Большие данные и высокопроизводительные вычисления Федулова И.А., к.ф.-м.н. IBM

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Большие данные и высокопроизводительные вычисленияФедулова И.А., к.ф.-м.н.IBM

Agenda
• Сравнениe HPC и Big Data– Задачи– Инфраструктура– Алгоритмы и программы
• Современные тренды в Big Data– Apache Spark
2

HPC: Задачи
Научное исследование
Физический эксперимент Теория Компьютерное
моделирование
3

HPC: Задачи
Науки о материалах и нанотехнологии
Геномика Системная биология
ГидродинамикаФинансы
и оценка рисков
Обработка геофизических
данныхМоделирование климата и землетрясений
Исследование пандемий
4

HPC: Алгоритмы и программы• Многие задачи сводятся к дифференциальным и интегральным уравнениям
• Алгоритмы требуют большого количества обменов между узлами– MPI = Message Passing Interface – PGAS = Partitioned Global Address Space
• Узлы многоядерные– OpenMP, CUDA– Гибридное программирование
• Математические библиотеки– ESSL, ScaLAPACK, FFTW, …
• Прикладные программы– Химия, биология, физика– Визуализация
http://www.fz-juelich.de/ias/jsc/EN/Expertise/Support/Software/_node.html
5

HPC: Hardware = «суперкомпьютеры»
• Суперкомпьютер– (почти) однородные узлы– очень быстрая сеть
• Архитектура – тор или дерево– Параллельная файловая система
• Lustre, IBM GPFS– Бенчмарк
• Linpack http://www.netlib.org/linpack/• Graph500 http://www.graph500.org/
– Основное внимание – утилизация cpu, memory, networkbandwidth
6

HPC: Примеры систем
• Top500– http://top500.org/lists/2014/11/
7

HPC: Как выглядит суперкомпьютер
8

9

Big Data: The Four V’s
• Volume = Объем• Variety = Разнообразие• Velocity = Скорость• Veracity = (Не)Достоверность
10

11http://www.ibmbigdatahub.com/infographic/four-vs-big-data

12http://www.ibmbigdatahub.com/infographic/four-vs-big-data

13http://www.ibmbigdatahub.com/infographic/four-vs-big-data

14http://www.ibmbigdatahub.com/infographic/four-vs-big-data

Big Data: Задачи
• Задачи, параллельные по данным– Применение одного преобразования ко всем элементам
• Машинное обучение• Примеры
– Анализ логов• Поведение пользователей в интернете
– Рекомендательные системы» Магазины» Банки » Сотовые операторы» …
• Internet Of Things: сенсоры– Anomaly detection
– Анализ графов• Социальные сети
15

Big Data: Алгоритмы и программы
16
• Data Mining and Machine Learning – Снижение размерности (“dimensionality reduction”)
• Principal Component Analysis, locally linear embedding, …– Регрессия– Классификация– Кластеризация– Anomaly detection– Supervised learning
• Нейросети, логистическая регрессия, support vector machines, k-NN
• Численные методы линейной алгебры
• External memory and cache obliviousness– Algorithms and data structures minimizing I/Os for data not fitting
on memory but fitting on disk. B-trees, buffer trees, multiwaymergesort, …

