Semantic Web 0 (2017) 1 1 IOS Press Machine Learning in the Internet of Things: a Semantic-enhanced Approach Michele Ruta a,* , Floriano Scioscia a , Giuseppe Loseto a , Agnese Pinto a , and Eugenio Di Sciascio a a Polytechnic University of Bari, Department of Electrical and Information Engineering, via E. Orabona 4, I-70125, Bari, Italy E-mail: [email protected] Abstract. New Internet of Things (IoT) applications and services more and more rely on an intelligent understanding of the environment from data gathered via heterogeneous sensors and micro-devices. Though increasingly effective, Machine Learning (ML) techniques generally do not go beyond classification of events with opaque labels, lacking meaningful representations and explanations of taxonomies. This paper proposes a framework for a semantic-enhanced data mining on sensor streams, amenable to resource-constrained pervasive contexts. It merges an ontology-based characterization of data distributions with non-standard reasoning for a fine-grained event detection by treating the typical classification problem of ML as a resource discovery. Outputs of classification are endowed with machine-understandable descriptions in standard Semantic Web languages, while explanation of matchmaking outcomes motivates confidence on results. A case study on road and traffic analysis allowed to validate the proposal and achieve an assessment with respect to state-of-the-art ML algorithms. Keywords: Semantic Web, Machine Learning, Non-standard Reasoning, Internet of Things 1. Introduction The Internet of Things (IoT) paradigm is emerg- ing through the widespread adoption of sensing and capturing micro- and nano-devices dipped in every- day environments and interconnected in low-power, lossy networks. The amount and consistency of perva- sive devices increases daily and then the rate of raw data available for processing and analysis exponen- tially grows-up. More than ever, effective methods are needed to treat data streams with the final goal to give a meaningful interpretation of retrieved information. The Big Data label was coined to denote the re- search and development of data mining techniques and management infrastructures to deal with "volume, velocity, variety and veracity" issues [22] emerging when very large quantities of information materialize and need to be manipulated. Hence, Machine Learn- ing (ML) is adopted to classify raw data and make pre- dictions oriented to decision support and automation. * Corresponding author. E-mail: [email protected]. Progress in ML algorithms and optimization goes with advances of pervasive technologies and Web-scale data management architectures, so that undeniable benefits have been produced from the data analysis point of view. Nevertheless, some not negligible weaknesses are still evident with respect to the increasing com- plexity and heterogeneity of pervasive computing chal- lenges. Particularly, the lack of meaningful, machine- understandable characterization of outputs from clas- sical ML techniques is a prominent limit for a possible exploitation in fully autonomic application scenarios. This paper introduces an overall framework aiming to enhance classical ML analysis on IoT data streams, associating semantic descriptions to information re- trieved from the physical world, as opposed to triv- ial classification labels. The basic idea is to treat a typical ML classification problem like an ontology- driven resource discovery. Steps include building a logic-based characterization of statistical data distri- butions and performing a fine-grained event detection, exploiting non-standard reasoning services for match- making [31]. 1570-0844/17/$35.00 c 2017 – IOS Press and the authors. All rights reserved

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Semantic Web 0 (2017) 1 1IOS Press
Machine Learning in the Internet of Things: aSemantic-enhanced ApproachMichele Ruta a,∗, Floriano Scioscia a, Giuseppe Loseto a, Agnese Pinto a, and Eugenio Di Sciascio a
a Polytechnic University of Bari, Department of Electrical and Information Engineering, via E. Orabona 4,I-70125, Bari, ItalyE-mail: [email protected]
Abstract. New Internet of Things (IoT) applications and services more and more rely on an intelligent understanding of theenvironment from data gathered via heterogeneous sensors and micro-devices. Though increasingly effective, Machine Learning(ML) techniques generally do not go beyond classification of events with opaque labels, lacking meaningful representations andexplanations of taxonomies. This paper proposes a framework for a semantic-enhanced data mining on sensor streams, amenableto resource-constrained pervasive contexts. It merges an ontology-based characterization of data distributions with non-standardreasoning for a fine-grained event detection by treating the typical classification problem of ML as a resource discovery. Outputsof classification are endowed with machine-understandable descriptions in standard Semantic Web languages, while explanationof matchmaking outcomes motivates confidence on results. A case study on road and traffic analysis allowed to validate theproposal and achieve an assessment with respect to state-of-the-art ML algorithms.
Keywords: Semantic Web, Machine Learning, Non-standard Reasoning, Internet of Things
1. Introduction
The Internet of Things (IoT) paradigm is emerg-ing through the widespread adoption of sensing andcapturing micro- and nano-devices dipped in every-day environments and interconnected in low-power,lossy networks. The amount and consistency of perva-sive devices increases daily and then the rate of rawdata available for processing and analysis exponen-tially grows-up. More than ever, effective methods areneeded to treat data streams with the final goal to givea meaningful interpretation of retrieved information.
The Big Data label was coined to denote the re-search and development of data mining techniquesand management infrastructures to deal with "volume,velocity, variety and veracity" issues [22] emergingwhen very large quantities of information materializeand need to be manipulated. Hence, Machine Learn-ing (ML) is adopted to classify raw data and make pre-dictions oriented to decision support and automation.
*Corresponding author. E-mail: [email protected].
Progress in ML algorithms and optimization goes withadvances of pervasive technologies and Web-scale datamanagement architectures, so that undeniable benefitshave been produced from the data analysis point ofview. Nevertheless, some not negligible weaknessesare still evident with respect to the increasing com-plexity and heterogeneity of pervasive computing chal-lenges. Particularly, the lack of meaningful, machine-understandable characterization of outputs from clas-sical ML techniques is a prominent limit for a possibleexploitation in fully autonomic application scenarios.
This paper introduces an overall framework aimingto enhance classical ML analysis on IoT data streams,associating semantic descriptions to information re-trieved from the physical world, as opposed to triv-ial classification labels. The basic idea is to treat atypical ML classification problem like an ontology-driven resource discovery. Steps include building alogic-based characterization of statistical data distri-butions and performing a fine-grained event detection,exploiting non-standard reasoning services for match-making [31].
1570-0844/17/$35.00 c© 2017 – IOS Press and the authors. All rights reserved

2 M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach
The proposal grounds on both ideas and technolo-gies of distributed knowledge-based systems [28],whose individuals (assertional knowledge) are phys-ically tied to objects disseminated in a given envi-ronment, without centralized coordination. Each an-notation refers to an ontology providing the concep-tualization and vocabulary for the particular knowl-edge domain. Furthermore, the proposed theoreticalmodel leverages an advanced matchmaking on meta-data stored in sensing and capturing devices dippedin a context, lacking fixed knowledge bases. Inferencetasks are distributed among devices which provideminimal computational capabilities. Stream reasoningtechniques provide the groundwork to harness the flowof semantically annotated updates inferred from low-level data, in order to enable adaptive context-awarebehaviors.
Along this vision, innovative analysis methods ap-plied to data extracted by inexpensive off-the-shelfsensor devices can provide useful results in eventrecognition without requiring large computational re-sources. Limits of capturing hardware could be coun-terbalanced by novel software-side data interpretationapproaches. The approach was tested and validated ina case study for road and traffic monitoring on a realdata set collected for experiments. Results were com-pared to classic ML algorithms in order to evaluateperformance. The test campaign and early experimentspreliminary assess both feasibility and sustainability ofthe proposed approach.
The remainder of the paper is as follows. Section2 outlines motivation grounding the approach beforediscussing in Section 3 both background and state ofthe art on semantic data mining and ML for the IoT.The proposed framework is presented in Section 4,while Section 5 and Section 6 reports on the case studyand the experiments, respectively. Conclusion finallycloses the paper.
2. Motivation
Main motivation for this paper moves from the ev-idence of actual limits in the IoT. In spite of perva-siveness (miniaturization) and connectivity (intercon-nection capability) strengthen physical infrastructures,large data corpuses materialize without having reallythe possibility of analyze them in depth locally. Com-monly adopted data mining techniques have two maindrawbacks: i) they basically carry out no more than aclassification task and ii) their precision is increased if
applied on very big data amounts so making unfeasiblean on-line analysis. These elements prevent de factothe possibility of realizing thinking things: the IoT isinterpreted almost exclusively as sensing by the envi-ronment while is really veiled the possibility of makingdecisions and taking actions locally after the sensingstage.
