1 Inferencia Estadística

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Inferencia Estadística

2
Inferencia Estadística
¿Qué es estadística?

3
¿Qué es estadística?
• La ciencia utiliza modelos para describir fenómenos.
Inferencia Estadística

4
¿Qué es estadística?
• La ciencia utiliza modelos para describir fenómenos.
• Un modelo es una explicación teórica del fenómeno objeto de estudio. Esta explicación suele expresarse en forma verbal, muchas veces mediante ecuaciones matemáticas.
Inferencia Estadística

5
¿Qué es estadística?
• La ciencia utiliza modelos para describir fenómenos.
• Un modelo es una explicación teórica del fenómeno objeto de estudio. Esta explicación suele expresarse en forma verbal, muchas veces mediante ecuaciones matemáticas.
• Existen modelos determinísticos y modelos no determinísticos.
Inferencia Estadística

6
¿Qué es estadística?
• Modelo determinístico:
Inferencia Estadística

7
¿Qué es estadística?
• Modelo determinístico: Es posible conocer un valor preciso de la variable de interés a partir de otras.
Inferencia Estadística

8
¿Qué es estadística?
• Modelo determinístico: Es posible conocer un valor preciso de la variable de interés a partir de otras.
• Modelo no determinístico:
Inferencia Estadística

9
¿Qué es estadística?
• Modelo determinístico: Es posible conocer un valor preciso de la variable de interés a partir de otras.
• Modelo no determinístico: No es posible determinar un valor preciso de la variable de interés pues está presente la incertidumbre.
Inferencia Estadística

10
No determinísticos
Inferencia Estadística

11
No determinísticos
• Duración de la batería de litio de una laptop.
Inferencia Estadística

12
No determinísticos
• Duración de la batería de litio de una laptop.
• Cantidad de personas que compran con tarjeta de crédito en una tienda en un período determinado.
Inferencia Estadística

13
No determinísticos
• Duración de la batería de litio de una laptop.
• Cantidad de personas que compran con tarjeta de crédito en una tienda en un período determinado.
• Promedio de notas en los estudios universitarios (conocido el promedio de notas en secundaria).
Inferencia Estadística

14
¿Qué es estadística?
La Estadística nos enseña cómo realizar juicios inteligentes y tomar decisiones en presencia de incertidumbre. Los métodos estadísticos están ideados para permitir evaluar el grado de incertidumbre de los resultados. La Estadística se ocupa de modelos y fenómenos no determinísticos.
Inferencia Estadística

15
¿Qué es estadística?
Asociado a modelos no determinísticos está el concepto de probabilidad. Existe la Estadística Descriptiva y la Estadística Inferencial.
Inferencia Estadística

16
¿Qué es estadística?
Estadística Descriptiva: Técnicas para describir o representar conjuntos de datos (gráficos y cálculo de medidas numéricas).
Inferencia Estadística

17
¿Qué es estadística?
Estadística Descriptiva: Técnicas para describir o representar conjuntos de datos (gráficos y cálculo de medidas numéricas). Estadística Inferencial: Métodos para derivar conclusiones acerca de un gran grupo de objetos al observar una parte de ellos.
Inferencia Estadística

18
Población y muestra
POBLACIÓN: Es todo conjunto de elementos, definido por una o más características, de las que gozan todos los elementos que lo componen, y sólo ellos.
Inferencia Estadística

19
Población y muestra
POBLACIÓN: Es todo conjunto de elementos, definido por una o más características, de las que gozan todos los elementos que lo componen, y sólo ellos. En muestreo, se entiende por población a la totalidad del universo que interesa conocer, y que es necesario que esté bien definido para que se sepa en todo momento qué elementos lo componen. Conviene recordar que población es el conjunto de elementos a los cuales se quieren inferir los resultados.
Inferencia Estadística

20
Población y muestra
MUESTRA: En todas las ocasiones en que no es posible o conveniente realizar un censo, lo que hacemos es trabajar con una muestra, entendiendo por tal una parte representativa y adecuada de la población.
Inferencia Estadística

21
Población y muestra
MUESTRA: En todas las ocasiones en que no es posible o conveniente realizar un censo, lo que hacemos es trabajar con una muestra, entendiendo por tal una parte representativa y adecuada de la población. Para que una muestra sea representativa, y por lo tanto útil, debe de reflejar las semejanzas y diferencias encontradas en la población, ejemplificar las características y tendencias de la misma. Cuando decimos que una muestra es representativa indicamos que reúne aproximadamente las características de la población que son importantes para la investigación.
Inferencia Estadística

22
Población y muestra
MUESTRA: En todas las ocasiones en que no es posible o conveniente realizar un censo, lo que hacemos es trabajar con una muestra, entendiendo por tal una parte representativa y adecuada de la población. Para que una muestra sea representativa, y por lo tanto útil, debe de reflejar las semejanzas y diferencias encontradas en la población, ejemplificar las características y tendencias de la misma. Cuando decimos que una muestra es representativa indicamos que reúne aproximadamente las características de la población que son importantes para la investigación. Cuando decimos que una muestra es adecuada, nos referimos a que contiene el número de unidades de estudio, tal que permita aplicar pruebas estadísticas que den validez a la inferencia de los resultados a la población.
Inferencia Estadística

23
Ventajas del muestreo
Inferencia Estadística

24
Ventajas del muestreo
• Costos reducidos.
Inferencia Estadística

25
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados.
Inferencia Estadística

26
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores:
Inferencia Estadística

27
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores: a) Volumen de trabajo reducido.
Inferencia Estadística

28
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores: a) Volumen de trabajo reducido. b) Puede existir mayor supervisión en el trabajo.
Inferencia Estadística

29
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores: a) Volumen de trabajo reducido. b) Puede existir mayor supervisión en el trabajo. c) Se puede dar más entrenamiento al personal.
Inferencia Estadística

30
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores: a) Volumen de trabajo reducido. b) Puede existir mayor supervisión en el trabajo. c) Se puede dar más entrenamiento al personal. d) Menor probabilidad de cometer errores durante el procesamiento de la información.
Inferencia Estadística

31
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores: a) Volumen de trabajo reducido. b) Puede existir mayor supervisión en el trabajo. c) Se puede dar más entrenamiento al personal. d) Menor probabilidad de cometer errores durante el procesamiento de la información. • Factibilidad de hacer el estudio cuando la toma de datos implica técnicas destructivas, por ejemplo:
Inferencia Estadística

32
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores: a) Volumen de trabajo reducido. b) Puede existir mayor supervisión en el trabajo. c) Se puede dar más entrenamiento al personal. d) Menor probabilidad de cometer errores durante el procesamiento de la información. • Factibilidad de hacer el estudio cuando la toma de datos implica técnicas destructivas, por ejemplo: a) Pruebas de germinación.
Inferencia Estadística

33
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores: a) Volumen de trabajo reducido. b) Puede existir mayor supervisión en el trabajo. c) Se puede dar más entrenamiento al personal. d) Menor probabilidad de cometer errores durante el procesamiento de la información. • Factibilidad de hacer el estudio cuando la toma de datos implica técnicas destructivas, por ejemplo: a) Pruebas de germinación. b) Análisis de sangre.
Inferencia Estadística

34
Ventajas del muestreo
• Costos reducidos. • Mayor rapidez para obtener resultados. • Mayor exactitud o mejor calidad de la información debido a los siguientes factores: a) Volumen de trabajo reducido. b) Puede existir mayor supervisión en el trabajo. c) Se puede dar más entrenamiento al personal. d) Menor probabilidad de cometer errores durante el procesamiento de la información. • Factibilidad de hacer el estudio cuando la toma de datos implica técnicas destructivas, por ejemplo: a) Pruebas de germinación. b) Análisis de sangre. c) Control de calidad.
Inferencia Estadística

35
Desventajas del muestreo
Inferencia Estadística

36
Desventajas del muestreo
• Siempre está presente el error de muestreo producto de la variabilidad intrínseca de los elementos del universo, existen diferencias entre las medidas muestrales (estadísticos) y los parámetros poblacionales llamada Error de Muestreo.
Inferencia Estadística

37
Desventajas del muestreo
• Siempre está presente el error de muestreo producto de la variabilidad intrínseca de los elementos del universo, existen diferencias entre las medidas muestrales (estadísticos) y los parámetros poblacionales llamada Error de Muestreo. El término error no debe entenderse como sinónimo de equivocación.
Inferencia Estadística

38
Desventajas del muestreo
• Siempre está presente el error de muestreo producto de la variabilidad intrínseca de los elementos del universo, existen diferencias entre las medidas muestrales (estadísticos) y los parámetros poblacionales llamada Error de Muestreo. El término error no debe entenderse como sinónimo de equivocación. También suelen introducirse errores por otras vías, los cuales se denominan errores sistemáticos: Los cuales son: - Imputables al observador. - Imputables al método de observación o medición. - Imputables a lo observado (unidad de muestreo).
Inferencia Estadística

39
Parámetro y estadístico
Inferencia Estadística

40
Parámetro y estadístico PARAMETRO: Son las medidas o datos que se obtienen sobre la población.
Inferencia Estadística

41
Parámetro y estadístico PARAMETRO: Son las medidas o datos que se obtienen sobre la población. ESTADISTICO: Los datos o medidas que se obtienen sobre una muestra y por lo tanto una estimación de los parámetros.
Inferencia Estadística

42
Parámetro y estadístico PARAMETRO: Son las medidas o datos que se obtienen sobre la población. ESTADISTICO: Los datos o medidas que se obtienen sobre una muestra y por lo tanto una estimación de los parámetros. ERROR MUESTRAL, de estimación o standard: Es la diferencia entre un estadístico y su parámetro correspondiente.
Inferencia Estadística
43
Tipos de muestreo
• PROBABILISTICO • NO PROBABILISTICO
Inferencia Estadística

44
Muestreo probabilístico
Inferencia Estadística

45
Muestreo probabilístico
Los métodos de muestreo probabilístico son aquellos que se basan en el principio de equiprobabilidad.
Inferencia Estadística

46
Muestreo probabilístico
Los métodos de muestreo probabilístico son aquellos que se basan en el principio de equiprobabilidad. Es decir, aquellos en los que todos los individuos tienen la misma probabilidad de ser elegidos para formar parte de una muestra y, consiguientemente, todas las posibles muestras de tamaño n tienen la misma probabilidad de ser elegidas.
Inferencia Estadística

47
Muestreo probabilístico
Los métodos de muestreo probabilístico son aquellos que se basan en el principio de equiprobabilidad. Es decir, aquellos en los que todos los individuos tienen la misma probabilidad de ser elegidos para formar parte de una muestra y, consiguientemente, todas las posibles muestras de tamaño n tienen la misma probabilidad de ser elegidas. Sólo estos métodos de muestreo probabilístico nos aseguran la representatividad de la muestra extraída y son, por tanto, los más recomendables
Inferencia Estadística

48
Muestreo no probabilístico
A veces, para estudios exploratorios, el muestreo probabilístico resulta excesivamente costoso y se acude a métodos no probabilístico, aun siendo conscientes de que no sirven para realizar generalizaciones, pues no se tiene certeza de que la muestra extraída sea representativa, ya que no todos los sujetos de la población tienen la misma probabilidad de se elegidos.
Inferencia Estadística

49
Muestreo no probabilístico
A veces, para estudios exploratorios, el muestreo probabilístico resulta excesivamente costoso y se acude a métodos no probabilístico, aun siendo conscientes de que no sirven para realizar generalizaciones, pues no se tiene certeza de que la muestra extraída sea representativa, ya que no todos los sujetos de la población tienen la misma probabilidad de se elegidos. En general se seleccionan a los sujetos siguiendo determinados criterios procurando que la muestra sea representativa.
Inferencia Estadística

50
Métodos de muestreo probabilístico • MUESTREO ALEATORIO SIMPLE • MUESTREO ALEATORIO SISTEMÁTICO • MUESTREO ALEATORIO ESTRATIFICADO • MUESTREO ALEATORIO POR CONGLOMERADOS
Inferencia Estadística

51
Métodos de muestreo no probabilístico • MUESTREO POR CUOTAS • MUESTREO OPINÁTICO O INTENCIONAL • MUESTREO CASUAL O INCIDENTAL • BOLA DE NIEVE
Inferencia Estadística

52
EJERCICIO 1 Decida, para cada uno de los problemas siguientes, si es apropiado un estudio estadístico o no. En caso afirmativo explique la razón de su respuesta e identifique la población:
Inferencia Estadística

53
EJERCICIO 1 Decida, para cada uno de los problemas siguientes, si es apropiado un estudio estadístico o no. En caso afirmativo explique la razón de su respuesta e identifique la población: 1. Se investigará la opinión de 50000 trabajadores que se verán afectados por
el cambio de la jornada laboral tradicional, de ocho horas diarias durante cinco días a la semana, a la de diez horas diarias por espacio de cuatro días a la semana.
Inferencia Estadística

54
EJERCICIO 1 Decida, para cada uno de los problemas siguientes, si es apropiado un estudio estadístico o no. En caso afirmativo explique la razón de su respuesta e identifique la población: 1. Se investigará la opinión de 50000 trabajadores que se verán afectados por
el cambio de la jornada laboral tradicional, de ocho horas diarias durante cinco días a la semana, a la de diez horas diarias por espacio de cuatro días a la semana.
2. Un despacho de arquitectos debe presentar una cotización para un proyecto de cableado. Están disponibles siete contratistas eléctricos para la tarea. Se pretende determinar el costo promedio estimado del proyecto y el tiempo promedio proyectado que se requeriría para que cualquiera de los contratistas realice el proyecto.
Inferencia Estadística

55
EJERCICIO 1 Decida, para cada uno de los problemas siguientes, si es apropiado un estudio estadístico o no. En caso afirmativo explique la razón de su respuesta e identifique la población: 1. Se investigará la opinión de 50000 trabajadores que se verán afectados por
el cambio de la jornada laboral tradicional, de ocho horas diarias durante cinco días a la semana, a la de diez horas diarias por espacio de cuatro días a la semana.
2. Un despacho de arquitectos debe presentar una cotización para un proyecto de cableado. Están disponibles siete contratistas eléctricos para la tarea. Se pretende determinar el costo promedio estimado del proyecto y el tiempo promedio proyectado que se requeriría para que cualquiera de los contratistas realice el proyecto.
3. Un sistema de cómputo está conectado a cierto número de terminales distantes. A fin de decidir si se aumenta dicho número o no, es necesario estudiar la variable aleatoria X, el tiempo por sesión de cada usuario en las terminales actualmente instaladas.
Inferencia Estadística

56
EJERCICIO 2 Se quiere estimar la cantidad de tiempo promedio que los profesores del INTEC emplean calificando las tareas de cierta semana. Describa una forma de obtener a) Una muestra aleatoria simple b) Una muestra sistemática c) Una muestra estratificada
Inferencia Estadística

57
Distribuciones muestrales de medias y de proporciones

58
Distribución muestral de medias Considere la población 1, 3, 5, 7 Se desea obtener una muestra de tamaño 2, mediante muestreo aleatorio simple, sin reemplazamiento y sin importar el orden. a) ¿Cuántas muestras posibles hay? b) Encuentre la distribución muestral de medias. c) Calcule la media de la población. d) Calcule la media de todas las medias muestrales.
Inferencia Estadística

59
Distribución muestral de medias Considere la población 1, 3, 5, 7 Se desea obtener una muestra de tamaño 2, mediante muestreo aleatorio simple, con reemplazamiento y se considera el orden. a) ¿Cuántas muestras posibles hay? b) Encuentre la distribución muestral de medias. c) Calcule la media de todas las medias muestrales.
Inferencia Estadística

60
EJERCICIO 1 Una marca particular de jabón para lavadora de platos se vende en tres tamaños: 25 oz, 40 oz y 65 oz. El 20% de todos los compradores seleccionan la caja de 25 oz, el 50% seleccionan una caja de 40 oz y el 30% restante selecciona una caja de 65 oz. Sean X1 y X2 los tamaños de paquete seleccionados por dos compradores independientemente seleccionados. Determine la distribución muestral de medias.
Inferencia Estadística

61
Teorema del límite central Sea X1, X2, … Xn es una muestra aleatoria de una
distribución con media μ y varianza σ².
Entonces, si n es suficientemente grande, X tiene
aproximadamente una distribución normal con
μ = μ X σ σ = X √ n
Inferencia Estadística

62
EJERCICIO 2 Se tiene un lote de 12 artículos, el cual tiene 4 defectuosos. Se van a seleccionar 5 artículos al azar de ese lote sin reemplazo. Genere la distribución muestral de proporciones para el número de piezas defectuosas.
Inferencia Estadística

63
Estimación

64
Estimación En Inferencia Estadística, a través de una muestra se trata de:
Inferencia Estadística

65
Estimación En Inferencia Estadística, a través de una muestra se trata de: • Estimar un parámetro desconocido
Inferencia Estadística

66
Estimación En Inferencia Estadística, a través de una muestra se trata de: • Estimar un parámetro desconocido (ESTIMACION)
Inferencia Estadística

67
Estimación En Inferencia Estadística, a través de una muestra se trata de: Estimación puntual • Estimar un parámetro desconocido (ESTIMACION)
Inferencia Estadística
68
Estimación En Inferencia Estadística, a través de una muestra se trata de: Estimación puntual • Estimar un parámetro desconocido (ESTIMACION) Estimación por intervalos
Inferencia Estadística

69
Estimación En Inferencia Estadística, a través de una muestra se trata de: Estimación puntual • Estimar un parámetro desconocido (ESTIMACION) Estimación por intervalos • Verificar si el parámetro es o no igual a cierto valor
Inferencia Estadística

70
Estimación En Inferencia Estadística, a través de una muestra se trata de: Estimación puntual • Estimar un parámetro desconocido (ESTIMACION) Estimación por intervalos • Verificar si el parámetro es o no igual a cierto valor (PRUEBA DE HIPOTESIS)
Inferencia Estadística

71
Estimación Para estimar el parámetro poblacional θ se utiliza el
estadístico θ.
Inferencia Estadística

72
Estimación Para estimar el parámetro poblacional θ se utiliza el
estadístico θ.
Ejemplos
Inferencia Estadística
Parámetro Estimador
μ x
σ² s²
σ s
p p

73
Estimación El estimador no tiene que ser único.
Inferencia Estadística

74
Estimación El estimador no tiene que ser único.
Por ejemplo, en una distribución simétrica, otro estimador
de μ es la mediana.
Inferencia Estadística

