Web Crawling Tools and Services from the Internet Archive: Archive-It and Contract Crawling Courtney C. Mumma, Internet Archive November 17, 2016 - Dutch Institute for Sound and Vision

Internet Archive: Archive-It and Contract Crawling, C. Mumma
Apr 16, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Web Crawling Tools and Services from the Internet Archive: Archive-It and Contract Crawling
Courtney C. Mumma, Internet ArchiveNovember 17, 2016 - Dutch Institute for Sound and Vision

Talk overview● Archiving the web at IA● Partnerships and services
○ Contract crawls○ Archive-It
■ Research Services○ Interoperability & Distributed Preservation
● New technology for new challenges

The Internet ArchiveNon-Profit Library
Founded in 1996 by Brewster Kahle
Universal Access to All Knowledge

30,000,000,000,000,000 Bytes Archived(30 PetaBytes)
20 Years of Archiving the Web500,000,000,000+ URLs
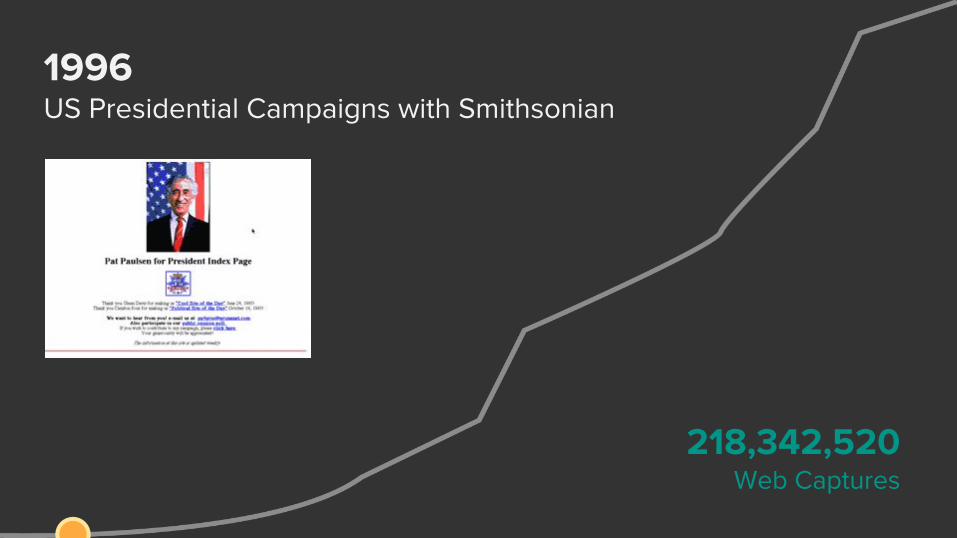
1996 US Presidential Campaigns with Smithsonian
218,342,520 Web Captures

1997 First Full Crawl
525,362,846Web Captures

1998 Donation of Crawl to the Library Of Congress
1,166,891,826Web Captures
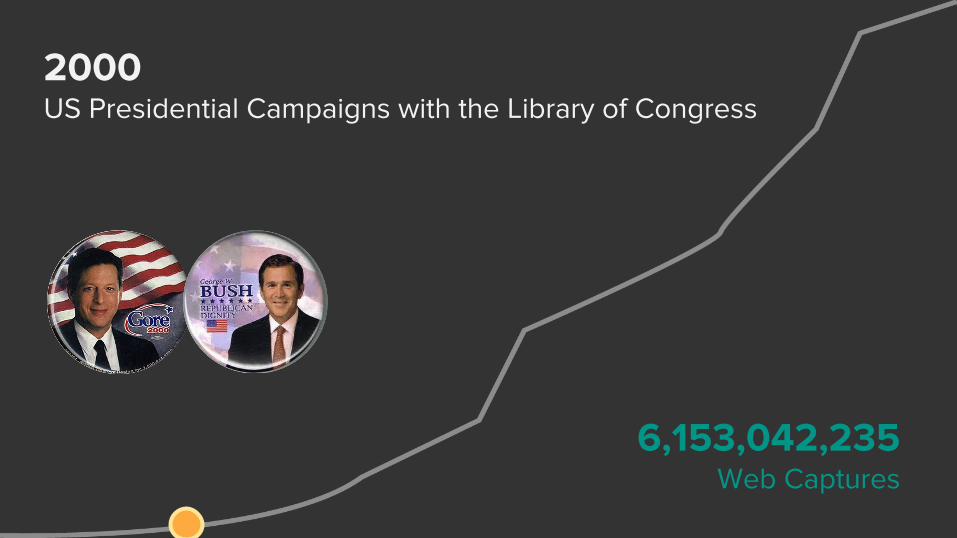
2000US Presidential Campaigns with the Library of Congress
6,153,042,235Web Captures

2001Launch of the WayBack Machine
12,082,859,018Web Captures
2003International Internet Preservation Consortium Founded
38,868,116,181Web Captures

