Edizioni dell’Orso Alessandria Linguistica e filologia digitale: aspetti e progetti a cura di Paola Cotticelli Kurras

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Edizioni dell’OrsoAlessandria
Linguistica e filologia digitale:aspetti e progetti
a cura di Paola Cotticelli Kurras

© 2011Copyright by Edizioni dell’Orso s.r.l.via Rattazzi, 47 15121 Alessandriatel. 0131.252349 fax 0131.257567e-mail: [email protected]://www.ediorso.it
Redazione informatica e impaginazione a cura di ARUN MALTESE ([email protected])
È vietata la riproduzione, anche parziale, non autorizzata, con qualsiasi mezzo effettuata,compresa la fotocopia, anche a uso interno e didattico. L’illecito sarà penalmente persegui-bile a norma dell’art. 171 della Legge n. 633 del 22.04.41
ISBN 978-88-6274-263-4

Indice
PAOLA COTTICELLI – KURRASPresentazione 7
SERGIO ALIVERNINI / CARLO MATTEO SCALZOTwo Applications of “Semantic Web Technologies” to the Studies of Ancient Near East. 9
MANUELA ANELLIL’edizione digitale dei testi epigrafici come strumento di ricerca. I: il progetto Iscrizioni Latine Arcaiche. 19
MANUEL BARBERAIntorno a “Schema e storia del Corpus Taurinense”. 27
FEDERICO BOSCHETTIParallelization of Ancient Greek OCR. 49
MARINA BUZZONIThe ‘Electronic Hêliand Project’: theoretical and practical updates. 55
PAOLA COTTICELLI – KURRAS / ALFREDO TROVATOLessico di linguistica online: progetto di un archivio digitale. 69
FEDERICO GIUSFREDI / ALFREDO RIZZAZipf’s law and the distribution of written signs. 87
ODD EINAR HAUGENDo we need all these characters? On the transcription and Encoding of Medieval Primary Sources. 101
STEFANO MINOZZILatin WordNet: a semantic network for Latin. 121
MARTA MUSCARIELLOL’edizione digitale dei testi epigrafici come strumento di ricerca.II: qualche nota sul progetto Iscrizioni Latine Arcaiche. 131
MATTEO ROMANELLOThe digital critical edition of fragments: theoretical problems and technical solutions. 147
GIULIA SARULLOL’edizione digitale dei testi epigrafici come strumento di ricerca. III: The Encoding of the Archaic Latin Inscriptions. 157
MARCO TOMATISComputational and methodological aspects of the Corpus Taurinense disambiguation process. 171


Intorno a “Schema e storia del Corpus Taurinense”
Manuel Barbera
0. LO SFONDO
Lo scopo, assolutamente confessato, di questa relazione è pubblicitario: fare co-noscere il mio volume (Schema e storia del “Corpus Taurinense”: linguistica dei cor-pora dell’italiano antico, Alessandria, Dell’Orso, 2009) ed il corpus che ne è oggetto(Corpus Taurinense: http://www.bmanuel.org/projects/ct-HOME.html);disegnando però un percorso (tra i molti possibili) nella corpus linguistics che sperosia di qualche interesse e pertinenza al presente convegno.
0.1. LA LINGUISTICA DEI CORPORA
Il Natural Language Processing (NLP/TAL) comprende molte attività: quasi-sot-toinsiemi1 ne sono, tra le altre, la filologia digitale od informatica umanistica (FD/IU)e la linguistica dei corpora (CL), attività questa talmente paradigmatica da diven-tarne (impropriamente) una sorta di sinonimo, e sulla quale voglio focalizzarmi.
1 Si tratta informalmente di intersezioni tali per cui le differenze FD-NLP e CL-NLP sono ir-rilevanti nel nostro discorso.
Tav. 1.
Anzi, mi concentrerò su un particolare tipo di CL, quella posta all’intersezione deitre insiemi: zona che è certo ancora più piccola, ma proprio perché rappresentativadi tutti i tipi di attività presi in considerazione, è ancora più paradigmatica e signifi-

cativa. Tra l’altro, già dello stesso concetto di corpus, di cui tanto spesso si parla moltoa spanna, faccio riferimento ad una definizione abbastanza “stretta”,
Raccolta di testi (scritti, orali o multimediali) o parti di essi in numero finito in formato elet-tronico trattati in modo uniforme (ossia tokenizzati ed addizionati di markup adeguato)così da essere gestibili ed interrogabili informaticamente; se (come spesso) le finalità sonolinguistiche (descrizione di lingue naturali o loro varietà), i testi sono perlopiù scelti inmodo da essere autentici e rappresentativi. Barbera / Corino / Onesti (2007b: 70); Barbera(2009: 126)
0.2. MATERIALE DI RIFERIMENTO
Le riflessioni che vi offro sono, infatti, a margine di quell’impresa decennale cheha recentemente trovato illustrazione nel “voluminoso volume” di cui sopra e che sicolloca proprio in quella intersezione vitale: la linguistica storica dei corpora.
0.2.1. Il Corpus Taurinense
L’impresa in questione consiste nel cantiere del Corpus Taurinense (257.185token,2 18.876 type, 8.325 lemmi), costituito da ventidue testi fiorentini della secondametà del XIII secolo, annotati e completamente disambiguati per parti del discorso,categorie morfosintattiche, genere letterario, caratteristiche filologiche ed articola-zione paragrafematica del testo, portando le esperienze e le tecniche più avanzatedella linguistica dei corpora dalle lingue moderne a quelle antiche. Costruito, infatti,secondo specifiche EAGLES>ISLE compatibili nel formato CWB (Corpus WorkBench, sviluppato dall’IMS Stuttgart), e rilasciato sotto licenza Creative CommonsShare Alike, è liberamente consultabile con CQP (Corpus Query Processor) alla suahomepage.
0.2.2. Schema e storia del CT
Il volume Schema e storia del “Corpus Taurinense”: linguistica dei corpora del-l’italiano antico, il “voluminoso volume” frutto di questa ricerca decennale, è ap-punto di notevole ampiezza quantitativa (circa 1.300 pagine, con 4.195 citazioni tratteda 254 testi e 510 query CQP) e funzionale, fungendo da pratico manuale di riferi-mento ed accurata documentazione del Corpus Taurinense, storia di una ricerca e va-demecum dell’aspirante costruttore di corpora, ma anche riassuntivo punto diriferimento sulla linguistica dei corpora dell’italiano antico, e soprattutto consuntivodei rapporti tra linguistica teorica, storica e computazionale.
28 Manuel Barbera
2 Per motivi di uniformità editoriale, anche i forestierismi usati come termini tecnici vengonoposti in corsivo, applicando quindi la prassi della curatrice del volume e non quella dell’autore, cheusa e teorizza (cf. ad es. Barbera 2009: 7-13) un sistema del tutto differente.

0.2.3 Pertinenza dei materiali
Le osservazioni che vi offrirò partono, quindi, proprio da quell’intersezione tra lin-guistica dei corpora e filologia digitale cui accennavo prima: costruzione di corporadi testi antichi, con tutto quel che ciò comporta; In questo senso potranno, spero, in-teragire con altre, non di corpus linguistics, presen tate a questo convegno, anche se,in realtà, sono poi solo un invito alla lettura del volume.
0.3 OBIETTIVI
Partirò da alcune considerazioni teoriche, innestandovi la discussione di due par-ticolari vincoli che ne derivano, uno relativo all’obbligatorietà della rappresentazionedei token (con ricadute filologiche), e l’altro alla univocità del tagging (con ricadutepiù linguistiche), portandone esemplificazioni.
1. STATUS TEORICO DELLA CL
È opinione comune tra i linguisti di corpora che la CL sia una disciplina auto-noma, con un proprio ubi consistam teorico. Peccato che lo pensino solo loro, e chein definitiva tale opinione poggi quasi solo sui risultati ottenuti e non su seri presup-posti teorici. Il problema è tale tanto da un punto di vista di storiografia della lingui-stica, quanto da quello di chi, come me, sente sempre una necessità di fondazione(anche nel senso filosofico di Grund) teorica in quello che fa. Ed anche quandoquello che fa è corpus linguistics.
L’argomento è troppo grosso per essere qui esaurito (prima o poi lo vorrò tema-tizzare in una sede monografica adeguata), ma un’idea della prospettiva in cui mimuovo, almeno come ho cercato di abbozzarla in Schema e storia, va data, se nonvogliamo che ogni mia affermazioni resti sospesa nell’aria, come le interpretazioni inWittgenstein, Ricerche, I.198 (“Ogni interpretazione è sospesa nell’aria insieme conl’interpretato”).
1.1. LA SCORTESIA DI CHOMSKY
Dai corpora non si può imparare nulla, Chomky dixit (almeno pare, perché dellastorica boutade, in realtà, non ho mai trovato i riferimenti precisi; quindi forse per-lomeno non scripsit). Pare che non si possa non cominciare da questa storica scorte-sia, che i linguisti dei corpora si sono davvero legata al dito (non del tutto a torto,visto che molti progetti di ricerca, anche importanti, negli States negli anni di mag-gior sbornia generativa, non furono finanziati proprio in base a quell’opinione): nesono discese molte conseguenze negative, ben al di là del suo contenuto fattuale. Lapeggiore delle quali è stata la “costruzione” della CL come sorta di “antigenerativi-smo” radicale, che solo raramente (penso soprattutto a Sampson) ha trovato unaqualche solidità teorica, capendo perlopiù del programma generativo solo quello chevoleva: molto poco.
Intorno a “Schema e storia del Corpus Taurinense” 29