75
Estimación El estimador no tiene que ser único.
Por ejemplo, en una distribución simétrica, otro estimador
de μ es la mediana.
Otro estimador pudiera ser la media 10% recortada.
Inferencia Estadística

76
Estimación El estimador no tiene que ser único.
Por ejemplo, en una distribución simétrica, otro estimador
de μ es la mediana.
Otro estimador pudiera ser la media 10% recortada.
min + max Y otro estimador podría ser 2
Inferencia Estadística

77
Estimación El estimador no tiene que ser único.
Por ejemplo, en una distribución simétrica, otro estimador
de μ es la mediana.
Otro estimador pudiera ser la media 10% recortada.
min + max Y otro estimador podría ser 2 En general se cumple que θ = θ + error de estimación
Inferencia Estadística

78
Propiedades de un buen estimador
Inferencia Estadística

79
Propiedades de un buen estimador 1. Ausencia de sesgo o imparcialidad, es decir, que sea
insesgado. Esto es E( θ ) = θ
Inferencia Estadística

80
Propiedades de un buen estimador 1. Ausencia de sesgo o imparcialidad, es decir, que sea
insesgado. Esto es E( θ ) = θ
2. Eficacia o eficiencia, esto significa que su varianza es mínima.
Inferencia Estadística

81
Propiedades de un buen estimador 1. Ausencia de sesgo o imparcialidad, es decir, que sea
insesgado. Esto es E( θ ) = θ
2. Eficacia o eficiencia, esto significa que su varianza es mínima.
3. Consistencia o coherencia. Un estimador es consistente cuando su valor tiende a acercarse al correspondiente valor del parámetro.
Inferencia Estadística

82
Propiedades de un buen estimador 1. Ausencia de sesgo o imparcialidad, es decir, que sea
insesgado. Esto es E( θ ) = θ
2. Eficacia o eficiencia, esto significa que su varianza es mínima.
3. Consistencia o coherencia. Un estimador es consistente cuando su valor tiende a acercarse al correspondiente valor del parámetro.
4. Suficiencia, o sea, que agota toda la información sobre el parámetro contenida en la muestra.
Inferencia Estadística

83
Propiedades de un buen estimador
La media muestral y la varianza corregida son buenos estimadores de la media poblacional y la
varianza poblacional.
Inferencia Estadística

84
Intervalos de confianza para la media poblacional

85
La estimación puntual, o sea, estimar un parámetro a través de un único valor no es muy conveniente pues con ella no se puede determinar el error de muestreo, ni la precisión de la estimación, ni la confianza que merece tal estimación.
Inferencia Estadística

86
Existen otros métodos para estimar parámetros poblacionales, que son mucho más precisos. Por ejemplo,
Inferencia Estadística

87
Existen otros métodos para estimar parámetros poblacionales, que son mucho más precisos. Por ejemplo, • Método de los mínimos cuadrados
Inferencia Estadística

88
Existen otros métodos para estimar parámetros poblacionales, que son mucho más precisos. Por ejemplo, • Método de los mínimos cuadrados • Método de los momentos
Inferencia Estadística

89
Existen otros métodos para estimar parámetros poblacionales, que son mucho más precisos. Por ejemplo, • Método de los mínimos cuadrados • Método de los momentos • Método de la máxima verosimilitud
Inferencia Estadística

90
Existen otros métodos para estimar parámetros poblacionales, que son mucho más precisos. Por ejemplo, • Método de los mínimos cuadrados • Método de los momentos • Método de la máxima verosimilitud • Método de estimación por intervalos de confianza
Inferencia Estadística
91
Algunos conceptos
Inferencia Estadística

92
Algunos conceptos
α = probabilidad de que el intervalo NO incluya al verdadero valor del parámetro.
Inferencia Estadística

93
Algunos conceptos
α = probabilidad de que el intervalo NO incluya al verdadero valor del parámetro. 1 – α = probabilidad de que el intervalo incluya al verdadero valor del parámetro = nivel de confianza
Inferencia Estadística

94
Algunos conceptos
α = probabilidad de que el intervalo NO incluya al verdadero valor del parámetro. 1 – α = probabilidad de que el intervalo incluya al verdadero valor del parámetro = nivel de confianza Ejemplo: α = 5% = 0.05 1 – α = 95% = 0.95
Inferencia Estadística
95
Teorema del límite central
Inferencia Estadística

96
Teorema del límite central Sea X1, X2, … Xn es una muestra aleatoria de una
distribución con media μ y varianza σ².
Entonces, si n es suficientemente grande, X tiene
aproximadamente una distribución normal con
μ = μ X σ σ = X √ n
Inferencia Estadística
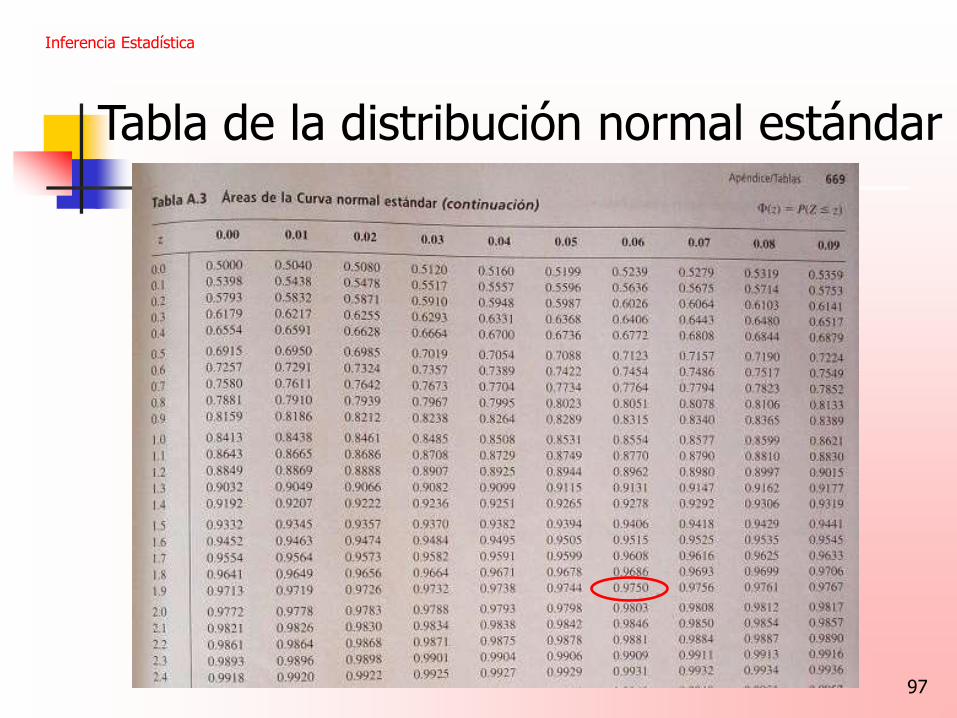
97
Tabla de la distribución normal estándar
Inferencia Estadística

98
Intervalo de confianza al 95% (para la media μ siendo σ conocida)
σ σ x - 1.96 ≤ μ ≤ x + 1.96 √ n √ n
Inferencia Estadística

99
Tabla de la distribución normal estándar
Inferencia Estadística
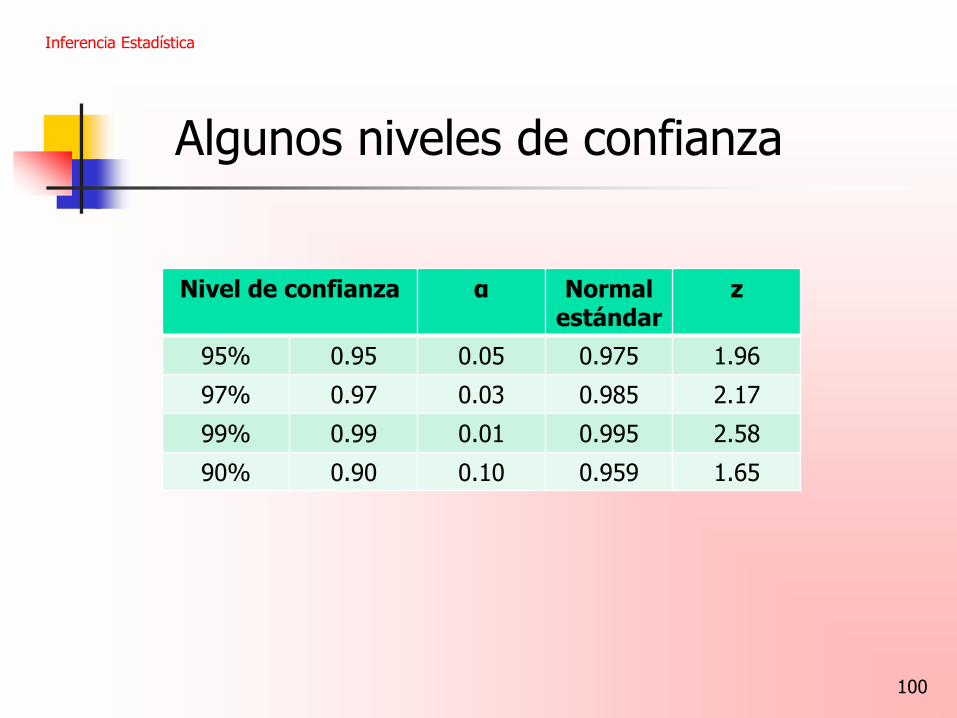
100
Algunos niveles de confianza
Inferencia Estadística
Nivel de confianza α Normal estándar
z
95% 0.95 0.05 0.975 1.96
97% 0.97 0.03 0.985 2.17
99% 0.99 0.01 0.995 2.58
90% 0.90 0.10 0.959 1.65

101
Ejercicio 1
Un grupo de investigadores en medicina desean estimar el cambio medio de presión sanguínea por paciente en un sanatorio. Se ha seleccionado una muestra al azar de 30 pacientes y se halló una media de 5 puls/seg. Los investigadores saben que, según estudios anteriores, la desviación estándar de los cambios de presión sanguínea para todos los pacientes es de 3 puls/seg. Se desea estimar el cambio medio de la presión sanguínea por paciente con un intervalo del 95% de confianza, suponiendo que la variable aleatoria “cambios de presión sanguínea” tiene una distribución normal.
Inferencia Estadística

102
Intervalo de confianza al 95% (para la media μ para σ desconocida)
s s x - 1.96 ≤ μ ≤ x + 1.96 √ n √ n Como generalmente la desviación estándar poblacional es desconocida, se sustituye por la desviación estándar de la muestra.
Inferencia Estadística
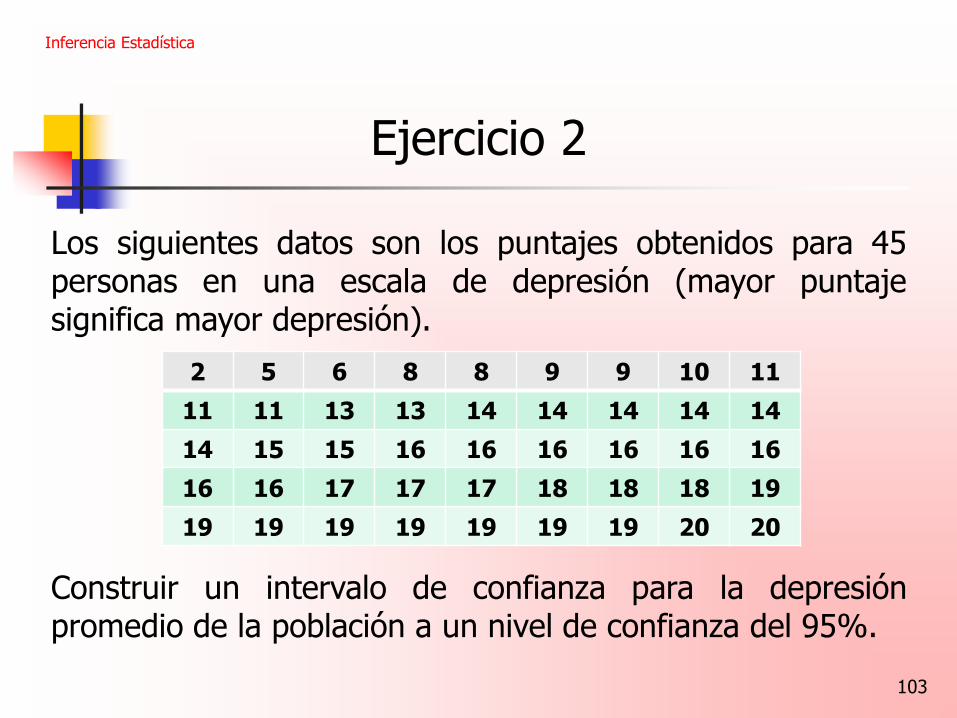
103
Ejercicio 2
Los siguientes datos son los puntajes obtenidos para 45 personas en una escala de depresión (mayor puntaje significa mayor depresión). Construir un intervalo de confianza para la depresión promedio de la población a un nivel de confianza del 95%.
Inferencia Estadística
2 5 6 8 8 9 9 10 11
11 11 13 13 14 14 14 14 14
14 15 15 16 16 16 16 16 16
16 16 17 17 17 18 18 18 19
19 19 19 19 19 19 19 20 20

104
Intervalos de confianza para proporciones
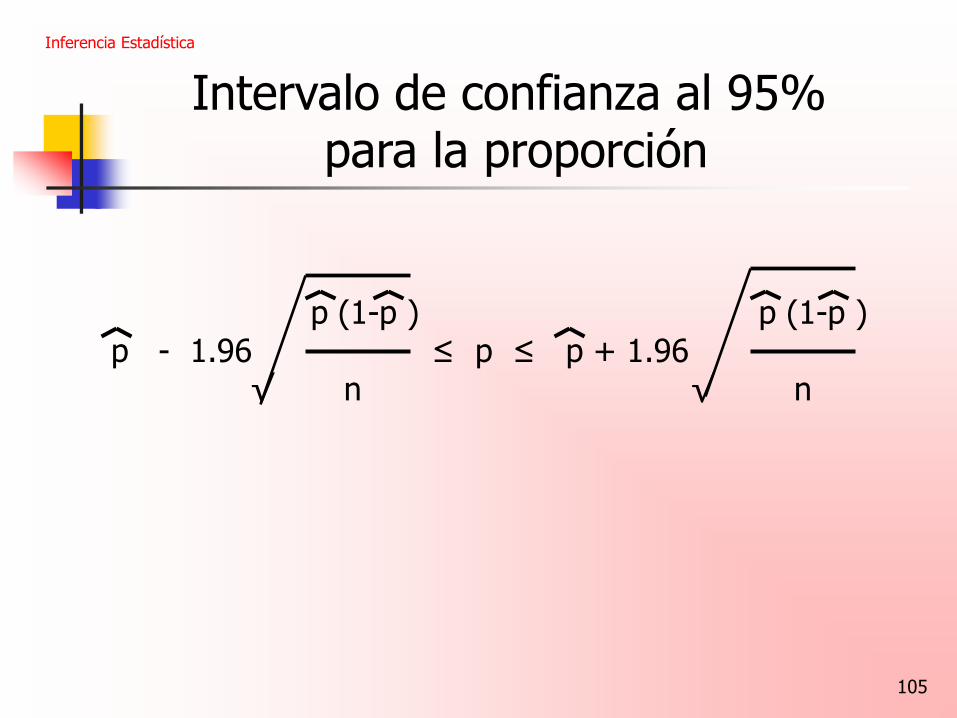
105
Intervalo de confianza al 95% para la proporción
p (1-p ) p (1-p ) p - 1.96 ≤ p ≤ p + 1.96 √ n √ n
Inferencia Estadística

106
Ejercicio 1
En un estudio de prevalencia de factores de riesgo en una cohorte de 412 mujeres mayores de 15 años en cierta región se encontró que el 17.6% eran hipertensas. Determine un intervalo de confianza al 95% para la proporción de mujeres hipertensas en la región estudiada.
Inferencia Estadística

107
Ejercicio 2
En cierta población se seleccionó aleatoriamente una muestra de 300 personas a las que se les sometió a cierto test cultural. De ellas resultaron aprobadas 225. Teniendo en cuenta esta información estimar el porcentaje de personas de esa población que resultarían aprobados si se les sometiera a dicho test cultural. Obtener con un nivel de confianza del 97% un intervalo de confianza para la proporción.
Inferencia Estadística

108
Ejercicio 3
Estamos interesados en conocer el consumo diario medio de cigarrillos entre los alumnos de cierta universidad. Seleccionada una muestra aleatoria de 100 alumnos se observó que fumaban una media de 8 cigarrillos diarios. Si admitimos que la varianza de dicho consumo es de 16 cigarrillos en el colectivo total, estime dicho consumo medio con un nivel de confianza del 90%.
Inferencia Estadística
2

109
Ejercicio 4
Tomada al azar una muestra de 120 estudiantes de una universidad se encontró que 54 de ellos hablaban inglés. Halle con un nivel de confianza del 90% un intervalo de confianza para estimar la proporción de estudiantes que habla el idioma inglés entre los estudiantes de esa universidad.
Inferencia Estadística

110
Ejercicio 5
Un diseñador industrial quiere determinar la cantidad promedio de tiempo que tarda un adulto en ensamblar un juguete “fácil de ensamblar”. Use los datos siguientes (en minutos), una muestra aleatoria, para construir un intervalo de confianza del 95% para la media de la población muestreada.
Inferencia Estadística
17 13 18 19 17 21 29 22 16 28 21 15
26 23 24 20 8 17 17 21 32 18 25 22
16 10 20 22 19 14 30 22 12 24 28 11

111
Intervalos de confianza para la diferencia de medias y la diferencia de proporciones

112
Intervalo de confianza para la diferencia de medias
Si x y x son los valores de las medias de muestras
aleatorias independientes de tamaños n y n de poblaciones
normales con las varianzas conocidas σ y σ entonces un
intervalo de confianza para la diferencia entre las dos
medias de las poblaciones es
Inferencia Estadística
1 2
1 2
2 2
1 2

113
Intervalo de confianza para la diferencia de medias
σ σ ( x - x ) - z + ≤ μ - μ ≤ √ n n σ σ ( x - x ) + z + √ n n
Inferencia Estadística
1 2
1 2
1 2
2 2
1 2
1 2
1 2
1 2
2 2

