1 SPSS 16.0 GIỚI THIỆU VÀ THIẾT KẾ BẢNG CÂU HỎI Ph ần m ềm SPSS (nguyên g ốc là từ vi ết t ắt của Statistical Package for Social Sciences) được dùng để phân tích các kết qu ả điều tra trong nhi ều lĩnh vực t ừ xã h ội, giáo dụ c, kinh tế, dị ch v ụ , marketing, nông nghi ệp, y khoa… Ngày nay SPSS for Windows đã trở thành m ột trong nh ững ph ần m ềm phân tích số li ệu th ống kê hi ệu qu ả, ph ổ bi ến nh ất và được nhi ều nhà nghiên cứu sử dụng để phân tích dữ li ệu trong nghiên cứu khoa h ọc. Ph ần m ềm SPSS dễ dàng cài đặt cho m ọi cấu hình củ a máy vi tính, v ới dung lượng th ấp người sử dụ ng không cần đến m ột máy vi tính có cấu hình th ật m ạnh. Vi ệc cài đặt SPSS đơn giản và tương tự như một số ph ần m ềm ứng dụ ng khác. Nhà nghiên cứu sử dụng chương trình SPSS trong máy vi tính để th ực hi ện các kỹ thu ật th ống kê, nhưng việc làm cho các con số th ống kê có ý nghĩa lại ph ụ thu ộc vào cách di ễn gi ải kết qu ả, suy di ễn và dự đoán để gi ải quy ết m ụ c tiêu củ a v ấn đề nghiên cứu. 1. LÀM QUEN VỚI SPSS Kh ởi động SPSS từ bi ểu tượng của chương trình trên Desktop hoặc t ừ Star/Program/SPSS SPSS có 2 cửa sổ làm vi ệc: Cửa sổ dữ li ệu (Dataset) và Cửa sổ kết qu ả x ử lý (Output) - Cửa s ổ d ữ li ệ u có 2 giao diệ n : Giao di ện mã hoá dữ li ệu (Variable View) và Giao di ện nh ập li ệu (Data View). Thay đổi giao di ện bằng cách nh ấp chu ột ch ọn ở g ốc trái bên dưới màn hình, hoặc bấm t ổ h ợp phím Ctrl+T. Thành ph ần Menu củ a cửa sổ dữ li ệu bao g ồm: File: giúp tạo t ập tin SPSS m ới, m ở t ập tin có sẵn, lưu, thoát … Edit: xác l ập các m ặc đị nh của chương trình (Option), cắt, dán, tìm ki ếm, thay th ế… View: cho hi ện dòng trạng thái, thanh công cụ , font ch ữ, giá trị nh ập vào hay nhãn ý nghĩa Data: bao g ồm các l ựa ch ọn chèn thêm bi ến, tìm nhanh m ột quan sát, sắp x ếp th ứ t ự quan sát, chia và ghép tập tin… Transform: g ồm các l ệnh tính toán, chuy ển đổi và mã hoá l ại bi ến … Analyze: ch ứa các công cụ phân tích số li ệu như: thống kê mô tả, phân tích bảng chéo, các ki ểm đị nh tham số và phi tham số, phân tích tương quan và hồi quy … Graphs: bao g ồm các công cụ liên quan đến bi ểu đồ và đồ th ị Utilities: tìm hi ểu thông tin v ề các bi ến, t ập tin…

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
SPSS 16.0
GIỚI THIỆU VÀ THIẾT KẾ BẢNG CÂU HỎI
Phần mềm SPSS (nguyên gốc là từ viết tắt của Statistical Package for Social Sciences) được dùng
để phân tích các kết quả điều tra trong nhiều lĩnh vực từ xã hội, giáo dục, kinh tế, dịch vụ, marketing, nông nghiệp, y khoa… Ngày nay SPSS for Windows đã trở thành một trong những phần
mềm phân tích số liệu thống kê hiệu quả, phổ biến nhất và được nhiều nhà nghiên cứu sử dụng để phân tích dữ liệu trong nghiên cứu khoa học.
Phần mềm SPSS dễ dàng cài đặt cho mọi cấu hình của máy vi tính, với dung lượng thấp người sử dụng không cần đến một máy vi tính có cấu hình thật mạnh. Việc cài đặt SPSS đơn giản và tương tự
như một số phần mềm ứng dụng khác.
Nhà nghiên cứu sử dụng chương trình SPSS trong máy vi tính để thực hiện các kỹ thuật thống kê, nhưng việc làm cho các con số thống kê có ý nghĩa lại phụ thuộc vào cách diễn giải kết quả, suy
diễn và dự đoán để giải quyết mục tiêu của vấn đề nghiên cứu.
1. LÀM QUEN VỚI SPSS
Khởi động SPSS từ biểu tượng của chương trình trên Desktop hoặc từ Star/Program/SPSS
SPSS có 2 cửa sổ làm việc: Cửa sổ dữ liệu (Dataset) và Cửa sổ kết quả xử lý (Output)
- Cửa sổ dữ liệu có 2 giao diện: Giao diện mã hoá dữ liệu (Variable View) và Giao diện nhập liệu
(Data View). Thay đổi giao diện bằng cách nhấp chuột chọn ở gốc trái bên dưới màn hình, hoặc bấm tổ hợp phím Ctrl+T.
Thành phần Menu của cửa sổ dữ liệu bao gồm:
File: giúp tạo tập tin SPSS mới, mở tập tin có sẵn, lưu, thoát …
Edit: xác lập các mặc định của chương trình (Option), cắt, dán, tìm kiếm, thay thế…
View: cho hiện dòng trạng thái, thanh công cụ, font chữ, giá trị nhập vào hay nhãn ý nghĩa
Data: bao gồm các lựa chọn chèn thêm biến, tìm nhanh một quan sát, sắp xếp thứ tự quan sát, chia và ghép tập tin…
Transform: gồm các lệnh tính toán, chuyển đổi và mã hoá lại biến …
Analyze: chứa các công cụ phân tích số liệu như: thống kê mô tả, phân tích bảng chéo, các kiểm
định tham số và phi tham số, phân tích tương quan và hồi quy …
Graphs: bao gồm các công cụ liên quan đến biểu đồ và đồ thị
Utilities: tìm hiểu thông tin về các biến, tập tin…
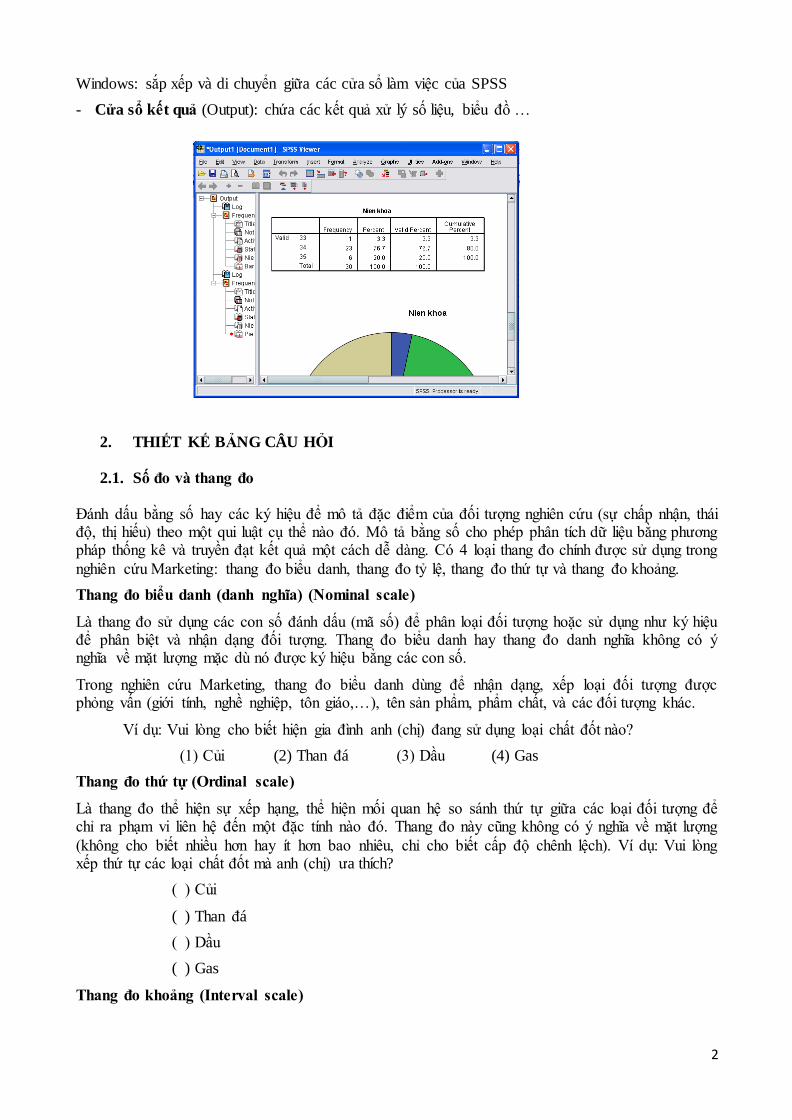
2
Windows: sắp xếp và di chuyển giữa các cửa sổ làm việc của SPSS
- Cửa sổ kết quả (Output): chứa các kết quả xử lý số liệu, biểu đồ …
2. THIẾT KẾ BẢNG CÂU HỎI
2.1. Số đo và thang đo
Đánh dấu bằng số hay các ký hiệu để mô tả đặc điểm của đối tượng nghiên cứu (sự chấp nhận, thái độ, thị hiếu) theo một qui luật cụ thể nào đó. Mô tả bằng số cho phép phân tích dữ liệu bằng phương pháp thống kê và truyền đạt kết quả một cách dễ dàng. Có 4 loại thang đo chính được sử dụng trong
nghiên cứu Marketing: thang đo biểu danh, thang đo tỷ lệ, thang đo thứ tự và thang đo khoảng.
Thang đo biểu danh (danh nghĩa) (Nominal scale)
Là thang đo sử dụng các con số đánh dấu (mã số) để phân loại đối tượng hoặc sử dụng như ký hiệu để phân biệt và nhận dạng đối tượng. Thang đo biểu danh hay thang đo danh nghĩa không có ý nghĩa về mặt lượng mặc dù nó được ký hiệu bằng các con số.
Trong nghiên cứu Marketing, thang đo biểu danh dùng để nhận dạng, xếp loại đối tượng được phỏng vấn (giới tính, nghề nghiệp, tôn giáo,…), tên sản phẩm, phẩm chất, và các đối tượng khác.
Ví dụ: Vui lòng cho biết hiện gia đình anh (chị) đang sử dụng loại chất đốt nào?
(1) Củi (2) Than đá (3) Dầu (4) Gas
Thang đo thứ tự (Ordinal scale)
Là thang đo thể hiện sự xếp hạng, thể hiện mối quan hệ so sánh thứ tự giữa các loại đối tượng để chỉ ra phạm vi liên hệ đến một đặc tính nào đó. Thang đo này cũng không có ý nghĩa về mặt lượng
(không cho biết nhiều hơn hay ít hơn bao nhiêu, chỉ cho biết cấp độ chênh lệch). Ví dụ: Vui lòng xếp thứ tự các loại chất đốt mà anh (chị) ưa thích?
( ) Củi
( ) Than đá
( ) Dầu
( ) Gas
Thang đo khoảng (Interval scale)

3
Là thang đo cũng có thể dùng để xếp hạng các đối tượng nghiên cứu nhưng khoảng cách bằng nhau trên thang đo đại diện cho khoảng cách bằng nhau trong đặc điểm của đối tượng. Một thang đo khoảng chứa đựng tất cả thông tin trong thang đo thứ tự nhưng nó cũng cho phép só sánh sự khác
biệt giữa các đối tượng. Ví dụ: sự khác biệt giữa “3” và “4” thì bằng sự khác biệt giữa “1” và “2”, hoặc sự khác biệt giữa “2” và “4” thì gấp đôi sự khác biệt giữa “1” và “2”.
Thang đo tỷ lệ (Ratio scale)
Là loại thang đo cao nhất, nó chứa đựng tất cả nội dung của thang đo biểu danh, thang đo thứ tự và thang đo khoảng. Trong thang đo tỷ lệ, ta có thể nhận dạng hoặc phân loại đối tượng, xếp hạng đối
tượng và so sánh sự khác biệt. Thang đo tỷ lệ không chỉ cho biết sự khác biệt giữa 2 và 5 thì bằng sự khác biệt giữa giữa 14 và 17 mà nó còn cho biết thêm 14 thì gấp 7 lấn của 2.
2.2. Tiến trình thiết kế bảng câu hỏi
Thiết kế bảng câu hỏi là một kỹ năng đòi hỏi thông qua kinh nghiệm, và nó còn là một nghệ thuật. Thiết kế bảng câu hỏi là một quá trình bao gồm 10 bước:
Bước 1: Xác định những thông tin cần thiết
Bước 2: Xác định hình thức phỏng vấn, thu dữ liệu
Bước 3: Xác định nội dung các câu hỏi cần thiết
Bước 4: Thiết kế câu hỏi để khắc phục trường hợp đáp viên không sẵn lòng trả lời
Bước 5: Quyết định cấu trúc câu hỏi (đóng, mở)
Bước 6: Quyết định từ ngữ sử dụng trong câu hỏi
Bước 7: Sắp xếp câu hỏi theo thứ tự hợp lý
Bước 8: Xác định hình thức bảng câu hỏi
Bước 9: Hoàn chỉnh bảng câu hỏi
Bước 10: Điều tra thử bảng câu hỏi
3. CÁCH THỨC MÃ HOÁ VÀ NHẬP LIỆU
3.1. Mã hóa dữ liệu
Tiến hành mã hóa dữ liệu ở giao diện Variable View. Bước mã hóa dữ liệu nên được hoàn thành trước khi tiến hành nhập liệu
Giao diện Variable View thể hiện:
- Các hàng là các biến
- Các cột là các thuộc tính của biến

4
Các thuộc tính của biến bao gồm:
- Tên biến (Name): ngắn gọn cho biết đang đề cập đến câu hỏi nào trong bảng câu hỏi. Độ dài tối đa là 8 ký tự, không sử dụng dấu cách hoặc các ký hiệu đặc biệt (như !, ?, *, và ‘). Tên
biến không được trùng lặp
- Loại dữ liệu (Type): mặc định là dạng số, có thể thay đổi định dạng biến ở phần Variable
Type.
- Số lượng con số hoặc chữ (With) tối đa có thể nhập vào, có thể thay đổi trong hộp Variable Type ở trên.
- Số lượng chữ số thập phân (Decimals), có thể thay đổi trong hộp Variable Type ở trên.
- Nhãn biến (Lable): mô tả chi tiết cho tên biến, có thể dài đến 256 ký tự, có thể dùng ký hiệu
đặc biệt.
- Nhãn trị số của biến (Value): dùng để mô tả cho từng trị số của biến (ví dụ mã số 1 đại diện cho nhóm nam và 2 đại diện cho nữ).
- Trị số khuyết thiếu (Missing): định nghĩa các trị số như là khuyết thiếu của người sử dụng để
giúp phân biệt trị số khuyết thiếu do đáp viên từ chối trả lời hay do câu hỏi đó không áp dụng đối với người này. Các trị số được chỉ định là khuyết thiếu của người sử dụng được đánh dấu để SPSS có thể nhận ra trong các phép tính toán.
- Canh lề (Align)
- Thang đo (Measure)
3.2. Nhập liệu
Sau khi mã hóa, trong giao diện Data View đã xuất hiện 1 form nhập dữ liệu. Tiến hành nhập liệu trong giao diện Data View. Nhập lần lượt từng bảng câu hỏi. Nhập trị số hay chuỗi theo bảng câu
hỏi.

