Big Data Infrastructure workshop A hands-on introduction Saturday, December 6, 2014

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Big Data Infrastructure workshop A hands-on introduction
Saturday, December 6, 2014

Agenda
08:30 AM Breakfast
09:00 AM Introduction and Strengths of Technologies
10:00 AM Start an EMR Cluster
10:15 AM break + set up query tool
10:30 AM Hadoop hands-on
10:55 AM break
11:10 AM Redshift hands-on
11:40 AM Operationalizing your code
12:00 PM adjourn
12/6/2014 2

Background on your presenters

DataKitchen Leadership
Chris Bergh (Executive Chef)
4
Gil Benghiat(VP Product)
Eric Estabrooks (VP Cloud and Data Services)
Software development origins and executive experience delivering enterprise software focused on Marketing and Health Care sectors.
Deep Analytic Experience: Spent past decade solving the analytic data preparation problem
New Approach To Data Preparation and Production: focused on the Analysts

5
Analysts And Their Teams Are Spending
60-80% Of Their Time On Data Preparation And Production

This creates an expectation gap
6
Analyze
Prepare Data
C
Analyze
Prepare Data
Business Customer Expectation
AnalystReality
Communicate
The business does not think that Analysts are preparing data
(Analysts don’t want to prepare data)

What Analyst Really Want: An Integrated Data Set Ready For Analysis
With: Autonomy & Agility
Without: All the Work & Anxiety

8
DataKitchen solves this problem.
We are on a mission to prepare data to
make analysts successful.

Agenda
08:30 AM Breakfast
09:00 AM Introduction and Strengths of Technologies
10:00 AM Start an EMR Cluster
10:15 AM break + set up query tool
10:30 AM Hadoop hands-on
10:55 AM break
11:10 AM Redshift hands-on
11:40 AM Operationalizing your code
12:00 PM adjourn
12/6/2014 9

Experience of Audience
• Who considers themselves
• Analyst
• Data scientist
• Programmer / Scripter
• On the Business side
• Who knows SQL – can write a simple select?
• Who had an AWS account before today?
12/6/2014 10

Hadoop & Redshift

What Is Apache Hadoop?
• Software framework
• Large scale processing
• Network of commodity hardware
• Handles hardware failures
12/6/2014 12
http://hadoop.apache.org/

What is Hadoop good for?
• Problems that are huge (batch), but not hard, and can be run in parallel over immutable data
• NOT OLTP (e.g. backend to e-commerce site)
• Providing a Map Reduce framework
12/6/2014 13

Map Reduce
12/6/2014 14
http://www.cs.berkeley.edu/~matei/talks/2010/amp_mapreduce.pdf

12/6/2014 15

You can write map reduce jobs in your favorite language
Streaming Interface
• Lets you specify mappers and reducer
• Supports• Java• Python• Ruby• Unix Shell• R• Any executable
Map Reduce “generators”
• Results in map reduce jobs
• PIG
• Hive
12/6/2014 16

Applications that lend themselves to map reduce
• Word Count
• PDF Generation (NY Times 11,000,000 articles)
• Analysis of stock market historical data (ROI and standard deviation)
• Geographical Data (Finding intersections, rendering map files)
• Log file querying and analysis
• Statistical machine translation
• Spam detection
• Analyzing Tweets
12/6/2014 17

Would you use an excavator to plant a tomato?
12/6/2014 18

Another use …Some people use a Hadoop cluster for a “data lake”
• Store all your raw data
• Cook it on demand
12/6/2014 19

12/6/2014 20http://pixgood.com/hadoop-ecosystem-diagram.html
Imp
ala

Pig
• Pig Latin - the scripting language
• Grunt – Shell for executing Pig Commands
12/6/2014 21
http://www.slideshare.net/kevinweil/hadoop-pig-and-twitter-nosql-east-2009

This is what it would be in Java
12/6/2014 22
http://www.slideshare.net/kevinweil/hadoop-pig-and-twitter-nosql-east-2009

Hive
You write SQL! Well, almost, it is HiveQL
12/6/2014 23
SELECT user.*FROM userWHERE user.active = 1;
JDBCSQL
Workbench
The first hands on session will focus on this.

In Amazon, the common workflow for batch processing starts and ends with s3.
12/6/2014 24
HiveScript

Impala
• Uses SQL very similar to HiveQL
• Runs 10-100x faster
• Runs in memory so it does not scale up as well
• Great for developing your code on a small data set
• Can use interactively with Tableau and other BI tools
• Some batch jobs run faster on Impala than Hive
12/6/2014 25

What is EMR?
• Hadoop offered by Amazon
• EMR = Elastic Map Reduce
• Amazon does almost all of the work to create a cluster
12/6/2014 26
OR

