Introduction to bioinformatics March 2002 Molecular biology databases Tore Samuelsson [email protected]

Introduction to bioinformaticsbio.lundberg.gu.se/courses/vt02/1.pdfIntroduction to bioinformatics March 2002 Molecular biology databases Tore Samuelsson [email protected]
Jul 10, 2020
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


2
Overview of molecular biology databases
- Sequence
DNAGenbank (www.ncbi.nlm.nih.gov)
- Entrez- BLAST
EMBL (European Molecular Biology Laboratory, www.ebi.ac.uk)- SRS : srs.ebi.ac.uk , www.sanger.ac.uk/srs6/
DDBJ (DNA Data Bank of Japan)
ProteinSwissprot (www.ebi.ac.uk)NCBI
Protein classification databasesProsite (expasy.hcuge.ch)Pfam (www.sanger.ac.uk/Pfam)InterPro (www.ebi.ac.uk/interpro)
Gene ontologywww.geneontology.org
- StructurePDB
Protein Data Bank, www.rcsb.org/pdb/cgi/queryForm.cgi(RCSB, Research Collaboratory for Structural Bioinformatics, rcsb.rutgers.edu)
Xray crystallographyNMRmodeling
KLOTHO (small molecules, www.ibc.wustl.edu/moirai/klotho/compound_list.html)

3
- GenomeGDB (Human Genome Data Base, www.gdb.org)Mouse genome database (www.informatics.jax.org)Yeast genome (genome-ftp.stanford.edu/Saccharomyces)Bacterial genomes (www.tigr.org)
- Human genome browsersNCBI www.ncbi.nlm.nih.govUCSC genome.ucsc.eduEBI www.ensembl.orgCelera www.celera.com
- Genetic disordersOMIM (Online Mendelian Inheritance in Man, www.ncbi.nlm.nih.gov)
- Taxonomy (www.ncbi.nlm.nih.gov)
- LiteraturePubMed (www.ncbi.nlm.nih.gov/Entrez)

4
Sequence databases
- DNA SequenceGenbank (www.ncbi.nlm.nih.gov)EMBL (European Molecular Biology Laboratory)(www.ebi.ac.uk )DDBJ (DNA Data Bank of Japan)

5
EMBL and Genbank formats
EMBL format
ID LISOD standard; DNA; PRO; 756 BP.XXAC X64011; S78972;XXSV X64011.1XXDT 28-APR-1992 (Rel. 31, Created)DT 30-JUN-1993 (Rel. 36, Last updated, Version 6)XXDE L.ivanovii sod gene for superoxide dismutaseXXKW sod gene; superoxide dismutase.XXOS Listeria ivanoviiOC Bacteria; Firmicutes; Bacillus/Clostridium group;OC Bacillus/Staphylococcus group; Listeria.XXRN [1]RX MEDLINE; 92140371.RA Haas A., Goebel W.;RT "Cloning of a superoxide dismutase gene from Listeria ivanovii byRT functional complementation in Escherichia coli and characterization of theRT gene product.";RL Mol. Gen. Genet. 231:313-322(1992).XXRN [2]RP 1-756RA Kreft J.;RT ;RL Submitted (21-APR-1992) to the EMBL/GenBank/DDBJ databases.RL J. Kreft, Institut f. Mikrobiologie, Universitaet Wuerzburg, Biozentrum AmRL Hubland, 8700 Wuerzburg, FRGXXDR SWISS-PROT; P28763; SODM_LISIV.XXFH Key Location/QualifiersFHFT source 1..756FT /db_xref="taxon:1638"FT /organism="Listeria ivanovii"FT /strain="ATCC 19119"FT RBS 95..100FT /gene="sod"FT terminator 723..746FT /gene="sod"FT CDS 109..717FT /db_xref="SWISS-PROT:P28763"FT /transl_table=11FT /gene="sod"FT /EC_number="1.15.1.1"FT /product="superoxide dismutase"FT /protein_id="CAA45406.1"FT /translation="MTYELPKLPYTYDALEPNFDKETMEIHYTKHHNIYVTKLNEAVSGFT HAELASKPGEELVANLDSVPEEIRGAVRNHGGGHANHTLFWSSLSPNGGGAPTGNLKAAFT IESEFGTFDEFKEKFNAAAAARFGSGWAWLVVNNGKLEIVSTANQDSPLSEGKTPVLGL

6
FT DVWEHAYYLKFQNRRPEYIDTFWNVINWDERNKRFDAAK"XXSQ Sequence 756 BP; 247 A; 136 C; 151 G; 222 T; 0 other; cgttatttaa ggtgttacat agttctatgg aaatagggtc tatacctttc gccttacaat 60 gtaatttctt ttcacataaa taataaacaa tccgaggagg aatttttaat gacttacgaa 120 ttaccaaaat taccttatac ttatgatgct ttggagccga attttgataa agaaacaatg 180 gaaattcact atacaaagca ccacaatatt tatgtaacaa aactaaatga agcagtctca 240 ggacacgcag aacttgcaag taaacctggg gaagaattag ttgctaatct agatagcgtt 300 cctgaagaaa ttcgtggcgc agtacgtaac cacggtggtg gacatgctaa ccatacttta 360 ttctggtcta gtcttagccc aaatggtggt ggtgctccaa ctggtaactt aaaagcagca 420 atcgaaagcg aattcggcac atttgatgaa ttcaaagaaa aattcaatgc ggcagctgcg 480 gctcgttttg gttcaggatg ggcatggcta gtagtgaaca atggtaaact agaaattgtt 540 tccactgcta accaagattc tccacttagc gaaggtaaaa ctccagttct tggcttagat 600 gtttgggaac atgcttatta tcttaaattc caaaaccgtc gtcctgaata cattgacaca 660 ttttggaatg taattaactg ggatgaacga aataaacgct ttgacgcagc aaaataatta 720 tcgaaaggct cacttaggtg ggtcttttta tttcta 756//

7
GenBank Format
LOCUS LISOD 756 bp DNA BCT 30-JUN-1993 DEFINITION L.ivanovii sod gene for superoxide dismutase. ACCESSION X64011 S78972 VERSION X64011.1 GI:44010 KEYWORDS sod gene; superoxide dismutase. SOURCE Listeria ivanovii. ORGANISM Listeria ivanovii Bacteria; Firmicutes; Bacillus/Clostridium group; Bacillaceae; Listeria. REFERENCE 1 (bases 1 to 756) AUTHORS Haas,A. and Goebel,W. TITLE Cloning of a superoxide dismutase gene from Listeria ivanovii by functional complementation in Escherichia coli and characterizatio ofthe gene product JOURNAL Mol. Gen. Genet. 231 (2), 313-322 (1992) MEDLINE 92140371 REFERENCE 2 (bases 1 to 756) AUTHORS Kreft,J. TITLE Direct Submission JOURNAL Submitted (21-APR-1992) J. Kreft, Institut f. Mikrobiologie, Universitaet Wuerzburg, Biozentrum Am Hubland, 8700 Wuerzburg, FRG FEATURES Location/Qualifiers source 1..756 /organism="Listeria ivanovii" /strain="ATCC 19119" /db_xref="taxon:1638" RBS 95..100 /gene="sod" gene 95..746 /gene="sod" CDS 109..717 /gene="sod" /EC_number="1.15.1.1" /codon_start=1 /transl_table=11 /product="superoxide dismutase" /protein_id="CAA45406.1" /db_xref="GI:44011" /db_xref="SWISS-PROT:P28763"
/translation="MTYELPKLPYTYDALEPNFDKETMEIHYTKHHNIYVTKLNEAVS GHAELASKPGEELVANLDSVPEEIRGAVRNHGGGHANHTLFWSSLSPNGGGAPTGNLK AAIESEFGTFDEFKEKFNAAAAARFGSGWAWLVVNNGKLEIVSTANQDSPLSEGKTPV LGLDVWEHAYYLKFQNRRPEYIDTFWNVINWDERNKRFDAAK" terminator 723..746 /gene="sod" BASE COUNT 247 a 136 c 151 g 222 t ORIGIN 1 cgttatttaa ggtgttacat agttctatgg aaatagggtc tatacctttc gccttacaat 61 gtaatttctt ttcacataaa taataaacaa tccgaggagg aatttttaat gacttacgaa 121 ttaccaaaat taccttatac ttatgatgct ttggagccga attttgataa agaaacaatg 181 gaaattcact atacaaagca ccacaatatt tatgtaacaa aactaaatga agcagtctca 241 ggacacgcag aacttgcaag taaacctggg gaagaattag ttgctaatct agatagcgtt 301 cctgaagaaa ttcgtggcgc agtacgtaac cacggtggtg gacatgctaa ccatacttta 361 ttctggtcta gtcttagccc aaatggtggt ggtgctccaa ctggtaactt aaaagcagca 421 atcgaaagcg aattcggcac atttgatgaa ttcaaagaaa aattcaatgc ggcagctgcg 481 gctcgttttg gttcaggatg ggcatggcta gtagtgaaca atggtaaact agaaattgtt 541 tccactgcta accaagattc tccacttagc gaaggtaaaa ctccagttct tggcttagat 601 gtttgggaac atgcttatta tcttaaattc caaaaccgtc gtcctgaata cattgacaca 661 ttttggaatg taattaactg ggatgaacga aataaacgct ttgacgcagc aaaataatta 721 tcgaaaggct cacttaggtg ggtcttttta tttcta //

8
FORMAT OF THE EMBL DATABASE
The nucleotide sequence database is composed of sequence entries. Each entry corresponds to a singlecontiguous sequence as contributed or reported in the literature. In many cases, entries have beenassembled from several papers reporting overlapping sequence regions. Conversely, a single paperoften provides data for several entries, as when homologous sequences from different organisms arecompared.
• 3.1 Classes of Data• 3.2 Database Divisions• 3.3 Structure of an Entry• 3.4 Line Structure
• 3.4.1 The ID Line• 3.4.2 The AC Line• 3.4.3 The NI Line• 3.4.4 The DT Line• 3.4.5 The DE Line• 3.4.6 The KW Line• 3.4.7 The OS Line• 3.4.8 The OC Line• 3.4.9 The OG Line• 3.4.10 The Reference (RN, RC, RP, RX, RA, RT, RL) Lines
• 3.4.10.1 The RN Line• 3.4.10.2 The RC Line• 3.4.10.3 The RP Line• 3.4.10.4 The RX Line• 3.4.10.5 The RA Line• 3.4.10.6 The RT Line• 3.4.10.7 The RL Line
• 3.4.11 The DR Line• 3.4.12 The FH Line• 3.4.13 The FT Line• 3.4.14 The SQ Line• 3.4.15 The Sequence Data Line• 3.4.16 The CC Line• 3.4.17 The XX Line• 3.4.18 The // Line

9
3.2.4 Feature key examples
Key Description
conflict Separate determinations of the "same" sequence differrep_origin Origin of replicationprotein_bind Protein binding site on DNACDS Protein-coding sequencemisc_RNA Generic label for an undefined RNAinsertion_seq Insertion elementD-loop Mitochondrial or other D-loop structure
3.3.4 Qualifier examples
Key Location/Qualifiers
CDS 86..742 /product="hypoxanthine phosphoribosyltransferase" /label=hprt /note="hprt catalyzes vital steps in the reutilization pathway for purine biosynthesis and its deficiency leads to forms of ""gouty"" arthritis"rep.origin 234..243 /direction=leftCDS 109..564 /usedin=X10009:catalase
3.5.3 Location examples
The following is a list of common location descriptors with their meanings:
Location Description
467 Points to a single base in the presented sequence
340..565 Points to a continuous range of bases bounded by and including the starting and ending bases
Common sequence formats
1. EMBL release format2. Genbank (ASN.1)3. FASTA format :
>X12345 Y098TR gene CGTATCTTACGAGCTACTACGA GGTCTTATCGGACGAGCGACTG ...