5
4. MỘT SỐ XỬ LÝ TRÊN BIẾN
4.1. Mã hóa lại biến
Trong quá trình phân tích dữ liệu người làm nghiên cứu đôi khi sẽ phải mã hoá lại biến để sử
dụng cho nhiều mục đích khác nhau, và trường hợp đơn cử nhất là:
Khi nhà nghiên cứu muốn chuyển một biến định lượng (thang đo tỷ lệ) sang một biến định
tính (thang đo biểu danh hay thứ tự).
Ví dụ: Khi thu thập thông tin về độ tuổi của bệnh nhân, chúng ta sử dụng thang đo tỷ lệ (dùng chính xác số tuổi của bệnh nhân: 52, 67, hay 81 tuổi…). Đến khi xử lý số liệu, nhà nghiên
cứu lại muốn sử dụng nhóm tuổi để phân tích và viết báo cáo:
1. < 30 tuổi
2. 30 – 39 tuổi
3. 40 – 49 tuổi
4. 50 – 59 tuổi
5. ≥ 60 tuổi
Quy trình mã hoá lại biến như sau:
1. Vào menu Transform Recode into Different Variables…
Nếu chúng ta chọn Recode into Same Variables… thì biến cũ (số tuổi chính xác) sẽ mất đi và được thay thế bằng một biến mới với các biểu hiện mới (là nhóm tuổi).
Thông thường ta sẽ chọn Recode into Different Variables… để tạo ra biến mới mà vẫn giữ lại biến cũ.
2. Xuất hiện hộp thoại sau:
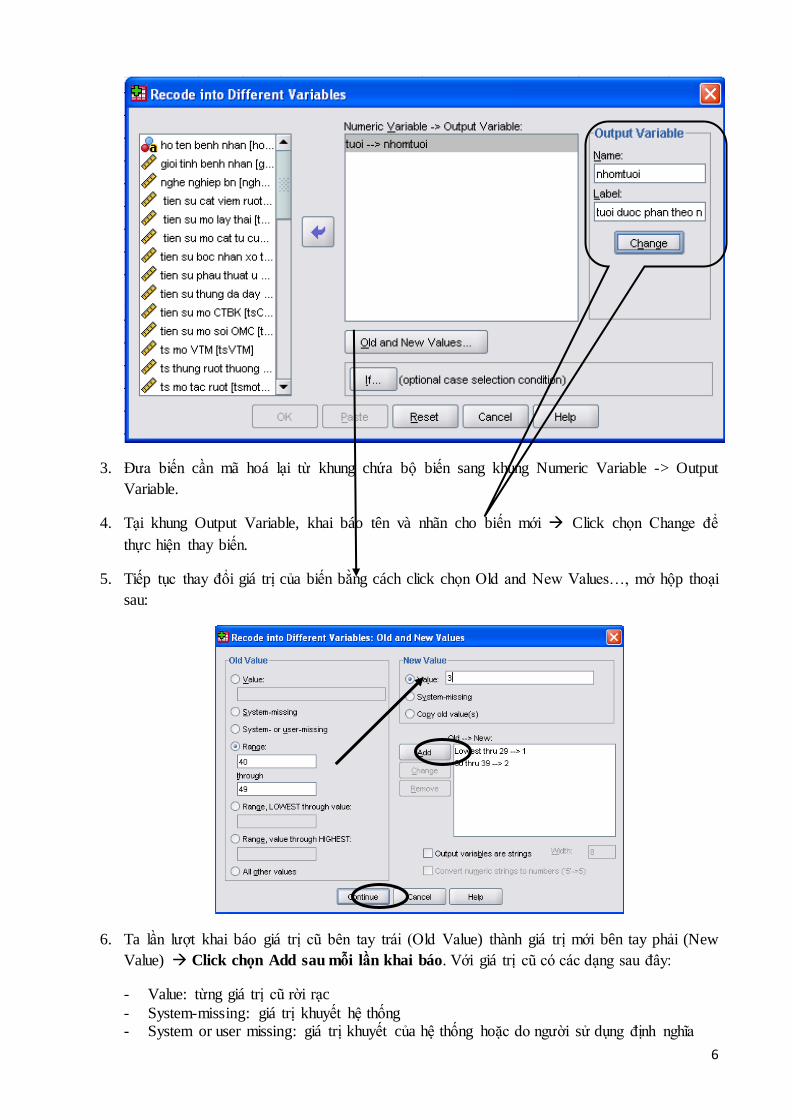
6
3. Đưa biến cần mã hoá lại từ khung chứa bộ biến sang khung Numeric Variable -> Output
Variable.
4. Tại khung Output Variable, khai báo tên và nhãn cho biến mới Click chọn Change để
thực hiện thay biến.
5. Tiếp tục thay đổi giá trị của biến bằng cách click chọn Old and New Values…, mở hộp thoại
sau:
6. Ta lần lượt khai báo giá trị cũ bên tay trái (Old Value) thành giá trị mới bên tay phải (New
Value) Click chọn Add sau mỗi lần khai báo. Với giá trị cũ có các dạng sau đây:
- Value: từng giá trị cũ rời rạc
- System-missing: giá trị khuyết hệ thống - System or user missing: giá trị khuyết của hệ thống hoặc do người sử dụng định nghĩa

7
- Range: một khoảng giá trị (từ … đến … / range: … through: …) - Range, LOWEST through value: một khoảng giá trị từ giá trị nhỏ nhất đến một giá trị
được nhập vào
- Range, value through HIGHEST: một khoảng giá trị từ giá trị nhập vào đến giá trị lớn nhất
7. Chọn Continue trở về hộp thoại trước, và chọn OK để hoàn tất kệnh.
8. Khai báo value cho biến vừa tạo tại ô Value của cửa sổ Variable View như hình sau:
Tiếp tục thực hiện các phép thống kê mô tả hay kiểm định dựa trên biến mới vừa tạo nhằm phục vụ cho mục tiêu nghiên cứu.
4.2. Làm sạch dữ liệu
Dữ liệu sau khi nhập xong có thể có sai sót do trong quá trình nhập liệu, nên việc làm sạch dữ liệu
là rất cần thiết. Có nhiều phương thức để làm sạch dữ liệu như: tìm ngay trên cửa sổ Data View, dùng bảng tần số đơn giản, hay bảng phối hợp 2 hay 3 biến… Trong những cách trên, việc lập bảng tần số để phát hiện lỗi trong quá trình nhập liệu là đơn giản nhất và hiệu quả cao.
Khi tiến hành lập bảng tần số (bằng lệnh Frequency – xem them phần tính tần số), có bảng kết quả như sau:
Gioi tinh
Frequency Percent Valid Percent Cumulative Percent
Valid Nam 38 76.0 76.0 76.0
Nu 11 22.0 22.0 98.0
12 1 2.0 2.0 100.0
Total 50 100.0 100.0
Nhìn vào bảng thấy có giá trị “12” xuất hiện trong bảng giới tính Nam và Nữ. Lỗi này có thể do quá
trình nhập liệu bị sai sót. Cách khắc phục là tìm ra chỗ nhập sai để chỉnh sửa lại cho hợp lý. Chúng ta sẽ dùng thủ tục Find để tìm lỗi.
Trên cửa sổ Data View, chọn toàn bộ cột tương ứng với biến có giá trị bị lỗi. Vào menu Edit Find để mở hộp thoại:

8
Nhập giá trị 12 vào ô Find rồi click chọn Find next thì vị trí chứa giá trị lỗi 12 xuất hiện trên màn hình. Truy ngược lại số thứ tự bảng câu hỏi để chỉnh sửa lại cho đúng.
4.3. Tính toán giá trị biến mới từ biến có sẵn
Có thể sử dụng SPSS để cộng, trừ, nhân chia các biến đã có sẵn để trở thành 1 biến mới (thủ tục
TransformCompute). Tuy nhiên biến mới được tính toán này không tự động thay đổi nếu ta thay đổi các biến thành phần như công cụ tính toán trong Excel. Vì vậy, thủ tục tính toán này thường được tiến hành sau khi đã chỉnh lý dữ liệu.
Thủ tục tính toán này được sử dụng khá nhiều trong phân tích số liệu. Đặc biệt đối với những đề tài có sử dụng phân tích nhân tố để gom nhóm.
9
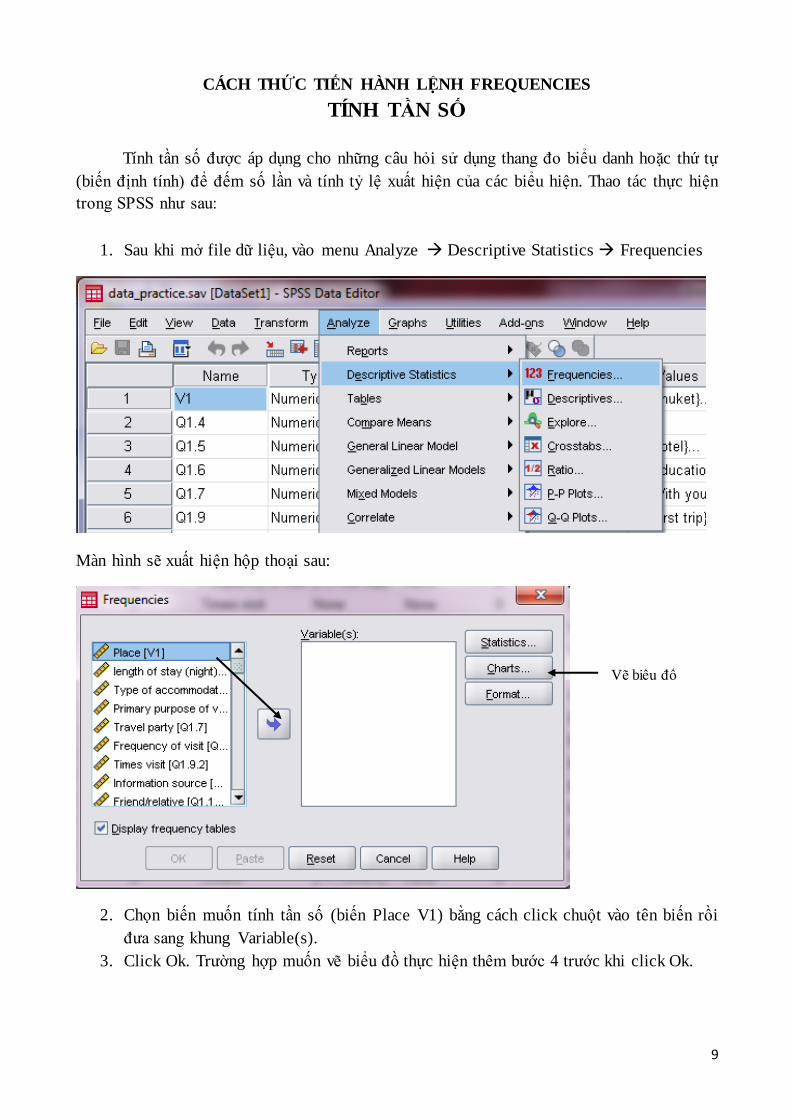
CÁCH THỨC TIẾN HÀNH LỆNH FREQUENCIES
TÍNH TẦN SỐ
Tính tần số được áp dụng cho những câu hỏi sử dụng thang đo biểu danh hoặc thứ tự
(biến định tính) để đếm số lần và tính tỷ lệ xuất hiện của các biểu hiện. Thao tác thực hiện
trong SPSS như sau:
1. Sau khi mở file dữ liệu, vào menu Analyze Descriptive Statistics Frequencies
Màn hình sẽ xuất hiện hộp thoại sau:
2. Chọn biến muốn tính tần số (biến Place V1) bằng cách click chuột vào tên biến rồi
đưa sang khung Variable(s).
3. Click Ok. Trường hợp muốn vẽ biểu đồ thực hiện thêm bước 4 trước khi click Ok.
Vẽ biểu đồ
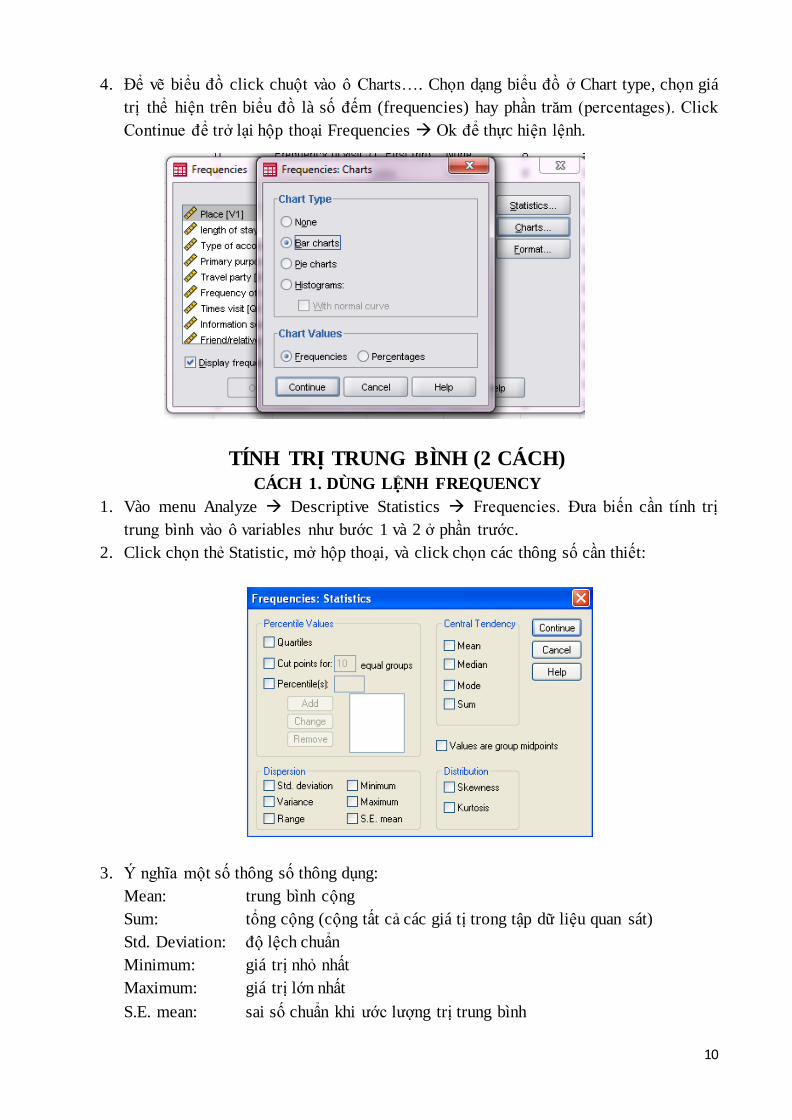
10
4. Để vẽ biểu đồ click chuột vào ô Charts…. Chọn dạng biểu đồ ở Chart type, chọn giá
trị thể hiện trên biểu đồ là số đếm (frequencies) hay phần trăm (percentages). Click
Continue để trở lại hộp thoại Frequencies Ok để thực hiện lệnh.
TÍNH TRỊ TRUNG BÌNH (2 CÁCH)
CÁCH 1. DÙNG LỆNH FREQUENCY
1. Vào menu Analyze Descriptive Statistics Frequencies. Đưa biến cần tính trị
trung bình vào ô variables như bước 1 và 2 ở phần trước.
2. Click chọn thẻ Statistic, mở hộp thoại, và click chọn các thông số cần thiết:
3. Ý nghĩa một số thông số thông dụng:
Mean: trung bình cộng
Sum: tổng cộng (cộng tất cả các giá tị trong tập dữ liệu quan sát)
Std. Deviation: độ lệch chuẩn
Minimum: giá trị nhỏ nhất
Maximum: giá trị lớn nhất
S.E. mean: sai số chuẩn khi ước lượng trị trung bình
11
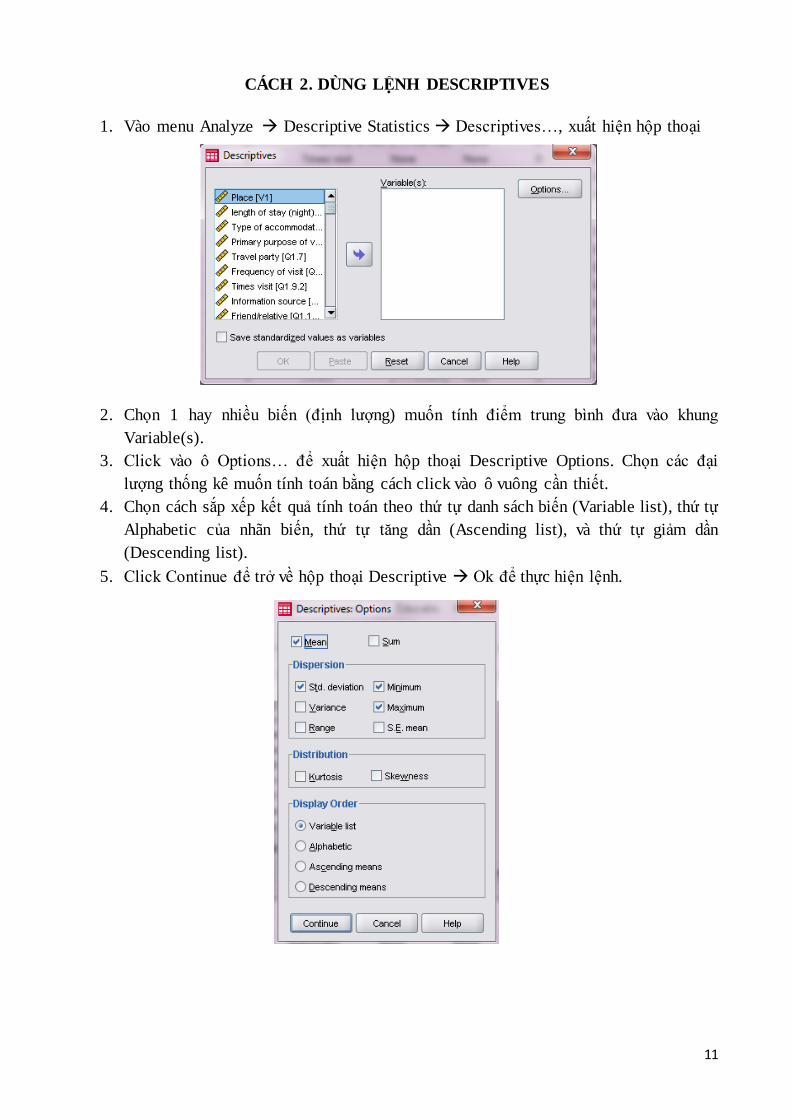
CÁCH 2. DÙNG LỆNH DESCRIPTIVES
1. Vào menu Analyze Descriptive Statistics Descriptives…, xuất hiện hộp thoại
2. Chọn 1 hay nhiều biến (định lượng) muốn tính điểm trung bình đưa vào khung
Variable(s).
3. Click vào ô Options… để xuất hiện hộp thoại Descriptive Options. Chọn các đại
lượng thống kê muốn tính toán bằng cách click vào ô vuông cần thiết.
4. Chọn cách sắp xếp kết quả tính toán theo thứ tự danh sách biến (Variable list), thứ tự
Alphabetic của nhãn biến, thứ tự tăng dần (Ascending list), và thứ tự giảm dần
(Descending list).
5. Click Continue để trở về hộp thoại Descriptive Ok để thực hiện lệnh.
12
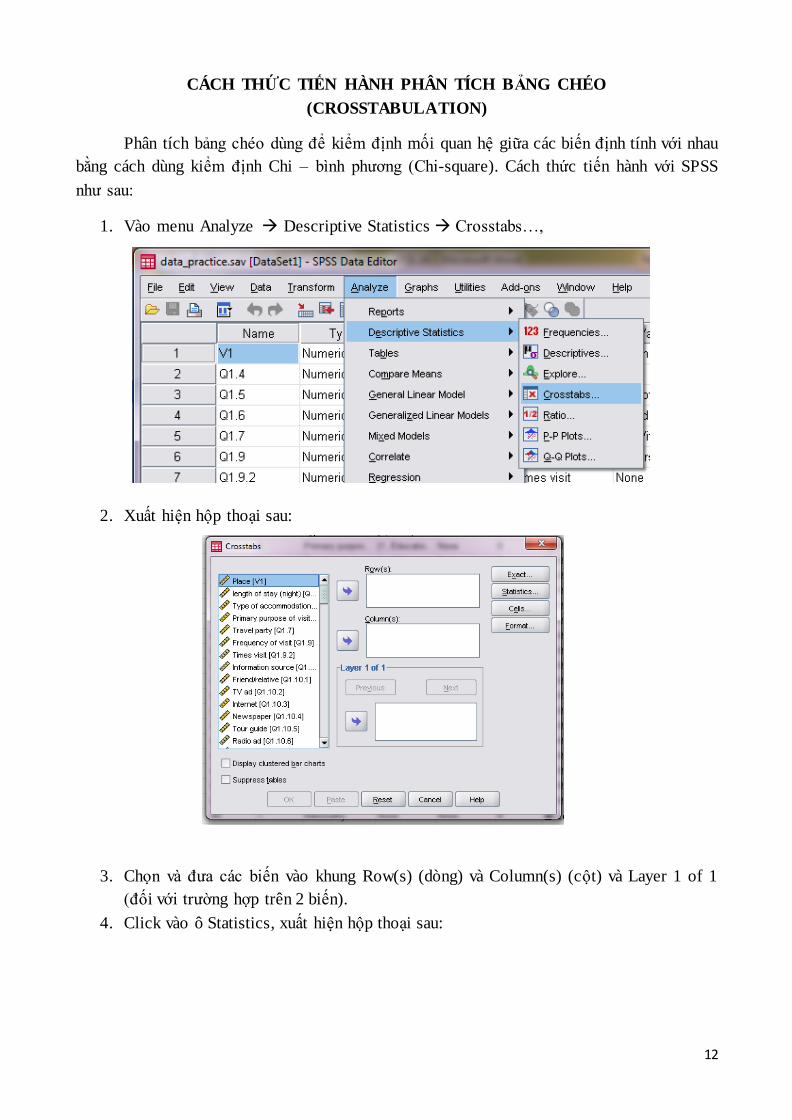
CÁCH THỨC TIẾN HÀNH PHÂN TÍCH BẢNG CHÉO
(CROSSTABULATION)
Phân tích bảng chéo dùng để kiểm định mối quan hệ giữa các biến định tính với nhau
bằng cách dùng kiểm định Chi – bình phương (Chi-square). Cách thức tiến hành với SPSS
như sau:
1. Vào menu Analyze Descriptive Statistics Crosstabs…,
2. Xuất hiện hộp thoại sau:
3. Chọn và đưa các biến vào khung Row(s) (dòng) và Column(s) (cột) và Layer 1 of 1
(đối với trường hợp trên 2 biến).
4. Click vào ô Statistics, xuất hiện hộp thoại sau:

13
5. Chọn các kiểm định cần thiết. Trong trường hợp này ta dùng kiểm định Chi – bình
phương (Chi-square).
- Các kiểm định ở ô Norminal dùng để kiểm định mối liên hệ giữa các biến biểu
danh.
- Các kiểm định ở ô Ordinal dùng để kiểm định mối liên hệ giữa các biến thứ tự.
6. Click vào continue để trở lại hộp thoại Crosstabs Click vào ô Cells, hộp thoại sau
xuất hiện:
7. Ở ô Counts chọn Observed (thể hiện tần số quan sát). Trong trường hợp muốn thể
hiện tần số mong đợi chọn Expected.
8. Chọn cách thể hiện phần trăm theo dòng hay theo cột ở ô Percentages.
9. Click Continue để trở lại hộp thoại Crosstabs Ok để thực hiện lệnh.

