Indexing

Indexing. Overview of the Talk zInverted File Indexing zCompression of inverted files zSignature files and bitmaps zComparison of indexing methods zConclusion.
Dec 24, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Indexing

Overview of the Talk
Inverted File Indexing Compression of inverted files Signature files and bitmaps Comparison of indexing methods Conclusion

Inverted File Indexing Inverted file index
contains a list of terms that appear in the document collection (called a lexicon or vocabulary)
and for each term in the lexicon, stores a list of pointers to all occurrences of that term in the document collection. This list is called an inverted list.
Granularity of an index determines the accuracy of representation of the location of the word Coarse-grained index requires less storage and more query
processing to eliminate false matches Word-level index enables queries involving adjacency and
proximity, but has higher space requirements
Usual granularity is document-level, unless a significant fraction of the queries are expected to be proximity-based.

Inverted File Index: Example
Doc Text1 Pease porridge hot, pease porridge
cold,2 Pease porridge in the pot,3 Nine days old. 4 Some like it hot, some like it cold,5 Some like it in the pot,6 Nine days old.
Terms Documents---------------------------cold <2; 1, 4>days <2; 3, 6>hot <2; 1, 4>in <2; 2, 5> it <2; 4, 5>like <2; 4,
5>nine <2; 3, 6>old <2; 3, 6>pease <2; 1, 2>porridge <2; 1, 2>pot <2; 2, 5>some <2; 4, 5>the <2; 2, 5>
Notation:
N: number of documents; (=6)n: number of distinct terms; (=13)f: number of index pointers; (=26)

Inverted File Compression
Each inverted list has the form 1 2 3 ; , , , ... ,
tt ff d d d d
A naïve representation results in a storage overhead of ( ) * logf n N
This can also be stored as 1 2 1 1; , ,...,t tt f ff d d d d d
Each difference is called a d-gap. Since
( ) ,d gaps N each pointer requires fewer than log N bits.
Assume d-gap representation for the rest of the talk, unless stated otherwise

Text Compression
Two classes of text compression methods Symbolwise (or statistical) methods
Estimate probabilities of symbols - modeling step Code one symbol at a time - coding step Use shorter code for the most likely symbol Usually based on either arithmetic or Huffman coding
Dictionary methods Replace fragments of text with a single code word
(typically an index to an entry in the dictionary).• eg: Ziv-Lempel coding, which replaces strings of characters
with a pointer to a previous occurrence of the string. No probability estimates needed
Symbolwise methods are more suited for coding d-gaps

Models
model
encoder
model
decodercompressed texttext text
Entropy, or the average amount of information per symbol over the whole alphabet, denoted H, is given by
Information content of a symbol s, denoted by I(s) is given by Shannon’s formula
()logPr[] Iss
Pr[ ]* ( ) Pr[ ]*log Pr[ ]s s
H s I s s s
Models can be static, semi-static or adaptive.
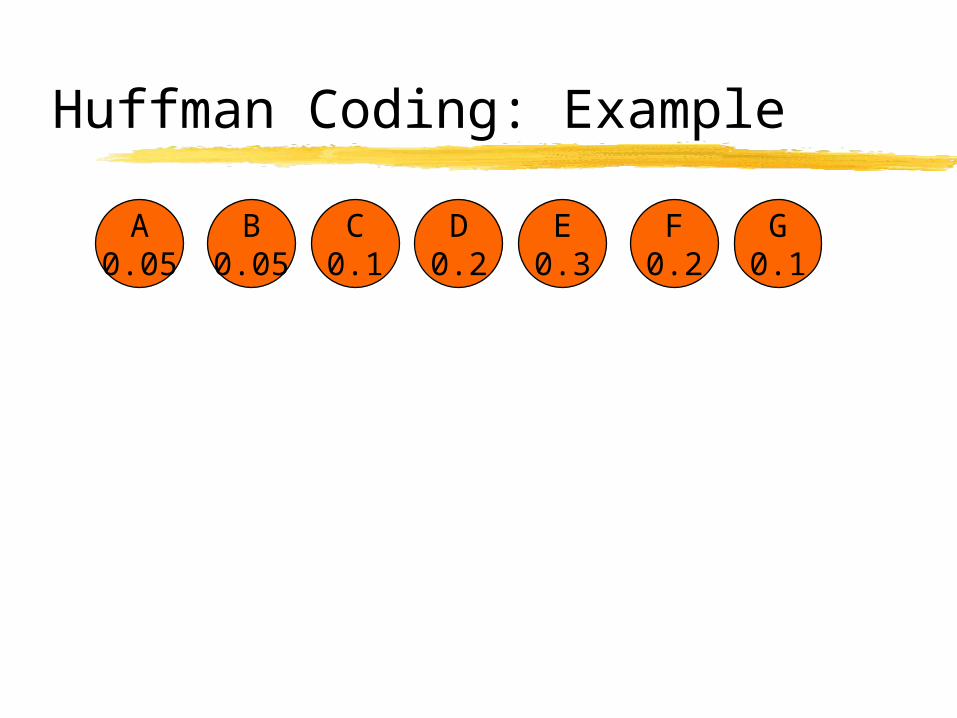
A0.05
B0.05
Huffman Coding: Example
C0.1
D0.2
E0.3
F0.2
G0.1

