How Technology can Find, Manage and Protect Personal Content in Unstructured Data

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

How Technology can Find, Manage and Protect Personal Content in Unstructured Data

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
Personal data exists in obvious documents and files, for example, spreadsheets created by specific users, such
as members of the finance team, located on specific servers. Finding and managing these files may be a
somewhat easy task, however, there may be personal data hidden deep in files that you may not know exists.
This is the content that will keep Data Protection Officers (DPO’s) up at night and will create risk for fines and
sanctions by the European Union regulatory body.
Complying with the GDPR will be a monumental task for most organizations. The sheer volume of data,
existing on unmanaged networks and file servers or clustered away in archives, will require technology and
intelligence to fully comply with this new regulation. The upside to this new regulation is that it will enforce a
new governance ready strategy that will not only streamline corporate data centers but also recoup costs by
managing data more intelligently and optimizing the data storage footprint.
Overview
Technology is the foundation that will help support GDPR compliance. Technology can classify data into
manageable groups, provide comprehensive search to find personal data, manage the disposition of this
content, implement automation to ensure an auditable workflow, and secure and protect sensitive data
ensuring it does not fall into the wrong hands.
Technology, combined with an intelligent workflow is the only approach to ensure that all personal data is
protected, managed and secured. Index Engines has developed a workflow that will not only allow personal
data to be found in support of the regulation, but to also ensure an auditable and defensible process that will
allow DPO’s to sleep well at night.
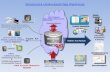
Workflow
Finding, restricting, rectifying and
deleting personal data will be the
new normal in 2018. Since
organizations have amassed
significant stockpiles of
unstructured user data over
decades, searching and finding
the relevant personal content can
be a challenge unless you
implement a smart workflow that
breaks down tasks into achievable
segments.
Index Engines’ software provides
comprehensive classification,
search, disposition, protection
and preservation capabilities all in
an integrated and automated
platform that scales to petabyte-
class data centers.

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
Step 1: Classify and Clean– Provide Insight into Unstructured Data
Understanding what data exists, determining its value, and classifying it to be in scope for the GDPR provides the
foundation for compliance with the regulation. Data classification is performed by scanning data sources at a
metadata level and capturing high-level information about the files.
Metadata fields such as owner and Active Directory membership (ie. Legal or HR department) enable you to
determine if these users typically work with personal data. Fields such as file type or folder/location can help you
determine if files such as presentations or spreadsheets contained on a shared marketing server would contain
personal data.
Additionally, you can utilize metadata to help classify data of value versus data that has long outlived its
usefulness. Using metadata fields such as last accessed over three years ago, or multimedia file types such as
photos and movies can help determine if the content has business value and then take the appropriate action.

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
ROT Data: Leveraging metadata classification, content can then be organized into a few manageable categories.
The first category can be defined as data that no longer has any business value, but is clogging up corporate
servers and complicating GDPR requests. This data could include redundant, obsolete or trivial (ROT) files or
simple content that has not been accessed in more than a few years. This data can easily be defensibly deleted,
so it will no longer get in the way of any future queries or data requests. This process of data minimization will be
discussed in more detail in the following section.
Out-Of-Scope Data: This category includes data that is out of scope for the GDPR - mainly content that, based on
the classification, would not contain personal data. This could be word documents created by members of the
engineering department contained on a specific set of servers. In many cases, traditional data mapping interviews
provide valuable information that will complement the metadata properties captured during the classification
process. In addition to leveraging metadata to organize files, you can enhance the process of classifying content
with information obtained from traditional data mapping interviews. Together this would provide you with a
comprehensive profile of your data assets based on detailed intelligence.
In-Scope Data: Finally, what will remain based on the classification process is data that is in scope for the GDPR.
This is content that would contain personal data. For example, spreadsheets created by members of the finance
department located in a specific set of servers or folder. This in-scope data set will become the target for future
GDPR queries and requests. This would typically encompass a much smaller set of data, typically around 10% to
20% of what exists on corporate networks.
Data classification will take the challenge of managing hundreds of terabytes or even petabytes of data in support
of the GDPR, down to a focused data set of in scope data that can amount to only 10 to 20% of the entire
environment. This will ensure you are finding all personal data using a more efficient and targeted approach.

