
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Hardware Support for Extracting Coarse-grain SpeculativeParallelism in Distributed Shared-Memory Multiprocessors�Renato J. FigueiredoDepartment of ECENorthwestern Universityr.�[email protected] Jos�e A. B. FortesDepartment of ECEUniversity of Floridafortes@u .eduAbstractData dependence speculation allows a compiler to re-lax the constraint of data-independence to issue tasksin parallel, increasing the potential for automaticextraction of parallelism from sequential programs.This paper proposes hardware mechanisms to sup-port a data-dependence speculative distributed shared-memory (DDSM) architecture that enable speculativeparallelization of programs with irregular data struc-tures and inherent coarse-grain parallelism. E�cientsupport for coarse-grain tasks requires large bu�ersfor speculative data; DDSM leverages cache and direc-tory structures to provide large bu�ers that are man-aged transparently from applications. The proposedcache and directory extensions provide support for dis-tributed speculative versions of cache blocks, run-timedetection of dependence violations, and program-orderreconciliation of cache blocks. This paper describes theDDSM architecture and presents a simulation-basedevaluation of its performance on �ve benchmarks cho-sen from the Spec95 and Olden suites. The proposedsystem yields simulated speedups of 3.8 to 12.5 in a16-node con�guration for programs with coarse-grainspeculative windows (millions of instructions and hun-dreds of KBytes of speculative data).1 IntroductionModern high-performance computers exploit implicitparallelism across instructions of a sequential stream(instruction-level), as well as explicit parallelism acrosstasks executing in distributed processing units (thread-level). The former type of parallelism - ILP - is oftenachieved transparently from a programmer via com-piler and hardware techniques. The latter - TLP - iscurrently achieved either via explicit parallel program-ming, or with the aid of parallelizing compilers [8, 7].Future high-performance computers will be able toleverage plentiful on-chip resources to support variousgranularities of parallelism [1, 6, 22]. While implicitparallelism has been traditionally studied at the in-struction level, several implicit techniques that exploitthe large transistor budget of next-generation proces-sors have recently been pursued in designs that exploitspeculative TLP [11, 12, 5, 20, 21, 24].�This work was partially funded by the National Science Foundationunder grants CCR-9970728 and EIA-9975275. Renato Figueiredo is alsosupported by a CAPES fellowship. Part of this work was performed whilethe authors were at the Department of ECE, Purdue University.
This paper proposes a novel data dependence specu-lation technique for distributed shared-memory (DSM)multiprocessors that allows for automatic extraction ofspeculative TLP from sequential programs with irreg-ular data structures and inherent coarse-grain paral-lelism. The speculation mechanisms extend existing L2caches and directory protocols to support a hardware-based data dependence speculative DSM. The paperdescribes the proposed technique and evaluates its per-formance via simulation.Previous work on thread-level speculation for mul-tiprocessors has considered solutions that exploit par-allelism at �ne [11, 12, 21] and coarse [24, 25] granu-larities. It is conceivable that large, high-performancemultiprocessors of the future will employ speculativetechniques at di�erent granularities. However, thereare limitations to the e�ciency of previous approachesthat need to be addressed to e�ciently support highlyspeculative distributed multiprocessors.First, performance gains for �ne-grain applicationstend to diminish as more processors are used in com-putation; the relative cost of the synchronization over-heads at start-up and commit time increases, and thesystem's e�ciency is reduced. This behavior is ob-served in the results reported in [20], where modestrelative performance improvements - at most 43% -are achieved as the number of processors is quadru-pled from 4 to 16.Second, there are applications that have inherentparallelism that can be exploited speculatively at acoarse granularity [24]. In this case, speculation hasthe potential to provide good parallel e�ciency, sincesynchronization costs are amortized across large taskbodies. For example, increasing the granularity of tasksvia loop unrolling has been shown to improve the per-formance of speculative parallelized applications [5, 16].However, in order to support coarse-grain tasks, largespeculative bu�ers must be available.This paper proposes a technique that addressesthese limitations in the context of DSM multipro-cessors. The proposed Data-Dependence Speculationtechnique | DDSM | di�ers from �ne-grain on-chip solutions [11, 12] in that a distributed protocolis employed, and large speculative bu�ers are sup-ported. The proposed technique also di�ers funda-mentally from �ne-grain, multi-chip solutions [5, 20]in that (1) all speculative state is encoded in cachelines and directory entries, and (2) protocol trans-actions follow the same sequence of events of con-ventional directory-based DSM coherence protocols.

DDSM treats cache blocks as self-contained specula-tive units, thereby leveraging existing cache-coherentmechanisms of DSMs. In contrast, speculative state inrelated proposals is distributed across cache lines andadditional hardware bu�ers (LMDT/GMDT tables [5],ORB bu�ers [20]).Related work on coarse-grain speculation forDSMs has considered solutions that support largebu�ers [24, 25]. While in these schemes hardware de-tects data dependence violations, copy-out softwareis responsible for bringing speculative data to non-speculative state. DDSM di�ers from these solutions inthat speculative versions of blocks are reconciled trans-parently from applications.In summary, the main contribution of this paper is anovel data dependence speculation technique for DSMsthat (1) is distributed, and (2) supports large cache-based speculative bu�ers that are managed transpar-ently from applications. Its performance is quantita-tively analyzed via simulation, based on a modi�ed ver-sion of RSIM [18]. The analysis considers a set of �veprograms chosen from the Spec95 and Olden [3] bench-mark suites, and a sparse matrix-based microbench-mark. These Fortran and C programs operate on bothstatic and pointer-based data structures.The analysis shows that the speculative DSM e�-ciently supports coarse-grain applications with low oc-currence (� 10%) of dependence violations, and deliv-ers speedups of 3.8 to 12.5 for the studied programs. Italso determines how its performance is a�ected by thesize of the speculative window, number of processors,and mis-speculation frequency for a sparse matrix-based microbenchmark.The rest of this paper is organized as follows. Sec-tion 2 describes the DDSM programming and execu-tion models. Section 3 describes the structures thatimplement the models of Section 2. Section 4 describesthe experimental methodology used in the performanceanalysis; results are summarized in Section 5. Section 6compares the approach with previous work, and Sec-tion 7 presents conclusions.2 Programming and execution modelsThe programmingmodel of DDSMs extends the single-program, multiple-data (SPMD) model to supportspeculative accesses to shared-memory. In SPMD, pro-cessors execute the same program on multiple dataduring parallel execution, and communicate and syn-chronize via shared-memory accesses. Parallel tasks inSPMD may be identi�ed manually by a programmer,or automatically by a compiler; they must be data-independent to ensure correct execution.Data-dependence speculation allows a compileror programmer to relax the constraint of data-independence to issue SPMD tasks in parallel; mecha-nisms to detect and recover from data dependence vi-olations are provided. The execution model is basedon a hierarchical enforcement of sequential seman-tics [19, 11, 12, 5]. To facilitate the bookkeepingof data-dependent tasks, the model conservatively as-sumes that all instructions in a task are data-dependenton the �rst instruction of the task.Figure 1 shows an example of a speculative exe-cution under this model. Consider a window of in-structions consisting of four tasks of a sequential pro-
