Identifying Objects in Legacy Systems A. Cimitile*, A. De Lucia”, G.A. Di Lucca’, A.R. Fasolino” (cimitile, dilucca, fasolino)@nadis.dis.unina.it, [email protected] * Dipartimento di Ingegneria dell’Informazioneed Ingegneria Elettrica University of Salerno, Faculty of Engineering at Benevento Palazzo Bosco Lucarelli, Piazza Roma - 82 100 Benevento, Italy O Dipartimento di Informatica e Sistemistica University of Naples “Federico 11” Via Claudio, 21 - 80125 Naples, Italy Abstract We present a new approach to decomposing legacy systems written in procedural languages into objects. The identification of the objects is centred around persistent data stores, such as files or tables in the database, while programs and subroutines are candidate to implement object methods. The approach proposed for assigning programs and subroutines as object methods exploits object-oriented design metrics. The rationale behind this choice is that any object-oriented decomposition of a legacy system should not lead to a poor design, as this would make the reengineered system more dificult to maintain. 1. Introduction Object technology is widely considered as the most suitable approach to moving towards open systems based on distributed client-server platforms, thus significantly reducing development and maintenance costs with respect to centralised mainframe systems. Encapsulation and inheritance features of object-oriented development ease the production of software systems based on reusable modules. Therefore, many organisations are migrating their system development activities towards object- oriented technology [ 101. On the other hand, most legacy software consists of procedurally oriented systems running on mainframes. Redeveloping legacy systems in an object-oriented fashion is generally a risky and expensive solution, as this process can take years before the old functions available ~~ This work is supported by “Progetto Strategic0 CINI-CNR - Informatica nella Pubblica Amministrazione - Sottoprogetto PROGRESS: PROcess-Guided REengineering Support System” on the mainframe can be replaced by a reliable and equivalent object-oriented system. The economic relevance of legacy software imposes salvaging strategies to be weighted against new object-oriented development. Object-oriented reengineering procedurally oriented systems seems to be a quicker solution, although it has to be considered as risky as redevelopment [ 161. Migrating an existing system might be an evolutionary process [12] requiring parts of the old system to remain temporarily in use. The coexistence between old procedural parts and new object-oriented parts of software systems is now made possible by new technologies such as the IBM’s System Object Model (SOM) and the OMG’s Common Object Request Broker Architecture (CORBA) that allow existing software components to be encapsulated into object wrappers [7, 161. The Italian Public Administration (PA) owns a huge asset of legacy software, whose maintenance costs have reached a critical point. The obsolescence of this software is destined to rapidly increase, not only for the introduction of new technologies, but also because a national research project on processes and data reengineering in the PA is being carried out by Italian universities and research centres. In addition to facing the problem of defining methods and processes for encapsulating legacy systems into object wrappers or replacing in a planned way too deteriorated and not renewable software with software developed ex-novo, within this project we also attack the problem of producing objects by reusing components extracted from legacy systems. The production of objects from legacy systems has to be integrated with the definition of the processes and data of the PA. In particular, the results of two processes have to be integrated, the first one consisting of the following activities: 138 1092-8138/97 $10.00 0 1997 IEEE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Identifying Objects in Legacy Systems
A. Cimitile*, A. De Lucia”, G.A. Di Lucca’, A.R. Fasolino” (cimitile, dilucca, fasolino) @nadis.dis.unina.it, [email protected]
* Dipartimento di Ingegneria dell’Informazione ed Ingegneria Elettrica University of Salerno, Faculty of Engineering at Benevento Palazzo Bosco Lucarelli, Piazza Roma - 82 100 Benevento, Italy
O Dipartimento di Informatica e Sistemistica University of Naples “Federico 11” Via Claudio, 21 - 80125 Naples, Italy
Abstract
We present a new approach to decomposing legacy systems written in procedural languages into objects. The identification of the objects is centred around persistent data stores, such as files or tables in the database, while programs and subroutines are candidate to implement object methods. The approach proposed for assigning programs and subroutines as object methods exploits object-oriented design metrics. The rationale behind this choice is that any object-oriented decomposition of a legacy system should not lead to a poor design, as this would make the reengineered system more dificult to maintain.
1. Introduction
Object technology is widely considered as the most suitable approach to moving towards open systems based on distributed client-server platforms, thus significantly reducing development and maintenance costs with respect to centralised mainframe systems. Encapsulation and inheritance features of object-oriented development ease the production of software systems based on reusable modules. Therefore, many organisations are migrating their system development activities towards object- oriented technology [ 101.
On the other hand, most legacy software consists of procedurally oriented systems running on mainframes. Redeveloping legacy systems in an object-oriented fashion is generally a risky and expensive solution, as this process can take years before the old functions available
~~
This work is supported by “Progetto Strategic0 CINI-CNR - Informatica nella Pubblica Amministrazione - Sottoprogetto PROGRESS: PROcess-Guided REengineering Support System”
on the mainframe can be replaced by a reliable and equivalent object-oriented system. The economic relevance of legacy software imposes salvaging strategies to be weighted against new object-oriented development. Object-oriented reengineering procedurally oriented systems seems to be a quicker solution, although it has to be considered as risky as redevelopment [ 161. Migrating an existing system might be an evolutionary process [12] requiring parts of the old system to remain temporarily in use. The coexistence between old procedural parts and new object-oriented parts of software systems is now made possible by new technologies such as the IBM’s System Object Model (SOM) and the OMG’s Common Object Request Broker Architecture (CORBA) that allow existing software components to be encapsulated into object wrappers [7, 161.
