Identification of regulatory elements using high-throughput binding evidence. Inference of population structure on large genetic data sets. Stoyan Georgiev advisors: Uwe Ohler and Sayan Mukherjee Computational Biology and Bioinformatics, Duke University February 2011

Identification of regulatory elements using high-throughput binding evidence. Inference of population structure on large genetic data sets. Stoyan Georgiev.
Dec 13, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Identification of regulatory elements using high-throughput binding evidence.
Inference of population structure on large genetic data sets.
Stoyan Georgiev
advisors: Uwe Ohler and Sayan MukherjeeComputational Biology and Bioinformatics, Duke University
February 2011

Outline
• Motif analysis
– Transcriptional regulation• genome-wide DNA binding data (Georgiev et al. 2010)
– Post-transcriptional regulation• transcriptome-wide RNA binding data (Mukherjee et al.,
under review; Corcoran* and Georgiev* et al., submitted)
• Inference of population structure– randomized algorithm

Motif analysis

Outline
• Introduction
• Transcriptional regulation
– Problem statement
– Genomic assays
– Statistical framework
– Results
• Post-transcriptional regulation

Gene regulation
Nucleus
Cytoplasm
Transcription
Splicing, Capping,Poly-adenylation
Export
Stability
Translation
RBP RNA-binding Proteins
miRBP
miR-RBP complexes
DNA motifs
RNA motifs

Gene regulatory code
• Transcriptional regulation: short patterns in DNA (motifs) control the initiation of production of gene transcripts– mechanism: sequence-specific DNA binding proteins (TFs)
Motif Discovery Tool: cERMIT (Georgiev et al. 2010)
• Post-transcriptional regulation: short patterns in RNA control the utilization of gene transcripts– mechanism: sequence-specific RNA binding proteins (RBPs), or
microRNA mediated
Motif Analysis Tool (Corcoran* and Georgiev* et al.; Mukherjee et al.)

Transcriptional regulation

Transcriptional regulation
• Chromatin arrangement
• Activity of transcription factors
- intra-cellular environment
- cis-regulatory code
• DNA methylation
• Copy Number Variation

Simplified abstraction
location

ChIP-seq

cERMIT
• Computational tool for de-novo motif discovery – Predict binding motif and functional targets of a specific transcription
factor of interest (e.g. TF) using genome-wide measurements of binding (e.g. ChIP-seq, ChIP-chip) (Georgiev et al. 2010)
• Input: set of sequence regions with assigned binding evidence• Output: ranked list of predicted binding motifs and
corresponding target locations

Brief introduction to cERMIT
• Binding site representation: consensus sequence • Search for the "best" binding site that explains the genome-
wide binding evidence.– "best“: occurs in regions that tend to have high evidence of being
bound (this is formalized as a normalized average score)– can evaluate all possible binding sites up to some reasonable
length...in theory– in practice, we try to cover as many as possible
• start with all possible 5-mers (AAAAA, AAAAG, AAAAC,...,TTTTT)
• for each, evaluate its "neighbours“ and replace it with the "best" one• repeat until no neighbour scores better than the current motif

Algorithmic view
sequence regions
high evidence
low evidence
RTGASTCA TGACTCARTGASTCAK GAWTCAYY TGACTCA TGAWTCAK
.
.
.
.
.
evolved motifs
ES = 15.0
sequence regions
512 seed motifs
ES = 1.5
AAAAAAAAAGAAAACAAAATAAAGA
.
.
.
.
.
TTTCTTTTTATTTTGTTTTCTTTTT
sequence regions
ES = normalized average binding evidence

Variable definitions
n1ii
n
1iijj
ijij
j
ii
i
}{sin soccurrence motif ofnumber x n
otherwise 0
sregion in present is m motif match to a if 1 x
motifs sequence candidate T} , . . . {1, j ,m
sregion sequencefor evidence binding y
regions sequence n} , . . . {1, i ,s

