IEEE TRANSACTIONS ON COMPUTERS, VOL. C-34, NO. 10, OCTOBER 1985 927 An Empirical Study of Automatic Restructuring of Nonnumerical Programs for Parallel Processors GYUNGHO LEE, CLYDE P. KRUSKAL, MEMBER, IEEE, AND DAVID J. KUCK, FELLOW, IEEE Abstract—The feasibility of automatic restructuring of non- numerical programs for parallel processing is studied through experiments using Parafrase, an automatic restructurer at the University of Illinois, Urbana-Champaign. We present parallel processing speedup results due to automatic restructuring for several basic nonnumerical problems. We classify at a low level the loops encountered. Based on the speedup results and the analyses of the loop types, the difficulty and the effectiveness of automatic restructuring are discussed. Our experiments suggest that automatic restructuring can be a useful tool for exploiting parallelism in the sequential form of nonnumerical programs. Index Terms — Analysis of programs, automatic program re- structuring, data dependence, multiprocessing, nonnumerical programs, parallel algorithms, parallel computation, program speedup. INTRODUCTION T HIS paper discusses the feasibility of automatically re- structuring nonnumerical programs for parallel process- ing. Automatic restructuring transforms programs from their original sequential form into a form suitable for parallel pro- cessing. It can be considered a convenient tool for exploiting parallelism in the sequential form of programs. This has been demonstrated with a wide collection of numerical programs (and even some complete numerical program packages [24], [35]) for array processors [23], pipeline processors [21], multiprocessors [31], and machines with virtual memory [1]. Intuitively, nonnumerical programs have more complicated dynamic program and data structures than numerical pro- grams. This characteristic seems to make nonnumerical pro- grams hard to restructure automatically. Through some small experiments, we attempt to formalize this notion and study how helpful automatic restructuring can be for nonnumerical programs. Parafrase is an automatic restructurer developed at the University of Illinois, Urbana-Champaign, that performs various transformations based on information available at compile time (see [3], [22], [25], and [38]). It can be coupled with various machine architectures like the single execution array (SEA) and multiple execution scalar (MES) machines Manuscript received February 1, 1985; revised May 29, 1985. This work was supported in part by the National Science Foundation under Grant DCR84-06916, in part by the U.S. Department of Energy under Contract DE-FG02-85ER25001, and in part by IBM. A preliminary version of this paper was presented at the IEEE 1985 International Conference on Parallel Process- ing, St. Charles, IL, Aug. 1985. The authors are with the Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana, IL 61801. (see [24]-[26]). In the SEA machine the processors are driven by a common control unit. In the MES machine mul- tiple scalar processors are interconnected, and each processor is driven by its own control unit. Because of its flexibility, we will consider only the MES machine in this paper. To mea- sure the performance of a restructured program, we will use the speedup S p and the efficiency E p . The speedup is the ratio TjT p where T { is the execution time of a given program on a base sequential machine before restructuring, and T p is the execution time of the restructured program on the target ma- chine with ρ processors. The efficiency E p is the ratio S p /p. The following assumptions are made about the machine architecture in measuring performance. The base sequential machine does not charge for subscript calculations that are linear functions of active DO loop indexes; all other subscript calculations are explicitly charged. The base machine is as- sumed to have an unlimited number of registers, which take no time to access. Memory fetches are ignored since it is assumed that they are overlapped with processing; memory stores are counted as one time step. All arithmetic and logical operations take one time step, but branching and loop control instructions are ignored. Since Parafrase measures per- formance without executing programs, branching proba- bilities of individual control statements are assumed, but this can be changed manually. The time taken to execute a se- quence of statements is multiplied by the expected number of times the sequence is executed. The MES machine is composed of ρ identical base se- quential machines. Although the base sequential machines execute asynchronously, there is no charge for synchroniza- tion. The MES machine allows concurrent reads to shared variables, but does not allow concurrent writes. For our experiments, we selected simple sequential algo- rithms for 15 nonnumerical problems that are found in a wide range of applications. The algorithms were coded in Fortran and restructured by Parafrase. The results from this experi- ment are the basis of our discussion. For the problems in which automatic restructuring resulted in "poor" speedup, we selected known parallel algorithms, coded them in Fortran (as sequential algorithms), and restructured them by Para- frase. The results of using sequential algorithms are com- pared with those of using parallel algorithms. To find a concrete reason for the difficulty of automatically restruc- turing nonnumerical programs, we analyze the loops that Parafrase was unable to parallelize. 1 The type of loops that 'We use "parallelize" to refer to transforming a program to run well on the MES model defined above. 0018-9340/85/1000-0927$01.00 © 1985 IEEE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

IEEE TRANSACTIONS ON COMPUTERS, VOL. C-34, N O . 10, OCTOBER 1985 927
An Empirical Study of Automatic Restructuring of Nonnumerical Programs for Parallel Processors
GYUNGHO LEE, CLYDE P. KRUSKAL, MEMBER, IEEE, AND DAVID J. KUCK, FELLOW, IEEE
Abstract—The feasibility of automatic restructuring of non-numerical programs for parallel processing is studied through experiments using Parafrase, an automatic restructurer at the University of Illinois, Urbana-Champaign. We present parallel processing speedup results due to automatic restructuring for several basic nonnumerical problems. We classify at a low level the loops encountered. Based on the speedup results and the analyses of the loop types, the difficulty and the effectiveness of automatic restructuring are discussed. Our experiments suggest that automatic restructuring can be a useful tool for exploiting parallelism in the sequential form of nonnumerical programs.
Index Terms — Analysis of programs, automatic program restructuring, data dependence, multiprocessing, nonnumerical programs, parallel algorithms, parallel computation, program speedup.
