Introduction to MapReduce ECE7610

Introduction to MapReduce ECE7610. The Age of Big-Data Big-data age Facebook collects 500 terabytes a day(2011) Google collects 20000PB a day (2011)
Dec 29, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Introduction to MapReduce
ECE7610

The Age of Big-Data
Big-data age Facebook collects 500 terabytes a day(2011) Google collects 20000PB a day (2011)
Data is an important asset to any organization Finance company; insurance company;
internet company We need new
Algorithms/data structures/programming model
2

What to do ? (Word Count)
Consider a large data collection and count the occurrences of the different words
3
Datacollectio
n
web 2
weed 1
green 2
sun 1
moon 1
land 1
part 1
ResultTable
Main
DataCollection
WordCounter
parse( )count( )
{web, weed, green, sun, moon, land, part, web, green,…}

What to do ?(Word Count)
4
Datacollectio
n
web 2
weed 1
green 2
sun 1
moon 1
land 1
part 1
Thread
DataCollection ResultTable
WordCounter
parse( )count( )
Main
1..*1..*
Multi-threadLock on shared data

What to do?(Word Count)
5
Datacollectio
n
Single machine cannot serve all the data: you need a distributed special (file) system
Large number of commodity hardware disks: say, 1000 disks 1TB each
Critical aspects: fault tolerance + replication + load balancing, monitoring
Exploit parallelism afforded by splitting parsing and counting
Provision and locate computing at data locations

What to do? (Word Count)
6
WordList
Thread
Main
1..*
1..*
DataCollection
Parser1..*
Counter
1..*
ResultTable
KEY web weed green sun moon land part web green …….
VALUE
web 2
weed 1
green 2
sun 1
moon 1
land 1
part 1
Datacollectio
n
Separate countersSeparate data
Datacollectio
nData
collection
Datacollectio
n
Datacollectio
n

It is not easy to parallel….
7
Fundamental issuesScheduling, data distribution, synchronization, inter-process communication, robustness, fault tolerance, …
Different programming modelsMessage Passing Shared Memory
Architectural issuesFlynn’s taxonomy (SIMD, MIMD, etc.), network topology, bisection bandwidth, cache coherence, …
Common problemsLivelock, deadlock, data starvation, priority inversion, …dining philosophers, sleeping barbers, cigarette smokers, …
Different programming constructs Mutexes, conditional variables, barriers, …masters/slaves, producers/consumers, work queues,. …
Actually, Programmer’s Nightmare….