It should be considered that in IoT scenarios, infor-mation is gathered through micro-devices attached toeveryday items or deployed in given environments andinterconnected wirelessly. Basically, due to their smallsize, such objects have minimum processing capabili-ties, a small storage and low-throughput communica-tion capabilities. They continuously produce raw datawhose volume makes necessary to be processed by ad-vanced remote applications. An intelligent interpreta-tion of retrieved information reduces dimensions andpossibly generates decisions on what detected, even ifat a remote stage. Classical Machine Learning tech-niques have been largely used for that, but their mainweakness is in the lack of a telling and significant rep-resentation of revealed events.
IoT relevance could be enhanced by annotatingreal-world objects, the data they gather and the envi-ronments they are dipped-in with concise, structuredand semantically rich descriptions. The combinationof the IoT with Semantic Web ideas and technolo-gies is bringing about the so-called Semantic Webof Things (SWoT) [28]. This paradigm aims to en-able novel classes of intelligent applications and ser-vices grounded on Knowledge Representation (KR),exploiting semantic-based automatic inferences to in-fer implicit information starting from an explicit eventand context detection [30].
By associating a structured and machine-understandabledescription in standard Semantic Web languages, eachclassification output could assume a non-ambiguousmeaning. Furthermore, explanation capabilities pro-vided by the underpinning semantic matchmaking al-low to justify outcomes, so increasing confidence insystem response. If pervasive micro-devices are ca-pable of efficient on-board processing on the locallyretrieved data, they can describe themselves and thecontext where they are located toward external devicesand applications. This would enhance interoperabilityand flexibility, facilitating pervasive knowledge-basedsystems with high degrees of autonomicity not yet al-lowed by typical IoT infrastructures and procedures.
Two important consequences are induced. First ofall also the human-computer interaction could be im-proved, by reducing the user effort required to benefit

M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach 3
from computing systems. In classical IoT paradigms,a user explicitly interacts with one device at a time toperform a task. On the contrary, user agents –runningon mobile computing devices– should be able to in-teract simultaneously with many embedded micro-components, providing users with context-aware per-sonalized task and decision support. Secondly, evenif machine learning techniques, algorithms and toolshave enabled novel classes of analyses (specially use-ful for Big Data Internet of Things perspective), theexploitation of logic-based and approximate discov-ery strategies –leveraging non-exact matching results–compensate possible faults in capturing activities, de-vice volatility and the unreliability of wireless commu-nications rolling out resilient IoT infrastructures reallyversatile for a widespread application.
3. Background
This section briefly recalls notions on MachineLearning and Description Logics, in order to make thepaper self-contained and easily understandable. Thenit discusses relevant related work.
3.1. Basics of Machine Learning
Machine Learning (ML) [36] is a branch of Artifi-cial Intelligence which aims to build systems capableof learning from past experience. Differently from ex-pert systems, ML algorithms and approaches are usu-ally data-driven, inductive and general in nature; theyare defined and applied to make predictions or deci-sions in some general class of tasks, e.g., spam filter-ing, handwriting recognition or activity detection.
Three major categories of ML problems exist:
– Classification1, consisting in the association of anobservation (sample) to one of a set of possiblecategories (classes), e.g., an e-mail message isspam or not. Classification has therefore a dis-crete n-ary output. This is the main problem con-sidered in this paper.
– Regression, defined as the estimation of the rela-tionship of a dependent variable from one or moreindependent variables, e.g., predicting the pur-chase cost of a house considering its size, age, lo-
1It should not be mistaken for the same-name problem in ontol-ogy management, consisting of finding all the implicit hierarchicalrelationships among concepts in an ontology.
cation and other features. In general, both the in-puts and the output in regression can vary in con-tinuous value ranges.
– Clustering, i.e., dividing a set of observationsinto groups (clusters), which maximize the simil-itude of samples within each group and the differ-ence between groups. Many pattern recognitionproblems are based on clustering.
The implementation of a ML system typically in-cludes two main stages: training and testing. In thetraining phase, the adopted ML algorithm builds amodel of the particular problem inductively from train-ing data. Based on the model, the algorithm then pro-duces outputs most likely matching the current inputsin the testing phase, which is executed during systemvalidation in order to check fitness of the learning sys-tem. In particular, evaluation of classification perfor-mance is based on considering one of the output classas the positive class and defining:
– true positives (T P): the number of samples cor-rectly labeled as in the positive class;
– false positives (FP): the number of samples in-correctly labeled as in the positive class;
– true negatives (T N): the number of samples cor-rectly labeled as not in the positive class;
– false negatives (FN): the number of samples in-correctly labeled as not in the positive class.
With the above definitions, the following perfor-mance metrics for classification are often adopted:
– Precision (a.k.a. positive predictive value), de-fined as P = T P
T P+FP– Recall (a.k.a. sensitivity), defined as R = T P
T P+FN– F-Score, defined as the harmonic mean of preci-
sion and recall: F = 2PRP+R
– Accuracy, defined as A = T P+T NT P+FP+T N+FN
Each available dataset to be classified is divided intoa training set for model building and a test set forvalidation. There exist several approaches for select-ing properly training and test components. Among oth-ers, in k-fold cross-validation, the dataset is partitionedinto k subsets of equal size; one of them is used fortesting and the remaining k-1 for training. The processis repeated k times, each time using a different subsetfor testing. The simpler holdout method, instead, di-vides the dataset randomly, usually assigning a largerproportion of samples to the training set and a smallerone to the test set.

4 M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach
ML methods can be divided into supervised or un-supervised. Supervised techniques require a relativelylarge corpus of labeled data to be built for training,usually by hand. Furthermore, the resulting modelsachieve good accuracy only for the specific scenar-ios they are built for. They are not reusable and scal-able when conditions change. Conversely, unsuper-vised methods try to build models directly from unla-beled data, and are prevalent in clustering problems.The availability of large data collections associatedwith partial human annotation has recently turned theattention to semi-supervised learning [37]. By com-bining small-scale expert labeled data and large-scaleunlabeled data based on certain assumptions, semi-supervised methods try to find the best tradeoff be-tween system accuracy and required human and com-putational effort.
As detailed in Section 6, classification performanceof the proposed approach has been compared to thefollowing popular ML approaches:
– C4.5 decision tree [26]: it adopts a greedy top-down approach for building the classification tree,starting with the creation of the root node. At eachnode, the information gain for each attribute iscalculated and the attribute with the highest in-formation gain is selected. The gain is defined asreduction in entropy caused by splitting the in-stances based on values taken by the attribute.
– Functional Tree [11,16]: a classification tree withlogistic regression functions at the inner nodesand leaves. The algorithm can deal with binaryand multiclass target variables, numeric and nom-inal attributes and missing values.
– K-Nearest Neighbors, KNN [1], an instance-based learning algorithm. It locates the k nearestinstances to the input instance and determines itsclass by identifying the single most frequent classlabel. It is generally considered not tolerant tonoise and missing values. Nevertheless, KNN ishighly accurate, insensitive to outliers and workswell with both nominal and numerical features.
– Random Tree [25]: it combines two other MLalgorithms, model trees and random forests, inorder to achieve both robustness and scalability.Model trees are decision trees where every leafholds a linear model optimized for the local sub-space of that leaf. Random forests are an ensem-ble learning approach which builds several deci-sion trees and picks the mode of their outputs.
3.2. Basics of Description Logics
Description Logics –also known as Terminologicallanguages, Concept languages– are a family of logiclanguages for Knowledge Representation in a decid-able fragment of First Order Logic [2]. Basic DL syn-tax elements are:
– concept (a.k.a. class) names, standing for sets ofobjects, e.g., vehicle, road, acceleration;
– role (a.k.a. object property) names, linking pairsof objects in different concepts, like hasTire, has-Traffic;
– individuals (a.k.a. instances), special named ele-ments belonging to concepts, e.g., Peugeot_207,Highway_A14.
A semantic interpretation is a pair I = (∆, ·I), con-sisting of a domain ∆ and an interpretation function ·Iwhich maps every concept to a subset of ∆, every roleto a subset of ∆×∆, and every individual to an elementof ∆. We assume different individuals are mapped todifferent elements of ∆, i.e., if a 6= b then aI 6= bI
(Unique Name Assumption, UNA).These elements can be combined using construc-
tors to form concept and role expressions. Each DLhas a different set of constructors. A constructor usedin every DL is the conjunction of concepts, usuallydenoted as u; some DLs include also disjunction tand complement ¬. Roles can be combined with con-cepts using existential role quantification (e.g., car u∃hasEngine.DieselEngine, which indicates the set ofcars with a Diesel engine) and universal role quantifi-cation (e.g., vehicle∀hasPneumatic.S nowTire, whichdescribes vehicles equipped only with snow tires).Other constructs may involve counting, as number re-strictions: car u ≤ 2 hasS eat denotes cars having atmost 2 seats, and vehicle u ≥ 7 hasS eat describes ve-hicles with at least 7 seats. Concept expressions can beused in inclusion and definition axioms, which modelknowledge elicited for a given domain by restrictingpossible interpretations.