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
Data Minimization
Organizations have amassed significant stockpiles of user data over decades. Leveraging the above method of
classifying data, it can be organized into meaningful groups simplifying the management of user files. One of the
larger classes of data that exists on corporate networks will be aged data that no longer has business value, or
redundant, obsolete and trivial files commonly referred to as ROT. This class of data can easily be found, tagged,
and migrated to low cost cloud storage or even purged.
Clearing out this useless content from the data center will simplify requests for personal data, making the
management of it a less complex task. Additionally, this data center housekeeping will generate a cost savings that
will help fund support for the GDPR. For organizations that have not budgeted sufficiently for technology to
manage personal data, data minimization will generate a return on investment that will recoup storage capacity
and data center resources thus funding the acquisition of software and services.
Typical classification categories that support data minimization include redundant data that has not been accessed
in years, files that are owned by ex-employees (based on Active Directory) that current users are not accessing,
trivial files such as logs, photos, movies, iTunes libraries, etc. Going further into the metadata analysis, you can find
file types owned by specific departments that have outlived their business value, such as old marketing
presentations or other obsolete content.
Many organizations realize 40% or more savings in storage capacity by executing a data minimization project. This
will result in a significant reduction in data center expenses as shown in the example below.

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
Step 2: Search and Find - Discover Personal Data
The GDPR provides citizens with the right to access, rectify, erase or restrict their personal data. Therefore,
search is core to any technology that will be implemented in support of the regulation.
Many search products will claim support for the discovery of personal data, however, there are many types of
data hidden in diverse types of files and locations. The search technology needs to find data you know exists, as
well as personal content you do not know about.
Beyond common keyword search, to find specific known
personal content in files and email, the use of Boolean
search (proximity, OR, AND, etc.) will allow for more
refined queries. More sophisticated pattern search is key
to finding personal data such as country identity or
driver’s license numbers. Every country in the EU may
have specific patterns that may not be included in the
search engine, therefore regular expressions (RegEX) will
allow for the custom definition of even the most obscure
patterns.
However, personal data that you don’t know exists can be
very difficult to find and the above techniques will prove
useless. To ensure compliance with the GDPR you will
need to find everything with confidence. Conceptual
search technology builds sophisticated search queries
based on machine learning algorithms and will find data
even when you don’t know what you are looking for.
Concept search learns what personal data looks like,
where it is contained, and will develop queries that you
can use to search across large data environments. When
you know personal data is typically hidden inside specific
finance documents, train the query engine to find similar
documents and these documents will be easily found.
Based on the definition of this regulation, you will need all
the search capabilities available to efficiently find and
manage personal data. Index Engines provides
comprehensive search technology, including conceptual
search, enabling you to find personal data with confidence.

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
Step 3: Manage and Protect – Disposition and management of sensitive data
Manage: Once personal data is discovered it needs to be managed according to the data owners request.
Deleting, migrating, archiving, restricting and correcting content will become the new normal in 2018.
Index Engines delivers integrated disposition, empowering users to search and find content then manage it
appropriately. This is critical to a defensible workflow. Once queries are executed, data can be tagged and
organized and then deleted, moved, secured or simply monitored as needed. All data actions will be logged to
maintain a defensible and auditable process. If disposition is not integrated, then the workflow will not be
defensible and personal data can easily be mismanaged.
Integrated archiving is also critical to preserving and securing personal data. Capturing sensitive data that is no
longer needed on the primary storage network, but must be maintained for long-term retention requirements,
should be moved to an archive. The archive can be easily managed and will ensure sensitive data is not left
unprotected on the
network. Retention
policies can be
defined, and
compliance teams
can easily search and
manage the content.
Leveraging cloud
storage to archive
data is not only cost
effective but is more
secure than leaving
this data on servers
and user shares
available to potential
rogue employees.
Protect: Protection of personal data against rogue employees and data breaches is a core aspect of the GDPR.
No longer can organizations accept the fact that sensitive data be left unprotected on networks and hope for the
best. As this regulation is enforced a typical data breach will become much more serious and it could impact a
business reputation as well as levy significant fines.
Indexing file properties including activity logs, who has accessed what, and ACLs, who has read/write/browse
permissions to specific files, facilitates a proactive approach to data protection. Many security tools will notify
you after the fact that some unusual behavior has occurred, but this regulation requires proactive assessment on
data security to secure data assets.

