answers are also on the same address.

Oct 19, 2015 Roberto Innocente [email protected] 137
Bonjour/Zeroconf/Avahi/2
From nmap.list :
● mdns 5353/tcp 0.000152 # Multicast DNS● zeroconf 5353/udp 0.100166 # Mac OS X
Bonjour/Zeroconf port● mdnsresponder 5354/udp 0.000661 # Multicast DNS Responder
IPC

Oct 19, 2015 Roberto Innocente [email protected] 138
Bonjour/Zeroconf/Avahi/3
List all service types :● avahibrowse bkBrowse all offered services with :● avahibrowse alrOr specifically browse ssh services :● bssh Equivalent to : avahibrowse _ssh._tcpOr VNC remote access services :● bvnc Equivalent to : avahibrowse _rfb._tcpResolve addresses : root@geist:~# avahiresolve n6 hawx.local hawx.local fe80::219:99ff:fe7b:feab root@geist:~# avahiresolve n4 hawx.local hawx.local 147.122.24.27Inverse address resolution : root@geist:~# avahiresolve a fe80::219:99ff:fe7b:feab fe80::219:99ff:fe7b:feabhawx.local
● Avahi-browse _printer._tcp● Avahi-browse _ssh._tcp● Avahi-browse _http._tcp

Oct 19, 2015 Roberto Innocente [email protected] 139
RFC4941 : Ipv6 privacy/1
Typically hosts configure addresses using SLAAC (StateLess Address AutoConfiguration) that inserts some parts of the MAC address into the ipv6 LinkLocal and Global addresses. This poses a privacy concern. What can we do ?We can insert a randomized interface id in the address instead of the mEUI64.● Ubuntu, lively change for a specific interface (not always works) :
– sudo sysctl net.ipv6.conf.eth0.use_tempaddr=2
– sudo /etc/init.d/networking restart or sudo “ip link set dev eth0 down; ip link set dev eth0 up “
● Ubuntu, change that works at reboot for all interfaces, that are attached after :– echo “net.ipv6.conf.all.use_tempaddr=2” >>/etc/sysctl.conf
– Because /etc/sysctl.conf will be applied after interfaces are already attached will not work as expected
● Windows by default generates random EUI64 addresses to insert into ipv6 addresses. To disable this behaviour :– netsh interface ipv6 set privacy state=disabled store=active
– netsh interface ipv6 set privacy state=disabled store=persistent
Privacy concerns can be of course better solved with use of DHCPv6.With teredo you get only 1 global unicast address that doesn't expose your MAC addr : you can't use temporary addresses with it.
inno@geist:~/ipv6$ sudo sysctl a|grep net.ipv6|grep tempaddrnet.ipv6.conf.all.use_tempaddr = 2net.ipv6.conf.default.use_tempaddr = 2net.ipv6.conf.eth0.use_tempaddr = 0net.ipv6.conf.lo.use_tempaddr = 1net.ipv6.conf.teredo.use_tempaddr = 1

Oct 19, 2015 Roberto Innocente [email protected] 140
RFC4941 IPv6 privacy /2
● The default on Linux when using privacy extension (privext) is to maintain the mEUI64derived address for inbound connections and use RFC4941 temporary addresses for outboundconnections.● Windows Vista and 7 (not Server 2008) even if you disable random suffixes, continues toconfigure temporary addresses (also Mac OS X since 10.7), against the advice of the RFC : “The use of temporary addresses may cause unexpected difficulties with some applications... Consequently, the use of temporary addresses SHOULD be disabled by default in order to minimize potential disruptions. Individual applications, which have specific knowledge about the normal duration of connections, MAY override this as appropriate.”●To disable completely the privacy extension you need to set :netsh interface ipv6 set privacy state=disabled store=activenetsh interface ipv6 set privacy state=disabled store=persistentand reboot.●

Oct 19, 2015 Roberto Innocente [email protected] 141
Linux IPv6 Name resolution
The GNU name service switch configuration /etc/nsswitch.conf decides in which order to search for host names :
hosts: files mdns_minimal [NOTFOUND=return] dnsThis line specifies to consult first the file /etc/hosts, then to consult the avahi ipv6 database (mdns6) for .local names and, if not found, return without proceeding. Then for other (not .local) addresses consult the internet dns.With this configuration (getent applies exactly these rules) :root@geist:~# getent hosts geist.localfe80::219:99ff:fe79:ff0 geist.localUnfortunately many applications dont use the GNU name service for host names.The commands host and nslookup use only dns services and dont resolve .local names :root@geist:~# host geist.localHost geist.local not found: 3(NXDOMAIN)root@geist:~# nslookup geist.localServer: 2001:4860:4860::8888Address: 2001:4860:4860::8888#53** server can't find geist.local: NXDOMAIN

Oct 19, 2015 Roberto Innocente [email protected] 142
Linux /etc/gai.conf switch
This is the getaddrinfo(3) configuration file (RFC3484).For hosts that have both ipv4 and ipv6 addresses, you can manage preference over address families adding at the end of file /etc/gai.conf :● Case 1: prefer IPv4
– precedence ::ffff:0:0/96 100
● Case 2: prefer IPv6 for specific hosts :– precedence 2001:760::/32 100
● Case 3: prefer IPv4 for specific hosts :– precedence 2001:760::/32 0
● Case 4: prefer IPv6 – precedence 2000::/3 100
– precedence fe80::/16 100
Test the cases with the command : getent hosts google.com
Default by RFC3484 and POSIX gai.conf :precedence ::1/128 50precedence ::/0 40precedence 2002::/16 30precedence ::/96 20precedence ::ffff:0:0/96 10

Oct 19, 2015 Roberto Innocente [email protected] 143
Windows resolvers and prefixpolicies
On windows : netsh inter ipv6 show dnsserver , netsh ipv6 add dnsserver
The equivalent of /etc/gai.conf on Windows is called prefixpolicies. Default is to prefer IPv6 over IPv4 except if teredo or 4to6.C:\netsh interface ipv6 show prefixpoliciesPrecedence Label Prefix ---------- ----------- ----------50 0 ::1/12840 1 ::/035 4 ::ffff:0:0/9630 2 2002::/165 5 2001::/323 13 fc00::/71 11 fec0::/101 12 3ffe::/161 3 ::/96
You can change precedence of the entries or insert new entries with something like :
C:\>netsh interface ipv6 set prefixpolicy ::/0 2 25

Oct 19, 2015 Roberto Innocente [email protected] 144
IPv6 Firewalls issues
● FTP– Is a complex protocol with many variants and
commands : PORT, LPRT, EPRT, PSV , EPSV, LPSV (RFC1639-2428)
– Not supported in all its variants in many IPv6 firewalls
– Probably HTTP with WEBDAV and DELTA will substitute it in the future
● Many firewalls don't support IPv6 H.323

Oct 19, 2015 Roberto Innocente [email protected] 145
ip6tables by handPacket filters for IPv6 are managed by an iptables version for IPv6 :
– ip6tables
Routing header type 0 is a threat only for forwarding nodes.# Flush & defaultip6tables F INPUTip6tables F OUTPUTip6tables F FORWARDip6tables F
# Enable the following lines only if a router!# Enabling IPv6 forwarding disables routeadvertisement reception.# A static gateway will need to be assigned.##echo "1" >/proc/sys/net/ipv6/conf/all/forwarding##End router forwarding rules
# Disable processing of any RH0 packet# Which could allow a pingpong of packetsip6tables A INPUT m rt rttype 0 j DROPip6tables A OUTPUT m rt rttype 0 j DROPip6tables A FORWARD m rt rttype 0 j DROP
# Allow anything on the local linkip6tables A INPUT i lo j ACCEPTip6tables A OUTPUT o lo j ACCEPT
# Allow LinkLocal addressesip6tables A INPUT s fe80::/10 j ACCEPTip6tables A OUTPUT s fe80::/10 j ACCEPT
# Allow multicastip6tables A INPUT d ff00::/8 j ACCEPTip6tables A OUTPUT d ff00::/8 j ACCEPT
# Allow ICMPip6tables A INPUT p icmpv6 j ACCEPTip6tables A OUTPUT p icmpv6 j ACCEPT#ip6tables A FORWARD p icmpv6 j ACCEPT
# Disable privileged ports for the outside, except ports 22, 515, and 631# Specifying an interface (i ethX) is probably a good idea to specify what is the outsideip6tables A INPUT p tcp dport 1:21 j REJECTip6tables A INPUT p udp dport 1:21 j REJECTip6tables A INPUT p tcp dport 23:514 j REJECTip6tables A INPUT p udp dport 23:514 j REJECTip6tables A INPUT p tcp dport 516:630 j REJECTip6tables A INPUT p udp dport 516:630 j REJECTip6tables A INPUT p tcp dport 632:1024 j REJECTip6tables A INPUT p udp dport 632:1024 j REJECT

