© 2013 IBM Corporation IBM Presentation to CAUDIT Page 1 IBM CAUDIT/RDSI Briefing 13 th August 2013 Presented by: Daniel Richards – HPC Architect Glen Lance - System Networking Specialist April Neoh – HPC Sales Lead

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 1
IBMCAUDIT/RDSI Briefing
13th August 2013
Presented by:Daniel Richards – HPC ArchitectGlen Lance - System Networking SpecialistApril Neoh – HPC Sales Lead

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 2
Agenda– Introduction– GPFS Storage Server (GSS)– CINDER Support on IBM Storage– Linear Tape File System (LTFS)– SONAS– Software Defined Networking (SDN)

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 3
GPFS Storage Server (GSS)

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 4
What is GPFS?
Storage
GPFS
All features included
HPC IO Checklist:Massive NamespaceCentral AdministrationSeamless GrowthLinux, AIX, Windows
GPFS is a mature product with established market presence. It has been generally available since 1998 with research development starting in 1991.

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 5
GPFS – History and Evolution
2005200219981995
Video Streaming
Tiger Shark-Real Time-Streaming-Read Perf-Wide Stripe
High Performance Computing
GPFS General File Serving
-Standards-POSIX Semantics-Large Block-Directory and -Small File perf-Data Management
VTS Virtual Tape Server
Linux Clusters (Multiple Architectures)
AIX Loose Clusters
GPFS 2.1-2.3
HPC
ResearchVisualizationDigital MediaSeismicWeather ExplorationLife Sciences
32 bit /64 bitInter-op (AIX & Linux)GPFS Multi-Cluster
GPFS Over WAN
Large Scale Clusters1000’s of nodes
GPFS 3.1
ILM- Storage Pools- Filesets- Policy Engine
Ease of Administration
Multiple-networks/ RDMA
Distributed Token Management
2006
GPFS 3.2
SLES/xenRed Hat 5/xenWindows (3.2.1.5)
Faster Failover
Multiple NSD servers
NFS v4 Support
Small File Performance
2007
First Called GPFS
We are now at version GPFS 3.3, which introduced administration/policy/performance improvements, additional supported platforms (RedHat 5.x, Windows Server 2008…) and a new licensing model.
GPFS 3.3
Restricted Admin Functions
Improved installation
New license model
Improved snapshot andBackup
Improved ILM policy engine
2009

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 6
DARPA HPCS File System and Storage HPCS file system requirements (a subset)
• “Balanced” capacity and performance (100 PB file system, 6 TB/s file I/O)• Reliability in the presence of localized failures• Support for full-up PERCS system (~64K nodes)• One trillion files to a single file system• 32K file creates per second• Streaming I/O at 30GB/s full duplex (for data capture)
Storage Requirements – Reasonable cost - 10-20% of system cost
• Large number of disk drives makes this difficult to achieve• Metadata performance requires substantial amount of expensive NVRAM or SSD
– Reliability - system must continue to be available in spite of component failures• One or more drives continually in rebuild• Hard error rate between 10-14 and 10-16
• “Silent” data corruption- errors after write require check on read
– Productivity - non-disruptive repair and rebuild
• Goal: rebuild overhead in the 2-3% range (normal RAID 30%)
• Parallel file system with wide striping: x% hit on one LUN causes same x% hit to entire file system

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 7
Perseus Software RAID - MotivationReduce storage subsystem cost! Expect storage to be 10-20% of system cost
– ... difficult to achieve with conventional external RAID controllers and dedicated storage network
The insight: leverage existing resources to lower storage cost– HFI switch, 500TB/s bisection bandwidth– P7 storage node (32 cores)– SAS-attached JBOD– SSD fast write cache (vs. battery-backed RAM)– Dense storage packaging using removable multi-disk carriers– 30-40% reduction in storage subsystem cost
Cluster Client Nodes
nic nic nic nic nic nic nic nic nic nic nic nic nic nic nic
nic
ioa
nic
ioa
I/O NSD nodes
SAS Fabric
SBOD drawers
PERSEUS with dual-ported SBODs
I/O NSD nodes
SAN
nic
ioa
nic
ioa
Traditional Storage Controller
Storage controller
JBOD drawers
ioa
ioa
ioa
ioa