14
CÁCH ĐỌC KẾT QUẢ KIỂM ĐỊNH
Khi thực hiện kiểm định, ta có 2 giả thuyết.
H0: không có mối quan hệ giữa các biến.
H1: có mối quan hệ giữa các biến.
Để kết luận là chấp nhận hay bác bỏ giả thuyết H0, ta sẽ dùng các kiểm định phù hợp.
Dựa vào giá trị P (p-value) (SPSS viết tắt p-value là sig.) để kết luận là chấp nhận hay bác
bỏ giả thuyết H0
p-value (sig.) ≤ α (mức ý nghĩa) bác bỏ giả thuyết H0. Có nghĩa là có mối quan hệ
có ý nghĩa giữa các biến cần kiểm định.
p-value (sig.) > α (mức ý nghĩa) chấp nhận H0. Không có mối quan hệ giữa các
biến cần kiểm định.
ĐỐI VỚI KIỂM ĐỊNH CHI – BÌNH PHƯƠNG
Hàng đầu tiên của bảng Chi-square tests thể hiện giá trị P
Chi-Square Tests
Value df Asymp. Sig. (2-sided)
Pearson Chi-Square 16.217a 8 .039
Likelihood Ratio 18.708 8 .017
Linear-by-Linear Association .202 1 .653
N of Valid Cases 511
a. 8 cells (44.4%) have expected count less than 5. The minimum expected count is 1.69.
Cuối bảng Chi-Square tests SPSS sẽ đưa ra dòng thông báo cho biết % số ô có tần
suất mong đợi dưới 5. Kiểm định Chi-bình phương chỉ có ý nghĩa khi số quan sát đủ lớn,
nếu có quá 20% số ô trong bảng chéo có tần số lý thuyết nhỏ hơn 5 thì giá trị chi-bình
phương không còn đáng tin cậy.
Trong ví dụ trên có đến 44.4% số ô có tần số mong đợi dưới 5, biện pháp cho trường
hợp này là ta sẽ gom các biểu hiện trên các biến lại để tăng số quan sát trong mỗi nhóm.
p-value
15
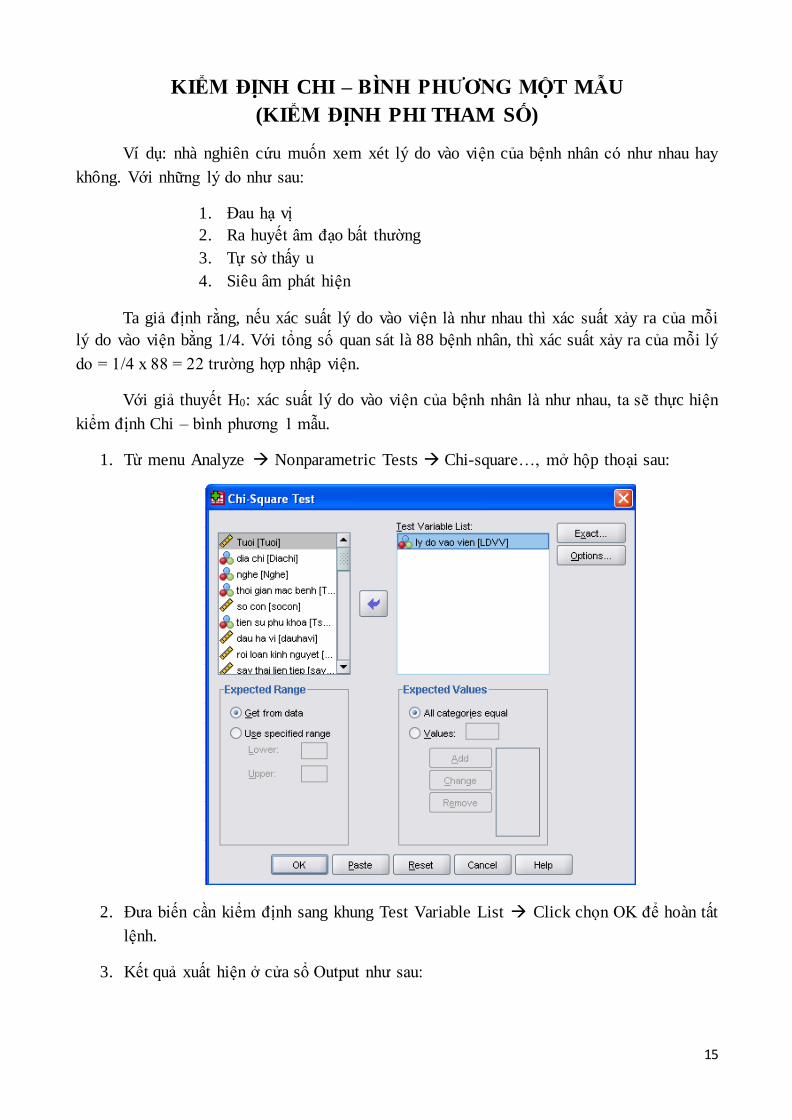
KIỂM ĐỊNH CHI – BÌNH PHƯƠNG MỘT MẪU
(KIỂM ĐỊNH PHI THAM SỐ)
Ví dụ: nhà nghiên cứu muốn xem xét lý do vào viện của bệnh nhân có như nhau hay
không. Với những lý do như sau:
1. Đau hạ vị
2. Ra huyết âm đạo bất thường
3. Tự sờ thấy u
4. Siêu âm phát hiện
Ta giả định rằng, nếu xác suất lý do vào viện là như nhau thì xác suất xảy ra của mỗi
lý do vào viện bằng 1/4. Với tổng số quan sát là 88 bệnh nhân, thì xác suất xảy ra của mỗi lý
do = 1/4 x 88 = 22 trường hợp nhập viện.
Với giả thuyết H0: xác suất lý do vào viện của bệnh nhân là như nhau, ta sẽ thực hiện
kiểm định Chi – bình phương 1 mẫu.
1. Từ menu Analyze Nonparametric Tests Chi-square…, mở hộp thoại sau:
2. Đưa biến cần kiểm định sang khung Test Variable List Click chọn OK để hoàn tất
lệnh.
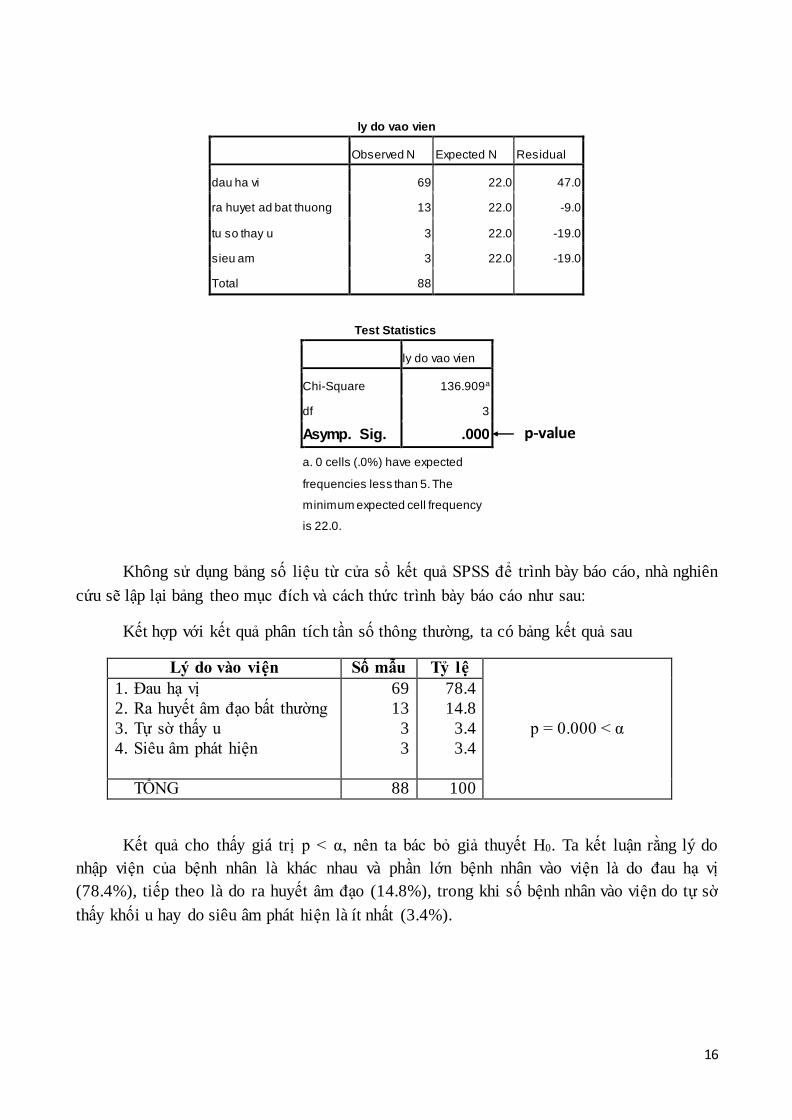
3. Kết quả xuất hiện ở cửa sổ Output như sau:
16
ly do vao vien
Observed N Expected N Residual
dau ha vi 69 22.0 47.0
ra huyet ad bat thuong 13 22.0 -9.0
tu so thay u 3 22.0 -19.0
sieu am 3 22.0 -19.0
Total 88
Test Statistics
ly do vao vien
Chi-Square 136.909a
df 3
Asymp. Sig. .000
a. 0 cells (.0%) have expected
frequencies less than 5. The
minimum expected cell frequency
is 22.0.
Không sử dụng bảng số liệu từ cửa sổ kết quả SPSS để trình bày báo cáo, nhà nghiên
cứu sẽ lập lại bảng theo mục đích và cách thức trình bày báo cáo như sau:
Kết hợp với kết quả phân tích tần số thông thường, ta có bảng kết quả sau
Lý do vào viện Số mẫu Tỷ lệ
p = 0.000 < α
1. Đau hạ vị
2. Ra huyết âm đạo bất thường
3. Tự sờ thấy u
4. Siêu âm phát hiện
69
13
3
3
78.4
14.8
3.4
3.4
TỔNG 88 100
Kết quả cho thấy giá trị p < α, nên ta bác bỏ giả thuyết H0. Ta kết luận rằng lý do
nhập viện của bệnh nhân là khác nhau và phần lớn bệnh nhân vào viện là do đau hạ vị
(78.4%), tiếp theo là do ra huyết âm đạo (14.8%), trong khi số bệnh nhân vào viện do tự sờ
thấy khối u hay do siêu âm phát hiện là ít nhất (3.4%).
p-value
17
CÁCH THỨC TIẾN HÀNH KIỂM ĐỊNH GIẢ THUYẾT VỀ TRỊ TRUNG BÌNH
CỦA 2 TỔNG THỂ ĐỘC LẬP (Independent Samples T-test)
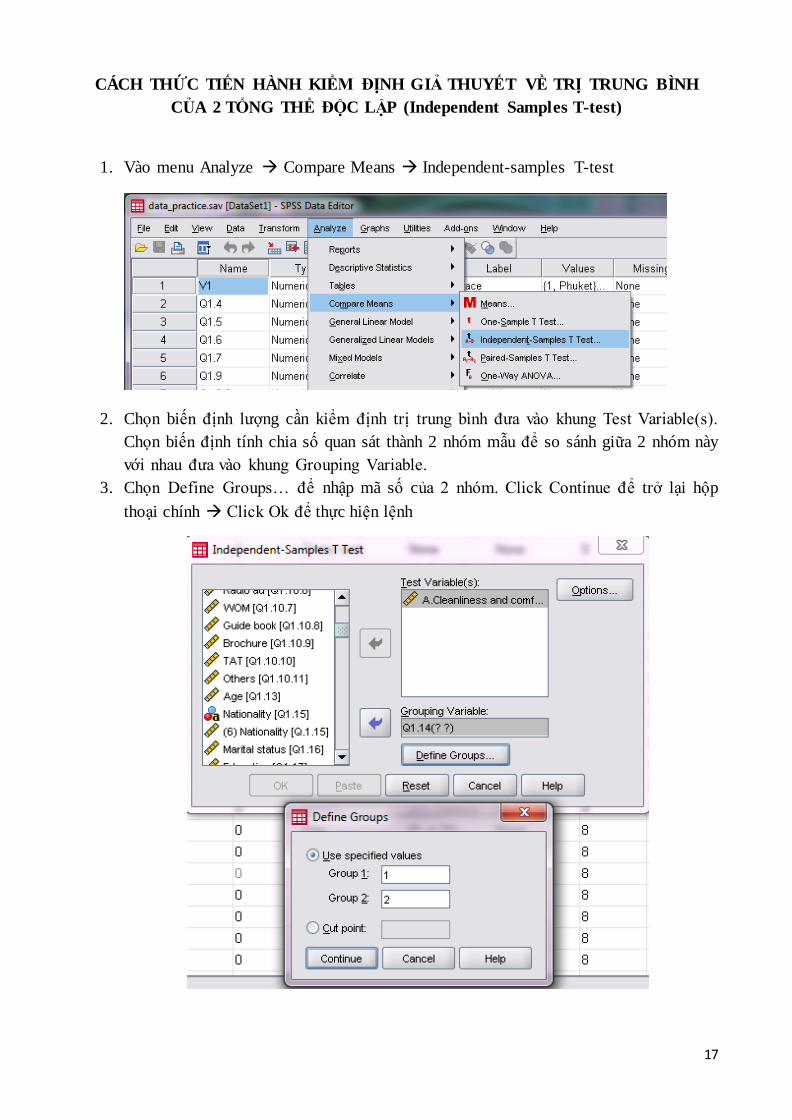
1. Vào menu Analyze Compare Means Independent-samples T-test
2. Chọn biến định lượng cần kiểm định trị trung bình đưa vào khung Test Variable(s).
Chọn biến định tính chia số quan sát thành 2 nhóm mẫu để so sánh giữa 2 nhóm này
với nhau đưa vào khung Grouping Variable.
3. Chọn Define Groups… để nhập mã số của 2 nhóm. Click Continue để trở lại hộp
thoại chính Click Ok để thực hiện lệnh
18
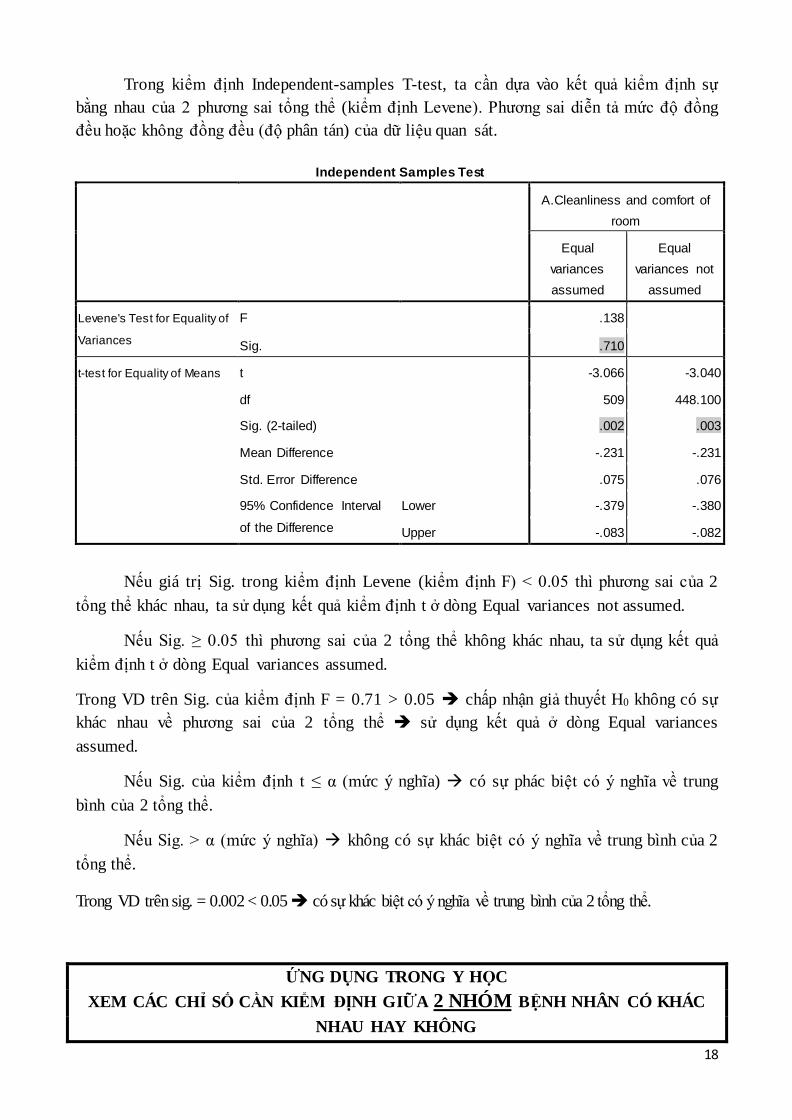
Trong kiểm định Independent-samples T-test, ta cần dựa vào kết quả kiểm định sự
bằng nhau của 2 phương sai tổng thể (kiểm định Levene). Phương sai diễn tả mức độ đồng
đều hoặc không đồng đều (độ phân tán) của dữ liệu quan sát.
Independent Samples Test
A.Cleanliness and comfort of
room
Equal
variances
assumed
Equal
variances not
assumed
Levene's Test for Equality of
Variances
F .138
Sig. .710
t-test for Equality of Means t -3.066 -3.040
df 509 448.100
Sig. (2-tailed) .002 .003
Mean Difference -.231 -.231
Std. Error Difference .075 .076
95% Confidence Interval
of the Difference
Lower -.379 -.380
Upper -.083 -.082
Nếu giá trị Sig. trong kiểm định Levene (kiểm định F) < 0.05 thì phương sai của 2
tổng thể khác nhau, ta sử dụng kết quả kiểm định t ở dòng Equal variances not assumed.
Nếu Sig. ≥ 0.05 thì phương sai của 2 tổng thể không khác nhau, ta sử dụng kết quả
kiểm định t ở dòng Equal variances assumed.
Trong VD trên Sig. của kiểm định F = 0.71 > 0.05 chấp nhận giả thuyết H0 không có sự
khác nhau về phương sai của 2 tổng thể sử dụng kết quả ở dòng Equal variances
assumed.
Nếu Sig. của kiểm định t ≤ α (mức ý nghĩa) có sự phác biệt có ý nghĩa về trung
bình của 2 tổng thể.
Nếu Sig. > α (mức ý nghĩa) không có sự khác biệt có ý nghĩa về trung bình của 2
tổng thể.
Trong VD trên sig. = 0.002 < 0.05 có sự khác biệt có ý nghĩa về trung bình của 2 tổng thể.
ỨNG DỤNG TRONG Y HỌC
XEM CÁC CHỈ SỐ CẦN KIỂM ĐỊNH GIỮA 2 NHÓM BỆNH NHÂN CÓ KHÁC
NHAU HAY KHÔNG
19
CÁCH THỨC TIẾN HÀNH KIỂM ĐỊNH GIẢ THUYẾT VỀ TRỊ TRUNG BÌNH
CỦA 2 TỔNG THỂ PHỤ THUỘC HAY PHỐI HỢP TỪNG CẶP
(Paired-Samples T-test)
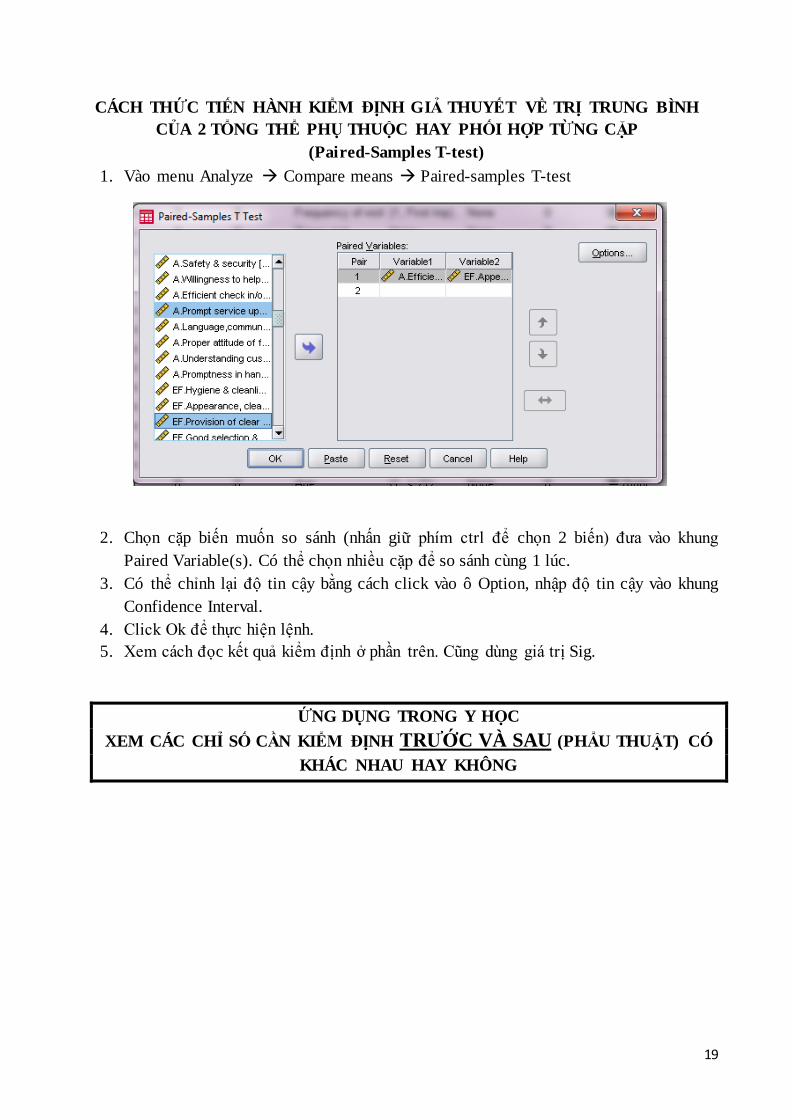
1. Vào menu Analyze Compare means Paired-samples T-test
2. Chọn cặp biến muốn so sánh (nhấn giữ phím ctrl để chọn 2 biến) đưa vào khung
Paired Variable(s). Có thể chọn nhiều cặp để so sánh cùng 1 lúc.
3. Có thể chỉnh lại độ tin cậy bằng cách click vào ô Option, nhập độ tin cậy vào khung
Confidence Interval.
4. Click Ok để thực hiện lệnh.
5. Xem cách đọc kết quả kiểm định ở phần trên. Cũng dùng giá trị Sig.
ỨNG DỤNG TRONG Y HỌC
XEM CÁC CHỈ SỐ CẦN KIỂM ĐỊNH TRƯỚC VÀ SAU (PHẨU THUẬT) CÓ
KHÁC NHAU HAY KHÔNG