A set of such axioms is called Terminological Box(TBox), a.k.a. ontology. Semantics of inclusions anddefinitions is based on set containment: an interpreta-tion I satisfies an inclusion C v D if CI ⊆ DI , and itsatisfies a definition C ≡ D when CI = DI . A modelof a TBox T is an interpretation satisfying all inclu-sions and definitions in T . A set of individual axioms(a.k.a. facts) forms an Assertion Box (TBox), whichtogether with its reference TBox constitutes a Knowl-edge Base, KB.

M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach 5
Adding new constructors makes DL languages moreexpressive. Nevertheless, this usually leads to a growthin computational complexity of inference services [4].Hence a tradeoff is needed. This paper refers specif-ically to the Attributive Language with unqualifiedNumber restrictions (ALN ) DL. It provides adequateexpressiveness to support the modeling patterns de-scribed in Section 4.1, while granting polynomial com-plexity to both standard and nonstandard inference ser-vices. Syntax and semantics of ALN constructors arereported in Table 1, along with corresponding elementsin the RDF/XML serialization of the Web OntologyLanguage (OWL 2)2 standard for the Semantic Web.OWL also supports annotation properties associatedto class and property names, e.g., for comments andversioning information.
3.3. Related work
In IoT scenarios, smart interconnected objects gatherdata samples, which can be used to identify and predictmany real-world phenomena exhibiting patterns. Ex-tracting high-level information from the raw data cap-tured by sensors translating in machine-understandablelanguages has several interesting applications. Thework [12] surveyed requirements, solutions and chal-lenges in the area of information abstraction andpresents an efficient workflow based on the currentstate of the art.
Semantic Web research addressed the task of de-scribing sensor and data features through ontologies.SSN-XG [7] is the most relevant and widely acceptedproposal. It is general enough to adapt to different ap-plications and is compatible with the Open GeospatialConsortium (OGC) Sensor Web Enablement (SWE)standards at the sensor and observation levels [3].OGC SWE was used in several frameworks aimed atgranting access to sensor data as RESTful servicesor Linked Data [14,9]. The problem of semantic dataflow compression in limited resource spaces was facedin [10] by developing a scalable middleware platformto publish semantically-annotated data streams on theWeb through HTTP.
Unfortunately, the above solutions only allowed el-ementary queries in SPARQL fragments on RDF an-notations. More effective techniques such as ontology-based Complex Event Processing (CEP) [5] exploited
2OWL 2 Web Ontology Language Document Overview (Sec-ond Edition), W3C Recommendation 11 December 2012, http://www.w3.org/TR/owl2-overview/
a shared domain conceptualization to define events andactions to be run on an event processing engine. Alsothe ENVISION project [19] combined CEP with se-mantic technologies to perform Semantic Event Pro-cessing from different sources: reasoning was used toprocess the incoming facts which populated a knowl-edge base. Using KR techniques on large amounts ofinstances could be in fact useful to annotate raw dataand produce high-level descriptions in a KB suitablefor advanced reasoning, aiming to improve standarddata mining and ML algorithms [27]. In [21] a post-processing of ML operations based on ontology con-sistency check aimed to improve results of associa-tion rule mining. Semantically inconsistent associa-tions were pruned and filtered out leveraging on logicreasoning for that. Extensions to standard reasoningalgorithms, supporting uncertainty and time relation-ships, have been also proved as effective in tasks suchas activity recognition [23].
Some of the most successful ML methods, such asArtificial Neural Networks (ANN) and deep learningtechniques, suffer from opaqueness of models, whichcannot be interpreted by human experts and thereforecannot explain reasons for the outcomes they provide.This is a serious issue for ML adoption in all those sec-tors which require accountability of decisions and ro-bustness of outputs against accidental or voluntary in-put manipulation [15,24]. Research efforts to build de-cipherable results of ML techniques and systems aretherefore growing. A conceptually simple approach isto exploit ensemble learning combining multiple low-dimensional submodels, where each individual sub-model is simple enough to be verifiable by domainexperts [24]. In [17] Bayesian learning was used togenerate lists of rules in the if . . . then form, whichcan provide readable reasons for their predictions. Themethod was found to be competitive with state-of-the-art techniques in a stroke prediction task over a largedataset, although training time appears as rather longfor IoT scenarios. The regression tool in [20] is ableto translate automatically components of the modelinto natural-language descriptions of patterns in thedata. It is based on a compositional grammar definedover a space of Gaussian regression models, which issearched greedily using marginal likelihood and theBayesian Information Criterion (BIC). The approachsupports variable dimensionality (number of parame-ters) in each regression model, thus allowing the selec-tion of the desired tradeoff between accuracy and easeof interpretation.

6 M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach
Table 1Syntax and semantics ofALN constructs
Name DL syntax OWL RDF/XML element Semantics
Top > <owl:Thing> ∆I
Bottom ⊥ <owl:Nothing> ∅Concept C <owl:Class> C
Role R <owl:ObjectProperty> C
Conjunction C u D <owl:intersectionOf> CI ∩ DI
Atomic negation ¬A <owl:disjointWith> ∆I\AI
Unqualified existential restriction ∃R <owl:someValuesFrom> {d1 | ∀d2 : (d1, d2) ∈ RI → d2 ∈ CI}Universal restriction ∀R.C <owl:allValuesFrom> {d1 | ∀d2 : (d1, d2) ∈ RI → d2 ∈ CI}Unqualified number ≥ nR <owl:minCardinality> {d1 | ]{d2 | (d1, d2) ∈ RI} ≥ n}restrictions ≤ nR <owl:maxCardinality> {d1 | ]{d2 | (d1, d2) ∈ RI} ≤ n}
Definition axiom A ≡ C <owl:equivalentClass> AI = CI
Inclusion axiom A v C <owl:subClassOf> AI ⊆ CI
Semantic-enhanced ML methods can achieve thesame goals through formal logic-based descriptionsof models in order to develop explanatory function-alities, so increasing users’ trust. Furthermore, theycan be integrated into larger cognitive systems, wheremodels and predictions are used for automated reason-ing. Particularly, Semantic data mining refers to datamining tasks which systematically incorporate domainknowledge into the process. The survey [8] includedontology-based rule mining, classification and cluster-ing. Ontologies are useful to bridge the semantic gapbetween raw data and applications, as well as to pro-vide data mining algorithms with prior knowledge toguide the mining process or reduce the search space.They have been successfully used in all steps of a typ-ical data mining workflow. In Ontology-Based Infor-mation Extraction (OBIE) [35] they are also exploitedto annotate the output of data mining. In [33], the au-thors proposed an approach using wireless sensor net-works and ontologies to represent and infer knowl-edge about traffic conditions. Raw data were classi-fied through an ANN and mapped to ontology classesfor performing rule-based reasoning. In [6], an unsu-pervised model was used for classifying Web Servicedatatypes in a large number of ontology classes, byadopting an extended ANN. Also in this case, how-ever, mining was exploited only to map data to a sin-gle class. Promising semantic-based approaches alsoinclude fuzzy DL learning [18], concept algebra [34]and tensor networks based on Real Logic [32]. Whiletheir prediction performance appears good, computa-tional efficiency must still be evaluated completely be-fore considering them suitable for IoT scenarios.
4. Automatic identification of events viaknowledge representation
The proposed framework preserves the classicaldata mining and machine learning workflow: datacollection and cleansing, model training, validationand system usage. Nevertheless, as reported in Fig-ure 1, semantic-based enhancements grounded on DLschange the way each step is performed.
Fig. 1. Framework architecture

M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach 7
Individual steps of the devised methodology are out-lined hereafter.
4.1. Ontology and data modeling
The workflow starts with raw data gathered e.g., bysensors dipped in a given environment for extractingseveral different parameters, generally named features.In order to support semantic-based data annotationand interpretation, an ontology T models the domainconceptualization along properly specified patterns. Tis assumed acyclic and expressed in the moderatelyexpressive ALN DL. This is required by the sub-sequent non-standard inferences for semantic match-making [31]. For each measuring parameter, T mustinclude a concept hierarchy (each one with its ownproperties), as in Figure 2, forming a partonomy of thetopmost concept. In other words, each parameter willbe represented via a class/subclass taxonomy featuringall significant value ranges and configurations it canhave in the domain of interest. The depth of the hier-archy and the breadth of each level will be chosen bythe knowledge modeler; they will typically be propor-tional to both resolution and range of sensing/captur-ing equipment, as well as to the needed degree of detailin data representation.
