Concise Preservation by combining Managed Forgetting and Contextualized Remembering

Information Consolidation and Concentration (WP4 ForgetIT 1st year review)
Jul 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Concise Preservation by combining Managed
Forgetting and Contextualized Remembering


Vasileios Mezaris
CERTH
WP 4 PresentationInformation Consolidation and Concentration
ForgetIT 1st Review Meeting, April 29-30, 2014
Kaiserslautern, Germany

WP Objectives
• Development of techniques for the
Analysis of similarity and redundancy in textual and multimedia data
Semantic multimedia analysis for condensation
Information condensation and consolidation
Focus of Year 1
• Report on the state of the art and planned approach in the research
topics of the WP from the perspective of information preservation
• First release of the ForgetIT techniques for information analysis,
consolidation and concentration and preliminary results of the
evaluation of the developed techniques.
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Objectives of WP and Year 1 Focus
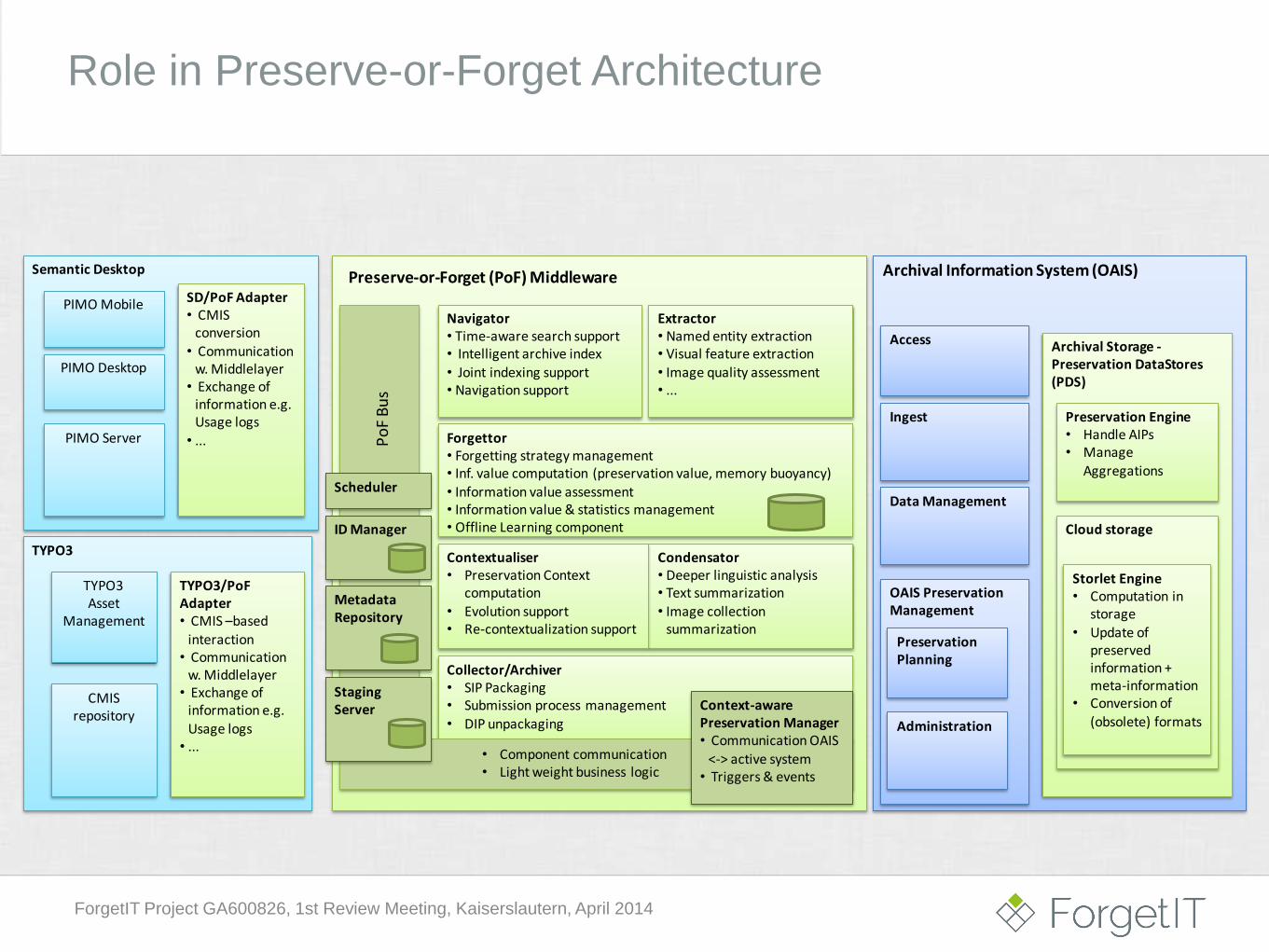
Semantic DesktopPreserve-or-Forget (PoF) Middleware
Forgettor• Forgetting strategy management• Inf. value computation (preservation value, memory buoyancy)• Information value assessment • Information value & statistics management • Offline Learning component
Navigator• Time-aware search support• Intelligent archive index• Joint indexing support• Navigation support
Extractor• Named entity extraction • Visual feature extraction• Image quality assessment• ...
Condensator• Deeper linguistic analysis• Text summarization• Image collection
summarization
Collector/Archiver• SIP Packaging • Submission process management• DIP unpackaging
TYPO3
TYPO3/PoF Adapter• CMIS –based
interaction• Communication
w. Middlelayer• Exchange of
information e.g. Usage logs
• ...
Archival Information System (OAIS)
Contextualiser• Preservation Context
computation • Evolution support• Re-contextualization support
• Component communication• Light weight business logic
Archival Storage -Preservation DataStores (PDS)
Ingest
PIMO Server
PIMO Desktop
Cloud storage
Storlet Engine• Computation in
storage• Update of
preserved information + meta-information
• Conversion of (obsolete) formats
Access
SD/PoF Adapter• CMIS
conversion• Communication
w. Middlelayer• Exchange of
information e.g. Usage logs
• ...
PIMO Mobile
OAIS Preservation Management
ID Manager
MetadataRepository
Scheduler
TYPO3Asset
Management
Context-awarePreservation Manager• Communication OAIS
