Information Seeking with Social Signals: Anatomy of a Social Tag-based Exploratory Search Browser Ed H. Chi, Rowan Nairn Palo Alto Research Center 2010 ACM International Conference on Intelligent User Interfaces Workshop on Social Recommender Systems Presented by Jun-Ming Chen 4/9/20

Information Seeking with Social Signals: Anatomy of a Social Tag-based Exploratory Search Browser Ed H. Chi, Rowan Nairn Palo Alto Research Center 2010.
Dec 14, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Information Seeking with Social Signals: Anatomy of a
Social Tag-based Exploratory Search Browser
Ed H. Chi, Rowan Nairn
Palo Alto Research Center
2010 ACM International Conference on Intelligent User InterfacesWorkshop on Social Recommender Systems
Presented by Jun-Ming Chen 4/9/2010

Outline
• Introduction• The TagSearch algorithm• MrTaggy browsing / Search interface• Experiment Design• Conclusion
2

Social Search Survey
[Evans & Chi, CSCW2008]
• 150 user surveys• Help understand the importance of:
– social cues and information exchanges– vocabulary problems– distribution and organization
3Brynn Evans, Ed H. Chi. Towards a Model of Understanding Social Search. In Proc. of Computer-Supported Cooperative Work (CSCW),ACM Press, 2008.

TagSearch Exploratory Focus
3 kinds of search
navigational transactional
28% 13%
You know what you want and where it is You know what you want to do
Existing search engines are OK
informational
59%
You roughly know what you want
but don’t know how to find it
Difficult for existing search engines
Opportunity
4

Introduction
5[10] Furnas, G.W., Landauer, T.K., Gomez, L.M. And Dumais, S.T.. The vocabulary problem in human-system communication. Communications of the ACM , 30 (1987), 964-971.
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Introduction
• Using social tagging data as “navigational advice” and suggestions for additional vocabulary terms
• To combat noisy patterns in tags, we have designed a system using probabilistic networks to model relationships between tags, which are treated as topic keywords– MrTaggy.com
6
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

7
The system enables users to quickly give relevance feedbacks to the system to narrow down to related concepts and relevant URLsThe system enables users to quickly give relevance feedbacks to the system to narrow down to related concepts and relevant URLs
A tag-based exploratory search system
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Introduction
• TagSearch algorithm– performs tag normalizations that reduces the noise and finds the patterns of
co-occurrence between tags to offer recommendations of related tags and contents [15]
• Experiment Design– provide a quick overview of the user study reported previously
8
[15] Kammerer, Y., Nairn, R., Pirolli, P., and Chi, E. H. 2009. Signpost from the masses: learning effects in an exploratory social tag search browser. In Proceedings of the 27th international Conference on Human Factors in Computing Systems CHI '09. ACM, New York, NY, 625-634.
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

The TagSearch algorithm
• Here we describe an algorithm called TagSearch that uses the relationships between tags and documents to suggest other tags and documents– First form a bi-graph between document and tagging pairs
(Bi-graph between document/tag)– Steps– TagSearch Architecture
9
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Bi-graph between document/tag
• Spreading Activation in a bi-graph– For a URL, the probability p(Tag|URL)
can be roughly estimated by the number of times a particular tag is applied by users divided by total number of times all tags are used for a URL
• Spreading activation have been used in many other systems for modeling concepts that might be related, or to model traffic flow through a website [5]
10
Tags URLs
P(URL|Tag)
P(Tag|URL)
1/3
1/3
1/3
1/2
1/2
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion
[5] Ed H. Chi, Peter Pirolli, Kim Chen, James Pitkow. Using Information Scent to Model User Information Needs and Actions on the Web. In Proc. of ACM CHI 2001 Conference on Human Factors in Computing Systems, pp. 490--497. ACM Press, April 2001. Seattle, WA.

蔓延激發( Spreading Activation )
• 意指從網路中提取訊息的心智活動
• 激發現象:就是提取訊息的處理過程,也是提取概念意義性的處理過程
• 關鍵特徵:就是激發沿著儲存的路徑蔓延到整個網路中;只要有一個概念被激發,則激發會從這個概念蔓延到全部與其有連接的概念上
11概念圖的原理:語意網路與命題敘述國立臺灣師範大學 教育與心輔導學系 陳學志 教授

• 當某一個語義節點處於激發狀態下,其激發程度會傳送給與之相聯結的其他語義節點– 激發節點僅與少數的語義節點相聯結,則每一個相鄰節點所能獲得的激
發量也就會越強• 產生的語意連結越強
– 激發節點 與很多的語義節點相聯結,則每一個相鄰節點平均所能分享的激發量也就越少
• 產生的語意連結越弱– 此即所謂的「發散效果」 ( fan effect; Anderson, 1984 )
• Bi-graph between document/tag• A sketch of the idea behind the algorithm is as follows
12
John R. Anderson and Peter L. Pirolli, Spread of Activation. Journal of Experimental Psychology: Learning, Memory, and Cognition1984, Vol. 10, No. 4, 791-798