The Italian Public Administration (PA) owns a huge asset of legacy software, whose maintenance costs have reached a critical point. The obsolescence of this software is destined to rapidly increase, not only for the introduction of new technologies, but also because a national research project on processes and data reengineering in the PA is being carried out by Italian universities and research centres. In addition to facing the problem of defining methods and processes for encapsulating legacy systems into object wrappers or replacing in a planned way too deteriorated and not renewable software with software developed ex-novo, within this project we also attack the problem of producing objects by reusing components extracted from legacy systems. The production of objects from legacy systems has to be integrated with the definition of the processes and data of the PA. In particular, the results of two processes have to be integrated, the first one consisting of the following activities:
138 1092-8138/97 $10.00 0 1997 IEEE

- observation of the procedural tasks and sub-tasks in a given domain of P.A.; formalisation and representation of these tasks by means of work-flow models and Petri nets; use of an intermediate representation based on OOCM (Object-Oriented Conceptual Modelling) methods mapping the above high level conceptual models to conceptual models oriented to the software system;
and the second one consisting of the following activities: - analysis of legacy systems to study the feasibility of
wrapping techniques and to define methods (candidature criteria) for the identification of candidate objects in source code;
- use of the candidature criteria to identify and extract candidate objects from legacy systems.
The reuse of legacy software is then submitted to a concept assignment process for mapping the extracted objects onto the OOCM conceptual model of the application domain.
In this paper we present a method for recovering an object oriented decomposition of procedurally oriented legacy systems. Different solutions to this problem have been proposed in the literature. Some of these methods identify objects or classes in software systems written in language such as Pascal, C or FORTRAN: typically, these approaches map global variables or formal parameters to object's state variables, while functions, procedures, and subroutines referencing these variables are candidate to implement object's methods [4, 14, 13, 191. The results of such methods can be integrated with objects identified by a top-down analysis of the system documentation [ 181, A different approach consists of recovering an object- oriented architecture of the system starting from design documents such as structure charts and data-flow diagrams [8, 91. Other approaches entail object-oriented reengineering of COBOL programs based either on Tormal methods [2] or on structural methods [15, 171. The method proposed by Breuer et al. [2] identifies objects based on the data definitions in the file sections of COBOL programs, while the other methods also look for volatile data definitions in the working storage sections. A common feature of these methods is that they focus on searching for objects at the program level, and suggest some solutions for merging instances of the same object class identified in different programs.
The method proposed in this paper is based on the identification of objects in data-centred software systems developed using a procedural language such as COBOL, PL1, or RPG. The identification of the objects is centred around persistent data stores, such as files or tables in the database, while programs and subroutines are candidate to implement object methods. The approach proposed for assigning programs and subroutines as object methods exploits object-oriented design metrics [5 ] . In particular,
-
-
the assignment is made while trying to minimise the coupling between the objects. The rationale behind this choice is that any object-oriented decomposition of a legacy system should not lead to a poor design, as this would make the reengineered system more difficult to maintain.
In this paper we also show the result from a pilot case study used to validate the proposed method. In this case study we cannot solve the problem of mapping the extracted objects onto the OOCM conceptual model of the P.A. institution, as this will only be available within the next year. However, we validated the method by a concept assignment process performed by human inspection of the extracted objects. The paper is organised as follows. In section 2 a new method for decomposing a legacy system into objects is presented, while section 3 illustrates the result from a case study. Concluding remarks are given in section 4.
2. A method for identifying objects in code Several methods for identifying objects in code can be
defined depending on the desired level of granularity. For example, when identifymg the data structures that implement the state of an object a software engineer may consider only persistent data stores, such as files and/or tables in the database, or also local data structures within a program. Similarly, in the identification of the methods, procedural components can be considered at different granularity levels, i.e. programs, internal procedures (paragraphs, sections, subroutines, etc.), program slices, single statements.
The choice of the granularity level is driven by the particular problem which motivated the search for objects in procedural legacy systems. Our research focus on the problem of migrating existing software resources, i.e. programs and persistent data, towards an object-oriented platform to make new object-oriented software able to exploit these existing resources. Therefore, our approach consists of searching for coarse-grained persistent objects, instead of fine-grained volatile objects. Moreover, our approach does not focus on data structures implementing user interfaces.
The method proposed in this paper for the object- oriented decomposition of legacy systems is then based on searching for objects whose structure consists of a persistent data store (one or more files or tables of the database) which defines the state of the object, and a number of services (or methods) each of which is implemented by a program in the system or by a subroutine (in the case of COBOL programs, paragraphs or sections can be considered) or a group of related subroutines on the call graph. In the following, the term data store will be used to refer to persistent data stores,
139

2.1 Identifying the data structure of objects Persistent data stores are candidate to be the elements
of interest and, in particular in the case of files, a refinement step is needed for solving the problems of synonyms and homonyms between the candidate elements.
We say two files are synonymous if they have different names, but the same record structure, thus corresponding to the same element of the application domain. The record descriptions of these files might be different, where the differences concern different levels of record fields decomposition.
We say two files are homonymous if they have the same name, but different record structure, thus corresponding to different elements of the application domain. In particular homonymy is due to the use of one and the same file in different programs each of which defines a different record structure for this file.
The process of identifying the objects' data structure can thus be decomposed in two phases. In the first phase a static analysis of the system, together with an analysis of the available documentation, are performed for identifymg the persistent data stores used within the programs and their structure. The second phase consists of refining the results of the first phase by performing synonym and homonym analysis and by using the available documentation to assign a concept of the application domain to each of the identified objects. Synonymous files should be grouped into the same object as they may correspond to the same concept of the application domain. On the contrary, homonymous files should be splitted because they represent different concepts in the application domain.
Generally, homonymous files are temporary files that are locally used in a program or a subsystem of the legacy application and whose state does not survive across different execution sessions. For example, these files are used in merge and/or sort operations. In some cases, temporary files are also synonyms of files whose state persists across different applications.
2.2 Associating services to objects Once the data stores defining the state of the
candidate objects have been identified, next step consists of identifymg the services of these objects. The granularity level chosen for this task is the program and subroutine level: therefore, the identification of the object services entails the assignment of programs and groups of subroutines to persistent data stores. This is achieved in two steps: first programs are assigned to data stores and then they are analysed in order to evaluate if they can be decomposed into simpler operations.
