IMPLEMENTACION EN R DE LA ESTIMACION DE UN MODELO ESPACIO DE LOS ESTADOS CON VARIABLES EXPLICATIVAS JUNIO 2017 Virginia Martí Lang DIRECTOR DEL TRABAJO FIN DE GRADO: Francisco Javier Cara Cañas Virginia Martí Lang TRABAJO FIN DE GRADO PARA LA OBTENCIÓN DEL TÍTULO DE GRADUADO EN INGENIERÍA EN TECNOLOGÍAS INDUSTRIALES

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

IMPLEMENTACION EN R DE LA ESTIMACION DE UN MODELO ESPACIO DE LOS ESTADOS CON VARIABLES EXPLICATIVAS
JUNIO 2017
Virginia Martí Lang
DIRECTOR DEL TRABAJO FIN DE GRADO:
Francisco Javier Cara Cañas
Vir
gin
ia M
art
í L
an
g
TRABAJO FIN DE GRADO PARA
LA OBTENCIÓN DEL TÍTULO DE
GRADUADO EN INGENIERÍA EN
TECNOLOGÍAS INDUSTRIALES


UNIVERSIDAD POLITÉCNICA DE MADRIDESCUELA TÉCNICA SUPERIOR DE INGENIEROS INDUSTRIALES
IMPLEMENTACIÓN EN R
DE LA ESTIMACIÓN DE UN MODELO
ESPACIO DE LOS ESTADOS
CON VARIABLES EXPLICATIVAS
Trabajo Fin de Grado
Grado en Ingenieria en Tecnologías Industriales
Especialidad en Organización Industrial
Autora: Virginia Martí Lang
Tutor: F. Javier Cara Cañas
Madrid, 2017

ii

AGRADECIMIENTOS
A mis padres, que me han acompañado y apoyado durante todo este trayecto y quesiempre han con�ado en que lo conseguiría.
A todas las personas que han estado a mi lado estos años y que ahora no son compa-ñeros sino amigos, que han hecho que este camino fuera toda una aventura.
A mi tutor, por darme la oportunidad y los conocimientos necesarios para continuaraprendiendo hasta el último momento.
i

ii AGRADECIMIENTOS

RESUMEN
Durante el siguiente proyecto, se va a tratar de crear desde cero un modelo que repre-sente el comportamiento de dos series temporales diferentes. Una vez creado, este modelose utilizará para la predicción de los valores de estas series en el futuro. Como base parael desarrollo de cada serie temporal, se va a partir del modelo de espacio de los estados,el cual se puede de�nir de la siguiente manera:
Yt = cXt + vt (1)
Xt+1 = aXt + wt (2)
Donde:
Yt: Variable observación para valores de t = 1, 2, 3...
c, a: Constantes características de la serie que se estudia.
Xt: Variable de estado, no observable, de�nida para valores de t = 1, 2, 3...
wt, vt: Componentes aleatorias que se pueden representar por un proceso de ruidoblanco, con distribución normal N(0, σw2) y N(0, σv2) respectivamente, para t =1, 2, 3..
Las dos series temporales que se van a estudiar son la evolución del precio del pe-tróleo y el número de conductores que han sufrido un accidente grave de trá�co, ambasentre los años 1969 y 1983 en Reino Unido. Para la predicción, se considerará como fechaactual diciembre de 1983, de tal manera que el año predicho será 1984. La decisión detomar esta fecha como actual se llevó a cabo para poder comparar los datos de la predic-ción del modelo con los reales del año 1984 y así evaluar con criterio la calidad del modelo.
Todos los modelos desarrollados y las diferentes metodologías empleadas se van a im-plementar a través de la utilización del programa estadístico R.
Estudio y creación del modelo del precio del petróleo en Reino Unido
La primera serie temporal a estudiar es la evolución del precio del petróleo. Para poderadaptar el modelo de espacio de los estados a esta serie hay que de�nir cada uno de sus
iii

iv RESUMEN
parámetros. El valor de estos parámetros se calcula mediante el método de estimaciónpor máxima verosimilitud. Este procedimiento se basa en considerar como aptos para elmodelo los parámetros que hagan máxima la función de verosimilitud. A través de unaiteración, se puede llegar al máximo buscado y por tanto, al valor de los parámetros con-siderados más adecuados para representar el comportamiento de la serie estudiada. Laiteración se puede realizar mediante la función optim(), de�nida en la biblioteca de R. Elvalor de la función de verosimilitud, viene determinado por las componentes s y k, cuyosvalores se hallan por la aplicación del �ltro de Kalman. De esta manera, por cada iteraciónse ejecutará el �ltro de Kalman y se devolverá un valor de la verosimilitud, repitiéndoseeste proceso hasta dar con el máximo.
Para realizar la parametrización del modelo, se parte de los datos históricos recogidosentre las fechas de enero de 1969 y diciembre de 1983. Los parámetros a los que se quieredar valor son las constantes a y c, los valores de las varianzas de los dos procesos de ruidoblanco, que se van a renombrar como Q, para wt y R para vt y los valores iniciales de laobservación y de la covarianza del error de la estimación, x1 y P1.
Como punto de partida en la iteración para la búsqueda de la máxima verosimilitud,se debe escoger un valor inicial para cada parámetro. Como la parametrización resultantepuede verse afectada por la elección de sus valores iniciales, es importante contar con uncriterio que permita medir la adecuación de los parámetros resultantes al modelo.
En este caso se optó por la aproximación de nuestro modelo a uno de autorregresiónde primer orden. Gracias a la función ar(), de�nida en la biblioteca de R, se puede sabercon facilidad los valores de los parámetros del modelo aproximado, que serán utilizadoscomo punto de partida en la parametrización por máxima verosimilitud. Una vez �naliza-do el modelo, si se ha de�nido correctamente, se podrá utilizar para calcular la predicciónde los valores futuros. Los valores de la predicción se hallan mediante la aplicación del�ltro de Kalman, aunque con una pequeña modi�cación que supone nulo el valor del errorde la estimación ante la falta de datos reales para su cálculo. Este nuevo �ltro de Kalmanpermite conocer el siguiente valor de la variable estado, a través de la cual se puede hallarel nuevo valor de la variable observación.
Como primer paso, se creó un código para la predicción del mes siguiente al conside-rado actual, es decir, enero de 1984. Después se realizó la predicción de un año, aunquecontando solo con los valores actualizados hasta diciembre de 1983. Por último, se pro-gramó el modelo de�nitivo, que calculaba la predicción de un año, pero actualizando losvalores hasta el mes anterior a cada predicción.
De esta manera y como es lógico, el error en la predicción disminuía considerablemente conrespecto a la predicción de un año sin actualizar los datos. Para medir la e�cacia del mo-delo, se halló el error MAPE correspondiente a los valores de la predicción, llegando a unvalor de 0.6% y del conjunto estimación más predicción, obteniendo un valor de un 2.31%.

v
En la siguiente grá�ca se pueden observar los resultados de la estimación y prediccióndel modelo, frente a los valores reales de la serie. Junto a estos valores se representantambién los intervalos de con�anza correspondientes al 95%.
Figura 1: Resultados del modelo desarrollado para el precio del petróleo.Rojo: Real, Azul: Estimación/Predicción, Verde: Intervalo de con�anza
Estudio y creación de un modelo del número de conductores víctimas deaccidentes graves en Reino Unido.
La siguiente serie temporal a estudiar es la del número de conductores que sufrieron unaccidente grave de trá�co o KSI Drivers (Killed or Seriously Injured Drivers). De nuevo,el procedimiento a seguir es parametrizar el modelo de espacio de los estados mediante elmétodo de máxima verosimilitud y una vez de�nido, realizar la predicción del año 1984,considerado como año siguiente a la fecha actual.
Al igual que se ha hecho en la serie del precio del petróleo, se deben escoger los valoresiniciales de los parámetros para la iteración del máximo valor de la función de verosimili-tud. Se debe recordar que la elección de estos parámetros iniciales puede repercutir en losresultados de la estimación del modelo. En este caso, el criterio utilizado para comprobarque estos valores son adecuados es el criterio Akaike, AIC.

vi RESUMEN
El criterio de Akaike considera que los parámetros más adecuados para un modelo son losque producen un menor valor de la función AIC, la cual depende del opuesto de la funciónde verosimilitud. En este caso se optó por este procedimiento porque después de hallarlos valores iniciales que se utilizarían en la estimación con el modelo de autorregresión deprimer orden, se observó que existía un conjunto de valores de menor AIC y por tanto,más adecuados para el modelo.
Una vez parametrizado el modelo con estos valores iniciales en la iteración, se pasó ahallar la predicción de los valores futuros de la serie. Al igual que en el caso anterior, serealizó primero una predicción para sólo el mes siguiente al actual. A continuación, semodi�có el código del programa para hacer la predicción de los meses del año 1984, aun-que sin la actualización de los datos desde diciembre de 1983. Por último, se completó elcódigo para realizar la estimación de 1984 actualizando los datos mes a mes. Este últimoprograma fue el que obtuvo mejores resultados con un error MAPE de 10.56% para elconjunto estimación-predicción y un valor de 9.11% para la predicción exclusivamente.
En la siguiente grá�ca, se puede observar la estimación de los valores pasados y la predic-ción de los futuros frente a los valores reales de la serie. También aparecen representadoslos intervalos de con�anza correspondientes al 95%.
Figura 2: Resultados del modelo desarrollado para KSI driversRojo: Real, Azul: Estimación/Predicción, Verde: Intervalo de con�anza
Estudio del modelo del número de conductores víctimas de accidentes gra-

vii
ves con la adición de variables explicativas.
Al igual que en el caso de la serie del precio del petróleo los resultados de la prediccióneran correctos para el nivel de profundización de este proyecto, los de la serie de las vícti-mas de accidentes no se ajustaban en la misma medida a la realidad. Por este motivo sebuscó una alternativa que permitiera mejorar el modelo y se introdujo una nueva variableque dependiera de valores previamente conocidos y que in�uyera directamente sobre elcomportamiento del sistema, es decir, una variable explicativa.
Para elegir el factor que iba a representar la variable explicativa, se barajó la hipóte-sis de que el número de conductores que sufrieron un accidente grave de trá�co podríaestar in�uenciado por el precio del petróleo en ese momento, siguiendo el siguiente ra-zonamiento: si el precio del petróleo sube, más personas harán uso de su vehículo y porlo tanto, las posibilidades de sufrir un accidente se incrementarán, y lo mismo en casocontrario.
Para comprobar esta hipótesis, se representó grá�camente el valor del precio del petróleofrente al número de víctimas correspondientes a cada mes y se calculó la recta de regresiónlineal existente entre ambos modelos, llegando al siguiente resultado:
Figura 3: Relación entre el precio del petróleo y KSI drivers
Mediante la interpretación de esta grá�ca se puede a�rmar que existe relación entreambos modelos. La introducción de una variable explicativa que simbolice la in�uencia de

viii RESUMEN
este factor en el modelo, proporciona información adicional sobre el funcionamiento de laserie. De esta manera, se puede estimar mejor su comportamiento y mejorar la calidad desus resultados.
La variable explicativa viene representada por una matriz de 180 columnas y 12 �las.En cada columna se encuentra, en la primera �la, la información relativa al precio delpetróleo y en las siguientes 11 �las, el mes al que corresponde ese dato, indicado con unvalor 1 ó 0. Esta matriz de 12x180, viene multiplicada a su vez por un vector de paráme-tros de dimensión 1x12. La primera componente contiene el parámetro que correspondeal precio del petróleo y las 11 siguientes son los parámetros que indican la diferencia queexiste en los valores del precio del petróleo entre los distintos meses.
Del mismo modo que en los casos anteriores, se debe determinar el modelo mediantela estimación de sus parámetros por máxima verosimilitud. Debido a la incorporación dela variable explicativa en el modelo, también hay que estimar las doce componentes delvector de parámetros.
Si se denomina a la matriz que representa a la variable explicativa como Ut y a su vectorde parámetros como d, el modelo de espacio de los estados completo se describe de lasiguiente forma:
Yt = cXt + dUt + vt (3)
Xt+1 = aXt + wt (4)
Para utilizar el método de máxima verosimilitud, hay que modi�car el �ltro de Kalmanutilizado anteriormente e incluir en su de�nición la actuación de la variable explicativa.Por medio de iteración y una vez modi�cado el código del �ltro de Kalman, se calculanlos valores de los parámetros que proporcionen un valor máximo de la función de verosi-militud. En este caso, los valores iniciales de los parámetros en la iteración se calculan através de una aproximación del modelo de espacio de los estados a uno de autorregresiónde primer orden, mediante la utilización de la función ar() de�nida en la biblioteca de R.
Una vez determinado el modelo del número de conductores víctimas de accidentes gra-ves, se procede a realizar la predicción. Para esta predicción, se utiliza de nuevo el Filtrode Kalman, aunque modi�cado, incluyendo así la in�uencia de la variable explicativa yconsiderando como nulo el error de la estimación en su de�nición. En primer lugar y aligual que anteriormente, se realiza la predicción de un año, 1984, de manera directa, sin laactualización de los datos desde diciembre de 1983. Después se completó el código adap-tando al programa para predecir los datos de un año actualizando los valores de partidapara cada predicción con los reales mes a mes.
El proceso para predecir cada mes del año se puede resumir en los siguientes pasos:

ix
Predecir el precio del petróleo del mes siguiente al actual.
Con ese valor en la variable explicativa predecir el valor del número de víctimas deaccidentes de ese mes.
Actualizar los valores de ese mes con los datos reales, pasando a considerarlo comoactual y con estos nuevos valores proceder a calcular la predicción del mes siguiente.
Para comprobar la e�cacia del modelo se hallaron de nuevo los errores MAPE del conjuntoestimación-predicción, obteniendo un valor de 10.03% y el de la predicción con un valorde 5.70%. Después de hallar la predicción del año 1984, se representaron grá�camenteresultados. A continuación se puede ver la estimación y predicción frente a los datosreales de la serie, acompañados por los intervalos de con�anza correspondientes al 95%.
Figura 4: Resultados del modelo de variables explicativas para KSI driversRojo: Real, Azul: Estimación/Predicción, Verde: Intervalo de con�anza
Conclusión
En el estudio de la serie temporal del precio del petróleo, se obtienen unos valores delerror MAPE que demuestran que el modelo creado cumple el objetivo principal de esteproyecto: Desarrollar paso a paso un modelo de una serie temporal que permita realizaruna predicción aceptable partiendo únicamente de datos históricos.

x RESUMEN
En el caso del estudio de la serie temporal de las víctimas de accidentes, los resulta-dos no se adaptaban en la misma medida a la realidad. Los errores MAPE eran mayoresy por tanto el modelo era menos exacto. Estas diferencias pueden deberse a la in�uenciade múltiples factores en la serie temporal que no se han tenido en cuenta y que a vecesdeterminan en gran medida su comportamiento.
Mediante la introducción de una variable explicativa que ponga de mani�esto la in�uenciade un factor en el modelo, se puede añadir al sistema información adicional que ayudea determinar con mayor exactitud su funcionamiento. Si se comparan los errores MAPEobtenidos en el modelo del número de conductores víctimas de accidentes graves de trá�coen el modelo con y sin variables explicativas se puede a�rmar que el modelo con variableexplicativa mejora apreciablemente sus resultados. De esta manera, se puede concluir quesi al estudiar una serie temporal se tiene en cuenta los factores adecuados, de fácil medidae in�uencia apreciable, se puede mejorar considerablemente la precisión de un modelo.

Índice general
AGRADECIMIENTOS i
RESUMEN iii
1. INTRODUCCIÓN, OBJETIVOS Y COMPETENCIAS. 11.1. Introducción. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2. Objetivos principales y competencias adquiridas . . . . . . . . . . . . . . . 2
2. FUNDAMENTO TEÓRICO 52.1. Conocimientos previos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1. Series Temporales. De�nición y tipos . . . . . . . . . . . . . . . . . 52.1.2. Ruido Blanco. De�nición, simulación y representación. . . . . . . . 82.1.3. Autocorrelación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2. Modelos matemáticos para la representación de series temporales . . . . . 122.2.1. Paseo aleatorio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.2. Local level model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.3. Espacio de los estados . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.4. Modelos autorregresivos, AR(p). Modelo autorregresivo de primer
orden AR(1). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.3. Filtro de Kalman . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.4. Máxima verosimilitud. Estimación de los parámetros del modelo. . . . . . . 212.5. Predicción de los valores del modelo . . . . . . . . . . . . . . . . . . . . . . 222.6. Criterios de validación del modelo . . . . . . . . . . . . . . . . . . . . . . . 23
2.6.1. Criterio de Akaike (AIC) . . . . . . . . . . . . . . . . . . . . . . . . 232.6.2. Error porcentual absoluto medio (MAPE) . . . . . . . . . . . . . . 24
3. ESTUDIO DE LA VARIACIÓN DEL PRECIO DEL PETRÓLEO. 253.1. Factores in�uyentes en el precio del petróleo. . . . . . . . . . . . . . . . . . 25
3.1.1. Marco histórico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.1.2. Otros factores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2. Desarrollo del modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
xi

xii ÍNDICE GENERAL
4. ESTUDIO DEL ÍNDICE KSI DRIVERS 394.1. Marco histórico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.2. Desarrollo del modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5. ESTUDIO DEL ÍNDICE KSI CON VARIABLES EXPLICATIVAS. 495.1. Estudio de la relación entre el precio del petróleo y los accidentes de trá�co 495.2. Desarrollo de un modelo con variable explicativa. . . . . . . . . . . . . . . 51
6. CONCLUSIONES 63
7. LÍNEAS FUTURAS 67
8. PLANIFICACIÓN TEMPORAL Y PRESUPUESTO 698.1. Plani�cación temporal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
8.1.1. Estructura del desarrollo del proyecto. . . . . . . . . . . . . . . . . 698.1.2. Plani�cación, estructura y distribución temporal. . . . . . . . . . . 708.1.3. Diagrama de Gant. . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
8.2. Presupuesto del proyecto. . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
9. RESPONSABILIDAD SOCIAL 75
BIBLIOGRAFÍA 77
A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R. 79A.1. Programas base utilizados en fundamento teórico . . . . . . . . . . . . . . 79
A.1.1. Simulación de un proceso de ruido blanco . . . . . . . . . . . . . . . 79A.1.2. Simulación de un proceso con paseo aleatorio . . . . . . . . . . . . . 79A.1.3. Simulación de un proceso con local level model . . . . . . . . . . . . 79A.1.4. Simulación del �ltro de Kalman aplicado a un proceso con modelo
local level model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80A.1.5. Simulación del �ltro de Kalman aplicado a un proceso con modelo
de espacio de los estados . . . . . . . . . . . . . . . . . . . . . . . . 81A.1.6. Biblioteca de las funciones generales de este apartado . . . . . . . . 81
A.2. Biblioteca de las funciones generales . . . . . . . . . . . . . . . . . . . . . . 83A.2.1. Funciones utilizadas durante estudio de las series temporales . . . . 83
A.3. Programas para la serie del precio del petróleo . . . . . . . . . . . . . . . . 87A.3.1. Estudio de la tendencia mediante la recta de regresión . . . . . . . 87A.3.2. Correlograma de los datos del precio del petróleo . . . . . . . . . . 87A.3.3. Obtención de los parámetros iniciales para la estimación mediante
AR(1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87A.3.4. Programa completo para el estudio, la estimación y predicción de
un año de la serie del precio del petróleo . . . . . . . . . . . . . . . 88A.4. Programas para la serie del índice KSI Drivers . . . . . . . . . . . . . . . . 89
A.4.1. Estudio de la tendencia del logaritmo de KSI drivers . . . . . . . . 89

ÍNDICE GENERAL xiii
A.4.2. Programa completo para el estudio, estimación y predicción de unaño del índice KSI drivers . . . . . . . . . . . . . . . . . . . . . . . 90
A.5. Programas para la serie KSI con variables explicativas . . . . . . . . . . . . 91A.5.1. Estudio de la relación entre el precio petróleo y el índice KSI drivers 91A.5.2. Obtención de los valores iniciales de los parámetros por AR(1) . . . 92A.5.3. Programa para el estudio, estimación y predicción de un año de la
serie KSI drivers con variables explicativas . . . . . . . . . . . . . . 92

xiv ÍNDICE GENERAL

Índice de �guras
1. Resultados del modelo desarrollado para el precio del petróleo. . . . . . . . v
2. Resultados del modelo desarrollado para KSI drivers . . . . . . . . . . . . vi
3. Relación entre el precio del petróleo y KSI drivers . . . . . . . . . . . . . . vii
4. Resultados del modelo de variables explicativas para KSI drivers . . . . . . ix
2.1. Simulación de un proceso de ruido blanco . . . . . . . . . . . . . . . . . . . 102.2. Autocorrelación del proceso de ruido blanco simulado . . . . . . . . . . . . 112.3. Simulación de un proceso de paseo aleatorio. . . . . . . . . . . . . . . . . . 132.4. Simulación de un proceso de local level model. . . . . . . . . . . . . . . . . 142.5. Simulación �ltro de Kalman con espacio de los estados. . . . . . . . . . . . 20
3.1. Evolución del precio del barril en crudo . . . . . . . . . . . . . . . . . . . . 273.2. Evolución del precio del petróleo en Reino Unido . . . . . . . . . . . . . . 293.3. Correlograma del precio del petróleo . . . . . . . . . . . . . . . . . . . . . 303.4. Resultados de la estimación y predicción de un mes. . . . . . . . . . . . . . 323.5. Correlograma del error absoluto. . . . . . . . . . . . . . . . . . . . . . . . . 323.6. Correlograma del error absoluto con los parámetros iniciales de AR(1). . . 343.7. Resultado del modelo con los parámetros iniciales de AR(1) para un mes. . 353.8. Resultado del modelo para predicción de un año sin actualizar los datos. . 363.9. Resultado del modelo para predicción de un año actualizando los datos. . . 37
4.1. Logaritmo de los datos de KSI frente al tiempo . . . . . . . . . . . . . . . 414.2. Correlograma del error. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424.3. Resultados del modelo en la estimación y predicción de un mes . . . . . . . 444.4. Resultados de la estimación y predicción de un año sin actualizar datos . . 454.5. Resultados de la estimación y predicción de un año actualizando datos . . 464.6. Correlograma del error absoluto de los resultados del modelo . . . . . . . . 47
5.1. Relación entre el precio del petróleo y los KSI drivers . . . . . . . . . . . . 505.2. Número KSI drivers frente al tiempo . . . . . . . . . . . . . . . . . . . . . 515.3. Media mensual de KSI y ocasiones que cada mes ha sido máximo . . . . . 525.4. Resultados de la estimación/predicción con los parámetros iniciales por AIC. 595.5. Resultados de la estimación/predicción con los parámetros iniciales por
AR(1). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
xv

xvi ÍNDICE DE FIGURAS
5.6. Correlograma modelo con parámetros iniciales por AIC. . . . . . . . . . . . 615.7. Correlograma modelo con parámetros iniciales por AR(1) . . . . . . . . . . 62
8.1. Plani�cación, estructura y distribución temporal. . . . . . . . . . . . . . . 718.2. Diagrama de Gant. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72

Índice de cuadros
8.1. Costes de la mano de obra. . . . . . . . . . . . . . . . . . . . . . . . . . . . 738.2. Costes hardware. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 738.3. Costes software. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 748.4. Coste total del proyecto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
xvii

xviii ÍNDICE DE CUADROS

Capítulo 1
INTRODUCCIÓN, OBJETIVOS YCOMPETENCIAS.
1.1. Introducción.
El análisis de series temporales ha permitido a muchos campos diferentes conocer conantelación los resultados de ciertos fenómenos para poder anteponerse, plani�car y actuarde la mejor manera posible. La previsión se basa a su vez en lo ocurrido en el pasado, detal manera que estudiando el comportamiento anterior de un fenómeno, se pueda buscarun patrón que represente de forma �el su funcionamiento. De este modo y suponiendo quelas condiciones no varían signi�cativamente, se puede prever su evolución en un futurocercano.
Se pueden encontrar numerosos ejemplos de series temporales en distintas áreas de cono-cimiento, como en física, química, economía, electricidad, transporte. . . En este proyectoen concreto se van a estudiar el valor del precio del petróleo y el número de conductoresque han sido víctimas de un accidente de trá�co grave (KSI) en Reino Unido, ambas entrelos años 1969 y 1983. En primer lugar se estudiará cada una de estas series por separado,después se analizará si existe relación entre ellas y de ser así, se creará un modelo quecontenga en su de�nición la in�uencia de una serie sobre la otra.
Como punto de partida, se van a repasar los fundamentos teóricos y conocimientos necesa-rios para desarrollar el modelo de una serie temporal. A continuación, se va a proceder alestudio y desarrollo del modelo de cada una de las series descritas anteriormente. Una vezcreado el modelo, se va a hallar la predicción de los valores de un año y se va a compararcon los valores reales de la serie para comprobar la e�cacia del modelo diseñado.
1

2 CAPÍTULO 1. INTRODUCCIÓN, OBJETIVOS Y COMPETENCIAS.
1.2. Objetivos principales y competencias adquiridas
El objetivo principal de este proyecto es desarrollar un modelo completo, paso a pa-so, que permita realizar predicciones con fundamento de los valores futuros de una serietemporal. Para poner en práctica este procedimiento, se va a realizar un estudio acercade la evolución del precio del petróleo en un intervalo de tiempo (1969-1984) en ReinoUnido y sobre el número de conductores que han fallecido o sufrido accidentes graves eneste mismo espacio temporal. Los datos que se poseen inicialmente han sido recopiladosmensualmente. Estas dos estructuras de datos se caracterizan por ser series temporales,por lo tanto su estudio vendrá determinado por las técnicas y herramientas del análisisde series temporales. Para ello es necesario re�exionar sobre diferentes modelos y escogerel que mejor pueda adaptarse a la evolución temporal de cada serie y que a la vez nosproporcione una vía fácil de análisis.
La predicción que debe realizar el modelo, estará basada en los datos históricos de laserie en particular desde 1969 hasta 1983. Para de�nir correctamente un modelo que seacapaz de simular el comportamiento de una serie temporal en instantes futuros, se debenestimar cada uno de los parámetros que le caracterizan. Todos los conocimientos nece-sarios para entender e implementar el modelo se explican con detalle en el capítulo deFundamento Teórico. Además del estudio por separado de ambas series, se va a estudiarsi guardan una relación entre ellas y de ser así, se creará un modelo que tenga en cuentaesta in�uencia en su funcionamiento. Se deberá también realizar una interpretación de losresultados, comparando los modelos y razonando cual se adapta mejor al comportamientode la serie. Por último, se explicarán las posibles limitaciones que pueda tener el modeloy formas posibles de mejorarlo.
Las predicciones de cada serie se han realizado para el plazo de un año con un avan-ce temporal de un mes, de tal manera que cada vez que se procede a realizar una nuevapredicción, se actualizan antes los datos históricos de partida. Esto permite reducir no-tablemente el error de predicción, contando siempre con la información desde el inicio derecopilación de datos hasta el mes anterior.
Como se describirá al �nal de esta memoria, este modelo tiene ciertas limitaciones quepodrán servir como objetivo para un proyecto futuro, pudiéndose realizar nuevas mejorasque reduzcan la incertidumbre del modelo y perfeccionen sus resultados.
Todo el procedimiento anterior se ha programado mediante R, un software estadísticomuy utilizado en diversos campos de investigación y muy popular para el manejo de basesde datos. Sus prestaciones permiten el desarrollo de este modelo en particular de unaforma lógica y sencilla, debido a que es un programa que destaca por su �exibilidad, suspaquetes herramientas estadísticas y sus grá�cos.