Motif model
; 1n
nn A
n
)y(y n1
σ ,)y(yn
1e
:Notation
,σ
eA E
:E Evidence Binding Motif
j
j
n
1i
2i
2j
1x:ii
jj
j
jj
j
ij

Motif model
j*
j
j
j
n
1i
2i
2j
1x:ii
jj
j
jj
E j
:m motif Optimal
; 1n
nn A
n
)y(y n1
σ ,)y(yn
1e
:Notation
,σ
eA E
:Evidence Binding Motif
T}{1,..,j
*
ij
max arg

ChIP-seq motif discovery
input
output

Results

ChIP-chip validation
• conservationfilter improvespredictionaccuracy
(Georgiev et al. 2010)

Example yeast ChIP-chip outputSKO1 GCN4

Human ChIP-seq
SRF
STAT1
CTCF
prediction literature
Barski et al. 2007
Robertson et al. 2007
Valouev et al. 2008

Post-transcriptionalcontrol

Gene regulatory code
• Post-transcriptional regulation: short patterns in RNA control the utilization of gene transcripts– mechanism: sequence-specific RNA binding proteins (RBPs), or
microRNA mediated to control translation
Motif Analysis Tool (Corcoran*, Georgiev* et al.; Mukherjee et al.)

PAR-CLIP
• CLIP: Cross linking and immunoprecipitation – a method of transcriptome-wide identification of RNA-
protein interaction sites – problem, quite noisy
• PAR-CLIP = CLIP + photoactivatable nucleotides– more efficient cross linking– directly observable evidence of Protein-RNA cross linking:
upon reverse transcription T->C conversion near or at the interaction site

PAR-CLIP
1. culture with 4-SU
2. cross-link
3. Immunoprecipitate & size-select
4. convert into a cDNA library & sequence
[Hafner et al. 2010]

RBP motif analysis pipeline
RBP
Motif seeds Motif predictions
cERMIT

Modified motif score

Variable definitions
covariates regression ofmatrix )c , . . . ,c ,(xZ
biases) sequence (e.g. sconfounder 1} p , . . . {1,k ,c
otherwise 0
sregion sequencein present is m motif match to a if 1 x
motifs sequence candidate T} , . . . {1, j ,m
evidence binding )y , . . . ,(yY
1j-p1jjj
nk
ijij
j
Tn1
-

Motif model
1j
Tj
2
β
Tj
1j
Tjj
nn2
j
)Z(ZσΣ ,yZ)Z(Z β
:fit OLS
)Ισ N(0,~ε , εβZY
:model
j
j

Motif model
)Σ(
βE
:E evidence binding motif
)Z(ZσΣ ,yZ)Z(Z β
:fit OLS
)Ισ N(0,~ε , εβZY
:model
11β
1jj
j
1j
Tj
2
β
*Tj
1j
Tjj
nn2
j*
j
j
j

Motif model
E j
:m is motif optimal
)Σ(
βE
: E evidenc binding motif
)Z(ZσΣ ,yZ)Z(Z β
:fit OLS
)Ισ N(0,~ε , εβZY
:model
jT}{1,...,j
*
j
11β
1jj
j
1j
Tj
2
β
*Tj
1j
Tjj
nn2
j*
max arg
*
j
j
j

Results

Pumilio
• 2 million mapped reads• # clusters with site / total # clusters = 1,162 / 8,483
predicted motif
(Hafner et al. 2010)

Summary
• cERMIT: motif discovery using genome-wide binding data– identify motifs that are highly enriched in targets with high
binding evidence. – applicable to RNA and DNA binding data – adjust for sequence biases and other potential confounders
using linear regression framework
• In progress…– Bayesian formulation– improve stability of predictions– more comprehensive search

Inference of population structure and generalized
eigendecomposition

Outline
• Motivation• Current approaches• Extensions
– large data sets– supervised dimension reduction
• Empirical results– Wishart simulation– WCCC Crohn’s disease data set

Motivation
• A classic problem in biology and genetics is to study population structure (Cavalli-Sforza 1978, 2003)
• Genotype data on millions of loci and thousands of individuals
• Can we detect structure based on the genetic data?– infer population demographic histories – correct for population structure in disease association
studies – correspondence to geography