To suggest tags To suggest documents
• form a “tag profile” for a tag– which is the set of other tags that are
related to the tag– To compute the tag profiles, we use the
bi-graph to perform a spreading activation to find a pattern of other tags that are related to a set of tags
– Once we have the tag profiles, we can find other tags that are related by comparing these tag profiles
– That is, for a given tag, we can compare its tag profile to other tag profiles in the system to find the top most related tags
• form a “document profile” for a tag, – which is the set of other documents that
are related to the tag, similarly using spreading activation
– then find other tags that are related using these document profiles
• form “tag profiles” for a document– which is the set of other tags that are
related to that document, – again using the spreading activation
method– then compare these tag profiles for
documents to other document tag profiles to find similar documents
• form “document profiles” for a document– Using the spreading activation method
over the bigraph – compare these document profiles for
documents to find similar documents
13

• construct a bi-graph between URLs and tagging keywords
• form [url, tag1, tag2, tag3, tag4, ….] [url, tag1], [url, tag2], and so on
• Given tuples in the form [url, tag], we can form a bi-graph of URLs linked to tags
14
Step 1Step 1 Step 2Step 2 Step 3Step 3

• construct “tag profiles” and “document profiles” for each URL and each tag in the system
• In this case, we use spreading activation to model tag and concept co-occurrences
15
Step 1Step 1 Step 2Step 2 Step 3Step 3

• Specifically, the tag profiles and document are computed using spreading activation iteratively as vectors A as follows:
16
Step 1Step 1 Step 2Step 2 Step 3Step 3

• After “n” steps (which can be varied based on experimentation),– depending on whether the spreading activation was stopped on the tag side of
the bi-graph or the document side of the bi-graph– we will have a pattern of weights on tags or documents
• These patterns of weights form the “tag profiles” or “document profiles”
17
Step 1Step 1 Step 2Step 2 Step 3Step 3

• Having constructed these profiles, we now have several options for retrieval. These profiles form the basis for doing similarity computations and lookups for retrieval, search, and recommendations
• For example, – For a given document,
• if we want to find more related document to it, we have three options• if we want to look for related tags to it, we have three options
– For a given tag, • if we want to find related documents or related tags to it
18
Step 1Step 1 Step 2Step 2 Step 3Step 3

if we want to find more related document if we want to find for related tags
a. Lookup the corresponding document profile for that document, and choose the top highest weighted documents in that profile and return that set
b. Use the corresponding document/tag profile for that document and compare it against all other document/tag profiles for other documents in the system, and find the most similar profiles and return the matching documents
c. If the document is not already in the bi-graph, we can first use standard information retrieval techniques (for example, cosine similarity of the document word vectors) to find the most similar document that is in our bi-graph, and use method (a) or (b) above to find related documents in our bi-graph
a. Lookup the corresponding tag profile for that document, and choose the top highest weighted documents in that profile and return that set
b. Use the corresponding document/tag profile for that tag and compare it against all other document/tag profiles for other tags in the system, and find the most similar profiles and return the matching tags
c. If the document is not already in the bi-graph, we can first use a standard information retrieval technique to find the most similar document that is in our bi-graph, and use method (a) or (b) above to find related documents in our bi-graph
19
For a given document,For a given document,

a. We can again use similar methods (a) or (b) as described above, if the tag already exists in our bi-graph
b. If the given tagging keyword is not in the bi-graph, we can first perform a standard keyword search to find the first initial related documents and tags
c. We can then further refine the result set by the above methods
20
For a given tag,For a given tag,
if we want to find related documents or related tags to it

TagSearch Architecture
• MapReduce computation over a large data set • 150 Million+ bookmarks
21
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Baseline Interface
22
MrTaggy browsing / Search interfaceMrTaggy browsing / Search interface

Exploratory Interface
23
MrTaggy browsing / Search interfaceMrTaggy browsing / Search interface
Related Tag FeedbackRelated Tag Feedback
Related Tag FeedbackRelated Tag Feedback