10
<345..500 Indicates that the exact lower boundary point of a feature is unknown. The location begins at some base previous to the first base specified (which need not be contained in the presented sequence) and con- tinues to and includes the ending base
<1..888 The feature starts before the first sequenced base and continues to and includes base 888
(102.110) Indicates that the exact location is unknown but that it is one of the bases between bases 102 and 110, in- clusive
(23.45)..600 Specifies that the starting point is one of the basesbetween bases 23 and 45, inclusive, and the end point isbase 600
(122.133)..(204.221) The feature starts at a base between 122 and 133,inclusive, and ends at a base between 204 and 221,inclusive
123^124 Points to a site between bases 123 and 124
145^177 Points to a site between two adjacent bases anywhere between bases 145 and 177
complement(34..(122.126)) Start at one of the bases complementary to those between122 and 126 on the presented strand and finish at thebase complementary to base 34 (the feature is on thestrand complementary to the presented strand)
join("acct",449..670) Concatenate the four bases 'acct' to the 5' end of the sequence from bases 449 to 670, inclusive
J00193:hladr Points to a feature whose location is described in an-other entry: the feature labelled 'hladr' in the entry(in this database) with primary accession number'J00193'
J00194:(100..202) Points to bases 100 to 202, inclusive, in the entry (in this database) with primary accession number 'J00194'

11
EMBL divisions
hum Human Sequences | |rod RodentSequences |>Mammals |mam Other Mammal Sequences | |> Vertebratesvrt Other Vertebrate Sequences |
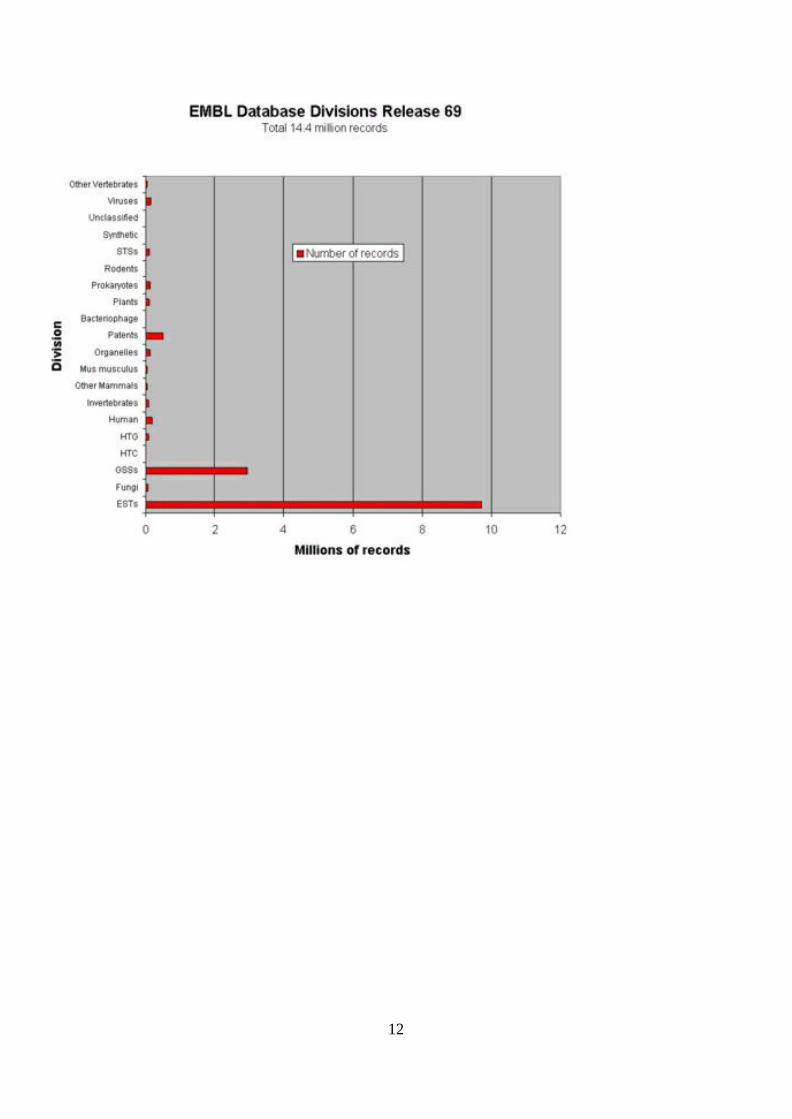
12

13
STS (Sequence Tagged Sites)
Sequence Tagged Sites (STS) are short DNA segments with a single location in thegenome. This feature of STS makes them useful tags for mapping.
EST (Expressed Sequence Tag)
Description Expressed Sequence Tags (ESTs) are sequences of cDNA which have beenreverse-transcribed from mRNA and their function is not necessarily known. They haveapplications in the discovery of new genes, mapping of various genomes, and identification ofcoding regions in genomic sequences.

14
Genome Survey Sequence (GSS)
This division is similar innature to the EST division, except that its sequences will be genomic rather than cDNA (mRNA). TheGSS division will contain (but not be limited to) thefollowing types of data:
- random "single pass read" genome survey sequences - single pass reads from cosmid/BAC/YAC ends - exon trapped genomic sequences - Alu PCR sequences
dbGSS release 021999
Summary by Organism - February 19, 1999
Number of public entries: 483,440
Homo sapiens (human) 404,755Oryza sativa (rice) 30,278Arabidopsis thaliana 29,835Magnaporthe grisea (rice blast fungus) 6,341Drosophila melanogaster 3,230Giardia intestinalis 2,345Cryptosporidium parvum 2,161Ciona intestinalis 1,486Lycopersicon esculentum (tomato) 1,251Trypanosoma brucei brucei 455Trypanosoma brucei rhodesiense 324Mus musculus 319Rhodobacter sphaeroides 283Ochrobactrum anthropi 143Enterococcus faecalis 41Capra hircus (goat) 40
High-Throughput Genomic Sequences
The High Throughput Genomic (HTG) Sequences division was created to accommodate a growingneed to make 'unfinished' genomic sequence data rapidly available to the scientific community. It wasdone in a coordinated effort between the three International Nucleotide Sequence databases: DDBJ,EMBL, and GenBank. The HTG division contains 'unfinished' DNA sequences generated by the high-throughput sequencing centers. Sequence data in this division are available for BLAST homologysearches against either the "htgs" database or the "month" database, which includes all newsubmissions for the prior month. The HTG division of GenBank was described in a [Genome Research(1997) 7(10)] article by Ouellette and Boguski.
Location of HTG records:Unfinished HTG sequences containing contigs greater than 2 kb areassigned an accession number and deposited in the HTG division. A typicalHTG record might consist of all the first pass sequence data generated from
15
a single cosmid, BAC, YAC, or P1 clone which together comprise morethan 2 kb and contain one or more gaps. A single accession number isassigned to this collection of sequences and each record includes a clearindication of the status (phase 1 or 2) plus a prominent warning that thesequence data is "unfinished" and may contain errors. The accessionnumber does not change as sequence records are updated; only the mostrecent version of a HTG record remains in GenBank. 'Finished' HTGsequences (phase 3) retain the same accession number, but are moved intothe relevant primary GenBank division. An example of a submission (oneaccession number) that has progressed through phase 1, phase 2, andphase 3 is available

16
www.tigr.org
Published complete microbial genomes
Genome Strain Domain Size (Mb) Institution Year
Haemophilus influenzae Rd KW20 B 1.83 TIGR 1995
Mycoplasma genitalium G-37 B 0.58 TIGR 1995
Methanococcus jannaschii DSM 2661 A 1.66 TIGR 1996
Mycoplasma pneumoniae M129 B 0.81 Univ. of Heidelberg 1996
Synechocystis sp. PCC 6803 B 3.57 Kazusa DNAResearch Inst.
1996
Archaeoglobus fulgidus DSM4304 A 2.18 TIGR 1997
Bacillus subtilis 168 B 4.2 InternationalConsortium
1997
Deinococcus radiodurans R1 B 3.28 TIGR 1997
Escherichia coli K-12 Strain MG1655 B 4.6 University ofWisconsin
1997
Helicobacter pylori 26695 B 1.66 TIGR 1997
Methanobacteriumthermoautotrophicum
delta H A 1.75 1997
Saccharomyces cerevisiae S288C E 13 InternationalConsortium
1996/1997
Aquifex aeolicus VF5 B 1.5 Diversa 1998
Chlamydia trachomatis serovar D (D/UW-3/Cx)
B 1.05 UC BerkeleyStanford
1998
Mycobacterium tuberculosis H37Rv (lab strain) B 4.4 Sanger Centre 1998
Pyrococcus horikoshii OT3 A 1.8 BiotechnologyCenter
1998
Rickettsia prowazekii Madrid E B 1.1 University ofUppsala
1998
Treponema pallidum Nichols B 1.14 TIGR 1998
Aeropyrum pernix K1 A 1.67 BiotechnologyCenter
1999
Chlamydia pneumoniae CWL029 B 1.23 UC BerkeleyStanford
1999

