© 2013 IBM Corporation IBM® PureData™ System for Analytics N200x Technical Overview Adriano Di Massimo PureData for Analytics Europe IOT

Ibm pure data system for analytics n200x
Oct 19, 2014
Pure Data for Analytics - Arild Kristensen
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

© 2013 IBM Corporation
IBM® PureData™ System for Analytics
N200x Technical Overview
Adriano Di Massimo
PureData for Analytics Europe IOT

© 2013 IBM Corporation2
Increasing
Variety of datarequires new techniques
Increasing
Velocity of datarequires higher performance
Increasing
Volume of datarequires growing capacity
35 ZB
by 2020
Big Data Challenges for Both Transactions and
Analytics are Increasing Demands on Data Systems
Millions oftransactions per second
Telco subscriber activity logging
Mobile CloudSocial Big DataCommerce
2020
50x
2010
Analytics
Billions ofdevices & sensors
Smart Meters, RFIDs, GPS)
© 2013 IBM Corporation
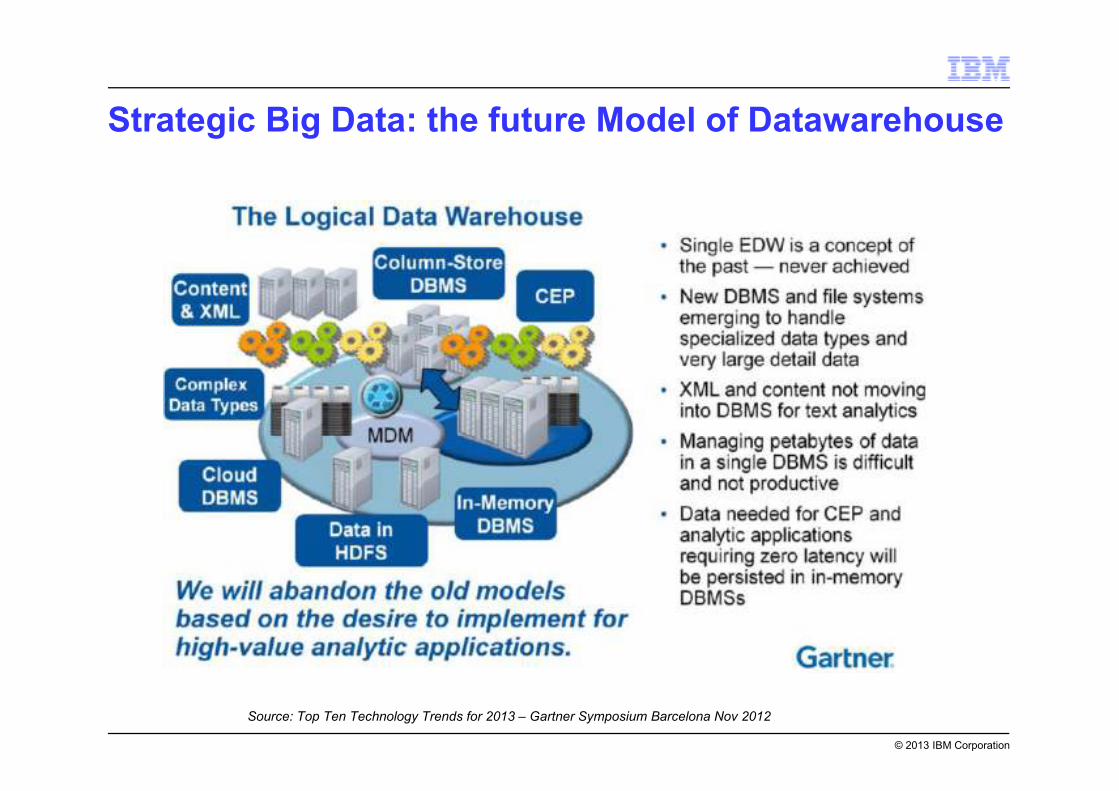
Strategic Big Data: the future Model of Datawarehouse
Source: Top Ten Technology Trends for 2013 – Gartner Symposium Barcelona Nov 2012

© 2013 IBM Corporation
IBM PureData System for Analytics (PDA)
� Purpose-built analytics engine
� Integrated database, server and storage
� Standard interfaces
� Low total cost of ownership
Speed: 10-100x faster than traditional systems
Simplicity: Minimal administration and tuning
Scalability: Peta-scale user data capacity
Smart: High-performance advanced analytics
Transforms the User Experience

© 2013 IBM Corporation5
Announcing a New Model!
PureData for Analytics now has TWO models� N1001 – economical, high performance and scalability
� N200x – highest performance appliance to-date
PureData for Analytics continues to provide:� Fastest Time to Value on the market today
� Optimized Big Data analytics performance
� Simple administration for fast and agile deployment
� Accelerate analytic performance using large library of analytic
functions
The new N200x model addresses these key challenges
� Increased performance
� Better density
� Data center efficiency
PureData System for Analytics N200x