2006Archive-It Started
103,943,903,726Web Captures

2007Ireland
184,277,909,308Web Captures

2008National Archive Government Crawls
209,160,715,829Web Captures

2009Archive-It Adds its 100th Partner7 National Library Partners
225,658,093,516Web Captures
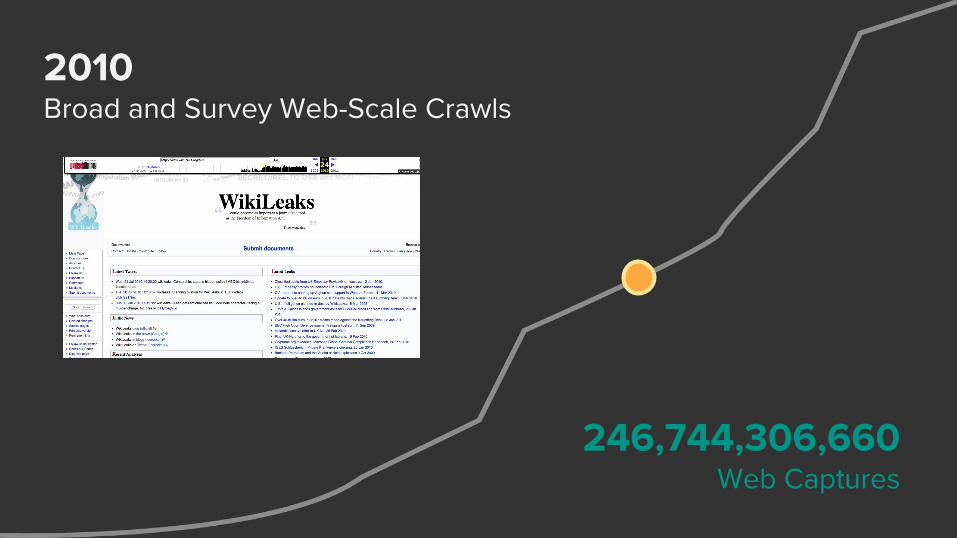
2010Broad and Survey Web-Scale Crawls
246,744,306,660Web Captures
2015Archive-It Adds its 400th Partner
467,195,419,069
Web Captures


Global Wayback
● Broad snapshot
● Deep crawl on popular
sites
● Broad crawl on known
domains
● No more 404s
● On-demand
● Donated and targeted crawls
● https://web-beta.archive.org/
with KEYWORD SEARCH
and more!

Support Open Source Software

Web Archiving Partnerships and Services

Domain Scale Web Preservation

Contract CrawlingDomain-scale • Run by Internet Archive • Average 300 million URLs per collection
Partial List of Partners• National Libraries of Australia and New Zealand• U.S. National Archives and Library of Congress• Luxembourg National Library• Israel National Library
Partial List of Collections• Iraq War (2003-2011)• 2005 US Supreme Court Nominations

Archive-ItCurated, Selective Web Archiving

Archive-It
Web based - nothing to install
Fully hosted service with
unlimited support
Simple to select, manage, scope
and catalog with metadata
10 different crawl frequencies
Includes quick access and
storage
html, videos, audio, social
media, PDFs, images, news
Full text search
Restricted access options
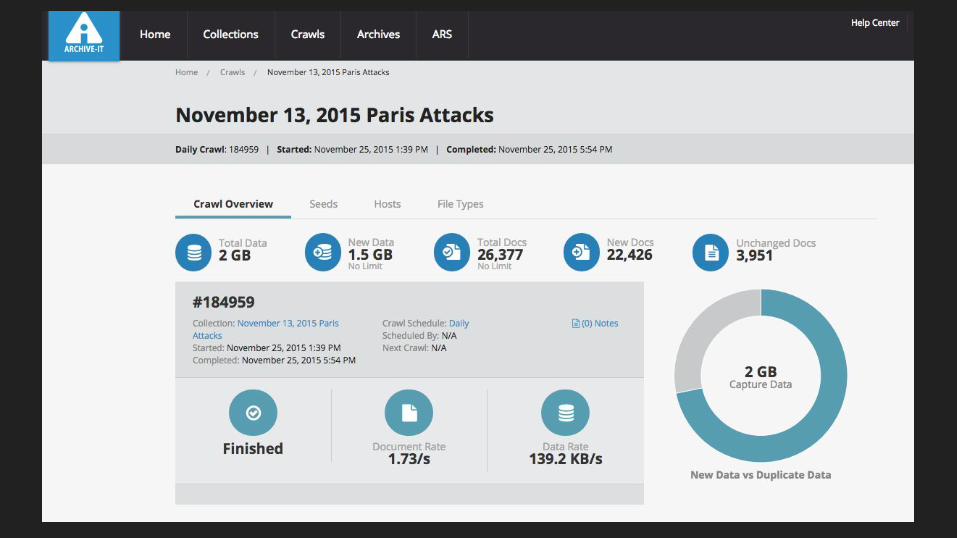