<-> active system• Triggers & events
Po
F B
us
Preservation Planning
Administration
Data Management
Preservation Engine• Handle AIPs• Manage
Aggregations
CMIS repository
Staging Server
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Role in Preserve-or-Forget Architecture
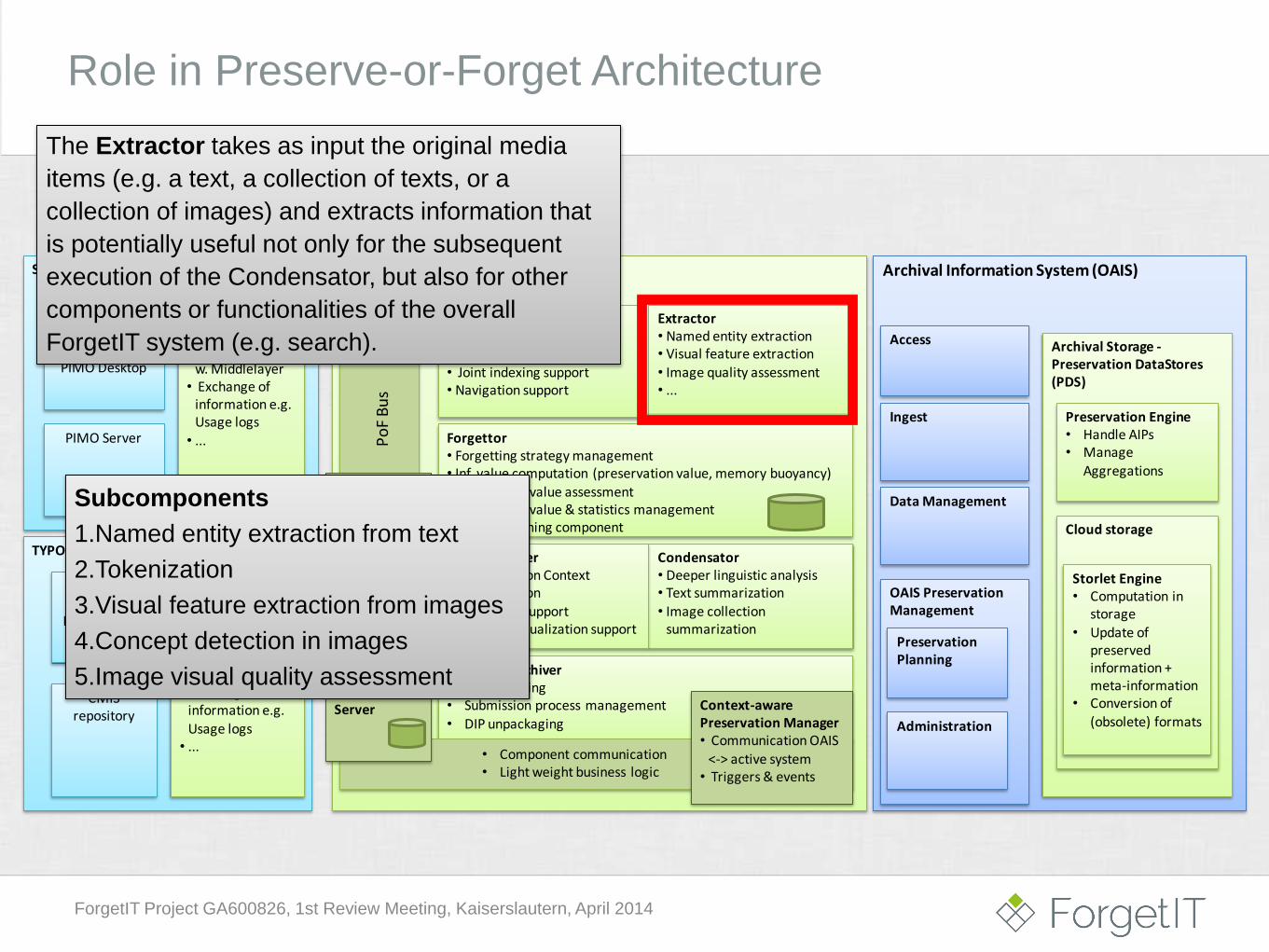
Semantic DesktopPreserve-or-Forget (PoF) Middleware
Forgettor• Forgetting strategy management• Inf. value computation (preservation value, memory buoyancy)• Information value assessment • Information value & statistics management • Offline Learning component
Navigator• Time-aware search support• Intelligent archive index• Joint indexing support• Navigation support
Extractor• Named entity extraction • Visual feature extraction• Image quality assessment• ...
Condensator• Deeper linguistic analysis• Text summarization• Image collection
summarization
Collector/Archiver• SIP Packaging • Submission process management• DIP unpackaging
TYPO3
TYPO3/PoF Adapter• CMIS –based
interaction• Communication
w. Middlelayer• Exchange of
information e.g. Usage logs
• ...
Archival Information System (OAIS)
Contextualiser• Preservation Context
computation • Evolution support• Re-contextualization support
• Component communication• Light weight business logic
Archival Storage -Preservation DataStores (PDS)
Ingest
PIMO Server
PIMO Desktop
Cloud storage
Storlet Engine• Computation in
storage• Update of
preserved information + meta-information
• Conversion of (obsolete) formats
Access
SD/PoF Adapter• CMIS
conversion• Communication
w. Middlelayer• Exchange of
information e.g. Usage logs
• ...
PIMO Mobile
OAIS Preservation Management
ID Manager
MetadataRepository
Scheduler
TYPO3Asset
Management
Context-awarePreservation Manager• Communication OAIS
<-> active system• Triggers & events
Po
F B
us
Preservation Planning
Administration
Data Management
Preservation Engine• Handle AIPs• Manage
Aggregations
CMIS repository
Staging Server
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Role in Preserve-or-Forget Architecture
The Extractor takes as input the original media
items (e.g. a text, a collection of texts, or a
collection of images) and extracts information that
is potentially useful not only for the subsequent
execution of the Condensator, but also for other
components or functionalities of the overall
ForgetIT system (e.g. search).
Subcomponents
1.Named entity extraction from text
2.Tokenization
3.Visual feature extraction from images
4.Concept detection in images
5.Image visual quality assessment

