Institute of Computer Sci ence, Prague 1 Neural Networks Marcel Jiřina

Institute of Computer Science, Prague 1 Neural Networks Marcel Jiřina.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Institute of Computer Science, Prague
1
Neural NetworksMarcel Jiřina

Institute of Computer Science, Prague
2
Introduction
Neural networks and their use to classification and other tasks
ICS AS CR Theoretical computer science Neural networks, genetic alg. and nonlinear methods Numeric algorithms ..1 mil. eq. Fuzzy sets, approximate reasoning, possibility th. Applications: Nuclear science, Ecology,
Meteorology, Reliability in machinery, Medical informatics …

Institute of Computer Science, Prague
3
Structure of talk
NN classification Some theory Interesting paradigms NN and statistics NN and optimization and genetic algorithms About application of NN Conlusions
Institute of Computer Science, Prague
4
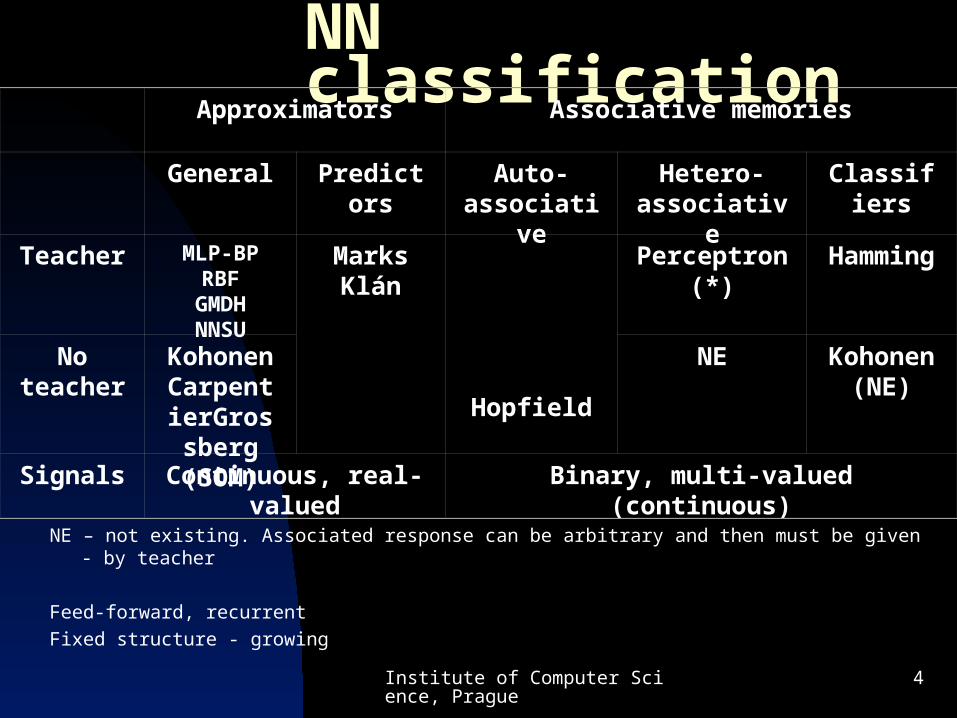
NN classification
NE – not existing. Associated response can be arbitrary and then must be given - by teacher
Feed-forward, recurrent
Fixed structure - growing
Approximators Associative memories
General Predictors Auto-associative
Hetero-associative
Classifiers
Teacher MLP-BPRBF
GMDHNNSU
MarksKlán
Hopfield
Perceptron(*) Hamming
No teacher
KohonenCarpentierGrossberg
(SOM)
NE Kohonen(NE)
Signals Continuous, real-valued Binary, multi-valued (continuous)

