Latency, Occupancy, and Bandwidth in DSM Multiprocessors: A Performance Evaluation Mainak Chaudhuri, Student Member, IEEE, Mark Heinrich, Member, IEEE, Chris Holt, Jaswinder Pal Singh, Member, IEEE, Edward Rothberg, and John Hennessy, Fellow, IEEE Abstract—While the desire to use commodity parts in the communication architecture of a DSM multiprocessor offers advantages in cost and design time, the impact on application performance is unclear. We study this performance impact through detailed simulation, analytical modeling, and experiments on a flexible DSM prototype, using a range of parallel applications. We adapt the logP model to characterize the communication architectures of DSM machines. The l (network latency) and o (controller occupancy) parameters are the keys to performance in these machines, with the g (node-to-network bandwidth) parameter becoming important only for the fastest controllers. We show that, of all the logP parameters, controller occupancy has the greatest impact on application performance. Of the two contributions of occupancy to performance degradation—the latency it adds and the contention it induces—it is the contention component that governs performance regardless of network latency, showing a quadratic dependence on o. As expected, techniques to reduce the impact of latency make controller occupancy a greater bottleneck. Surprisingly, the performance impact of occupancy is substantial, even for highly-tuned applications and even in the absence of latency hiding techniques. Scaling the problem size is often used as a technique to overcome limitations in communication latency and bandwidth. Through experiments on a DSM prototype, we show that there are important classes of applications for which the performance lost by using higher occupancy controllers cannot be regained easily, if at all, by scaling the problem size. Index Terms—Occupancy, distributed shared memory multiprocessors, communication controller, latency, bandwidth, queuing model, flexible node controller. æ 1 INTRODUCTION D ISTRIBUTED shared memory (DSM) multiprocessors are converging to a family of architectures that resemble a generic system architecture. This architecture consists of a number of processing nodes connected by a general interconnection network. Every node contains a processor, its cache subsystem, and a portion of the total main memory on the machine. It also contains a communication controller that is responsible for managing the communication both within and between nodes. Our interest in this paper is in the specific class of cache-coherent DSM machines. There are many ways to build cache-coherent DSM machines, arising from differences in desired performance and cost characteristics and in the extent to which one wants to use commodity parts and interfaces rather than build customized hardware. In keeping with current trends, we assume the use of a commodity microprocessor, cache subsystem, and main memory. The major sources of variability are in the network and in the communication controller, which together constitute the communication architecture of the multiprocessor. DSM networks vary in their latency and bandwidth characteristics, as well as in their topologies. They range from low-latency, high-bandwidth MPP networks, all the way to commodity local area networks (LANs). On the controller side, there are two important and related variables. One is the location where the communication controller is integrated into the processing node. This can be the cache controller, the memory subsystem, or the I/O bus. The other design variable is how customized the commu- nication controller is for the tasks it performs; for instance, it may be a hardware finite state machine, a special-purpose processor that runs protocol code in response to commu- nication-related events, or an inexpensive general-purpose processor. Because of the differences in design cost and design effort, all of these architectures are viable. Current and proposed architectures for cache-coherent DSM machines take different positions on the above trade offs and, thus, there are examples of real machines at almost every point in this design space. The question we address in this paper is how the performance characteristics of the network and controller affect how well the machines will run parallel programs written for cache-coherent multiprocessors. That is, as we move from more tightly integrated and specialized communication architectures to less tightly integrated and more commodity-based systems, how significant is the loss in parallel performance over a wide range of computations. We address this question by studying a range of important computations and communication architectures through a combination of detailed simulation, analytical modeling, and experiments on a flexible DSM prototype. IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003 1 . M. Chaudhuri and M. Heinrich are with the Computer Systems Laboratory, Cornell University, Ithaca, NY 14853. E-mail: {mainak, heinrich}@csl.cornell.edu. . C. Holt is with Transmeta, Inc., 3940 Freedom Circle, Santa Clara, CA 95054. E-mail: [email protected]. . J.P. Singh is with the Department of Computer Science, Princeton University, Princeton, NJ 08544. E-mail: [email protected]. . E. Rothberg is with ILOG, Inc., 1901 Landings Dr., Mountain View, CA 94043. E-mail: [email protected]. . J. Hennessy is with the Computer Systems Laboratory, Stanford University, Stanford, CA 94305. E-mail: [email protected]. Manuscript received 23 Jan. 2002; revised 12 Aug. 2002; accepted 27 Aug. 2002. For information on obtaining reprints of this article, please send e-mail to: [email protected], and reference IEEECS Log Number 115758. 0018-9340/03/$17.00 ß 2003 IEEE Published by the IEEE Computer Society

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Latency, Occupancy, and Bandwidth in DSMMultiprocessors: A Performance Evaluation
Mainak Chaudhuri, Student Member, IEEE, Mark Heinrich, Member, IEEE, Chris Holt,
Jaswinder Pal Singh, Member, IEEE, Edward Rothberg, and John Hennessy, Fellow, IEEE
Abstract—While the desire to use commodity parts in the communication architecture of a DSM multiprocessor offers advantages in
cost and design time, the impact on application performance is unclear. We study this performance impact through detailed simulation,
analytical modeling, and experiments on a flexible DSM prototype, using a range of parallel applications. We adapt the logP model to
characterize the communication architectures of DSM machines. The l (network latency) and o (controller occupancy) parameters are
the keys to performance in these machines, with the g (node-to-network bandwidth) parameter becoming important only for the fastest
controllers. We show that, of all the logP parameters, controller occupancy has the greatest impact on application performance. Of the
two contributions of occupancy to performance degradation—the latency it adds and the contention it induces—it is the contention
component that governs performance regardless of network latency, showing a quadratic dependence on o. As expected, techniques
to reduce the impact of latency make controller occupancy a greater bottleneck. Surprisingly, the performance impact of occupancy is
substantial, even for highly-tuned applications and even in the absence of latency hiding techniques. Scaling the problem size is often
used as a technique to overcome limitations in communication latency and bandwidth. Through experiments on a DSM prototype, we
show that there are important classes of applications for which the performance lost by using higher occupancy controllers cannot be
regained easily, if at all, by scaling the problem size.
Index Terms—Occupancy, distributed shared memory multiprocessors, communication controller, latency, bandwidth, queuing
model, flexible node controller.
�
1 INTRODUCTION
DISTRIBUTED shared memory (DSM) multiprocessors areconverging to a family of architectures that resemble a
generic system architecture. This architecture consists of anumber of processing nodes connected by a generalinterconnection network. Every node contains a processor,its cache subsystem, and a portion of the total main memoryon the machine. It also contains a communication controllerthat is responsible for managing the communication bothwithin and between nodes. Our interest in this paper is inthe specific class of cache-coherent DSM machines.
There are many ways to build cache-coherent DSM
machines, arising from differences in desired performance
and cost characteristics and in the extent to which one
wants to use commodity parts and interfaces rather than
build customized hardware. In keeping with current trends,
we assume the use of a commodity microprocessor, cache
subsystem, and main memory. The major sources of
variability are in the network and in the communication
controller, which together constitute the communicationarchitecture of the multiprocessor.
DSM networks vary in their latency and bandwidthcharacteristics, as well as in their topologies. They rangefrom low-latency, high-bandwidth MPP networks, all theway to commodity local area networks (LANs). On thecontroller side, there are two important and relatedvariables. One is the location where the communicationcontroller is integrated into the processing node. This can bethe cache controller, the memory subsystem, or the I/O bus.The other design variable is how customized the commu-nication controller is for the tasks it performs; for instance, itmay be a hardware finite state machine, a special-purposeprocessor that runs protocol code in response to commu-nication-related events, or an inexpensive general-purposeprocessor.
Because of the differences in design cost and designeffort, all of these architectures are viable. Current andproposed architectures for cache-coherent DSM machinestake different positions on the above trade offs and, thus,there are examples of real machines at almost every point inthis design space. The question we address in this paper ishow the performance characteristics of the network andcontroller affect how well the machines will run parallelprograms written for cache-coherent multiprocessors. Thatis, as we move from more tightly integrated and specializedcommunication architectures to less tightly integrated andmore commodity-based systems, how significant is the lossin parallel performance over a wide range of computations.We address this question by studying a range of importantcomputations and communication architectures through acombination of detailed simulation, analytical modeling,and experiments on a flexible DSM prototype.
IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003 1
. M. Chaudhuri and M. Heinrich are with the Computer SystemsLaboratory, Cornell University, Ithaca, NY 14853.E-mail: {mainak, heinrich}@csl.cornell.edu.
. C. Holt is with Transmeta, Inc., 3940 Freedom Circle, Santa Clara, CA95054. E-mail: [email protected].
. J.P. Singh is with the Department of Computer Science, PrincetonUniversity, Princeton, NJ 08544. E-mail: [email protected].
. E. Rothberg is with ILOG, Inc., 1901 Landings Dr., Mountain View, CA94043. E-mail: [email protected].
. J. Hennessy is with the Computer Systems Laboratory, StanfordUniversity, Stanford, CA 94305. E-mail: [email protected].
Manuscript received 23 Jan. 2002; revised 12 Aug. 2002; accepted 27 Aug.2002.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number 115758.
0018-9340/03/$17.00 � 2003 IEEE Published by the IEEE Computer Society

