Hesitant Fuzzy Linguistic Term Sets for Decision Making Rosa M. Rodr´ ıguez, Luis Mart´ ınez and Francisco Herrera Abstract— Dealing with uncertainty is always a challenging problem and different tools have been proposed to deal with it. Recently a new model based on hesitant fuzzy sets has been presented to manage situations in which experts hesitate between several values to assess an indicator, alternative, variable, etc. Hesitant fuzzy sets suit the modeling of quantitative settings, however, similar situations may occur in qualitative settings so that experts think of several possible linguistic values or richer expressions than a single term for an indicator, alternative, variable, etc. In this paper the concept of a Hesitant Fuzzy Linguistic Term Set is introduced to provide a linguistic and computational basis to increase the richness of linguistic elicitation based on the fuzzy linguistic approach and the use of context-free grammars by using comparative terms. Then a multicriteria linguistic decision making model is presented in which experts provide their assessments by eliciting linguistic expressions. This decision model manages such linguistic expressions by means of its representation using Hesitant Fuzzy Linguistic Term Sets. Index Terms— Hesitant fuzzy sets, linguistic information, fuzzy linguistic approach, context-free grammar, linguistic decision making. I. I NTRODUCTION Problems defined under uncertain conditions are common in real world decision making problems, but quite challenging due to the difficulty of modeling and coping with such uncertainty. Different tools have been used to solve problems such as probability, however in many situations uncertainty is not probabilistic in nature, but rather imprecise or vague. Hence other models, such as fuzzy logic and fuzzy sets theory [6], [39] have been successfully applied to handle imperfect, vague and imprecise information [26]. Nevertheless for handling vague and imprecise information whereby two or more sources of vagueness appear simultaneously, the modeling tools of ordinary fuzzy sets are limited. For this reason different generalizations and extensions of fuzzy sets have been introduced, such as: • Type 2 fuzzy sets [6], [24], and type n fuzzy sets [6] that incorporate uncertainty about the membership function in their definition. • Non-Stationary Fuzzy Sets [8] that introduce into the membership functions a connection that expresses a slight variation in the membership function. Rosa M. Rodr´ ıguez is with the Dept. of Computer Science, University of Ja´ en, 23071 - Ja´ en, Spain. E-mail: [email protected] Luis Mart´ ınez is with the Dept. of Computer Science, University of Ja´ en, 23071 - Ja´ en, Spain. E-mail: [email protected] Francisco Herrera is with the Dept. of Computer Science and A.I., Univer- sity of Granada, 18071 - Granada, Spain. E-mail: [email protected] • Intuitionistic fuzzy sets [1] that extend fuzzy sets by an additional degree, called degree of uncertainty. • Fuzzy multisets [37] based on multisets that allow re- peated elements in the set. • Hesitant fuzzy sets recently introduced by Torra [32] provide a very interesting extension of fuzzy sets. It tries to manage those situations where a set of values are possible in the definition process of the membership of an element. The previous fuzzy tools suit problems defined as quanti- tative situations, but uncertainty is often due to the vague- ness of meanings used by experts in problems whose nature is rather qualitative. In such situations, the fuzzy linguistic approach [40] has provided very good results in many fields and applications [2], [13], [19], [20], [27], [36]. However, in a similar way to the fuzzy sets, the use of the fuzzy linguistic approach presented some limitations, mainly regard- ing information modeling and computational processes, called processes of Computing with Words (CW) [9], [16], [21], [23]. Different linguistic models have tried to extend and improve the fuzzy linguistic approach from both points of view: • The linguistic model based on type-2 fuzzy sets repre- sentation [22], [33], [42] that represents the semantics of the linguistic terms by type-2 membership functions and using interval type-2 fuzzy sets for CW. • The linguistic 2-tuple model [12] that adds a parameter to the linguistic representation known as symbolic trans- lation which keeps the accuracy in the processes of CW. • The proportional 2-tuple model [34] generalizes and ex- tends the 2-tuple model by using two linguistic terms with their proportion to model the information and perform the processes of CW more accurately. • Other extensions based on previous ones were introduced in [5], [18]. Revising the fuzzy linguistic approach and the different linguistic extensions and generalizations, it is observed that the modeling of linguistic information is still quite limited, mainly because it is based on the elicitation of single and very simple terms that should encompass and express the information provided by the experts regarding a linguistic variable. However in different situations the experts involved in the problems defined with uncertainty cannot easily provide a single term as an expression of his/her knowledge, because she/he is thinking of several terms at the same time or looking for a more complex linguistic term that is not usually defined in the linguistic term set.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Hesitant Fuzzy Linguistic Term Sets for DecisionMaking
Rosa M. Rodrıguez, Luis Martınez and Francisco Herrera
Abstract— Dealing with uncertainty is always a challengingproblem and different tools have been proposed to deal withit. Recently a new model based on hesitant fuzzy sets has beenpresented to manage situations in which experts hesitate betweenseveral values to assess an indicator, alternative, variable, etc.Hesitant fuzzy sets suit the modeling of quantitative settings,however, similar situations may occur in qualitative settings sothat experts think of several possible linguistic values or richerexpressions than a single term for an indicator, alternative,variable, etc.
In this paper the concept of a Hesitant Fuzzy LinguisticTerm Set is introduced to provide a linguistic and computationalbasis to increase the richness of linguistic elicitation basedon the fuzzy linguistic approach and the use of context-freegrammars by using comparative terms. Then a multicriterialinguistic decision making model is presented in which expertsprovide their assessments by eliciting linguistic expressions. Thisdecision model manages such linguistic expressions by means ofits representation using Hesitant Fuzzy Linguistic Term Sets.
Index Terms— Hesitant fuzzy sets, linguistic information, fuzzylinguistic approach, context-free grammar, linguistic decisionmaking.
I. INTRODUCTION
Problems defined under uncertain conditions are commonin real world decision making problems, but quite challengingdue to the difficulty of modeling and coping with suchuncertainty. Different tools have been used to solve problemssuch as probability, however in many situations uncertaintyis not probabilistic in nature, but rather imprecise or vague.Hence other models, such as fuzzy logic and fuzzy setstheory [6], [39] have been successfully applied to handleimperfect, vague and imprecise information [26]. Neverthelessfor handling vague and imprecise information whereby twoor more sources of vagueness appear simultaneously, themodeling tools of ordinary fuzzy sets are limited. For thisreason different generalizations and extensions of fuzzy setshave been introduced, such as:• Type 2 fuzzy sets [6], [24], and type n fuzzy sets [6] that
incorporate uncertainty about the membership function intheir definition.
• Non-Stationary Fuzzy Sets [8] that introduce into themembership functions a connection that expresses a slightvariation in the membership function.
Rosa M. Rodrıguez is with the Dept. of Computer Science, University ofJaen, 23071 - Jaen, Spain. E-mail: [email protected]
Luis Martınez is with the Dept. of Computer Science, University of Jaen,23071 - Jaen, Spain. E-mail: [email protected]
Francisco Herrera is with the Dept. of Computer Science and A.I., Univer-sity of Granada, 18071 - Granada, Spain. E-mail: [email protected]
• Intuitionistic fuzzy sets [1] that extend fuzzy sets by anadditional degree, called degree of uncertainty.
• Fuzzy multisets [37] based on multisets that allow re-peated elements in the set.
• Hesitant fuzzy sets recently introduced by Torra [32]provide a very interesting extension of fuzzy sets. It triesto manage those situations where a set of values arepossible in the definition process of the membership ofan element.
