HDF5 collective HDF5 collective chunk IO chunk IO A Working Report A Working Report

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

HDF5 collective HDF5 collective chunk IOchunk IO
A Working ReportA Working Report

Motivation for this project Motivation for this project
►Found extremely bad performance of Found extremely bad performance of parallel HDF5 when implementing parallel HDF5 when implementing WRF-Parallel HDF5 IO module with WRF-Parallel HDF5 IO module with chunking storage. chunking storage.
►Found that parallel HDF5 does not Found that parallel HDF5 does not support MPI-IO collective write and support MPI-IO collective write and read. read.
►Had some time left in MEAD project.Had some time left in MEAD project.
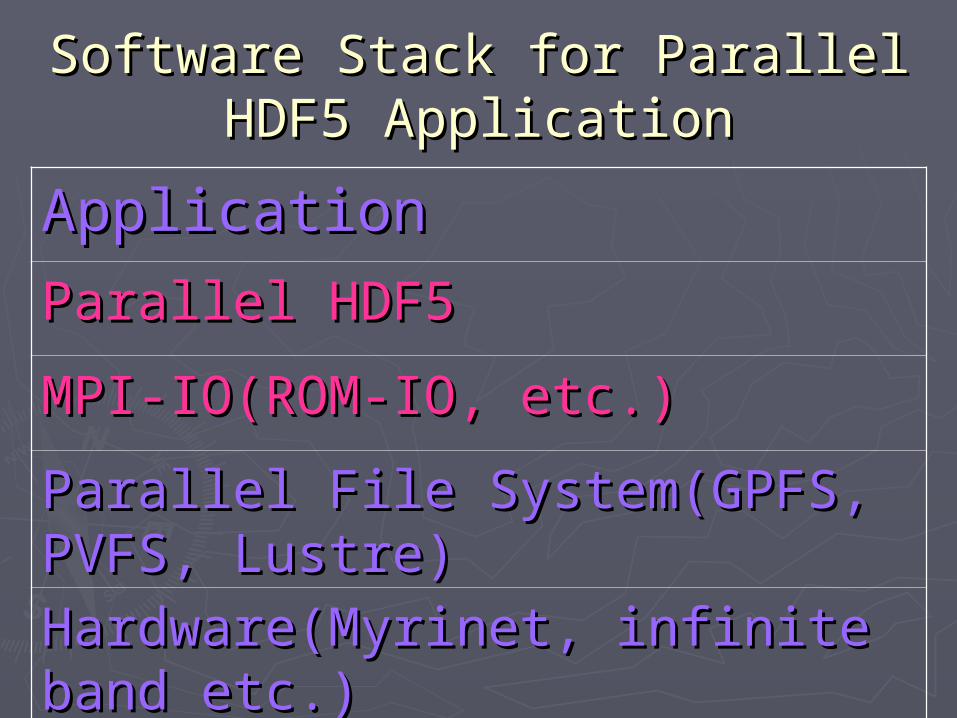
Software Stack for Parallel HDF5 Software Stack for Parallel HDF5 ApplicationApplication
ApplicationApplicationParallel HDF5Parallel HDF5MPI-IO(ROM-IO, etc.)MPI-IO(ROM-IO, etc.)Parallel File System(GPFS, PVFS, Parallel File System(GPFS, PVFS, Lustre)Lustre)Hardware(Myrinet, infinite band Hardware(Myrinet, infinite band etc.)etc.)

Why collective chunk IO?Why collective chunk IO?
►Why using chunk storage?Why using chunk storage?
1. Better performance when subsetting1. Better performance when subsetting
2. Dataset with unlimited dimension2. Dataset with unlimited dimension
3. Filters to be added3. Filters to be added
►Why collective IO?Why collective IO?
Take advantage of the performance Take advantage of the performance optimization provided by MPI-IO.optimization provided by MPI-IO.

MPI-IO Basic ConceptsMPI-IO Basic Concepts
►collective IOcollective IO
Contrary to independent IO, all Contrary to independent IO, all processes must participate in doing IO. processes must participate in doing IO.
MPI-IO can do optimization to improve MPI-IO can do optimization to improve IO performance by using IO performance by using MPI_FILE_SET_VIEW with collective IO. MPI_FILE_SET_VIEW with collective IO.

P0’s view
P1’s view
P2’s view
P3’s view
An Example with 4 processes
When doing independent IO, for worst case it may require 8 individual IO access.

