Invariant Generalised Ridgelet-Fourier for Shape-based Image Retrieval Mas Rina Mustaffa 1 , Fatimah Ahmad, Ramlan Mahmod, and Shyamala Doraisamy Department of Multimedia Faculty of Computer Science and Information Technology Universiti Putra Malaysia 43400 UPM Serdang, Selangor, Malaysia {MasRina 1 , Fatimah, Ramlan, shyamala}@fsktm.upm.edu.my Abstract— A new shape descriptor called the Invariant Generalised Ridgelet-Fourier is defined for the application of Content-based Image Retrieval (CBIR). The proposed spectral- based method is invariant to rotation, scaling, and translation (RST) as well as able to handle images of arbitrary size. The implementation of Ridgelet transform on the ellipse containing the shape and the normalisation of the Radon transform is introduced. The 1D Wavelet transform is then applied to the Radon slices. In order to extract the rotation invariant feature, Fourier transform is implemented in the Ridgelet domain. The performance of the proposed method is accessed on a standard MPEG-7 CE-1 B dataset in terms of few objective evaluation criteria. From the experiments, it is shown that the proposed method provides promising results compared to several previous methods. Keywords – CBIR; Shape descriptor; Ridgelet transform; Invariant to RST I. INTRODUCTION Content-based Image Retrieval (CBIR) technologies are developing amazingly due to the need of retrieval systems that will be able to retrieve images effectively and efficiently. This CBIR features make this technology useful in many areas such as crime prevention, medicine, law, science, fashion, and interior design. Compared to conventional image retrieval techniques that use indexing keywords to retrieve image files, CBIR works in a totally different manner by retrieving images on the basis of automatically derived low- level features, middle-level features, or high-level features. Among these features, the low-level features are the most popular due to their simplicity compared to other levels of features. Among the low-level features, shape is considered as one of the most important visual features and it is one of the basic features used to describe image content. This is because human beings are likely to distinguish scenes as being composed of individual objects and these individual objects are indeed usually identified by their shapes. It has been found that complicated shapes can be effectively characterised by using a description with multiple resolutions [1-2]. This multi-resolution property is very important as it provides a simple hierarchical framework for the interpretation of the image information [3]. At different resolutions, the details of an image generally characterise different physical structures of the scene. At a coarse resolution, these details correspond to the larger structures, which provide the image “context”. It is therefore natural to analyse first the image details at a coarse resolution and then gradually increase the resolution. One of the earliest descriptors with multi-resolution property that is used to describe shapes is the Wavelet [4-5]. However, methods based on Wavelet descriptor do not have the direction factor, which happens to be an important and unique feature of multi-dimensional signals. That brings us to other multi-resolution representations with the direction factor, which the traditional Wavelet fails to have, such as Ridgelet [6], Curvelet [7], Contourlet [8], and Beamlet [9]. Of all these transforms, the factor of direction is most obvious in Ridgelet. Ridgelet transform is introduced by Candes and Donoho [6] to deal effectively with line singularities instead of point singularities as in the case of Wavelet. Ridgelet transform can be described as the application of Wavelet to the Radon transform of an image. As the Radon space corresponds to the parameters of the lines in the image, and applying Wavelet allows detecting singularities, the Ridgelet transform will detect singularities in the Radon space, which will correspond to the parameters of relevant lines in the image. Therefore, the Ridgelet transform combines advantages from both transforms, which is the ability to detect lines from the Radon transform, and the multi-resolution property of a Wavelet to work at several levels of detail. The bivariate Ridgelet θ ψ , ,b a in 2 R can be defined as: ), / ) sin cos (( 2 / 1 , , a b y x a b a − + = − θ θ ψ ψ θ (1) where a > 0 is a scaling parameter, θ is an orientation parameter, b is a location scalar parameter, and (.) ψ is a Wavelet function. This function is constant along the lines = + θ θ sin cos y x constant. Transverse to these ridges is a Wavelet. Its Ridgelet coefficients can be defined as follows. Given an integrable bivariate image ) , ( y x f , as: 79 978-1-4244-5651-2/10/$26.00 ©2010 IEEE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Invariant Generalised Ridgelet-Fourier for Shape-based Image Retrieval
Mas Rina Mustaffa1, Fatimah Ahmad, Ramlan Mahmod, and Shyamala Doraisamy
Department of Multimedia
Faculty of Computer Science and Information Technology
Universiti Putra Malaysia
43400 UPM Serdang, Selangor, Malaysia
{MasRina1, Fatimah, Ramlan, shyamala}@fsktm.upm.edu.my
Abstract— A new shape descriptor called the Invariant
Generalised Ridgelet-Fourier is defined for the application of
Content-based Image Retrieval (CBIR). The proposed spectral-
based method is invariant to rotation, scaling, and translation
(RST) as well as able to handle images of arbitrary size. The
implementation of Ridgelet transform on the ellipse containing
the shape and the normalisation of the Radon transform is
introduced. The 1D Wavelet transform is then applied to the
Radon slices. In order to extract the rotation invariant feature,
Fourier transform is implemented in the Ridgelet domain. The
performance of the proposed method is accessed on a standard
MPEG-7 CE-1 B dataset in terms of few objective evaluation
criteria. From the experiments, it is shown that the proposed
method provides promising results compared to several
previous methods.