Big Data: Алгоритмы и программы (2)
17
High dim. data
Locality sensitive hashing
Clustering
Dimensionality
reduction
Graph data
PageRank, SimRank
Community Detection
Spam Detection
Infinite data
Filtering data
streams
Web advertising
Queries on streams
Machine learning
SVM
Decision Trees
Perceptron, kNN
Apps
Recommender
systems
Association Rules
Duplicate document detection
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
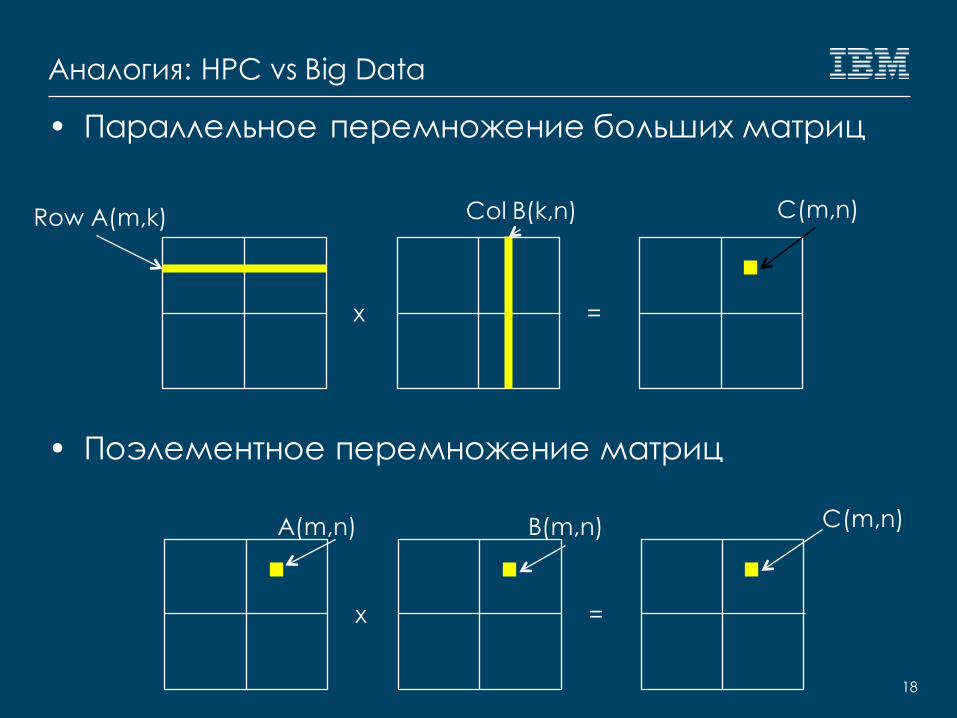
Аналогия: HPC vs Big Data
• Параллельное перемножение больших матриц
• Поэлементное перемножение матриц
x =
C(m,n)Row A(m,k) Col B(k,n)
C(m,n)
x =
B(m,n)A(m,n)
18

Big Data: Hardware = «датацентры»
• Commodity Cluster– Традиционный – on premise– Cloud
• Сеть может быть не очень быстрая и/или очень неоднородная– Архитектура интерконнекта – обычно «черный ящик» (особенно на cloud)
• Большой объем HDD– Параллельная файловая система
• Так как датацентрыстроят из обычных компонентов, то велик failure rate– Необходима избыточность и fault tolerant software
• Бенчмарк– 1PB Parallel sort
• Основной фокус – нагрузка на HDD, network bandwidth
19

Big Data: примеры датацентров• Google
– ~1 миллион серверов– Проиндексировано 60*10^12 веб страниц– Суммарное энергопотребление - 260MW– 3*10^6 поисков в минуту– http://www.google.com/about/datacenters
• Microsoft– ~1 миллион серверов– Bing, One Drive, Azure cloud, …
• Facebook– ~200 000 серверов– Обеспечивает трафик для 1.35 миллиарда пользователей– …которые закачивают 750Тб контента в сутки– Собственная инфраструктура сети – data center fabric
• Yandex– Около 10 датацентров– http://habrahabr.ru/company/yandex/blog/258823/
20

21

Map Reduce
• Программная модель для обработки распределенных данных– Идея пришла из функциональных языков
• Map() = применение некоторой элементарной операции ко всем элементам списка
• Reduce() = «свёртка» – преобразование списка к одному значению при помощи заданной функции
• Google MapReduce (2004)– http://research.google.com/archive/mapreduce.html
• Apache Hadoop – opensource реализация– Всю работу по распределению работы фреймворк берет на себя
22

