Hierarchical DNA Memory based on Nested PCR Satoshi Kashiwamura, Masahito Yamamoto, Atsushi Kameda, Toshikazu Shiba and Azuma Ohuchi, 8th International Workshop on DNA-based Computers , volume 2568 of LNCS. Springer-Verlag, pp. 112-123 (2003) Summarized by HaYoung Jang

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Hierarchical DNA Memory based on Nested PCR
Satoshi Kashiwamura, Masahito Yamamoto, Atsushi Kameda, Toshikazu Shiba and Azuma Ohuchi,
8th International Workshop on DNA-based Computers, volume 2568 of LNCS. Springer-Verlag, pp. 112-123 (2003)
Summarized by HaYoung Jang

Outline
Nested PCR
Hierarchical DNA Memory (NPMM)
Design of Sequences
Experimental results
Concluding Remarks
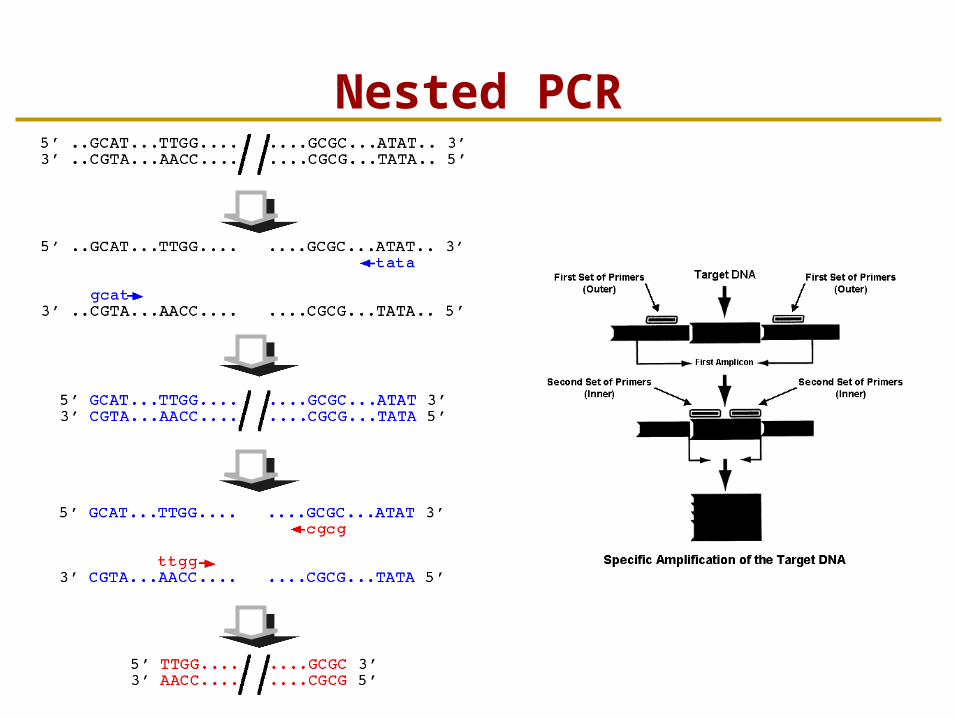
Nested PCR