Keywords – CBIR; Shape descriptor; Ridgelet transform;
Invariant to RST
I. INTRODUCTION
Content-based Image Retrieval (CBIR) technologies are
developing amazingly due to the need of retrieval systems
that will be able to retrieve images effectively and efficiently.
This CBIR features make this technology useful in many
areas such as crime prevention, medicine, law, science,
fashion, and interior design. Compared to conventional image
retrieval techniques that use indexing keywords to retrieve
image files, CBIR works in a totally different manner by
retrieving images on the basis of automatically derived low-
level features, middle-level features, or high-level features.
Among these features, the low-level features are the most
popular due to their simplicity compared to other levels of
features. Among the low-level features, shape is considered
as one of the most important visual features and it is one of
the basic features used to describe image content. This is
because human beings are likely to distinguish scenes as
being composed of individual objects and these individual
objects are indeed usually identified by their shapes.
It has been found that complicated shapes can be
effectively characterised by using a description with multiple
resolutions [1-2]. This multi-resolution property is
very important as it provides a simple hierarchical framework
for the interpretation of the image information [3]. At
different resolutions, the details of an image generally
characterise different physical structures of the scene. At a
coarse resolution, these details correspond to the larger
structures, which provide the image “context”. It is therefore
natural to analyse first the image details at a coarse resolution
and then gradually increase the resolution. One of the earliest descriptors with multi-resolution
property that is used to describe shapes is the Wavelet [4-5].
However, methods based on Wavelet descriptor do not have
the direction factor, which happens to be an important and
unique feature of multi-dimensional signals. That brings us to
other multi-resolution representations with the direction
factor, which the traditional Wavelet fails to have, such as
Ridgelet [6], Curvelet [7], Contourlet [8], and Beamlet [9].
Of all these transforms, the factor of direction is most
obvious in Ridgelet. Ridgelet transform is introduced by
Candes and Donoho [6] to deal effectively with line
singularities instead of point singularities as in the case of
Wavelet. Ridgelet transform can be described as the
application of Wavelet to the Radon transform of an image.
As the Radon space corresponds to the parameters of the
lines in the image, and applying Wavelet allows detecting
singularities, the Ridgelet transform will detect singularities
in the Radon space, which will correspond to the parameters
of relevant lines in the image. Therefore, the Ridgelet
transform combines advantages from both transforms, which
is the ability to detect lines from the Radon transform, and
the multi-resolution property of a Wavelet to work at several
levels of detail.
The bivariate Ridgelet θψ ,,ba in 2R can be defined as:
),/)sincos((2/1,, abyxaba −+= − θθψψ θ (1)
where a > 0 is a scaling parameter, θ is an orientation
parameter, b is a location scalar parameter, and (.)ψ is a
Wavelet function. This function is constant along the lines
=+ θθ sincos yx constant. Transverse to these ridges is a
Wavelet. Its Ridgelet coefficients can be defined as follows.