17
Helicobacter pylori J99 B 1.64 Astra ResearchCenter BostonGenomeTherapeutics
1999
Thermotoga maritima MSB8 B 1.8 TIGR 1999
Bacillus halodurans C-125 B 4.2 Japan MarineScience andTechnology Center
2000
Buchnera sp. APS B 0.64 Univ. Tokyo /RIKEN
2000
Campylobacter jejuni NCTC 11168 B 1.64 Sanger Centre 2000
Chlamydia pneumoniae AR39 B 1.23 TIGR 2000
Chlamydia trachomatis MoPn B 1.07 TIGR 2000
Halobacterium sp. NRC-1 A 2.57 Halobacteriumgenome consortium
2000
Neisseria meningitidis MC58 B 2.27 TIGR 2000
Neisseria meningitidis serogroup A strainZ2491
B 2.18 Sanger Centre 2000
Pseudomonas aeruginosa PAO1 B 6.3 University ofWashington
2000
Thermoplasma acidophilum A 1.56 Max-Planck-Institute forBiochemistry
2000
Thermoplasma volcanum GSS1 A 1.58 AIST 2000
Ureaplasma urealyticum serovar 3 B 0.75 Applied Biosystems/
2000
Vibrio cholerae serotype O1, BiotypeEl Tor, strain N16961
B 4 TIGR 2000
Xylella fastidiosa 9a5c B 2.68 ONSA Consortium 2000
Escherichia coli O157:H7 strainEDL933
B 4.1 University ofWisconsin
2001
Borrelia burgdorferi B31 B 1.44 TIGR 1997 / 2000

18
Genome MOT, Genome monitoring table
http://www.ebi.ac.uk/genomes/mot/index.html
March 2001:% Finished % Finished+Draft
Drosophila 100 C. elegans 100A. thaliana 100H. sapiens 79.9 165.6Mouse 4.4 26.1Rat 0.3 41.2
MB Genes
S. cerevisiae 12 6,000S. pombe 13 6,000Caenorhabditis elegans 97 20,000Drosophila melanogaster 120 14,000Arabidopsis thaliana 110 26,000Tetraodon nigroviridis 350 ?H. sapiens 3200 30-40,000?
Human genomeNCBI www.ncbi.nlm.nih.govUCSC genome.ucsc.eduEBI www.ensembl.orgCelera www.celera.com

19
The flow of genetic information
DNA -> RNA -> protein -> conformation
Translation products of DNA - Amino acids in three letter code
ValArgIleArgIleSerAsp TyrGlyPheGlyPheArgMet ThrAspSerAspPheGlyCys 5' GUACGGAUUCGGAUUUCGGAUGC 3' 3' CAUGCCUAAGCCUAAAGCCUACG 5' TyrProAsnProAsnArgIle ValSerGluSerLysProHis ArgIleArgIleGluSerAla
Amino acids in one letter code
V R I R I S D Y G F G F R M T D S D F G C5' GUACGGAUUCGGAUUUCGGAUGC 3'3' CAUGCCUAAGCCUAAAGCCUACG 5' Y P N P N R I V S E S K P H R I R I E S A
Three- and one-letter codes of the amino acids.
Alanine Ala AArginine Arg RAsparagine Asn NAspartate Asp DCysteine Cys CGlutamate Glu EGlutamine Gln QGlycine Gly GHistidine His HIsoleucine Ile ILeucine Leu LLysine Lys KMetionine Met MFenylalanine Phe FProline Pro PSerine Ser STreonine Thr TTryptofan Trp WTyrosine Tyr YValine Val V

20
4. THE GENETIC CODE
UUU Phe UCU Ser UAU Tyr UGU Cys UUC Phe UCC Ser UAC Tyr UGC Cys UUA Leu UCA Ser UAA Stop UGA Stop UUG Leu UCG Ser UAG Stop UGG Trp
CUU Leu CCU Pro CAU His CGU Arg CUC Leu CCC Pro CAC His CGC Arg CUA Leu CCA Pro CAA Gln CGA Arg CUG Leu CCG Pro CAG Gln CGG Arg
AUU Ile ACU Thr AAU Asn AGU Ser AUC Ile ACC Thr AAC Asn AGC Ser AUA Ile ACA Thr AAA Lys AGA Arg AUG Met ACG Thr AAG Lys AGG Arg
GUU Val GCU Ala GAU Asp GGU Gly GUC Val GCC Ala GAC Asp GGC Gly GUA Val GCA Ala GAA Glu GGA Gly GUG Val GCG Ala GAG Glu GGG Gly
Table I. The genetic code

21
Sequence symbols: Nucleotides
Symbol Meaning Complement
A A T
C C G
G G C
T/U T A
M A or C K
R A or G Y
W A or T W
S C or G S
Y C or T R
K G or T M
V A or C or G B
H A or C or T D
D A or G or T H
B C or G or T V
X/N G or A or T or C X
. not G or A or T or C .

22
Deviations from the standard genetic code
# Cilian protozoa
UAA = Gln:Q UAG = Gln:Q
# Yeast mitochondria
UGA = Trp:W CUU = Thr:T CUC = Thr:T CUA = Thr:T CUG = Thr:T AUA = Met:M
# Mammalian mitochondria
UGA = Trp:W AUU = Ile:I AUC = Ile:I AUA = Met:M AGA = * :* AGG = * :*
# Drosophila mitochondria
UGA = Trp:W AUU = Ile:I AUA = Met:M AGA = Ser:S AGG = Ser:S
# mycoplasma
UGA = Trp
23
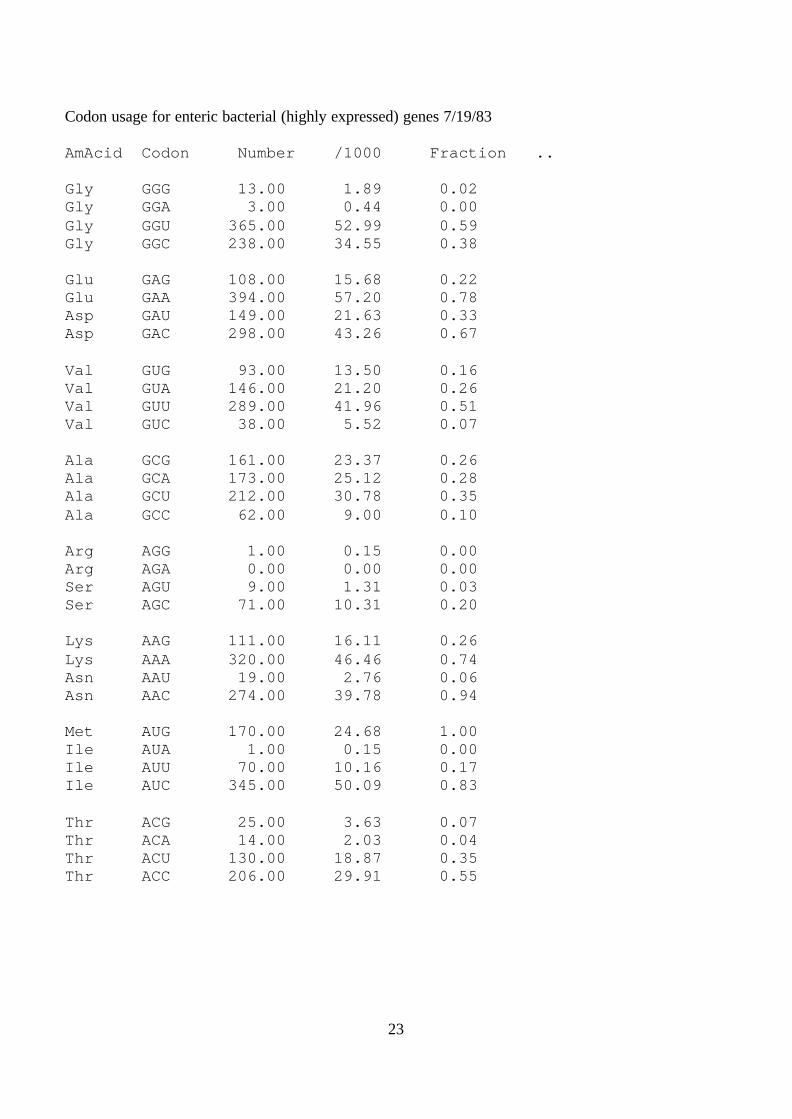
Codon usage for enteric bacterial (highly expressed) genes 7/19/83
AmAcid Codon Number /1000 Fraction ..
Gly GGG 13.00 1.89 0.02Gly GGA 3.00 0.44 0.00Gly GGU 365.00 52.99 0.59Gly GGC 238.00 34.55 0.38
Glu GAG 108.00 15.68 0.22Glu GAA 394.00 57.20 0.78Asp GAU 149.00 21.63 0.33Asp GAC 298.00 43.26 0.67
Val GUG 93.00 13.50 0.16Val GUA 146.00 21.20 0.26Val GUU 289.00 41.96 0.51Val GUC 38.00 5.52 0.07
Ala GCG 161.00 23.37 0.26Ala GCA 173.00 25.12 0.28Ala GCU 212.00 30.78 0.35Ala GCC 62.00 9.00 0.10
Arg AGG 1.00 0.15 0.00Arg AGA 0.00 0.00 0.00Ser AGU 9.00 1.31 0.03Ser AGC 71.00 10.31 0.20
Lys AAG 111.00 16.11 0.26Lys AAA 320.00 46.46 0.74Asn AAU 19.00 2.76 0.06Asn AAC 274.00 39.78 0.94
Met AUG 170.00 24.68 1.00Ile AUA 1.00 0.15 0.00Ile AUU 70.00 10.16 0.17Ile AUC 345.00 50.09 0.83
Thr ACG 25.00 3.63 0.07Thr ACA 14.00 2.03 0.04Thr ACU 130.00 18.87 0.35Thr ACC 206.00 29.91 0.55