1.2. COSA C’È DAVVERO SUL TAPPETO
“La costruzione “barricadera”, cui abbiamo assistito, di una linguistica dei cor-pora come disciplina teoricamente definita “alla inglese”, avatar di un moderno em-pirismo, contrapposta al razionalismo innatista della linguistica generativa […]; cosìcome anche certe esagerazioni di Chomsky dall’altra parte”, secondo dicevamo inBarbera (2009: 23), hanno, secondo me, in larga misura oscurato i problemi veri. Unadiscussione più articolata (ma ancora insufficiente) si trova nel “volumone”, ma bre-vemente, i punti centrali da dibattere sono 4:
1.2.1. Invito alla moderazione
L’affermazione famigerata di Chomsky va piuttosto intesa à la Fillmore:
“I don’t think there can be any corpora, however large, that contain information about allof the areas of English lexicon and grammar that I want to explore […]. Every corpus Ihave had the chance to examine, however small, has taught me facts I couldn’t imaginefinding out any other way”, Fillmore (1992: 35).
1.2.2. Riqualificazione della parole
Quello che linguisticamente va meglio messo a fuoco è la definizione dei concetticompetence : performance, langue : parole, di quali ne siano i rapporti3 e di cosa vipertenga o meno, in particolare di dove si ponga quel livello che io chiamerei testuale(di non facile collocazione anche all’interno del paradigma saussuriano e strutturale,tra l’altro), basilare ai miei fini.
1.2.3. Diversità dei fini
Quello di cui metalinguisticamente (fini della linguistica) bisogna rendersi contoè che lo scopo vero di un’indagine generativa è cognitivo (le strutture dell’I-Lan-guage) laddove quello delle indagini linguistiche “tradizionali” è piuttosto antropo-logico (le strutture di una data langue), ed è generativisticamente interessante solocome materiale potenzialmente falsificante, sede di experimenta crucis.
1.2.4. Alla filosofia quel che è della filosofia
Il problema filosofico, poi, affatto aperto, è quello delle basi, interniste od ester-
30 Manuel Barbera
3 In particolare fatale per la CL sarebbe la impossibilità di inferire da una performance alcun-ché riguardo alla competence; divieto che trae le sue radici da una componente spesso sottovalu-tata nella “creazione” del generativismo: la reazione, viscerale, antibehavouristica, cf. Chomsky(1959); 50 anni dopo negare fin la forma più debole di comportamentismo, cioè che da compor-tamenti si possano inferire stati mentali, pare francamente esagerato.

niste, della semantica: ma è tutt’altro discorso dalle generiche contrapposizioni diempirismo e razionalismo (cf. ad es. il classico McEnery / Wilson (19961, 20012)) damanualetto liceale.
1.3. LA MIA POSIZIONE
La mia posizione, altrettanto brevemente, è a favore di una linguistica dei cor-pora corpus-based di ascendenza fillmoriana (e non corpus-driven di ascendenza sin-clairiana), che faccia oggetto della propria indagine un dato stato di langue a partireda testi. Obiettivo diverso, certo, ma non necessariamente in contraddizione con unopiù “generativo”: prova ne sia la mia collaborazione contemporanea al progetto diItalAnt.
1.4. IL PROBLEMA STORIOGRAFICO
Storiograficamente, pertanto, non credo affatto che vadano sminuiti i ruoli rivo-luzionari giocati dalla semiologia saussuriana e dallo strutturalismo nel primo No-vecento e (forse anche più) dalla speculazione chomskyana e dal programma gene-rativo nel secondo Novecento, quasi che la linguistica dei corpora fosse un terzoprogramma che, un po’ hegelianamente, li superi. Anzi, usando una metafora musi-cale, ho voluto paragonare il ruolo della linguistica dei corpora a quello giocato, se-condo Schönberg, da Brahms nella polemica tra classicisti e wagneriani, im pli -citamente, tra l’altro, ammettendo che la contrapposizione smaccata di generativismoe strutturalismo sia altrettanto pretestuosa, ed esplicitamente riconnettendo la lin-guistica dei corpora alla “vecchia pratica” della linguistica filologica (come Brahmsa Bach e Mozart), tracciando così una linea di continuità (“tradizione nell’innova-zione”, per usare il felice slogan di Schönberg) al di sotto delle rivoluzioni che scan-discono la storia dei paradigmi linguistici moderni.
1.5. QUID EST ISTINC NOBIS?
La cosa è nell’ottica del nostro discorso pertinente e rilevante in quanto attribui-sce, così, alle esperienze dei corpora “storici”, che sono un po’ le rare Cenerentoledella corpus linguistics contemporanea, un ruolo fondante che conferma l’esempla-rità delle nostre ricerche (oltre che porre rimedio all’incipiente schizofrenia di chi,come me, è sia filologo sia linguista, e per soprammisura pure computazionale).
2. OBBLIGATORIETÀ DELLA RAPPRESENTAZIONE DEI TOKEN
Scendiamo al primo dei due punti in agenda.
Intorno a “Schema e storia del Corpus Taurinense” 31

2.1. TOKEN
La rappresentazione elettronica di un testo in un corpus presuppone che questosia articolato in unità minime, dette token (con termine che risale a Peirce (1906), ci-tato e commentato in Barbera (2009: 126-129)), che materialmente si configuranocome una successione di posizioni discrete: un corpus è la totalità dei suoi token.
“A common mode of estimating the amount of matter in a MS. or printed book is to countthe number of words. There will ordinarily be about twenty the’s on a page, and of coursethey count as twenty words. In another sense of the word “word”, however, there is butone word “the” in the English language; and it is impossible that this word should lie visi-bly on a page or be heard in any voice, for the reason that it is not a Single thing or Singleevent. It does not exist; it only determines things that do exist. Such a definitely significantForm, I propose to term a Type. A Single event which happens once and whose identity islimited to that one happening or a Single object or thing which is in some single place at anyone instant of time, such event or thing being significant only as occurring just when andwhere it does, such as this or that word on a single line of a single page of a single copy ofa book, I will venture to call a Token. An indefinite significant character such as a tone ofvoice can neither be called a Type nor a Token. I propose to call such a Sign a Tone. Inorder that a Type may be used, it has to be embodied in a Token which shall be a sign ofthe Type, and thereby of the object the Type signifies. I propose to call such a Token of aType an Instance of the Type”. Peirce (1906/31-58: 537 Prolegomena to an Apology forPragmaticism).
2.2. POSIZIONI ED ATTRIBUTI
Così, l’ultimo verso del sonetto XLVII del Cavalcanti, una volta immesso in uncorpus risulterebbe in una successione di 9 token, che computazionalmente sono rap-presentati da 9 posizioni, gestite numericamente da una sorta di database:
Fa’ 1ch’ 2om 3non 4rida 5il 6tuo 7proponimento 8! 9
Tav. 2 (già Tav. 230 in Barbera (2009)).
Più accuratamente, il token è l’attributo obbligatorio di ogni posizione: ad unaposizione possono essere poi associati anche molti altri attributi (nel gergo del CWB,il software usato per il CT, detti attributi posizionali: lemma, POS Tagging, ecc; nelCT sono ben 11), ma una posizione non esiste se non è associata al suo token.
32 Manuel Barbera