© 2013 IBM Corporation
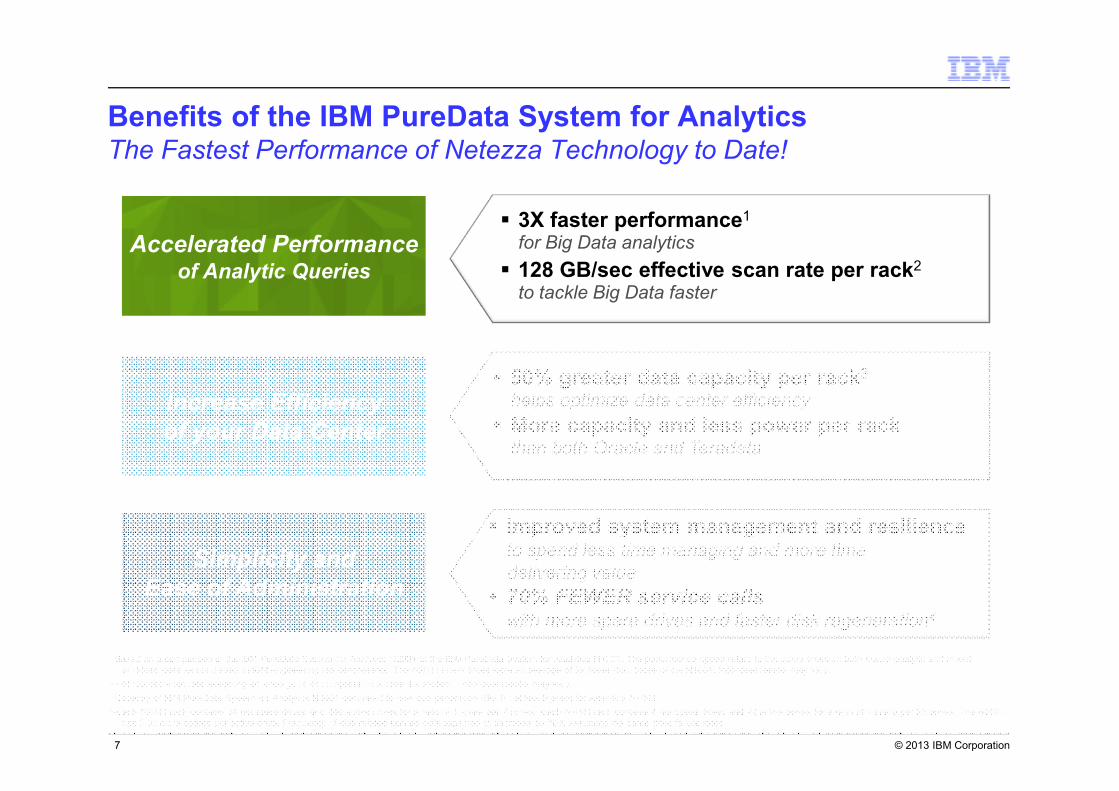
Benefits of the IBM PureData System for Analytics The Fastest Performance of Netezza Technology to Date!
6
1 Based on a comparison of the IBM PureData System for Analytics N2001 to the IBM PureData System for Analytics N1001. The performance speed refers to the query times on both macro-analytic and mixed
workload tests as conducted in IBM engineering lab benchmarks. The N2001 query times were an average of 3x faster than those of the N1001. Individual results may vary.
2 128 GB/sec scan rate assuming an average of 4x compression across the system. Individual results may vary.
3 Capacity of IBM PureData System for Analytics N2001 compared to previous generation IBM PureData System for Analytics N1001.
4-Each N2001 rack contains 34 hot spare drives and 240 active drives for a ratio of 1 spare per 7 drives. Each N1001 rack contains 4 hot spare drives and 92 active drives for a ratio of 1 spare per 23 drives. The N2001
has 3.3x more spares per active drive. Frequency of disk related service calls expected to decrease by 70% assuming the same drive failure rates.
Accelerated Performanceof Analytic Queries
Accelerated Performanceof Analytic Queries
Increased Efficiency
of your Data Center
Increased Efficiency
of your Data Center
Simplicity and
Ease of Administration
Simplicity and
Ease of Administration
� 3X faster performance1
for Big Data analytics
� 128 GB/sec effective scan rate per rack2
to tackle Big Data faster
� Improved system management and resilienceto spend less time managing and more time
delivering value
� 70% FEWER service calls with more spare drives and faster disk regeneration4
� 50% greater data capacity per rack3
helps optimize data center efficiency
� More capacity and less power per rackthan both Oracle and Teradata
© 2013 IBM Corporation
Benefits of the IBM PureData System for Analytics The Fastest Performance of Netezza Technology to Date!
7
1 Based on a comparison of the IBM PureData System for Analytics N2001 to the IBM PureData System for Analytics N1001. The performance speed refers to the query times on both macro-analytic and mixed
workload tests as conducted in IBM engineering lab benchmarks. The N2001 query times were an average of 3x faster than those of the N1001. Individual results may vary.
2 128 GB/sec scan rate assuming an average of 4x compression across the system. Individual results may vary.
3 Capacity of IBM PureData System for Analytics N2001 compared to previous generation IBM PureData System for Analytics N1001.
4-Each N2001 rack contains 34 hot spare drives and 240 active drives for a ratio of 1 spare per 7 drives. Each N1001 rack contains 4 hot spare drives and 92 active drives for a ratio of 1 spare per 23 drives. The N2001
has 3.3x more spares per active drive. Frequency of disk related service calls expected to decrease by 70% assuming the same drive failure rates.
Accelerated Performanceof Analytic Queries
Accelerated Performanceof Analytic Queries
Increase Efficiency
of your Data Center
Increase Efficiency
of your Data Center
Simplicity and
Ease of Administration
Simplicity and
Ease of Administration
� 3X faster performance1
for Big Data analytics
� 128 GB/sec effective scan rate per rack2
to tackle Big Data faster
� Improved system management and resilienceto spend less time managing and more time
delivering value
� 70% FEWER service calls with more spare drives and faster disk regeneration4
� 50% greater data capacity per rack3
helps optimize data center efficiency
� More capacity and less power per rackthan both Oracle and Teradata
© 2013 IBM Corporation
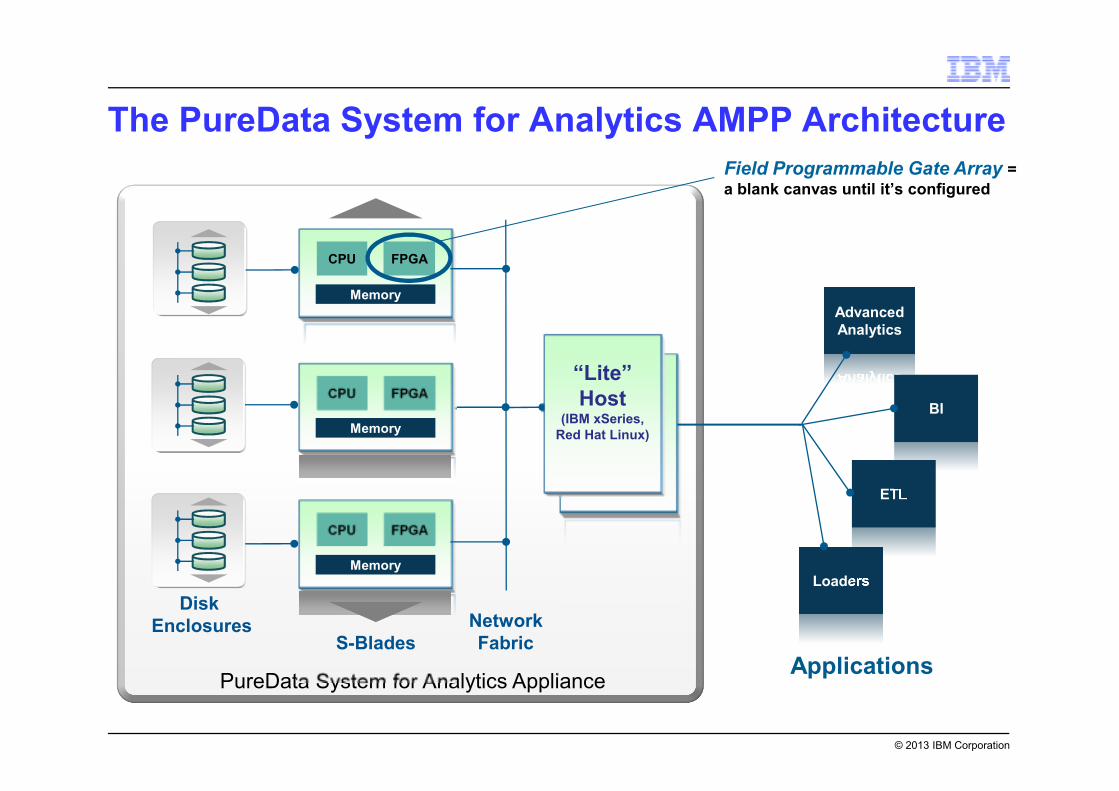
The PureData System for Analytics AMPP Architecture
PureData System for Analytics Appliance
FPGA
Memory
CPU
FPGA
Memory
CPU
FPGA
Memory
CPU
S-Blades
Network
Fabric
Field Programmable Gate Array =
a blank canvas until it’s configured
Advanced
Analytics
Advanced
Analytics
LoadersLoaders
ETLETL
BIBI
Applications
Disk
Enclosures
“Lite”
Host(IBM xSeries,
Red Hat Linux)
© 2013 IBM Corporation
The PureData System for Analytics AMPP Architecture
PureData System for Analytics Appliance
FPGA
Memory
CPU
FPGA
Memory
CPU
FPGA
Memory
CPU
S-Blades
Network
Fabric
Field Programmable Gate Array =
a blank canvas until it’s configured
Advanced
Analytics
Advanced
Analytics
LoadersLoaders
ETLETL
BIBI
Applications
Disk
Enclosures
“Lite”
Host(IBM xSeries,
Red Hat Linux)
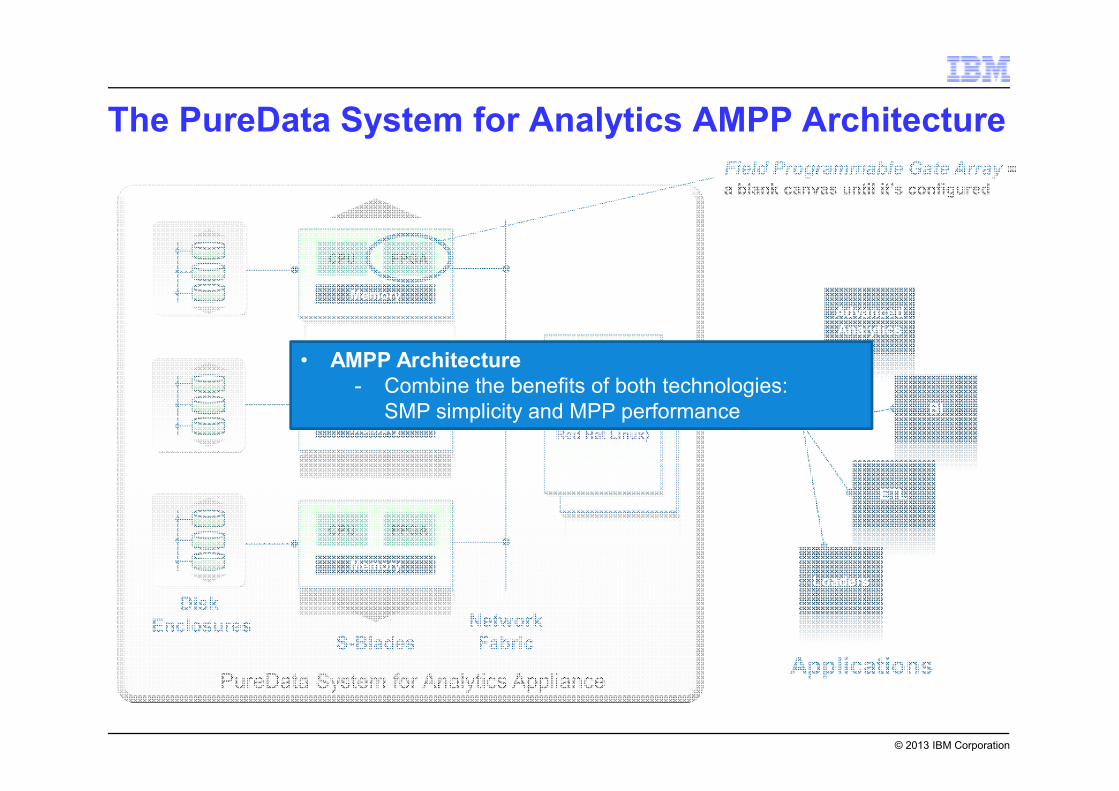
• AMPP Architecture
- Combine the benefits of both technologies:
SMP simplicity and MPP performance
© 2013 IBM Corporation
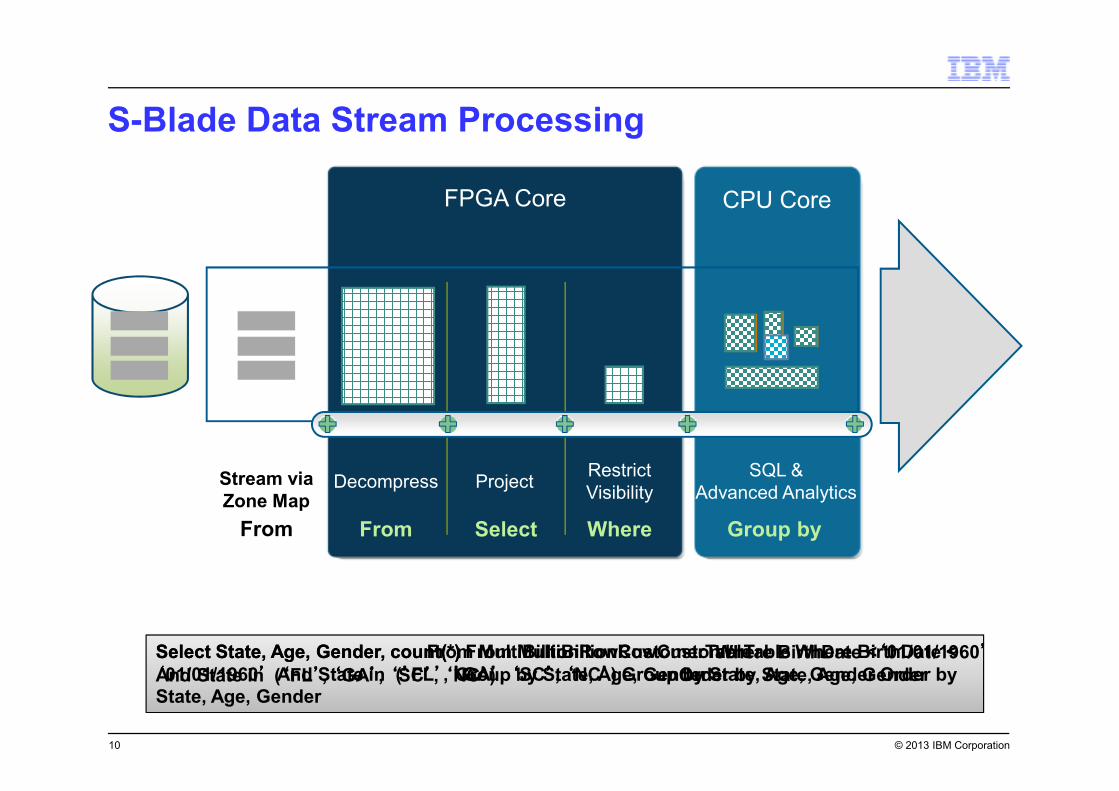
Select State, Age, Gender, count(*) From MultiBillionRowCustomerTable Where BirthDate <
‘‘‘‘01/01/1960’’’’ And State in (’’’’FL’’’’, ’’’’GA’’’’, ‘‘‘‘SC’’’’, ‘‘‘‘NC’’’’) Group by State, Age, Gender Order by
State, Age, Gender
S-Blade Data Stream Processing
FPGA Core CPU Core
Decompress ProjectRestrict
Visibility
SQL &
Advanced Analytics
From MultiBillionRowCustomerTableWhere BirthDate <‘‘‘‘01/01/1960’’’’Group by State, Age, Gender
Select State, Age, Gender, count(*)
And State in (‘‘‘‘FL’’’’, ‘‘‘‘GA’’’’, ‘‘‘‘SC’’’’, ‘‘‘‘NC’’’’) Order by State, Age, Gender
From Select Where Group by
Stream via
Zone Map
From
10
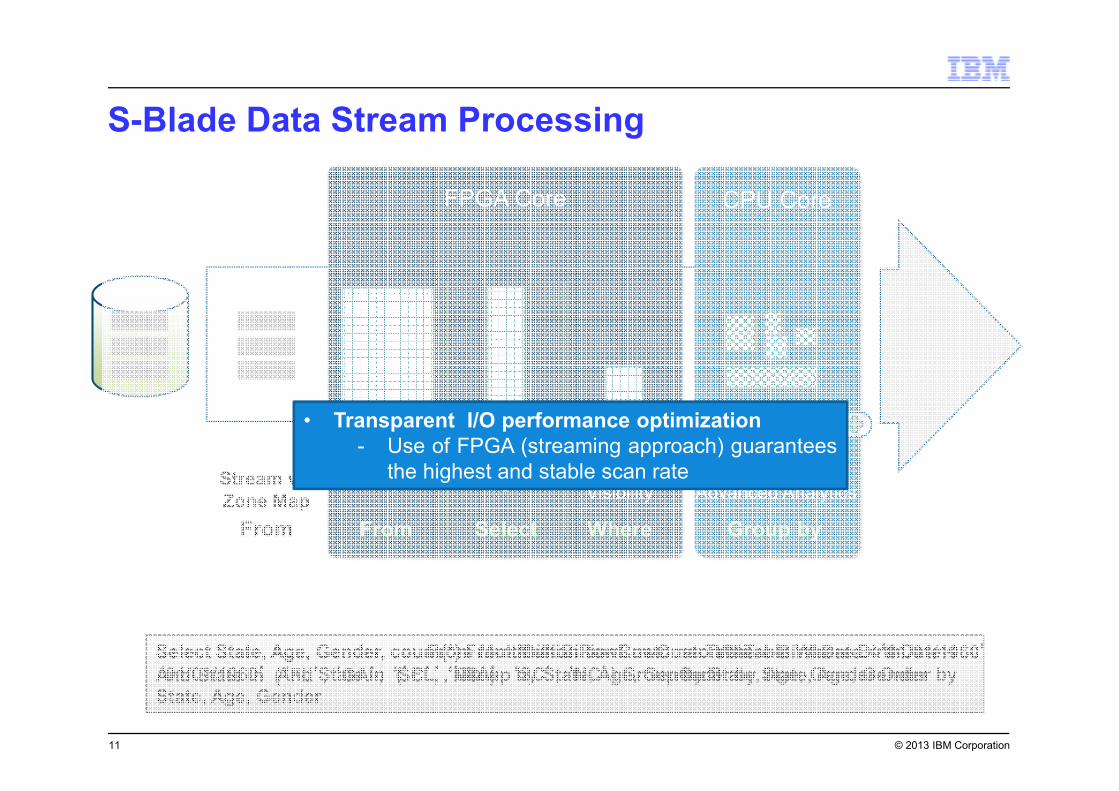
© 2013 IBM Corporation
Select State, Age, Gender, count(*) From MultiBillionRowCustomerTable Where BirthDate <
‘‘‘‘01/01/1960’’’’ And State in (’’’’FL’’’’, ’’’’GA’’’’, ‘‘‘‘SC’’’’, ‘‘‘‘NC’’’’) Group by State, Age, Gender Order by
State, Age, Gender
S-Blade Data Stream Processing
FPGA Core CPU Core
Decompress ProjectRestrict
Visibility
SQL &
Advanced Analytics
From MultiBillionRowCustomerTableWhere BirthDate <‘‘‘‘01/01/1960’’’’Group by State, Age, Gender
Select State, Age, Gender, count(*)
And State in (‘‘‘‘FL’’’’, ‘‘‘‘GA’’’’, ‘‘‘‘SC’’’’, ‘‘‘‘NC’’’’) Order by State, Age, Gender
From Select Where Group by
Stream via
Zone Map
From
• Transparent I/O performance optimization
- Use of FPGA (streaming approach) guarantees
the highest and stable scan rate
11
© 2013 IBM Corporation
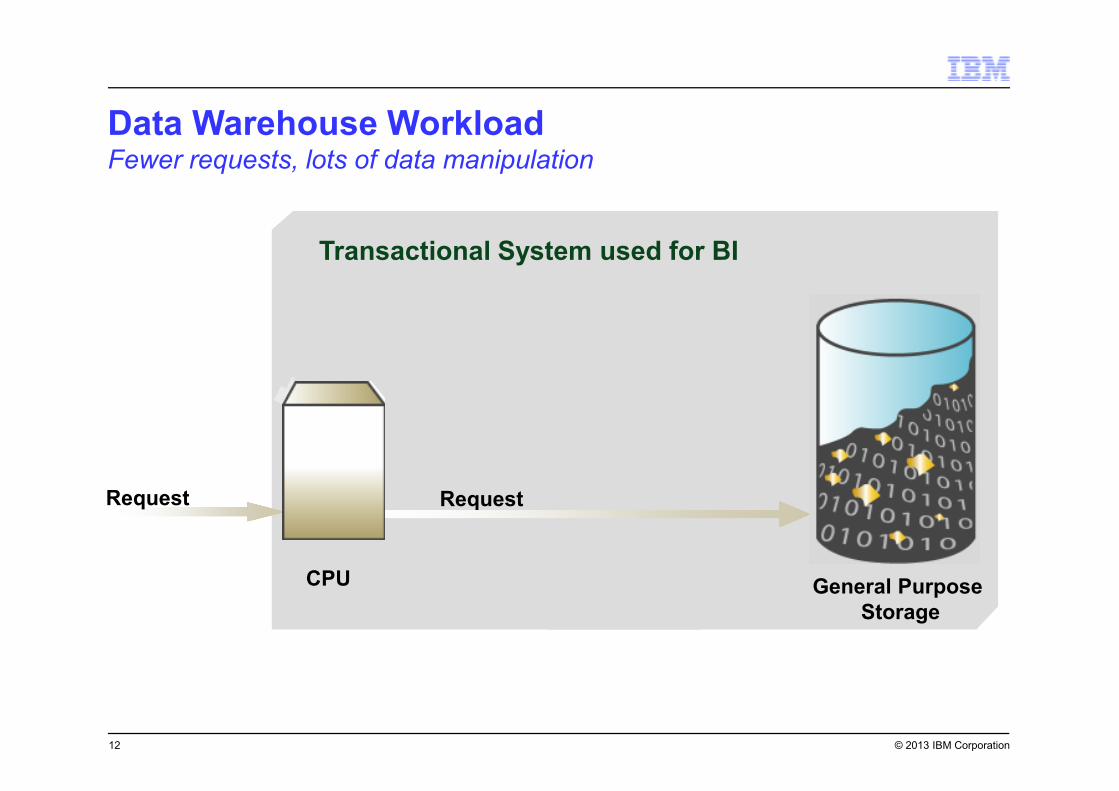
CPU
Request
General Purpose
Storage
Request
Transactional System used for BI
Data Warehouse WorkloadFewer requests, lots of data manipulation
12
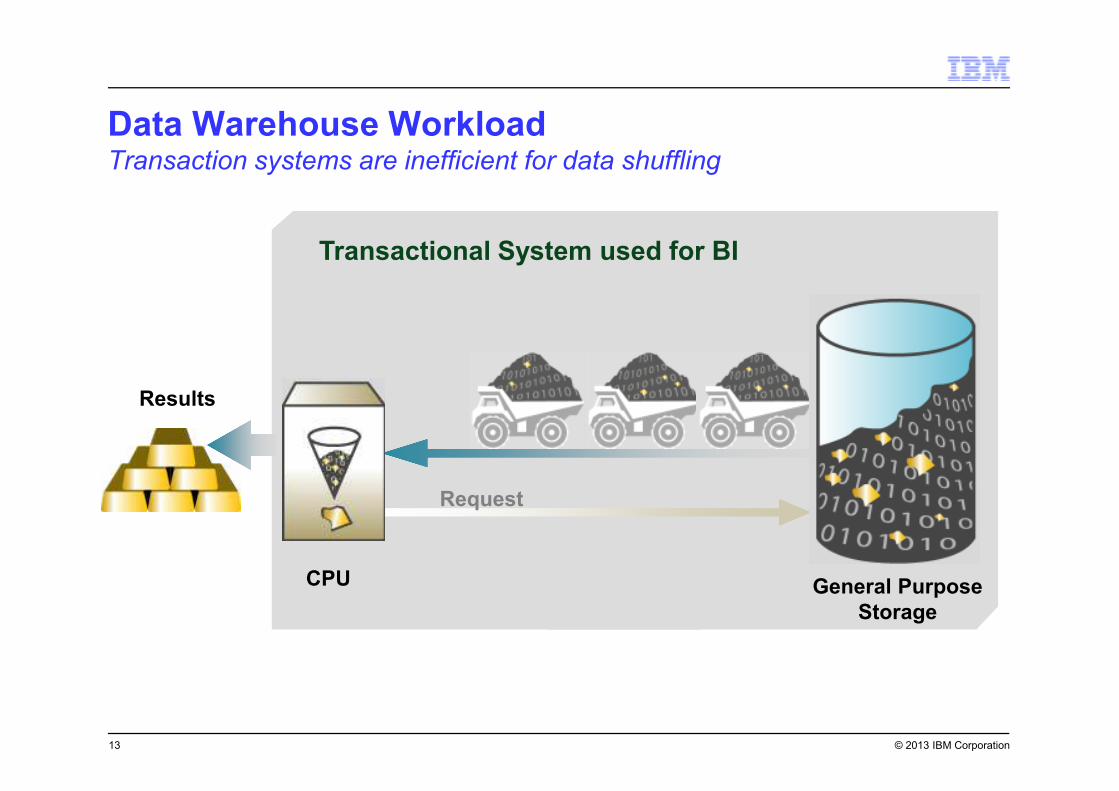
© 2013 IBM Corporation
Results
Transactional System used for BI
Request
General Purpose
Storage
CPU
Data Warehouse WorkloadTransaction systems are inefficient for data shuffling
13
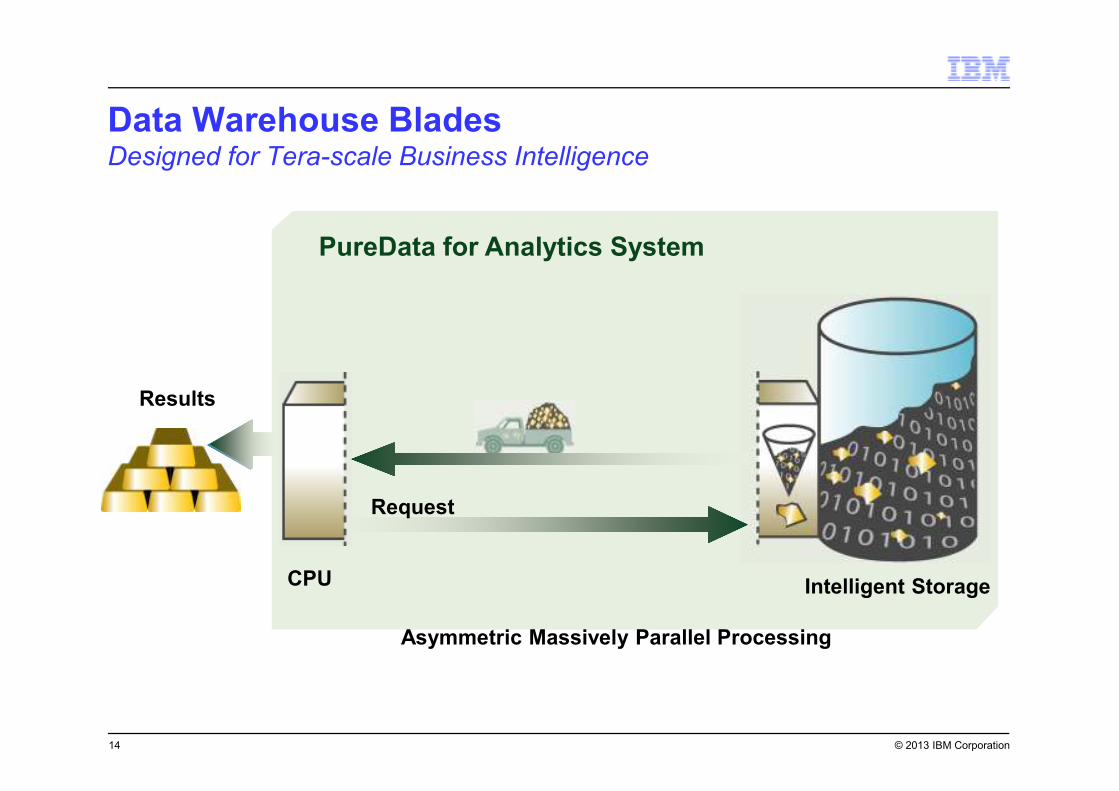
© 2013 IBM Corporation
Results
PureData for Analytics System
Intelligent StorageCPU
Request
Asymmetric Massively Parallel Processing
Data Warehouse BladesDesigned for Tera-scale Business Intelligence
14
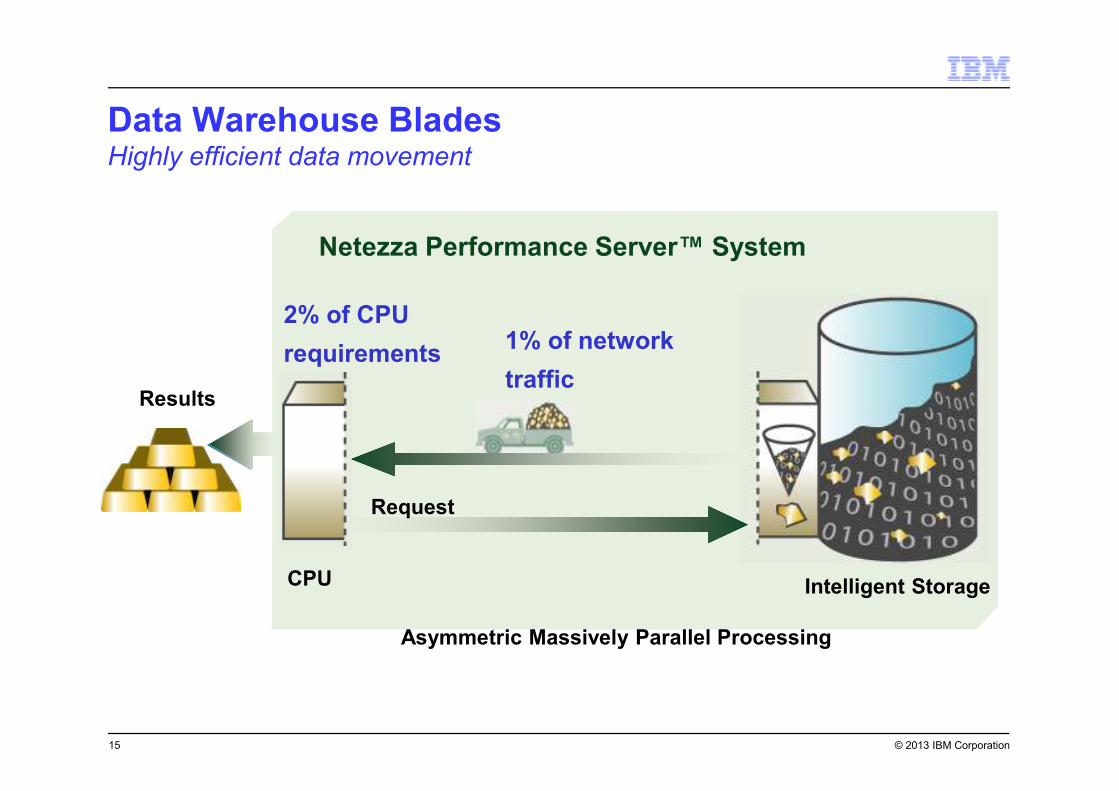
© 2013 IBM Corporation
Results
Netezza Performance Server™ System
Intelligent StorageCPU
Request
1% of network
traffic
2% of CPU
requirements
Asymmetric Massively Parallel Processing
Data Warehouse BladesHighly efficient data movement
15
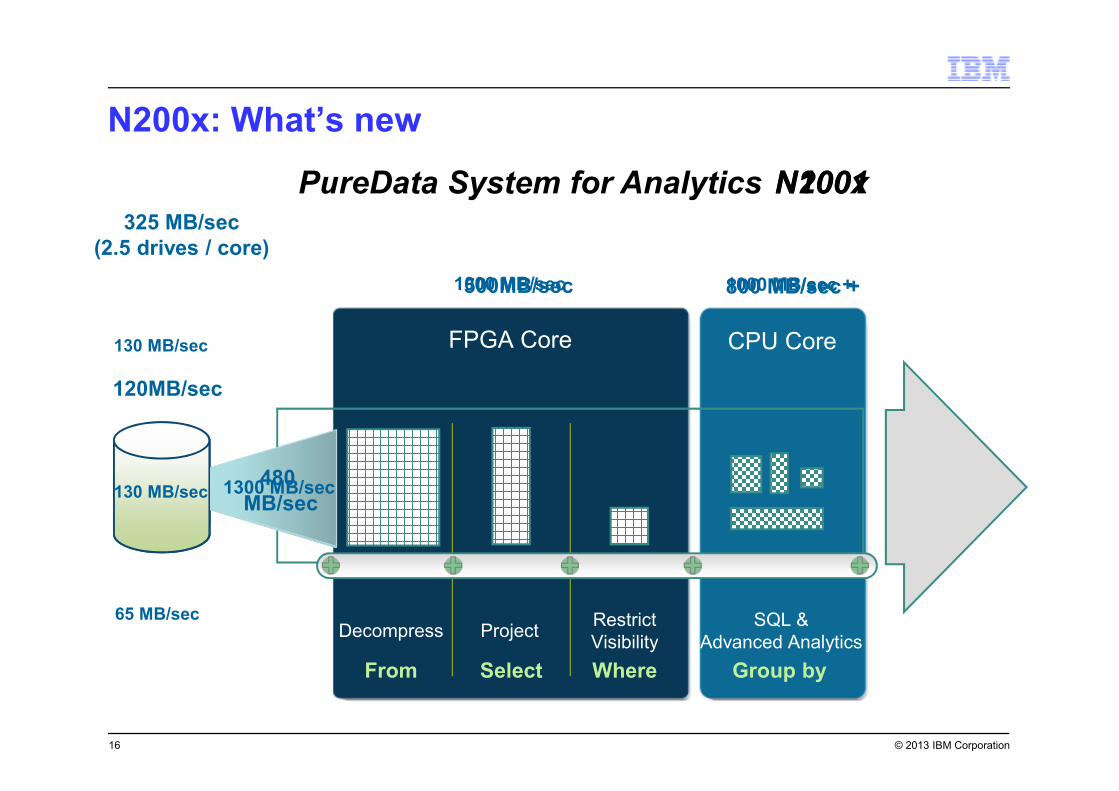
© 2013 IBM Corporation
N200x: What’s new
16
FPGA Core CPU Core
Decompress ProjectRestrict
Visibility
SQL &
Advanced Analytics
From Select Where Group by
120MB/sec
500MB/sec 800 MB/sec +
480
MB/sec
N1001N200x
65 MB/sec
130 MB/sec
130 MB/sec
325 MB/sec
(2.5 drives / core)
1000 MB/sec 1000 MB/sec +
1300 MB/sec
PureData System for Analytics
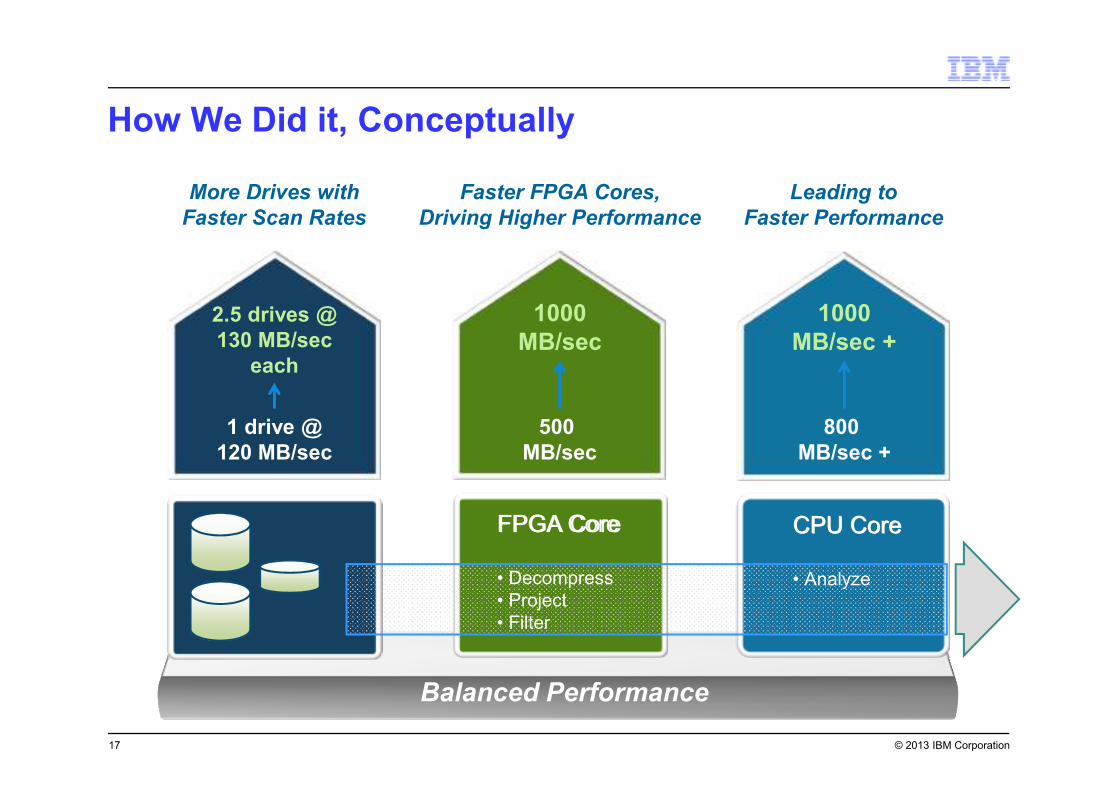
© 2013 IBM Corporation
How We Did it, Conceptually
17
Balanced Performance
FPGA Core CPU Core
500
MB/sec
800
MB/sec +
1 drive @
120 MB/sec
More Drives with
Faster Scan Rates
Leading to
Faster Performance
Faster FPGA Cores,
Driving Higher Performance
2.5 drives @
130 MB/sec
each
1000
MB/sec
1000
MB/sec +
CPU Core
• Analyze
FPGA Core
• Decompress
• Project
• Filter
© 2013 IBM Corporation
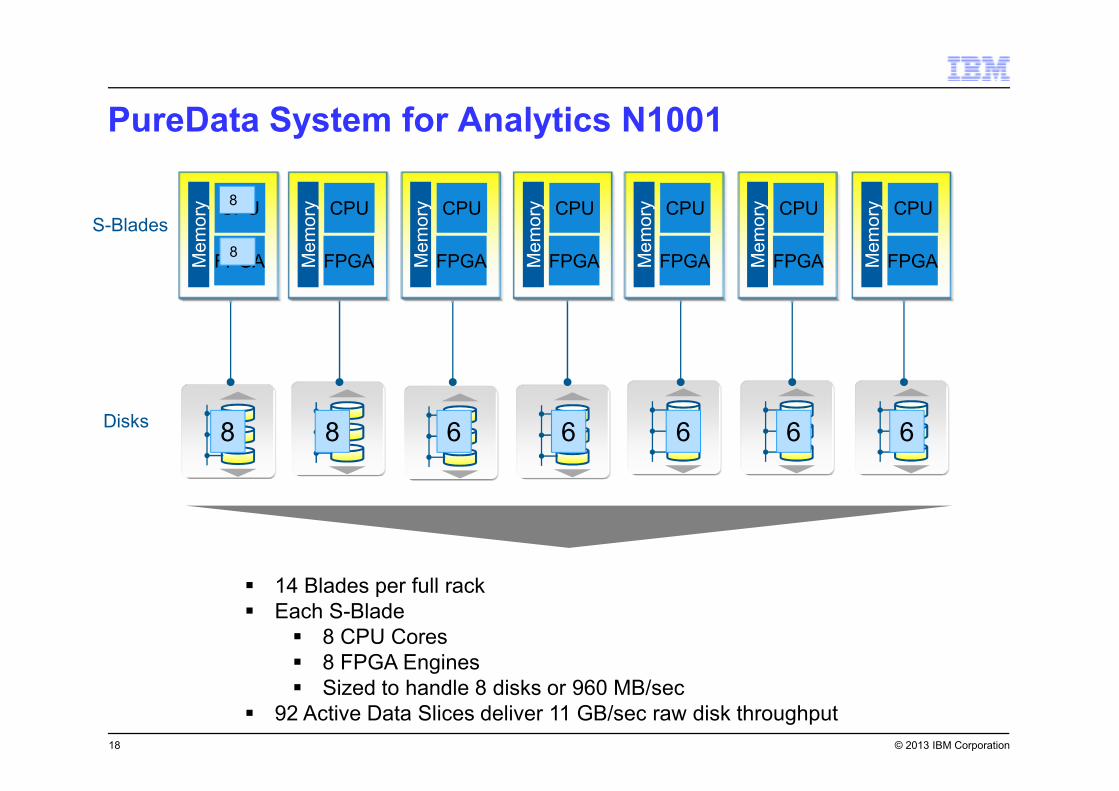
PureData System for Analytics N1001
18
S-Blades
Disks
Mem
ory CPU
FPGA
8 8 6 6 6 6 6
� 14 Blades per full rack
� Each S-Blade
� 8 CPU Cores
� 8 FPGA Engines
� Sized to handle 8 disks or 960 MB/sec
� 92 Active Data Slices deliver 11 GB/sec raw disk throughput
8
8
Mem
ory CPU
FPGA Mem
ory CPU
FPGA Mem
ory CPU
FPGA Mem
ory CPU
FPGA Mem
ory CPU
FPGA Mem
ory CPU
FPGA
© 2013 IBM Corporation
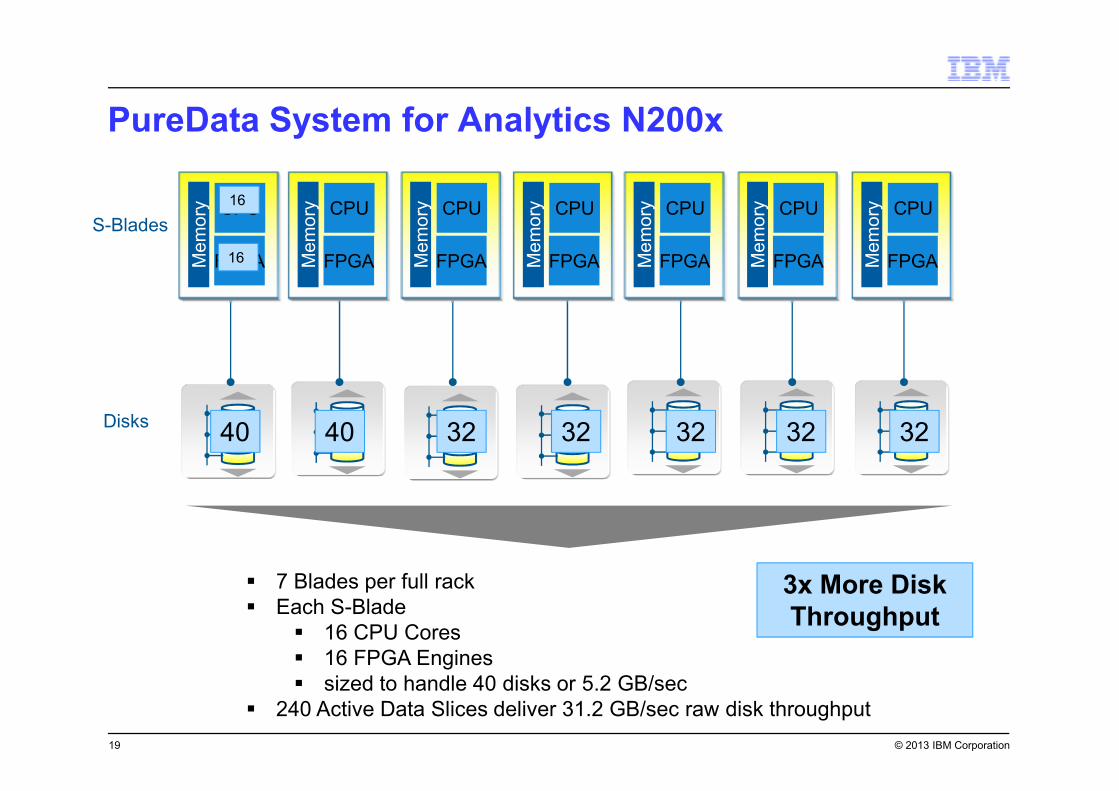
PureData System for Analytics N200x
19
S-Blades
Disks40 40 32 32 32 32 32
� 7 Blades per full rack
� Each S-Blade
� 16 CPU Cores
� 16 FPGA Engines
� sized to handle 40 disks or 5.2 GB/sec
� 240 Active Data Slices deliver 31.2 GB/sec raw disk throughput
3x More Disk
Throughput
Mem
ory CPU
FPGA Mem
ory CPU
FPGA Mem
ory CPU
FPGA Mem
ory CPU
FPGA Mem
ory CPU
FPGA Mem
ory CPU
FPGAMem
ory CPU
FPGA
16
16