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 8
As long as we’re implementing our own RAID…
– Reduce impact of RAID rebuild on performance• HPC file systems stripe data across all IO nodes,
performance is only as good as slowest controller when rebuilding• At petascale, the system is always rebuilding!!*• Perseus Declustered RAID reduces the impact of RAID rebuild on
performance– Improve data integrity with stronger RAID codes
• 1-fault-tolerant RAID-5 (8+P): MTTDL about 4 days• 2-fault-tolerant RAID-6 (8+2P): MTTDL about 100 years
Assuming max PERCS system, 600-GB SAS drives with MTTF=600khrs, hard error rate = 1E-15, and uncorrelated failures, MTTDL ~ 100 years
• 3-fault-tolerant RAID (8+3P): MTTDL is 6 orders of magnitude betterSame assumptions above, MTTDL ~ 130 million years
– Eliminate silent data corruption• Occasionally you don’t get back what you wrote!• Disks exhibit silent errors, RAID firmware bugs, etc.• Perseus on-disk checksums provide end-to-end error detection
*100,000 disks * 24 hr/600,000 hr MTBF = 4 failures/day

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 9
Ok, enough of the Intro, what is GSS
© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 10
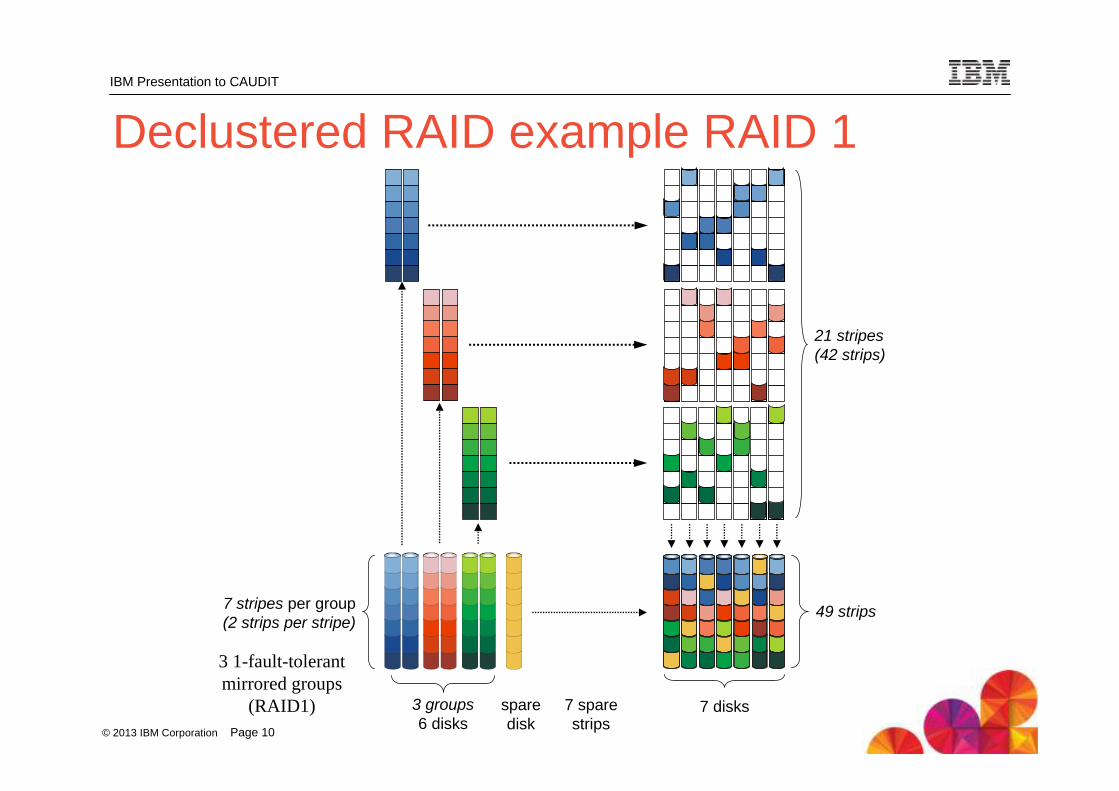
Declustered RAID example RAID 1
7 disks3 groups6 disks
sparedisk
21 stripes(42 strips)
49 strips7 stripes per group(2 strips per stripe)
7 sparestrips
3 1-fault-tolerantmirrored groups
(RAID1)