The previous fuzzy tools suit problems defined as quanti-tative situations, but uncertainty is often due to the vague-ness of meanings used by experts in problems whose natureis rather qualitative. In such situations, the fuzzy linguisticapproach [40] has provided very good results in many fieldsand applications [2], [13], [19], [20], [27], [36]. However,in a similar way to the fuzzy sets, the use of the fuzzylinguistic approach presented some limitations, mainly regard-ing information modeling and computational processes, calledprocesses of Computing with Words (CW) [9], [16], [21], [23].Different linguistic models have tried to extend and improvethe fuzzy linguistic approach from both points of view:
• The linguistic model based on type-2 fuzzy sets repre-sentation [22], [33], [42] that represents the semantics ofthe linguistic terms by type-2 membership functions andusing interval type-2 fuzzy sets for CW.
• The linguistic 2-tuple model [12] that adds a parameterto the linguistic representation known as symbolic trans-lation which keeps the accuracy in the processes of CW.
• The proportional 2-tuple model [34] generalizes and ex-tends the 2-tuple model by using two linguistic terms withtheir proportion to model the information and perform theprocesses of CW more accurately.
• Other extensions based on previous ones were introducedin [5], [18].
Revising the fuzzy linguistic approach and the differentlinguistic extensions and generalizations, it is observed thatthe modeling of linguistic information is still quite limited,mainly because it is based on the elicitation of single andvery simple terms that should encompass and express theinformation provided by the experts regarding a linguisticvariable. However in different situations the experts involvedin the problems defined with uncertainty cannot easily providea single term as an expression of his/her knowledge, becauseshe/he is thinking of several terms at the same time or lookingfor a more complex linguistic term that is not usually definedin the linguistic term set.

2
Therefore, we work with a view to overcoming such limita-tions, taking into account the idea under the concept of hesitantfuzzy sets provided by Torra [32] to deal with several values ina membership function in a quantitative setting. In this paper,we propose the concept of Hesitant Fuzzy Linguistic Term Set(HFLTS), based on the fuzzy linguistic approach, that willserve as the basis of increasing the flexibility of the elicitationof linguistic information by means of linguistic expressions.Additionally, different computational functions and propertiesof HFLTS are introduced, and we then present how it canbe used to improve the elicitation of linguistic information byusing the fuzzy linguistic approach and context-free grammars.This is very important because it allows us to use different ex-pressions to represent decision makers’ knowledge/preferencesin Decision Making.
In order to answer the question:how to justify the concept of HFLTS and its use in decisionmaking?We present a multicriteria linguistic decision making model inwhich experts provide their assessments by means of linguisticexpressions based on comparative terms close to the expres-sions used by human beings. This decision model managesthe linguistic expressions represented by HFLTS. We proposethe use of two symbolic aggregation operators that allow usto obtain a linguistic interval associated with each alternative,and an exploitation process based on the application of thenon-dominance choice degree to a preference relation obtainedfrom the previous linguistic intervals.
We are only aware of two papers on linguistic decision mak-ing that use linguistic expressions instead of single terms [15],[30]. In [30] Tang and Zheng presented a linguistic model thatdealt with linguistic expressions generated by applying logicalconnectives to the linguistic terms. Ma et al. introduced in[15] the concepts of determinacy and consistency of linguisticterms in multicriteria decision making problems and presenteda model based on a fuzzy-set in which decision makers couldprovide their assessments by using several linguistic termsand the reliability degree of each term. These proposals arenot very close to human beings’ cognitive processes and theyare simpler than the model proposed in this paper that useslinguistic expressions based on comparative terms.
The paper is organised as follows: Section 2 briefly re-views some preliminary concepts that will be used in theHFLTS proposal. Section 3 introduces the concept of HFLTSand several basic properties and operations to carry out theprocesses of CW. Section 4 presents the use of HFLTS tofacilitate and increase flexibility to elicit linguistic information.Section 5 presents a multicriteria linguistic decision makingmodel and defines two symbolic aggregation operators toaccomplish the processes of CW by using linguistic intervals.An illustrative example is also introduced in this section. InSection 6 we make some concluding remarks and suggestfuture research in this area. Appendix I contains a briefreview of several necessary concepts to compare HFLTS andAppendix II contains some definitions to build a preferencerelation between numeric intervals.
II. PRELIMINARIES
Due to the fact that our proposal is based on the fuzzy lin-guistic approach [40] and hesitant fuzzy sets [32], this sectionreviews their main concepts, necessary to understanding theproposal of HFLTS and its use.
A. Fuzzy linguistic approach
In many real decision situations the use of linguistic in-formation is suitable and straightforward due to the natureof different aspects of the problem. In such situations onecommon approach to model the linguistic information is thefuzzy linguistic approach [40] that uses the fuzzy set theory[39] to manage the uncertainty and model the information.
Zadeh [40] introduced the concept of linguistic variableas “a variable whose values are not numbers but words orsentences in a natural or artificial language”. A linguisticvalue is less precise than a number, but it is closer to humancognitive processes used to successfully solve problems deal-ing with uncertainty. A linguistic variable is formally definedas follows:
Definition 1: [41] A linguistic variable is characterized bya quintuple (H,T(H),U,G,M) in which H is the name of thevariable; T(H) (or simply T) denotes the term set of H, i.e.,the set of names of linguistic values of H, with each valuebeing a fuzzy variable denoted generically by X and rangingacross a universe of discourse U which is associated with thebase variable u; G is a syntactic rule (which usually takes theform of a grammar) for generating the names of values of H;and M is a semantic rule for associating its meaning with eachH, M(X), which is a fuzzy subset of U.
To deal with linguistic variables it is necessary to choose thelinguistic descriptors for the term set and their semantics. Fig.1 shows a linguistic term set with the syntax and semanticsof their terms.
0 0.17 1
medium high very high
0.5 0.670.33 0.83
perfectnothing lowvery low
Fig. 1. A set of 7 terms with its semantics
There are different approaches to selecting the linguisticdescriptors and different ways to define their semantics [38],[40]. The selection of the linguistic descriptors can be per-formed by means of:
1) An ordered structure approach: this defines the linguisticterm set by means of an ordered structure providing theterm set distributed on a scale at which a total orderhas been defined [10], [38]. For example, a set of seventerms, S, could be given as follows:

3
S = {s0 : nothing, s1 : very low, s2 : low, s3 : medium,s4 : high, s5 : very high, s6 : perfect}
In these cases, the existence of the following is usuallyrequired:
a) A negation operator Neg(si) = sj so that j = g-i(g+1 is the granularity of the term set).
b) A maximization operator: Max(si, sj) = si if si ≥sj .
c) A minimization operator: Min(si, sj) = si if si ≤sj .
2) A context free grammar approach: this defines the lin-guistic term set by means of a context-free grammar, G,so that the linguistic terms are sentences generated by G[3], [4], [40]. A grammar G is a 4-tuple (VN , VT , I, P ),where VN is the set of non-terminal symbols, VT is theset of terminals’ symbols, I is the starting symbol, and Pthe production rules defined in an extended Backus NaurForm [4]. Among the terminal symbols of G, we can findprimary terms (e.g., low, medium, high), hedges (e.g.,not, much, very), relations (e.g., lower than, higher than),conjunctions (e.g., and, but), and disjunctions (e.g., or).Thus, choosing I as any non-terminal symbol and usingP could be generated linguistic expressions such as,{lower than medium, greater than high, . . .}.