© 2013 IBM Corporation
Netezza Platform Software v7.1Highlights�Scheduler rules for WLM
�Short query prioritization
�Snippet Result Cache
�Faster Bulk Fetching with ODBC
�Password aging and expiry
� nzPortal enhancements
�Cryptographic Standards (s800-131a)
�Support for Replication v1.5
�Support for INZA 3.0
Resiliency�Faster rebalance for failed disks
�Disk validation support
� Large scale disk replacement
�Call Home v1.0
�Enhanced System Health Checks v2.2
� ILMT support for Growth on Demand
Platform & OS�Client Kit support for AIX 7.1
�RHEL 6.4 certification
SQL Enhancements�Multiple Schema (3-part naming)
�Orphan column query
�NOT IN / EXIST improvements
�CASE WHEN improvements
�Support 24 hour datetime
�CESU-8 support
Transaction Enhancement�Truncate table in TXN
� Improved view validation
�Temp table enhancements
�Deprecate Web Admin
ETL�ODBC loader support for INTERVAL
Netezza Performance Portal�Cryptographics standards (s800-131a)
�Scheduler rules
�History type AUDIT
�Restrict nzPortal users
�Groom dialogs
20
© 2013 IBM Corporation
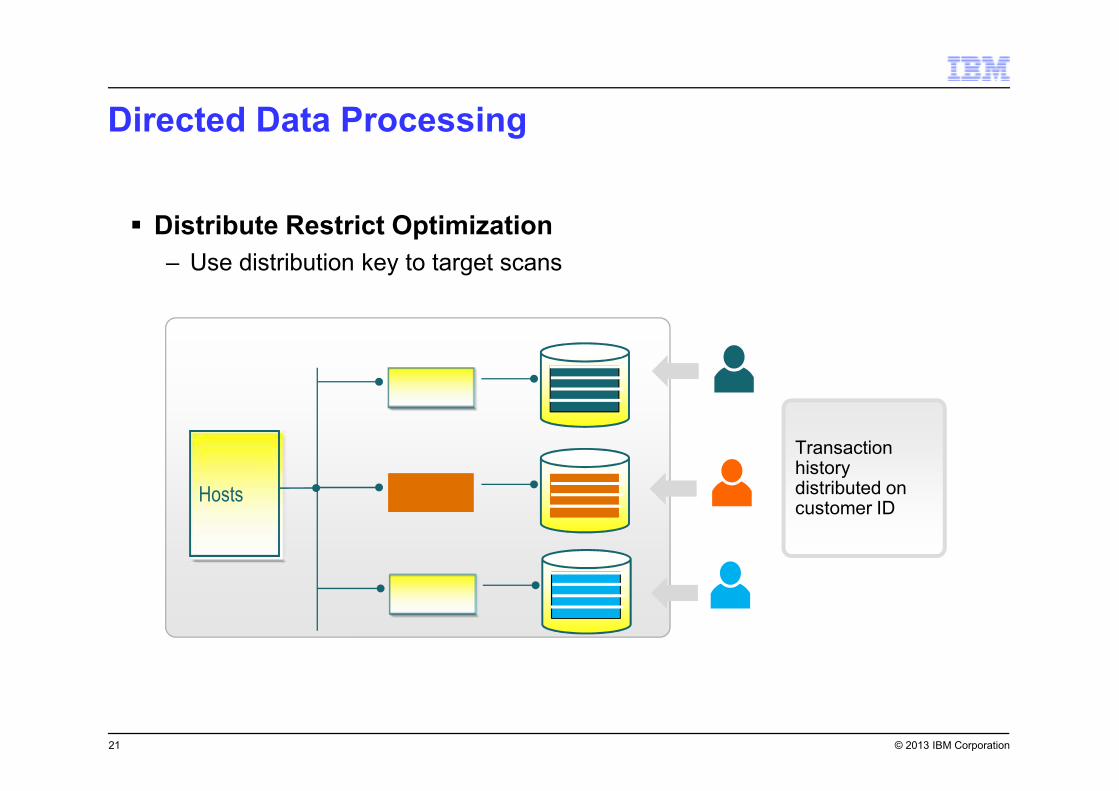
Directed Data Processing
21
� Distribute Restrict Optimization
– Use distribution key to target scans
Transaction history distributed on customer ID
Hosts
© 2013 IBM Corporation
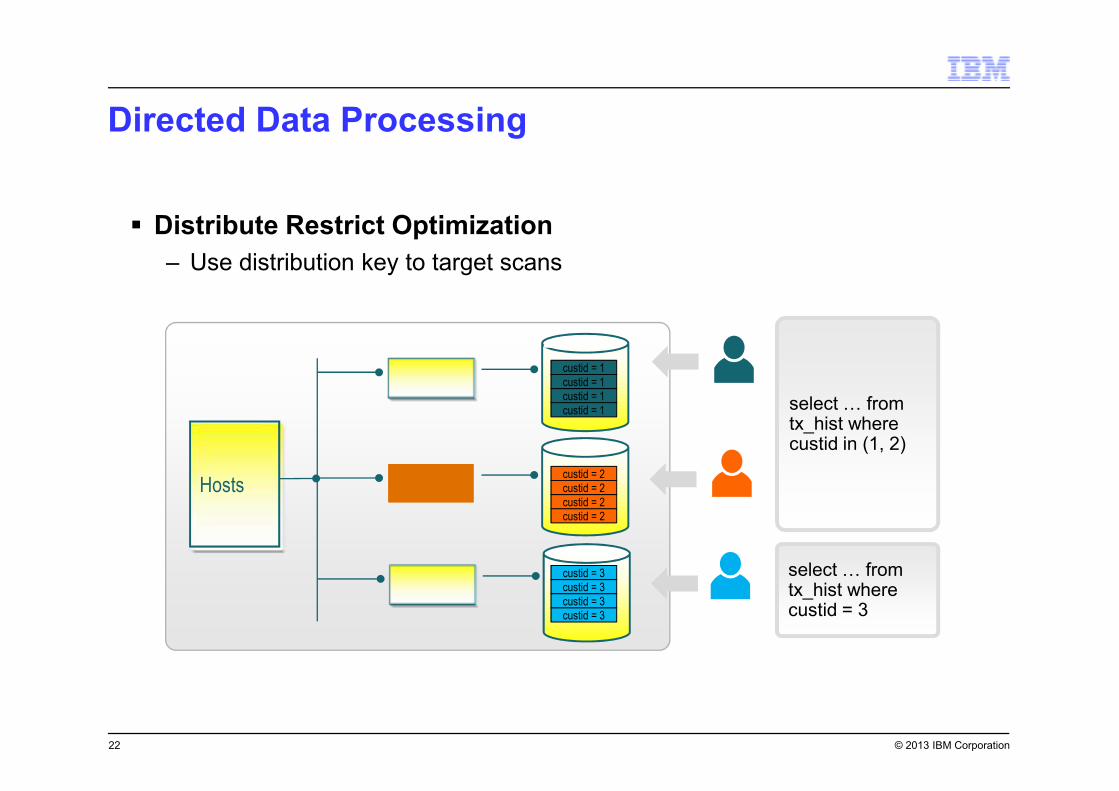
Directed Data Processing
22
� Distribute Restrict Optimization
– Use distribution key to target scans
Hosts
select ) from tx_hist where custid in (1, 2)
custid = 1
custid = 1
custid = 1
custid = 1
custid = 2
custid = 2
custid = 2
custid = 2
custid = 3
custid = 3
custid = 3
custid = 3
select ) from tx_hist where custid = 3
© 2013 IBM Corporation
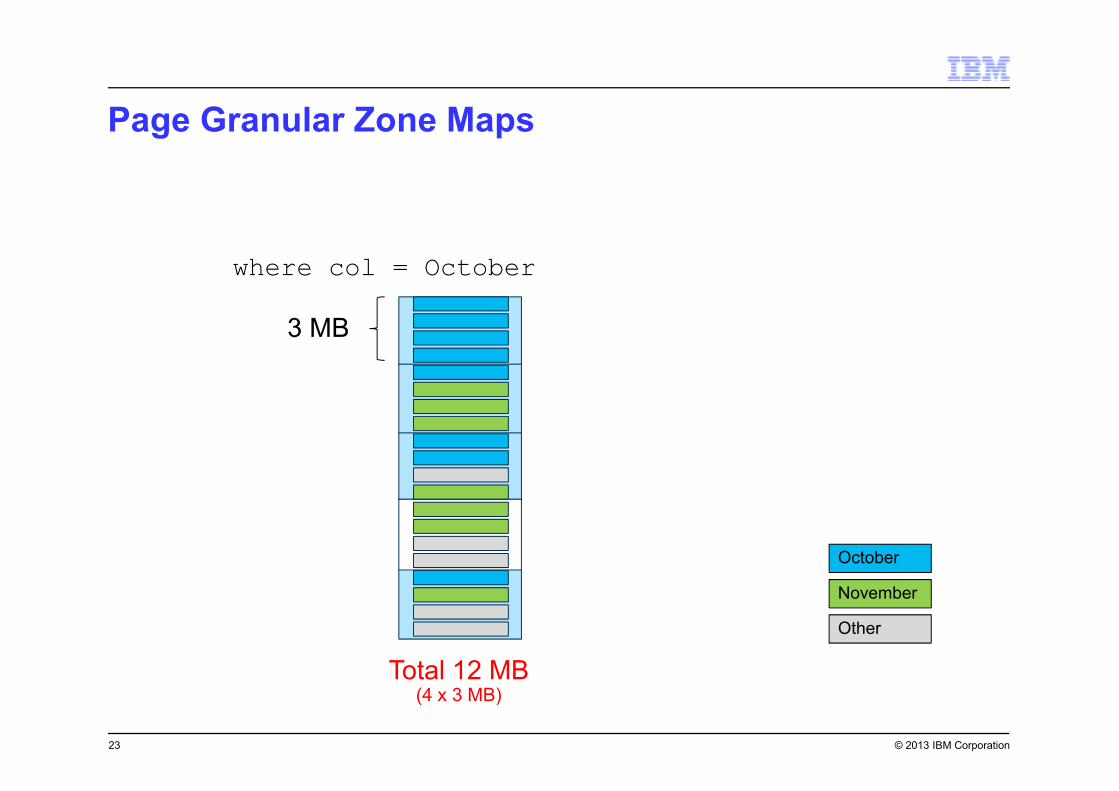
Page Granular Zone Maps
23
October
November
Other
3 MB
where col = October
Total 12 MB(4 x 3 MB)
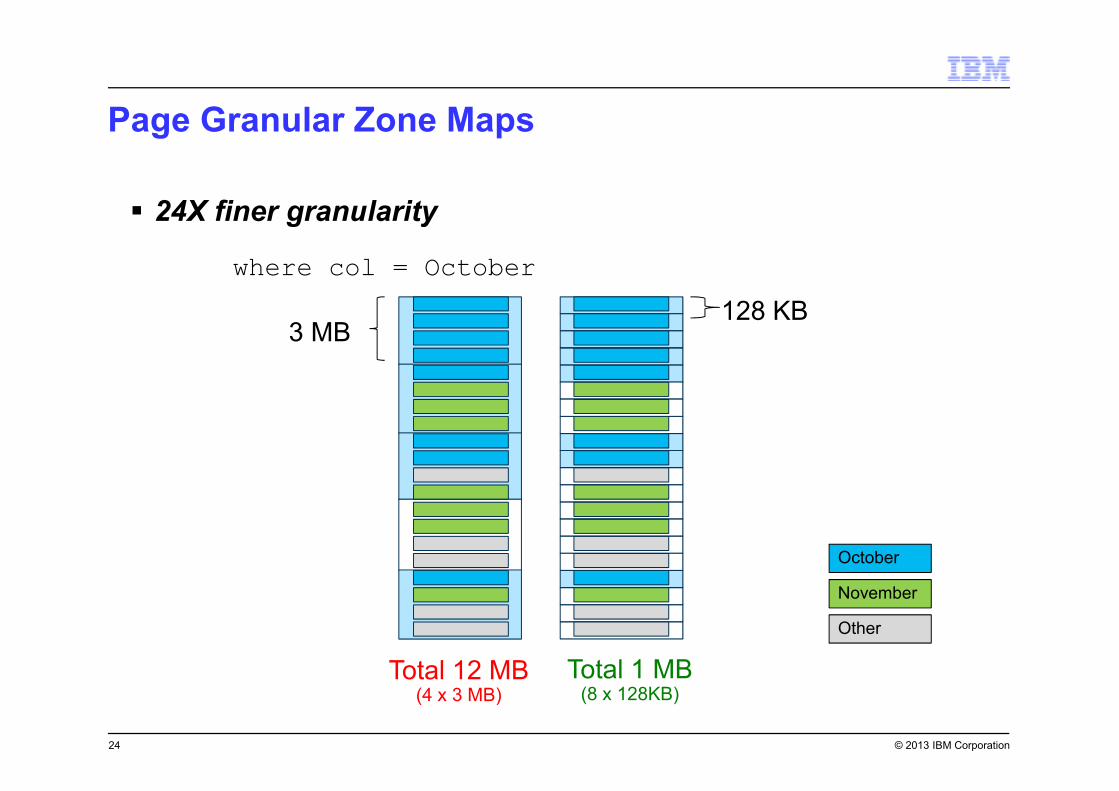
© 2013 IBM Corporation
Page Granular Zone Maps
24
� 24X finer granularity
October
November
Other
Total 12 MB(4 x 3 MB)
Total 1 MB(8 x 128KB)
3 MB128 KB
where col = October