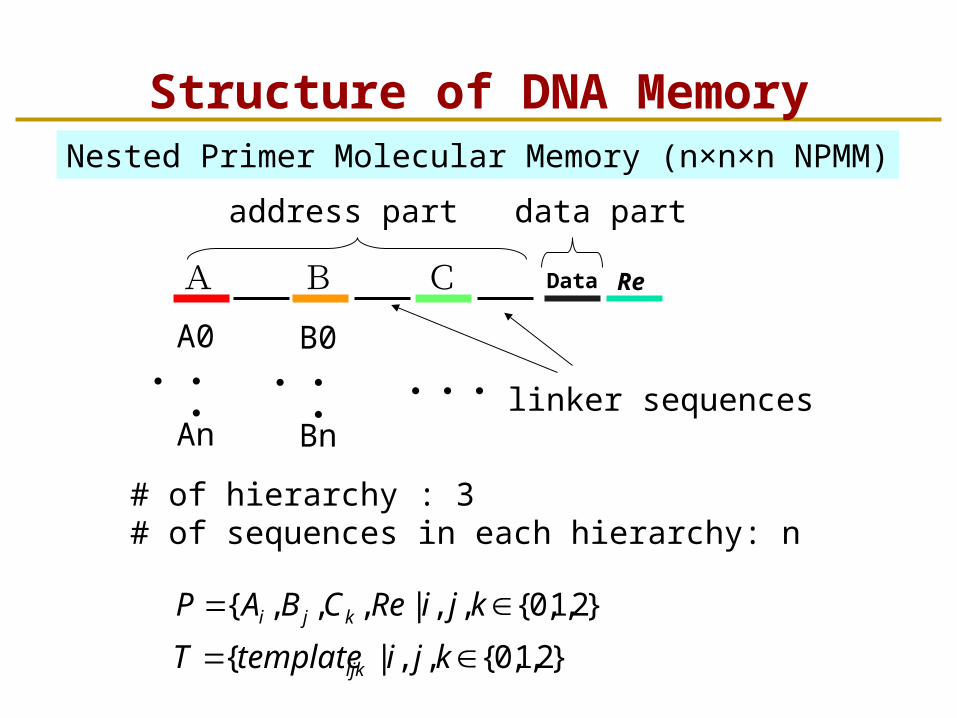
Structure of DNA Memory
A B C Data Re
・・・
A0
An・・・・・・
B0
Bn
# of hierarchy : 3 # of sequences in each hierarchy: n
Nested Primer Molecular Memory (n×n×n NPMM)
address part data part
linker sequences
}2,1,0{,,|{
}2,1,0{,,|,,,{
kjitemplateT
kjiReCBAP
ijk
kji
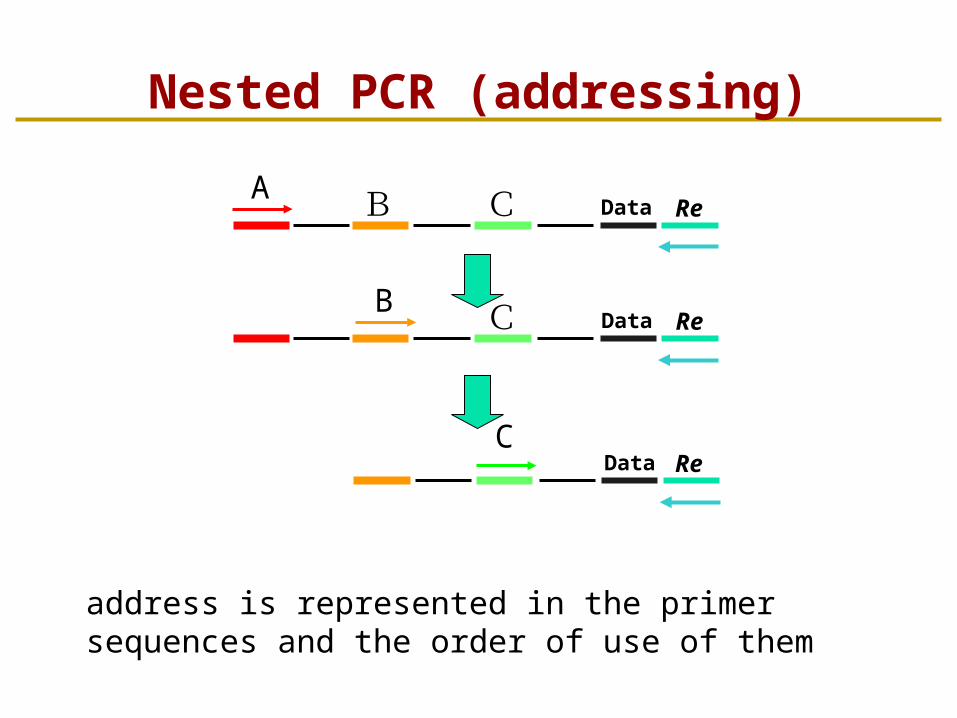
Nested PCR (addressing)
A B C Data Re
B C Data Re
Data ReC
address is represented in the primer sequences and the order of use of them

Hierarchical DNA Memory
NPMM provides a high level of data securityNPMM has a large capacity with a high reaction specificity
Enlarge the address space by using a small number of primer sequencesReduce the total errors by removing (diluting) the error products in each step.