Experiment Design
• We recently completed a 30-subject study of MrTaggy and Kammerer et al. describes the study in detail [15]– In this study, we analyzed the interaction and UI design– The main aim was to understand whether and how MrTaggy is beneficial for
domain learning
• We compared the full exploratory MrTaggy interface to a baseline version of MrTaggy that only supported traditional query-based search
• In a learning experiment, we tested participants’ performance in three different topic domains and three different task types
24[15] Kammerer, Y., Nairn, R., Pirolli, P., and Chi, E. H. 2009. Signpost from the masses: learning effects in an exploratory social tag search browser. In Proceedings of the 27th international Conference on Human Factors in Computing Systems CHI '09. ACM, New York, NY, 625-634.
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Experiment Design• 2 interface x 3 task domain design
– 2 Interface (between-subjects)
• Exploratory vs. Baseline– 3 task domains (within-subjects)
• Future Architecture, Global Warming, Web Mashups• 30 Subjects (22 male, 8 female)
– Intermediate or advanced computer and web search skills– Half assigned Exploratory, half Baseline.
• For each domain, single block with 3 task types:– Easy and Difficult Page Collection Task– Summarization Task– Keyword Generation Task
25
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Page Collection
26
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Summarization Tasks
27
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Procedure
• Prior Knowledge Test• Task Domain
– Interaction Behaviors– summarization– keyword generation task
28
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Results: Interaction Behaviors
• Number of Queries– Effect of Interface on number of queries (p < .01)
• Exploratory (M=7.81) > Baseline (M=3.77)
• Time Taken– Effect of Interface on time taken (p < .01)
• Exploratory (7.7min) > Baseline (6.6min)
Subjects using the MrTaggy full exploratory interface took advantage of the additional features provided by relevance feedback,
– without giving up their usual manual query typing behavior– They also spent more time on tasks and appear to be more engaged in
exploration than the participants using the baseline system
29
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion
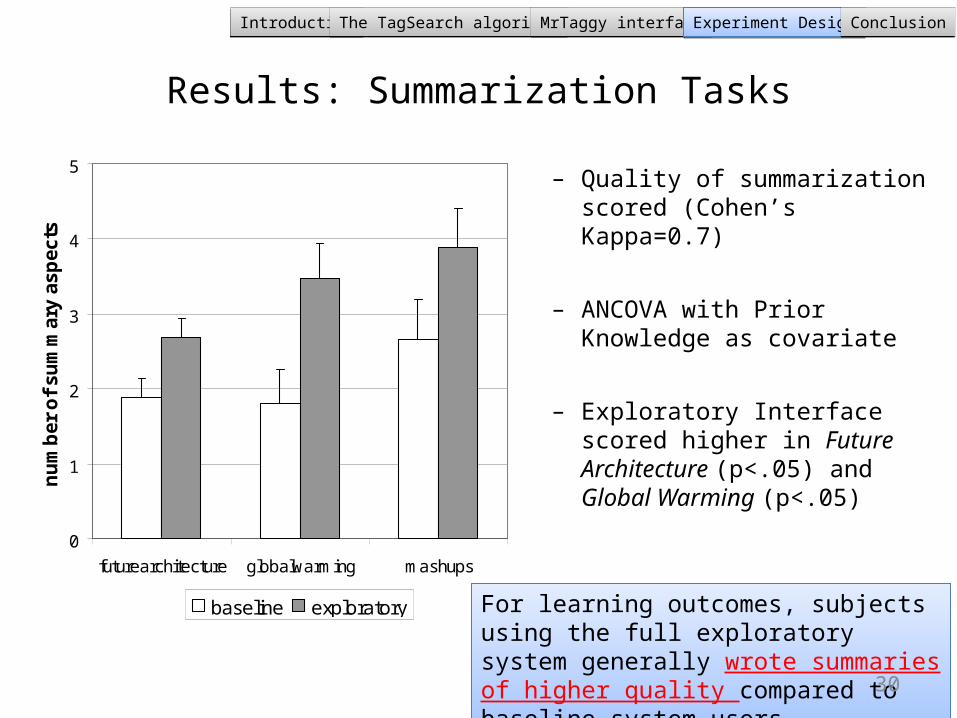
0
1
2
3
4
5
futurearchitecture globalwarming mashups
nu
mb
er
of
sum
mar
y a
sp
ect
s
baseline exploratory For learning outcomes, subjects using the full exploratory system generally wrote summaries of higher quality compared to baseline system users
For learning outcomes, subjects using the full exploratory system generally wrote summaries of higher quality compared to baseline system users
Results: Summarization Tasks
– Quality of summarization scored (Cohen’s Kappa=0.7)
– ANCOVA with Prior Knowledge as covariate
– Exploratory Interface scored higher in Future Architecture (p<.05) and Global Warming (p<.05)
30
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Results: Keyword Generation Tasks
0
2
4
6
8
10
12
14
16
18
globalwarming futurearchitecture mashups
nu
mb
er o
f ke
yw
ord
s
baseline exploratory
– Subjects using the exploratory system were able to generate more reasonable keywords than the baseline system users for topic domains of medium and high ambiguity
31
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Summary of the evaluation
• Exploratory interface users:– performed more queries, – took more time, – wrote better summaries (in 2/3 domains), – generated more relevant keywords (in 2/3 domains)
• Suggestive of deeper engagement and better learning• Some evidence of scaffolding for novices in the keyword generation and
summarization tasks
32
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Conclusion
• In this paper, we described the detailed implementation of the TagSearch algorithm. We also summarized a past study on the effectiveness of the exploratory tool
• Harnessing user-generated tags to enrich content for social search• The results of this project point to the promise of social search to fulfill a
need in providing navigational signposts to the best contents
• Weaknesses of social tagging systems is Tag Noise and Inconsistency– Difficult to leverage for search– Use data mining techniques to normalize and reduce noise– Apply normalized tag data in new search algorithm
33
IntroductionIntroduction The TagSearch algorithmThe TagSearch algorithm MrTaggy interfaceMrTaggy interface Experiment DesignExperiment Design ConclusionConclusion