INTRODUCTION
THIS paper discusses the feasibility of automatically restructuring nonnumerical programs for parallel process
ing. Automatic restructuring transforms programs from their original sequential form into a form suitable for parallel processing. It can be considered a convenient tool for exploiting parallelism in the sequential form of programs. This has been demonstrated with a wide collection of numerical programs (and even some complete numerical program packages [24], [35]) for array processors [23], pipeline processors [21], multiprocessors [31], and machines with virtual memory [1]. Intuitively, nonnumerical programs have more complicated dynamic program and data structures than numerical programs. This characteristic seems to make nonnumerical programs hard to restructure automatically. Through some small experiments, we attempt to formalize this notion and study how helpful automatic restructuring can be for nonnumerical programs.
Parafrase is an automatic restructurer developed at the University of Illinois, Urbana-Champaign, that performs various transformations based on information available at compile time (see [3], [22], [25], and [38]). It can be coupled with various machine architectures like the single execution array (SEA) and multiple execution scalar (MES) machines
Manuscript received February 1, 1985; revised May 29, 1985. This work was supported in part by the National Science Foundation under Grant DCR84-06916, in part by the U.S. Department of Energy under Contract DE-FG02-85ER25001, and in part by IBM. A preliminary version of this paper was presented at the IEEE 1985 International Conference on Parallel Processing, St. Charles, IL, Aug. 1985.
The authors are with the Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana, IL 61801.
(see [24]-[26]) . In the SEA machine the processors are driven by a common control unit. In the MES machine multiple scalar processors are interconnected, and each processor is driven by its own control unit. Because of its flexibility, we will consider only the MES machine in this paper. To measure the performance of a restructured program, we will use the speedup Sp and the efficiency Ep. The speedup is the ratio TjTp where T{ is the execution time of a given program on a base sequential machine before restructuring, and Tp is the execution time of the restructured program on the target machine with ρ processors. The efficiency Ep is the ratio Sp/p.
The following assumptions are made about the machine architecture in measuring performance. The base sequential machine does not charge for subscript calculations that are linear functions of active DO loop indexes; all other subscript calculations are explicitly charged. The base machine is assumed to have an unlimited number of registers, which take no time to access. Memory fetches are ignored since it is assumed that they are overlapped with processing; memory stores are counted as one time step. All arithmetic and logical operations take one time step, but branching and loop control instructions are ignored. Since Parafrase measures performance without executing programs, branching probabilities of individual control statements are assumed, but this can be changed manually. The time taken to execute a sequence of statements is multiplied by the expected number of times the sequence is executed.
The MES machine is composed of ρ identical base sequential machines. Although the base sequential machines execute asynchronously, there is no charge for synchronization. The MES machine allows concurrent reads to shared variables, but does not allow concurrent writes.
For our experiments, we selected simple sequential algorithms for 15 nonnumerical problems that are found in a wide range of applications. The algorithms were coded in Fortran and restructured by Parafrase. The results from this experiment are the basis of our discussion. For the problems in which automatic restructuring resulted in "poor" speedup, we selected known parallel algorithms, coded them in Fortran (as sequential algorithms), and restructured them by Parafrase. The results of using sequential algorithms are compared with those of using parallel algorithms. To find a concrete reason for the difficulty of automatically restructuring nonnumerical programs, we analyze the loops that Parafrase was unable to parallelize. 1 The type of loops that
'We use "parallelize" to refer to transforming a program to run well on the MES model defined above.
0018-9340/85/1000-0927$01.00 © 1985 IEEE

928 IEEE TRANSACTIONS ON COMPUTERS, VOL. C-34, N O . 10, OCTOBER 1985
limit the effectiveness of automatic restructuring can be identified, and improvement of automatic restructuring can be pursued. We present the frequency of each type of loop and speedup improvements when they are parallelized.
AN OVERVIEW OF PARAFRASE
Although a detailed explanation of Parafrase is out of the scope of this paper, we look at it briefly to establish some notions required for our discussion (see [22], [24], and [38] for more details on Parafrase itself). A familiarity with dependence analysis of programs is helpful in reading this paper (see [21], [25], and [26]).
Parafrase consists of numerous transformations, which utilize a program dependence graph. For a particular experiment on Parafrase, a user specifies a list of transformations and the order in which to apply them. A different sequence of transformations may result in different performance. In general, it is not well understood how to obtain the best sequence of transformations. Parafrase currently has several predefined sequences for general experiments, which are set empirically. For our experiments, we used the sequence predefined for MES machines.
Most transformations done by Parafrase reform the given program to expose the parallelism while preserving the semantics (so as to produce the same results). For example, it is well known that by renaming or expanding scalar variables, some dependences can be removed from the program [22], [38]. Notice that this kind of transformation never changes an algorithm fundamentally, but only changes its representation to expose the inherent parallelism in the program by reorganizing and removing dependences. Another kind of transformation tries to change the algorithm used to one more suitable for a particular architecture. One example is recurrence recognition, which identifies a specific loop structure for a recurrence and replaces the loop with a fast parallel algorithm for solving the recurrence. Parafrase recognizes first-order linear recurrences of size n, denoted by R(n, 1), which can be represented in the form
Xi — cii * JC/_I + ci9 (1 < / < n ) .
The general R(n, 1) recurrence is solved using the algorithm in [9].
A naively produced dependence graph will contain some unnecessary dependences. Parafrase contains several sophisticated tests for eliminating them using direction vectors. Suppose statements S\ and S 2 are enclosed in a loop that has index /, and suppose S'{ is an instance of Si when i = ix. If S22 is dependent on S\l, we denote it as S^SSfc the dependence is said to have a distance i2 — U [27]. If the dependence distance is positive, the dependence has a direction vector ( and is denoted as SX8({)S2.
We can improve the results from Parafrase with user assistance, which can have several forms. For example, assertions can supply useful information that is not discernible automatically. Providing a value for the probability of taking a branch of an IF statement is a typical assertion. Another
form of user assistance is changing an algorithm to one more suitable for parallel processing. We call this form of user assistance algorithm change.