114
Intervalo de confianza para la diferencia de medias
En virtud del teorema del límite central esta fórmula puede
usarse también para muestras aleatorias independientes de
poblaciones no normales con varianzas conocidas cuando
los valores de n y n son grandes (mayores que 30).
Inferencia Estadística
1 2

115
Intervalo de confianza para la diferencia de medias
Si las varianzas σ y σ son desconocidas, entonces se
sustituyen sus valores en la fórmula por s y s y se procede
como antes.
Inferencia Estadística
1 2
1 2
2 2
2 2

116
Ejercicio 1
Construya un intervalo de confianza al 94% para la diferencia entre las vidas medias de dos clases de bombillos dado que una muestra aleatoria de 40 bombillos de la primera clase duró un promedio de 418 horas de uso continuo y 50 bombillos de la segunda clase duraron en promedio 402 horas de uso continuo. Las desviaciones estándar de las poblaciones se sabe que son σ = 26 y σ =22 (en
horas).
Inferencia Estadística
1 2

117
Intervalo de confianza para la diferencia de proporciones
Si p y p son los valores de las proporciones de dos
muestras tamaños grandes n y n entonces un intervalo de
confianza para la diferencia de proporciones p – p es
Inferencia Estadística
1 2
1 2
1 2
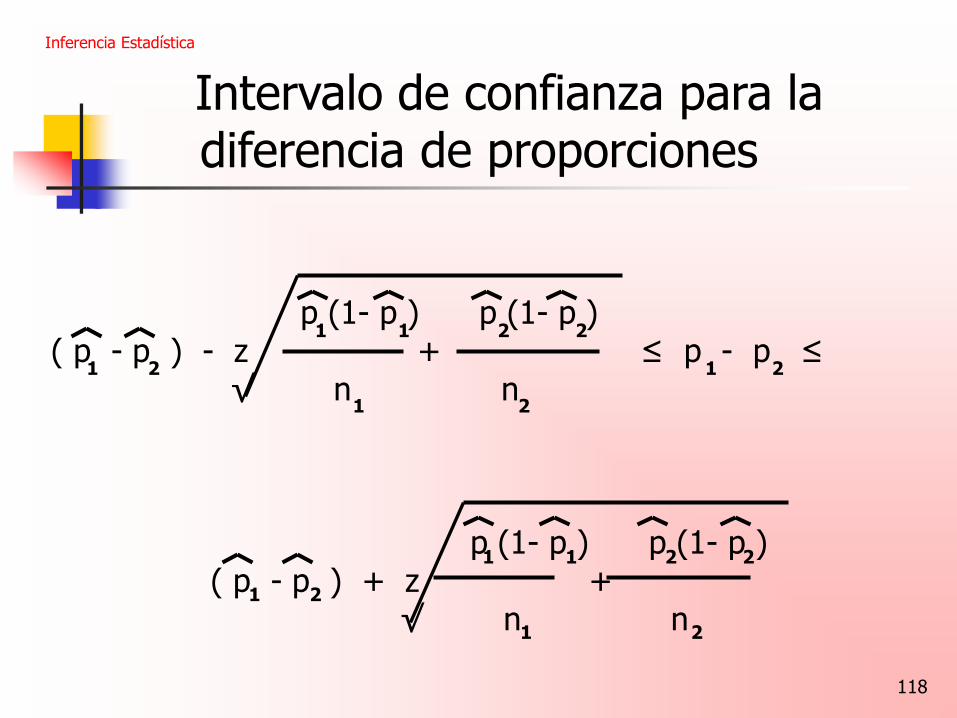
118
Intervalo de confianza para la diferencia de proporciones
p (1- p ) p (1- p ) ( p - p ) - z + ≤ p - p ≤ √ n n p (1- p ) p (1- p ) ( p - p ) + z + √ n n
Inferencia Estadística
1 1 2 2
1 2
1 2
1 2
1 1 2 2
1 2
1 2

119
Ejercicio 2
Si 132 de 200 votantes hombres y 90 de 159 votantes mujeres están a favor de cierto candidato que hace campaña, encuentre un intervalo de confianza del 99% para la diferencia entre las proporciones reales de votantes hombres y votantes mujeres que están a favor del candidato.
Inferencia Estadística

120
Ejercicio 3
Un estudio del crecimiento anual de ciertos cactus mostró que 64 de ellos, seleccionados aleatoriamente en una región desértica, crecieron en promedio 52.80 mm con una desviación estándar de 4.5 mm. Construya un intervalo de confianza del 99% para el verdadero promedio de crecimiento anual de la clase dada de cactus.
Inferencia Estadística

121
Ejercicio 4
Un estudio de dos clases de equipos de fotocopiado muestra que 61 averías del equipo de la primera clase se llevaron en promedio 80.7 minutos en ser reparados, con una desviación estándar de 19.4 minutos, mientras que 61 averías del equipo de segunda clase se llevaron en promedio 88.1 minutos en ser reparados, con una desviación estándar de 18.8 minutos. Encuentre un intervalo de confianza del 99% para la diferencia entre los verdaderos promedios del tiempo que toma reparar las averías de las dos clases de equipo de fotocopiado.
Inferencia Estadística

122
Ejercicio 5 En una muestra aleatoria de 300 personas que comen en una cafetería de una tienda departamental solo 102 pidieron postre. Si usamos 102/300 = 0.34 como una estimación de la verdadera proporción correspondiente, ¿con qué confianza podemos afirmar que nuestro error es menor que 0.05?
Inferencia Estadística

123
Límites de confianza para la varianza poblacional y para el cociente de dos varianzas

124
Intervalo de confianza para la varianza poblacional
Si s es el valor de la varianza de una muestra
aleatoria de tamaño n de una población normal,
entonces un intervalo de confianza del (1-α)100%
para σ es
Inferencia Estadística
2
2

125
Intervalo de confianza para la varianza poblacional
Si s es el valor de la varianza de una muestra
aleatoria de tamaño n de una población normal,
entonces un intervalo de confianza del (1-α)100%
para σ es
(n-1) s (n-1) s < σ < χ χ
Inferencia Estadística
2
2
2 2
2 2
α , n-1 2
1 - α , n-1 2
2
Prueba chi-cuadrado de bondad de
ajuste
126
Distribución chi-cuadrado
Inferencia Estadística
Si la variable aleatoria X tiene una distribución normal estándar,
entonces la variable aleatoria X tiene una distribución chi-cuadrado 2
127
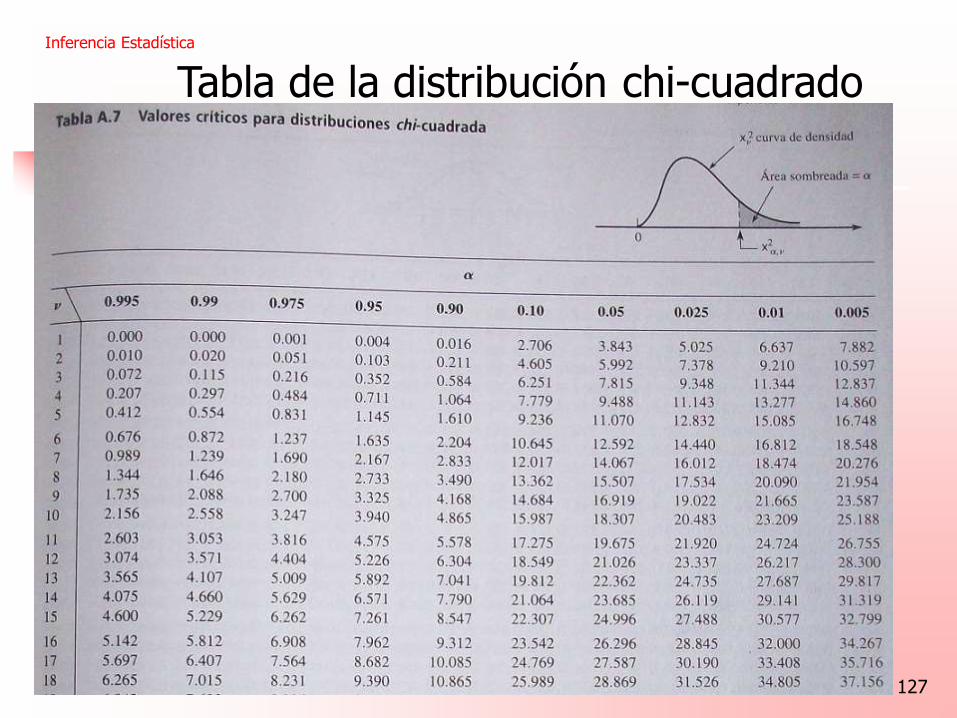
Tabla de la distribución chi-cuadrado
Inferencia Estadística

128
Ejercicio 1
En 16 corridas de prueba el consumo de gasolina
de un motor experimental tiene una desviación
estándar de 2.2 galones. Construya un intervalo de
confianza del 99% para σ que mide la verdadera
variabilidad del consumo de gasolina del motor.
Inferencia Estadística
2

1
2
2
129
Límites de confianza para el cociente de dos varianzas
Si s y s son los valores de dos varianzas de
muestras aleatorias independientes de tamaños n
y n de poblaciones normales, entonces un
intervalo de confianza del (1-α)100% para es
Inferencia Estadística
2 2
1 2
1
2
σ σ 2
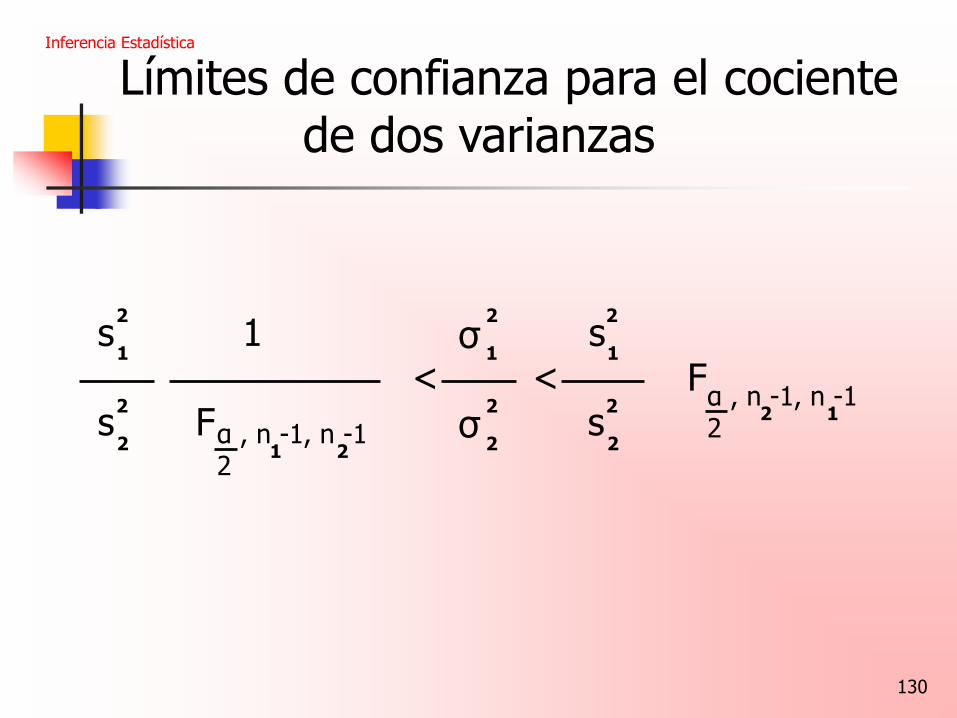
α , n -1, n -1 2
130
Límites de confianza para el cociente de dos varianzas
s 1 s < < F s F s
Inferencia Estadística
2
1 2
2
2
2 2 1 α , n -1, n -1 2
2
2
1
2
σ σ
2
1 1
2
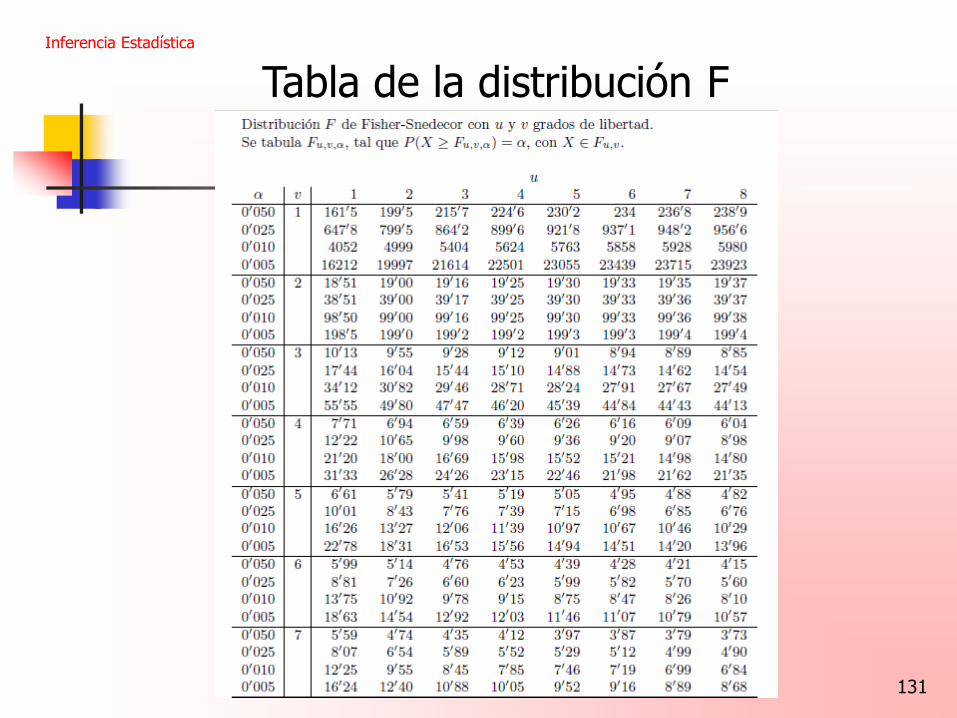
131
Tabla de la distribución F
Inferencia Estadística

132
Ejercicio 2
Se hizo un estudio para comparar los contenidos de nicotina de dos marcas de cigarrillos. Diez cigarrillos de la marca 1 tuvieron un contenido promedio de 3.1 miligramos con una desviación estándar de 0.5 miligramos mientras que ocho cigarrillos de la marca 2 tuvieron un contenido promedio de nicotina de 2.7 miligramos con una desviación estándar de 0.7 miligramos. Suponga que los dos conjuntos de datos son muestras aleatorias independientes de poblaciones normales. Encuentre un intervalo de confianza del 98% para el cociente de las varianzas σ y σ .
Inferencia Estadística
1 2
2 2
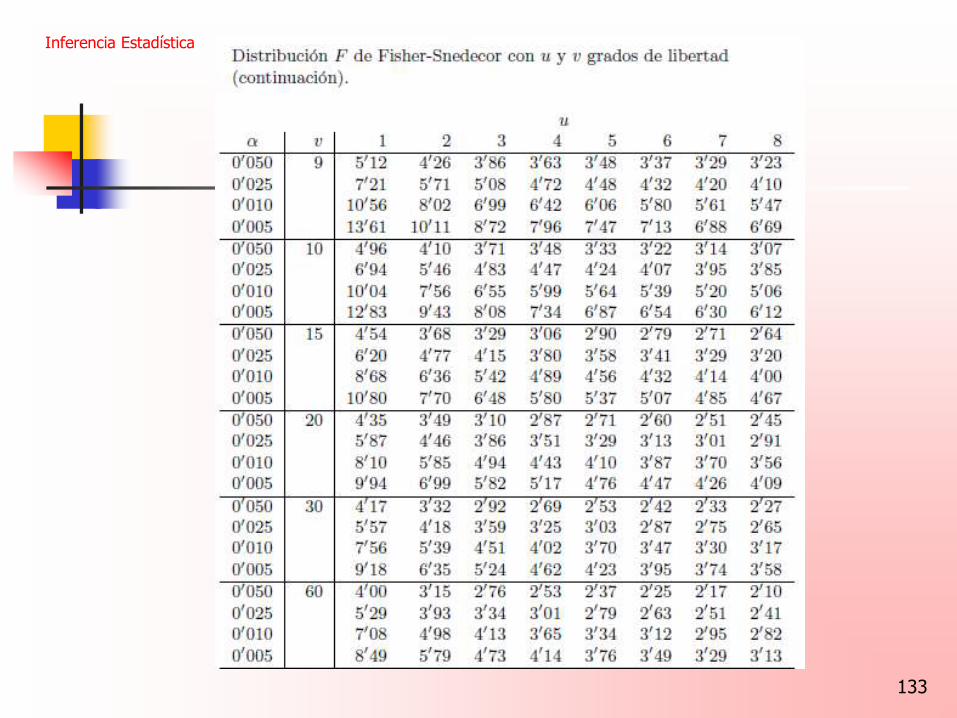
133
Inferencia Estadística

134
Inferencia Estadística

135
Ejercicio 3
Un estudio del crecimiento anual de ciertos cactus mostró que 64 de ellos, seleccionados aleatoriamente en una región desértica, crecieron en promedio 52.80 mm con una desviación estándar de 4.5 mm. Construya un intervalo de confianza del 99% para la desviación estándar del crecimiento anual de la clase de cactus dada.
Inferencia Estadística