24
Trp UGG 55.00 7.98 1.00End UGA 0.00 0.00 0.00Cys UGU 22.00 3.19 0.49Cys UGC 23.00 3.34 0.51
End UAG 0.00 0.00 0.00End UAA 0.00 0.00 0.00Tyr UAU 51.00 7.40 0.25Tyr UAC 157.00 22.79 0.75
Leu UUG 18.00 2.61 0.03Leu UUA 12.00 1.74 0.02Phe UUU 51.00 7.40 0.24Phe UUC 166.00 24.10 0.76
Ser UCG 14.00 2.03 0.04Ser UCA 7.00 1.02 0.02Ser UCU 120.00 17.42 0.34Ser UCC 131.00 19.02 0.37
Arg CGG 1.00 0.15 0.00Arg CGA 2.00 0.29 0.01Arg CGU 290.00 42.10 0.74Arg CGC 96.00 13.94 0.25
Gln CAG 233.00 33.83 0.86Gln CAA 37.00 5.37 0.14His CAU 18.00 2.61 0.17His CAC 85.00 12.34 0.83
Leu CUG 480.00 69.69 0.83Leu CUA 2.00 0.29 0.00Leu CUU 25.00 3.63 0.04Leu CUC 38.00 5.52 0.07
Pro CCG 190.00 27.58 0.77Pro CCA 36.00 5.23 0.15Pro CCU 19.00 2.76 0.08Pro CCC 1.00 0.15 0.00

25
SWISS-PROT Protein Sequence Data Bank is a database ofprotein sequences produced collaboratively by Amos Bairoch(University of Geneva) and the EBI. It contains high-qualityannotation, is non-redundant, and cross-referenced to manyother databases.Release 39.0 of SWISS-PROT contains 86'593 sequenceentries.
SWISS-PROT is accompanied by TrEMBL, a computer-annotated supplement to SWISS-PROT. TrEMBL containsthe translations of all coding sequences (CDS) present in theEMBL Nucleotide Sequence Database not yet integrated intoSWISS-PROT.
TrEMBL (June 2001) contains 540'195 sequence entries
NCBI protein database : 736'311 sequences

26
RELATIONSHIPS BETWEEN SWISS-PROT AND SOME BIOMOLECULAR DATABASES
************ * EMBL Nucleotide * * Sequence Database * * [EBI] * *********************** ^ ^ ^ ^ ^ ^ ^ ^ ^****************** | | | I | | | | | *********************** FlyBase * <-------+ | | I | | | | +-------> * MGD [Mouse] ******************* | | | I | | | | | ********************** | | | I | | | | |****************** | | | I | | | | | *********************** SubtiList * <---------+ | I | | | +---------> * GCRDb [7TM recep.] ** [B.subtilis] * | | | I | | | | | **************************************** | | | I | | | | | | | | I | | | | | **************************************** | | | I | | +-----------> * EcoGene [E.coli] ** Mendel [Plant] * <-----+ | | | I | | | | | **************************************** | | | | I | | | | | | | | | I | | | | | **************************************** | | | | I +---------------> * SGD [Yeast] ** MaizeDb * <-----------+ I | | | | | *********************** [Zea mays] * | | | | I | | | | |****************** | | | | I | | | | | ********************** | | | | I | +-------------> * DictyDB [D.disco.] ******************* | | | | I | | | | | *********************** WormPep * | | | | I | | | | |* [C.elegans] * <---+ | | | | I | | | | | **************************************** | | | | | I | | | | | +-----> * ENZYME [Nomencl.] * | | | | | I | | | | | | **************************************** | v v v v v v v v v v v v* REBASE * ************************* *********************** [Restriction * <-- * SWISS-PROT * ----> * OMIM [Human] ** enzymes] * * Protein Sequence * **************************************** * Data Bank * ************************* **************************************** ^ ^ ^ ^ ^ ^ ^ | ^ ^ ^ * ECO2DBASE [2D] ** StyGene * | | | | | | | | | | +--------> *********************** [S.Typhimurium]* <----+ | | | | | | | | |****************** | | | | | | | | | ********************** | | | | | | | | +----------> * Maize-2DPAGE [2D] ******************* | | | | | | | | *********************** TRANSFAC * <------+ | | | | | | |****************** | | | | | | | ********************** | | | | | | +------------> * SWISS-2DPAGE [2D] ******************* | | | | | | *********************** Harefield [2D] * <--------+ | | | | |****************** | | | | | ********************** | | | | +--------------> * Aarhus/Ghent [2D] ******************* | | | | *********************** PROSITE * | | | |* [Patterns and * <----------+ | | +----------------> *********************** profiles] * | | * YEPD [Yeast] [2D] ******************* | +----------------+ ********************** | v | | *********************** +-> ********************** +--------> * PDB [3D structures] * <----- * HSSP [3D similar.] * *********************** **********************

27
Swissprot entry
ID PRIO_HUMAN STANDARD; PRT; 253 AA.AC P04156;DT 01-NOV-1986 (REL. 03, CREATED)DT 01-NOV-1986 (REL. 03, LAST SEQUENCE UPDATE)DT 01-NOV-1997 (REL. 35, LAST ANNOTATION UPDATE)DE MAJOR PRION PROTEIN PRECURSOR (PRP) (PRP27-30) (PRP33-35C) (ASCR).GN PRNP.OS HOMO SAPIENS (HUMAN).OC EUKARYOTA; METAZOA; CHORDATA; VERTEBRATA; TETRAPODA; MAMMALIA;OC EUTHERIA; PRIMATES.RN [1]RP SEQUENCE FROM N.A.RX MEDLINE; 86300093.RA KRETZSCHMAR H.A., STOWRING L.E., WESTAWAY D., STUBBLEBINE W.H.,RA PRUSINER S.B., DEARMOND S.J.;RL DNA 5:315-324(1986).RN [2]RP SEQUENCE OF 8-253 FROM N.A.RX MEDLINE; 86261778.RA LIAO Y.-C.J., LEBO R.V., CLAWSON G.A., SMUCKLER E.A.;RL SCIENCE 233:364-367(1986).RN [3]RP VARIANT AMYLOID GSS, SEQUENCE OF 58-85 AND 111-150.RX MEDLINE; 91160504.RA TAGLIAVINI F., PRELLI F., GHISO J., BUGIANI O., SERBAN D.,RA PRUSINER S.B., FARLOW M.R., GHETTI B., FRANGIONE B.;RL EMBO J. 10:513-519(1991).RN [4]RP REVIEW ON VARIANTS.RX MEDLINE; 93372867.RA PALMER M.S., COLLINGE J.;RL HUM. MUTAT. 2:168-173(1993).RN [5]RP REVIEW ON VARIANTS.RX MEDLINE; 94029646.RA PRUSINER S.B.;RL ARCH. NEUROL. 50:1129-1153(1993).RN [6]RP VARIANT GSS LEU-102.RX MEDLINE; 89159432.RA HSIAO K., BAKER H.F., CROW T.J., POULTER M., OWEN F.,RA TERWILLIGER J.D., WESTAWAY D., OTT J., PURSINER S.B.;RL NATURE 338:342-345(1989).RN [7]RP VARIANTS LEU-102; VAL-117 AND VAL-129.RX MEDLINE; 89392018.RA DOH-URA K., TATEISHI J., SASAKI H., KITAMOTO T., SAKAKI Y.;RL BIOCHEM. BIOPHYS. RES. COMMUN. 163:974-979(1989).RN [8]RP VARIANT FFI ASN-178.RX MEDLINE; 92195483.RA MEDORI R., MONTAGNA P., TRITSCHLER H.J., LEBLANC A., CORTELLI P.,RA TINUPER P., LUGARESI E., GAMBETTI P.;RL NEUROLOGY 42:669-670(1992).RN [9]RP VARIANT CJD ASN-178.

28
RX MEDLINE; 91124933.RA GOLDFARB L.G., HALTIA M., BROWN P., NIETO A., KOVANEN J.,RA MCCOMBIE W.R., TRAPP S., GAJDUSEK D.C.;RL LANCET 337:425-425(1991).RN [10]RP VARIANT CJD LYS-200.RX MEDLINE; 90355709.RA GOLDFARB L., MITROVA E., BROWN P., TOH B.K., GAJDUSEK D.C.;RL LANCET 336:514-515(1990).RN [11]RP VARIANT GSS ARG-217.RX MEDLINE; 93250977.RA HSIAO K., DLOUHY S.R., FARLOW M.R., CASS C., DA COSTA M.,RA CONNEALLY P.M., HODES M.E., GHETTI B., PRUSINER S.B.;RL NAT. GENET. 1:68-71(1992).RN [12]RP VARIANTS CJD ILE-180 AND ARG-223.RX MEDLINE; 93213314.RA KITAMOTO T., OHTA M., DOH-URA K., HITOSHI S., TERAO Y., TATEISHI J.;RL BIOCHEM. BIOPHYS. RES. COMMUN. 191:709-714(1993).RN [13]RP VARIANT CJD ILE-210.RX MEDLINE; 94071412.RA POCCHIARI M., SALVATORE M., CUTRUZZOLA F., GENUARDI M.,RA ALLCATELLI C.T., MASULLO C., MACCHI G., ALEMA G., GALGANI S., XI Y.G.,RA PETRAROLI R., SILVESTRINI M.C., BRUNORI M.;RL ANN. NEUROL. 34:802-807(1993).RN [14]RP VARIANT GSS LEU-105.RX MEDLINE; 94077414.RA YAMADA M., ITOH Y., FUJIGASAKI H., NARUSE S., KANEKO K., KITAMOTO T.,RA TATEISHI J., OTOMO E., HAYAKAWA M., TANAKA J., MATSUSHITA M.,RA MIYATAKE T.;RL NEUROLOGY 43:2723-2724(1993).RN [15]RP VARIANT GSS LEU-105.RX MEDLINE; 95213742.RA ITOH Y., YAMADA M., HAYAKAWA M., SHOZAWA T., TANAKA J., MATSUSHITA M.,RA KITAMOTO T., TATEISHI J., OTOMO E.;RL J. NEUROL. SCI. 127:77-86(1994).RN [16]RP VARIANT CJD LYS-200.RX MEDLINE; 94142912.RA INOUE I., KITAMOTO T., DOH-URA K., SHII H., GOTO I., TATEISHI J.;RL NEUROLOGY 44:299-301(1994).RN [17]RP VARIANT CJD LYS-200.RX MEDLINE; 94316708.RA GABIZON R., ROSENMAN H., MEINER Z., KAHANA I., KAHANA E., SHUGART Y.,RA OTT J., PRUSINER S.B.;RL PHILOS. TRANS. R. SOC. LOND., B, BIOL. SCI. 343:385-390(1994).RN [18]RP VARIANT GSS LEU-102.RX MEDLINE; 95303274.RA YOUNG K., JONES C.K., PICCARDO P., LAZZARINI A., GOLBE L.I.,RA ZIMMERMAN T.R., DICKSON D.W., MCLACHLAN D.C., ST GEORGE-HYSLOP P.,RA LENNOX A.;RL NEUROLOGY 45:1127-1134(1995).CC -!- FUNCTION: THE FUNCTION OF PRP IS NOT KNOWN. PRP IS ENCODED IN THECC HOST GENOME AND IS EXPRESSED BOTH IN NORMAL AND INFECTED CELLS.CC -!- SUBUNIT: PRP HAS A TENDENCY TO AGGREGATE YIELDING POLYMERS CALLED