And the definition of their semantics can be accomplishedas in [38], [40]:
1) A semantics based on membership functions and asemantic rule: this approach assumes that the meaningof each linguistic term is given by means of a fuzzysubset defined in the interval [0,1], which is describedby membership functions [4]. This semantic approachis used when the linguistic descriptors are generated bymeans of a context-free grammar. Thus, it contains twoelements: (i) the primary fuzzy sets associated with theprimary linguistic terms and (ii) a semantic rule M forproviding the fuzzy sets of the non-primary linguisticterms [40].
2) A semantics based on an ordered structure of the lin-guistic term set: it introduces the semantics from thestructure defined over the linguistic term set. So, theusers provide their assessments by using an orderedlinguistic term set [31], [38]. The distribution of alinguistic term set on a scale [0,1] can be distributedsymmetrically [38] or non-symmetrically [11], [31].
3) Mixed semantics: this assumes elements from the afore-mentioned semantic approaches.
B. Hesitant fuzzy sets
Torra in [32] introduced a new extension for fuzzy sets tomanage those situations in which several values are possiblefor the definition of a membership function of a fuzzy set.Though this situation might be modeled by fuzzy multisetsthey are not completely adequate for these situations.
An HFS is defined in terms of a function that returns a setof membership values for each element in the domain [32]:
Definition 2: Let X be a reference set, a hesitant fuzzy seton X is a function h that returns a subset of values in [0,1].
h : X → {[0, 1]}Therefore, given a set of fuzzy sets a hesitant fuzzy set is
defined as the union of their membership functions.Definition 3: Let M = {µ1, µ2, ..., µn} be a set of n
membership functions. The hesitant fuzzy set associated withM , hM , is defined as:
hM : M → {[0, 1]}hM (x) =
⋃
µ∈M
{µ(x)}
Some basic operations with HFS were defined [32]:Definition 4: Given a hesitant fuzzy set, h, its lower and
upper bounds are:
h−(x) = min h(x)
h+(x) = max h(x)Definition 5: Let, h, be a hesitant fuzzy set, its complement
is defined as:hc(x) =
⋃
γ∈h(x)
{1− γ}
Proposition 1: [32] The complement is involutive.
(hc)c = hDefinition 6: Let, h1 and h2, be two hesitant fuzzy sets,
their union is defined as:
(h1 ∪ h2)(x) = {h ∈ (h1(x) ∪ h2(x))/h ≥ max(h−1 , h−2 )}Definition 7: Let, h1 and h2, be two hesitant fuzzy sets,
their intersection is defined as:
(h1 ∩ h2)(x) = {h ∈ (h1(x) ∩ h2(x))/h ≤ min(h+1 , h+
2 )}Definition 8: Let, h, be a hesitant fuzzy set, the envelope
of h, Aenv(h), is defined as:
Aenv(h) = {x, µA(x), νA(x)}Being Aenv(h) the intuitionistic fuzzy set [1] of h with µ
and v defined as: µA(x) = h−(x)
vA(x) = 1− h+(x)
III. HESITANT FUZZY LINGUISTIC TERM SETS
Similarly to the situations described and managed by hesi-tant fuzzy sets in [32], where an expert may consider severalvalues to define a membership function, in the qualitativesetting it may occur that experts hesitate among several valuesto assess a linguistic variable. The fuzzy linguistic approach is,however, aimed at statically assessing single linguistic termsfor the linguistic variables. Hence it is clear that, when expertshesitate about several values for a linguistic variable, thefuzzy linguistic approach is very limited. As pointed out inthe introduction, there are two proposals that use linguisticexpressions instead of single terms [15], [30]. However neitherof them is adequate to fulfil the necessities and requirementsof experts in hesitant situations.

4
Consequently, bearing in mind the idea under the hesitantfuzzy sets [32], in this section the concept of HFLTS basedon the fuzzy linguistic approach and the hesitant fuzzy sets isintroduced. Some basic operations of HFLTS are then definedand some properties of such operations revised.
A. Concept and Basic Operations
Definition 9: Let S be a linguistic term set, S ={s0, . . . , sg}, an HFLTS, HS , is an ordered finite subset ofconsecutive linguistic terms of S.
Let S be a linguistic term set, S = {s0, . . . , sg}, we thendefine the empty HFLTS and the full HFLTS for a linguisticvariable, ϑ, as follows:• Empty HFLTS: HS(ϑ) = {}• Full HFLTS: HS(ϑ) = S
Any other HFLTS is formed with at least one linguistic termin S.
Example 1: Let S be a linguistic term set, S = {s0 :nothing, s1 : very low, s2 : low, s3 : medium, s4 :high, s5 : very high, s6 : perfect}, a different HFLTS mightbe:
HS(ϑ) = {s1 : very low, s2 : low, s3 : medium}HS(ϑ) = {s3 : medium, s4 : high, s5 : very high,
s6 : perfect}Once it the concept of HFLTS has been defined, it is
necessary to introduce the computations and operations thatcan be performed on them.
Let S be a linguistic term set, S = {s0, . . . , sg} and HS ,H1
S , and H2S three HFLTS:
Definition 10: The upper bound, HS+ , and lower bound,HS− , of the HFLTS, HS , are defined as:• HS+ = max(si) = sj , si ∈ HS and si ≤ sj ∀i• HS− = min(si) = sj , si ∈ HS and si ≥ sj ∀iDefinition 11: The complement of HFLTS, HS , is defined
as:
HcS = S −HS = {si/si ∈ S and si /∈ HS}
Proposition 2: The complement of an HFLTS is involutive:
(HcS)c = HS
Proof.:Using the definition of a complement of an HFLTS,
(HcS)c = S −Hc
S = S − (S −HS) = HS
Definition 12: The union between two HFLTS, H1S and H2
S
is defined as:
H1S ∪H2
S = {si/si ∈ H1S or si ∈ H2
S}the result will be another HFLTS.
Definition 13: The intersection of two HFLTS, H1S and H2
S
is:
H1S ∩H2
S = {si/si ∈ H1S and si ∈ H2
S}the result of this operation is another HFLTS.
The comparison of linguistic terms is necessary in manyproblems and it has always been defined in the differentlinguistic approaches. An HFLTS is a linguistic term subsetand the comparison among these elements is not simple.Therefore, we introduce the concept of envelope for an HFLTSin order to simplify these operations as shown later on.
Definition 14: The envelope of the HFLTS, env(HS), is alinguistic interval whose limits are obtained by means of upperbound (max) and lower bound (min), hence:
env(HS) = [HS− ,HS+ ], HS− <= HS+
Example 2: Let S = {nothing, very low, low, medium,high, very high, perfect} be a linguistic term set, and HS ={high, very high, perfect} be a HFLTS of S, its envelope is:
HS−(high, very high, perfect) = highHS+(high, very high, perfect) = perfect
env(HS) = [high, perfect]
Definition 15: The definition of the comparison betweentwo HFLTS is based on the concept of envelope of the HFLTS,env(HS). Hence, the comparison between, H1
S and H2S is
defined as follows:
H1S(ϑ) > H2
S(ϑ) iff env(H1S(ϑ)) > env(H2
S(ϑ))
H1S(ϑ) = H2
S(ϑ) iff env(H1S(ϑ)) = env(H2
S(ϑ))
Consequently the comparison is conducted by interval val-ues. In Appendix I different approaches to comparing intervalsare briefly reviewed and how to compare HFLTS is thenclarified.
