Neural Networks Dr. Randa Elanwar Lecture 7

Introduction to Neural networks (under graduate course) Lecture 7 of 9
Jul 17, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Neural Networks
Dr. Randa Elanwar
Lecture 7

Lecture Content
• NN Learning techniques:
– Supervised learning
– Unsupervised learning
– Reinforcement learning
• Other learning laws: Hebbian learning rule
2Neural Networks Dr. Randa Elanwar

Basic models of ANN
3Neural Networks Dr. Randa Elanwar
Basic Models of ANN
Activation function
Interconnections Learning rules

Learning
• It’s a process by which a NN adapts itself to a stimulus by making proper parameter adjustments, resulting in the production of desired response
• Two kinds of learning
– Parameter learning:- connection weights are updated
– Structure Learning:- change in network structure
4Neural Networks Dr. Randa Elanwar

Training
• The process of modifying the weights in the connections between network layers with the objective of achieving the expected output is called training a network.
• This is achieved through– Supervised learning
– Unsupervised learning
– Reinforcement learning
5Neural Networks Dr. Randa Elanwar

Supervised Learning
• Child learns from a teacher
• Each input vector requires a corresponding target vector.
• Training pair=[input vector, target vector]
NeuralNetwork
W
ErrorSignal
Generator
X
(Input)
Y
(Actual output)
(Desired Output)
Error
(D-Y) signals
6Neural Networks Dr. Randa Elanwar

Supervised learning
7Neural Networks Dr. Randa Elanwar
Supervised learning does minimization of error

Supervised Learning
• Learning is performed by presenting pattern with target
• During learning, produced output is compared with the desired output
– The difference between both output is used to modify learning weights according to the learning algorithm
• Recognizing hand-written digits, pattern recognition and etc.
• Neural Network models: perceptron, feed-forward, radial basis function, support vector machine.
8Neural Networks Dr. Randa Elanwar
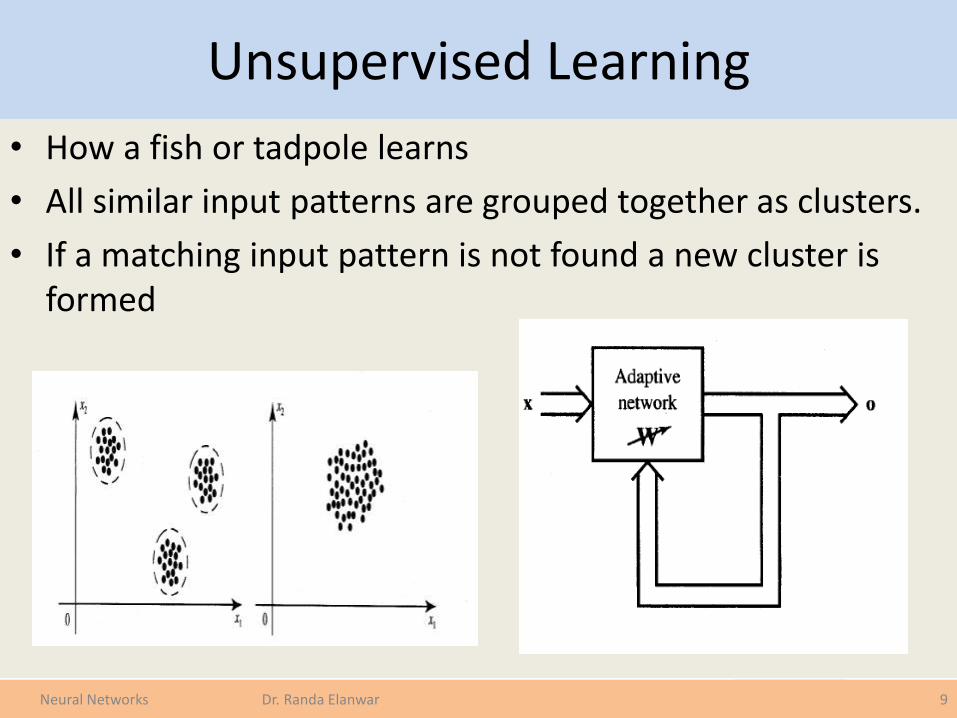
Unsupervised Learning
• How a fish or tadpole learns
• All similar input patterns are grouped together as clusters.
• If a matching input pattern is not found a new cluster is formed
9Neural Networks Dr. Randa Elanwar

Unsupervised Learning
• Targets are not provided
• Appropriate for clustering task
– Find similar groups of documents in the web, content addressable memory, clustering.
• Neural Network models: Kohonen, self organizing maps, Hopfield networks.
10Neural Networks Dr. Randa Elanwar

Self-organizing
• In unsupervised learning there is no error feedback
• Network must discover patterns, regularities, features for the input data over the output
• While doing so the network might change in parameters
• This process is called self-organizing
11Neural Networks Dr. Randa Elanwar