29
CC "RODS".CC -!- SUBCELLULAR LOCATION: ATTACHED TO THE MEMBRANE BY A GPI-ANCHOR.CC -!- DISEASE: PRP IS FOUND IN HIGH QUANTITY IN THE BRAIN OF HUMANS ANDCC ANIMALS INFECTED WITH NEURODEGENERATIVE DISEASES KNOWN ASCC TRANSMISSIBLE SPONGIFORM ENCEPHALOPATHIES OR PRION DISEASES, LIKE:CC CREUTZFELDT-JACOB DISEASE (CJD), GERSTMANN-STRAUSSLER SYNDROMECC (GSS), FATAL FAMILIAL INSOMNIA (FFI) AND KURU IN HUMANS; SCRAPIECC IN SHEEP AND GOAT; BOVINE SPONGIFORM ENCEPHALOPATHY (BSE) INCC CATTLE; TRANSMISSIBLE MINK ENCEPHALOPATHY (TME); CHRONIC WASTINGCC DISEASE (CWD) OF MULE DEER AND ELK; FELINE SPONGIFORMCC ENCEPHALOPATHY (FSE) IN CATS AND EXOTIC UNGULATE ENCEPHALOPATHYCC (EUE) IN NYALA AND GREATER KUDU. THE PRION DISEASES ILLUSTRATECC THREE MANIFESTATIONS OF CNS DEGENERATION: (1) INFECTIOUS (2)CC SPORADIC AND (3) DOMINANTLY INHERITED FORMS. TME, CWD, BSE, FSE,CC EUE ARE ALL THOUGHT TO OCCUR AFTER CONSUMPTION OF PRION-INFECTEDCC FOODSTUFFS.CC -!- DISEASE: CJD OCCURS PRIMARILY AS A SPORADIC DISORDER (1 PERCC MILLION), WHILE 10-15% ARE FAMILIAL. ACCIDENTAL TRANSMISSION OFCC CJD TO HUMANS APPEARS TO BE IATROGENIC (CONTAMINATED HUMAN GROWTHCC HORMONE (HGH), CORNEAL TRANSPLANTATION, ELECTROENCEPHALOGRAPHICCC ELECTRODE IMPLANTATION. . .). EPIDEMIOLOGIC STUDIES HAVE FAILED TOCC IMPLICATE THE INGESTION OF INFECTED ANNIMAL MEAT IN THECC PATHOGENESIS OF CJD IN HUMAN. THE TRIAD OF MICROSCOPIC FEATURESCC THAT CHARACTERIZE THE PRION DISEASES CONSISTS OF (1) SPONGIFORMCC DEGENERATION OF NEURONS, (2) SEVERE ASTROCYTIC GLIOSIS THAT OFTENCC APPEARS TO BE OUT OF PROPORTION TO THE DEGREE OF NERF CELL LOSS,CC AND (3) AMYLOID PLAQUE FORMATION. CJD IS CHARACTERIZED BYCC PROGRESSIVE DEMENTIA AND MYOCLONIC SEIZURES, AFFECTING ADULTS INCC MID-LIFE. SOME PATIENTS PRESENT SLEEP DISORDERS, ABNORMALITIES OFCC HIGH CORTICAL FUNCTION, CEREBELLAR AND CORTICOSPINAL DISTURBANCES.CC THE DISEASE ENDS IN DEATH AFTER A 3-12 MONTHS ILLNESS.CC -!- DISEASE: GSS IS A HETEROGENEOUS DISORDER AND WAS DEFINED AS ACC "SPINOCEREBELLAR ATAXIA WITH DEMENTIA AND PLAQUELIKE DEPOSITS".CC GSS INCIDENCE IS LESS THAN 2 PER 100 MILLION.CC -!- DISEASE: KURU IS TRANSMITTED DURING RITUALISTIC CANNIBALISM, AMONGCC NATIVES OF THE NEW GUINEA HIGHLANDS. PATIENTS EXHIBIT VARIOUSCC MOVEMENT DISORDERS LIKE CEREBELLAR ABNORMALITIES, RIGIDITY OF THECC LIMBS, AND CLONUS. EMOTIONNAL LABILITY IS PRESENT, AND DEMENTIA ISCC CONSPICUOUSLY ABSENT. DEATH USUALLY OCCURS FROM 3 TO 12 MONTHCC AFTER ONSET.CC -!- SIMILARITY: TO OTHER PRP.CC -!- DATABASE: NAME=HotMolecBase; NOTE=PrP entry;CC WWW="http://bioinformatics.weizmann.ac.il/hotmolecbase/entries/prp.htm".DR EMBL; M13667; G190470; -.DR EMBL; M13899; G190468; -.DR EMBL; D00015; G220016; -.DR PIR; A05017; A05017.DR PIR; A24173; A24173.DR PIR; S14078; S14078.DR MIM; 176640; -.DR MIM; 123400; -.DR MIM; 137440; -.DR MIM; 245300; -.DR MIM; 600072; -.DR PROSITE; PS00291; PRION_1; 1.DR PROSITE; PS00706; PRION_2; 1.KW PRION; BRAIN; GLYCOPROTEIN; GPI-ANCHOR; REPEAT; SIGNAL;KW POLYMORPHISM; DISEASE MUTATION.FT SIGNAL 1 22FT CHAIN 23 230 MAJOR PRION PROTEIN.FT PROPEP 231 253 REMOVED IN MATURE FORM (BY SIMILARITY).

30
FT LIPID 230 230 GPI-ANCHOR (BY SIMILARITY).FT CARBOHYD 181 181 PROBABLE.FT CARBOHYD 197 197 PROBABLE.FT DISULFID 179 214 BY SIMILARITY.FT DOMAIN 51 91 5 X 8 AA TANDEM REPEATS OF P-H-G-G-G-W-G-FT Q.FT REPEAT 51 59 1.FT REPEAT 60 67 2.FT REPEAT 68 75 3.FT REPEAT 76 83 4.FT REPEAT 84 91 5.FT VARIANT 102 102 P -> L (IN GSS).FT VARIANT 105 105 P -> L (IN GSS).FT VARIANT 117 117 A -> V (LINKED TO DEVELOPMENT OFFT DEMENTING GSS).FT VARIANT 129 129 M -> V (DETERMINES THE DISEASE PHENOTYPEFT IN PATIENTS WHO HAVE A PRP MUTATION ATFT CODON 178: PATIENTS WITH MET DEVELOP FFI,FT THOSE WITH VAL DEVELOP CJD).FT VARIANT 178 178 D -> N (IN FFI AND CJD).FT VARIANT 180 180 V -> I (IN CJD).FT VARIANT 198 198 F -> S (IN A ATYPICAL FORM OF GSS WITHFT NEUROFIBRILLARY TANGLES).FT VARIANT 200 200 E -> K (IN CJD).FT VARIANT 210 210 V -> I (IN CJD).FT VARIANT 217 217 Q -> R (IN GSS WITH NEUROFIBRILLARYFT TANGLES).FT VARIANT 232 232 M -> R (IN CJD).FT CONFLICT 118 118 MISSING (IN REF. 2).SQ SEQUENCE 253 AA; 27661 MW; FD5373AD CRC32; MANLGCWMLV LFVATWSDLG LCKKRPKPGG WNTGGSRYPG QGSPGGNRYP PQGGGGWGQP HGGGWGQPHG GGWGQPHGGG WGQPHGGGWG QGGGTHSQWN KPSKPKTNMK HMAGAAAAGA VVGGLGGYML GSAMSRPIIH FGSDYEDRYY RENMHRYPNQ VYYRPMDEYS NQNNFVHDCV NITIKQHTVT TTTKGENFTE TDVKMMERVV EQMCITQYER ESQAYYQRGS SMVLFSSPPV ILLISFLIFL IVG//

31
PROSITE entries.
Example I
ID ATP_GTP_A; PATTERN.AC PS00017;DT APR-1990 (CREATED); APR-1990 (DATA UPDATE); NOV-1990 (INFO UPDATE).DE ATP/GTP-binding site motif A (P-loop).PA [AG]-x(4)-G-K-[ST].CC /TAXO-RANGE=ABEPV;3D 1EFM; 1ETU; 1Q21; 2Q21; 4Q21; 5Q21; 6Q21;DO PDOC00017;
Example II
ID ZINC_FINGER_C2H2; PATTERN.AC PS00028;DT APR-1990 (CREATED); JUN-1994 (DATA UPDATE); NOV-1997 (INFO UPDATE).DE Zinc finger, C2H2 type, domain.PA C-x(2,4)-C-x(3)-[LIVMFYWC]-x(8)-H-x(3,5)-H.NR /RELEASE=35,69113;NR /TOTAL=1932(412); /POSITIVE=1891(372); /UNKNOWN=6(6); /FALSE_POS=35(34);NR /FALSE_NEG=3; /PARTIAL=1;CC /TAXO-RANGE=??E?V; /MAX-REPEAT=37;CC /SITE=1,zinc; /SITE=3,zinc; /SITE=7,zinc; /SITE=9,zinc;DR P21192, ACE2_YEAST, T; P07248, ADR1_YEAST, T; P39413, AEF1_DROME, T;DR Q00900, AGIE_RAT , T; P41696, AZF1_YEAST, T; Q01954, BASO_HUMAN, T;DR P41182, BCL6_HUMAN, T; P41183, BCL6_MOUSE, T; P55201, BR14_HUMAN, T;DR Q01295, BRC1_DROME, T; Q01296, BRC2_DROME, T; Q01293, BRC3_DROME, T;DR P10069, BRLA_EMENI, T; Q01713, BTEB_RAT , T; Q01522, CF23_DROME, T;DR P20385, CF2_DROME , T; P19538, CID_DROME , T; Q05620, CREA_ASPNG, T;DR Q01981, CREA_EMENI, T; Q08705, CTCF_CHICK, T; P49711, CTCF_HUMAN, T;DR P36197, DEFI_CHICK, T; P23792, DISC_DROME, T; P26632, EGR1_BRARE, T;DR P18146, EGR1_HUMAN, T; P08046, EGR1_MOUSE, T; P08154, EGR1_RAT , T;DR Q05159, EGR2_BRARE, T; P26633, EGR2_CRILO, T; P26634, EGR2_DUSTH, T;DR P11161, EGR2_HUMAN, T; P08152, EGR2_MOUSE, T; P26635, EGR2_POERE, T;DR P51774, EGR2_RAT , T; Q08427, EGR2_XENLA, T; Q06889, EGR3_HUMAN, T;DR P43300, EGR3_MOUSE, T; P43301, EGR3_RAT , T; Q05215, EGR4_HUMAN, T;.. ( I edited out a lot of very interesting information here ...).DR P49782, S3AE_BACSU, F; P24804, TA29_TOBAC, F; P36810, VE6_HPV32 , F;DR P15024, VL1_REOVD , F; P03527, VSI3_REOVD, F; P30211, VSI3_REOVJ, F;DR P07939, VSI3_REOVL, F; Q93098, WN8B_HUMAN, F; P51028, WNT8_BRARE, F;DR P28026, WNT8_XENLA, F; P20201, Y15K_SSV1 , F; P20198, Y5K6_SSV1 , F;DR P43558, YFE4_YEAST, F; P37127, YFFG_ECOLI, F; P38890, YH07_YEAST, F;DR Q09441, YP83_CAEEL, F;3D 1ARD; 1ARE; 1ARF; 1PAA; 1ZAA; 1AAY; 2GLI; 1SP1; 1SP2; 1NCS; 1ZFD; 1TF3;3D 2DRP; 1ZNF; 3ZNF; 4ZNF; 1BBO; 5ZNF; 7ZNF;DO PDOC00028;