B. Properties
To conclude this section some relevant properties of theHFLTS operations are reviewed.
Let H1S , H2
S and H3S be three HFLTS and S = {s0, . . . , sg},
then• Commutativity
H1S ∪H2
S=H2S ∪H1
S
H1S ∩H2
S=H2S ∩H1
S
Proof. of the union:⊆Let si ∈ S be a linguistic value, si ∈ H1
S ∪H2S , then by
the definition of union, si ∈ H1S or si ∈ H2
S , if si ∈ H2S
or si ∈ H1S , then si ∈ H2
S ∪H1S
⊇Let si ∈ H2
S ∪H1S , then si ∈ H2
S or si ∈ H1S , if si ∈ H1
S
or si ∈ H2S , then si ∈ H1
S ∪H2S
The demonstration of the intersection would be similarto the union.
• AssociativeH1
S ∪ (H2S ∪H3
S)=(H1S ∪H2
S) ∪H3S
H1S ∩ (H2
S ∩H3S)=(H1
S ∩H2S) ∩H3
S
Proof. of the union:⊆Let si ∈ S be a linguistic value, si ∈ H1
S ∪ (H2S ∪H3
S)then, si ∈ H1
S or si ∈ H2S ∪ H3
S . On the second case,

5
si ∈ H2S or si ∈ H3
S , so if si ∈ H1S ∪H2
S or si ∈ H3S ,
then si ∈ (H1S ∪H2
S) ∪H3S
⊇Let si ∈ (H1
S∪H2S)∪H3
S then, si ∈ H1S∪H2
S or si ∈ H3S .
On the first case, si ∈ H1S or si ∈ H2
S , so if si ∈ H1S or
si ∈ H2S ∪H3
S , then si ∈ H1S ∪ (H2
S ∪H3S)
In a similar way, the associative property of the intersec-tion can be demonstrated.
• DistributiveH1
S ∩ (H2S ∪H3
S)=(H1S ∩H2
S) ∪ (H1S ∩H3
S)H1
S ∪ (H2S ∩H3
S)=(H1S ∪H2
S) ∩ (H1S ∪H3
S)Proof. of the union:⊆Let si ∈ (H1
S ∪ H2S) ∩ H3
S , then si ∈ H1S ∪ H2
S andsi ∈ H3
S . So si ∈ H1S or si ∈ H2
S .If si ∈ H1
S , then si ∈ H1S ∩H3
S
If si ∈ H2S , then si ∈ H2
S ∩H3S
Thus, si ∈ H1S ∩ H3
S or si ∈ H2S ∩ H3
S , this is mean,si ∈ (H1
S ∩H3S) ∪ (H2
S ∩H3S)
⊇Let si ∈ (H1
S∩H3S)∪(H2
S∩H3S). Then si ∈ H1
S∩H3S or
si ∈ H2S ∩H3
S . On the first case, as si ∈ H1S , then si ∈
H1S ∪H2
S , so si ∈ (H1S ∪H2
S)∩H3S . On the second case,
as si ∈ H2S , then si ∈ H1
S∪H2S , so si ∈ (H1
S∪H2S)∩H3
S
Similarly to the property of the union, the distributiveproperty of the intersection can be demonstrated.
IV. ELICITATION OF LINGUISTIC INFORMATION BASED ONHFLTS
Throughout the paper it has been pointed out that the aimof the HFLTS is to improve the elicitation of linguistic infor-mation, mainly when experts hesitate among several values toassess linguistic variables.
So far, the concept of HFLTS it has been introduced assomething that can be directly used by the experts to elicitseveral linguistic values for a linguistic variable, but suchelements are not similar to human beings way of thinking andreasoning. Therefore in this section, the definition of simplebut elaborated linguistic expressions that are more similar tohuman beings’ expressions is proposed to be semanticallyrepresented by means of HFLTS and generated by a context-free grammar.
A simple context-free grammar, GH , is introduced to sup-port the type of linguistic information that we want to allowthe experts to elicit in order to increase the flexibility andexpressiveness of linguistic information, denoted by ll.
Besides the previous grammar, GH , it is also necessary todefine how its linguistic expressions will be represented andmanaged in processes of CW. To do so, a function, E(ll),is presented that transforms such linguistic expressions intoHFLTS.
The context-free grammar, GH , and the transformationfunction, E(·) are further detailed in the subsections below.
A. Context-free grammar for eliciting linguistic informationbased on HFLTS
A context-free grammar, G, provides a way to generatelinguistic terms and linguistic expressions by means of its
different elements. Our objective is to define a context-freegrammar, GH , that generates simple but rich linguistic ex-pressions that can be easily represented by means of HFLTS.Therefore, the context-free grammar, GH , is defined to gen-erate the type of linguistic expressions that we want to modelin hesitant situations:
Definition 16: Let GH be a context-free grammar and S ={s0, . . . , sg} a linguistic term set. The elements of GH =(VN , VT , I, P ) are defined as follows:
VN = {〈primary term〉, 〈composite term〉,〈unary relation〉, 〈binary relation〉, 〈conjunction〉}
VT = {lower than, greater than, between, and, s0,s1, . . . , sg}
I ∈ VN
The production rules are defined in an extended BackusNaur Form so that the brackets enclose optional elements andthe symbol | indicates alternative elements [4]. For the context-free grammar, GH , the production rules are as follows:
P = {I ::= 〈primary term〉|〈composite term〉〈composite term〉 ::= 〈unary relation〉〈primary term〉|
〈binary relation〉〈primary term〉|〈conjunction〉〈primary term〉〈primary term〉 ::= s0|s1| . . . |sg
〈unary relation〉 ::= lower than|greater than〈binary relation〉 ::= between〈conjunction〉 ::= and}Remark 1: The unary relation has some limitations. If the
non-terminal symbol is lower than, the primary term cannot bes0 and if the non-terminal symbol is greater than the primaryterm cannot be sg .
Remark 2: In the binary relation the primary term of theleft side must be less than the primary term of the right side.
Example 3: Let S = {nothing, very low, low, medium,high, very high, perfect} be a linguistic term set, somelinguistic expressions obtained by means of the context-freegrammar, GH , might be:
ll1 = highll2 = lower than mediumll3 = greater than highll4 = between medium and very high
These linguistic expressions are close to the linguistic struc-tures used by human beings to provide their assessments inreal world problems where they are not sure about one singlevalue to assess the criteria or the alternatives. Therefore, thehesitant situation is modeled by means of linguistic structuresgenerated by the production rules, P ∈ GH , being necessaryto model semantically such information. To do so, the use ofHFLTS is proposed.
B. Transforming linguistic expressions of GH into HFLTS
The transformation of the linguistic expressions, ll, pro-duced by GH into HFLTS is done by means of the trans-formation function EGH
.Definition 17: Let EGH be a function that transforms lin-
guistic expressions, ll, obtained by GH , into HFLTS, HS ,where S is the linguistic term set used by GH .
EGH: ll −→ HS
6
The linguistic expressions generated by using the produc-tion rules will be transformed into HFLTS in different waysaccording to their meaning.• EGH
(si) = {si/si ∈ S}• EGH (less than si) = {sj/sj ∈ S and sj ≤ si}• EGH
(greater than si) = {sj/sj ∈ S and sj ≥ si}• EGH
(between si and sj) = {sk/sk ∈ S and si ≤ sk ≤sj}
Fig. 2. HFLTS associated to the linguistic expressions
With the previous definition of EGH it is easy to figure outthe representation of the initial linguistic expressions, ll, intoHFLTS. Fig. 2 shows these transformations graphically.