MapReduce: Automate for you Important distributed parallel programming paradigm for large-scale
applications. Becomes one of the core technologies powering big IT companies, like
Google, IBM, Yahoo and Facebook. The framework runs on a cluster of machines and automatically
partitions jobs into number of small tasks and processes them in parallel.
Features: fairness, task data locality, fault-tolerance.
8
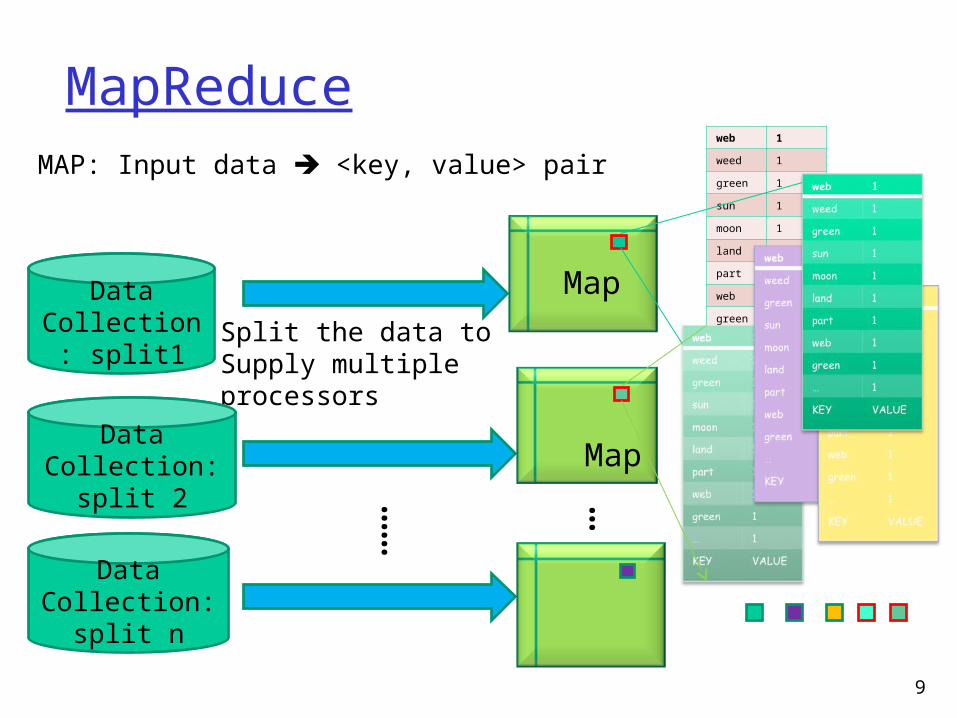
MapReduce
9
MAP: Input data <key, value> pair
DataCollection:
split1
web 1
weed 1
green 1
sun 1
moon 1
land 1
part 1
web 1
green 1
… 1
KEY VALUE
Split the data toSupply multipleprocessors
DataCollection:
split 2
DataCollection:
split n
Map
… …Map
…
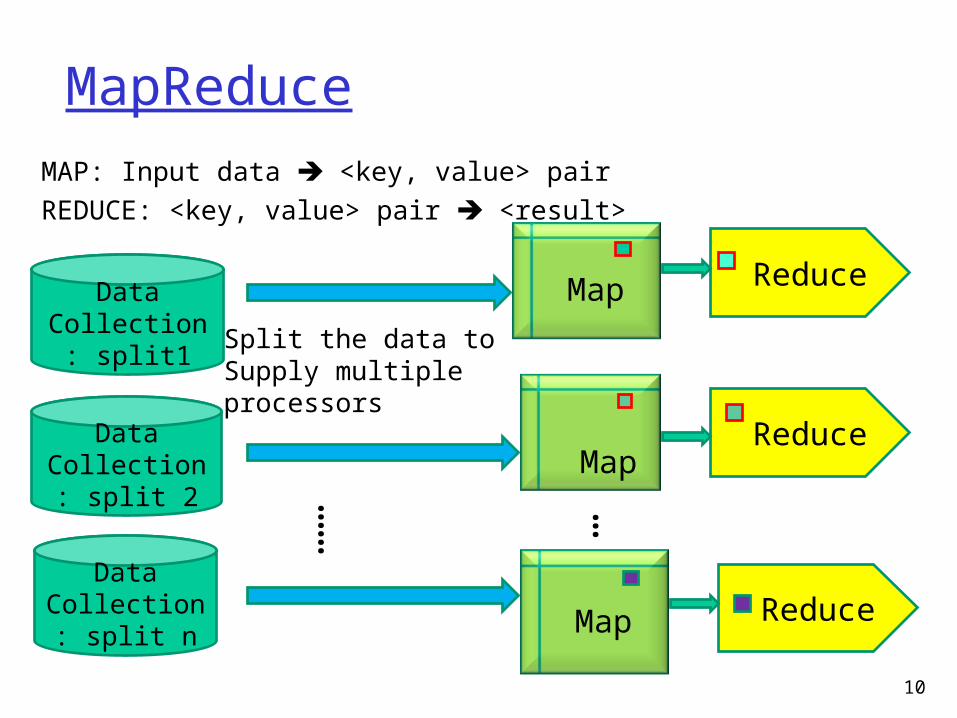
MapReduce
10
Reduce
Reduce
Reduce
MAP: Input data <key, value> pairREDUCE: <key, value> pair <result>
DataCollection:
split1Split the data toSupply multipleprocessors
DataCollection:
split 2
DataCollection:
split n Map
Map…
…
Map
…
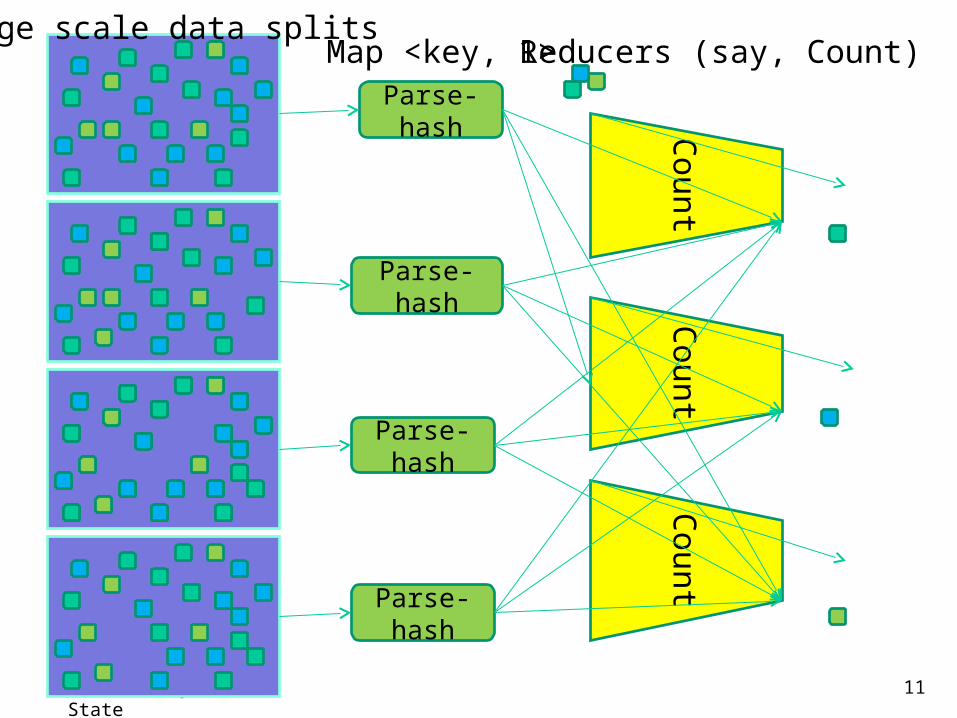
C. Xu @ Wayne State 11
Cou
nt
Cou
nt
Cou
nt
Large scale data splits
Parse-hash
Parse-hash
Parse-hash
Parse-hash
Map <key, 1>Reducers (say, Count)