© 2013 IBM Corporation
Snippet Result Cache
Observation
• BI/Web page generated reports create queries with limited variation
• Repeated tables, columns, restrictions
Keep intermediate results
• From simple table scans
• Using existing storage
Internal Benchmarking Results
• Up to 2.5X faster for tactical queries
25
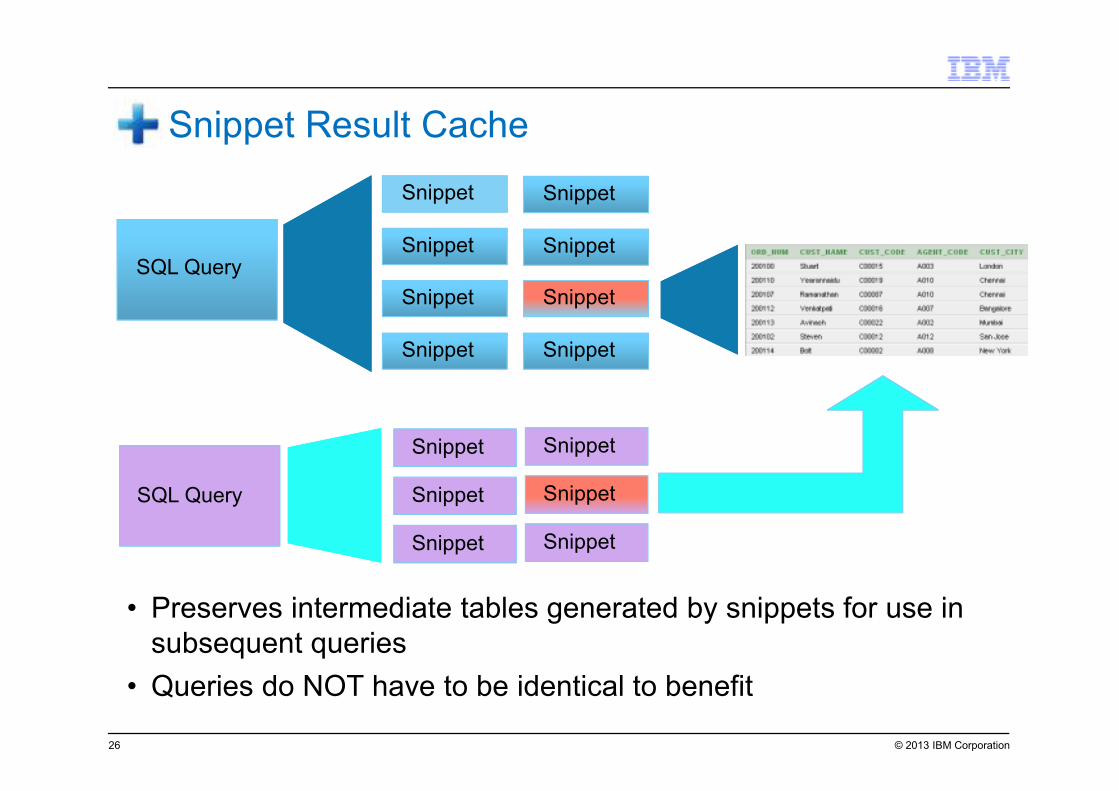
© 2013 IBM Corporation
Snippet Result Cache
SQL Query
• Preserves intermediate tables generated by snippets for use in
subsequent queries
• Queries do NOT have to be identical to benefit
Snippet
Snippet
Snippet
Snippet
Snippet
Snippet
Snippet
Snippet
SQL Query
Snippet
Snippet
Snippet
Snippet
Snippet
Snippet
26

© 2013 IBM Corporation
ODBC Bulk Fetch Enhancements
Delivers a more competitive select performance!
‒ Eliminates expensive conversion routines when the
client and database share the same data type
‒ Nearly 4X faster for select data types!
Sample improvements:
Data Type Today NPS 7.1 Times Faster % Gain
Char(ns) 175.704 45.009 3.90 74%
Int1 101.38 54.86 1.85 46%
Int8 76.421 24.198 3.16 68%
Boolean (bit) 195.27 133.3441 1.46 31%
Double 75.684 31.271 2.42 58%
27
© 2013 IBM Corporation
Benefits of the IBM PureData System for Analytics The Fastest Performance of Netezza Technology to Date!
30
1 Based on a comparison of the IBM PureData System for Analytics N2001 to the IBM PureData System for Analytics N1001. The performance speed refers to the query times on both macro-analytic and mixed
workload tests as conducted in IBM engineering lab benchmarks. The N2001 query times were an average of 3x faster than those of the N1001. Individual results may vary.
2 128 GB/sec scan rate assuming an average of 4x compression across the system. Individual results may vary.
3 Capacity of IBM PureData System for Analytics N2001 compared to previous generation IBM PureData System for Analytics N1001.
4-Each N2001 rack contains 34 hot spare drives and 240 active drives for a ratio of 1 spare per 7 drives. Each N1001 rack contains 4 hot spare drives and 92 active drives for a ratio of 1 spare per 23 drives. The N2001
has 3.3x more spares per active drive. Frequency of disk related service calls expected to decrease by 70% assuming the same drive failure rates.
Accelerate Performanceof Analytic Queries
Accelerate Performanceof Analytic Queries
Increased Efficiency
of your Data Center
Increased Efficiency
of your Data Center
Simplicity and
Ease of Administration
Simplicity and
Ease of Administration
� 3X faster performance1
for Big Data analytics
� 128 GB/sec effective scan rate per rack2
to tackle Big Data faster
� Improved system management and resilienceto spend less time managing and more time
delivering value
� 70% FEWER service calls with more spare drives and faster disk regeneration4
� 50% greater data capacity per rack3
helps optimize data center efficiency
� More capacity and less power per rackthan both Oracle and Teradata

© 2013 IBM Corporation
Benefits of the IBM PureData System for Analytics The Fastest Performance of Netezza Technology to Date!
32
1 Based on a comparison of the IBM PureData System for Analytics N2001 to the IBM PureData System for Analytics N1001. The performance speed refers to the query times on both macro-analytic and mixed
workload tests as conducted in IBM engineering lab benchmarks. The N2001 query times were an average of 3x faster than those of the N1001. Individual results may vary.
2 128 GB/sec scan rate assuming an average of 4x compression across the system. Individual results may vary.
3 Capacity of IBM PureData System for Analytics N2001 compared to previous generation IBM PureData System for Analytics N1001.
4-Each N2001 rack contains 34 hot spare drives and 240 active drives for a ratio of 1 spare per 7 drives. Each N1001 rack contains 4 hot spare drives and 92 active drives for a ratio of 1 spare per 23 drives. The N2001
has 3.3x more spares per active drive. Frequency of disk related service calls expected to decrease by 70% assuming the same drive failure rates.
Accelerate Performanceof Analytic Queries
Accelerate Performanceof Analytic Queries
Increase Efficiency
of your Data Center
Increase Efficiency
of your Data Center
Simplicity and
Ease of Administration
Simplicity and
Ease of Administration
� 3X faster performance1
for Big Data analytics
� 128 GB/sec effective scan rate per rack2
to tackle Big Data faster
� Improved system management and resilienceto spend less time managing and more time
delivering value
� 70% FEWER service calls with more spare drives and faster disk regeneration4
� 50% greater data capacity per rack3
helps optimize data center efficiency
� More capacity and less power per rackthan both Oracle and Teradata
© 2013 IBM Corporation
Spend Less Time Managing and More Time Innovating
33
� No dbspace/tablespace sizing and configuration
� No redo/physical/Logical log sizing and configuration
� No page/block sizing and configuration for tables
� No extent sizing and configuration for tables
� No Temp space allocation and monitoring
� No RAID level decisions for dbspaces
� No logical volume creations of files
� No integration of OS kernel recommendations
� No maintenance of OS recommended patch levels
� No JAD sessions to configure host/network/storage
Data Experts, not
Database Experts
� Easy Administration Portal
� No software installation
� No indexes and tuning
� No storage administration

© 2013 IBM Corporation
IBM Netezza Performance Portal 2.0Consolidating WebAdmin and Portal for Simple Admin
34
� Simple web user interface– Part of the PureData System for Analytics
� New functional and usability
enhancements– Administrative Functions
• Hardware view & alerts
• Database objects administration
• User & Group management
• View active sessions
• Workload Management
• View Events
• Table skew/storage search
• Capacity Planning
– Monitor enhancements
• Usability improvements – allow to resize
monitors and mark not-monitored periods
– Customer requested improvements
• Show locks
• Monitor System Resources
• Perform System Administration
• Understand & Predict Capacity