32
PROSITE documentation
{PDOC00004}{PS00004; CAMP_PHOSPHO_SITE}{BEGIN}***************************************************************** cAMP- and cGMP-dependent protein kinase phosphorylation site *****************************************************************
There has been a number of studies relative to the specificity of cAMP- andcGMP-dependent protein kinases [1,2,3]. Both types of kinases appear to sharea preference for the phosphorylation of serine or threonine residues foundclose to at least two consecutive N-terminal basic residues. It is importantto note that there are quite a number of exceptions to this rule.
-Consensus pattern: [RK](2)-x-[ST] [S or T is the phosphorylation site]-Last update: June 1988 / First entry.
[ 1] Fremisco J.R., Glass D.B., Krebs E.G. J. Biol. Chem. 255:4240-4245(1980).[ 2] Glass D.B., Smith S.B. J. Biol. Chem. 258:14797-14803(1983).[ 3] Glass D.B., El-Maghrabi M.R., Pilkis S.J. J. Biol. Chem. 261:2987-2993(1986).{END}

33
Pfam
www.sanger.ac.uk/Pfam/
Pfam is a database of multiple alignments of protein domains or conserved protein regions. Hopefullythey represent some evolutionary conserved structure which has implications for the protein'sfunction.
Version 6.6, August 2001, 3071 families
Over 65% of the proteins in SWISSPROT 38 and TrEMBL-11 have at least one match to a Pfamfamily.
Pfam is actually formed in two separate ways. Pfam-A are accurate human crafted multiple alignmentswhereas Pfam-B is an automatic clustering of the rest of SWISSPROT and TrEMBL derived from theProdom database.
How is Pfam used?
Pfam has very accurate descriptions of protein domains. There are basically two main ways you willwant to use this information
-Using an established SWISSPROT sequence where we have pre-computed the domain structure ofthe protein.-Using a completely new protein sequence and asking what Pfam thinks the domain structure is.
What is actually kept for each multiple alignment?
Each family has the following data:A seed alignment which is a hand edited multiple alignment representing the domain.A Hidden Markov Model (HMM) derived from the seed alignment which can be used to find newmembers of the domain and also take a set of sequences to realign them to the modelA full alignment which is a automatic alignment of all the examples of the domain using the HMMto find and then align the sequencesAn annotation file which contains a brief description of the domain, some parameters for Pfammethods, and links to other databases.
Pfam
www.sanger.ac.uk/Pfam/

34

35

36
Gene ontology consortiumwww.geneontology.org
Major principles• Molecular function• Biological process• Cellular component

37
Extract of gene assocation table:SP O00115 DRN2_HUMAN GO:0003677 F Deoxyribonuclease II precursorSP O00115 DRN2_HUMAN GO:0004519 F Deoxyribonuclease II precursorSP O00115 DRN2_HUMAN GO:0004531 F Deoxyribonuclease II precursorSP O00115 DRN2_HUMAN GO:0005764 C Deoxyribonuclease II precursorSP O00116 ADAS_HUMAN GO:0005777 C Alkyldihydroxyacetonephosphate..SP O00116 ADAS_HUMAN GO:0005777 C Alkyldihydroxyacetonephosphate..

38
Taxonomy database
www3.ncbi.nlm.nih.gov/Taxonomy/tax.html
This is the top level of the taxonomy database maintained byNCBI/GenBank. You can explore any of the taxa listed below by clicking it.
Archaea Eubacteria Eukaryotae Viroids Viruses Other Unclassified
This is a searchable index. You can enter the name of superspecific taxa (e.g., Porifera) orthe name of a particular organism (e.g., Thalarctos maritimus for the polar bear or polarbear itself).
Query:Use query string as : Complete match Regular expression Set of tokens
The "Set of tokens" option returns longer names that include the search terms, e.g., hybrid taxa.See what happens if you query "Bos taurus" using the "Complete match" option versus the "Set oftokens" option.
These are direct links to some of the organisms most commonly used inmolecular research projects:
Arabidopsis thaliana Caenorhabditis elegans Danio rerio (zebrafish) Drosophila Escherichia coli Hepatitis C virus Homo sapiens Mus musculus Mycoplasma Oryza sativa Plasmodium falciparum Pneumocystis carinii Rattus Saccharomyces cerevisiae Schizosaccharomyces pombe Xenopus laevis

39
Structure databases
Protein Data Bank http://www.rcsb.org/pdb/index.html
Research Collaboratory for Structural Bioinformatics
.

40

41
Example of PDB entryHEADER HORMONE 30-OCT-92 1BPH 1BPH 2COMPND INSULIN (CUBIC) IN 0.1M SODIUM SALT SOLUTION AT PH9 1BPH 3SOURCE BOVINE (BOS $TAURUS) PANCREAS 1BPH 4AUTHOR O.GURSKY,J.BADGER,Y.LI,D.L.D.CASPAR 1BPH 5REVDAT 2 31-OCT-93 1BPHA 1 REMARK HET FORMUL 1BPHA 1REVDAT 1 15-JAN-93 1BPH 0 1BPH 6JRNL AUTH O.GURSKY,J.BADGER,Y.LI,D.L.D.CASPAR 1BPH 7JRNL TITL CONFORMATIONAL CHANGES IN CUBIC INSULIN CRYSTALS 1BPH 8JRNL TITL 2 IN THE PH RANGE 7-11 1BPH 9JRNL REF BIOPHYS.J. V. 63 1210 1992 1BPH 10JRNL REFN ASTM BIOJAU US ISSN 0006-3495 030 1BPH 11REMARK 1 1BPH 12REMARK 1 REFERENCE 1 1BPH 13REMARK 1 AUTH O.GURSKY,Y.LI,J.BADGER,D.L.D.CASPAR 1BPH 14REMARK 1 TITL MONOVALENT CATION BINDING IN CUBIC INSULIN 1BPH 15REMARK 1 TITL 2 CRYSTALS 1BPH 16REMARK 1 REF BIOPHYS.J. V. 61 604 1992 1BPH 17REMARK 1 REFN ASTM BIOJAU US ISSN 0006-3495 030 1BPH 18REMARK 1 REFERENCE 2 1BPH 19REMARK 1 AUTH J.BADGER 1BPH 20REMARK 1 TITL FLEXIBILITY IN CRYSTALLINE INSULINS 1BPH 21REMARK 1 REF BIOPHYS.J. V. 61 816 1992 1BPH 22REMARK 1 REFN ASTM BIOJAU US ISSN 0006-3495 030 1BPH 23REMARK 1 REFERENCE 3 1BPHA 2REMARK 1 AUTH J.BADGER,M.R.HARRIS,C.D.REYNOLDS,A.C.EVANS, 1BPH 25REMARK 1 AUTH 2 E.J.DODSON,G.G.DODSON,A.C.T.NORTH 1BPH 26REMARK 1 TITL STRUCTURE OF THE PIG INSULIN DIMER IN THE CUBIC 1BPH 27REMARK 1 TITL 2 CRYSTAL 1BPH 28REMARK 1 REF ACTA CRYSTALLOGR.,SECT.B V. 47 127 1991 1BPH 29REMARK 1 REFN ASTM ASBSDK DK ISSN 0108-7681 622 1BPH 30REMARK 1 REFERENCE 4 1BPHA 3REMARK 1 AUTH J.BADGER,D.L.D.CASPAR 1BPH 32REMARK 1 TITL WATER STRUCTURE IN CUBIC INSULIN CRYSTALS 1BPH 33REMARK 1 REF PROC.NAT.ACAD.SCI.USA V. 88 622 1991 1BPH 34REMARK 1 REFN ASTM PNASA6 US ISSN 0027-8424 040 1BPH 35REMARK 1 REFERENCE 5 1BPHA 4REMARK 1 AUTH E.J.DODSON,G.G.DODSON,A.LEWITOVA,M.SABESAN 1BPH 37REMARK 1 TITL ZINC-FREE CUBIC PIG INSULIN: CRYSTALLIZATION AND 1BPH 38REMARK 1 TITL 2 STRUCTURE DETERMINATION 1BPH 39REMARK 1 REF J.MOL.BIOL. V. 125 387 1978 1BPH 40REMARK 1 REFN ASTM JMOBAK UK ISSN 0022-2836 070 1BPH 41REMARK 2 1BPH 42REMARK 2 RESOLUTION. 2.0 ANGSTROMS. 1BPH 43REMARK 3 1BPH 44REMARK 3 REFINEMENT. 1BPH 45REMARK 3 PROGRAM PROLSQ 1BPH 46REMARK 3 AUTHORS HENDRICKSON AND KONNERT 1BPH 47REMARK 3 R VALUE 0.160 1BPH 48REMARK 3 RMSD BOND DISTANCES 0.014 ANGSTROMS 1BPH 49REMARK 3 RMSD BOND ANGLE DISTANCES 0.043 ANGSTROMS 1BPH 50REMARK 4 1BPH 51REMARK 4 THIS CRYSTAL FORM CONTAINS ONE INSULIN MOLECULE PER 1BPH 52REMARK 4 ASYMMETRIC UNIT. THE SOLVENT VOLUME IS 64 PERCENT OF THE 1BPH 53REMARK 4 CRYSTAL VOLUME. THERE ARE MANY ALTERED SIDE CHAIN TORSION 1BPH 54REMARK 4 ANGLES AND MAIN CHAIN DISPLACEMENTS IN THE CUBIC CRYSTAL 1BPH 55REMARK 4 STRUCTURE COMPARED TO OTHER INSULIN CRYSTAL FORMS. ABOUT 1BPH 56REMARK 4 30 PER CENT OF THE AMINO ACID RESIDUES CAN ADOPT MULTIPLE 1BPH 57REMARK 4 CONFORMATIONS WHICH WERE RELIABLY IDENTIFIED BY COMPARISON 1BPH 58REMARK 4 OF THE DATA SETS COLLECTED FROM THE CRYSTALS IN THE PH 1BPH 59REMARK 4 RANGE 7 - 11. THE WEIGHTS OF MANY OF SUCH MULTIPLE PROTEIN 1BPH 60REMARK 4 AND SOLVENT CONFORMATIONS DEPEND ON SOLVENT IONIC 1BPH 61REMARK 4 CONDITIONS (PH AND SALT CONCENTRATION). 1BPH 62REMARK 5 1BPH 63REMARK 5 THERE ARE FOUR RELATED ENTRIES: 1BPH 64REMARK 5 1APH 0.1M SODIUM SALT SOLUTION AT PH 7 1BPH 65