MapReduce
12

How to store the data ?
13
Compute Nodes
What’s the problem here?

Distributed File System
Don’t move data to workers… Move workers to the data! Store data on the local disks for nodes in the cluster Start up the workers on the node that has the data local
Why? Not enough RAM to hold all the data in memory Network is the bottleneck, disk throughput is good
A distributed file system is the answer GFS (Google File System) HDFS for Hadoop
14

GFS/HDFS Design Commodity hardware over “exotic” hardware High component failure rates Files stored as chunks
Fixed size (64MB) Reliability through replication
Each chunk replicated across 3+ chunkservers Single master to coordinate access, keep metadata
Simple centralized management No data caching
Little benefit due to large data sets, streaming reads Simplify the API
Push some of the issues onto the client
15

GFS/HDFS
16

MapReduce Data Locality
Master scheduling policy Asks HDFS for locations of replicas of input file blocks Map tasks typically split into 64MB (== GFS block
size) Locality levels: node locality/rack locality/off-rack Map tasks scheduled as close to its input data as
possible
Effect Thousands of machines read input at local disk
speed. Without this, rack switches limit read rate and network bandwidth becomes the bottleneck.
17

MapReduce Fault-tolerance
Reactive way Worker failure
• Heartbeat, Workers are periodically pinged by master
– NO response = failed worker
• If the processor of a worker fails, the tasks of that worker are reassigned to another worker.
Master failure• Master writes periodic checkpoints• Another master can be started from the last
checkpointed state• If eventually the master dies, the job will be
aborted
18

MapReduce Fault-tolerance
Proactive way (Speculative Execution) The problem of “stragglers” (slow workers)
• Other jobs consuming resources on machine• Bad disks with soft errors transfer data very
slowly• Weird things: processor caches disabled (!!)
When computation almost done, reschedule in-progress tasks
Whenever either the primary or the backup executions finishes, mark it as completed
19