Ease of extracting the target data from MPNN
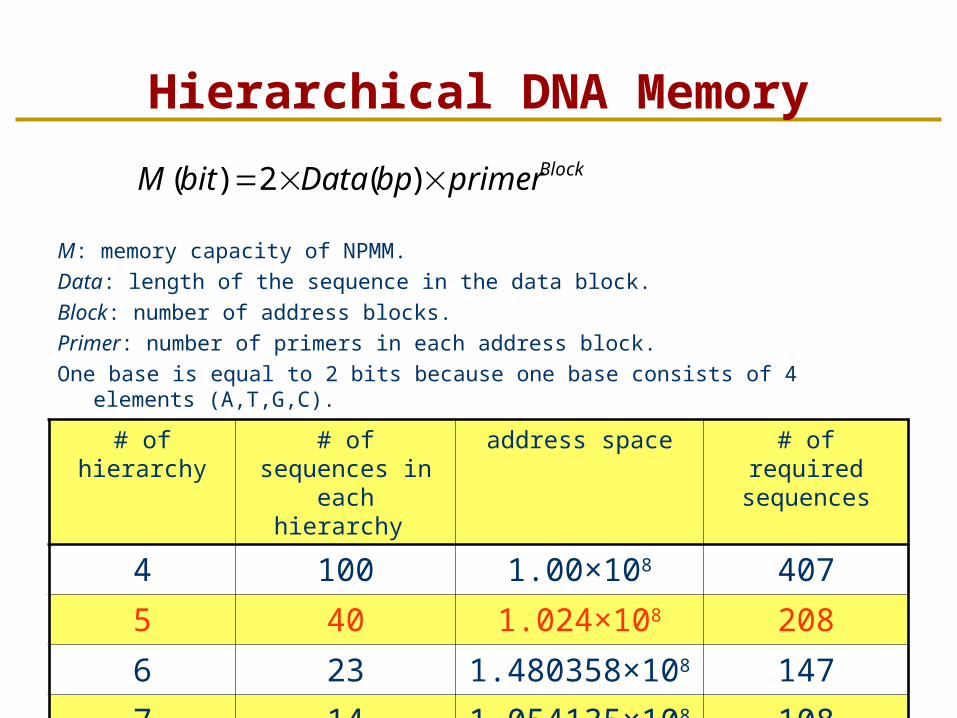
Hierarchical DNA Memory
M: memory capacity of NPMM.Data: length of the sequence in the data block.Block: number of address blocks.Primer: number of primers in each address block.One base is equal to 2 bits because one base consists of 4 elements (A,T,G,C).