Two transformations specifically designed for exploiting the flexibility of MES machines are doacross and low-level spreading. Doacross tries to overlap the execution of loops in a pipelined fashion [13]. Low-level spreading tries to maximize the number of independent operations in an assignment statement using tree-height reduction and assigns processors to statements based on the dependence graph for a block of assignment statements [30] , [35]. We will not present the results of using doacross and low-level spreading. These particular transformations changed the speedup results little in our experiments except in one case, which we will note when the results are presented.
EXPERIENCE WITH PARAFRASE
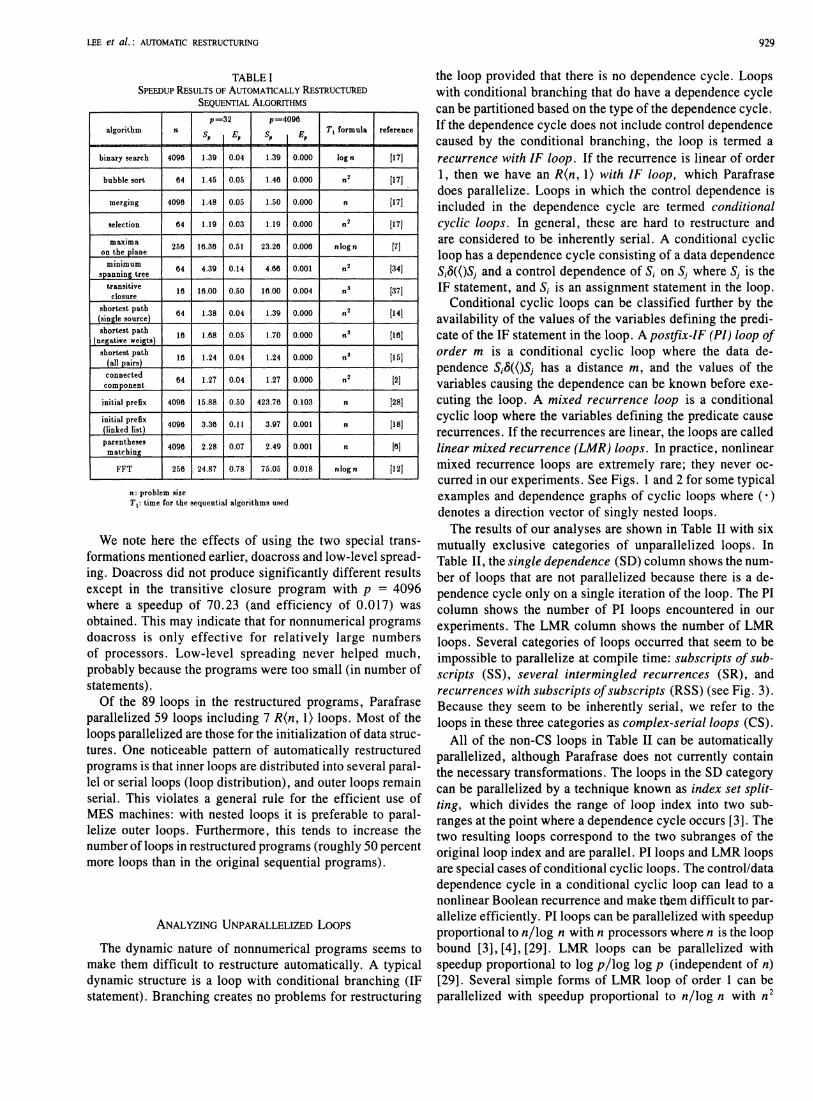
The 15 basic algorithms selected were coded in Fortran without the code for handling error conditions (see Table I for a list of the algorithms). Since Parafrase does not parallelize WHILE-like loops in general, we changed all WHILE-like loops to DO loops — the DO bounds were supplied based on worst case performance.
Each problem size was chosen so that the time for a sequential machine to solve the problem was approximately 4096 units where the units were chosen to be "natural" for the particular problem. This means that, if 4096 processors could work completely efficiently, they could solve each problem in approximately 1 time unit. The experiments were done for ρ = 32 and ρ = 4096. The machine sizes were chosen to help to expose the effect of the "major" loops in a program with a limited number of processors (p = 32), and the inherent limit of the parallelism with a large number of processors (p = 4096). To show a typical performance with a limited number of processors,/? = 32 seems to be a reasonable choice, although it is hard to generalize for the various problems.
Tab le I s h o w s s p e e d u p r e s u l t s w h e n ρ = 32 and ρ = 4096. As can be seen, in most cases automatic restructuring did not significantly improve the performance of these nonnumerical programs. For ρ = 32, we consider efficiency Ep > 0.1 as acceptable performance and efficiency Ep > 0.3 as good performance (see [24] for an explanation of these criteria). Almost all interesting problems require at least Θ((η/ρ) + log n) time to solve (see [11]), so the above criteria with ρ = 4096 would almost always yield unacceptable performance. Therefore, for ρ = 4096, we will say that Ep > 0.01 is acceptable performance, and Ep > 0.03 is good performance. For both ρ = 32 and ρ = 4096, acceptable performance is about 10 percent of what one might ideally achieve, and good performance is about 30 percent. For ρ = 32, out of the 15 programs, automatic restructuring shows acceptable (but not good) performance for only 2 programs and good performance for only 4 programs. For ρ = 4096, only one program shows acceptable performance and only one shows good performance.