2.2.1 Associating programs to objects Let us suppose the analysed software system is
composed of a set PP of n programs and a set DD of m persistent data stores. Any method for assigning programs as methods of objects can be based on a system representation model consisting of a bipartite graph, whose set of nodes is PP v DD and whose set of edges depicts accesses of programs to data stores. Depending on the particular assignment method, edges of the graph may be weighted (for example, the weight may indicate the number of accesses of a program to a data store). In this case the set of edges represents the relation ACCESSES G PP x DD x %, where % is the set of real numbers used to represent edges' weights. It is worth stressing that this relation can be obtained by static analysis of the programs of a legacy system.
The relation ACCESSES can be modelled by an n x m matrix whose rows and columns correspond to programs and data stores, respectively, and whose generic entry aij depends on the accesses program i makes to data store j . Also the assignment of programs to data stores can be modelled by an n x m matrix X whose entries xii assume either the value 1 if the program i is
assigned to the data storej, or the value 0 otherwise. The sets of constraints that must hold can be expressed as follows:
V l I i I n m
&j=l
The first set of constraints states that any program i must be assigned to only one data store j , while the second set of constraints states that a program can be assigned to a data store if and only if it accesses the data store (i.e., the weight of the access is non-zero).
Different strategies can be followed to assign programs to data stores. For each strategy there will be one or more assignments that better meet its requirements. From a mathematical point of view, the assignment strategy can be modelled by an objective function f(x> on the variables x i j . Any solution which minimises (or maximises) the objective function can be considered as a candidate assignment. We have defined an assignment strategy based on object-oriented design metrics. The reason for this approach arises from the observation that any object-oriented decomposition of a legacy system should not lead to a poor design, as this
140

would make the reengineered system more difficult to maintain. For example, an assignment strategy could be based on the Weighted number of Methods per Class (WMC) measure proposed by Chidamber and Kemerer [5]. If ci denotes the weight of the program i, where ci can be computed depending on quality characteristics of the program (e.g., its complexity), the WMC si of an object j can be expressed as:
n
i=l
In this case, the goal of the assignment strategy should produce a distribution of weighted programs to objects as uniform as possible. This can be obtained by minimising the following function:
f ( X ) = max(s,) - min (si) l < j < m IS j l m
A uniform distribution of complexity strategy is achieved if a program complexity measure is used as program weight c i . A particular case of this approach is the uniform distribution of services strategy obtained when all program weights ci are 1. This approach privileges the assignments that produce distributions of programs to data stores as uniform as possible. It is based on the assumption that objects with a limited number of services could be meaningless, while objects with too many services could produce scarcely cohesive or potpourri modules [3].
Two main limitations of WMC based assignment strategies are: (i) the possibility to produce several different, but not necessarily meaningful, assignments that minimise the objective function and (ii) the fact that they do not consider in the objective function the weight of accesses of programs to data stores. The method proposed in this paper overcomes both this limitations and is based on coupling metrics between objects.
2.2.1. I Assignment based on minimum coupling between objects
A different measure that can be considered as an indicator of the quality of an object-oriented design is the coupling between the objects. Excessive coupling between objects is detrimental to modular design and prevents reuse [5 ] . The more independent an object is, the easier it is to be reused in other applications. Moreover, highly coupled objects increase testing costs. This means that in a good object-oriented design coupling between objects should be kept to a minimum.
In a procedural legacy system, the relations that can be considered in the computation of the coupling between candidate objects built around the data stores are mainly
the accesses that programs assigned to an object make to data stores of other objects. Hence, an assignment strategy based on the minimisation of coupling can be formulated as follows:
min f ( X ) , where:
For each object j , the function considers the costs av of the accesses made by all programs i that have not been assigned t o j (i.e., the value of xg is 0). Each cost ag can be computed as the weighted sum of the number of accesses program i makes to data store j. Pilot experiments are required to define the weight of each YO operation. However, in general the weight of operations, such as write, that modify the state of a file has to be considered higher than the weight of other operations, such as read, that do not alter the file content.
2.2.2 Refining the object's methods Once programs have been associated to objects, a
concept assignment process is required to identify whether the minimum coupling method produced meaningful objects. A program that accesses only a data store is undoubtedly to be considered as a method of the corresponding object. However, usually programs access more than one data store. In this case, if the cost of the accesses a program makes to a data store is predominant with respect to the costs of the accesses to the other data stores, then the program is likely to implement a method of the first object which passes messages to the other objects (by invoking YO operations on the corresponding data stores). A different case is given by a program which accesses data stores of different objects in a quite uniform way. In this case, the probability that the program actually implements a method of the object it accesses more is low.
In any case, user interaction is required in order to validate the hypotheses formulated about the program, to understand its actual meaning and to associate it with a concept. This activity is also useful to understand if the program can be further decomposed into simpler methods. For unstructured programs preliminary restructuring operations are required before any decomposition of the program can be made [17]. If the program can be decomposed, first the functional decomposition of the program based on the subroutine call graph (in the case of COBOL programs this is actually a paragraph andor section perform graph) is reconstructed and then the method for assigning subroutines to objects based on minimisation of coupling is applied. Dominance analysis 1111 is then performed on
14 1

the subroutine call graph in order to identify object methods composed of groups of subroutines on the call dominance tree [6].
At the end of this process a new refined object- oriented decomposition of the system is obtained and the software engineer interaction is then required to validate the hypotheses formulated during this decomposition. The set of operations obtained with the refining step may contain several subroutines (or groups of subroutines) that access the data store of only one object, while other subroutines still access more than one data store. However, as effect of the decomposition, the number of data stores accessed by a subroutine should be significantly less than the number of data stores accessed by the whole program. For each program andor subroutine that accesses data stores of more than one object (and that cannot be decomposed) a concept assignment process is performed in order to understand if it either implements a method of an object, while passing messages to the other objects it accesses, or implements a method of a more general object that includes all the objects it accesses. In some case, these programs or subroutines can suggest a way to group within the same object two or more persistent data stores.