Semantic DesktopPreserve-or-Forget (PoF) Middleware
Forgettor• Forgetting strategy management• Inf. value computation (preservation value, memory buoyancy)• Information value assessment • Information value & statistics management • Offline Learning component
Navigator• Time-aware search support• Intelligent archive index• Joint indexing support• Navigation support
Extractor• Named entity extraction • Visual feature extraction• Image quality assessment• ...
Condensator• Deeper linguistic analysis• Text summarization• Image collection
summarization
Collector/Archiver• SIP Packaging • Submission process management• DIP unpackaging
TYPO3
TYPO3/PoF Adapter• CMIS –based
interaction• Communication
w. Middlelayer• Exchange of
information e.g. Usage logs
• ...
Archival Information System (OAIS)
Contextualiser• Preservation Context
computation • Evolution support• Re-contextualization support
• Component communication• Light weight business logic
Archival Storage -Preservation DataStores (PDS)
Ingest
PIMO Server
PIMO Desktop
Cloud storage
Storlet Engine• Computation in
storage• Update of
preserved information + meta-information
• Conversion of (obsolete) formats
Access
SD/PoF Adapter• CMIS
conversion• Communication
w. Middlelayer• Exchange of
information e.g. Usage logs
• ...
PIMO Mobile
OAIS Preservation Management
ID Manager
MetadataRepository
Scheduler
TYPO3Asset
Management
Context-awarePreservation Manager• Communication OAIS
<-> active system• Triggers & events
Po
F B
us
Preservation Planning
Administration
Data Management
Preservation Engine• Handle AIPs• Manage
Aggregations
CMIS repository
Staging Server
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Role in Preserve-or-Forget Architecture
The Condensator gets as input the Extractor’s
output and possibly also the original media
items that were processed by the latter in order
to generate this output (or a subset of these
media items).
Subcomponents
1.Deeper linguistic analysis
2.Text summarization
3.Face detection and clustering
4.Image collection summarization

Text analysis
• Text summarization
Summary creation of a single document or of a collection of documents
Determines which sections are useful in terms of content
Extracts representative, weighted terms (words, entities etc.)
Its output is a text / corpus summary (e.g. term cloud) – lossy condensation
• Text condensation
Performs linguistic processing for document length reduction
Removes or replaces potentially redundant words without changing the
meaning of the text – lossless condensation
• Semantic text composition
Provides context for the text at the time it is being composed
Infers and suggesting related entities to the user; semi-automatic approach
Saves the user the time and effort of manually searching for and annotating
the entities in the text – facilitates subsequent summarization / condensation
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Achievements in Year 1

