Inferring the Source of Encrypted HTTP Connections Michael Lin CSE 544

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Inferring the Source of Encrypted HTTP Connections
Michael LinCSE 544

Hiding your identity
• You can wear a mask, but some distinguishing characteristics are visible:
• Height
• Weight
• Hair
• Clothing
• Even if everyone looked the same, we can determine some things about people based on their habits
• People who go to school everyday are probably students or teachers
• If you follow a strict schedule everyday (school, coffee shop, gym), you can be identified to some degree of accuracy
• “There are 10 people who follow this exact schedule everyday.”

Profiling
• How would you identify someone in a world of clones?
• Determine their schedule
• Determine their habits
• Profiling allows us to identify something without knowing what it is

Hiding your online identity
• Encryption will save us from prying eyes. Or will it?
• We can hide the header and contents of a packet behind encryption
• But can we still say something about the packet itself?
• Packet size
• Packet direction
• What about traffic patterns?
• Packet arrival rate/distribution

HTTP traffic profiling
• Using only packet size and direction, create profiles of traces of HTTP traffic for certain websites
• Instance - <Packet size, direction>
• Class - URL
• Create sets of instances for each class and use these sets to identify other traces to unknown sites
• These sets are surprisingly unique

Comparing HTTP traces
• Two relatively simple methods to get a rating of the similarity of two sets
• Jaccard’s coefficient
• Intersection of two sets divided by union of two sets
• Think about this and it makes sense
• Naive Bayes classifier (Idiot’s Bayes)
• “Naive” because it assumes every event is independent
• A surprisingly good indicator of similarity
• Important: you need something to compare against!

Collecting HTTP traces
• Gathered 100,000 URLs from DNS server logs
• Used Firefox to access top 2000 pages over an SSH tunnel 4 times a day over 2 months
• Used tcpdump to collect header information from these connections
• Analyzed the logs to get packet length and direction for connections to each site
• Create a library of profiles for sites

This is where the magic happens
• Now we have two methods for comparing sets and a big library of site profiles
• Say we intercepted some encrypted HTTP traffic and want to guess where it’s going...
• Compare with all sites in the library to find the best match or two or ten

How well does it work?
• Surprisingly well
• Lots of variables to play with:
• Size of “training set” - the data used to create the library profile
• Size of test set
• Time between collection of training and test set
• Desired accuracy (top 1 most likely site or top k, k = 2, 3, 5, 10...)
• Number of sites in library
• Jaccard’s coefficient is generally better than naive Bayes
• Bottom line: for a training set of 4 samples and a test set of 4 samples, they got ~75% accuracy

Effect of variables
• Increasing size of training set up to 4 greatly improves accuracy, after 4 they get diminishing returns
• Increasing k increases accuracy (duh)
• Time between training set and test set matters, but the difference is less than 10%, even after 4 weeks
• It doesn’t matter if the training set comes from before or after the test set
• The fewer total sites there are in the library, the better the accuracy, but the drop in accuracy is relatively slow from 200-2000 (will this hold true to 40 million?)

• This is a philosophical question
• Given the relatively small amount of data collected for each site, I think this is good enough to be interesting
• This kind of accuracy requires a training and test set of size 4+
• How likely are you to get a test set of that size?
• Even with perfect data, a maximum of ~75% accuracy is limiting
Is this good enough?