Oct 19, 2015 Roberto Innocente [email protected] 146
Default ip6tables on RedHat/CentOS/Fedora
Routing header type 0 is a threat only if the node is forwarding packets.Configuration is in file /etc/sysconfig/ip6tables :
*filter:INPUT ACCEPT [0:0]:FORWARD ACCEPT [0:0]:OUTPUT ACCEPT [0:0]:RHFirewall1INPUT [0:0]A INPUT j RHFirewall1INPUTA FORWARD j RHFirewall1INPUTA RHFirewall1INPUT i lo j ACCEPTA RHFirewall1INPUT i eth0 j ACCEPTA RHFirewall1INPUT i br0 j ACCEPTA RHFirewall1INPUT p icmpv6 j ACCEPTA RHFirewall1INPUT p 50 j ACCEPTA RHFirewall1INPUT p 51 j ACCEPTA RHFirewall1INPUT p udp dport 5353 d ff02::fb j ACCEPTA RHFirewall1INPUT p udp m udp dport 631 j ACCEPTA RHFirewall1INPUT p tcp m tcp dport 631 j ACCEPTA RHFirewall1INPUT p udp m udp dport 32768:61000 j ACCEPTA RHFirewall1INPUT p tcp m tcp dport 32768:61000 ! syn j ACCEPTA RHFirewall1INPUT j REJECT rejectwith icmp6admprohibitedCOMMIT
● To open ssh, insert before the last reject :– A RHFirewall1INPUT m tcp
p tcp dport 22 j ACCEPT
● And restart everything typing :– sudo service ip6tables restart
● Automatic set up of a restricted fw by script :
.
.
#!/bin/bashIPT="/sbin/ip6tables"IF="eth0"$IPT -F;$IPT -X;$IPT -t mangle -F;$IPT -t mangle -X#unlimited access to loopback$IPT -A INPUT -i lo -j ACCEPT; $IPT -A OUTPUT -o lo -j ACCEPT# DROP all incomming traffic$IPT -P INPUT DROP; $IPT -P OUTPUT DROP; $IPT -P FORWARD DROP
# Allow full outgoing connection but no incomming stuff$IPT -A INPUT -i $IF -m state --state ESTABLISHED,RELATED -j ACCEPT$IPT -A OUTPUT -o $IF -m state --state NEW,ESTABLISHED,RELATED -j ACCEPT
# allow incoming ICMP ping pong stuff$IPT -A INPUT -i $IF -p ipv6-icmp -j ACCEPT$IPT -A OUTPUT -o $IF -p ipv6-icmp -j ACCEPT ############# add your rules below ############### open IPv6 port 22$IPT -A INPUT -i $IF -p tcp --destination-port 22 -j ACCEPT################### log everything else$IPT -A INPUT -i $IF -j LOG; $IPT -A INPUT -i $IF -j DROP

Oct 19, 2015 Roberto Innocente [email protected] 147
ip6tables by butler ufw (Uncomplicated Firewall)
It manages at the same time (by default) ipv4 and ipv6 filters using iptables and ip6tables. We say it is ip-agnostic because the rules apply to both stacks.● sudo aptget install ufw
Be sure in /etc/default/ufw there is a line : IPV6=yes.Do the following :
ufw statusufw default denyufw logging onufw allow 22/tcpufw enableufw status
This will configure the ip[6]tables firewall to (for both ipv4 and ipv6) :● Block any incoming connection except ssh● Let go all outgoing connections
It will insert automatically for ipv6 proper defaults that :● Will drop pkts with routing header RH0 on all
chains● Will drop NDP pkts with hop limit less than 255● If the pkt belongs to an established connection
pass it on● Accept echo replies from link local addresses● Accept some safe icmp pkts● Allow dhcp● Allow mDNS● Drop pkts not belonging to an established
connection
There is a graphical interface too : aptget install gufw
Status: activeTo Action From-- ------ ----22/tcp ALLOW Anywhere22/tcp (v6) ALLOW Anywhere (v6)

Oct 19, 2015 Roberto Innocente [email protected] 148
Ufw/2On input :Target prot src dstACCEPT all ::/0 ::/0
DROP all ::/0 ::/0 rt type:0 segsleft:0 # pkt with rh type 0ACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 135 HL match HL == 255 # neighbor solicitationACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 136 HL match HL == 255 # neighbor advertisement
ACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 133 HL match HL == 255 # router solicitationACCEPT icmpv6 ::/ ::/0 ipv6icmptype 134 HL match HL == 255 # router advertisement
ACCEPT all ::/0 ::/0 ctstate RELATED,ESTABLISHEDACCEPT icmpv6 fe80::/10 ::/0 ipv6icmptype 129 # echo reply
DROP all ::/0 ::/0 ctstate INVALIDACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 1 # Destination Unreachable
ACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 2 # Packet too bigACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 3 # Time exceededACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 4 # Parameter problem
ACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 128 # echo requestACCEPT udp fe80::/10 fe80::/10 udp spt:547 dpt:546 # dhcp server/relay to client
ACCEPT udp ::/0 ff02::fb udp dpt:5353 # mDNSACCEPT udp ::/0 ff02::f udp dpt:1900 # Simple Service Discovery Protocol
On output :
target prot src dst ACCEPT all ::/0 ::/0 DROP all ::/0 ::/0 rt type:0 segsleft:0 # pkt with rh type 0
ACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 135 HL match HL == 255 # neighbor solicitationACCEPT icmpv6 ::/0 ::/0 ipv6icmptype 136 HL match HL == 255 # neighbor advertisement
ACCEPT all ::/0 ::/0 ctstate RELATED,ESTABLISHED

Oct 19, 2015 Roberto Innocente [email protected] 149
Windows advfirewall● Reset firewall :
– netsh advfirewall reset
● Enable/Disable fw :– netsh advfirewall set allprofiles
state on
● Query rules : – netsh advfirewall firewall show rule
name=all
● Set/Change log file :– netsh advfirewall set
currentprofile logging filename "C:\.....”
● Allow a program :– netsh advfirewall firewall add
rule name="Allow Messenger" dir=in action=allow
● Import/Export rules
● Most of the rules are ip-agnostic, there are some ipv6 specific
● Long list to read, many exceptions activated by application and not by port :– firefox C:\Program Files
(x86)\MozillaFirefox\firefox.exe allowed (any any , any any ) !

Oct 19, 2015 Roberto Innocente [email protected] 150
Node startup with randomized interface ID
Router Prefix 2001:db8:bb:10::/64
MAC 00:19:99:79:0f:f0
1.Receives RouterSolicitation, sends RouterAdvertisement to ip6-allnodes multicast for prefix 2001:db8:bb:10::/64
1.LinkLocal address created using random suffix of 64 bits : fe80::374:12f8:8a7e:54d2/64
2.NDP Neighbor Solicitation Message sent according to DAD for LL address
3.NDP Router Solicitation sent to ip6-allrouters multicast address
4.Receives RouteAdv, sets Global Unicast address to the prefix heard + random interface ID created in step 1: 2001:db8:bb:10:374:12f8:8a7e:54d2
5.Performs DAD on the Global Unicast address sending a Neighbor Solicitation message
Internet ipv6

Oct 19, 2015 Roberto Innocente [email protected] 151
RFC3315/RFC3736 – DHCPv6/1
A device can receive an IPv6 dynamic address without using DHCPv6 but using SLAAC : from the ICMPv6 Router Advertisement (RA) gets the network ID and creates the interface ID by itself.There are 2 kinds of DHCPv6 services :1) Stateful, DHCP RFC3315, similar to
dhcpv4, the node gets the address(because of the M=1 flag of the RA) and other params from the dhcp server
2) Stateless, DHCP RFC3736 , M=0,O=1, nodes get other info (DNS, default gw,..) from dhcpv6 server
The following terms conserve their IPv4 meaning :● DHCPv6 client● DHCPv6 server● DHCPv6 relayNew terms :● DUID DHCPv6 Unique Identifier (2
bytes type + LL addr + time, LL addr ,..)
● IA Identity Association : a collection of addresses assigned to a client per interface
● IAID Identity Association Identifier chosen by the client unique between all IA of that client

Oct 19, 2015 Roberto Innocente [email protected] 152
DHCPv6/2
Instead of the broadcasts used by dhcpv4, dhcpv6 uses multicast addresses :● All_DHCP_Relay_Agents_and_S
ervers (FF02::1:2) used by clients to communicate with servers and relays
● All_DHCP_Servers (FF05::1:3) used by relays to communicate with servers
Ports :● UDP port 546 : clients listen on this
port● UDP port 547 : clients send messages
to servers and relays over this portDHCPv4 is using port 67 and 68.
Most important DHCPv6 messages :1) SOLICIT sent by clients to
discover servers (v4 discover)2) ADVERTISE sent by server
as answer to a client SOLICIT (v4 offer)
3) REQUEST sent by client to request parameters
7) REPLY to answer to a client REQUEST with addresses and other parameters (v4 ack)

Oct 19, 2015 Roberto Innocente [email protected] 153
DHCPv6/3
Normal (rfc3315) :● Client → multicast: solicit● Server → client: advertise● Client → server: request● Server → client: reply
Rapid commit option:● Client → multicast : solicit● Server → client : reply
DHCPv6 DUID :Clients in IPv6 don't use just MAC addresses to identify themselves (problems : multiple interface, multiple VM ,mobility,..) but a long lived Unique Identifier.DUID : Device Unique Identifier Used by both clients and servers : it should be stored in permanent memory. 3 methods were defined in rfc3315 for its generation :● LinkLayer address + time (LLT)● Vendor assigned Unique ID based on Enterprise Number● LinkLayer addresshttp://www.tc.mtu.edu/ipv6/wide_mkduid.plEach interface has an IAID Interface Association Identifier that is a binding between an interface and 1 or more ipv6 addresses. DHCPv6 gives addresses based on DUID and IAID.