We characterize the communication architectures ofDSM multiprocessors by a few key parameters that aresimilar to those in the logP model [6]. Our characterizationsand the design space that they represent are described inSection 2. Section 3 describes the framework and methodol-ogy we use to study the effectiveness of different types ofDSM architectures. Section 4 presents and analyzes oursimulation results. Section 5 presents a queuing model toanalyze the contention in the communication controller anduses that model to predict the parallel efficiency ofapplications running on different communication architec-tures. Section 6 describes the effect of varying theoccupancy of a programmable protocol engine in a flexibleDSM architecture and shows that it is very difficult toregain the lost performance by increasing the problem sizeas the controller becomes slower. Section 7 concludes thepaper.
1.1 Related Work
The logP model suggested in [6], introduced a machine-independent model to reason about the performance ofmessage-passing parallel programs. In a 1995 technicalreport [13], we first adapted this model to describe a genericDSM architecture, where o was the occupancy of the DSMcommunication controller, and carried out a simulation-based study to show the effects of latency (l) and occupancy(o) on the performance of large-scale parallel applicationsand computational kernels. This was followed by a similarstudy by others on a high-performance NOW [18]. Theeffects of processor overhead, network interface occupancy,node-to-network bandwidth, and interrupt overhead havealso been studied in the context of shared virtual memoryclusters [2].
Inspired by our previous study, many research groupshave proposed designing controllers with lower occupancy[20] and have explored methods to reduce the contention ofthe communication controller [7], [9], [12], [19], [21], [34].Also, it has been suggested that, if the controller is slowerthan the node-to-network interface, increasing the coher-ence granularity may help reduce contention [33]. Theeffects of bisection bandwidth and ratio of processor cycletime to network latency have been studied for severalversions of shared memory and message passing applica-tions running on the Alewife machine [1]. However, thisstudy does not discuss the performance effects of nodecontroller occupancy and node-to-network bandwidth, orhow these parameters interact with each other as one movesfrom one point to another in the design space. In [27], aperformance model for shared memory machines is pre-sented as a function of various architectural and statisticalparameters of the system. We present a much more simpleanalytical model in this paper and show how the modelbehaves with varying communication architecture para-meters. In this paper, we expand the ideas in our originalreport, make the analysis more concrete with a queuingmodel, and augment the simulation results with experi-mental results obtained from a programmable DSM proto-type. The experimental results allow us to look at the effectsof controller occupancy at larger problem sizes than it ispossible to simulate and determine whether less aggressivecommunication controllers can regain their lost perfor-mance at these larger problem sizes.
2 PARAMETERS AND DESIGN SPACE
Using the logP model, we abstract the multiprocessorcommunication architecture of a parallel machine in termsof four parameters. The l parameter in the logP model is thenetwork latency from the moment the first flit of a messageenters the network at a source node to the moment themessage arrives at the destination node, o is the overhead ofsending a message, g is the gap (reciprocal of node-to-network bandwidth through the network interface), and Pis the number of processors. The only difference betweenour DSM model and the logP model developed formessage-passing machines is in the o parameter. In logP,the overhead, o, is the time during which the mainprocessor is busy initiating or receiving a message andcannot do anything else. In most DSM machines, however,protocol processing is off-loaded to a separate communica-tion controller, and the main processor is free to continuedoing independent work while the controller is occupied.The o parameter in our DSM model then stands for theoccupancy of the communication controller per protocolaction or message; that is, the time for which the controlleris tied up with one action and cannot perform another.Alternatively, occupancy can be viewed as the reciprocal ofthe communication controller’s message bandwidth orservice rate. However, since controller bandwidth may beconfused with (the very different) network bandwidthparameter, we prefer to use the term controller occupancy.
Our original study fixed the number of processors at 64.In this paper, we simulate two values of P , P ¼ 32 andP ¼ 64, and we carry out a study on the effect of varyingoccupancy on a real 16 and 32-node DSM multiprocessorwith a programmable protocol engine. We also brieflyexplore the effect of speeding up the main processor relativeto the memory system. The other three parameters thatcharacterize the communication architecture—latency, oc-cupancy, and bandwidth (or gap)—all have complicatedaspects to them, and we make certain simplifying assump-tions. Let us discuss each parameter individually beforesetting the range in which we vary these parameters in thecontext of realistic machines.
2.1 Latency
The latency of a message through the network depends on,among other things, how many hops the message travels inthe network. For the moderate-scale machines that weconsider (� 64 processors), the overhead of getting themessage from the processor into the network and vice versausually dominates the topology-related component of theend-to-end latency seen by the processor. We, therefore,ignore topology and compute network latency as theaverage network transit time between two nodes in a two-dimensional mesh topology. By taking into account thetopology-related effects, our experimental model can beeasily adapted to the cases where latency is not homo-geneous over the entire network or when there are somenonnegligible variations of latency over time. However, thisstudy is beyond the scope of this paper.
2.2 Occupancy
The occupancy that the controller incurs for a requestaffects performance in two ways. First, it contributesdirectly to the end-to-end latency of the current requestbecause the request must pass through the controller.
2 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003

Second, it can contribute indirectly to the end-to-endlatencies of subsequent requests, through contention forthe occupied controller. Occupancy is more difficult torepresent as an abstract parameter than network latency fortwo reasons. First, we have to decide which types oftransactions invoke actions on the controller and, hence,incur occupancy. Second, the occupancy of a remote miss isactually distributed between two (or three) of the con-trollers in the system, and the occupancies of each of theindividual transactions may not be the same. While wewould like to represent occupancy by a single value of o,occupancy in real machines often depends on the type ofthe transaction. Let us examine these issues separately.
Clearly, all events related to internode communicationand protocol processing incur controller occupancy. Theseinclude cache misses that need data from another node,processor references that require the communication ofstate changes to other nodes, and incoming requests andreplies from the network containing data and protocolinformation. We assume that cache misses that access localmemory and do not generate any communication, do notinvoke the controller and, thus, incur no occupancy [25].However, note that we do take into account the contentionbetween the main processor and the communicationcontroller in accessing local memory. We also assume thatthe state lookup that determines if a local cache miss needsto invoke the controller is free, and we assume uniprocessornodes, so that the communication controller has to handlethe requests of only one local processor. All of theseassumptions minimize the burden on the communicationcontroller and, hence, expose more fundamental limitations.Machines with multiple processors per node and machineswhere the controller handles local memory references mayperform worse than the results presented in this paper forthe same values of controller occupancy, indicating that, forsome architectures, controller occupancy may be even moreimportant than we will show it to be.
In many machines, particularly those in which thecommunication controller runs software code sequencesfor protocol processing, the occupancies of the controller aredifferent for different types of protocol actions. We makethe following assumptions about occupancy. When thecommunication controller is simply generating a requestinto the network or receiving a reply from the network, itincurs occupancy o. When the communication controller isthe home of a network request, it incurs occupancy 2obecause it has to retrieve data from memory and/ormanipulate coherence state information [11]. In this case,we assume the data memory access happens in parallelwith the operation of the controller. If the state lookup at thehome reveals that the requested line is dirty in the homenode’s cache, the communication controller incurs an extrafixed occupancy C, while retrieving the data from theprocessor’s cache. If the requested line is dirty in a thirdprocessor’s cache, the home node incurs an occupancy of 2oand forwards the request to that processor, and thecommunication controller at that node incurs an occupancyof 2oþ C. Occupancy is also incurred when the commu-nication controller at the home node services a write requestand sends invalidations to all nodes that are sharing thedata. In this case, the controller incurs an additionaloccupancy of one system clock cycle per invalidation thatit sends. In addition, occupancy is incurred while receiving
acknowledgments corresponding to certain requests (e.g.,invalidation acknowledgments) and while receiving own-ership transfer messages (e.g., sharing writebacks). Thecontroller handles these messages similarly to normalreplies, incurring an occupancy of o.
2.3 Bandwidth or Gap
The gap (g) parameter specifies the reciprocal of node-to-network bandwidth. It determines how fast data can betransferred through the network interface (between thecommunication controller and the network itself). Ouroriginal study did not vary node-to-network bandwidth.In this paper, we explore the effect of varying g over a widerange of values. While studying the effects of l and o only,we fix 1=g at 400 MB/s peak, which corresponds to MPPnetworks on recent machines. For coherence messages thatdo not carry data, the occupancy of the communicationcontroller always dominates this gap limitation. Formessages that carry data, the gap parameter can theoreti-cally become the bottleneck before controller occupancy forthe two lowest occupancies we examine. We show that thisis actually the case for some applications.
2.4 Design Space
Given these assumptions about l, o, and g, let us examinethe path and cost of a read miss to a cache line that isallocated on a remote node and is clean at its home. Therequest travels through the communication controller onthe requesting node (o), traverses the network (l), travelsthrough the communication controller at the home wherethe request is satisfied (2o), traverses the network again (l)and, finally, travels back through the communicationcontroller at the source node (o). Including the fixedexternal processor interface and network interface delaysinto and out of each controller (PIin, PIout, NIin, and NIout),leads to a total round-trip latency as seen by the processor(without any contention) of PIin þ o þNIout þl þNIinþ2oþNIout þlþNIin þoþ PIout for the miss, or 2lþ 4oþPIin þ PIout þ2ðNIin þNIoutÞ. If the line were dirty in thehome node’s cache, there would be an extra fixed cost of Cat the home for retrieving the data from the cache. For a linethat is dirty in the cache of a third processor (not therequester or the home), the latency would be 3lþ 6oþ C þPIin þPIout þ 3ðNIin þNIoutÞ. However, this is only thelatency seen by the requester. The controller at the homenode of the request has to handle a subsequent ownershiptransfer reply. The total latency of this transaction is givenby NIout at the previous owner, plus l to traverse thenetwork, plus NIin þ o at the home, leading to a totallatency of lþ oþNIin þNIout.
The network latency l and the controller occupancy o arethe variables in the above costs. In the analysis presentedabove, we assume that data transmission/receptionthrough network interfaces is completely pipelined and iscompletely overlapped with other activities in the commu-nication architecture. Therefore, we do not include g-relatedlatency terms in this analysis. Additive g-related latencyterms may appear in systems with fast controllers havingvery slow network interfaces. But, we will show that this ismost often not the case in practice.
We focus on a range of values for l and o, as shown inTables 1 and 2, covering a variety of possible architecturalalternatives. Our latencies (l) vary from tightly coupled,
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 3

low-latency MPP networks, through physically distributed
MPP networks, all the way to LANs composed of
commodity switches. Table 1 shows the average latency
for 64 processors. Our system cycles correspond to a 100
MHz system clock frequency. Table 2 describes the
controller occupancies in our design space. Small values
of occupancy represent communication controllers that are
tightly integrated, hardwired state machines. Such con-
trollers appear in the MIT Alewife machine [1], the KSR1
machine [15], the Stanford DASH multiprocessor [17], and
the SGI Origin 2000 [16]. As o increases, the controller
becomes less hardwired and more general-purpose, from
specialized coprocessors like those in the Stanford FLASH
multiprocessor [14] and the Sun S3.mp [22], through
inexpensive off-the-shelf processors on the memory bus as
in Typhoon-1 [23], to a controller on the I/O bus of the main
processor like those in SHRIMP [3], and the IBM SP2 [28].
We also vary the node-to-network bandwidth from 400
MB/s (g1) down to 25 MB/s (g16), to analyze the effect of
reducing network bandwidth on the applications under
consideration.
3 FRAMEWORK AND METHODOLOGY
The applications [31] and the base problems sizes that weuse in our simulation study are summarized in Table 3.They include three complete applications (Barnes-Hut,Ocean, and Water) and three computational kernels (FFT,LU, and Radix-Sort). The programs were chosen becausethey represent a variety of important scientific computa-tions with different communication patterns and require-ments. Descriptions of the applications can be found in:Barnes-Hut [26], Radix-Sort and Ocean [32], Water [31], andFFT and LU [24]. The communication characteristics of theapplications can be found in [24], [31]. The applications arehighly optimized to improve communication performance,particularly to reduce spurious hot-spotting or contentioneffects that adversely impact controller occupancy. Evenwith these optimizations, we will show that occupancy stillremains an important determinant of performance. Thecodes for the applications are taken from the SPLASH-2application suite [31], although Radix-Sort was modified touse a tree data structure (rather than a linear key chain) tocommunicate ranks and densities efficiently.
We explore the performance effects of varying l; o; g; Pand the problem sizes of these applications. The standarddefinition of parallel efficiency is used as the metric tomeasure the performance of a particular communicationarchitecture or a particular problem size. Parallel efficiencyis defined as the speedup over a sequential implementationof the application on a uniprocessor, divided by the numberof processors (P ). Some machine designers argue that cost-performance is the best overall figure of merit [30]. Thoughthis may be an important factor in the decision to purchasemachines, it is difficult to pinpoint the costs of machines atevery point in our design space, especially as advances intechnology cause the costs to change over time. Instead, we
4 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003
TABLE 1Network Latencies in the Design Space
TABLE 3Applications, Communication Patterns, and Base Problem Sizes
TABLE 2Controller Occupancies in the Design Space