if(MyId==0) Head=0; /* shared */Barrier();Begin_Spec();
violated=1;
violated=0; /* volatile, private */
epilogue
prologue
Flush_Commit();Barrier();Head++;
End_Spec();while(MyId!=Head) {spin()};
Task(MyId);
if(violated) while(MyId!=Head) {spin()};
Tas
k 3
non-speculativecode
Tas
k 2
Tas
k 1
Tas
k 0
Tas
k 0
Speculative window
Tas
k 3
Tas
k 2
Tas
k 1
Figure 1: Example of sequential code speculatively exe-cuted in parallel by 4 processors.gram. Tasks 0 through 3 speculatively execute inparallel: if the tasks in the speculative window aredata-independent, their parallel execution preservesthe original sequential semantics. If they are not data-independent, the dependence violation(s) must be de-tected, and the violated tasks must be re-issued to pre-serve sequential ordering.In the DDSM realization of the hierarchical exe-cution model, speculative tasks are issued in parallel,commit in sequential order, and are synchronized viaa barrier. Tasks that violate dependences during exe-cution are blocked by software and are re-executed insequential order. Sequential order is implied by theunique identi�ers of the processors executing specula-tive tasks. Speculative execution may involve all pro-cessors in the system, or may involve only a subset ofthem. The Head task is de�ned as the earliest task ofa speculative program that has yet to commit.Program segments that are amenable to speculativeparallelization under this model include loops and se-quences of subroutine calls [17] with statically knowncontrol dependences. These segments are assigned tospeculative execution through the addition of prologueand epilogue wrappers to the source code (Figure 1).Section 3.5 describes the DDSM software interface.3 DDSM speculation methodsA speculative multiprocessor needs to provide mech-anisms for (1) bu�ering speculative state until com-mit time, (2) detecting data dependence violations, (3)committing program-order speculative data, (4) dis-carding non-program order speculative data, and (5)checkpointing the beginning/end of speculative execu-tion. The support for these mechanisms in DDSM isdiscussed in the rest of this section.3.1 Speculative bu�ersSpeculative data in DDSMs is bu�ered in extendedcache lines. In order to leverage conventional cache or-ganizations to hold speculative data, extra state infor-mation is appended to the state of conventional cacheblocks, and the cache controller is extended to handlespeculative accesses. The novel state extensions pro-

Directory
Readers State
Handler
Writers Data
Data
2
cpu, cache messages
directory messages
Memory
5 checkpoint
3commit
4
Data
Node j+1
State
Data Statebuffer
1
L2
MaskFwdSLSP
Table 2
CPUSwrite
Node i
check
(A)
(B)
squashL2
Rec. data
Node j
MaskFwdSL
recovercontext
SP
gang-clear
yes squashRid, ..., N
Data
Data
buffer
Encoder
Mask
Mask
(C)
(D)
SoftwareNode i+1
Software
contextCPU
Rid = min{Readers[i+1,...,N]}
i < Rid?
Get_SW(i)
Figure 2: Overview of DDSM speculation methods described in Sections 3.1-3.5. In the �gure, node i issues a speculativewrite that violates a data dependence violation, and speculative data from nodes j, j + 1 are reconciled. 1 extensions to L2cache allow for bu�ering of speculative shared-memory data; 2 the directory checks the list of read sharers for RAW violations.When a violation occurs, the data-dependent tasks are squashed 4 : speculative cache blocks transition to the squashed state,and the processor context - checkpointed at the beginning of speculation 5 - is restored. At the end of speculation, caches ush committed speculative blocks to the directory, which employs a reconciling function 3 to commit the program-orderversion of speculative blocks to memory.posed in this paper encode the speculative state of amemory block in two bits (SP-bits).A cache block in DDSM may be in one of the follow-ing four states, with respect to its speculative status:SP IN (speculative), SP CO (contents are safe to becommitted to main memory), SP SQ (contents havebeen squashed), and SP NO (not speculative)1. Fig-ure 3 shows the state diagram for speculative DDSMcache blocks. Transitions in the diagram are triggeredby speculative reads and writes (Sreads, Swrites), com-mit, squash and ush requests.In addition to SP-bits, each cache block has anSL bit ( ags that the block has been speculativelyloaded), a Fwd bit ( ags that the block has been for-warded), and a per-word write mask. Write masksallow for accesses at a �ner granularity than a cacheblock [11, 12, 5]: they determines which words of theblock have been speculatively written. The resultingcache block is depicted in Figure 2 1 .Although the bu�ering of speculative state takesplace in L2 cache blocks, DDSMs allow caching of spec-1Conventional cache-coherent block states, such as shared-clean anddirty, apply to non-speculative (SP NO) blocks.SP_NO
SP_CO
SP_INSP_SQSread,Swrite
Squash
Sread,Swrite
Sread,Swrite
FlushCommitFigure 3: State machine for speculative L2 cache blocks.
ulative data in L1 caches for high performance by ex-tending the L1 cache lines with speculative-state bits.Tables 1 and 2 show how speculative memory ac-cesses to a sub-word i of a cache blockB are resolved bythe cache controller. The �rst speculative read (write)access to B triggers the sending of a Get SR (Get SW )message to B's home node. These are detected testingthe value of the block's SL and write-mask bits, andare used by the directory to dynamically build a recordof all speculative readers and writers of a block. Sub-sequent reads and/or writes are satis�ed locally by theL2 cache, without involving the directory.There are two special cases handled by the con-troller. First, if a speculative read is to a word pre-viously written speculatively by the same processor,the access is satis�ed locally by the cache, without in-volving the home node. Second, if a speculative writeaccesses a forwarded block, the system squashes subse-quent speculative tasks (Section 3.6).3.2 Ordering violation detectionOut-of-order memory accesses may violate data depen-dences imposed by the sequential semantics of a pro-gram. DDSM maintains ordering information of spec-Message DescriptionGet SR Request spec. block from home;home marks requester as readerGet SW Request spec. block from home;home marks requester as writerRec ush Flush spec. block to hometo be reconciledRec squash Request a partially reconciledcopy of block from directoryTable 1: Speculative messages of DDSM L2 caches.