Oct 19, 2015 Roberto Innocente [email protected] 154
DHCPv6/4
A duplicate DUID can cause a client not to be able to obtain an address from the DHCP server, the DUID is unique for the client for all interfaces.On windows delete the DUID registry key and reboot. Ipconfig /all :Ethernet adapter Ethernet: Physical Address. . . . . . . . . : B4-B6-76-60-58-8C DHCPv6 IAID . . . . . . . . . . . : 621412391 DHCPv6 Client DUID. . . . . . . . : 00-01-00-01-1D-6C-FF-06-B4-B6-76-60-58-8COn linux the duid is created when the dhcp client is installed and stored in /var/lib/dhcpv6 :hexdump -e '"%07.7_ax " 1/2 "%04x" " " 14/1 "%02x:" "\n"' /var/lib/dhcpv6/dhcp6c_duid
Remove it, or reinstall.$ man dhcp6c

Oct 19, 2015 Roberto Innocente [email protected] 155
ISC DHCPv6/5
The DHCPv6 server has a new functionality for home and SOHO environments : it can ask a range of IPv6 addresses from the DHCPv6 server of the provider.The ISC DHCP server supports IPv6, you provide also a separate configuration file, to start and debug it in foreground :# /usr/sbin/dhcpd -6 -d -cf /etc/dhcp/dhcpd6.conf eth0

Oct 19, 2015 Roberto Innocente [email protected] 156
ISC DHCPv6/6
default-lease-time 600;max-lease-time 7200; log-facility local7; subnet6 2001:db8:0:18::/64 { # Range for clients range6 2001:db8:0:18::100 2001:db8:0:1::a00; # 2560 addresses for normal dhcp # Range for clients requesting a temporary address range6 2001:db8:0:19::/64 temporary; # 2^64 addresses as temporary addresses/priv # Additional options option dhcp6.name-servers fec0:0:0:ffff::1; # follow windows default for dns servers option dhcp6.domain-search "sissa.it"; # Prefix range for delegation to sub-routers prefix6 2001:db8:0:100:: 2001:db8:0:f00:: /56; # Example for a fixed host address host specialhost { host-identifier option dhcp6.client-id 22:21:10:d9:ac:21:a4:33:01:17:a4:aa:32:51; fixed-address6 2001:db8:0:18::2ab; }
}
● Lease time 10 min● Max lease time 2h● Range for public
permanent addresses separated from that of temporary
Uses the file /var/lib/dhcpv6/dhcp6c_duid as unique identity : created at first start.Its a 14 bytes key with an initial 2 bytes length : hexdump -e '"%07.7_ax " 1/2 "%04x" " " 14/1 "%02x:" "\n"' /var/lib/dhcpv6/dhcp6c_duid

Oct 19, 2015 Roberto Innocente [email protected] 157
DNS/1
Any record related to IPv6 can be stored and served in a normal DNSv4 server. With DNSv6 we mean a server that can answer queries and eventually make them(recursive resolver) over IPv6.By default BIND9 doesn't listen on ipv6 :options { listen-on-v6 { any;};};Behaviour changed on bind 9.10 : now by default listen on all ipv4/ipv6 addresses. And it can use ipv6/ipv4 on recursive queries indifferently.If you want to use only v4 or v6 start named with :named -4named -6

Oct 19, 2015 Roberto Innocente [email protected] 158
DNS/2IPv6 and DNS - RFC1886
● Simple solution: IPv6 128 bits addresses are registered in the DNS with an AAAA record (being 128 bits, 4 times 32 bits of an A address)
ipv6-host AAAA 2001:db8:12::213:45ea:3aef● Reverse addresses : registered in the new .ip6.arpa. domain :
f.e.a.3.a.e.5.4.3.1.2.0.0.0.0.0.0.0.0.2.1.0.0.8.b.d.0.1.0.0.2.ip6.arpa IN PTR ipv6-host.example.com
It's simpler to see it than to explain it : each hex digit of the IPv6 address in reverse order is now a label in the hierarchy.NB. pronounce AAAA as quad A, not AAAAAAAAAAAAAHH !

Oct 19, 2015 Roberto Innocente [email protected] 159
DNS forward mapping/3
Not many changes had to be done for direct mapping of names. Simply a new record for 128 bits addresses was added and its type name set to AAAA (four time more bits than the normal IPv4 A record, aka quad A) Web.example.org A 10.1.0.3 AAAA 2001:db8::11:1
For the reverse mapping, the story was a bit more complicate and after a proposed suffix of ip6.int, now deprecated, the ip6.arpa suffix is now used. 1.0.0.0.1.1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa. PTR web.example.org.
Better to declare an origin like the given prefix to avoid errors :$ORIGIN 0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa.1.0.0.0.1.1.0.0 PTR web.example.org.zone “0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa” { type master; File “db.2001:db8::” ;};
Perfectly legitimateto use shortcuts for IPv6 addresses in conf files, but not on reverse zones !

Oct 19, 2015 Roberto Innocente [email protected] 160
DNS reverse mapping/4 emtpy reverse-mapping zones
There are many reserved address ranges in IPv6Latest ISC BIND 9 includes built-in reverse-mappings for these empty zones, so that any request it receives for those, will result in a negative answer :0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.ip6.arpa Unspecified IPv6address1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.ip6.arpa IPv6 Loopback Address8.b.d.0.1.0.0.2.ip6.arpa IPv6 Documentation Networkd.f.ip6.arpa Unique Local Addresses8.e.f.ip6.arpa LinkLocal Addresses9.e.f.ip6.arpa LinkLocal Addressesa.e.f.ip6.arpa LinkLocal Addressesb.e.f.ip6.arpa LinkLocal Addresses
To disable one of the empty zones without creating a zone for it :
options { disable emptyzone : “d.f.ip6.arpa”; };

Oct 19, 2015 Roberto Innocente [email protected] 161
DNS/5IPv6 inserting reverse DNS records
● Very prone to error if inserted manually● Prefer Dynamic DNS● Otherwise use dig to produce the right question and display it. Some cut and paste and
it's done.
inno@geist:~$ dig x 2001:db8:0:18::1
; <<>> DiG 9.9.59ubuntu0.3Ubuntu <<>> x 2001:db8:0:18::1;; global options: +cmd;; Got answer:;; >>HEADER<< opcode: QUERY, status: NXDOMAIN, id: 58002;; flags: qr aa rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
;; OPT PSEUDOSECTION:; EDNS: version: 0, flags:; udp: 4096;; QUESTION SECTION:;1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.1.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa. IN PTR

Oct 19, 2015 Roberto Innocente [email protected] 162
DNS/6Setup reverse zone IPv6 delegations
Delegations are made on nibble boundaries because each nibble is a new leaf in the DNSv6 reverse tree ip6.arpa. If your prefix is not divisible by 4 then you receive a multiple zone delegation till to the next nibble :2200:0480::/31 implies you get a delegation for=> 2200:0480::/32=> 2200:0481::/32The same if you want to delegate not on a nibble boundary.On linux use : ipv6calc

Oct 19, 2015 Roberto Innocente [email protected] 163
DNS/7
● Sending queries from a specific address:– options {query-source-v6 address
2001:db8:cafe:1::1;};
● Port randomization:– By default bind 9 chooses random ports in the
range from port 1024 to port 65535(kaminski hack)
– You can limit the range with an option

Oct 19, 2015 Roberto Innocente [email protected] 164
DNS/8
IPv6 master/slavezone "sissa.it" {type slave;masters {2001:db8:dead:caf::1;};file "bak.sissa.it";};IPv6 zone xferoptions {transfer-source-v6 2001:db8:dead:1::1;notify-source-v6 2001:db8:dead:1::1;};
allow-query {192.249.249/24;192.253.253/24;2001:db8:cafe:1::/64;2001:db8:cafe:2::/64;};

Oct 19, 2015 Roberto Innocente [email protected] 165
DNS/9$TTL 3600$ORIGIN ipv6.sissa.it.@ IN SOA ghost.ipv6.sissa.it. inno.ghost.ipv6.sissa.it. ( 2015092202 ; serial 21600 ; refresh after 6 hours (forslaves) 3600 ; retry after 1 hour (for slaves) 604800 ; expire after 1 week (for slaves) 3600 ) ; minimum TTL of 1 hour (for resolvers)
@ IN NS ghost.ipv6.sissa.it.
ghost IN AAAA fd00::22:b6b6:76ff:fe60:588c IN AAAA fd00::18:b6b6:76ff:fe60:588c geist IN AAAA fd00::22:219:99ff:fe79:ff0 IN AAAA fd00::18:219:99ff:fe79:ff0
; SPF record
$TTL 1h; 1 1 1 1 1 1 1 9 8 7 6 5 4 3 2 1; 6 5 4 3 2 1 0$ORIGIN 8.1.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa.; 8 bytes = 16 nibbles = 64 bits prefix
@ IN SOA 8.1.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa. \inno.ghost.ipv6.sissa.it. ( 2015092202 ; serial 21600 ; refresh after 6 hours(for slaves) 3600 ; retry after 1 hour (for slaves) 604800 ; expire after 1 week (for slaves) 3600 ) ; minimum TTL of 1 hour (for resolvers)@ IN NS ghost.ipv6.sissa.it.; 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1; 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7c.8.8.5.0.6.e.f.f.f.6.7.6.b.6.b IN PTR ghost.ipv6.sissa.it.0.f.f.0.9.7.e.f.f.f.9.9.9.1.2.0 IN PTR geist.ipv6.sissa.it.
ipv6.sissa.it.file 8.1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa.file

Oct 19, 2015 Roberto Innocente [email protected] 166
ipv6calc
ipv6calc mac_to_eui64 00:19:99:79:0f:f0No action type specified,try autodetection...found type: geneui64219:99ff:fe79:ff0ipv6calc q i 2001:0:53aa:64c:109d:f226:6c85:e7b5Address type: unicast, globalunicast, productive, teredoCountry Code: ITError getting AS number from IPv6 addressRegistry for address: reserved(RFC4380#6)IPv4 address: 147.122.24.74 (TEREDOCLIENT)IPv4 address type: unicast, globalCountry Code: ITIPv4 registry[147.122.24.74]: RIPENCCGeoIP country name and code for [147.122.24.74]: Italy (IT)IPv4 address: 83.170.6.76 (TEREDOSERVER)IPv4 address type: unicast, globalCountry Code: A2IPv4 registry[83.170.6.76]: RIPENCCGeoIP country name and code for [83.170.6.76]: Satellite Provider (A2)Address type is Teredo and included IPv4 server address is: 83.170.6.76 and client port: 3545IPv4 registry for Teredo server address: RIPENCC
ipv6calc q out revnibbles.arpa 2001:0:53aa:64c:109d:f226:6c85:e7b55.b.7.e.5.8.c.6.6.2.2.f.d.9.0.1.c.4.6.0.a.a.3.5.0.0.0.0.1.0.0.2.ip6.arpa.