use a pure performance metric and keep the study free ofcost issues. If designers want to spend less money and usecheaper, slower components, our results will still indicatethe performance of shared memory programs running onthose less aggressive architectures. In fact, cost can befactored in separately with our performance results to usecost-performance as a metric.
In this paper, we present simulation results as well asexperimental results gathered from an existing program-mable DSM prototype. The simulator models contention indetail within the communication controller, between thecontroller and its external interfaces, at main memory, andfor the system bus. The input and output queue sizes in thecontroller’s processor interface are uniformly set at 16 andtwo entries, respectively, while those for the networkinterface are uniformly set at two and 16 entries, respec-tively. We assume processor interface delays of one systemcycle inbound and four system cycles outbound andnetwork interface delays of eight system cycles inboundand four system cycles outbound. We assume that thelatencies through the interfaces remain fixed as controllerand network characteristics are varied. We also fix theaccess time of main memory DRAM at 140 ns (14 systemcycles), resulting in a local read miss time of 190 ns, onesystem cycle faster than the SGI Origin 2000. Fixing theinterface delays and the memory access time is realistic [11]and allows us to focus on the performance of thecommunication architecture and the effects of varyingl; o; g and P .
The processor controls its own secondary cache, and thesimulator uses 27 processor cycles (5 ns each cycle) for C,the time it charges the controller to retrieve state informa-tion from the processor cache when necessary. This latencyis close to the latencies reported in previous studies [11].There are separate 64 KB primary instruction and datacaches that are two-way set associative and have a line sizeof 64 bytes. The secondary cache is unified, 2 MB in size,two-way set associative, and has a line size of 128 bytes. Wealso assume that the processor ISA includes a prefetchinstruction. In our processor model, a load miss stalls theprocessor until the first double-word of data is returned,while prefetch and store misses will not stall the processorunless there are already references outstanding to fourdifferent cache lines.
4 SIMULATION RESULTS
This section presents and analyzes the simulation results ofall the six SPLASH-2 applications that we are looking at.
4.1 What We Expect To See
As l and o increase for fixed values of g and P with a givenproblem size, we expect that parallel efficiency shoulddecrease. To get a rough idea about how the parallelefficiency should vary with l and o, we use the model ofparallel efficiency we suggested in [13]:
� ¼ Tcomp
Tcomp þ VcommðTL þ TCÞ; ð1Þ
where Tcomp is the uniprocessor computation time, Vcomm isthe total volume of communication, and TL and TC are theaverage stall times due to latency and contention, respec-tively, for each communication. We define communication
to be any transaction that incurs occupancy on thecommunication controller. Note that TL includes thelatencies for all protocol transactions, not just remote readmisses clean at the home. Equation 1 is considered here,only to get some intuitive idea about the expected results.The readers should not take it as a formal definition ofparallel efficiency, although this equation models theparallel efficiency fairly well under the assumptions ofperfect load-balance and an equal distribution of volume ofcommunication across the nodes in the system. But, thisequation fails to explain the well-known phenomenon ofsuperlinear speedup that may happen due to cache effectsrelated to the problem size on one versus multipleprocessors. The parallel efficiency of our simulation runsis calculated as speedup divided by the number ofprocessors. We do not use (1) for that purpose.
For a fixed problem size, a fixed number of processors,and fixed g, both Tcomp and Vcomm are constants. We willshow that TL varies linearly with l and o. To see why this istrue, observe that the uncontended latency of any transac-tion is given by alþ boþ c, where a and b are constants thatdepend on the type of the transaction and c is a constantthat depends on the time spent in various interfacesbetween the communication controller, the processor, andthe network. The average over all these uncontendedlatencies will have the same linear behavior. Finally, weturn to TC , the average contention in the communicationcontroller. If the contention in the controller was fixed at aconstant value as we traverse the design space, we wouldsee the same parallel efficiency for various values of o aslong as we hold TL at a constant value. On the other hand, ifTC increases with increasing o, we would expect to see agradual decrease in parallel efficiency as we move from O1
to O16 for a fixed value of TL.Next, we explore the question of varying the gap (i.e., the
node-to-network bandwidth). As node-to-network band-width decreases, we expect to see a decrease in parallelefficiency. The importance of g depends on the node-to-network bandwidth requirement of the application underconsideration. Although the average bandwidth require-ments of the applications reported in [13] were less than thecapacity of the network, we will see that g can still beimportant if the communication pattern is bursty.
The next two dimensions in our design space are P andthe problem size. With increasing P , we expect to see adecrease in parallel efficiency for the same communicationarchitecture. This is simply because TC increases as Pincreases. Further, the average number of hops a messageneeds to travel also increases leading to a correspondingincrease in TL. We also expect that increasing problem size,up to a point, will increase parallel efficiency. But, the effectof problem size depends on the communication-to-compu-tation ratio of the application, and the question that remainsis: How big does the problem size need to be for lessaggressive architectures to regain their lost performance, ifit is possible at all?
In the following simulation results, we will focus on bothprefetched and nonprefetched applications. Since prefetch-ing can introduce extra and, sometimes, unnecessarycommunication traffic (if prefetching is not timely), inTable 4, we show how effective prefetching was for FFT,Ocean, Radix-Sort, and LU in an L1O1g1 simulation for thebase problem sizes and 64 processors. Prefetching iseffective if the read miss rate is reduced without increasing
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 5

the write miss rate. For FFT, prefetching was found to bequite effective because it reduced the L1 data cache readmiss rate from 0.55 percent to 0.33 percent withoutsignificantly changing the L1 data cache write miss rate(in this case, write miss rate also decreased from 2.1 percentto 2.06 percent). Also, all the prefetches missed in the L1data cache, meaning that all of the prefetch instructionswere useful. For Ocean and Radix-Sort, prefetching waseffective for the L1 network latency, but we found that itcould not hide the latency well as the network approachedless aggressive MPP networks and commodity LANs.Finally, for LU, prefetching did not help in reducing theread miss rate. This is mostly because of a very smallnumber of prefetch misses (23,488) compared to the totalnumber of load misses (1,008,479) in the L1 data cache,which, in turn, is due to the fact that the total number ofprefetches is small compared to the total number of loads.Also, prefetched LU may introduce certain hot-spots in thememory system because, during the perimeter updatephase, all the processors owning the perimeter blocks maytry to send prefetches to the owner of the correspondingdiagonal block at the same time. For all the applications,almost all prefetches missed in the L1 data cache. Therefore,prefetching did not introduce any unnecessary instructionoverhead.
4.2 Case Studies: FFT and Ocean
First, we select two representative applications from theSPLASH-2 application suite to explore, in detail, how l, o, g,P , and the problem size affect the performance of DSM
multiprocessors. We select FFT because it is an easilyunderstood application that has a regular communicationpattern, and we select Ocean because it is a complex, large-scale application.
4.2.1 Experience with FFT
First, we examine the effects of l and o on nonprefetchedand prefetched FFT. In our simulations, the ratio ofprocessor clock speed to the system clock speed is set totwo. Increasing this ratio is equivalent to increasing theprocessor clock rate or, alternatively, to having a moreaggressive superscalar processor that can issue requests tothe memory subsystem at a faster rate [10]. We will varythis ratio as a part of our case study, and we will see thathigher ratios will result in worse parallel performance dueto a higher TC and a smaller Tcomp for the same problemsize. Fig. 1 plots parallel efficiency against averagecommunication latency (TL) in processor clock cycles fornonprefetched and prefetched FFT with the base problemsize (1M points) running on 64 processors. Different curvesfor different values of o indicate that we do haveoccupancy-induced contention in the node-controller. Thesix points along each o-curve corresponds to the six networkarchitectures ranging from L1 (tightly coupled MPP latency)to L32 (commodity LAN latency). In this paper, all theefficiency curves that show effects of only l and o have aconstant node-to-network bandwidth of 400 MB/s (a g1configuration).
Without prefetching: As already indicated, the multipleefficiency curves show that the contention component of the
6 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003
TABLE 4Effect of Hand-Inserted Prefetches
Fig. 1. (a) Nonprefetched and (b) prefetched 1M-point FFT running on 64 processors.

