Introduction to Apache Spark

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Introduction to Apache Spark

www.mammothdata.com | @mammothdataco
Lab Overview
● ‘Hello world’ RDD example● Importing a dataset● Dataframe operations and visualizations● Using MLLib on dataset

www.mammothdata.com | @mammothdataco
Lab — Hello World
● ./run_spark

www.mammothdata.com | @mammothdataco
Lab — Hello World
● val text = sc.parallelize(Seq(“your text here”))● val words = text.flatMap(line => line.split(" "))● words.collect

www.mammothdata.com | @mammothdataco
Lab — Hello World
● val taggedWords = words.map(word => (word,1))● val counts = taggedWords.reduceByKey(_ + _)● counts.collect()

www.mammothdata.com | @mammothdataco
Lab — Dataset
● https://archive.ics.uci.edu/ml/datasets/Wine● Information on 3 different types of wine from Genoa● 178 entries (small!)

www.mammothdata.com | @mammothdataco
Lab — Loading The Wine Dataset
● val wines = sqlContext.read.json("wine.json")● wines.registerTempTable(“wines”)

www.mammothdata.com | @mammothdataco
Lab — Showing the generated Schema
● wines.printSchema

www.mammothdata.com | @mammothdataco
Lab — Dataframe Operations
● wines.first

www.mammothdata.com | @mammothdataco
Lab — Dataframe Operations
● sqlContext.sql("SELECT Type, count(Type) AS count FROM wines GROUP BY Type").show

www.mammothdata.com | @mammothdataco
Lab — Dataframe Operations
● Experiment with %sql on the dataset (SELECT, COUNT, etc)

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering
● K-Means clustering is an unsupervised algorithm which splits a dataset into a number of clusters (k) based on a notion of similarity between points. It is often applied to real-world data to obtain a picture of structure hidden in large datasets, for example, identifying location clusters or breaking down sales into distinct purchasing groups.

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering
k initial "means" (in this case k=3) are randomly generated within the
data domain (shown in colour).

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering
k (in this case, 3) clusters are created by comparing each data
point to the closest mean.
www.mammothdata.com | @mammothdataco
Lab — K-means Clustering
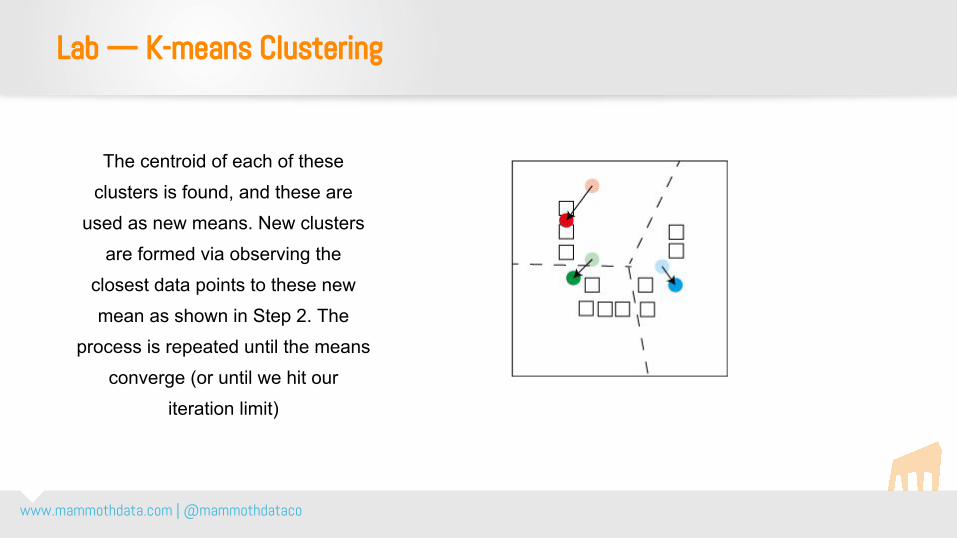
The centroid of each of these clusters is found, and these are
used as new means. New clusters are formed via observing the
closest data points to these new mean as shown in Step 2. The
process is repeated until the means converge (or until we hit our
iteration limit)

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: Imports
● import org.apache.spark.mllib.clustering.KMeansimport org.apache.spark.mllib.linalg.Vectors
● import org.apache.spark.sql._

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: Features
● val featureCols = wines.select("Alcohol", "Hue", "Proline")● val features = featureCols.rdd.map { case Row(a: Double, h:
Double, p: Double) => Vectors.dense(a,h,p) }● features.cache

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: Training Model
● val numClusters = 2● val numIterations = 20● val model = KMeans.train(features, numClusters,
numIterations)

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: Finding k
● k can be any number you like!● WSSSE - Within Set Sum of Squared Error● Squared sum of distances between points and their respective
centroid● val wssse = model.computeCost(features)

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: Finding k
● Test on k = 1 to 5● (1 to 5 by 1).map (k => KMeans.train(features, k,
numIterations).computeCost(features)) ● WSSSE normally decreases as k increases● Look for the ‘elbow’

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: Training Model
● val numClusters = 1● val numIterations = 20● val wssse = KMeans.train(features, numClusters,
numIterations).computeCost(features)

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: k = 3
● val numClusters = 3● val numIterations = 10● val model = KMeans.train(features, numClusters,
numIterations)

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: Obtaining Type Predictions
● val predictions = features.map ( feature => model.predict(feature))

www.mammothdata.com | @mammothdataco
Lab — K-means Clustering: Comparing To Labels
● val counts = predictions.map (p => (p,1)).reduceByKey(_+_)● counts.collect

www.mammothdata.com | @mammothdataco
Lab — Next Steps
● Looks good, right? Let’s look at what the labels for each point really are.
● val features = featureCols.rdd.map { case Row(t: Double, a: Double, h: Double, p: Double) => (t,Vectors.dense(a,h,p)) }
● val predictions = features.map ( feature => (feature._1, model.predict(feature._2)))
● val counts = predictions.map (p => (p,1)).reduceByKey(_+_)● counts.collect● A slightly different story!

www.mammothdata.com | @mammothdataco
Lab — Next Steps
● k-means clustering - useful! But not perfect!● Try again with more features in the vector and see if it
improves the clustering.● Bayes? Random Forests? All in MLLib and with similar
interfaces!

www.mammothdata.com | @mammothdataco
Lab — Next Steps
● spark.apache.org

www.mammothdata.com | @mammothdataco
Lab — Questions
● ?
Related Documents