1.2. OBJETIVOS PRINCIPALES Y COMPETENCIAS ADQUIRIDAS 3
A continuación se exponen los objetivos y competencias a desarrollar a lo largo delproyecto:
Objetivos principales
Estudiar la variación del precio del petróleo en Reino Unido en un intervalo temporalde 15 años (1969-1983).
Estudiar la evolución del número de conductores fallecidos o heridos de gravedadpor accidentes de trá�co en Reino Unido en un intervalo temporal de 15 años (1969-1983).
Estudiar qué tipo de serie temporal es cada uno de los dos conjuntos de datosestudiados y las características que poseen.
Comprobar si es posible la utilización del modelo de Espacio de los Estados paraadaptarlo al funcionamiento de las series temporales escogidas.
Programar y simular con R las funciones necesarias para la implementación delmodelo.
Emplear el modelo autorregresivo de primer orden para seleccionar unos valoresiniciales adecuados para la estimación.
Expresar y programar el modelo de Espacio de los Estados en R, estimando todos losparámetros que lo de�nen mediante el método de Máxima Verosimilitud combinadocon el Filtro de Kalman, a través de sus datos históricos.
Estimar a través del modelo creado y parametrizado de Espacio de los Estados losvalores anteriores de cada serie y compararlos con los reales para así medir la validezdel modelo.
Programar una función que permita realizar la predicción de valores futuros de laserie partiendo del modelo de�nido.
Realizar la predicción de los valores de los doce meses de un año (1984), con un mesde antelación en cada predicción, contando siempre con los datos históricos hasta elmes que se considere actual.
Comparar los datos obtenidos de la predicción del año 1984 con los reales, calcularel error.
Estudiar si existe relación entre las dos series temporales estudiadas anteriormentemediante su recta de regresión lineal.
Estudiar la opción de crear un modelo con variables explicativas, en el que se tengaen cuenta la in�uencia de un factor externo en la serie temporal.

4 CAPÍTULO 1. INTRODUCCIÓN, OBJETIVOS Y COMPETENCIAS.
De�nir un nuevo modelo de Espacio de los Estados que incluya una nueva variableque represente esta in�uencia y como en el caso anterior, estimarla.
Realizar una estimación a partir del nuevo modelo con variable explicativa de losdatos pasados y compararlos con los reales para comprobar la calidad de la estima-ción.
Realizar la predicción del valor de los siguientes 12 meses (1984), mes a mes, ycompararlos con los valores reales. Calcular el error.
Comparar la calidad del modelo sin variables explicativas y el de con variables ex-plicativas, razonar e interpretar los resultados de ambos modelos.
Competencias adquiridas.
Desarrollo de nuevos conocimientos del campo estadístico.
Aumento de la capacidad de análisis y del razonamiento lógico para solucionarproblemas e interpretar resultados.
Aprendizaje del software de R, así como la utilización de sus herramientas de unaforma adecuada, sintetizando y evitando instrucciones o bucles innecesarios quepuedan ralentizar su funcionamiento.
Capacidad de transmitir de forma escrita la información y los resultados obtenidos,describiendo el proceso de una manera ordenada, clara y concisa.
Capacidad de detectar nuevas vías de mejora durante el desarrollo del proyecto.
Aprendizaje del programa LáTex, utilizado para la redacción de la memoria escritadel proyecto.
Detección de las limitaciones del modelo y su efecto sobre los resultados.

Capítulo 2
FUNDAMENTO TEÓRICO
2.1. Conocimientos previos
2.1.1. Series Temporales. De�nición y tipos
Una serie temporal es un conjunto de valores obtenidos mediante observaciones de unavariable a lo largo de intervalos regulares de tiempo (cada día, mes, año. . . ). Cada serietemporal se diferencia por el periodo de observación, por el fenómeno observado y porlas propiedades que la caracterizan. Dado que los sucesos ocurridos en el pasado puedenin�uir en gran medida en los hechos futuros, el tiempo es un parámetro vital en el análisisde las series temporales, de hecho, los datos históricos sirven como punto de partida paraestimar y predecir el comportamiento de un modelo.
Como primera clasi�cación, se de�ne como serie estable o estacionaria, a aquella queoscila alrededor de un valor constante y en la que no se observa ninguna tendencia cre-ciente o decreciente evidente con el tiempo. Por otro lado, una serie no estacionaria secaracteriza por no ser claramente estable, aumentando o disminuyendo su nivel con eltiempo. Dependiendo de su comportamiento, será de tendencia positiva si a largo plazolos valores aumentan o de tendencia negativa si éstos disminuyen. La mayoría de las se-ries de carácter económico o social no son estables con el tiempo, es decir, estacionariasy presentan tendencias más o menos marcadas. La tendencia en estos casos, se puedeaproximar mediante una ecuación lineal, aunque es normal que a medida que se avanceen los datos de la muestra la pendiente de la recta varíe por otros muchos factores que noson constantes con el tiempo. En este caso se diría que la tendencia no es constante, sinovariable en el tiempo. Esta propiedad se adecúa más a las series reales, donde es difícilencontrar una tendencia constante en periodos amplios de observación. En algunos casos,es posible observar una tendencia evolutiva o cambiante con el tiempo en la que inclusola pendiente pase de ser positiva a negativa o viceversa. También es frecuente encontrarseries que varían su tendencia siguiendo un ciclo.
Del mismo modo en que una serie queda de�nida en gran medida por ser estacionaria
5

6 CAPÍTULO 2. FUNDAMENTO TEÓRICO
o no estacionaria, hay otro comportamiento que permite conocer mejor el patrón de unaserie: la estacionalidad. Este fenómeno se aprecia cuando aparece una conducta que serepite a lo largo del tiempo, en periodos iguales o inferiores a un año y que se reproducende una forma reconocible en diferentes años. Debido a la estacionalidad, el valor mediode una variable es dependiente del mes considerado. La estacionalidad puede aparecertanto en series estacionarias, como en series con cierta tendencia y es muy frecuente en elámbito económico, social o climático.
Una serie temporal es un conjunto de valores ordenados en el tiempo. La teoría clásicapermite diferenciar tres componentes dentro de una serie que la caracterizan: tendencia,variaciones estacionales, variaciones residuales. De esta manera, una serie temporal sepodría descomponer como una combinación de estas componentes:
Yt = µt + δt + vt (2.1)
Donde:
Yt: representa el valor de la serie en el instante i (i = 1, 2, 3...N observaciones).
µt : Representa la tendencia.
δt: Representa la estacionalidad.
vt: Representa las variaciones residuales.
La tendencia y la estacionalidad ya han sido descritas previamente.
Las variaciones residuales o aleatorias son �uctuaciones que se producen de manera impre-decible y que no tienen un carácter periódico. Están causadas por fenómenos singulares yafectan a la variable estudiada de forma casual y no permanente. Podría decirse que estacomponente es producto de la incapacidad del modelo de representar a la perfección larealidad de la serie temporal escogida.
Cuando se quiere conocer el patrón de comportamiento que sigue una serie es de granayuda analizar cada una de las componentes teóricas por separado, de manera que sa-biendo la in�uencia que tiene cada una de ellas, se pueda justi�car la evolución de la seriecon el tiempo. Representar los datos de una serie mediante un grá�co puede ser de granayuda para entender el comportamiento de una serie.
Después de de�nir las componentes que pueden intervenir en una serie temporal, se va aesbozar el estudio de la tendencia mediante el método de ajuste analítico. Este método sebasa en realizar un ajuste por regresión de los valores de las observaciones, de manera quela evolución general de la serie quede representada en una función dependiente del tiem-po de forma sencilla. La función de ajuste se va a designar por Z(t). Se pueden realizarajustes a tendencias de muchos tipos:

2.1. CONOCIMIENTOS PREVIOS 7
Tendencia lineal: es una recta del tipo Z(t) = a+ bt que se ajusta correctamente alos datos, donde b representa la pendiente de la recta que describe la evolución de laserie. Un ajuste de este tipo indica básicamente si la muestra disminuye o aumentaa un ritmo constante a lo largo del tiempo. Mediante el coe�ciente de determinaciónlineal, R2, se cuanti�ca el carácter lineal de la serie con el tiempo, señalando lo bieno mal que se ajusta el conjunto de datos representados por puntos a una recta. Elcoe�ciente de determinación toma valores entre 0 y 1, siendo mejor el ajuste de larecta con respecto a los datos cuanto más cercano sea su valor a 1.
Tendencia logarítmica: es del tipo Z(t) = klog(a+ bt)+ c, una curva que resulta útilcuando los datos aumentan o disminuyen rápidamente para luego estabilizarse.
Tendencia polinómica: se representa por una ecuación del tipo Z(t) = a+ bt+ ct2+. . . ctn y se utiliza cuando los datos evolucionan según una ecuación polinómica.
Tendencia potencial: es una línea curva Z(t) = atb. Se utiliza cuando los datosaumentan a un ritmo concreto. Para utilizar este ajuste, la muestra debe carecer dedatos negativos o iguales a cero.
Tendencia exponencial: es una curva del tipo Z(t) = ea+bt , útil cuando los datosaumentan o disminuyen en intervalos cada vez mayores de tiempo.
Tendencia de media móvil: este tipo de tendencias atenúa las �uctuaciones para asíapreciar la tendencia de una manera más clara. Se basa en construir una línea detendencia mediante los promedios de los datos de la serie. Dependiendo del periodou orden, se tendrán en cuenta más o menos datos cercanos para determinar cadapunto.
Como última clasi�cación, se distingue entre series univariantes y multivariantes.
Series univariantes: se basa en el análisis de una sola serie temporal a través de suhistoria.
Series multivariantes: permiten estudiar la relación dinámica entre dos o más series.Al construir un modelo multivariante, se supone que hay una dependencia entre lospasados de las diferentes series. Esta relación puede darse de una manera unidirec-cional (es decir, que una serie A depende de B pero no al contrario) o de formabidireccional (es decir, que existe realimentación entre las dos series).
Los objetivos principales que se buscan al realizar el análisis de una serie temporal son:
Entender el funcionamiento de una serie y diferenciar cada una de las componentesteóricas anteriormente descritas que la caracterizan.

8 CAPÍTULO 2. FUNDAMENTO TEÓRICO
Adaptar la serie temporal a un modelo, estimando cada uno de sus parámetros apartir de datos históricos, para poder así plasmar su comportamiento a lo largo deltiempo y representar �elmente la realidad.
Mediante la utilización del modelo creado, predecir valores futuros de las variables.De este modo y suponiendo que las condiciones no varían signi�cativamente, se pue-de prever la evolución de la serie en un futuro cercano.
A continuación se va a describir el procedimiento teórico a seguir para llevar a cabo elanálisis de una serie temporal.
2.1.2. Ruido Blanco. De�nición, simulación y representación.
Se denomina proceso estocástico Xt, a una sucesión ordenada de variables aleatoriasXt, donde t es un parámetro que toma valores del conjunto S. Una serie temporal sepuede representar por un modelo matemático como el de proceso estocástico, pero con laparticularidad de que el parámetro t, que en este caso representa al tiempo, sea discretoy que los valores que tome de S estén ordenados y sean equidistantes en el tiempo.
El concepto de estacionareidad surge para poder estimar las propiedades transversales delproceso, supuestas constantes, mediante su evolución longitudinal. Se dice que un procesoestocástico es estacionario en sentido estricto si las características del proceso no sufrenalteraciones en tiempos históricamente diferentes, es decir, que sus variables están igual-mente distribuidas a lo largo del tiempo. Por tanto, si un proceso estocástico Xt es esta-cionario en sentido estricto, la distribución de probabilidad del conjunta (Xt1, Xt2, . . . Xtn)para t = 1, 2. . . n, será igual que la del conjunto (Xt1+m, Xt2+m, . . . Xtn+m), siendo m unnúmero entero. Como consecuencia, la media y la varianza serán iguales para todas lasvariables y la covarianza y el coe�ciente de correlación serán sólo dependientes del retar-do entre las variables. Imponer esta condición puede resultar demasiado extremista en lapráctica, porque para ello se necesita la distribución conjunta de todas las variables, poresta razón se suele imponer la de estacionareidad en sentido débil, más fácil de contrastar.Un proceso será estacionario en sentido débil si:
La media del proceso es constante
µt = µ = cte (2.2)
La varianza del proceso es constante
σt = σ = cte (2.3)
La covarianza entre dos valores es sólo función del espacio temporal considerado.

2.1. CONOCIMIENTOS PREVIOS 9
A la hora de comprobar si se cumplen estas hipótesis, si la serie a estudiar posee unatendencia apreciable, se podrá concluir que su media no es constante en el tiempo y quepor lo tanto, la serie no es estacionaria en sentido débil. En el caso de observar que laserie varía su amplitud con el tiempo, se podrá deducir que la varianza no es constanteen el tiempo y que por tanto, que la serie no es estacionaria de segundo orden.
Una vez esbozado el signi�cado de un proceso estocástico estacionario, se va a estudiar ysimular un caso particular.
Se denomina ruido blanco a un proceso estocástico con estacionareidad de�nido por lassiguientes propiedades:
E[Xt] = 0, para t = 1, 2, 3...n
V ar(Xt) = σ2, para t = 1, 2, 3...n
Cov(Xt, Xt−k) = 0, para k = ±1,±2, . . .
La primera condición decreta que la esperanza es siempre igual a cero, la segunda que lavarianza es constante y la tercera que las variables no guardan ninguna correlación paratodos los retardos. Es un proceso que no tiene memoria, es decir, que cada nuevo valores independiente de los anteriores. El ruido blanco no tiene por qué ser estacionario ensentido estricto, sino que es su�ciente con las condiciones que dicta la estacionareidad ensentido débil. Esto se debe a que lo imprescindible en el ruido blanco es que las variablesestén incorreladas, sin ser necesario que sean independientes. Si además se cumple la in-dependencia de variables, estaremos ante un ruido blanco denominado estricto.
Como durante el desarrollo de este proyecto se va a utilizar el ruido blanco en numerosasocasiones, se ha creado un primer programa para entender y observar su funcionamiento.
Un proceso de ruido blanco se puede simular mediante un código de programa muy sen-cillo, generando una serie de valores aleatorios que siguieran una distribución normal demedia cero y varianza constante, N(0, σ2). En el caso particular que se ha realizado, seha optado por una muestra de 500 valores aleatorios de media cero y varianza constantee igual a 1, (N(0, 1)). A continuación, se muestra la grá�ca que representa el valor delruido blanco frente al tiempo, t.

10 CAPÍTULO 2. FUNDAMENTO TEÓRICO
Figura 2.1: Simulación de un proceso de ruido blanco
El proceso de ruido blanco será utilizado a lo largo del proyecto para generar la com-ponente aleatoria en ciertos modelos estudiados.
2.1.3. Autocorrelación
Se denomina función de autocovarianzas a aquella que proporciona la covarianza co-rrespondiente entre dos valores de tiempo escogidos.
Cov(t1, t2) = Cov(t2, t1) = Cov(X1, X2) (2.4)
Se denomina función de autocorrelación a aquella que estandariza la función de covarian-zas, lo cual signi�ca que mide la relación que existe entre las distintas observaciones deuna serie temporal, en concreto entre el valor considerado y los anteriores. Mediante lafunción de autocorrelación, se puede calcular la in�uencia que tienen los valores pasadosde la muestra en el actual. Su representación grá�ca se realiza a través del correlogramamuestral, de gran importancia a la hora de analizar una serie temporal. Para realizar uncorrelograma muestral, se debe partir de una muestra su�cientemente grande como paradetectar relaciones entre las observaciones, considerándose un tamaño muestral adecuado

2.1. CONOCIMIENTOS PREVIOS 11
aquel que supere los 50 datos. Normalmente se estudia la in�uencia de un número deter-minado de datos anteriores, pues en el caso de series estacionarias, cuando la diferenciatemporal supera un valor, la autocorrelación va disminuyendo hasta ser prácticamentedespreciable. Para una muestra de T observaciones se debería calcular para valores dek < T/4. En la práctica, para un proceso estocástico estacionario, la media de la muestrase puede estimar de la siguiente manera:
X =T∑t=1
Xt
T(2.5)
La función de autocorrelación muestral se calcula como:
rk =
∑Tt=1 (Xt −X)(Xt−1 −X)∑T
t=1 (Xt −X)2(2.6)
Todo ello para valores de k = 1, 2, 3. . .
Cada uno de los valores de k, indican el coe�ciente de autocorrelación de orden k. Elcoe�ciente de correlación de orden cero, siempre tiene como valor 1, y corresponde a larelación de la variable con ella misma. A la hora de representar el correlograma muestral,se suelen incluir en el grá�co los intervalos superior e inferior de con�anza. En el casoparticular del ruido blanco, el corelograma tiene el siguiente aspecto:
Figura 2.2: Autocorrelación del proceso de ruido blanco simulado

12 CAPÍTULO 2. FUNDAMENTO TEÓRICO
Como se puede observar en el grá�co, todos los coe�cientes de autocorrelación, exceptoel de orden cero, se encuentran dentro de las dos líneas discontinuas que representan losintervalos de con�anza. En este caso, como para hallar la función de autocorrelación seha utilizado la función acf() ya de�nida en R, el valor del intervalo de con�anza es de un95% por defecto. Este porcentaje representa la probabilidad de encontrar cada uno de losvalores dentro del intervalo de�nido.
Como se ha comentado anteriormente, el coe�ciente de orden cero siempre es 1, debi-do a que representa la relación de la variable consigo misma. Como el ruido blanco es unproceso estocástico estacionario, cada una de las observaciones es independiente de lasanteriores y es por esto por lo que los siguientes coe�cientes de correlación se encuentranencuadrados entre los intervalos superior e inferior de con�anza.
2.2. Modelos matemáticos para la representación de se-ries temporales
A continuación, se van a de�nir una serie de modelos matemáticos que pueden repre-sentar el comportamiento de una serie temporal, empezando por los de menor di�cultadhasta llegar al modelo utilizado en este proyecto, el de espacio de los estados.
2.2.1. Paseo aleatorio
El paseo aleatorio es un proceso estocástico en el que el valor actual de una variableestá de�nido por su valor en el pasado, más un error simbolizado por el ruido blanco, wt.Algebraicamente, se puede escribir de la siguiente manera:
Xt = Xt−1 + wt (2.7)
Este modelo determina que la mejor predicción de la variable X para el instante t, es suvalor en el instante anterior, t − 1. El paseo aleatorio no permite predecir la variación(Xt−Xt−1), porque ésta es totalmente aleatoria. Normalmente, se impone una condicióninicial, X0, a partir de la cual se desarrolla la serie. Se puede demostrar que la media deun paseo aleatorio es constante e igual a X0, pero no su varianza, de valor tσ2
e , crecientecon el tiempo. Como consecuencia, al no cumplir la condición de varianza constante a lolargo del tiempo, este modelo se clasi�ca como no estacionario. En la siguiente grá�ca sepuede observar la simulación de un proceso de paseo aleatorio para una muestra de 100valores con un valor de X1 = −1.