controller is indeed important, even without prefetching.The curves also begin to flatten as o is increased, whichindicates that the controller starts to saturate, and its highutilization becomes the performance bottleneck in themachine, regardless of the network latency.
Note that all efficiency curves nearly converge at highvalues of l, implying that, at today’s commodity networklatencies, controller occupancy does not have a large impacton overall performance for this problem size withoutprefetching. Conversely, for a range of MPP and distributedMPP network latencies (small values of l), controlleroccupancy is a critical determinant of overall performance.Increases in TC account for the efficiency lost whilecommunication latency is held constant and controlleroccupancy is increased.
With prefetching: In this case, there are also multipleparallel efficiency curves that flatten out as o increases.Unlike the nonprefetched case, the curves no longerconverge at commodity LAN latency because the conten-tion component of occupancy affects overall performance,even at high network latencies. At our highest networklatency, an O1 machine is 1.5 times faster than an O16
machine in the prefetched case, but only 1.3 times faster inthe nonprefetched case. Prefetching improves performancemore at low o and low-to-moderate l than it does at highervalues of o and l. At moderate l, prefetching cannot hide allthe network latency and increases in latency begin to hurtthe prefetched case at the same rate as the nonprefetchedcase. At medium o, the controller becomes a bottleneck, as itis unable to match the increased bandwidth needs of
prefetching. We see, therefore, to support prefetching inDSM machines, it is crucial to keep controller occupancylow.
Effect of faster processors: The performance gapbetween the processor and the memory subsystem is ever-increasing. Fig. 2 shows the efficiency curves for processor/memory speed ratios of 3 and 4. As expected, the shapes ofthe curves remain unchanged, while the parallel efficiencycorrespondingly decreases. Also, note that the decrease inparallel efficiency is more for slower controllers than thelow-occupancy ones. For example, with an agressive MPPnetwork (L1 configuration), the parallel efficiency for an O1
controller drops from 0.98 to 0.96 as the system moves froma speed ratio of 3 to 4. On the other hand, for an O16
controller with the same network, the parallel efficiencydrops from 0.47 to 0.39 as the speed ratio changes from 3 to4. This drop is significant given that an efficiency of 0.47corresponds to a speedup of 30.08, while 0.39 correspondsto a speedup of 24.96 on a 64-processor system, which inturn translates into a large difference in execution times.This suggests that, as the gap between the clock rates of theprocessor and the memory subsystem continue to increase,DSM controllers will need to become more tightly inte-grated and have even lower occupancy. The remainder ofour simulation results uses our base processor/memoryspeed ratio of two. This is generous toward less aggressivecontrollers and networks, yet, even so, we will see that theirperformance in DSM systems is still poor.
Effect of varying node-to-network bandwidth: Next, weexplore the effect of varying g on FFT. Fig. 3 plots the
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 7
Fig. 2. Prefetched 1M-point FFT with processor/memory speed ratios of (a) 3 and (b) 4 on 64 processors.
Fig. 3. Effect of varying l, o, and g on prefetched 1M-point FFT for (a) 32 and (b) 64 processors.
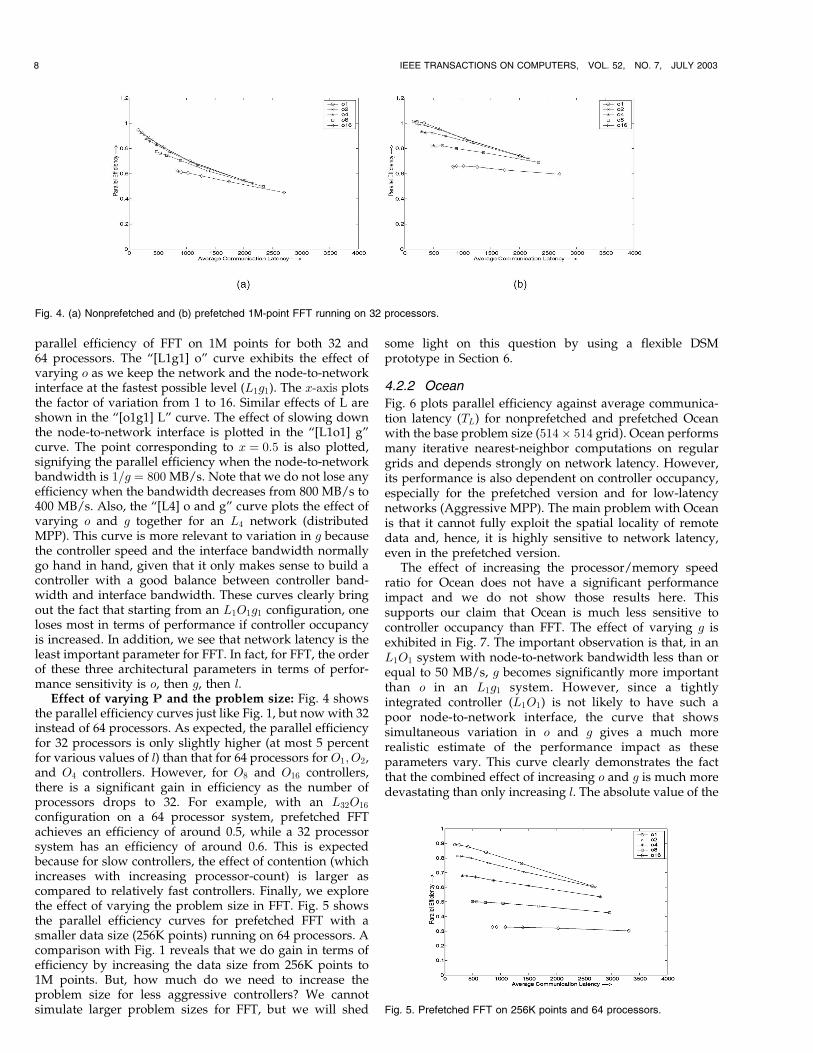
parallel efficiency of FFT on 1M points for both 32 and64 processors. The “[L1g1] o” curve exhibits the effect ofvarying o as we keep the network and the node-to-networkinterface at the fastest possible level (L1g1). The x-axis plotsthe factor of variation from 1 to 16. Similar effects of L areshown in the “[o1g1] L” curve. The effect of slowing downthe node-to-network interface is plotted in the “[L1o1] g”curve. The point corresponding to x ¼ 0:5 is also plotted,signifying the parallel efficiency when the node-to-networkbandwidth is 1=g ¼ 800 MB/s. Note that we do not lose anyefficiency when the bandwidth decreases from 800 MB/s to400 MB/s. Also, the “[L4] o and g” curve plots the effect ofvarying o and g together for an L4 network (distributedMPP). This curve is more relevant to variation in g becausethe controller speed and the interface bandwidth normallygo hand in hand, given that it only makes sense to build acontroller with a good balance between controller band-width and interface bandwidth. These curves clearly bringout the fact that starting from an L1O1g1 configuration, oneloses most in terms of performance if controller occupancyis increased. In addition, we see that network latency is theleast important parameter for FFT. In fact, for FFT, the orderof these three architectural parameters in terms of perfor-mance sensitivity is o, then g, then l.
Effect of varying P and the problem size: Fig. 4 showsthe parallel efficiency curves just like Fig. 1, but now with 32instead of 64 processors. As expected, the parallel efficiencyfor 32 processors is only slightly higher (at most 5 percentfor various values of l) than that for 64 processors for O1; O2,and O4 controllers. However, for O8 and O16 controllers,there is a significant gain in efficiency as the number ofprocessors drops to 32. For example, with an L32O16
configuration on a 64 processor system, prefetched FFTachieves an efficiency of around 0.5, while a 32 processorsystem has an efficiency of around 0.6. This is expectedbecause for slow controllers, the effect of contention (whichincreases with increasing processor-count) is larger ascompared to relatively fast controllers. Finally, we explorethe effect of varying the problem size in FFT. Fig. 5 showsthe parallel efficiency curves for prefetched FFT with asmaller data size (256K points) running on 64 processors. Acomparison with Fig. 1 reveals that we do gain in terms ofefficiency by increasing the data size from 256K points to1M points. But, how much do we need to increase theproblem size for less aggressive controllers? We cannotsimulate larger problem sizes for FFT, but we will shed
some light on this question by using a flexible DSMprototype in Section 6.
4.2.2 Ocean
Fig. 6 plots parallel efficiency against average communica-tion latency (TL) for nonprefetched and prefetched Oceanwith the base problem size (514� 514 grid). Ocean performsmany iterative nearest-neighbor computations on regulargrids and depends strongly on network latency. However,its performance is also dependent on controller occupancy,especially for the prefetched version and for low-latencynetworks (Aggressive MPP). The main problem with Oceanis that it cannot fully exploit the spatial locality of remotedata and, hence, it is highly sensitive to network latency,even in the prefetched version.
The effect of increasing the processor/memory speedratio for Ocean does not have a significant performanceimpact and we do not show those results here. Thissupports our claim that Ocean is much less sensitive tocontroller occupancy than FFT. The effect of varying g isexhibited in Fig. 7. The important observation is that, in anL1O1 system with node-to-network bandwidth less than orequal to 50 MB/s, g becomes significantly more importantthan o in an L1g1 system. However, since a tightlyintegrated controller (L1O1) is not likely to have such apoor node-to-network interface, the curve that showssimultaneous variation in o and g gives a much morerealistic estimate of the performance impact as theseparameters vary. This curve clearly demonstrates the factthat the combined effect of increasing o and g is much moredevastating than only increasing l. The absolute value of the
8 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003
Fig. 4. (a) Nonprefetched and (b) prefetched 1M-point FFT running on 32 processors.
Fig. 5. Prefetched FFT on 256K points and 64 processors.

slope of the latency curve is consistently less than the otherthree curves. This also supports the view that latency is lessimportant than occupancy and bandwidth. The slopes ofthe other three curves are similar, although, at some points,the g-curve has a lower slope compared to the o-curve. Thismeans that, for Ocean, the message bandwidth of thecontroller should be well-balanced with the link bandwidthof the interface; otherwise, one of them will be under-utilized and the other one will become the bottleneck.
As we decrease the number of processors from 64 to 32,we observe the same trend as in FFT—parallel efficiencyincreases. In fact, an L1O1 controller achieves superlinearspeedup for prefetched Ocean. However, when we changethe grid size to 258� 258, we observe a big change inperformance (see Fig. 8). With the reduced data set, theefficiency achieved by an L1O1 controller is less than that of
an L1O8 controller on the bigger grid size. Again, we willsee the effect of occupancy variation with larger problemsizes in Section 6.
4.3 Other Simulation Results
In the following, we present the remaining simulationresults for Radix-Sort, LU, Barnes-Hut, and Water. Since wecontinue to see similar trends when P is decreased from 64to 32, we mainly focus on results for 64 processors and pointout the effects of varying l, o, and g.
Radix-Sort: The results for Radix-Sort shown in Fig. 9 aresimilar to FFT, with a few notable exceptions. Like FFT,without prefetching, all the efficiency curves almostconverge by today’s LAN latencies (our rightmost points).While the O1 and O2 controllers have similar performance,the O8 curve is much flatter than it is in FFT, and the O16
curve is almost totally flat. This indicates that, in Radix-Sort,contention induced by slower controllers matters even morethan it does in FFT.
In the prefetched version of Radix-Sort, we see a biggerlinear dependence on network latency than that in pre-fetched FFT (i.e., prefetching is not as successful in Radix-Sort as it is in FFT for networks slower than the L1
configuration because of the irregular sender-initiatedbursty communication in the permutation phase). Prefetch-ing helps much more at lower values of o, indicating that itis critical to keep occupancy low when prefetching, evenwith LAN network latencies.
Fig. 10 shows the effect of varying g. For an L1O1
controller, g is much more important than o is for an L1g1controller. This is because of the permutation phase in
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 9
Fig. 6. (a) Nonprefetched and (b) prefetched Ocean running on 64 processors and a 514� 514 grid.
Fig. 7. Effect of varying l, o, and g on prefetched Ocean for (a) 32 and (b) 64 processors with a 514� 514 grid.
Fig. 8. Prefetched Ocean on a 258� 258 grid and 64 processors.
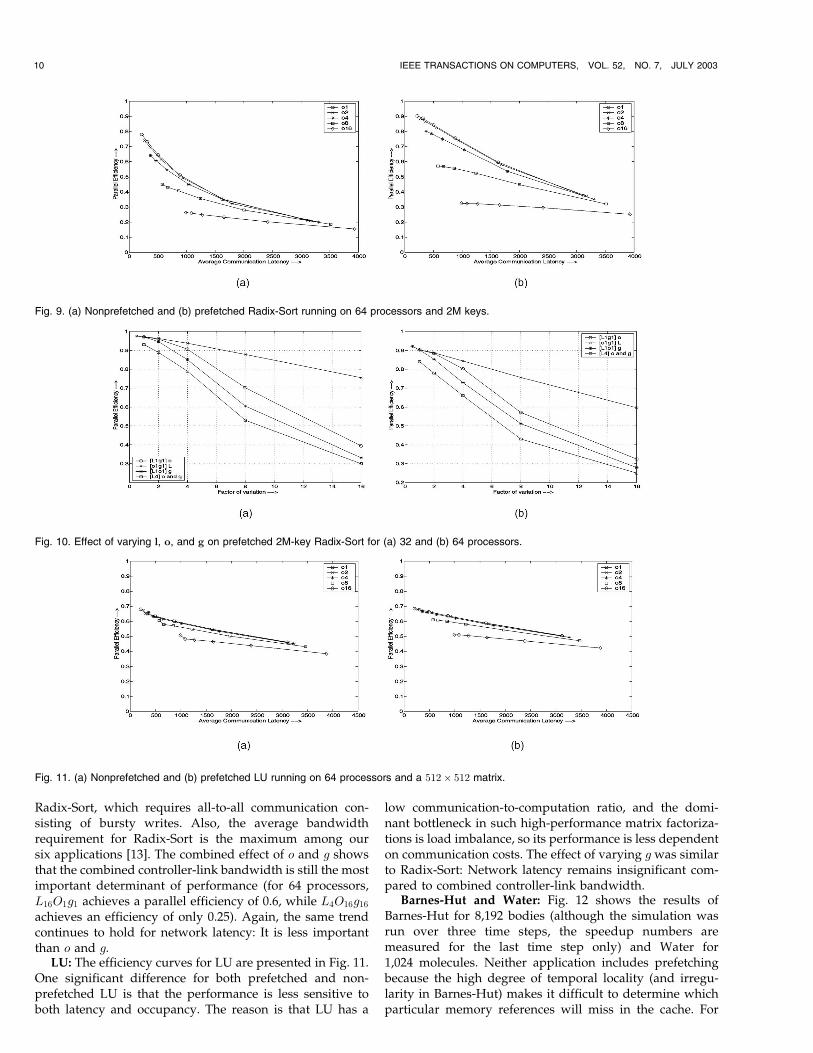
Radix-Sort, which requires all-to-all communication con-sisting of bursty writes. Also, the average bandwidthrequirement for Radix-Sort is the maximum among oursix applications [13]. The combined effect of o and g showsthat the combined controller-link bandwidth is still the mostimportant determinant of performance (for 64 processors,L16O1g1 achieves a parallel efficiency of 0.6, while L4O16g16achieves an efficiency of only 0.25). Again, the same trendcontinues to hold for network latency: It is less importantthan o and g.
LU: The efficiency curves for LU are presented in Fig. 11.One significant difference for both prefetched and non-prefetched LU is that the performance is less sensitive toboth latency and occupancy. The reason is that LU has a
low communication-to-computation ratio, and the domi-nant bottleneck in such high-performance matrix factoriza-tions is load imbalance, so its performance is less dependenton communication costs. The effect of varying g was similarto Radix-Sort: Network latency remains insignificant com-pared to combined controller-link bandwidth.
Barnes-Hut and Water: Fig. 12 shows the results ofBarnes-Hut for 8,192 bodies (although the simulation wasrun over three time steps, the speedup numbers aremeasured for the last time step only) and Water for1,024 molecules. Neither application includes prefetchingbecause the high degree of temporal locality (and irregu-larity in Barnes-Hut) makes it difficult to determine whichparticular memory references will miss in the cache. For
10 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003
Fig. 9. (a) Nonprefetched and (b) prefetched Radix-Sort running on 64 processors and 2M keys.
Fig. 10. Effect of varying l, o, and g on prefetched 2M-key Radix-Sort for (a) 32 and (b) 64 processors.
Fig. 11. (a) Nonprefetched and (b) prefetched LU running on 64 processors and a 512� 512 matrix.