20
CÁCH THỨC TIẾN HÀNH PHÂN TÍCH PHƯƠNG SAI
(ANOVA – Analysis of Variance)
Phân tích phương sai ANOVA là phương pháp so sánh trị trung bình của 3 nhóm trở
lên. Có 2 kỹ thuật phân tích phương sai: ANOVA 1 yếu tố (một biến yếu tố để phân loại các
quan sát thành các nhóm khác nhau) và ANOVA nhiều yếu tố(2 hay nhiều biến để phân
loại). Ở phần thực hành cơ bản chỉ đề cập đến phân tích phương sai 1 yếu tố (One-way
ANOVA).
Một số giả định đối với phân tích phương sai một yếu tố:
- Các nhóm so sánh phải độc lập và được chọn một cách ngẫu nhiên.
- Các nhóm so sánh phải có phân phối chuẩn hoặc cỡ mẫu phải đủ lớn để được xem
như tiệm cận phân phối chuẩn.
- Phương sai của các nhóm so sánh phải đồng nhất.
1. Từ menu Analyze Compare Means One-Way ANOVA, xuất hiện hộp thoại
sau:
2. Đưa biến định lượng (trị trung bình) vào khung Dependent list.
Đưa biến phân loại xác định các nhóm cần so sánh với nhau vào khung Factor.
3. Click vào nút Option để mở hộp thoại One-Way ANOVA Options.
Trong hộp thoại One-way ANOVA Options:
- Click chọn ô Descriptive để tính đại lượng thống kê mô tả (tính trị trung bình)
theo từng nhóm so sánh.
- Click chọn ô Homogeneity of variance test để kiểm định sự bằng nhau của các
phương sai nhóm (thực hiện kiểm định Levene).
2 kỹ thuật dùng để
kiểm định sâu
ANOVA

21
4. Click chọn Continue để trở lại hộp thoại ban đầu click Ok để thực hiện lệnh.
5. Dựa vào kết quả kiểm định ANOVA, nếu H0 được chấp nhận thì kết luận không có
sự khác biệt có ý nghĩa giữa các nhóm với nhau. Nếu H0 bị bác bỏ có sự khác biệt
có ý nghĩa giữa các nhóm trở lại hộp thoại One – way ANOVA để thực hiện kiểm
định sâu ANOVA nhằm xác định cụ thể trung bình của nhóm nào khác với nhóm
nào, nghĩa là tìm xem sự khác biệt của các nhóm xảy ra ở đâu.
6. Tuy nhiên có thể thực hiện kiểm định ANOVA và sâu ANOVA cùng lúc với nhau.
Dựa vào sự chấp nhận hay bác bỏ giả thuyết H0 để quan tâm hay không quan tâm đến
kết quả kiểm định sâu ANOVA.
Phân tích sâu ANOVA – Xác định chỗ khác biệt
Có 2 phương pháp để phân tích sâu ANOVA, đó là kiểm định “trước” (kiểm định
Priori Contrasts) và kiểm định “sau” (kiểm định Post-Hoc test). Phương pháp kiểm định gần
với phương pháp nghiên cứu thực là Post-Hoc test. Nên trong phần này ta sẽ sử dụng Post-
Hoc test để thực hiện kiểm định sâu ANOVA nhằm tìm ra chỗ khác biệt.
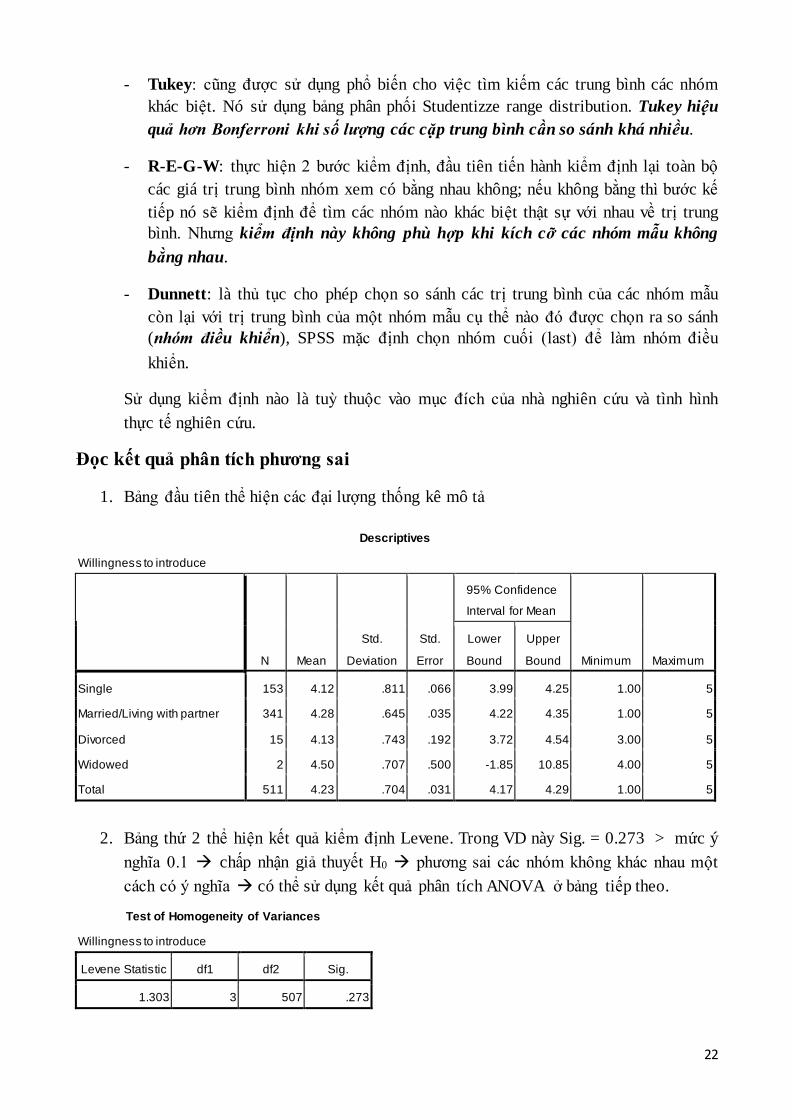
Các phương pháp kiểm định thống kê của Post-Hoc test thường được sử dụng:
- LSD: đây là phép kiểm định dùng kiểm định t lần lượt cho từng cặp trung bình
nhóm, do vậy nhược điểm của nó là độ tin cậy không cao vì làm gia tăng mức độ
phạm sai lầm tương ứng với việc so sánh nhiều nhóm cùng một lúc.
- Bonferroni : giống quy tắc của LSD nhưng điều chỉnh được mức ý nghĩa khi tiến
hành so sánh bội dựa trên số lần tiến hành so sánh. Đây là một trong những thủ
tục kiểm định đơn giản nhất và hay được sử dụng cho mục tiêu này.
22
- Tukey: cũng được sử dụng phổ biến cho việc tìm kiếm các trung bình các nhóm
khác biệt. Nó sử dụng bảng phân phối Studentizze range distribution. Tukey hiệu
quả hơn Bonferroni khi số lượng các cặp trung bình cần so sánh khá nhiều.
- R-E-G-W: thực hiện 2 bước kiểm định, đầu tiên tiến hành kiểm định lại toàn bộ
các giá trị trung bình nhóm xem có bằng nhau không; nếu không bằng thì bước kế
tiếp nó sẽ kiểm định để tìm các nhóm nào khác biệt thật sự với nhau về trị trung
bình. Nhưng kiểm định này không phù hợp khi kích cỡ các nhóm mẫu không
bằng nhau.
- Dunnett: là thủ tục cho phép chọn so sánh các trị trung bình của các nhóm mẫu
còn lại với trị trung bình của một nhóm mẫu cụ thể nào đó được chọn ra so sánh
(nhóm điều khiển), SPSS mặc định chọn nhóm cuối (last) để làm nhóm điều
khiển.
Sử dụng kiểm định nào là tuỳ thuộc vào mục đích của nhà nghiên cứu và tình hình
thực tế nghiên cứu.
Đọc kết quả phân tích phương sai
1. Bảng đầu tiên thể hiện các đại lượng thống kê mô tả
Descriptives
Willingness to introduce
N Mean
Std.
Deviation
Std.
Error
95% Confidence
Interval for Mean
Minimum Maximum
Lower
Bound
Upper
Bound
Single 153 4.12 .811 .066 3.99 4.25 1.00 5
Married/Living with partner 341 4.28 .645 .035 4.22 4.35 1.00 5
Divorced 15 4.13 .743 .192 3.72 4.54 3.00 5
Widowed 2 4.50 .707 .500 -1.85 10.85 4.00 5
Total 511 4.23 .704 .031 4.17 4.29 1.00 5
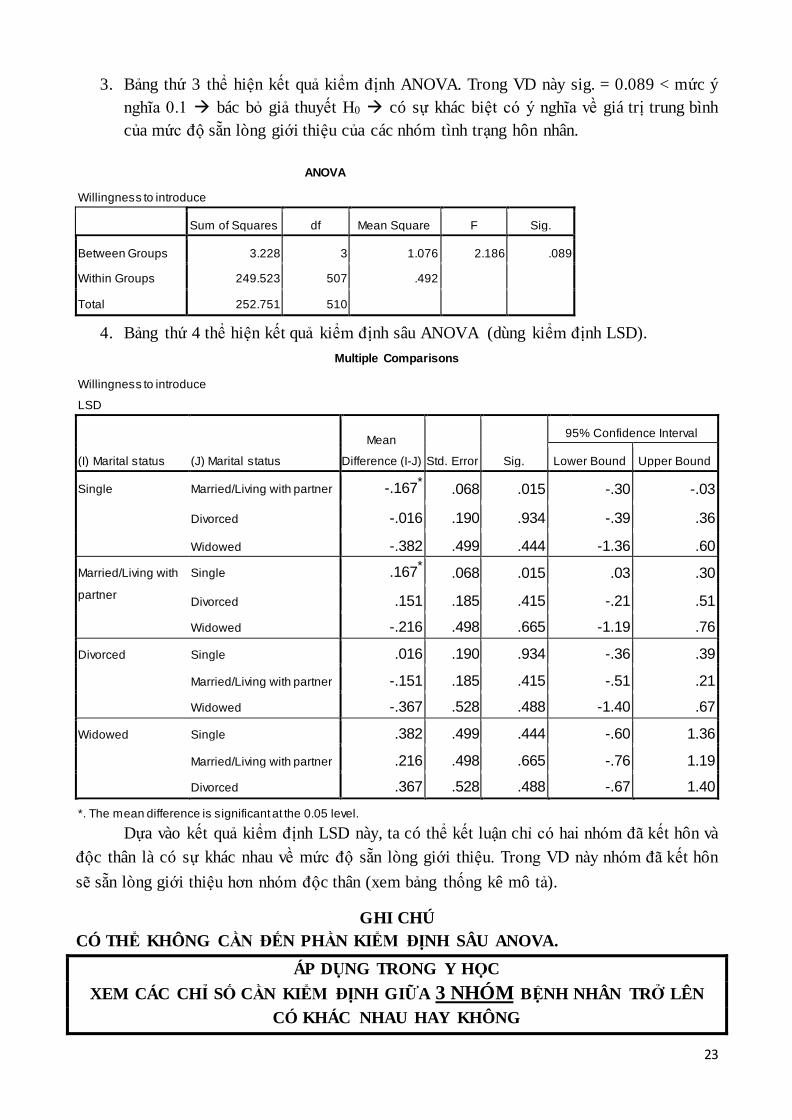
2. Bảng thứ 2 thể hiện kết quả kiểm định Levene. Trong VD này Sig. = 0.273 > mức ý
nghĩa 0.1 chấp nhận giả thuyết H0 phương sai các nhóm không khác nhau một
cách có ý nghĩa có thể sử dụng kết quả phân tích ANOVA ở bảng tiếp theo.
Test of Homogeneity of Variances
Willingness to introduce
Levene Statistic df1 df2 Sig.
1.303 3 507 .273
23
3. Bảng thứ 3 thể hiện kết quả kiểm định ANOVA. Trong VD này sig. = 0.089 < mức ý
nghĩa 0.1 bác bỏ giả thuyết H0 có sự khác biệt có ý nghĩa về giá trị trung bình
của mức độ sẵn lòng giới thiệu của các nhóm tình trạng hôn nhân.
ANOVA
Willingness to introduce
Sum of Squares df Mean Square F Sig.
Between Groups 3.228 3 1.076 2.186 .089
Within Groups 249.523 507 .492
Total 252.751 510
4. Bảng thứ 4 thể hiện kết quả kiểm định sâu ANOVA (dùng kiểm định LSD).
Multiple Comparisons
Willingness to introduce
LSD
(I) Marital status (J) Marital status
Mean
Difference (I-J) Std. Error Sig.
95% Confidence Interval
Lower Bound Upper Bound
Single Married/Living with partner -.167* .068 .015 -.30 -.03
Divorced -.016 .190 .934 -.39 .36
Widowed -.382 .499 .444 -1.36 .60
Married/Living with
partner
Single .167* .068 .015 .03 .30
Divorced .151 .185 .415 -.21 .51
Widowed -.216 .498 .665 -1.19 .76
Divorced Single .016 .190 .934 -.36 .39
Married/Living with partner -.151 .185 .415 -.51 .21
Widowed -.367 .528 .488 -1.40 .67
Widowed Single .382 .499 .444 -.60 1.36
Married/Living with partner .216 .498 .665 -.76 1.19
Divorced .367 .528 .488 -.67 1.40
*. The mean difference is significant at the 0.05 level.
Dựa vào kết quả kiểm định LSD này, ta có thể kết luận chỉ có hai nhóm đã kết hôn và
độc thân là có sự khác nhau về mức độ sẵn lòng giới thiệu. Trong VD này nhóm đã kết hôn
sẽ sẵn lòng giới thiệu hơn nhóm độc thân (xem bảng thống kê mô tả).
GHI CHÚ
CÓ THỂ KHÔNG CẦN ĐẾN PHẦN KIỂM ĐỊNH SÂU ANOVA.
ÁP DỤNG TRONG Y HỌC
XEM CÁC CHỈ SỐ CẦN KIỂM ĐỊNH GIỮA 3 NHÓM BỆNH NHÂN TRỞ LÊN
CÓ KHÁC NHAU HAY KHÔNG