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 11
Declustered RAID Rebuildfailed diskfailed disk
Rd Wr
time
Rebuild activity confined to just a few disks – slow rebuild,
disrupts user programs
Rd-Wr
time
Rebuild activity spread across many disks, less
disruption to user programs
Rebuild overhead reduced by 3.5x

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 12
Declustered RAID6 Example
Declusterdata, parity and
spare
14 physical disks / 3 traditional RAID6 arrays / 2 spares 14 physical disks / 1 declustered RAID6 array / 2 spares
Declusterdata, parity and
spare
14 physical disks / 3 traditional RAID6 arrays / 2 spares 14 physical disks / 1 declustered RAID6 array / 2 spares
failed disks failed disks
failed disksfailed disksNumber of faults per stripe
Red Green Blue
0 2 0
0 2 0
0 2 0
0 2 0
0 2 0
0 2 0
0 2 0
Number of faults per stripe
Red Green Blue
1 0 1
0 0 1
0 1 1
2 0 0
0 1 1
1 0 1
0 1 0
Number of stripes with 2 faults = 1Number of stripes with 2 faults = 7

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 13
GNR – Data Integrity

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 14
GNR – Disk Hospital

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 15
Model 26 Logical layout

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 16
GSS Summary
Better performance
Better Resilience–3 + P–End to Check-sum–Intelligent rebuild–Disk hospital
Cheaper

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 17
OpenStackCINDER Support

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 18
GPFS: A Reliable, Scalable, POSIX-Compliant Enterprise File System that storesCompute images, Volumes and Objects
GPFS: A Reliable, Scalable, POSIX-Compliant Enterprise File System that storesCompute images, Volumes and Objects
Swift (Objects)Swift (Objects)
GPFS Object DriverGPFS Object Driver
Cinder (Volumes) Cinder (Volumes)
GPFS Volume DriverGPFS Volume Driver
Nova / Glance (Compute)Nova / Glance (Compute)
GPFS Placement DriverGPFS Placement Driver
GPFS As the Enterprise Storage Layer for OpenStack
A common storage layer for images, volumes and objects– Avoids data copy– Local access of data
Adds enterprise storage management features to OpenStack– Rapid volume and virtual machine provisioning using file system level copy-on-write
function– Scale out IO performance through support for shared nothing clusters– Resilient volumes through transparent pipeline replication

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 19
IBM Storage Systems support for OpenStack
Storwize family including and SVC – Supported since Folsom release
• Upgraded for Grizzly– iSCSI or Fibre Channel– Supports advanced Storewize features
such as Real-time Compression and Easy Tier,
• Software defined placement via OpenStack filter scheduler
XIV– Supported since Folsom release

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 20
Self-provisioning of Storwize volumes via OpenStack dashboard

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 21
Self-provisioning of Storwize volumes via OpenStack dashboard

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 22
Linear Tape File System (LTFS)

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 23
What is LTFS•A self-describing tape file system
•LTFS can write files directly to tape media by using operating system commands and without any additional application.
•The tape drive appears on the operating system as though it is a USB-attached disk drive.
•IBM created – but open.
•Single drive, Library and EE

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 24
Tape Partitioning
LTO 5: 1.5TB, 1280 tracks, 16 tracks per wrap, 80 wraps in total.TS1140: 4TB, 2560 tracks, 32 tracks per wrap, 80 wraps in total.