2.2. MODELOSMATEMÁTICOS PARA LA REPRESENTACIÓN DE SERIES TEMPORALES13
Figura 2.3: Simulación de un proceso de paseo aleatorio.
2.2.2. Local level model
Como se ha descrito al comienzo de este apartado, una serie temporal se puede de�nircomo la suma de una componente tendencia, una estacional y una aleatoria:
Yt = µt + δt + vt (2.8)
Para desarrollar un modelo adecuado para la tendencia, µt, y para la estacionalidad, δt,necesitamos el concepto de paseo aleatorio, que determina la relación Xt+1 = Xt + wt,donde los valores de wt son independientes entre sí y siguen una distribución normalN(0, σ2). Considerando una simpli�cación del modelo de la ecuación (3.8), que carezca deestacionalidad (δt = 0), cuyas variables aleatorias estén distribuidas normalmente, con vtdistribuida mediante una normal N(0, σ2) y con µt = Xt de�nida como un paseo aleatorio,se llega al siguiente modelo:
Xt+1 = Xt + wt wt ⇒ N(0, σ2w) para t = 1, 2...n. (2.9)
Yt = Xt + vt vt ⇒ N(0, σ2v) para t = 1, 2...n. (2.10)
Este modelo se conoce como local level model y aunque parezca simple, es una de lasbases más importantes para el análisis de series temporales reales. La primera ecuación es

14 CAPÍTULO 2. FUNDAMENTO TEÓRICO
conocida como ecuación de estado y la segunda es la ecuación de observación. Observandolas distribuciones de las componentes wt y vt, es lógico pensar que éstas se pueden re-presentar mediante un proceso de ruido blanco. Como se ha visto anteriormente, el paseoaleatorio es un proceso no estacionario. Como consecuencia, al estar X de�nida medianteun paseo aleatorio, las distribuciones de Xt y de Yt son no estacionarias y variarán con eltiempo. Realizando una simulación con R para una muestra de tamaño 100, se representaen la siguiente grá�ca el resultado, donde aparece el valor de los estados, Xt, y el de lasobservaciones, Yt.
Figura 2.4: Simulación de un proceso de local level model.Rojo:Estados, Azul: Observaciones
2.2.3. Espacio de los estados
Después de hacer una pequeña introducción y simulación de modelos estructurales deseries temporales más sencillos, se va a explicar el modelo de Espacio de los Estados,más completo que los anteriores y la base del desarrollo de este proyecto. Para de�nireste modelo, se va a partir de una ecuación que represente los datos observados, Yt, de lasiguiente manera:
Yt = cXt + vt (2.11)
Donde Yt es el valor de la observación en el instante t, c es una constante que suponemosconocida, Xt es la variable de estado no observable en t y vt es una componente de ruido

2.2. MODELOSMATEMÁTICOS PARA LA REPRESENTACIÓN DE SERIES TEMPORALES15
blanco de distribución normal N(0, σ2v). Todo ello para valores de t = 1, 2. . . n. Por otra
parte, la evolución dinámica de las variables de estado viene determinada por la siguienteecuación, denominada de estado:
Xt+1 = aXt + wt (2.12)
Donde a es una constante supuestamente conocida y wt otra componente de ruido blancode normal N(0, σ2
w). A partir de ahora y por mayor comodidad a la hora de programar,se va a renombrar σ2
v como R y del mismo modo, se renombra σ2w como Q.
En el caso que se estudia a lo largo de este trabajo, las componentes de las ecuacio-nes anteriormente de�nidas serán escalares, aunque hablando genéricamente, también esposible encontrarlas como expresiones vectoriales y matriciales.
Interpretando las dos ecuaciones que de�nen este modelo, se deduce que el valor de lavariable observada en el instante t, Yt , depende del valor de la variable de estado, lacual es no observable,Xt, en ese mismo instante. Esta relación viene determinada por elvalor de la constante c, que es conocida. El término representado por vt, simboliza el errorvinculado a cada observación. Por otra parte, la ecuación de observación muestra que elvalor de la variable de estado en t, depende de su valor en t− 1 más un error de mediciónrepresentado por la componente wt.
Se puede apreciar que el modelo de Local level model no es más que un caso particu-lar del de Espacio de los Estados para a = 1 y c = 1.
La simulación en R que se ha realizado con espacio de los estados aparecerá, combinadacon nuevos conceptos, cuando se hayan descrito más adelante.
2.2.4. Modelos autorregresivos, AR(p). Modelo autorregresivo deprimer orden AR(1).
El modelo de proceso autorregresivo, pone de mani�esto la relación de dependenciaexistente entre una serie temporal y sus valores en el pasado. Se trata de un modelo sen-cillo que utiliza la regresión para expresar la relación entre variables de un proceso. Paracomenzar, el modelo de regresión simple puede de�nir de la siguiente manera:
Zt = KXt + pt (2.13)
Donde K es una constante y a es una variable que sigue una distribución normal de mediacero y varianza constante, N(0, σ2). Si se renombran las componentes Zt como Yt y Xt
como Yt−1, dándoles el valor de dos observaciones consecutivas de una serie temporal, sellega al modelo conocido como autorregresivo de primer orden, AR(1). La interpretación

16 CAPÍTULO 2. FUNDAMENTO TEÓRICO
de este modelo es que el nuevo valor de la variable de observación de una serie temporaldepende sólo de su valor en el instante anterior. Observando la ecuación anterior, se de-duce que además esta dependencia será lineal. Este modelo se puede extender a valoresmás lejanos en el tiempo, poniendo de mani�esto la dependencia de la variable actual conrespecto a valores con retardos mucho mayores. Hablando genéricamente, si se conside-ran los p retardos anteriores se trataría de un modelo autorregresivo de orden p, AR(p),adquiriendo la forma siguiente:
Yt = KYt−s +KYt−2s + ...+KYt−ps + pt (2.14)
Siendo s el número de periodos que distan entre el instante actual y cada instante pasadoque se considere. Por tanto, un modelo autorregresivo AR, describe un proceso donde lasobservaciones de un momento dado se pueden predecir a través de sus valores en periodosprevios más una componente que representa el error, pt. Como en este proyecto se va autilizar el modelo autorregresivo de primer orden, AR(1), se va a profundizar más estecaso particular.
Un modelo autorregresivo de primer orden mide la evolución de una variable a travésde la siguiente ecuación:
Yt = KYt−1 + pt (2.15)
Donde como se ha dicho, K es una constante de valor |K| < 1 y at es un proceso deruido blanco de distribución N(0, σ2). La variable que viene representada por at se de-nomina innovación y simboliza la información que se agrega al proceso en cada nuevoinstante de tiempo. El hecho de que los valores de K tengan que cumplir que |K| < 1se debe a que si no fuera así el proceso sería no estacionario (se recuerda que para queun proceso sea estacionario, tanto su media como su varianza deben ser constantes y lacovarianza entre dos de sus valores sólo función del espacio temporal considerado). Por lotanto, si se desarrolla el proceso la observación en el instante t tendrá el siguiente aspecto:
Yt =t−1∑i=0
Kipt−i +KtY0 (2.16)
Siendo Y0 la condición inicial de la serie. Si se toman esperanzas a ambos lados de laecuación, teniendo en cuenta que E[pt] = 0, se llega a la siguiente expresión:
E[Yt] = KtY0 (2.17)
Para que la media del proceso sea constante, la función anterior no puede depender de t.Si |K| < 1, el término de la derecha de la ecuación converge a cero. Respecto a la varianza

2.3. FILTRO DE KALMAN 17
de un proceso AR(1), viene representada por la siguiente ecuación:
σ2y =
σ2p
1−K2(2.18)
Donde σ2p representa a la varianza del ruido blanco pt, que es constante. Para que la
varianza del proceso sea una constante, �nita y positiva, de nuevo el valor |K| < 1.
Llegado a este punto, es interesante realizar una pequeña observación. Si en el caso ante-rior |K| = 1, el proceso sería no estacionario y el modelo un paseo aleatorio.
Yt = Yt−1 + pt (2.19)
Si |K| > 1, se dice que la serie tiene un comportamiento explosivo, con la particularidadde que las innovaciones lejanas tienen más importancia en el instante actual que las máspróximas. Este tipo de comportamiento, no suele ser muy normal en procesos con datosreales.
Como en los casos de los modelos anteriores, para que éstos puedan representar �el-mente el comportamiento de una serie temporal, se deben estimar los parámetros quelos de�nen. Esto no es siempre una tarea sencilla y en algunos casos se debe recurrir ainstrumentos o algoritmos que faciliten el proceso. En el caso particular de los modelosautorregresivos de primer orden, existe una función de la biblioteca de R que permiteestimar los valores de K y de σp
2, la función ar(). En el caso del modelo de espacio de losestados, los parámetros pueden ser estimados mediante la utlización del Filtro de Kalmancombinado con el método de Máxima Verosimilitud. A continuación se van a explicar elfuncionamiento y la aplicación de estos nuevos conceptos.
2.3. Filtro de Kalman
El �ltro de Kalman es un algoritmo de predicción recursiva. Esto quiere decir quecada vez que cuente con un nuevo dato, debido al avance discreto del tiempo, el siste-ma parte desde el anterior sin necesidad de reprocesar de nuevo toda la información previa.
El punto de partida para poder realizar y de�nir el Filtro de Kalman es el modelo deespacio de los estados:
Yt = cXt + vt (2.20)
Xt+1 = aXt + wt (2.21)
La aplicación del �ltro de Kalman es útil porque permite:

18 CAPÍTULO 2. FUNDAMENTO TEÓRICO
Estimar el valor del estado futuro a partir del actual, que también debe estimarseporque no es directamente observable.
Predecir a partir del estado estimado el próximo valor de la observación.
Con el nuevo valor real de la observación, revisar y modi�car si fuera necesario laestimación del estado para repetir estas pautas en un nuevo instante.
Para conseguir esto, hace uso de:
La información que posee acerca del sistema y del instrumental de medida, quedeterminará en gran proporción los valores del ruido, tanto en la medición de laobservación como en la del estado.
Los valores históricos de cada una de las variables.
Las condiciones iniciales.
En primer lugar, se estima el próximo valor de la variable estado partiendo de la es-timación del valor actual. Suponiendo que se tienen los valores de las observacionesYt−1 = {Y1, Y2, ...Yt−1} y de la estimación de la variable de estado Xt−1, se quiere es-timar el próximo valor de estado Xt|t−1, partiendo del estimado y del conjunto de lasobservaciones Yt−1. Esto se halla partiendo de la ecuación (3.21) tomando esperanzas con-dicionadas a Yt−1 a ambos lados de la igualdad dando lugar a:
E[Xt|Yt−1] = Xt|t−1 = aXt−1 (2.22)
Durante todo este desarrollo, se va a simpli�car la notación cambiando la expresión Zm|mpor Zm para cualquier Z y m.
El error de la estimación será el valor real de la variable estado menos el estimado:
Xt − Xt|t−1 = a(Xt−1 − Xt−1) + wt (2.23)
La varianza del error de la estimación a priori va a ser denominada como Pt|t−1:
Pt|t−1 = var(Xt|Yt−1) = a2Pt−1 +Q (2.24)
Esto quiere decir que la incertidumbre de la estimación de la variable de estado en t par-tiendo de la información recopilada hasta t − 1, es la suma de las incertidumbres de laecuación de estado, es decir, del valor del estado anterior y del ruido Q. La constante aaparece por la relación entre los valores de las variables en t y en t− 1. En segundo lugar,se realiza la predicción del valor de la nueva observación Y , a partir de los datos hasta

2.3. FILTRO DE KALMAN 19
t− 1. Esto se consigue tomando esperanzas en la ecuación (3.20) condicionadas a Yt−1:
Yt|t−1 = cXt|t−1 (2.25)
Por tanto, se puede hallar el error de la estimación como la diferencia entre el valor realde la observación y el estimado, denominando a este error innovación:
et = Yt − Yt|t−1 = Yt − cXt|t−1 (2.26)
Cuya varianza se de�ne como:
St|t−1 = var(et) = c2Pt|t−1 +R (2.27)
Observando esta ecuación, se puede comprobar que la incertidumbre de la predicción esla suma de la del estado y la del error de medida en las observaciones.
En tercer y último lugar, se compara la información del valor del estado obtenido a travésde la estimación con el de los nuevos datos reales. Ahora se posee información hasta elinstante t y por tanto se tendrá una nueva observación, Yt = {Y1, Y2, . . . Yt−1, Yt}. Coneste nuevo valor, se realizará la estimación del estado en el instante siguiente, Xt medianteregresión.
X t = aXt|t−1 +acSt|t−1
Pt|t−1(Yt − Yt|t−1) (2.28)
Se de�ne como ganancia de Kalman, Kt a la siguiente componente, que representa a larealimentación del error:
Kt =acPt|t−1
St|t−1(2.29)
Si se analiza la ecuación (3.28), se puede veri�car que la calidad de la estimación va adepender del error en la predicción de la observación. Si éste fuera nulo, se continúa conla misma estimación; en el caso de que no lo fuera, se modi�can los valores de las compo-nentes de la siguiente manera:
et = Yt − Yt|t−1 (2.30)
Xt+1|t = aXt|t−1 +Ktet (2.31)
St = c2Pt|t−1 +R (2.32)
Pt+1|t = a2Pt|t−1 +Q−K2t St (2.33)

20 CAPÍTULO 2. FUNDAMENTO TEÓRICO
Con los valores modi�cados, se puede calcular la predicción para t+1. Para la aplicacióndel �ltro de Kalman con espacio de los estados, es necesario proporcionar unas condicionesiniciales a partir de las cuales se va a desarrollar todo el modelo: X1|0 y P1|0. Tambiénes necesario facilitar el valor de las constantes a y c, los valores históricos de las obser-vaciones y los valores constantes de las varianzas del ruido blanco de la observación, R ydel estado, Q. Todos estos parámetros, vienen de�nidos por la actuación del sistema, demanera que cuando se estudie una serie temporal concreta, se deberán estimar sus valorespara que representen de forma �el el comportamiento del sistema.
Más adelante en las series estudiadas durante este proyecto, se procederá a la estima-ción de todos los parámetros que de�nen cada sistema. No obstante, para una primerasimulación realizada con R del �ltro de Kalman con espacio de los estados, se escogenunos parámetros cualesquiera, (X1|0, Q = 1, R = 1, a = 0,5, c = 2, P1|0) obteniéndose lasiguiente grá�ca:
Figura 2.5: Simulación �ltro de Kalman con espacio de los estados.Naranja: Real, Azul: Estimada
Como se puede observar, el valor de la observación real y la estimada siguen unaprogresión similar, aunque la amplitud de los valores de la observación real es claramentemayor y se observa un retardo por parte de la observación estimada. Esto puede deberse adiversos factores, pero el más in�uyente es sin duda debido al valor de los parámetros que

2.4. MÁXIMAVEROSIMILITUD. ESTIMACIÓN DE LOS PARÁMETROS DELMODELO.21
rigen el modelo, que como se ha comentado anteriormente, han sido escogidos sin ningúntipo de criterio. Por esta razón, se va a estudiar a continuación el procedimiento a seguirpara la estimación de los parámetros de un modelo de series temporales.
2.4. Máxima verosimilitud. Estimación de los paráme-tros del modelo.
El método de máxima verosimilitud sirve para estimar los parámetros que de�nen elmodelo de espacio de los estados. Para su utilización, se debe escoger un valor inicial paracada parámetro a partir del cual se va a empezará la estimación. Con el �n de facilitar eldesarrollo que viene a continuación, se van a agrupar todos los parámetros iniciales parala estimación en un vector, α = {X0, a, c, Q,R, P0}. El método de máxima verosimilitudse lleva a cabo bajo las siguientes hipótesis:
El estado inicial, X0 sigue una distribución normal.
Los errores wt y vt siguen una distribución normal y no están correlacionados.
La verosimilitud se calcula a través de las innovaciones, et, las cuales son valores aleatoriosGaussianos con media cero, cuya varianza es como se ha visto anteriormente:
St|t−1 = var(et) = c2Pt|t−1 +R (2.34)
Obviando la constante de integración, podemos llegar a la siguiente expresión de la vero-similitud:
−lnLY (α) =1
2
n∑t=1
log|St(α)|+1
2
n∑t=1
e2t (α)
St(α)(2.35)
Es importante resaltar la dependencia de las innovaciones con respecto a los parámetros,α. Como se puede observar, esta expresión no es lineal, y es una función complicada deparámetros desconocidos. El procedimiento habitual consiste en �jar primero X0 y luegodesarrollar un conjunto de recursiones para la función de verosimilitud y sus dos primerasderivadas. A continuación, se van actualizando los valores de los parámetros para quepartiendo de los iniciales que se han propuesto para la estimación, se llegue a los quehagan mínimo el opuesto de la función de verosimilitud.
Los pasos a seguir para realizar la estimación son los siguientes:
1. Elegir los valores iniciales de los parámetros, α0 = X0, a, c, Q,R, P0
2. Iniciar el �ltro de Kalman usando los valores iniciales de los parámetros que sehan elegido, α0 y obtener las nuevas innovaciones, e0t y varianzas del error, S0
t parat = 1, 2. . . n.

22 CAPÍTULO 2. FUNDAMENTO TEÓRICO
3. Realizar una iteración para encontrar el mínimo de −lnLY (α) para obtener un nuevoconjunto de estimaciones, α1.
4. En la iteración k, (k = 1, 2. . . ) se repite el segundo paso pero utilizando αk en lugarde αk−1 para obtener un nuevo conjunto de innovaciones ekt y S
kt para t = 1, 2. . . n. A
continuación, se repite el paso 3 para obtener la nueva estimación, αk+1. El procesode estimación terminará cuando el valor de la función de verosimilitud o el de lasestimaciones de los parámetros se estabilicen.
Aunque resolver este proceso puede resultar una tarea larga y repetitiva, resulta sencillomediante su programación en R gracias a funciones como optim(), que se encarga debuscar el mínimo de −lnLY (α) en cada iteración. En la programación que se ha realizadoen R, se conocerá al término −lnLY (α) como Linn.
2.5. Predicción de los valores del modelo
Como se ha mencionado al principio de la memoria, el principal objetivo de este tra-bajo es obtener una predicción. Toda la base teórica vista hasta ahora va a servir pararepresentar una serie temporal a partir de un modelo de espacio de los estados correcta-mente parametrizado. Si el modelo se desarrolla de la manera adecuada, éste tiene queser capaz de representar el comportamiento de la serie, tanto en el pasado mediante unaestimación, como en el futuro mediante una predicción.
La herramienta utilizada para realizar la predicción es el �ltro de Kalman. Partien-do de los datos de la variable de observación hasta el instante que se considere actualYt = {Y1, Y2, . . . Yt} y de los parámetros estimados, se ejecuta el �ltro de Kalman paraobtener el valor predicho del siguiente estado, a través de la ecuación que se ha de�nidoanteriormente:
Xt+1|t = aeXt|t−1 +Ktet (2.36)
Este valor, Xt+1|t, servirá como condición inicial de la variable de estado para ejecutar unsegundo �ltro de Kalman. Lo mismo pasa con la varianza del error de la estimación.
Pt+1|t = a2ePt|t−1 +Qe −K2t St (2.37)
Donde Pt+1|t servirá como condición inicial. Los valores de ae, ce, Qe, y Re serán los delos parámetros estimados por Máxima Verosimilitud. Entonces, partiendo de los valoresXt+1|t, Pt+1|t, ae, ce, Qe, Re, se ejecuta un nuevo �ltro de Kalman con la particularidad deque, como no se puede hallar el nuevo error por no disponer del valor real de la observación,se supone que es nulo, et = 0, dando lugar al siguiente modelo:

2.6. CRITERIOS DE VALIDACIÓN DEL MODELO 23
St = c2ePt|t−1 +Re (2.38)
Kt =aecePt|t−1
St|t−1(2.39)
Yt|t−1 = ceXt|t−1 (2.40)
Xt+1|t = aeXt|t−1 (2.41)
Pt+1|t = a2Pt|t−1 +Qe −K2t St (2.42)
Este particular Filtro de Kalman se ejecutará tantas veces como meses futuros se quierapredecir.
2.6. Criterios de validación del modelo
2.6.1. Criterio de Akaike (AIC)
En el momento de escoger entre los diferentes modelos estimados para representaruna serie temporal, conviene utilizar una metodología que muestre de manera inequívocael grado de ajuste del modelo a la serie, es decir, con qué exactitud representa su com-portamiento. El criterio Akaike, se basa en buscar el modelo que produzca una mayorverosimilitud esperada. El valor estimado de la verosimilitud de cada modelo correspon-derá con la iteración que dé con su valor máximo y por lo tanto, con el valor estimado desus parámetros. La función AIC, es directamente proporcional al opuesto de la funciónde verosimilitud, por lo tanto, el modelo que produzca un menor valor de AIC será másadecuado para representar a la serie temporal.
La función AIC (Akaike Information Criteria) tiene la siguiente forma:
AIC(n) =1
n[−2log(Like) + 2K] (2.43)
Donde n es la dimensión de la muestra, Like es la función de verosimilitud y k es elnúmero de parámetros a estimar. En este proyecto, la función AIC no se va a utilizarentre modelos diferentes para encontrar el mejor, sino para encontrar dentro de un mismomodelo los valores iniciales de los parámetros para el proceso de parametrización queden lugar a la mejor representación de la serie. De esta manera, se propusieron variosconjuntos de valores iniciales para la parametrización y se seleccionó los que dieron lugaral mayor valor de AIC.

24 CAPÍTULO 2. FUNDAMENTO TEÓRICO
2.6.2. Error porcentual absoluto medio (MAPE)
A la hora de comprobar la calidad de un modelo durante este proyecto, se va a escogercomo indicador de su precisión el error MAPE, que se de�ne de la siguiente manera:
MAPE =1
n
n∑t=1
|yrealt − yt||yrealt|
(2.44)
Donde yreal, como indica su nombre, es el valor real de la observación e y es el valorestimado si es para un instante pasado o predicho si lo es para uno futuro a lo largo deltiempo, t.

Capítulo 3
ESTUDIO DE LA VARIACIÓN DELPRECIO DEL PETRÓLEO.
El petróleo consiste en una mezcla líquida de hidrocarburos que se forman a partirde organismos vegetales y animales acumulados bajo capas de sedimentos. A causa de sudescomposición, la presión que ejercen las capas de sedimentos y las altas temperaturas, seproduce una combinación de moléculas de hidrógeno y carbono que dan lugar a la mezclade hidrocarburos diferentes que conforman el petróleo. Es un proceso extremadamentelento, necesitándose millones de años y unas condiciones especí�cas para su formación. Espor esto por lo que el petróleo es una fuente de energía no renovable, es decir, que poseeunas reservas limitadas que se van agotando por una creciente necesidad. Esta es la razónprincipal que le convierte en un bien tan valorado.
Desde hace más de un siglo, el petróleo se ha convertido en la fuente de energía másimportante del mundo, siendo indispensable en los países industrializados. Su precio vie-ne de�nido por el precio de referencia del mercado, que es de carácter global y el porcentajede impuestos que aplique cada país. Es un producto muy vulnerable a variaciones en suprecio por múltiples factores y por esta razón, conviene tener en cuenta el marco históricomundial del periodo que se va a estudiar.
3.1. Factores in�uyentes en el precio del petróleo.
3.1.1. Marco histórico.
Desde el año 1945 y hasta la crisis de 1973, las necesidades mundiales de petróleose habían ido duplicando cada 10 años. Las principales zonas con fuentes de abasteci-miento, se encontraban en países subdesarrollados. Para hacer llegar el petróleo hasta lospuntos donde se consumía, las naciones occidentales se encargaban a través de diferen-tes compañías de explotar los yacimientos, el transporte y su comercialización, pagando
25

26 CAPÍTULO 3. ESTUDIO DE LA VARIACIÓN DEL PRECIO DEL PETRÓLEO.
a los países productores un porcentaje de los bene�cios obtenidos en concepto de derechos.
Los precios se acordaban entre americanos y europeos occidentales en centros de decisión,asegurándose un abastecimiento energético abundante y de bajo precio. Este mecanismofuncionó durante casi toda la historia económica del petróleo, pero a partir de 1960, lospaíses productores de petróleo comenzaron a sublevarse frente a la reducción desorbitadade los precios. Así, se fundó en 1960 la Organización de Países Exportadores de Petróleo(OPEP), que tenía como integrantes a Venezuela, Irán, Irak, Arabia Saudita, Kuwait yQatar.
A partir de este momento, se irían adhiriendo nuevos países a la OPEP, elevándose sunúmero de miembros. Su principal objetivo era exigir unas mejores condiciones y formarparte de las decisiones tomadas. En el año 1973, la OPEP decide alzar los precios un11.9%, lo que provoca la llamada Crisis Energética, acabando con el aumento lineal delos precios que se había ido desarrollando desde el �nal de la II Guerra Mundial. Esteacontecimiento, vino acompañado de la Guerra del Yom Kippur, en Oriente Medio, endonde se encontraban por aquel momento dos terceras partes de las reservas de petróleo.Este fue el punto de in�exión que provocó la utilización del petróleo como arma. Los pue-blos árabes, conscientes de la presión política que podían ejercer por poseer esta codiciadafuente de energía, formaron la Organización de Países Árabes Exportadores de Petróleo(OPAEP). La OPAEP, amenazaba con retirar el suministro de petróleo a los países quese posicionaran del bando de Israel en la guerra, obligando a países como Estados Unidosy Países Bajos a presionar a Israel para devolver los territorios ocupados en 1967 y 1973.Esto produjo un aumento generalizado del precio del barril, pasando de 3 a 5 $. Se habíallegado al �n de la era barata de la energía.
Al cabo de los meses, se acordó cesar el embargo a Estados Unidos debido a la evolu-ción favorable del con�icto de Oriente Medio.
En diciembre de 1974, la OPEP acordó subir el precio del barril de crudo a 10.46$. A estenuevo valor del barril en crudo, le siguieron un goteo de subidas durante los siguientesaños. Estos aumentos de precio fueron absorbidos por la economía mundial sin grandesproblemas hasta el año 1979, donde comenzó el segundo choque del valor económico delpetróleo. Este nuevo acontecimiento vino marcado por la caída del gobernador Reza Pal-hevi en Irán, el que por entonces era el segundo país en la exportación de crudos. Con ladestitución del soberano persa por el imán Jomeini, los principales exportadores no lle-garon a un acuerdo y por la inestabilidad del régimen iraní, los precios llegaron a valoresde 25.75$ por barril, duplicando virtualmente la cotización del petróleo en tan sólo un año.
En 1980, al comenzar la Guerra del Golfo por la invasión de Irak a Irán, el precio delbarril subió de nuevo y a �nales de este año tras un acuerdo entre los miembros de laOPEP se llegó a la máxima cotización del petróleo.