LEE et al.: AUTOMATIC RESTRUCTURING 929
T A B L E J SPEEDUP RESULTS OF AUTOMATICALLY RESTRUCTURED
SEQUENTIAL ALGORITHMS
algorithm η P =
SP
32
EP
ρ = 4
SP
096
EP Γ, formula reference
binary search 4096 1.39 0.04 1.39 0.000 log η [17]
bubble sort 64 1.45 0.05 1.46 0.000 η 2 117]
merging 4096 1.48 0.05 1.50 0.000 η [17]
selection 64 1.19 0.03 1.19 0.000 η 2 [17]
maxima on the plane 256 16.36 0.51 23.26 0.006 η log η [7]
minimum spanning tree 64 4.39 0.14 4.66 0.001 η 2 [34]
transitive closure 16 16.00 0.50 16.00 0.004 η 3 [37]
shortest path (single source) 64 1.38 0.04 1.39 0.000 η 2 [14]
shortest path (negative weigts) 16 1.68 0.05 1.70 0.000 η 3 [16]
shortest path (all pairs) 16 1.24 0.04 1.24 0.000 η 3 [15]
connected component 64 1.27 0.04 1.27 0.000 π 2 [2]
initial prefix 4096 15.88 0.50 423.76 0.103 η [28]
initial prefix (linked list) 4096 3.36 0.11 3.97 0.001 η [18]
parentheses matching 4096 2.28 0.07 2.49 0.001 η [θ]
FFT 256 24.87 0.78 75.05 0.018 η log η [12]
η: problem size Τχ\ time for the sequential algorithms used
We note here the effects of using the two special transformations mentioned earlier, doacross and low-level spreading. Doacross did not produce significantly different results except in the transitive closure program with ρ = 4096 where a speedup of 70.23 (and efficiency of 0.017) was obtained. This may indicate that for nonnumerical programs doacross is only effective for relatively large numbers of processors. Low-level spreading never helped much, probably because the programs were too small (in number of statements).
Of the 89 loops in the restructured programs, Parafrase parallelized 59 loops including 7 R(n, 1) loops. Most of the loops parallelized are those for the initialization of data structures. One noticeable pattern of automatically restructured programs is that inner loops are distributed into several parallel or serial loops (loop distribution), and outer loops remain serial. This violates a general rule for the efficient use of MES machines: with nested loops it is preferable to parallelize outer loops. Furthermore, this tends to increase the number of loops in restructured programs (roughly 50 percent more loops than in the original sequential programs).
ANALYZING UNPARALLELIZED LOOPS
The dynamic nature of nonnumerical programs seems to make them difficult to restructure automatically. A typical dynamic structure is a loop with conditional branching (IF statement). Branching creates no problems for restructuring
the loop provided that there is no dependence cycle. Loops with conditional branching that do have a dependence cycle can be partitioned based on the type of the dependence cycle. If the dependence cycle does not include control dependence caused by the conditional branching, the loop is termed a recurrence with IF loop. If the recurrence is linear of order 1, then we have an R(n, 1) with IF loop, which Parafrase does parallelize. Loops in which the control dependence is included in the dependence cycle are termed conditional cyclic loops. In general, these are hard to restructure and are considered to be inherently serial. A conditional cyclic loop has a dependence cycle consisting of a data dependence SiS(()Sj and a control dependence of St on Sj where Sj is the IF statement, and S,- is an assignment statement in the loop.
Conditional cyclic loops can be classified further by the availability of the values of the variables defining the predicate of the IF statement in the loop. A postfix-IF (PI) loop of order m is a conditional cyclic loop where the data dependence Si8(()Sj has a distance m, and the values of the variables causing the dependence can be known before executing the loop. A mixed recurrence loop is a conditional cyclic loop where the variables defining the predicate cause recurrences. If the recurrences are linear, the loops are called linear mixed recurrence (LMR) loops. In practice, nonlinear mixed recurrence loops are extremely rare; they never occurred in our experiments. See Figs. 1 and 2 for some typical examples and dependence graphs of cyclic loops where ( · ) denotes a direction vector of singly nested loops.
The results of our analyses are shown in Table II with six mutually exclusive categories of unparallelized loops. In Table II, the single dependence (SD) column shows the number of loops that are not parallelized because there is a dependence cycle only on a single iteration of the loop. The PI column shows the number of PI loops encountered in our experiments. The LMR column shows the number of LMR loops. Several categories of loops occurred that seem to be impossible to parallelize at compile time: subscripts of subscripts (SS), several intermingled recurrences (SR), and recurrences with subscripts of subscripts (RSS) (see Fig. 3). Because they seem to be inherently serial, we refer to the loops in these three categories as complex-serial loops (CS).
All of the non-CS loops in Table II can be automatically parallelized, although Parafrase does not currently contain the necessary transformations. The loops in the SD category can be parallelized by a technique known as index set splitting, which divides the range of loop index into two subranges at the point where a dependence cycle occurs [3]. The two resulting loops correspond to the two subranges of the original loop index and are parallel. PI loops and LMR loops are special cases of conditional cyclic loops. The control/data dependence cycle in a conditional cyclic loop can lead to a nonlinear Boolean recurrence and make them difficult to parallelize efficiently. PI loops can be parallelized with speedup proportional to n / log η with η processors where η is the loop bound [3], [4], [29]. LMR loops can be parallelized with speedup proportional to log p/\og log ρ (independent of n) [29]. Several simple forms of LMR loop of order 1 can be parallelized with speedup proportional to n/ log η with η2

930 IEEE TRANSACTIONS ON COMPUTERS, VOL. C-34, NO. 10, OCTOBER 1985
c n t = 0 D O 1 j = 1, η
IF (mf2( i j ) ) T H E N c n t = c n t + 1
c ( c n t ) = a( i ) C O N T I N U E
a) r e c u r r e n c e l o o p w i t h IF
D O 1 i = 2 , η IF (c( i ) . G T . c ( i - l ) ) T H E N c ( i + l ) = w ( i + l ) E L S E c ( i + l ) = v ( i + l )
1 C O N T I N U E
b) pos t f ix - IF l o o p o f o r d e r 2
D O 1 i = 2 , η IF ( x ( i - l ) . G T . 0 ) T H E N x( i ) = x ( i - l ) * 2 - t E L S E x( i ) = h( i )
1 C O N T I N U E
c ) l inear m i x e d - r e c u r r e n c e l o o p of o r d e r 1
Fig. 1. Examples of some cyclic loops.