Given an integrable bivariate image ),( yxf , as:
79978-1-4244-5651-2/10/$26.00 ©2010 IEEE

∫= dxdyyxfba
baR ),(,,
),,( θψθ (2)
Eq. (2) can be deduced into an application of 1D Wavelet
transform to the projections of the Radon transform where the
Radon transform is denoted as:
,)sincos(),(),( dxdyyxyxfRaT ρθθδρθ −+= (3)
where δ is the Dirac distribution. So Ridgelet transform is
precisely the application of a 1D Wavelet transform to the
slices of the Radon transform where the angular variable θ is
constant and ρ is varying.
Ridgelet transform has successfully been applied to
astronomical image representation, image denoising, image
deconvolution, grey and colour image contrast enhancement,
etc. Some of the applications of Ridgelet transform in the
above-mentioned field can be found in [10-13]. However, the
transformation has enjoyed very little exposure in describing
shapes for image retrieval. Apart from that, many of the
existing Ridgelet transforms mentioned in the literature are
only applied to images of size M×M or the M× N images
will need to be pre-segmented into several congruent blocks
with fixed side-length (M×M sub-images) in order to process
them (note that M and N represents the width and height of an
image, respectively). The analysis of arbitrary images
requires the definition of a general descriptor. Therefore, the
existing approaches put a huge limitation in describing
shapes, as they are not flexible for images of various sizes.
Another weakness of the existing Ridgelet transform is that
they are usually defined on square images. According to [14],
Ridgelet transform defined on square images is not suitable
for extracting rotation-invariant features. They propose a
rotation-invariant Ridgelet transform defined on a circular
disc. However, in order to achieve rotation-invariant Ridgelet
transform which can suitably accommodate M × N images,
using circular disc is not suitable either.
Therefore, this work aims to tackle the above-mentioned
issues by introducing a rotation, scaling, and translation (RST)
invariant shape descriptor based on Ridgelet transform that is
able to handle images of arbitrary size. The proposed method
will be tested on few different objective performance
measurements to prove the stability of the method. The
outline of this paper is as follows. Section II explains the
proposed Invariant Generalised Ridgelet-Fourier descriptor.
The proposed framework for evaluation and analysis of
results on the other hand are described in Section III. Finally,
the conclusion is presented in Section IV.
II. INVARIANT GENERALISED RIDGELET-FOURIER
DESCRIPTOR
This research is based on the work done by Chen et al.
[14] where enhancements on their work have been made so
that the descriptor will now results in a RST invariant
Ridgelet transform for images of arbitrary size, hence given
the name Invariant Generalised Ridgelet-Fourier descriptor.
First of all, the M×N images will have to go through the
translation and rotation invariant process. The translation
invariant can be achieved by shifting the centroid of the
pattern image to the image centre through regular moments.
Regular moments mpq are defined as:
),,(1
0
1
0
yxfyxm qM
x
N
y
ppq ∑ ∑=
−
=
−
= (4)
where M and N represents the number of columns and rows,
respectively. The ,, 0110 mm and 00m are found using (4)
above. The value obtained for the respective regular moments
will then be plugged-in into (5) to obtain the centroid location,
x and y .
00
01
00
10 ,m
my
m
mx == (5)
The scaling invariant on the other hand can be done by using
the following equation:
,)()(max 22
0),( yyxxa yxf −+−= ≠ (6)
where a is the longest distance from ),( yx to a point ),( yx
on the pattern.
Next, the pixels of the translation and scaling invariant
image that fall outside of the ellipse template centred at (M/2,
N/2) will be ignored. The Radon transform is then performed
on the elliptical pattern of the image. There are two important
parameters that need to be determined for this process where
one is the theta (θ) and the other parameter is the rho (p). In
order to make the framework suitable for M× N images, the
number of θ will need to be robust for arbitrary image size
and the number of ρ will have to be in the form of 2n to put
up for the 1D Wavelet transform. Therefore, the Radon
transform will be normalised to 128 points for both the θ and
the ρ . In order to ease the calculation, the same number of θ
and ρ is selected for each set. More explanation on the
ellipse template setting and the Radon transform
normalisation can be found in [15].
After normalising the Radon transform, the next step is to
apply the 1D Daubechies-4 Wavelet transform (Db4) on each
of the Radon slice to obtain the Ridgelet coefficients. Db4 is
found to be one of the best Wavelet families to be used for
shape representation [24, 26]. The Db4 low-pass scaling
coefficients are G = [0.483, 0.837, 0.224, -0129] while the
Db4 high-pass scaling coefficients are H = [-0.129, -0.224,
0.837, -0.483].