© 2013 IBM Corporation
Netezza Performance Portal 2.1
• Support for Scheduler rules
• Ability to restrict users from adding Hosts
• New panel for Resource Allocation Performance History
• Ability to view history of BAR operations
• Support for EXPLAIN command with Query History enabled
• Client field filters for Query History view
• History type AUDIT added to Query History
• IBM HTTP server replaces Apache server
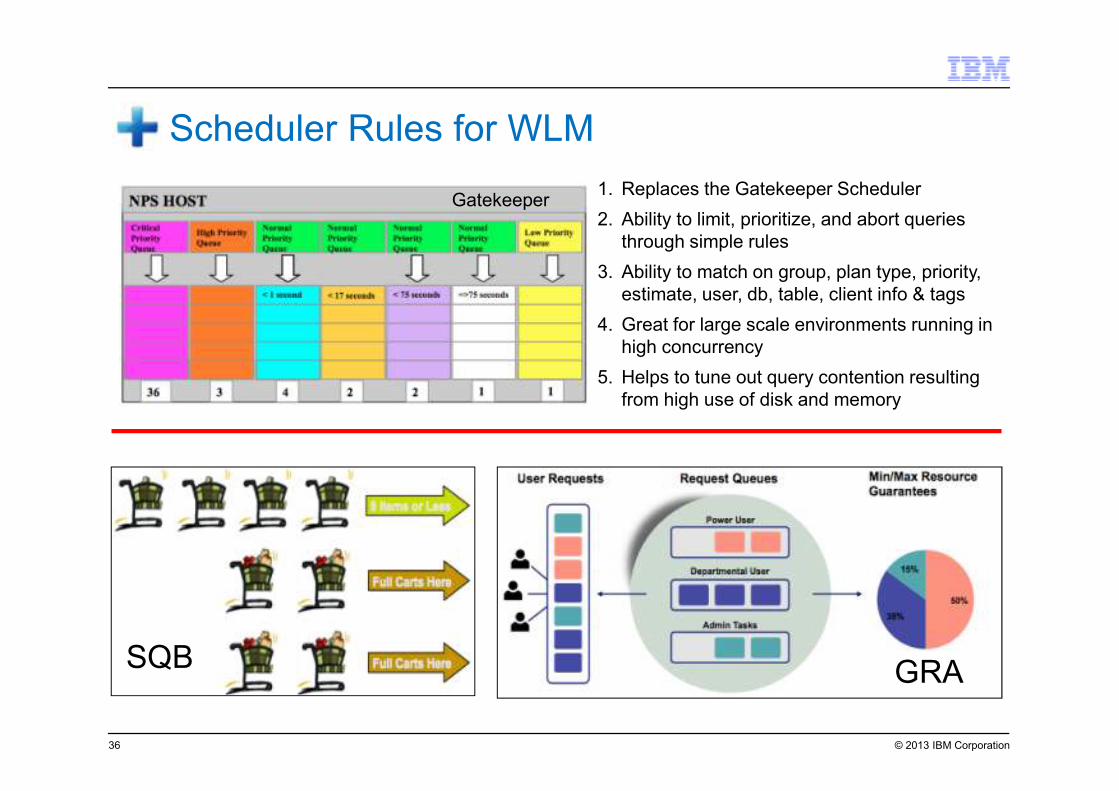
© 2013 IBM Corporation
Scheduler Rules for WLM
1. Replaces the Gatekeeper Scheduler
2. Ability to limit, prioritize, and abort queries
through simple rules
3. Ability to match on group, plan type, priority,
estimate, user, db, table, client info & tags
4. Great for large scale environments running in
high concurrency
5. Helps to tune out query contention resulting
from high use of disk and memory
Gatekeeper
GRASQB
36

© 2013 IBM Corporation
Scheduler Rule Examples
� Modifying scheduler rules:– IF USER IS sam THEN INCREASE PRIORITY
– IF TYPE IS LOAD THEN SET PRIORITY LOW
– IF TAG IS eom THEN EXECUTE AS RESOURCEGROUP group42
– IF ESTIMATE >= 5 ESTIMATE < 12 THEN INCREASE PRIORITY
– IF CLIENT_APPLICATION_NAME IS Cognos THEN ABORT
– IF CLIENT_ACCOUNTING_STRING IN (‘weekly_report’, ‘daily_report’)
THEN SET PRIORITY HIGH
� Limiting scheduler rules:– IF TAG IS cube THEN LIMIT 1
– IF TAG IS cube USER IS sam THEN LIMIT 2
– IF TYPE IS GENERATE STATISTICS THEN LIMIT 1
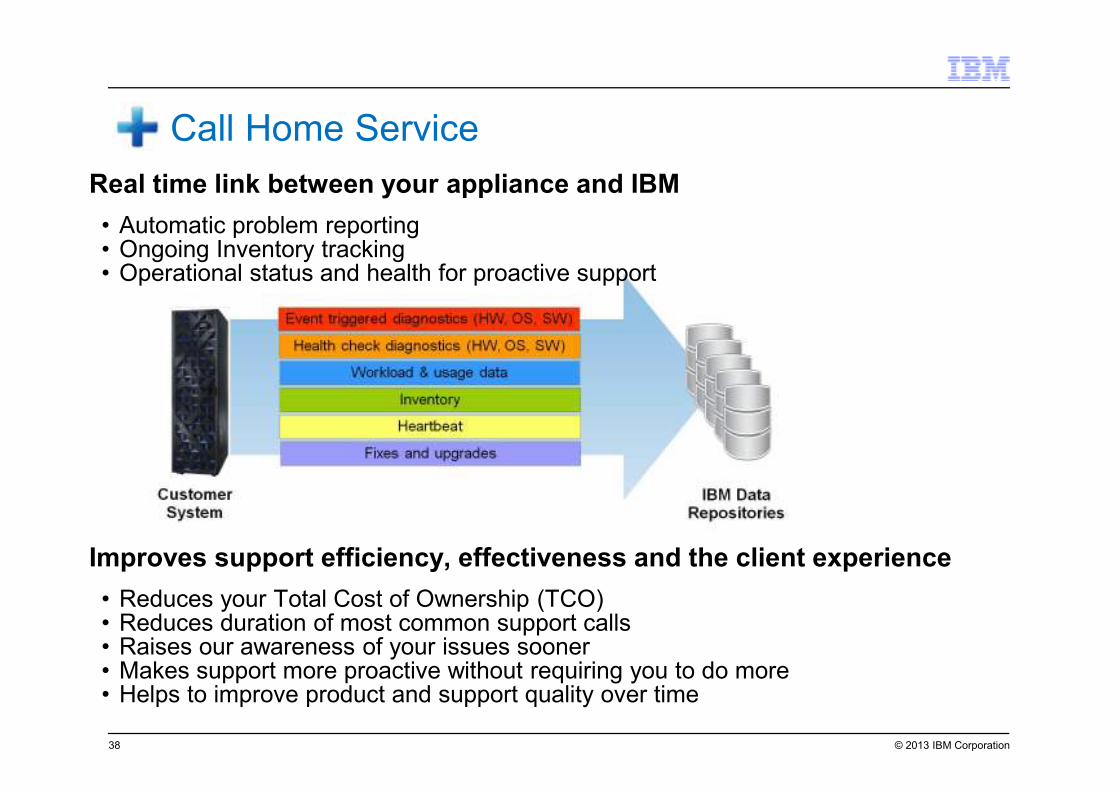
© 2013 IBM Corporation38
Real time link between your appliance and IBM
• Automatic problem reporting• Ongoing Inventory tracking• Operational status and health for proactive support
Improves support efficiency, effectiveness and the client experience
• Reduces your Total Cost of Ownership (TCO)• Reduces duration of most common support calls• Raises our awareness of your issues sooner• Makes support more proactive without requiring you to do more• Helps to improve product and support quality over time
Call Home Service

© 2013 IBM Corporation39
How it Works• Targeted NZEVENTs automatically run nzOpenPmr, collect data and email
IBM
• New email identifies you, appliance (identity, location and status) and fault data
• Attached diagnostics include:
+ sysmgr and eventmgr logs
+ SMART logs for disks
+ cluster logs for Host issues
+ crash stacks for core dumps (avg. size: 15 Kbytes)
• Automation opens PMR, posts diagnostic data and replies w/ PMR
Configuration and Enablement• Requires recent NPS fixpack and functional SMTP routing
• Additional configuration in callHome.txt+ IBM Customer (ICN)
+ Machine Type, Model and S/N
• Identity your Support contact and email alias
• nzOpenPmr configuration creates new event table entry
SAMPLE callHome.txt
# /nz/data/config/callHome.txt
# Installation-specific attributes.
customer.company = Your Business
customer.address1 = Appliance Install Address
customer.address2 = Installed City, State, Zip
customer.ICN = 1234567
contact1.name = Joe SysAdmin
contact1.phone = 1.617.555.1212
contact1.email = [email protected]
contact1.cell = 1-508-555-9876
contact1.events = ALL
contact2.name = D.B. Admin
contact2.phone = +1.508.555.1212
contact2.email = [email protected]
contact2.cell = +1.508.555.2121
system.description = Test System
system.location = Rm 122 Aisle F Slot 2
system.model = N2001-005
system.MTM = 3565 / DD0
system.serial = NZ3xxxx
system.CC = 2 char Country Code (ISO)
Call Home Service – How it Works
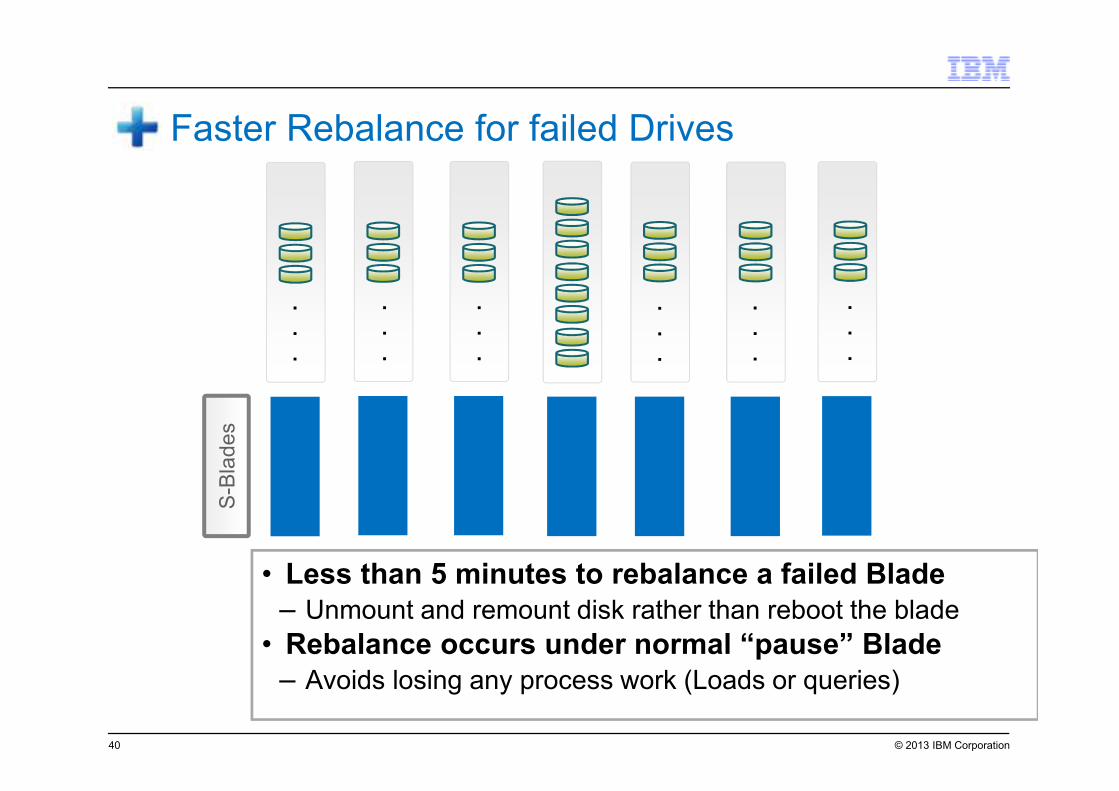
© 2013 IBM Corporation40
• Less than 5 minutes to rebalance a failed Blade
– Unmount and remount disk rather than reboot the blade
• Rebalance occurs under normal “pause” Blade
– Avoids losing any process work (Loads or queries)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
S-B
lad
es
.
.
.
Faster Rebalance for failed Drives

© 2013 IBM Corporation
Summary of competitive advantages
41
� Transparent I/O performance optimization– Use of FPGA (streaming approach) guarantees the highest and stable scan rate,
without any need of expensive performance improvement features like:• automatic dynamic storage differentiated by data access behaviour («virtual storage»)
• «in-memory» solution or
• «columnar» storage
� Specific RDMS– Optimized software by removing all unnecessary and expensive typical OLTP
RDBMS features like:• Log/journaling management
• Lock management
• Referential integrity feature management
� AMPP Architecture– Combine the benefits of both technologies: SMP simplicity and MPP performance
– Symmetric «Shared Nothing» Architecture has limitations:• Frequent «bottlenecks» due to the mix of heterogenuous processes on the same physical
resources
• Risk of unbalanced use of clustered resources due to bad access configuration

© 2013 IBM Corporation
Summary of competitive advantages
� Workload Management– World-class workload manager functionalities
– Maximize resource usage without complex workload management settings
� Availability and Resiliency– No need of «fallback-like» / table mirroring functionalities
• Disk availability is guaranteed by Raid1
• Zero-downtime in case of node failure is guaranteed by built-in spare S-blades
– Efficient Incremental backup avoiding complex techniques like partitioning archive
� Simplicity– Zero-tuning
• «Zone-map»: automatic anti-index approach to avoid scanning of unnecessary data for
users query
• Automatic update of data demographic statistics
• Automatic partitioning
• Ad-hoc query enabling technology
– Near-zero administration
– Data model agnostic
42