!<->
a) r e c u r r e n c e l o o p w i t h IF
Θ Θ
b) pos t f ix - IF l o o p of o r d e r 2
Θ
c ) l inear m i x e d r e c u r r e n c e l o o p of o r d e r 1
d a t a d e p e n d e n c e : c o n t r o l d e p e n d e n c e :
T A B L E II LOOP TYPES IN THE RESTRUCTURED PROGRAMS
Fig. 2. Dependence graphs for some cyclic loops.
processors [29]. Three of the five LMR loops in our experiments were of the simple forms.
We parallelized the non-CS loops of Table II by hand. The improved speedup results are shown in Table III. As can be seen, the speedup results are still not impressive. For ρ = 32, one program shows acceptable (but not good) performance, and eight show good performance. For ρ = 4096, four programs show acceptable performance, and two show good performance. Notice that performance improved even for programs in which automatic restructuring had already produced acceptable performance.
a l g o r i t h m C S
S S S R R S S S D PI L M R
t o t a l n u m b e r o f l o o p s *
b i n a r y s e a r c h 1 2(1)
b u b b l e s o r t 1 1 3(1)
m e r g i n g 1 3 ( 2 )
s e l e c t i o n ο 9 ( 7 )
m a x i m a o n t h e p l a n e 1 1 1 1 20(16)
m i n i m u m s p a n n i n g t r e e
1 1 8(6)
t r a n s i t i v e c l o s u r e
1 1 3(1)
s h o r t e s t p a t h ( s i n g l e s o u r c e )
1 1 1 6 (3 )
s h o r t e s t p a t h ( n e g a t i v e w e i g h t )
1 1 7 ( 5 )
s h o r t e s t p a t h (all pa i r s )
2 2 1 9(4)
c o n n e c t e d c o m p o n e n t 1 2 4(1)
in i t ia l pref ix 1(1)
in i t ia l pref ix ( l i n k e d l is t )
1 4 (3)
p a r e n t h e s e s m a t c h i n g 1 3 ( 2 )
F F T 1 7(6)
n u m b e r o f l o o p s
1 9 5 5 5 5 8 9 ( 5 9 )
* : e n t r i e s in t h e p a r e n t h e s i s are t h e n u m b e r of p a r a l l e l i z e d l o o p s i n c l u d i n g R < n , l >
C S : c o m p l e x - s e r i a l l o o p S D : s i n g l e d e p e n d e n c e S S - s u b s c r i p t s of s u b s c r i p t s PI : p o s t f i x - I F l o o p S R - s e v e r a l i n t e r m i n g l e d r e c u r r e n c e ? L M R : l i n e a r m i x e d r e c u r r e n c e R S S - r e c u r r e n c e s w i t h S S
D O 1 i = 1, -1 + n i p ( i + l ) = n e x t ( i p ( i + l ) )
1 C O N T I N U E
a) a n S S l o o p
D O 1 k = 1, η I F ( . N O T . f 3 ( k ) ) G O T O 2 i x ( k , k ) = i x ( k , k - l ) G O T O 3
2 i x ( k , k ) = k 3 D O 5 I = 1, In
I F ( f5 (k , l ) ) G O T O 5 f 5 ( k , k ) = c ( k , l ) X T . c ( k , i x ( k , l ) ) i x ( k , k ) = 1
5 C O N T I N U E
1 C O N T I N U E
b ) a n S R l o o p ( t h e o u t e r l o o p )
D O 1 k = 1, η I F ( p t r ( s ( t ( k ) ) ) . E Q . 0 ) G O T O 1 w = v t x ( p t r ( s ( t ( k ) ) ) ) p t r ( s ( t ( k ) ) ) = l i n k ( p t r ( s ( t ( k ) ) ) ) I F ( m ( w ) . E Q . 0 ) G O T O 2 t ( k + l ) = t ( k ) G O T O 1
2 m ( w ) = c n u m t ( k + l ) = t ( k ) + 1
s ( t ( k ) ) = w 1 C O N T I N U E
c ) a R S S l o o p
Fig. 3. Complex serial loops.

LEE et al: AUTOMATIC RESTRUCTURING 931
T A B L E III EFFECTS OF PARALLELIZING LOOP TYPES IN TABLE II
algorithm s; ρ = 3 2
EP R ν ι
2.62
ρ = 4 0 9 6
1 fi>
0.001
R
binary search 1.79 0.06 1.29
ν ι 2.62
ρ = 4 0 9 6
1 fi>
0.001 1.88
bubble sort 1.45 0.05 1.00 3.95 0.001 2.71
merging 1.48 0.05 1.00 3.50 0.001 2.33
selection 1.19 0.03 1.00 1.19 0.000 1.00
maxima on the plane
24.36 0.76 1.49 46.84 0.011 2.01
minimum spanning tree
10.37 0.32 2.36 18.38 0.004 3.94
transitive closure
16.00 0.50 1.00 100.00 0.024 6.25
shortest pa th (single source)
10.41 0.33 7.54 12.90 0.003 9.28
shortest pa th (negative weight)
16.58 0.52 9.87 27.26 0.007 16.04
shortest pa th (all pairs)
28.78 0.90 23.21 293.41 0.072 236.63
connected component
1.27 0.04 1.00 1.27 0.000 1.00
initial prefix 15.88 0.50 1.00 423.76 0.103 1.00
initial prefix (linked list)
3.36 0.11 1.00 3.97 0.001 1.00
parentheses matching
2.28 0.07 1.00 2.49 0.001 1.00
FFT 24.87 0.78 1.00 75.05 0.018 1.00
S*: improved speedup Sp: original speedup in Table 1
ALGORITHM CHANGE
When a program fails to obtain good performance through automatic restructuring, algorithm change is the last resort. We selected known parallel algorithms for the cases in Table III in which the results due to automatic restructuring have efficiency Ep < 0.5 for ρ = 32. These parallel algorithms were coded in Fortran and passed through Parafrase. Some parallel algorithms, like (p + l)-ary search and parallel prefix, use the number of processors ρ as a parameter. Since this cannot be recognized at compile time by Parafrase when represented in sequential Fortran, we programmed these algorithms for each fixed p. The algorithms for parallel prefix and parentheses matching carefully schedule processors through subscripts of subscripts. Due to the extreme use of subscripted variables, Parafrase was unable to exploit the parallelism, so we provided assertions to help it in these two cases. Table IV shows the speedup results due to algorithm change. For consistency with the results shown earlier, the sequential time 7^ used in Table I is also used as Tx for computing the speedup results in Table IV.