# of hierarchy
# of sequences in each
hierarchy
address space # of required sequences
4 100 1.00×108 407
5 40 1.024×108 208
6 23 1.480358×108
147
7 14 1.054135×108
108
BlockprimerbpDatabitM )(2)(
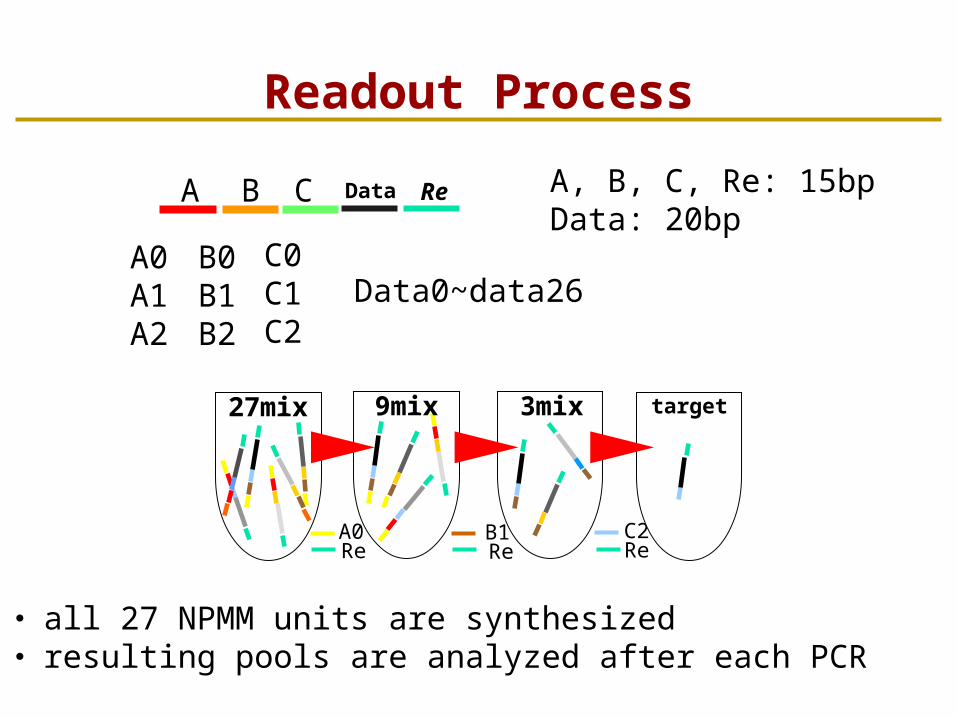
Readout Process
A B C Data Re
A0A1A2
B0B1B2
C0C1C2
Data0~data26
・ all 27 NPMM units are synthesized・ resulting pools are analyzed after each PCR
A, B, C, Re: 15bpData: 20bp
A0Re
C2Re
B1Re
27mix 9mix 3mix target

Design of Sequences
GC_content
Hamming distance
3’end_complementary
PnumbermaxGCGCCGvalueGC pdefine /__))max((_ 2
nscombinatioALLnumberH_maxtpHtpHvalueH MM _/_)),(),,(max(_
nscombinatioALLerE_max_numbtpEtpEvalueE nM
nM _/)),(),,(max(_
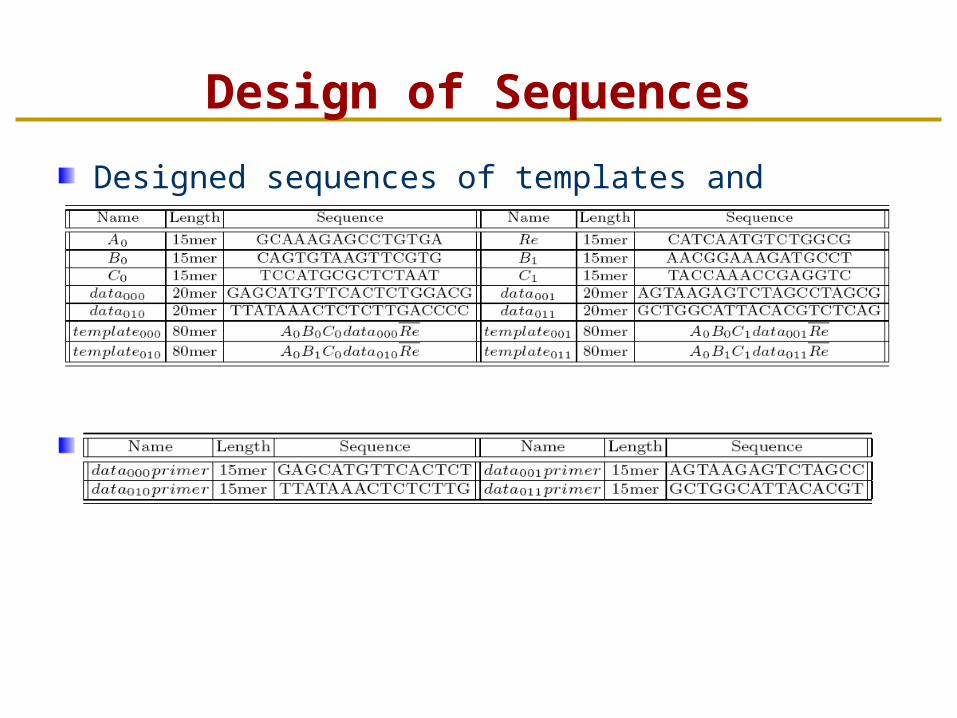
Design of Sequences
Designed sequences of templates and primers
Sequence of data primers

Laboratory Experiments
Extracting target data sequence using PCR
M: 100 bp ladder.