2.3. IMPOSTAZIONE DEL PROBLEMA
Beh, si dirà: tutto abbastanza ovvio e, probabilmente, noto. Certo, ma forse nonè così plain sailing per tutte le conseguenze che ne derivano, specie se i testi rappre-sentati nel corpus sono testi per cui una veste filologica sia imprescindibile, comemolto spesso i testi storici (e lo stesso capita per testi “delicati” moderni, come au-tografi olografi e simili). Come la mettiamo con cassature, integrazioni ed espun-zioni, ad esempio? Dovranno, per poter essere rappresentate in un corpus, averedelle posizioni associate, ma esistono come token? E se non, come potranno avereuna posizione?
Restringiamoci, per ovvi vincoli di tempo, soprattutto alle cassature/espunzioniper vedere come il problema possa essere impostato (e forse, spero, risolto). È, tral’altro, una di quelle “piccole cose” che ci hanno dato molto filo da torcere, e per cuiabbiamo dovuto aggiustare il tiro in itinere, dopo avere constatato che la nostra primasoluzione non risolveva nulla ed anzi rendeva il corpus impossibile da interrogare.
2.3.1. Premessa: gli attributi posizionali del CT
Per esaminare quel che vogliamo esaminare dobbiamo premettere che il CT ha,come dicevamo, 12 attributi (contando il token, che è l’attributo di default, che inCWB convenzionalmente si numera 0 e si etichetta word):
Intorno a “Schema e storia del Corpus Taurinense” 33
0 word il token mangia
1 lemma il lemma cui il token è stato ricondotto mangiare
2 pos il POS-tag con le sue HDF (Hierarchy-DefiningFeatures) in ShN (Short Notation)
v.m.f.ind.pr
3 kat • i codici di MSF (Morphosyntactic Features)• i codici di HCF (Hierarchy-Collapsed Features)
3,0,6,0,0111
4 typ il “tipo testuale” di un (-a parte di) testo: {prosa;verso; rubrica}; incrociato con type
/P
5 corr se la forma del token muta nel ms. o nell’edizione y
6 genre il genere letterario di un testo: {documentario, di-dat tico, storico, narrativo, lirico}; incrociato congenr
nar
7 msform il token inalterato che compare de facto nel ms. magia
8 philform la resa filologica del token, con i diacritici consueti(parentesi tonde e quadre, corsivo)
ma(n)gia; ma[n]gia;ma¦n¦gia
9 mwlword il lemma-MW a°÷l°postutto
10 mwlkat la pos-MW 45
11 mwlnum la successione dei token-MW 1…
Tav. 3 (dalla Tav. 250 di Barbera (2009)).
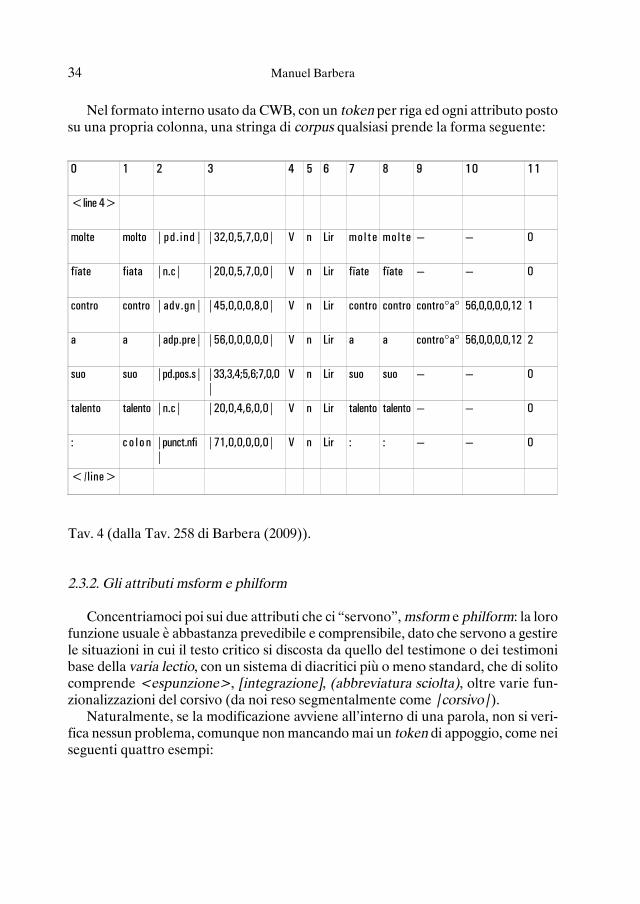
Nel formato interno usato da CWB, con un token per riga ed ogni attributo postosu una propria colonna, una stringa di corpus qualsiasi prende la forma seguente:
34 Manuel Barbera
0 1 2 3 4 5 6 7 8 9 10 11
<line 4>
molte molto |pd. ind| |32,0,5,7,0,0| V n Lir mol te molte — — 0
fïate fiata |n.c| |20,0,5,7,0,0| V n Lir fïate fïate — — 0
contro contro |adv.gn| |45,0,0,0,8,0| V n Lir contro contro contro°a° 56,0,0,0,0,12 1
a a |adp.pre| |56,0,0,0,0,0| V n Lir a a contro°a° 56,0,0,0,0,12 2
suo suo |pd.pos.s| |33,3,4;5,6;7,0,0|
V n Lir suo suo — — 0
talento talento |n.c| |20,0,4,6,0,0| V n Lir talento talento — — 0
: c o l o n |punct.nfi|
|71,0,0,0,0,0| V n Lir : : — — 0
</line>
Tav. 4 (dalla Tav. 258 di Barbera (2009)).
2.3.2. Gli attributi msform e philform
Concentriamoci poi sui due attributi che ci “servono”, msform e philform: la lorofunzione usuale è abbastanza prevedibile e comprensibile, dato che servono a gestirele situazioni in cui il testo critico si discosta da quello del testimone o dei testimonibase della varia lectio, con un sistema di diacritici più o meno standard, che di solitocomprende <espunzione>, [integrazione], (abbreviatura sciolta), oltre varie fun-zionalizzazioni del corsivo (da noi reso segmentalmente come |corsivo|).
Naturalmente, se la modificazione avviene all’interno di una parola, non si veri-fica nessun problema, comunque non mancando mai un token di appoggio, come neiseguenti quattro esempi:

Tav. 5 (dalla Tav. 261 di Barbera (2009)).
2.4. RIPROPOSIZIONE DEL PROBLEMA
Fin qui tutto bene, ma il problema esplode quando troviamo segmenti di testocome: In questo mezzo genti che passavano <per la via> per lo camino trovaro ilmorto di novello , e Catone intorno lui , sì pensaro certamente che Catone avessefatto il malificio , e perciò fu ÷e esso accusato di quella morte (Brunetto, Rettorica,LVII.3, p. 115): <per la via> sono token cassati, che non esistono. Come inserirlinel corpus se non ne sono token?
2.4.1. Primo tentativo
Il primo tentativo è stato il più ovvio e banale: trasformare ogni elemento cassatoin token, diacritico compreso, trasformando ossia il segmento che ci interessa al modoseguente:
Intorno a “Schema e storia del Corpus Taurinense” 35
0 1 2 3 4 5 6 7 8 9 1 0 1 1
[Di]pravamento
Dipravamento dipravamento |n.p| |21,0,4,6,0,0| P n D i d pravamento [Di]pravamento — — 0
ano(verai)
anoverai annoverare |v.m.f.ind.pt| |113,1,0,6,0,0| P n Doc ano ano(verai) — — 0
c(entinaio)
centinaio centinaio |n.c| |20,0,4,6,0,0| P n Doc c c(entinaio) — — 0
percha¦mena¦
perchamena pergamena |n.c| |20,0,5,6,0,0| P y Doc percha percha¦mena¦ — — 0
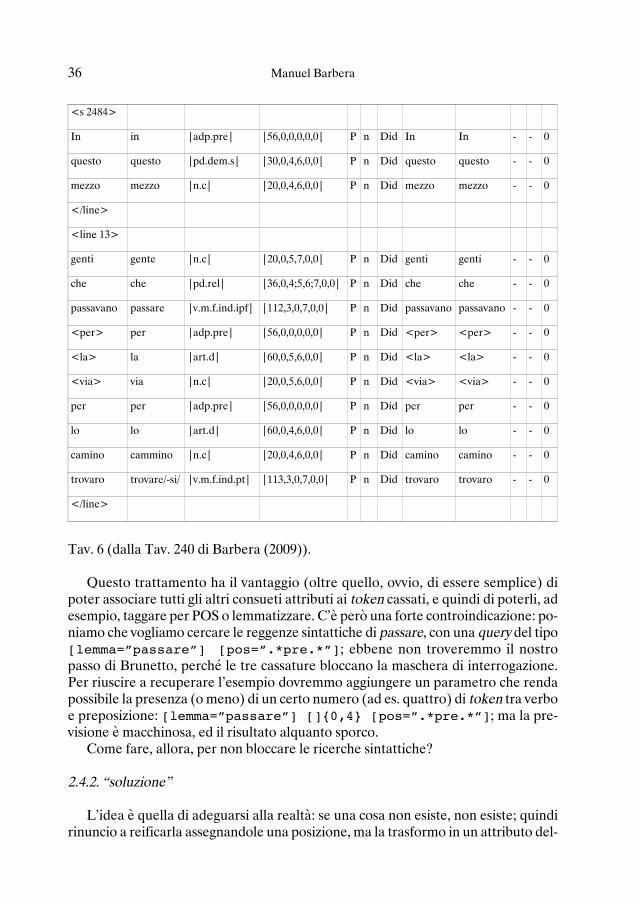
Tav. 6 (dalla Tav. 240 di Barbera (2009)).
Questo trattamento ha il vantaggio (oltre quello, ovvio, di essere semplice) dipoter associare tutti gli altri consueti attributi ai token cassati, e quindi di poterli, adesempio, taggare per POS o lemmatizzare. C’è però una forte controindicazione: po-niamo che vogliamo cercare le reggenze sintattiche di passare, con una query del tipo[lemma=”passare”] [pos=”.*pre.*”]; ebbene non troveremmo il nostropasso di Brunetto, perché le tre cassature bloccano la maschera di interrogazione.Per riuscire a recuperare l’esempio dovremmo aggiungere un parametro che rendapossibile la presenza (o meno) di un certo numero (ad es. quattro) di token tra verboe preposizione: [lemma=”passare”] []{0,4} [pos=”.*pre.*”]; ma la pre-visione è macchinosa, ed il risultato alquanto sporco.
Come fare, allora, per non bloccare le ricerche sintattiche?
2.4.2. “soluzione”
L’idea è quella di adeguarsi alla realtà: se una cosa non esiste, non esiste; quindirinuncio a reificarla assegnandole una posizione, ma la trasformo in un attributo del-
36 Manuel Barbera
<s 2484>
In in |adp.pre| |56,0,0,0,0,0| P n Did In In - - 0
questo questo |pd.dem.s| |30,0,4,6,0,0| P n Did questo questo - - 0
mezzo mezzo |n.c| |20,0,4,6,0,0| P n Did mezzo mezzo - - 0
</line>
<line 13>
genti gente |n.c| |20,0,5,7,0,0| P n Did genti genti - - 0
che che |pd.rel| |36,0,4;5,6;7,0,0| P n Did che che - - 0
passavano passare |v.m.f.ind.ipf| |112,3,0,7,0,0| P n Did passavano passavano - - 0
<per> per |adp.pre| |56,0,0,0,0,0| P n Did <per> <per> - - 0
<la> la |art.d| |60,0,5,6,0,0| P n Did <la> <la> - - 0
<via> via |n.c| |20,0,5,6,0,0| P n Did <via> <via> - - 0
per per |adp.pre| |56,0,0,0,0,0| P n Did per per - - 0
lo lo |art.d| |60,0,4,6,0,0| P n Did lo lo - - 0
camino cammino |n.c| |20,0,4,6,0,0| P n Did camino camino - - 0
trovaro trovare/-si/ |v.m.f.ind.pt| |113,3,0,7,0,0| P n Did trovaro trovaro - - 0
</line>
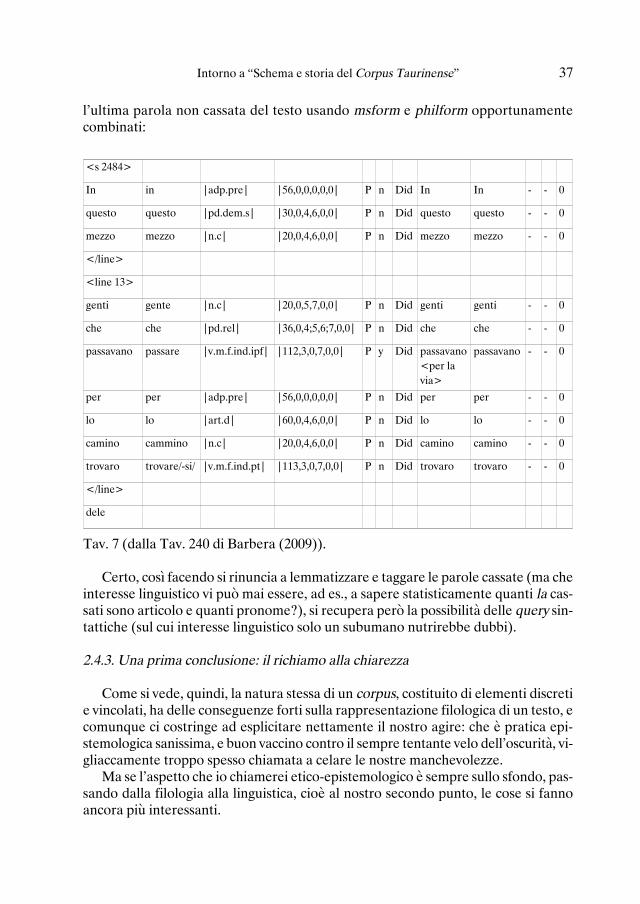
l’ultima parola non cassata del testo usando msform e philform opportunamentecombinati:
Intorno a “Schema e storia del Corpus Taurinense” 37
<s 2484>
In in |adp.pre| |56,0,0,0,0,0| P n Did In In - - 0
questo questo |pd.dem.s| |30,0,4,6,0,0| P n Did questo questo - - 0
mezzo mezzo |n.c| |20,0,4,6,0,0| P n Did mezzo mezzo - - 0
</line>
<line 13>
genti gente |n.c| |20,0,5,7,0,0| P n Did genti genti - - 0
che che |pd.rel| |36,0,4;5,6;7,0,0| P n Did che che - - 0
passavano passare |v.m.f.ind.ipf| |112,3,0,7,0,0| P y Did passavano<per lavia>
passavano - - 0
per per |adp.pre| |56,0,0,0,0,0| P n Did per per - - 0
lo lo |art.d| |60,0,4,6,0,0| P n Did lo lo - - 0
camino cammino |n.c| |20,0,4,6,0,0| P n Did camino camino - - 0
trovaro trovare/-si/ |v.m.f.ind.pt| |113,3,0,7,0,0| P n Did trovaro trovaro - - 0
</line>
dele
Tav. 7 (dalla Tav. 240 di Barbera (2009)).
Certo, così facendo si rinuncia a lemmatizzare e taggare le parole cassate (ma cheinteresse linguistico vi può mai essere, ad es., a sapere statisticamente quanti la cas-sati sono articolo e quanti pronome?), si recupera però la possibilità delle query sin-tattiche (sul cui interesse linguistico solo un subumano nutrirebbe dubbi).
2.4.3. Una prima conclusione: il richiamo alla chiarezza
Come si vede, quindi, la natura stessa di un corpus, costituito di elementi discretie vincolati, ha delle conseguenze forti sulla rappresentazione filologica di un testo, ecomunque ci costringe ad esplicitare nettamente il nostro agire: che è pratica epi-stemologica sanissima, e buon vaccino contro il sempre tentante velo dell’oscurità, vi-gliaccamente troppo spesso chiamata a celare le nostre manchevolezze.
Ma se l’aspetto che io chiamerei etico-epistemologico è sempre sullo sfondo, pas-sando dalla filologia alla linguistica, cioè al nostro secondo punto, le cose si fannoancora più interessanti.