Algorithm change provides good performance for ρ = 32 in all but two cases. Although searching showed poor performance, the algorithm is provably optimal [20]. Selection showed only acceptable performance because of computational overhead in the parallel algorithm. With a larger problem size, selection should also show good performance. For
ρ = 4096, four programs show acceptable performance, and seven show good performance.
The unparallelized loops are analyzed in Table V. Of the 163 loops in the restructured programs, 132 are parallel, including 13 R(n, 1) loops. All of the loops in the CS category are originally serial loops in the parallel algorithms used. The few remaining loops in the other categories can be parallelized by the techniques mentioned earlier, but they have little effect on performance. As can be seen, algorithm change introduced different loop structures. This can be explained by the fact that the major loops in the sequential algorithms are in the CS category, which seem to be inherently serial, so performance improvements can be obtained only by solving the problems in different ways. Simply parallelizing all of the non-CS loops in the sequential algorithms does not achieve performance comparable to algorithm change.
CONCLUSION
Automatic restructuring of nonnumerical programs was examined through the study of 15 programs. Our analysis focused on the loop types that caused programs not to be parallelized. Although, intuitively, nonnumerical programs seem hard to parallelize, this study helps us to understand the fundamental difficulties at a low level. Armed with this knowledge, improvements of automatic restructurers can be pursued. For example, since conditional cyclic loops were not uncommon, we developed a way to parallelize them [29].
Subscripts of subscripts (SS), several intermingled recurrences (SR), and recurrences with subscripts of subscripts (RSS) turned out to be the bottlenecks in automatically restructuring nonnumerical programs. Programs seriously slowed down by these loops were rewritten using parallel algorithms. We consider the good speedup results from algorithm change encouraging. Parafrase recognized almost all of the parallelism in these parallel algorithms. This shows that automatic restructuring can be a useful tool in programming parallel machines. Furthermore, this suggests that good parallel programming languages do not necessarily have to have constructs that make explicit all of the underlying parallelism.
Although we discuss automatic restructuring of non-numerical programs mainly through control structures (loop types), data structures also play an important role. For example, as we show in Table I, automatic restructuring for initial prefix produces drastically different results with respect to the data structures used. Parafrase cannot recognize parallelism when there are complicated SS's , as in modifying a linked list. Since many important nonnumerical problems are solved using linked list data structures, this flaw may in some cases be critical. Although it is hard to correct this flaw, we may sometimes avoid it by including assertions or by recognizing some patterns of data structure usages. For instance, it may be useful to have a prefix recognizer for linked list data structures because operations on linked lists are

932 IEEE TRANSACTIONS ON COMPUTERS, VOL. C-34, NO. 10, OCTOBER 1985
T A B L E IV SPEEDUP RESULTS DUE TO ALGORITHM CHANGE
a l g o r i t h m η
ρ = 3 2
EP R si ρ = 4 0 9 6
EP R Tp f o r m u l a r e f e r e n c e
( p + l ) - a r y
s e a r c h 4 0 9 6 1.86 0 . 0 6 1.84 5 .01 0 . 0 0 1 1.91
l o g ( n + l )
l o g ( p + l ) [20]
e n u m e r a t i o n
s o r t 6 4 1 5 . 9 6 0 . 5 0 11 .01 3 2 4 . 1 0 0 . 0 7 9 8 2 . 0 5 Ρ [33]
m e r g i n g 4 0 9 6 1 6 . 6 8 0 . 5 2 1 1 . 2 7 1 7 5 . 7 2 0 . 0 4 3 5 0 . 2 1 s e e
r e f e r e n c e |8 ) , 120]
o d d - e v e n
m e r g i n g 4 0 9 6 1 2 . 4 8 0 . 3 9 8 . 4 3 3 4 1 . 0 8 0 . 0 8 3 9 7 . 4 5
η l o g η
Ρ (5!
s e l e c t i o n 6 4 5 . 5 9 0 . 1 7 4 . 6 9 4 6 . 0 1 0 . 0 1 1 3 8 . 6 6 s e e
r e f e r e n c e [19]
m i n i m u m
s p a n n i n g t ree 6 4 1 5 . 1 5 0 .47 1.46 3 0 . 9 4 0 . 0 0 8 1 .68
η 2 , η — + l o g 2 n
Ρ [10]
s h o r t e s t p a t h
( s ing le s o u r c e ) 6 4 2 5 . 5 2 0 . 8 0 2 . 4 5 6 1 . 6 7 0 . 0 1 5 4 . 7 6 — + η l og ρ
Ρ 1321
c o n n e c t e d
c o m p o n e n t 6 4 2 1 . 6 6 0 . 6 8 1 7 . 0 6 3 4 . 1 0 0 . 0 0 8 2 6 . 8 5 — + l o g 2 n
Ρ 1101, [36]
p a r a l l e l pref ix
( l i n k e d l ist) 4 0 9 6 1 8 . 9 4 0 . 5 9 5 .64 3 0 3 . 3 7 0 . 0 7 4 7 6 . 4 2
l og η η l o g ( 2 n / p ) ρ
[18]
p a r e n t h e s e s m a t c h i n g
4 0 9 6 2 5 . 6 4 0 . 8 0 1 1 . 2 5 2 6 9 . 5 9 0 . 0 6 6 1 0 8 . 2 7 η .