136
Ejercicio 4
Un estudio de dos clases de equipos de fotocopiado muestra que 61 averías del equipo de la primera clase se llevaron en promedio 80.7 minutos en ser reparados, con una desviación estándar de 19.4 minutos, mientras que 61 averías del equipo de segunda clase se llevaron en promedio 88.1 minutos en ser reparados, con una desviación estándar de 18.8 minutos. Encuentre un intervalo de confianza del 98% para la razón de las varianzas de las poblaciones muestreadas.
Inferencia Estadística
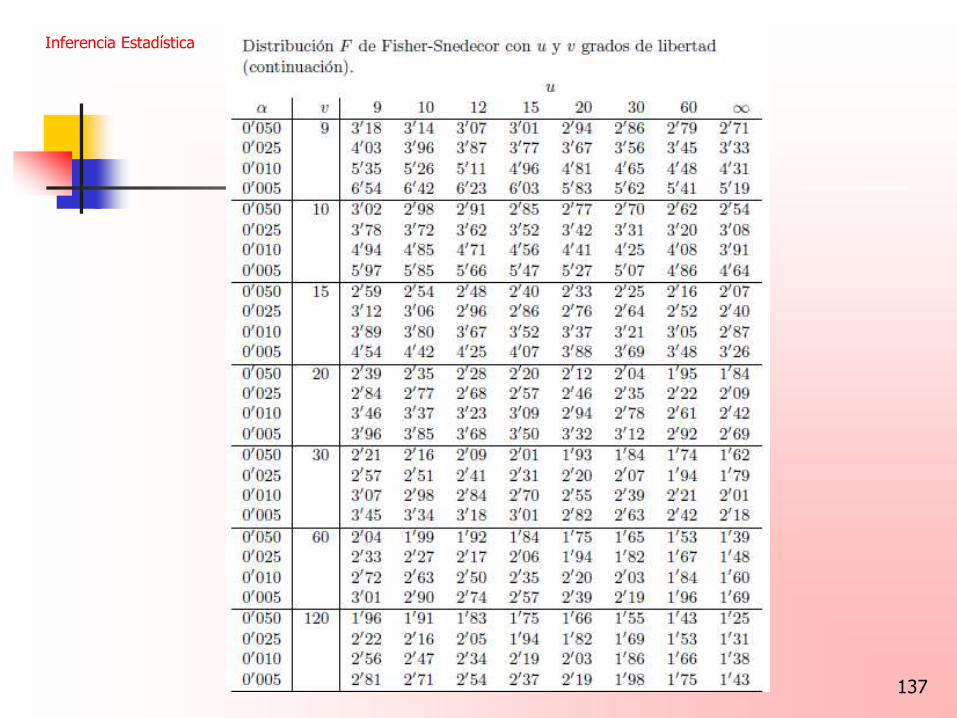
137
Inferencia Estadística

138
Intervalos de confianza para muestras pequeñas

139
Muestras pequeñas Cuando estamos tratando con una muestra aleatoria de una población normal con n<30 y σ desconocida, Si x y s son los valores de la media y la desviación estándar de una muestra aleatoria de tamaño n de una población normal entonces un intervalo con (1-α)100% de confianza para la media de la población es s s x – t . < μ < x + t . √ n √ n
Inferencia Estadística
α , n-1 2
α , n-1 2
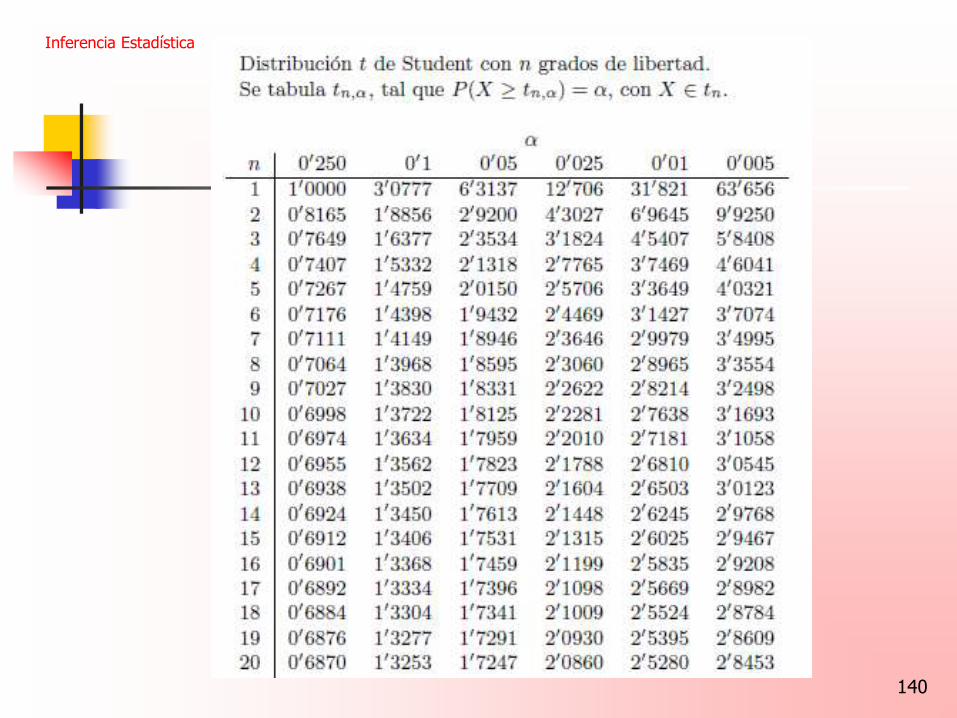
140
Inferencia Estadística

141
Ejercicio 1
Un fabricante de pinturas quiere determinar el tiempo
promedio de secado de una pintura para muros interiores. Si
para 12 áreas de prueba del mismo tamaño ha obtenido una
media de tiempo de secado de 66.3 minutos y una
desviación estándar de 8.4 minutos, construya un intervalo
de confianza del 95% para la media verdadera μ.
Inferencia Estadística

142
Pruebas de hipótesis

143
Hay problemas como:
• Un ingeniero debe decidir, con base a datos muestrales, si el verdadero promedio de vida de cierta clase de neumáticos es por lo menos 22000 millas.
Inferencia Estadística

144
Hay problemas como:
• Un ingeniero debe decidir, con base a datos muestrales, si el verdadero promedio de vida de cierta clase de neumáticos es por lo menos 22000 millas. • Un agrónomo debe decidir, con base en experimentos, si una clase de fertilizantes produce un rendimiento más alto de frijol de soya que otro.
Inferencia Estadística

145
Hay problemas como:
• Un ingeniero debe decidir, con base a datos muestrales, si el verdadero promedio de vida de cierta clase de neumáticos es por lo menos 22000 millas. • Un agrónomo debe decidir, con base en experimentos, si una clase de fertilizantes produce un rendimiento más alto de frijol de soya que otro. • Un fabricante de productos farmacéuticos tiene que decidir, con base en muestras, si el 90% de todos los pacientes que reciben un nuevo tratamiento se recuperarán de cierta enfermedad.
Inferencia Estadística

146
Hipótesis estadística es una afirmación o conjetura acerca de la distribución de una o más variables aleatorias.
Inferencia Estadística

147
Frecuentemente las hipótesis se formulan diciendo exactamente lo contrario de lo que se quiere demostrar. Ejemplo Se quiere probar que los estudiantes de INTEC tienen, en promedio, más alto IQ que los estudiantes de otra universidad. Se formula la hipótesis de que no hay diferencias, es decir, que μ = μ
Inferencia Estadística
1 2

148
Como muchas de las hipótesis se formulan en el lenguaje “no hay diferencias”, se usa el término hipótesis nula, aunque el término es válido para cualquier hipótesis que quisiéramos probar. Se consideran siempre dos hipótesis:
H : hipótesis nula (ejemplo: μ = μ )
H : hipótesis alternativa (ejemplo: μ > μ )
Inferencia Estadística
1
0 1 2
1 2

149
Prueba de hipótesis
Procedimiento de prueba: Es una regla, basada en datos muestrales, para decidir si se rechaza o no Ho. Un procedimiento de prueba consta de: • Un estadístico de prueba, o sea, una función de los datos muestrales en los cuales ha de basarse la decisión (rechazar Ho, no rechazar Ho) • Una región de rechazo, que es el conjunto de todos los valores del estadístico de prueba para los cuales Ho será rechazada. La hipótesis nula será rechazada si y solo si el valor del estadístico de prueba observado o calculado queda en la región de rechazo.
Inferencia Estadística
150
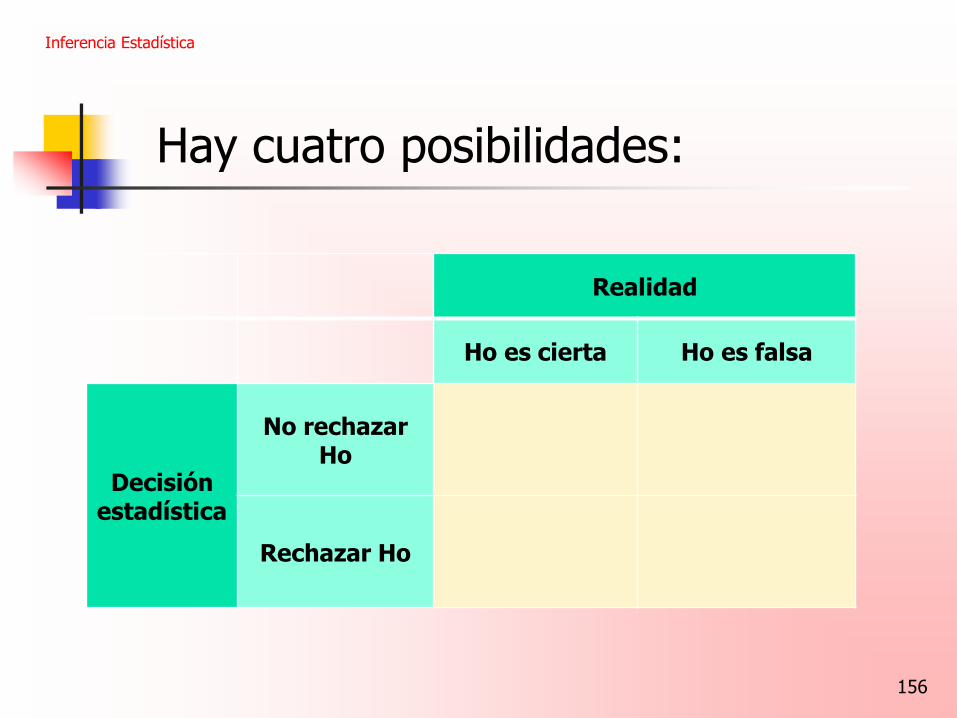
Hay cuatro posibilidades:
Inferencia Estadística

151
Realidad
Hay cuatro posibilidades:
Inferencia Estadística

152
Realidad
Ho es cierta
Hay cuatro posibilidades:
Inferencia Estadística
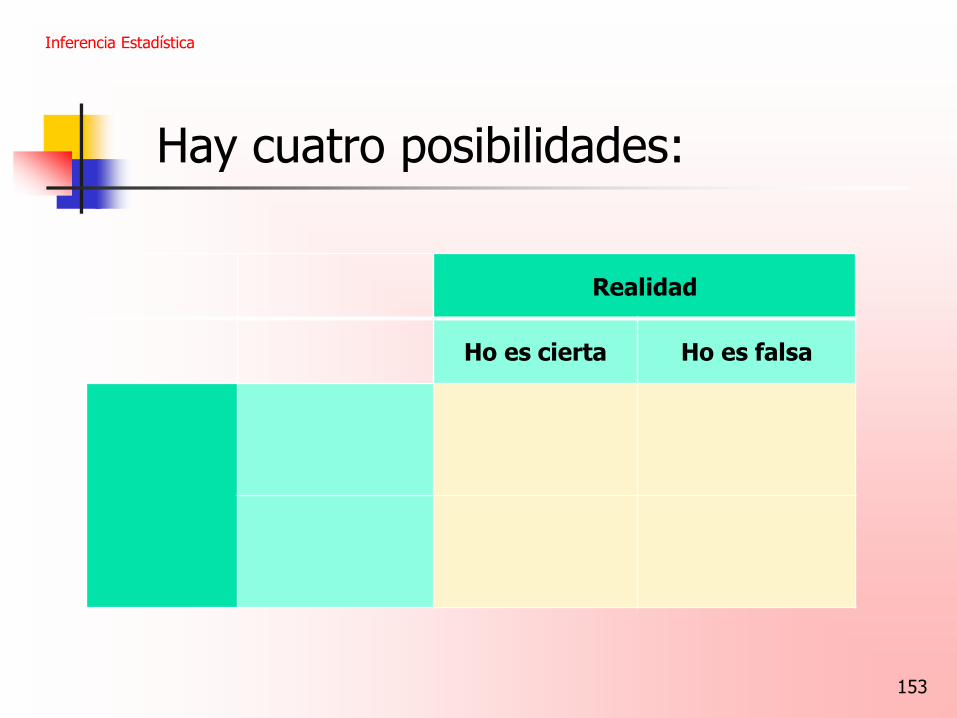
153
Realidad
Ho es cierta Ho es falsa
Hay cuatro posibilidades:
Inferencia Estadística
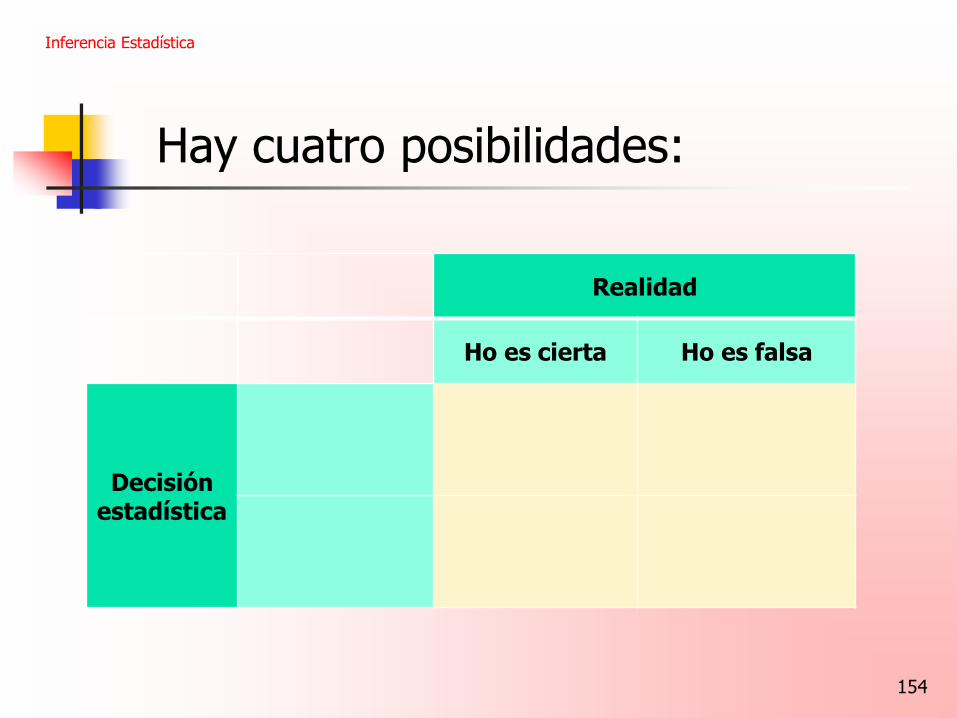
154
Realidad
Ho es cierta Ho es falsa
Decisión estadística
Hay cuatro posibilidades:
Inferencia Estadística
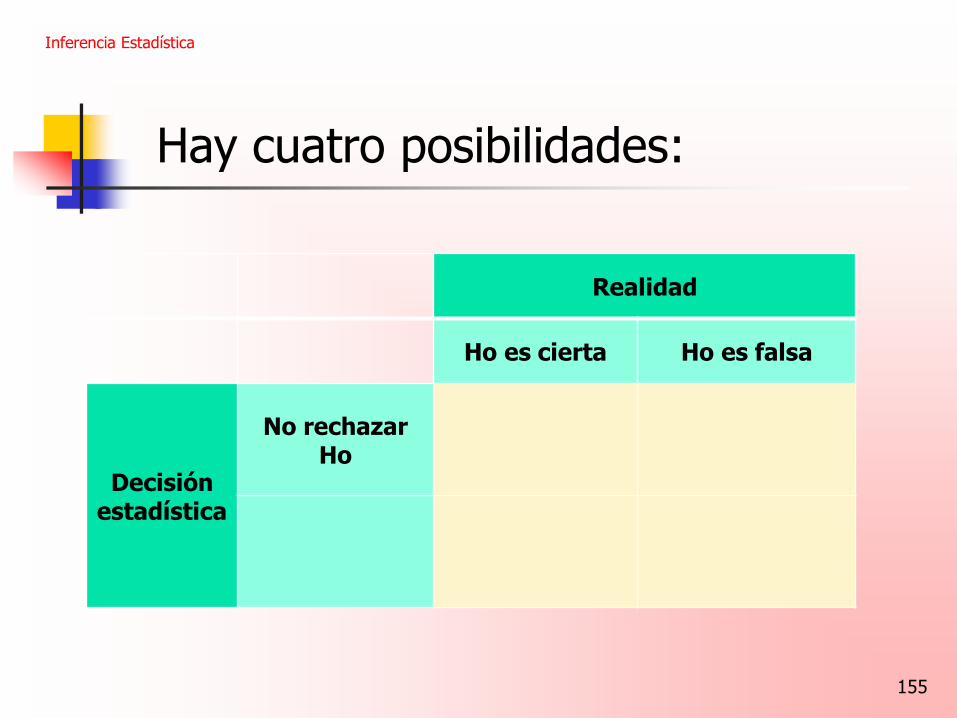
155
Realidad
Ho es cierta Ho es falsa
Decisión estadística
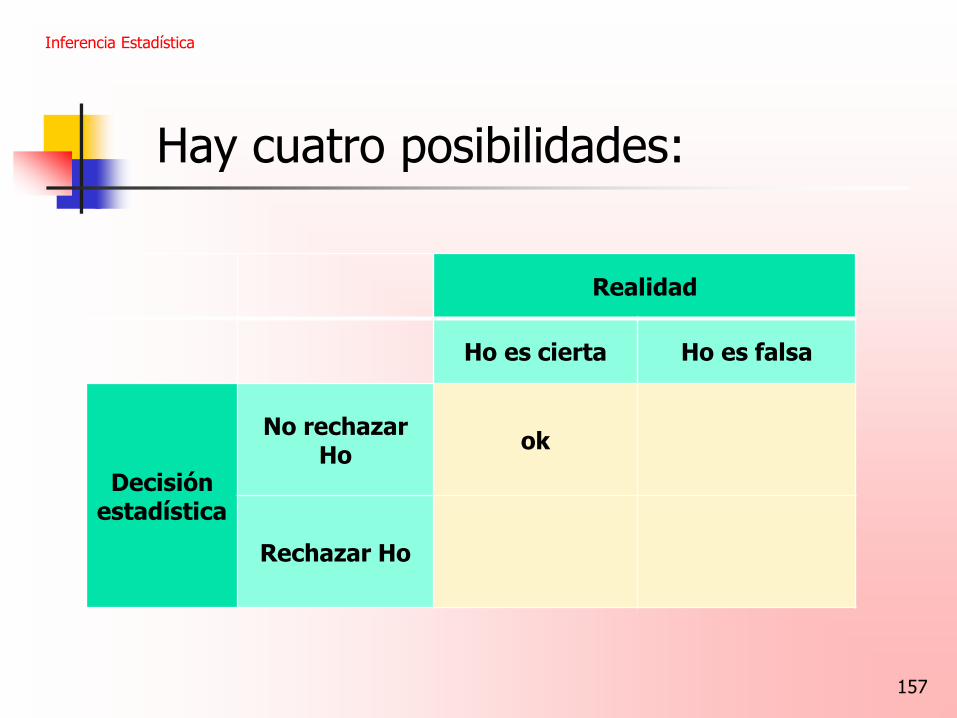
No rechazar Ho
Hay cuatro posibilidades:
Inferencia Estadística
156
Realidad
Ho es cierta Ho es falsa
Decisión estadística
No rechazar Ho
Rechazar Ho
Hay cuatro posibilidades:
Inferencia Estadística
157
Realidad
Ho es cierta Ho es falsa
Decisión estadística
No rechazar Ho
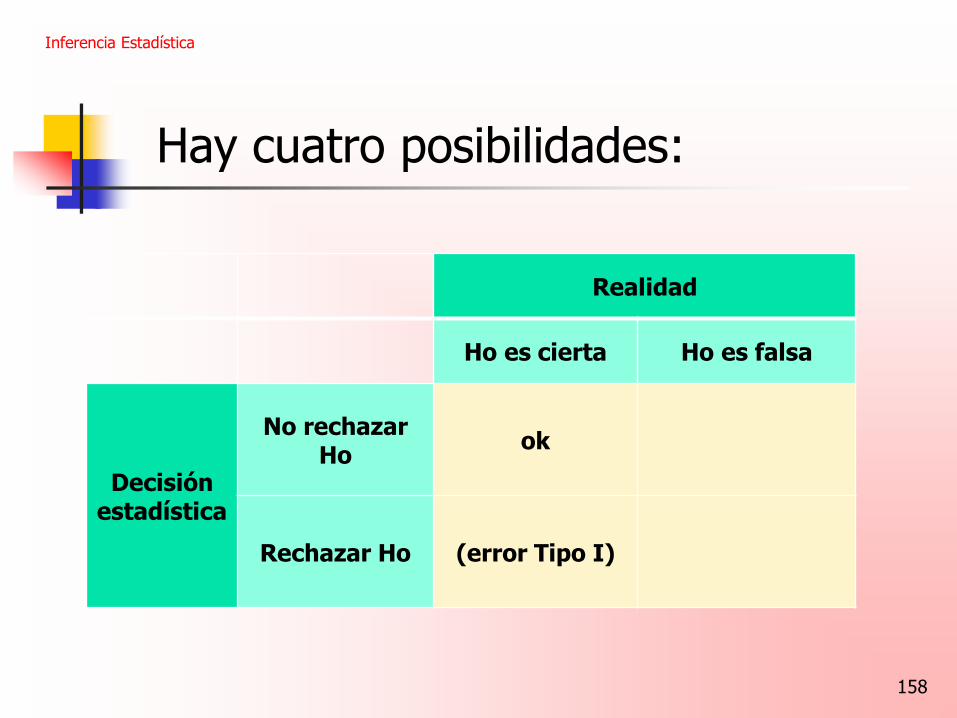
ok
Rechazar Ho
Hay cuatro posibilidades:
Inferencia Estadística
158
Realidad
Ho es cierta Ho es falsa
Decisión estadística
No rechazar Ho
ok
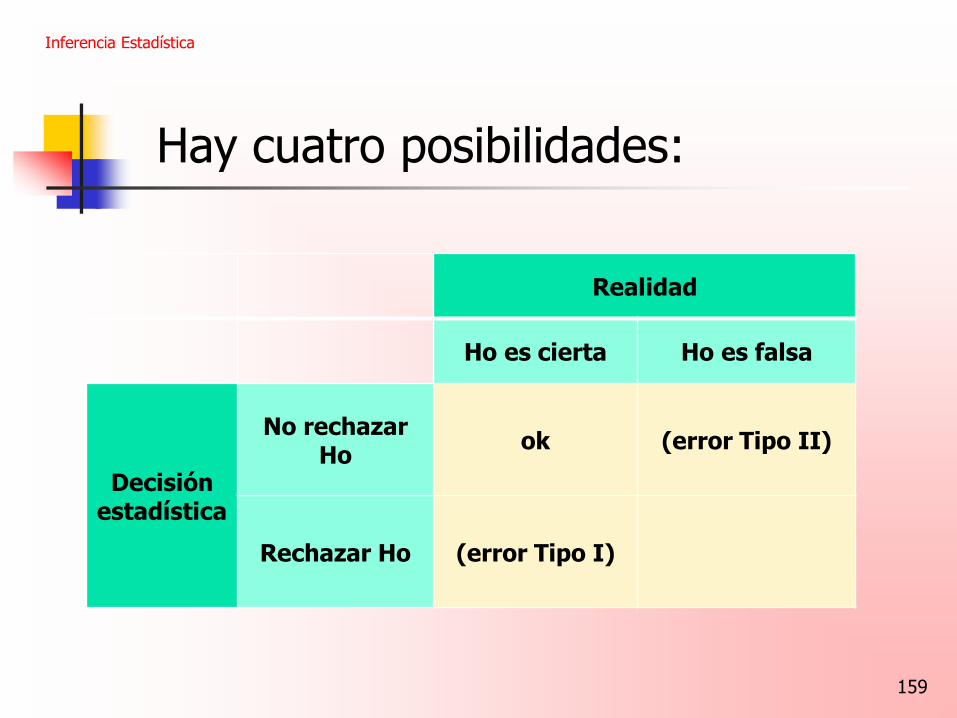
Rechazar Ho (error Tipo I)
Hay cuatro posibilidades:
Inferencia Estadística
159
Realidad
Ho es cierta Ho es falsa
Decisión estadística
No rechazar Ho
ok (error Tipo II)
Rechazar Ho (error Tipo I)
Hay cuatro posibilidades:
Inferencia Estadística
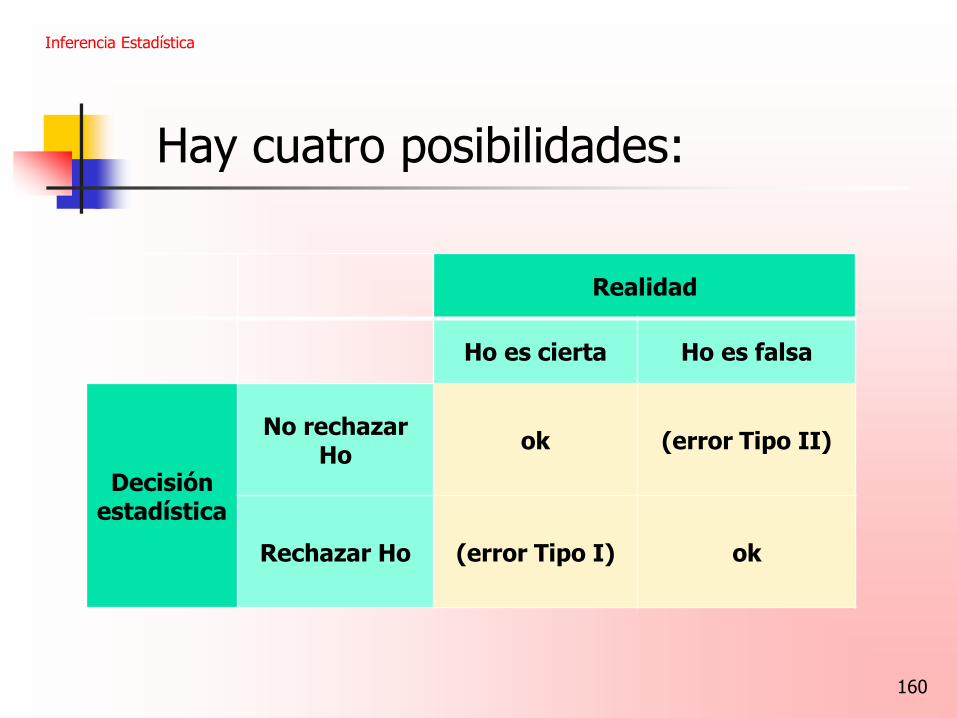
160
Realidad
Ho es cierta Ho es falsa
Decisión estadística
No rechazar Ho
ok (error Tipo II)
Rechazar Ho (error Tipo I) ok
Hay cuatro posibilidades:
Inferencia Estadística