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
Step 4: Monitor - Ongoing management and defensible audit trails
Monitor: Organizations will need to provide a defensible and auditable workflow when the regulators
come to review their support of the GDPR. Implementing a fully integrated platform to manage all aspects of
personal data protection, as outlined above, will empower organizations to not only comply but ensure a
repeatable and reliable process.
Data Protection Officers will need to depend on these tools to understand how data is protected while
refining and improving upon processes based on the data management logs and activity. Without an
integrated approach there will be too many aspects to the workflow and too many areas that can fail when
managing significant volumes of personal data.
Index Engines provides an enterprise index that is incrementally refreshed as the data changes. This allows a
current view into data and actionable insight into new and sensitive data that must be proactively managed.
A dashboard with pre-defined reports and queries will provide visual knowledge of data assets allowing
organizations to refine and audit data policies as needed. Additionally, notifications can be defined, and
emails delivered based on stored queries that are customized to support compliance with the GDPR.
Combined, these tools provide a defensible and auditable workflow that will provide confidence to any data
protection officer that personal data is protected and managed.
Audit: When the EU regulatory body comes to audit the workflow and processes, it is imperative that all
activity be logged and accountable. Index Engines maintains a defensible log of all disposition activity,
allowing for an audit and review of citizens requests.
Detailed reports can be run on the data, to visually review content and determine if there are breaches in
policies and if sensitive data is vulnerable to a breach. Once these policies are defined, simply storing them
and scheduling execution will deliver a detailed report via email for review and management.

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
Legacy Data on Backup Tapes
And what about your legacy backup tape? This data was initially preserved for disaster recovery but now is an
archive of all your long-term retention data.
Personal and sensitive data exists on backup tapes. In order to comply with the regulation, this data must be
managed as well. Simply managing your network data would leave a legacy instance in your backup data that
would cause risk and liability in the future.
The easiest approach would be to profile the backup data once it is no longer used for disaster recovery,
determine what is required
for long-term retention, and
migrate this content out of
backup and into a policy-
based archive. Once this is
accomplished, the backup
data can be purged.
By eliminating the practice of
saving old backup data,
specifically backup tapes,
companies eliminate the
need to manage - and go to -
these repositories in the
future. By leveraging the
GDPR to clean up and
remediate legacy tapes,
offsite tape costs and ad-hoc
eDiscovery costs can be
recouped.
Finding the data that has
value, and selectively
migrating this content makes
for cost-effective
management of these
records. The policies that are
defined to support GDPR on
the network data content
can easily be applied to
legacy tape data in order to
streamline the migration.

www.indexengines.com [email protected] 732-817-1060
Copyright 2017. All rights reserved. Index Engines Inc. All products mentioned are trademarked
by their respective organizations.
Index Engines Support for the GDPR
The GDPR is a significant information management challenge. Organizations must embrace technology to help
meet and exceed the requirements of the regulation. It is critical to deploy a solution that can meet the
following requirements:
Petabyte-class indexing platform
Support for all classes of data, including legacy data on backup tapes
Comprehensive search and reporting
Integrated management and disposition capabilities
Secure archiving to support secure preservation and access
Automated processing and monitoring of data policies
Index Engines is architected to support management and governance of sensitive data in support of corporate
policies. Only Index Engines can deliver a workflow as outlined above on all classes of data, including legacy
data on backup tapes.
Getting started in your efforts to support the GDPR can be accomplished today. Index Engines enables
organizations to deploy technology in stages. Start with some critical data servers, understand what exists,
and then develop a policy that will provide sound support for personal data management. Then use this
footprint to expand the environment and incorporate more data sources, including legacy backup data.
Index Engines delivers a number of deployment options, and services that make easy work of compliance with
the GDPR.
Contact us today at [email protected] or learn more at www.indexengines.com/gdpr
Related Documents