— Η l o g η Ρ
|β]
η : p r o b l e m s i z e , ^ " " ^
5*: i m p r o v e d s p e e d u p
S p
a : s p e e d u p in T a b l e 3
T A B L E V LOOP TYPES IN RESTRUCTURED PROGRAMS AFTER ALGORITHM CHANGE
a l g o r i t h m CS PI L M R t o t a l n u m b e r
of l o o p s *
( p + l ) - a r y s e a r c h
1 3 ( 2 )
e n u m e r a t i o n s o r t
5 ( 5 )
m e r g i n g 3 1 3 0 ( 2 6 )
o d d - e v e n m e r g i n g
1 4 ( 3 )
s e l e c t i o n 2 3 7 ( 3 5 )
m i n i m u m s p a n n i n g t r e e
3 3 2 2 ( 1 6 )
s h o r t e s t p a t h ( s ing le s o u r c e )
3 1 0 ( 7 )
c o n n e c t e d c o m p o n e n t
3 2 0 ( 1 7 )
para l l e l prefix ( l i n k e d l ist)
4 1 1 ( 7 )
p a r e n t h e s e s m a t c h i n g
5 2 1 ( 1 6 )
n u m b e r of l o o p s
25 3 1 6 3 ( 1 3 4 )
CS: c o m p l e x - s e r i a l l o o p SD: s i n g l e d e p e n d e n c e PI : pos t f ix - IF l o o p L M R : l inear m i x e d r e c u r r e n c e * : e n t r i e s in t h e p a r e n t h e s i s are t h e n u m b e r of
p a r a l l e l i z e d l o o p s i n c l u d i n g R < n , l >
fundamental in many important sparse graph problems (see [18]). As linear recurrence recognition helps Parafrase in restructuring numerical programs, linear recurrence recognition on linked lists may help Parafrase in restructuring nonnumerical programs.
ACKNOWLEDGMENT
The authors wish to thank A. Veidenbaum for interesting discussions and helpful comments on the paper. They also thank S. Abraham and H. Hussman for reading preliminary versions.
REFERENCES
[1] W. Abu-Sufah, D.J. Kuck, and D.H. Lawrie, "Automatic program transformations for virtual memory computers," in Proc. 1979 Nat. Corn-put. Conf., vol. 48, pp. 969-974, June 1979.
[2] A. Aho, J. Hopcroft, and J. Ullman, The Design and Analysis of Computer Algorithms. Reading, MA: Addison-Wesley, 1974.
[3] U. Banerjee, "Speedup of ordinary programs," Ph.D dissertation, Dep. Comput. Sci., University of Illinois, Urbana-Champaign, 1979.
[4] U. Banerjee and D. Gajski, "Fast evaluation of loops with IF statement," IEEE Trans. Comput., vol. C-33, pp. 1030-1033, 1984.
[5] K. Batcher, "Sorting networks and their applications," in Proc. AFIPS Spring Joint Comput. Conf, vol. 32, Apr. 1968, pp. 307-314.
[6] I. Bar-On and U. Vishkin, "Optimal parallel generation of a computation tree form," ACM Trans. Programming Lang. Syst., vol. 7, no. 2, pp. 348-357, Apr. 1985.
[7] J. L. Bentley, "Multidimensional divide-and-conquer," Commun. ACM, vol. 23, no. 4, pp. 214-229, Apr. 1980.
[8] A. Borodin and J. Ε. Hopcroft, "Routing, merging, and sorting on parallel models of computations," J. Comput. Syst. Sci., vol. 30, no. 1, pp. 130-145, Feb. 1985.
[9] S. Chen, D. Kuck, and A. Sameh, "Practical band triangular system solvers," ACM Trans. Math. Software, vol. 4, no. 3, pp. 270-277, Sept. 1978.
[10] F. Y. Chin, J. Lam, and I. Chen, "Efficient parallel algorithms for some graph problems," Commun. ACM, vol. 25, no. 9, pp. 659-665, Sept. 1982.
[11] S. A. Cook and C. Dwork, "Bounds on the time for parallel RAM's to compute simple functions," in Proc. Mth Annu. ACM Symp. Theory Comput., pp. 231-233, 1982.

LEE et al: AUTOMATIC RESTRUCTURING 933
[12] J. M. Cooley and J. W. Tukey, "An algorithm for the machine calculation of complex Fourier series," Math. Comput., vol. 19, 1965.
[13] R.G. Cytron, "Compile-time scheduling and optimization for multiprocessors," Ph.D dissertation, Dep. Comput. Sci., Univ. Illinois, Urbana-Champaign, 1984.
[14] E.W. Dijkstra, "A note on two problems in connexion with graphs," Numerische Math., vol. 1, pp. 269-271, 1959.
[15] R. W. Floyd, "Algorithm 97: Shortest path," Commun. ACM, vol. 5, 1962.
[16] L. R. Ford, Jr. and D. R. Fulkerson, Flows in Network. Princeton, NJ: Princeton Univ. Press, 1962.
[17] D. E. Knuth, The Art of Computer Programming: Sorting and Searching, Vol. 3. Reading, MA: Addison-Wesley, 1973.
[18] C. P. Kruskal, L. Rudolph, and M. Snir, "The power of parallel prefix," IEEE Trans. Comput., this issue, pp. 965-968; see also, , in Proc. 1985 Int. Conf Parallel Processing, 1985.
[19] C P . Kruskal, "Algorithms for replace-add based paracomputers," in Proc. 1982 Int. Conf Parallel Processing, pp. 219-223, Aug. 1982.
[20] , "Searching, merging, and sorting in parallel computation," IEEE Trans. Comput., vol. C-32, pp. 942-946, Oct. 1983.
[21] D. J. Kuck, R. H. Kuhn, B. Leasure, and M. Wolfe, "The structure of an advanced vectorizer for pipelined processors," in Proc. 4th Int. Comput. Software Appl. Conf, Oct. 1980, pp. 709-715.