Huffman Coding: Example
C0.1
D0.2
E0.3
F0.2
G0.1
A0.05
B0.05
0.1

Huffman Coding: Example
A0.05
0.1
1.0
0.4
0.2 0.6
B0.05
0.3
G0.1
F0.2
E0.3
D0.2
C0.1
0 1
1
0
0 1
10 1
0 1
0
Symbol Code ProbabilityA 0000 0.05B 0001 0.05C 001 0.1D 01 0.2E 10 0.3F 110 0.2G 111 0.1

Arithmetic Coding
Pr[c]=1/3
Pr[b]=1/3
Pr[a]=1/3
1.0000
0.6667
0.3333
0.0000
A)
Interval used to code b
B)
0.6667
0.5834
0.4167
0.3333
Interval used to code c
Pr[c]=1/4
Pr[b]=2/4
Pr[a]=1/4
0.6667
0.6334
0.6001
0.5834
0.6667
0.6501
0.6390
0.6334
Final interval(represents whole output)
Pr[c]=2/5
Pr[b]=2/5
Pr[a]=1/5
Pr[c]=3/6
Pr[b]=2/6
Pr[a]=1/6
C)
String = bccbAlphabet = {a, b, c}
Code = 0.64

Arithmetic Coding: Conclusions
High probability events do not reduce the size of the interval in the next step very much, whereas low-probability events do.
A small final interval requires many digits to specify a number guaranteed to be in the interval.
Number of bits required is proportional to the negative logarithm of the size of the interval.
A symbol s of probability Pr[s] contributes -log Pr[s] bits to the output.
Arithmetic Coding produces near-optimal codes, given an accurate model

Methods for Inverted File Compression
Methods for compressing d-gap sizes can be classified into global: each list is compressed using the same model local: the model for compressing an inverted list is
adjusted according to some parameter, like the frequency of the term
Global methods can be divided into non-parameterized: probability distribution for d-gap
sizes is predetermined. parameterized: probability distribution is adjusted
according to certain parameters of the collection. By definition, local methods are parameterized.

Non-parameterized modelsUnary code: An integer x > 0, is coded as (x-1) ‘1’ bits followed by a ‘0’ bit.
code of log x bits that represents log2 xx in binary.
γ code: Number x is coded as a unary code for 1 log x followed by a
3
9, log 3
1110
9 2 001
For x x
Unary part
Binarypart Binary code for
δ code: Number of bits in binary is represented using γ code.9, log 3
(3 1) 11000
001
For x x
code code for
Binary part
For small integers, δ codes are longer than γ codes, but for large integers, the situation reverses.

Non-parameterized modelsEach code has an underlying probability distribution, which can be derived using Shannon’s formula.
2
2
log Pr[ ] Pr[ ] 2
: Pr[ ] 2
1: 1 2 log Pr[ ]
2
: 1 2 log(1 log ) log
1 2log log log
1Pr[ ]
2 (log )
xlx
xx
x
x
l x x
Unary l x x
l x xx
l x x
x x
xx x
Probability assumed by unary is too small.