With collective IOWith collective IO
P0 P1 P2 P3
It may only need one IO access to the disk.check http://hdf.ncsa.uiuc.edu/apps/WRF-ROMS/parallel-netcdf.pdfand the reference of that report for more information.

Challenges to support collective Challenges to support collective IO with chunking storage inside IO with chunking storage inside
HDF5HDF5► Have to fully understand how chunking is Have to fully understand how chunking is
implemented inside HDF5.implemented inside HDF5.► Have to fully understand how MPI-IO is Have to fully understand how MPI-IO is
supported inside HDF5, especially how supported inside HDF5, especially how collective IO works with contiguous storage collective IO works with contiguous storage inside HDF5.inside HDF5.
► Have to find out how difficult to implement Have to find out how difficult to implement collective chunk IO inside HDF5.collective chunk IO inside HDF5.

Strategy to do the projectStrategy to do the project
► First to see whether we can First to see whether we can implement collective chunk IO for implement collective chunk IO for some special cases such as one big some special cases such as one big chunk to cover all singular hyperslab chunk to cover all singular hyperslab selections.selections.
►Then to gradually increase the Then to gradually increase the complexity of the problem until we can complexity of the problem until we can solve the general case.solve the general case.

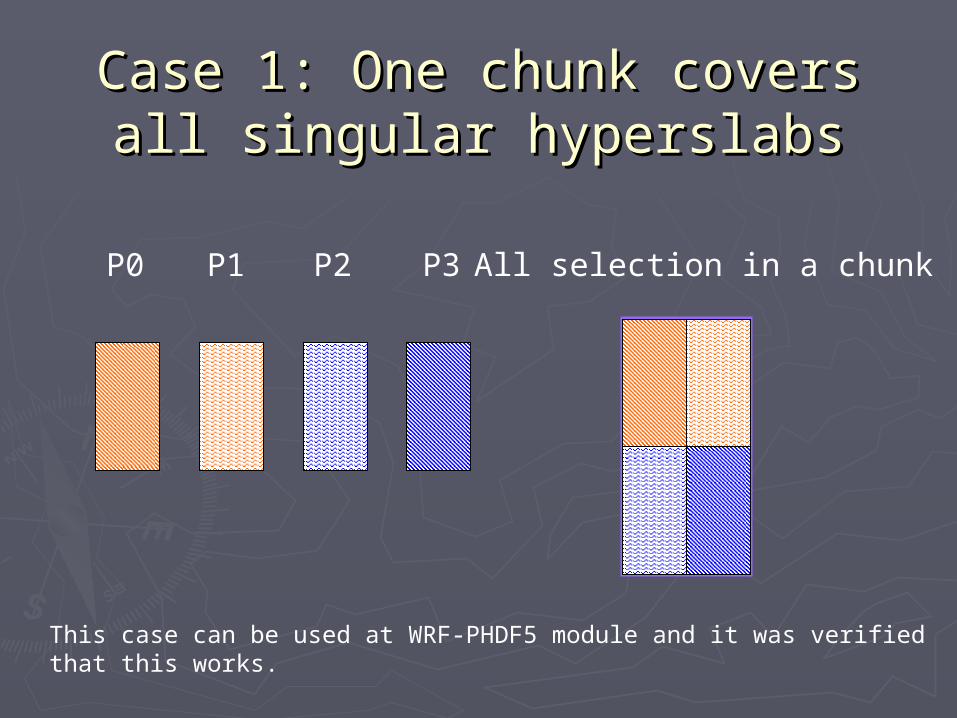
Case 1: One chunk covers all Case 1: One chunk covers all singular hyperslabssingular hyperslabs
P0 P2 All selection in a chunkP1 P3

Progresses made so farProgresses made so far
►Unexpected easy connection between Unexpected easy connection between HDF5 chunk code and collective IO HDF5 chunk code and collective IO code.code.
►Found that the easy connection works Found that the easy connection works for more general test cases than I for more general test cases than I expected.expected.
►Wrote the test-suite and checked into Wrote the test-suite and checked into HDF5 CVS in both 1.6 and 1.7 branch.HDF5 CVS in both 1.6 and 1.7 branch.
►Tackled with more general cases.Tackled with more general cases.