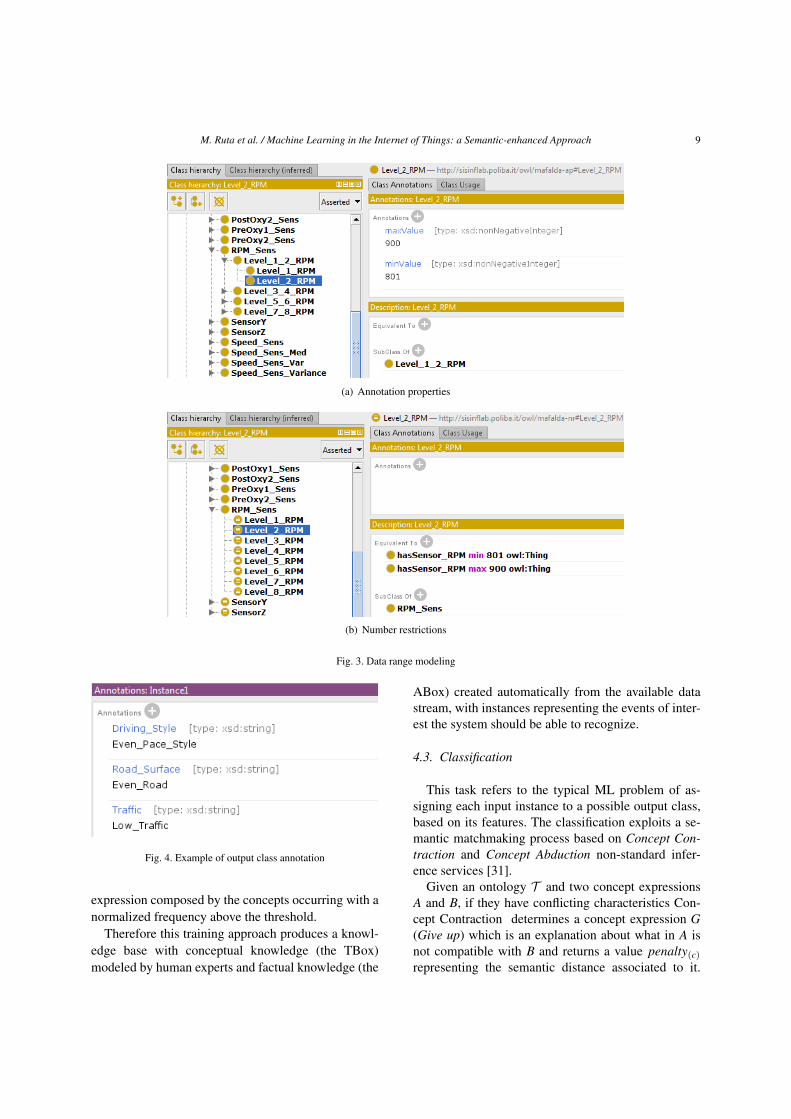
As an example, Figure 2 shows the class hierarchyof the domain ontology modeled for the case study inSection 5. Two different modeling approaches were in-vestigated to represent data ranges for the measuredparameters within the knowledge base3. In the firstone, each data range associated to a concept was mod-eled by means of a pair of OWL annotation properties,named maxValue and minValue, indicating themaximum and minimum value, respectively. For ex-ample, the concept Level_2_RPM –corresponding tovalues from 801 to 900 engine revolutions per minute–was annotated as in Figure 3(a). Afterwards, this ap-proach was modified: the modeling preserves the hi-erarchy of concepts, but to the range of potential vari-ability of each measured parameter is given an explicitsemantics by means of number restrictions associatedto each subconcept. See the Level_2_RPM conceptexpressed in this way in Figure 3(b).
The second approach allows a semantic-based selec-tion also in the preliminary step of raw data collection:numerical data are translated to number restrictionsand the correct corresponding concept subclass is iden-
3Both proposed OWL ontologies are available on the projectrepository: http://github.com/sisinflab-swot/mafalda
tified exactly by means of the Consistency Check rea-soning service [31]. Performance differences related tothe above modeling approaches are described in Sec-tion 6.
According to the proposed data modeling approach,a generic data corpus can be translated in a OWL-based dataset where each record corresponds to anOWL individual in a proper KB. Regardless of theparticular ontology modeling, each individual also in-cludes a set of annotation properties defining the realoutput class for each observable event. As shown inFigure 4, the annotation property name reflects theoutput attribute, while the annotation value refers tothe output label associated during the dataset building.
4.2. Training
Like in classical ML, the goal of this step is to usetraining data to define the model to be used afterwardby the ML algorithm to make predictions on test data.In the proposed approach, the model consists of a se-mantic annotation for each possible output class, con-noting the observed event/phenomenon according toinput data. The annotations will be expressed in Con-cept Components according to the following recursivedefinition:
Definition 1 (Concept Component) Let C be anALNconcept formalized as C1 u · · · u Cm. The Con-cept Components of C are defined as follows: if C j,with j = 1 . . . ,m is either a concept name, or anegated concept name, or a number restriction, thenC j is a concept component of C; if C j = ∀R.E, withj = 1 . . . ,m , then ∀R.Ek is a concept component of C,for each Ek concept component of E.
Every complex description is built by joining the con-cepts modeled in the previous step in conjunctive ex-pressions.
The training phase works on a set S of n trainingsamples, each with at most m features. Let us supposew distinct outputs exist in the training set and the sys-tem must be trained to recognize them. Each featurevalue is mapped to the most specific correspondingconcept in the reference ontology T . Therefore the i-thsample ∀ i = 1, . . . , n is composed of: (a) up to m con-cept components Ci,1, . . . ,Ci,m annotating its features;(b) an observed output Oi labeled with a class in theontology.
Samples are processed sequentially by Algorithm 1in order to build the so-called Training MatrixM (the

8 M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach
Fig. 2. Class hierarchy in the domain ontology for the case study
pseudocode uses a MATLAB-like notation for matrixaccess). M is a (w + 1) × (k + 1) matrix having allthe different outputs on the first column, all the k dis-tinct concept components occurring in the training seton the first row and, in each element, the number ofoccurrences of the column header concept componentin the samples having the row header output. Basi-cally, Algorithm 1 takes the i-th training sample andfirst checks its associate class Oi (lines 4-11): if it isnot yet in M (no previous sample was associated tothat class), it appends a row toM initializing its valuesto zeros. Subsequently, for each concept componentsCi, j, if Ci, j is not yet inM (i.e., no previous sample in-cluded that concept component), it appends a columnand initializes its values to zeros (lines 13-20). Finally,it increases by 1 the value of the cell corresponding toOi and Ci, j (line 21).M gives a complete picture of the training set. Each
output class can now be defined as the conjunctionof the concepts having greater-than-zero occurrencesin the corresponding row. By doing so, however, evenvery rare concept components are included, which mayhave low significance in representing the class. There-fore it is useful to define a significance threshold Ts
as the minimum number of samples a concept compo-nent must appear in, to be considered significant forthe occurrence of a particular output. The structure ofM suggests the possibility to define different thresh-
olds for each output and for each feature:
Ts(i, j) = θ(i, j) |S |
with 0 < θ(i, j) ≤ 1 ∀i, j being adaptive ratios com-puted through e.g., a cross-validation process on thetraining dataset.
Customized thresholds allow to focus sensitivity onthe features with highest variance and/or the outputsmost difficult to predict. In the road monitoring casestudy described in Section 5 the threshold value wascalculated in such a way, so as not to penalize sen-sors with lower sampling rate or events which occurless often in the training dataset. In detail, each ele-ment M(i,j) is normalized according: (i) to the indi-vidual feature w.r.t. all the features belonging to thesame class hierarchy (i.e., all classes annotating e.g.,temperature value ranges) and (ii) based on a singleevent with respect to the remaining ones (e.g., if “un-even road” is much less frequent than “even road”, nor-malization will increase all the values on the “unevenroad” row inM).
The adopted formula is:
Ts(i, j) = Tbase ∗maxoccur(i, j)− minoccur(i, j)
2
where Tbase is a user-defined base percentage thresh-old. The result of the training is the association of ev-ery output class label Oi with a conjunctive concept
M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach 9
(a) Annotation properties
(b) Number restrictions
Fig. 3. Data range modeling
Fig. 4. Example of output class annotation
expression composed by the concepts occurring with anormalized frequency above the threshold.