[22] D.J. Kuck, R.H. Kuhn, D. A. Padua, B. Leasure, and M. Wolfe, "Dependence graph and compiler optimizations," in Supercomputers: Design and Applications, K. Hwang, Ed., 1984; see also, , in Proc. 8th ACM Symp. Principles Programming Lang., Williamsburg, VA, Jan. 1981.
[23] D. J. Kuck, Y. Muraoka, and S.C. Chen, "On the number of operations simultaneously executable in Fortran-like programs and their resulting speed-up," IEEE Trans. Comput., vol. C-21, pp. 1293-1310, Dec. 1972.
[24] D.J. Kuck, A. Sameh, R. Cytron, A. Veidenbaum, C. Poly-chronopoulos, G. Lee, T. McDaniel, B. Leasure, C. Beckman, J. Davies, and C. P. Kruskal, "The effects of program restructuring, algorithm change, and architecture choice on program performance," in Proc. 1984 Int. Conf. Parallel Processing, pp. 129-138, Aug. 1984.
[25] D.J . Kuck, The Structure of Computers and Computations, Vol. I. New York: Wiley, 1978.
[26] , "Automatic program restructuring for high-speed computation," in Proc. CONPAR'81, 1981.
[27] R. H. Kuhn, "Optimization and interconnection complexity for: Parallel processors, single-stage networks, and decision trees," Ph.D dissertation, Dep. Comput. Sci., Univ. Illinois, Urbana-Champaign, 1980.
[28] R. E. Ladner and M. J. Fischer, "Parallel prefix computation," J. ACM, vol. 27, no. 4, pp. 831-838, Oct. 1980.
[29] G. Lee and C. P. Kruskal, "Parallelizing loops with conditional branching," Cen. Supercomput. Res. Develop., Univ. Illinois, Urbana-Champaign, Cedar doc , 1985.
[30] Y. Muraoka, "Parallelism exposure and exploitation in programs," Ph.D dissertation, Dep. Comput. Sci., Univ. Illinois, Urbana-Champaign, 1971.
[31] D.A. Padua, D.J. Kuck, and D. H. Lawrie, "High-speed multiprocessors and compilation techniques," Special Issue on Parallel Processing, IEEE Trans. Comput., vol. C-29, pp. 763-776, Sept. 1980.
[32] R.C. Paige and C P . Kruskal, "Parallel algorithms for shortest path problems," in Proc. 1985 Int. Conf. Parallel Processing, Aug. 1985.
[33] F. P. Preparata, "New parallel-sorting scheme," IEEE Trans. Comput., vol. C-27, pp. 669-673, 1978.
[34] R . C Prim, "Shortest connection networks and some generalizations," Bell Syst. Tech. J., vol. 36, 1957.
[35] A. Veidenbaum, "Compiler optimization and architecture design for high-speed multiprocessors," Ph.D dissertation, Dep. Comput. Sci., Univ. Illinois, Urbana-Champaign, 1985.
[36] U. Vishkin, "An optimal parallel connectivity algorithm," IBM T. J. Watson Res. Cen., Tech. Rep. RC9149(#40043), p. 14, 1981.
[37] S. Warshall, "A theorem on Boolean matrices," J. ACM, vol. 9, no. 1, pp. 11-12, 1962.
[38] M.J. Wolfe, "Optimizing super compilers for supercomputers," Ph.D dissertation, Dep. Comput. Sci., Univ. Illinois, Urbana-Champaign, 1982.
Gyungho Lee was born on July 5, 1954 in Seoul, Korea. He received the B.S. degree in mathematics from Sogang University, Seoul, in 1977 and the M.S. degree in computer science from the Korea Advanced Institute of Science, Seoul, in 1979.
During the year 1979 he worked for the Economic Planning Board of Korea, and he had been on the Faculty of Computer Science of Dongguk University, Seoul, until 1982. He is currently a graduate student of computer science in the University of Illinois, Urbana-Champaign. His main research in
terests are the design and analysis of parallel computers.
Clyde P. Kruskal (M'83) was born on May 25, 1954. He received the Α.Β. degree in mathematics and computer science from Brandeis University, Waltham, MA, in 1976 and the M.S. and Ph.D. degrees in computer science from the Courant Institute of New York University, New York, in 1978 and 1981, respectively.
Since 1981 he has been an Assistant Professor of Computer Science at the University of Illinois, Urbana. His research interests include the analysis of sequential and parallel algorithms and the design of parallel computers.
Dr. Kruskal is a member of the Association for Computing Machinery and the IEEE Computer Society.
David J. Kuck (S'59-M'69-SM , 83-F85) was born in Muskegon, MI, on October 3, 1937. He received the B.S.Ε.Ε. degree from the University of Michigan, Ann Arbor, in 1959 and the M.S. and Ph.D. degrees from Northwestern University, Evanston, IL, in 1960 and 1963, respectively.
From 1963 to 1965 he was a Ford Postdoctoral Fellow and Assistant Professor of Electrical Engineering at the Massachusetts Institute of Technology, Cambridge. In 1965 he joined the Department of Computer Science, University of Illinois, Urbana.
He is now a Professor of Computer Science and Electrical and Computer Engineering and Director of the Center for Supercomputing Research and Development. Currently, his research interests are in the coherent design of hardware and software systems. This includes the development of the Parafrase system, a program transformation facility for array and multiprocessor machines. He was a principal designer of the Burroughs Scientific Processor and the Illiac IV and is now engaged in the Cedar system design effort. He has consulted with many computer manufacturers and users and is the founder and President of Kuck and Associates, Inc., an architecture and restructuring compiler company.
Dr. Kuck has served as an Editor for a number of professional journals, including the IEEE TRANSACTIONS ON COMPUTERS and the Journal of the Association for Computing Machinery. Among his publications is The Structure of Computers and Computations, Vol. I (Wiley, 1978).
Related Documents