In order to make the descriptor invariant to rotation, the
1D Fourier transform is performed along the θ direction on
the d3 and d4 Wavelet decomposition levels. The intermediate
scale Wavelet coefficients are usually preferable as the high
80

frequency Wavelet decomposition levels are very sensitive to
noise and accumulation errors while the low frequency
Wavelet decomposition levels have lost important
information of the original image. For each of the mentioned
Wavelet decomposition levels, only 15 Fourier magnitude
spectrums are captured to represent the shape. Therefore, the
total coefficients for each image using the proposed Invariant
Generalised Ridgelet-Fourier is 360, which is still a
reasonable size for shape representation.
III. EVALUATION AND ANALYSIS OF RESULTS
In this section, the retrieval performance of the proposed
Invariant Generalised Ridgelet-Fourier descriptor is
compared and tested. A series of experiments are conducted
on an Intel Pentium Dual-Core 2.5 GHz desktop. The
experiments are performed on the standard MPEG-7 CE-1 B
dataset, which is usually used to test the overall robustness of
the shape representations towards rotation, scaling, and
translation invariant as well as similarity retrieval. It consists
of 1400 shapes of 70 groups. There are 20 similar shapes in
each group, which provide the ground truth. The dataset can
be
downloaded at http://www.imageprocessingplace.com/root_fi
les_V3/ image_databases.htm. For the experiments, 50
classes from this dataset are considered which brings us to a
total of 1000 images. Some examples of the images used for
the evaluations of the proposed work are shown in Fig. 1
below.
Figure 1. Some samples of the images used for the evaluation
In order to show the robustness and stability of the
proposed descriptor, the comparison and evaluation are done
based on few evaluation criteria, namely average precision-
recall, Average Retrieval Rate (ARR), Average Normalized
Modified Retrieval Rank (ANMRR), average r-measure, and
average p1-measure.
Precision and recall measures have been widely used for
evaluating the performance of the CBIR system. This is due
to its simple calculations and results obtained from these
measures can be easily interpreted. Apart from that, the
results obtained from these measures are usually visualised
through
graph representations, which will make it easier to analyse.
The retrieval precision, Precision (q) of a system with respect
to a query q is defined as the ratio of the number of retrieved
relevant images, N (q), over the number of total retrieved
images, M (q) [16]. Given a set of Q queries, the average
retrieval precision of the system is then given by (7):
∑=
= Q
qqM
qN
QPrecisionAverage
1)(
)(1 (7)
On the other hand, the retrieval recall, Retrieval (q) of a
system with respect to a query q is the ratio of the number of
retrieved relevant images, N (q), over the total number of
relevant images in the database for the respective query, G
(q) [16]. Given a set of Q queries, the average retrieval recall
of the system is then given by (8) below:
∑=
= Q
q qG
qN
QRecallAverage
1 )(
)(1 (8)
It is a common case where as the number of images returned
to the user increases, precision will decrease while the recall
will increase. Due to this fact, instead of using average
precision or average recall as separate performance measures
for CBIR systems, the precision-recall curve is usually
adopted.
Another popular CBIR performance measurement is the
Retrieval Rate (RR). The retrieval rate, RR (q) of a system
with respect to a query q is defined as the ratio of the number
of ground truth images found within the first α retrievals
),( qF α over the total number of relevant images in the
database for the respective query, G (q). Given a set of Q
queries, the ARR can then be obtained based on the following
equation:
∑=
= Q
q qG
qF
QRRAverage
1 )(
),(1 α (9)
The factor α should be 1≥ , where a largerα is more tolerant.
However, α should not be too large as this would result in
the system being less discriminative between very good
retrieval results and the not so good ones. It has been
suggested in [17] that for relatively large ground truth set
(approximately between 20 – 25 items), the system will still
be judged as useful if the items of the ground truth are found
within )(2 qG× . Therefore for this experiment, 202×=α is
used, which is equivalent to the first 40 retrievals. ANMRR
on the other hand is a new accuracy evaluation method
proposed in MPEG-7 [18]. Unlike precision and recall, this
81
performance measurement can determine both how many
correct images are retrieved as well as how high they are
ranked among the retrieval results. The ANMRR is computed
as follows:
,
1
)(1
∑=
=Q
q
qNMRRQ
ANMRR (10)
where Q is the number of queries and q is the query. The
ARR and the ANMRR is always in a range of 0 to 1. A high
ARR value represents a good performance in terms of
retrieval rate, and a low ANMRR value indicates a good
performance in terms of retrieval rank.