Barnes-Hut, the O1 and O2 controllers have almost identicalperformance. For some values of o (e.g., 16), increasing thenetwork latency sometimes increases the performance. Weobserved that this anomaly happens because of reducedsynchronization stall time with a slow network. With arelatively slow network and for some particular eventtiming the lock accesses from different processors maybecome nicely staggered in time leading to lower lockcontention. For Water, the efficiency curves are similar tothose for LU. But, Water shows higher sensitivity to latencyand occupancy than LU. For Barnes-Hut with a reducedproblem size (4,096 bodies), [not shown] there was not assignificant performance loss as in Water with smallerproblem size (512 molecules) [not shown] for fast con-trollers (O1; O2; O4). For Water with 512 molecules, therewas a significant performance loss. The parallel efficiencyachieved by an O1 controller for all latencies with512 molecules was consistently less than that achieved byan O8 controller running on 1,024 molecules. The graphs forthese results are not presented here because of spaceconstraints, but are available in our technical report [4]. Thegap parameter g was not found to be important for eitherapplication.
Application Summary: As we expected, increasingnetwork latency uniformly decreases overall performanceacross all the applications. Prefetching is often very effectiveat improving performance, but requires low occupancycontrollers. Also, we observed that controller occupancy ismuch more important than network latency. For some ofthe applications (e.g., Radix-Sort), the node-to-networkbandwidth is more important than the controller occupancyfor fast controllers (e.g., hardwired). But, we do not expectthe node-to-network bandwidth to ever become a bottle-neck because fast controllers are expected to have fastnetwork interfaces. In other words, the node-to-networkbandwidth may become a bottleneck in certain applicationswith bursty communication phases if the message band-width of the controller is not well-balanced with thebandwidth of the network interface. We noticed that thecontention effect of controller occupancy is particularlyacute at low values of network latency. In addition, thepoint at which the efficiency curves begin to flatten occursat relatively small values of occupancy, typically either O4
or O8, and by O16 (communication controller on the I/Obus), the curves are almost flat. From a design standpoint,
these results show that controller occupancy will become abottleneck unless the communication controller is a hard-wired or customized controller integrated on the memorybus of the main processor. The only hope for less aggressivecontrollers is that larger problem sizes will restore some lostparallel efficiency. We explore this possibility via experi-mentation on a DSM prototype in Section 6.
5 ANALYTICAL MODELING
In this section, we develop a mathematical model to furtherunderstand the impact of latency and occupancy-inducedcontention on the execution time of an application. Weshow that it is easy to model the average communicationlatency, but extremely difficult to predict how contentionvaries across our design space.
Let the execution time for the L1O1 model be t1 and thatfor the LxOy model be t2. We expect that
t2 ¼ t1 þ V T ð�TL þ �TCÞ; ð2Þ
where V T is the per-node average transaction volume, �TL
is the average change in uncontended transaction latency,and �TC is the average change in communication controllercontention per protocol transaction. If we want to predict t2from t1, we need three parameters, namely, V T , �TL, and�TC . We explore each of these parameters separately.
5.1 Modeling �TL
We can predict �TL for prefetched FFT within 2 percent ofour simulation results in most cases. We can achieve similaraccuracy for the other five applications as well. From thedetailed L1O1 simulation of prefetched FFT, we find that theaverage transaction latency is given by the equation
TL ¼ 1:42lþ 3oþ 51 ð3Þ
in processor clock cycles. Since the transaction volume andtransaction pattern remain more or less unchanged as l ando are varied, we expect that this equation holds even forvalues of x and y other than 1. Table 5 shows the validity ofthis equation as we try to predict the average transactionlatency (in processor clock cycles) using this equation, andcompare them against the real values obtained throughsimulation. As can be seen from the table, the predictedvalues are, in most cases, within 1 percent of the values
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 11
Fig. 12. (a) Barnes-Hut (8,192 bodies) and (b) Water (1,024 molecules) running on 64 processors.
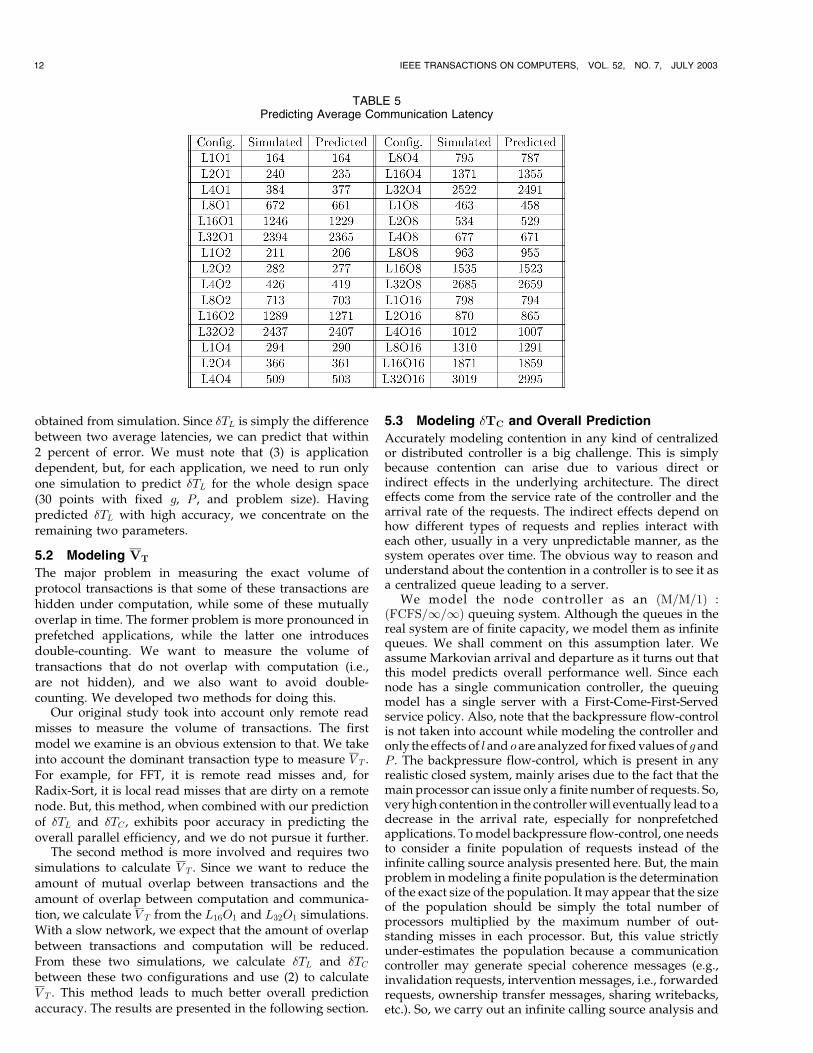
obtained from simulation. Since �TL is simply the differencebetween two average latencies, we can predict that within2 percent of error. We must note that (3) is applicationdependent, but, for each application, we need to run onlyone simulation to predict �TL for the whole design space(30 points with fixed g, P , and problem size). Havingpredicted �TL with high accuracy, we concentrate on theremaining two parameters.
5.2 Modeling VT
The major problem in measuring the exact volume ofprotocol transactions is that some of these transactions arehidden under computation, while some of these mutuallyoverlap in time. The former problem is more pronounced inprefetched applications, while the latter one introducesdouble-counting. We want to measure the volume oftransactions that do not overlap with computation (i.e.,are not hidden), and we also want to avoid double-counting. We developed two methods for doing this.
Our original study took into account only remote readmisses to measure the volume of transactions. The firstmodel we examine is an obvious extension to that. We takeinto account the dominant transaction type to measure V T .For example, for FFT, it is remote read misses and, forRadix-Sort, it is local read misses that are dirty on a remotenode. But, this method, when combined with our predictionof �TL and �TC , exhibits poor accuracy in predicting theoverall parallel efficiency, and we do not pursue it further.
The second method is more involved and requires twosimulations to calculate V T . Since we want to reduce theamount of mutual overlap between transactions and theamount of overlap between computation and communica-tion, we calculate V T from the L16O1 and L32O1 simulations.With a slow network, we expect that the amount of overlapbetween transactions and computation will be reduced.From these two simulations, we calculate �TL and �TC
between these two configurations and use (2) to calculateV T . This method leads to much better overall predictionaccuracy. The results are presented in the following section.
5.3 Modeling �TC and Overall Prediction
Accurately modeling contention in any kind of centralizedor distributed controller is a big challenge. This is simplybecause contention can arise due to various direct orindirect effects in the underlying architecture. The directeffects come from the service rate of the controller and thearrival rate of the requests. The indirect effects depend onhow different types of requests and replies interact witheach other, usually in a very unpredictable manner, as thesystem operates over time. The obvious way to reason andunderstand about the contention in a controller is to see it asa centralized queue leading to a server.
We model the node controller as an ðM=M=1Þ :ðFCFS=1=1Þ queuing system. Although the queues in thereal system are of finite capacity, we model them as infinitequeues. We shall comment on this assumption later. Weassume Markovian arrival and departure as it turns out thatthis model predicts overall performance well. Since eachnode has a single communication controller, the queuingmodel has a single server with a First-Come-First-Servedservice policy. Also, note that the backpressure flow-controlis not taken into account while modeling the controller andonly the effects of l and o are analyzed for fixedvalues of g andP . The backpressure flow-control, which is present in anyrealistic closed system, mainly arises due to the fact that themain processor can issue only a finite number of requests. So,very high contention in the controllerwill eventually lead to adecrease in the arrival rate, especially for nonprefetchedapplications. Tomodel backpressure flow-control, one needsto consider a finite population of requests instead of theinfinite calling source analysis presented here. But, the mainproblem inmodeling a finite population is the determinationof the exact size of the population. It may appear that the sizeof the population should be simply the total number ofprocessors multiplied by the maximum number of out-standing misses in each processor. But, this value strictlyunder-estimates the population because a communicationcontroller may generate special coherence messages (e.g.,invalidation requests, intervention messages, i.e., forwardedrequests, ownership transfer messages, sharing writebacks,etc.). So, we carry out an infinite calling source analysis and
12 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003
TABLE 5Predicting Average Communication Latency