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 25
The Solution – Tiered Network StorageC:/user defined namespace
Smaller
Easier to protectFaster Time to recoverySmaller backup footprint
Time critical applications/dataDat
a P
rote
ctio
nO
pera
tiona
lSingle file system view
LTFS LTFS LTFS LTFS LTFS LTFS LTFS LTFS LTFS LTFS
Smaller Scalable
Lower cost, scalable storageData types/uses for tape
Static data, rich media, etc.Replication backup strategies
High use data, databases, email, etc
Static data, rich media, unstructured, archivePolicy Based Tier Migration
© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 26
Movie1.mpgMemo.txt
Database.db2
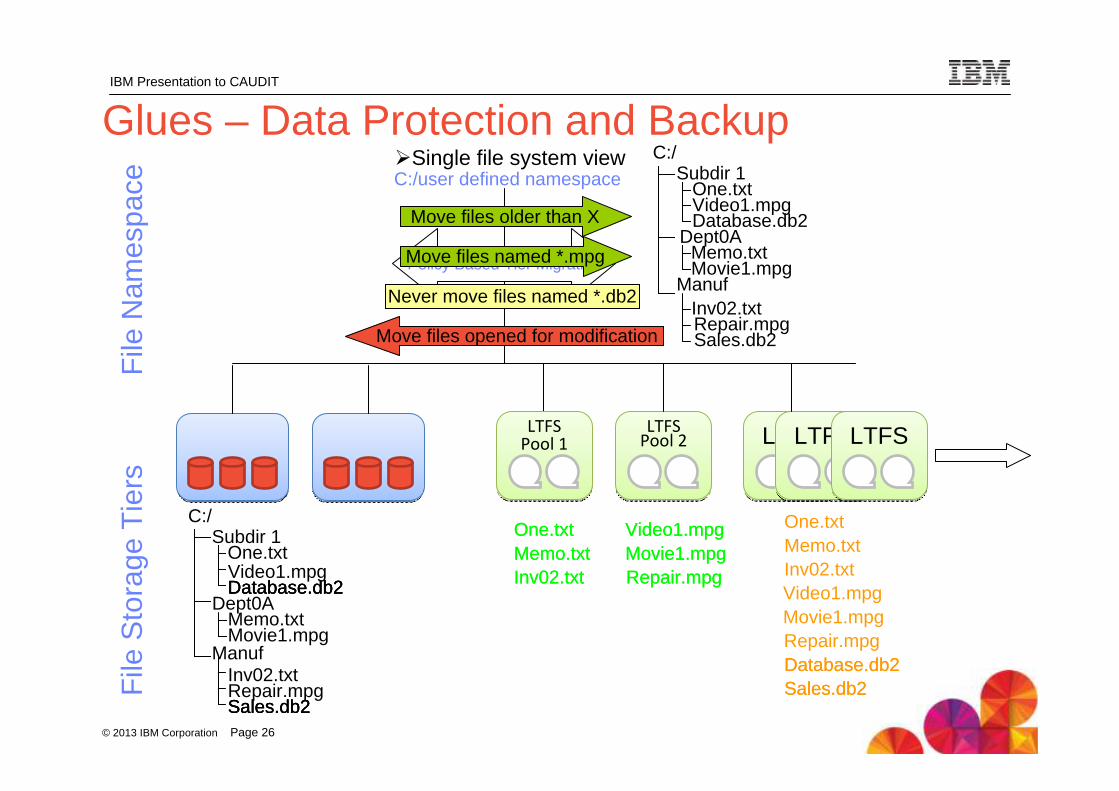
Glues – Data Protection and BackupC:/user defined namespace
File
Sto
rage
Tie
rsFi
le N
ames
pace
Single file system view
LTFS Pool 1LTFS Pool 1
LTFS Pool 2LTFS Pool 2 LTFS LTFS LTFS LTFS LTFS LTFS
Policy Based Tier Migration
Manuf
Repair.mpgInv02.txt
Sales.db2
C:/
Dept0A
Subdir 1
Video1.mpgOne.txt
Manuf
Repair.mpgInv02.txt
Sales.db2
C:/
Dept0A
Movie1.mpgMemo.txt
Subdir 1
Database.db2Video1.mpgOne.txt
Move files older than X
Move files named *.mpg
Never move files named *.db2
Move files opened for modification
One.txtMemo.txtInv02.txt
Video1.mpgMovie1.mpgRepair.mpg
One.txtMemo.txtInv02.txtVideo1.mpgMovie1.mpgRepair.mpgDatabase.db2Sales.db2
One.txtMemo.txtInv02.txt
Video1.mpgMovie1.mpgRepair.mpgDatabase.db2
Sales.db2
Database.db2
Sales.db2
Database.db2Sales.db2