Current approaches
• Structure (Pritchard et al. 2000)
– Bayesian model-based clustering of genotype data
• Eigenstrat (Patterson et al. 2006)
– PCA-based inference of axis of genetic variation

Population structure within Europe
(Novembre et al. 2008)

Eigenstrat (Patterson et al. 2006)
• Combines Principal Component Analysis and Random Matrix Theory
statistic Widom-Tracy using cesignificanfor test and ,...,order 4.
)1m(
)1m(
n' :size" population effective" Estimate .3
MMn
1 X .2
n1,..., j m;1,..., i ;
2
ˆ1
2
ˆ
ˆCM .1
m1
i
2i
i
2i
ii
T
jj
jijij

• Runtime O(m2n) computation• The challenge: future (current?) genetic data sets
n ≥ 500, 000m ≥ 20, 000
(e.g. WTCCC Nature 2007: 17,000 individuals, 500K snp array) • Can we extend Eigenstrat to this data to be run on a
standard desktop?• Assume low rank, k << min(m,n)• Approx algorithm in O(kmn) computation
Eigenstrat (Patterson et al. 2006)

Randomized PCA
Basic steps:1. Random projection (approx. preserves distances)
• project data onto low dimensional space–
• do SVD on Y -- similar to SVD on M
2. Power method : when spectrum decay is slow
nkr N(0,1),~G r),-by-G(nn)-by-M(mY ij
... 2, 1, i G,)MM(Y iT

Properties of Randomized PCA
• Error bound on the k rank approximation :
power iteration drives the leading constant to one exponentially fast as i increases!
• Top k eigenvalues and eigenvectors can be well approximated in time O(ikmn)– rapid convergence when close to low rank structure (i=1-
3)– slowly decaying singular values require more iterations
• Clearly no benefit when ik ≈ m << n
1k12i
1
k C)(1 ||A - A||E
kA

Properties of Randomized PCA
• Empical observations– we don’t seem to need power iteration, as random
projection good enough (data is low rank)– eigenvalue accuracy estimate can be “sloppy” if emphasis
is on subspace estimation, assuming a spectral gap– often we care mainly about subspace estimation accuracy

Generalized eigdecomposition
1. (Semi) supervised dimension reduction– add prior information by means of class labels– linear and non-linear variations: (L)SIR (Li et al. 1991, Wu et al. 2010)
2. (Non-) linear embeddings– Laplacian Eigenmaps (Belkin and Niyogi 2002)
– Locality Preserving Projections (He and Niyogi, 2003)
3. Canonical Correlation Analysis

Empirical results
• Wishart Covariance Structure– independent N(0,1) entries for data matrix
• The Wellcome Trust Case Control Consortium (Nature 2007)– Crohn’s Disease; 500K SNP array; 5,000 individuals

Subspace distance metric
• Exact method -- subspace A, approx. method -- subspace B (consider column spaces)
• Construct projection operators
• Define distance metric: (Ye and Weiss, 2003)
1 B)dist(A,0
)Ptr(Pn
1 - 1 B)dist(A, BA
T1-TB
T-1TA
BB)B(BP
AA)A(AP

Wishart covariance
• Data matrix: independent N(0,1) entries• Runtime improvement over exact

Spiked wishart (rank = 5)

WTCCC Crohn’s disease data set

Subspace distance metric (WTCCC)

Subspace distance metric (WTCCC)

Acknowledgements
• Uwe Ohler1,2 & Sayan Mukherjee2,3
• David Corcoran1,2
• Nick Patterson4
• Ohler & Mukherjee Group
1 Department of Biostatistics and Bioinformtics, Duke University2 Institute for Genome Sciences and Policy, Duke University3 Department of Statistical Sciences, Duke University4 Broad Institute, Harvard and MIT

Thank you!