Oct 19, 2015 Roberto Innocente [email protected] 167
Google/Cisco public nameservers
Google provides public nameservers not only over ipv4 but also over ipv6 :Ipv4 : 8.8.8.8 8.8.4.4Ipv6 : 2001:4860:4860::8888 2001:4860:4860::8844
Cisco/opendns
2620:0:ccc::2 2620:0:ccd::2

Oct 19, 2015 Roberto Innocente [email protected] 168
Bundy/1
ISC stopped the development of BIND 10 some years ago and left it in the public domain on github the release 1.2.BIND 10 is a complete rewrite in C++ and python of the DNS package and it incorporates also DHCP for both IPv4 and IPv6. It is modular and it can use different databases for its backend operations.It is now in the hands of a different set of developers who called it bundy and whose site ishttp://www.bundy.de

Oct 19, 2015 Roberto Innocente [email protected] 169
Bundy/2
● If you download the source, as usual : – ./configure; make; make install● It will install itself by default in /usr/local, therefore cd /usr/local ● Create a managing user :
– sbin/bundycmdctl usermgr add root● Start the server : sbin/bundy
By default DNS and DHCP are not started, so : bin/bundyctl● config add Init/Components bundy auth● config add Init/Components/bundy/auth/special auth ●config add Init/Componenents/bundyauth/kind needed ●config commit quitTest it : dig @::1 c CH t TXT version.bind

Oct 19, 2015 Roberto Innocente [email protected] 170
Bundy/3
●Load zones (direct, reverse ipv4,reverse ipv6) : bin/bundyloadzone c '{“databasefile”: “/usr/local/var/bundy/zone.sqlite3”}' your.zone.example.org your.zone.example.org.file- bin/bundyloadzone c '{“databasefile”: “/usr/local/var/bundy/zone.sqlite3”}' 24.122.147.inaddr.arpa 24.122.147.inaddr.arpa.file- bin/bundyloadzone c '{“databasefile” : “/usr/local/var/bundy/zone.sqlite3”}' 0.0.0.0.0.0.0.0.0.0.0.0.8.1.0.0.0.0.0.0.8.b.d.0.0.0.1.2.ip6.arpa. 0.0.0.0.0.0.0.0.0.0.0.0.8.1.0.0.0.0.0.0.8.b.d.0.0.0.1.2.ip6.arpa.file Try it : dig @::1 your.zone.example.org

Oct 19, 2015 Roberto Innocente [email protected] 171
Cisco configuration for variousdynamics methods
Stateful address assignementMeans dhcpv6 is responsible to assign an address and keep a record of it, like in dhcpv4:ipv6 dhcp pool DHCP_POOL_V6 address prefix 2001:DB8::18:/64 lifetime infinite infinite linkaddress 2001:DB8::18:1/64 dnsserver 2001:DB8::19:2 domainname example.orginterface gigabit 0/0 ipv6 address 2001:DB8::18:1/64 ipv6 nd ra suppress # can suppress RA ipv6 dhcp server DHCP_POOL_V6 ipv6 address dhcp # everything by dhcp ipv6 enable
Stateless address assignmentNew feature in ipv6. Clients get their addresses based on theprefix advertised on their interfaces : Stateless AddressAutoconfiguration (SLAAC). SLAAC usually gives only anaddress and a default gateway, other parameters should beconfigured on the server to be provided to the client. Requirement for SLAAC is that the LAN segment must use a /64 mask.DHCPv6 is used only to give out domain-names, DNS serversand other parameters that should be configured on DNS server.ipv6 dhcp pool DHCP_POOL_V6 dnsserver 2001:DB8::19:2 domainname example.orginterface Ethernet0/0 ipv6 address 2001:DB8::18:1/64 ipv6 nd otherconfigflag ipv6 dhcp server DHCP_POOL_V6 ipv6 address autoconfig ipv6 enable
To debug : debug ipv6 dhcp detail

Oct 19, 2015 Roberto Innocente [email protected] 172
IPv6 ACLs (Access Control Lists)
IPv6 ACLs are very similar to IPv4 ACLs.At the end of every ACL list implicitly the following is added :
● permit icmp any any nd-na● permit icmp any any nd-ns● deny ipv6 any any

Oct 19, 2015 Roberto Innocente [email protected] 173
IPv6 mobility
● IETFIPv6 mobility :– Mobile IPv6 (Host mobility)
– NEMO BS (Network Mobility Basic support )
● SHISA project implemented it on BSD ( the people of KAME fame)
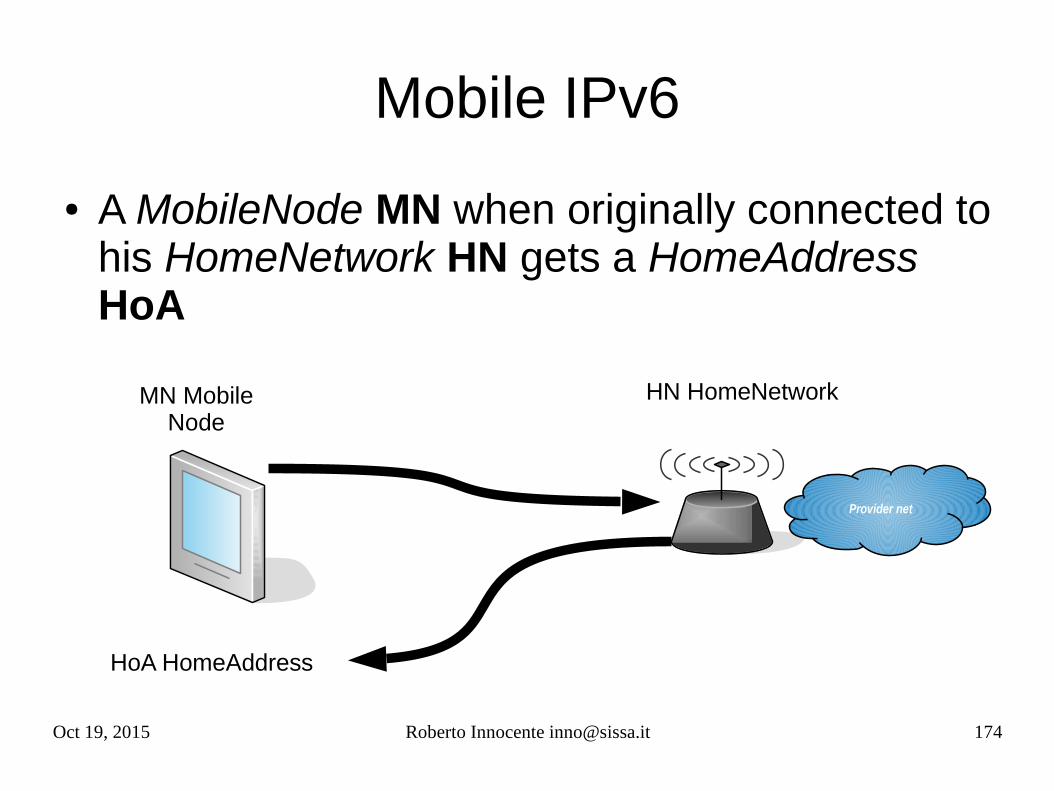
Oct 19, 2015 Roberto Innocente [email protected] 174
Mobile IPv6
● A MobileNode MN when originally connected to his HomeNetwork HN gets a HomeAddress HoA
Provider net
MN Mobile Node
HN HomeNetwork
HoA HomeAddress

Oct 19, 2015 Roberto Innocente [email protected] 175
Mobile IPv6/2
● When a MobileNode MN moves to a ForeignNetwork FN it gets a Care-of-Address CoA and sends a BindingUpdate BU to its HomeAgent
MN Mobile Node
FN ForeignNetwork
HoA HomeAddress
HN HomeNetwork
CoA Care-of-Address
HA HomeAgent
BU BindingUpdate
(2)
BU Binding Update =HoA , CoA
(3)
(1)

Oct 19, 2015 Roberto Innocente [email protected] 176
Mobile IPv6/3
● After the HomeAgent HA receives the BU it creates a tunnel between itself and the Care-of-Address. It intercepts then everything for HoA and tunnels it to CoA, and vice versa.
MN Mobile Node
FN ForeignNetwork
HoA HomeAddress
HN HomeNetwork
CoA Care-of-Address
HA HomeAgent
TunnelCoA - HoA

Oct 19, 2015 Roberto Innocente [email protected] 177
Mobile IPv6/4
Direct RoutingIt is contemplated that home agents can redirect the correspondent to directly reach the Mobile Node at the CareOfAddress(bypassing) the encapsulation at the HomeAgent.