Get_SWadd to readers/writers vector
Get_SR
Private
Uncached
Shared
Speculative
ReadWrite
ReadWrite
Read,Write
Get_SR,Get_SW
Rec_flush
fetch-invalidate from ownerwrite-back to memory
Get_SWinvalidatesharers
Get_SWGet_SR,
Get_SR,
Rec_squashFigure 4: Extended DDSM state machine for cache blocksat the directory. Extended states and transitions are shownin boldface.ulative data to detect violations at a coherence blockgranularity at the directory. The main motivation forusing the directory to track memory ordering and de-tect memory violations stems from the fact that ac-cesses to a memory block are serialized by the directorycontroller [24].The DDSM directory extends conventional CC-NUMA protocols with extra states to track mem-ory access ordering. Conventional protocols store thestate and one read-sharers bit-vector for each memoryblock [15]. The DDSM directory protocol uses two bit-vectors to record both speculative readers and specu-lative writers of a block, and de�nes one extra blockstate (Speculative).The use of directory state to track ordering di�ersfrom the solution by Ste�an et al. [20]. Although theirsolution requires less storage than DDSM, the fact thatthe directory has no knowledge of ordering has po-tential implications on the number of transactions in-volved in a remote memory access. In their solution,Access SP-bits ActionSP NO Send Get SR to home(B)Sread SP IN If SL = 1 or Mask(B[i]) = 1,request is satis�ed by L2;(B[i]) else send Get SR to home(B)SP SQ Send Rec squash to home(B)SP NO Send Get SW to home(B)SP IN If Fwd = 1, multicast violation;Swrite else, if OR(Mask) = 1, then(B[i]) request is satis�ed by L2;else send Get SW to home(B)SP SQ Send Rec squash to home(B) ush SP CO Send Rec ush to home(B)commit SP IN Change B's state to SP COsquash SP IN Change B's state to SP SQTable 2: Actions performed by the cache controller for spec-ulative reads/writes to sub-word i of blockB (Flush, Commitand Squash requests apply to the entire block B).
any request received by the directory that may trig-ger an ordering violation must be communicated to allsharers of the block so that dependence checks can beperformed. The potential performance degradationsof such transactions may not be noticeable with smallcon�gurations or when communication occurs in a bus.However, for larger, distributed con�gurations, thesetransactions can become costly.In contrast, a DDSM performs dependence checksat the directory, without requiring further messages tobe sent to sharers. This functionality requires an ex-tra vector of sharers to distinguish speculative readersfrom writers. Although a full-map directory has beenassumed in this paper, solutions that provide storagefor limited number of sharers [4] can be leveraged; ifthe number of speculative writers exceeds the maxi-mum number of sharers, correctness can be ensured byforcing dependence violations.The DDSM protocol operates with blocks thatcan be either non-speculative or speculative. Blocksbecome speculative when the directory receives anyGet SR or Get SW request. Blocks become non-speculative only after a reconciling request (Rec ush)is satis�ed by the directory. The extended protocoltransactions are summarized in Figure 4.When a speculative request for a non-speculativeblock is received by the DDSM directory controller,all sharers of the block are invalidated. If the block isexclusive (dirty), it is written back to main memory.The block then becomes speculative, and its memorycontents are sent to the requester's cache. Subsequentspeculative accesses to the block are serialized by thedirectory controller, and the requester's identi�er isrecorded in the readers/writers bit-vectors. The di-rectory includes the memory contents for the block inthe reply, unless the request requires forwarding.Blocks in the Speculative state may be modi�ed inthe L2 caches of multiple processors; DDSM producesa single, consistent version of the block at the end ofspeculation (Section 3.3). This support for multiple,distributed writable copies allows for automatic pri-vatization of speculative blocks. Output- and anti-dependences (WAW, WAR) are resolved via this re-naming mechanism, and do not cause dependence vio-lations. Violations of true (RAW) dependences, how-ever, are detected and trigger recovery mechanisms.The directory checks for a RAW violation everytime a speculative write (Get SW) request is received.The check consists of comparing the processor iden-ti�er of the writer | Wid | to the identi�er of theearliest speculative reader (stored in the Readers[]vector) that may be data dependent on the writer(Rid = minfReaders[(Wid+1); :::; N ]g). IfWid < Rid,a RAW violation is detected, and the directory multi-casts a squash message to all processors with identi�ersgreater than or equal to Rid. Figure 2 2 shows an ex-ample of this check for Wid = i.3.3 Task commitsThe DDSM directory protocol allows multiple out-standing writable copies of a shared-memory block toreside in L2 caches during speculative execution. Atthe end of speculative execution, the DDSM directoryapplies a reconciliation operation to all speculative ver-sions of a block to commit its program-order version to

main memory.Committing speculative data to global memory isperformed in two steps. In the �rst step, each pro-cessor marks all SP-bits of speculative cache blocks ascommitted (SP CO) in the L2 cache, similarly to thegang-commit operation in SVC [11]. This operation islocal to a processor; processors are guaranteed to per-form this operation in sequential order by synchroniz-ing via the Head variable, as discussed in Section 3.5.In the second step, SP CO blocks across distributedcaches are globally reconciled to produce the program-order version of each block. This step is performed inparallel by the caches and directory controllers.The second step requires that caches ush SP COblocks to their respective home nodes. At the timethe ush operation is initiated, speculative blocks areguaranteed to be in the SP CO state across multi-ple cache lines, since all processors have �nished the�rst commit step in sequential order. When the homecontroller receives the �rst reconciliation request for agiven block, it allocates a temporary bu�er with num-ber of entries equal to the number of processors N . Thecontroller then multicasts fetch-and-invalidate requeststo the speculative sharers of the block and sets a replycounter with the expected number of replies.When a remote cache receives a fetch-and-invalidaterequest, it replies with the block's contents and itswrite mask, and invalidates the block. For each suchreply received by the directory, the block's contents andmask are copied to the temporary bu�er at the positiongiven by the sender's identi�er. When all versions arereceived (i.e., the reply counter reaches zero), a priorityencoding operation, equivalent to the one performed byHydra [12], produces the �nal version of the block. Thepriority encoder selects, among all write-masks, the IDof the latest speculative writer for each sub-word of ablock. This selection drives the output of data multi-plexers that generate the program-order �nal versionof each sub-word.The