Wishart Covariance Structure
• Data matrix: independent N(0,1) entries• Runtime improvement over exact

Decreasing difference in dimension size

Random wishart (# iter = 1)

Random wishart (# iter = 2)

Random wishart (# iter = 3)

Spiked wishart (rank = 5)

WTCCC data (# iter = 1)

WTCCC data (# iter = 2)

Sequence region binding evidence
TCATGCTATTTTAGCGATCTGATCGTAGACTGTTAGTCGATGCTGTGTATTTGCA
T-TT-C
[David Corcoran]
X-linked clusters
binding evidence = log[# T-> C conversion events]
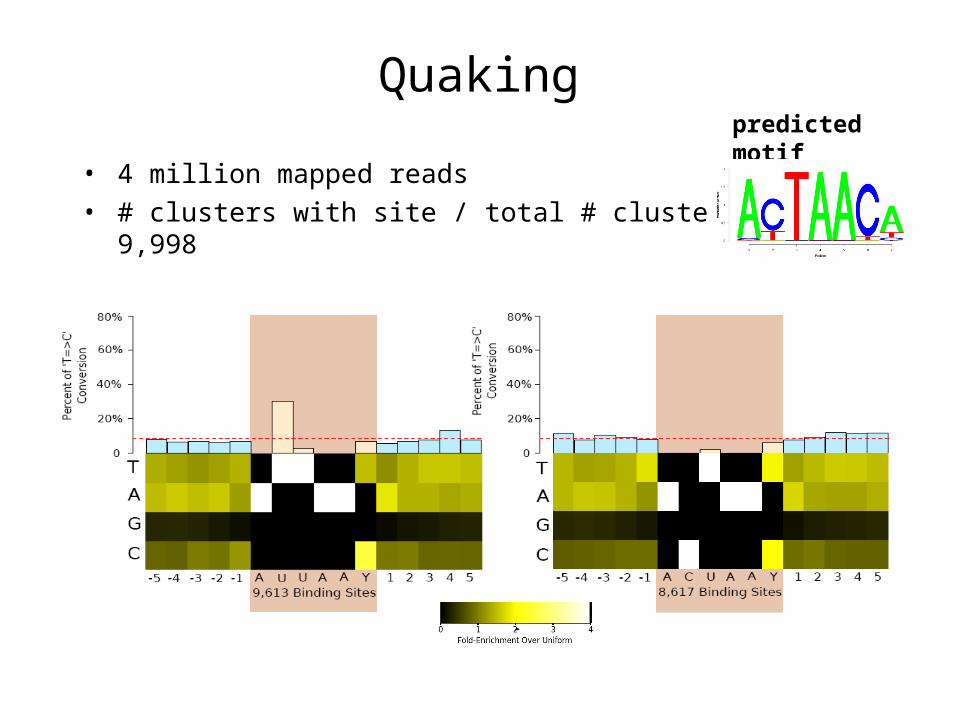
Quaking
• 4 million mapped reads• # clusters with site / total # clusters = 3,740 / 9,998
predicted motif

Bibliography[1] Jonathan K. Pritchard, Matthew Stephens, and Peter Donnelly. Inference of Population Structure Using
Multilocus Genotype Data (2000). Genetics, Vol. 155, 945-959[2] Novembre J, Johnson T, Bryc K, Kutalik Z, Boyko AR, Auton A, Indap A, King KS, Bergmann S, Nelson MR,
Stephens M, Bustamante CD. Genes mirror geography within Europe (2008). Nature. Nov 6; 456 (7218): 98-101
[3] Patterson N, Price AL, Reich D: Population Structure and Eigenanalysis (2006). PLoS Genetics (12): e190. doi:10.1371/journal.pgen.0020190
[4] Rokhlin V, SzlamA and Tygert M: A randomized algorithm for principal component analysis (2009). SIAM Journal on Matrix Analysis and Applications, 31 (3): 1100-1124
[5] Halko N, Martinsson P., Tropp JA. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. arXiv:0909.4061v2 [math.NA]
[6] Ye and Weiss RE: Using the bootstrap to select one of a new class of dimension reduction methods (2003). Journal of the American Statistical Association. 98, pp. 968979.
[7] Zhu Y and Zeng P: Fourier methods for estimating the central subspace and the central mean subspace inregression (2006). Journal of the American Statistical Association. 101, pp. 16381651.
[8] The Wellcome Trust Case Control Consortium: Genome-wide association study of 14,000 cases of sevencommon diseases and 3,000 shared controls (2007). Nature. 447, pp. 661-678.