3.1. FACTORES INFLUYENTES EN EL PRECIO DEL PETRÓLEO. 27
Las grandes crisis del petróleo 1973-74, 1979-80, fueron asumidas por los países con-sumidores con políticas de reducción del consumo. Tan grande fue esta reducción que sellegó a producir un exceso de la oferta frente a la demanda, obligando a los productoresa reducir la extracción para reducir así la oferta y poder mantener sus precios. Durante1982 la OPEP decidió �jar un techo máximo de producción global para poder congelarlos precios, manteniéndose de este modo un precio de 29$ por barril entre esta 1982 y1985. A partir de 1986, el valor del petróleo volvió a sufrir una crisis, pero en esta oca-sión se produjo un descenso en el precio, causado por el exceso de oferta, llegando a unprecio por barril de crudo de 14.38$. Este cambio se debió principalmente a que los paísesindustrializados más importantes comenzaron a apostar por fuentes de energía alternas.
A continuación se muestra una �gura con la media anual del valor del precio del ba-rril de crudo desde un año antes hasta un año después del intervalo de estudio. En ellase puede comprobar cómo efectivamente, las dos grandes crisis del petróleo tuvieron unaimportante repercusión, siendo los dos puntos que corresponden a estas fechas los quecorresponden a las subidas más pronunciadas de su valor para el periodo que abarca esteestudio.
Figura 3.1: Evolución del precio del barril en crudo

28 CAPÍTULO 3. ESTUDIO DE LA VARIACIÓN DEL PRECIO DEL PETRÓLEO.
3.1.2. Otros factores
Hay que mencionar que el factor político es meramente importante en la variacióndel valor del petróleo, pero no es el único. Otro factor muy in�uyente es la interacciónoferta-demanda.
En el caso de las guerras, la demanda es la causante de las grandes variaciones en elvalor del petróleo. Ante una situación de incertidumbre, los países que importan petró-leo, aumentan su demanda para ampliar sus reservas. La oferta, se mantiene estable porlas di�cultades que conlleva ofertar más petróleo durante una guerra. Por lo tanto unasituación como ésta aumenta, que aumenta la demanda y mantiene la oferta, provocainevitablemente una subida en los precios.
Otros factores que pueden in�uenciar en la demanda y por lo tanto el valor del petróleoson el desarrollo económico, el aumento de población o el desarrollo de nuevas fuentesde energía. Las variaciones de la oferta tienen la misma repercusión, y normalmente serealizan bajo rigurosos estudios que buscan aumentar los bene�cios.
La interacción oferta-demanda se podría clasi�car como un proceso cíclico. Cuando subeel precio del petróleo, ante un aumento en sus ingresos, las petroleras realizan inversionespara encontrar nuevos yacimientos que permitan incrementar su oferta. A su vez, se pro-duce un exceso en la cantidad de petróleo ofertada y una bajada en los precios. A causade no disponer de fondos su�cientes para invertir, las petroleras se ven obligadas de nuevoa aumentar sus precios, volviendo al punto anterior.
Como se ha comentado anteriormente, el precio en cada región del petróleo viene engran medida determinado por el precio de referencia del mercado del barril en crudo. Poresta razón los factores que tuvieron repercusión en el mercado global, también afectaronal precio del petróleo en Reino Unido. A continuación, se va a mostrar una grá�ca querepresenta el valor del precio del petróleo en Reino Unido entre los años 1969 y 1985. Si semantienen al margen las pequeñas dispersiones causadas por la variación del precio de lastasas, se puede ver claramente cómo de nuevo, las dos crisis del petróleo de 1973 y 1979,tuvieron repercusión en los valores mostrados. También se puede observar cómo existe unretardo del orden de meses entre la fecha exacta del acontecimiento detonante de ambascrisis y la variación brusca de los precios en Reino Unido.

3.2. DESARROLLO DEL MODELO 29
Figura 3.2: Evolución del precio del petróleo en Reino Unido
3.2. Desarrollo del modelo
Después de conocer los diferentes factores que durante los años de estudio han in�uidoen la variación del valor del petróleo, se va a desarrollar el modelo en R que permitaestimar su comportamiento y predecir sus valores futuros. El capítulo de FundamentoTeórico contiene las explicaciones necesarias para comprender el desarrollo del modelo.
El punto de partida son las 180 observaciones del precio del petróleo correspondientesa los meses desde 1969 hasta 1983. Si se halla la función de autocorrelación de esta serieen particular, se puede observar que cada observación viene in�uenciada por los valoresde las observaciones anteriores, de tal manera que cuanto mayor sea el intervalo de tiempoentre la observación actual y las anteriores, menor será esta in�uencia.
A continuación se muestra la grá�ca de la autocorrelación de la muestra mediante eluso de R a través de la función acf(), la cual viene de�nida en su biblioteca. Se puede con-siderar que el valor actual viene in�uenciado por alguno de los retrasos anteriores cuandosu valor sobresale las líneas discontinuas que representan el intervalo de con�anza, de un95% por defecto.

30 CAPÍTULO 3. ESTUDIO DE LA VARIACIÓN DEL PRECIO DEL PETRÓLEO.
Figura 3.3: Correlograma del precio del petróleo
Mirando la grá�ca se deduce que el valor de cada observación de la muestra vienein�uenciado por sus 19 valores anteriores, así que cada uno de los datos de una serieproporciona, en principio, la información su�ciente para hallar los valores futuros. Poreste motivo se va a estimar todo este modelo partiendo sólo de los datos históricos de lamuestra.
El modelo escogido para representar el comportamiento de la serie es el de espacio delos estados:
Yt = cXt + vt (3.1)
Xt+1 = aXt + wt (3.2)
Donde:
Yt es la variable observación.
Xt es la variable estado.
a y c son dos constantes cuyos valores son iguales para todo t.
vt es el ruido blanco de la observación, que sigue una distribución N(0, R).
wt es el ruido blanco del estado del sistema, que sigue una distribución N(0, Q).

3.2. DESARROLLO DEL MODELO 31
Para caracterizar este modelo, se deben estimar los parámetros a, c, Q y R.
El primer paso, fue de�nir la función Linn(), que depende de los parámetros a, c,Q,R,X1, P1
y devuelve el valor opuesto de la verosimilitud mediante una llamada a la función queejecuta el �ltro de Kalman, llamada FiltroKalman(). A través de la función optim() ypartiendo de un valor inicial en cada parámetro, a0, c0, Q0, R0, X0
1 , P01 , se minimiza la
función Linn(), encontrando el punto de�nido por los parámetros cuyos valores corres-ponden a la máxima verosimilitud.
Una vez se conoce el valor de los parámetros que se van a utilizar para de�nir el modelo, sepuede estimar su comportamiento en el pasado partiendo del modelo parametrizado y delos valores iniciales estimados X1 y P1. Los resultados de la estimación, serán comparadoscon los datos reales históricos para medir la calidad del modelo.
Para predecir los valores futuros de la serie, se programa la función pred(). Esta nue-va función parte del modelo de espacio de los estados ya parametrizado y de los datoshistóricos hasta el instante que se considera actual, t. En este caso, se va a considerarque el instante actual es diciembre de 1983. De esta manera, todos los datos desde enerode 1969 hasta la fecha actual serán los históricos en los que se base el modelo. Los datoscorrespondientes al año 1984 se considerarán datos futuros para poder comparar así lacalidad de la predicción con los datos reales. Mediante una llamada al �ltro de Kalmande�nida dentro del código de pred(), se puede averiguar el valor para el instante siguiente,t + 1. Este �ltro de Kalman tiene una pequeña variación con respecto al utilizado enla estimación, basada en la suposición de que el error de la observación es nulo por nodisponer de datos su�cientes para hallarlo. La función pred() se ejecutará tantas vecescomo meses en el horizonte se quieran predecir, y vendrá determinado por el valor que sele asigne a la constante nahead.
Una vez hallados los valores estimados correspondientes al pasado y los predichos corres-pondientes a instantes futuros, se comparan grá�camente, en color azul, con los valoresreales, en rojo. Para ello se crea un vector que contenga en sus 184 primeras posiciones losvalores hallados por la estimación y en las últimas posiciones los valores de la predicciónde los nahead meses siguientes y se representan grá�camente los valores de sus compo-nentes frente al tiempo, medido en meses. En esta misma grá�ca se representa también,en verde, los intervalos de con�anza hallados a partir de la estimación y de la predicción,colocados por orden en un nuevo vector de�nido. En la primera vez que se ejecutó elprograma, sólo se calculó la predicción de un mes, es decir, nahead tenía un valor de 1.

32 CAPÍTULO 3. ESTUDIO DE LA VARIACIÓN DEL PRECIO DEL PETRÓLEO.
Figura 3.4: Resultados de la estimación y predicción de un mes.Rojo: Real, Azul: Estimación/Predicción, Verde: Intervalo de con�anza
También se calcula y se representa grá�camente la autocorrelación del error absoluto,que es la diferencia entre el valor real de cada observación y el estimado, en caso de seranterior a t o el predicho si fuera posterior a t.
Figura 3.5: Correlograma del error absoluto.

3.2. DESARROLLO DEL MODELO 33
Como se puede observar, el error absoluto del valor de cada observación se ve in�uen-ciado por los errores de las observaciones de retardo 2, 9 y 11. Este resultado no es elesperado, pues el error absoluto correspondiente a cada observación no debería estar co-rrelacionado con los errores absolutos anteriores. Por esta razón, se va a repasar el modelo,buscando posibles mejoras que mejoraran su funcionamiento.
El primer paso para intentar corregir esta desviación del modelo fue utilizar el crite-rio Akaike. La �nalidad de este criterio es encontrar entre diferentes modelos el que mejorse adapte a la serie real. En este caso, no se utilizó entre diferentes modelos, sino entre elmismo modelo pero con diferentes valores iniciales para los parámetros en la estimación desu valor. De este modo, se programó la función AIC() y se vieron diferentes agrupacionesde valores iniciales. El criterio dice que el que proporcione un menor valor de AIC() seráel que mejor se adapte a la realidad estudiada.
El problema estaba en que algunos de los valores que se utilizaban para inicializar laestimación de los parámetros se escogían sin demasiado fundamento y mediante aproxi-maciones. Además el modelo era muy sensible al cambio de los parámetros iniciales yexistían in�nitas posibilidades diferentes a escoger. Por esta razón, se decidió ir un pasomás lejos y buscar unos valores iniciales que estuvieran un fundamento teórico justi�cán-dolos.
El método utilizado para calcular los valores iniciales de los parámetros en su estima-ción fue la implementación del modelo autorregresivo de primer orden, AR(1).
El modelo AR(1), de�nido anteriormente, tiene la siguiente forma:
Yt = KYt−1 + pt (3.3)
Se ha escogido este modelo porque cuenta con una función en la biblioteca de R quepermite estimar el valor de los parámetros K y pt. Por tanto, si partiendo del modelo deespacio de los estados se tomara a = K, c = 1, Q = var(pt) y R = 0 o un valor muypequeño (por ejemplo Q/1000) se podría transformar el modelo de espacio de los estadosde partida en un modelo con la misma estructura que un AR(1).
Xt = KXt−1 + pt (3.4)
Yt = 1 ·Xt (3.5)
De esta manera, partiendo de los datos históricos y del modelo AR(1) descrito por lasdos ecuaciones anteriores, se crea un código que devuelva los valores estimados de losparámetros K y var(pt). El resultado obtenido es:
K = 0,9621
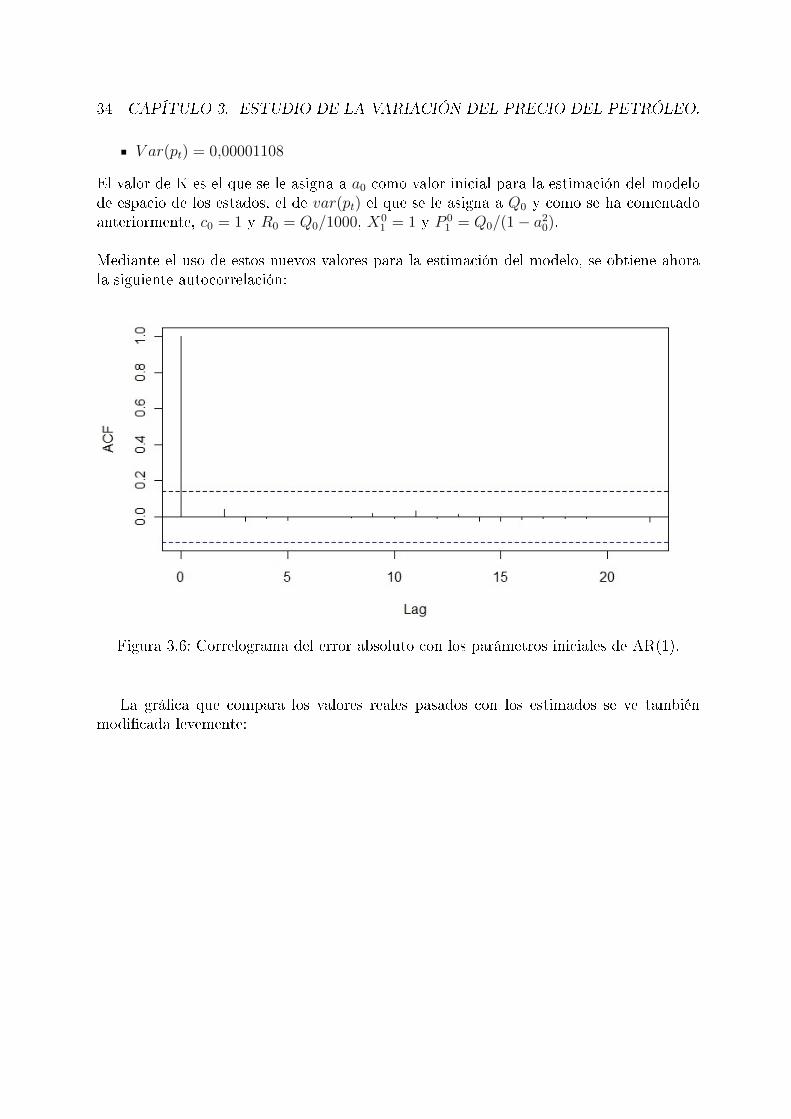
34 CAPÍTULO 3. ESTUDIO DE LA VARIACIÓN DEL PRECIO DEL PETRÓLEO.
V ar(pt) = 0,00001108
El valor de K es el que se le asigna a a0 como valor inicial para la estimación del modelode espacio de los estados, el de var(pt) el que se le asigna a Q0 y como se ha comentadoanteriormente, c0 = 1 y R0 = Q0/1000, X0
1 = 1 y P 01 = Q0/(1− a20).
Mediante el uso de estos nuevos valores para la estimación del modelo, se obtiene ahorala siguiente autocorrelación:
Figura 3.6: Correlograma del error absoluto con los parámetros iniciales de AR(1).
La grá�ca que compara los valores reales pasados con los estimados se ve tambiénmodi�cada levemente:

3.2. DESARROLLO DEL MODELO 35
Figura 3.7: Resultado del modelo con los parámetros iniciales de AR(1) para un mes.Rojo: Real, Azul: Estimación/Predicción, Verde: Intervalo de con�anza
Si se observa la grá�ca del modelo modi�cado y se compara con la del modelo sinmodi�cación, se comprueba que los nuevos valores iniciales de los parámetros en la esti-mación no tienen una gran repercusión en el comportamiento del modelo, no siendo éstemuy sensible a las diferentes variaciones a las que se sometan estos valores. Para justi�caranalíticamente esta mejora se calcula el error MAPE del modelo sin y con modi�cación.Los resultados obtenidos son, para el conjunto estimación-predicción de un 2.29% en elmodelo con los parámetros iniciales aproximados por autorregresión y de un 2.33% en elcaso contrario. Respecto al error MAPE exclusivamente de los valores de la predicción seobtienen un 0.08% y un 0.05% respectivamente. Aunque los valores del MAPE son muysimilares, concluyen que en efecto la utilización del modelo AR(1) para hallar los valoresde los parámetros no solo produce un error absoluto sin autocorrelación, sino que mejoralevemente los resultados del modelo. También se puede comprobar que el modelo no esmuy sensible a los parámetros iniciales para la estimación, ya que en los dos casos losresultados que se obtienen son muy similares.
Una vez de�nido el modelo en su totalidad, se quiso perfeccionar el programa. Lo quese buscaba era emular el comportamiento real de un sistema de predicción. Normalmentelos programas destinados a la predicción de un modelo no predicen los datos de un añodirectamente desde el momento actual, porque en este caso se acumularía el error delsistema y los datos más lejanos en el tiempo no serían �ables. Lo habitual es realizarla predicción de un periodo de tiempo pero partiendo del mes anterior al que se prediceactualizando mes a mes los datos de partida. Esto quiere decir que, si por ejemplo el mesactual es enero, se podrá predecir febrero, pero no se podrá predecir abril hasta que se

36 CAPÍTULO 3. ESTUDIO DE LA VARIACIÓN DEL PRECIO DEL PETRÓLEO.
disponga de los datos reales hasta marzo.
Figura 3.8: Resultado del modelo para predicción de un año sin actualizar los datos.Rojo: Real, Azul: Estimación/Predicción, Verde: Intervalo de con�anza
En la �gura anterior se muestra una captura de la grá�ca resultante de realizar laestimación a 12 meses directamente, tomando como datos de partida sólo los históricosde hasta diciembre de 1983. Se puede apreciar cómo al �nal de la serie el valor de lapredicción se desvía del real. Esta diferencia apreciable grá�camente en los datos de lapredicción también podía observarse a través del error MAPE de la predicción de un solomes, que pasaba de valer un 0.05% a un 1.93%. Es lógico pensar que este error debíaaumentar al predecir un año en vez de un mes, debido a que el error es acumulativo encada predicción. A pesar de esta razón, el modelo se podía mejorar si se optaba por laactualización de los datos históricos en la predicción.
En este caso en particular, como no se disponía de un año para ir mes a mes y losdatos en realidad eran de años anteriores, se creó un bucle que cada vez que se ejecutararepresentara el paso de un mes al siguiente. Como se tomó como fecha actual 1983, el añoque se buscaba predecir era 1984, así que cada vez que el modelo realizaba la predicciónde un mes, el bucle se ejecutaba, pasando al mes siguiente y dotando al modelo de losdatos reales conocidos hasta ese mes.
Esta nueva mejora hacía que el error MAPE obtenido en la predicción de un año sinla actualización de datos históricos pasara de ser un 1.93% a un 0.6%. Por lo tanto, elerror MAPE de este último modelo es de un 2.31% si se analizan la estimación y pre-

3.2. DESARROLLO DEL MODELO 37
dicción en conjunto y de un 0.6% si se considera exclusivamente los datos de los docemeses de la predicción. Debido a los errores MAPE obtenidos, se considera el modelo conlos parámetros iniciales en la estimación obtenidos por autorregresión de primer orden ycon predicción de un año con actualización de los datos históricos mes a mes como el quemejor se adapta a la realidad de la serie temporal.
En la siguiente grá�ca se puede observar perfectamente cómo la predicción mes a mescon actualización de datos es la que mejor representa el comportamiento del modelo.
Figura 3.9: Resultado del modelo para predicción de un año actualizando los datos.Rojo: Real, Azul: Estimación/Predicción, Verde: Intervalo de con�anza

38 CAPÍTULO 3. ESTUDIO DE LA VARIACIÓN DEL PRECIO DEL PETRÓLEO.

Capítulo 4
ESTUDIO DEL ÍNDICE KSIDRIVERS
4.1. Marco histórico
Del mismo modo que se ha estudiado la serie temporal del petróleo, se va a estudiarel comportamiento de una nueva serie temporal que de�na la evolución de los accidentesde trá�co en Reino Unido. En concreto, el estudio se va a central en aquellas víctimasque resultaron gravemente heridas o que fallecieron al volante. En Reino Unido existeun indicador de esta cifra, el llamado índice KSI (killed o seriusly injured drivers). Elintervalo de tiempo que se va a estudiar es de nuevo, desde enero de 1969 hasta diciembrede 1983. La �nalidad de este estudio vuelve a ser el desarrollo de un modelo que repre-sente el comportamiento de esta serie en particular y que permita realizar la prediccióncorrespondiente al año 1984, mes a mes.
Como se ha realizado con el caso del petróleo, lo primero que se va a analizar es elmarco histórico para tener en cuenta aquellos hechos que puedan in�uir en el desarrollode los accidentes durante el intervalo de estudio.
El número de coches matriculados en Reino Unido ha evolucionado de aproximadamenteunos 12 millones en 1969 hasta alcanzar en 1984 los 19 millones, creciendo en media un3% anualmente. Puede parecer que este aumento en el número de coches pueda tenerrepercusión negativa a priori, porque cuantos más coches haya, más posibilidades hay desufrir accidentes, sin embargo, a lo largo de los años también se han tomado medidas paraconcienciar a los conductores y disminuir el número de accidentes.
La medida más importante y que repercutió en gran medida en el número de accidentesregistrados fue la ley de obligatoriedad del cinturón de seguridad. Los dispositivos de re-tención para los viajeros de un vehículo se instalaron por primera vez a �nales de los 60's.A partir de 1972, el cinturón de seguridad de los asientos delanteros se convirtió en unaparte obligatoria del equipamiento en todos los coches nuevos registrados en Reino Unido.
39