reconciling transaction is based on a request-multicast-reply event sequence and can be imple-mented as an extension to the read-exclusive trans-action to a shared block of existing directory proto-cols [15]. An example of the reconciling protocol trans-action is discussed next and illustrated in Figure 2A-D. It begins when a reconciling request (Rec ush) isreceived from a remote cache (node j, (A)). The di-rectory handler allocates a bu�er for this transaction,copies contents and mask of the requester to the bu�er,and multicasts fetch-invalidate requests to the sharersof the block (node j + 1, (B)). When the directoryreceives all outstanding replies for the block (C), thepriority encoding function is applied to the reconcilingbu�er (D) and the �nal version of the block is com-mitted to memory.3.4 Task squashesThe DDSM caches are responsible for squashing alldata produced by a speculative task that has violateda data dependence. Squashing is achieved by glob-ally setting all SP-bits of speculative cache blocks tothe state SP SQ, and resetting the respective Fwd,SL and Mask bits, as shown in Figure 2 4 . When arestarted task accesses a SP SQ block, the cache con-troller requests a partially reconciled copy of the block
from the directory (Rec squash, Table 2). A partiallyreconciled block requested by task i is generated fromversions of tasks 0; :::; i� 1.When a task is squashed, its execution is restartedby recovering the processor context (saved at the be-ginning of speculative execution) via an interrupt.Restarted tasks execute in sequential order.3.5 CheckpointingThe DDSM software/hardware interface is provided bya set of three system calls: Begin Spec, End Spec andFlush Commit (Figure 1). The interface requires twoextensions to the CPU. First, the processor must beable to save its context before speculation begins, andretrieve it when a violation interrupt is received. Onlyone speculative context needs to be stored; it is alsopossible to implement context saving/retrieving in soft-ware traps. Second, the instruction set needs to sup-port speculative instances of all memory operations.This can be achieved by assigning one bit in the in-struction opcode to determine whether the access isspeculative or not. This bit is not used during decod-ing; it is passed on to the data cache controllers todetermine whether the access is subject to the conven-tional (non-speculative) or to the DDSM reconcilingprotocol (speculative).When a compiler for DDSM speculatively paral-lelizes a sequence of tasks, it (1) generates prologuecode to set up the beginning of speculation, (2) marksthe memory instructions inside the body of the task asspeculative, and (3) generates epilogue code to set upthe end of speculation. The prologue and epilogue con-sist of barriers, system calls, accesses to a local variable(violated), and non-speculative accesses to a shared-memory variable that stores the identi�er of the Headtask, as shown in Figure 12.The prologue code initializes the Head variable,saves the processor context (Begin Spec), and enforcessequential re-issue of data-dependent tasks by spinningon the value of Head if the task has been restarted (i.e.,if the private variable violated equals 1). The epiloguecode enforces in-order commits of speculative blocks tolocal L2 caches (End Spec, synchronized by Head) andinitiates the global reconciliation of committed blocks(Flush Commit, synchronized by a barrier).3.6 Forwarding optimizationSome dynamic RAW dependences can be resolved viadata-forwarding without incurring violations. The ba-sic DDSM reconciling directory does not provide auto-matic support for data forwarding. However, full sup-port for forwarding across distributed nodes can sub-stantially increase protocol complexity.DDSM supports a write-violate forwarding schemethat allows a processor Pi to forward a speculativelywritten block to later processor(s), as long as the for-warded block is not re-written speculatively by Pi. For-2Since a vendor compiler was used in this paper, the distinction betweenspeculative and non-speculative memory operations was not implementedin the generated instruction set, but emulated via a CPU state bit that isset/reset via system calls. Accordingly, the non-speculative Head variablewas represented as a special CPU register in the simulations, with accesstime equal to the average latency of incrementing a global variable with16 processors. The performance impact of this simpli�cation is negligiblefor the coarse-grain speculative windows of the studied benchmarks.

Unit Con�gurationCPU 300MHz, 4-way out-of-order2 ALUs, 2 FPUs, 2 address unitsL1 cache 16KB, write-through, direct-mapped,1-cycle hit latencyL2 cache 2MB, write-back, 8-way associative,8-cycle hit latencyMemory 60ns DRAM latencyLocal miss: 48 cycles,Remote miss: 134 cyclesTable 3: Model parameters (all caches have 64B blocks).warding of a block is initiated by the directory con-troller if there is any earlier (program-order) writerrecorded in the block's bit vector. The latest of suchwriters provides the data for the cache-to-cache trans-action. If a forwarded block (i.e. Fwd = 1) is specula-tively re-written by a task, all later tasks are squashedand restarted (Table 2).3.7 Cache replacementsWhen a speculatively written block is replaced froma cache, it causes false dependence invalidations: theblock cannot be written back to memory, since it is notguaranteed to be valid; nor can it simply be discarded,since its contents are needed to perform reconciliation.Since the replacement of speculatively written linescauses false dependence invalidations and performancedegradation, it is important to reduce the probabilityof their occurrence. Although not studied in this paper,the use of main-memory node caches [9], in addition toL2 caches, can potentially provide a large, associativecache for speculative data and reduce the probabilityof capacity- or con ict-induced restarts.These are optimizations that may be applied toimplementations of DDSMs. In related work, it hasbeen shown that Stache main-memory node caches canbe used in conjunction with a reconciling protocol toavoid cache replacements to be sent to remote homenodes [14]. Since in DDSM the entire speculative stateis encoded in cache blocks and directory entries, exist-ing mechanisms to store evicted lines in main memorycan be leveraged.The experiments described in this paper do not as-sume the availability of node caches. In this scenario,upon replacement, the DDSM conservatively squashesall tasks data-dependent on a replaced block.4 Experimental methodology4.1 Machine model and con�gurationThe machine model assumed in this work is a release-consistent3 CC-NUMA multi-processor with hardwaresupport for DDSM speculation. The system consistsof up to 16 identical nodes connected by a 2-D meshnetwork. Each node has a memory bus connecting asingle processor with on-chip L1 and L2 caches, mainmemory, directory controller and network interface.3Speculative memory accesses may be issued out-of-order across DDSMprocessors, but eventually commit in sequential order. The machine sup-ports release-consistency for non-speculative DSM accesses.