show that this simplemodel is accurate enough in predictingthe contention in the communication controller. Anotherreason forusinga simplemodel is thatwewanted (if possible)to devise an easy way to predict the parallel efficiency.
The contention in the system is measured as the expectedwaiting time in the queue, Wq, which is given by [29]:
Wq ¼�
�ð1� �Þ ; ð4Þ
where � is the effective traffic in the system and is given by� ¼ �=�, � being the arrival rate (number of requestsarriving per processor clock cycle) and � the service rate(number of requests serviced per processor clock cycle). Weassume that the arrival rate � is inversely proportion to thenetwork latency, i.e., for an LxOy model � ¼ KL=x, whereKL is a system and application dependent constant.Similarly, we assume that the service rate � ¼ KO=y. Thus,we have
Wq ¼KLy
2
KOðKOx�KLyÞ: ð5Þ
Observe that, for fixed occupancy (i.e., fixed y), as latencyincreases (i.e., x increases), contention decreases, which isthe expected result. From the contention in the LxO1 modelwe try to predict that in LxOy model. LetWq1 andWq2 be thecontention in the LxO1 model and LxOy model, respec-tively. Therefore, we have
Wq2 ¼ y2KOx�KL
KOx�KLy
� �Wq1: ð6Þ
This equation directly follows from (5). It is interesting tonote that growth in contention (i.e., Wq2=Wq1) for fixedlatency (i.e., x) is faster than quadratic in occupancybecause, for y > 1, the bracketed term in (6) is bigger than1 and this term increases in magnitude as x (i.e., latency) iskept fixed and y (i.e., occupancy) is increased. Further, notethat, for fixed y (i.e., fixed occupancy), the ratio Wq2=Wq1
does not vary much with x (i.e., latency). So, our claim thatoccupancy affects contention more than latency does is bornout analytically. We use (6) to predict the contention ofLxOy configuration from that in LxO1 configuration as y isvaried and x is kept fixed. To carry out this prediction, weonly need to carry out the six simulations (versus the30 simulations that cover our entire design space) for theLxO1 model as x takes on values 1, 2, 4, 8, 16, and 32. Fromthese simulation results, we can calculate the contention forthese six models. The next task is to estimate KL and KO.We approximate the arrival rate as the total volume oftransactions per communication controller divided by theparallel execution time. From this, we calculate KL. Next,we approximate the service rate as the reciprocal ofcommunication controller occupancy per protocol handlerinvocation. From this, we calculate KO.
Using the Analytical Model: For architectures with fastnetworks (i.e., low values of x), if the controller is relativelyslow (i.e., relatively bigger values of y), this model willmispredict contention. Whether it will underpredict oroverpredict contention depends on the communicationstructure of the underlying application. The main reason forthis misprediction is that the fast network exposes the finitequeue length limitation and the system behaves more like anðM=M=1Þ : ðFCFS=N=1Þ model, where N is the maximum
number of outstanding requests in the system.At this point, alinearwaiting timemodel (for fixedx, e.g., forL1 network, thecontention increases linearly with y) works quite well. To bemore precise, in the linear model the contention for LxO2
configuration is exactly double that ofLxO1 configuration forfixed x. For prefetched FFT, the linear waiting time modelpredicts theparallel efficiencywithin1percent error forL1O2,L2O2, L1O4, L2O4, L1O8, and within 5 percent for L1O16
configurations (see Fig. 13; the simulated curves are in solidlines, while the predicted ones are in dotted lines). V T ispredicted by the second method described in Section 5.2.However, we observed that the prediction error of the linearmodel for prefetched Radix-Sort is as big as 5 percent to10 percent for the low-latency configurations (interestedreaders are refered to [4]). The reason for this is mainly thelack of knowledge about the exact V T . With low-latencynetworks, prefetching can hide latency, and our modelmispredicts V T , especially when the communication struc-ture is irregular andbursty.Ourexperience says thatdifferentqueuing models are necessary to predict the performance ofdifferent applications due to the vastly different communica-tion structures of different applications. Our dual queuingmodel (to be introduced shortly) predicts the parallelefficiency of our applications within a small percentage forall our configurations.
We now present a mathematical proof to explain why alinear waiting time model works well for the low-latencynetwork configurations. As we have already pointed out. forthese configurations the system behaves more like anðM=M=1Þ : ðFCFS=N=1Þmodel. For thismodel, the expectedsystem queue length is given by [29]:
Ls ¼�½1� ðN þ 1Þ�N þN�Nþ1�
ð1� �Þð1� �Nþ1Þ : ð7Þ
The average queue length is given by
Lq ¼ Ls ��eff
�; ð8Þ
where effective arrival rate, �eff is given by
�eff ¼ � 1� 1� �
1� �Nþ1
� ��N
� �: ð9Þ
For a fast network and a slow controller, it is reasonable toassume that � is large. So, for reasonable values of N (e.g.,16 for the PI inbound queues in our simulator), it is logical
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 13
Fig. 13. Prediction accuracy of the linear model for prefetched FFT on 64
processors.

to assume that 1=�Nþ1 is negligible. With these simplifica-tions, we obtain
�eff ¼ � 1� 1=�� 1
�1
� �� �; ð10Þ
i.e., �eff ¼ �, which is expected because now the arrival rateis governed by the service rate since the queue remains fullmost of the time and there is no space to accommodate newrequests until a pending request gets serviced. Therefore,
Wq ¼Lq
�eff; ð11Þ
which, from (8) and the relation �eff ¼ �, reduces to
Wq ¼1
�ðLs � 1Þ ¼ 1
KOðLs � 1Þy: ð12Þ
Now, for a fixed network model (i.e., fixed x), it isreasonable to assume that Ls remains constant as y isvaried. This assumption is justified by the fact that for a fastnetwork and relatively slow controller, Ls is almost alwaysclose to N and it is more affected by the arrival rate than bythe service rate since the service rate is much smaller thanthe arrival rate. We present an approximate analysis tosupport this view. In (7), assuming that � is large, we obtain
Ls ¼�
�� 1
� �N �N þ 1
�
� �; ð13Þ
which we can approximate to
Ls ¼ N �N þ 1
�¼ N �N þ 1
��; ð14Þ
with the assumption that � >> 1. Now, if � is large, thenðN þ 1Þ=� is small, and multiplying it by a small � will notchange Ls much as we decrease � from L1O1 to L1O16. Thus,(12) precisely describes the linear waiting time model—thecontention varies linearly with occupancy factor y for fixedx. This completes our proof. Also, note that, for a fixedoccupancy, as latency increases, the arrival rate decreasesand Ls also decreases leading to less contention. But, thisequation fails to hold as latency increases beyond that of anL2 network because this model dictates a faster decrease incontention than actually occurs in practice.
As thenetworkgets slower, finite queue length isno longera problem and our original quadratic contention model (6)
works quite well. For example, in prefetched FFT, we foundthat this model predicts the parallel efficiency within6 percent error for L4O4, L4O8, L8O8, L2O16, L4O16, L8O16,and L16O16 configurations (see Fig. 14a). To predict parallelefficiency for the other points, Fig. 14a uses the linear waitingtimemodel. The combination of these twomodels give rise toa hybrid queuingmodel, whichwe call theDSM dual queuingmodel.
As the network gets even slower, a completely newphenomenon takes over. Now, network contention comesinto play and the outbound queue length becomes abottleneck. As the outbound queues fill up, the controllerstalls more frequently and is unable to send out messages.As a result, the service rate gets affected and the inputqueues start filling up, once again exposing the finite lengthof inbound queues. Again, the linear contention modelworks well, as can be seen from Figs. 13 and 14.
The failure of the linear waiting time model to predictthe efficiency for Radix-Sort at low latency indicates a majorproblem in modeling the contention of a CC-NUMAsystem. The difficulty is in perfectly calculating the volumeof protocol transactions that really cannot be hidden undercomputation. Also, a problem arises in using only thetransactions that do not overlap in time so that we avoiddouble-counting. However, for nonprefetched FFT, weobserved that the linear waiting time model predicts theefficiency curves quite well (see Fig. 14b). The maximumprediction error is 1 percent. This is expected sincecontention in the communication controller will be lesswithout prefetching than with prefetching. But, still, for O16,the linear waiting time model under-predicts the contentionfor moderate values of l. This is why we observe highervalues of predicted efficiency for L4O16 and L8O16 ascompared to the simulated efficiency. This means that evenwithout latency hiding techniques, the growth rate ofcontention tends to be faster than linear in occupancy asthe communication controller moves more toward com-modity microprocessors on the memory or I/O bus.
Finally, we summarize our findings about modeling thecontention in the communication controller. The systemswitches between two models as we traverse the designspace and we call it the DSM dual queuing model. The exactpoints where the system moves from one model to anotherare highly dependent on the communication structure ofthe running application. But, our experience says that, forO4; O8 and O16 controllers, the system switches from the
14 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003
Fig. 14. (a) Prediction accuracy of prefetched FFT with the DSM dual queuing model and (b) prediction accuracy of nonprefetched FFT with the
linear model.

linear model to the quadratic model around L2 networklatency and reverts back to the linear model at L32 networklatency and above. Overall, contention is much moreimportant than latency since the latter scales only linearlywith l and o.
6 VARYING OCCUPANCY ON A DSM PROTOTYPE
In this section,wepresent the effects of varyingoccupancy forlarger problem sizes (that we could not simulate). Normally,it is not possible to increase occupancy in a DSM machineonce it is built. However, we have the luxury of using theprogrammable protocol processor of a 16 and 32-nodeStanford FLASH multiprocessor for this purpose. The75 MHz communication controller has an embedded RISCprotocol processor that runs software handlers to satisfyprotocol requests. The main processor is a 225 MHz MIPSR10000. Although we can vary occupancy, we cannot vary land g on FLASH because the message send/receive mechan-ism in FLASH is hard-wired and integrated into the networkinterface.
6.1 Locating FLASH in the Design Space
To properly interpret the results obtained from theprogrammable protocol engine, we first try to locate FLASHin our design space using the parallel efficiency obtainedfrom a 16-node FLASH multiprocessor. FLASH uses an SGISpider router [8] that takes eight network cycles to get theheader through the chip. The data payload, if any, followspipelined at four bytes per network clock. The networkclock speed of the current FLASH prototype is 150 MHz.Thus, the peak node-to-network bandwidth is 600 MB/s.Since the communication controller (MAGIC) is running at75 MHz, the network hop time is four system cycles, i.e.,approximately 50ns. In our design space, for a 64-processormesh topology, the L1 network latency is 25 system cycles.Since the average number of hops for a mesh topology on64 nodes is 5.33, the average per-hop time is approximatelyfive system cycles, i.e., 50ns at 100 MHz system clockfrequency. Therefore, the FLASH network is close to L1 andthe node-to-network interface is also greater than g1 (whichis 400 MB/s), though we have seen that this does notimprove performance for our applications. To figure out theoccupancy of FLASH, we ran simulations for prefetched
FFT and Ocean with our base problem sizes on a 16-nodeconfiguration with processor/memory speed ratios of 3 and4, and tried to map the corresponding results from FLASHonto our simulation results. While doing this comparison,we had to be careful in our choice of compiler. For a targetarchitecture of an R10000, the MipsPro cc compilerproduces better code than gcc. But, since our simulationenvironment uses gcc to compile the applications, we usedthe same compiler for compiling the applications forFLASH that we use in this comparison. Fig. 15a shows thenormalized execution times of FFT (1M points) and Ocean(514� 514 grid) on a single processor. All times arenormalized to uniprocessor FLASH execution time of FFTwith gcc compiler. A comparison between the simulationswith speed ratio 4 and FLASH gcc results tells us that aspeed ratio of 4 in our simulations models the FLASHmachines fairly well. This was also found to be true in [10].Using a speed ratio of 4 on 16 processors to locate FLASH inour design space, we find that L1O2g1 simulation results areclosest to the 16 processor FLASH results. To see how wellthey match, we present the results for FFT (1M points) andOcean (514� 514 grid) in Fig. 15b. All times are againnormalized to 16 processor FLASH execution time of FFTwith gcc compiler. Thus, we have calibrated FLASH as anL1O2g1 system in our simulation study using the samecompilers. But, in the results presented below, to show howoccupancy affects performance on FLASH, we use theMipsPro cc compiler with O2 optimization because itproduces better code than gcc.
6.2 Effect of Increasing Occupancy
Since FLASH is a working DSM prototype, we can runbigger problem sizes than we can simulate and, therefore,we can examine the performance of controllers with largeoccupancy at these larger problem sizes. We are able tomodel higher occupancy machines on FLASH by increasingthe occupancy of the handlers run by the programmableprotocol processor. To vary the occupancy of the commu-nication controller, we doubled the occupancy of eachprotocol handler at every step by inserting the appropriatenumber of NOPs in the handler code. We checked that thecommunication controller instruction cache miss rateremains unchanged for the instrumented code and doesnot cloud our results. Figs. 16 and 17 show the results for
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 15
Fig. 15. (a) Calibration of uniprocessor simulations against FLASH and (b) locating FLASH in the design space.