Further analyses have to be performed in order to eliminate redundant duplicated methods of an object: these can be subroutines or groups of subroutines identified in different programs that constitute a duplication or near duplication [l] of each other (i.e., they may just differ for the names used for variables and record fields). Finally, some considerations have also to be made for programs that do not access any object data store and that have not been considered by the minimum coupling method. To this aim the software engineer can use an approach based on the call graph of the system. This can be modelled by a relation CALLS c PP x PP x Y? which defines an n x n matrix whose rows and columns correspond to programs and whose generic entry y i j is the weight (e.g., the number)
of the calls program i makes to program j . Hypotheses can be made about the way programs are related. For example, if a program only calls programs that have been assigned to one object, then it can be considered as a more complex method of such object. Similarly, if a program is only invoked by methods of one object it can be considered as a private method of this object. Programs that are called by methods of different objects can be clustered into an object implementing general utility services, while a program invoking methods of different objects may be considered as a method of an object obtained by grouping the accessed objects. More precise results can be obtained by modelling this problem
by an objective function f ( X ) on the variables xu based on object coupling minimisation.
3. A case study
The method proposed in the previous section has been validated in a controlled experiment. The case study consists of a university's hall and residence information system written in COBOL and is composed of 103 programs and 90 copybooks describing file records and screen formats: the overall size of the system is approximately 200 KLOC. The software system was designed by adopting a functional decomposition approach. Different functionalities are implemented in different subsystems. The main functionalities, as described in the user documentation, are listed below: - resident room offer, confirmation, check-in and
- rent invoicing and reminder system - resident list production (sorted by name, nationality,
course, etc.) generation of electoral roll and community charge lists
check-out
-
- automatic room re-offer allocation - housekeeping reports - diary and reminder system - inventory system - decorating plan system.
Figure 1 shows the system program names. All programs are well structured in subroutines implemented as COBOL paragraphs (the verb perform is used to activate paragraphs). For programs between 500 and 1000 LOC, the average number of paragraphs is about 3 1 with an average number of 23 LOC per paragraph.
3.1 Identifying the data structure of objects The first step of the method is the identification of the
persistent data stores candidate to implement the state of the object. In our case study persistent data stores are only implemented by files. We used a commercial tool for statically analysing the source code in order to extract the information about disk file names and their record structure. In particular, this information has been extracted from the input-output section of the environment division and the file section of the data division. As result of the analysis we identified 52 disk files whose names are reported in Figure 2.
The refinement step for solving synonym and homonym problems identified 45 candidate objects. In particular, 7 files (-SORT.TMP, -OUT.TMP, -IN.TMP, UNSORT.TMP, SORT.TMP, OUTSCR.TMP, 1 N S C R . m ) were both homonym (because the structure
142

ADDCOMPCBL ADDEXPCBL ADJUSTH.CBL AGECBL AUDIT. CBL BATCH. CBL BOOKER.CBL BURNCBL CALCDATE.CBL CAPSCBL CARNORM.CBL CENTRAL.CBL CHRGREW. CBL CLASS-A.CBL CLASS-D.CBL CLASS-LCBL CLASSIFYCBL CLEAR.CBL CLEARMCBL CLEARSCBL CMDLINE.CBL
ACCOUNTS.LIS AHISTORY.AUD ARCHIVE. ARC ARCHIVE.TMP CASH.DAT CHARGES.AUD CHARGEKDAT COLLEGE.GNT CONFIG.DAT CONIN. AUD CONOUT. AUD
COLLADM. CBL COMPARE.CBL CONFIG. CBL CONVDATE.CBL DAMAGE.CBL DATERELSCBL D AYWEEK.CBL DECORATE. CBL DELCA NC. CBL DELCOUT.CBL DELEXP. CBL DETAILS. CBL DIARY. CBL D u m . CBL ENCRPYT.CBL ERROR.CBL CRERROR.CBL ERRORGEN. CBL FINANCEXCBL FULLDATE.CBL GETCITZCBL
GETDEPT. CBL GETFAC. CBL HEDIT,CBL HISTORY. CBL 1NDEXER.CBL INVOICECBL ITEM1NV.CBL ITEMXCBL JOBL1ST.CBL LCONFIGCBL LElTGEN.CBL LISTA.CBL LISTARCCBL LISTB. CBL LISTC. CBL LISTD. CBL LISTE. CBL LISTF.CBL LISTG. CBL LISTH. CBL LISTS.CBL
LOGINCBL LOWER.CBL MAKERECCBL MISSING. CBL M O V m . C B L NAMEXCBL PICKNAMECBL RECEIPTCBL REFUND. CBL REOFFER.CBL REP0RTS.CBL RES ALT.CBL RESETD.CBL RES1DENT.CBL RHISTORXCBL ROOMADM.CBL ROOMCOMP.CBL ROOMINVCBL ROOMNORMCBL ROOMSCBL RSORT.CBL
CREDIT.AUD DEPOSIT. AUD HARRISLBT INSCR.TMP MASTER.DAT NAMESTMP NONCASH.DAT 0UTSCR.TMP PAYMENT. AUD REPAY .AUD SELECT.TMP
Figure 1: The COBOL programs of the system
SORT.TMP UNSORT.TMP B ATCH.DAT -CITIZEN.DAT -DAMAGE.DAT - DUTY .DAT -DEPART.DAT -FACULTY .DAT -HISTORY .DAT IN.TMP
- 1TEMINV.DAT LAST.DAT -0UT.TMP -PREFER.D AT -PROCESS.DAT -REQUEST.DAT _REcEIPT.TMP - ROOM.DAT -ROOMINV.DAT -SORT.TMP
Figure 2: The files used in the system
of each of these files was different in different programs) and synonymous files (the record structure of each of these files was the same as the record structure of other files). Indeed, these files were mainly used in sort statements to locally sort their global synonymous files: for this reason each of them was associated to the object identified by the corresponding synonymous file. In one case the record structure of the three synonymous files SORT.TMP, OUTSCR.TMP, and 1NSCR.TMP conceptually identified an object ROOM-NAME-FILE not associated with any other file. Other synonymous files were ARCHIVE.TMP and ARCHIVE.ARC. Again, the first file was used as temporary file to sort the second file.