24
XỬ LÝ CÂU HỎI NHIỀU LỰA CHỌN
1. MÃ HOÁ
Trong quá trình nghiên cứu, có những câu hỏi cho phép người trả lời chọn nhiều hơn
1 lựa chọn. Ví dụ: câu hỏi về tiền sử phẫu thuật, bệnh nhân có thể cùng một lúc có nhiều
phẩu thuật trước đây. Đây được gọi là câu hỏi nhiều lựa chọn.
Số thứ tự Tên phẫu thuật Đánh dấu và ghi chú (nếu có)
1. Cắt viêm ruột thừa
2. Mổ lấy thai
3. Cắt tử cung
4. Phẫu thuật u buồng trứng
5. Viêm túi mật
6. Phẫu thuật khác
Đối với câu hỏi nhiều lựa chọn, mỗi một lựa chọn sẽ được mã hoá thành 1 biến. Theo
ví dụ trên ta sẽ mã hoá thành 6 biến.
Cách thức khai báo Value: có 2 cách thức
- Cách 1: dùng dạng câu hỏi phân đôi Có – Không (Dạng biến Dichotomy)
- Cách 2: dùng chính số thứ tự của biến để mã hoá. Nếu bệnh nhân nào có tiền sử
cắt viêm ruột thừa sẽ nhập vào số 1, có tiền sử mổ lấy thai sẽ nhập vào số 2.
(Dạng biến Category)
25
2. CÁCH THỨC XỬ LÝ
Đối với câu hỏi nhiều lựa chọn, khi cần phân tích tần số chúng ta không sử dụng
công cụ thống kê mô tả tính Frequency thông thường. Công cụ dùng xử lý câu hỏi nhiều lựa
chọn là Multiple Response.
2.1. Định dạng biến tổng hợp
1. Từ menu Analyze Multiple Response Define Variable Sets… để mở hộp
thoại sau:
2. Chọn tất cả các biến thuộc câu nhiều lựa chọn đưa vào khung Variables in Set.
3. Khai báo cách mã hoá ở khung Variables Are Coded As:
- Nếu dùng cách mã hoá 1: dùng dạng câu hỏi phân đôi Có – Không, ta sẽ khai báo
biến ở dòng Dichotomies. Và sẽ đếm giá trị “Có” ở ô Counted value. Đối với ví
dụ trên, do ta khai báo 1. Không, 2. Có, nên ở ô này ta sẽ nhập giá trị cần đếm là
“2”
- Nếu dùng cách mã hoá 2, ta sẽ khai báo ở dòng Categories, và đếm các số thứ tự
của biến. Trong ví dụ trên có 6 biến, ta sẽ đếm từ giá trị 1 đến 6 tại ô Range: 1
through: 6.
4. Khai báo tên và nhãn biến ở khung Name và Label.
5. Click vào Add để xác nhận biến tổng hợp đã được tạo Click chọn Close để
hoàn tất quá trình định dạng biến tổng hợp.

26
2.2. Phân tích tần số (Frequency)
1. Từ menu Analyze Multiple Response Frequency, xuất hiện hộp thoại sau:
2. Đưa biến tổng hợp vừa tạo ở phần trên vào ô Tables for Click chọn Ok để hoàn
tất thao tác.
3. Kết quả hiện ra ở cửa sổ Output như sau:
$TSPHAUTHUATTH Frequencies
Responses Percent of
Cases N Percent
TIEN SU PHAU THUAT
TONG HOPa
tien su cat viem ruot thua 38 69.1% 76.0%
tien su mo lay thai 3 5.5% 6.0%
tien su mo cat tu cung 2 3.6% 4.0%
tien su phau thuat u buong
trung 3 5.5% 6.0%
ts mo do benh khac 9 16.4% 18.0%
Total 55 100.0% 110.0%
a. Dichotomy group tabulated at value 2.
- Percent of Cases: phần trăm trên tổng số bệnh nhân được quan sát (50 bệnh nhân) - Percent of Responses: phần trăm trên tổng sự trả lời (vì mỗi bệnh nhân có thể có nhiều
tiền sử phẩu thuật nên tổng sự trả lời = 55 > cỡ mẫu quan sát = 50)
27
CÁCH THỨC TIẾN HÀNH PHÂN TÍCH NHÂN TỐ
1. Từ menu Analyze Data Reduction Factor
2. Xuất hiện hộp thoại sau:
3. Chọn tất cả các biến cần gom nhóm vào ô Variables.
4. Click chọn ô Descriptives…, xuất hiện hộp thoại sau:

28
- Chọn các tham số thống kê mô tả.
- Chọn tính các ma trận hệ số tương quan.
- Chọn kiểm định Bartlett. Trong phân tích nhân tố, cần kiểm định mối tương quan
của các biến với nhau (H0: các biến không có tương quan với nhau trong tổng
thể). Nếu giả thuyết H0 không được bác bỏ thì phân tích nhân tố có khả năng
không thích hợp.
- Click continue để trở lại hộp thoại Factor analysis
5. Click chọn ô Extraction để mở hộp thoại sau:
- Chọn phương pháp rút trích nhân tố, phương pháp mặc định là rút các thành phần
chính – Principal components.
- Phân tích ma trận tương quan hay hiệp phương sai ở ô Analyze.
- Thể hiện phương án nhân tố chưa xoay và vẽ biểu đồ dốc ở ô Display.
- Xác định tiêu chuẩn rút trích nhân tố hay số lượng nhân tố cần rút trích.
Có 2 cách để xác định tiêu chuẩn này ở ô Extract:
Xác định từ trước dựa vào ý đồ của nhà nghiên cứu và kết quả của các cuộc
nghiên cứu trước. Nhà nghiên cứu xác định số nhân tố ở ô Number of factors.
Xác định dựa vào Eigenvalue (Determination based on eigenvalue. Chỉ có
những nhân tố nào lớn hơn 1 mới được giữ lại trong mô hình phân tích.
- Click Continue để trở lại hộp thoại Factor Analysis.
6. Click chọn ô Rotation (Xoay nhân tố) để mở hộp thoại sau:
Xoay nhân tố là thủ tục giúp ma trận nhân tố trở nên đơn giản và dễ giải thích hơn.