FFT, LU, Radix-Sort, and Ocean on a 32-node FLASH. Fig. 18shows the results for Water on both a 16 and 32-nodeFLASH. Due to shortage of space, we do not show thegraphs of 16-node runs for FFT, LU, Radix-Sort, and Ocean.We only mention the salient observations from these runs.Interested readers are refered to [4].
Although prefetched FFT scales well up to an O8
controller on 16 processors (not shown), only O2 and O4
controllers scale well for 32 processors (Fig. 16a). On16 processors, an O8 controller achieves a parallel efficiencyof 0.66 with 16M points, while on 32 processors, the parallelefficiency is only 0.5. Also, the O16 controller with 16Mpoints fails to achieve even the efficiency achieved byFLASH on 256K points for both the processor counts. Acareful examination of the slopes of the O8 and O16 curvesclearly tells us that the performance gap between these two
controllers will continue to increase (the curves diverge) aswe keep quadrupling the problem size. This, in turn, meansthat, to regain the lost performance on an O16 controller, weneed an extremely fast growth rate in problem size. FFT hasa computation time of Oðn lognÞ and a communicationvolume of OðnÞ, where n is the number of points. Thus, thecomputation-to-communication ratio is OðlognÞ, whichclearly increases with problem size. But, just as in manystructured applications, communication in FFT is isolated indifferent phases from local computation. As a result,although the overall computation-to-communication ratioover the whole application increases with problem size,within the communication phases the ratio remains con-stant as problem size grows.
Prefetched LU (Fig. 16b) shows some interesting proper-ties which are not present in FFT. In FFT, we see a big drop in
16 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003
Fig. 16. (a) Prefetched FFT and (b) prefetched LU on 32-processor FLASH.
Fig. 17. (a) Prefetched Radix-Sort and (b) prefetched Ocean on 32-processor FLASH.
Fig. 18. Water on (a) 16 and (b) 32-processor FLASH.

performance as we go from an O4 to an O8 controller,indicating that there is a minimum level of controllerperformance necessary to achieve good performance. But,for LU this is not the case. A comparison of the slopes of thecurves in FFT and LU tells us that occupancy is not as big aproblem for LU as for FFT, which, in turn, supports oursimulation findings. LU requires a much smaller growth ratein problem size as compared to FFT. But, still, in a 32-nodesystem, LU’s performance increases relatively slowly withincreasingproblemsizes for anO16 controller as the controllerstarts to saturate. The slower growth rate in problem size forLU as compared to FFT is explained by the fact that LU has alinear growth rate in computation-to-communication ratio(computation of Oðn3Þ and communication of Oðn2Þ), whileFFT has only a logarithmic growth rate in computation-to-communication ratio.
The performance of prefetched Radix-Sort (Fig. 17a) hasa striking similarity to that of FFT. However, a carefulexamination of the problem sizes of Radix-Sort actually tellsus that its performance is much worse than FFT. Itsperformance is not very encouraging for high-occupancycontrollers. Even with a problem size of 128M keys, the O16
controller achieves an efficiency of only 0.3 on 16 processorsand 0.23 on 32 processors. It is difficult to scale Radix-Sortbecause of its bursty write behavior [31]. As the problemsize grows, these writes also tend to be remote, which, ineffect, doubles the number of protocol transactions andleads to excessive contention. Also, the irregular commu-nication pattern causes hot-spots in the memory system,resulting in even worse performance. Finally, Radix-Sorthas a constant overall computation-to-communication ratio.
Prefetched Ocean (Fig. 17b) scales well up to an O4
controller, but the efficiency curve has a very small slope foran O16 controller. At O16, Ocean achieves a parallelefficiency of only 0.3 for a grid size of 2; 050� 2; 050 on16 processors and 0.19 on 32 processors. We continue to seea big gap between O4 and O8 curves, in addition to the bigperformance gap between O8 and O16 curves. AlthoughOcean has a linear growth rate in computation-to-commu-nication ratio, it also communicates data in structuredphases leading to a constant computation-to-communica-tion ratio within those phases. One final scaling problem inOcean is that a larger number of grid points causes moretime to be spent in the multigrid equation solver, which hasthe lowest computation-to-communication ratio and theworst load-imbalance in the application.
Water scales well for all controller architectures on16 nodes (Fig. 18a), but we observe a clear saturating trendin performance for O8 and O16 controllers on 32 nodes(Fig. 18b). This result helps us establish the fact that, as thesystem moves toward even larger DSM multiprocessors,controller occupancy will become even more important forparallel performance.
Overall, significant increases in problem size are neces-sary for the less aggressive controllers to achieve the desiredefficiency on 16 and 32-processor systems with a fast MPPnetwork. There are many important classes of applications(transform methods, sorting, multigrid equation solver) forwhich the efficiency lost by a less aggressive architecture—-in latency or occupancy—is extremely difficult or impos-sible to regain by increasing problem size. In most of theapplications, contention owing to the occupancy of thecontroller played an important role in determining the
required growth in problem size. We observed a generaltrend that all applications scaled reasonably well up to anO4 controller. But, for an O16 controller, none of theapplications showed promising performance on a 32-nodesystem. As we scale the number of processors further, weexpect similar subpar performance for O8 controllers.Therefore, as the network becomes slower and the systemgrows toward even larger DSM multiprocessors, we expectthat only the more tightly integrated, aggressive commu-nication controllers will achieve acceptable DSM perfor-mance, regardless of problem size.
7 CONCLUSIONS
DSM machines can be characterized in terms of fourfundamental parameters: network latency, controller occu-pancy, node-to-network bandwidth, and the number ofprocessors. Through simulation, analytical modeling, andexperimentation on a flexible DSM prototype, we evaluatedthe performance impact of latency, occupancy, node-to-network bandwidth, and processor count over a range ofrepresentative scientific applications. Our results showedthat it is possible to achieve good parallel efficiency for arange of applications on machines with low-occupancy,hardwired or special-purpose communication controllers,and low-latency MPP networks. As expected, networklatency impacted overall performance, but its importancediminished with high-occupancy controllers, or whenapplications employed latency hiding mechanisms. We alsoobserved that, for a fast hardwired controller or acustomized coprocessor used as the communication con-troller, node-to-network bandwidth can become important,especially for applications with bursty communicationphases. Stated differently, for these applications thecontroller message bandwidth should be well-balancedwith the link-bandwidth of the interface so that neitherbecomes a bottleneck. However, the node-to-network inter-face speed is typically related to the controller speed,therefore, we do not expect the node-to-network bandwidthto be a problem for aggressive controller designs.
Our main result is that the occupancy of the commu-nication controller is critical to good performance in DSMmachines and, in most cases, is more important than bothnetwork latency and node-to-network bandwidth. Formachines with tightly coupled MPP networks, we foundthat controller occupancy has a large performance impactregardless of whether or not applications incorporatedlatency hiding techniques. For machines with loosely-coupled networks, we showed that while without latencyhiding occupancy did not matter to overall performance,with latency hiding, controller occupancy once againbecame a performance bottleneck. Since machines withhigh-latency networks will need to incorporate latencyhiding whenever possible to obtain good performance,these results show that it is important to use low-occupancycommunication controllers at any network latency. Recal-ling that controller occupancy is the reciprocal of controllerbandwidth (in messages), we found that it was easier tohide network latencies than it was to overcome commu-nication bandwidth shortage.
Moreover, it was not the latency component of the higheroccupancy controllers that caused performance degrada-tion, but rather the contention component, even without
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 17