ChIP-seq papers
CTCF: Barski A, Cuddapah S, Cui K, Roh T, Schones D, Wang Z, Wei G, Chepelev I, Zhao K High-resolution profiling of histone methylations in the human genome. Cell 2007
STAT1: Robertson G, Hirst M, Bainbridge M, Bilenky M, Zhao Y, Zeng T, Euskirchen G, Bernier B, Varhol R, Delaney A, Thiessen N, Griffith O, He A, Marra M, Snyder M, Jones S Genome-wide profiles of STAT1 DNA association using chromatin immunoprecipitation and massively parallel sequencing. Nat Methods 2007
SRF: Valouev A, Johnson DS, Sundquist A, Medina C, Anton E, Batzoglou S, Myers RM, Sidow A Genome-wide analysis of transcription factor binding sites based on ChIP-Seq data. Nat Methods 2008

Example of cluster generation in the Argonaute dataset

Eigenstrat

Properties of Randomized PCA
• Empical observations– we don’t seem to need power iteration, as random
projection good enough (data is low rank)– eigenvalue accuracy estimate can be “sloppy” if emphasis
is on subspace estimation, assuming a spectral gap– often we care mainly about subspace estimation accuracy
• Lot’s of “painful” implementation details– efficient matrix multiply– data packing

Inference of population structure and generalized
eigendecomposition(with Sayan Mukherjee1 and Nick Patterson2)
1 Department of Statistical Sciences, Duke University2 Broad Institute, Harvard and MIT

PARalyzer• non-parametric kernel-density estimate classifier to identify
the RNA-protein interaction sites from a combination of T=>C conversions and read density
1. reads that have been aligned to the genome and overlap by at least 1 nucleotide are grouped together.
2. Within each read-group we generate two smoothened kernel density estimates; the first of T=>C transitions and the other of non-transition events.
3. Nucleotides within the grouped-reads that maintain a minimum read depth, and where the relative likelihood of T=>C conversion is higher than non-conversion, are considered interaction sites
4. This region is then extended either to include the underlying reads, or by a generic window size (by 3nt for Pum)

AGO• largest number of clusters for the Argonaute dataset was
found in intergenic regions • requiring at least two separate locations with observed T=>C
conversions within the cluster removed a large proportion (67%) of those sites, while only removing a small proportion (24%) of clusters found in 3'UTRs
• We therefore require all clusters to have more than one location with a T=>C conversion for all subsequent analysis.
• To increase the stringency of the CCRs, we required the mode location to have had at least 20% T=>C conversion

Argaunote(AGO) PAR-CLIP Analysis

microRNA Enrichment Analysis Tool (mEAT)
sequence regions
high evidence
low evidence miR seeds
miR-93 miR-15 let-7
.
.
.
.
.
.
ES = 15.0
sequence regions
ES = average binding evidence across miR canonical seeds

Variable Definitions
sconfounder k} p , . . . {1,k ,c
indicatormatch seed miR k} , . . . {1,r ,1} {0,x
ntscoeffiecie regression )β ., . . ,β ,β , . . . ,(β β
covariates regression )c , . . . ,c , x, . . . ,(xZ
seeds canonical miR ofnumber k
evidence binding )y , . . . ,(yY
nk
njr
Tpj1jkkj1j
k-p1jkj1j
T*n
*1
*
j
-

miR seed enrichment
1j
Tj
2
β
*Tj
1j
Tjj
n2
j*
)Z(ZσΣ ,yZ)Z(Z β
:fit OLS
)Ισ N(0,~ε , εβZY
:model
j
j