161
Prueba de hipótesis
La probabilidad de cometer un error de tipo I se denota por α. La probabilidad de cometer un error de tipo II se denota por β.
Inferencia Estadística

162
Prueba de hipótesis
Si el tamaño de la muestra y el estadístico de prueba ya están fijos entonces, si se reduce el tamaño de la región de rechazo para disminuir α, se obtiene un valor más grande de β. En la práctica se fija el valor de α, lo cual se conoce como nivel de significación de la prueba. Son usuales los niveles de significación 0.1, 0.05 y 0.01.
Inferencia Estadística

163
Pruebas de hipótesis sobre la media Sea X1, X2, … Xn es una muestra aleatoria de una
distribución con media μ y varianza σ².
Sabemos que, si n es suficientemente grande, X tiene
aproximadamente una distribución normal con
μ = μ X σ σ = X √ n
Inferencia Estadística

164
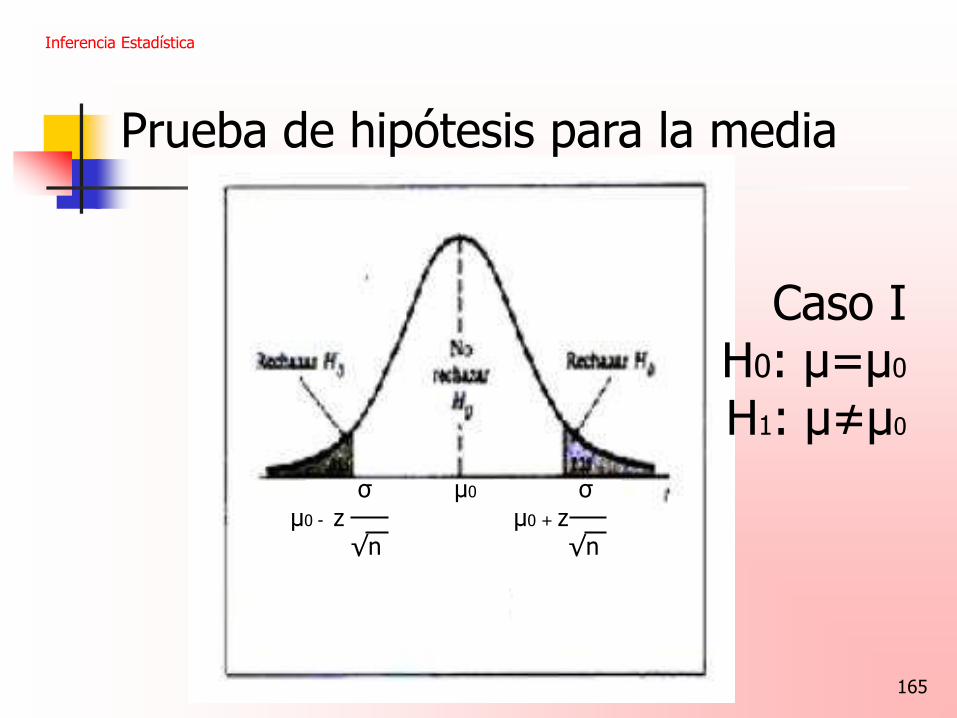
Pruebas de hipótesis sobre la media Consideremos la hipótesis nula H0: μ = μ0
Si H0 es verdadera entonces μ = μ0
X X – μ0
El estadístico z = es una medida natural de σ la distancia entre X (estima- dor de μ) y μ0 (valor espera- √ n do cuando H0 es verdadera) Si la distancia es demasiado grande H0 debe ser rechazada.
Inferencia Estadística
165
Inferencia Estadística
Prueba de hipótesis para la media
Caso I
H0: μ=μ0
H1: μ≠μ0
σ μ0 σ μ0 - z μ0 + z √n √n
166
Inferencia Estadística
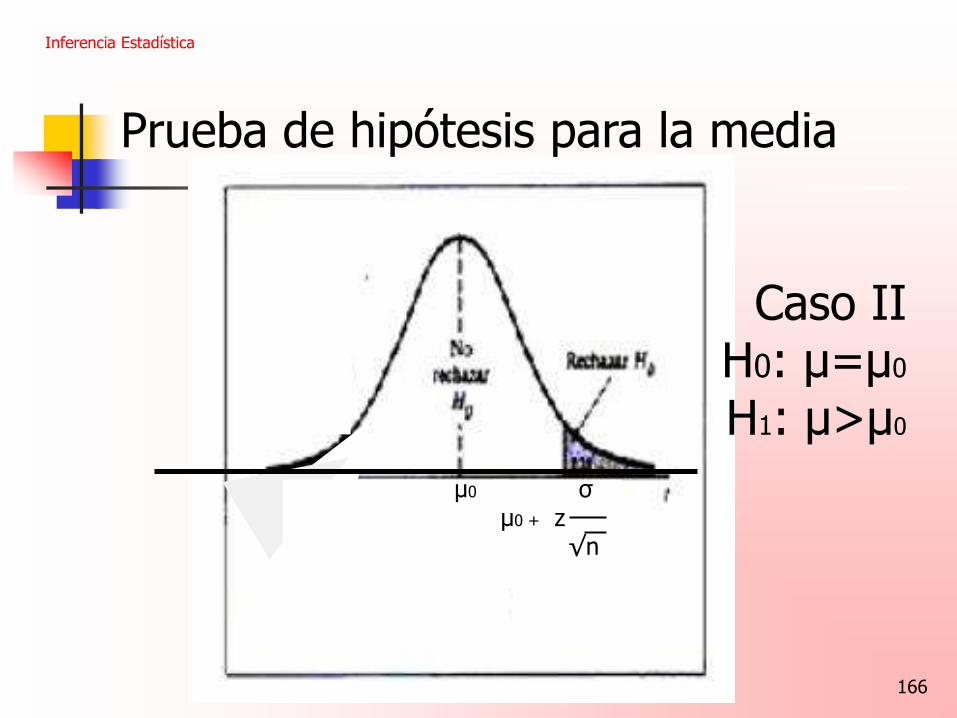
Prueba de hipótesis para la media
Caso II
H0: μ=μ0
H1: μ>μ0
σ μ0 σ μ0 - μ0 + z √n √n
167
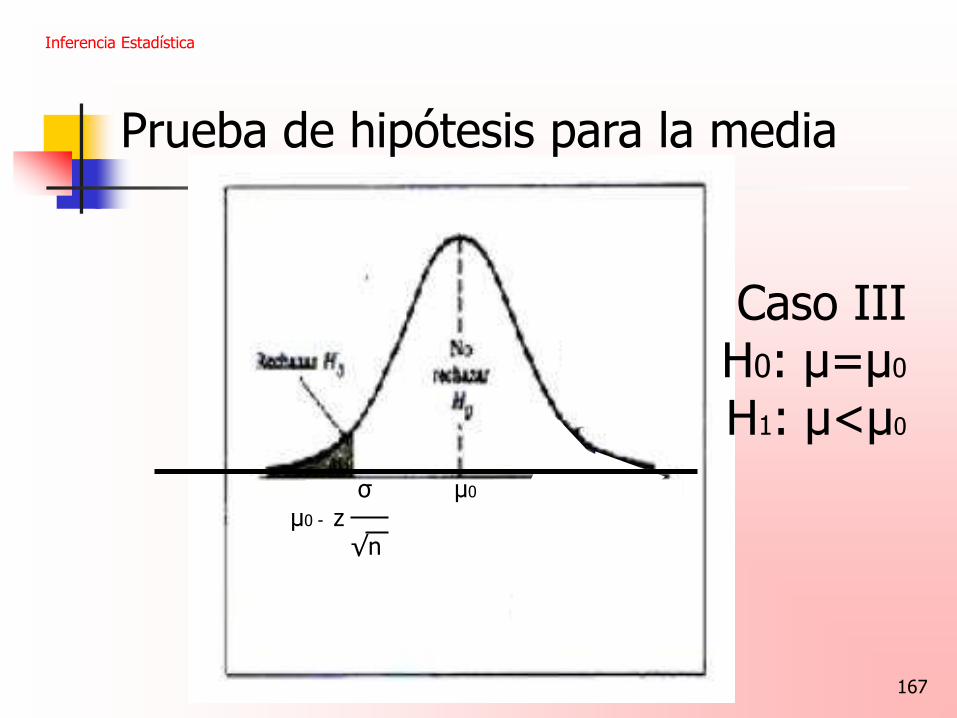
Inferencia Estadística
Prueba de hipótesis para la media
Caso III
H0: μ=μ0
H1: μ<μ0
σ μ0 σ μ0 - z μ0 +
√n √n

168
Pruebas de hipótesis sobre la media
Si n es grande y σ es desconocida usaremos X – μ0
el estadístico z = s √ n
Inferencia Estadística

169
Ejercicio 1
Suponga que por experiencia se sabe que la desviación estándar del peso de paquetes de 8 onzas de galletas en cierta pastelería es de 0.16 onzas. Para comprobar si su producción está bajo control en un día dado, esto es, comprobar si el peso promedio verdadero de los paquetes de galletas es 8 onzas, los empleados seleccionan una muestra aleatoria de 36 paquetes y encuentran que la media de su peso es 8.077 onzas. Puesto que la pastelería pierde dinero si μ>8 y el cliente pierde cuando μ<8, pruebe la hipótesis nula μ=8 contra la hipótesis alternativa μ≠8 al nivel 0.01 de significación.
Inferencia Estadística