Another popular evaluation criteria used to evaluate
retrieval effectiveness is the pair known as r-measure and p1-
measure. From this pair, the average r-measure and the
average p1-measure can then be obtained. These performance
measurements have been utilised in [19-20]. Let
),( 1 Qqq ..., be the set of query images. For a query Iq , let
Ii be the unique correct answer (for this experiment,
Ii would be the second item among the 20 items of ground
truth being retrieved for query Iq ). The r-measure calculates
the sum of the rank of correct answer of all queries as shown
in (11). The average r-measure is then obtained by dividing it
with the number of queries Q, as shown in (12).
)(1∑ =
=−Q
I Iirankmeasurer (11)
Q
measurermeasurerAverage
−=− (12)
In contrast, the p1-measure computes the sum of the precision
at the recall equal to one while the average p1-measure can
then be obtained by dividing r-measure with the number of
queries Q. Both calculations can be referred to (13) and (14)
respectively.
)(
1
1
1
∑ =
=−Q
IIirank
measurep (13)
Q
measurepmeasurepAverage
−=− 1
1 (14)
Note that a method is good if it has a low r-measure and a
high p1-measure.
To benchmark the retrieval performance, the proposed
Invariant Generalised Ridgelet-Fourier’s results are compared
to that of Ridgelet-Fourier (RF) method by [14] and the basic
Ridgelet descriptor. The parameters setting for each of the
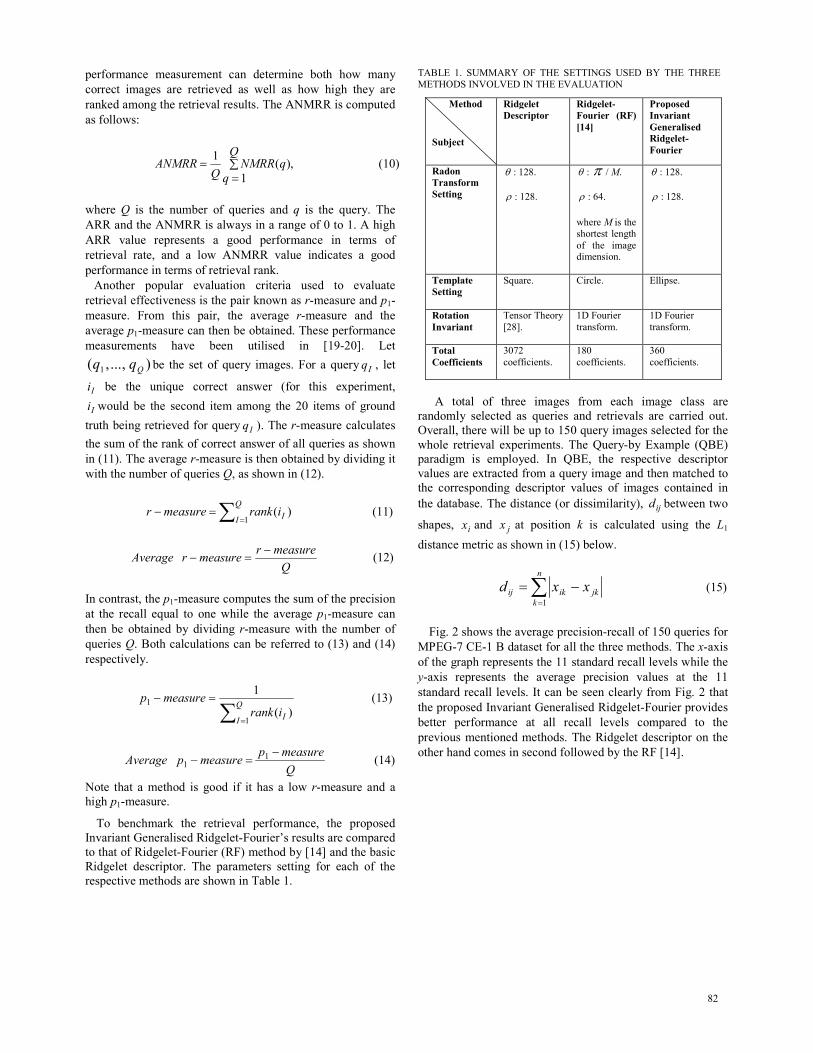
respective methods are shown in Table 1.