Institute of Computer Science, Prague
5
Some theoryKolmogorov theorem
Kůrková – Theorem
Sigmoid transfer function
Institute of Computer Science, Prague
6
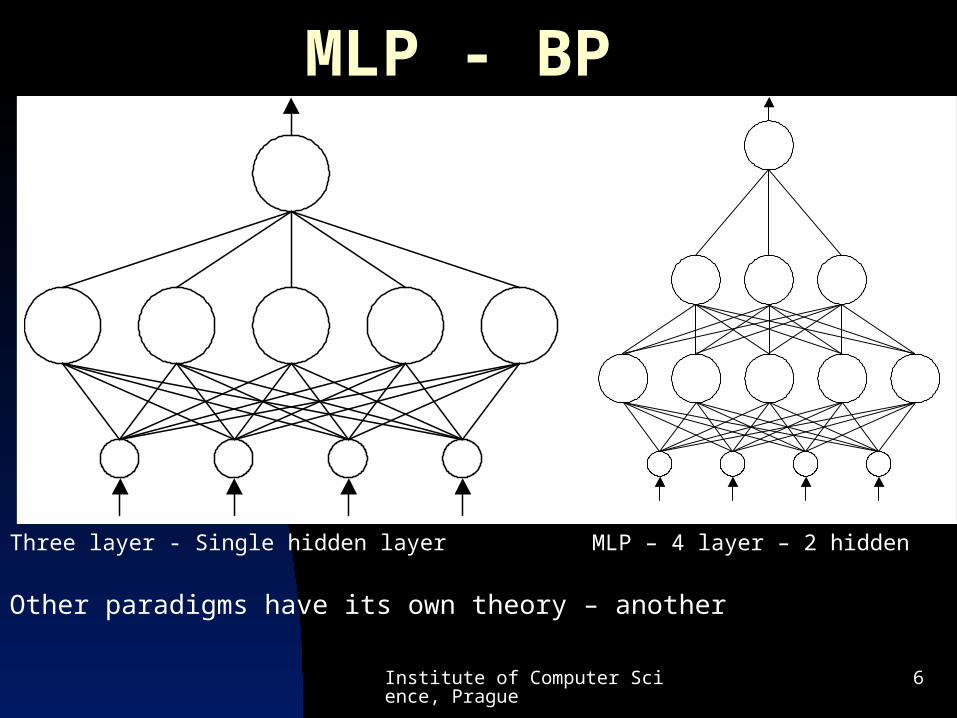
MLP - BP
Three layer - Single hidden layer MLP – 4 layer – 2 hidden
Other paradigms have its own theory – another

Institute of Computer Science, Prague
7
Interesting paradigmsParadigm – general notion on structure, functions
and algorithms of NN MLP - BP RBF GMDH NNSU
All: approximators
Approximator + thresholding = Classifier
Institute of Computer Science, Prague
8
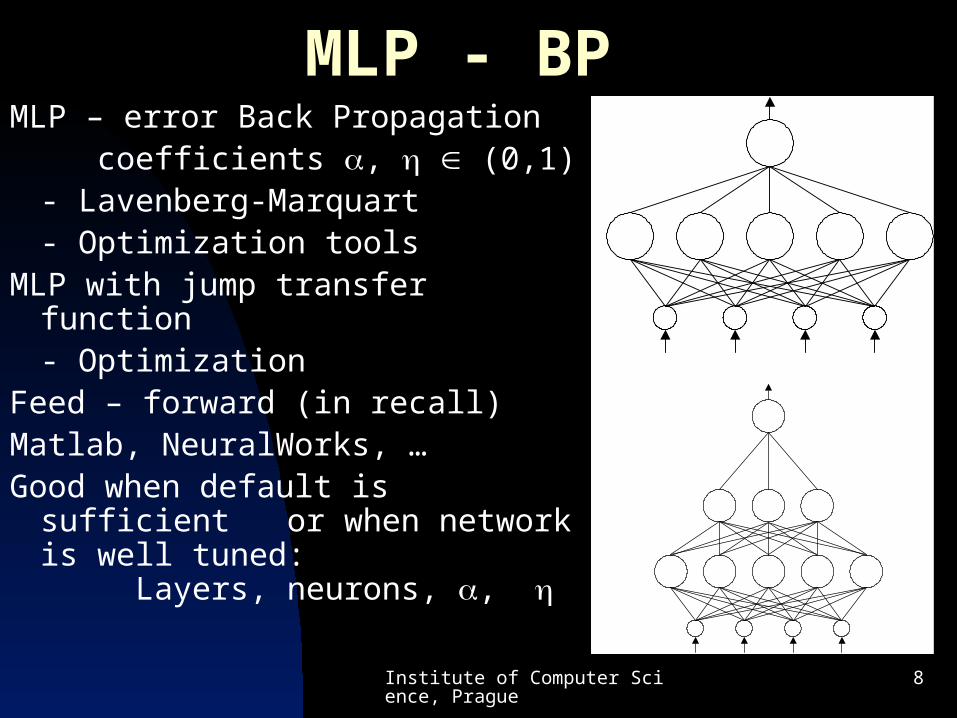
MLP - BPMLP – error Back Propagation
coefficients , (0,1)- Lavenberg-Marquart- Optimization tools
MLP with jump transfer function- Optimization
Feed – forward (in recall)Matlab, NeuralWorks, …Good when default is sufficient
or when network is well tuned: Layers, neurons, ,