Example 4: By using the linguistic expressions obtainedin Example 3, ll1, ll2, ll3, and ll4 their transformation intoHFLTS by the transformation function, EGH , is:
EGH(high) = {high}
EGH (lower than medium) = {nothing, very low, low,medium}
EGH(greater than high) = {high, very high, perfect}
EGH(between medium and very high) = {medium,
high, very high}
V. MULTICRITERIA LINGUISTIC DECISION MAKING MODELWITH LINGUISTIC EXPRESSIONS BASED ON COMPARATIVE
TERMS
This section presents a multicriteria linguistic decision mak-ing model in which decision makers can provide their assess-ments by means of linguistic expressions based on comparativeterms close to the natural language used by human beingsor by means of single linguistic terms. This decision modelmanages such linguistic expressions by its representation usingHFLTS. To fuse these linguistic expressions, we propose twosymbolic aggregation operators, min upper and max lowerthat provide a linguistic interval for each alternative. Finally,an exploitation process based on the application of the non-dominance choice degree to obtain the solution set of alterna-tives is proposed.
An example of a decision making problem is also introducedto understand easily the model proposed.
A. Multicriteria linguistic decision making problem
A multicriteria linguistic decision making problem consistsof a finite set of alternatives, X = {x1, . . . , xn}, where each
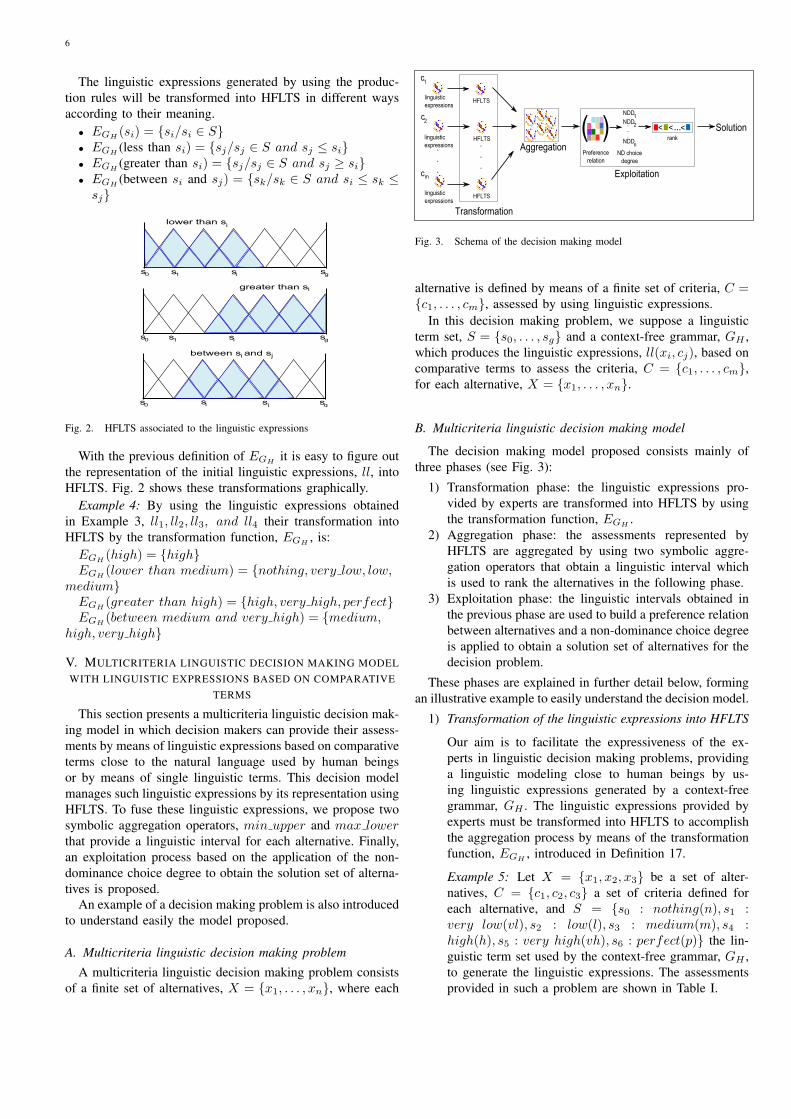
Fig. 3. Schema of the decision making model
alternative is defined by means of a finite set of criteria, C ={c1, . . . , cm}, assessed by using linguistic expressions.
In this decision making problem, we suppose a linguisticterm set, S = {s0, . . . , sg} and a context-free grammar, GH ,which produces the linguistic expressions, ll(xi, cj), based oncomparative terms to assess the criteria, C = {c1, . . . , cm},for each alternative, X = {x1, . . . , xn}.
B. Multicriteria linguistic decision making model
The decision making model proposed consists mainly ofthree phases (see Fig. 3):
1) Transformation phase: the linguistic expressions pro-vided by experts are transformed into HFLTS by usingthe transformation function, EGH .
2) Aggregation phase: the assessments represented byHFLTS are aggregated by using two symbolic aggre-gation operators that obtain a linguistic interval whichis used to rank the alternatives in the following phase.
3) Exploitation phase: the linguistic intervals obtained inthe previous phase are used to build a preference relationbetween alternatives and a non-dominance choice degreeis applied to obtain a solution set of alternatives for thedecision problem.
These phases are explained in further detail below, formingan illustrative example to easily understand the decision model.
1) Transformation of the linguistic expressions into HFLTS
Our aim is to facilitate the expressiveness of the ex-perts in linguistic decision making problems, providinga linguistic modeling close to human beings by us-ing linguistic expressions generated by a context-freegrammar, GH . The linguistic expressions provided byexperts must be transformed into HFLTS to accomplishthe aggregation process by means of the transformationfunction, EGH , introduced in Definition 17.
Example 5: Let X = {x1, x2, x3} be a set of alter-natives, C = {c1, c2, c3} a set of criteria defined foreach alternative, and S = {s0 : nothing(n), s1 :very low(vl), s2 : low(l), s3 : medium(m), s4 :high(h), s5 : very high(vh), s6 : perfect(p)} the lin-guistic term set used by the context-free grammar, GH ,to generate the linguistic expressions. The assessmentsprovided in such a problem are shown in Table I.

7
TABLE IASSESSMENTS PROVIDED FOR THE DECISION PROBLEM
criteriall c1 c2 c3x1 between vl and m between h and vh h
alternatives x2 between l and m m lower than lx3 greater than h between vl and l greater than h
The transformation of such expressions into HFLTS bymeans of the transformation function, EGH
, is shown inTable II.
TABLE IIASSESSMENTS TRANSFORMED INTO HFLTS
criteria
HjS(xi) c1 c2 c3
x1 {vl, l, m} {h, vh} {h}alternatives x2 {l, m} {m} {n, vl, l}
x3 {h, vh, p} {vl, l} {h, vh, p}
2) Aggregation of the assessments represented by HFLTS
Once the assessments are represented by HFLTS, it isnecessary to fuse the set of criteria for each alternativeby using symbolic aggregation operators. In decisionmaking it is common to use two different points ofview [29], the pessimistic and the optimistic. To finda balance between both approximations, we shall definetwo aggregation operators, min upper and max lowerthat carry out the aggregation by using HFLTS. Themin upper operator selects the worst of the superiorvalues and the max lower selects the best of the inferiorvalues. The result of applying these operators is twolinguistic terms that will be used to build a linguisticinterval. To do so, the minimum linguistic term will bethe left limit of the interval and the maximum one willbe the right. Each alternative has a linguistic intervalassociated that represents the core information of theHFLTS aggregated.