29
Có nhiều phương pháp xoay khác nhau trong đó được sử dụng rộng rãi nhất là
Varimax procedure (xoay nguyên góc các nhân tố để tối thiểu hoá số lượng biến có hệ số
lớn tại cùng một nhân tố, vì vậy sẽ tăng cường khả năng giải thích các nhân tố).
Click Continue để trở lại hộp thoại chính.
7. Click chọn ô Factor Score để tính điểm các nhân tố
Nếu nhà nghiên cứu muốn xác định tập hợp nhân tố ít hơn để sử dụng trong các
phương pháp phân tích đa biến tiếp theo (phân tích ANOVA, hồi quy…), ta có thể tính toán
ra các nhân số (trị số của các biến tổng hợp) cho từng trường hợp quan sát một. Nhân số của
nhân tố thứ i bằng:
Fi = Wi1X1 + Wi2X2 + Wi3X3 + … + WikXk
Máy tính sẽ tính các nhân số này và tự động save vào file dữ liệu những biến mới
này.
- Mặc định của chương trình là phương pháp tính nhân số Regression (theo đơn vị
đo lường độ lệch chuẩn).
- Chọn thể hiện bảng trọng số nhân tố bằng cách click vào ô Display factor …
- Click Continue để trở lại hộp thoại ban đầu click Ok để thực hiện lệnh.
30
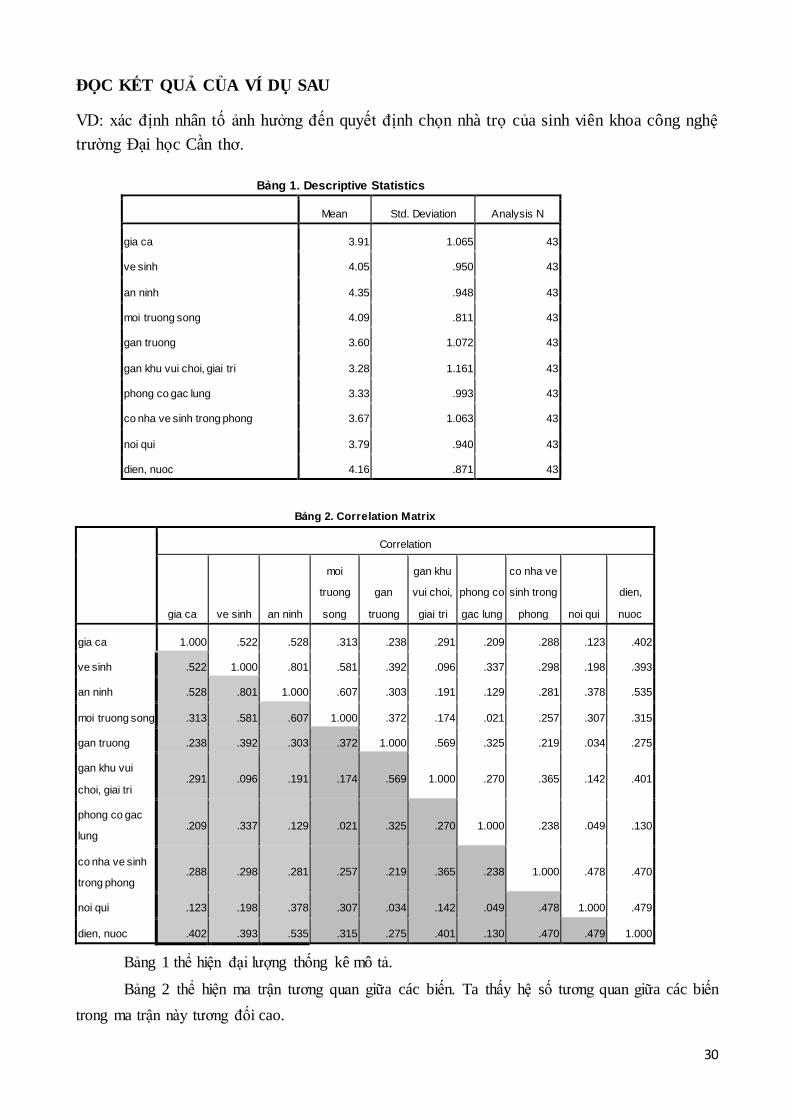
ĐỌC KẾT QUẢ CỦA VÍ DỤ SAU
VD: xác định nhân tố ảnh hưởng đến quyết định chọn nhà trọ của sinh viên khoa công nghệ
trường Đại học Cần thơ.
Bảng 1. Descriptive Statistics
Mean Std. Deviation Analysis N
gia ca 3.91 1.065 43
ve sinh 4.05 .950 43
an ninh 4.35 .948 43
moi truong song 4.09 .811 43
gan truong 3.60 1.072 43
gan khu vui choi, giai tri 3.28 1.161 43
phong co gac lung 3.33 .993 43
co nha ve sinh trong phong 3.67 1.063 43
noi qui 3.79 .940 43
dien, nuoc 4.16 .871 43
Bảng 2. Correlation Matrix
Correlation
gia ca ve sinh an ninh
moi
truong
song
gan
truong
gan khu
vui choi,
giai tri
phong co
gac lung
co nha ve
sinh trong
phong noi qui
dien,
nuoc
gia ca 1.000 .522 .528 .313 .238 .291 .209 .288 .123 .402
ve sinh .522 1.000 .801 .581 .392 .096 .337 .298 .198 .393
an ninh .528 .801 1.000 .607 .303 .191 .129 .281 .378 .535
moi truong song .313 .581 .607 1.000 .372 .174 .021 .257 .307 .315
gan truong .238 .392 .303 .372 1.000 .569 .325 .219 .034 .275
gan khu vui
choi, giai tri .291 .096 .191 .174 .569 1.000 .270 .365 .142 .401
phong co gac
lung .209 .337 .129 .021 .325 .270 1.000 .238 .049 .130
co nha ve sinh
trong phong .288 .298 .281 .257 .219 .365 .238 1.000 .478 .470
noi qui .123 .198 .378 .307 .034 .142 .049 .478 1.000 .479
dien, nuoc .402 .393 .535 .315 .275 .401 .130 .470 .479 1.000
Bảng 1 thể hiện đại lượng thống kê mô tả.
Bảng 2 thể hiện ma trận tương quan giữa các biến. Ta thấy hệ số tương quan giữa các biến
trong ma trận này tương đối cao.
31
Bảng 3 thể hiện kết quả của kiểm định Barlett. Dựa vào kết quả này ta có thể bác bỏ H0 (Các
biến không có tương quan với nhau). Phân tích nhân tố là phương pháp phù hợp để phân
tích ma trận tương quan ở bảng 2.
Bảng 3. KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .714
Bartlett's Test of Sphericity Approx. Chi-Square 167.933
df 45
Sig. .000
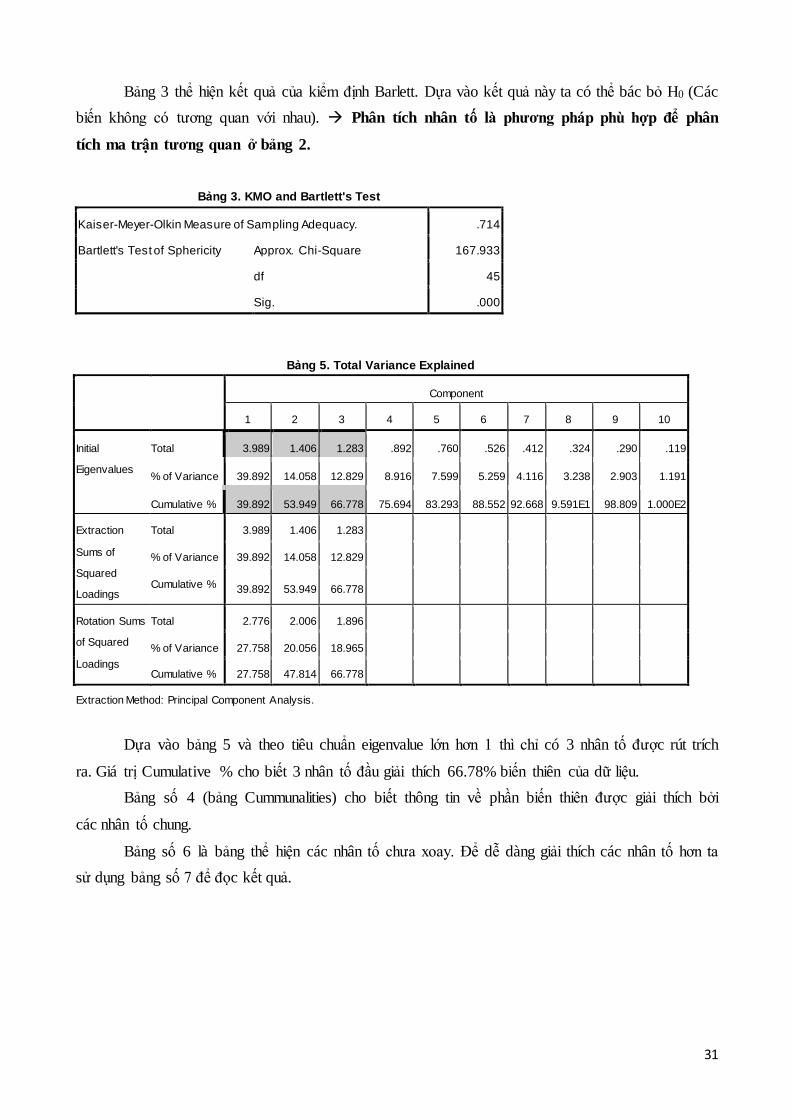
Dựa vào bảng 5 và theo tiêu chuẩn eigenvalue lớn hơn 1 thì chỉ có 3 nhân tố được rút trích
ra. Giá trị Cumulative % cho biết 3 nhân tố đầu giải thích 66.78% biến thiên của dữ liệu.
Bảng số 4 (bảng Cummunalities) cho biết thông tin về phần biến thiên được giải thích bởi
các nhân tố chung.
Bảng số 6 là bảng thể hiện các nhân tố chưa xoay. Để dễ dàng giải thích các nhân tố hơn ta
sử dụng bảng số 7 để đọc kết quả.
Bảng 5. Total Variance Explained
Component
1 2 3 4 5 6 7 8 9 10
Initial
Eigenvalues
Total 3.989 1.406 1.283 .892 .760 .526 .412 .324 .290 .119
% of Variance 39.892 14.058 12.829 8.916 7.599 5.259 4.116 3.238 2.903 1.191
Cumulative % 39.892 53.949 66.778 75.694 83.293 88.552 92.668 9.591E1 98.809 1.000E2
Extraction
Sums of
Squared
Loadings
Total 3.989 1.406 1.283
% of Variance 39.892 14.058 12.829
Cumulative % 39.892 53.949 66.778
Rotation Sums
of Squared
Loadings
Total 2.776 2.006 1.896
% of Variance 27.758 20.056 18.965
Cumulative % 27.758 47.814 66.778
Extraction Method: Principal Component Analysis.
32
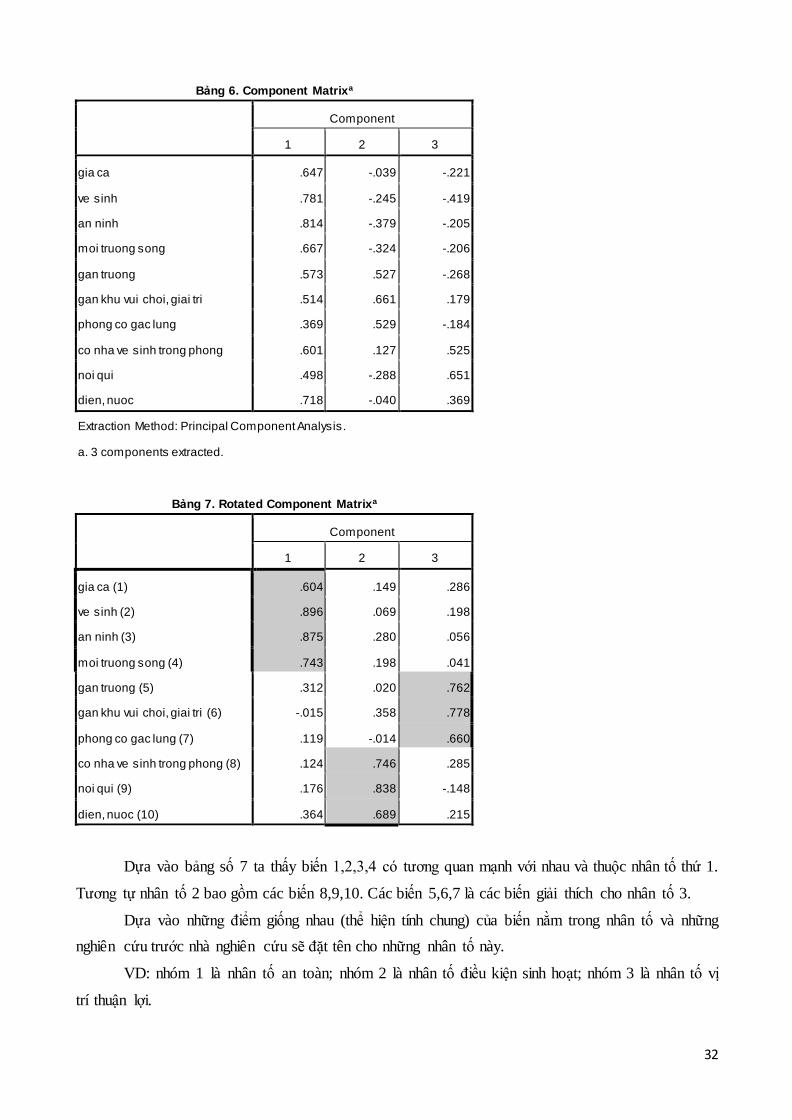
Bảng 6. Component Matrixa
Component
1 2 3
gia ca .647 -.039 -.221
ve sinh .781 -.245 -.419
an ninh .814 -.379 -.205
moi truong song .667 -.324 -.206
gan truong .573 .527 -.268
gan khu vui choi, giai tri .514 .661 .179
phong co gac lung .369 .529 -.184
co nha ve sinh trong phong .601 .127 .525
noi qui .498 -.288 .651
dien, nuoc .718 -.040 .369
Extraction Method: Principal Component Analysis.
a. 3 components extracted.
Bảng 7. Rotated Component Matrixa
Component
1 2 3
gia ca (1) .604 .149 .286
ve sinh (2) .896 .069 .198
an ninh (3) .875 .280 .056
moi truong song (4) .743 .198 .041
gan truong (5) .312 .020 .762
gan khu vui choi, giai tri (6) -.015 .358 .778
phong co gac lung (7) .119 -.014 .660
co nha ve sinh trong phong (8) .124 .746 .285
noi qui (9) .176 .838 -.148
dien, nuoc (10) .364 .689 .215
Dựa vào bảng số 7 ta thấy biến 1,2,3,4 có tương quan mạnh với nhau và thuộc nhân tố thứ 1.
Tương tự nhân tố 2 bao gồm các biến 8,9,10. Các biến 5,6,7 là các biến giải thích cho nhân tố 3.
Dựa vào những điểm giống nhau (thể hiện tính chung) của biến nằm trong nhân tố và những
nghiên cứu trước nhà nghiên cứu sẽ đặt tên cho những nhân tố này.
VD: nhóm 1 là nhân tố an toàn; nhóm 2 là nhân tố điều kiện sinh hoạt; nhóm 3 là nhân tố vị
trí thuận lợi.
33
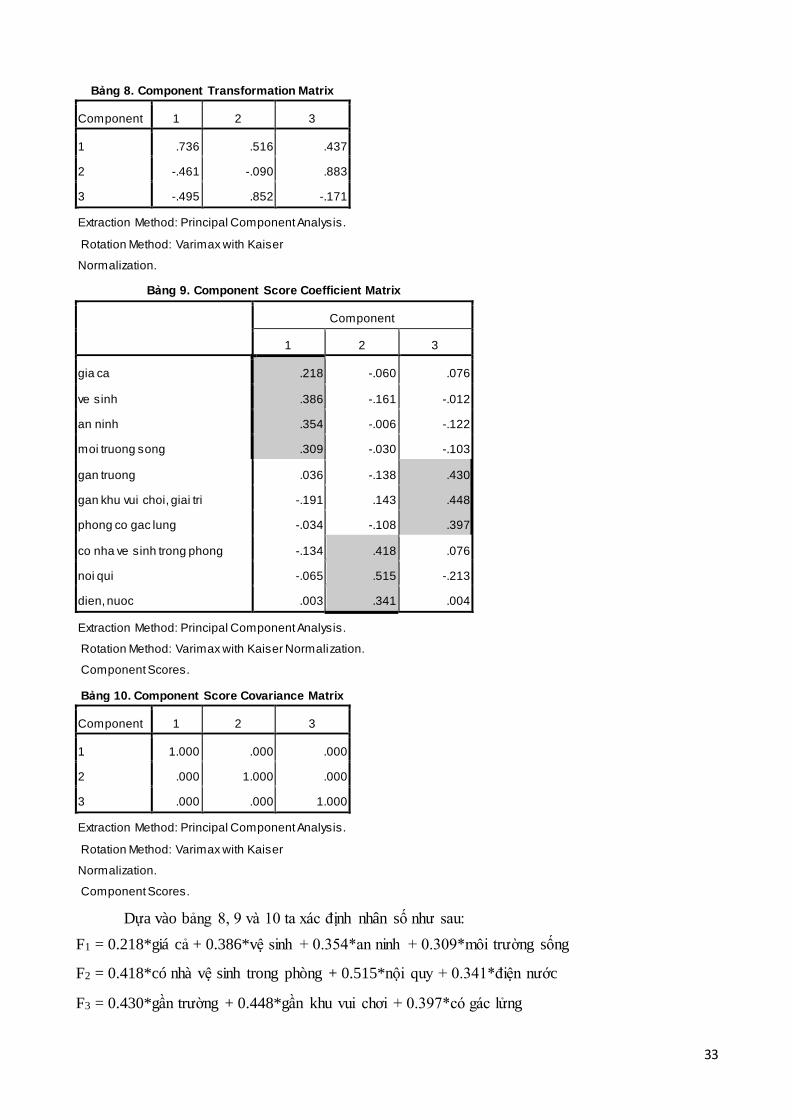
Bảng 8. Component Transformation Matrix
Component 1 2 3
1 .736 .516 .437
2 -.461 -.090 .883
3 -.495 .852 -.171
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser
Normalization.
Bảng 9. Component Score Coefficient Matrix
Component
1 2 3
gia ca .218 -.060 .076
ve sinh .386 -.161 -.012
an ninh .354 -.006 -.122
moi truong song .309 -.030 -.103
gan truong .036 -.138 .430
gan khu vui choi, giai tri -.191 .143 .448
phong co gac lung -.034 -.108 .397
co nha ve sinh trong phong -.134 .418 .076
noi qui -.065 .515 -.213
dien, nuoc .003 .341 .004
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
Component Scores.
Bảng 10. Component Score Covariance Matrix
Component 1 2 3
1 1.000 .000 .000
2 .000 1.000 .000
3 .000 .000 1.000
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser
Normalization.
Component Scores.
Dựa vào bảng 8, 9 và 10 ta xác định nhân số như sau:
F1 = 0.218*giá cả + 0.386*vệ sinh + 0.354*an ninh + 0.309*môi trường sống
F2 = 0.418*có nhà vệ sinh trong phòng + 0.515*nội quy + 0.341*điện nước
F3 = 0.430*gần trường + 0.448*gần khu vui chơi + 0.397*có gác lửng
34
MÔ HÌNH HỒI QUY TUYẾN TÍNH BỘI
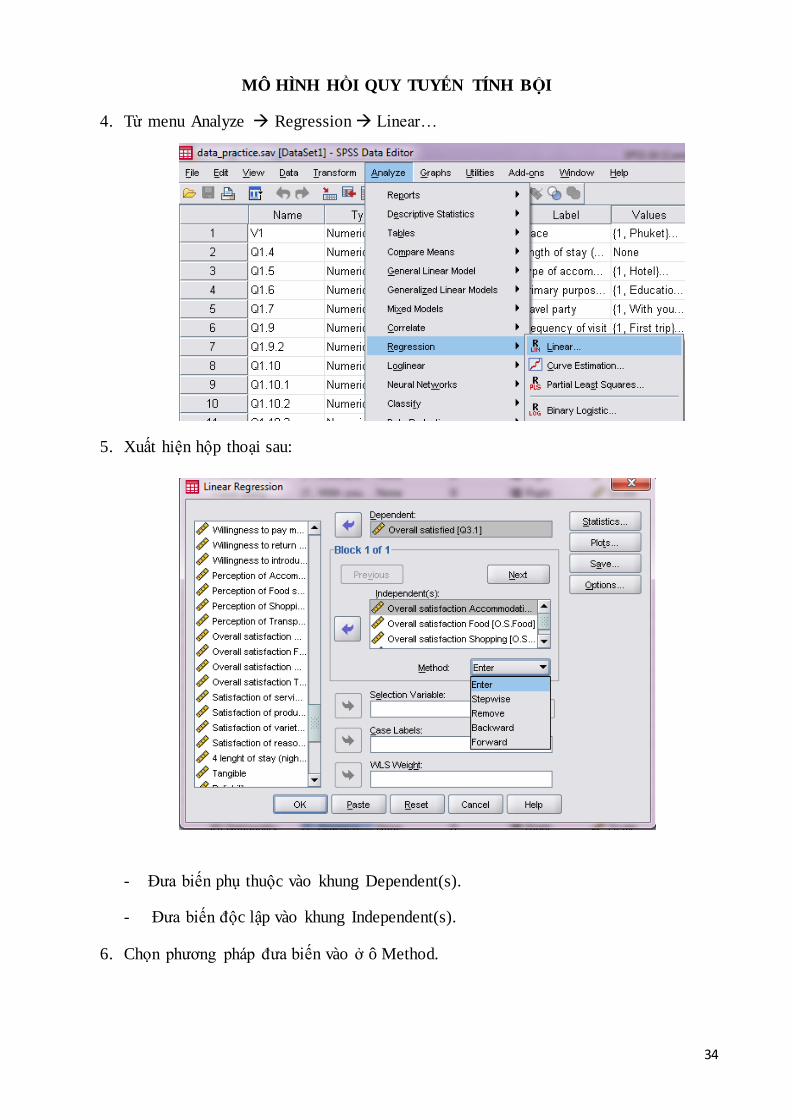
4. Từ menu Analyze Regression Linear…
5. Xuất hiện hộp thoại sau:
- Đưa biến phụ thuộc vào khung Dependent(s).
- Đưa biến độc lập vào khung Independent(s).
6. Chọn phương pháp đưa biến vào ở ô Method.

35
- Mặc định SPSS sẽ chọn phương pháp đưa biến vào là Enter. Đây là phương pháp
mà SPSS sẽ xử lý tất cả các biến độc lập mà nhà nghiên cứu muốn đưa vào mô
hình.
- Phương pháp đưa vào dần (forward selection). Biến độc lập đầu tiên được xem
xét để đưa vào mô hình là biến có tương quan lớn nhất với biến phụ thuộc. Tiếp
tục SPSS sẽ xét điều kiện để đưa các biến độc lập còn lại vào mô hình. Nếu biến
đầu tiên không thoả điều kiện vào thì thủ tục này sẽ chấm dứt, không có biến nào
được đưa vào mô hình.
- Phương pháp loại trừ dần (backward elimination). Đầu tiên tất cả các biến độc
lập được đưa vào mô hình, biến có hệ số tương quan nhỏ nhất sẽ được kiểm tra
đầu tiên, nếu không thoả điều kiện sẽ bị loại ra. Lúc này mô hình này sẽ được tính
toán lại mà không có biến độc lập vừa loại. Tiếp theo SPSS sẽ lặp lại thủ tục trên
cho đến khi nào giá trị F của biến có hệ số tương quan nhỏ nhất lớn hơn điều kiện
thì quá trình này sẽ dừng lại.
Tham khảo điều kiện để đưa vào và loại ra PIN, FIN, FOUT, POUT.
- Phương pháp chọn từng bước (stepwise selection) là sự kết hợp của phương pháp
đưa vào dần vào loại trừ dần và là phương pháp được sử dụng thông thường nhất.
Sử dụng phương pháp đưa biến vào nào phụ thuộc vào tính chất của cuộc
nghiên cứu. Và phương pháp được sử dụng nhiều nhất là phương pháp chọn
từng bước (stepwise selection).
7. Click vào ô Statistics…, để mở hộp thoại sau:
- Click chọn ô Collinearity diagnostics để kiểm tra hiện tượng Đa cộng tuyến
(Multicollinearity). Độ chấp nhận của biến (Tolerances) và hệ số phóng đại
phương sai (Variance inflation factor – VIF) được dùng để phát hiện hiện tượng
đa cộng tuyến. Quy tắc là khi VIF vượt quá 10 là dấu hiệu của đa cộng tuyến.