© 2013 IBM Corporation
Inside the Q
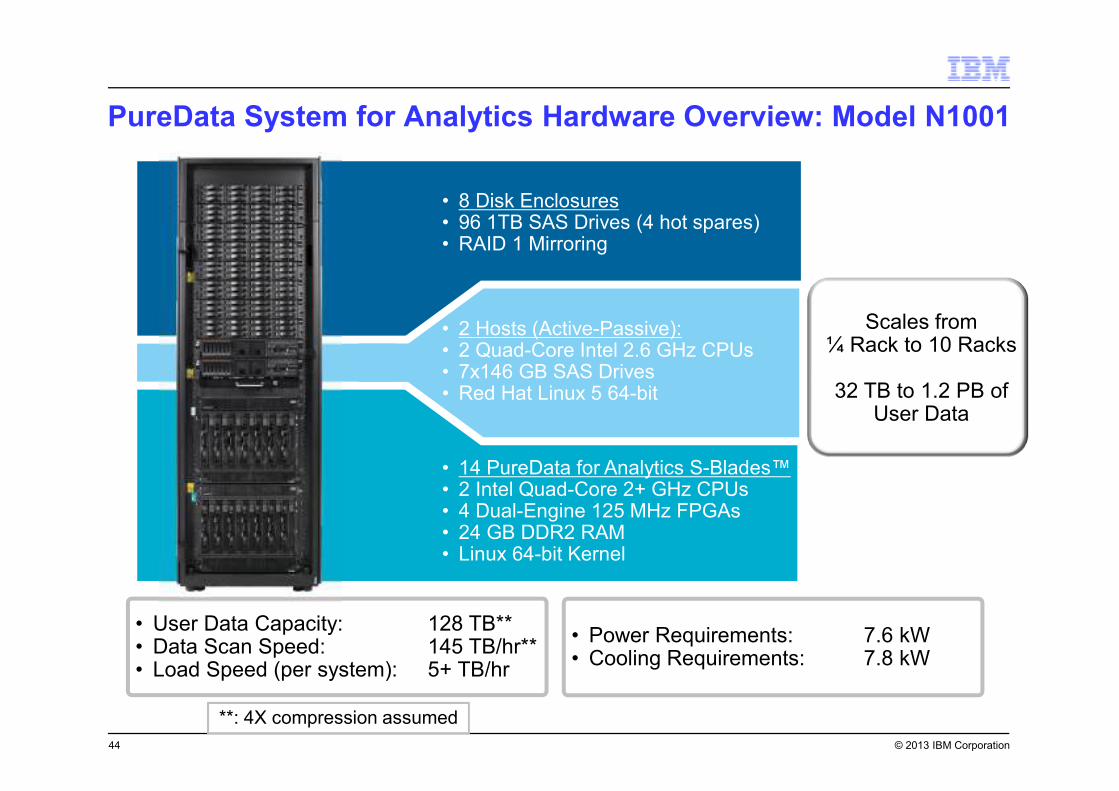
© 2013 IBM Corporation
• 8 Disk Enclosures• 96 1TB SAS Drives (4 hot spares)• RAID 1 Mirroring
• 14 PureData for Analytics S-Blades™• 2 Intel Quad-Core 2+ GHz CPUs• 4 Dual-Engine 125 MHz FPGAs• 24 GB DDR2 RAM• Linux 64-bit Kernel
• 2 Hosts (Active-Passive):• 2 Quad-Core Intel 2.6 GHz CPUs• 7x146 GB SAS Drives• Red Hat Linux 5 64-bit
• User Data Capacity: 128 TB**• Data Scan Speed: 145 TB/hr**• Load Speed (per system): 5+ TB/hr
• Power Requirements: 7.6 kW• Cooling Requirements: 7.8 kW
**: 4X compression assumed
Scales from ¼ Rack to 10 Racks
32 TB to 1.2 PB of User Data
PureData System for Analytics Hardware Overview: Model N1001
44
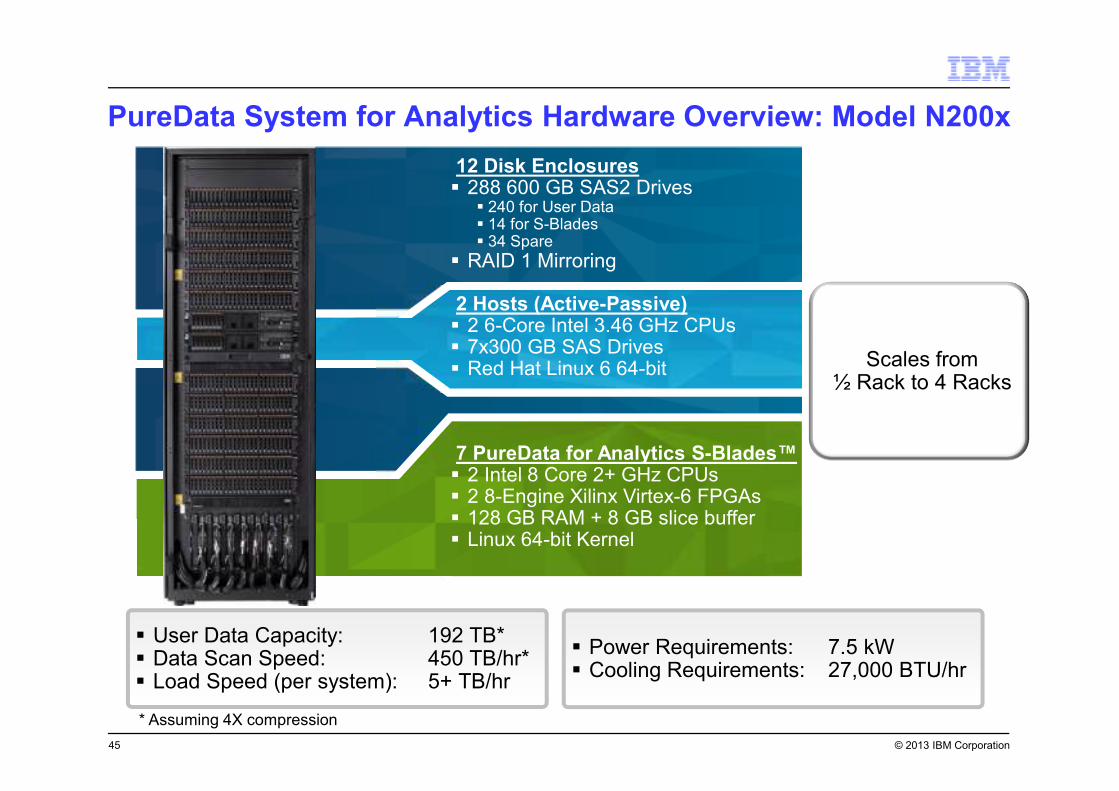
© 2013 IBM Corporation
PureData System for Analytics Hardware Overview: Model N200x
� User Data Capacity: 192 TB*� Data Scan Speed: 450 TB/hr*� Load Speed (per system): 5+ TB/hr
� Power Requirements: 7.5 kW� Cooling Requirements: 27,000 BTU/hr
* Assuming 4X compression
2 Hosts (Active-Passive)� 2 6-Core Intel 3.46 GHz CPUs� 7x300 GB SAS Drives� Red Hat Linux 6 64-bit
7 PureData for Analytics S-Blades™� 2 Intel 8 Core 2+ GHz CPUs� 2 8-Engine Xilinx Virtex-6 FPGAs� 128 GB RAM + 8 GB slice buffer� Linux 64-bit Kernel
12 Disk Enclosures� 288 600 GB SAS2 Drives
� 240 for User Data� 14 for S-Blades� 34 Spare
� RAID 1 Mirroring
Scales from ½ Rack to 4 Racks
45
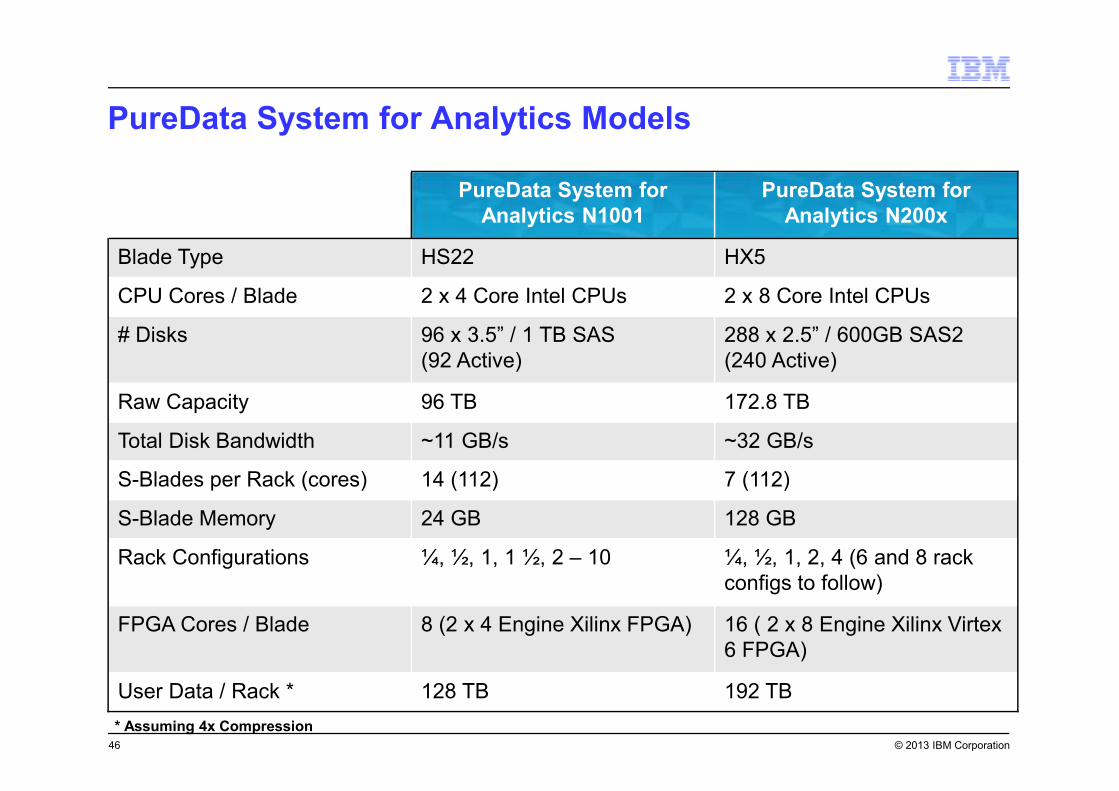
© 2013 IBM Corporation
PureData System for Analytics Models
46
PureData System for
Analytics N1001
PureData System for
Analytics N200x
Blade Type HS22 HX5
CPU Cores / Blade 2 x 4 Core Intel CPUs 2 x 8 Core Intel CPUs
# Disks 96 x 3.5” / 1 TB SAS
(92 Active)
288 x 2.5” / 600GB SAS2
(240 Active)
Raw Capacity 96 TB 172.8 TB
Total Disk Bandwidth ~11 GB/s ~32 GB/s
S-Blades per Rack (cores) 14 (112) 7 (112)
S-Blade Memory 24 GB 128 GB
Rack Configurations ¼, ½, 1, 1 ½, 2 – 10 ¼, ½, 1, 2, 4 (6 and 8 rack
configs to follow)
FPGA Cores / Blade 8 (2 x 4 Engine Xilinx FPGA) 16 ( 2 x 8 Engine Xilinx Virtex
6 FPGA)
User Data / Rack * 128 TB 192 TB
* Assuming 4x Compression

© 2013 IBM Corporation
New Offerings for the Entry-Level Market
47
� PureData System for Analytics ‘Lite’ (Q4’13)
– Entry-Level Striper Configuration (N2002-002)
– 32 TB usable capacity
– 50% better performance than a TwinFin-3 (N1001-
002)
– Improved resiliency over TwinFin-3 with more spare
drives
� IBM Netezza Platform Development Software
– Virtualized Image supporting VMWare vSphere 5.1
– Documented reference architecture and best
practices
– Install Licensing
– 16+ TB usable capacity (compressed)
– Development and Test Only
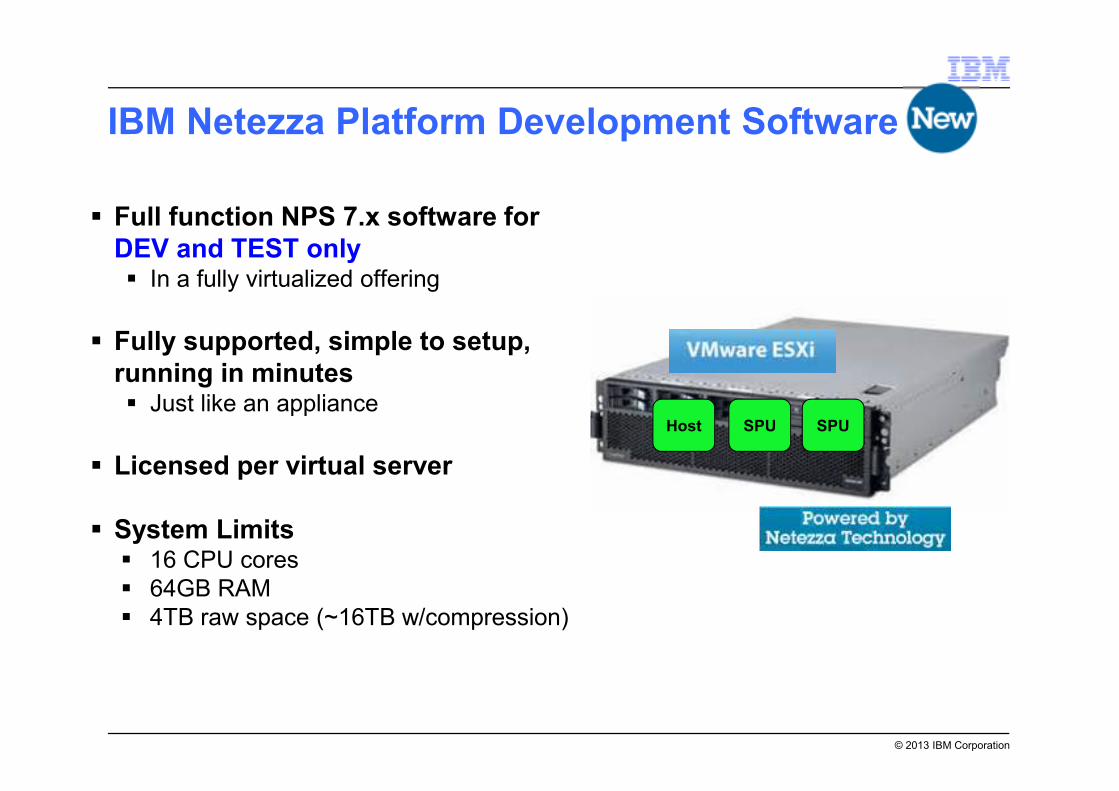
© 2013 IBM Corporation
IBM Netezza Platform Development Software
� Full function NPS 7.x software for
DEV and TEST only� In a fully virtualized offering
� Fully supported, simple to setup,
running in minutes� Just like an appliance
� Licensed per virtual server
� System Limits� 16 CPU cores
� 64GB RAM
� 4TB raw space (~16TB w/compression)
Host SPU SPU

© 2013 IBM Corporation
IBM Announces Growth on Demand for PureData System for Analytics
Program BasicsProgram Basics
Instant UpgradeInstant Upgrade
Simple DeploymentSimple Deployment
� New Offering called “Growth on Demand”
� Purchase a larger system, license 50% of the capacity and performance
� Grow in easy steps
� Additional capacity enabled by licensing and software configuration
� Capacity can be added, but not reduced with this program
� Provision one system
� Expand through licensing
� Zero impact on data center operations
49
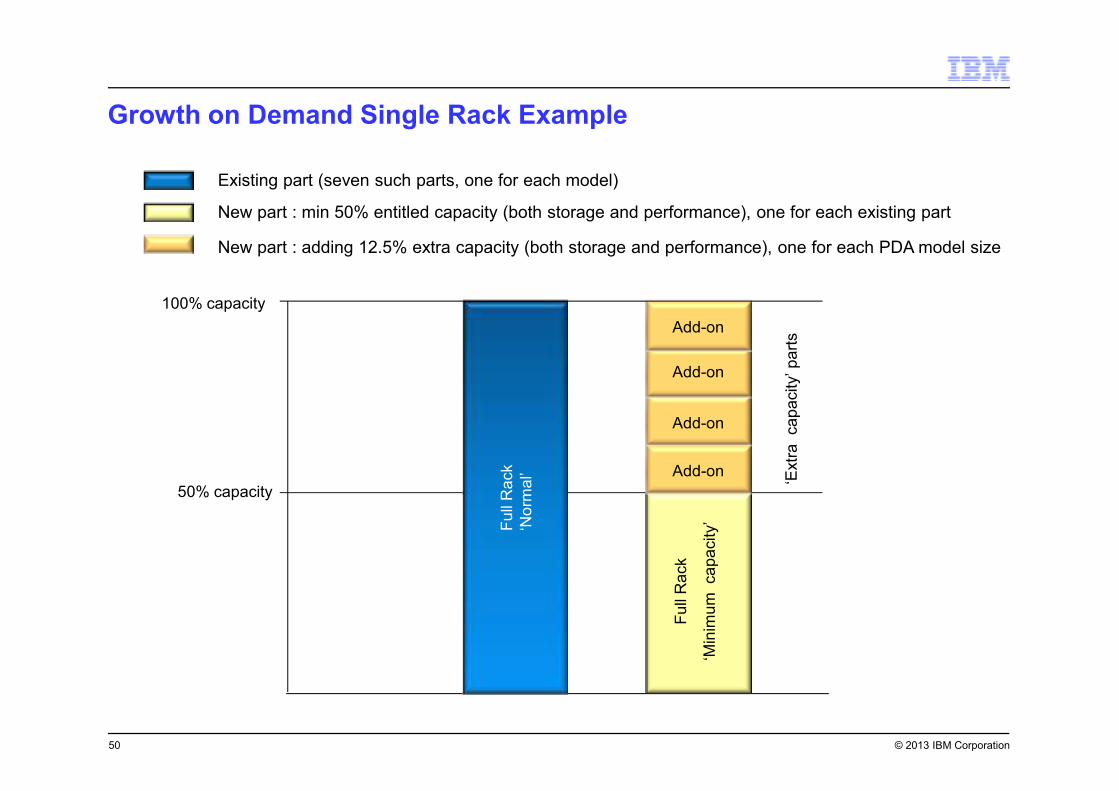
© 2013 IBM Corporation
Growth on Demand Single Rack Example
Existing part (seven such parts, one for each model)
New part : min 50% entitled capacity (both storage and performance), one for each existing part
New part : adding 12.5% extra capacity (both storage and performance), one for each PDA model size
50% capacity
100% capacity
Fu
ll R
ack
‘No
rma
l’
Fu
ll R
ack
‘Min
imu
m ca
pa
city’
Add-on
Add-on
Add-on
Add-on
‘Extr
a
ca
pa
city’p
art
s
50

© 2013 IBM Corporation
IBM DB2 Analytics AcceleratorNow even faster with N200x
� The PureData System for
Analytics N200x is also the
next generation DB2 Analytics
Accelerator
� Providing the same
improvements to our DB2 for
zOS customers

© 2013 IBM Corporation
Big Data Meets Deep Analytics
52
Analytics without constraint
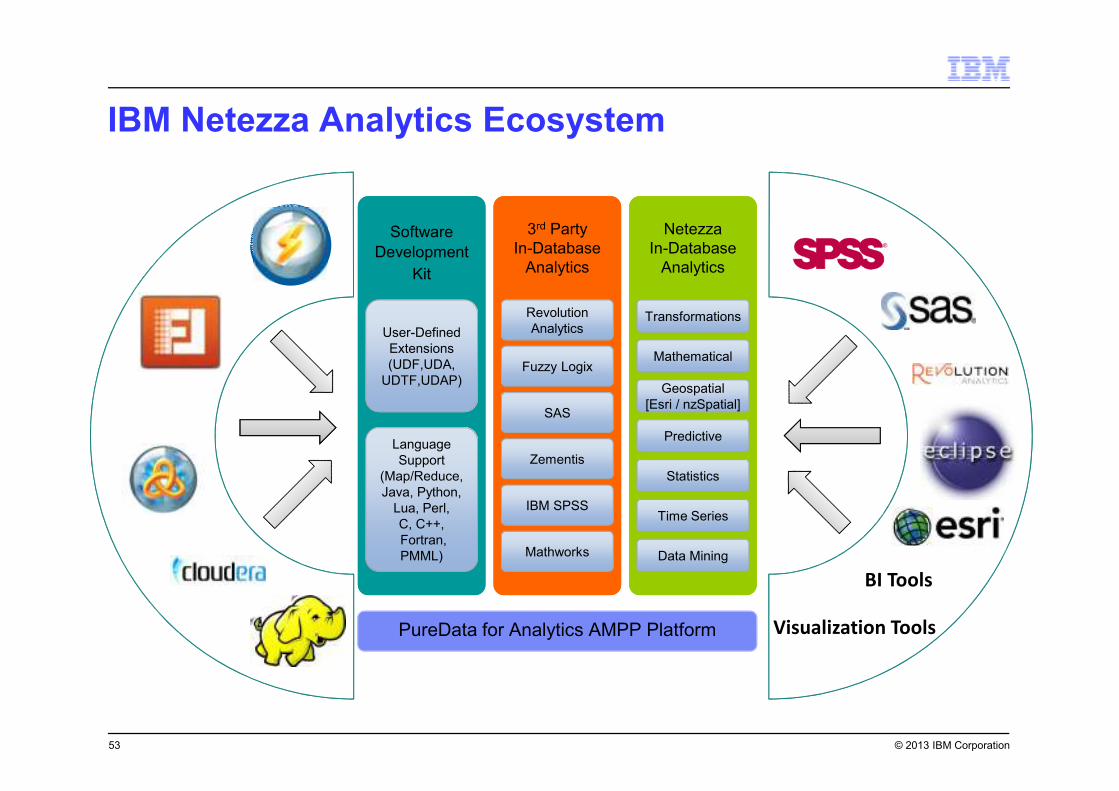
© 2013 IBM Corporation
IBM Netezza Analytics Ecosystem
PureData for Analytics AMPP Platform
Software
Development
Kit
Software
Development
Kit
3rd Party
In-Database
Analytics
3rd Party
In-Database
Analytics
Netezza
In-Database
Analytics
Netezza
In-Database
Analytics
User-Defined
Extensions
(UDF,UDA,
UDTF,UDAP)
Transformations
Mathematical
Geospatial
[Esri / nzSpatial]
Predictive
Statistics
Time Series
Data Mining
Fuzzy Logix
SAS
Zementis
IBM SPSS
Language
Support
(Map/Reduce,
Java, Python,
Lua, Perl,
C, C++,
Fortran,
PMML) Mathworks
Revolution
Analytics
BI Tools
Visualization Tools
53

