Importance Importance Resampling for Resampling for Global Global Illumination Illumination Justin Talbot, David Cline, and Justin Talbot, David Cline, and Parris Egbert Parris Egbert Brigham Young University Brigham Young University Provo, UT Provo, UT

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Importance Resampling Importance Resampling for Global Illuminationfor Global Illumination
Justin Talbot, David Cline, and Parris Justin Talbot, David Cline, and Parris EgbertEgbert
Brigham Young UniversityBrigham Young UniversityProvo, UTProvo, UT

TermsTerms
Importance Sampling (IS)Importance Sampling (IS)
• Variance reduction technique for Monte Carlo integrationVariance reduction technique for Monte Carlo integration
Sampling Importance Resampling (SIR)Sampling Importance Resampling (SIR)
• Developed in statistical literatureDeveloped in statistical literature• Two stage technique for generating samples from a Two stage technique for generating samples from a
difficult distributiondifficult distribution
Resampled Importance Sampling (RIS)Resampled Importance Sampling (RIS)
• Novel variance reduction technique for Monte Carlo Novel variance reduction technique for Monte Carlo integration using SIR to generate samplesintegration using SIR to generate samples

OutlineOutline
Related WorkRelated Work Importance ResamplingImportance Resampling Resampled Importance SamplingResampled Importance Sampling Selection of parametersSelection of parameters ResultsResults ConclusionConclusion

Related Work – ISRelated Work – IS
Multiple Importance Sampling [Veach Multiple Importance Sampling [Veach and Guibas 1995]and Guibas 1995]
Weighted Importance Sampling Weighted Importance Sampling [Bekaert et al. 2000][Bekaert et al. 2000]
Combined Correlated and Importance Combined Correlated and Importance Sampling [Szécsi 2004]Sampling [Szécsi 2004]

Related Work - SIRRelated Work - SIR
Sampling Importance Resampling Sampling Importance Resampling [Rubin 1987][Rubin 1987]
Importance Resampling [Smith and Importance Resampling [Smith and Gelfand 1992]Gelfand 1992]

Related Work - ResamplingRelated Work - Resampling
Reducing Shadow Rays [Lafortune Reducing Shadow Rays [Lafortune and Willems 1995]and Willems 1995]
Direct Lighting Calculations [Shirley Direct Lighting Calculations [Shirley et al. 1996]et al. 1996]
Bidirectional Importance Sampling Bidirectional Importance Sampling [Burke 2004, Burke et al. 2005][Burke 2004, Burke et al. 2005]

Importance ResamplingImportance Resampling
Goal: generate samples from a Goal: generate samples from a distribution with pdf distribution with pdf gg, where, where
• gg is not (necessarily) normalized. is not (necessarily) normalized.
• gg can only be evaluated. can only be evaluated.

Importance ResamplingImportance Resampling First, First,
• Generate M “fake” samples, Generate M “fake” samples, XX11……XXMM, from a , from a source distribution with pdf source distribution with pdf pp
Second, Second,
• Weight samples,Weight samples, w(X w(Xii) = g(X) = g(Xii)/p(X)/p(Xii))
• Select a “real” sample Select a “real” sample YY with probability with probability proportional to its weightproportional to its weight