Therefore this training approach produces a knowl-edge base with conceptual knowledge (the TBox)modeled by human experts and factual knowledge (the
ABox) created automatically from the available datastream, with instances representing the events of inter-est the system should be able to recognize.
4.3. Classification
This task refers to the typical ML problem of as-signing each input instance to a possible output class,based on its features. The classification exploits a se-mantic matchmaking process based on Concept Con-traction and Concept Abduction non-standard infer-ence services [31].
Given an ontology T and two concept expressionsA and B, if they have conflicting characteristics Con-cept Contraction determines a concept expression G(Give up) which is an explanation about what in A isnot compatible with B and returns a value penalty(c)representing the semantic distance associated to it.

10 M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach
Algorithm 1 Creation of the Training MatrixRequire:
– Description Logic L;– acyclic TBox T ;– w output classes O1,O2, . . . ,Ow;– training set S = {S 1, S 2, . . . S n}, with S i =
(Ci,1, . . . ,Ci,m,Oi) ∀ i = 1, . . . , n;– all Ci, j and Oi are expressed in L and satisfiable in T .
Ensure:–M : (w + 1)× (k + 1) matrix of occurrences ofthe concepts for each observed output, where k isthe total number of distinct concepts appearing in S
1: M := 0 // start with a (1× 1) matrix2: r := 1, c := 1
3: for i := 1 to |S | do4: ur := findConceptIndex(Oi,M(:, 1))
5: if ur = null then6: append a row toM7: r := r + 1
8: ur := r9: M(ur , 1) := Oi
10: initializeM(ur , 2 : c) to zeros11: end if12: for j := 1 to m do13: uc := findConceptIndex(Ci, j,M(1, :))
14: if uc = null then15: append a column toM16: c := c + 1
17: uc := c18: M(1, uc) := Ci, j19: initializeM(2 : r, uc) to zeros20: end if21: M(ur , uc) =M(ur , uc) + 1 // update occurrences22: end for23: end for24: return M
Otherwise, if A is compatible with B but does notcover it fully, Concept Abduction calculates a conceptexpression H (Hypothesis) representing what shouldbe hypothesized (i.e., is underspecified) in B in or-der to completely satisfy A, and it provides a relatedpenalty(a) value. Concept Contraction and ConceptAbduction can be considered as extensions respec-tively to Satisfiability and Subsumption standard infer-ence services, which can only provide “yes/no” an-swers in KR systems.
The proposed framework first labels data of the in-stance to be classified with respect to the reference on-tology, like in Section 4.1. Their conjunction is thentaken as annotation of the instance itself. A linear com-bination of the penalty values obtained from match-making yields the semantic distance between the in-put instance and each event description Oi generatedduring training.
In particular, based on the different ontology mod-eling techniques proposed in Section 4.1, two seman-tic distance functions were defined. In case of annota-tion properties, the penalty score is computed via thefollowing formula:
SD(R, S ) =penalty(a)(R,S )
penalty(a)(R,>)
where penalty(a)(R, S ) measures the Abduction-induceddistance between an event description R and sensordata annotation S ; this value is normalized dividingby the distance between R and the universal concept> which depends only on axioms in the ontology. In-stead, when using number restrictions, the function isdefined as:
SD(R, S ) =α∗penalty(c)(R,S )+β∗penalty(a)(R,S )
penalty(a)(R,>)
where penalty(c)(R, S ) indicates the Contraction-inducedsemantic distance. This value is now present becausenumber restrictions introduce explicit incompatibili-ties between concepts due to disjoint numeric ranges.Two tunable weighting factors combine both contri-butions and enable a ranking mainly based on eitherconflict or missing features.
The predicted/recognized event will be the onewith the lowest distance. Since semantic matchmak-ing associates a logic-based explanation to ranked(dis)similarity measures, the classification outcomehas a formally grounded and understandable confi-dence value. This is a fundamental benefit with re-spect to the majority of standard ML techniques, whichproduce opaque predictions. Furthermore, notice thatthe approach does not take the instance annotation di-rectly as the output, because the inherent data volatilityin IoT contexts could lead to inconsistent assertions,which would be impossible to reason on.
4.4. Evaluation
System evaluation works with a test set, consistingof several classified instances referred to the same on-tology used for building the training set. The goal isto check how often (and possibly, how much) the pre-dicted event classes correspond to the actual events as-sociated to each instance of the test set. Beyond clas-sical performance indicators for classifying ML algo-rithms like the confusion matrix and statistical metrics(such as accuracy, precision and recall), the graded na-ture of predictions in the proposed approach, e.g., theaverage semantic distance of the predicted class from

M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach 11
the actual one, allows to evaluate applying typical errormeasures of regression analysis like Root Mean SquareError (RMSE).
Cross-validation can be used to tune system param-eters if performance is not satisfactory. Moreover, ifcomputing resources permit it, incoming test data canalso be used to update the training matrix on-the-fly, inorder to allow the model to evolve when new data isobserved.
5. Case study: road and traffic monitoring
Mobility services are one of the main IoT appli-cation areas. As a case study, a prototypical systemfor road and traffic monitoring was created e.g., toimprove the functionality of navigation systems withreal-time driver assistance. Useful insight on travelconditions is provided both among nearby vehicles(in a peer-to-peer fashion through VANETs – Vehicu-lar Ad-hot NETworks) and on a large scale (e.g., byupdating a remote Geographical Information Systemwith real-time and history information toward roadpolicy makers).
The proposed knowledge-based system exploits thesemantic descriptions of vehicles and context annota-tions to:
1. interpret vehicle data extracted via the mandatoryOn-Board Diagnostics4 (OBD-II) port;
2. integrate environmental information;3. detect potential risk factors.
Besides providing warnings, the detected knowledgeallows giving suggestions to the driver and evaluatingcar efficiency and environmental impact in real time[29].
The Java language was chosen for the implemen-tation, in order to be compatible with both Java SE(Standard Edition) and Android platforms. The pro-totype included the Mini-ME lightweight matchmaker[31], which provides the required inferences for theALN DL (under the assumption of acyclic TBoxes).The above ML framework was used to extract high-level indications starting from a large number of low-level parameters acquired by the car via OBD-II andthrough the micro-devices embedded in the user smart-phone, with the goal of accurately characterizing the
4California Environmental Protection Agency, On-Board Di-agnostics (OBD) Program, http://www.arb.ca.gov/msprog/obdprog/obdprog.htm
overall system composed by driver, vehicle and envi-ronment.
A dedicated dataset was collected for further ex-periments5. Raw data were retrieved and stored usingthe Torque Lite (OBD-II & Car)6 Android applicationon seven different routes: suburban, urban and mixedones, with medium and long distance. An average offive traces per route were recorded, sampling OBD-II parameters and smartphone data at 1 Hz frequency.About 10,000 records were collected on average foreach route, taken on different days, in various trafficconditions and with three different cars (and drivers):particularly a Peugeot 207 (two routes), an Opel Corsa(two routes) and a Peugeot 308 (three routes) wereused.
The case study aimed to identify the driving style,the road characteristics in terms of consistence andtraffic conditions, by analyzing parameters gathered bythe car and the user smartphone. It is purposely simpleto give just an immediate proof of concept, but classi-fication can be largely enriched at will without modi-fying theoretical settings. In detail, the system shoulddetect the following classes:
– Even, Slightly Uneven or Uneven Road;– Low, Medium or High Traffic;– Aggressive or Even Pace driving style.
During the dataset creation, each driver who col-lected a trace was asked to label manually the recordswith the event characteristic for each of the above cat-egories. Gathered information represent the raw datain the ML problem. Timestamp and GPS coordinates(also taken through the smartphone) were added toeach record.
Analyzed data consisted of:
– altitude change, calculated over 10 seconds;– speed: current value, average and variance in the
last 60 seconds and change in speed for every sec-ond of detection;
– longitudinal and vertical acceleration, measuredby the smartphone accelerometer and pre-processedwith a low-pass filter to delete high frequency sig-nal components due to electrical noise and exter-nal forces;
– engine load, expressed as a percentage;– engine coolant temperatures;
5A subset of the collected data is publicly available on the projectgithub repository cited in Section 4.1.
6http://torque-bhp.com/

12 M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach
– Manifold Air Pressure (MAP), a parameter the in-ternal combustion engine uses to compute the op-timal air/fuel ratio;
– Mass Air Flow (MAF) Rate measured in g/s, usedby the engine to set fuel delivery and spark tim-ing;
– Intake Air Temperature (IAT) at the engine en-trance;
– Revolutions Per Minute (RPM) of the engine;– average fuel consumption calculated as needed
liters per 100 km.