Oct 19, 2015 Roberto Innocente [email protected] 178
Source and destinationation addresses choice RFC6724/1
Unlike in IPv4, in IPv6 is very common for an interface to have multiple addresses :● Scopes : it has a mandatory link local address
then normally it has a global unique address and evenutally a local unique address
● States : autoconfigured addresses can be in a preferred or deprecated state
● Use : from global prefixes interfaces can derive temporary addresses using a pseudorandom interface ID to access the Internet and a permanent public address derived using mEUI64. Mobile nodes can have a HomeAddress and CareOfAddress.
Applications use API like getaddrinfo() that returns a list of addresses also with mixed IPv4 IPv6 addr. It would then pass a destination using sendto() or connect() and normally the app would go down the list in order. For this reason the RFC requires the API to return addresses in order according to preferences choosen.
The algorithm to choose addresses for a communication is made of 2 parts:● Best address as source(unless the app
specifies the source)● Best address as destinationspecified by RFC6724 as based on a prefix policy table that has the following columns:● Precedence higher is preferred.
Best entry is determined by longest prefix match
● Label when 2 source addresses S1, S2 can be choosen but one S1 has the same label of the destination then S1 is choosen !
● Prefix an IPv6 prefix

Oct 19, 2015 Roberto Innocente [email protected] 179
Source and destinationation addresses choice as per RFC6724/2
1. Prefer destination/source pairs with same scope
2. Prefer smaller scopes over larger3. Prefer non deprecated addresses4. Avoid using tunneling addresses
when native ipv6 is available5. Prefer pairs with longest common
matching prefixAs source address prefer temporary address over public address.In mobile prefer home-address over care-of-address RFC6724 suggested policy prefers ipv6 to
ipv4 unless ipv6 is a tunnel like teredo or 6to4 or link local address. If it is not configurable the implementation should follow strictly the rules in the table. Both Linux, BSD and Windows have configurable policies.
Prefix Precedence Label
::1/128 50 0 Loopback
::/0 40 1 IPv6
::ffff:0:0/96 35 4 IPv4 compat
2002::/16 30 2 6tp4
2001::/32 5 5 teredo
Fc00::/7 3 13 ULA
::/96 1 3 deprecated
Fec0::/10 1 11 Link Local
3ffe::/16 1 12 6bone

Oct 19, 2015 Roberto Innocente [email protected] 180
Ipv6 threats already circulating
Source routing attack :● RH0 extension header with 90 waypoints (amplify by
90)Man in the middle attack during NS/NA , RS/RA :● Spoof NA : reply to NS with fake NA with override flag
and hijack all traffic● Denial of Service or Hijacking using fake router : send
RA with high priority● DOS with IP conflicts : always reply to DAD positively
in such a way that hosts can't get an address● DOS with neighbor floods : flood lan with bogus NA

Oct 19, 2015 Roberto Innocente [email protected] 181
IPv6 FHS (Security at First Hop)
First Hop in ipv6 is prone to security risks : ND, RA, NS, RS, multicasts are easily spoofable.Therefore vendors already provide First Hop Security measures
● IPv6 snooping : it snoops NDP, DHCPv6 and populates the binding table. Depending on security level can block RA and DHCP replies.– IPv6 router advertisement
Guard : it validates or blocks RA
– IPv6 Destination Guard
– Binding Table Recovery
– IPv6 Source Guard
– IPv6 prefix Guard

Oct 19, 2015 Roberto Innocente [email protected] 182
IPv6 FHS/2
Router Advertisement (RA) :
A host on the LAN can spoof an advertisement of the legal router RTR setting the expiry time to 2h (In this case the PIO are not checked) and then takeover with a higher priority the legal router.
SLAAC
Often 1st hop is a Catalyst switch.On user ports block dhcp server traffic and router advertisements with the following PACL (Port ACL) for Catalysts :
ipv6 accesslist ACCESS_PORT
remark Block DHCP server>client
deny udp any eq 547 any eq 546
remark Block RA
deny icmp any any routeradvertisement
permit any any
!
interface gigabitethernet 1/1/3
switchport
ipv6 trafficfilter ACCESS_PORT in

Oct 19, 2015 Roberto Innocente [email protected] 183
IPv6 FHS/3
● IPv6 snooping : captures traffic like in NDP or DHCPv6 to populate the binding table.
● IPv6 Router Advertisement Guard (RA Guard) : checks and validates the RAs (should come from a router port) and eventually blocks the unwanted ones.
● IPv6 Destination Guard (DG) : filters traffic addressed to non-existant addresses and blocks NDP Resolution for addresses not in the binding table.
● DHCPv6 Guard : filters dhcp replies by ports that are not DHCPv6 servers or relays.● IPv6 Source Guard (SG) : filters packets from a port having a
source address that is not in the binding table for that port (anti-spoofing).● IPv6 Prefix Guard (PG): filters ingress packets having a source
address outside any known prefix (prefixes are know trough RA snooping )
IPv6 Snooping
Prefix GuardSource GuardDHCPv6 GuardRA Guard

Oct 19, 2015 Roberto Innocente [email protected] 184
IPv6 FHS Cisco deployment
● 3 phases :– 1st since 2010 : RA Guard and port based ACL, in
the beginning only on datacenter switches 15.0(2) on C2960S and C3560-X
– 2nd since beginning of 2012 : DHCPv6 Guard and NDP snooping (not sure when available on access layer switches), available on Cat 4500, Cat 4948,..
– 3rd since beginning of 2013 : Destination Guard (to mitigate NDISC attacks), available on same switches on which Cisco has implemented phase 2

Oct 19, 2015 Roberto Innocente [email protected] 185
Cisco IPv6 snooping
● dev>enable● dev#config t● dev(config)#ipv6 snooping
policy policyname● dev(configipv6snooping)#exit● dev(config)#interface type
number● dev(configif)#ipv6 snooping
attachpolicy policyname
Introduced in IOS :12.2(50)SY15.0(1)SY15.0(2)SE15.1(2)SG15.3(1)SCisco IOS XE Release 3.2SECisco IOS XE Release 3.8SCisco IOS XE Release 3.9SCisco IOS Release 15.2(1)E

Oct 19, 2015 Roberto Innocente [email protected] 186
IPv6 Alcatel-Lucent snooping
Alcatel AOS >6.7.1R01 :
● ipv6 helper dhcp-snooping enable- Globally enables dhcpv6 snooping and dhcpv6 pkts are filtered
● ipv6 helper dhcp-snooping vlan● Ipv6 helper dhcp-snooping port 1/24 [ trusted | block | client-only-untrusted |client-
only-trusted]● ipv6 helper dhcp-snooping linkagg number [ trusted | block | client-only-untrusted |
client-only-trusted]● ipv6 helper dhcp-snooping binding enable
- The binding table contains the linklocal address, ipv6 address, vlan, interface info ● ipv6 helper dhcp-snooping ip-source-filter port 1/64 enable
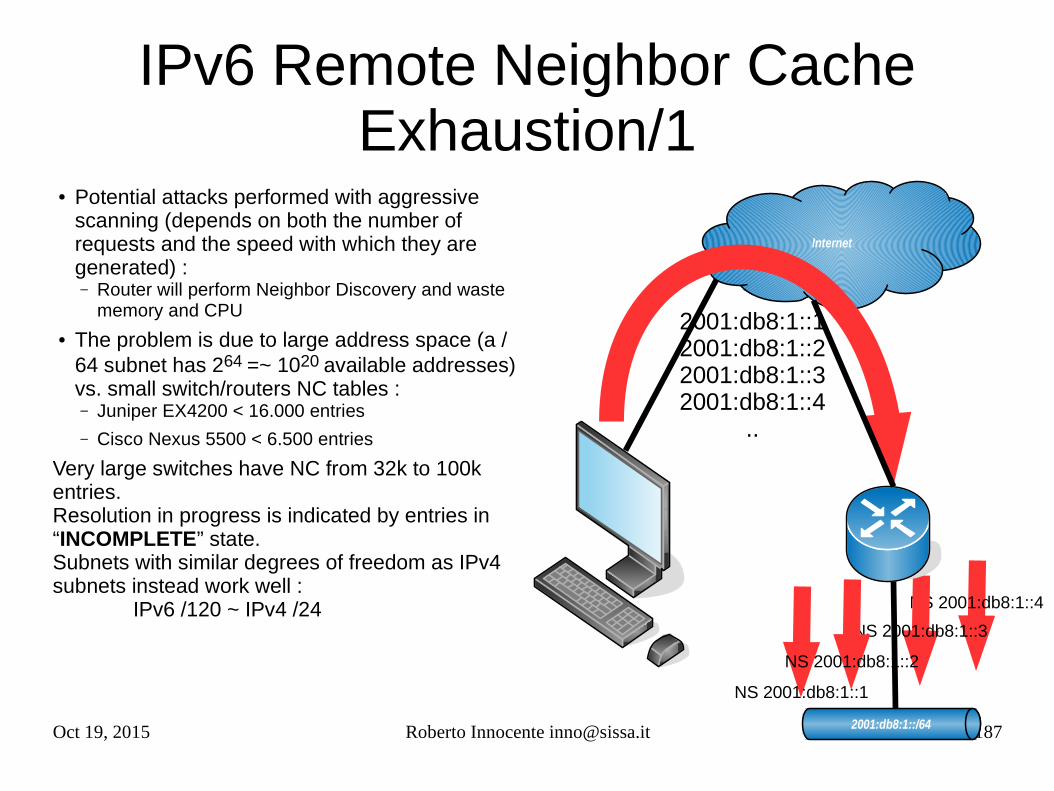
Oct 19, 2015 Roberto Innocente [email protected] 187
NS 2001:db8:1::4
NS 2001:db8:1::3
NS 2001:db8:1::1
NS 2001:db8:1::2
IPv6 Remote Neighbor Cache Exhaustion/1
● Potential attacks performed with aggressive scanning (depends on both the number of requests and the speed with which they are generated) :– Router will perform Neighbor Discovery and waste
memory and CPU
● The problem is due to large address space (a /64 subnet has 264 =~ 1020 available addresses) vs. small switch/routers NC tables :– Juniper EX4200 < 16.000 entries
– Cisco Nexus 5500 < 6.500 entries
Very large switches have NC from 32k to 100k entries.Resolution in progress is indicated by entries in “INCOMPLETE” state.Subnets with similar degrees of freedom as IPv4 subnets instead work well : IPv6 /120 ~ IPv4 /24
Internet
2001:db8:1::/64
2001:db8:1::12001:db8:1::22001:db8:1::32001:db8:1::4
..