Importance ResamplingImportance Resampling
For M=1, the distribution of For M=1, the distribution of YY is is pp
As M → ∞, the distribution of As M → ∞, the distribution of YY will will approach approach gg..
For any finite M>1, the distribution For any finite M>1, the distribution will be a blend of will be a blend of pp and and gg..
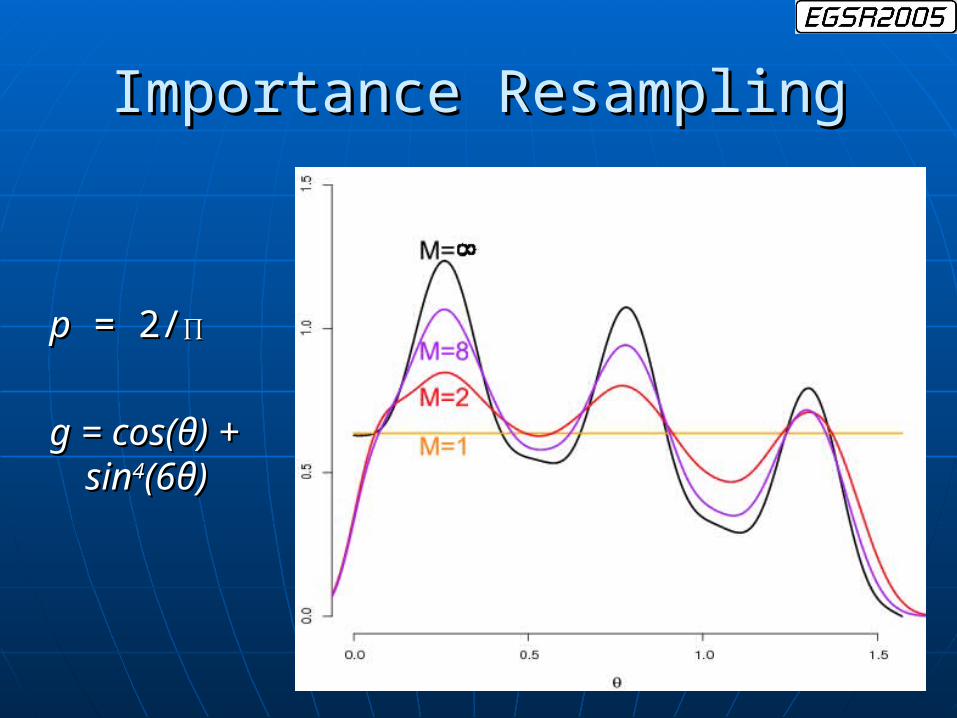
Importance ResamplingImportance Resampling
pp = 2/ = 2/∏∏
g = cos(g = cos(θθ) + ) + sinsin44(6(6θθ))

Importance ResamplingImportance Resampling
Provides a way to generate samples Provides a way to generate samples from a “difficult” distribution.from a “difficult” distribution.
Caveat: Distribution is an Caveat: Distribution is an approximation for any finite Mapproximation for any finite M

Resampled Importance SamplingResampled Importance Sampling
Importance Resampling for Global Illumination?Importance Resampling for Global Illumination?
Use Importance Resampling to generate samples Use Importance Resampling to generate samples for Monte Carlo integrationfor Monte Carlo integration
• Can generate samples from more difficult distributions Can generate samples from more difficult distributions
• Sampling distribution can match function being Sampling distribution can match function being integrated betterintegrated better
• Lower variance (better importance sampling)Lower variance (better importance sampling)

NotationNotation ff – function to be integrated – function to be integrated
gg – sampling density – sampling density• May be unnormalizedMay be unnormalized• Can be evaluatedCan be evaluated
pp – source density – source density• Can easily be sampled using standard techniques (CDF Can easily be sampled using standard techniques (CDF
inversion)inversion)
M – number of fake samples per real sampleM – number of fake samples per real sample
N – number of real samplesN – number of real samples

Resampled Importance SamplingResampled Importance Sampling
Formulate as weighted ISFormulate as weighted IS
To be unbiased, weight must account for:To be unbiased, weight must account for:• gg is unnormalized is unnormalized• YYii are only approximately distributed are only approximately distributed

Resampled Importance SamplingResampled Importance Sampling
Correct weight: Average of the weights Correct weight: Average of the weights computed in the resampling stepcomputed in the resampling step
This estimate is unbiased for any M>0!This estimate is unbiased for any M>0!

Resampled Importance SamplingResampled Importance Sampling
When M=1, reduces to standard IS using When M=1, reduces to standard IS using pp
As M → ∞, approaches standard IS using As M → ∞, approaches standard IS using g g (normalized)(normalized)

VarianceVariance
Some intuition, see paper for the gory detailsSome intuition, see paper for the gory details
Compared to importance samplingCompared to importance sampling• Using Using gg (instead of (instead of pp) reduces variance) reduces variance• The weighting term increases varianceThe weighting term increases variance

VarianceVariance
For a fixed N, RIS is at least as good as For a fixed N, RIS is at least as good as standard importance sampling.standard importance sampling.
Assuming Assuming gg is a better sampling density is a better sampling density than than pp