Image analysis
• Feature extraction and concept detection for images
Extracts a vector representation for each image
Utilizes machine learning techniques for quantifying the relation between the
image and a set of visual concepts
• Image quality assessment
Quantifies different visual quality characteristics (blur, contrast, etc.)
• Face detection for clustering
Detects faces in an image
Will be extended to clustering the faces in a collection
Person coverage can be one dimension for image collection summarization
• Image clustering for summarization
Groups similar images and creates a visual summary if the collection
Currently works with low-level features or concept detection output
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Achievements in Year 1

Integration efforts
• Several analysis techniques available as REST services
• Semantic text composition integrated in PIMO (WP9)
• Image feature extraction and concept detection as a storlet (WP7, in
progress)
Evaluation
• Preliminary analysis evaluation results reported in D4.2
• Participation (together with EU projects LinkedTV and MediaMixer)
to the semantic indexing task of the TRECVID 2013 benchmark
Reporting and publication of results
• Deliverables D4.1, D4.2 delivered on time
• Five conference papers & one book chapter published/accepted
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Achievements in Year 1

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Text summarization
Generation of visual summaries
• Content Detection analyzes a
document to determine which
sections are useful in terms of
content (e.g. removing the generic
menus in a web page; avoids
irrelevant material biasing the
summary)
• TermRaider extracts
representative, weighted terms
(words, entities etc.) from
documents which can provide a
summary (e.g. as a term cloud)
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
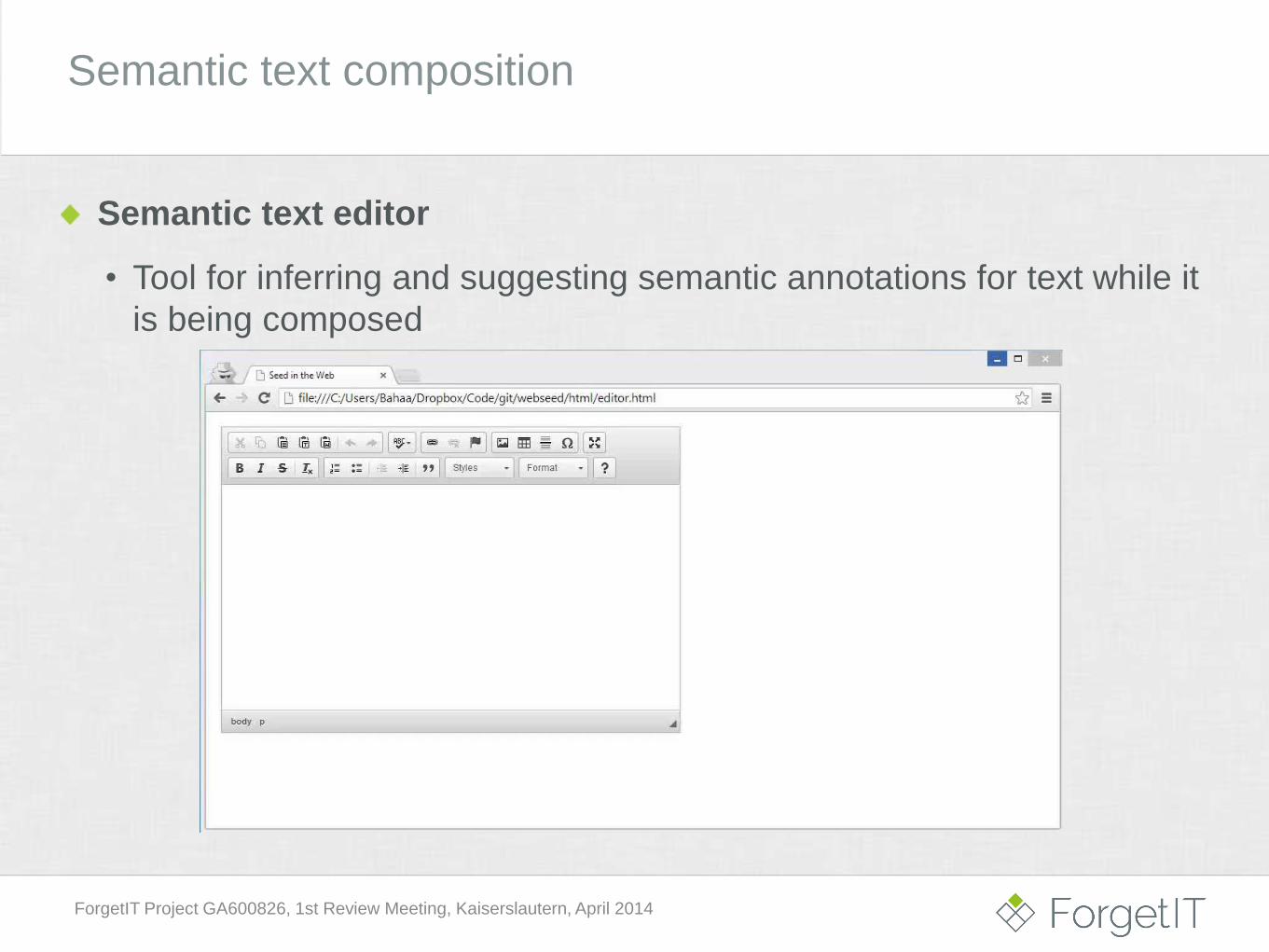
Semantic text composition
Semantic text editor
• Tool for inferring and suggesting semantic annotations for text while it
is being composed

