Improving Classification Accuracy Using Automatically Extracted Training Data Ariel Fuxman A. Kannan, A. Goldberg, R. Agrawal, P. Tsaparas, J. Shafer Search Labs Microsoft Research – Silicon Valley Mountain View, CA

Improving Classification Accuracy Using Automatically Extracted Training Data Ariel Fuxman A. Kannan, A. Goldberg, R. Agrawal, P. Tsaparas, J. Shafer Search.
Jan 03, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Improving Classification Accuracy Using Automatically Extracted Training Data
Ariel FuxmanA. Kannan, A. Goldberg, R. Agrawal,
P. Tsaparas, J. Shafer
Search LabsMicrosoft Research – Silicon Valley
Mountain View, CA

• For classification tasks, large amounts of training data can significantly improve accuracy
• How do we create large training sets?– Conventional methods of using human labelers
are expensive and do not scale
• Thesis: The Web can be used to automatically create labeled data
Web as a Source of Training Data
2

In this talk
• Validate the thesis on a task of practical importance: Retail intent identification in Web Search
• Present desirable properties of sources of labeled data
• Show how to extract labeled data from the sources
3
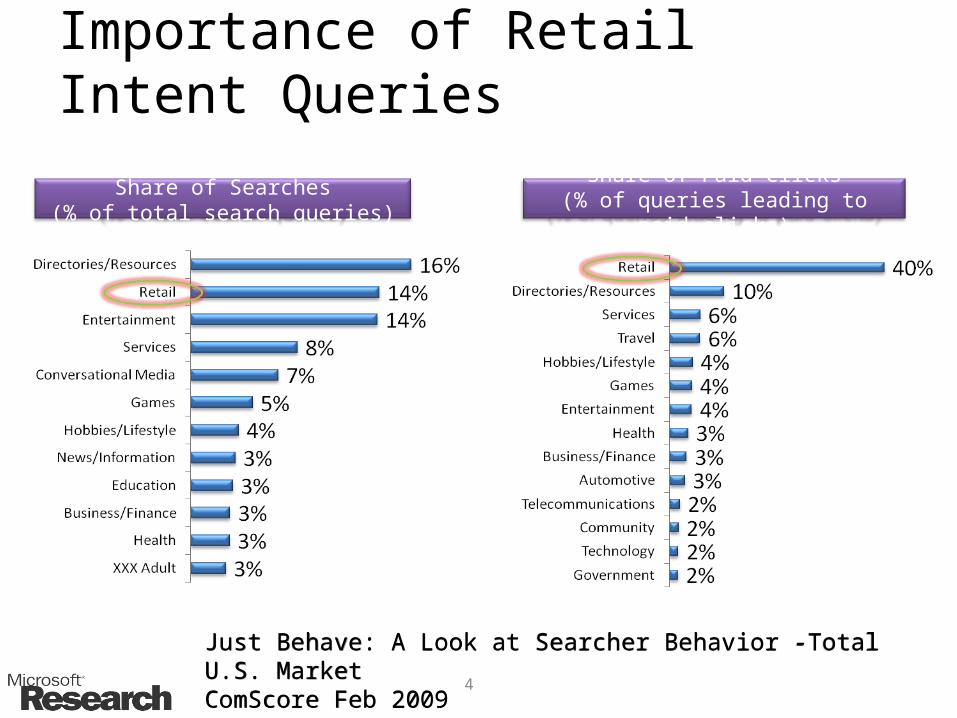
Importance of Retail Intent Queries
4
Just Behave: A Look at Searcher Behavior -Total U.S. MarketComScore Feb 2009Just Behave: A Look at Searcher Behavior -Total U.S. MarketComScore Feb 2009
Share of Searches(% of total search queries)
Share of Paid Clicks(% of queries leading to paid clicks)

Application of Retail Intent
5
• Provide enhanced user experience around Commerce Search

Retail intent identificationDefinition:
A query posed to a search engine has retail intent if most users who type the query have the intent to buy a tangible product
Examples :Queries with retail intent Queries without retail
intent
Zune 80 gb Medical insurance
Buy ipod Free ringtones
Digital camera lenses Digital camera history

Data Sources for Retail Intent• Sources
– Web sites of retailers (e.g., Amazon, Walmart, Buy.com)
• Training Data– Queries typed directly on search box of retailers
• Extraction from toolbar logs
7
URL in toolbar log

Desirable Properties of Web Data Sources
• Popularity– Sources should yield large amounts of data
• Orthogonality– Sources should provide training data about
different regions of the training space
• Separation– Sources should provide either positive or negative
examples of the target class, but not both
8

Popularity• Sources should yield large amounts of
data• For retail intent identification
–Web site traffic is a proxy for popularity –More traffic means more queries–Choose Web sites of retailers based on
publicly available traffic report (Hitwise)
9

Orthogonality
• For retail intent identification• Positive examples: top sites from “Departmental Stores” and
“Classified Ads” (Amazon and Craigslist)
• Negative examples: top site from “Reference” (Wikipedia)
10
• Sources should provide training data about different regions of the training space

Separation
• Training examples must unambiguously reflect the intended meaning of most users
– Example: there is a book called “World War I”, but the intent of the query is mostly non-commercial
• Can be enforced by removing groups of confusable queries from the sources

Method to Enforce Separation
• Create “groups” of positive queries• Compare the word frequency distribution of
each group against the negative class using Jensen-Shannon divergence
• Remove groups with low divergence
12

Groups for Retail Intent
• Extracting groups from the toolbar log
13
URL in toolbar log

Enforcing separation property• JS Divergence of Amazon and Craigslist with
respect to Wikipedia
See paper for experimental validation

Experiments
• Setup– Built multiple classifiers using manual and
automatically extracted labels in the training sets– Classification method: logistic regression, using
unigrams and bigrams as features– Test set: 5K queries randomly sampled from a
query log and labeled using Mechanical Turk

Automatic vs. Manual
16
Accuracy of extracted labels classifier on par with manual labels classifier

Combining Manual and Automatically Extracted
Marginally different from using only automatically extracted labels

Using Unlabeled Data
18
Performance of the automatic labels classifier is still on par with classifiers that start with manual labels and exploit unlabeled data using self-training

Conclusions
• By carefully choosing the data sources, we can extract valuable training data
• Using large amounts of automatically extracted training data, we can get classifiers that are on par with those trained with manual labels
• As future work, we would like to apply this experience to other classification tasks
19
Related Documents