A different case of synonymy was given by the files - CITIZEN.DAT, DEPART.DAT, -FACULTY.DAT, and ZLIST-FILE. The first three are names of physical files associated with three different concepts and then cannot be grouped, while ZLIST-FILE is a logical file name that may correspond to each of the previous files in different contexts (it is actually a variable that can assume each of the previous values). In this case, we can formulate the hypothesis that the classes of the first three
RUSAGE. CBL SAVE. CBL SELECT.CBL SETDIRCBL SETLIP.CBL SPARE.CBL SPECIAL.CBL SSORT. CBL STARTUP.CBL SUBDATECBL SYSADM.CBL TIMENOW.CBL UPDATE.CBL UPPER.CBL V ALDATECBL VALIDATE.CBL VERIFTCBL WITHIN.CBL ZCONFIG.CBL
-US AGE.DAT USER.DAT
BACKUP-F~ILE CONFIG-FILE DIARY-FILE ERROR-FILE INSTALL-FILE JOURNAL-FILE TEXT-FILE ZLIST-FILE
objects inherit from the class of the object associated with ZLIST-FILE.
3.2 Associating programs to objects The association of programs as methods of candidate
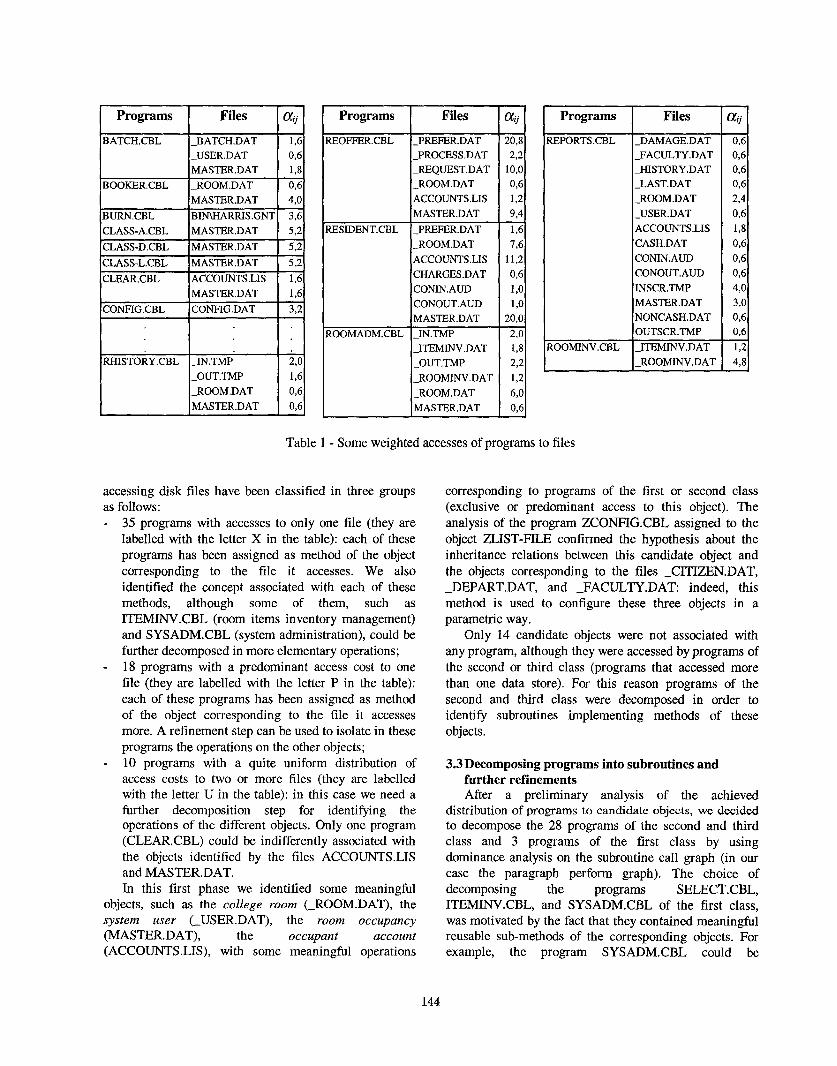
objects entails the computation of the cost of program accesses to data stores. To this aim, disk file operations have been considered with different weights depending on their type. In particular, a weight 0.6 has been assigned to read and start statements, while a weight 1 has been assigned to write, rewrite, and delete statements; the sort statement has been associated with a weight 0.6 with reference to the input file and with a weight 1 with reference to the output file. As result of the analysis, we identified 63 programs with disk file accesses (their names are in italic in Figure 1) and 40 programs with no access to persistent data stores. Table 1 shows a fragment of the matrix containing the costs ag of the accesses of programs to files. Most programs of the second class were used as general utility services. We associated each program of the first class as method of one object, as shown in Table 2. The 63 programs
143
Programs
BATCHCBL
300KER.CBL
3URN.CBL CILASS-A.CBL :LASS-D.CBL :LASS-L.CBL 2LEAR.CBL
CONFIG.CBL I : / : RHISTORY.CBL -1N.TMP
Files
- BATCH.DAT - USER.DAT MASTER.DAT -ROOM.DAT MASTER.DAT B1NlHARRIS.G" MASTER.DAT MASTER.DAT MASTER.DAT ACCOUNTS.LIS MASTER.DAT CONFTG.DAT
0UT.TMP -ROOM.DAT
Programs Files
REOFFER.CBL -PREFER.DAT -PROCESS.DAT -REQUEST.DAT -ROOM.DAT ACCOUNTS.LIS MASTER.DAT
RESIDENT.CBL -PREFER.DAT -ROOM.DAT ACCOUNTS.LIS CHARGESDAT CONIN. AUD CONOUT. AUD MASTER.DAT
ROOMADM.CBL IN.TMP
Programs
EPORTS.CBL
Files
- DAMAGE.DAT -FACULTY .DAT - HISTORY .DAT LAST.DAT -ROOM.DAT -USER.DAT ACCOUNTS.LIS CASH.DAT CONIN.AUD CONOUT.AUD 'INSCR.TMP 1 MASTER.DAT NONCASH.DAT ~OUTSCR.TMP I
I-ITEMINV.DAT I 1,s) IROOMINV.CBL IITEMINV.DAT
Table 1 - Some weighted accesses of programs to files
accessing disk files have been classified in three groups as follows: - 35 programs with accesses to only one file (they are
labelled with the letter X in the table): each of these programs has been assigned as method of the object corresponding to the file it accesses. We also identified the concept associated with each of these methods, although some of them, such as 1TEMINV.CBL (room items inventory management) and SYSADM.CBL (system administration), could be further decomposed in more elementary operations; 18 programs with a predominant access cost to one file (they are labelled with the letter P in the table): each of these programs has been assigned as method of the object corresponding to the file it accesses more. A refinement step can be used to isolate in these programs the operations on the other objects; 10 programs with a quite uniform distribution of access costs to two or more files (they are labelled with the letter U in the table): in this case we need a further decomposition step for identifymg the operations of the different objects. Only one program (CLEAR.CBL) could be indifferently associated with the objects identified by the files ACCOUNTS.LIS and MASTER.DAT. In this first phase we identified some meaningful
objects, such as the college room (-ROOM.DAT), the system user (-USER. DAT), the room occupancy (MASTER.DAT), the occupant account (ACCOUNTS.LIS), with some meaningful operations
-
-
corresponding to programs of the first or second class (exclusive or predominant access to this object). The analysis of the program ZCONFIG.CBL assigned to the object ZLIST-HLE confirmed the hypothesis about the inheritance relations between this candidate object and the objects corresponding to the files -CITIZEN.DAT, - DEPART.DAT, and -FACULTY.DAT: indeed, this method is used to configure these three objects in a parametric way.