How can we make it worse?
• This analysis is based entirely on packet size
• Change the packet size, change the results
• 4 simple packet size padding methods:
• Linear
• Exponential
• Mice & elephants
• MTU
• All increase packet sizes in a deterministic manner
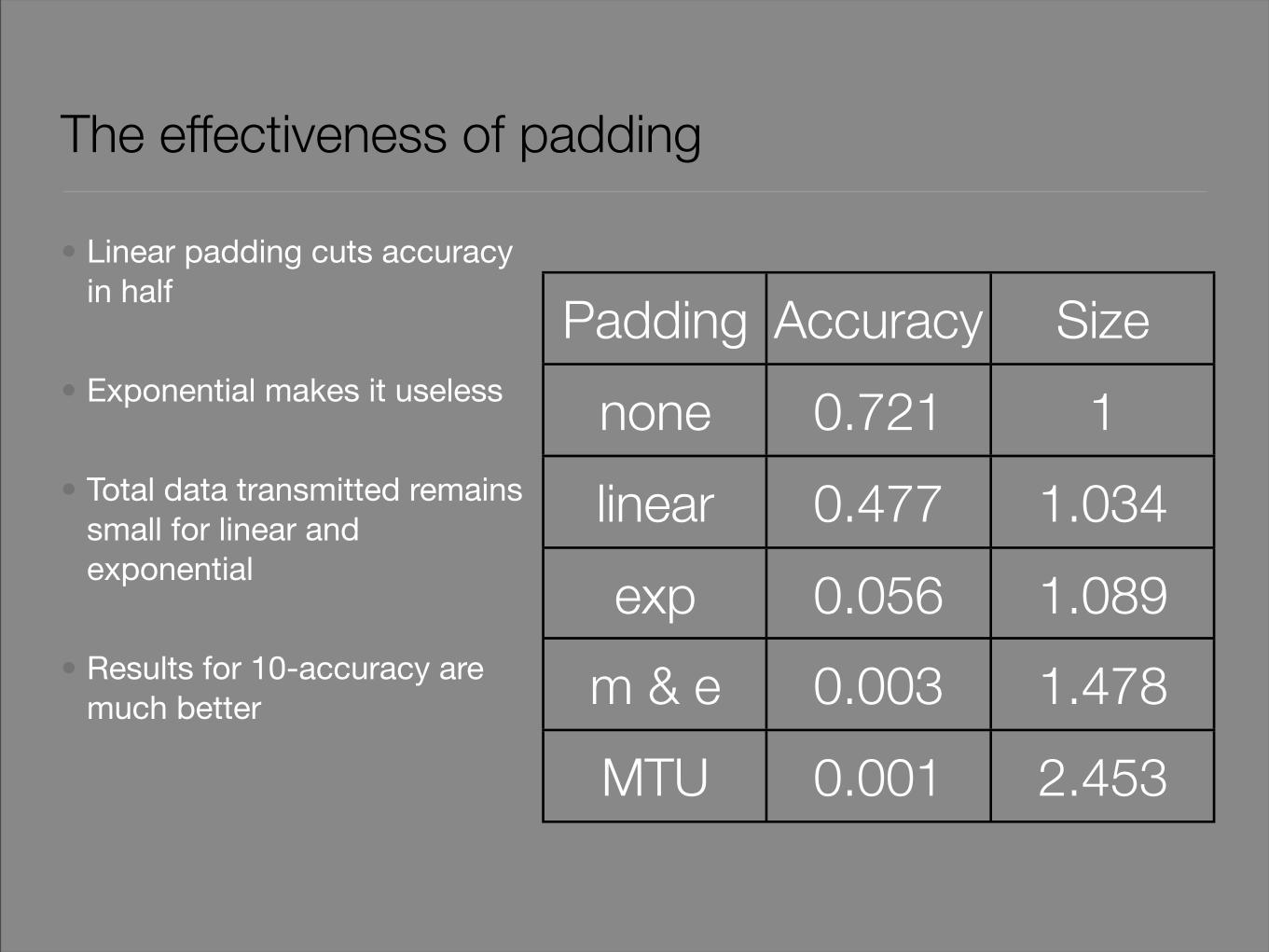
The effectiveness of padding
• Linear padding cuts accuracy in half
• Exponential makes it useless
• Total data transmitted remains small for linear and exponential
• Results for 10-accuracy are much better
Padding Accuracy Size
none 0.721 1
linear 0.477 1.034
exp 0.056 1.089
m & e 0.003 1.478
MTU 0.001 2.453

The not so great...
• For this to be useful, you need a library of every website
• Collecting this much data isn’t easy
• How accurate will this be? With 38 million websites there’s going to be a lot of sites that look the same
• They show that trivial packet padding makes this useless
• No results for test sets of size < 4

Future work
• Current analysis is weak to packet padding, they are looking to use packet arrival times to overcome this
• Even for non-padded packets, packet timing can be important (but also hard to use)
• Padding packets non-deterministically may be even stronger against profiling
• How reasonable is building a huge library of profiles for the entire Internet?
• In the end, is 75% accuracy good enough?

Take away
You can say a lot about a book by its cover.
Related Documents