4 Se solo si leggesse un po’ più spesso il capitolo dedicato alla dottrina dello schematismo tra-scendentale (II.I.ij.1) nella prima Critica di Kant!
5 Didatticamente, ad esempio, ho imparato che è meglio non stancarsi mai di insistere che un
38 Manuel Barbera
3. OBBLIGATORIETÀ NELLA SCELTA DEL POS-TAG
Questa volta, infatti, voglio spostarmi dall’attributo-0 “token” (o word) e con-centrarmi su un altro degli attributi che sono stati implementati nel CT, l’attributo-2, il “POS-tag” (o pos).
3.1. I PRESUPPOSTI
I concetti presupposti da quanto voglio dire sono, pertanto, essenzialmente due:POS e tagset. Per fortuna su entrambi sono già entrato in argomento diffusamentein contributi monografici, cui posso rimandare, limitandomi a pochi accenni.
3.1.1. Le POS
“Sotto le varie etichette di “partes orationis” (parti del discorso, parties du di-scours, Redeteile) o, più anglicamente à la page “Parts of Speech” (“PoS” o “POS”)sono spesso riferiti concetti, tradizioni e pratiche linguistiche molto diversi, a voltesenza neppure esplicitamente darne conto; concetti, peraltro, che si intrecciano conle “intuizioni ingenue” che tutti ne abbiamo”, come dicevo in Barbera (2008 i.s.),dove cercavo di mettere in chiaro la nozione che POS riveste in corpus linguistics, in-serendola nella storia della nostra linguistica. Se per ogni dettaglio rinvio a quel miolavoro, qui basterà sottolineare le due caratteristiche chiave di una POS così come va,secondo me, intesa in CL: la categoria è metalinguistica (ossia non ha alcuna pretesadi realismo) e definisce classi lessicali (ossia a base morfologica, con rapporti para-digmatici) e non costituenti frasali (laddove sarebbe a base sintattica, con rapportisintagmatici). È pertanto intesa ben diversamente dalla nozione aristotelica origina-ria e, mutatis mutandis, dalla nozione generativa (dove è un costituente sintattico,corrispondente ad uno stato mentale definito da una serie di regole presenti nellacompetence del parlante), ma anche da quella tipologica (che non definisce mai chia-ramente le proprie categorie, se non quando fa ricorso alla teoria dei prototipi, concompleta discesa nella follia: un prototipo è, per definizione, la generalizzazione diun certo numero di immagini sensoriali; ed avere immagine sensoriali di un nome odi un verbo4, od anche di un soggetto e di un predicato, se si preferisce, è cosa checomporta, nella migliore delle ipotesi, l’assunzione di sostanze che è meglio non con-sumare …).
La prima caratteristica è dovuta principalmente alla vocazione interlinguistica(nel senso di langue e non I-language) della disciplina, ma anche alla sua natura ap-plicata (come meglio spiegheremo nel punto seguente) per cui la scelta di una unitàtassonomica e di un nome per quella unità risponde a motivazioni di molti tipi e nonsolo linguistiche5.

predicato non è necessariamente un verbo, tanto più se i nostri studenti studiano arabo o russo: edare alle varie categorie “nomi” (labels) distinti e non ambigui giova. Addirittura, scommetto chemolti studenti ricorderebbero più facilmente l’opposizione Topolino-Godzilla-Bubu / Topo-lino/Bubu/Godzilla che non SVO/SOV e soprattutto la precipuità di lingue Godzilla-final; ma nonesageriamo.
6 In certi ambienti, addirittura, se ne nega la possibilità; la realtà è che a certe condizioni e conuna data percentuale di errore è possibile; chiedersi se sia possibile in assoluto, non ha, a mio pa-rere, molto senso: l’assoluto ha poco a che fare con l’umano.
Intorno a “Schema e storia del Corpus Taurinense” 39
La seconda caratteristica è dovuta alla maggiore pulizia di distinguere sintassi emorfologia, assegnandole a due fasce separate di tagging (POS-tagging e Treeban-king) anziché farle collassare in una, rischiando di confondere funzioni distinte, masoprattutto alla maggiore facilità di effettuare computazionalmente l’ardua6 analisisintattica (parsing) partendo da una precedente analisi morfologica (POS-tagging).
3.1.2. Il tagset
Il tagset non è altro che la completa griglia tassonomica (in cui i POS-tags corri-spondono ai taxa, e le labels ai nomi dei taxa) delle POS che viene utilizzata nel tag-ging dei corpora di una data lingua. Data la natura metalinguistica delle POS, va dasé che la costruzione di un tagset, che per giunta è sempre una pratica di natura ap-plicata e non teorica, in realtà deve in generale adeguarsi solo al principio di tolle-ranza di Carnap (1937/34: 51-52 e 1974/63: 19).
Non voglio troppo sostarvi, divagando dal filo principale del mio discorso; bastidire che nel corso degli anni, attraverso vari studi (cf. Barbera, 2000 i.s.; 2007a; 2007b;2008 i.s.; e 2009: 45-54) sono giunto a sostanziare praticamente questo assunto, ed acodificare una sorta di Arte della costruzione dei tagset, che riposerebbe su undiciprincipi, che qui mi limito a riportare apoditticamente:
1 Consensualità e neutralità;2 adeguatezza descrittiva;3 standardizzazione;4 praticità computazionale;5 tag e labels EAGLES-compatibili (corollario di 3);6 ancoramento morfologico;7 struttura tipata (hierarchy-defining features: HDF);8 evitamento dei cross-branchings con gerarchie separate di MSF (morpho-
syntactic features);9 contenimento dei tag sotto i 70 (corollario di 4);10 espansione esplicita di ogni tag gerarchico (corollario di 7);11 ottimizzazione ed univocità delle labels (corollario di 5).
Tav. 7 (già Tav. 18 di Barbera (2008 i.s.)).

3.1.3. Il tagging
Ciò premesso, taggare un corpus, cioè associare ad ogni token la POS opportunascelta all’interno di un insieme definito (tagset) di valori (tag) ognuno con la propriaetichetta (label), significa computazionalmente che ogni posizione del corpus deveavere associato, oltre all’attributo word di default, un altro attributo, chiamato pos,il cui valore è un membro dell’insieme tagset. Non in tutti i corpora ciò è fatto (anzici sono scuole della corpus linguistics che ne teorizzano il farne deliberatamente ameno), non è infatti intrisecamente necessario perché un corpus sia un corpus (cf. ladefinizione data in precedenza); molti comunque convengono che ciò costituisca unforte “valore aggiunto”, e rappresenta una delle caratteristiche del CT cui più sforziho dedicato (gran parte del volume di cui sto discutendo è dedicato proprio a ciò).
3.2. IMPOSTAZIONE DEL PROBLEMA
Ed adesso, si dirà, la montagna ha partorito il topolino, tante premesse per unaquestione apparentemente ovvia: taggare un corpus rappresentativo di una data lin-gua è diverso dallo scrivere una grammatica della medesima lingua. Sotto questo ap-parente truismo, ci sono però molte questioni che sfuggirebbero ai non acuti occhi diMonsieur de Lapalisse, ed è su una di queste che vorrei sostare.
Sgombriamoci prima terminologicamente il cammino. Taggare un corpus è solola prima manifestazione pratica che attua quella teorica di studiare linguisticamenteun corpus, che si può anche tradurre in un oggetto metadescrittivo come gran partedel “volumone” di cui vi sto parlando. Giusto per semplificarci la vita nel parlare,propongo di chiamare il primo oggetto (la grammatica scientifica ideale, intesa come“descrizione scientifica di riferimento”, non come strumento, a vari titoli, “didat-tico”) grammatica descrittiva ed il secondo (la grammatica ottenuta da un corpus,corrispondente al suo tagging) grammatica corpus-based.
In generale, una grammatica descrittiva è tale se riesce a descrivere esauriente-mente ed efficacemente il complesso di regole che costituisce una data langue, o, sepreferiamo, quel complesso di regole che definisce la competence di un parlanteideale di quella lingua. Possiamo, nell’economia del presente discorso, fingere che ledue cose siano lo stesso, anche se, naturalmente, non lo sono, perché la cosa ci por-terebbe troppo lontano7.
Una grammatica corpus-based, invece, è tale se riesce a descrivere esauriente-mente ed efficacemente il complesso di regole di una data langue/competence chetrovano espressione nel corpus: queste non coincideranno idealmente mai col si-
40 Manuel Barbera
7 Ci si dovrebbe, tra l’altro, domandare se la competence, parlando di italiano antico, sia unobiettivo perseguibile o meno; il che, in altri termini, equivale a porre la domanda che cosa è unalingua morta? E: l’italiano antico va considerato una lingua morta come, ad es., l’ugaritico o l’it-tita? Ho le mie idee in proposito, peraltro espresse nel consueto “volumone”, ma non è qui il casodi imprunarvisi.