Special cases to work with Special cases to work with
►One chunk to cover all singular hyperslab One chunk to cover all singular hyperslab selections for different processes.selections for different processes.
►One chunk to cover all regular hyperslab One chunk to cover all regular hyperslab selections for different processes.selections for different processes.
►All hyperslab selections are singular and All hyperslab selections are singular and the number of chunks inside each the number of chunks inside each hyperslab selection should be the same. hyperslab selection should be the same.
Case 1: One chunk covers all Case 1: One chunk covers all singular hyperslabssingular hyperslabs
This case can be used at WRF-PHDF5 module and it was verifiedthat this works.
P0 P2 All selection in a chunkP1 P3

Case 2: One chunk covers all Case 2: One chunk covers all regular hyperslabsregular hyperslabs
chunk
P0
P2
P1
P3
Whether MPI collective chunk IO can optimize this pattern is another question andis out of our discussion.

Case 3: Multiple chunks cover Case 3: Multiple chunks cover singular hyperslabssingular hyperslabs
each chunk size
P0
P2
P1
P3
Condition for this case: number of chunks for each process must be equal.

More general caseMore general case
►Hyperslab does not need to be singular.Hyperslab does not need to be singular.►One chunk does not need to cover all One chunk does not need to cover all
hyperslab selections for one process.hyperslab selections for one process.►Number of chunks does NOT have to be Number of chunks does NOT have to be
the same to cover hyperslab selections the same to cover hyperslab selections for processes.for processes.
►How about irregular hyperslab How about irregular hyperslab selection?selection?

What does it look like?What does it look like?
CHUNK
hyperslab selection

More detailsMore details
In each chunk, the overall selection becomes irregular, we cannot use the contiguous MPI collective IO code to describe the above shape.

A little more thoughtA little more thought
►The current HDF5 implementation needs The current HDF5 implementation needs an individual IO access for data stored in an individual IO access for data stored in each chunk. With large number of each chunk. With large number of chunks, that will cause bad performance.chunks, that will cause bad performance.
►Can we avoid the above case in Parallel Can we avoid the above case in Parallel HDF5 layer?HDF5 layer?
► Is it possible to do some optimization Is it possible to do some optimization and push the above problem into MPI-IO and push the above problem into MPI-IO layer?layer?

What should we doWhat should we do
► Build MPI derived datatype to describe this Build MPI derived datatype to describe this pattern for each chunk and we hope that pattern for each chunk and we hope that when MPI-IO obtains the whole picture, it will when MPI-IO obtains the whole picture, it will figure out that this is a regular hyperslab figure out that this is a regular hyperslab selection and do the optimized IO. selection and do the optimized IO.
► To understand how MPI Derived data type To understand how MPI Derived data type works, please check “Derived Data Types with works, please check “Derived Data Types with MPI” from MPI” from http://www.msi.umn.edu/tutorial/scicomp/genhttp://www.msi.umn.edu/tutorial/scicomp/general/MPI/content6.htmleral/MPI/content6.html at supercomputing institute of University of at supercomputing institute of University of Minnesota.Minnesota.

MPI Derived DatatypeMPI Derived Datatype► Why?Why?
To provide a portable and efficient way To provide a portable and efficient way to describe non-contiguous or mixed to describe non-contiguous or mixed types in a message.types in a message.
► What?What?
Built from the basic MPI datatypes;Built from the basic MPI datatypes;
A sequence of basic datatypes and A sequence of basic datatypes and displacements.displacements.

How to construct the DDTHow to construct the DDT
►MPI_Type_contiguousMPI_Type_contiguous►MPI_Type_vectorMPI_Type_vector►MPI_Type_indexedMPI_Type_indexed►MPI_Type_structMPI_Type_struct

MPI_TYPE_INDEXEDMPI_TYPE_INDEXED
► parameters: parameters:
count, blocklens[], offsets[], oldtype, *newtypecount, blocklens[], offsets[], oldtype, *newtype
count: number of blocks to be addedcount: number of blocks to be added
blocklens: number of elements in blockblocklens: number of elements in block
offsets: displacements for each blockoffsets: displacements for each block
oldtype: datatype of each elementoldtype: datatype of each element
newtype: handle(pointer) for new derived typenewtype: handle(pointer) for new derived type