40 CAPÍTULO 4. ESTUDIO DEL ÍNDICE KSI DRIVERS
Sin embargo, su uso obligatorio no llegó hasta más de una década después, en 1983. Loscinturones de seguridad de los asientos traseros se volvieron equipamiento obligatorio delvehículo 3 años más tarde, en 1986 y su uso obligatorio se estableció a partir de 1991.Los resultados fueron sorprendentes, aumentando el uso del cinturón tras implementar lanueva ley de seguridad de un 37% a un 95%. Gracias a esta medida se redujeron en un35% los traumatismos que necesitaban hospitalización.
4.2. Desarrollo del modelo
Como se ha comentado en el capítulo de Fundamento Teórico, el comportamiento deuna serie temporal puede aproximarse mediante un ajuste analítico lineal por regresiónsimple, de tal manera que a través de una recta adaptada correctamente a los datos, sepueda ver a simple vista si los datos de la muestra disminuyen o aumentan a lo largo deltiempo.
La regresión simple representa la relación lineal que existe entre una variable dependiente,Y y una variable independiente, X, que en este caso particular será el tiempo. Se puedeconsiderar además que existe un error o perturbación aleatoria, ε, que hace exista unaincertidumbre entre las dos variables y que por tanto, su relación lineal no sea perfecta.Este error puede ser representado por un proceso de ruido blanco, de distribución normalN(0, σ2). El modelo de regresión lineal para valores de i = 1, 2. . . n, se puede representarde la siguiente manera:
Yi = a+ bXi + εi (4.1)
Los coe�cientes a y b del modelo y la varianza del error se pueden estimar mediante elmétodo de mínimos cuadrados de la siguiente forma:
b =
∑ni=1(Xi − X)Yi∑ni=1(Xi − X)2
(4.2)
a = Y − bX (4.3)
σ2ε =
∑ni=1(Yi − a− bXi)
2
(n− 2)(4.4)
Donde X e Y representan la media aritmética de las variables X e Y.
Para el caso particular de estudio, se va a utilizar en vez de los datos de la muestra
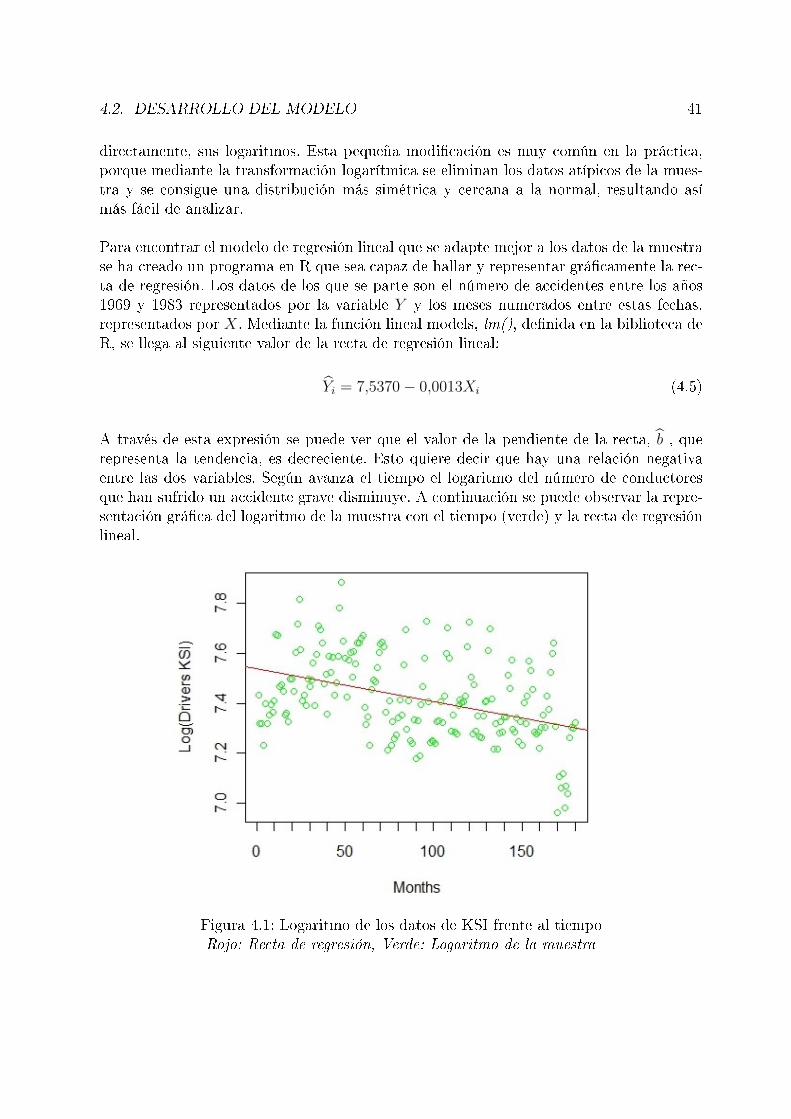
4.2. DESARROLLO DEL MODELO 41
directamente, sus logaritmos. Esta pequeña modi�cación es muy común en la práctica,porque mediante la transformación logarítmica se eliminan los datos atípicos de la mues-tra y se consigue una distribución más simétrica y cercana a la normal, resultando asímás fácil de analizar.
Para encontrar el modelo de regresión lineal que se adapte mejor a los datos de la muestrase ha creado un programa en R que sea capaz de hallar y representar grá�camente la rec-ta de regresión. Los datos de los que se parte son el número de accidentes entre los años1969 y 1983 representados por la variable Y y los meses numerados entre estas fechas,representados por X. Mediante la función lineal models, lm(), de�nida en la biblioteca deR, se llega al siguiente valor de la recta de regresión lineal:
Yi = 7,5370− 0,0013Xi (4.5)
A través de esta expresión se puede ver que el valor de la pendiente de la recta, b , querepresenta la tendencia, es decreciente. Esto quiere decir que hay una relación negativaentre las dos variables. Según avanza el tiempo el logaritmo del número de conductoresque han sufrido un accidente grave disminuye. A continuación se puede observar la repre-sentación grá�ca del logaritmo de la muestra con el tiempo (verde) y la recta de regresiónlineal.
Figura 4.1: Logaritmo de los datos de KSI frente al tiempoRojo: Recta de regresión, Verde: Logaritmo de la muestra

42 CAPÍTULO 4. ESTUDIO DEL ÍNDICE KSI DRIVERS
Este modelo de regresión lineal ha servido para entender la forma de la muestra y parapoder prever la tendencia, pero sin embargo no va a servir para representar el comporta-miento de la serie. Esto se debe a que la hipótesis de la que se ha partido es que el errorsigue una distribución normal N(0, σ2) y que los valores del error aleatorios, es decir, queson independientes entre sí. Sin embargo, si se halla el correlograma del error, se obtienela siguiente grá�ca, que indica lo contrario:
Figura 4.2: Correlograma del error.
Por esta razón, se va un paso más lejos en la elección del modelo y se opta por unmodelo de espacio de los estados. Más adelante, una vez que se haya desarrollado el mo-delo completo, se comparará el correlograma obtenido anteriormente con el del modelodesarrollado con espacio de los estados.
Como se ha visto anteriormente, un modelo de este tipo tiene la siguiente forma:
Yt = cXt + vt (4.6)
Xt+1 = aXt + wt (4.7)
Donde:
Yt es la variable observación.

4.2. DESARROLLO DEL MODELO 43
Xt es la variable estado.
a y c son dos constantes cuyos valores son iguales para todo t.
vt es el ruido blanco de la observación, que sigue una distribución N(0, R).
wt es el ruido blanco del estado del sistema, que sigue una distribución N(0, Q).
Para de�nir este nuevo modelo, como en el caso de la serie temporal del precio del petró-leo, se debe realizar una estimación de los parámetros a, c, Q y R que representen bien elcomportamiento de la muestra.
De nuevo, se crea un programa en R que sea capaz de estimar los parámetros del modelode espacio de los estados mediante el método de máxima verosimilitud para después uti-lizarlo en la predicción de datos futuros. En primer lugar se buscaba crear un programamás sencillo que predijera los datos del mes siguiente al considerado actual, después secali�caría la calidad del modelo contrastando los datos predichos con los reales y se reali-zarían las modi�caciones pertinentes hasta conseguir que el programa represente �elmenteel comportamiento de la serie.
Todo el proceso que se ha seguido para conseguir este propósito es muy similar al seguidoen el caso de la serie temporal del precio del petróleo. En primer lugar, para estimar losparámetros del modelo, se ha utilizado de nuevo la función Linn(), la cual depende deun vector llamado param[] que contiene en sus componentes los parámetros que se quiereestimar, a, c, Q, R, X1 y P1. Dentro del cuerpo de la función Linn(), hay una llamadaa la función FiltroKalman() que tiene como datos de entrada las componentes del vectorparam[], de tal manera que cada vez que se ejecute esta función, el valor devuelto es el dela verosimilitud. Por lo tanto los valores que se escojan como parámetros del modelo seránaquellos que proporcionen un valor de verosimilitud máximo. Para ello se utiliza la funciónoptim() aplicada a Linn() que mediante iteración y partiendo del valor inicial asignado acada parámetro, busca el mínimo del opuesto de la verosmilitud, es decir, el máximo. Unavez realizada la parametrización, se llega a un modelo que representa el comportamientode la serie, así que se estiman sus valores desde 1969 hasta 1983 para compararlos másadelante con los reales que se poseen. Con el �ltro de Kalman y los parámetros del modelo,se puede hallar el valor de la variable estado en el instante siguiente al actual, Xt+1|t, asícomo los de la varianza del error de la estimación Pt+1|1. Estos dos valores serán el puntode partida junto con los parámetros del modelo para hallar la predicción a través de un�ltro de Kalman levemente modi�cado de�nido dentro de la función pred(). La diferenciade este �ltro y el utilizado anteriormente es que se supone, por carecer de datos futuros,que la innovación, et, es nula. La función pred() tiene un parámetro de entrada que indicael número de meses siguientes al actual que quieres estimar, n.ahead. A nivel de código,el valor de n.ahead indica el número de veces que se ejecuta el �ltro de Kalman modi�cado.
Una vez realizada la estimación del pasado hasta el momento actual y la predicción de

44 CAPÍTULO 4. ESTUDIO DEL ÍNDICE KSI DRIVERS
n.ahead meses futuros, se crea un vector que contenga, en su comienzo y por orden, la es-timación y en sus últimas componentes, los valores correspondientes a las predicciones delos meses venideros. Este vector se representará grá�camente junto con los valores realesde los meses tanto pasados (1969-1983), como los futuros (1984).
En la siguiente grá�ca se puede observar el resultado del primer programa que se desa-rrolló, más sencillo, con la predicción correspondiente a un mes en adelante al actual. Enrojo aparecen los valores reales de la serie, en azul los estimados hasta el instante actualy los predichos en meses futuros y en verde los intervalos de con�anza del modelo.
Figura 4.3: Resultados del modelo en la estimación y predicción de un mesRojo: Real, Azul: Estimación/Predicción, Verde: Intervalos de con�anza
Los valores iniciales que se utilizaron en la parametrización fueron escogidos medianteel criterio de Akaike, AIC. Este método mide el grado de adaptación de un modelo con-creto a una serie temporal basándose en la verosimilitud esperada. Los parámetros queden lugar a la máxima verosimilitud serán los más adecuados para representar el modelo,y como el valor de AIC depende del opuesto de la verosimilitud, los parámetros buscadosserán aquellos que proporcionen un menor valor de AIC.
Si se realizara con este programa la predicción de los doce meses del año 1984 direc-tamente, partiendo de los datos históricos hasta diciembre de 1983, se desviarían en gran
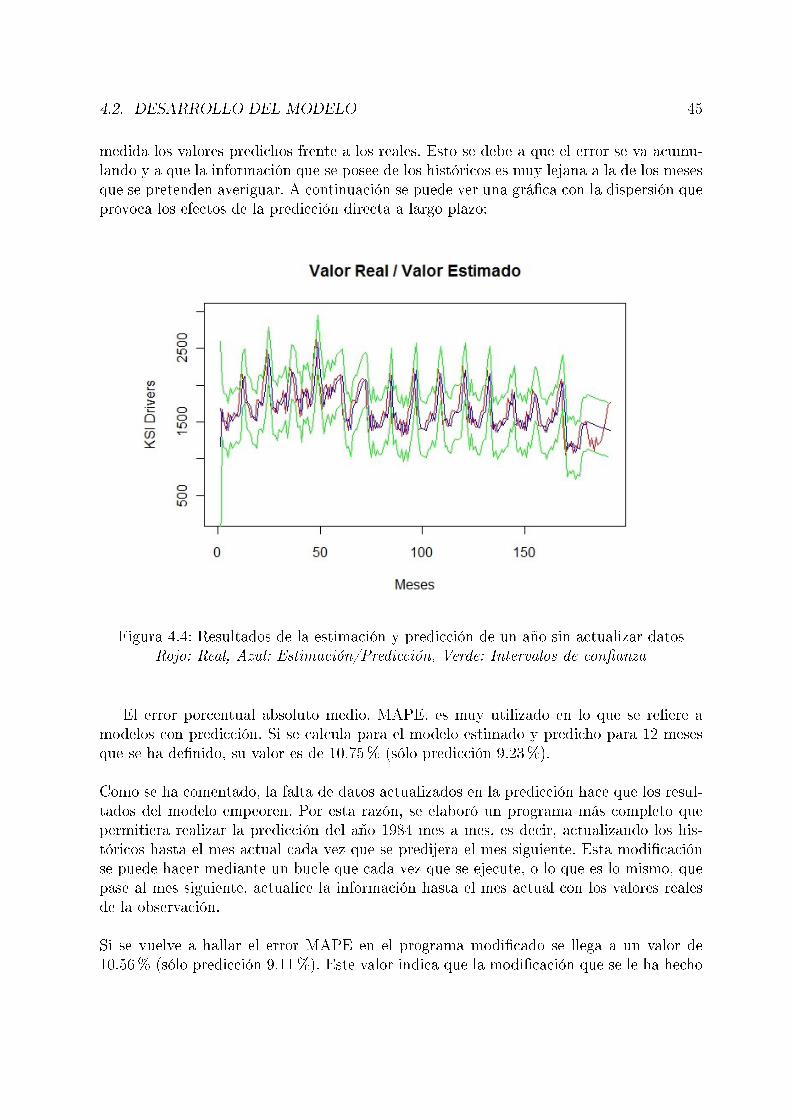
4.2. DESARROLLO DEL MODELO 45
medida los valores predichos frente a los reales. Esto se debe a que el error se va acumu-lando y a que la información que se posee de los históricos es muy lejana a la de los mesesque se pretenden averiguar. A continuación se puede ver una grá�ca con la dispersión queprovoca los efectos de la predicción directa a largo plazo:
Figura 4.4: Resultados de la estimación y predicción de un año sin actualizar datosRojo: Real, Azul: Estimación/Predicción, Verde: Intervalos de con�anza
El error porcentual absoluto medio, MAPE, es muy utilizado en lo que se re�ere amodelos con predicción. Si se calcula para el modelo estimado y predicho para 12 mesesque se ha de�nido, su valor es de 10.75% (sólo predicción 9.23%).
Como se ha comentado, la falta de datos actualizados en la predicción hace que los resul-tados del modelo empeoren. Por esta razón, se elaboró un programa más completo quepermitiera realizar la predicción del año 1984 mes a mes, es decir, actualizando los his-tóricos hasta el mes actual cada vez que se predijera el mes siguiente. Esta modi�caciónse puede hacer mediante un bucle que cada vez que se ejecute, o lo que es lo mismo, quepase al mes siguiente, actualice la información hasta el mes actual con los valores realesde la observación.
Si se vuelve a hallar el error MAPE en el programa modi�cado se llega a un valor de10.56% (sólo predicción 9.11%). Este valor indica que la modi�cación que se le ha hecho

46 CAPÍTULO 4. ESTUDIO DEL ÍNDICE KSI DRIVERS
al programa ha mejorado sus resultados.
En la siguiente grá�ca se puede observar a simple vista cómo mejora el modelo con respec-to a la grá�ca del primer programa sin modi�car, debido a la implantación de predicciónmes a mes:
Figura 4.5: Resultados de la estimación y predicción de un año actualizando datosRojo: Real, Azul: Estimación/Predicción, Verde: Intervalos de con�anza
Por último, se puede observar el correlograma que se obtiene con este modelo. Comopuede observarse, prácticamente todos los retardos se encuentran dentro del intervalo decon�anza excepto el decimosegundo. Si se compara este correlograma con el presentadoal principio de este capítulo, se puede concluir que el modelo de espacio de los estados esmucho más adecuado para representar esta serie, ya que la independencia entre los valoresdel error absoluto mejora notablemente.

4.2. DESARROLLO DEL MODELO 47
Figura 4.6: Correlograma del error absoluto de los resultados del modelo

48 CAPÍTULO 4. ESTUDIO DEL ÍNDICE KSI DRIVERS

Capítulo 5
ESTUDIO DEL ÍNDICE KSI CONVARIABLES EXPLICATIVAS.
Cuando se desarrolla un modelo de una serie temporal, cualquier información adicio-nal sobre su comportamiento puede ayudar a conseguir resultados mucho más precisos.Como se ha ido viendo a lo largo de este proyecto, una serie temporal depende de muchosfactores, muchas veces impredecibles, que repercuten de manera directa o indirecta o queni siquiera son medibles. Es interesante por tanto, aumentar el horizonte de estudio ybuscar nuevas variables que cuanti�quen la in�uencia de otros factores en la serie en laque se quiera profundizar.
5.1. Estudio de la relación entre el precio del petróleoy los accidentes de trá�co
Si se observan los errores MAPE conseguidos en la predicción de las dos series ante-riormente estudiadas, un 0.60% en el caso del precio del petróleo y un 9.11% en el casode los conductores que han sufrido un accidente grave, es bastante lógico centralizar estenuevo análisis en la serie que mayor error tenga en su predicción, ya que será más fácildisminuirlo en gran medida.
Para llevar a cabo este procedimiento, lo primero que habría que hacer es encontrarun factor de fácil estudio cuyos valores repercutan en la cantidad de accidentes graves detrá�co. Llegado a este punto, es razonable pensar que el precio de petróleo puede ser elfactor buscado. Antes de comprobar nada analíticamente, se baraja la hipótesis de que,si sube el precio del petróleo, menos gente cogerá el coche y por tanto, habría menosposibilidades de sufrir un accidente. Lo mismo en sentido contrario, si bajara el preciodel petróleo, más gente cogería el coche para sus desplazamientos y las posibilidades desufrir un accidente aumentarían. Esta teoría es relativamente fácil de comprobar mediante
49

50 CAPÍTULO 5. ESTUDIO DEL ÍNDICE KSI CON VARIABLES EXPLICATIVAS.
regresión lineal simple.
Si se consideran dos variables, Y, para la serie de los accidentes de trá�co y U parala del precio del petróleo y se representan una con respecto a la otra con la recta deregresión correspondiente a los datos de la muestra se obtiene lo siguiente:
Figura 5.1: Relación entre el precio del petróleo y los KSI driversRojo: Recta de regresión entre KSI drivers y precio del petróleo
Cuya recta de regresión se de�ne mediante la expresión analítica:
Yi = 2799− 10893Ui (5.1)
Se puede por tanto comprobar, como en efecto una disminución en el precio del petróleoprovoca un aumento en el número de accidentes y un aumento hace que el número deaccidentes disminuyan.

5.2. DESARROLLO DE UN MODELO CON VARIABLE EXPLICATIVA. 51
5.2. Desarrollo de un modelo con variable explicativa.
Otro factor que podría in�uir indirectamente en la serie temporal que se analiza, através de su in�uencia en el precio del petróleo es el mes del año en el que se encuentra. Sise observa la grá�ca siguiente, la cual posee los datos de la muestra a lo largo del intervalode estudio, se puede distinguir un patrón similar repetitivo a lo largo de cada año y en latabla que aparece a continuación, la media mensual de KSI y el número de ocasiones enel que cada mes ha dado el máximo KSI en el intervalo de estudio (1969-1983).
Si se observa la tabla que representa el número de veces que cada mes ha sido máxi-mo durante el año en el número de víctimas graves de accidentes registrados, se puedeapreciar como hay meses que destacan sobre los demás. Por este motivo, a la hora de de-clarar la variable explicativa del precio del petróleo se van a tener en cuenta la in�uenciade los meses en su de�nición. De esta manera, se relacionará cada valor del precio del pe-tróleo con el mes correspondiente al que pertenece y así se podrá cuanti�car la diferenciaque existe en los datos del petróleo entre los distintos meses.
Figura 5.2: Número KSI drivers frente al tiempo

52 CAPÍTULO 5. ESTUDIO DEL ÍNDICE KSI CON VARIABLES EXPLICATIVAS.
Figura 5.3: Media mensual de KSI y ocasiones que cada mes ha sido máximo
La introducción de una componente que cuanti�que la in�uencia de este nuevo factordentro del modelo de espacio de los estados se puede hacer mediante la inclusión de unavariable explicativa, U . Esta variable contendrá los datos del precio del petróleo y del mespara cada una de las cifras de los accidentes de trá�co correspondientes. Para incluir todosestos datos nuevos dentro de una única variable, ésta tendrá que estar de�nida como unamatriz.
La matriz U tendrá tantas columnas como meses de estudio (desde enero de 1969 hastadiciembre de 1983) y tantas �las como número de variables se quiera que abarque en sude�nición. En este caso, la matriz U tendrá colocados en la primera �la, todos los valoresdel precio del petróleo de cada uno de los meses estudiados, que en total serán 180 datos.En las siguientes once �las, vendrán determinados cada uno de los meses del año medianteel valor 1 cuando los datos del petróleo de la primera �la correspondan a ese mes o con elvalor cero en caso contrario. El valor del mes correspondiente a diciembre no dispondrá deuna �la en la matriz, porque se asignará como mes de diciembre a aquel dato del preciodel petróleo que no tenga ningún uno en el resto de la columna.

5.2. DESARROLLO DE UN MODELO CON VARIABLE EXPLICATIVA. 53
Por tanto, la dimensión de la matriz U será de 12x180, 12 �las correspondientes al preciodel petróleo y los meses del año (menos diciembre) y 180 columnas que vienen determi-nadas por el número de meses de estudio o, lo que es lo mismo, por el número de datosdel precio del petróleo. Esquemáticamente la matriz U tiene el siguiente aspecto:
U =
p p p p p p p p p p p p1 0 0 0 0 0 0 0 0 0 0 00 1 0 0 0 0 0 0 0 0 0 00 0 1 0 0 0 0 0 0 0 0 00 0 0 1 0 0 0 0 0 0 0 00 0 0 0 1 0 0 0 0 0 0 00 0 0 0 0 1 0 0 0 0 0 00 0 0 0 0 0 1 0 0 0 0 00 0 0 0 0 0 0 1 0 0 0 00 0 0 0 0 0 0 0 1 0 0 00 0 0 0 0 0 0 0 0 1 0 00 0 0 0 0 0 0 0 0 0 1 0
(5.2)
Para de�nir esta matriz de grandes dimensiones en código de R se decidió, por cuestiónde di�cultad, crear dos matrices por separado para luego juntarlas mediante la funciónrbind() de la biblioteca de R, que une matrices por �las. La primera matriz, era en reali-dad un vector de 180 componentes de longitud con los datos reales del precio del petróleo.Para de�nir la segunda matriz, se creó primero una matriz de apoyo de dimensión 2x180con un bucle que asignara en la primera �la el precio del petróleo y en la segunda losmeses a los que correspondía cada dato del petróleo numerados del 1 al 12. Además depor simpli�car la creación de la matriz U , se decidió dar este paso intermedio con estamatriz de apoyo porque de esta manera se daba la opción de buscar de una forma sencillael precio del petróleo correspondiente a un mes en particular. Una vez de�nida la matrizde apoyo y mediante otro bucle, se creó una matriz que tuviera de dimensión 11x180 conlos valores de 1 ó 0 correspondientes a cada mes.
Después de formar las dos matrices por separado, se juntaron por �las dando lugar ala matriz U que se ha de�nido anteriormente.
Al igual que en el caso de las otras variables que intervienen en el sistema, la matrizU tendrá que venir acompañada de un parámetro que cuanti�que la in�uencia que ejer-ce un factor en el modelo. En la de�nición del vector de los parámetros de la variableexplicativa, la primera componente representa el parámetro correspondiente al precio delpetróleo y los once siguientes representan los parámetros que indican la diferencia exis-tente entre cada uno de los meses en el valor del petróleo.
Como se puede observar, en el vector de parámetros no existe una componente que re-

54 CAPÍTULO 5. ESTUDIO DEL ÍNDICE KSI CON VARIABLES EXPLICATIVAS.
presente el mes de diciembre. Esto se debe a que como se ha comentado anteriormente, elvalor de diciembre está determinado por una columna de ceros en la variable explicativa,es decir, el mes de diciembre corresponderá a aquel en el que el resto de los meses sean cero.
d = ( dpetrol dene dfeb dmar dabr dmay djun djul dago dsep doct dnov ) (5.3)
Después de introducir las nuevas componentes que se van a incluir en la mejora del siste-ma, el modelo resultante tendrá el siguiente aspecto:
Yt = cXt + dUt + vt (5.4)
Xt+1 = aXt + wt (5.5)
Con este modelo mejorado se realizará una estimación del comportamiento de la serietemporal que representa el número de víctimas mortales o graves que conducían duranteun accidente de trá�co y la predicción de los valores del año siguiente al considerado ac-tual, es decir, la predicción del año 1984.
Del mismo modo que en las series analizadas anteriormente, para conseguir un mode-lo que represente de forma �el la realidad, hay que estimar cada uno de los parámetrosque lo componen. El método utilizado para estimar los parámetros que de�nen el modelovuelve a ser el de máxima verosimilitud.
En primer lugar, se de�ne la función Linn(), que depende de un vector llamado param[]en el que cada componente contiene uno de los parámetros que se desea estimar. En es-te caso, además de los parámetros a, c,Q,R, x1 y P1, también deben incluirse 12 nuevascomponentes, correspondientes al vector d, en la estimación. A pesar de que d se tratade un vector de parámetros, sus 12 componentes se estimarán por separado y una vez seobtengan sus valores se unirán de nuevo en un solo vector.
En el cuerpo de la función Linn(), hay de�nida una llamada a la función KalmanExp()que tiene como datos de entrada los del vector param[] y las observaciones reales hastael instante considerado actual, es decir, los datos del número de víctimas de accidentesde trá�co desde enero de 1969 hasta diciembre de 1983. Esta nueva función del Filtro deKalman tiene alguna diferencia con respecto a la vista hasta ahora en el estudio de lasseries del precio del petróleo y de las víctimas de accidentes de trá�co por separado. El�ltro de Kalman para el estudio de variables explicativas se de�ne de la siguiente manera:

5.2. DESARROLLO DE UN MODELO CON VARIABLE EXPLICATIVA. 55
et = Yt − Yt|t−1 − dUt (5.6)
St = c2Pt|t−1 +R (5.7)
Kt =acPt|t−1
St|t−1(5.8)
Xt+1|t = aXt|t−1 +Ktet (5.9)
Pt+1|t = a2Pt|t−1 +Q−K2t St (5.10)
Como se puede observar, ahora la innovación tiene una componente más: la variable ex-plicativa.
Cada vez que se ejecute la función Linn(), el valor devuelto será el de la verosimilitud detal manera que los valores de los parámetros que hagan máxima la verosimilitud serán losconsiderados más adecuados para el modelo. Los diferentes valores de los parámetros conlos que se busca la máxima verosimilitud serán los proporcionados por la función optim(),que se basa en la iteración para buscar un valor óptimo de una función. Los diferentesvalores que proporciona optim() para la estimación parten de los valores iniciales de cadaparámetro que se le proporcionen. Más adelante se comentará los diferentes valores ini-ciales que se facilitaron a optim() y los escogidos �nalmente como punto de partida porla mejora en los resultados del modelo. Por defecto, la función optim() busca el mínimode la función a la que se aplica, por lo tanto, explorará el mínimo del valor opuesto de lafunción de verosimilitud, o lo que es lo mismo, el máximo.
Una vez encontrados los valores de los parámetros que proporcionan la máxima verosimi-litud de la serie temporal de los accidentes de trá�co, se repite el mismo procedimientocon los de la serie temporal del precio del petróleo. Disponer del modelo que representael comportamiento de la serie del petróleo es muy importante, porque cuando se realicela predicción de los datos futuros del número de accidentes, no se conoce el que será elprecio del petróleo en ese momento, sino sólo el actual. Por lo tanto, el código que seva a programar en R tiene que ser capaz de predecir el valor del precio del petróleo delmes siguiente al actual, para así con ese valor simbolizado en la variable explicativa ycontando con el resto del modelo principal de�nido por la parametrización, predecir elvalor del número de accidentes del próximo mes.
En el código desarrollado en R, se optó por hacer la parametrización del precio del pe-tróleo con la llamada a una nueva función de�nida en la biblioteca de funciones, de estamanera, se acortaba y simpli�caba el código del programa principal.