TABLE 1. SUMMARY OF THE SETTINGS USED BY THE THREE
METHODS INVOLVED IN THE EVALUATION
Method
Subject
Ridgelet
Descriptor
Ridgelet-
Fourier (RF)
[14]
Proposed
Invariant
Generalised
Ridgelet-
Fourier
Radon
Transform
Setting
θ : 128.
ρ : 128.
θ : π / M.
ρ : 64.
where M is the
shortest length
of the image dimension.
θ : 128.
ρ : 128.
Template
Setting
Square. Circle. Ellipse.
Rotation
Invariant
Tensor Theory
[28].
1D Fourier
transform.
1D Fourier
transform.
Total
Coefficients
3072
coefficients.
180
coefficients.
360
coefficients.
A total of three images from each image class are
randomly selected as queries and retrievals are carried out.
Overall, there will be up to 150 query images selected for the
whole retrieval experiments. The Query-by Example (QBE)
paradigm is employed. In QBE, the respective descriptor
values are extracted from a query image and then matched to
the corresponding descriptor values of images contained in
the database. The distance (or dissimilarity), ijd between two
shapes, ix and jx at position k is calculated using the L1
distance metric as shown in (15) below.
∑=
−=n
k
jkikij xxd1
(15)
Fig. 2 shows the average precision-recall of 150 queries for
MPEG-7 CE-1 B dataset for all the three methods. The x-axis
of the graph represents the 11 standard recall levels while the
y-axis represents the average precision values at the 11
standard recall levels. It can be seen clearly from Fig. 2 that
the proposed Invariant Generalised Ridgelet-Fourier provides
better performance at all recall levels compared to the
previous mentioned methods. The Ridgelet descriptor on the
other hand comes in second followed by the RF [14].
82
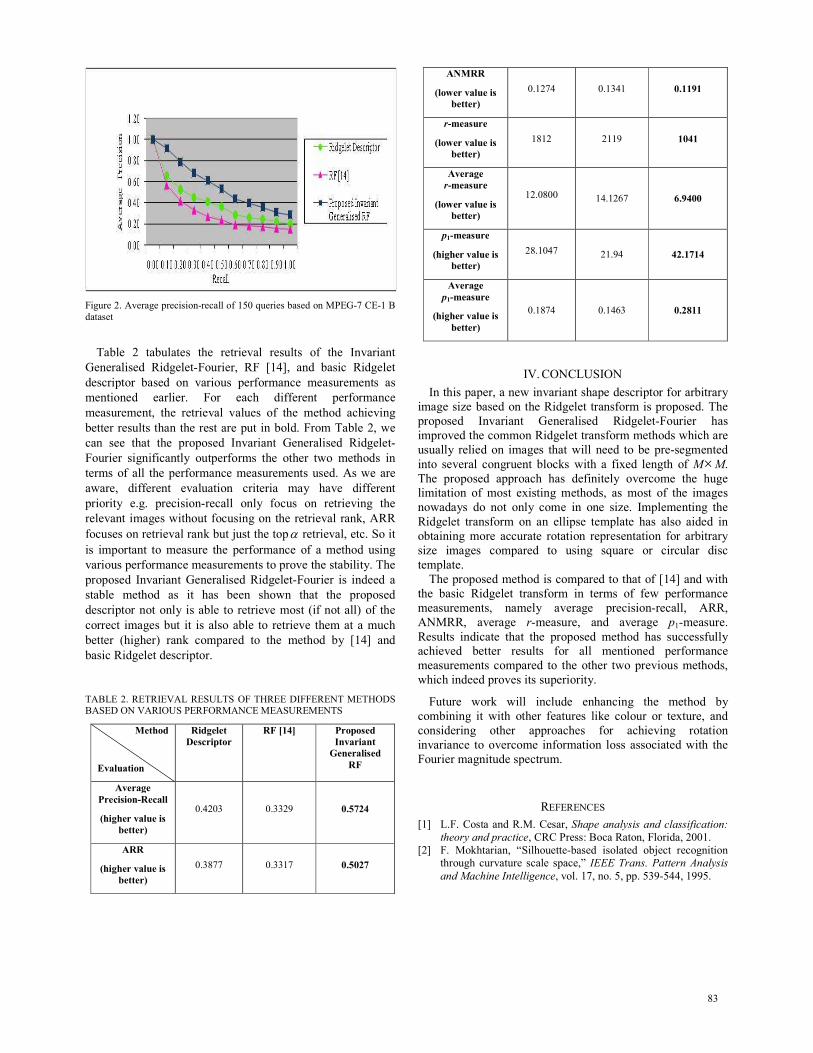
Figure 2. Average precision-recall of 150 queries based on MPEG-7 CE-1 B
dataset
Table 2 tabulates the retrieval results of the Invariant
Generalised Ridgelet-Fourier, RF [14], and basic Ridgelet
descriptor based on various performance measurements as
mentioned earlier. For each different performance
measurement, the retrieval values of the method achieving
better results than the rest are put in bold. From Table 2, we
can see that the proposed Invariant Generalised Ridgelet-
Fourier significantly outperforms the other two methods in
terms of all the performance measurements used. As we are
aware, different evaluation criteria may have different
priority e.g. precision-recall only focus on retrieving the
relevant images without focusing on the retrieval rank, ARR
focuses on retrieval rank but just the topα retrieval, etc. So it
is important to measure the performance of a method using
various performance measurements to prove the stability. The