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Semantic text composition
Semantic text editor components
• Editor
An extended version of the open-source HTML-based rich text editor
CKEditor, which allows for annotating and tracking arbitrary parts of the text
• Natural Language Processing component
Named entity recognition locates and classifies atomic elements in text into
predefined categories such as people, organizations, and locations
Coreference resolution identifies which words refer to which things in a text
Relation extraction extracts binary relations from the text being composed
• Linked Open Data component
Entity disambiguation distinguishes between different entities that have similar
or identical names
Relation extraction searches for relations among entities
Context inference finds contextual information about entities mentioned in the
text

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image analysis
http://multimedia.iti.gr/ForgetIT/
CostaRica/demonstrator.html
ForgetIT visual analysis
technologies demonstrator
• Concept detection and feature
extraction
• Visual quality assessment
• Image clustering
• Face detection

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
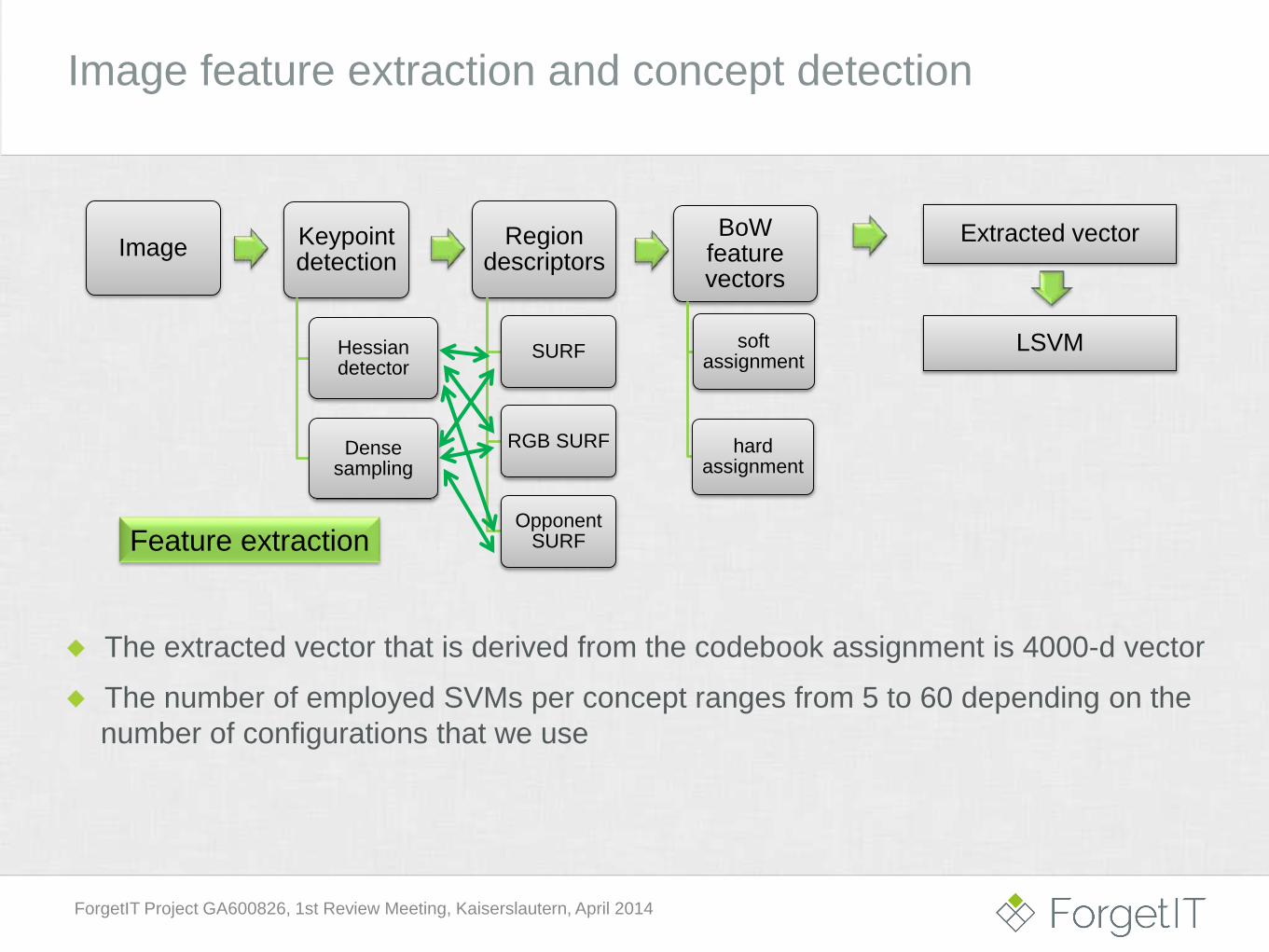
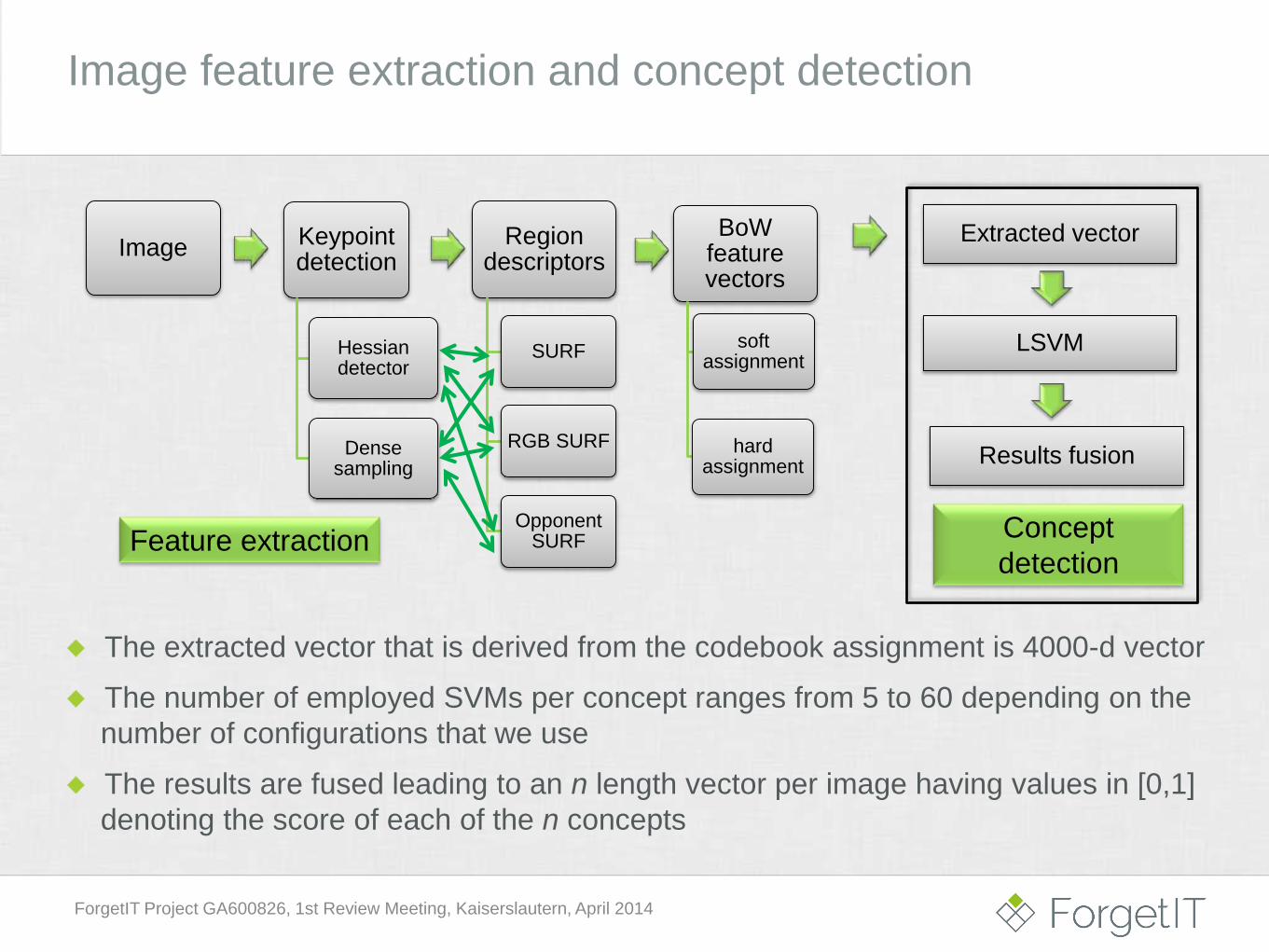
Image feature extraction and concept detection
Image

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Image Keypointdetection
Hessian detector
Dense sampling

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Image Keypointdetection
Hessian detector
Dense sampling
Region descriptors
SURF
RGB SURF
Opponent SURF

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Image Keypointdetection
Hessian detector
Dense sampling
Region descriptors
SURF
RGB SURF
Opponent SURF
BoWfeature vectors
soft assignment
hard assignment