Global parameterized modelsProbability that a random document contains a random term, Assuming a Bernoulli process,
1Pr[ ] (1 )xx p p Arithmetic coding:
11
1 1
Pr[ ] 1 (1 ) & Pr[ ] 1 (1 )x x
x x
i i
lowbound i p highbound i p
Huffman-style coding (Golomb coding):
1 1
, 0 .
1
1 log log .
,
(1 ) (1 ) 1 (1 ) (1 ) ,b b b b
For some parameter b code x in two parts
xCode q in unary and then
b
Code r x qb in binary with b or b bits
If b satisfies
p p p p
this method generates anoptimal prefix freecode for a ge
.ometric distribution
*
fp
n N

Global observed frequencymodel
Use exact d-gap values and then use arithmetic or Huffman coding
Only slightly better than γ or δ code
Reason: pointers are not scattered randomly in the inverted file
Need local methods for any improvement

Local methods
Local Bernoulli Use a different p for each inverted list Use γ code for storing
Skewed Bernoulli Local Bernoulli model is bad for clusters Use a cross between γ and Golomb, with b=median gap size Need to store b (use γ representation) This is still a static model
Need an adaptive model that is good for clusters
tf

Interpolative code
7;3,8,9,11,12,13,17 20where N Consider an inverted list
Documents 8, 9, 11, 12 and 13 form a cluster7;3,8,9,11,12,13,17
3 [1,7] 3
9 [9 10] 1
12 [12 12] 0
17 [14 20] 3
bits
bit
bits
bits
3;8,11,13
8 [2,9] 3
13 [13 19] 3
bits
bits
1;11
11 [4,17] 4bits
Can do better with a minimal binary code

Performance of index compression methods
Global methods Bible GNUbib Comact TRECUnary 262 909 487 1918Binary 15.00 16.00 18.00 20.00Bernoulli 9.86 11.06 10.90 12.30 6.51 5.68 4.48 6.63 6.23 5.08 4.35 6.38Observed Frequency 5.90 4.82 4.20 5.97
Local methods Bible GNUbib Comact TRECBernoulli 6.09 6.16 5.40 5.84Skewed Bernoulli 5.65 4.70 4.20 5.44Batched Frequency 5.58 4.64 4.02 5.41Interpolative 5.24 3.98 3.87 5.18
Compression of inverted files in bits per pointer

Signature Files Each document is given a signature, that captures its
content Hash each document term to get several hash values Bits corresponding to those values are set to 1
Query processing: Hash each query term to get several hash values If a document has all bits corresponding to those values set to
1, it may contain the query term False matches
set several bits for each term make the signatures sufficiently long
Naïve representation: may have to read the entire signature file for each query term
Use bitslicing to save on disk transfer time

Signature files: Conclusion
Design involves many tradeoffs wide, sparse signatures reduce number of false matches short, dense signatures require more disk accesses
For reasonable query times, requires more space than compressed inverted file
Inefficient for documents of varying sizes Blocking makes simple queries difficult to answer
Text is not random

Bitmaps
Simple representation: For each term in the lexicon, store a bitvector of length N. A bit is set if and only if the corresponding document contains the term.
Efficient for boolean queries Enormous amount of storage requirement, even after
removing stop words Have been used to represent common words

Compression of signature files and bitmaps
Signature files are already in compressed form Decompression affects query time substantially Lossy compression results in false matches
Bitmaps can be compressed by a significant amount
0000 0010 0000 0011 1000 0000 0100 0000 0000 0000 0000 0000 0000 0000 0000 0000
0101 1010 0000 0000
1100 Compressed code:1100 : 0101, 1010 : 0010, 0011, 1000, 0100

Comparison of indexing methods
All indexing methods are variations of the same basic idea!! Signature files and inverted files require an order of
magnitude less secondary storage than bitmaps Signature files cause unnecessary access to the document
collection unless signature width is large Signature files are disastrous when record lengths vary a lot Advantages of signature files
no need to keep lexicon in memory better for conjunctive queries involving common terms
Compressed inverted files are the most useful for indexing a collection of variable length text documents

Conclusion
For practical purposes, the best index compression algorithm is the local Bernoulli method (using Golomb coding)
Compressed inverted indices are almost always better than signature files and bitmaps in most practical situations, in terms of both space and response time for queries
Related Documents