Bench. Working set TasksTurb3d 32x32x32, 3 iter. loop/subr.Health 7 levels, 24 iter. recursive subr.Power 3200 customers loop/subr.Perimeter 4K x 4K, 8 levels recursive subr.TreeAdd 256K nodes recursive subr.Ssm 1K-64K integers loop iter.Table 4: Benchmarks used in the performance analysis.Table 3 shows the parameters assumed for proces-sors, caches and memory inside each node of the ma-chine. The average simulated remote vs. local memoryread latency ratio between adjacent nodes is 2.8. Allsimulation parameters not displayed in the table areset to RSIM [18] defaults. The con�guration of the L2cache (size and associativity) loosely models a systemthat supports speculative execution without the occur-rence of replacement-induced restarts for the programsunder study, such as one with Simple-COMA main-memory caches [9, 14].4.2 Workloads and simulation modelThe performance analysis of Section 5 is based on thesimulation of the speculatively parallelized benchmarkslisted in Table 4 (with respective working sets) from theSpec95 and Olden suites, in addition to a sparse-matrixmicrobenchmark developed by the authors.Turb3d is a benchmark from the Spec95 suite thatsimulates isotropic, homogeneous turbulence in a cube.Turb3d has available parallelism across procedures thatcompute Fast-Fourier Transforms (FFTs) along dis-tinct dimensions. Data dependence speculation allowsparallelization across FFT subroutine calls without theneed for inter-procedural analysis.The Olden benchmarks Health, Power, Perimeterand TreeAdd are written in C and represent codes withdynamic data structures, where parallelism is hardto be detected automatically at compile-time. Oldenbenchmarks are distributed in two versions: the se-quential version, and a hand-parallelized version basedon futures [3]. Hand-parallelized Olden programs havebeen studied previously in systems without data de-pendence speculation. In contrast, this paper beginswith the sequential version of the Olden programs.The sequential versions of these programs are manu-ally prepared for speculative parallelization in this pa-per. This preparation consists of the addition of pro-logue/epilogue wrappers to sequential regions in thesource code; no manual dependence analyses are per-formed. This interface is simpler for a compiler thanthe traditional SPMD model because threads do notneed to be proved data-independent at compile time.The task of the compiler is then to only identify po-tentially parallel threads for speculative execution andinsert prologue/epilogue codes (Figure 1). Such codeis application-independent and can be encapsulated insystem libraries.The benchmark Power solves a power system opti-mization problem. Parallelism in Power is di�cult todetect automatically, due to the pointer structures thatare used in its computation. However, Power can bespeculatively-parallelized in the outermost loop.The Health benchmark simulates the Columbian

P3 spec. task
P0 spec. task
P1 spec. task
b=Divide(); a=Divide();
} return a+b;
Divide() {
P2 spec. task
DivideInline() {
c=Divide(); d=Divide();
return(a+b+c+d);}
b=Divide(); a=Divide();
a)
b) Divide() { Divide(); Divide(); Combine();}
DivideInline() { Divide();
Combine();
Divide(); Divide(); Combine();
Combine();
P1 waits for P0
P3 waits for
P3 waits for P2
P0, P1
}
Divide();
barrier
barrierc)
Figure 5: Partial inlining of recursive calls to expose sub-routine parallelism across 4 processors (c). The combine stepof the recurrence uses partial-sum reductions (a) or explicitserialization (b).health care system. Health utilizes pointer-based listswith elements that are dynamically inserted/removed,and traversed recursively. It is speculatively paral-lelized by partially inlining recursive calls and spec-ulating across subroutine calls.TreeAdd is a benchmark that computes the sum-mation of values in a tree. Perimeter computes theperimeter of a set of quad-tree encoded raster images.Both TreeAdd and Perimeter use pointer-based treestructures. Similarly to Health, partial inlining is usedin these two benchmarks.Procedure-level speculation is exploited in thebenchmarks with recursive subroutine calls by applyingpartial inlining (Figure 5). Conventional compilers useinlining to both reduce procedure call overhead and en-large the window of operations that can be inspectedfor global optimizations. In DDSM, partial inliningdoes not target either of these goals: it is used to ex-pose speculative parallelism by increasing the numberof procedure calls.During speculative execution, these procedures areissued in parallel (Figure 5c)). After their executionhave completed, the \combine" phase of the recursionmay require either code serialization (Figure 5a)), or,when applicable, a reduction (Figure 5b)) to avoid datadependence violations.The remaining benchmark, Ssm, is a microbench-mark that models indirect addressing of array elements.The pseudo-code for this program is as follows:for(i=0;i<Niterations;i++)for(j=0;j<Nitems;j++)Array[j] += Array[indirect(i,j)];This program is not parallelizable automatically un-less all data dependences implied by the indirect()function are known at compile time. However, it canbe speculatively parallelized across the j loop. Thisprogram is used to study the behavior of DDSMs un-der several speculative window sizes (controlled by the
parameter Nitems), mis-speculation frequencies (func-tion indirect()) and number of processors.All programs are compiled with Sun's Workshop CCompiler4, version 4.2, with optimization level -xO4.Two versions of each program are simulated: the se-quential version (without speculation and synchroniza-tion code, executing in a single node) and the specu-lative version. Speedups are measured as executiontime ratios (sequential/parallel) after data initializa-tion. The programs are simulated by a modi�ed ver-sion of RSIM [18] that models the DDSM methods de-scribed in this paper.5 Performance AnalysisThe performance analysis is divided in two parts. Inthe �rst part, the DDSM performance for the Ssm mi-crobenchmark is studied in detail. The second part an-alyzes the performance of the remaining benchmarks ofTable 4. The following terms are used throughout theperformance analysis of this section:� Window size: total number of instructions, ex-ecuted by the original sequential program, thatare speculatively executed in parallel.� Task size: number of instructions executed spec-ulatively by a task - approximately (windowsize/number of tasks) for load-balanced tasks.� State size: maximum amount of data stored inspeculative L2 cache blocks of a single node.� Violation frequency: ratio of restarted specula-tive tasks versus total number of tasks.� Flushing overhead (Fov): ratio of stall time dueto ushing over total execution time for a specu-lative task.5.1 Microbenchmark performanceIn this analysis, the performance of DDSMs for thebenchmark Ssm is analyzed as a function of the fol-lowing parameters: number of speculative tasks (4 and16); window size (160K, 630K, 2.5M, and 10M instruc-tions); state size (256 Bytes - 128 KBytes); and viola-tion frequency (0% - 20%).Figure 6 shows plots of parallel speedup versus vi-olation frequency for 16 and 4 processors and fourwindow sizes. These plots show that DDSMs achievegood speedups for large task granularities and 0% vio-lation frequency. The plots also show that, as windowsizes decrease and violation frequencies increase, per-formance degrades.The performance degradation due to both smallerwindows and larger number of violations is more se-vere for DDSMs with larger numbers of processors. Awindow size reduction from 2.5M to 630K instructionsyields speedup reductions of 55% and 9% for 16 and4 processors, respectively. At 10% violation frequency,the performance degradations for the largest windowsize and 16 and 4 processors are 63% and 38%.In addition to window sizes and violation frequency,4The benchmark Turb3d is converted from Fortran to C with f2c.