As shown in Figure 2, the above parameters wererepresented in the domain ontology and divided in sub-classes, each characterized by a value range. At the endof the training phase, the ABox was created automat-ically from the available data stream, with instancesrepresenting the events that the system should be ableto recognize.
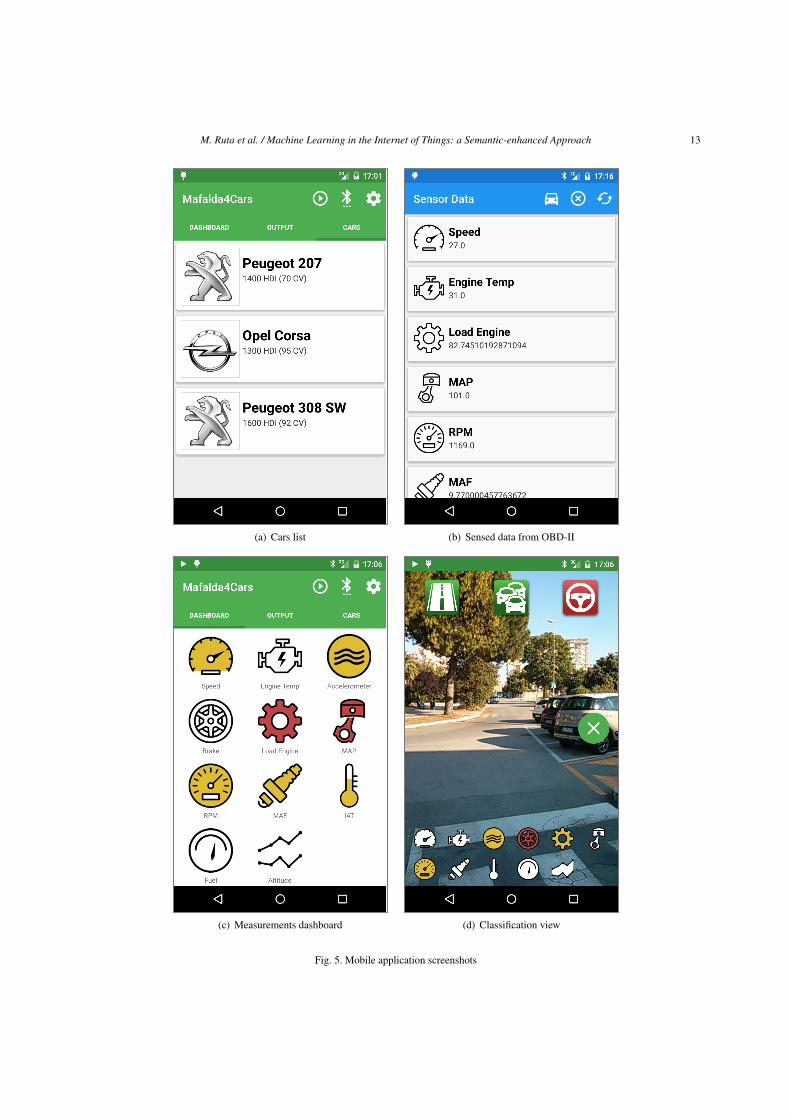
In addition to evaluations on the static data set, amobile application for smartphones was also devel-oped to validate the framework in real-time usage. It isan evolution of [29], devoted to evaluate vehicle healthand driver risk level, exploiting semantic-based match-making to suggest users how to reduce or even elim-inate danger and get better vehicle performance andlower environmental impact. By exploiting this newversion, implemented using Android SDK Tools, Re-vision 24.1.2 –corresponding to Android Platform ver-sion 5.1, API level 22– and tested on a LG E960 Nexus4 smartphone, the user can:
– select a dataset related to the cars used in the ex-periments (Figure 5(a)) and train the predictionmodel;
– view and query all available sensed data, asshown in Figure 5(b);
– open a measurements dashboard (see the screen-shot in Figure 5(c)). For each device, a coloredicon indicates a low (white), medium (yellow) orhigh (red) measured value.
Moreover, the user can start the classification viewin Figure 5(d). The smartphone camera viewfinderis used as background to allow the user to see theclassification outputs without looking away from theroad. The application queries vehicle information viaOBD-II and executes the algorithm described in Sec-tion 4. The user interface shows at the bottom a com-pact device dashboard (like in Figure 5(c), but smaller)whereas at the top three large icons are displayed, re-lated to the event outputs (road conditions, traffic and
driving style). Also in this case, classified output lev-els correspond to different colors (green, yellow andred). In the picture, the algorithm detects an even roadand low traffic (green icons) and an aggressive drivingstyle (red icon).
6. Experiments
This section reports on the experiments carried outon the dataset collected as explained before. Resultsare summarized and displayed through classic MLmetrics such as weighted precision, recall, f-score andoverall accuracy.
A preliminary test (Table 2) compares performanceindexes of the modeling techniques described in Sec-tion 4.1 with data ranges expressed through numberrestrictions (NRi) and annotation properties (AP j), re-spectively. For each route, the whole dataset was di-vided in a training set and a test set by holdout, mix-ing the records randomly in 70% and 30% ratios, re-spectively. The training set generated the model, whilethe test set allowed to evaluate the classification per-formance. Training and test set were processed in sev-eral configurations obtained by varying Tbase, i.e., thenormalization threshold value, as well as α and β, usedto compute the semantic distance in the classificationtask. For each test configuration, performance mea-sures were calculated. Precision and recall values areplotted in Figure 6. The best configuration is AP1, pre-senting the highest values for recall, f-score and ac-curacy; precision is only slightly lower than configu-rations with larger Tbase. It is important to notice thatconfigurations including number restrictions presentlower values due to the disjunction of intervals in mod-eling concepts of ontology: semantic descriptions pro-duced by the training phase were all similar, penaliz-ing the later stages. Indeed, in the classification phase,the matchmaking between the output description gen-erated from the training phase and the sample from testset tended to have increased penalty values due to dis-joint number restrictions, frequently producing an in-correct classification output.
The same training and test sets were used with clas-sical Machine Learning algorithms to compare andevaluate results obtained with the best configurationof the proposed approach (nicknamed MAFALDA, asMAtchmaking Features for mAchine Learning DataAnalisys). The four algorithms recalled in Section 3.1
M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach 13
(a) Cars list (b) Sensed data from OBD-II
(c) Measurements dashboard (d) Classification view
Fig. 5. Mobile application screenshots

14 M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach
Table 2Experiments report in several different test configurations
ID α β Tbase Precision Recall F-Score Accuracy
KB withNumber Restrictions
NR1 0.2 0.8 50 0.741 0.575 0.648 0.575NR2 0.5 0.5 50 0.846 0.661 0.709 0.661NR3 0.2 0.8 20 0.742 0.609 0.669 0.609NR4 0.5 0.5 20 0.890 0.672 0.766 0.672
KB withAnnotation Properties
AP1 - - 15 0.861 0.813 0.836 0.813AP2 - - 20 0.866 0.798 0.831 0.798AP3 - - 30 0.867 0.764 0.812 0.764AP4 - - 50 0.866 0.665 0.752 0.665AP5 - - 65 0.837 0.624 0.715 0.624
50
55
60
65
70
75
80
85
90
45 50 55 60 65 70 75 80 85
Re
call
(%)
Precision (%)
NR1 NR2 NR3 NR4 AP1 AP2 AP3 AP4 AP5
Fig. 6. Precision/recall plot
were used for the comparison, in the implementationof Weka7 [13]:
– J48 implementation of C4.5;– Functional Tree (FT);– K-Nearest Neighbours (k-NN);– Random Tree (RT).
