
Introduction to MapReduce and Hadoop
Aug 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


Expected … what to be said!
● History.● What is Hadoop.● Hadoop vs SQl.● MapReduce.● Hadoop Building Blocks.● Installing, Configuring and Running Hadoop.● Anatomy of MapReduce program.

Hadoop Series Resources


How hadoop was born?
Doug Cutting

Challenges of Distributed Processing of Large Data
● How to distribute the work?● How to store and distribute the data itself?● How to overcome failures?● How to balance the load?● How to deal with unstructured data?● ...

Hadoop tackles these challenges!
So, what’s Hadoop?

What is Hadoop?
Hadoop is an open source framework for writing and running dis tributed applications that process large amounts of data.
Key distinctions of Hadoop:● Accessible● Robust● Scalable● Simple

Hadoop vs SQL
● Structured and Unstructured data.● Datastore and Data Analysis.● Scale-out and Scale-up.● Offline batch processing and Online
transactions.

Hadoop Uses MapReduce
What is MapReduce?...

● Parallel programming model for clusters of commodity machines.
● MapReduce provides:o Automatic parallelization & distribution.o Fault tolerance.o Locality of data.
What is MapReduce?
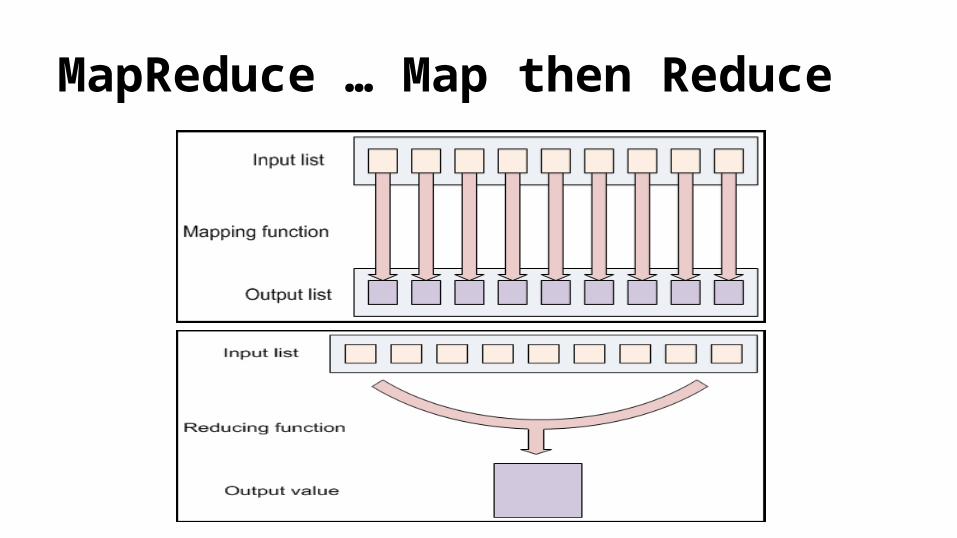
MapReduce … Map then Reduce

Keys and Values
● Key/Value pairs.
● Keys divide Reduce Space.
Input Output
Map <k1, v1> list(<k2, v2>)
Reduce <k2, list(v2)> list(<k3, v3>)

WordCount in Action
Input:
foo.txt: “This is the foo file”
bar.txt: “And this is the bar one”
Mapper(s):this1is1the1foo1file1and1this1is1the1bar1one1
Reduce#2:Input:Output:is, [1, 1] is, 2
Reduce#1:Input:Output:this, [1, 1]this, 2
Reduce#3:Input:Output:foo, [1]foo, 1 .
.
Final output:this 2is 2the 2foo 1file 1and 1bar 1one 1

WordCount with MapReducemap(String filename, String document) {
List<String> T = tokenize(document);
for each token in T {emit ((String)token,
(Integer) 1);}
}
reduce(String token, List<Integer> values) {Integer sum = 0;
for each value in values {sum = sum + value;
}emit ((String)token, (Integer) sum);
}

Hadoop Building Blocks
How does hadoop work?...

Hadoop Building Blocks
1. NameNode2. DataNode3. Secondary NameNode4. JobTracker5. TaskTracker

HDFS: NameNode and DataNodes
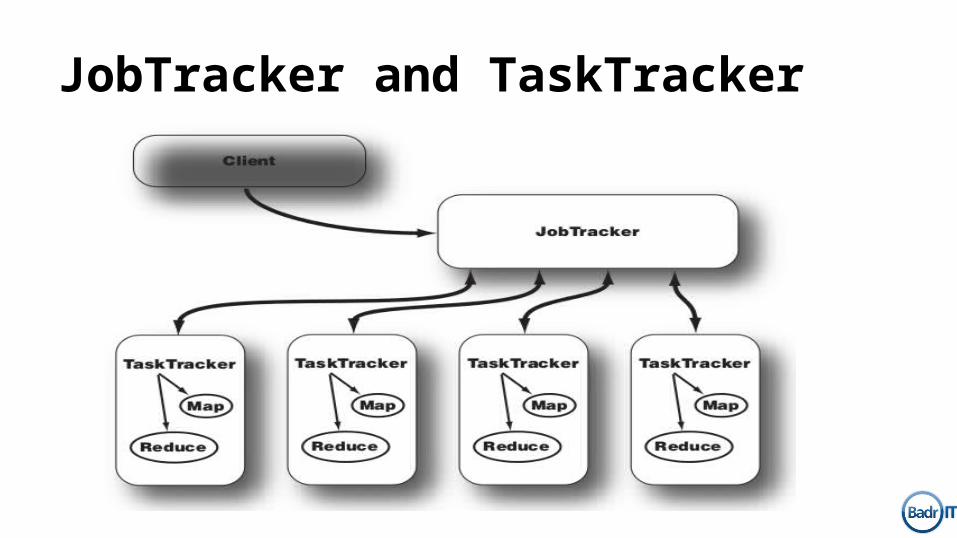
JobTracker and TaskTracker

Typical Hadoop Cluster

Running Hadoop
Three modes to run Hadoop:1. Local (standalone) mode.2. Pseudo-distributed mode “cluster of one” .3. Fully distributed mode.