© 2013 IBM Corporation
Integrated by DesignIBM Netezza Analytics Version 2.0
54
Netezza In-Database Analytics 2.0
� Transformations
� Mathematical
� Geospatial
� Predictive
� Statistics
� Time Series
� Data Mining
� No data movement
� Analyze deep and wide data
� High performance, parallel computation
© 2013 IBM Corporation55
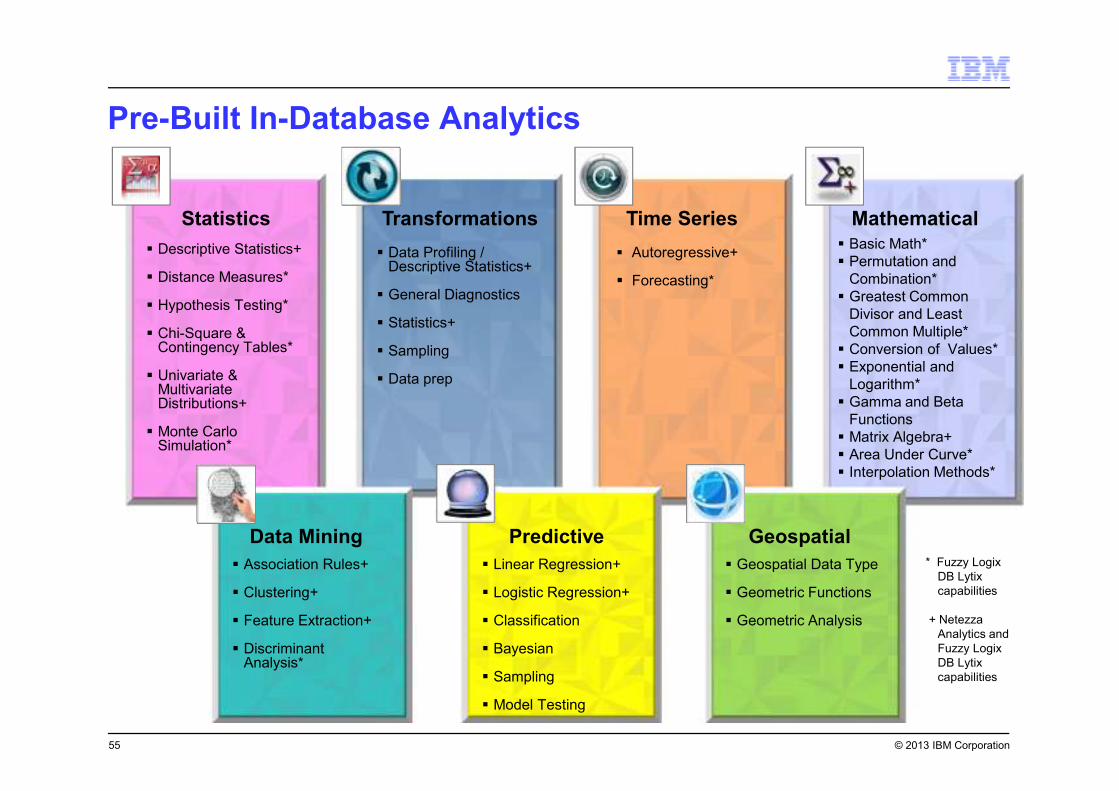
� Basic Math*
� Permutation and
Combination*
� Greatest Common
Divisor and Least
Common Multiple*
� Conversion of Values*
� Exponential and
Logarithm*
� Gamma and Beta
Functions
� Matrix Algebra+
� Area Under Curve*
� Interpolation Methods*
Transformations MathematicalTime Series
� Linear Regression+
� Logistic Regression+
� Classification
� Bayesian
� Sampling
� Model Testing
� Geospatial Data Type
� Geometric Functions
� Geometric Analysis
Predictive Geospatial* Fuzzy Logix
DB Lytix
capabilities
+ Netezza
Analytics and
Fuzzy Logix
DB Lytix
capabilities
� Data Profiling / Descriptive Statistics+
� General Diagnostics
� Statistics+
� Sampling
� Data prep
Pre-Built In-Database Analytics
� Descriptive Statistics+
� Distance Measures*
� Hypothesis Testing*
� Chi-Square & Contingency Tables*
� Univariate & Multivariate Distributions+
� Monte Carlo Simulation*
� Autoregressive+
� Forecasting*
� Association Rules+
� Clustering+
� Feature Extraction+
� Discriminant Analysis*
Data Mining
Statistics

© 2013 IBM Corporation56
What’’’’s New in N200x: Summary
� 50% Greater Storage Capacity per rack
� 3x scan rate vs N1001 series
� Improved Resiliency and Fault Tolerance– More spare drives per cabinet
– Faster drive regeneration
– Online Firmware upgrades
� NPS 7.0– Distribute Restrict Optimization
– Page Granular Zone Maps

© 2013 IBM Corporation
Catch the
Striper “Wave”Why Upgrade to the
IBM PureData System for Analytics N2000 Series Appliance

© 2013 IBM Corporation
Why Upgrade Your TwinFin System?
PureData System for Analytics N2002 provides:
� The latest hardware– 3x faster scan rates1 – 128 GB/sec effective scan rate per rack2
– 6x more memory per Blade server
– Leverage future software enhancements longer
� Increased data center efficiency with 50% greater data
capacity per rack3
� Improved system management & resiliency
� 70% fewer service calls with more spare drives and faster
disk regeneration4
Catch the Striper Wave before TwinFin comes to end of life
1 Based on a comparison of the IBM PureData System for Analytics N200x to the IBM PureData System for Analytics N1001. The performance speed refers to the query times on both macro-
analytic and mixed workload tests as conducted in IBM engineering lab benchmarks. The N200x query times were an average of 3x faster than those of the N1001. Individual results may
vary.
2128 GB/sec scan rate assuming an average of 4x compression across the system. Individual results may vary.
3 Capacity of IBM PureData System for Analytics N200x compared to previous generation IBM PureData System for Analytics N1001.
4 Each N200x rack contains 34 hot spare drives and 240 active drives for a ratio of 1 spare per 7 drives. Each N1001 rack contains 4 hot spare drives and 92 active drives for a ratio of 1
spare per 23 drives. The N200x has 3.3x more spares per active drive. Frequency of disk related service calls expected to decrease by 70% assuming the same drive failure rates.
© 2013 IBM Corporation
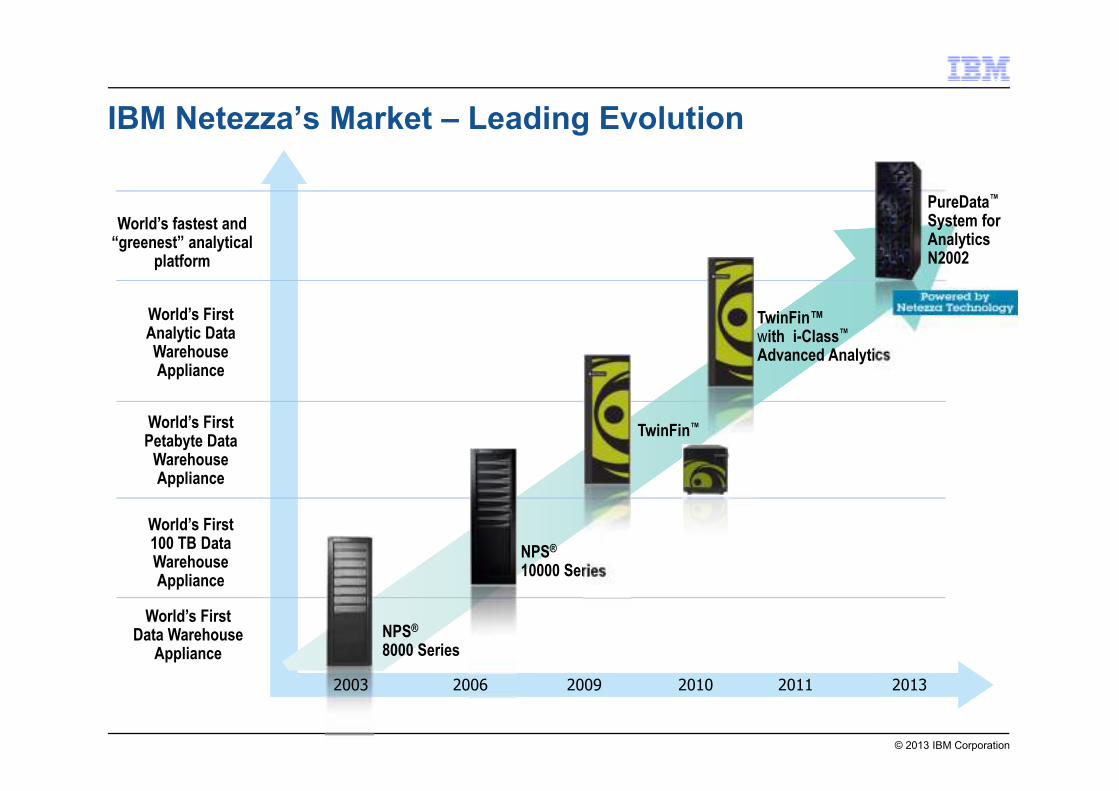
IBM Netezza’s Market – Leading Evolution
World’s FirstData WarehouseAppliance
World’s First100 TB DataWarehouse Appliance
World’s FirstPetabyte DataWarehouse Appliance
World’s FirstAnalytic Data Warehouse Appliance
NPS®
8000 Series
TwinFin™ with i-Class™
Advanced Analytics
NPS®
10000 Series
TwinFin™
World’s fastest and “greenest” analytical
platform
2003 2006 2009 2010 2011 2013
PureData™
System for AnalyticsN2002
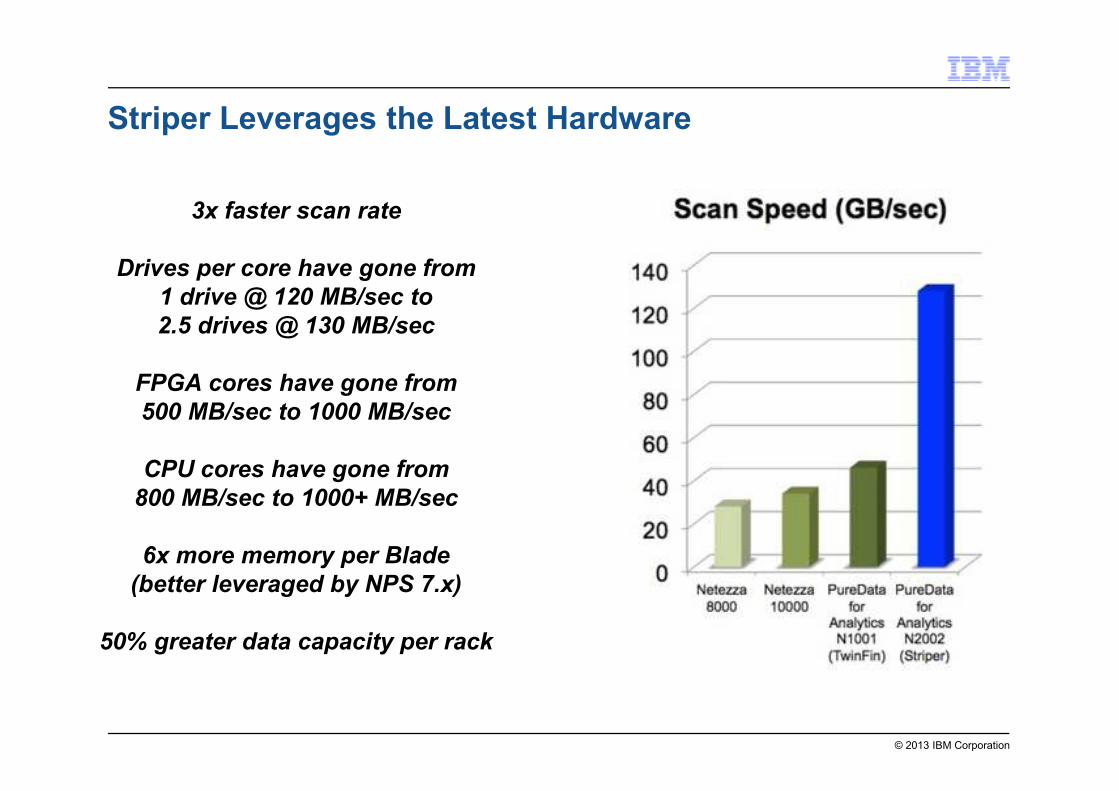
© 2013 IBM Corporation
Striper Leverages the Latest Hardware
3x faster scan rate
Drives per core have gone from
1 drive @ 120 MB/sec to
2.5 drives @ 130 MB/sec
FPGA cores have gone from
500 MB/sec to 1000 MB/sec
CPU cores have gone from
800 MB/sec to 1000+ MB/sec
6x more memory per Blade
(better leveraged by NPS 7.x)
50% greater data capacity per rack

© 2013 IBM Corporation
Striper vs. TwinFinHardware Comparison
PureData System for
Analytics N1001 (TwinFin)
PureData System for Analytics
N2002 (Striper)
Blade Type HS22 HX5
CPU Cores / Blade 2 x 4 Core Intel CPUs 2 x 8 Core Intel CPUs
# Disks 96 x 3.5” / 1 TB SAS
(92 Active)
288 x 2.5” / 600GB SAS2
(240 Active)
Raw Capacity 96 TB 172.8 TB
Total Disk Bandwidth ~11 GB/s ~32 GB/s
S-Blades per Rack (cores) 14 (112) 7 (112)
S-Blade Memory 24 GB 128 GB
Rack Configurations ¼, ½, 1, 1 ½, 2 – 10 entry level, ½, 1, 2, 4
FPGA Cores / Blade 8 (2 x 4 Engine Xilinx FPGA) 16 ( 2 x 8 Engine Xilinx Virtex-6 FPGA)
User Data / Rack * 128 TB 192 TB
* Assuming 4x Compression

© 2013 IBM Corporation
PureData System for Analytics N2002 HW Overview
� User Data Capacity: 192 TB2
� Data Scan Speed: 478 TB/hr*� Load Speed (per system): 5+ TB/hr
� Power Requirements: 7.5 kW� Cooling Requirements: 27,000 BTU/hr
1 Clients interested in a smaller entry point should refer to the N2002-002 model2 Assuming 4X compression
Scales from ½ Rack to 4
Racks 1
2 Hosts (Active-Passive)� 2 Intel 2.7 GHz Sandy Bridge CPUs� 7x300 GB SAS Drives� Red Hat Linux 6 64-bit
7 PureData for Analytics S-Blades™� 2 Intel 8 Core 2+ GHz CPUs� 2 8-Engine Xilinx Virtex-6 FPGAs� 128 GB RAM + 8 GB slice buffer� Linux 64-bit Kernel
12 Disk Enclosures� 288 600 GB SAS2 Drives
• 240 for User Data• 14 for S-Blades• 34 Spare
� RAID 1 Mirroring

© 2013 IBM Corporation
Striper Wave Offer
� Best discounting on the purchase of Striper ever!– Must return TwinFin machine(s)
� Leave the migration to us!* (estimated migration 1-2 weeks based on data and network)
– Review Migration Planning Questionnaire– Develop Migration Plan– Support development of test strategy– Prepare Environment & Install tools for Data & Code Migration– Migrate Data & Code to new appliance*– Removal and secure disposal of TwinFin machine(s)
� Most favorable financing available – Pick your Plan**– Defer Payments for 90 days or more; or– 0% financing with No Upfront Cost; or– Lowest FMV Leasing Rates Available.
* Beyond 100 hours of service, IBM can provide additional fee-based migration services via IBM’’’’s Lab Service Team for test execution support, complex environment considerations, handling for large data volumes, etc.
** With approved credit

© 2013 IBM Corporation
Appliance Migration Service
Benefits� Reduce migration risks with proven
guidance and expertise
� Leverage best practices & tools to
accelerate migration activities
� Accelerate your ROI of new appliance
Deliverables� Migration Plan
� Migrated data/code in new Appliance*
Features� Up to 100 hours of Migration Services from
IBM for one environment (20 Client Technical Professionals/80 Lab Services)
– Project Management– Review Migration Planning
Questionnaire– Develop Migration Plan– Support development of Test Strategy– Prepare Environment & Install tools for
Data & Code Migration– Migrate Data & Code to new appliance*
� Beyond 100 hours of service, IBM can provide additional fee-based migration services via IBM’s Lab Service Team for test execution support, complex environment considerations, handling for large data volumes, etc.
Quickly migrate your old Netezza Appliance to the latest PureData System for Analytics Appliance!
* IBM will provide ETL/ Netezza connectivity, however 100 hours does not include manipulation of ETL code or enablement of newer ETL features
*100 hours does not include test execution
* Large data volumes/low capacity network may require additional fee-based Services time to complete migration
* Estimated migration 1-2 weeks based on data and network, per environment

© 2013 IBM Corporation
TwinFin to Striper Summary
� Better Longevity
– TwinFin has been in the field since 2009
– IBM PureData System for Analytics N2000 series appliances
have been out since February 1, 2013 – now is the time to
make the switch
– The new system is fully supported and allows you to take full
advantage of many new enhancements
� Faster scan rates
� Better resiliency
� Greater density for data center efficiency
� Appealing Financials
– Most favorable discount on Striper possible
– Financing options from IGF
– Bundled migration services

© 2013 IBM Corporation
IBM Netezza Replication Services v1.5
Asynchronous, Homogeneous Replication for
PureData System for Analytics (formerly Netezza)
Simplifying Data Replication for Disaster Recovery and Scale