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Image Keypointdetection
Hessian detector
Dense sampling
Region descriptors
SURF
RGB SURF
Opponent SURFFeature extraction
BoWfeature vectors
soft assignment
hard assignment

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Image Keypointdetection
Hessian detector
Dense sampling
Region descriptors
SURF
RGB SURF
Opponent SURF
Extracted vector
Feature extraction
BoWfeature vectors
soft assignment
hard assignment
The extracted vector that is derived from the codebook assignment is 4000-d vector
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Image Keypointdetection
Hessian detector
Dense sampling
Region descriptors
SURF
RGB SURF
Opponent SURF
Extracted vector
Feature extraction
LSVM
BoWfeature vectors
soft assignment
hard assignment
The extracted vector that is derived from the codebook assignment is 4000-d vector
The number of employed SVMs per concept ranges from 5 to 60 depending on the
number of configurations that we use

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Image Keypointdetection
Hessian detector
Dense sampling
Region descriptors
SURF
RGB SURF
Opponent SURF
Extracted vector
Feature extraction
LSVM
Results fusion
BoWfeature vectors
soft assignment
hard assignment
The extracted vector that is derived from the codebook assignment is 4000-d vector
The number of employed SVMs per concept ranges from 5 to 60 depending on the
number of configurations that we use
The results are fused leading to an n length vector per image having values in [0,1]
denoting the score of each of the n concepts
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Image Keypointdetection
Hessian detector
Dense sampling
Region descriptors
SURF
RGB SURF
Opponent SURF
Extracted vector
Feature extraction
LSVM
Results fusion
Concept
detection
BoWfeature vectors
soft assignment
hard assignment
The extracted vector that is derived from the codebook assignment is 4000-d vector
The number of employed SVMs per concept ranges from 5 to 60 depending on the
number of configurations that we use
The results are fused leading to an n length vector per image having values in [0,1]
denoting the score of each of the n concepts

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection
Number of
configurations
Interest point
detector
Descriptor BoW strategy xinfAP (%)
single dense sampling SURF soft 6,97
single dense sampling SIFT soft 6,08
single dense sampling RGB SURF soft 7,86
single dense sampling RGB SIFT soft 7,02
single dense sampling opponent SURF soft 7,33
single dense sampling opponent SIFT soft 7,12
fusion of 3 dense sampling SURF, RGB SURF, opponent SURF soft 12,87
fusion of 3 dense sampling SIFT, RGB SIFT, opponent SIFT soft 10,81
fusion of 6 dense sampling SURF, RGB SURF, opponent SURF hard- soft 13
fusion of 6 dense sampling SIFT, RGB SIFT, opponent SIFT hard- soft 10,57
fusion of 6 Hessian SURF, RGB SURF, opponent SURF hard- soft 9,1
fusion of 6 Harris - Laplace SIFT, RGB SIFT, opponent SIFT hard- soft 9,1
xinfAP: Extended Inferred Average PrecisionSURF works a bit better than SIFT
Fusion of 3 configurations is better than any single configuration
Fusion of 6 configurations is slightly better than fusion of 3 configurations but
considerably slower

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image feature extraction and concept detection

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image clustering for summarization
Three feature vector types
• HSV histograms
• BoW (SIFT descriptors, soft assignment)
• Model vectors
Six clustering algorithms
• k-means
• Hierarchical clustering using complete
linkage (hier-comp)
• Hierarchical clustering using single linkage
(hier-single)
• Partitioning Around Medoids (PAM)
• Affinity Propagation (AP)
• Farthest First Traversal Algorithm
Normalized Mutual Information (NMI) between
the automatic clustering and the manually
created cluster ground truth.
Input data feature
HSV BoW Model
vectors
Clu
ste
rin
g A
lgo
rith
m
kmeans 0.2653 0.2361 0.5979
hier-comp 0.1778 0.1912 0.5148
hier-single 0.1317 0.1885 0.1073
PAM 0.2957 0.197 0.4959
AP 0.2928 0.2403 0.5499
farthest first 0.1669 0.2164 0.464
Tests on 9 image and
video collections