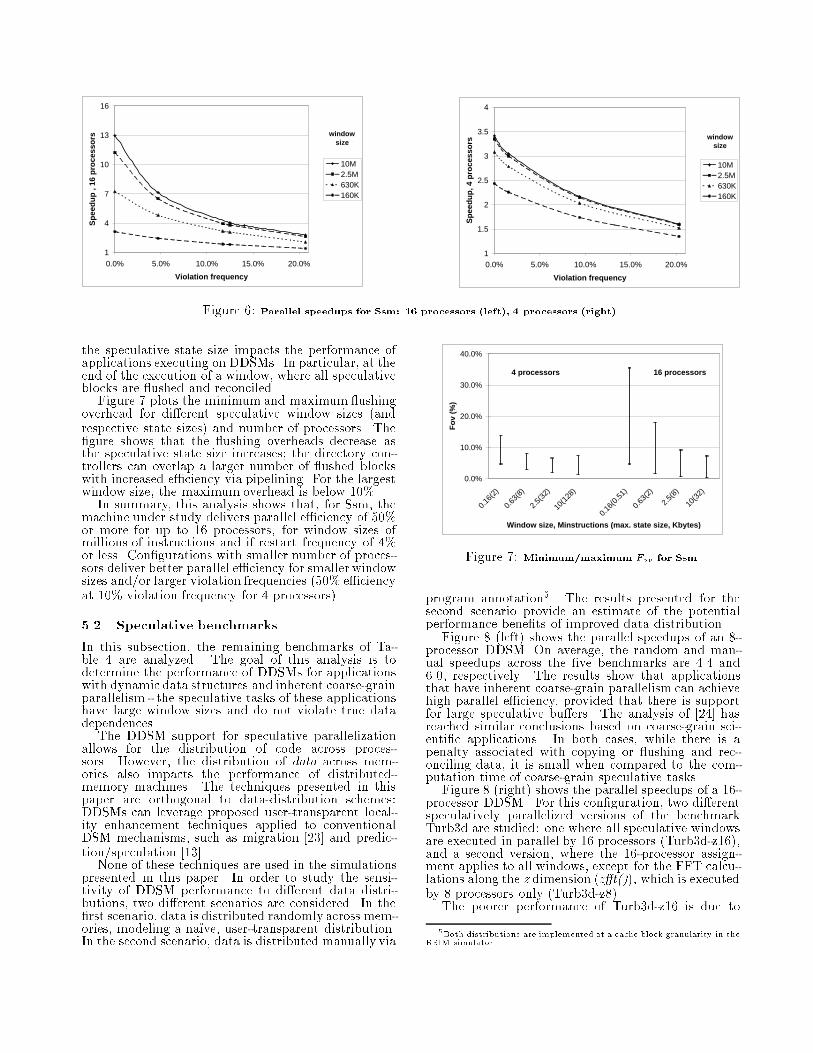
1
4
7
10
13
16
0.0% 5.0% 10.0% 15.0% 20.0%
Violation frequency
Sp
eed
up
, 16
pro
cess
ors
10M2.5M630K160K
windowsize
1
1.5
2
2.5
3
3.5
4
0.0% 5.0% 10.0% 15.0% 20.0%
Violation frequency
Sp
eed
up
, 4 p
roce
sso
rs
10M2.5M630K160K
windowsize
Figure 6: Parallel speedups for Ssm: 16 processors (left), 4 processors (right).the speculative state size impacts the performance ofapplications executing on DDSMs. In particular, at theend of the execution of a window, where all speculativeblocks are ushed and reconciled.Figure 7 plots the minimum and maximum ushingoverhead for di�erent speculative window sizes (andrespective state sizes) and number of processors. The�gure shows that the ushing overheads decrease asthe speculative state size increases; the directory con-trollers can overlap a larger number of ushed blockswith increased e�ciency via pipelining. For the largestwindow size, the maximum overhead is below 10%.In summary, this analysis shows that, for Ssm, themachine under study delivers parallel e�ciency of 50%or more for up to 16 processors, for window sizes ofmillions of instructions and if restart frequency of 4%or less. Con�gurations with smaller number of proces-sors deliver better parallel e�ciency for smaller windowsizes and/or larger violation frequencies (50% e�ciencyat 10% violation frequency for 4 processors).5.2 Speculative benchmarksIn this subsection, the remaining benchmarks of Ta-ble 4 are analyzed. The goal of this analysis is todetermine the performance of DDSMs for applicationswith dynamic data structures and inherent coarse-grainparallelism - the speculative tasks of these applicationshave large window sizes and do not violate true datadependences.The DDSM support for speculative parallelizationallows for the distribution of code across proces-sors. However, the distribution of data across mem-ories also impacts the performance of distributed-memory machines. The techniques presented in thispaper are orthogonal to data-distribution schemes:DDSMs can leverage proposed user-transparent local-ity enhancement techniques applied to conventionalDSM mechanisms, such as migration [23] and predic-tion/speculation [13].None of these techniques are used in the simulationspresented in this paper. In order to study the sensi-tivity of DDSM performance to di�erent data distri-butions, two di�erent scenarios are considered. In the�rst scenario, data is distributed randomly across mem-ories, modeling a na��ve, user-transparent distribution.In the second scenario, data is distributed manually via
0.0%
10.0%
20.0%
30.0%
40.0%
0.16
(2)
0.63
(8)
2.5(
32)
10(1
28)
0.16
(0.5
1)
0.63
(2)
2.5(
8)
10(3
2)
Window size, Minstructions (max. state size, Kbytes)
Fo
v (%
)
4 processors 16 processors
Figure 7: Minimum/maximum Fov for Ssm.program annotation5. The results presented for thesecond scenario provide an estimate of the potentialperformance bene�ts of improved data distribution.Figure 8 (left) shows the parallel speedups of an 8-processor DDSM. On average, the random and man-ual speedups across the �ve benchmarks are 4.4 and6.0, respectively. The results show that applicationsthat have inherent coarse-grain parallelism can achievehigh parallel e�ciency, provided that there is supportfor large speculative bu�ers. The analysis of [24] hasreached similar conclusions based on coarse-grain sci-enti�c applications. In both cases, while there is apenalty associated with copying or ushing and rec-onciling data, it is small when compared to the com-putation time of coarse-grain speculative tasks.Figure 8 (right) shows the parallel speedups of a 16-processor DDSM . For this con�guration, two di�erentspeculatively parallelized versions of the benchmarkTurb3d are studied: one where all speculative windowsare executed in parallel by 16 processors (Turb3d-z16),and a second version, where the 16-processor assign-ment applies to all windows, except for the FFT calcu-lations along the z dimension (z�t()), which is executedby 8 processors only (Turb3d-z8).The poorer performance of Turb3d-z16 is due to5Both distributions are implemented at a cache block granularity in theRSIM simulator.