MapReduce Scheduling Fair Sharing
conducts fair scheduling using greedy method to maintain data locality
Delay uses delay scheduling algorithm to achieve good data
locality by slightly compromising fairness restriction LATE(Longest Approximate Time to End)
improves MapReduce applications' performance in heterogenous environment, like virtualized environment, through accurate speculative execution
Capacity introduced by Yahoo, supports multiple queues for
shared users and guarantees each queue a fraction of the capacity of the cluster
20
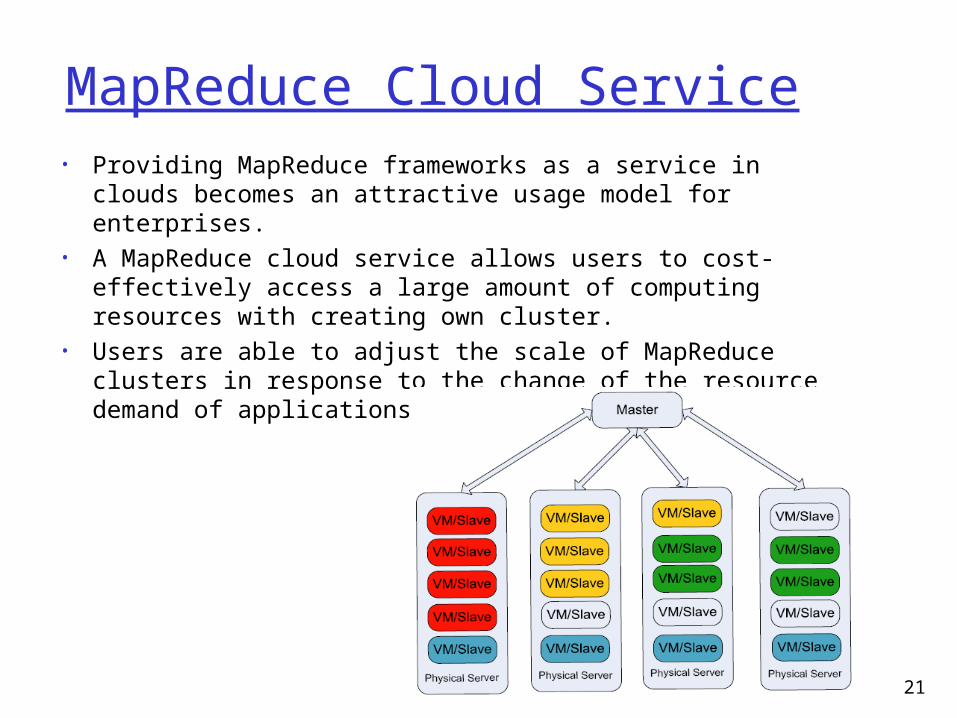
MapReduce Cloud Service• Providing MapReduce frameworks as a service in clouds
becomes an attractive usage model for enterprises. • A MapReduce cloud service allows users to cost-
effectively access a large amount of computing resources with creating own cluster.
• Users are able to adjust the scale of MapReduce clusters in response to the change of the resource demand of applications.
21

Amazon Elastic MR
You
1. Scp data to cluster2. Move data into HDFS
3. Develop code locally
4. Submit MapReduce job4a. Go back to Step 3
5. Move data out of HDFS6. Scp data from cluster
0. Allocate Hadoop cluster
EC2
Your Hadoop Cluster
7. Clean up!

New Challenges
Interference between co-hosted VMs Slow down the job 1.5-7 times
Locality preserving policy no long effective Lose more than 20% locality (depends)
Need specifically designed scheduler for virtual MapReduce cluster Interference-aware Locality-aware
23

MapReduce Programming Hadoop implementation of MR in Java (version 1.0.4) WordCount example:
hadoop-1.0.4/src/examples/org/apache/hadoop/examples/WordCount.java
24

MapReduce Programming
25

Map
Implement your own map class extending the Mapper class
26

Reduce
Implement your own reducer class extending the reducer class
27

Main()
28

Demo
29
Related Documents