36
8. Click Continue để trở lại hộp thoại Linear Regressions click Ok để thực hiện lệnh.
Các bước đánh giá mô hình
VD: sử dụng stepwsise để đưa các biến độc lập vào mô hình.
Mô hình: sự hài lòng của DK về điểm đến = α + β1 (sự hài lòng về dịch vụ lưu trú)
+ β2 (sự hài lòng về dịch vụ ăn uống)
+ β3 (sự hài lòng về dịch vụ mua sắm)
+ β4 (sự hài lòng về dịch vụ vận chuyển)
Giá trị Tolerances và VIF ở bảng số 3 (bảng Coefficients) cho thấy không hiện diện
hiện tượng đa cộng tuyến của các biến. tiếp tục đánh giá mô hình.
1. Đánh giá độ phù hợp của mô hình
Hệ số xác định R2 và R2 hiệu chỉnh (Adjusted R square) được dùng để đánh giá độ phù
hợp của mô hình. Vì R2 sẽ tăng khi đưa thêm biến độc lập vào mô hình nên dùng R2 hiệu
chỉnh sẽ an toàn hơn khi đánh giá độ phù hợp của mô hình. R2 hiệu chỉnh càng lớn thể hiện
độ phù hợp của mô hình càng cao.
Model Summary
Model R R Square
Adjusted R
Square
Std. Error of the
Estimate
1 .618a .382 .381 .461
2 .664b .441 .439 .439
3 .677c .459 .455 .432
4 .684d .468 .463 .429
R2 hiệu chỉnh của mô hình số 4 là 0.463 46.3% sự biến thiên của mức độ hài lòng của
DK về điểm đến được giải thích bởi mối liên hệ tuyến tính của các biến độc lập. Mức độ
phù hợp của mô hình tương đối cao. Tuy nhiên sự phù hợp này chỉ đúng với dữ liệu mẫu.
Để kiểm định xem có thể suy diễn mô hình cho tổng thể thực hay không ta phải kiểm định
độ phù hợp của mô hình.
2. Kiểm định độ phù hợp của mô hình
Giả thuyết H0: β1 = β2 = β3 = β4 = 0.
Để kiểm định độ phù hợp của mô hình hồi quy tuyến tính đa bội ta dùng giá trị F ở bảng
phân tích ANOVA sau:
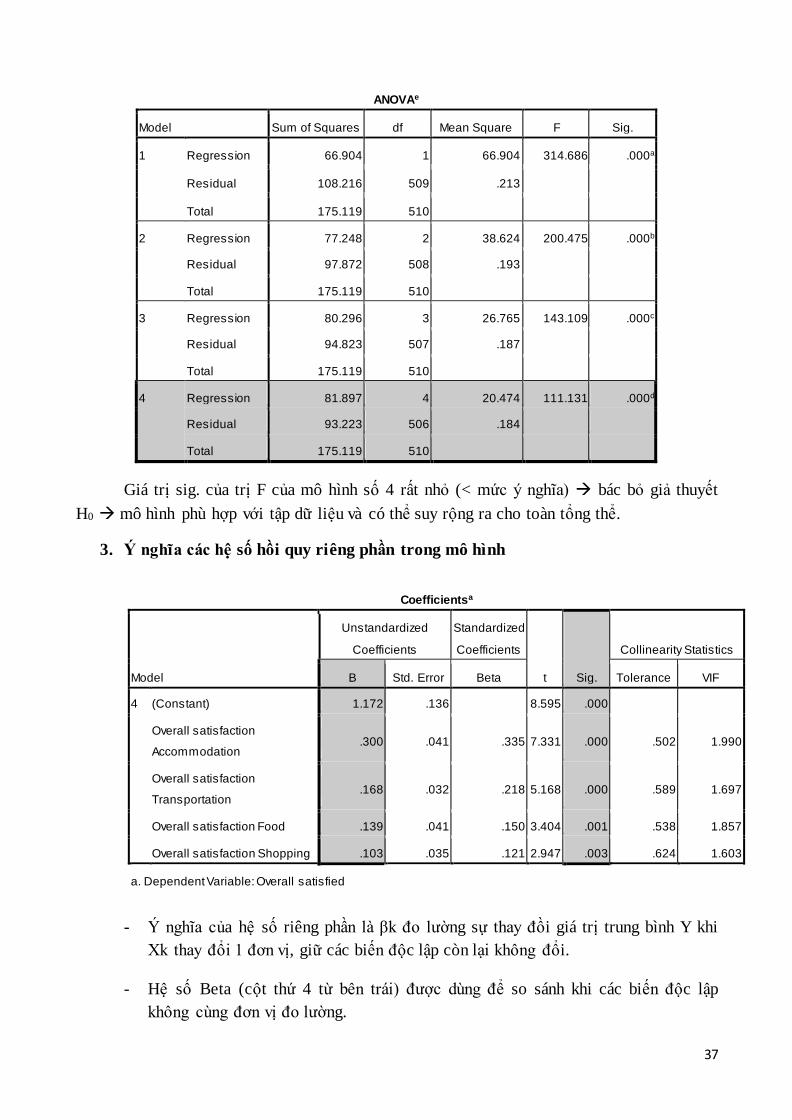
37
Giá trị sig. của trị F của mô hình số 4 rất nhỏ (< mức ý nghĩa) bác bỏ giả thuyết
H0 mô hình phù hợp với tập dữ liệu và có thể suy rộng ra cho toàn tổng thể.
3. Ý nghĩa các hệ số hồi quy riêng phần trong mô hình
- Ý nghĩa của hệ số riêng phần là βk đo lường sự thay đồi giá trị trung bình Y khi
Xk thay đổi 1 đơn vị, giữ các biến độc lập còn lại không đổi.
- Hệ số Beta (cột thứ 4 từ bên trái) được dùng để so sánh khi các biến độc lập
không cùng đơn vị đo lường.
ANOVAe
Model Sum of Squares df Mean Square F Sig.
1 Regression 66.904 1 66.904 314.686 .000a
Residual 108.216 509 .213
Total 175.119 510
2 Regression 77.248 2 38.624 200.475 .000b
Residual 97.872 508 .193
Total 175.119 510
3 Regression 80.296 3 26.765 143.109 .000c
Residual 94.823 507 .187
Total 175.119 510
4 Regression 81.897 4 20.474 111.131 .000d
Residual 93.223 506 .184
Total 175.119 510
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.
Collinearity Statistics
B Std. Error Beta Tolerance VIF
4 (Constant) 1.172 .136 8.595 .000
Overall satisfaction
Accommodation .300 .041 .335 7.331 .000 .502 1.990
Overall satisfaction
Transportation .168 .032 .218 5.168 .000 .589 1.697
Overall satisfaction Food .139 .041 .150 3.404 .001 .538 1.857
Overall satisfaction Shopping .103 .035 .121 2.947 .003 .624 1.603
a. Dependent Variable: Overall satisfied

38
- Ở VD này ta có thể viết lại mô hình như sau:
Hài lòng về điểm đến = 1.172 + 0.300(hài lòng về lưu trú) + 0.168(hài lòng về vận chuyển) + 0.139(hài lòng về ăn uống) + 0.103(hài lòng về mua sắm).
Giải thích mô hình: Phương trình hồi quy bội được phương pháp stepwise ước
lượng cho thấy sự hài lòng của du khách về 4 dịch vụ: lưu trú, vận chuyển, ăn uống, và mua
sắm có tác động tỷ lệ thuận với sự hài lòng chung của du khách về điểm đến. Trong đó sự
hài lòng về dịch vụ lưu trú có tác động mạnh nhất đến sự hài lòng về điểm đến.
MỘT SỐ BIỆN PHÁP KHẮC PHỤC HIỆN TƯỢNG ĐA CỘNG TUYẾN TRONG
MÔ HÌNH HỒI QUY TUYẾN TÍNH
(Đề nghị tham khảo chi tiết hơn trong giáo trình Kinh tế lượng của Tiến sĩ Mai Văn Nam)
1. Sử dụng thông tin tiên nghiệm
Thông tin tiên nghiệm có thể từ các công việc thực tế trước đây trong đó đã xảy ra hiện
tượng cộng tuyến nhưng ít nghiêm trọng hoặc từ các lý thuyết tương ứng trong lĩnh vực
nghiên cứu.
2. Loại trừ một biến giải thích ra khỏi mô hình
Bước 1: Xem cặp biến có quan hệ chặc chẽ. Giả sử X3 và X4 có tương quan chặc chẽ với
nhau.
Bước 2: Tính R2 đối với các hàm hồi quy: có mặt cả 2 biến; không có mặt 1 trong 2 biến.
Bước 3: Loại biến mà giá trị R2 tính được khi không có mặt biến đó lớn hơn.
VD: R2 của hàm có mặt 2 biến là 0.94; R2 của mô hình không có biến X3 là 0.92; R2 của mô
hình không có biến X4 là 0.87 loại biến X3 ra khỏi mô hình.
3. Thu thập thêm số liệu hoặc lấy mẫu mới
Vấn đề đa cộng tuyến là một đặc tính của mẫu, có thể là trong một mẫu khác, các biến
cộng tuyến có thể không nghiêm trọng như trong mẫu đầu tiên. Vì vậy, tăng cỡ mẫu có thể
làm giảm bớt vấn đề cộng tuyến.

39
HỒI QUY BINARY LOGISTIC
Hồi quy Binary Logistic sử dụng biến phụ thuộc dạng nhị phân để ước lượng xác
suất một sự kiện sẽ xảy ra với những thông tin của biến độc lập mà ta có được. Khi biến phụ
thuộc ở dạng nhị phân (hai biểu hiện 0 và 1) thì không thể phân tích với dạng hồi quy thông
thường mà phải sử dụng hồi quy Binary Logistic.
I. Cách thức tiến hành phân tích hồi quy Binary Logistic với SPSS
1. Vào menu Analyze Regression Binary Logistic, xuất hiện hộp thoại sau:
2. Đưa biến phụ thuộc Y dạng nhị phân vào ô dependent, và biến độc lập sang khung
Covariate.
3. Chọn phương pháp đưa biến vào (Method) tương tự như hồi quy tuyến tính thông
thường. Tuy nhiên điều kiện căn cứ trên số thống kê likelihood-ratio (tỷ lệ thích hợp)
hay số thống kê Wald.
- Enter: đưa vào bắt buộc, các biến trong khối biến độc lập được đưa vào trong một
bước.
- Forward: Conditional là phương pháp đưa dần vào theo điều kiện. Nó kiểm tra
việc loại biến căn cứ trên xác suất của số thống kê Likelihood-ratio dựa trên
những ước lượng thông số có điều kiện.
- Forward: LR là phương pháp đưa dần vào kiểm tra việc loại biến căn cứ trên xác
suất của số thống kê Likelihood-ratio dựa trên ước lượng khả năng xảy ra tối đa
(maximum-likelihood estimates).
- Forward: Wald là phương pháp đưa dần vào kiểm tra việc loại biến căn cứ trên
xác suất của số thống kê Wald.

40
- Backward: Conditional là phương pháp loại trừ dần theo điều kiện. Nó kiểm tra
việc loại biến căn cứ trên xác suất của số thống kê Likelihood-ratio dựa trên
những ước lượng thông số có điều kiện.
- Backward: LR là phương pháp loại trừ dần vào kiểm tra việc loại biến căn cứ trên
xác suất của số thống kê Likelihood-ratio dựa trên ước lượng khả năng xảy ra tối
đa.
- Backward: Wald là phương pháp đưa dần vào kiểm tra việc loại biến căn cứ trên
xác suất của số thống kê Wald.
- Stepwise: hồi quy từng bước, số thống kê được sử dụng cho các biến được đưa
vào và loại ra căn cứ trên số thống kê Likelihood-ratio, hay số thống kê Wald.
4. Để hiện đồ thị phân loại giá trị thật và giá trị dự báo của biến phụ thuộc, chọn
Option, chọn Classification plots trong phần Statistics and plots. Click Continue trở
về hộp thoại đầu tiên.
5. Muốn tính được giá trị dự đoán, là xác suất mà một đối tượng sẽ … (biến phụ thuộc
Y), ta chọn Predict value trong hộp thoại Save. Chọn Continue Ok để thực hiện
lệnh.
41
II. Cách thức đọc kết quả phân tích hồi quy Binary Logistic
Ví dụ: sử dụng phương pháp đưa biến vào mặc định là Enter. Phân tích mức độ ảnh
hưởng của sự hài lòng về 4 dịch vụ đến mức độ hài lòng chung về điểm đến khi đi du lịch
của du khách.
Y: mức độ hài lòng chung về điểm đến (0: không hài lòng, 1: hài lòng)
X1 X4: mức độ hài lòng về 4 dịch vụ (tương tự như phần hồi quy tuyến tính)
Thực hiện các bước trên để tiến hành phân tích. Kết quả xuất hiện với rất nhiều bảng.
Ta sẽ chú ý phân tích các bảng sau:
Bảng 1. Omnibus Tests of Model Coefficients
Chi-square df Sig.
Step 1 Step 178.459 4 .000
Block 178.459 4 .000
Model 178.459 4 .000
Ở bảng 1, ta đọc kết quả kiểm định H0: 1 = 2 = … = k = 0. Kiểm định này xem xét
khả năng giải thích biến phụ thuộc của tổ hợp biến độc lập.
Kết quả ở bảng 1 cho thấy độ phù hợp tổng quát có mức ý nghĩa quan sát sig. = 0,000
nên ta bác bỏ H0. Nghĩa là tổ hợp liên hệ tuyến tính của toàn bộ các hệ số trong mô hình có
ý nghĩa trong việc giải thích cho biến phụ thuộc.
Bảng 2. Model Summary
Step -2 Log likelihood
Cox & Snell R
Square
Nagelkerke R
Square
1 26.793a .595 .769
a. Estimation terminated at iteration number 6 because
parameter estimates changed by less than .001.
Bảng 2 thể hiện kết quả độ phù hợp của mô hình. Khác với hồi quy tuyến tính thông
thường hệ số R2 càng lớn thì mô hình càng phù hợp, hồi quy Binary Logistic sử dụng chỉ
tiêu -2LL (-2 log likelihood) để đánh giá độ phù hợp của mô hình. -2LL càng nhỏ càng thể
hiện độ phù hợp cao. Giá trị nhỏ nhất của -2LL là 0 (tức là không có sai số) khi đó mô hình
có độ phù hợp hoàn hảo.
Kết quả bảng 2 cho thấy giá trị của -2LL = 26,472 không cao lắm, như vậy nó thể
hiện một độ phù hợp khá tốt của mô hình tổng thể.
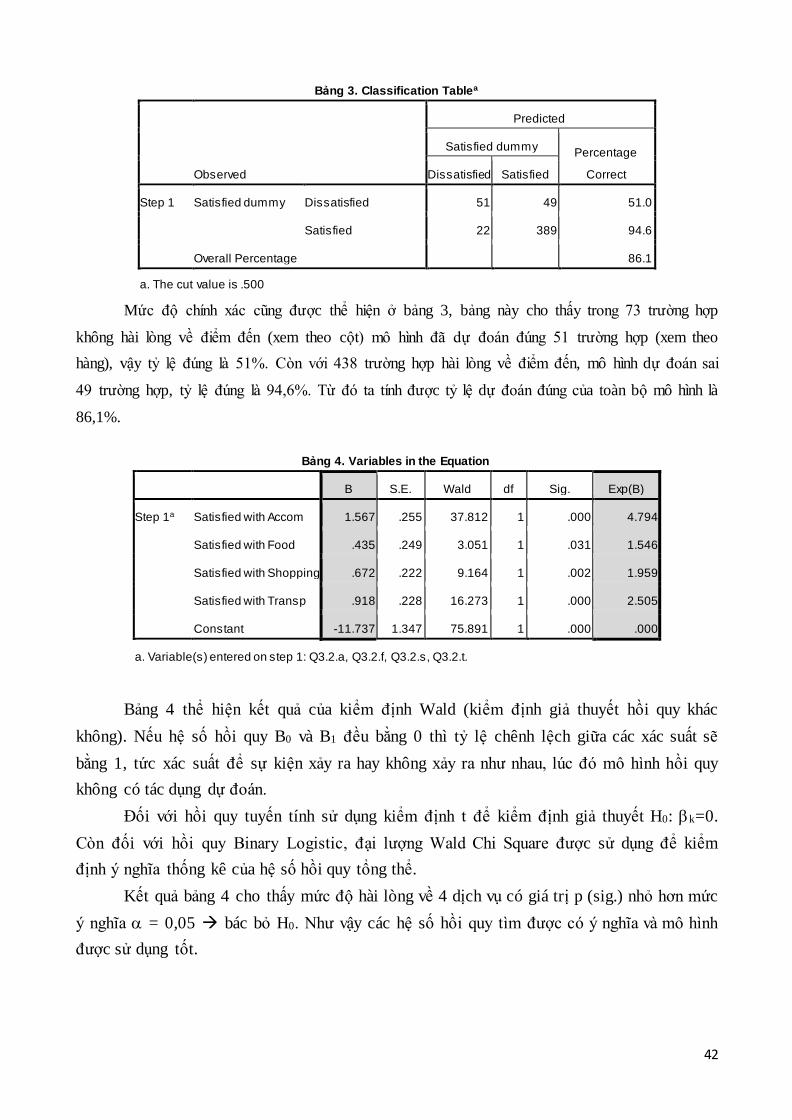
42
Bảng 3. Classification Tablea
Observed
Predicted
Satisfied dummy Percentage
Correct Dissatisfied Satisfied
Step 1 Satisfied dummy Dissatisfied 51 49 51.0
Satisfied 22 389 94.6
Overall Percentage 86.1
a. The cut value is .500
Mức độ chính xác cũng được thể hiện ở bảng 3, bảng này cho thấy trong 73 trường hợp
không hài lòng về điểm đến (xem theo cột) mô hình đã dự đoán đúng 51 trường hợp (xem theo
hàng), vậy tỷ lệ đúng là 51%. Còn với 438 trường hợp hài lòng về điểm đến, mô hình dự đoán sai
49 trường hợp, tỷ lệ đúng là 94,6%. Từ đó ta tính được tỷ lệ dự đoán đúng của toàn bộ mô hình là
86,1%.
Bảng 4. Variables in the Equation
B S.E. Wald df Sig. Exp(B)
Step 1a Satisfied with Accom 1.567 .255 37.812 1 .000 4.794
Satisfied with Food .435 .249 3.051 1 .031 1.546
Satisfied with Shopping .672 .222 9.164 1 .002 1.959
Satisfied with Transp .918 .228 16.273 1 .000 2.505
Constant -11.737 1.347 75.891 1 .000 .000
a. Variable(s) entered on step 1: Q3.2.a, Q3.2.f, Q3.2.s, Q3.2.t.
Bảng 4 thể hiện kết quả của kiểm định Wald (kiểm định giả thuyết hồi quy khác
không). Nếu hệ số hồi quy B0 và B1 đều bằng 0 thì tỷ lệ chênh lệch giữa các xác suất sẽ
bằng 1, tức xác suất để sự kiện xảy ra hay không xảy ra như nhau, lúc đó mô hình hồi quy
không có tác dụng dự đoán.
Đối với hồi quy tuyến tính sử dụng kiểm định t để kiểm định giả thuyết H0: k=0.
Còn đối với hồi quy Binary Logistic, đại lượng Wald Chi Square được sử dụng để kiểm
định ý nghĩa thống kê của hệ số hồi quy tổng thể.
Kết quả bảng 4 cho thấy mức độ hài lòng về 4 dịch vụ có giá trị p (sig.) nhỏ hơn mức
ý nghĩa = 0,05 bác bỏ H0. Như vậy các hệ số hồi quy tìm được có ý nghĩa và mô hình
được sử dụng tốt.