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image clustering for summarization
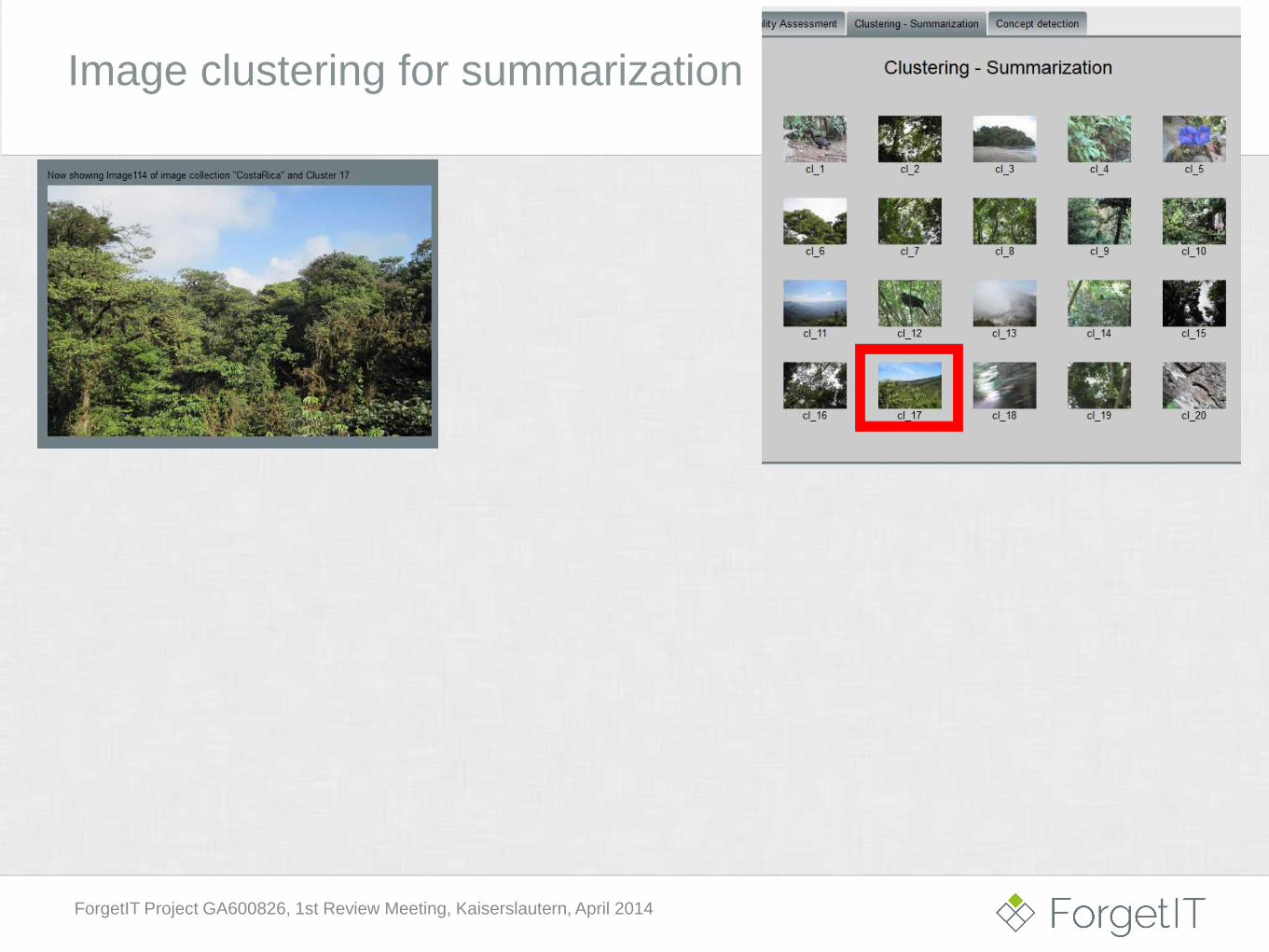
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image clustering for summarization

ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Image clustering for summarization

P. Sidiropoulos, V. Mezaris, I. Kompatsiaris, "Enhancing video concept detection with the use of
tomographs", Proc. IEEE International Conference on Image Processing (ICIP 2013), Melbourne,
Australia, September 2013.
W. Allasia, F. Barresi, G. Battista, and J. Pellegrino, Quantistic approach for classification of images,
Proceedings of the 5th Internation Conference on Advances in Multimedia (MMEDIA2013), Venice, Italy,
April 2013, ISBN: 978-1-61208-265-3
F. Markatopoulou, A. Moumtzidou, C. Tzelepis, K. Avgerinakis, N. Gkalelis, S. Vrochidis, V. Mezaris, I.
Kompatsiaris, "ITI-CERTH participation to TRECVID 2013", Proc. TRECVID 2013 Workshop,
Gaithersburg, MD, USA, November 2013.
C. Tzelepis, N. Gkalelis, V. Mezaris, I. Kompatsiaris, "Improving event detection using related videos and
Relevance Degree Support Vector Machines", Proc. ACM Multimedia 2013 (MM’13), Barcelona, Spain,
October 2013.
N. Gkalelis, V. Mezaris, I. Kompatsiaris, T. Stathaki, "Video event recounting using mixture subclass
discriminant analysis", Proc. IEEE International Conference on Image Processing (ICIP 2013),
Melbourne, Australia, September 2013.
N. Gkalelis, V. Mezaris, M. Dimopoulos, I. Kompatsiaris, "Video Event Understanding", Encyclopedia of
Information Science and Technology, IGI Global, 2014, to appear.
ForgetIT Project GA600826, 1st Review Meeting, Kaiserslautern, April 2014
Publications


Thank you for your attention!
Related Documents