miR seed enrichment
k
1r
(r)jj
th
rrjβ
rj(r)j
1j
Tj
2
β
*Tj
1j
Tjj
n2
j*
0]1[mn
seed) miR r ofion (contribut 0 ,)Σ(
β max m
:evidence binding seed miR
)Z(ZσΣ ,yZ)Z(Z β
:fit OLS
)Ισ N(0,~ε , εβZY
:model
j
j

miR seed enrichment
k
1r
(r)j
j
miRj
k
1r
(r)jj
th
rrjβ
rj(r)j
1j
Tj
2
β
*Tj
1j
Tjj
n2
j*
Sn
1S
:evidence binding miR
validation-cross usingfit a ;a]1[Sn
seed) miR r ofion (contribut 0 ,)Σ(
β max S
:evidence binding seed miR
)Z(ZσΣ ,yZ)Z(Z β
:fit OLS
)Ισ N(0,~ε , εβZY
:model
j
j

Results

cluster # miRbase 8-mer expression rank microRNA score # targets cumulative # targets1 hsa-mir-106b GCACTTTA 5 11.42 1028 1028(9.8%)
hsa-mir-20a GCACTTTA 9 11.42hsa-mir-519c TGCACTTT 287 9.93hsa-mir-519c-3p TGCACTTT NA 9.93hsa-mir-519a-2 TGCACTTT NA 9.93hsa-mir-519b-3p TGCACTTT NA 9.93hsa-mir-519a-1 TGCACTTT NA 9.93hsa-mir-106a GCACTTTT 121 9.84hsa-mir-526bstar GCACTTTC NA 9.77hsa-mir-93 GCACTTTG 1 8.96hsa-mir-17 GCACTTTG 10 8.96hsa-mir-20b GCACTTTG 225 8.96hsa-mir-519d GCACTTTG 288 8.96hsa-mir-520d-3p AGCACTTT NA 7.44hsa-mir-520b AGCACTTT NA 7.44hsa-mir-520e AGCACTTT NA 7.44hsa-mir-372 AGCACTTT NA 7.44hsa-mir-520c-3p AGCACTTT NA 7.44hsa-mir-520a-3p AGCACTTT NA 7.44
2 hsa-mir-16-2 TGCTGCTA 22 10.32 795 1799(17.2%)hsa-mir-15b TGCTGCTA 53 10.32hsa-mir-15a TGCTGCTA 64 10.32hsa-mir-195 TGCTGCTA 218 10.32hsa-mir-16-1 TGCTGCTA NA 10.32hsa-mir-424 TGCTGCTG 60 7.61hsa-mir-497 TGCTGCTG 133 7.61hsa-mir-103-2 ATGCTGCT 2 7.6hsa-mir-107 ATGCTGCT 39 7.6hsa-mir-103-1 ATGCTGCT NA 7.6hsa-mir-503 CGCTGCTA 97 6.81
3 hsa-mir-92a-1 GTGCAATA 4 8.68 329 2098(20.1%)hsa-mir-32 GTGCAATA 95 8.68hsa-mir-92b GTGCAATA 101 8.68hsa-mir-92a-2 GTGCAATA NA 8.68hsa-mir-25 GTGCAATG 11 7.44hsa-mir-363 GTGCAATT 130 7.21hsa-mir-367 GTGCAATT NA 7.21
4 hsa-mir-19b-1 TTTGCACA 6 7.93 570 2367(22.6%)hsa-mir-19a TTTGCACA 7 7.93hsa-mir-19b-2 TTTGCACA NA 7.93
5 hsa-mir-454 TTGCACTA 108 7.74 745 2367(22.6%)hsa-mir-301a TTGCACTG 18 6.36hsa-mir-130a TTGCACTG 47 6.36hsa-mir-130b TTGCACTG 56 6.36hsa-mir-301b TTGCACTG 74 6.36hsa-mir-3666 TTGCACTG NA 6.36hsa-mir-4295 TTGCACTG NA 6.36