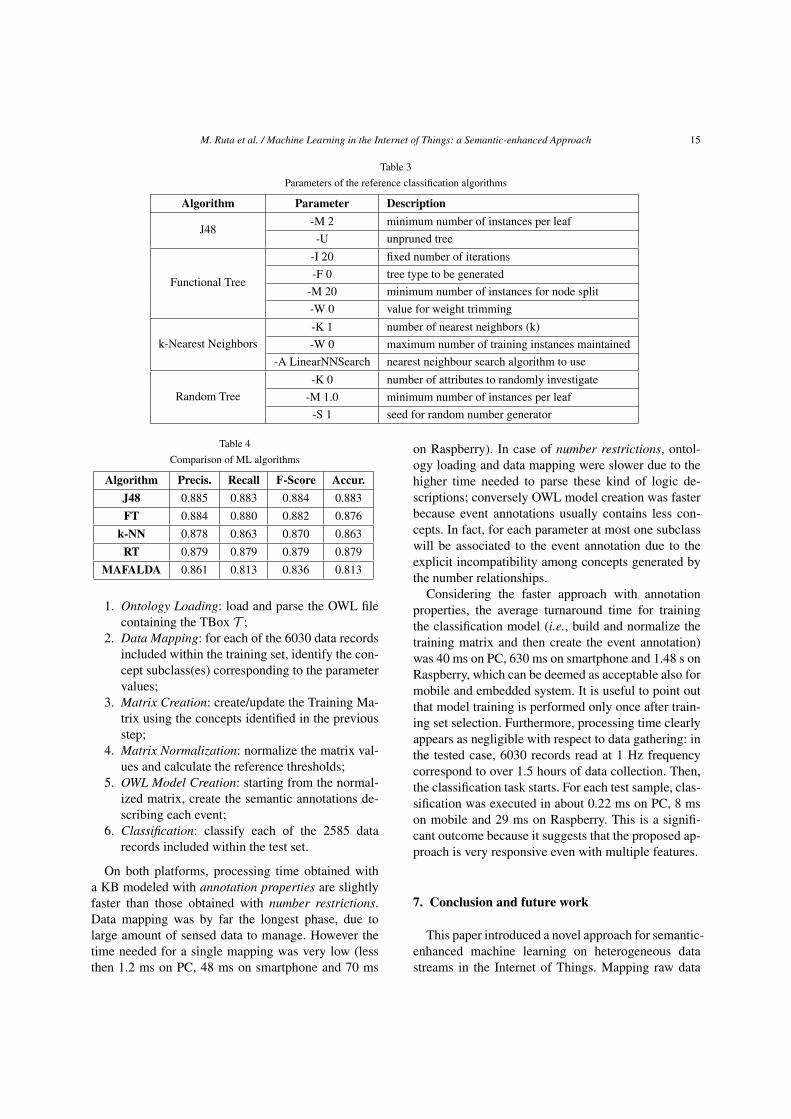
Also in this case, each algorithm was used for test-ing different configurations obtained by setting con-veniently parameters in Table 3. Results correspond-ing to the configurations with the highest accuracyare reported in Table 4. MAFALDA presented compa-rable precision, albeit with slightly lower recall val-ues. Overall, it represents a competitive alternative toclassical ML algorithms, with the benefit of producinginterpretable semantic-based annotated concept repre-sentation.
Experimental analysis about processing time wascarried out on three different platforms:
7Weka version 3.6.12, http://www.cs.waikato.ac.nz/ml/weka/
– PC testbed, equipped with Intel Core i7-3770KCPU at 3.5 GHz, 12 GB DDR3 SDRAM memory,2 TB SATA (7200 RPM) hard disk, 64-bit Mi-crosoft Windows 7 Professional and 64-bit Java 8SE Runtime Environment, build 1.8.0_31-b13;
– Nexus 4 smartphone, equipped with QualcommSnapdragon S4 Quad-core CPU at 1.5 GHz, 2 GBRAM and Android 5.1.1 operating system;
– Raspberry Pi Model B8, equipped with a single-core ARM11 CPU at 700 MHz, 512 MB RAM(shared with GPU), 8 GB storage memory on SDcard, Raspbian Wheezy OS.
The test was executed using the first Peugeot 207dataset consisting of 8615 records; 6030 used as train-ing set and 2585 as test set. Each test was repeated fivetimes and the average value was taken, as reported inFigure 7.
The overall process included several sub-steps:
8http://www.raspberrypi.org/products/model-b/
M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach 15
Table 3Parameters of the reference classification algorithms
Algorithm Parameter Description
J48-M 2 minimum number of instances per leaf-U unpruned tree
Functional Tree
-I 20 fixed number of iterations-F 0 tree type to be generated
-M 20 minimum number of instances for node split-W 0 value for weight trimming
k-Nearest Neighbors-K 1 number of nearest neighbors (k)-W 0 maximum number of training instances maintained
-A LinearNNSearch nearest neighbour search algorithm to use
Random Tree-K 0 number of attributes to randomly investigate
-M 1.0 minimum number of instances per leaf-S 1 seed for random number generator
Table 4Comparison of ML algorithms
Algorithm Precis. Recall F-Score Accur.J48 0.885 0.883 0.884 0.883FT 0.884 0.880 0.882 0.876
k-NN 0.878 0.863 0.870 0.863RT 0.879 0.879 0.879 0.879
MAFALDA 0.861 0.813 0.836 0.813
1. Ontology Loading: load and parse the OWL filecontaining the TBox T ;
2. Data Mapping: for each of the 6030 data recordsincluded within the training set, identify the con-cept subclass(es) corresponding to the parametervalues;
3. Matrix Creation: create/update the Training Ma-trix using the concepts identified in the previousstep;
4. Matrix Normalization: normalize the matrix val-ues and calculate the reference thresholds;
5. OWL Model Creation: starting from the normal-ized matrix, create the semantic annotations de-scribing each event;
6. Classification: classify each of the 2585 datarecords included within the test set.
On both platforms, processing time obtained witha KB modeled with annotation properties are slightlyfaster than those obtained with number restrictions.Data mapping was by far the longest phase, due tolarge amount of sensed data to manage. However thetime needed for a single mapping was very low (lessthen 1.2 ms on PC, 48 ms on smartphone and 70 ms
on Raspberry). In case of number restrictions, ontol-ogy loading and data mapping were slower due to thehigher time needed to parse these kind of logic de-scriptions; conversely OWL model creation was fasterbecause event annotations usually contains less con-cepts. In fact, for each parameter at most one subclasswill be associated to the event annotation due to theexplicit incompatibility among concepts generated bythe number relationships.
Considering the faster approach with annotationproperties, the average turnaround time for trainingthe classification model (i.e., build and normalize thetraining matrix and then create the event annotation)was 40 ms on PC, 630 ms on smartphone and 1.48 s onRaspberry, which can be deemed as acceptable also formobile and embedded system. It is useful to point outthat model training is performed only once after train-ing set selection. Furthermore, processing time clearlyappears as negligible with respect to data gathering: inthe tested case, 6030 records read at 1 Hz frequencycorrespond to over 1.5 hours of data collection. Then,the classification task starts. For each test sample, clas-sification was executed in about 0.22 ms on PC, 8 mson mobile and 29 ms on Raspberry. This is a signifi-cant outcome because it suggests that the proposed ap-proach is very responsive even with multiple features.
7. Conclusion and future work
This paper introduced a novel approach for semantic-enhanced machine learning on heterogeneous datastreams in the Internet of Things. Mapping raw data

16 M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach
1
10
100
1000
10000
100000
1000000
Ontology Loading Data Mapping Matrix Creation Matrix Normaliz. OWL Model Creation Classification
Tim
e (
ms)
PC (AP) PC (NR) Smartphone (AP) Smartphone (NR) Raspberry (AP) Raspberry (NR)
Fig. 7. Processing Time
to ontology-based concept labels provides a low-levelsemantic interpretation of the statistical distributionof information, while the conjunctive aggregation ofconcept components allows building automatically arich and meaningful representation of events duringthe model training phase. Finally, the exploitation ofnon-standard matchmaking inferences enables a fine-grained event detection by treating the ML classifica-tion problem as a resource discovery.
A concrete case study on driving assistance wasdeveloped through data gathered from real vehiclesvia On-Board Diagnostics protocol (OBD-II) and ex-ploiting sensing micro-devices (accelerometer, gyro-scope, GPS) embedded on users’ smartphones. A re-alistic dataset was so built for experimentation. Subse-quent extensive evaluations allowed to assess the effec-tiveness of the proposed approach whose performanceresults were compared with state-of-the-art ML tech-nologies, in order to highlight benefits and limits of theproposal.
Several future perspectives are open for semantic-enhanced ML and particularly for the devised frame-work. A proper extension of the baseline training al-gorithm can enable a continuously evolving modelthrough a fading mechanism allowing the system to“forget” the oldest training samples. A further exten-sion of the training algorithm will aim at a processingdistributed on more than one node with a final merg-ing step. This could reduce the communication over-head within a sensor network if intermediate nodeshave storage capacity enough. Further variants could
increase the flexibility of the proposed approach in theclassification phase. For example it could be useful toinvestigate the possibility to create dynamically super-classes with a range that combine those of the con-cepts found in the description: this would avoid affect-ing the result of the inference algorithms for descrip-tions that would otherwise be similar. Finally, adoptinga more expressive logic language such as ALN (D) tomodel the domain ontologies could allow introducingdata-type properties to better characterize typical IoTdata features. Further experiments will have to be car-ried out to assess and optimize the proposed methodsin terms of both accuracy and resource efficiency.