170
Ejercicio 2
Suponga que 100 neumáticos que cierto fabricante produce duraron en promedio 21819 millas, con una desviación estándar de 1295 millas. Pruebe la hipótesis nula μ=22000 millas contra la hipótesis alternativa μ<22000 en el nivel 0.05 de significación.
Inferencia Estadística
171
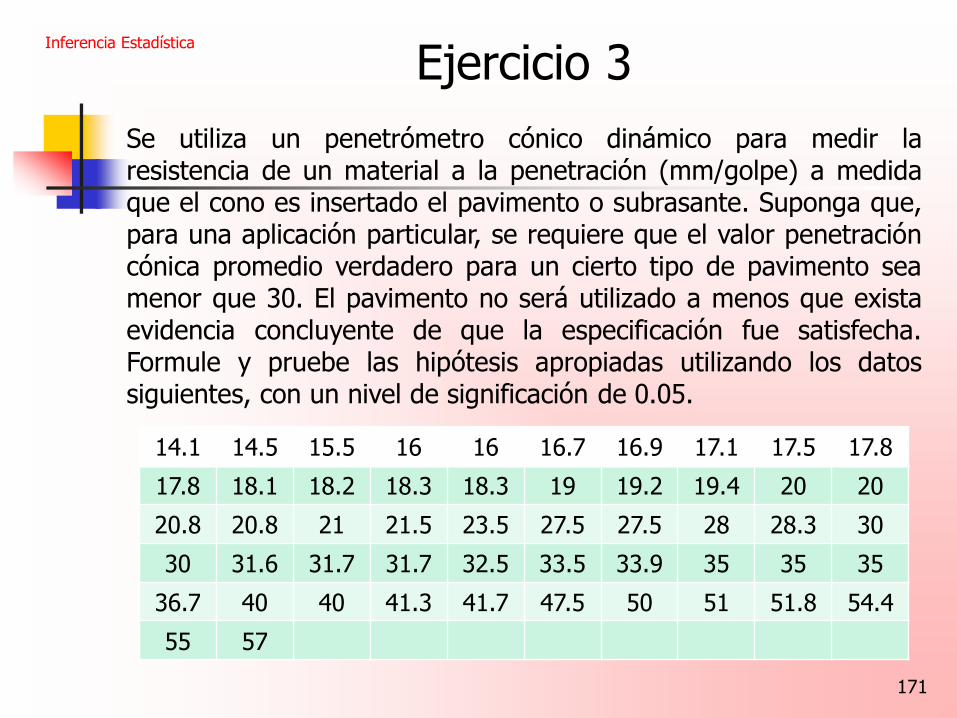
Ejercicio 3 Se utiliza un penetrómetro cónico dinámico para medir la resistencia de un material a la penetración (mm/golpe) a medida que el cono es insertado el pavimento o subrasante. Suponga que, para una aplicación particular, se requiere que el valor penetración cónica promedio verdadero para un cierto tipo de pavimento sea menor que 30. El pavimento no será utilizado a menos que exista evidencia concluyente de que la especificación fue satisfecha. Formule y pruebe las hipótesis apropiadas utilizando los datos siguientes, con un nivel de significación de 0.05.
Inferencia Estadística
14.1 14.5 15.5 16 16 16.7 16.9 17.1 17.5 17.8
17.8 18.1 18.2 18.3 18.3 19 19.2 19.4 20 20
20.8 20.8 21 21.5 23.5 27.5 27.5 28 28.3 30
30 31.6 31.7 31.7 32.5 33.5 33.9 35 35 35
36.7 40 40 41.3 41.7 47.5 50 51 51.8 54.4
55 57

172
Pruebas de hipótesis sobre la media Si el tamaño de la muestra es pequeño y σ es desconocida usaremos X – μ0
el estadístico t = que tiene una distribución t s con n-1 grados de libertad √ n
Inferencia Estadística

173
Ejercicio
Las especificaciones para cierta clase de cinta piden una media de la resistencia al rompimiento de 185 libras. Si cinco piezas, seleccionadas aleatoriamente de diferentes rollos, tienen una resistencia al rompimiento de 171.6, 191.8, 178.3, 184.9 y 189.1 libras, pruebe la hipótesis nula μ=185 libras contra la hipótesis alternativa μ‹185 libras en el nivel 0.05 de significación.
Inferencia Estadística

174
Pruebas de hipótesis sobre la diferencia de medias
Supongamos que tenemos dos muestras aleatorias independientes de tamaños n1 y n2 de dos poblaciones normales que tienen las medias μ1 y μ2 y las desviaciones estándar conocidas σ1 y σ2 entonces para las pruebas de hipótesis: Ho: μ1 – μ2 = δ contra las hipótesis alternativas H1: μ1 – μ2 ≠ δ , H1: μ1 – μ2 > δ , H1: μ1 – μ2 < δ
Inferencia Estadística

175
Pruebas de hipótesis sobre la diferencia de medias
Usaremos el estadígrafo de prueba x1 – x2 – δ z = 2 2 σ1 + σ2 √ n1 n2 Las regiones respectivas son |z| ≥ Zc , z ≥ Zc , z ≤ Zc
Inferencia Estadística

176
Pruebas de hipótesis sobre la diferencia de medias
Si σ1 y σ2 son desconocidas y n1 y n2 suficientemente grandes x1 – x2 – δ z = 2 2 s1 + s2 √ n1 n2
Inferencia Estadística

177
Ejercicio
Se hace un experimento para determinar si el contenido promedio de nicotina de una clase de cigarrillos excede al de otra clase en 0.20 miligramos. Si 50 cigarrillos de la primera clase tuvieron en promedio un contenido de nicotina de 2.61 miligramos con una desviación estándar de 0.12 miligramos en tanto que 40 cigarrillos de la otra clase tuvieron un contenido promedio de nicotina de 2.38 miligramos, con una desviación estándar de 0.14 miligramos, pruebe la hipótesis nula “el contenido promedio de nicotina de la primera clase de cigarrillos excede en 0.20 miligramos al de la segunda” contra la hipótesis alternativa “el contenido promedio de nicotina de la primera clase de cigarrillos no excede en 0.20 miligramos al de la segunda”. Considere el nivel de significación 0.1.
Inferencia Estadística

178
Pruebas de hipótesis sobre proporciones Si n es grande (n > 100) usaremos el estadístico de prueba p - p0 z = p0 (1 – p0) √ n Las regiones respectivas son |z| ≥ Zc , z ≥ Zc , z ≤ Zc
Inferencia Estadística

179
Ejercicio
Una compañía petrolera afirma que menos del 20% de los propietarios de vehículos no han probado su gasolina. Pruebe esta afirmación en el nivel 0.01 de significación si una comprobación aleatoria revela que 22 de 200 propietarios de vehículos no han probado la gasolina de la compañía.
Inferencia Estadística

180
Pruebas de hipótesis sobre diferencia de proporciones
Si p1=x1/n1 y p2=x2/n2 son proporciones en dos muestras de tamaños n1 y n2 respectivamente, p1 - p2 z = x1+x2 x1+x2 1 1 1- + √ n1+n2 n1+n2 n1 n2 es estadístico de prueba.
Inferencia Estadística

181
Ejercicio
En una muestra aleatoria de 200 personas que no tomaron desayuno, 82 reportaron que tuvieron fatiga a media mañana y en otra muestra aleatoria de 300 personas que tomaron desayuno, 87 personas reportaron que tuvieron fatiga a media mañana. Prueba la hipótesis nula de que no hay diferencias entre las proporciones correspondientes de la población contra la hipótesis alternativa de que la fatiga a media mañana está más extendida entre las personas que no toman desayuno, al nivel de significación 0.05.
Inferencia Estadística

182
Pruebas de hipótesis sobre la varianza Dada una muestra aleatoria de tamaño n de una población
normal queremos probar la hipótesis nula H0: σ² = σ² contra
una de las hipótesis H1: σ² ≠ σ², H1: σ² > σ², H1: σ² < σ²
(n-1) s² Usaremos el estadístico χ² = σ²
Inferencia Estadística
0
0
0 0 0

183
Pruebas de hipótesis sobre la varianza Las regiones críticas son:
Para H1: σ² ≠ σ² χ² ≥ χ² χ²≤χ²
Para H1: σ² > σ² χ² ≥ χ²
Para H1: σ² < σ² χ²≤χ²
Inferencia Estadística
α , n-1 2
1- α , n-1 2
α , n-1
1-α , n-1
0
0
0

184
Ejercicio
Suponga que las mediciones del espesor de una muestra aleatoria de 18 partes usadas de un semiconductor tiene la varianza s²=0.68, donde las mediciones son en milésimas de pulgada. El proceso se considera que está bajo control si la variación del espesor está dada por una varianza no mayor que 0.36. Suponga que las mediciones constituyen una muestra aleatoria de una población normal, pruebe la hipótesis nula σ²=0.36 contra la hipótesis alternativa σ²>0.36 en el nivel 0.05 de significación.
Inferencia Estadística
185
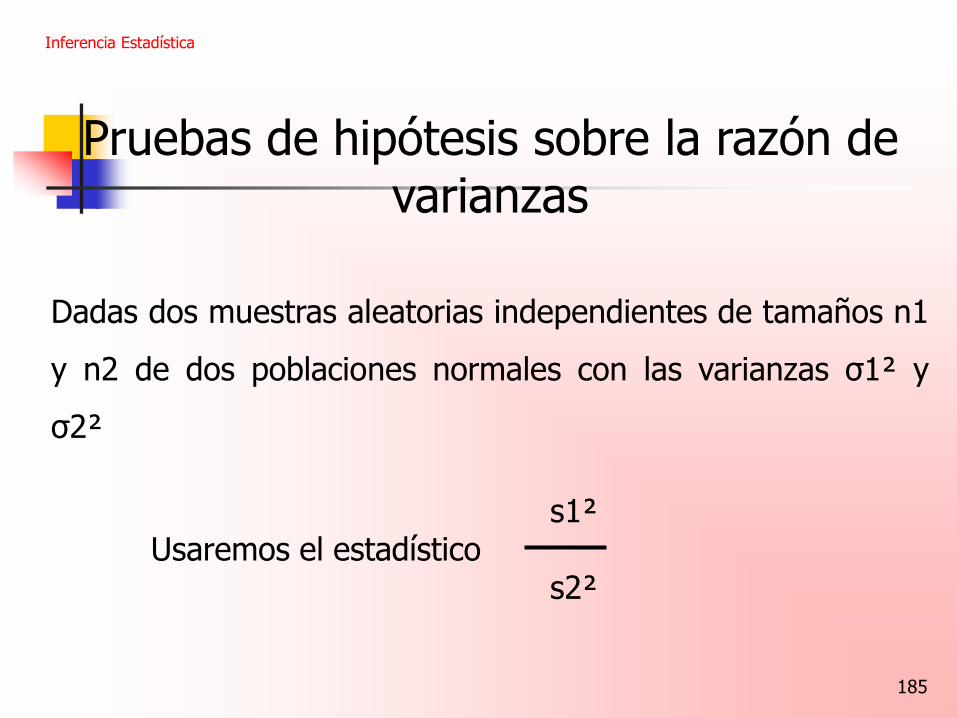
Pruebas de hipótesis sobre la razón de varianzas
Dadas dos muestras aleatorias independientes de tamaños n1
y n2 de dos poblaciones normales con las varianzas σ1² y
σ2²
s1² Usaremos el estadístico s2²
Inferencia Estadística

186
Ejercicio
Al comparar la variabilidad de la resistencia a la tracción de dos clases de acero estructural, un experimento dio los resultados siguientes: n1=13, s1²=19.2, n2=16 y s2²=3.5, donde las unidades de medición son 1000 libras por pulgada cuadrada. Suponga que las mediciones constituyen variables aleatorias independientes de dos poblaciones normales, prueba la hipótesis nula σ1²=σ2² contra la alternativa σ1²≠σ2² en el nivel 0.02 de significación.
Inferencia Estadística
187
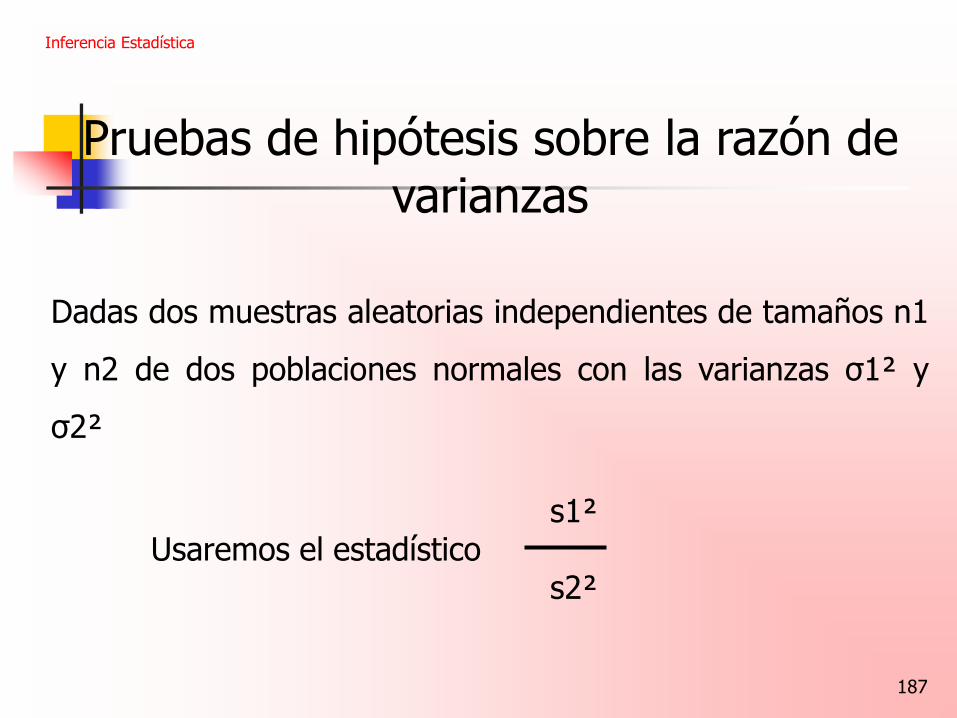
Pruebas de hipótesis sobre la razón de varianzas
Dadas dos muestras aleatorias independientes de tamaños n1
y n2 de dos poblaciones normales con las varianzas σ1² y
σ2²
s1² Usaremos el estadístico s2²
Inferencia Estadística

188
Ajuste a distribuciones teóricas.
Tablas de contingencia. Prueba de chi-cuadrado

189
Prueba de bondad de ajuste
Una distribución de frecuencias es la representación empírica, y por tanto una aproximación, de una distribución teórica (distribución de probabilidades).
Inferencia Estadística

190
Prueba de bondad de ajuste
Una distribución de frecuencias es la representación empírica, y por tanto una aproximación, de una distribución teórica (distribución de probabilidades). Se trata de decidir si la distribución de frecuencia muestral se ajusta bien o no a la distribución de probabilidades (frecuencia) hipotética de la población en estudio.
Inferencia Estadística

191
Prueba de bondad de ajuste
H0: las frecuencias observadas coinciden con las frecuencias esperadas H1: las frecuencias observadas no coinciden con las frecuencias esperadas
Inferencia Estadística

192
Prueba de bondad de ajuste
H0: fij = eij para todo i,j i=1,2,3,…,r j=1,2,3,…,c
H1: fij ≠ eij para algún i
Inferencia Estadística
193
Tabla de contingencia
r c
Inferencia Estadística
11 12 13 14 15
21 22 23 24 25
31 32 33 34 35
41 42 43 44 45
194
Prueba de chi-cuadrado
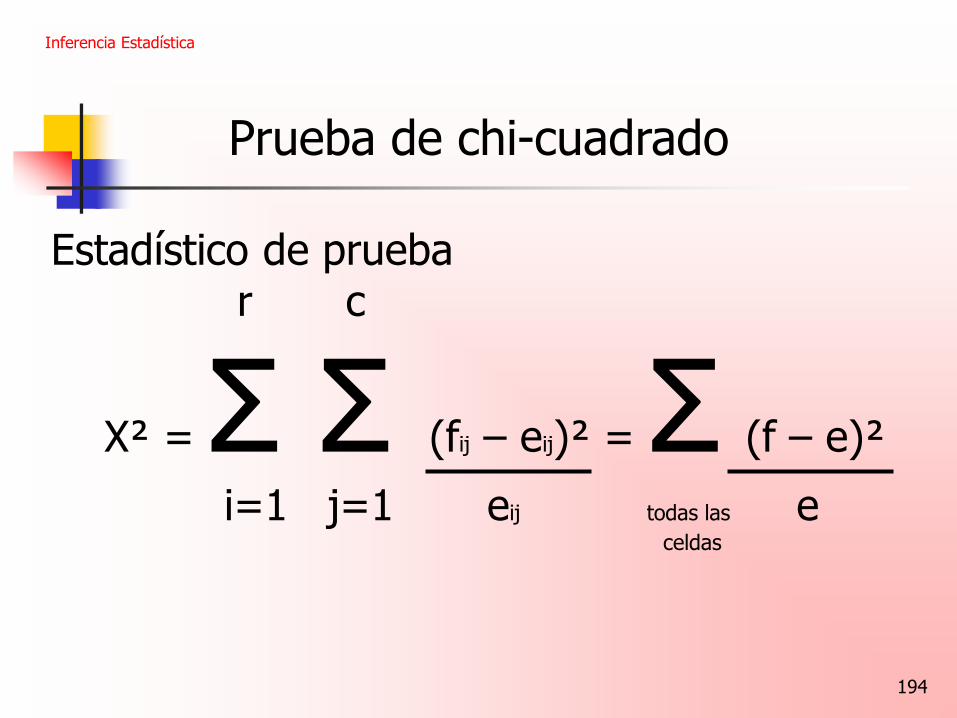
Estadístico de prueba r c
Χ² = Σ Σ (fij – eij)² = Σ (f – e)²
i=1 j=1 eij todas las e celdas
Inferencia Estadística