Only 14 candidate objects were not associated with any program, although they were accessed by programs of the second or third class (programs that accessed more than one data store). For this reason programs of the second and third class were decomposed in order to identify subroutines implementing methods of these objects.
3.3 Decomposing programs into subroutines and further refinements After a preliminary analysis of the achieved
distribution of programs to candidate objects, we decided to decompose the 28 programs of the second and third class and 3 programs of the first class by using dominance analysis on the subroutine call graph (in our case the paragraph perform graph). The choice of decomposing the programs SELECT.CBL, ITEMINV.CBL, and SYSADM.CBL of the first class, was motivated by the fact that they contained meaningful reusable sub-methods of the corresponding objects. For example, the program SYSADM.CBL could be
144
LAST.DAT SAVE.CBL
PREFER.DAT REOFFER.CBL
- PROCESS.DAT
-RECEIPT.TMP RECEIFT.CBL -REQUEST.DAT
-ROOM.DAT ITEMSCBL ROOMADM.CBL
- ROOMINV.DAT DECORATECBL ROOMINV.CBL
-USAGE.DAT COLLADMCBL
-USER.DAT LOGIN.CBL
U
P
X
P P
X P X
X
I CLEAR.CBL l u AHISTORY.AUD I AUDIT.CBL I u
Files Programs
I I ARCHIVE.ARC I SPECIAL.CBL I P
T
I LISTARCCBL I X CASH.DAT I I
ACCOUNTS.LIS CHRGRENT.CBL DETAILKCBL
SSORTCBL BATCH.DAT
U X
I I CITIZEN.DAT GETCITZCBL X
CONFIG-FILE
DIARY-FILE
UIASTER.DAT
-DAMAGE.DAT
-DUTY.DAT
-DEPART.DAT
FACULTY .D AT
-HISTORY .DAT
JTEMINV.DAT
DIARY .CBL P
BATCHCBL BOOKER.CBL CLASS-A.CBL CLASS-D.CBL CLASS-L.CBL DELCANCCBL DELCOUTCBL DELEXP.CBL FINANCESCBL INDEXER.CBL LISTA.CBL LISTBCBL LISTC.CBL LISTD.CBL LISTE.CBL LISTF.CBL LISTG.CBL LISTH.CBL MAKERECCBL MISSING.CBL REPORTS.CBL RESIDENT.CBL RHISTORY .CBL RUSAGECBL VALID ATEXBL CLEAR. CBL D AMAGE.CBL
ERROR-FTLE
INSTALL-FILE
GETDEPTCBL
GETFACCBL
ADJUSTH.CBL HISTORY.CBL 1TEMINV.CBL
DUTY .CBL U ERROR.CBL X ERRORGEN.CBL X SETUP.CBL X
I
U P X X X X P X U X P P X P X X P P X X U P P U P U P - - - X
X
X P X
- - - I
JOURNAL-FILE
TEXT-FILE HE?DIT.CBL X
I SYSADM.CBL I X BACKUP-FILE I I 1
I LETTGENCBL I X ZLIST-FILE I ZCONFIG.CBL I X (-CITIZIEN.DAT , DEPART.DAT, -FACULTY .DAT \ I I I I I
ROOM-NAME- I RSORTCBL Ix
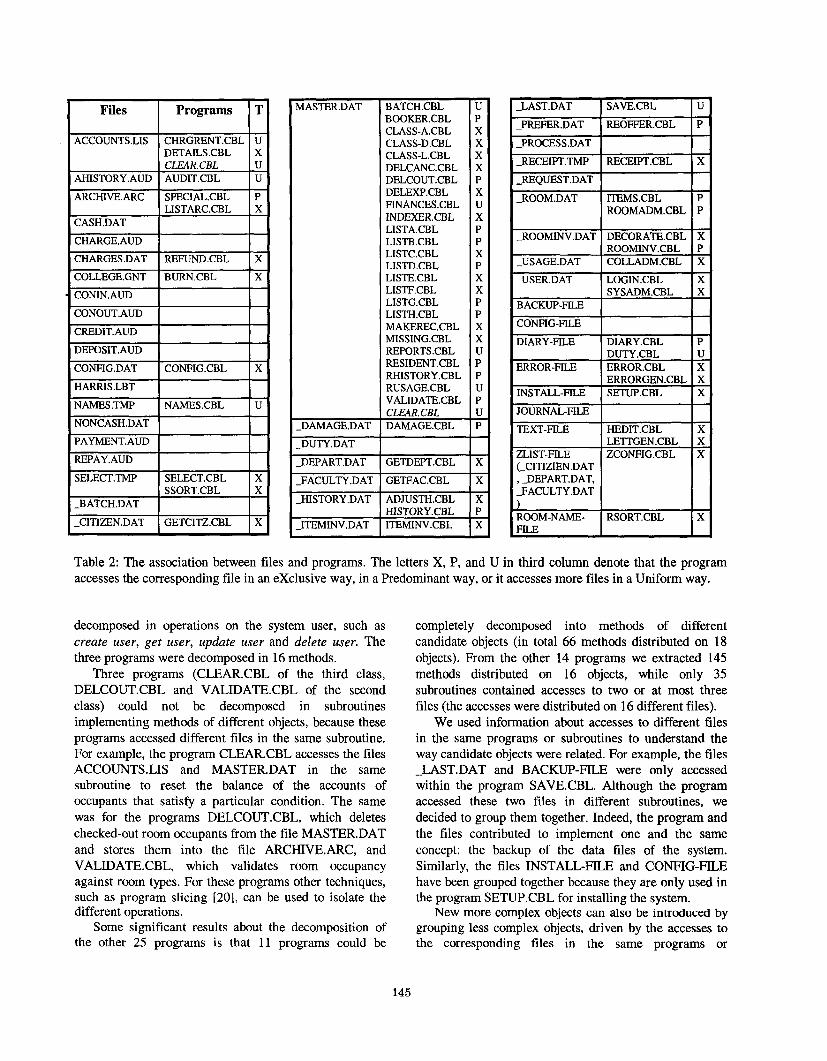
Table 2: The association between files and programs. The letters X, P, and U in third column denote that the program accesses the corresponding file in an exclusive way, in a Predominant way, or it accesses more files in a Uniform way.
decomposed in operations on the system user, such as create user, get user, update user and delete user. The three programs were decomposed in 16 methods.
Three programs (CLEAR.CBL of the third class, DELCOUT.CBL and VALIDATE.CBL of the second class) could not be decomposed in subroutines implementing methods of different objects, because these programs accessed different files in the same subroutine. For example, the program CLEAR.CBL accesses the files ACCOUNTS.LIS and MASTER.DAT in the same subroutine to reset the balance of the accounts of occupants that satisfy a particular condition. The same was for the programs DELCOUT.CBL, which deletes checked-out room occupants from the file MASTER.DAT and stores them into the file ARCHIVE.ARC, and VALIDATE.CBL, which validates room occupancy against room types. For these programs other techniques, such as program slicing [20], can be used to isolate the different operations.
Some significant results about the decomposition of the other 25 programs is that 11 programs could be