stema langue/competence completo, questo era infatti il senso della “scortesia” diChomsky, anche nella sua versione “temperata” à la Fillmore, in cui più mi ricono-sco. E quindi per me lo scopo ultimo di una grammatica corpus- based è il mede-simo, descrivere una langue/competence, ma con una doppia differenza.
(1) in negativo: una grammatica corpus-based è chiamata a costruire il frammentopiù ampio che può di una langue in base a quello che nel corpus ha attestato e quelloche a partire dagli spunti del corpus riesce a rinvenire altrove; se l’oggetto totale nonè raggiungibile non ha per ciò stesso fallito il suo compito; una vera grammatica de-scrittiva, invece, se non riesce olisticamente a descrivere una competence è issofattofallita.
(2) in positivo: nulla presente nel corpus può passare sotto silenzio ed ogni singolotoken deve sempre avere un valore discreto ed esplicito dell’attributo pos espresso;una grammatica descrittiva può onestamente scegliere di tacere o piuttosto eviden-ziare singole regole perché meglio ne riesca la descrizione del sistema complessivo,o furfantescamente scegliere di “oscurare” questioni che non riesce a spiegare, senzache poi l’utilizzatore della grammatica se ne riesca facilmente ad accorgere.
È su questo secondo aspetto che voglio soffermarmi, perché le sue due implica-zioni, che esaminerò partitamente anche se nei fatti sono perlopiù intrecciate (comesi vedrà dai due esempi che ne farò), sono entrambe rilevanti, anche in sede storio-grafica e teorica.
3.2.1. L’obbligatorietà del tag
Essere obbligati a tutto interpretare, senza poter nascondere le schifezze fasti-diose ramazzandole sotto il tappeto, è certo una cosa eticamente ed epistemologi-camente salutare, anche se a volte scomoda ed imbarazzante: lo svantaggio è chequestioni inerentemente ambigue del tipo di la porta è aperta (perché è stata apertada qualcuno o perché si trova aperta?) vanno comunque in qualche modo risolte (macf. il punto successivo); il vantaggio è che si è impossibilitati a cadere nella tentazionedi non affrontare questioni che già si sanno ingrate: non c’è trucchi, e nel librone,nella fattispecie, troverete francamente esibiti anche quegli scheletri che sarebbeparso più “di buon gusto” nascondere nell’armadio.
Storiograficamente, è questo uno di quei punti che pone sulla stessa linea lingui-stica filologica d’antan e presente corpus linguistics, nesso per me assai importante.Anche il filologo-linguista di un tempo doveva poter rendere conto di tutte le formepresenti nel testo che editava, e parimenti doveva sempre disambiguare laddove fosseil caso (che <ja> grafico in un testo oitanico, ad esempio, fosse da stampare ja, epertanto da considerare il normale avverbio < JAM, o piuttosto j’a, e quindi da con-siderare un peculiare piccardismo per ‘io ho’, è scelta cui non poteva sottrarsi); al-trettanto, però, non era chiamato ad esprimersi su questioni in absentia: se nel suotesto (sempre ipoteticamente oitanico) non ci fosse stato alcun condizionale secondodi faire, nessuno avrebbe preteso che l’editore ci dicesse come sarebbe dovuta esseretale forma nella lingua dell’autore che sta pubblicando.
Intorno a “Schema e storia del Corpus Taurinense” 41

3.2.2. La discretezza del tag
La questione della porta aperta che dicevamo prima ci introduce ad un altroaspetto eticamente ed epistemologicamente salutare della corpus linguistics: la ten-tazione di ricorrere a continua, “fluidi”, “scale” ed altre consimili diavolerie escogi-tate dalla linguistica moderna per evitare di decidere alcunché in questioni complesseè negata per principio, in quanto il valore di un attributo deve essere una entità di-screta.
Infatti, visto che la POS è una entità metalinguistica, che senso avrebbe se fosse“elastica”? L’utilità di un metro di gomma non può essere sostenuta neanche dal piùspudorato geometra truffaldino di questo mondo. Non sembra, invece, putroppo im-barazzare affatto molti linguisti moderni. Non credo, personalmente, che neppurerealisticamente8 simili categorie “colloidali” e “sfuggenti” abbiano alcuna sostanza,ma non è questa la sede per dimostrarlo: metalinguisticamente, la cosa dovrebbe es-sere ovvia, e spero possa servire a rintuzzare un malcostume diffuso.
Non si creda, tra l’altro che il rifiuto dei continua comporti per ciò stesso un ma-nicheismo naif. La logica moderna, dai sistemi a valore variabile di verità inauguratida Łukasiewicz e perfezionati dalla logica polacca, alle più recenti logiche fuzzy, ci hainsegnato perfettamente a maneggiare in modo responsabile oggetti per cui tertium(e ben oltre) datur senza ricorre a cialtronerie che equivalgono a gettare la spugna,facendo però finta di no. La lezione della corpus linguistics è quindi anche metodo-logicamente interessante per la linguistica contemporanea.
3.3. ESEMPI
Ma alcuni esempi tratti dal consueto librone dovrebbero illustrare più efficace-mente come questo obbligo dell’esplicitezza e della discretezza si sostanzi nei fatti (aldi là di far lavorare il linguista di corpora quindici volte più dello scansafatiche “lin-guista dei continua”), e come le esperienze descritte da Schema e storia abbiano,spero, interesse anche fuori dei cultori dell’italiano antico e da quelli della lingui-stica dei corpora.
3.3.1. Il clitico ne
Nell’italiano antico del CT la stringa di caratteri <ne> sembra avere quattro va-lori, come riassunto nella tavola seguente, cioè, come si dice usualmente in CL, tran-scategorizza tra quattro valori:
42 Manuel Barbera
8 Anzi, di solito uno dei problemi principali della realtà è proprio che non riusciamo molto asfuggirne, e che quando ci battiamo il naso dentro la troviamo di consistenza tutt’altro che “fluida”.Sulla nozione di continuum si veda peraltro il recente contributo di Venier (1998), meno delibe-ratamente ostile, ma serio e ben argomentato.

Tav. 8 (dalla Tav. 124 + ess. 82a, 83a, 84 e 85 di Barbera (2009)).
In molti casi, come negli esempi esibiti nella tavola, la scelta del valore appro-priato è evidente; in altri è, almeno per un italiano moderno, apparentemente inde-cidibile, potendosi dare entrambi i due valori centrali. Come ho dimostrato inBarbera (2008) e Barbera - Fesenmeier (2010), e poi ripetuto in Barbera (2009: 217-234), esistono dei criteri testuali abbastanza netti per decidere, ed il frutto di tali de-cisioni sono le cifre esibite nell’ultima colonna della tabella. Non solo, vi sonoelementi per sostenere che l’ambiguità in questione non esistesse affatto per un fio-rentino del Duecento: ossia che nella competence di un parlante nativo vi fosserosolo quattro valori netti, e non esistesse un “quinto valore” consapevolmente ambi-guo (l’alternanza regolare tra ‘di quello’ ed ‘a noi’, in ispecie, si ha sistematicamentenelle partite di conto di mercanti e banchieri, dove l’esplicitezza è fuor di discus-sione). Niente continua, quindi.
3.3.2. Valori del type d’
Un caso diverso e più difficile è quello della stringa di caratteri <d’>: avremo ache fare con forme apocopate di di o di da, o di nessuno dei due? Quantitativamente
Intorno a “Schema e storia del Corpus Taurinense” 43
kat (p.3) pos (p.2) pos (label espansa) glossa # token
46 adv.pc adverb.particle ne avverbiale e lo-cativo
154
E poi ch’ i’ l’ ei pensato , | n’ [46] andai davanti lei | e driz-zai gli occhi miei | a mirar suo corsaggio . (Brunetto, Tesoretto, j.2, v.245, p.184)
31 pd.dem.w pro-det.demonstrative.weak ne dimostrativo epartitivo
642
E se sentirete le dette pene stando ne ÷l mondo , non vo’ | cheve ne [31] crucciate né vi lamentiate di me , ma con molta pa-zienzia | le portiate in pace per mio amore . (Bono, Libro Vizi, vj.12, p.17)39 pd.per.w.ob pro-det.personal.weak.obli-
quene personale di 1p 168
Quando lo Nostro Signore Gesù Cristo parlava umanamente | connoi , in fra l’ altre sue parole ne [39] disse che de ÷ll’ |abondanza de ÷l cuore parla la lingua . (Novellino, 0.1, p. 117)
56 adp.pre adposition.preposition preposizione in 1513
Lamentando ÷mi duramente ne [56] ÷lla profundità d’ una oscuranotte | ne [56] ÷l modo che avete udito di sopra , e dirottamentepiangendo | e luttando , m’ apparve sopra capo una figura , […](Bono, Libro Vizi, ij.1, p. 47)