195
Prueba de chi-cuadrado
Rechazamos H0 cuando Χ² ≥ Χ²
Inferencia Estadística
α , (r -1)(c -1)
196
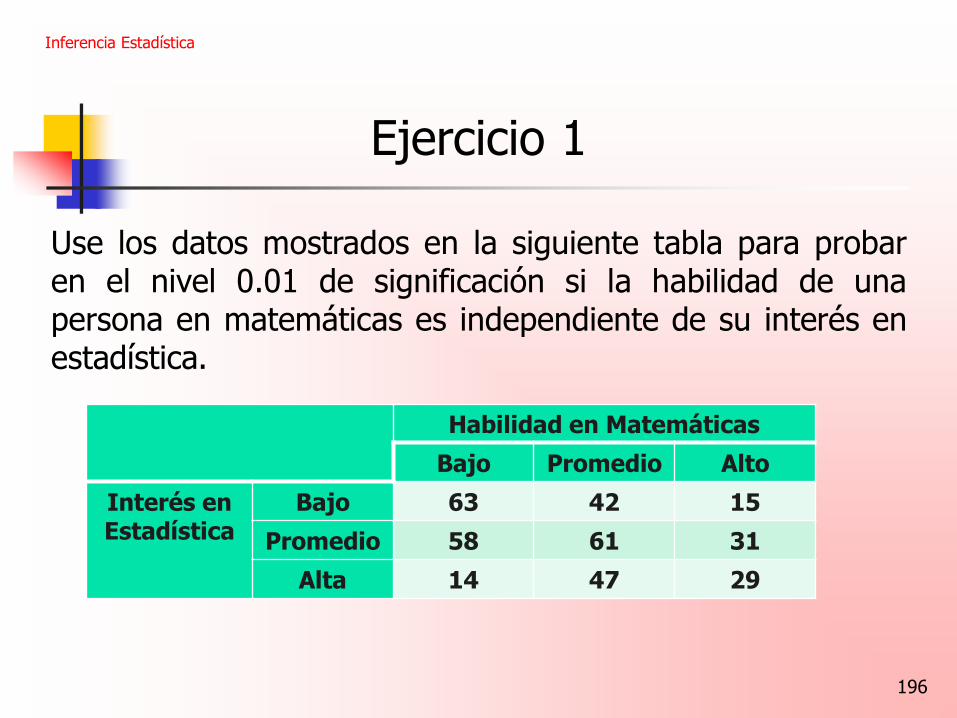
Ejercicio 1
Use los datos mostrados en la siguiente tabla para probar en el nivel 0.01 de significación si la habilidad de una persona en matemáticas es independiente de su interés en estadística.
Inferencia Estadística
Habilidad en Matemáticas
Bajo Promedio Alto
Interés en Estadística
Bajo 63 42 15
Promedio 58 61 31
Alta 14 47 29
197
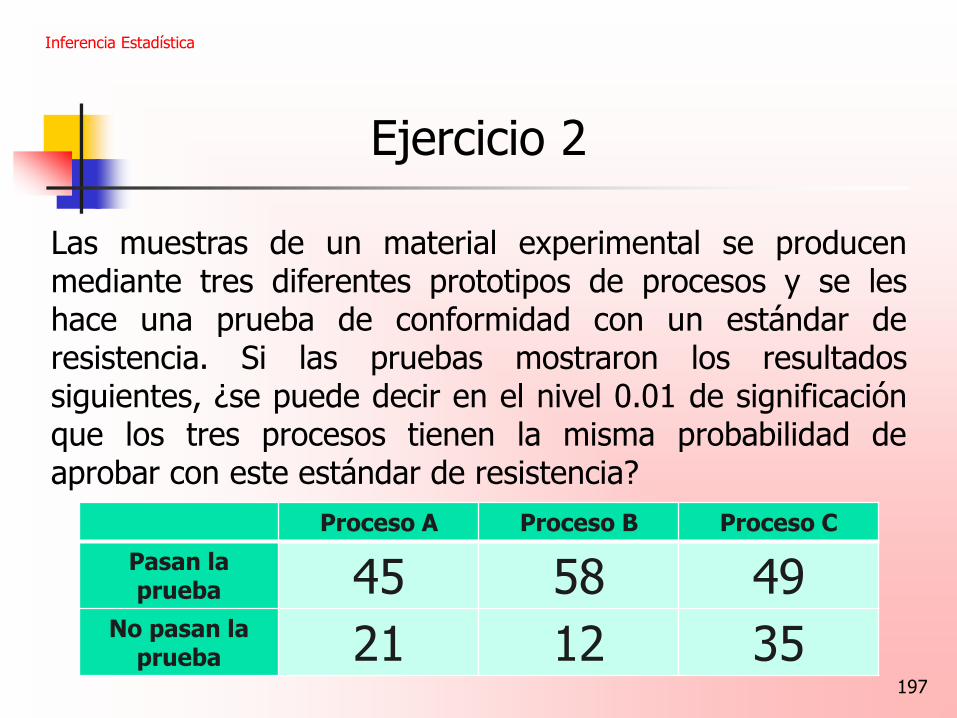
Ejercicio 2
Las muestras de un material experimental se producen mediante tres diferentes prototipos de procesos y se les hace una prueba de conformidad con un estándar de resistencia. Si las pruebas mostraron los resultados siguientes, ¿se puede decir en el nivel 0.01 de significación que los tres procesos tienen la misma probabilidad de aprobar con este estándar de resistencia?
Inferencia Estadística
Proceso A Proceso B Proceso C
Pasan la prueba 45 58 49
No pasan la prueba 21 12 35

198
Función de potencia de una prueba

199
Función de potencia
Para evaluar los méritos de un criterio de prueba o una región crítica tenemos que considerar las probabilidades α(θ) de cometer error de tipo I para todos los valores de θ dentro del dominio especificado bajo la hipótesis nula H0 y las probabilidades β(θ) de cometer error de tipo II dentro del dominio especificado bajo la hipótesis alternativa H1.
Inferencia Estadística

200
Función de potencia
Recordemos que: α : probabilidad de rechazar H0 siendo verdadera probabilidad de cometer error de tipo I β : probabilidad de no rechazar H0 siendo falsa probabilidad de cometer error de tipo II
Inferencia Estadística

201
Función de potencia
Recordemos que: α : probabilidad de rechazar H0 siendo verdadera probabilidad de cometer error de tipo I β : probabilidad de no rechazar H0 siendo falsa probabilidad de cometer error de tipo II Entonces 1 – β : probabilidad de rechazar H0 siendo falsa probabilidad de no cometer error de tipo II
Inferencia Estadística

202
Función de potencia
La función de potencia de una prueba de hipótesis estadística H0 contra una hipótesis alternativa H1 está dada por α(θ) para los valores de θ bajo H0
π(θ) = 1- β(θ) para los valores de θ bajo H1
Inferencia Estadística

203
Función de potencia
Los valores de la función de potencia son las probabilidades de rechazar la hipótesis nula H0 para los diferentes valores del parámetro θ. α(θ) para los valores de θ bajo H0
π(θ) = 1- β(θ) para los valores de θ bajo H1
Inferencia Estadística

204
Función de potencia
Ejemplo Supongamos que el fabricante de un nuevo medicamento quiere decidir, sobre la base de muestras, si el 90% de todos los pacientes que reciben ese nuevo medicamento se recuperarán de cierta enfermedad. Su estadístico de prueba es X, el número de éxitos observados (recuperaciones) en 20 intentos. Consideremos H0: θ = 0.90 H1: θ < 0.90 Investigue la función de potencia correspondiente al criterio de prueba “aceptar la hipótesis nula si X>14 y rechazarla si X≤14”
Inferencia Estadística

205
Función de potencia
Ejemplo Calculemos las probabilidades α(θ) de rechazar H0 siendo verdadera. Si H0 es verdadera, entonces p(X≤14) = p(X=0) + p(X=1) + p(X=2) + … + p(X=14) 20 a 20-a Siendo p(X=a) = (0.90) (1 – 0.90) a Obtenemos p(X ≤14) = 0.0113
Inferencia Estadística

206
Función de potencia
Ejemplo Calculemos las probabilidades β(θ) de no rechazar H0 (aceptar H0) siendo H0 falsa (H1 verdadera). Si H1 es verdadera, entonces θ < 0.90. Calculemos β(θ) para algunos valores de θ, por ejemplo, θ=0.85, 0.80, 0.75, … , 0.45
Inferencia Estadística

207
Función de potencia
Ejemplo Si θ=0.85 p(X>14) = p(X=15) + p(X=16) + p(X=17) + … + p(X=20) 20 a 20-a Siendo p(X=a) = (0.85) (1 – 0.85) a Obtenemos p(X >14) = 0.9252
Inferencia Estadística
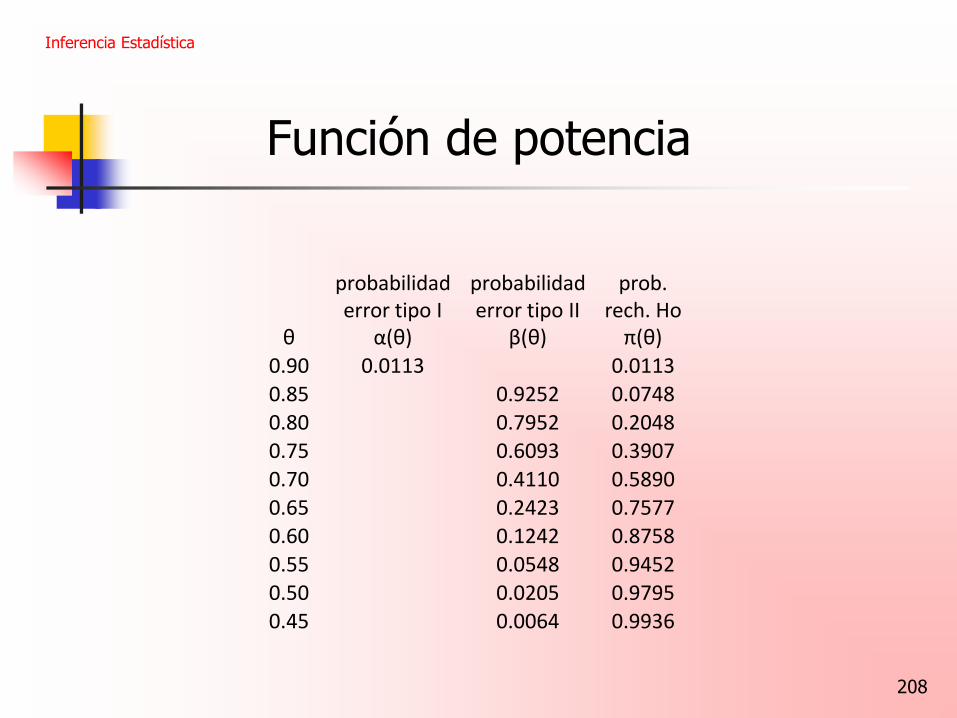
208
Función de potencia
Inferencia Estadística
θ
probabilidad error tipo I
α(θ)
probabilidad error tipo II
β(θ)
prob. rech. Ho π(θ)
0.90 0.0113 0.0113
0.85 0.9252 0.0748
0.80 0.7952 0.2048
0.75 0.6093 0.3907
0.70 0.4110 0.5890
0.65 0.2423 0.7577
0.60 0.1242 0.8758
0.55 0.0548 0.9452
0.50 0.0205 0.9795
0.45 0.0064 0.9936
209
Función de potencia
Inferencia Estadística
0.0000
0.1000
0.2000
0.3000
0.4000
0.5000
0.6000
0.7000
0.8000
0.9000
1.0000
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
π(θ)
θ
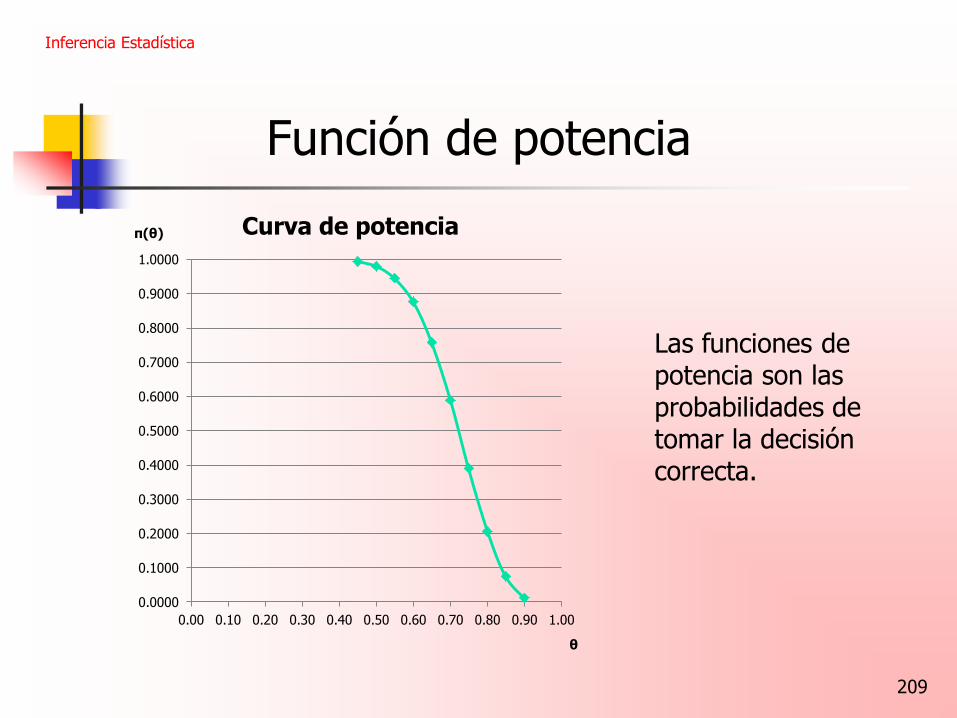
Curva de potencia
Las funciones de potencia son las probabilidades de tomar la decisión correcta.

210
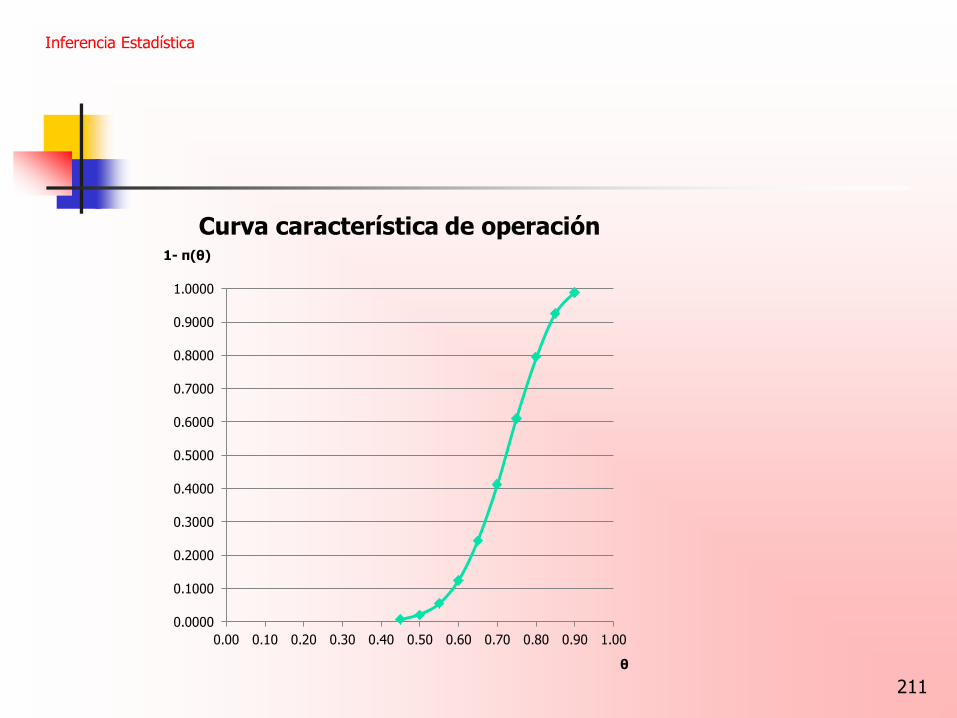
Curva característica de operación
Pudieran graficarse las probabilidades de aceptar H0, que sería la función 1-π(θ). Obtendríamos entonces la CURVA CARACTERISTICA DE OPERACIÓN (o curva CO)
Inferencia Estadística
θ
prob. No rechazar
Ho 0.45 0.0064 0.50 0.0205 0.55 0.0548 0.60 0.1242 0.65 0.2423 0.70 0.4110 0.75 0.6093 0.80 0.7952 0.85 0.9252 0.90 0.9887
211
Inferencia Estadística
0.0000
0.1000
0.2000
0.3000
0.4000
0.5000
0.6000
0.7000
0.8000
0.9000
1.0000
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
1- π(θ)
θ
Curva característica de operación

212
Correlación y regresión lineal

213
Análisis de regresión y correlación
Un objetivo importante de muchas investigaciones estadísticas es establecer las relaciones que hagan posible predecir una o más variables en términos de otras. Ejemplos • ventas potenciales de un nuevo producto en función de un precio. • gastos familiares en entretenimiento en función del ingreso familiar. • consumo percápita de ciertos alimentos en función de sus valores nutricionales y la cantidad de dinero que se gasta en hacerles publicidad en la televisión.
Inferencia Estadística

214
Análisis de regresión y correlación
El análisis de regresión es la parte de la estadística que se ocupa de investigar la relación entre dos o más variables relacionadas en una forma no determinística. En la regresión simple hay solo dos variables: • la variable cuyo valor fija el investigador, se denota por X, se llama variable independiente, pronosticadora, explicativa. • la variable Y que depende de X, se llama variable dependiente o de respuesta. En la regresión múltiple hay una variable dependiente y más de una variable independiente.
Inferencia Estadística

215
Regresión lineal simple
Inferencia Estadística
216
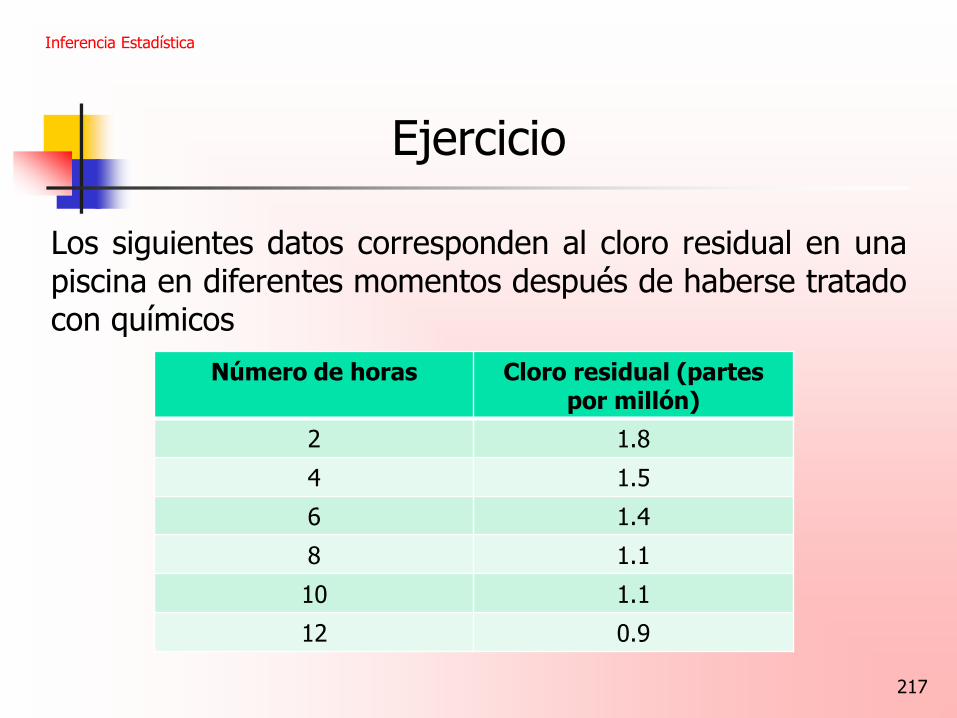
Ejemplo
Consideremos los datos siguientes sobre el número de horas que diez personas estudiaron para una prueba de francés y sus calificaciones en dicha prueba.
Inferencia Estadística
Horas 4 9 10 14 4 7 12 22 1 17
Nota 31 58 65 73 37 44 60 91 21 84
217
Ejercicio
Los siguientes datos corresponden al cloro residual en una piscina en diferentes momentos después de haberse tratado con químicos
Inferencia Estadística
Número de horas Cloro residual (partes por millón)
2 1.8
4 1.5
6 1.4
8 1.1
10 1.1
12 0.9