42
REMARK 5 1BPH 0.1M SODIUM SALT SOLUTION AT PH 9 1BPH 66REMARK 5 1CPH 0.1M SODIUM SALT SOLUTION AT PH 10 1BPH 67REMARK 5 1DPH 1.0M SODIUM SALT SOLUTION AT PH 11 1BPH 68REMARK 6 1BPH 69REMARK 6 IN 1BPH AND 1CPH, THE SIDE CHAIN OF GLU A 4 CAN ADOPT TWO 1BPH 70REMARK 6 ALTERNATIVE POSITIONS WHICH OVERLAP. THEIR RELATIVE WEIGHT 1BPH 71REMARK 6 AND THE ATOMIC POSITIONS OF THE SECOND CONFORMER ARE NOT 1BPH 72REMARK 6 ACCURATELY DETERMINED. 1BPH 73REMARK 7 1BPH 74REMARK 7 IN 1APH, 1BPH, AND 1DPH, THE SIDE CHAIN OF GLU B 21 IS 1BPH 75REMARK 7 DISORDERED. IT HAS BEEN MODELED AS SUPERPOSITION OF TWO 1BPH 76REMARK 7 CONFORMATIONS BUT ATOMIC POSITIONS FOR THESE CONFORMATIONS 1BPH 77REMARK 7 ARE PROBABLY NOT VERY ACCURATE. 1BPH 78REMARK 8 1BPH 79REMARK 8 THE SIDE CHAIN OF LYS B 29 IS POORLY DEFINED IN THE 1BPH 80REMARK 8 ELECTRON DENSITY MAPS. IN 1APH AND 1CPH, IT IS INCLUDED 1BPH 81REMARK 8 WITH PARTIAL OCCUPANCY. IN 1BPH AND 1DPH, ITS COORDINATES 1BPH 82REMARK 8 HAVE BEEN OMITTED FROM THE ENTRY. 1BPH 83REMARK 13 1BPHA 5REMARK 13 CORRECTION. RENUMBER REFERENCES SEQUENTIALLY. INSERT 1BPHA 6REMARK 13 MISSING HET AND FORMUL RECORDS FOR NA. 31-OCT-93. 1BPHA 7SEQRES 1 A 21 GLY ILE VAL GLU GLN CYS CYS ALA SER VAL CYS SER LEU 1BPH 106SEQRES 2 A 21 TYR GLN LEU GLU ASN TYR CYS ASN 1BPH 107SEQRES 1 B 30 PHE VAL ASN GLN HIS LEU CYS GLY SER HIS LEU VAL GLU 1BPH 108SEQRES 2 B 30 ALA LEU TYR LEU VAL CYS GLY GLU ARG GLY PHE PHE TYR 1BPH 109SEQRES 3 B 30 THR PRO LYS ALA 1BPH 110HET DCE 200 4 1,2-DICHLOROETHANE(ETHYLENE DICHLORIDE) 1BPH 111HET NA 88 1 SODIUM ION 1BPHA 8FORMUL 3 DCE C2 H4 CL2 1BPH 112FORMUL 4 NA NA1 1BPHA 9FORMUL 5 HOH *55(H2 O1) 1BPHA 10HELIX 1 A1 GLY A 1 VAL A 10 1 1BPH 114HELIX 2 A2 SER A 12 GLU A 17 5 NOT IDEAL 1BPH 115HELIX 3 B1 SER B 9 GLY B 20 1 1BPH 116TURN 1 1B1 CYS B 19 ARG B 22 1BPH 117TURN 2 1B2 GLY B 20 GLY B 23 1BPH 118SSBOND 1 CYS A 6 CYS A 11 1BPH 119SSBOND 2 CYS A 7 CYS B 7 1BPH 120SSBOND 3 CYS A 20 CYS B 19 1BPH 121CRYST1 78.900 78.900 78.900 90.00 90.00 90.00 I 21 3 24 1BPH 122ORIGX1 1.000000 0.000000 0.000000 0.00000 1BPH 123ORIGX2 0.000000 1.000000 0.000000 0.00000 1BPH 124ORIGX3 0.000000 0.000000 1.000000 0.00000 1BPH 125SCALE1 0.012674 0.000000 0.000000 0.00000 1BPH 126SCALE2 0.000000 0.012674 0.000000 0.00000 1BPH 127SCALE3 0.000000 0.000000 0.012674 0.00000 1BPH 128ATOM 1 N GLY A 1 13.994 47.196 31.798 1.00 35.87 1BPH 129ATOM 2 CA GLY A 1 14.277 46.226 30.708 1.00 38.67 1BPH 130ATOM 3 C GLY A 1 15.574 45.507 31.085 1.00 31.18 1BPH 131ATOM 4 O GLY A 1 16.078 45.660 32.217 1.00 22.60 1BPH 132ATOM 5 N ILE A 2 16.088 44.766 30.126 1.00 28.39 1BPH 133ATOM 6 CA ILE A 2 17.342 44.034 30.404 1.00 23.76 1BPH 134ATOM 7 C ILE A 2 18.526 44.939 30.686 1.00 25.29 1BPH 135ATOM 8 O ILE A 2 19.425 44.457 31.392 1.00 18.74 1BPH 136ATOM 9 CB ILE A 2 17.571 43.072 29.158 1.00 27.36 1BPH 137ATOM 10 CG1 ILE A 2 18.638 42.049 29.605 1.00 18.03 1BPH 138ATOM 11 CG2 ILE A 2 17.859 43.936 27.903 1.00 25.54 1BPH 139ATOM 12 CD1 ILE A 2 18.914 40.930 28.590 1.00 17.07 1BPH 140ATOM 13 N VAL A 3 18.619 46.195 30.192 1.00 24.42 1BPH 141ATOM 14 CA VAL A 3 19.774 47.080 30.436 1.00 30.26 1BPH 142ATOM 15 C VAL A 3 19.952 47.453 31.895 1.00 19.08 1BPH 143ATOM 16 O VAL A 3 21.018 47.421 32.561 1.00 28.15 1BPH 144ATOM 17 CB VAL A 3 19.719 48.274 29.462 1.00 33.87 1BPH 145ATOM 18 CG1 VAL A 3 20.847 49.225 29.754 1.00 30.40 1BPH 146ATOM 19 CG2 VAL A 3 19.868 47.724 28.044 1.00 24.51 1BPH 147...