•Target is provided, but the desired output is absent.
•The net is only provided with guidance to determine the produced output is correct or vise versa.
•Weights are modified in the units that have errors
Reinforcement Learning
12Neural Networks Dr. Randa Elanwar

Reinforcement Learning
NNW
ErrorSignal
Generator
X
(Input)
Y
(Actual output)
Error
signals R
Reinforcement signal
13Neural Networks Dr. Randa Elanwar

When Reinforcement learning is used?
• If less information is available about the target output values (critic information)
• Learning based on this critic information is called reinforcement learning and the feedback sent is called reinforcement signal
• Feedback in this case is only evaluative and not instructive
14Neural Networks Dr. Randa Elanwar

Some learning algorithms we will learn are
• Supervised:• Adaline, Madaline
• Perceptron
• Back Propagation
• multilayer perceptrons
• Radial Basis Function Networks
• Unsupervised• Competitive Learning
• Kohenen self organizing map
• Learning vector quantization
• Hebbian learning
15Neural Networks Dr. Randa Elanwar

Some learning algorithms we will learn are
• The only NN learning rule we have studied so far is the “perceptron learning” also known as “Error-Correction learning” or “delta rule”.
• The learning signal is equal to the error signal: difference between the desired and the actual neuron output
• We will consider also “Hebbian learning” and “Competitive learning”
16Neural Networks Dr. Randa Elanwar

Hebbian learning Rule
• Feedforward unsupervised learning also known as “coincidence learning”
• The learning signal is equal to the neuron’s output
• To update the weights of a neuron i, the inputs to neuron i come from a preceding neuron j (xj)
wi,j = wi,j + wi,j
wi,j = * outputi * inputj
wi,j = oixj
• It is clear that Hebbian learning is not going to get our Perceptron to learn a set of training data, since weight changes depend only on the actual outputs and we don’t have desired outputs to compare to.
• Hebb rule can be used for pattern association, pattern categorization, pattern classification and over a range of other areas
17Neural Networks Dr. Randa Elanwar

Hebbian learning Rule
• If oixj is positive the results is increase in weight else vice versa
• In other words:1. If two neurons on either side of a connection are activated simultaneously (i.e. synchronously), then the strength of that connection (weight) is selectively increased.
2. If two neurons on either side of a connection are activated asynchronously, then that connection is selectively weakened or eliminated.
• so that chance coincidences do not build up connection strengths.
18Neural Networks Dr. Randa Elanwar

Hebbian learning Rule
• Example: Consider a 4-input perceptron that uses the bipolar binary sgnfunction
+1 if net>0sgn(net) =
-1 if net<0
• to compute the output value o. If the weight vector w1 = (1 -1 0 0.5) and given that the learning constant = 1:
• Use the Hebbian learning rule to train the perceptron using each of the following input vectors:
• x1 = (1 -2 1.5 0)t
• x2 = (1 -0.5 -2 -1.5)t
• x3 = (0 1 -1 1.5)t
19Neural Networks Dr. Randa Elanwar

Hebbian learning Rule
• Update weight vector for iteration 1
• Update weight vector for iteration 2
20Neural Networks Dr. Randa Elanwar
11,3
05.12
1
]5.0011[1.)0(
oXW
5.0
5.1
3
2
1.. 1)0()1( XOWWTT
12,75.0
5.12
5.01
]5.05.132[2.)1(
oXW
2
5.3
5.2
1
2.. 2)1()2( XOWWTT

Hebbian learning Rule
• Update weight vector for iteration 3
21Neural Networks Dr. Randa Elanwar
13,3]5.1110.[
5.11
10
]25.35.21[3.)2(
oXW
5.0
5.4
5.3
1
3.. 3)2()3( XOWWTT

Hebbian learning Rule
• Example: OR function implementation
• Use bipolar data in the place of binary data
• Initially the weights and bias are set to zero
w1=w2=b=0
22Neural Networks Dr. Randa Elanwar
X1 X2 B Y (desired)
1 1 1 1
1 -1 1 1
-1 1 1 1
-1 -1 1 -1

Hebbian learning Rule
• Update weight vector for iteration 1
• Update weight vector for iteration 2
23Neural Networks Dr. Randa Elanwar
11,0
1
1
1
].000[1.)0(
oXW
1
1
1
1..1)0()1( XOWW
TT
12,1
1
1
1
].111[2.)1(
oXW
2
0
2
2..2)1()2( XOWW
TT
Ok
Ok

Hebbian learning Rule
• Update weight vector for iteration 3
• Update weight vector for iteration 4
• Since we are given desired outputs we have to correlate themto the actual outputs i.e. o4 = +1*ydes=-1
24Neural Networks Dr. Randa Elanwar
13,0
1
1
1
].202[3.)2(
oXW
3
1
1
3..3)2()3( XOWW
TT
Ok
14,1
1
1
1
].311[4.)3(
oXW
2
2
2
4..4)3()4( XOWW
TT
Wrong
Related Documents