• Min upper operatorThis is a symbolic aggregation operator introducedto combine HFLTS and it obtains the worst of themaximum linguistic terms.
Definition 18: Let X = {x1, . . . , xn} be a set ofalternatives, C = {c1, . . . , cm} a set of criteria,S = {s0, . . . , sg} be a linguistic term set and{Hj
S(xi)/i ∈ {1, . . . , n}, j ∈ {1, . . . , m}} a setof HFLTS, the min upper operator consists of twosteps:a) Apply the upper bound, HS+ , for each HFLTS
associated with each alternative:HS+(xi) = {H1
S+(xi), . . . ,HmS+(xi)}, i ∈
{1, . . . , n}b) Obtain the minimum linguistic term for each
alternative:HS+
min(xi) = min{Hj
S+(xi) / j ∈
{1, . . . , m}}, i ∈ {1, . . . , n}According to Example 5 the aggregation with suchan operator is carried out as follows:a) Apply the upper bound for each HFLTS (see
Table III):
TABLE IIIUPPER BOUND FOR EACH HFLTS
criteria
Hj
S+ (xi) c1 c2 c3x1 {m} {vh} {h}
alternatives x2 {m} {m} {l}x3 {p} {l} {p}
b) Obtain the minimum linguistic term of the setof criteria for each alternative (see Table IV):
TABLE IVMINIMUM LINGUISTIC TERM OF THE SET OF CRITERIA
alternatives/HS+
min
(xi)
x1 x2 x3
{m} {l} {l}
• Max lower operator
This symbolic operator is also introduced to com-bine HFLTS, but it is the opposite to the previousone, because it obtains the best of the minimumlinguistic terms.
Definition 19: Let X = {x1, . . . , xn} be a set ofalternatives, C = {c1, . . . , cm} a set of criteria,S = {s0, . . . , sg} be a linguistic term set and{Hj
S(xi)/i ∈ {1, . . . , n}, j ∈ {1, . . . , m}} a set ofHFLTS, the max lower operator consists also oftwo steps:a) Apply the lower bound for each HFLTS associ-
ated with each alternative:HS−(xi) = {H1
S−(xi), . . . , HmS−(xi)}, i ∈
{1, . . . , n}b) Obtain the maximum linguistic term for each
alternative:HS−max
(xi) = max{HjS−(xi) / j ∈
{1, . . . , m}}, i ∈ {1, . . . , n}Following the previous Example 5 the results ob-tained from applying the max lower operator areas follows:a) Apply the lower bound for each HFLTS (see
Table V):

8
TABLE VLOWER BOUND FOR EACH HFLTS
criteria
Hj
S− (xi) c1 c2 c3x1 {vl} {h} {h}
alternatives x2 {l} {m} {n}x3 {h} {vl} {h}
b) Obtain the maximum linguistic term of the setof criteria for each alternative (see Table VI) :
TABLE VIMAXIMUM LINGUISTIC TERM OF THE SET OF CRITERIA
alternatives/HS−max
(xi)
x1 x2 x3
{h} {m} {h}
• The linguistic terms obtained from the previousaggregation operators are used to build a linguisticinterval for each alternative that represents the coreinformation of the HFLTS aggregated. The left limitis the minimum of them and the right limit is themaximum:
H ′max(xi) = max{HS+
min(xi),HS−max
(xi)}
H ′min(xi) = min{HS+
min(xi),HS−max
(xi)}
H ′(xi) = [H ′min(xi),H ′
max(xi)]
Keep doing the Example 5 the linguistic intervalsobtained are shown in Table VII.
TABLE VIILINGUISTIC INTERVALS FOR THE ALTERNATIVES
alternatives/H′(xi)x1 x2 x3
[m, h] [l, m] [l, h]
3) Exploitation phase
Once the linguistic information has been aggregated,the exploitation phase it is carried out, where the setof alternatives will be ordered to select the best one/saccording to the following steps:
a) Extraction of a preference relation. Now the ag-gregated information regarding each alternative isexpressed by a linguistic interval. Hence to ordersuch alternatives, first a binary preference relationis built [7], [25] between alternatives. This prefer-ence relation is obtained by adapting the methodproposed by Wang et. al. in [35]. In the AppendixII one such method is revised.
b) Applying of a choice degree. For ranking alterna-tives from the preference relation, different choicefunctions could be applied [25], [28]. Here, wepropose the use of a non-dominance choice degree,NDD, which indicates the degree to which the
alternative xi is not dominated by the remainingones. Its definition is given as:Definition 20: [25] Let P = [pij ] be a preferencerelation defined over a set of alternatives X . For thealternative xi, its non-dominance degree, NDDi,is obtained as:
NDDi = min{1− pSji, j 6= i}
where pSji = max{pji − pij , 0} represents the
degree to which xi is strictly dominated by xj .
c) Finally, we obtain the set of non-dominated alter-natives as follows:
XND = {xi/xi ∈ X, NDDi = maxxj∈X{NDDj}}
Following Example 5, the exploitation phase consists ofthe following steps:
a) Extract the preference degrees by using the defini-tion introduced by Wang et al [35]. This functionmust be adapted to deal with linguistic intervals,so Ind(si) = i (it provides the index associated tothe label), si ∈ S = {s0, . . . , sg}.
P (x1 > x2)=max(0,Ind(s4)−Ind(s2))−max(0,Ind(s3−Ind(s3))
(Ind(s4)−Ind(s3))+(Ind(s3−Ind(s2))=1
P (x2 > x1)=max(0,Ind(s3)−Ind(s3))−max(0,Ind(s2−Ind(s4))
(Ind(s4)−Ind(s3))+(Ind(s3−Ind(s2))=0
P (x1 > x3)=max(0,Ind(s4)−Ind(s2))−max(0,Ind(s3−Ind(s4))
(Ind(s4)−Ind(s3))+(Ind(s4−Ind(s2))=0.667
P (x3 > x1)=max(0,Ind(s4)−Ind(s3))−max(0,Ind(s2−Ind(s4))
(Ind(s4)−Ind(s3))+(Ind(s4−Ind(s2))=0.333
P (x2 > x3)=max(0,Ind(s3)−Ind(s2))−max(0,Ind(s2−Ind(s4))
(Ind(s3)−Ind(s2))+(Ind(s4−Ind(s2))=0.333
P (x3 > x2)=max(0,Ind(s4)−Ind(s2))−max(0,Ind(s2−Ind(s3))
(Ind(s3)−Ind(s2))+(Ind(s4−Ind(s2))=0.667
PD =
− 1 0.6670 − 0.333
0.333 0.667 −
b) A non-dominance choice degree, NDDi, is ap-plied to the preference relation:
PSD =
− 1 0.3340 − 00 0.334 −
NDD1 = min{(1− 0), 1− 0)} = 1NDD2 = min{(1− 1), (1− 0.334)} = 0NDD3 = min{1− 0.334), (1− 0)} = 0.664
c) Finally, the solution set of alternatives is:
XND = {x1}

9
VI. CONCLUDING REMARKS AND FUTURE WORKS
This paper has introduced the concept of HFLTS to increasethe flexibility and richness of linguistic elicitation based onthe fuzzy linguistic approach and the use of context-freegrammars to support the elicitation of linguistic informationby experts in hesitant situations under qualitative settings.In addition, different computational functions and propertiesof HFLTS have been presented. Afterwards, a multicriterialinguistic decision making model in which experts providetheir assessments by using linguistic expressions based oncomparative terms has been presented and applied to a decisionmaking problem to show the usefulness of the HFLTS indecision making.