56 CAPÍTULO 5. ESTUDIO DEL ÍNDICE KSI CON VARIABLES EXPLICATIVAS.
La función encargada de devolver los valores estimados de los parámetros de la seriedel petróleo es la llamada EstimacionPetrol(), que tiene como datos de entrada los datosreales del precio del petróleo hasta el instante considerado actual. Respecto al código de-�nido dentro de esta función, el procedimiento y la metodología escogida es exactamentela misma que en la estimación de los parámetros del modelo del capítulo de este proyectodedicado al estudio de esta serie. Por lo tanto, de nuevo la parametrización se realizapor medio del método de máxima verosimilitud, el cual toma como punto de partida pa-ra la iteración los valores iniciales de cada parámetro proporcionados por el modelo deautorregresión de primer orden. Los datos que devuelve la función EstimacionPetrol() alprograma principal son los estimados de cada parámetro del modelo del precio del petróleo.
Una vez que se han estimado los dos modelos, tanto el de la serie del precio del petróleocomo el del número de víctimas graves o mortales que conducían durante un accidente detrá�co se procede a realizar la predicción. La predicción se realizaba mediante la llamadaa la función predExp(), denominada así por hacer la predicción de un modelo con varia-bles explicativas. Esta función se de�nió dentro la biblioteca de funciones por cuestiónde simpli�cación del código del programa principal. El procedimiento para realizar unapredicción con variables explicativas es ligeramente distinta a la vista hasta ahora en elestudio de las series del precio del petróleo y de las víctimas de accidentes por separado.A continuación se van a mostrar estas diferencias.
Como se vio en el capítulo de Fundamento teórico, la predicción de una serie tempo-ral se realiza mediante el �ltro de Kalman. Como se ha indicado anteriormente, al ser unmodelo con variable explicativa, el �ltro de Kalman que se utiliza ahora en esta nuevapredicción incluye en su de�nición una componente más en la innovación, la correspon-diente a la variable explicativa. A través de los valores de los parámetros estimados, delos históricos de la observación del número de víctimas en los accidentes de trá�co, delprecio del petróleo actual y del mes, se ejecuta el �ltro de Kalman desde el primer datohasta el actual. Una vez alcanzado el instante actual en el bucle, el �ltro de Kalmanproporciona el valor de Xt+1 y Pt+1. Estos dos valores serán los puntos de partida parala predicción, junto con el mes correspondiente y la predicción del precio del petróleo eneste nuevo mes, ambos incluidos dentro del valor de la variable explicativa. Al igual quesucede con el �ltro de Kalman, la metodología para hallar la predicción varía ligeramentecon respecto al caso de una serie sin variables explicativas.
St = c2ePt +Re (5.11)
Kt =aecePt|t−1
St|t−1(5.12)
Yt = ceXt + dUpt (5.13)
Xt+1 = aeXt (5.14)

5.2. DESARROLLO DE UN MODELO CON VARIABLE EXPLICATIVA. 57
Pt+1 = a2Pt +Qe −K2t St (5.15)
Como se puede observar, para hallar el nuevo valor predicho de la observación tambiénin�uye la componente de la variable explicativa. Esta nueva matriz Up, es diferente a lade�nida anteriormente para la estimación, y contiene, en su primera �la los datos obte-nidos en la predicción de futuro del precio del petróleo y en las once �las siguientes losmeses futuros que corresponderían a cada dato predicho. Para la creación de la matrizUp se llama a la función PetrolPred() de�nida en la biblioteca de funciones. La funciónPetrolPred() emplea la misma metodología para la predicción que la que se desarrollópara el capítulo del estudio de esta serie. A través de los datos predichos del precio delpetróleo y asignando el mes correspondiente a cada uno, se forma la matriz Up.
Por lo tanto, la función predExp() tiene como datos de entrada el vector de observaciónde los datos históricos de los accidentes de trá�co, los valores estimados de los parámetrosdel modelo, la matriz U de variables explicativas con los datos del precio del petróleo yde cada mes correspondiente, todos ellos hasta los datos del instante actual y además lamatriz Up con los datos de la predicción tanto del petróleo como de los meses futuros.
A nivel de código antes de realizar la predicción de un año mes a mes se hicieron dosprogramas más sencillos. El primero, hallaba directamente la predicción de un año to-mando como datos de partida los históricos tanto de los accidentes como del petróleohasta el mes de diciembre de 1983. Como se comentó en los capítulos del estudio de lasdos series por separado, realizar una predicción directamente a doce meses produce unerror muy considerable. Además, en la práctica tiene poco sentido, porque es mejor saberlo que va a pasar con un mes de antelación y con un error pequeño a saber lo que va a pa-sar dentro de un año pero sabiendo que los resultados reales pueden variar notablementea causa del gran error que se comete.
El segundo, hallaba la predicción sólo del mes siguiente, pero con los datos actualiza-dos hasta el mes considerado actual. El problema de este programa era que los datosestimados del precio del petróleo no estaban incluidos dentro del código ni conectados aél mediante una llamada a una función, sino que se cogían del programa que se desarrollóen el capítulo del estudio de la serie temporal del petróleo y se introducían manualmenteen el programa de variables explicativas. Como cada vez que se quería hacer la predicciónde un mes había que ejecutar dos programas diferentes y cambiar los datos de partidamanualmente, se decidió hacer un programa que mediante la utilización de un bucle lohiciera automáticamente.

58 CAPÍTULO 5. ESTUDIO DEL ÍNDICE KSI CON VARIABLES EXPLICATIVAS.
De esta manera, se llegó al que iba a ser el programa de�nitivo, el cual de maneraesquemática realizaba la predicción mediante los siguientes pasos:
1. Lectura de datos históricos del precio del petróleo y del número de víctimas graveso mortales que conducían el coche durante un accidente de trá�co en Reino Unido(1969-1983).
2. Creación a través de los datos históricos del precio del petróleo y de los mesescorrespondientes a cada dato de la matriz de variables explicativas, U.
3. Estimación de los parámetros a, c, Q, R, d, X1, P1, por máxima verosimilitud delmodelo de las víctimas de accidentes que tienen como valor estimado ae, ce, Qe, Re,de, X1e, P1e.
4. Estimación de los parámetros del modelo del precio del petróleo ap, cp, Qp, Rp, X1p,P1p, mediante la llamada a la función EstimacionPetrol(), que tiene como datos deentrada los históricos de esta serie y como salida los parámetros estimados de estemodelo, ape, cpe, Qpe, Rpe, X1pe, P1pe.
5. Entrada en un bucle que se ejecutará doce veces, una para cada mes del año quese quiere predecir, 1984, actualizando los datos históricos añadiéndole como últimodato el valor real cada vez que se pase a la predicción del mes siguiente.
6. Llamada a la función PetrolPred(), que a través de los parámetros estimados de laserie del precio del petróleo y sus datos históricos proporciona la predicción del messiguiente al considerado actual.
7. Creación de la matriz Up con el valor predicho del precio del petróleo y el valor delmes correspondiente.
8. Llamada a la función predExp() que tiene como datos de entrada los parámetrosestimados del modelo de los accidentes de trá�co, sus datos históricos y las matricesU y Up y como datos de salida el valor predicho del número de accidentes del messiguiente al actual.
9. Actualización de la matriz U , añadiéndole el valor real del mes del petróleo que seacaba de predecir como el último dato histórico, ya que ahora se considera el queera actual como pasado y el predicho como el actual. Volver al paso 5), ejecutandode nuevo el bucle hasta llegar al mes de diciembre de 1984.

5.2. DESARROLLO DE UN MODELO CON VARIABLE EXPLICATIVA. 59
Después de realizar la predicción, se representarán grá�camente los resultados. Paraello, se va a crear un vector que contenga en sus primeras componentes los valores esti-mados de las víctimas de los accidentes de trá�co y en las últimas doce, los valores de lapredicción que se han obtenido. Estos datos, se representarán en una grá�ca frente a losdatos reales. También vendrá representado el intervalo de con�anza del 95%.
Lo único que queda por determinar para llevar a cabo todo el desarrollo anterior sonlos valores iniciales de los parámetros en la estimación por máxima verosimilitud, valoresde los que partirá la función optim() para la iteración. Si se utilizan los valores inicialesde los parámetros que se eligieron en el estudio de la serie de los accidentes sin variablesexplicativas los resultados estimados y predichos se diferenciaban en gran medida de losreales. En la siguiente grá�ca se puede observar el resultado. Esto puede deberse a que estemodelo, al contrario que los anteriormente estudiados es muy sensible al valor inicial delos parámetros en la estimación de su valor. Con estos valores, se obtenía un error MAPEtotal, es decir, de los valores estimados y predichos, de un 25.69%. El error MAPE de losvalores sólo de la predicción era de un 5.9%.
Figura 5.4: Resultados de la estimación/predicción con los parámetros iniciales por AIC.Rojo: Real, Azul: Estimación/predicción, Verde: Intervalo de con�anza

60 CAPÍTULO 5. ESTUDIO DEL ÍNDICE KSI CON VARIABLES EXPLICATIVAS.
Si se opta, al igual que en el caso de la serie del precio del petróleo, por recurrir almodelo de autorregresión de primer orden para hacer una estimación de los valores de losparámetros se obtiene la siguiente grá�ca de resultados.
Figura 5.5: Resultados de la estimación/predicción con los parámetros iniciales por AR(1).Rojo: Real, Azul: Estimación/predicción, Verde: Intervalo de con�anza
Los errores MAPE del modelo con los datos iniciales obtenidos por autorregresión deprimer orden son, en el caso de los valores que porporciona el modelo estimados y predi-chos de un 10.03% y en el caso de solamente los predichos de un 5.70%. Esto demuestraque esta elección produce una mejor respuesta en el modelo, representando con un errormenor los datos reales.
Además de reducir el error MAPE, el correlograma del error absoluto de este últimomodelo da unos resultados notablemente mejores. Se recuerda que el correlograma midela in�uencia que tienen los valores de los retardos sobre el que se considera actual. Alcomienzo del desarrollo de este modelo se ha considerado la hipótesis de que el error delsistema era un proceso de ruido blanco y por lo tanto, los diferentes valores del errordeberían estar incorrelados, o lo que es lo mismo, independientes entre sí. Si existe au-tocorrelación entre los residuos de una muestra signi�ca que los estimadores son poco

5.2. DESARROLLO DE UN MODELO CON VARIABLE EXPLICATIVA. 61
e�cientes. Si el modelo está bien ejecutado y es de gran calidad los valores del correlo-grama deberían situarse dentro del intervalo de con�anza del 95%, que en el caso de lafunción acf() de la biblioteca de R, viene de�nido por defecto. A continuación se observaen primer lugar la grá�ca correspondiente al primer modelo con los parámetros inicialesescogidos para la serie de los accidentes de trá�co por el criterio de Akaike, AIC.
Figura 5.6: Correlograma modelo con parámetros iniciales por AIC.
Como se puede ver, prácticamente todos los retardos del error absoluto se encuentranfuera del intervalo de con�anza, y en concreto, el segundo y del decimosegundo retardo,se encuentran muy alejados de éste. Podría decirse entonces que este modelo no cumplela independencia de los residuos y que no es adecuado para representar la serie temporalestudiada. Si ahora se compara este último correlograma con el obtenido por el modelocuyos parámetros iniciales se escogieron usando la autorregresión de primer orden, se vecómo mejora notablemente la independencia entre residuos.

62 CAPÍTULO 5. ESTUDIO DEL ÍNDICE KSI CON VARIABLES EXPLICATIVAS.
Figura 5.7: Correlograma modelo con parámetros iniciales por AR(1)
De nuevo el decimosegundo retardo vuelve a estar entre los más problemáticos, perosin embargo todos los demás se reducen considerablemente.

Capítulo 6
CONCLUSIONES
A continuación, se van a recapitular los datos relevantes del estudio de cada serie a lavez que se relacionan con las conclusiones obtenidas.
A lo largo del análisis anterior se ha realizado el estudio de dos series temporales:
La evolución del precio del petróleo en Reino Unido (1969-1984).
El número de conductores que han sufrido un accidente de trá�co, resultando gra-vemente heridos o habiendo fallecido, entre los años 1969 y 1984 en Reino Unido(drivers killed or seriously injured, KSI, in the United Kingdom).
Para el desarrollo del modelo de la serie temporal correspondiente al precio del petróleose tomó, como punto de partida, el modelo matemático de espacio de los estados. Parade�nir este modelo correctamente, había que estimar los parámetros que lo determinaban,para que de esta manera representara �elmente el comportamiento de la serie. El métodoescogido para la parametrización del modelo fue el de máxima verosimilitud. Una vezde�nido el modelo, se realizó una predicción tomando como base el �ltro de Kalman paralos doce meses del año 1984 y se comparó con los datos reales para medir la calidad delmodelo.
Después de probar la e�cacia del modelo, se halló el error porcentual absoluto medio,MAPE, obteniendo un error del 2.31% si se analizaba la estimación y predicción y un0.6% teniendo en cuenta sólo la predicción.
A través de los resultados de este modelo se puede vislumbrar, cómo partiendo sólo de losdatos históricos de la variable observación, se puede conseguir un modelo razonable parael alcance de este proyecto.
Para la segunda serie temporal, se desarrollaron dos modelos diferentes. El primero, fuecreado mediante un procedimiento muy similar al utilizado en el estudio de la serie delprecio del petróleo. Se basaba de nuevo en el modelo de espacio de los estados y por tan-to, se tuvieron que estimar los parámetros que conformaban el modelo mediante máxima
63

64 CAPÍTULO 6. CONCLUSIONES
verosimilitud.
Tras de�nir el modelo, se hizo con él una predicción de los valores del año siguienteal considerado actual, 1984 y se compararon los resultados con los datos reales. Paramedir la validez del modelo, se hallaron los valores del error MAPE tanto del conjuntoestimación-predicción, como únicamente la predicción. Los valores de estos errores fueronun 10.56% y un 9.11% respectivamente. En comparación con la serie anterior se puedever cómo éste modelo no se adapta tan adecuadamente a esta serie en particular. Estose debe a que existen factores que in�uyen en su comportamiento que no se han tenidoen cuenta y que, aunque en el caso de la serie del precio del petróleo tampoco se hayanestudiado, en este caso en concreto su in�uencia en la serie es mucho más pronunciada.
Para intentar mejorar este resultado, se optó por la introducción en el modelo de es-pacio de los estados de una nueva variable explicativa, que tuviera en cuenta la in�uenciadel precio del petróleo sobre el número de accidentes de trá�co. El procedimiento seguidopara la de�nición del modelo vuelve a ser el de máxima verosimilitud, aunque con lasvariaciones pertinentes en su metodología para adaptarlo al modelo en cuestión. Durantela predicción realizada para el año 1984, también se modi�caron partes del código paraintroducir la presencia de la variable explicativa.
Este sistema es más complejo que el anterior y busca representar el comportamiento de lamisma serie pero dotando al modelo de más información para obtener mejores resultados.Si se ha de�nido correctamente, el error debería ser menor que en el caso del modelo mássimple sin variable explicativa. Al hallar el error MAPE, los resultados que se obtuvieronfueron de un 10.03% para el error de la estimación más la predicción y de un 5.70%para el de exclusivamente la predicción. A la vista de los resultados, se comprueba cómola implementación del nuevo modelo con variable explicativa mejora, tanto la estimacióncomo la predicción. Además, se observa cómo la modi�cación del modelo mejora sobretodo los datos de la predicción.
Como el principal objetivo de este proyecto era el de realizar una buena predicción de unaserie temporal, se puede considerar adecuada la ampliación del modelo.
El estudio de series temporales permite entender el funcionamiento y evolución de muchosfenómenos. Gracias a los resultados que nos proporciona la predicción de un modelo sepueden plani�car con antelación cómo intervenir en un proceso, permitiendo así optimizarlos resultados o realizar acciones preventivas, como en el caso de los accidentes de trá�co.
Después de todo este análisis conviene concluir, como es lógico, que una serie tempo-ral estará mejor de�nida cuantos más factores in�uyentes se tengan en cuenta. Ante unproyecto de este alcance, conviene escoger adecuadamente entre los diferentes factoresel que más aporte al modelo sin complicar de forma extrema su estudio. No siempre esfácil medir la presencia de factores dentro del modelo ni identi�carlos, pero resulta de

65
gran interés su análisis ya que, como se ha comprobado, pueden mejorar en gran medidael modelo y a�nar su comportamiento, obteniendo así una mejor representación de larealidad.

66 CAPÍTULO 6. CONCLUSIONES

Capítulo 7
LÍNEAS FUTURAS
Una vez analizados los resultados de los modelos desarrollados, se plantean otras po-sibles vías que permitan mejorar la precisión del modelo, reduciendo así los errores obte-nidos.
En primer lugar, una forma de mejorar la calidad del modelo es teniendo en cuenta en sude�nición la presencia de más factores. De esta manera, cuanta más información posea elmodelo, mejor podrá representar las variaciones que caracterizan su comportamiento.
Factor meteorológico como variable explicativa.
Un factor importante que no se ha tenido en cuenta y que puede afectar en los resul-tados obtenidos en la serie de los conductores víctimas graves de accidentes es el factormeteorológico. Esto se debe a que las condiciones atmosféricas pueden alterar el entornoo las circunstancias del conductor en gran medida. Por ejemplo, unas altas temperaturaspueden afectar al bienestar del conductor, creando una atmósfera no adecuada para laconducción y que pueda in�uir en la toma de decisiones al volante o en la concentración.También es peligroso conducir con malas condiciones meteorológicas como la lluvia, lanieve, la niebla o con la presencia de hielo en el asfalto, en este caso más característicasde Reino Unido. De este modo, añadiendo una variable explicativa que ponga de mani-�esto las condiciones meteorológicas, se puede predecir en qué momentos la conducciónes menos segura y por tanto, cuándo las probabilidades de sufrir un accidente aumentan.
Modelo con estacionalidad.
Si se observan los datos de las víctimas graves que sufrieron un accidente de trá�co enel intervalo de tiempo estudiado (1969-1984), se puede comprobar que hay determinadosmeses en los que el número de accidentes registrados es notablemente mayor que en otros.Esto puede deberse a las condiciones meteorológicas extremas características de determi-nados meses del años, condición que se ha comentado anteriormente. No obstante, otrofactor que puede in�uir directamente en los datos de esta serie temporal son las fechas
67

68 CAPÍTULO 7. LÍNEAS FUTURAS
en las que la gente suele realizar viajes más largos al volante. Cuando se presentan díasfestivos o épocas preferidas para vacaciones se producen una gran cantidad de desplaza-mientos. Está comprobado que cuando las carreteras están más concurridas, los riesgos deaccidente son mayores y por tanto la concentración del conductor debe aumentar frentea situaciones de trá�co �uido. También es muy común que durante estas fechas la dura-ción de los viajes en coche aumente en gran medida, por esta razón, si no se realizan losdescansos necesarios, la capacidad del conductor para llevar el coche correctamente puedeverse afectada. Por estas razones, un modelo con estacionalidad, es decir, que busque unpatrón repetitivo a lo largo del tiempo puede predecir de forma más precisa las fechas queson más vulnerables a accidentes de trá�co.
Mejoras en el manejo de datos.
Durante el desarrollo de las dos series temporales de este proyecto, los modelos �nalesse han obtenido a través de una estimación por máxima verosimilitud que toma comopunto de partida únicamente los datos históricos. Por lo tanto, si la base de datos histó-ricos se aumentara, el modelo tendría más información a cerca de las variaciones en losmodelos para un plazo de tiempo mayor. No obstante, también conviene separar los he-chos aislados que cambian bruscamente trayectoria de los datos y que pueden contaminarel modelo, como por ejemplo las dos crisis del petróleo de 1973 y 1979.

Capítulo 8
PLANIFICACIÓN TEMPORAL YPRESUPUESTO
8.1. Plani�cación temporal.
8.1.1. Estructura del desarrollo del proyecto.
1. Estudio previo.
a) Lectura y repaso de asignaturas cursadas durante el grado.
Estadística.
Diseño de Experimentos y Regresión.
Control Estadístico de Procesos.
b) Estudio de los conocimientos aplicados durante el proyecto.
Explicación teórica y práctica por parte del tutor.
Series temporales. Tipos, funcionamiento y modelos.
• Modelo de paseo aleatorio.
• Modelo de local level model.
• Modelo de espacio de los estados.
• Modelo autorregresivo de primer orden.
• Modelo de espacio de los estados con variables explicativas.
Procesos estocásticos.
• Proceso de ruido blanco.
Filtro de Kalman. De�nición y aplicación.
Método de máxima verosimilitud. Estimación.
Predicción de una serie temporal mediante el �ltro de Kalman.
Concepto de autocorrelación. Correlograma muestral.
Criterio de Akaike para la validación de un modelo.
69

70 CAPÍTULO 8. PLANIFICACIÓN TEMPORAL Y PRESUPUESTO
c) Lectura comprensiva del manual del software de R para su correcta utilizacióndurante este proyecto.
2. Programación en R.
a) Simulación de los modelos estudiados.
b) Simulación del �ltro de Kalman.
c) Creación de la biblioteca de funciones que se van a aplicar durante el estudioy desarrollo del modelo de las series temporales.
d) Desarrollo del código del programa de estimación del modelo y predicción co-rrespondiente a la serie temporal del precio del petróleo.
e) Desarrollo del código del programa de estimación del modelo y predicción de laserie temporal del número de conductores víctimas de un accidente de trá�cograve.
f ) Desarrollo del código del programa de estimación del modelo con variables ex-plicativas y predicción de la serie temporal del número de conductores víctimasde accidentes de trá�co graves.
3. Recopilación y análisis de los resultados.
a) Elección de los parámetros iniciales para la estimación.
b) Evaluación de la calidad de cada modelo desarrollado.
c) Comparación de los resultados obtenidos en el modelo con o sin variables ex-plicativas.
d) Conclusiones.
4. Lectura del manual de LaTex para la posterior redacción del proyecto.
5. Redacción del proyecto.
a) Redacción del borrador en Word.
b) Revisión y corrección.
c) Formato y redacción en LaTex.
8.1.2. Plani�cación, estructura y distribución temporal.
A continuación se presenta un cuadro con la duración de cada una de las actividadesexpuestas en el punto anterior. Debido a que el desarrollo del proyecto se combinó con elestudio de otras asignaturas y la realización de prácticas extracurriculares, la distribuciónde los días no fue continua y por lo tanto se clasi�ca con respecto a su duración. La fechade comienzo fue el 10/09/2016 y la de �nalización el 05/06/2017.