An ActionRunning Hadoop on Local Machine

Actions ...
1. Installing Hadoop.2. Configuring Hadoop (Pseudo-distributed mode).3. Running WordCount example.4. Web-based cluster UI.

HDFS
1. HDFS is a filesystem designed for large-scale distributed data processing.
2. HDFS isn’t a native Unix filesystem.
Basic File Commands:$ hadoop fs -cmd <args>$ hadoop fs –ls$ hadoop fs –mkdir /user/chuck$ hadoop fs -copyFromLocal

Anatomy of a MapReduce program
MapReduce and beyond

Hadoop
1. Data Types2. Mapper3. Reducer4. Partitioner5. Combiner6. Reading and Writing
a. InputFormatb. OutputFormat

Anatomy of a MapReduce program

Hadoop Data Types
● Certain defined way of serializing key/value pairs.● Values should implement Writable Interface.● Keys should implement WritableComparable interface.● Some predefined classes:
o BooleanWritable.o ByteWritable.o IntWritableo ...

Mapper

Mapper
1. Mapper<K1,V1,K2,V2>2. Override method:
void map(K1 key, V1 value, Context context)3. Use context.write(K2, V2) to emit key/value pairs.

WordCount Mapperpublic static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key, Text value, Context
context){String line = value.toString();StringTokenizer tokenizer = new
StringTokenizer(line);while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());context.write(word, one);
}}
}

Predefined Mappers
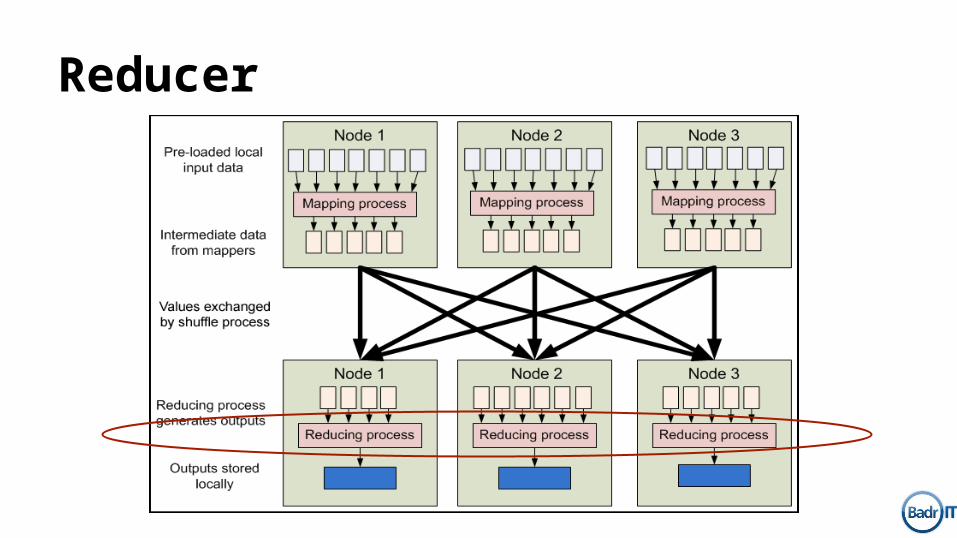
Reducer

Reducer
1. Extends Reducer<K1,V1,K2,V2>2. Overrides method:
void reduce(K2, Iterable<V2>, Context context)3. Use context.write(K2, V2) to emit key/value pairs.

WordCount Reducerpublic static class Reduceextends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context){
int sum = 0;for (IntWritable val : values) {
sum += val.get();}context.write(key, new IntWritable(sum));
}}

Predefined Reducers

Partitioner

Partitioner
The partitioner decides which key goes where
class WordSizePartitioner extends Partitioner<Text, IntWritable> {
@Overridepublic int getPartition(Text
word, IntWritable count, int numOfPartions) {
return 0;}
}

Combiner

CombinerIt’s a local Reduce Task at Mapper.
WordCout Mapper Output:1. Without Combiner:<the, 1>, <file,
1>, <the, 1>, …
2. With Combiner:<the, 2>, <file, 2>, ...

Reading and Writing

Reading and Writing
1. Input data usually resides in large files.2. MapReduce’s processing power is the splitting of the
input data into chunks(InputSplit).3. Hadoop’s FileSystem provides the class
FSDataInputStream for file reading. It extends DataInputStream with random read access.

InputFormat Classes
● TextInputFormato <offset, line>
● KeyValueTextInputFormato key\tvaue => <key, value>
● NLineInputFormato <offset, nLines>
You can define your own InputFormat class ...

1. The output has no splits.2. Each reducer generates output file named
part-nnnnn, where nnnnn is the partition ID of the reducer.
Predefined OutputFormat classes:> TextOutputFormat <k, v> => k\tv
OutputFormat

Recap

END OF SESSION #1

Q
Related Documents