completely decomposed into methods of different candidate objects (in total 66 methods distributed on 18 objects). From the other 14 programs we extracted 145 methods distributed on 16 objects, while only 35 subroutines contained accesses to two or at most three files (the accesses were distributed on 16 different files).
We used information about accesses to different files in the same programs or subroutines to understand the way candidate objects were related. For example, the files -LAST.DAT and BACKUP-FILE were only accessed within the program SAVE.CBL. Although the program accessed these two files in different subroutines, we decided to group them together. Indeed, the program and the files contributed to implement one and the same concept: the backup of the data files of the system. Similarly, the files INSTALL-FILE and CONFIG-FILE have been grouped together because they are only used in the program SETUP.CBL for installing the system.
New more complex objects can also be introduced by grouping less complex objects, driven by the accesses to the corresponding files in the same programs or
145

subroutines. For example, a new object can be obtained by grouping the file ACCOUNTS.LIS, containing information about room occupant accounts, and the set of files identified by JOURNAL-FILE, each of which contains information about the transactions made on a single account, Similarly, the files -USER.DAT, containing information about system user, and the set of files identified by DIARY-FILE, each of which contains information about the duties' diary of each user, can be grouped into a more complex object. Other complex objects can be obtained by grouping: the files - ROOM.DAT and ROOM-NAME-FILE, both referring to the room object; the files -PEFER.DAT, - REQUEST.DAT, -PROCESS.DAT referring to room preferences and requests in booking operations and accessed together in the program REOFFER.CBL; the files CASH.DAT and NONCASH.DAT, both referring to payments; the files COLLEGE.LBT and NAMESCBL, both only accessed by the program NAMESCBL.
The decomposition process also revealed cases of duplicated code and dead code. Duplicated code was due to the reuse of the same subroutines (about 30) in different programs, while dead code was due to the presence of about 40 subroutines never performed in the programs used to list information stored in the file MASTER.DAT (LISTA.CBL, LISTB.CBL, and so on). In particular, all the subroutines of the program LISTG.CBL containing accesses to the file MASTER.DAT constitute dead code. This program that had been previously assigned to MASTER.DAT was decomposed in two methods assigned to the candidate objects corresponding to the files CONIN.AUD and CONOUT.AUD, respectively (these two files store information about checked-in and checked-out room occupants, respectively).
At the end of the refinement process all the identified objects have been associated with meaningful methods. About the remaining subroutines that access files corresponding to different objects, slicing techniques can be used to isolate the different operations. Other analyses may be performed on the programs that do not access any file. Although most of these programs are candidate to be methods of objects implementing general utility services, some of them can be considered as methods of previously identified objects. For example, the program LISTS.CBL is candidate to implement a method of the object corresponding to the file MASTE?R.DAT, as it is the only program invoking the listing methods of this object. Similarly, the program CLASSIFY.CBL is the only program that invokes the programs CLASS-A.CBL, CLASS-D.CBL, CLASS-L.CBL, assigned as methods to the same object.