token # lemma # pos #
d’ 1.483 di 1.254 pre 1.087
(inc. D’) (inc. 7) conj 167
da 45 pre 39
conj 6
di;da 184 pre 178
conj 6
Tav. 9.
La situazione, come vedete, è meno netta che nel caso precedente, e sembra es-servi un residuo inanalizzato; non solo, se le inferenze che sviluppo nel volume sonocorrette, è probabile che, almeno in parte, non tanto di “residuo inanalizzato” si tratti,quanto di dato in re, esistente nella competence dei parlanti fiorentini del Duecento.Già mi vedo i virtuosi dei continua fare finta di spiegare la cosa dicendo che di e dasono i due poli prototipici di una scala sul cui continuum9 si piazzerebbero i valoridella varie forme occorrenti. Non è così. Penso invece che la competence del nostroparlante avesse due lemmi di e da, i cui usi avevano zone di sovrapposizione; alcunedi queste zone di sovrapposizione funzionale coincidevano poi con le neutralizza-zioni fonologiche causate dai regolari procedimenti fonosintattici della lingua: si sa-rebbe venuto così a costituire un sistema a tre valori, uno di, uno da, ed uno“neutralizzato”, intersezione dei due insiemi precedenti. Elementi esterni possonoeventualmente disambiguare i neutralizzati, che in sé non si trovano su una scala mo-bile tra di e da, ma che hanno un valore discreto espresso dalla nostra etichetta di; da.
4. CONCLUSIONI
Con questa breve carrellata, credo di avere mostrato la rilevanza anche per la lin-guistica generale, oltre che per la filologia romanza e digitale e per la corpus lingui-
9 Forse “[di]—[dI]—[de]—[dε]—[dæ]—[da]” ?!?
44 Manuel Barbera
(quasi 1.500 token nel CT) e qualitativamente è un problema di quelli che si prefe-rirebbe evitare: solo per abbozzarne una soluzione in Schema e storia mi ci sono vo-lute ben 200 pagine (pp. 714-918); è forse questo l’esempio più evidente del costo intermini di lavoro che comporta accettare la schiettezza epistemologica imposta dallacorpus linguistics.
Le conclusioni cui sono pervenuto sono riassunte nella tavola seguente (in cui il<;> vale ‘or’ o V)

Intorno a “Schema e storia del Corpus Taurinense” 45
stics, delle esperienze narrate in Schema e storia. Spero anche di avere introdottoquello sfondo teorico del problema della disambiguazione che viene affrontato in-formaticamente dal contributo di Tomatis in questo stesso volume. Ma soprattutto,e questa è la conclusione vera anche se smaccata: compratemi!
BIBLIOGRAFIA
ANTONY, Louise M. / HORNSTEIN, Norbert (eds.), 2003, Chomsky and his critics, Malden(MA) - Oxford, Blackwell Pub., “Philosophers and their critics” 10.
/Aristotélouj Perì 2rmhneíaj: Aristotelis opera. Edidit Academia Regia Borusica.Volumen primum. Aristoteles graece ex recensione Immanuelis Bekkeri, Volumenprius, Berolini, apud Georgium Reimerum - ex Officina Academica, 1831, pp. 16-24.Cf. Aristote, Organon. I Catégories, II De l’interprétation, traduction nouvelle etnotes par J[ules] Tricot, Paris, Librairie Philosophique J. Vrin, 1997 “Bibliothèquedes textes philosophiques”.
BARBERA, Manuel, 2000 i.s., “Italiano antico e linguistica dei corpora: un Tagset per Ita-lAnt”, intervento al convegno SILFI 2000, Duisburg, 8 giugno - 2 luglio 2000, in corsodi stampa negli Atti. Abstract reperibile online: http://www.uniduisburg.de/FB3/SILFI/SILFI2000/abstracts/ papers/Barbera_co040.html.
BARBERA, Manuel, 2002, Introduzione alla linguistica generale. Corso online (dal 29 di-cembre 2002, ultima revisione del 2 ottobre 2010): http://www.bmanuel.org/corling/corling_idx.html.
BARBERA, Manuel, 2007a, “Un tagset per il Corpus Taurinense. Italiano antico e lingui-stica dei corpora”. In: BARBERA / CORINO / ONESTI (2007a): 135-168.
BARBERA, Manuel, 2007b, “Mapping dei tagset in bmanuel.org / corpora.unito.it. Traguide lines e prolegomeni”. In: BARBERA / CORINO / ONESTI (2007a): 373-388.
BARBERA, Manuel, 2008 i.s, “Partes Orationis”, “Parts of Speech”, “Tagset” e dintorni.Un prospetto storico-linguistico. Revisione della lezione tenuta a Basilea il 9 maggio2008, presso l’Istituto di Italianistica dell’Universität Basel, col titolo Parti del di-scorso ed annotazione di corpora elettronici.
BARBERA, Manuel, 2008, “Per una grammatica testuale del Libro di conti: il clitico nenel Libro Riccomanni”. In: FERRARI (2009), vol. I: 205-225.
BARBERA, Manuel, 2009, Schema e storia del “Corpus Taurinense”. Linguistica dei cor-pora dell’italiano antico, Alessandria, Edizioni dell’Orso.
BARBERA, Manuel / CORINO, Elisa / ONESTI, Cristina (a c. di), 2007a, Corpora e lingui-stica in rete, Perugia, Guerra Edizioni, “L’officina della lingua. Strumenti” 1.
BARBERA, Manuel / CORINO, Elisa / ONESTI, Cristina, 2007b, “Cosa è un corpus? Per unadefinizione più rigorosa di corpus, token, markup”. In: BARBERA/ CORINO /ONESTI(2007a): 25-88.
BARBERA, Manuel / FESENMEIER, Ludwig, 2010, “(Ri)fare i conti: Überlegungen zu einer(Neu)Edition altitalienischer Kontobücher”. In: Romania urbana. Die Stadt des Mit-telalters und der Renaissance und ihre Bedeutung für die romanischen Sprachen undLiteraturen, herausgegeben von Sabine HEINEMANN / Rembert EUFE, München: Mar-tin Meidenbauer, “Mittelalter und Renaissance in der Romania” 3: 127-146.
BECK, David, 2004, “Prototypical Conceptual Types and Typological Variation in Parts-

46 Manuel Barbera
of-Speech Systems”, presented to the Conference on Conceptual Structure, Dis-course, and Languages, University of Alberta 2004. Online: http://www.ualberta.ca/~dbeck/CSDL2004.pdf.
BERGMAN, Mats / PAAVOLA, Sami (eds.), 2003, The Commens Dictionary of Peirce’sTerms. Peirce’s Terminology in His Own Words. Sito: http://www.helsin ki.fi/sci-ence/commens/dictionary.html.
BIBER, Douglas / CONRAD, Susan / REPPEN, Randi / AITCHISON, Jean, 1998, Corpus Lin-guistics: Investigating Language Structure and Use, Cambridge, Cambridge Univer-sity Press, “Cambridge Approaches to Linguistics”.
CARNAP, Rudolf, 1934/3, The Logical Syntax of Language, English translation by AmetheSmeaton Countess von Zeppelin, London, Routledge & Kegan Paul, 1937 [19677;edizione originale Logische Syntax der Sprache, Wien 1934].
CARNAP, Rudolf, 1963/74, “Autobiografia intellettuale”. In: SCHILPP (1963/74): 1-85 e997-998. [Edizione originale: Intellectual Autobiography, in SCHILPP 1963].
CHOMSKY, Noam, 1959/67, “Review” of B[urrhus] Frederik Skinner, Verbal Behaviour(New York, Appleton - Century - Crofts, 1957). In Language 35: 26-58; poi, con unanuova prefazione (pp. 142-143) anche in JAKOBOVITS / MIRON (1967): 142sgg. Di-sponibile online: http://cogprints. org/1148/0/chomsky.htm.
CHOMSKY, Noam, 1966, Cartesian Linguistics. A Chapter in the History of RationalistThought, New York, Harper & Row; ristampa: Lanham (MD) - New York (NY) -London (EN), University Press of America, 1983.
CHOMSKY, Noam, 2000, New Horizons in the Study of Language and Mind, Cambridge,Cambridge University Press.
CHRIST, Oliver / SCHULZE, Bruno M[aximilian] / HOFMANN, Anja / KÖNIG, Esther, 1999,The IMS Corpus Workbench: Corpus Query Processor (CQP). User’s Manual,Stuttgart, Institut für maschinelle Sprachverarbeitung, August 16, 1999 (CQP V2.2),online come file HTML (http://www.im s.uni-st uttgart.de/projekte/CorpusWork-bench/CQPUserManual/HTML/), PS (http://www.ims.uni-stuttgart. de/projekte/Cor-pusWorkbench/CQPUserManual/PS/cqpman.ps.gz) o PDF (http://www.ims.uni-stuttgart. de/projekte/CorpusWorknbench/CQPUserManual/PDF/cqpman.pdf).
DOMOKOS, Györgyi / SALVI, Giampaolo (eds.), 2002, Lingue romanze nel Medioevo. Attidel convegno, Piliscsaba, 22-23 marzo 2002, = Verbum. Analecta Neolatina 4/2: 267-526.
FERRARI, Angela (a c. di), 2009, Sintassi storica e sincronica dell’italiano: subordina-zione, coordinazione, giustapposizione. Atti del X Congresso della Società di Lin-guistica e Filologia Italiana (Basilea, 30 giugno - 3 luglio 2008), a cura di Ferrari,Firenze, Franco Cesati Editore, 3 volumi.
FILLMORE, Charles J., ““Corpus linguistics” or “Computer-aided armchair linguistics””.In: SVARTVIK (1992): 35-60.
GRAFFI, Giorgio, 1994, Sintassi, Bologna, il Mulino, “Strumenti. Le strutture del lin-guaggio” [4].
GRAFFI, Giorgio, 2001, 200 Years of Syntax. A Critical Survey, Amsterdam - Philadelphia,John Benjamins Publishing Company, “Amsterdam Studies in the Theory and Historyof Linguistic Science. Series III. Studies in the History of the Language Science” 98.
HAACK, Susan, 1997, Deviant Logic, Fuzzy Logic. Beyond the Formalism, Chicago - Lon-don, The University of Chicago Press.