M': DNA marker of length 65, 50, and 35 bp.
Lane 1: B0 after.
Lane 2: B1 after.
Lane 3: B0C0 after.
Lane 4: B0C1 after.
Lane 5: B1C0 after.
Lane 6: B1C1 after.
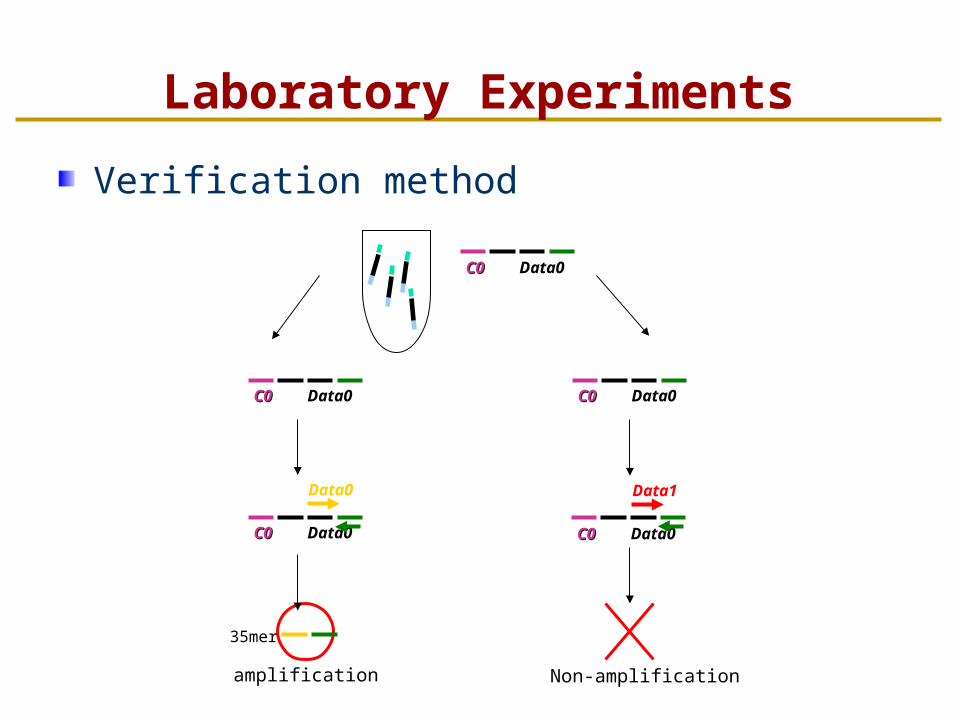
Laboratory Experiments
Verification method
CC00 Data0
CC00 Data0 CC00 Data0
CC00 Data0 CC00 Data0
Data0 Data1
amplification Non-amplification
35mer

Laboratory ExperimentsDetection of amplified sequence
M: DNA marker of length 65, 50, and 35 bp.
Lane 1: use data000primer. Lane 2: use data001primer.
Lane 3: use data010primer. Lane 4: use data011primer.

Laboratory ExperimentsAmplification using concatenation primer
M: DNA marker of length 65, 50, and 35 bp.
Lane 1: the solution set aside from the thermal cycler at the 17th cycle.
Lane 2: 19th cycle. Lane 3: 21st cycle. Lane 4: 23rd cycle. Lane 5: 25th cycle.

Concluding Remarks
Hierarchical DNA memory based on nested PCR (NPMM)
DNA memory with high capacity, high data security and high specificity of chemical reaction
The feasibility of NPMM through some experiments
Related Documents