0
1
2
3
4
5
6
7
Turb3d Health Perimeter Power TreeAdd
Sp
eed
up
, 8 p
roce
sso
rsRandomManual
0
2
4
6
8
10
12
14
Turb3d-z16 Turb3d-z8 Health Perimeter Power TreeAdd
Sp
eed
up
, 16
pro
cess
ors
RandomManual
Figure 8: 8-processor (left) and 16-processor (right) DDSM speedup for two di�erent data distribution policies: random andmanual.speculative false-sharing. Although the tasks inTurb3d are data-independent, they operate on sub-words of cache blocks. When speculative tasks aredistributed across 16 processors, some accesses to dif-ferent sub-words of the same cache block are issuedby di�erent tasks during speculative execution of z�t()calls. The pattern of these accesses in the 16-processorcase yields multiple read-write operations, which arenot supported by the write-violate forwarding opti-mization. The protocol must conservatively squash andrestart tasks sequentially.The analysis of the Ssm microbenchmark in Sec-tion 5.1 shows that both state size and window sizeimpact the performance of DDSMs. Table 5 shows asummary of the speculative window and state sizes foreach benchmark simulated with 8 processors. Theseapplications have coarse-grain speculative windows ofthe order of millions of instructions, and speculativestates that are unlikely to �t in �ne-grain bu�ers (ofthe order of hundreds of KBytes per processor).Table 5 shows that Health and TreeAdd have thesmallest ratios of speculative task size versus state size.These programs perform less computation per specula-tive block fetched from the memory system, and there-fore are more sensitive to data placement. The tablealso shows the minimum and maximum ushing over-heads (as de�ned in Section 5.1) for the benchmarksunder study. With the exception of Health, the execu-tion time overheads due to ushing range from 1% to11%.6 Related WorkRelated data-dependence speculative designs have beenrecently proposed in the literature for several targetarchitectures. A related speculative solution for theMultiscalar [19] architecture manages speculative datain Speculative Versioning L1 Caches (SVC [11]). Themethods for bu�ering speculative data and enforcingaccess ordering in DDSM bear similarities with theSVC approach. As in SVC, a DDSM cache containsboth non-speculative and speculative data, which aredi�erentiated via extra states. However, SVC employsa more complex encoding of speculative state informa-tion to support on-demand, per-word commits.
The Hydra [12] design targets CMPs and specula-tively parallelized thread-based code. DDSM uses apriority encoding function similar to Hydra to commitspeculative blocks to main memory. However, unlikeHydra and other on-chip designs, DDSM employs adistributed structure to track memory access ordering.The solution proposed by the IACOMA group in [24,25] targets DSMs and distributed coarse-grain, par-tially parallel loops. The DDSM design proposed inthis paper also targets coarse-grain tasks with low oc-currence of mis-speculations. However, it di�ers fromthe IACOMA solution in a very important aspect. InDDSM, speculative copies are reconciled transparentlyfrom applications. This simpli�es the programming in-terface, specially when speculation is performed on ir-regular data structures.Related hardware solutions for distributed systemshave been proposed in [5] and [20]. Both solu-tions consider systems with a small number of chip-multiprocessor building blocks and target �ne-grainspeculative parallelism. In contrast, DDSM supportse�cient speculative execution of coarse-grain specula-tive windows for machines with larger number of dis-tributed nodes.The use of reconciling functions to allow loosely-coherent copies of shared-memory data (LCM) wasproposed in [14]. Although the LCM scheme allows forbu�ering and reconciliation of shared-memory data, itdoes not provide speculation mechanisms to supportdata-dependence violation detection and recovery.7 Conclusions and outlookThis paper proposes and evaluates a novel hardware-based approach for data-dependence speculation inDSM multiprocessors. The proposed technique allowsfor automatic extraction of speculative coarse-grainTLP from codes with statically unanalyzable shared-memory data dependences.The architecture is based on extensions to the statestored in cache and directory entries of DSMs. Theextensions allow bu�ering of speculative data of largewindows in L2 caches, and violation detection and rec-onciliation of speculative versions of memory blocks atthe directory.The simulation-based performance analysis pre-