EfficiencyEfficiency
Efficiency - Variance reduction per timeEfficiency - Variance reduction per time
Increasing M means decreasing N and vice versa.Increasing M means decreasing N and vice versa.
There is an efficiency optimal trade off between M There is an efficiency optimal trade off between M and Nand N

EfficiencyEfficiency
If efficiency optimal M > 1, then RIS is betterIf efficiency optimal M > 1, then RIS is better
Generally occurs when:Generally occurs when:• gg is a lot better than is a lot better than pp
AND/ORAND/OR• Computing Computing gg and and pp is much cheaper than computing is much cheaper than computing ff

Example - Direct LightingExample - Direct Lighting
Direct Lighting: accounts for light arriving Direct Lighting: accounts for light arriving at a surface directly from a light sourceat a surface directly from a light source
To use RIS, we must chooseTo use RIS, we must choose• pp – like standard importance sampling – like standard importance sampling• gg• MM• NN

Example - Choosing gExample - Choosing g Remember, RIS is better when:Remember, RIS is better when:
• gg is a lot better than is a lot better than ppAND/ORAND/OR
• Computing Computing gg and and pp is much cheaper than computing is much cheaper than computing ff
So, we want a So, we want a gg that is very similar to that is very similar to ff and cheap to and cheap to computecompute
An obvious(?) choice is:An obvious(?) choice is:
gg must be real-valued, so take luminance must be real-valued, so take luminance

Example - Choosing M and NExample - Choosing M and N
N=100, M=1(Better shadows, color)
N=1, M=450(Better direct lighting)↔

Robustly choosing M and NRobustly choosing M and N Finding the Finding the truetrue optimal values of M and N can be optimal values of M and N can be
difficult:difficult:
• There are different optimal values of M and N for each There are different optimal values of M and N for each pixelpixel
• Requires estimating Requires estimating TTXX – Time to compute fake sample, – Time to compute fake sample, TTYY – Time to compute real sample, – Time to compute real sample, and variance and variance
for each pixel.for each pixel.
• See paper for detailsSee paper for details

Robustly choosing M and NRobustly choosing M and N Instead, we approximate a single pair for Instead, we approximate a single pair for
the entire image using just Tthe entire image using just TXX and T and TYY::
• M’ = TM’ = TYY/T/Txx
• N’ = Remainder of timeN’ = Remainder of time
Using M’ and N’ will result in no more than Using M’ and N’ will result in no more than 2 times the variance of the true optimal 2 times the variance of the true optimal valuesvalues
• For common scenes, the bound will be much For common scenes, the bound will be much smaller.smaller.

Results – Direct LightingResults – Direct Lighting
RIS using estimated optimal values:
N’=64.8, M’=3.37
57% variance reduction (equal time)

Results – Direct LightingResults – Direct Lighting
N=100, M=1 N=64.8, M=3.37(N*M≈218)
N=1, M=450

Results IIResults II
34% variance reduction

ResultsResults
10-70% variance reduction10-70% variance reduction
Variance reduction is scene Variance reduction is scene dependentdependent
Using approximate optimal values of Using approximate optimal values of M and N may be worse than standard M and N may be worse than standard importance samplingimportance sampling

Concluding ThoughtsConcluding Thoughts
Resampled Importance SamplingResampled Importance Sampling
• New general unbiased variance reduction New general unbiased variance reduction techniquetechnique
• Demonstrated how to choose parameters Demonstrated how to choose parameters robustlyrobustly
• Demonstrated successful variance reduction on Demonstrated successful variance reduction on some scenessome scenes

Concluding ThoughtsConcluding Thoughts
RIS is better than IS when:RIS is better than IS when:
g g is much better than is much better than ppAND/ORAND/OR
Computing Computing gg and and pp is much cheaper than is much cheaper than computing computing ff
Intuition: RIS takes advantage of Intuition: RIS takes advantage of differences in variance or differences in variance or computation expensecomputation expense

Concluding ThoughtsConcluding Thoughts
Future WorkFuture Work
• Application to other problems in rendering or Application to other problems in rendering or other fieldsother fields
• Development of better choices of Development of better choices of gg and and pp
• Combining RIS and Multiple Importance Combining RIS and Multiple Importance SamplingSampling
• Stratifying RISStratifying RIS

QuestionsQuestions
Related Documents