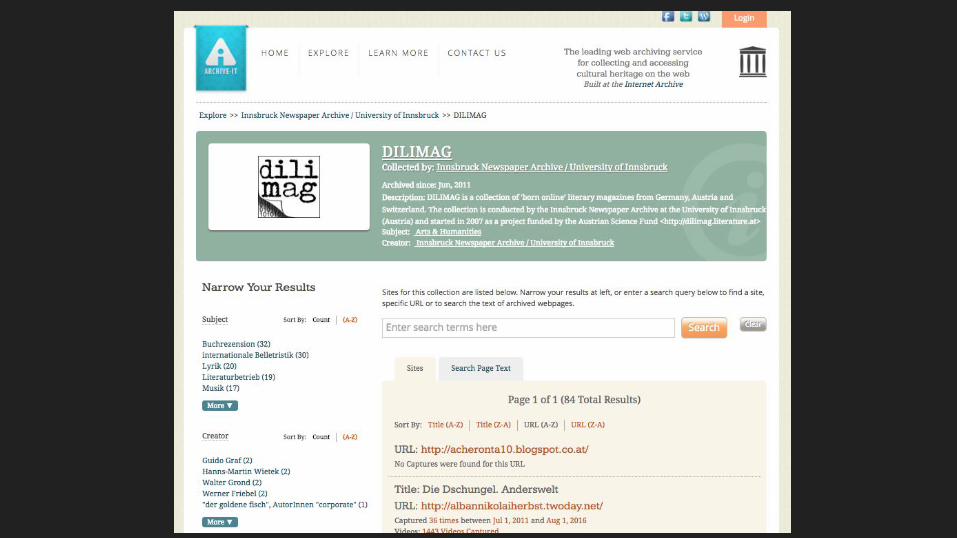

How our partners use Archive-It
● Enhance and supplement traditional offline collections ○ archives, topical collections
● Support records retention and archival policies● Capture event-based content
○ Spontaneous○ Planned
● Individual organizations and Consortial collaboration

Research Services

Goals of Archive-It Research Services
● Expand access models for web archives
● Enable new insights into collections
● Leverage Internet Archive infrastructure for large-scale
processing to produce datasets for research
● Facilitate computational analysis and new use cases
● Increase use, visibility, and value of Archive-It partner
collections

Web Archives Datasets
Archive-It Research Serviceshttp://bit.ly/ait_ars

Exploring the Canadian Political Interest Group and Political Parties Web Sphere via WAT files
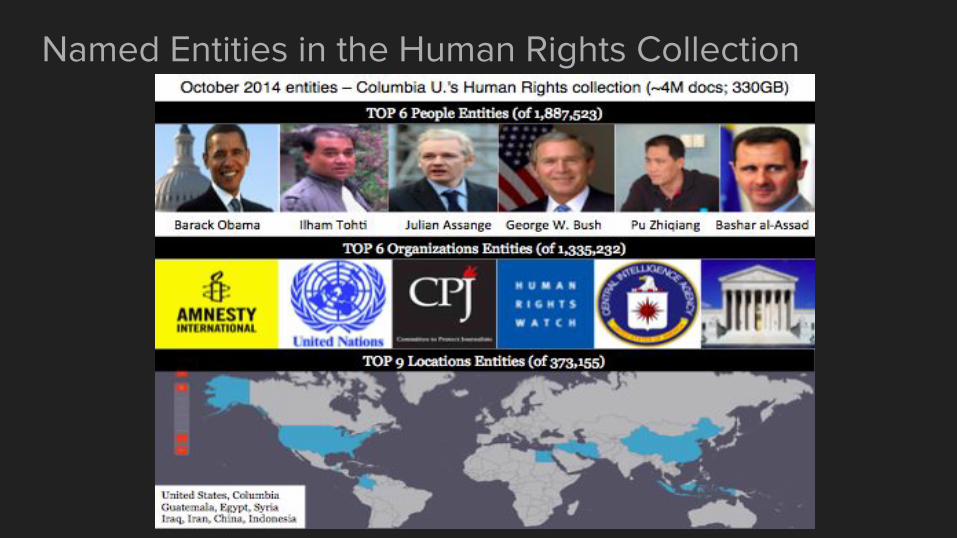
Named Entities in the Human Rights Collection

Systems Interoperability and Distributed Preservation

Lost in the maze in Labyrinth (1986, LucasFilm, screen capture)
WARCs, CDXs
and derivatives
Access
Storage
Preservation
Content Mgmt
Web Archiving Tools


APIs(*application programming interfaces)
● Interoperability ● Flexibility and modularity● Loose coupling of services (so we can improve pieces as
needed)● Scalability - Bulk data upload and download

New technology to face new challenges


Ongoing efforts
• Open Wayback
• Social media / Dynamic content
– Brozzler and Umbra (Archive-It)
– Social Feed Manager (GWU)
• URL nomination tools (UNT)
• Capture tools (GWU, IA, Rhizome)
• WASAPI - Community building and API
• Memento
BROZZLER!

Related Documents