218
Ejercicio
a) Ajuste una recta de mínimos cuadrados (recta de regresión) con la cual podamos predecir el cloro residual en términos del número de horas transcurridas, luego de haberse tratado con químicos.
b) Use la ecuación de la recta de regresión para estimar el cloro residual 5 horas después de haberse tratado con químicos.
Inferencia Estadística

219
Coeficiente de correlación lineal
Existen situaciones en las cuales el objetivo al estudiar el comportamiento conjunto de dos variables es ver si están relacionados en lugar de utilizar una para predecir el valor de la otra.
Inferencia Estadística
220
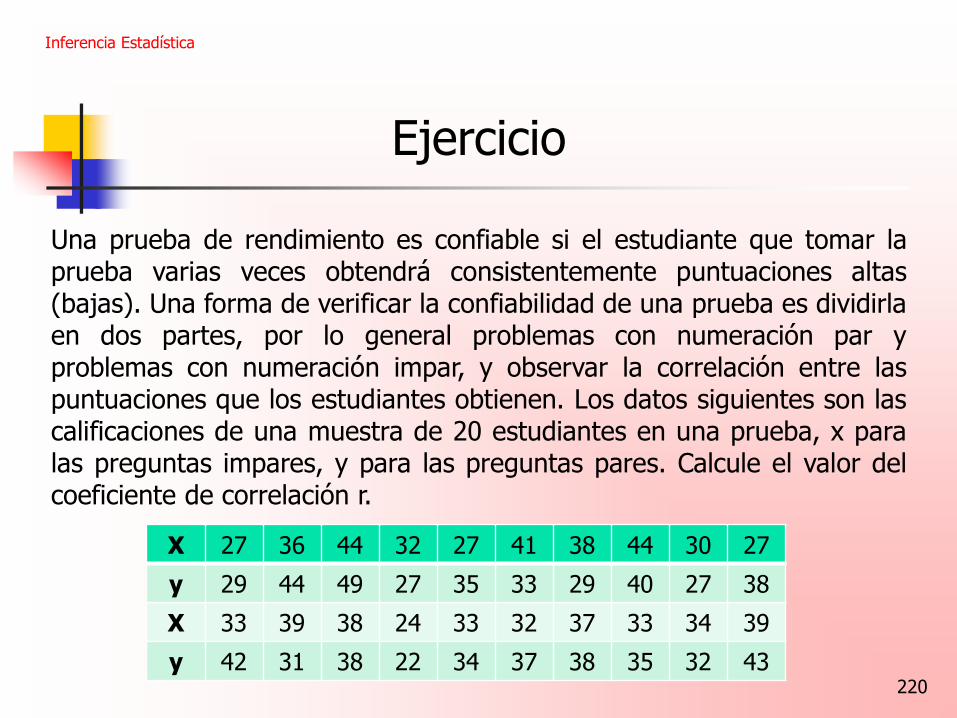
Ejercicio
Una prueba de rendimiento es confiable si el estudiante que tomar la prueba varias veces obtendrá consistentemente puntuaciones altas (bajas). Una forma de verificar la confiabilidad de una prueba es dividirla en dos partes, por lo general problemas con numeración par y problemas con numeración impar, y observar la correlación entre las puntuaciones que los estudiantes obtienen. Los datos siguientes son las calificaciones de una muestra de 20 estudiantes en una prueba, x para las preguntas impares, y para las preguntas pares. Calcule el valor del coeficiente de correlación r.
Inferencia Estadística
X 27 36 44 32 27 41 38 44 30 27
y 29 44 49 27 35 33 29 40 27 38
X 33 39 38 24 33 32 37 33 34 39
y 42 31 38 22 34 37 38 35 32 43

221
Regresión múltiple

222
Regresión múltiple
Si la variable y depende no solo de x sino de más variables tendríamos en lugar del modelo de regresión simple (lineal) y = a + bx el modelo de regresión lineal múltiple y = a + b1 x1 + b2 x2 + … + bk xk
Inferencia Estadística
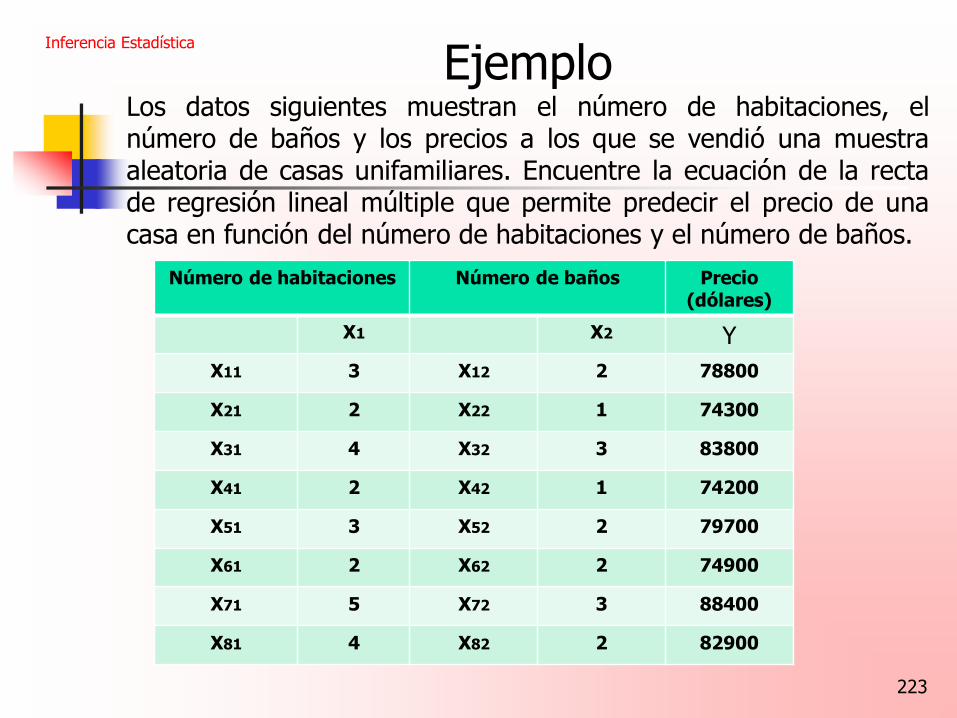
223
Ejemplo Los datos siguientes muestran el número de habitaciones, el número de baños y los precios a los que se vendió una muestra aleatoria de casas unifamiliares. Encuentre la ecuación de la recta de regresión lineal múltiple que permite predecir el precio de una casa en función del número de habitaciones y el número de baños.
Inferencia Estadística
Número de habitaciones Número de baños Precio (dólares)
X1 X2 Y
X11 3 X12 2 78800
X21 2 X22 1 74300
X31 4 X32 3 83800
X41 2 X42 1 74200
X51 3 X52 2 79700
X61 2 X62 2 74900
X71 5 X72 3 88400
X81 4 X82 2 82900

224
Análisis de varianza (ANOVA)

225
Análisis de varianza
El análisis de varianza, o más brevemente, ANOVA, es un método estadístico para decidir si las diferencias entre dos o más medias muestrales se puede atribuir al azar o si hay diferencias reales entre las medias de las poblaciones muestreadas.
Inferencia Estadística

226
Análisis de varianza
Ejemplos • ¿Hay diferencias en la eficacia de tres métodos para enseñar una lengua extranjera? • ¿Hay diferencias en los efectos de cinco marcas diferentes de gasolina con respecto a la eficiencia de operación de un motor? • ¿Hay diferencias en cuanto al crecimiento de bacterias en cuatro soluciones azucaradas: glucosa, fructosa, sucrosa y una mezcla de las tres?
Inferencia Estadística

227
Análisis de varianza de un factor
También se llama unifactorial, unidireccional, en un sentido. Hay un solo factor. Hay varios niveles o tratamientos.
Inferencia Estadística
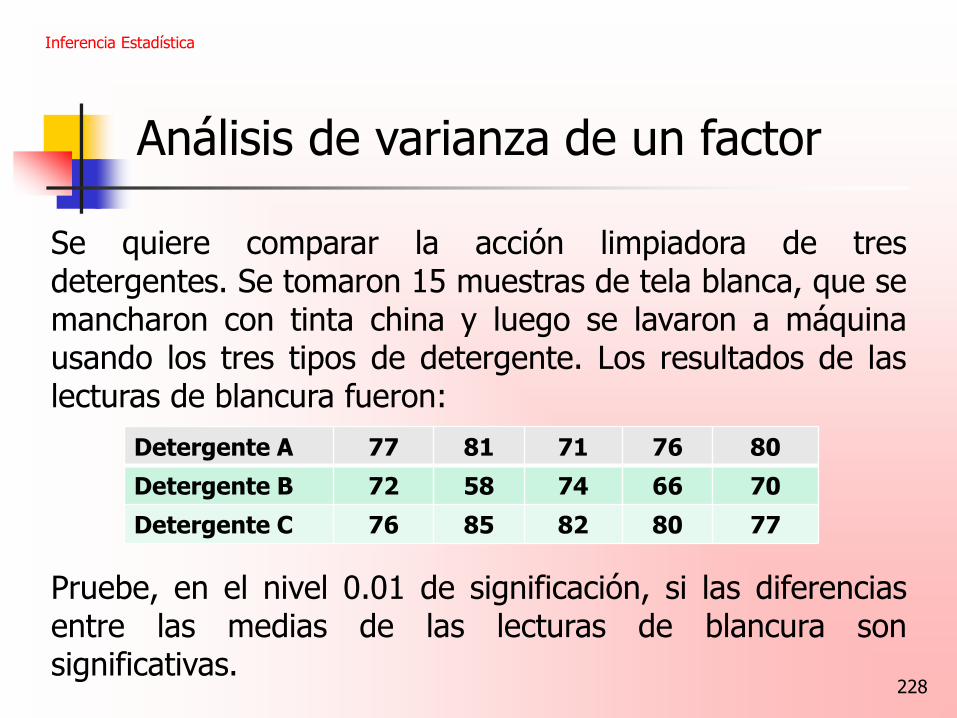
228
Análisis de varianza de un factor
Se quiere comparar la acción limpiadora de tres detergentes. Se tomaron 15 muestras de tela blanca, que se mancharon con tinta china y luego se lavaron a máquina usando los tres tipos de detergente. Los resultados de las lecturas de blancura fueron: Pruebe, en el nivel 0.01 de significación, si las diferencias entre las medias de las lecturas de blancura son significativas.
Inferencia Estadística
Detergente A 77 81 71 76 80
Detergente B 72 58 74 66 70
Detergente C 76 85 82 80 77

229
Análisis de varianza de un factor
Tres grupos de seis conejillos de indias se inyectaron, cada uno, con respectivamente 0.5 miligramos, 1.0 miligramos, 1.5 miligramos de un nuevo tranquilizante. A continuación se muestra el número de minutos que tardaron en quedarse dormidos Pruebe, en el nivel 0.05 de significación, si se puede rechazar la hipótesis nula de que las diferencias en dosificación no tienen efecto.
Inferencia Estadística
0.5 miligramos 21 23 19 24 25 23
1.0 miligramos 19 21 20 18 22 20
1.5 miligramos 15 10 13 14 11 15
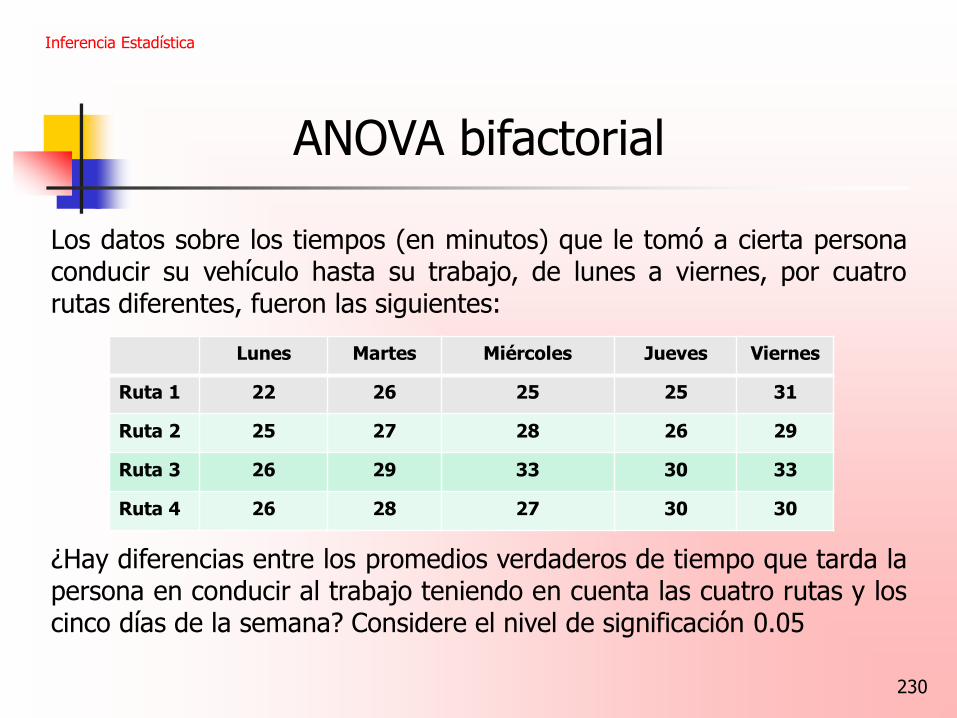
230
ANOVA bifactorial
Los datos sobre los tiempos (en minutos) que le tomó a cierta persona conducir su vehículo hasta su trabajo, de lunes a viernes, por cuatro rutas diferentes, fueron las siguientes: ¿Hay diferencias entre los promedios verdaderos de tiempo que tarda la persona en conducir al trabajo teniendo en cuenta las cuatro rutas y los cinco días de la semana? Considere el nivel de significación 0.05
Inferencia Estadística
Lunes Martes Miércoles Jueves Viernes
Ruta 1 22 26 25 25 31
Ruta 2 25 27 28 26 29
Ruta 3 26 29 33 30 33
Ruta 4 26 28 27 30 30
231
ANOVA bifactorial
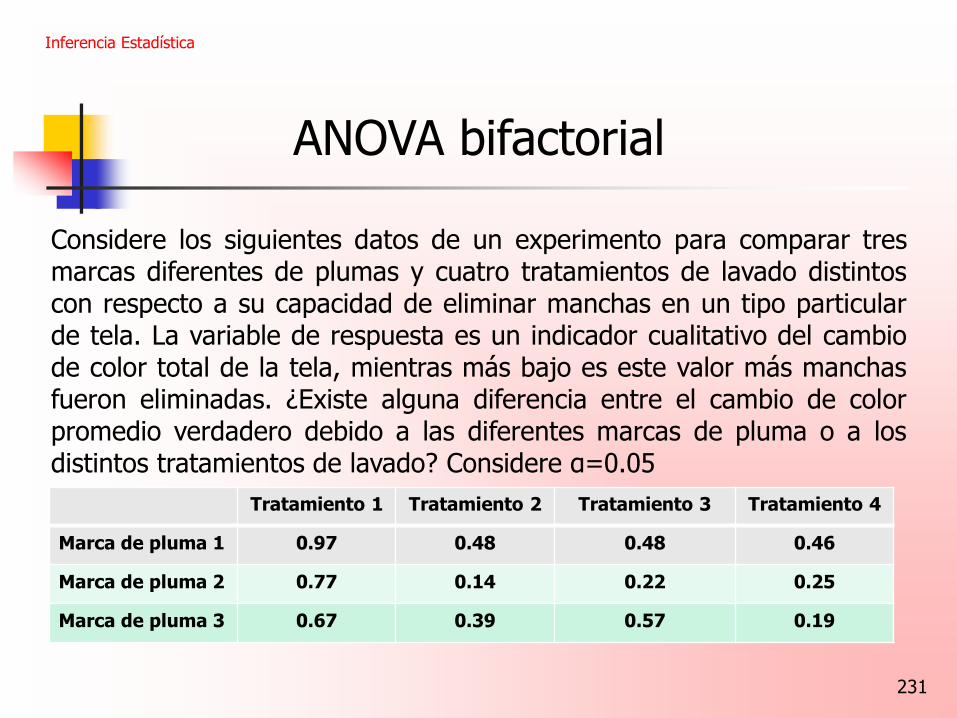
Considere los siguientes datos de un experimento para comparar tres marcas diferentes de plumas y cuatro tratamientos de lavado distintos con respecto a su capacidad de eliminar manchas en un tipo particular de tela. La variable de respuesta es un indicador cualitativo del cambio de color total de la tela, mientras más bajo es este valor más manchas fueron eliminadas. ¿Existe alguna diferencia entre el cambio de color promedio verdadero debido a las diferentes marcas de pluma o a los distintos tratamientos de lavado? Considere α=0.05
Inferencia Estadística
Tratamiento 1 Tratamiento 2 Tratamiento 3 Tratamiento 4
Marca de pluma 1 0.97 0.48 0.48 0.46
Marca de pluma 2 0.77 0.14 0.22 0.25
Marca de pluma 3 0.67 0.39 0.57 0.19
Related Documents