In the future, the application of HFLTS to group decisionmaking problems defined with uncertainty will be exploredwhere the experts will be able to provide their assessments bymeans of preference relations by using linguistic expressionsbased on HFLTS.
APPENDIX I
Due to the fact that the comparison of HFLTS is basedon their envelope, which are intervals, in this appendix abrief review is made of several methods to compare numericintervals that could be used in the comparison of HFLTS, butfirst the concept of numeric interval is revised.
Definition 21: [14] An interval is defined by an ordered pairin brackets as:
A = [aL, aR] = {a : aL <= a <= aR}where aL is the left limit and aR is the right limit of A.
Definition 22: [14] The interval is also denoted by its centerand width as:
A = 〈aC , aW 〉 = {a : aC − aW <= a <= aC + aW }where aC is the center and aW is the width of A.
From definitions 21 and 22, the center and width of aninterval may be calculated as:
aC =12(aR + aL)
aW =12(aR − aL)
Different approaches to comparing intervals have beenintroduced in the literature. Tanaka and Ishibuchi presentedtwo order relations in [14]. One of them is defined by the leftand right limits of an interval. This order relation is partial andthere are many pairs of intervals that cannot be compared withsuch a relation. To overcome this limitation the authors defineda second order relation by the center and width of the interval,but it is also a partial order relation. Kundu in [17] defineda fuzzy preference relation between two intervals on the realline by means of a formula that uses probability relations.The disadvantage of this approach is that it does not takeinto account the width of the intervals, and it could therefore,find that two intervals are equal, although their widths weredifferent.
Afterwards, Sengupta in [29] presented two approaches tocompare any two interval numbers. In the following we presentone of them, which we consider suitable to accomplish thecomparison of HFLTS by using their envelopes, because itovercomes the drawbacks of Tanaka, Ishibuchi and Kundu’sapproaches, in further detail. Such a method introduces an ac-ceptability function which indicates the grade of acceptabilityregarding the first interval is inferior to the second intervaland is defined as follows:
Definition 23: [29] Let I be the set of all closed intervalson the real line <, and A and B two intervals, A,B ∈ I . Theacceptability function A< : I × I −→ [0,∞) is defined as:
A< =bC − aC
bW + aW
where bW + aW 6= 0, aC ≤ bC , being aC , bC , aW and bW
the center and width of the intervals A and B.This grade of acceptability is a real number that represents
the grade of acceptance of the interval A is inferior to theinterval B and is interpreted as:• if A< = 0 then it is not accepted that the interval A is
inferior to B• if 0 < A< < 1, then A< is accepted with different grades
of satisfaction from zero to one.• if A< >= 1, it is absolutely true that the interval A is
inferior to B
APPENDIX II
Appendix I revises the comparison between numeric inter-vals by means of a grade of acceptability that indicates if thefirst interval is inferior to the second one, but it does enableus to discover the reciprocal preference degree between bothintervals. Therefore, in this appendix the method proposed byWang et. al. [35] is reviewed to obtain a preference relationfrom a vector of intervals and it is used in the exploitationphase of the multicriteria linguistic decision making modelpresented in Section V.
Definition 24: [35] Let A = [a1, a2] and B = [b1, b2] betwo interval utilities, the preference degree of A over B (orA > B) is defined as:
P (A > B) =max(0, a2 − b1)−max(0, a1 − b2)
(a2 − a1) + (b2 − b1)
and the preference degree of B over A (or B > A) as:
P (B > A) =max(0, b2 − a1)−max(0, b1 − a2)
(a2 − a1) + (b2 − b1)
It is obvious that P (A < B) + P (B > A) = 1 and P (A >B) = P (B > A) = 0.5 when A = B, i.e. a1 = b1 anda2 = b2.
Therefore, the preference relation for the alternatives isobtained as follows:
Definition 25: [35] Let PD be a preference relation,
PD =
− p12 . . . p1n
p21 − . . . p2n
......
. . ....
pn1 pn2 . . . −

10
wherepij = P (xi > xj) = max(0,xiR−xjL)−max(0,xiL−xjR)
(xiR−xiL)−(xjR−xjL) isthe preference degree of the alternative xi over xj ; i, j ∈{1, . . . , n}; i 6= j, and xi = [xiL, xiR], xj = [xjL, xjR]
ACKNOWLEDGEMENTS
This work is partially supported by the Research ProjectTIN-2009-08286, P08-TIC-3548 and FEDER funds.
REFERENCES
[1] K.T. Atanassov. Intuitionistic fuzzy sets. Fuzzy sets and systems, 20:87–96, 1986.
[2] H. Becker. Computing with words and machine learning in medicaldiagnosis. Information Sciences, 134:53–69, 2001.
[3] P.P. Bonissone. A fuzzy sets based linguistic approach: theory andapplications. Approximate Reasoning in Decision Analysis, North-Holland, 1982. 329-339.
[4] G. Bordogna and G. Pasi. A fuzzy linguistic approach generalizingboolean information retrieval: A model and its evaluation. Journal ofthe American Society for Information Science, 44:70–82, 1993.
[5] Y. Dong, Y. Xu, and S. Yu. Computing the numerical scale of thelinguistic term set for the 2-tuple fuzzy linguistic representation model.IEEE Transactions on Fuzzy Systems, 17(6):1366–1378, 2009.
[6] D. Dubois and H. Prade. Fuzzy Sets and Systems: Theory andApplications. Kluwer Academic, New York, 1980.
[7] Z..P. Fan, J. Ma, and Q. Zhang. An approach to multiple attributedecision making based on fuzzy preference information alternatives,.Fuzzy Sets and Systems, 131(1):101–106, 2002.
[8] J.M. Garibaldi, M. Jaroszewski, and S. Musikasuwan. Nonstationaryfuzzy sets. IEEE Transactions on Fuzzy Systems, 16(4):1072–1086,2008.
[9] F. Herrera, S. Alonso, F. Chiclana, and E. Herrera-Viedma. Computingwith words in decision making: Foundations, trends and prospects. FuzzyOptimization and Decision Making, 8(4):337–364, 2009.
[10] F. Herrera, E. Herrera-Viedma, and L. Martınez. A fusion approachfor managing multi-granularity linguistic terms sets in decision making.Fuzzy Sets and Systems, 114(1):43–58, 2000.
[11] F. Herrera, E. Herrera-Viedma, and L. Martınez. A fuzzy linguisticmethodology to deal with unbalanced linguistic term sets. IEEETransactions on Fuzzy Systems, 16(2):354–370, 2008.
[12] F. Herrera and L. Martınez. A 2-tuple fuzzy linguistic representationmodel for computing with words. IEEE Transactions on Fuzzy Systems,8(6):746–752, 2000.
[13] H. Ishibuchi, T. Nakashima, and M. Nii. Classification and Modelingwith Linguistic Information Granules: Advanced Approaches to Linguis-tic Data Mining. Springer, Berlin, 2004.
[14] H. Ishibuchi and H. Tanaka. Theory and methodology: Multiobjectiveprogramming in optimization of the interval objective function. Euro-pean journal of operational research, 48:219–225, 1990.