proposed Invariant Generalised Ridgelet-Fourier is indeed a
stable method as it has been shown that the proposed
descriptor not only is able to retrieve most (if not all) of the
correct images but it is also able to retrieve them at a much
better (higher) rank compared to the method by [14] and
basic Ridgelet descriptor.
TABLE 2. RETRIEVAL RESULTS OF THREE DIFFERENT METHODS BASED ON VARIOUS PERFORMANCE MEASUREMENTS
Method
Evaluation
Ridgelet
Descriptor
RF [14] Proposed
Invariant
Generalised
RF
Average
Precision-Recall
(higher value is
better)
0.4203 0.3329 0.5724
ARR
(higher value is
better)
0.3877 0.3317 0.5027
ANMRR
(lower value is
better)
0.1274 0.1341 0.1191
r-measure
(lower value is
better)
1812 2119 1041
Average
r-measure
(lower value is
better)
12.0800 14.1267 6.9400
p1-measure
(higher value is
better)
28.1047 21.94 42.1714
Average
p1-measure
(higher value is
better)
0.1874 0.1463 0.2811
IV. CONCLUSION
In this paper, a new invariant shape descriptor for arbitrary
image size based on the Ridgelet transform is proposed. The
proposed Invariant Generalised Ridgelet-Fourier has
improved the common Ridgelet transform methods which are
usually relied on images that will need to be pre-segmented
into several congruent blocks with a fixed length of M×M.
The proposed approach has definitely overcome the huge
limitation of most existing methods, as most of the images
nowadays do not only come in one size. Implementing the
Ridgelet transform on an ellipse template has also aided in
obtaining more accurate rotation representation for arbitrary
size images compared to using square or circular disc
template.
The proposed method is compared to that of [14] and with
the basic Ridgelet transform in terms of few performance
measurements, namely average precision-recall, ARR,
ANMRR, average r-measure, and average p1-measure.
Results indicate that the proposed method has successfully
achieved better results for all mentioned performance
measurements compared to the other two previous methods,
which indeed proves its superiority.
Future work will include enhancing the method by
combining it with other features like colour or texture, and
considering other approaches for achieving rotation
invariance to overcome information loss associated with the
Fourier magnitude spectrum.
REFERENCES
[1] L.F. Costa and R.M. Cesar, Shape analysis and classification:
theory and practice, CRC Press: Boca Raton, Florida, 2001.
[2] F. Mokhtarian, “Silhouette-based isolated object recognition through curvature scale space,” IEEE Trans. Pattern Analysis
and Machine Intelligence, vol. 17, no. 5, pp. 539-544, 1995.