Oct 19, 2015 Roberto Innocente [email protected] 188
IPv6 Remote Neighbor Cache Exhaustion- Remedies/2
Cisco ios >=15.1(3)T or ios-xe >=2.6 :● Cisco since 15.1(3)T
– Ipv6 nd cache interface limit
● Cisco IOS-XE 2.6 – Ipv6 nd resolution data limit
● Destination-Guard will be available in FHS phase 3
Using /64 on pt-to-pt links : a lot of addresses to scan => use /127 on pt-to-pt links (RFC6164).ACL filters to permit from outside only pkts to a few statically configured host (apart those of established connections), not to a network (Don't configure a service network or DMZ /64 and let them be reachable completely to make your job easier ). Allocate /64 but configure /120 (breaks SLAAC) : good solution for DMZ or server networks.
Jupiter, required MX series router, Junos at least 15.1 :
● per ip6 interface, set queue limit :– set interfaces ge-0/3/0 unit 5 family
inet6 nd6 max-cache limit
● per ip6 interface, set unresolved entries limit:– set interfaces ge-0/3/0 unit 5 family
inet6 nd6-new-hold-limit limit
● global limit– set system nd-system-cache-limit
limit
When the system limit is X, the interface internal routing discovery is Y (defautl 200), then : Public max cache limit Z = 80% *(X-Y) Mgmt if cacheolimit M = 20%*(X-Y)

Oct 19, 2015 Roberto Innocente [email protected] 189
IPv6 Remote Neighbor Cache Exhaustion- Remedies/3
Linux ( > 3. ) :● Garbage collection over Neighbor Table or Cache :
– if entries are < gc_thresh1 (default = 128) it exits doing nothing
– If entries are > gc_thresh1 (default = 128), entries are cleaned and the process is repeated every gc_interval seconds
– If entries are > gc_thresh2 (default = 512) for more than 5 seconds then the gc is run (independently from gc_interval)
– If entries = gc_thresh3 (default = 1024) : gc runs continuously
To see the GC at work list all NUD (Network Unreachability Detection) entries and count them :● ip 6 neigh show nud all | wc ● ip 6 ntableYou can change these defaults, trying to keep them scaled as they are : gc_thresh3 = 2 * gc_thresh2 = 4 * gc_thresh1● ip 6 ntable change name name [dev DEV] parmsWith which we can change thresh1, thresh2, thresh3, gc_interval, … most of the kernel parameters related to NDISC.If you use the system as a router better values are :● gc_interval = 3600 ms● gc_stale_time = 3600 ms ● gc_thresh1 = 1024, gc_thresh2 = 2048, gc_thresh3 = 4096

Oct 19, 2015 Roberto Innocente [email protected] 190
IPv6 Secure Neighbor DiscoverySEND(RFC3971/2)
SEND fights ND threats, it is an extension of Neighbor Discovery (ND). (Not supported by windows , on linux experimental versions).
It defines 2 new ND options and 2 new ND messages :● CPS(Certification Path solicitation)● CPA (Certification Path Answer)
SEND is A Public-Key-Infrastructure (PKI), implemented generating all addresses according to the Cryptographically-Generated-Addresses (CGA) standard.All NDP traffic is signed and authenticated, for this a central CA (Certification Authority) is used(easily a router).
Request
Certificate
Request Certificate
Certificate sent
CA server/router
LAN router
CA server/router
LAN router
Router Solicitation RSA signed
Router Advertisement RSA signed

Oct 19, 2015 Roberto Innocente [email protected] 191
IPv6 SEND/2CA
server/router
LAN router
Certification Path Solicitation
Certification Path Advertisement
Neighbor Solicitation RSA signed
CA server/router
LAN router
Neighbor AdvertisementRSA Signed
Neighbor Solicitation w/o RSA sign
Cisco:ipv6 nd secured fullsecure

Oct 19, 2015 Roberto Innocente [email protected] 192
IPv6 SEND/3CA
server/router
LAN router
Neighbor A
dvertisement
w/ R
SA sign
Cisco:no ipv6 nd secured fullsecure
Nei
g hbo
r Adv
e rtis
e me n
t w
/RS
A s
ign
Neighbo
r Adv
ertisement
w/o RSA si
gn
ROUTERS :Cisco supports SEND on some routers >12.4.24 on ISRJuniper supports it.HP, Huawei support it using ipv6-send-cga Linux pkg.
HOSTS:Windows seems does'nt support it natively : only with 2 apps . TrustRouter application and WinSEND.Apple : Trust Router.Linux :● Easy-SEND● ND-Protector● Ipv6-send-cgaA Patent exists ! (US 2008/0307516 A1 : from Cisco )

Oct 19, 2015 Roberto Innocente [email protected] 193
CGA (Experimental Protocol)(Cryptographically Generated Addresses)
New autoconfiguration mechanism based on the hash of a public key and some other parameters. Sketch :1.Generate a key pair : P,S (RSA
algorithm)2.InterfaceID = fingerprint eg
sha1(P,CGA params, ...)3.IPv6 = prefix + sha1(P,CGA
params,...)4.Ip -6 addr add IPv65.DDNS publish address
Draft is evolving and now CGA params used in fingerprint are :● Modifier (Random
128 bits)● Subnet prefix (64 bits)● Collision count(8 bits)● Public key (variable
length)

Oct 19, 2015 Roberto Innocente [email protected] 194
Configuring SEND (Secure ND)
Cisco :● crypto key generate rsa label key-label on
devicename:● ipv6 cga modifier rsakeypair key-label
sec-label 1● crypto pki trustpoint name● enrollment url url [pem]● revocation-check● exit● crypto pki authenticate name● ipv6 nd secured sec-level value● interface gi0/0● ipv6 cga rsakeypair key-label● ipv6 address address/prefix-len link-
local cga● ipv6 nd secured timestamp● exit● ipv6 nd secured full-secure
Juniper : Generate RSA key pair:● request security pki generate key-
pair type rsa certificate-id certificate-id-name size size
● set protocols neighbor-discovery secure security-level secure-messages-only
● set protocols neighbor-discovery secure cryptographic-address key-length 1024
● set protocols neighbor-discovery secure cryptographic-address key-pair /var/etc/rsa_key
● set protocols neighbor-discovery secure timestamp

Oct 19, 2015 Roberto Innocente [email protected] 195
Amnesiak NDProtector
● Part of the MobiSEND project funded by ANR (french research agency).
● It implements the SEND(Secure ND) protocol of RFC3756 using CGA addresses (as per RFC3972) in linux userspace to avoid kernel patches.
● When an ND msg is received or emitted a hook in ip6tables transfers the msg in userspace before going to the net/kernel (this is done trough libnetfilter_queue).
● A modified version of scapy6 is then used to extract and inspect the msg and add an RSA signature for outgoing pkts or let correct SEND signed pkts go in.
http://amnesiak.org/NDprotector/

Oct 19, 2015 Roberto Innocente [email protected] 196
Windows sorcery
When some windows system have only a link-local and/or teredo address they will not query the DNS for an AAAA if an A record is present (only literal ipv6 url will use ipv6) but will use ipv4.Go to the following registry key:HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\Dnscache\ParametersAdd a DWORD value: AddrConfigControl = 0You will have DNS resolving through the Teredo tunnel.