Map Reduce: Пример
• Word Count
23
Image source: http://blog.trifork.com/2009/08/04/introduction-to-hadoop/

Hadoop Distributed File System
• Основные идеи– Hardware failure tolerance– Batch processing oriented
• High throughput instead of low latency– Large datasets
• 10000+ nodes, ~450PB– Simple Coherency Model
• Write once, read many - no appending writes– “Moving Computation is Cheaper than Moving Data”– Portability
• HDFS живет поверх файловой системы ОС
24

Hadoop Distributed File System (2)
https://www.cac.cornell.edu/vw/MapReduce/dfs.aspx
Block size = 64MBReplication factor = 3
25

Big Data: Экосистема
Image: www.facebook.com/hadoopers 26

Map Reduce и дисковые операции
27Итеративные алгоритмы работают очень медленно

Spark
• Развитие идей Hadoop Map Reduce • Хранение промежуточных результатов в оперативной памяти– До 100 раз быстрее, чем Hadoop
• Итеративные алгоритмы машинного обучения• Интерактивное изучение данных • Real-time stream processing
• Написан на Scala– + поддерживает Python, Java
28

Основная идея Spark
• Алгоритм формулируется в терминах преобразований датасетов
• Resilient Distributed Dataset (RDD)– Коллекция объектов, которые могут храниться в памяти или на диске
– Построена при помощи параллельных преобразований– Последовательность преобразований (lineage) записывается– В случае сбоев объекты автоматически вычисляются заново
• Всю работу по распределению работы фреймворк берет на себя
29

Возможные операции над RDD
map
filter
groupBy
union
join
leftOuterJoin
rightOuterJoibn
reduce
count
fold
reduceByKey
groupByKey
cogroup
flatMap
take
first
partitionBy
pipe
distinct
save
...
30

Word Count: From Map Reduce to Spark
Map Reduce Spark
31
http://www.slideshare.net/databricks/bdtc2

Hadoop vs Spark
32
http://www.slideshare.net/databricks/bdtc2

Spark Components
• Spark streaming• MLLib• SparkSQL• GraphX• SparkR• …
33

Berkeley Data Analytics Stack
https://amplab.cs.berkeley.edu/software
34

IBM and Spark
• http://www.ibm.com/analytics/us/en/technology/spark/
• IBM SystemML – технология машинного обучения будет встроена в Spark
• IBM Analytics продукты будут поддерживать Sparkна IBM BlueMix
• Будет открыт Spark Technology Center в Сан-Франциско• MOOC Обучение для data scientists
35

Big Data Online Education
• edX– Introduction to Big Data with Apache Spark
• https://courses.edx.org/courses/BerkeleyX/CS100.1x/1T2015/info
– Scalable Machine Learning with Apache Spark• https://courses.edx.org/courses/BerkeleyX/CS190.1x/1T2015/info
• Udacity– Intro To Hadoop and Map Reduce
• https://www.udacity.com/course/intro-to-hadoop-and-mapreduce--ud617
• Coursera– Mining Massive Datasets
• https://www.coursera.org/course/mmds
– Machine Learning• https://www.coursera.org/learn/machine-learning/home/info
• IBM Big Data University– http://bigdatauniversity.com/
• Kaggle competitions– https://www.kaggle.com/
36

Заключение
• HPC vs Big Data– Нужно определиться с терминологией– «Разные» задачи?– «Разная» инфраструктура?
• Beouwlf cluster == HPC of 1994 == “Big Data” cluster of today• Infiniband + Hadoop = HPC?
37
HPC BigData
BigCompute

Related Documents






![Containerization for HPC in the Cloud: Docker vs Singularity1277794/FULLTEXT01.pdf · typical HPC cluster compute worfklows to public cloud platforms arose [15, 25]. 1.1 Moving High](https://static.cupdf.com/doc/110x72/5fbc9929cb7dce071847d7dd/containerization-for-hpc-in-the-cloud-docker-vs-1277794fulltext01pdf-typical.jpg)