83

[3] J.J. Koenderink, “The structure of images,” Biological
Cybernetics, vol. 50, no. 5, pp. 363-370, 1984.
[4] M.G. Albanesi and L. Lombardi, “Wavelets for multi-
resolution shape recognition,” in LNCS, vol. 1311, A.D, Bimbo
Ed. London: Springer-Verlag, 1997, pp. 276-283.
[5] I.E. Rube', M. Ahmed, and M. Kamel, “Wavelet
approximation-based affine invariant shape representation
functions,” IEEE Trans. Pattern Analysis and Machine
Intelligence, vol. 28, no. 2, pp. 323-327, 2006. [6] E.J. Candès and D.L. Donoho, “Ridgelets: a key to higher
dimensional intermittency?,” Philosophical Trans. Royal
Society A: Mathematical, Physical and Engineering Sciences,
vol. 357, no. 1760, pp. 2495-2509, 1999.
[7] E.J. Candès and D.L. Donoho, “Curvelets – a surprisingly
effective non-adaptive representation for objects with edges, curves, and surfaces,” in Curve and Surface Fitting, A. Cohen,
C. Rabut, and L.L. Schumaker Eds. Nashville, TN: Vanderbilt
University Press, 1999.
[8] M.N. Do and M. Vetterli, “The contourlet transform: an
efficient directional multi-resolution image representation,”
IEEE Trans. Image Processing, vol. 14, no. 12, pp. 2091-2106, 2005.
[9] D. Donoho and X. Huo, “Beamlet pyramids: a new form of
multi-resolution analysis, suited for extracting lines, curves,
and objects from very noisy image data,” Proc. SPIE, vol.
4119, 2000. [10] W. Pan, T.D. Bui, and C.Y. Suen, “Rotation invariant texture
classification by ridgelet transform and frequency-orientation
space decomposition,” Signal Processing, vol. 88, no. 1, pp.
189-199, 2008.
[11] S. Arivazhagan, L. Ganesan, and T.G. Kumar, “Texture
classification using ridgelet transform,” Pattern Recognition
Letters, vol. 27, no. 16, pp. 1875-1883, 2006.
[12] Z. Yao and N. Rajpoot, “Radon/ridgelet signature for image
authentication,” Proc. International Conference on Image
Processing (ICIP '04), vol. 1, pp. 43-46, 2004.
[13] J. Xiaa, L. Ni, and Y. Miao, “A new digital implementation of
ridgelet transform for images of dyadic length,” Journal of Network and Computer Applications, vol. 30, no. 4, pp. 1346-
1355, 2007.
[14] Y. Chen, D. Bui, and A. Krzyzak, “Rotation invariant feature
extraction using ridgelet and fourier transforms,” Pattern
Analysis and Applications, vol. 9, no. 1, pp. 83-93, 2006.
[15] Mas Rina Mustaffa, Fatimah Ahmad, Ramlan Mahmod, and Shyamala Doraisamy, “Generalised ridgelet-fourier for M× N
images: determining the normalisation criteria,” Proc. IEEE
International Conference on Signal & Image Processing
Applications (ICSIPA’09), 18-19 November 2009. in press.
[16] G. Salton and M.J. McGill, Introduction to Modern Information Retrieval, McGraw-Hill: New York, 1982.
[17] B.S. Manjunath, J.R. Ohm, V.V. Vasudevan, and A. Yamada,
“Colour and texture descriptors,” IEEE Trans. Circuits and
Systems for Video Technology, vol. 11, no. 6, pp. 703-715,
2001.
[18] MPEG-7 Visual Part of eXperimentation Model Version 2.0.
ISO/MPEG MPEG-7 Output Document, 1999.
[19] J. Huang, S. Kumar, M. Mitra, W. Zhu, and R. Zabih, “Spatial
colour indexing and applications,” Intl. J. of Computer Vision,
vol. 35, no. 3, pp. 245–268, 1999.
[20] Jongan Park, Youngeun An, Ilhoe Jeong, Gwangwon Kang,
and K. Pankoo, “Image indexing using spatial multi-resolution colour correlogram,” Proc. IEEE International Workshop on
Imaging Systems and Techniques (IST '07), pp. 1-4, 2007.
84
Related Documents