Three ways to pay for EMR
• On Demand - highest price, by the hour, no commitment
• m1.small $0.055 per Hour
• i2.8xlarge $7.09 per hour
• (29 different machine options)
• Reservation - 1 and 3 year terms (No, All, & Partial Upfront)
• Spot - lowest price, machine can be taken away
Do I leave my cluster up all the time?
12/6/2014 27
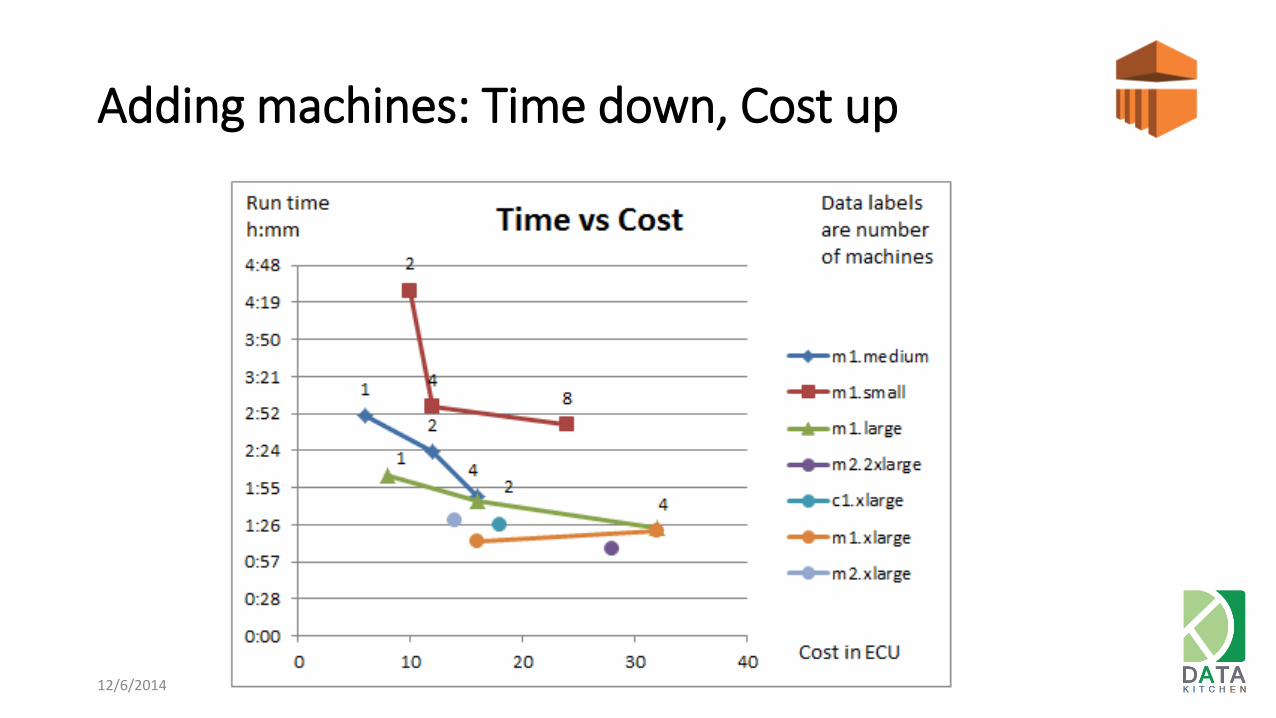
Adding machines: Time down, Cost up
12/6/2014 28
Cost in ECU

What Is Redshift?
• Columnar database
• Great for reads
• Scale by adding machines
• Two ways to pay
• On Demand
• Reservation
• Good for SQL-based ETL too
12/6/2014 29
http://hadoop.apache.org/

Redshift Machine Options (on demand prices)
12/6/2014 30
Petabyte scale
Remember: Amazon charges for s3 storage too

Redshift usage pattern
• Load data to s3 first
• Use BI tools to send in SQL
• Amazon Redshift is based on PostgreSQL
12/6/2014 31
The second hands on session will focus on this.
JDBCSQL
Workbench

Agenda
08:30 AM Breakfast
09:00 AM Introduction and Strengths of Technologies
10:00 AM Start an EMR Cluster
10:15 AM break + set up query tool
10:30 AM Hadoop hands-on
10:55 AM break
11:10 AM Redshift hands-on
11:40 AM Operationalizing your code
12:00 PM adjourn
12/6/2014 32

Should I use Redshift or EMR?
Redshift for
• Structured data
• Interactive queries
• Speed
Hadoop for
• Data format flexibility
• Computation flexibility
• Super Big Data
12/6/2014 33
• Try both
• Compare costs
• If it works in Redshift, start there

Performance comparison (3. Join Query)
12/6/2014 34https://amplab.cs.berkeley.edu/benchmark/

Recap
• Started a Hadoop cluster via the AWS Console (Web UI)
• Loaded Data
• Wrote some queries
• Same for Redshift
Eventually, you will do this for real and have a script that has value.
Now what?
12/6/2014 35

To run your data job you need to …
• Wait for the new data to arrive
• Move it to s3
• Start a cluster
• Load the data
• Run your SQL scripts
• Wait for it to finish
• Shut down your cluster
12/6/2014 36

And hope …
• The new data is in the right format
• Assumptions you made during development are still true
• Someone did not mess up your code with an "easy change“
• The new data transfers run successfully
• A table you depend on has been updated correctly
• The new data has not been truncated by the source
• No data quality issues with the source data
Wouldn’t it be great to turn your hopes into tests?
12/6/2014 37

DataKitchen: We produce the data
12/6/2014 38
SQL, tests and the check list
go into a Recipe
You data are
Ingredients
The results are
Servings

DataKitchen brings reality in line with expectations
39
Analyze
Prepare Data
C
Analyze
Prepare Data
Business Customer Expectation
AnalystReality
Communicate
Analyze
Prepare Data
With DataKitchen
Communicate

The story of our first Recipe
12/6/2014 40

The story of our first Recipe
With DataKitchen, we got 75% of our time back!
… and we don’t have to remember to shut down our cluster.
12/6/2014 41

Remember to shut down your clusters

Related Documents