Institute of Computer Science, Prague
9
RBF Structure same as in MLP Bell-shaped transfer function (Gauss)
Number and positions of centers: random – cluster analysis “broadness” of that bell Size of individual bells Learning methods
Theory similar to MLP Matlab, NeuralWorks, …
Good when default is sufficient or when network is well tuned : Layers mostly one hidden, # neurons, transfer function, proper cluster analysis (fixed No. of clusters, variable? Near – Far metric or criteria)

Institute of Computer Science, Prague
10
GMDH 1 (…5)Group Method Data Handling
– Group – initially a pair of signals only
“per partes” or successive polynomial approximator Growing network “parameterless” – parameter-barren
– No. of new neurons in each layer only (processing time)– (output limits, stopping rule parameters)
Overtraining – learning set is split to – Adjusting set – Evaluation set
GMDH 2-5: neuron, growing network, learning strategy, variants

Institute of Computer Science, Prague
11
GMDH 2 – neuron Two inputs x1, x2 only
– True inputs
– Outputs from neurons of the preceding layer
Full second order polynomial
y = a x12 + b x1 x2 + c x2
2 + d x1 + e x2 + f
y = neuron’s output n inputs => n(n-1)/2 neurons in the first layer Number of neurons grows exponentially Order of resulting polynomial grows exponentially: 2, 4, 8,
16, 32, … Ivakhnenko polynomials … some elements are missing

Institute of Computer Science, Prague
12
GMDH 3 – learning a neuron Matrix of data: inputs and desired value
u1, u2 , u3, …, un , y sample 1
u1, u2 , u3, …, un , y sample 1…. sample m
A pair of two u’s are neuron’s inputs x1, x2
m approximating equations, one for each samplea x1
2 + b x1 x2 + c x22 + d x1 + e x2 + f = y
Matrix X = Y = (a, b, c, d, e, f)t
Each row of X is x12+x1x2+x2
2+x1+x2+1 LMS solution = (XtX)-1XtY If XtX is singular, we omit this neuron
Institute of Computer Science, Prague
13
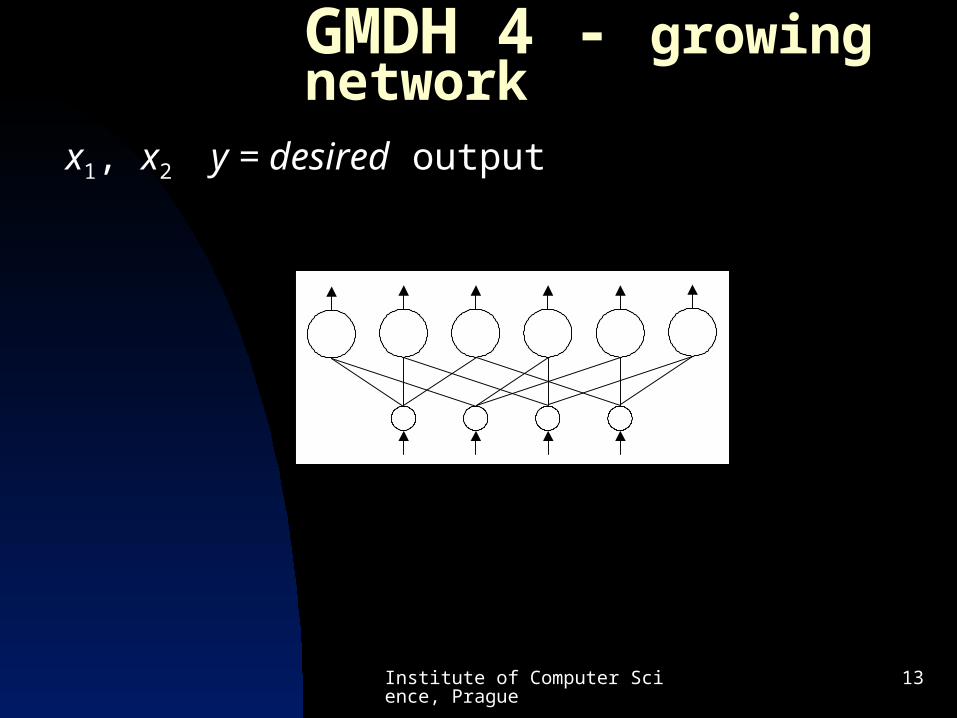
GMDH 4 - growing network
x1, x2 y = desired output