Research Vision
Augmented Social Cognition
• Cognition: the ability to remember, think, and reason; the faculty of knowing.
• Social Cognition: the ability of a group to remember, think, and reason; the construction of knowledge structures by a group.
• Augmented Social Cognition: Supported by systems, the enhancement of the ability of a group to remember, think, and reason; the system-supported construction of knowledge structures by a group.
Citation: Ed H. Chi. The Social Web: Opportunities for Research. IEEE Computer, Sept 2008
34
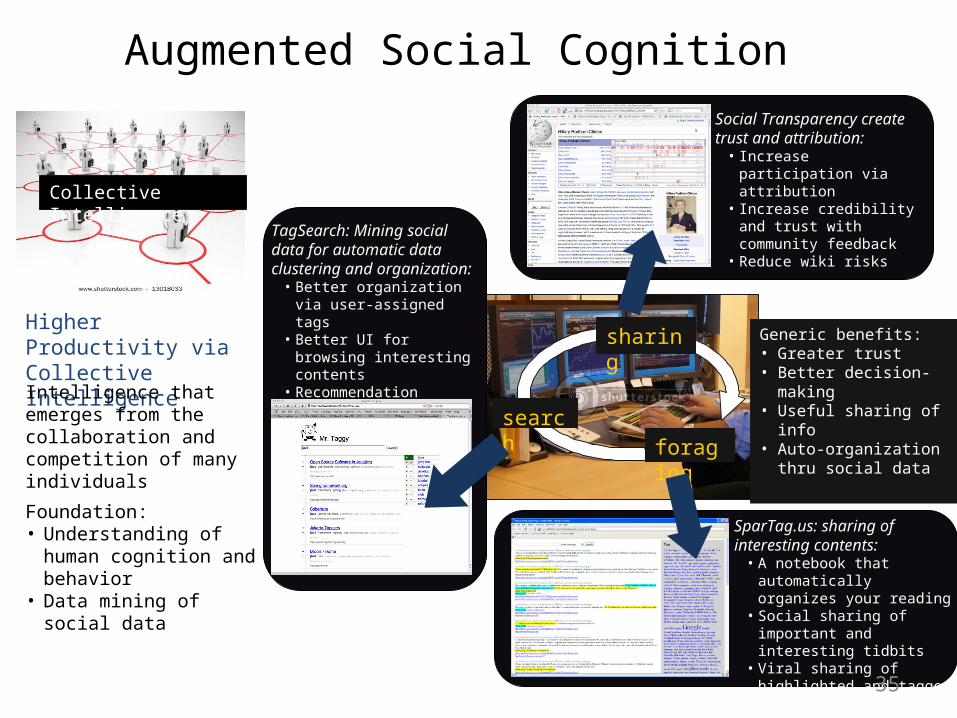
Collective Intelligence
Augmented Social Cognition
Higher Productivity via Collective Intelligence
Intelligence that emerges from the collaboration and competition of many individuals
search
sharing
foraging
TagSearch: Mining social data for automatic data clustering and organization:
• Better organization via user-assigned tags
• Better UI for browsing interesting contents
• Recommendation instead of just search
Social Transparency create trust and attribution:
• Increase participation via attribution
• Increase credibility and trust with community feedback
• Reduce wiki risks
SparTag.us: sharing of interesting contents:
• A notebook that automatically organizes your reading
• Social sharing of important and interesting tidbits
• Viral sharing of highlighted and tagged paragraphs
Foundation:• Understanding of human
cognition and behavior• Data mining of social data
Generic benefits:• Greater trust• Better decision-making• Useful sharing of info• Auto-organization thru
social data
35
Related Documents