Oct 19, 2015 Roberto Innocente [email protected] 197
Cisco ASA configuration● interface gigabitethernet 0/0
– no shutdown
– nameif inside
– ipv6 enable
– ipv6 address 2001::db8:2:3::1/64
– security level 100
● interface gigabitethernet 0/1– ipv6 address 2001:db8:2:2::2/64
– nameif outside
– security level 0
● ipv6 route outside ::0/0 2001:db8:2:2::1/64
● ipv6 router ospf 1 – passiveinterface default
– no passiveinterface outside
– logadjacencychanges
– redistribute connected
– exit
ASA can be configured to accept only mEUI64 addresses :● ipv6 enforceeui64 nameif
“As of ASA Version 9.0(1), all ACLs on the ASA are unified, which means that an ACL supports a mix of both IPv4 and IPv6 entries in the same ACL.In ASA Versions 9.0(1) and later, the ACLs are simply merged together and the single, unified ACL is applied to the interface via the access-group command.”
ASA(Adaptive Security Appliance) works with security levels (0-100). BGP with IPv6 still not supported on ASA.
Level 100 is the most trusted, 0 the least trusted. By default all connections are allowed from a more trusted security level to a lower trusted one and viceversa. Usually the internet has security level 0, the DMZ 50 and the core network 100.
The routing extension header type 0 can be matched by :
● policymap type inspect ipv6 – match header routing type eq 0
Common debug commands :● debug ipv6 routing
● debug ipv6 nd
● debug ipv6 ospf ?
Interface is given a Link local
Ipv6 address
Static route
OSPF

Oct 19, 2015 Roberto Innocente [email protected] 198
Dynamic Routing protocols
Intra Domain Routing or IGP (Interior Gateway Protocol) : routing within an AS, ignores the Internet outside the Autonomous System.
– Distance-vector protocols : routers get summary information from neighbors only (not first hand information : ”routing by rumors” ). Use distributed Bellmann-Ford algorithm. RIPng is an extension of RIPv2 supporting IPv6 prefixes.
– Link-state protocols : all routers have complete information about the network trough the exchange over all routers of LinkStates. Use distributed Dijkstra algorithm. OSPFv3 (Open Shortest Path First) extends OSPF2 with support for IPv6.
Inter Domain Routing or EGP (Exterior Gateway Protocol) : routing between AS, assumes the Internet is a collection of AS
– Path-vector protocols : use a path-vector for each prefix , eliminating paths that contain its ASN. Based on Autonomous System Numbers. BGP4+ is the extension of BGP4 for IPv6.

Oct 19, 2015 Roberto Innocente [email protected] 199
Distributed distance-vector protocols
● Each router keeps a vector of distances (or costs) from routers with next hops: it is assumed that each router knows its address and distances (costs) to reach neighbor routers.
● It communicates this table periodically to neighbor routers
● Each router when it receives an update from neighbors recalculates distances adding the own link distance and keeps the shortest announcements (Bellmann-Ford Algorithm)
● Someone said it's like the kids' old telephone game : 1st kid says a sentence to the 2nd, etc. when it arrives to the last kid the sentence is garbled ..
.
.
I. Table : Da(b)=min cost from a to bII. Announcement from c: Dc(b) = min
cost from c to bIII. Update : Da(b) = min(cost(a,c)
+Dc(b),Da(b)), next hop =old or c
aa
bc
d
Dc(b)
22
2
13
Node Da
Next Hop
a 0 -b 3 cc 2 cd 2 d
Node Da
Next Hop
a 0 -b ¥ -c 2 cd 2 d
InitialDistance Vector for node a
Distance Vector After Update D
c(b)=1

Oct 19, 2015 Roberto Innocente [email protected] 200
Distributed distance-vector routing/2
Remedies to some of the problems :● Hold downs● Loop avoidance● Split horizon/poison
reverse● Triggered updates
RIPng (RFC2080)Distance vector with hop as metric.
Sends updates every 30 seconds, plus triggered updates for link failures.
Infinity is 16 hops(max dist 15).
Split horizon/poison reverse
Routes by default are given a validity lifetime of 3 minutes(6 updates).
Uses UDP port 521 instead of port 520 used by RIPv2.
Uses standard IPsec AH/ESP authentication /encryption.
Stay away from it if possible !
Distance-vector protocols were abandoned in favour of the more cpu intensive, but with faster convergence times link-state protocols.

Oct 19, 2015 Roberto Innocente [email protected] 201
Distributed distance-vector routing/3
● Defect : slow convergence !
1 432 5
T1 D2(5)=3 D
3(5)=2 D
4(5)=1
Problem : Counting to infinity ..
After convergence node 5 breaks :X
3,2,1,0,12,1,0,1,21,0,1,2,30,1,2,3,4
D1(5)=4 D
3(5)=2D
2(5)=3
6 update times = 180 sec=3 min
before route expiry
T7 D2(5)=3 D
3(5)=2
D1(5)=4 D
3(5)=2D
2(5)=3
3,2,1,0,32,1,0,1,41,0,1,2,30,1,2,3,4

Oct 19, 2015 Roberto Innocente [email protected] 202
Distance vector failures
● RIPng can't properly manage the different link properties and sends traffic along the 1 ® 3 path (all links cost 1)
● Count to infinity : only way to break looping of information (slow convergence and requires use of small number for infinity)
2
31
FastEther 100mb/s
GigaEther 1Gb/sG
igaE
ther
1G
b/s
1 5432 X

Oct 19, 2015 Roberto Innocente [email protected] 203
Configure RIPng (RIPv2 for IPv6)/1RFC2080 on Cisco
In global configuration mode :● ipv6 unicastrouting● ipv6 router rip ripng1
In interface configuration mode :● interface gigabitethernet 0/0– ipv6 address fd00:0:ffff::1/127
– ipv6 rip ripng1 enable
Configuration file results in :..hostname r1ipv6 unicastrouting..int gi0/0ipv6 address fd00:0:1::1/64ipv6 rip ripng1 enableno shutdownint gi0/1ipv6 address fd00:0:ffff::1/127ipv6 rip ripng1 enableno shutdown..ipv6 router rip ripng1

Oct 19, 2015 Roberto Innocente [email protected] 204
Configure RIPng and debug/2on Cisco
Common commands :● show ipv6 route rip● show ipv6 rip ripng1 database● show ipv6 rip ripng1 nexthop● debug ipv6 packet● debug ipv6 icmp● debug ipv6 rip

Oct 19, 2015 Roberto Innocente [email protected] 205
Configure RIPng/3on Cisco
Encryption trough the IPSec ipv6 mechanism :● crypto isakmp policy 1● authentication preshare● crypto isakmp key cisco address ipv6 2001:DB8:3:2::1/64
● crypto ipsec transformset 3des ahshahmac esp3des
● crypto ipsec transformset my3des ahshahmac esp3des
● crypto ipsec profile myipsecprofile0● set transformset 3des● interface Tunnel2
– no ip address
– ipv6 address 2001:DB8:1212::1/64
– ipv6 enable
– ipv6 rip myrip enable
● tunnel source GigaEthernet0/0● tunnel destination 2001:DB8:3:2::2● tunnel mode ipsec ipv6● tunnel protection ipsec profile myipsecprofile0
BGP, IS-IS, EIGRP for IPv6 use their own MD5 authentication mechanismOSPF3, RIPng , PIM can use IPv6 intrinsic IPSec authentication and/or encryption AH/ESP

Oct 19, 2015 Roberto Innocente [email protected] 206
Link-state routing/1
● Forwarding : needs to be fast performed for every packet. Routing : can go slower, make sure next-hop goes to destination
● Each host computes routes based on global topology knowledge
● First IGP protocol to implement link state was IS-IS (Intermediate Systems to Intermediate Systems) initially thought for Decnet V and then accepted for ISO/OSI
● IETF to keep up with novelty and stay away from proprietary/uncoded protocols, devised OSPF
● IS-IS had a resurrection when double stack ISP wanted a unique IGP for both IPv4 and IPv6 and OSPFv3 needed to run together with OSPFv2 to provide that. Recently also OSPFv3 allowed similar multiprotocol support (IPv4/v6).
● Each router tells everything it knows about its links and their costs
● 2 phases :– Reliable flooding (tell all
routers what you know about your local topology)
– Shortest Path calculation (Dijkstra)

Oct 19, 2015 Roberto Innocente [email protected] 207
Link-state routing/2
Dijkstra's Shortest Path Tree calculation :
S={} //set of nearest |S| nodesT=<remaining nodes by distance>while T != {}// extract nearest node from T
● u=NodeWithMinDistance(T)● S = S + {u} //u is done● T = T - {u}● for each node vÎT adjacent
to u :– “relax” the cost of v
Flooding :● Each router transmits a Link State
Packet/Advertisement (LSP or LSA) on all links
● The neighbor routers forward it to all links except to the incoming
● Ack and re-txmit● LSPs have sequence numbers : send
a LSP with cost infinity to signal a link down. TTL in every LSP decremented at each router
Flood is done at :● Topology change● Periodically (30 sec)OSPF and IS-IS are the most used link-state protocols.