8.1. PLANIFICACIÓN TEMPORAL. 71
Figura 8.1: Plani�cación, estructura y distribución temporal.

72 CAPÍTULO 8. PLANIFICACIÓN TEMPORAL Y PRESUPUESTO
8.1.3. Diagrama de Gant.
Figura 8.2: Diagrama de Gant.

8.2. PRESUPUESTO DEL PROYECTO. 73
8.2. Presupuesto del proyecto.
A continuación se hace referencia a los sistemas utilizados durante este proyecto, a lasherramientas para su desarrollo y a la mano de obra necesaria, todo ello junto con suscostes asociados.
Mano de obra
La mano de obra incluye tanto la trabajada por el alumno como la del tutor. Durantela realización del proyecto se han contabilizado las horas empleadas para su desarrollo.
Recurso Tiempo(h) Precio (e/h) Coste(e)Trabajo del alumno 520 10 5200Trabajo del tutor 35 32 1120
Total 6320 e
Cuadro 8.1: Costes de la mano de obra.
Hardware
Actualmente, la vida útil de un ordenador se sitúa en torno a los 5 años, tanto si setrata de un portátil o un PC de sobremesa. En este caso, el ordenador portátil se adquiriópor 600 euros durante el año 2016 y el ordenador de sobremesa por 1000 euros en el 2017.Si se considera una amortización constante, es decir, de un 20% anual, los costes seríanlos siguientes:
Elemento Tiempo(h) Precio (e) Amortización Coste(e)Ordenador de sobremesa 400 100 20% anual 49.31Ordenador portátil 50 60 20% anual 6.57
Total 55.88 e
Cuadro 8.2: Costes hardware.
Software
Respecto al software utilizado, la mayoría fueron versiones gratuitas disponibles dedescarga. En el caso del Paquete O�ce, se trataba de una suscripción mensual cuyo pre-cio eran 7 euros al mes. El paquete O�ce se utilizó para redactar el borrador de la memoriadel proyecto en Word y para el Excel en el diagrama de Gant y algunos grá�cos de datosdel proyecto. Por tanto el coste asociado para el software es:

74 CAPÍTULO 8. PLANIFICACIÓN TEMPORAL Y PRESUPUESTO
Programa Tiempo(h) Precio (e/mes) Amortización Coste(e)R Project 2.12.2 240 Software libre 0 0R Studio 240 Software libre 0 0LaTex 66 Software libre 0 0MikTex 66 Software libre 0 0Adobe Reader DC 4 Versión gratuita 0 0Paquete O�ce 2017 264 7 0 0
Total 35.00 e
Cuadro 8.3: Costes software.
Presupuesto total para el proyecto
Concepto Coste asociado e)Mano de obra 6320.00Hardware 55.88Software 35.00
Total 6410.88 e
Cuadro 8.4: Coste total del proyecto.
Por tanto, una vez hechos los cálculos por separado se llega a un presupuesto total de6410.88 euros.

Capítulo 9
RESPONSABILIDAD SOCIAL
El estudio y conocimiento de la evolución y funcionamiento de las dos series tempo-rales que se han analizado a lo largo de este proyecto puede resultar bene�cioso para lasociedad, contribuyendo en tres aspectos diferentes: seguridad, medioambiente y econo-mía.
Gracias a la predicción de los datos de una serie temporal como la correspondiente alnúmero de conductores fallecidos o gravemente heridos en accidentes de trá�co se puedeconocer con antelación los periodos de tiempo más vulnerables para este tipo de inciden-tes. Mediante el desarrollo de modelos de estudio más completos que permitan acceder conantelación a la información, se pueden tomar medidas y reducir el número de víctimas,contribuyendo así a crear una sociedad más segura y concienciada.
Hoy en día es primordial la concienciación de los conductores, que al �n y al cabo, sonlos que deben presentar una mayor responsabilidad al volante. Frente a un aumento enel número de accidentes o unos valores en predicción preocupantes, las campañas deconcienciación y las medidas deben intensi�carse para evitar que se den este tipo de cir-cunstancias.
Con respecto a la serie del precio del petróleo, un conocimiento sobre su evolución ysus variaciones a lo largo del tiempo permite concienciar a la gente de que no se realiceun uso exhaustivo, dando opciones más económicas y menos contaminantes como puedeser el uso del transporte público. También, como se ha visto en el estudio de esta serie,el precio del petróleo sigue una tendencia ascendente y por lo tanto su precio se irá en-careciendo cada vez más a lo largo de los años. Otro aspecto negativo que se ha visto eneste estudio es la volatilidad del mercado del petróleo, sujeto a múltiples variaciones ensu precio debido a factores políticos y a su escasez.
Es importante buscar alternativas que además de ser más limpias con el medio ambientesean a la larga una inversión para los usuarios que reduzca sus gastos económicos y queles proporcione independencia con respecto a las alteraciones en el precio del combustible.
75

76 CAPÍTULO 9. RESPONSABILIDAD SOCIAL
Medidas como éstas están disponibles ya en el mercado, como pueden ser los vehículoseléctricos o los híbridos.

Bibliografía
[1] Técnicas Avanzadas de Predicción / César Pérez lópez (2016)
[2] Series Temporales : Técnicas y Herramientas / César Pérez López (2011)
[3] An Introduction to the Kalman Filter/ Greg Welch, Gary Bishop (2001)
[4] Análisis de Series Temporales / Daniel Peña (2010)
[5] Introducción al Análisis de Series Temporales / Ezequiel Uriel, Amado Peiró(2005)
[6] An Introduction to State Space Time Series Analysis / Jacques J.F. Com-mandeur, Siem Jan Koopman (2007)
[7] Time Series Analysis and Its Applications/ Robert H.Shumway, David S.Sto�er(third edition, 2010)
[8] Introduction to Time Series and Forecasting / Peter J. Brockwell,Richard A.Davis (third edition, 2016)
[9] Introduction to Modern Time Series Analysis / Gebhard Kirchgässner, JürgenWolters, Uwe Hassler (second edition, 2013)
[10] Estadística con R/ Eduardo Caro Huertas, Jaime Carpio Huertas, Jesús Juan Ruiz,Alberto Rodríguez Galledo, Francisco Santos Penido (2012)
[11] The Art of R Programming/ Normal Matlo� (2011)
[12] Tutorial: The Kalman Filter/ Tony Lacey (1998)
[13] Análisis de Series Temporales: Modelos ARIMA / María Pilar González Ca-simiro (2009)
[14] Series Temporales / Teresa Villagarcía
[15] Econometría / A. Novales (1993)
[16] Reported Road Accident Statistics / Matthew Keep, Tom Rutherford (2013)
77

78 BIBLIOGRAFÍA
[17] Tendencia Histórica de los Precios del Petróleo (1860-2004) / GeraldineLeón (2007)
[18] El Precio del Crudo y su Historia / Eugenia Stratta (2016)
[19] Enciclopedia Durvan (1997)

Apéndice A
DEFINICIÓN DE LOS PROGRAMASDESARROLLADOS EN R.
A.1. Programas base utilizados en fundamento teórico
A.1.1. Simulación de un proceso de ruido blanco
#Simulacion de l ru ido b lanco para una muestra de 500w<−rnorm(500 ,0 , 1 )print (w)
#Representacion g r a f i c a d e l proceso de ruido b lancoplot . ts (w, main="Ejemplo Ruido Blanco" , xlab="Tiempo , t " , ylab="Valor
" , col="red" )#Correlograma de l proceso de ruido b lanco ha l l a do
c<−ac f (w, main="Autocor r e l ac i on Ruido Blanco" , xlab=" re tardo " , ylab="ACF" , col="red" )
A.1.2. Simulación de un proceso con paseo aleatorio
#Simulacion de ruido b lanco con dimension 100 y muestro su va l o rw<−rnorm(100 ,0 , 1 )print (w)x=rnorm(100)
#Se l e as igna a l a s e r i e e l v a l o r i n i c i a l de −1x [ 1 ]<−−1
#Se ha l l an l o s v a l o r e s de l a s e r i e u t i l i z a n d o un proceso de paseo a l e a t o r i ofor ( i in 1 : ( length ( x ) ) ) {x [ i +1]=x [ i ]+w[ i ] }
#Se muestran y representan l o s v a l o r e s de l a s e r i e en pan t a l l aprint ( x )plot . ts (x , main="Paseo a l e a t o r i o " , xlab="Tiempo , t " , ylab="Valor Xt"
, col="Blue" )
A.1.3. Simulación de un proceso con local level model
79

80 APÉNDICE A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R.
#Se crean dos procesos de ruido blanco , w y v , para una muestra de n=100n=100w<−rnorm(n , 0 , 1 )print (w)v<−rnorm(n , 0 , 1 )print ( v )
# Se de f i n e e l v e c t o r y de n componentes para l a observac iony<−rep (0 , n)
# Se de f i n e e l v e c t o r x y su va l o r i n i c i a l , 1x<−rep (0 , n+1)x [1 ]=1
# Se ap l i c a e l modelo de l o c a l l e v e l model para h a l l a r yfor ( i in 1 : n ) {y [ i ]<−x [ i ]+v [ i ]x [ i +1]<−x [ i ]+w[ i ] }
#Se muestra l o s v a l o r e s de x e yprint ( x )print ( y )
#Se representan l o s v a l o r e s de x e y en una gra f i ca , en ro jo y a zu lplot . ts (y , main="Local Leve l Model" , col="blue " , xlab="Tiempo , t " ,
ylab=" va lo r Xt , Yt" )l ines (x , col="red" )
A.1.4. Simulación del �ltro de Kalman aplicado a un proceso conmodelo local level model
#Se de f i n e l a fuen t e que cont i ene l a s func ionessource ( " B ib l i o t e caFunc ione s .R" )
#Se f i j a n l o s v a l o r e s a l e a t o r i o sset . seed (1 )
#Se u t i l i z a l a func ion EspacioEstados para a=1 y c=1 para h a l l a r y#Se dan va l o r a todas l a s v a r i a b l e s de entrada de l a func ion EspacioEstados
x1=0Q=1R=1a=1c=1n=20l s t S o l u c i o n e e<−EspacioEstados ( x1 ,Q,R, a , c , n )
#Se muestran por p an t a l l a l o s v a l o r e s de s a l i d a de l a func ionEspacioEstados
print ( l s t S o l u c i o n e e )#U t i l i z o l a v a r i a b l e de s a l i d a y de EspacioEstados para ent rar con e l l a en
FiltroKalman#Doy va l o r a todas l a s v a r i a b l e s de entrada de l a func ion F i l t r o Kalman
p1=0l s tSo luc ionka lman<−FiltroKalman ( l s t S o l u c i o n e e$y , a , c ,Q,R, x1 , p1 , n)
#Se muestran por p an t a l l a l o s v a l o r e s de s a l i d a de l a func ion FiltroKalmanprint ( l s tSo luc ionka lman )
#Se representan gra f i camente l o s v a l o r e s de x r e a l f r e n t e a xe ( est imada )plot . ts ( l s tSo luc ionka lman$xe , col="red" )

A.1. PROGRAMAS BASE UTILIZADOS EN FUNDAMENTO TEÓRICO 81
l ines ( l s t S o l u c i o n e e$x , col="green " )#Se ha l l an l o s v a l o r e s est imados de l a observac ion , ye a t r a v e s de l o s
est imados de xeye<−rep (0 , n)ye=c∗ l s tSo luc ionka lman$xe [ 1 : n ]
#Se representan gra f i camente l o s v a l o r e s de y r e a l f r e n t e a y est imadaplot . ts ( l s t S o l u c i o n e e$y , col="orange " )l ines ( ye , col="blue " )
A.1.5. Simulación del �ltro de Kalman aplicado a un proceso conmodelo de espacio de los estados
#Se de f i n e l a fuen t e a l a que va a r e c u r r i r e s t e programa para hacer uso desus func iones
source ( " B ib l i o t e caFunc ione s .R" )#Se f i j a n l o s v a l o r e s a l e a t o r i o s para que no var ien cada vez que se e j e c u t e
e l programaset . seed (1 )
#Se l lama a l a func ion EspacioEstados para h a l l a r y#Se dan va l o r e s a l e a t o r i o s a todas l a s v a r i a b l e s de entrada de l a func ion
x1=0Q=1R=1a=0.5c=2n=20l s t S o l u c i o n e e<−EspacioEstados ( x1 ,Q,R, a , c , n )
#Se muestran por p an t a l l a l o s v a l o r e s de s a l i d a de l a func ionEspacioEstados
print ( l s t S o l u c i o n e e )#Se u t i l i z a l a v a r i a b l e de s a l i d a y para ent rar en FiltroKalman#Se dan va l o r a todas l a s v a r i a b l e s de entrada de l a func ion
p1=0l s tSo luc ionka lman<−FiltroKalman ( l s t S o l u c i o n e e$y , a , c ,Q,R, x1 , p1 , n)
#Se muestran por p an t a l l a l o s v a l o r e s de s a l i d a de l a func ion FiltroKalmanprint ( l s tSo luc ionka lman )
#Se representan gra f i camente l o s v a l o r e s x r e a l f r e n t e a xe ( est imada )plot . ts ( l s t S o l u c i o n e e$x , col="red" )l ines ( l s tSo luc ionka lman$xe , col="green " )
#Se h a l l a e l v a l o r de ye , est imada a t r a v e s d e l de xe , est imadaye<−rep (0 , n)ye=c∗ l s tSo luc ionka lman$xe [ 1 : n ]
#Graf ica que repre sen ta y , en co l o r naranja , f r e n t e a ye en co l o r a zu lplot . ts ( l s t S o l u c i o n e e$y , main=" F i l t r o de Kalman con Espacio de l o s
Estados " ) l ines ( ye , col="blue " )
A.1.6. Biblioteca de las funciones generales de este apartado
#BIBLIOTECA DE FUNCIONES BASE#Funcion para un proceso de espac io de l o s e s tados#Var iab l e s de entrada a l a func ion :

82 APÉNDICE A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R.
#x1 , va l o r i n i c i a l de l a v a r i a b l e observac ion en e l modelo#Q y R, var ianzas de l o s ru idos b lancos v y w#a y c , cons tan te s d e l modelo#n , cant idad de datos de l a muestra#Var iab l e s de s a l i d a : y , observac ion y x , es tado .
EspacioEstados=function ( x1 ,Q,R, a , c , n ) {w<−rnorm(n , 0 , sqrt (Q) )v<−rnorm(n , 0 , sqrt (R) )x<−rep (0 , n+1)x [ 1 ]<−x1
y<−rep (0 , n)for ( i in 1 : n ) {x [ i +1]<−( a∗x [ i ]+w[ i ] )y [ i ]<−(c∗x [ i ]+v [ i ] )}l s t e e=l i s t ( x=x , y=y)return ( l s t e e )
}
#Funcion F i l t r o de Kalman#Var iab l e s de entrada a l a func ion :#x1 , P1 va l o r e s i n i c i a l e s d e l modelo#y , v a r i a b l e observac ion#Q y R, var ianzas de l o s ru idos b lancos v y w#a y c , cons tan te s d e l modelo#n , cant idad de datos#Var iab l e s de sa l i da , xe est imada
FiltroKalman=function (y , a , c ,Q,R, x1 , p1 , n) {w<−rnorm(n , 0 , sqrt (Q) )v<−rnorm(n , 0 , sqrt (R) )xe<−rep (0 , n+1)xe [ 1 ]<−x1p<−rep (0 , n+1)p [ 1 ]<−p1e<−rep (0 , n)s<−rep (0 , n)k<−rep (0 , n)for ( i in 1 : n ) {e [ i ]<−( y [ i ]−c∗xe [ i ] )s [ i ]<−( ( c^2)∗p [ i ]+R)k [ i ]<−( a∗c∗p [ i ] /s [ i ] )xe [ i +1]<−( a∗xe [ i ]+k [ i ] ∗e [ i ] )p [ i +1]<−( ( a^2)∗p [ i ]+Q−(k [ i ]^2)∗s [ i ] )}l s tka lman=l i s t ( xe=xe , p=p , e=e , s=s , k=k)return ( l s tka lman )
}

A.2. BIBLIOTECA DE LAS FUNCIONES GENERALES 83
A.2. Biblioteca de las funciones generales
A.2.1. Funciones utilizadas durante estudio de las series tempo-rales
####################### BIBLIOTECA DE FUNCIONES #####################
#FILTRO DE KALMAN
FiltroKalman=function (y , a , c ,Q,R, x1 , P1) {n =length ( y )xe<−rep (0 , n+1)xe [ 1 ]<−x1
P<−rep (0 , n+1)P [ 1 ]<−P1e<−rep (0 , n)s<−rep (0 , n)k<−rep (0 , n)Like=−(n/2)∗log (2∗pi )for ( i in 1 : n ) {
e [ i ] <− y [ i ]−c∗xe [ i ]s [ i ] <− c^2∗P[ i ]+Rk [ i ]<−( a∗c∗P[ i ] /s [ i ] )xe [ i +1]<−( a∗xe [ i ]+k [ i ] ∗e [ i ] )P [ i +1]<− ( a^2)∗P[ i ]+Q−(k [ i ]^2)∗s [ i ]
Like <− Like −0.5∗ ( log ( s [ i ] )+ e [ i ]^2/s [ i ] )}
l s tka lman=l i s t ( xe=xe ,P=P, e=e , s=s , k=k , Like=Like )return ( l s tka lman )
}
#FUNCION AIC
AIC=function (y , a , c ,Q,R, x1 , P1) {so l fka lman<−FiltroKalman (y , a , c ,Q,R, x1 , P1)Like<−so l fka lman$Likea i c<−1/length ( y )∗(−2∗length ( y )∗Like+2∗6)return ( a i c=a i c )
}
#FUNCION AIC PARA VARIABLES EXPLICATIVAS
AICEXP=function (y , u , a , c ,Q,R, d , x1 , P1) {so l fka lman<−KalmanExp(y , u , a , c , d ,Q,R, x1 , P1)Like<−so l fka lman$Likea i c<−1/length ( y )∗(−2∗length ( y )∗Like+2∗18)return ( a i c=a i c )
}

84 APÉNDICE A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R.
#FUNCION PARA PREDICCION#par te de datos observados y y con e l l o s y l a es t imacion de sus parametros#ob t i ene una predicc iOn con un a lcance en e l tiempo de n . ahead
pred=function (y , ae , ce ,Qe ,Re, x1e , P1e , n . ahead ) {xp<−rep (0 , n . ahead+1)Pp<−rep (0 , n . ahead+1)e<−rep (0 , n . ahead )s<−rep (0 , n . ahead )k<−rep (0 , n . ahead )yp<−rep (0 , n . ahead )
l s tSo luc ionka lman<−FiltroKalman (y , ae , ce ,Qe ,Re, x1e , P1e )xp [ 1 ]<−l s tSo luc ionka lman$xe [ length ( y )+1]Pp [ 1 ]<−l s tSo luc ionka lman$P[ length ( y )+1]ye<−ce∗ l s tSo luc ionka lman$xe [ 1 : length ( y ) ]se<−sqrt ( l s tSo luc ionka lman$s )for (m in 1 : n . ahead ) {
s [m]<−ce^2∗Pp [m]+Rek [m]<−ae∗ce∗Pp [m] /s [m]yp [m]<−ce∗xp [m]xp [m+1]<−ae∗xp [m]Pp [m+1]<−ae^2∗Pp [m]+Qe−k [m]^2∗s [m]
}ypSE<−sqrt ( s )l s t S o l u c i onp r ed<−l i s t ( yp=yp , ypSE=ypSE , ye=ye , se=se )return ( l s t S o l u c i onp r ed )
}
#FILTRO DE KALMAN PARA VARIABLES EXPLICATIVAS
KalmanExp=function (y , u , a , c , d ,Q,R, x1 , P1) {n =length ( y )xe<−rep (0 , n+1)xe [ 1 ]<−x1P<−rep (0 , n+1)P [ 1 ]<−P1e<−rep (0 , n )s<−rep (0 , n )k<−rep (0 , n )Like=−(n/2)∗log (2∗pi )for ( i in 1 : n ) {
e [ i ] <− y [ i ]−c∗xe [ i ]−d%∗%u [ , i ]s [ i ] <− c^2∗P[ i ]+Rk [ i ]<−( a∗c∗P[ i ] /s [ i ] )xe [ i +1]<−( a∗xe [ i ]+k [ i ] ∗e [ i ] )P [ i +1]<− ( a^2)∗P[ i ]+Q−(k [ i ]^2)∗s [ i ]Like <− Like −0.5∗ ( log ( s [ i ] )+ ( e [ i ]^2)/s [ i ] )
}
lstkalmanExp=l i s t ( xe=xe ,P=P, e=e , s=s , k=k , Like=Like )return ( lstkalmanExp )
}

A.2. BIBLIOTECA DE LAS FUNCIONES GENERALES 85
#FUNCION PREDICCION PARA VARIABLES EXPLICATIVAS
predExp=function (y , u , up , ae , ce ,de ,Qe ,Re, x1e , P1e , n . ahead ) {xp<−rep (0 , n . ahead+1)Pp<−rep (0 , n . ahead+1)e<−rep (0 , n . ahead )s<−rep (0 , n . ahead )k<−rep (0 , n . ahead )yp<−rep (0 , n . ahead )l s tSo lka lman<−KalmanExp(y , u , ae , ce ,de ,Qe ,Re, x1e , P1e )
xp [ 1 ]<−l s tSo lka lman$xe [ length ( y )+1]Pp [ 1 ]<−l s tSo lka lman$P[ length ( y )+1]ye<−ce∗ l s tSo lka lman$xe [ 1 : length ( y ) ]se<−sqrt ( l s tSo lnka lman$s )for (m in 1 : n . ahead ) {s [m]<−ce^2∗Pp [m]+Rek [m]<−ae∗ce∗Pp [m] /s [m]xp [m+1]<−ae∗xp [m]Pp [m+1]<−ae^2∗Pp [m]+Qe−k [m]^2∗s [m]yp [m]<−ce∗xp [m]+de%∗%up [ ,m]}
ypSE<−sqrt ( s )l s t S o l u c i onp r ed<−l i s t ( yp=yp , ypSE=ypSE , ye=ye , se=se )return ( l s t S o l u c i onp r ed )
}
#ESTIMACION PETROL (DEVUELVE VALOR DE LOS PARAMETROS ESTIMADOS DEL MODELODEL PRECIO DEL PETROLEO)
Est imac ionPetro l=function ( uobs ) {y<−uobs
Linn=function ( param) {a<−param [ 1 ]c<−param [ 2 ]Q<−param [3 ]^2R<−param [4 ]^2x1<−param [ 5 ]P1<−param [6 ]^2kf = FiltroKalman (y , a , c ,Q,R, x1 , P1)return(−kf$Like ) }
a0=0.9621c0=1Q0=0.00001108R0=Q0/1000x10=0P10=Q0/(1−a0^2)i n i t . par<−c ( a0 , c0 ,Q0,R0 , x10 , P10 )e s t = optim( i n i t .par , Linn , gr=NULL, method="BFGS" ,
he s s i an=TRUE, control=l i s t ( trace=1,REPORT=1,maxit=500) )

86 APÉNDICE A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R.
paramest=e s t$parae=paramest [ 1 ]ce=paramest [ 2 ]Qe=paramest [ 3 ]^2Re=paramest [ 4 ]^2x1e=paramest [ 5 ]P1e=paramest [ 6 ]^2Estim=l i s t ( ae=ae , ce=ce ,Qe=Qe ,Re=Re, x1e=x1e , P1e=P1e )return ( Estim )
}
#VALOR PETROL DEVUELVE PREDICCION DE nahead MESES
ValorPetro l=function ( uobs , nahead ) {y<−uobs
Linn=function ( param) {a<−param [ 1 ]c<−param [ 2 ]Q<−param [3 ]^2R<−param [4 ]^2x1<−param [ 5 ]P1<−param [6 ]^2kf = FiltroKalman (y , a , c ,Q,R, x1 , P1)return(−kf$Like ) }
a0=0.9621c0=1Q0=0.00001108R0=Q0/1000x10=0P10=Q0/(1−a0^2)I n i t . par<−c ( a0 , c0 ,Q0,R0 , x10 , P10 )e s t = optim( i n i t .par , Linn , gr=NULL, method="BFGS" ,
he s s i an=TRUE, control=l i s t ( trace=1,REPORT=1) )paramest=e s t$par
ae=paramest [ 1 ]ce=paramest [ 2 ]Qe=paramest [ 3 ]^2Re=paramest [ 4 ]^2x1e=paramest [ 5 ]P1e=paramest [ 6 ]^2Pe t r o lP r ed i c t i on<−pred (y , ae , ce ,Qe ,Re, x1e , P1e , nahead
)yp<−Pet r o lP r ed i c t i on$ypl s tVa lo rPe t ro lPred<−l i s t ( yp=yp )return ( l s tVa lo rPe t ro lPred )
}