43
ATOM 127 N GLU A 17 17.257 34.367 30.913 1.00 17.57 1BPH 255ATOM 128 CA GLU A 17 16.353 33.393 30.338 1.00 13.26 1BPH 256ATOM 129 C GLU A 17 14.968 33.889 30.001 1.00 22.70 1BPH 257ATOM 130 O GLU A 17 14.234 33.275 29.212 1.00 25.00 1BPH 258ATOM 131 CB GLU A 17 16.183 32.146 31.209 1.00 17.01 1BPH 259ATOM 132 CG GLU A 17 17.252 31.160 30.695 1.00 14.38 1BPH 260ATOM 133 CD GLU A 17 16.968 29.843 31.385 1.00 24.91 1BPH 261ATOM 134 OE1 GLU A 17 16.230 29.713 32.350 1.00 25.72 1BPH 262ATOM 135 OE2 GLU A 17 17.675 28.984 30.830 1.00 22.42 1BPH 263ATOM 136 N ASN A 18 14.618 35.021 30.563 1.00 22.30 1BPH 264ATOM 137 CA ASN A 18 13.371 35.753 30.369 1.00 29.65 1BPH 265ATOM 138 C ASN A 18 13.330 36.318 28.943 1.00 23.17 1BPH 266ATOM 139 O ASN A 18 12.197 36.611 28.486 1.00 30.58 1BPH 267ATOM 172 N PHE B 1 28.961 32.694 34.302 1.00 38.09 1BPH 300ATOM 173 CA PHE B 1 29.545 33.933 33.691 1.00 44.75 1BPH 301ATOM 174 C PHE B 1 28.483 35.030 33.562 1.00 18.46 1BPH 302ATOM 175 O PHE B 1 28.656 36.170 33.083 1.00 29.15 1BPH 303ATOM 176 CB PHE B 1 30.190 33.486 32.346 1.00 36.50 1BPH 304ATOM 177 CG PHE B 1 29.191 32.986 31.322 1.00 29.77 1BPH 305ATOM 178 CD1 PHE B 1 28.691 31.688 31.351 1.00 22.29 1BPH 306ATOM 179 CD2 PHE B 1 28.736 33.844 30.327 1.00 30.11 1BPH 307ATOM 180 CE1 PHE B 1 27.758 31.234 30.415 1.00 30.11 1BPH 308ATOM 181 CE2 PHE B 1 27.822 33.423 29.377 1.00 29.49 1BPH 309ATOM 182 CZ PHE B 1 27.329 32.125 29.428 1.00 27.29 1BPH 310ATOM 183 N VAL B 2 27.235 34.671 33.935 1.00 25.09 1BPH 311ATOM 184 CA VAL B 2 26.085 35.571 33.793 1.00 23.88 1BPH 312ATOM 185 C VAL B 2 25.902 36.506 34.969 1.00 24.42 1BPH 313ATOM 186 O VAL B 2 25.269 37.560 34.801 1.00 19.63 1BPH 314ATOM 187 CB VAL B 2 24.846 34.751 33.391 1.00 28.89 1BPH 315.ATOM 413 N PRO B 28 16.809 47.082 24.129 1.00 39.30 1BPH 541ATOM 414 CA PRO B 28 17.550 47.958 25.065 1.00 50.32 1BPH 542ATOM 415 C PRO B 28 16.747 49.100 25.692 1.00 51.41 1BPH 543ATOM 416 O PRO B 28 16.922 49.526 26.848 1.00 52.87 1BPH 544ATOM 417 CB PRO B 28 18.744 48.435 24.231 1.00 33.07 1BPH 545ATOM 418 CG PRO B 28 18.261 48.353 22.779 1.00 28.91 1BPH 546ATOM 419 CD PRO B 28 17.355 47.133 22.751 1.00 30.72 1BPH 547ATOM 420 N LYS B 29 15.830 49.593 24.905 1.00 58.03 1BPH 548ATOM 421 CA ALYS B 29 14.935 50.708 25.214 0.50 56.38 1BPH 549ATOM 422 CA BLYS B 29 15.106 50.841 24.970 0.50 57.81 1BPH 550ATOM 423 C ALYS B 29 13.602 50.396 25.876 0.50 73.09 1BPH 551ATOM 424 C BLYS B 29 13.915 50.201 25.692 0.50 66.40 1BPH 552ATOM 425 O ALYS B 29 13.044 51.332 26.517 0.50 80.92 1BPH 553ATOM 426 O BLYS B 29 12.908 49.842 25.053 0.50 53.34 1BPH 554ATOM 427 CB ALYS B 29 14.689 51.541 23.932 0.50 58.98 1BPH 555ATOM 428 CB BLYS B 29 14.658 51.386 23.598 0.50 45.66 1BPH 556ATOM 429 N AALA B 30 13.056 49.194 25.782 0.50 74.55 1BPH 557ATOM 430 N BALA B 30 14.075 50.102 27.005 0.50 71.75 1BPH 558ATOM 431 CA AALA B 30 11.762 48.878 26.416 0.50 75.29 1BPH 559ATOM 432 CA BALA B 30 13.075 49.536 27.915 0.50 73.80 1BPH 560ATOM 433 C AALA B 30 11.853 47.818 27.515 0.50 68.10 1BPH 561ATOM 434 C BALA B 30 12.867 50.426 29.144 0.50 73.94 1BPH 562ATOM 435 O AALA B 30 10.774 47.235 27.799 0.50 65.90 1BPH 563ATOM 436 O BALA B 30 12.394 49.828 30.144 0.50 69.68 1BPH 564ATOM 437 CB AALA B 30 10.728 48.457 25.375 0.50 76.93 1BPH 565ATOM 438 CB BALA B 30 13.512 48.144 28.366 0.50 73.70 1BPH 566ATOM 439 OXTAALA B 30 12.952 47.610 28.048 0.50 63.45 1BPH 567ATOM 440 OXTBALA B 30 13.182 51.623 29.061 0.50 76.41 1BPH 568TER 441 ALA B 30 1BPH 569HETATM 442 CL1 DCE 200 26.950 41.213 19.536 0.50 34.85 1BPH 570HETATM 443 C1 DCE 200 28.222 40.003 20.178 0.50 24.42 1BPH 571HETATM 444 C2 DCE 200 28.307 38.776 19.363 0.50 24.99 1BPH 572HETATM 445 CL2 DCE 200 26.941 37.681 19.833 0.50 33.75 1BPH 573HETATM 446 NA NA 88 20.339 43.145 38.263 0.50 13.22 1BPH 574HETATM 447 O HOH 1 26.102 28.408 28.110 0.33 28.57 1BPH 575HETATM 448 O HOH 2 26.719 28.525 28.242 0.66 30.29 1BPH 576HETATM 449 O HOH 3 19.213 33.037 38.295 1.00 42.10 1BPH 577HETATM 450 O HOH 4 21.104 32.216 20.645 1.00 26.61 1BPH 578
44
HETATM 451 O HOH 5 21.954 33.637 38.117 1.00 22.77 1BPH 579HETATM 498 O HOH 52 19.217 52.503 35.050 1.00 68.12 1BPH 626HETATM 499 O HOH 53 15.376 24.434 25.540 1.00 82.81 1BPH 627HETATM 500 O HOH 54 21.768 55.234 32.076 1.00 85.97 1BPH 628HETATM 501 O HOH 55 22.667 52.737 33.359 1.00 81.22 1BPH 629CONECT 48 47 78 1BPH 630CONECT 54 53 235 1BPH 631CONECT 78 48 77 1BPH 632CONECT 161 160 331 1BPH 633CONECT 235 54 234 1BPH 634CONECT 331 161 330 1BPH 635CONECT 442 443 1BPH 636CONECT 443 442 444 1BPH 637CONECT 444 443 445 1BPH 638CONECT 445 444 1BPH 639MASTER 97 0 2 3 0 2 0 6 499 2 10 5 1BPHA 11END 1BPH

45
3D viewers
Several programs are available for viewing protein and nucleic 3D structures:
Rasmol www.umass.edu/microbio/rasmol/Weblab www.msi.comKinemage www.cryst.bbk.ac.uk/PPS/vsns-pps/technology/kinemage.htmlChime www.umass.edu/microbio/rasmol/Proteinexplorer www.umass.edu/microbio/chime/explorer/Cn3D www.ncbi.nlm.nih.gov/EntrezSwissPDBviewer expasy.proteome.org.au/spdbv/(Molscript www.avatar.se/molscript/)
Introduction to Rasmol
Rasmol is a computer program for visualisation of macromolecules, mainly proteins. It is available formost computer platforms. It is free and can be retrieved from the net (see for instancehttp://www.umass.edu/microbio/rasmol/getras.htm).
First download a pdb file from the net. You can do that usingwww.ncbi.nlm.nih.gov/Entrez or www.rcsb.org/pdb/cgi/queryForm.cgi orget the Ras protein from www.medkem.gu.se/edu/pdb/ras.pdbMake sure that you save the file in your local directory.
Then type
% rasmol [name of your downloaded pdb file]
Keep left mouse button pressed and rotate the molecule by moving the mouse.

46
Test different representations of the molecule from the menus "Display" and "Colours", for instanceDisplay-Spacefill. Rotate the molecule.
In addition the display window there is a command line window
Click on an atom in the graphical window. You should now see the identity of the atom in thecommand line window.
In the command line window we could also achieve more advanced representations by typingcommands from the keyboard. Test the following to color all lysines in your protein: Rasmol> select lysRasmol> color blueRasmol> spacefillMore information about Rasmol is at :http://www.umass.edu/microbio/rasmol/ andhttp://www.umass.edu/microbio/rasmol/distrib/rasman.htm

47
Molecular biology databases – text searches and retrieval of data.
With Internet tools such as- Entrezor- Sequence Retrieval System (SRS)
you can search the annotation section of molecular biology databases using one or more words and byselecting specific fields in the database. For instance to find all insulin proteins in a protein databaseyou can search Entrez – protein database , use ”insulin” as search word and selecting ”All fields” or”Protein Name”.
Help for Entrez and SRS :
http://www.ncbi.nlm.nih.gov/entrez/query/static/help/helpdoc.html
http://srs.ebi.ac.uk/ --> Information --> SRS Users manual
Fields that may be specified in the nucleotide, protein and Pubmed databases of Entrez:
Nucleotide
All FieldsAccessionAuthor NameEC/RN NumberFeature keyGene NameIssueJournal NameKeywordModification dateOrganismPage NumberPrimary AccessionPropertiesProtein NamePublication DateSeqID StringSequence LengthSubstance NameText WordTitle WordVolumeSequence ID
Protein
All FieldsAccessionAuthor NameEC/RN NumberGene NameIssueJournal NameKeywordModification dateOrganismPage NumberPrimary AccessionPropertiesProtein NamePublication DateSeqID StringSequence LengthSubstance NameText WordTitle WordVolumeSequence ID
Medline
All FieldsAffiliationAuthor NameEC/RN NumberEntrez DateIssueJournal NameLanguageMeSH Major TopicMeSH TermsPagePublication DatePublication TypeSubheadingSubstance NameText WordTitle WordVolumeMEDLINE IDPubMed ID

48
SRS servers
WEHI, Melbourne, AustraliaBelgian EMBnet Node (BEN), Brussels, BelgiumIBMM-DBM, Université Libre, Brussels, BelgiumDBBM-IOC, Fiocruz, Rio de Janeiro, BrazilThe Genome Mine, Base4 Bioinformatics, CanadaCBI EMBnet Node, University of Beijing, ChinaCSC, Otaniemi, Espoo, FinlandINFOBIOGEN, Villejuif, FranceInstitut Pasteur, Paris, FranceDKFZ, Heidelberg, GermanyEMBL, Heidelberg, Germany www.embl-heidelberg.de:80/srs5/GBF, Braunschweig, GermanyINCBI EMBnet Node, Dublin, IrelandWeizmann Institute BCD, Rehovot, IsraelIVR, Kyoto University, JapanBiotek EMBnet Node, Oslo, NorwayBIC, National University Hospital, SingaporeBiomedical Centre (BMC), Uppsala, SwedenExPASy, Geneva, SwitzerlandCAOS/CAMM Center, Nijmegen, The NetherlandsAdlib, CAB International, Wallingford, UKEMBL-EBI, Hinxton, Cambridge, UK srs.ebi.ac.uk:5000/srs5/HGMP-RC, Hinxton, Cambridge, UKMBDC Oxford, Oxford University, UKSEQNET EMBnet Node, Daresbury, UKSanger Centre, Hinxton, Cambridge, UKsIUBio, Indiana University, USA

49
Related Documents