Intorno a “Schema e storia del Corpus Taurinense” 47
HASPELMATH, Martin, 2001, “Word Classes / Parts of Speech”. In: BALTES, Paul B. /SMELSER, Neil J. (eds.), International Encyclopedia of the Social and Behavioral Sci-ences, Amsterdam, Pergamon: 16538-16545. Anche ondine: http://email.eva.mpg.de/~haspelmt/2001wcl.pdf.
JAKOBOVITS, Leon A. / MIRON, Murray S. (eds.), 1967, Readings in the Psychology ofLanguage, [Upper Saddle River, NJ], Prentice-Hall Inc.
KANT, Immanuel Kant, 1787/1910/91, Kritik der reinen Vernunft: Zweite hin und wiederverbesserte Auflage, Riga, Hartnoch, 17872 [17811]. Trad. it. di Giovanni Gentile eGiuseppe Lombardo-Radice, Critica della ragion pura, Roma - Bari, Laterza, 199122
“Biblioteca Universale Laterza” 19 [19101 “Classici della filosofia moderna”].KLAVANS, Judith L. / RESNIK, Philip (eds.), 1996, The Balancing Act. Combining Symbolic
and Statistical Approaches to Language, Cambridge (Mass.) - London (England),MIT Press.
LEMNITZER, Lothar / ZINSMEISTER, Heike, 2006, Korpuslinguistik: eine Einführung, Tü-bingen, Gunter Narr Verlag, “Narr Studienbücher”.
MCENERY, Tony / WILSON, Andrew, 2001, Corpus Linguistics. An Introduction, Edin-burgh, Edinburgh University Press, 20012 [19961, 2005r] “Edinburgh Textbooks inEmpirical Linguistics”.
MANNING, Christopher D. / SCHÜTZE, Hinrich, 1999, Foundations of Statistical NaturalLanguage Processing, Cambridge (Massachusetts) - London (England), The MITPress, 20003 [19991].
MAZZOLENI, Marco, 1999, “Il prototipo “cognitivo” ed il prototipo “linguistico”: equi-valenti o inconciliabili?”. In Lingua e stile 34/1: 51-66.
MITKOV, Ruslan (ed.), 2003, The Oxford Handbook of Computational Linguistics, Ox-ford, Oxford University Press.
MONACHINI, Monica, 1996, ELM-IT: EAGLES Specifications for Italian Morphosyntax- Lexicon Specifications and Classification Guidelines, Pisa, EAGLES DocumentEAG-CLWG-ELM-IT/F, May 1996.
MONACHINI, Monica / CALZOLARI, Nicoletta, 1996, Synopsis and Comparison of Mor-phosyntactic Phenomena Encoded in Lexicons and Corpora. A Common Proposaland Application to European Languages, Pisa, EAGLES Document EAG-CLWG-MORPHSYN/R, May 1996. Disponibile online alla pagina: http:// www.ilc.cnr.it/EA-GLES/browse.html.
PEIRCE, Charles Sanders, 1906/31-58, Prolegomena to an Apology for Pragmaticism,1906, in Collected Papers of Charles Sanders Peirce, 8 volumes, vols. 1-6, eds. CharlesHartshorne and Paul Weiss, vols. 7-8, ed. Arthur W. Burks. Cambridge (Mass.), Har-vard University Press, 1931-1958, vol. IV.
RENZI, Lorenzo (a c. di), 1998, ITALANT: per una Grammatica dell’Italiano Antico, Pa-dova, Centro Stampa di Palazzo Maldura.
RENZI, Lorenzo, 2002, “Il progetto ItalAnt e la “grammatica del corpus””. In: DOMOKOS/ SALVI (2002): 271-294.
RENZI, Lorenzo / SALVI, Giampaolo (a c. di), 2010, Grammatica dell’italiano antico [Ita-lAnt], Bologna, il Mulino.
SAMPSON, Geoffrey, 1995, English for the Computer. The SUSANNE Corpus and An-notation Scheme, Oxford, Clarendon Press.
SAMPSON, Geoffrey, 2001, Empirical Linguistics, London - New York, Continuum.

48 Manuel Barbera
SAMPSON, Geoffrey / MCCARTHY, Diana (eds.), 2004, Corpus Linguistics. Readings in aWidening Discipline, London - New York, Continuum.
SAUSSURE, Ferdinand de, 1916/67/95, Cours de linguistique générale, publié par CharlesBailly et Albert Séchehaye, avec la collaboration de Albert Riedingler, édition cri-tique préparée par Tullio de Mauro, postface de Louis-Jean Calvet, Paris, Payot, 2001r
[19953, 19721] “Grande bibliothèque Payot”. Edizione originaria: ibidem, 1916. Edi-zione italiana: Corso di linguistica generale, introduzione traduzione e commento diTullio De Mauro, Roma - Bari, Laterza, 19671.
SCHILPP, Paul Arthur (a c. di), La filosofia di Rudolf Carnap, trad. di Maria Grazia Cri-stofaro Sandrini, Milano, il Saggiatore, 1974 “Biblioteca di filosofia e metodo scien-tifico”. [Edizione originale: The Philosophy of Rudolf Carnap, edited by P[aul]A[rthur] Schilpp, La Salle (Illinois), 1963 “The Library of Living Philosophers”].
SCHÖNBERG, Arnold, 1933/50/60, “Brahms il progressivo”, conferenza tenuta il 12 feb-braio 1933 e poi riprodotta rielaborata in SCHÖNBERG (1950/60): 56-104.
SCHÖNBERG, Arnold, 1950/60, Style and Idea, New York, Philosophical Library, 1950.Traduzione italiana di Maria Giovanna Moretti e Luigi Pestalozza: Stile e idea, conun saggio di Luigi Pestalozza, Milano, Feltrinelli, 19803 [19752, 19601] “I fatti e le idee.Saggi e biografie” 293.
SINCLAIR, J[ohn] M[cHardy] Sinclair (ed.), 1987, Looking up: an Account of theCOBUILD Project in Lexical Computing and the Development of the CollinsCOBUILD English Language Dictionary, edited by London - Glasgow, Collins ELT.
SVARTVIK, Jan (ed.), 1992, Directions in Corpus Linguistics. Proceedings of the NobelSymposium 82. Stockholm, 4-8 August 1991, Berlin, Mouton de Gruyter, “Trends inLinguistics. Studies and Monographs” 65.
TOGNINI-BONELLI, Elena, 2001, Corpus Linguistics at Work, Amsterdam - Philadelphia,John Benjamins Publishing Company, “Studies in Corpus Lingui stics” 6.
VENIER, Federica, 2008, “Cosa c’è dietro al continuum. Riflessioni sulla polifunzionalitàdi alcuni elementi dell’italiano (avverbio / preposizione, pronome / congiunzione …)”.In: FERRARI (2009), vol. II: 857-882.
WITTGENSTEIN, Ludwig, 1941-7/53/67, Philosophische Untersuchungen, ds., 1941-47, poiOxford, Basil Blackwell, 1953. Edizione italiana: Idem, Ricerche filosofiche, edizioneitaliana a cura di Mario Trinchero, Torino, Einaudi, 19835 “Paperbacks” 148 [19671].
Manuel BarberaDipartimento di
Università degli Studi di [email protected]
Related Documents