4. Conclusion In this paper an approach for recovering an object-
oriented decomposition of procedurally oriented legacy systems has been presented. The method focuses on the identification of objects whose data structure is centred around persistent data stores, such as files and tables in the database. The identification of object methods is driven by the minimisation of coupling between objects, whose measure accounts the accesses programs and subroutines make to persistent data stores. A top-down approach has been followed that consists of analysing the whole system first, by considering programs as single entities, and then decomposing programs that cannot be associated as methods of a single object.
The paper has illustrated the results from a case study on a COBOL software system composed of about 200 KLOC. Hypotheses made during the structural decomposition of the system have been bottom-up validated by a concept assignment process. Several programs have been identified as methods of single objects either because each of them only accessed the data stores of one object, or because of the predominant cost of the accesses made to the data stores of one object. In the latter case, subroutines corresponding to methods of not predominant objects have been isolated. Programs that could not significantly be associated to one object have been decomposed into groups of subroutines, most of which have been identified as object methods. Programs and subroutines that accessed data stores of different objects and that could not be decomposed into methods of different objects have been used to identify more complex objects and relationships among them.
Some considerations have to be made about the reeengineering phase. The decomposition of a program into object methods that access the persistent data stores of the corresponding object involves the insertion in each method of new open and close operations on the persistent data stores. This causes two main problems to be considered. The first problem concerns system performance: excessive message passing between different objects degrades the performance of the system due to the execution of a high number of open and close operations. The second problem regards methods that sequentially access a file. For example, in the case of COBOL, if the file organisation is relative and the access operation is a read next record, then the key of the last record read has to be passed to the method and a start operation has to be added to the body of the method. If the file organisation is sequential then it has to be first transformed in relative.
Further work concerns the definition of a method based on coupling metrics and on the analysis of the call graph of the system that focus on programs that do not
146

access any data store; these may be either assigned as more complex methods of already identified objects or used for identifying new objects and relationships between them. Moreover, methods based on object oriented metrics can be experimented for identifying fine grained objects centred around volatile data stores. Finally, we plan to extend our approach to also consider data structures of display and printer files that are candidate to implement user presentation objects.
Acknowledgements The authors wish to thank Gerard0 Canfora and Ugo De Carlini for their precious suggestions.
References B.S. Baker, “On finding duplication and near- duplication in large software systems”, Proceedings of 2nd IEEE Working Conference on Reverse Engineering, Toronto, Canada, 1995, IEEE Comp. Soc. Press, pp. 86-95. P.T. Breuer, H. Haughton, K. Lano, “Reverse- engineering COBOL via formal methods”, Journal of Software Maintenance: Research and Practice, vol. 5 ,
F.W. Calks, B.J. Cornelius, “Potpurri Module Detection”, Proceedings of IEEE International Conference on Software Maintenance, S . Diego, CA, 1990, IEEE Comp. Soc. Press, pp. 46-51. G. Canfora, A. Cimitile, M. Munro, “An improved algorithm for identifymg reusable objects in code”, Software Practice and Experiences, vol. 26, no. 1,
S.R. Chidamber and C.F. Kemerer, “A metrics suite for object oriented design”, IEEE Transactions on Software Engineering, vol. 20, no. 6, June 1994, pp.
A. Cimitile, G. Visaggio, “Software salvaging and the call dominance tree”, The Journal of Systems and Software, vol. 28, no. 2, February 1995, pp. 117-127. W. Dietrich, I. Nackman, L. Gram, “Saving a legacy with objects”, Proceedings of OOPSLA, 1989, pp. 77- 88. H. Gall, R. Klosch, “Finding objects in procedural programs: an alternative approach”, Proceedings of 2nd IEEE Working Conference on Reverse Engineering, Toronto, Canada, 1995, IEEE Comp. Soc. Press, pp. 208-216. J. George, B.D. Carter, “A strategy for mapping from function oriented software models to object oriented software models”, ACM Software Engineering Notes, vol. 21, no. 2, March 1996, pp. 56-63. I. Graham, Migrating to Object Technology, Addison Wesley, 1994. M.S. Hecht, Flow Analysis of Computer Programs, Elsevier North-Holland, New York, 1977.
1993, pp. 13-35.
1996, pp. 24-48.
476-493.
I. Jacobson, F. Lindstrom, “Re-engineering of old systems to an object-oriented architecture”, Proceedings of OOPSLA, 1991, pp. 340-350. S . Liu, N. Wilde, “Identifying objects in a conventional procedural language: an example of data design recovery”, Proceedings of IEEE Conference on Sofbvare Maintenance, San Diego, CA, 1990, IEEE Comp. Soc. Press, pp. 266-271. P.E. Livadas, T. Johnson, “A new approach to finding objects in programs”, Journal of Software Maintenance: Research and Practice, vol. 6, 1994, pp.
P. Newcomb, G. Kotik, “Reengineering procedural into object-oriented systems”, Proceedings of 2nd IEEE Working Conference on Reverse Engineering, Toronto, Canada, 1995, IEEE Comp. Soc. Press, pp.
H.M. Sneed, “Encapsulating legacy software for use in clientherver systems”, Proceedings of 3rd IEEE Working Conference on Reverse Engineering, Monterey, CA, 1996, IEEE Comp. Soc. Press, pp. 104- 119. H.M. Sneed, “Object-oriented COBOL recycling”, Proceedings of 3rd IEEE Working Conference on Reverse Engineering, Monterey, CA, 1996, IEEE Comp. Soc. Press, pp. 169-178. G.V. Subramaniam, E.J. Bwime, “Deriving an object model from legacy FORTRAN code’’, Proceedings of IEEE International Conference on Software Maintenance, Monterey, CA, 1996, IEEE Comp. Soc. Press, pp. 3-12. A.S. Yeh, D.R. Harris, H.B. Rubenstein, “Recovering abstract data types and object instances from a conventional procedural language”, Proceedings of 2nd IEEE Working Conference on Reverse Engineering, Toronto, Canada, 1995, IEEE Comp. Soc. Press, pp. 227-236. M. Weiser, “Program slicing”, IEEE Transactions on Software Engineering, vol. SE-10, no. 4, July 1984,
249-260.
237-249.
pp. 352-357.
147
Related Documents