References
[1] D. Aha, D. Kibler, and M. Albert. Instance-based learning al-gorithms. Machine Learning, 6(1):37–66, 1991.
[2] F. Baader, D. Calvanese, D. L. McGuinness, D. Nardi, andP. Patel-Schneider. The Description Logic Handbook. Cam-bridge University Press, 2002.
[3] M. Botts, G. Percivall, C. Reed, and J. Davidson. OGC R© sen-sor web enablement: Overview and high level architecture. InGeoSensor networks, pages 175–190. Springer, 2008.
[4] R. Brachman and H. Levesque. The Tractability of Subsump-tion in Frame-based Description Languages. In 4th NationalConference on Artificial Intelligence (AAAI-84), pages 34–37.Morgan Kaufmann, 1984.
[5] K. Cao, Y. Wang, and F. Wang. Context-aware DistributedComplex Event Processing Method for Event Cloud in Inter-net of Things. Advances in Information Sciences & ServiceSciences, 5(8):1212–1222, 2013.
[6] E. S. Chifu and I. A. Letia. Unsupervised semantic annota-tion of Web service datatypes. In Intelligent Computer Com-

M. Ruta et al. / Machine Learning in the Internet of Things: a Semantic-enhanced Approach 17
munication and Processing (ICCP), 2010 IEEE InternationalConference on, pages 43–50. IEEE, 2010.
[7] M. Compton, P. Barnaghi, L. Bermudez, R. García-Castro,O. Corcho, S. Cox, J. Graybeal, M. Hauswirth, C. Henson,A. Herzog, et al. The SSN ontology of the W3C semantic sen-sor network incubator group. Web Semantics: Science, Servicesand Agents on the World Wide Web, 17:25–32, Dec. 2012.
[8] D. Dou, H. Wang, and H. Liu. Semantic data mining: A sur-vey of ontology-based approaches. In Semantic Computing(ICSC), 2015 IEEE International Conference on, pages 244–251. IEEE, 2015.
[9] M. Fazio and A. Puliafito. Cloud4sens: a cloud-based architec-ture for sensor controlling and monitoring. CommunicationsMagazine, IEEE, 53(3):41–47, 2015.
[10] J. A. Fisteus, N. F. García, L. S. Fernández, and D. Fuentes-Lorenzo. Ztreamy: A middleware for publishing semanticstreams on the web. Web Semantics: Science, Services andAgents on the World Wide Web, 25:16–23, 2014.
[11] J. Gama. Functional trees. Machine Learning, 55(3):219–250,2004.
[12] F. Ganz, D. Puschmann, P. Barnaghi, and F. Carrez. A practi-cal evaluation of information processing and abstraction tech-niques for the Internet of Things. IEEE Internet of Things jour-nal, 2(4):340–354, 2015.
[13] M. Hall, E. Frank, G. Holmes, B. Pfahringer, P. Reutemann,and I. H. Witten. The WEKA data mining software: An update.SIGKDD Explorations, 11(1), 2009.
[14] K. Janowicz, A. Bröring, C. Stasch, S. Schade, T. Everding,and A. Llaves. A restful proxy and data model for linked sen-sor data. International Journal of Digital Earth, 6(3):233–254,2013.
[15] M. Jordan and T. Mitchell. Machine learning: Trends, perspec-tives, and prospects. Clin. Pharmacol. Ther, 349(6245):255–260, 2015.
[16] N. Landwehr, M. A. Hall, and E. Frank. Logistic model trees.Machine Learning, 59(1-2):161–205, 2005.
[17] B. Letham, C. Rudin, T. H. McCormick, D. Madigan, et al. In-terpretable classifiers using rules and Bayesian analysis: Build-ing a better stroke prediction model. The Annals of AppliedStatistics, 9(3):1350–1371, 2015.
[18] F. A. Lisi and U. Straccia. A logic-based computational methodfor the automated induction of fuzzy ontology axioms. Funda-menta Informaticae, 124(4):503–519, 2013.
[19] A. Llaves, H. Michels, P. Maué, and M. Roth. Semantic eventprocessing in ENVISION. In Proceedings of the 2nd Interna-tional Conference on Web Intelligence, Mining and Semantics,page 25. ACM, 2012.
[20] J. R. Lloyd, D. Duvenaud, R. Grosse, J. B. Tenenbaum, andZ. Ghahramani. Automatic construction and natural-languagedescription of nonparametric regression models. In Proceed-ings of the Twenty-Eighth AAAI Conference on Artificial Intel-ligence, pages 1242–1250. AAAI Press, 2014.
[21] C. Marinica and F. Guillet. Knowledge-based interactive post-mining of association rules using ontologies. Knowledgeand Data Engineering, IEEE Transactions on, 22(6):784–797,2010.
[22] A. McAfee, E. Brynjolfsson, T. H. Davenport, D. Patil, andD. Barton. Big data. The management revolution. Harvard BusRev, 90(10):61–67, 2012.
[23] M. H. M. Noor, Z. Salcic, I. Kevin, and K. Wang. Enhanc-ing ontological reasoning with uncertainty handling for activityrecognition. Knowledge-Based Systems, 114:47–60, 2016.
[24] C. Otte. Safe and interpretable machine learning: a method-ological review. In Computational Intelligence in IntelligentData Analysis, pages 111–122. Springer, 2013.
[25] B. Pfahringer. Random model trees: an effective and scal-able regression method. Technical report, The University ofWaikato, 2010.
[26] J. R. Quinlan. C4.5: programs for machine learning. MorganKaufmann Publishers Inc., San Francisco, CA, USA, 1993.
[27] A. Rettinger, U. Lösch, V. Tresp, C. d’Amato, and N. Fanizzi.Mining the Semantic Web. Data Mining and Knowledge Dis-covery, 24(3):613–662, 2012.
[28] M. Ruta, F. Scioscia, and E. Di Sciascio. Enabling the Se-mantic Web of Things: framework and architecture. In SixthIEEE International Conference on Semantic Computing (ICSC2012), pages 345–347. IEEE, IEEE, sep 2012.
[29] M. Ruta, F. Scioscia, F. Gramegna, G. Loseto, and E. Di Sci-ascio. Knowledge-based Real-Time Car Monitoring and Driv-ing Assistance. In L. T. Nicola Ferro, editor, 20th Italian Sym-posium on Advanced Databases Systems (SEBD 2012), pages289–294. Edizioni Libreria Progetto, jun 2012.
[30] M. Ruta, F. Scioscia, A. Pinto, E. Di Sciascio, F. Gramegna,S. Ieva, and G. Loseto. Resource annotation, disseminationand discovery in the Semantic Web of Things: a CoAP-basedframework. In Internet of Things (iThings/CPSCom), IEEEInternational Conference on, pages 527–534. IEEE, 2013.
[31] F. Scioscia, M. Ruta, G. Loseto, F. Gramegna, S. Ieva, A. Pinto,and E. Di Sciascio. A mobile matchmaker for the UbiquitousSemantic Web. International Journal on Semantic Web andInformation Systems, 10(4):77–100, 2014.
[32] L. Serafini, I. Donadello, and A. d’Avila Garcez. Learning andReasoning in Logic Tensor Networks: Theory and Applicationto Semantic Image Interpretation. In 2017 Symposium on Ap-plied Computing, pages 1252–130. ACM, 2017.
[33] M. Stocker, M. Ronkko, and M. Kolehmainen. Situationalknowledge representation for traffic observed by a pavementvibration sensor network. Intelligent Transportation Systems,IEEE Transactions on, 15(4):1441–1450, 2014.
[34] Y. Wang, Y. Tian, and K. Hu. Semantic Manipulations and For-mal Ontology for Machine Learning based on Concept Alge-bra. International Journal of Cognitive Informatics and Natu-ral Intelligence, 5(3):1–29, 2011.
[35] D. C. Wimalasuriya and D. Dou. Ontology-based informationextraction: An introduction and a survey of current approaches.Journal of Information Science, 36(3):306–323, 2010.
[36] I. H. Witten, E. Frank, M. A. Hall, and C. J. Pal. Data Min-ing: Practical machine learning tools and techniques. MorganKaufmann, 2016.
[37] X. Zhu. Semi-supervised learning. In Encyclopedia of Ma-chine Learning, pages 892–897. Springer, 2011.
Related Documents