MPI_TYPE_INDEXEDMPI_TYPE_INDEXED
11 22 33 44 55 66 77 88 99 1010 1111
1122
1133
1144
1155
blocklengths[0] = 4; displacements[0] = 5;
count = 2;
blocklengths[1] = 2; displacements[1] = 12;
MPI_TYPE_INDEXED(count,blocklengths,displacements,MPI_INT,&indexMPI_TYPE_INDEXED(count,blocklengths,displacements,MPI_INT,&indextype);type);

Approach Approach
► We will build a one MPI Derived Data type for We will build a one MPI Derived Data type for each processeach process
Use MPI_TYPE_STRUCT or MPI_TYPE_INDEXED Use MPI_TYPE_STRUCT or MPI_TYPE_INDEXED to generate the derived data typeto generate the derived data type
► Then use MPI_TYPE_STRUCT to generate the Then use MPI_TYPE_STRUCT to generate the final MPI derived data type for each processfinal MPI derived data type for each process
► Set MPI file set viewSet MPI file set view► Inside MPI-IO layer to let MPI-IO figure out Inside MPI-IO layer to let MPI-IO figure out
how to optimize thishow to optimize this

Approach (continued)Approach (continued)
► Start with building the “basic” MPI derived data type inside one Start with building the “basic” MPI derived data type inside one chunkchunk
► Use “basic” MPI derived data types to build an “advanced” MPI Use “basic” MPI derived data types to build an “advanced” MPI derived data type for each processderived data type for each process
► Use MPI_Set_file_view to glue this together.Use MPI_Set_file_view to glue this together.
Done!Done!
Obtain hyperslab Selection information
Build “basic” MPI derived datatype PER CHUNK based on
selection information
Build “advanced” MPI derived data
type PER PROCESS based on “basic” MPI derived data type
Set MPI File View based on
“advanced” MPI derived data type
Send to MPI-IO layer, done

Schematic for MPI Derived Data Schematic for MPI Derived Data Types to support collective Types to support collective
chunk IO inside Parallel HDF5chunk IO inside Parallel HDF5
...P0
chunk 1
chunk 2
chunk i
chunk n
...P1
chunk n+1 chunk n+2
chunk n+i
chunk n+m

How to startHow to start
►HDF5 used Span-tree to implement HDF5 used Span-tree to implement general hyperslab selectiongeneral hyperslab selection
►The starting point is to build an MPI The starting point is to build an MPI derived data type for irregular hyperslab derived data type for irregular hyperslab selection with contiguous layoutselection with contiguous layout
►After this step is finished, we will build an After this step is finished, we will build an MPI derived data type for chunk storage MPI derived data type for chunk storage following the previous approach following the previous approach

Now a little off-track for the Now a little off-track for the original projectoriginal project
► We are trying to build MPI derived We are trying to build MPI derived data type for irregular hyperslab with data type for irregular hyperslab with contiguous storage. If this is solved, contiguous storage. If this is solved, HDF5 can support collective IO for HDF5 can support collective IO for irregular hyperslab selection. irregular hyperslab selection.
► It may also improve the performance It may also improve the performance for independent IO.for independent IO.
►Then we will build an advanced MPI Then we will build an advanced MPI derived data type for chunk storage.derived data type for chunk storage.

How to describe this hyperslab selection?Span-tree should handle this well.

Span tree handling with the Span tree handling with the overlapping of the hyperslaboverlapping of the hyperslab
+ +

Some Performance HintsSome Performance Hints
► It was well-known that Performance was not It was well-known that Performance was not very good with MPI derived data type. very good with MPI derived data type. People use MPI PACK and MPI UNPACK in People use MPI PACK and MPI UNPACK in order to gain performance in real order to gain performance in real application.application.
► The recent performance study shows that The recent performance study shows that using MPI derived data type can achieve using MPI derived data type can achieve comparable performance compared with MPI comparable performance compared with MPI Pack and MPI Unpack.Pack and MPI Unpack.
(http://nowlab.cis.ohio-state.edu/publications/(http://nowlab.cis.ohio-state.edu/publications/tech-reports/2004/TR19.pdf).tech-reports/2004/TR19.pdf).

Related Documents




![arXiv:1912.09898v1 [astro-ph.IM] 20 Dec 2019 · several PyTables HDF5 storage optimizations, including indexing for faster lookup and chunk-ing/compression to minimize file sizes.](https://static.cupdf.com/doc/110x72/5fad023094eedd00ff4d481b/arxiv191209898v1-astro-phim-20-dec-2019-several-pytables-hdf5-storage-optimizations.jpg)