Institute of Computer Science, Prague
14
GMDH 5 learn. strategyProblem: Number of neurons grows exponentially
NN=n(n-1)2 Let the first layer of neurons grow unlimited In next rows:
[learning set split to adjusting set and evaluating set] Compute parameters a,…f using adjusting set Evaluate error using evaluating set and sort Select some n best neurons and delete the others Build the next layer OR Stop learning if stopping condition is met.
Institute of Computer Science, Prague
15
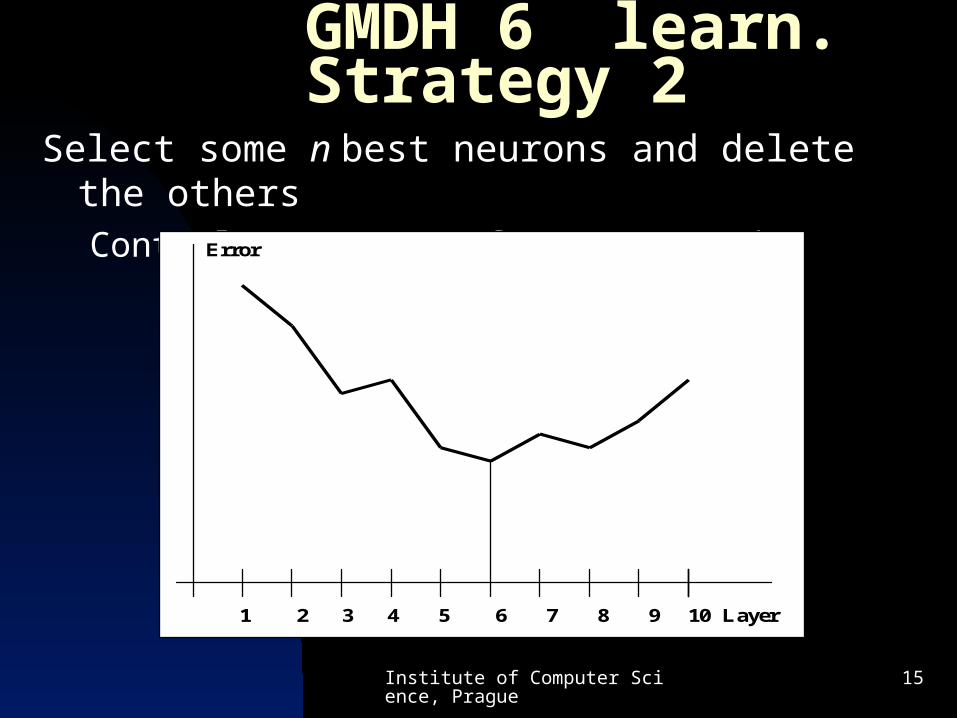
GMDH 6 learn. Strategy 2Select some n best neurons and delete the others
Control parameter of GMDH network Error
1 2 3 4 5 6 7 8 9 10 Layer

Institute of Computer Science, Prague
16
GMDH 7 - variants
Basic – full quadratic polynomial – Ivakh. poly Cubic, Fourth order simplified …
Reach higher order in less layers and less params Different stopping rules Different ratio of sizes of adjusting set and
evaluating set

Institute of Computer Science, Prague
17
NNSU GANeural Network with Switching Units
learned by the use of Genetic Algorithm
Approximator by lot of local hyper-planes; today also by local more general hyper-surfaces
Feed-forward network Originally derived from MLP for optical
implementation Structure looks like columns above individual inputs
More … František

Institute of Computer Science, Prague
18
Learning and testing set
Learning set Adjusting (tuning) set Evaluation set
Testing set
One data set – the splitting influences results
Fair evaluation problem

Institute of Computer Science, Prague
19
NN and statistics MLP-BP mean squared error minimization
Sum of errors squared … MSE criterion Hamming distance for (pure) classifiers
No other statistical criteria or tests are in NN: NN transforms data, generates mapping statistical criteria or tests are outside NN
(2, K-S, C-vM,…) Is NN good for K-S test? … is y=sin(x) good for 2 test?
Bayes classifiers, k-th nearest neighbor, kernel methods …

Institute of Computer Science, Prague
20
NN and optimization and genetic algorithms
Learning is an optimization procedure Specific to given NN General optimization systems or methods Whole NN Parts – GMDH and NNSU - linear regression Genetic algorithm
Not only parameters, the structure, too May be faster than iterations

Institute of Computer Science, Prague
21
About application of NN Soft problems
Nonlinear Lot of noise Problematic variables Mutual dependence of variables
Application areas Economy Pattern recognition Robotics Particle physics …

Institute of Computer Science, Prague
22
Strategy when using NN For “soft problems” only NOT for
Exact function generation periodic signals etc.
First subtract all “systematics” Nearly noise remains Approximate this nearly noise Add back all systematics
Understand your paradigm Tune it patiently or Use “parameterless” paradigm

Institute of Computer Science, Prague
23
Conlusions
Powerfull tool Good when well used Simple paradigm, complex behavior
Special tool Approximator Classifier
Universal tool Very different problems Soft problems
Related Documents