43
Từ các hệ số hồi quy này ta viết được phương trình:
Diễn giải ý nghĩa của các hệ số hồi quy Binary Logistic như sau:
Mức độ hài lòng về 4 dịch vụ đều làm tăng xác suất hài lòng chung về điểm
đến của du khách, trong đó hài lòng về DV lưu trú tác động mạnh nhất. Cụ thể tác
động biên của mức độ hài lòng về DV lưu trú lên mức độ hài lòng chung với xác
suất ban đầu = 0,5 thì tác động này bằng 0,5(1-0,5)1,57 = 0,3925.
VẬN DỤNG MÔ HÌNH HỒI QUY BINARY LOGISTIC CHO MỤC ĐÍCH DỰ BÁO
Mô hình hồi quy Binary Logistic có thể được áp dụng để dự báo khả năng trả nợ khi
đối tượng đi vay hay dự báo nhu cầu sử dụng một sản phẩm cụ thể nào đó. Ta sử dụng công
thức sau:

44
PHÂN TÍCH BIỆT SỐ
Phân tích phân biệt được dùng để giải quyết một số tình huống khi nhà nghiên cứu
muốn tìm thấy sự khác biệt giữa những nhóm đối tượng nghiên cứu với nhau, ví dụ phân
biệt khách hàng trung thành và không trung thành bằng một số đặc điểm nhân khẩu học,
phân biệt các phân khúc khách hàng bằng một số tiêu chí lợi ích khi sử dụng một sản
phẩm…
Điều kiện của phân tích phân biệt là phải có một biến phụ thuộc (là biến dùng để
phân loại đối tượng thường sử dụng thang đo định danh hoặc thứ tự), và một số biến độc lập
(là một số đặc tính dùng để phân tích sự khác biệt giữa các nhóm đối tượng, thường sử dụng
thang đo khoảng hoặc tỷ lệ). Phân tích biệt số có thể thực hiện các việc sau:
- Xây dựng các hàm phân tích phân biệt (discriminant functions) để phân biệt rõ xã
biểu hiện của biến phụ thuộc.
- Nghiên cứu xem các nhóm có sự khác biệt có ý nghĩa hay không khi được xét về
các yếu tố độc lập.
- Xác định biến độc lập là nguyên nhân chính nhất gây ra sự khác biệt giữa các
nhóm.
Có 2 trường hợp phân tích biệt số: phân tích biệt số 2 nhóm (khi biến phụ thuộc có 2
biểu hiện), phân tích biệt số bội (khi biến phụ thuộc có từ 3 biểu hiện trở lên).
Ví dụ: khi phân tích về lợi nhuận của những hộ tham gia làng nghề nhà nghiên cứu
đã phân thành 2 nhóm: hộ có lợi nhuận (lợi nhuận > 0) và hộ không có lợi nhuận (LN ≤ 0).
Nhà nghiên cứu muốn xem xét sự khác biệt giữa 2 nhóm hộ có lợi nhuận như trên về các
yếu tố: tuổi, năm kinh nghiệm, vốn, số lao động, số mặt hàng, tính chất làng nghề (1-đã
được công nhận, 0 – chưa được công nhận), tính chất hoạt động của hộ (1-hộ chuyên, 0 – hộ
kiêm).
Để giải quyết cho tình huống trên, phân tích biệt số được tiến hành như sau:
1. Bước 1. Chia mẫu quan sát thành 2 phần
Đối với phân tích phân biệt, ta phải chia mẫu quan sát thành 2 phần: mẫu ước lượng
hay mẫu phân tích (là phần dung để ước lượng hàm phân biệt); phần còn lại là để kiểm tra
tính đúng đắn của hàm phân biệt (mẫu kiểm tra). Khi cỡ mẫu đủ lớn, ta có thể chia thành 2
phần bằng nhau và theo tỷ lệ của toàn bộ mẫu.
Ví dụ: trong ví dụ trên, cỡ mẫu là 122 mẫu (có 66 mẫu ko có LN – chiếm 54% và 56
mẫu có LN – chiếm 46%). Ta sẽ tiến hành chia thành 2 phần, mỗi phần gồm 61 mẫu: trong
đó có 33 mẫu ko có LN và 28 mẫu có LN.
2. Bước 2. Tiến hành phân tích biệt số trên SPSS
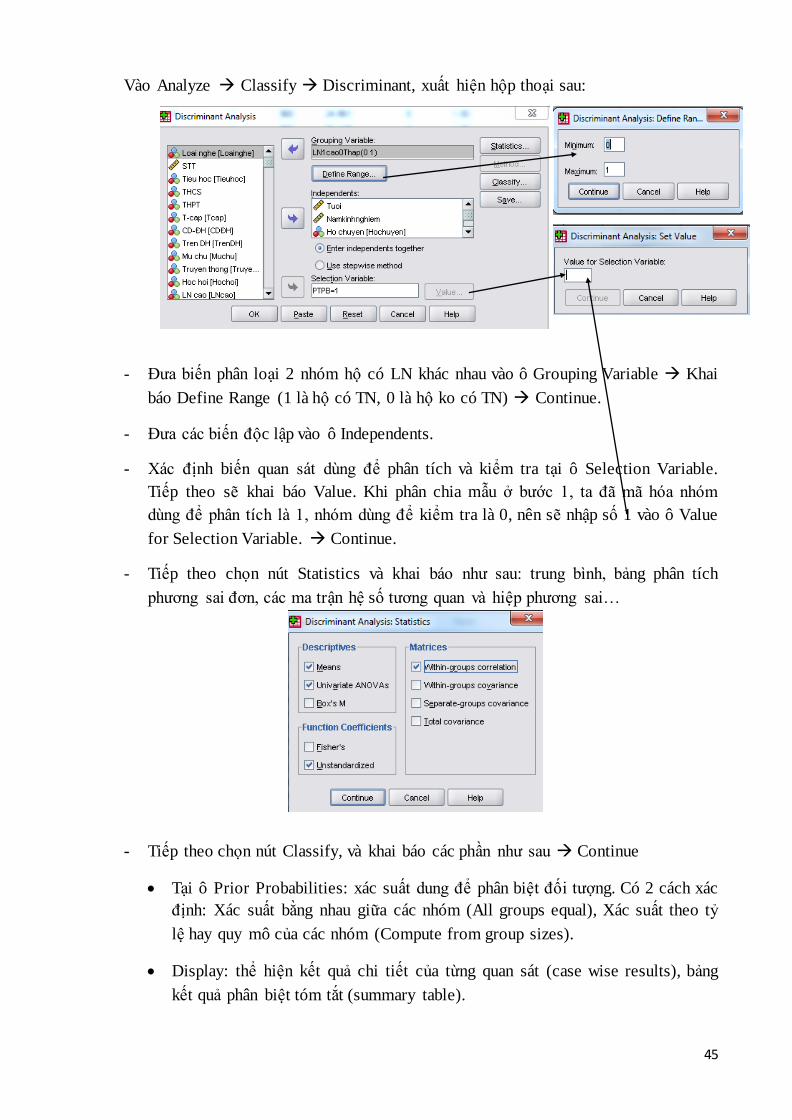
45
Vào Analyze Classify Discriminant, xuất hiện hộp thoại sau:
- Đưa biến phân loại 2 nhóm hộ có LN khác nhau vào ô Grouping Variable Khai
báo Define Range (1 là hộ có TN, 0 là hộ ko có TN) Continue.
- Đưa các biến độc lập vào ô Independents.
- Xác định biến quan sát dùng để phân tích và kiểm tra tại ô Selection Variable.
Tiếp theo sẽ khai báo Value. Khi phân chia mẫu ở bước 1, ta đã mã hóa nhóm
dùng để phân tích là 1, nhóm dùng để kiểm tra là 0, nên sẽ nhập số 1 vào ô Value
for Selection Variable. Continue.
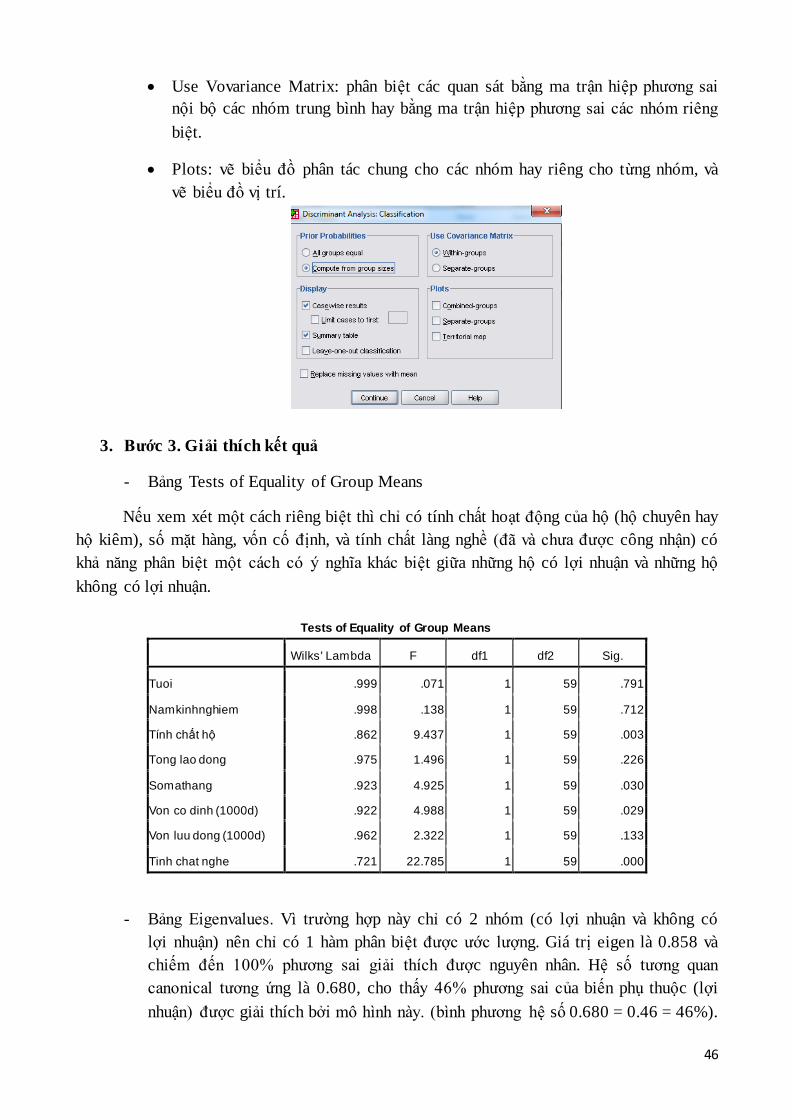
- Tiếp theo chọn nút Statistics và khai báo như sau: trung bình, bảng phân tích
phương sai đơn, các ma trận hệ số tương quan và hiệp phương sai…
- Tiếp theo chọn nút Classify, và khai báo các phần như sau Continue
Tại ô Prior Probabilities: xác suất dung để phân biệt đối tượng. Có 2 cách xác
định: Xác suất bằng nhau giữa các nhóm (All groups equal), Xác suất theo tỷ
lệ hay quy mô của các nhóm (Compute from group sizes).
Display: thể hiện kết quả chi tiết của từng quan sát (case wise results), bảng
kết quả phân biệt tóm tắt (summary table).
46
Use Vovariance Matrix: phân biệt các quan sát bằng ma trận hiệp phương sai
nội bộ các nhóm trung bình hay bằng ma trận hiệp phương sai các nhóm riêng
biệt.
Plots: vẽ biểu đồ phân tác chung cho các nhóm hay riêng cho từng nhóm, và
vẽ biểu đồ vị trí.
3. Bước 3. Giải thích kết quả
- Bảng Tests of Equality of Group Means
Nếu xem xét một cách riêng biệt thì chỉ có tính chất hoạt động của hộ (hộ chuyên hay
hộ kiêm), số mặt hàng, vốn cố định, và tính chất làng nghề (đã và chưa được công nhận) có
khả năng phân biệt một cách có ý nghĩa khác biệt giữa những hộ có lợi nhuận và những hộ
không có lợi nhuận.
Tests of Equality of Group Means
Wilks' Lambda F df1 df2 Sig.
Tuoi .999 .071 1 59 .791
Namkinhnghiem .998 .138 1 59 .712
Tính chất hộ .862 9.437 1 59 .003
Tong lao dong .975 1.496 1 59 .226
Somathang .923 4.925 1 59 .030
Von co dinh (1000d) .922 4.988 1 59 .029
Von luu dong (1000d) .962 2.322 1 59 .133
Tinh chat nghe .721 22.785 1 59 .000
- Bảng Eigenvalues. Vì trường hợp này chỉ có 2 nhóm (có lợi nhuận và không có
lợi nhuận) nên chỉ có 1 hàm phân biệt được ước lượng. Giá trị eigen là 0.858 và
chiếm đến 100% phương sai giải thích được nguyên nhân. Hệ số tương quan
canonical tương ứng là 0.680, cho thấy 46% phương sai của biến phụ thuộc (lợi
nhuận) được giải thích bởi mô hình này. (bình phương hệ số 0.680 = 0.46 = 46%).

47
Eigenvalues
Function Eigenvalue % of Variance Cumulative % Canonical Correlation
1 .858a 100.0 100.0 .680
a. First 1 canonical discriminant functions were used in the analysis.
- Tiếp theo sẽ xác định xem hàm phân biệt được ước lượng có ý nghĩa về mặt
thống kê hay không. Với hệ số Wilk là 0.538 và giá trị p là 0.000 nhỏ hơn mức
ý nghĩa 5% rất nhiều, nên có thể kết luận sự phân biệt có ý nghĩa thống kê ở mức
ý nghĩa 5%, và có thể tiến hành giải thích kết quả
Wilks' Lambda
Test of Function(s) Wilks' Lambda Chi-square df Sig.
1 .538 34.068 8 .000
- Kết quả được giải thích như sau:
Tầm quan trọng của các biến được thể hiện qua độ lớn trị tuyệt đối của hệ số chuẩn
hóa (bảng Standardized Canonical Discriminant Function Coefficients). Các biến có trị
tuyệt đối hệ số chuẩn hóa càng lớn thì càng đóng góp nhiều hơn vào khả năng phân biệt của
hàm. Hoặc có thể xem xét điều này tại bảng Structure Matrix, mức độ tác động của các biến
được xếp theo thứ tự giảm dần.
Standardized Canonical Discriminant Function Coefficients
Function
1
Tuoi .147
Namkinhnghiem .316
Tính chất hộ .551
Tong lao dong .105
Somathang .229
Von co dinh (1000d) .464
Von luu dong (1000d) .197
Tinh chat nghe .816
Theo kết quả, ta thấy biến tính chất làng nghề là biến dự đoán quan trọng nhất dùng
để phân biệt 2 nhóm lợi nhuận, tiếp đến là biến tính chất hoạt động của hộ, vốn cố định và
số mặt hàng.
Dấu của các hệ số của tất cả các biến dự đoán đều dương cho thấy rằng những hộ
tham gia làng nghề đã được công nhận, hộ chuyên sản xuất, vốn cố định và vốn lưu động
48
càng cao, số mặt hang càng nhiều, tổng lao động nhiều, nhiều kinh nghiệm và tuổi chủ hộ
càng cao thì hộ sẽ càng có khả năng có lợi nhuận.
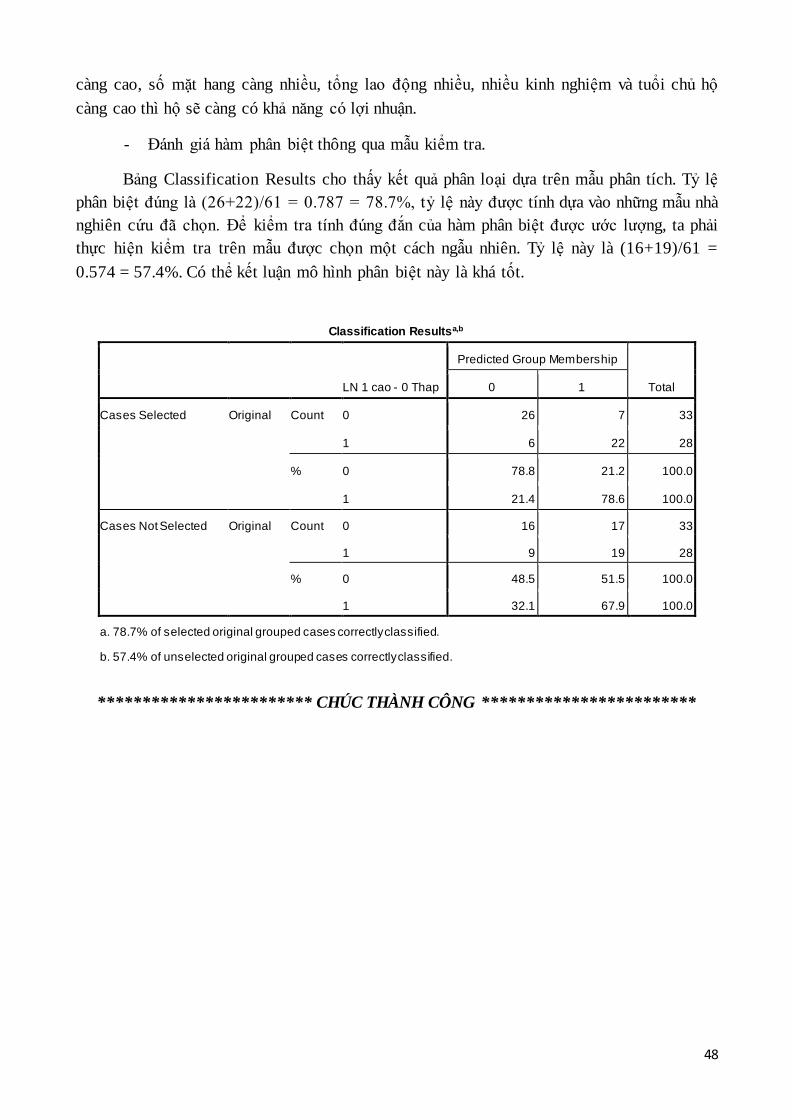
- Đánh giá hàm phân biệt thông qua mẫu kiểm tra.
Bảng Classification Results cho thấy kết quả phân loại dựa trên mẫu phân tích. Tỷ lệ
phân biệt đúng là (26+22)/61 = 0.787 = 78.7%, tỷ lệ này được tính dựa vào những mẫu nhà
nghiên cứu đã chọn. Để kiểm tra tính đúng đắn của hàm phân biệt được ước lượng, ta phải
thực hiện kiểm tra trên mẫu được chọn một cách ngẫu nhiên. Tỷ lệ này là (16+19)/61 =
0.574 = 57.4%. Có thể kết luận mô hình phân biệt này là khá tốt.
Classification Resultsa,b
LN 1 cao - 0 Thap
Predicted Group Membership
Total 0 1
Cases Selected Original Count 0 26 7 33
1 6 22 28
% 0 78.8 21.2 100.0
1 21.4 78.6 100.0
Cases Not Selected Original Count 0 16 17 33
1 9 19 28
% 0 48.5 51.5 100.0
1 32.1 67.9 100.0
a. 78.7% of selected original grouped cases correctly classified.
b. 57.4% of unselected original grouped cases correctly classified.
************************ CHÚC THÀNH CÔNG ************************
Related Documents