Oct 19, 2015 Roberto Innocente [email protected] 208
Link-state routing/3
OSPFv3 (RFC5340) is the adaptation of OSPFv2 for IPv6.The cost of each link is a unitless number assigned by network admin. The accumulated network cost between network segments in OSPF must be less than 65.535.It no longer provides authentication as the v2 for IPv4 because it wants to use the standard IPsec provided by IPv6 : AH/ESP. But see RFC6506(not widely implemented yet).It is sent as an upper layer PDU with next header type 89 (it doesn't run on top of UDP or TCP). It provides Equal Cost Multipath (ECM).
Normally it uses the link-local IPv6 address of the interface where it runs as source address. Depending on the situation OSPF msgs can be sent as unicasts to a specific neighbor, or as multicasts to multiple neighbors. Two multicasts are reserved for this:AllSPFRouters : ff02::5AllDRouters : ff02::5RFC5838 : OSPFv3 was born for IPv6 support only, now rfc5838 establishes the possibility to support multiple address family with OSPv3 (like IS-IS to which some people migrated to support their double stack environment)

Oct 19, 2015 Roberto Innocente [email protected] 209
Shortest Path Tree (Dijkstra)
1
5
4
3
21
1
1
2
2
3
0 1
5
4
3
21
1
1
2
2
3
01
5
4
3
21
1
1
2
2
3
2
1
5
4
3
21
1
1
2
2
3 1
5
4
3
21
1
1
2
2
3
0
1
5
4
3
21
1
1
2
2
3
0
1
5
4
3
21
1
1
2
2
3
1
5
4
3
21
1
1
2
2
3
1
5
4
3
21
12
2
3
1
5
4
3
21
1
1
2
2
3
1
¥
¥
¥
¥ 1
2
¥
¥
¥
¥
0
1
2
4
S={1,2}, Nearest:
S={1,2,3},Nearest:
S={}, Nearest: S={1}, Relax:
S={1,2,3,5}, Relax:S={1,2},Relax:
0
2 2
11
4 4
¥¥
4
3
1
23
5
4
Shortest PathTree
4 4
In greenEqual CostMultipathsto node 4
12
4
4
4
3

Oct 19, 2015 Roberto Innocente [email protected] 210
Configure OSPFv3/1RFC5340 on Cisco
● OSPFv3 to reduce the computing required for large installation divides the network in areas.
● Shortest path tree is computed indipendently for each area and external destinations are reached via OSPF area 0 (= Backbone)
Conf R0 :● ipv6 unicastrouting● interface serial 0/0
– ipv6 enable
– ipv6 address fd00:ffff::/64 eui64
– ipv6 ospf 1 area 2
● ipv6 router ospf 1– routerid 5.5.5.5
– area 2 stub
Conf R1 :● ipv6 unicastrouting● int serial 0/0
– ipv6 enable
– ipv6 address fd00:ffff::/64 eui64
– ipv6 ospf 1 area 0
● ipv6 router ospf 1– routerid 4.4.4.4
– area 2 stub

Oct 19, 2015 Roberto Innocente [email protected] 211
Configure OSPFv3/2RFC5340 on Cisco
The metric in OSPF is a number from 0 to 100. No path can cost more than 64k.
By default any link 100mb/s or faster is assigned a cost of 1, loopback a cost of 0. In this case a FastEthernet will be treated equal to a Gigabit Ethernet : cost=1.
Cost in OSPF3 is computed simply :Interface Cost = Reference Bw/Interface bw
By default reference bandwidth is 100Mb/s (100 Mbit/s indicated by Mb/s) , therefore :
Interface Cost = 102/Interface bw in Mbit/s
Not useful today : everything ³ 100 Mb/s gets a cost of 1.
You can change the reference bandwidth with :router ospf 100
● autocost referencebandwith 10000● Exit
In this case the reference bandwidth will be 10 Gb/s and the automatic costs for different links will be :● 10 gb/s cost 1● 1 gb/s cost 10● 100 mb/s cost 100
With these costs the problem of the 3 nodes, 3 links at slide 188, unsolvable by RIPng, will be easily managed by OSPF3.
You can also change by hand the cost of a specific link :
router ospf 100● neighbor fd00:0:3::1 cost 3● exit

Oct 19, 2015 Roberto Innocente [email protected] 212
IS-IS and others
IS-IS (Intermediate Systems to Intermediate Systems) was the first link-state routing protocol with a large diffusion, developed by DEC for its DECNET V, became then an ISO std (ISO 10589/1992) .
● It is a link layer protocol (differently from OSPF that is based on IP or IPv6 and runs over the network layer)
● In the last times there was a revival of this protocol due to :– Instabilities of Spanning Tree Protocol or (M/R)STP in
large installations (when STP fails, it fails disgracefully)
– Waste of available bandwidth by STP due to shutdown of links for loop avoidance
– Necessity of having a routing protocol for both IPv4 and IPv6
– Need of lower convergence times (STP needs 20/30 sec)
Shortest Path Bridging (SPB 802.1aq, IEEE std, 2012) based on an extended IS-IS with equal cost multipath. It computes ECMT (Equal Cost Multipath Trees). Avaya, Alcatel-Lucent and Huawei at InterOp 2013 demonstrated their SPD interoperability. Devised to replace (M/R)Spanning Tree in large installations and datacenters.
TRILL (TRansparent Interconnection of a Lot of Links), standardized by IETF as RFC 6325, 7172/3/5/6/7 :
– uses special switches(RBridges) that can run IS-IS between them
FabricPath is a proprietary ( Cisco ) pre-standard implementation of it, as it is the Brocade Virtual Cluster Switching (both not interoperable and non standard).
MC-LAG or MLAG (Multichassis Link Aggregation .., or Fat Trees) 802.1AX-2008

Oct 19, 2015 Roberto Innocente [email protected] 213
Path-vector protocols
● Inter domain routing (routing between administrative separate entities)
● Autonomous system : set of nodes with same routing goals ( GARR , an ISP,…). Sissa had 2 ASNs (1352, 1353) around 1990 but after the first uses garr required the use of ASN 137
● Called this way because they keep a vector of paths for each net prefix :– Prefix ASN_PATH
– 2001:bd8:2::/64 100,12,58,59
– 2001:bd8:3::/64 12,58,59
Meaning : to reach net 2001:bd8:2::/64 you need to pass ASes 100,12,58,59
● Shortest path doesn't work : impossible to accommodate a metric for all uses. Incompatible with commercial relationships
NationalISP1
NationalISP2
Regionalisp1
Regionalisp2
Regionalisp3
Customer1
Customer2
Customer3
Transit agreement
Peering agreement
Transit agreement
Peering agreement
Peering agreement

Oct 19, 2015 Roberto Innocente [email protected] 214
AS relationships
● Transit agreement :– Provider comunicates all
the routes he has to the customer, it accepts from the customer only the customer's prefixes.
– Usually it is payed : stipulated between a large player and a smaller one that has to pay a fee for connecting
● Peering agreement :– Each peer comunicates to
the other only networks that are part of its AS (Regional ISP3 can't exchange with ISP2 traffic for ISP1)
– Usually free : stipulated between similar size subjects
Tier 1 providers (those in the Default-free zone) don't pay each other. But are required to peer with each other over multiple continents.

Oct 19, 2015 Roberto Innocente [email protected] 215
Path vector routing
● An extension of distance vector : for each entry keeps the complete ASN path to destination
● It avoids loops discarding annoucements that contain its ASN
● Usually keeps best path (minimum number of ASNs in the path)
ASN 2
ASN 3
ASN 1
a
a=path(1)
a=path(3,2,1)
a=path(2,1)
Rejected

Oct 19, 2015 Roberto Innocente [email protected] 216
Multiprotocol BGP for IPv6
MP-BGP4 : RFC2858, RFC2545.On cisco supported EGP(Exterior Gateway Protocol) for IPv6 and IPv6 multicast.Packet types :● Hello● Database Description● Link State Request● Link State Update● Link State Acknowledgement

Oct 19, 2015 Roberto Innocente [email protected] 217
BGP4+/1
● BGP4 is since long the established standard used by providers to exchange routing information among them. It is an Inter-domain Routing Protocol meaning that it supports the tidy exchange of routing information between administrative boundaries. It doesnt pretend to create the best and more efficient path between 2 nodes, but to nicely obey all the administrative rules given, avoiding loops by construction (RFC4271, RFC6286).
● BGP4+ adds to this protocol the possibility to exchange IPv6 routes (RFC2545, RFC4760).
● It bases its work on entities called Autonomous System (AS) that are indicated by an Autonomous System Number (ASN). These are adminstratevely separate entities (like a single ISP, GARR,..).
● It's not usually a protocol that runs on nodes, but on routers.

Oct 19, 2015 Roberto Innocente [email protected] 218
BGP4+/2
BGP bases its routing decisions on 10 parameters :
● Origin (IGP,EGP, other=INCOMPLETE)● AS_path length● Next Hop● Multi-Exit Discriminator (MED)● Local Preference● Atomic Aggregate● Aggregator● Community● Originator ID● Cluster List
● Weight is a local attribute never propagated. If 2 advertisements are received for the same network a local weight will be set for them :
– Both routes will be recorded in the bgp routing table
– Only the one with the max weight will be installed in the IP routing table
● Best path selection :– Prefer highest weight
– Prefer highest local pref (default 100)
– Prefer path locally originated
– Prefer path with shortest AS_PATH
– Prefer lowest origin : IGP < EGP < Incomplete
– Prefer lowest MultiExit Discriminator (MED)
– Prefer eBGP over iBGP
– If both paths external prefer the 1st received
– Prefer the route that comes from the BGP router with lowest router-id
– ...

Oct 19, 2015 Roberto Innocente [email protected] 219
BGP4+/3 onCisco IOS
router bgp 1352 no synchronization neighbor 2001:DB8:3:2::2 remoteas 1353 no autosummary addressfamily ipv4 no neighbor 2001:DB8:3:2::2 activate exit addressfamily addressfamily ipv6 redistribute connected redistribute static redistribute isis level2 neighbor 2001:DB8:3:2::2 activate neighbor 2001:DB8:3:2::2 softreconfiguration inbound aggregateaddress 2001:DB8:2:::/61 summaryonly no synchronization exit addressfamily

Oct 19, 2015 Roberto Innocente [email protected] 220
Routing Lab
>>
Fd00:0:20::/64
FastEthernet 100 Mb/s
GigabitEthernet 1 G
b/sGigabit
Ether
net 1
Gb/
s
1 Gb/s
1 Gb/s1 Gb/s
fd00:0:30::1/64
fd00:0:20::1/64
fd00:0:10::1/64
fd00:0:3::1/127
fd00:0:3::0/127fd
00:0
:2::1
/127
fd00:0
:2::0
/127
fd00:0:1::1/127fd00:0:1::0/127
3
2
1
Related Documents