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 27
SONAS

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 28
SONAS ArchitectureCIFS
ClientsCIFS
ClientsHTTP ClientsHTTP Clients
FTP ClientsFTP
ClientsNFS
ClientsNFS
Clients
Virtual Management
Node
Virtual Management
Node
Interface Node
Interface Node ...
IP Network
ExternalStorage
Interface Node
Interface Node
Other ClientsOther Clients
....Interface Node
Interface Node
Global Namespace
Infiniband Data NetworkIP Mgmt. Network
...
Storage Pod
Storage controller &
disk
Storage controller &
disk
Storage NodeStorage NodeStorage Node Storage Node
Storage Expansion
Storage Expansion
Storage Pod
Storage controller &
disk
Storage controller &
disk
Storage NodeStorage NodeStorage Node Storage Node
Storage Expansion
Storage Expansion
This is the internal GPFS parallel file
system global cluster
•All nodes share workload equallyin global SONAS cluster
•Nodes provide high availability dynamic failover for each other
•Global cluster can be dynamically upgraded / changed by adding or removing nodes and/or storage, file system stays up while doing this
•Massive scalability: max interface nodes = 30, max storage nodes = 60
All interconnect components in SONAS global cluster are
duplexed

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 29
Allows for “immediate”monitoring during environmental changes
Monitor and analyze status including performance
Proactively plan for more capacity, performance growth as needed
Manage more with less effort with new SONAS GUI
Common GUI across IBM storage portfolio:IBM XIV, Storwize V7000 Unified, DS8000 and SONAS

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 30
Software Defined Networks (SDN)

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 31
What is - Software Defined Networks?“Software Defined” – managing complex hardware interactions with software
31
The ultimate goal is, to make your networks have the properties of virtualised software systems as far as innovation, provisioning speed, and upgrade speed
You should want your networks to be as flexible and as agile as compute is
IBM Software Defined Network for Virtual Environments (IBM SDN VE) is distributed virtual network overlay software that virtualises a physical data centre network.
IBM SDN VE is a multi-hypervisor, high-availability server-centric solution comprising multiple connections that overlay virtual networks onto any physical network that provides IP connectivity
It can be best described as “VMware for data centre networking”.

© 2013 IBM Corporation
System Networking
Cut network provisioning from days to hours Secure VM mobility across Layer 2 networks and data centers
IBM SDN VE Network
Existing Network
Existing Network
RED Virtual Network
Yellow Virtual Network
Manual physical network configuration change Time consuming network provisioning Server virtualization gated by network provisioning
Existing Network
No physical network configuration change Automated network provisioning Server virtualization not gated by physical network
Network with IBM SDN VE-Enabled Servers
Physical network change for virtual workload connectivity
Speeds application provisioning
VMVM VMVM VMVM VMVM
32

© 2013 IBM Corporation
System Networking
A hypervisor for the network
33
VM Virtual Network 1VM Virtual Network 2
VM Virtual Network 3
Virtual Network 1
Virtual Network 2
Virtual Network 3
IBM SDN VEVirtualized Network
IBM SDN VE Gateway Existing IP Network
RESTful, Quantum
APIsOpenStack
Cloud/DC Provisioning
Applications
Existing IP Network
Hypervisor
VM
VM
VM
IBM SDN VE vSwitch
Virtual Appliance
IBM SDN VE Management
ConsoleVirtual Appliance
IBM SDN VE Connectivity
Server
End Station
End Station
Virtual Network 3
Hypervisor
VM
VM
VM
IBM SDN VE vSwitch
Hypervisor
VM
VM
VM
IBM SDN VE vSwitch
Based on IBM’s Distributed Overlay Virtual Ethernet (DOVE) technology Uses existing IP infrastructure — No change to existing physical network Provides server-based connectivity for virtual workloads Enables secure and scalable multi-tenancy
16,000Virtual
NetworksToday
16 MillionVirtual
NetworksFuture

© 2013 IBM Corporation
IBM Presentation to CAUDIT
Page 34
Questions??
Related Documents