A.3. PROGRAMAS PARA LA SERIE DEL PRECIO DEL PETRÓLEO 87
#FUNCION QUE DEVUELVE EL ERROR MAPE
MAPE=function ( yrea l , yep ) {n<−length ( y r e a l )mape<−0for ( i in 1 : n ) {mape<−mape+(100/n)∗abs ( ( y r e a l [ i ]−yep [ i ] ) /y r e a l [ i ] )}MAPE<−l i s t (mape=mape)return (MAPE)
}
A.3. Programas para la serie del precio del petróleo
A.3.1. Estudio de la tendencia mediante la recta de regresión
#Se de f i n e l a fuen t e de l a s func iones u t i l i z a d a ssource ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )rm( l i s t=l s ( ) )
#Lectura de datos d e l v a l o r d e l p e t r o l e oda to spe t r o l e o<−scan ( " da to spe t r o l e o . txt " )
#Se muestran l o s datos importados d e l f i c h e r o . t x t d e l p rec io d e l p e t r o l e oprint ( da to spe t r o l e o )ypet<−( da to spe t r o l e o )
#Se crea un vec t o r que contenga l a numeracion de l o s mesesmonths<−( 1 : 1 92 )
#Se crea y repre sen ta gra f i camente l a l i n e a de r e g r e s i onr e g r e s i on2 <− lm( ypet ~ months )plot . ts ( ypet , col="orange " , xlab="Months" , ylab="Pet ro l p r i c e " )abline ( r e g r e s i on2 )
A.3.2. Correlograma de los datos del precio del petróleo
#Def in i c i on de l a fuen t e de l a s func iones u t i l i z a d a srm( l i s t=l s ( ) )source ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )
#Lectura de l o s datos d e l f i c h e r o . t x t d e l p rec io d e l p e t r o l e oda to sp e t r o l<−scan ( " da to spe t r o l e o . txt " )Prec io_Pet ro l eo<−da to sp e t r o l
#Correlograma de l o s h i s t o r i c o s d e l p rec io d e l p e t r o l e oac f ( Prec io_Pet ro l eo )
A.3.3. Obtención de los parámetros iniciales para la estimaciónmediante AR(1)
#Def in i c i on de l a fuen t e de l a s func iones u t i l i z a d a srm( l i s t=l s ( ) )source ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )
#Se l een l o s datos de un f i c h e r o . t x t sobre e l p rec io d e l p e t r o l e o

88 APÉNDICE A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R.
ype t r o l<−scan ( " da to spe t r o l e o . txt " )#Se r e a l i z a una es t imacion de l o s parametros de un modelo AR(1)#Modelo AR(1) : y [ t ] = a1∗y [ t−1] + e t#Var iab l e de entrada de l a funcion , datos de l a observac ion , y p e t r o l#Var iab l e s de s a l i d a : a , Q=var ( e t )
ParamPetrol<−ar ( ypetro l , a i c=TRUE, order .max=1)print ( ParamPetrol )
A.3.4. Programa completo para el estudio, la estimación y pre-dicción de un año de la serie del precio del petróleo
#Def in i c i on de l a fuen t e de l a s func iones u t i l i z a d a srm( l i s t=l s ( ) )source ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )
#Lectura de datos d e l v a l o r d e l p e t r o l e o desde 1969 has ta 1983 , yy<−scan ( " dato spe t ro l eo1983 . txt " )print ( y )
#Lectura de datos d e l v a l o r d e l p e t r o l e o 1969−1984 , y fyf<−scan ( " da to spe t r o l e o . txt " )
#Funcion Linn dependiente de l o s parametros a , c , Q, R, x1 , P1#Con su op t imizac ion se h a l l a r a e l v a l o r de l o s parametros
Linn=function ( param) {a<−param [ 1 ]c<−param [ 2 ]Q<−param [3 ]^2R<−param [4 ]^2x1<−param [ 5 ]P1<−param [6 ]^2kf = FiltroKalman (y , a , c ,Q,R, x1 , P1)return(−kf$Like )
}#Valores de par t i da para i n i c i a r l a op t imizac ion y op t imizac ion
a0=0.9621c0=1Q0=0.00001108R0=Q0/1000x10=0P10=Q0/(1−a0^2)i n i t . par<−c ( a0 , c0 ,Q0,R0 , x10 , P10 )e s t = optim( i n i t .par , Linn , gr=NULL, method="BFGS" , he s s i an=TRUE,
control=l i s t ( trace=1,REPORT=1,maxit=500) )ae=paramest [ 1 ]ce=paramest [ 2 ]Qe=paramest [ 3 ]^2Re=paramest [ 4 ]^2x1e=paramest [ 5 ]P1e=paramest [ 6 ]^2
#Con l o s v a l o r e s est imados de cada parametro , ae , ce , Qe , Re , x1e , P1e#se pred icen doce meses con a c t u a l i z a c i on de datos mes a mes
ya<−yyp<−rep (0 , 12 )

A.4. PROGRAMAS PARA LA SERIE DEL ÍNDICE KSI DRIVERS 89
ypSE<−rep (0 , 12 )for ( i in 1 : 12 ) {
n . ahead=1Pe t r o lP r ed i c t i on<−pred ( ya , ae , ce ,Qe ,Re, x1e , P1e , n . ahead )yp [ i ]<−Pet r o lP r ed i c t i on$ypypSE [ i ]<−Pet r o lP r ed i c t i on$ypSEya [ length ( y )+i ]<−yf [ length ( y )+i ]
}print ( yp )
#Representacion g r a f i c a : yrea l , yestimada , ypred icha e i n t e r v a l o s#Se crean v e c t o r e s con l a informacion est imada y pred icha
sep<−Pet r o lP r ed i c t i on$sefor ( i in ( length ( y )+1) : ( length ( y )+12) ) {
sep [ i ]<−ypSE [ ( i )−length ( y ) ]}yep<−Pet r o lP r ed i c t i on$yefor ( i in ( length ( y )+1) : ( length ( y )+12) ) {
yep [ i ]<−yp [ ( i )−length ( y ) ]}
#Calcu lo de l o s i n t e r v a l o s de con f ianzaInterva loSup=rep (0 , length ( yep ) )I n t e r v a l o I n f=rep (0 , length ( yep ) )for ( j in 1 : length ( yep ) ) {
Interva loSup [ j ]<−( yep [ j ]+2∗sep [ j ] )I n t e r v a l o I n f [ j ]<−( yep [ j ]−2∗sep [ j ] )
}plot . ts ( yf , col="red" , ylim=c ( 0 . 0 7 , 0 . 1 5 ) , x lab="Meses" , ylab="Prec io
Pet ro l eo " ) l ines ( yep , col="blue " ) l ines ( IntervaloSup , col="green ") l ines ( I n t e r va l o I n f , col="green " )
#Calcu lo AIC por e l c r i t e r i o de Akaikea i c<−AIC(y , ae , ce ,Qe ,Re, x1e , P1e )print ( a i c )
#Error de l a es t imacion y pred i c c i on repre s en tac ion g r a f i c ae<−( yf−yep )mean( e )plot ( e )
#Autocorre lac ion de l e r rorac f ( e )
#Error MAPE todo e l modelo en l a es t imacion y pred i c c i onmape<−MAPE( yf , yep )
#Error MAPE so l o de l a p red i c c i onmapep<−MAPE( yf [ 1 8 0 : 1 9 2 ] , yep [ 1 8 0 : 1 9 2 ] )
A.4. Programas para la serie del índice KSI Drivers
A.4.1. Estudio de la tendencia del logaritmo de KSI drivers
#Def in i c i on de l a fuen t e de l a s func iones que se u t i l i z a nrm( l i s t=l s ( ) )source ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )
#Lectura d e l numero de conductores v i c t imas de acc i d en t e s 1969−1983

90 APÉNDICE A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R.
ycond<−scan ( " da to sv i a j e r o s 1983 . txt " )#Creacion de un vec to r que contenga l a po s i c i on de cada mes
months<−( 1 : length ( ycond ) )#Representacion g r a f i c a de l o s datos con l a r ec t a de r e g r e s i on
r e g r e s i o n<−lm( ycond ~ months )plot ( ycond , col="green " , xlab="Months" , ylab="Log ( Dr iver s KSI ) " )abline ( r eg r e s i on , col="red" )
#Error d e l l ogar i tmo de l a s e r i e en e l modelo de r e g r e s i on y corre logramae r r o r<−( ycond−7.537075+0.001303∗months )a c f ( e r ror , main="Autocor r e l ac i on de l e r r o r " )print (mean( e r r o r ) )print (var ( e r r o r ) )
A.4.2. Programa completo para el estudio, estimación y predic-ción de un año del índice KSI drivers
#Def in i c i on de l a fuen t e de l a s func iones que se u t i l i z a nrm( l i s t=l s ( ) )source ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )
#Lectura de l numero de conductores v i c t imas acc i d en t e s 1969−1983y<−scan ( " da to sv i a j e r o s 1983 . txt " )
#Lectura de l numero de conductores v i c t imas acc i d en t e s 1969−1984yf<−scan ( " d a t o s v i a j e r o s . txt " )
#Funcion Linn dependiente de l o s parametros a , c , Q, R, x1 , P1#Con su op t imizac ion se ob t i enen l o s parametros est imados
Linn=function ( param) {a<−param [ 1 ]c<−param [ 2 ]Q<−param [3 ]^2R<−param [4 ]^2x1<−param [ 5 ]P1<−param [6 ]^2kf = FiltroKalman (y , a , c ,Q,R, x1 , P1)return(−kf$Like )
}#Valores de par t i da para i n i c i a r l a op t imizac ion mediante i t e r a c i o n
a0=0.1c0=0.1Q0=sqrt ( 0 . 0 1 )R0=sqrt ( 0 . 0 1 )x10=0P10=Q0/(1−a0^2)i n i t . par<−c ( a0 , c0 ,Q0,R0 , x10 , P10 )e s t = optim( i n i t .par , Linn , gr=NULL, method="BFGS" , he s s i an=TRUE,
control=l i s t ( trace=1,REPORT=1) )paramest=e s t$parae=paramest [ 1 ]ce=paramest [ 2 ]Qe=paramest [ 3 ]^2Re=paramest [ 4 ]^2x1e=paramest [ 5 ]

A.5. PROGRAMAS PARA LA SERIE KSI CON VARIABLES EXPLICATIVAS 91
P1e=paramest [ 6 ]^2#Con l o s v a l o r e s est imados de cada parametro , ae , ce , Qe , Re , x1e , P1e#Se estiman 12 meses ac tua l i z ando datos mes a mes ( ya=y ac tua l )
ya<−yyp<−rep (0 , 12 )ypSE<−rep (0 , 12 )for ( i in 1 : 12 ) {
n . ahead=1Dr iv e r sPr ed i c t i on<−pred ( ya , ae , ce ,Qe ,Re, x1e , P1e , n . ahead )yp [ i ]<−Dr iv e r sPr ed i c t i on$ypypSE [ i ]<−Dr iv e r sPr ed i c t i on$ypSEya [ length ( y )+i ]<−yf [ length ( y )+i ]
}#Representacion de yrea l , yest imada e ypred icha con sus i n t e r v a l o s#Se crean v e c t o r e s que contengan es t imacion/pred i c c i on de s
sep<−Dr iv e r sPr ed i c t i on$sefor ( i in ( length ( y )+1) : ( length ( y )+12) ) {
sep [ i ]<−ypSE [ ( i )−length ( y ) ]}
#Se crean v e c t o r e s que contengan es t imacion/pred i c c i on de yyep<−Dr iv e r sPr ed i c t i on$yefor ( i in ( length ( y )+1) : ( length ( y )+12) ) {
yep [ i ]<−yp [ ( i )−length ( y ) ]}
#Graf ica con l o s datos r ea l e s , est imados , pred i chos e i n t e r v a l o s#Se ha l l an l o s i n t e r v a l o s de con f ianza
Interva loSup=rep (0 , length ( yep ) )I n t e r v a l o I n f=rep (0 , length ( yep ) )for ( j in 1 : length ( yep ) ) {
Interva loSup [ j ]<−( yep [ j ]+2∗sep [ j ] )I n t e r v a l o I n f [ j ]<−( yep [ j ]−2∗sep [ j ] )
}plot . ts ( yf , col="red" , xlab="Meses" , ylab="KSI Dr iver s " ,main="Valor
Real / Valor Estimado" ) l ines ( yep , col="blue " ) l ines ( IntervaloSup ,col="green " ) l ines ( I n t e r va l o I n f , col="green " )
#Error MAPE todo e l modelomape<−MAPE( yf , yep )
#Error MAPE so l o p red i c c i onmapep<−MAPE( yf [ 1 8 0 : 1 9 2 ] , yep [ 1 8 0 : 1 9 2 ] )
#Error ab so l u t o y au t o r r e l a c i on de l e r rorError_Absoluto<−( yf−yep )ac f ( Error_Absoluto )
A.5. Programas para la serie KSI con variables expli-cativas
A.5.1. Estudio de la relación entre el precio petróleo y el índiceKSI drivers
#Def in i c i on de l a fuen t e de l a s func iones que se u t i l i z a n

92 APÉNDICE A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R.
rm( l i s t=l s ( ) )source ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )set . seed (1 )
#Lectura de datos de ambas s e r i e s tempora lesy<−scan ( " d a t o s v i a j e r o s . txt " )u<−scan ( " da to spe t r o l e o . txt " )
#Graf ica de ambas s e r i e s con l a r ec t a de r e g r e s i on ent re ambasplot (u , y , main="Relac ion Prec io Pet ro l eo/ KSI Dr iver s " , xlab="
Prec io p e t r o l e o " , ylab="KSI Dr iver s " , col="blue " )abline (lm( y~u) , col="red" )
A.5.2. Obtención de los valores iniciales de los parámetros porAR(1)
#Def in i c i on de l a fuen t e de l a s func iones que se u t i l i z a nrm( l i s t=l s ( ) )source ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )
#Lectura de l o s datos de un f i c h e r o . t x t sobre l o s KSI d r i v e r syd r i v e r s<−scan ( " d a t o s v i a j e r o s . txt " )
#Se r e a l i z a una es t imacion de l o s parametros de un modelo AR(1)#Modelo AR(1) : y [ t ] = a1∗y [ t−1] + e t#Var iab l e de entrada de l a funcion , datos de l a observac ion , y d r i v e r s#Var iab l e s de s a l i d a : a , Q=var ( e t )#Se r e a l i z a una es t imacion de l o s parametros de un modelo AR(1)
ParamDrivers<−ar ( ydr ive r s , a i c=TRUE, order .max=1)print ( ParamDrivers )
A.5.3. Programa para el estudio, estimación y predicción de unaño de la serie KSI drivers con variables explicativas
#Def in i c i on de l a fuen t e de l a s func iones que se u t i l i z a nrm( l i s t=l s ( ) )source ( "Bib l io tecaFunc ionesLy con mod i f i c a c i one s .R" )
#Lectura de l o s datos r e a l e s de ambas s e r i e s 1969−1983y<−scan ( " da to sv i a j e r o s 1983 . txt " )uobs<−scan ( " dato spe t ro l eo1983 . txt " )
#Lectura de l o s datos r e a l e s de ambas s e r i e s 1969−1984yf<−scan ( " d a t o s v i a j e r o s . txt " )uobs f<−scan ( " da to spe t r o l e o . txt " )
#Creacion de l a matr iz u , con l o s datos de l a v a r i a b l e e x p l i c a t i v a , e lp r ec io d e l
#pe t r o l e o y e l mes corre spond i en te a cada dato con va l o r 1#In i c i a lmen t e se crea una matr iz de apoyo de dimension 2x180 , f echa
yea r i =1969nmonth=length ( uobs )nyear=nmonth%/%12fecha=matrix (0 , nrow = 2 , ncol=nmonth)for ( i in 0 : nyear ) {
for (m in 1 : 12 ) {c<−( i ∗12+m)i f (c>nmonth) {break}

A.5. PROGRAMAS PARA LA SERIE KSI CON VARIABLES EXPLICATIVAS 93
f e cha [ 1 , c ]= yea r if e cha [ 2 , c ]=m
}yea r i<−( y e a r i +1)
}#Creacion de l a matr iz u fecha con e l apoyo de l a matr iz fecha , cuyas 11#f i l a s cont ienen l o s v a l o r e s d e l mes cor re spond i en te a cada dato
ufecha=matrix (0 , nrow =11 ,ncol=nmonth)for ( i in 1 : nmonth ) {
i f ( f echa [ 2 , i ]==1){ ufecha [ 1 , i ]=1}i f ( f echa [ 2 , i ]==2){ ufecha [ 2 , i ]=1}i f ( f echa [ 2 , i ]==3){ ufecha [ 3 , i ]=1}i f ( f echa [ 2 , i ]==4){ ufecha [ 4 , i ]=1}i f ( f echa [ 2 , i ]==5){ ufecha [ 5 , i ]=1}i f ( f echa [ 2 , i ]==6){ ufecha [ 6 , i ]=1}i f ( f echa [ 2 , i ]==7){ ufecha [ 7 , i ]=1}i f ( f echa [ 2 , i ]==8){ ufecha [ 8 , i ]=1}i f ( f echa [ 2 , i ]==9){ ufecha [ 9 , i ]=1}i f ( f echa [ 2 , i ]==10){ ufecha [ 10 , i ]=1}i f ( f echa [ 2 , i ]==11){ ufecha [ 11 , i ]=1}
}#upe t ro l , con t i ene l o s datos d e l p rec io d e l p e t r o l e o 1969−1983
upe t ro l<−uobs#matr iz u , uniendo por f i l a s l a s matr ices up e t r o l y ufecha
u<−rbind ( upetro l , u fecha )print (u)
#Estimacion de l o s parametros de KSI d r i v e r s por maxima v e r o s im i l i t u d#Funcion Linn a op t imizar para es t imar l o s parametros a , c ,Q,R, x1 ,P1 , d
Linn=function ( param) {a<−param [ 1 ]c<−param [ 2 ]Q<−param [3 ]^2R<−param [4 ]^2x1<−param [ 5 ]P1<−param [6 ]^2d<−param [ 7 : 1 8 ]k f = KalmanExp(y , u , a , c , d ,Q,R, x1 , P1)return(−kf$Like )
}#Parametros i n i c i a l e s a0 , c0 , Q0, R0, x10 , P10 , d0 por aproximacion a AR(1)#Se opt imiza Linn por i t e r a c i o n
a0=0.7092c0=1Q0=41906R0=Q0/1000x10=0P10=Q0/(1−a0^2)d0=rep (0 , 12 )i n i t . par<−c ( a0 , c0 ,Q0,R0 , x10 , P10 , d0 )e s t = optim( i n i t .par , Linn , gr=NULL, method="BFGS" , he s s i an
=TRUE, control=l i s t ( trace=1,REPORT=1,maxit=500) )paramest=e s t$par

94 APÉNDICE A. DEFINICIÓN DE LOS PROGRAMAS DESARROLLADOS EN R.
#Parametros est imados ob t en idosae=paramest [ 1 ]ce=paramest [ 2 ]Qe=paramest [ 3 ]^2Re=paramest [ 4 ]^2x1e=paramest [ 5 ]P1e=paramest [ 6 ]^2de<−paramest [ 7 : 1 8 ]
#Estimacion de l o s parametros d e l modelo de l a s e r i e d e l p rec io de p e t r o l e o#Llamada a l a func ion Est imacionPetro l
ParamEstPetrol=Est imac ionPetro l ( uobs )aeP<−ParamEstPetrol$aeceP<−ParamEstPetrol$ceQeP<−ParamEstPetrol$QeReP<−ParamEstPetrol$Rex1eP<−ParamEstPetrol$x1eP1eP<−ParamEstPetrol$P1e
#PREDICCION DEL NUMERO DE CONDUCTORES VICTIMAS DE ACCIDENTES GRAVES CON#VARIABLES EXPLICATIVAS#Con l o s parametros estimados , ae , ce , Qe , Re , x1e , P1e , de#Predicc ion de doce meses con a c t u a l i z a c i o n de datos mes a mes#KSI de l mes an t e r i o r y pred i c c i on de l p rec io d e l p e t r o l e o d e l mes ac t ua l
uactpet<−uobsyp<−rep (0 , 12 )ypPetro l<−rep (0 , 12 )ypSE<−rep (0 , 12 )
#Bucle doce mesesfor ( i in 1 : 12 ) {
uactpet [ nmonth+i −1]<−uobsf [ nmonth+i −1]#up , une l a p red i c c i on de l p e t r o l e o y d e l mes s i g u i e n t e#uppe t r o l d e l mes s i g u i e n t e est imado
Petro lPred<−pred ( uactpet , aeP , ceP ,QeP,ReP , x1eP , P1eP , 1 )ypPetro l [ i ]<−Petro lPred$yp
#upfecha de l mes s i g u i e n t eupfecha<−matrix (0 , nrow=11, ncol=1)
i f ( (m+i ) <13){upfecha [m+i −1 ,]<−1}else {m<−(− i +1)}
#upup<−rbind ( ypPetro l [ i ] , upfecha )
#Predicc ion de l numero de conductores para e l proximo mesDriversPredExp<−predExp (y , u , up , ae , ce ,de ,Qe ,Re, x1e , P1e , 1 )yp [ i ]=DriversPredExp$ypypSE [ i ]=DriversPredExp$ypSE
#Actua l i z ac i on de l a matr iz u con l o s v a l o r e s r e a l e s#ua , u ac t ua l con e l nuevo va l o r d e l p e t r o l e o r e a l y d e l mes
ua<−matrix (0 ,nrow=12,ncol=1)uafecha<−upfechaua<−rbind ( uobs f [ nmonth+i ] , uafecha )
#uu<−cbind (u , ua )y [ nmonth+i ]<−yf [ nmonth+i ]

A.5. PROGRAMAS PARA LA SERIE KSI CON VARIABLES EXPLICATIVAS 95
}#Representacion g r a f i c a de l o s r e s u l t a d o s#Se repre sen ta yrea l , yest imada e ypred icha con sus i n t e r v a l o s#Se crean nuevos v e c t o r e s con es t imacion/pred i c c i on para s
sep<−DriversPred ict ionExp$se [ 1 : nmonth ]for ( i in (nmonth+1) : ( nmonth+12) ) {sep [ i ]<−ypSE [ ( i )−nmonth ] }
#Se crean nuevos v e c t o r e s con es t imacion/pred i c c i on para yyep<−DriversPred ict ionExp$ye [ 1 : nmonth ]for ( i in (nmonth+1) : ( nmonth+12) ) {yep [ i ]<−yp [ ( i )−nmonth ] }
#Se ha l l an l o s i n t e r v a l o s de con f ianza y se d i bu j a l a g r a f i c aInterva loSup=rep (0 , length ( yep ) )I n t e r v a l o I n f=rep (0 , length ( yep ) )
for ( j in 1 : length ( yep ) ) {Interva loSup [ j ]<−( yep [ j ]+2∗sep [ j ] )I n t e r v a l o I n f [ j ]<−( yep [ j ]−2∗sep [ j ] )
}plot . ts ( yf , col="red" , xlab="Meses" , ylab="Num de KSI" )l ines ( yep , col="blue " )l ines ( IntervaloSup , col="green " )l ines ( I n t e r va l o I n f , col="green " )
#Error MAPE de todo e l modelo ( p red i c c i on y es t imacion )mape<−MAPE( yf , yep )
#Error MAPE so l o de l a p red i c c i onmapep<−MAPE( yf [ 1 8 0 : 1 9 2 ] , yep [ 1 8 0 : 1 9 2 ] )
#Error ab so l u t o y au t o r r e l a c i on de l e r rorError_Absoluto<−( yf−yep )mean( Error_Absoluto )plot ( Error_Absoluto )a c f ( Error_Absoluto )
Related Documents