Regression Interpretation
cERMITj
regjj
regj
T}{1,..,j
*reg
cERMITj
j
OLSjreg
j
j1x:i
*i
j
OLSj
2iijiji
jj
SSnn
S max arg m SA
1
σ
β S
ey n
1 β
)σ N(0,~ε ,εβx yy :Model
m motiffor t coefficien regressionβ
ij


PARalayzer (PAR-CLIP data analyzer)
mRNAs translation into protein can be regulated through sequence motifs on the mRNA transcript
RNA binding proteins (RBPs)
Input: binding evidence for transcribed mRNAs
library of mRNA sequence motifs
Output: enriched mRNA sequence motifs
[David Corcoran]

PARalayzer (PAR-CLIP data analyzer)
1. Align reads to a reference genome
2. Group adjacent reads into clusters (sequence regions)
3. Assign binding evidence to each cluster: log2[# reads]
4. Use clusters to find enriched motifs
[David Corcoran]

PARalayzer (PAR-CLIP data analyzer)
1. Align reads to a reference genome, allowing for up to 3 mismatches (i.e. up to 3 T->C conversion events per read)
2. Group overlapping reads– groups with ≥ 5 reads are further analyzed– Clusters are extended to either the longest read that overlaps a ‘positive’
signal or until there are no longer at least 5 reads at a location– filter groups based on known repeat regions
3. Within each group generate sub-groups (clusters) based on the observed T->C conversion events– identify regions with enriched T->C relative to T->T – use non-parametric smoothing (KDE) to call peaks
4. Use sub-groups in downstream motif enrichment analysis
[David Corcoran]




mEATmEAT Input data: Argonaute X-linked clusters, miRbase seeds
miR seeds: 8mer, 7mer-M1, 7mer-A1, 7mer-1-7, 7mer-2-8
miR seed enrichment: normalized average enrichment score for the set of clusters with a seed match [3]
Targets miR i: indexes of clusters, containing a match to the top enriched seed for miR i
Goal: find the most highly enriched miRs
mEAT Input data: Argonaute X-linked clusters, miRbase seeds
miR seeds: 8mer, 7mer-M1, 7mer-A1, 7mer-1-7, 7mer-2-8
miR seed enrichment: normalized average enrichment score for the set of clusters with a seed match [3]
Targets miR i: indexes of clusters, containing a match to the top enriched seed for miR i
Goal: find the most highly enriched miRs

mEAT: Enrichment vs. Expression
Top expressed miRsTop expressed miRs
Top expressed miRsTop expressed miRsTop expressed miRsTop expressed miRsTop expressed miRsTop expressed miRs

Gene expression in the eukaryotic cell

ChIP-seq
PAR-CLIP1. culture with 4-SU
2. cross-link
3. Immunoprecipitate & size-select
4. convert into a cDNA library & sequence
[Hafner et al. 2010]


Motif model (Georgiev et al. 2010)
jT}{1,..,j
*cERMIT
j
jj
j
22
j1x:i
*i
jj
j
i*
i2
ii
2
n}{1,...,ii
m max arg m
:motif Optimal
σ
eA m
:Evidence Binding Motif
n
σσ ;y
n
1e ;
1n
nn A
;yyy ;)y (y n
1σ ;y
n
1y
:Notation
ij

HuR# reads = 20M, aligned 13M,# clusters = 250K, # clusters after pre-processing = 125K,“explained” with presence of binding motif = 25% long, 75% two short plots with T->C conversions (David),
- in vitro binding studies, which have shown that HuR is capable of binding to AREs including, AUUUA pentamers, long poly-U stretches, and 3 to 5 nucleotide stretches of Usseparated by A, C, or G (Levine et al., 1993; Meisner et al., 2004).

Quaking
• # clusters with site / total # clusters = 3,740 / 9,998
• # reads, # clusters, # “explained” with presence of binding motif, plots with T->C conversions (David),
• Group using reads, as not all X-linked

Pumilio
Related Documents