latency hiding. We introduced a DSM dual queuing modelto analytically describe this contention. This model showedthat the growth rate of contention is more than quadratic inoccupancy for moderate-latency networks (e.g., distributedMPP and fast LANs). Thus, our model showed analyticallythat occupancy is more important than latency because ofits impact on contention in the system.
Finally, a thorough study on a real DSMmachine showedthat for many classes of applications it is extremely difficultfor architectures with higher values of controller occupancyto achieve high parallel efficiency. The problem sizes neededto achieve high parallel efficiency quickly become unreason-able. For the applications we have considered here, it isimpossible to regain the lost performance as one movesbeyond hardwired and customized controllers and moretoward general purpose microprocessors on the memory orI/O bus. On the other hand, the occupancies of specialized orhardwired controllers on the memory bus were low enoughtoachievegoodefficiency forall theapplications in this study.
The tendency among DSM designers has been to focus onlatency and network bandwidth as the important perfor-mance issues in the communication architecture. Our resultsdemonstrate that the occupancy of the communicationcontroller is the most important architectural parameter thataffects the parallel performance of aDSMmultiprocessor andthat the message bandwidth of the controller should be well-balanced with the link bandwidth of the network interface toachieve good parallel performance.
REFERENCES
[1] A. Agarwal et al. “The MIT Alewife Machine: Architecture andPerformance,” Proc. 22nd Int’l Symp. Computer Architecture, pp. 2-13, June 1995.
[2] A. Bilas and J.P. Singh, “The Effects of Communication Para-meters on End Performance of Shared Virtual Memory Clusters,”Proc. 1997 Supercomputing Conf. High Performance Networking andComputing, Nov. 1997.
[3] M.A. Blumrich et al. “A Virtual Memory Mapped NetworkInterface for the SHRIMP Multicomputer,” Proc. 21st Int’l Symp.Computer Architecture, pp. 142-153, Apr. 1994.
[4] M. Chaudhuri et al. “Latency, Occupancy, and Bandwidth in DSMMultiprocessors: A Performance Evaluation,” Technical ReportCSL-TR-2002-1025, Computer Systems Laboratory, Cornell Univ.,Ithaca, NY 14853. Available at http://www.csl.cornell.edu/TR/CSL-TR-2002-1025.ps, July 2002.
[5] F.T. Chong et al. “The Sensitivity of Communication Mechanismsto Bandwidth and Latency,” Proc. Fourth Int’l Symp. HighPerformance Computer Architecture, pp. 37-46, Feb. 1998.
[6] D. Culler et al. “LogP: Toward a Realistic Model of ParallelComputation,” Proc. Fourth Symp. Principles and Practice of ParallelProcessing, pp. 1-12, May 1993.
[7] D. Dai and D.K. Panda, “Building Efficient Limited Directory-Based DSMs: A Multidestination Message Passing Based Ap-proach,” Technical Report OSU-CISRC-4/96-TR21, Dept. ofComputer and Information Science, Ohio State Univ., Columbus,OH 43210-1277, 1996.
[8] M. Galles, “Spider: A High-Speed Network Interconnect,” IEEEMicro, vol. 17, no. 1, pp. 34-39, Jan.-Feb. 1997.
[9] K. Gharachorloo et al. “Architecture and Design of AlphaServerGS320,” Proc. Ninth Int’l Conf. Architectural Support for Program-ming Languages and Operating Systems, pp. 13-24, Nov. 2000.
[10] J. Gibson et al. “FLASH vs. (Simulated) FLASH: Closing theSimulation Loop,” Proc. Ninth Int’l Conf. Architectural Support forProgramming Languages and Operating Systems, pp. 49-58, Nov.2000.
[11] M. Heinrich et al. “The Performance Impact of Flexibility in theStanford FLASH Multiprocessor,” Proc. Sixth Int’l Conf. Architec-tural Support for Programming Languages and Operating Systems,pp. 274-285, Oct. 1994.
[12] M. Heinrich and E. Speight, “Providing Hardware DSM Perfor-mance at Software DSM Cost,” Technical Report CSL-TR-2000-1008, Computer Systems Lab., Cornell Univ., Ithaca, NY 14853,2000.
[13] C. Holt et al. “The Effects of Latency, Occupancy, and Bandwidthin Distributed Shared Memory Multiprocessors,” TechnicalReport CSL-TR-95-660, Computer Systems Laboratory, StanfordUniv., Stanford, CA 94305, 1995.
[14] J. Kuskin et al. “The Stanford FLASH Multiprocessor,” Proc. 21stInt’l Symp. Computer Architecture, pp. 302-313, Apr. 1994.
[15] Kendall Square Research, “KSR1 Technical Summary,”technicalreport, Waltham, MA, 1992.
[16] J. Laudon and D. Lenoski, “The SGI Origin: A ccNUMA HighlyScalable Server,” Proc. 24th Int’l Symp. Computer Architecture,pp. 241-251, June 1997.
[17] D. Lenoski et al. “The Stanford DASH Multiprocessor,” IEEEComputer, vol. 25, no. 3, pp. 63-79, Mar. 1992.
[18] R.P. Martin et al. “Effects of Communication Latency, Overhead,and Bandwidth in a Cluster Architecture,” Proc. 24th Int’l Symp.Computer Architecture, pp. 85-97, June 1997.
[19] M. Michael at al. “Coherence Controller Architectures for SMP-Based CC-NUMA Multiprocessors,” Proc. 24th Int’l Symp. Com-puter Architecture, pp. 219-228, June 1997.
[20] A.K. Nanda et al. “High-Throughput Coherence Controllers,”Proc. Sixth Int’l Symp. High-Performance Computer Architecture,pp. 145-155, Jan. 2000.
[21] C.C. Niessen and D.G. Meyer, “High Performance NetworkInterfaces,” Proc. First Midwest Workshop Parallel Processing, Aug.1999.
[22] A. Nowatzyk et al. “The S3.mp Scalable Shared Memory Multi-processor,” Proc. 24th Int’l Conf. Parallel Processing, pp. 1-10, Aug.1995.
[23] S.K. Reinhardt, R.W. Pfile, and D.A. Wood, “Decoupled HardwareSupport for Distributed Shared Memory,” Proc. 23rd Int’l Symp.Computer Architecture, pp. 34-43, May 1996.
[24] E. Rothberg, J.P. Singh, and A. Gupta, “Working Sets, Cache Sizes,and Node Granularity for Large-Scale Multiprocessors,” Proc. 20thInt’l Symp. Computer Architecture, pp. 14-25, May 1993.
[25] I. Schoinas et al. “Fine-Grain Access Control for DistributedShared Memory,” Proc. Sixth Int’l Conf. Architectural Support forProgramming Languages and Operating Systems, pp. 297-306, Oct.1994.
[26] J.P. Singh et al. “Load Balancing and Data Locality in AdaptiveHierarchical N-Body Methods: Barnes-Hut, Fast Multipole andRadiosity,” J. Parallel and Distributed Computing, vol. 27, no. 2,pp. 118-141, June 1995.
[27] D.J. Sorin et al. “Analytic Evaluation of Shared-Memory Systemswith ILP Processors,” Proc. 25th Int’l Symp. Computer Architecture,pp. 380-391, June 1998.
[28] C.B. Stunkel et al. “The SP2 High-Performance Switch,” IBMSystems J., vol. 34, no. 2, pp. 185-204, Feb. 1995.
[29] H.A. Taha, Operations Research: An Introduction, sixth ed. 1996.[30] D.A. Wood and M.D. Hill, “Cost-Effective Parallel Computing,”
IEEE Computer, vol. 28, no. 2, pp. 69-72, Feb. 1995.[31] S.C. Woo et al. “The SPLASH-2 Programs: Characterization and
Methodological Considerations,” Proc. 22nd Int’l Symp. ComputerArchitecture, pp. 24-36, June 1995.
[32] S.C. Woo, J.P. Singh, and J.L. Hennessy, “The PerformanceAdvantages of Integrating Block Data Transfer in Cache-CoherentMultiprocessors,” Proc. Sixth Int’l Conf. Architectural Support forProgramming Languages and Operating Systems, pp. 219-229, Oct.1994.
[33] Y. Zhou et al. “Relaxed Consistency and Coherence Granularity inDSM Systems: A Performance Evaluation,” Proc. Sixth Symp.Principles and Practice of Parallel Programming, pp. 193-205, June1997.
[34] Z. Zhou, W. Shi, and Z. Tang, “A Novel Multicast Scheme toReduce Cache Invalidation Overheads in DSM Systems,” Proc.19th IEEE Int’l Performance, Computing, and Comm. Conf., pp. 597-603, Feb. 2000.
18 IEEE TRANSACTIONS ON COMPUTERS, VOL. 52, NO. 7, JULY 2003

Mainak Chaudhuri received the Bachelor ofTechnology degree with honors in electronicsand electrical communication engineering fromthe Indian Institute of Technology, Kharagpur, in1999, and the MS degree in electrical andcomputer engineering from Cornell University,Ithaca, New York in 2001, where he is currentlyworking toward his PhD degree. His researchinterests include parallel computer architecture,cache coherence protocol design, and cache-
aware parallel algorithms for scientific computation. He also has specialinterests in theoretical computer science and applied mathematics. He isa student member of the IEEE and the IEEE Computer Society.
Mark Heinrich received the PhD degree inelectrical engineering from Stanford University in1998, the MS degree from Stanford University in1993, and the BSE degree in electrical engineer-ing and computer science from Duke Universityin 1991. He is an assistant professor in theSchool of Electrical and Computer Engineeringat Cornell University and a cofounder of itsComputer Systems Laboratory. His researchinterests include novel computer architectures,parallel computer architecture, data-intensive
computing, scalable cache coherence protocols, active memory and I/O subsystems, multiprocessor design and simulation methodology, andhardware/software codesign. He is the recipient of a US NationalScience Foundation CAREER Award supporting novel research in data-intensive computing. He is a member of the IEEE and the IEEEComputer Society.
Chris Holt received the MS degree fromStanford University in 1992, and the BSE degreein computer engineering from Carnegie MellonUniversity in 1990. He works at TransmetaCorporation. His interests include dynamic bin-ary compilation, computer architecture, garbagecollection, and operating systems.
Jaswinder Pal Singh received the PhD degreefrom Stanford University in 1993, and the BSEdegree from Princeton University in 1987. He isan associate professor in the Computer ScienceDepartment at Princeton University. His re-search interests are on the boundary of paralleland distributed applications and multiprocessorsystems, both architecture and software, and inapplications of high-performance and distributedcomputing. At Stanford, he participated in the
DASH and FLASH multiprocessor projects, leading the applicationsefforts there. He has led the development and distribution of theSPLASH and SPLASH-2 suites of parallel programs, which are widelyused in parallel systems research. At Princeton, he has led the PRISMresearch group, which does application-driven research in supportingprogramming and communication models on a variety of communicationarchitectures, as well as in novel applications of high-performancecomputing such as simulating the immune system. He has coauthored agraduate textbook called “Parallel Computer Architecture: A Hardware-Software approach.” He is a Sloan Research Fellow and a recipient ofthe Presidential Early Career Award for Scientists and Engineers(PECASE). He is a member of the IEEE and the IEEE ComputerSociety.
Edward Rothberg received the PhD degree incomputer science from Stanford University in1993, the MS degree in computer science fromStanford University in 1989, and the BS degreein mathematical and computational sciencesfrom Stanford University in 1986. He managesthe development of the CPLEX mathematicalprogramming package for ILOG, Inc. His inter-ests include linear and integer programming,sparse linear algebra, and parallel numerical
computing.
John Hennessy, President of Stanford Univer-sity, received the BE degree in electricalengineering from Villanova University in 1973.He received the Masters and PhD degrees incomputer science from the State University ofNew York at Stony Brook in 1975 and 1977,respectively. Since September 1977, he hasbeen a faculty member at Stanford University,where he is currently a professor of ElectricalEngineering and Computer Science. Prior to
becoming President, Professor Hennessy served as the UniversityProvost, the Dean of the School of Engineering, and was chairman ofthe Computer Science Department. He is the recipient of the 1983 JohnJ. Gallen Memorial Award, awarded by Villanova University to the mostoutstanding young engineering alumnus. He is the recipient of a 1984US National Science Foundation Presidential Young Investigator Awardand, in 1987, was named the Willard and Inez K. Bell Professor ofElectrical Engineering and Computer Science. In 1991, he received theDistinguished Alumnus Award from the State University of New York atStony Brook. He is a fellow of the IEEE, a member of the NationalAcademy of Sciences, a member of the National Academy ofEngineering, a Fellow of the American Academy of Arts and Sciences,and a Fellow of the Association for Computing Machinery. He is therecipient of the 1994 IEEE Piore Award, the 2000 ASEE R. LammeMedal, the 2000 John Von Neumann Medal, the 2001 Eckert MauchlyAward, and the 2001 Seymour Cray Award. In 2001, he received anhonorary doctorate from Villanova, and an honorary degree of sciencefrom SUNY Stony Brook.
. For more information on this or any other computing topic,please visit our Digital Library at http://computer.org/publications/dlib.
CHAUDHURI ET AL.: LATENCY, OCCUPANCY, AND BANDWIDTH IN DSM MULTIPROCESSORS: A PERFORMANCE EVALUATION 19
Related Documents