© 2013 IBM Corporation
What’s This Replication Thing?
� IBM Netezza Replication Services keeps a collection of databases
identical across multiple Netezza appliances. Our solution focuses
on replication for Disaster Recovery.
Disaster recovery: a replication use case in which failure of hardware
or software in its operational environment causes no permanent
loss of data or functionality.
Data
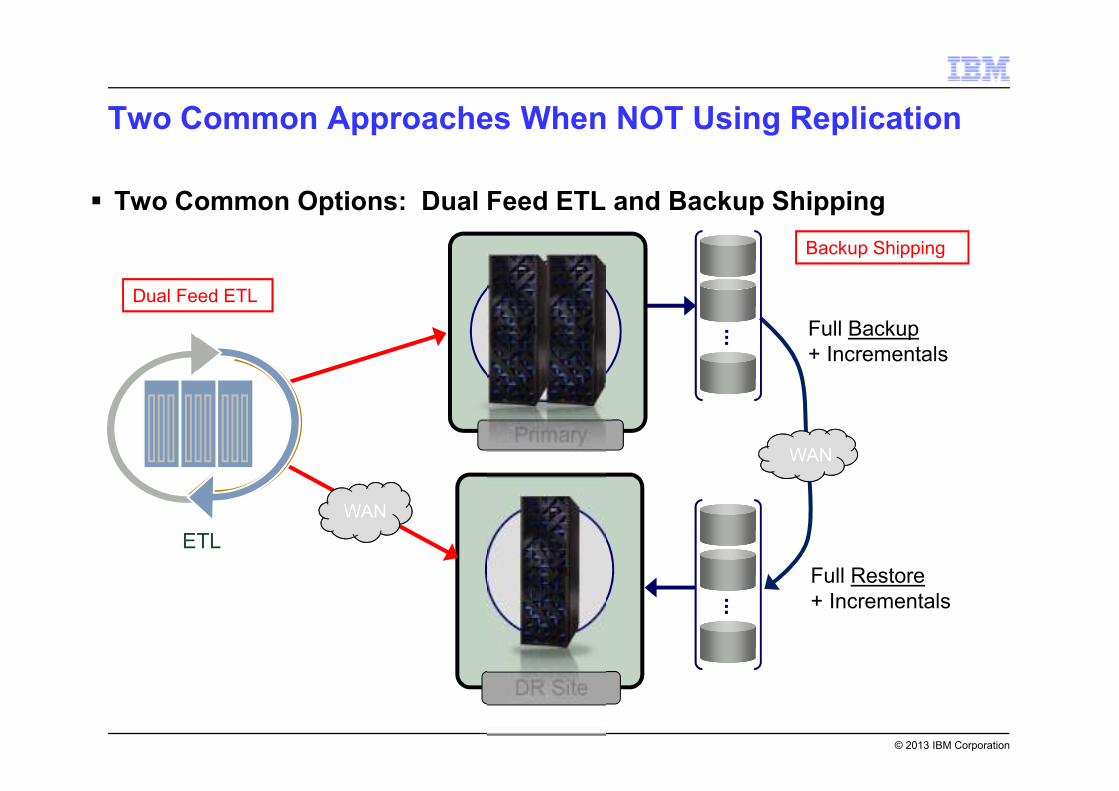
© 2013 IBM Corporation
Two Common Approaches When NOT Using Replication
� Two Common Options: Dual Feed ETL and Backup Shipping
Primary
DR Site
ETL
WAN
WAN
Full Backup
+ Incrementals
Full Restore
+ Incrementals
Dual Feed ETL
Backup Shipping

© 2013 IBM Corporation
Two Common Approaches When NOT Using Replication
Dual ETL Feed Backup and Restore
Benefits
Drawbacks
Benefits
Drawbacks
� Data can arrive at both systems at
roughly the same time.
� Easier to “flip” DR site to be primary
site in the event of a failure.
� Some processes (such as
sequences) may result in different
values.
� In the event of an ETL error, bad data
can be propagated to the DR site.
� Additional overhead for customer
� Only changed data is moved across
the network.
� Backups can later be stored as part
of backup strategy.
� Offers more control over timing of DR
loads, not tied to ETL process.
� Occasional full backups recommended to
ensure consistency, especially if backup
files are later used for backup storage.
� Can result in very large data transfers,
especially during initial full backups.
� Incremental backups do have some
impact on system performance.

© 2013 IBM Corporation
Replication Requirements Targeted with Our Solution
� Disaster Recovery solution for PureData Systems for Analytics– Protect business critical data
– Meet regulatory requirements
� Scalable infrastructure that supports:– Growing user populations
– Distributed access to BI and DW applications
– Geographically dispersed user populations
– Higher levels of concurrent access for BI and DW apps
– Reduced application connection and access latencies (“put the data closer”)
70

© 2013 IBM Corporation
Replication Solution Overview
� Homogeneous (PDA / Netezza only)
� Asynchronous, “warm stand-by” ( there is latency to the DR box)– Synchronous commit for the source PTS
– Asynchronous transfer to the subordinate PTS, Subordinate Appliance(s)
� Hybrid Replication: SQL Statement & By Value • (Intelligence of solution decides which mode to use)
– SQL statement-level replication (preferred, default)
– Replication By-Value (when necessary)

© 2013 IBM Corporation
• IBM PureData System for Analytics N200x (Striper)
• IBM PureData System for Analytics N1001 (TwinFin)
• IBM PureData System for Analytics N1000 (TwinFin)
• IBM Netezza 100 (Skimmer)
• IBM Netezza High Capacity Appliance C1000
• NEC InfoFrame DWH Appliance
Supported Appliances
72
You can upgrade to IBM Netezza release 7.1.0.x from any 6.0.x or 6.1.x release, or from an earlier release of 7.1.0.x to a later 7.1.0.x release.
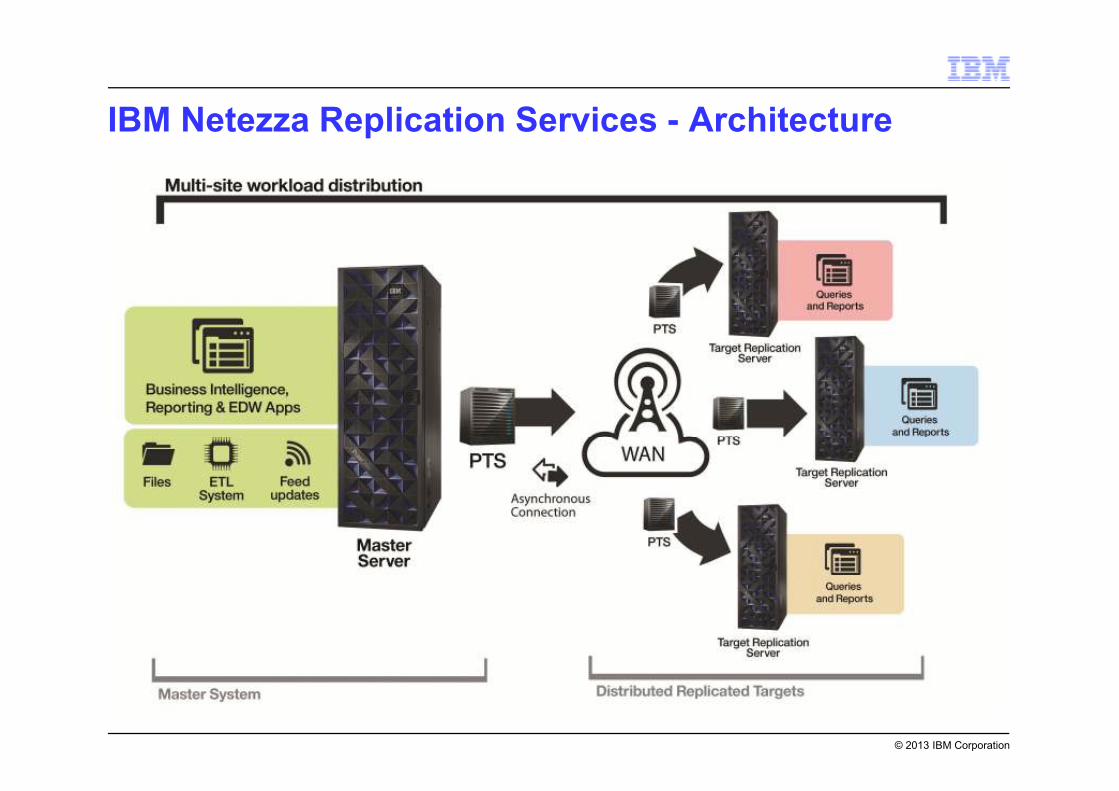
© 2013 IBM Corporation
IBM Netezza Replication Services - Architecture

© 2013 IBM Corporation
Description of “by SQL” Replication Method
� Preferred method of replication for our solution– Master node accepts SQL Data Manipulation Language (DML) and Data
Definition Language (DDL) that update the replicated databases.
– SQL statements captured to a replication log
– Logs copied across the network to multiple Netezza nodes
– Subordinates replay the SQL
– Fewer performance implications to customer workloads (near zero impact)• Small amount of information to log/transfer
� The SQL statement that made the change
• External table files logged that are referenced by DML operations � Byte for byte identical to original imported data
• Incoming load rates for up to three simultaneous parallel loads

© 2013 IBM Corporation
Description of “by Value” Replication Method
� Alternative method of replicating changes– Used when DML or DDL SQL statements are detected to potentially produce different results on the subordinate.
– Replays the rows which changed (and DDL to ensure appropriate table structure)
� Steps – On the master
• Detect non deterministic SQL DML operations.
• Mark the entire transaction as required to be replicated by the rows that changed and the DDL statements issued against
replicated databases.
• During commit processing of the transaction on the master, the set of rows which changed (inserted, updated or deleted) for
each of the tables affected by DML are captured to the replication log.
– On the subordinate• DDL statements against replicated databases are replayed
• For each modified table, the new rows are inserted, and old rows deleted.
� Requirement to log the underlying row changes to tables – Performance impacted by waiting for rows to log to disk on source system.
– Performance = length of time required for a transaction to complete will generally be longer than the time when
replication is disabled.
� This method may be optimal for some workloads compared to “by SQL”– Session variable available to force the selection of this method when logging transactions
• SET REPLICATE_ALWAYS_BY_VALUE=ON;
� nzreplshowsql command will output more details

© 2013 IBM Corporation
IBM Netezza Replication Services - Roles
Subordinate:
Role in a replication set in which execution of UPDATE transactions against non-
temporary tables or sequences in a replicated database are prohibited. Temporary
table UPDATEs and persistent table SELECTs are fully supported.
Master:
Appliance that is the single source of changes to
replicated databases and to global data. The other
appliances in the replication set are subordinates.
The role of master can be changed from one appliance
to another by an administrator, typically
in response to failures and planned outages, or to
“follow the sun” across time zones.
One master and many subordinates are permitted in a replication set. A subordinate
replication host can perform query transactions for load balancing, including creating and
updating temporary tables.
Subordinate appliances can have databases outside of replication scope and they have no
write restrictions.

© 2013 IBM Corporation
The Persistent Transport System (PTS)
� External server collocated with every node in replication cluster
� A PTS has three major purposes:
– Move data and files (synchronize transaction logs) from one node to another.
– Send control messages from one node to another.
– Act as a persistent store for recovery from failures.
� PTS H/W Specs:
– 4 cores, 16GB RAM, 5TB+ of disk space, 250MB/s disk write rate for logs
– Redhat Linux 5.7+
� Can Be a Virtual Machine (VM)
The New *flexible* PTS!
(Valid option as of February 2014.)
Note: we encourage customers to have a test environment, so please consider the need for
not only appliances but appropriate PTS in your test environment.

© 2013 IBM Corporation
Performance Benefits of a Replicated Environment
� Across the replicated cluster, the advantages of asynchronous
replication: Because applications do not have to wait for transactions
on the master to be transported and applied on target systems,
asynchronous solutions can be deployed over long distances with
(a) negligible impact on application performance, and (b) minimal
network bandwidth consumption.
� On the master system, improve performance by offloading BI reporting to one or more replication target systems.
� On target systems, reduce network and database connection latencies by storing data closer to users and client applications.
� Across the replicated cluster, optimal use of network bandwidth,a direct consequence of the "by-SQL" approach to replicating load file and SQL statement when possible. This contrasts with other databases which log and transmit index and data structure changes.

© 2013 IBM Corporation
� Replication PTS HA: The ability to add a second host into
the PTS HW to ensure if there is an issue with the host.
(Note: this requires appropriate hardware and the RedHat
Availability Add-On.)
� Replication Relaxed Serializability: Replication is
compatible with the NPS feature relaxed serializability.
� Replication Master Continue on PTS Error: The ability to
allow the source appliance to continue to change data
even though a replication error occurred and it can not log
to its PTS.
Reduced Restrictions: The removal of restrictions in the SQL
allowed on replicated databases.
(Sequences, Non deterministic SQL, DML which
selects from non-replicated data, Stored
procedures which manipulate timestamps, TEMP
tables now work identically when replication is
enabled vs. disabled)
Increased Resiliency, and Compatibility with Customer WorkloadsIBM Netezza Replication Services v1.5

© 2013 IBM Corporation
NPS v7.1 is a Prereq for Replication v1.5
80
Highlights�Scheduler rules for WLM
�Short query prioritization
�Snippet Result Cache
�Faster Bulk Fetching with ODBC
�Password aging and expiry
�nzPortal enhancements
�Cryptographic Standards (s800-131a)
�Support for Replication v1.5
�Support for INZA 3.0
Resiliency�Faster rebalance for failed disks
�Disk validation support
�Large scale disk replacement
�Call Home v1.0
�Enhanced System Health Checks v2.2
�ILMT support for Growth on Demand
Platform & OS�Client Kit support for AIX 7.1
�RHEL 6.4 certification
SQL Enhancements�Multiple Schema (3-part naming)
�Orphan column query
�NOT IN / EXIST improvements
�CASE WHEN improvements
�Support 24 hour datetime
�CESU-8 support
Transaction Enhancement�Truncate table in TXN
�Improved view validation
�Temp table enhancements
�Deprecate Web Admin
ETL�ODBC loader support for INTERVAL
Netezza Performance Portal�Cryptographics standards (s800-131a)
�Scheduler rules
�History type AUDIT
�Restrict nzPortal users
�Groom dialogs

© 2013 IBM Corporation
New Features in NPS 7.1 / Replication 1.5
� WHAT IS IT– A system parameter (replContinueOnLogError) in the replc.cfg file.
� HOW IT WORKS– False (default): If a PTS error occurs while capturing the transaction log, the master aborts any active
transaction.
– True: Enables the master to continue processing transactions, regardless of the logging error, but
replication stops so that loads can continue. The master node enters a "continue on error" state, where
write workloads continue even though they are not recorded in the replication log. Because the
transaction log is then invalid due to missing data, you must re-synchronize all nodes after resolving
the PTS issues.
� HOW TO RECOVER– To recover from the replication suspension that results from the "master continue on error" feature,
you must follow the backup and restore procedure. First, run the nzreplanalyze command to generate
a directive file for synchronization and progress the master node from "continue on error" to a
suspended state. Then, use nzreplbackup to create backup and activate master node. Finally, use
nzreplrestore to restore the replication data to the subordinate(s).
� *No other database has this configuration setting!
Master Continue on Error

© 2013 IBM Corporation
New Features in NPS 7.1 / Replication 1.5
� As of NPS 7.1 and Replication version 1.5, customers can utilize the "relaxed
serializability" setting in NPS on replication databases!– This functionality utilizes an invisibility list. The invisibility list on the master is replicated
for use on the subordinate.
– There are no constraints around using this setting on the master or subordinate in
replication environments.
– To be clear, the serial execution on the subordinate did not change from the prior
replication release but now it has the invisibility list to "see" the appropriate state of the
database.
– Its worth noting that the appliances behave the same way with relaxed serializability
regardless of replication being turned on or off.
� NPS Configuration Notes (A best practice is to use it at a session level.)– It can be set system wide (globally). This requires a stop and start of the appliance.
– It can be set with a session variable.
Relaxed Serializability Support
NOTE: customers need to know what is occurring to turn serializability to false. Therefore, it is
a best practice to utilize it in session scope (as opposed to globally).
NPS Feature will be documented as of NPS 7.1 for the first time

© 2013 IBM Corporation
Replication Reduced Restrictions
� Reduced restrictions – Key software development project since January 2013
� Things that now work fine with replication– SEQUENCES
– Non deterministic SQL (ie. LIMIT 5, Random(), Window functions)
– DML which selects from non-replicated data (system tables, databases)
– Stored procedures which manipulate timestamps
– Session scope temporary tables and variables
- TEMP tables now work identically when replication is enabled vs disabled
– Transactions larger than 300KB of SQL statements now supported
– UDF, UDTF and UDA

© 2013 IBM Corporation
Features
� This QuickStart includes the following activities:
� Install the 10 Gb NIC cards in the Netezza appliances, establish and validate connectivity with replication hardware and Netezza appliance.
� Install and configure a basic Netezza Replication Software Solution from one Netezza source to one target.
� Provide information sharing on how to best use and leverage the Netezza Replication Solution.
� Conduct a planning workshop to document disaster and recovery scenarios based on the requirements.
� The scope is limited to one Netezza source and one target. Additional nodes can be supported and quoted separately.
� The site survey / pre-engagement checklist is reviewed and completed by the client before any IBM resources come on-site.
Deliverables
� Installation Report
� Disaster and Recovery Scenarios Document
Ensure your solution is implemented efficiently with low risk
Benefits
� Get a basic replication solution installed and configured quickly realizing your solution ROI faster
� Leverage IBM deep product expertise to define optimum disaster recovery solutions to satisfy your requirements
� Obtain a replication solution foundation to protect one of your most important assets, your data!
Backed by world-class industry and product experts in deploying
Information Management Software
Duration
� 4 weeks
PureData System for Analytics Replication QuickStart Offering

© 2013 IBM Corporation
Announcementhttp://www-01.ibm.com/common/ssi/cgi-
bin/ssialias?infotype=AN&subtype=CA&htmlfid=897/ENUS214-055&appname=USN
Fix Centralhttp://www-
933.ibm.com/support/fixcentral/swg/selectFixes?product=ibm/Information+Management/Netez
za+NPS+Software+and+Clients&release=NPS_7.1.0&platform=All&function=all
Knowledge Centerhttp://www-01.ibm.com/support/knowledgecenter/
Replication Serviceshttps://w3-connections.ibm.com/communities/community/NetezzaReplication
Netezza Developer Network download site:https://www14.software.ibm.com/webapp/iwm/web/reg/pick.do?source=swg-im-ibmndn&lang=en_US
ContactsDoug Dailey, Netezza Product Manager (NPS), [email protected]
Chris Gerlt, Netezza Product Manager (Replication), [email protected]
Questions about NPS 7.1 & Replication 1.5

© 2013 IBM Corporation
© International Business Machines Corporation 2014
International Business Machines Corporation New Orchard Road Armonk, NY 10504
IBM, the IBM logo, PureSystems, PureFlex, PureApplication, PureData and ibm.com are trademarks of International Business Machines Corporation, registered in many jurisdictions worldwide.
A current list of IBM trademarks is available on the Web at www.ibm.com/legal/copytrade.shtml
All rights reserved.
Related Documents