[15] Y. Xu J. Ma, D. Ruan and G. Zhang. A fuzzy-set approach to treatdeterminacy and consistency of linguistic terms in multi-criteria decisionmaking. International Journal of Approximate Reasoning, 44(2):165–181, 2007.
[16] J. Kacprzyk and S. Zadrozny. Computing with words is an im-plementable paradigm: Fuzzy queries, linguistic data summaries, andnatural-language generation. IEEE Transactions on Fuzzy Systems,18(3):461–472, 2010.
[17] S. Kundu. Min-transitivity of fuzzy leftness relationship and its appli-cation to decision making. Fuzzy Sets and Systems, 86:357–367, 1997.
[18] D.F. Li. Multiattribute group decision making method using extendedlinguistic variables. International Journal of Uncertainty, Fuzziness andKnowledge-Based Systems, 17(6):793–806, 2009.
[19] D.F. Li. Topsis-based nonlinear-programming methodology for multi-attribute decision making with interval-valued intuitionistic fuzzy sets.IEEE Transactions on Fuzzy Systems, 18(2):299–311, 2010.
[20] L. Martınez. Sensory evaluation based on linguistic decision analysis.International Journal of Approximate Reasoning, 44(2):148–164, 2007.
[21] L. Martinez, D. Ruan, and F. Herrera. Computing with words in decisionsupport systems: An overview on models and applications. InternationalJournal of Computational Intelligence Systems, 3(1):362–395, 2010.
[22] J.M. Mendel. An architecture for making judgement using computingwith words. International Journal of Applied Mathematics and Com-puter Sciences, 12(3):325–335, 2002.
[23] J.M. Mendel, L.A. Zadeh, R.R. Yager, J. Lawry, H. Hagras, andS. Guadarrama. What computing with words means to me. IEEEComputational Intelligence Magazine, 5(1):20–26, 2010.
[24] M. Mizumoto and K. Tanaka. Some properties of fuzzy sets of type 2.Information Control, 31:312–340, 1976.
[25] S.A. Orlovsky. Decision-making with a fuzzy preference relation. FuzzySets Systems, 1:155–167, 1978.
[26] S. Parsons. Current approaches to handling imperfect information indata and knowledge bases. IEEE Transactions on Knowledge DataEngineering, 8(3):353–372, 1996.
[27] W. Pedrycz and S. Mingli. Analytic hierarchy process (ahp) in groupdecision making and its optimization with an allocation of informationgranularity. IEEE Transactions on Fuzzy Systems, 19(3):527–539, 2011.
[28] M. Roubens. Some properties of choice functions based on valued binaryrelations. European Journal of Operational Research, 40:309–321, 1989.
[29] A. Sengupta and T. Kumar Pal. On comparing interval numbers.European Journal of Operational Research, 127:28–43, 2000.
[30] Y. Tang and J. Zheng. Linguistic modelling based on semantic similarityrelation among linguistic labels. Fuzzy Sets and Systems, 157(12):1662–1673, 2006.
[31] V. Torra. Negation function based semantics for ordered linguistic labels.International Journal of Intelligent Systems, 11:975–988, 1996.
[32] V. Torra. Hesitant fuzzy sets. International Journal of IntelligentSystems, 25(6), 2010.
[33] I.B. Turksen. Type 2 representation and reasoning for CWW. FuzzySets and Systems, 127:17–36, 2002.
[34] J.H. Wang and J. Hao. A new version of 2-tuple fuzzy linguisticrepresentation model for computing with words. IEEE Transactionson Fuzzy Systems, 14(3):435–445, 2006.
[35] Y.M. Wang, J.B. Yang, and D.L. Xu. A preference aggregation methodthrough the estimation of utility intervals. Computers and OperationsResearch, 32:2027–2049, 2005.
[36] D. Wu and J.M. Mendel. Computing with words for hierarchical decisionmaking applied to evaluating a weapon system. IEEE Transactions onFuzzy Systems,, 18(3):441–460, 2010.
[37] R.R. Yager. On the theory of bags. International Journal GenerationSystem, 13:23–37, 1986.
[38] R.R. Yager. An approach to ordinal decision making. InternationalJournal of Approximate Reasoning, 12:237–261, 1995.
[39] L.A. Zadeh. Fuzzy sets. Information and Control, 8:338–353, 1965.[40] L.A. Zadeh. The concept of a linguistic variable and its applications to
approximate reasoning. Information Sciences, Part I, II, III, 8,8,9:199–249,301–357,43–80, 1975.
[41] L.A. Zadeh. The concept of a linguistic variable and its applications toapproximate reasoning. Part I. Information Sciencies, 8:199–249, 1975.
[42] S.M. Zhou, R.I. John, F. Chiclana, and J.M. Garibaldi. On aggregatinguncertain information by type-2 OWA operators for soft decision mak-ing. International Journal of Intelligent Systems, DOI 10.1002/int.20420,2010.
R osa M. Rodrıguez received her M.Sc. degreein Computer Science from the University of Jaen,Spain, in 2008.
She is currently a Ph.D. student in the ComputerScience Department, University of Jaen, Jaen, Spain.Her research interests include linguistic preferencemodeling, decision making and fuzzy logic.

11
L uis Martınez received his M.Sc. and Ph.D. de-grees in Computer Science from the University ofGranada, Spain, in 1993 and 1999, respectively.
He is currently a Professor in the ComputerScience Department, and director of the AdvancedResearch Center in IT at the University of Jaen, Jaen,Spain.
He currently acts as manager editor of the journalSoft Computing and area editor of the InternationalJournal of Computational Intelligence Systems.
His current research interests are linguistic prefer-ence modelling, decision making, fuzzy logic-based systems, computer-aidedlearning, sensory evaluation, recommender systems and e-commerce.
F rancisco Herrera received his M.Sc. in Mathemat-ics in 1988 and Ph.D. in Mathematics in 1991, bothfrom the University of Granada, Spain.
He is currently a Professor in the Departmentof Computer Science and Artificial Intelligence atthe University of Granada. He has had more than200 papers published in international journals. He iscoauthor of the book ”Genetic Fuzzy Systems: Evo-lutionary Tuning and Learning of Fuzzy KnowledgeBases” ( World Scientific, 2001).
He currently acts as Editor in Chief of the interna-tional journal ”Progress in Artificial Intelligence (Springer) and serves as areaeditor of the Journal Soft Computing (area of evolutionary and bioinspiredalgorithms) and International Journal of Computational Intelligence Systems(area of information systems). He acts as associated editor of the journals:IEEE Transactions on Fuzzy Systems, Information Sciences, Advances inFuzzy Systems, and International Journal of Applied Metaheuristics Com-puting; and he serves as member of several journal editorial boards, amongothers: Fuzzy Sets and Systems, Applied Intelligence, Knowledge and Infor-mation Systems, Information Fusion, Evolutionary Intelligence, InternationalJournal of Hybrid Intelligent Systems, Memetic Computation, Swarm andEvolutionary Computation.
He received the following honors and awards: ECCAI Fellow 2009, 2010Spanish National Award on Computer Science ARITMEL to the ”SpanishEngineer on Computer Science”, and International Cajastur ”Mamdani” Prizefor Soft Computing (Fourth Edition, 2010).
His current research interests include computing with words and decisionmaking, data mining, bibliometrics, data preparation, instance selection, fuzzyrule based systems, genetic fuzzy systems, knowledge extraction based onevolutionary algorithms, memetic algorithms and genetic algorithms.
Related Documents