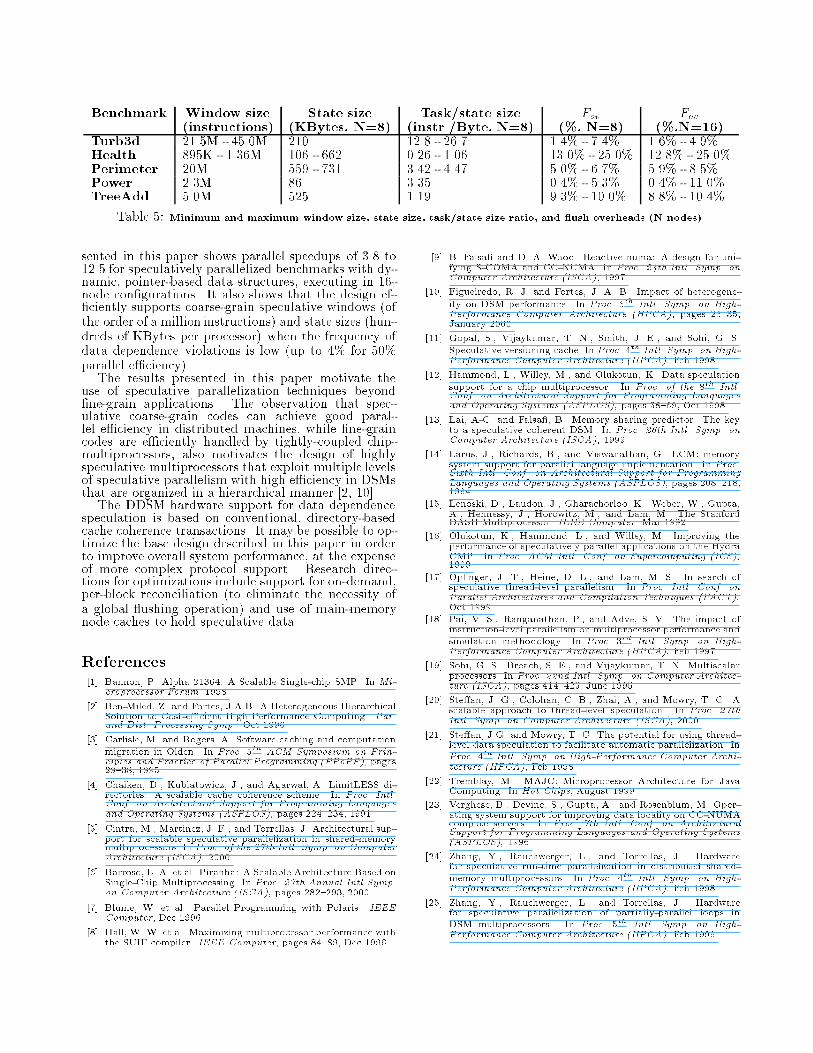
Benchmark Window size State size Task/state size Fov Fov(instructions) (KBytes, N=8) (instr./Byte, N=8) (%, N=8) (%,N=16)Turb3d 21.5M - 45.0M 210 12.8 - 26.7 1.4% - 7.4% 1.6% - 4.9%Health 895K - 1.36M 106 - 662 0.26 - 1.06 13.0% - 25.0% 12.8% - 25.0%Perimeter 20M 559 - 731 3.42 - 4.47 5.0% - 6.7% 5.9% - 8.5%Power 2.3M 86 3.35 0.4% - 5.3% 0.4% - 11.0%TreeAdd 5.0M 525 1.19 9.3% - 10.0% 8.8% - 10.4%Table 5: Minimum and maximum window size, state size, task/state size ratio, and ush overheads (N nodes).sented in this paper shows parallel speedups of 3.8 to12.5 for speculatively parallelized benchmarks with dy-namic, pointer-based data structures, executing in 16-node con�gurations. It also shows that the design ef-�ciently supports coarse-grain speculative windows (ofthe order of a million instructions) and state sizes (hun-dreds of KBytes per processor) when the frequency ofdata dependence violations is low (up to 4% for 50%parallel e�ciency).The results presented in this paper motivate theuse of speculative parallelization techniques beyond�ne-grain applications. The observation that spec-ulative coarse-grain codes can achieve good paral-lel e�ciency in distributed machines, while �ne-graincodes are e�ciently handled by tightly-coupled chip-multiprocessors, also motivates the design of highlyspeculative multiprocessors that exploit multiple levelsof speculative parallelism with high e�ciency in DSMsthat are organized in a hierarchical manner [2, 10].The DDSM hardware support for data dependencespeculation is based on conventional, directory-basedcache coherence transactions. It may be possible to op-timize the base design described in this paper in orderto improve overall system performance, at the expenseof more complex protocol support. Research direc-tions for optimizations include support for on-demand,per-block reconciliation (to eliminate the necessity ofa global ushing operation) and use of main-memorynode caches to hold speculative data.References[1] Bannon, P. Alpha 21364: A Scalable Single-chip SMP. In Mi-croprocessor Forum, 1998.[2] Ben-Miled, Z. and Fortes, J.A.B. A Heterogeneous HierarchicalSolution to Cost-e�cient High Performance Computing. Par.and Dist. Processing Symp., Oct 1996.[3] Carlisle, M. and Rogers, A. Software caching and computationmigration in Olden. In Proc. 5th ACM Symposium on Prin-ciples and Practice of Parallel Programming (PPoPP), pages29{38, 1995.[4] Chaiken, D., Kubiatowicz, J., and Agarwal, A. LimitLESS di-rectories: A scalable cache coherence scheme. In Proc. Intl.Conf. on Architectural Support for Programming Languagesand Operating Systems (ASPLOS), pages 224{234, 1991.[5] Cintra, M., Martinez, J. F., and Torrellas, J. Architectural sup-port for scalable speculative parallelization in shared-memorymultiprocessors. In Proc. of the 27th Intl. Symp. on ComputerArchitecture (ISCA), 2000.[6] Barroso, L. A. et al. Piranha: A Scalable Architecture Based onSingle-Chip Multiprocessing. In Proc. 27th Annual Intl Symp.on Computer Architecture (ISCA), pages 282{293, 2000.[7] Blume, W. et al. Parallel Programming with Polaris. IEEEComputer, Dec 1996.[8] Hall, W. W. et al. Maximizing multiprocessor performance withthe SUIF compiler. IEEE Computer, pages 84{89, Dec 1996.
[9] B. Falsa� and D. A. Wood. Reactive numa: A design for uni-fying S-COMA and CC-NUMA. In Proc. 24th Intl. Symp. onComputer Architecture (ISCA), 1997.[10] Figueiredo, R. J. and Fortes, J. A. B. Impact of heterogene-ity on DSM performance. In Proc. 6th Intl. Symp. on High-Performance Computer Architecture (HPCA), pages 26{35,January 2000.[11] Gopal, S., Vijaykumar, T. N., Smith, J. E., and Sohi, G. S.Speculative versioning cache. In Proc. 4th Intl. Symp. on High-Performance Computer Architecture (HPCA), Feb 1998.[12] Hammond, L., Willey, M., and Olukotun, K. Data speculationsupport for a chip multiprocessor. In Proc. of the 8th Intl.Conf. on Architectural Support for Programming Languagesand Operating Systems (ASPLOS), pages 58{69, Oct 1998.[13] Lai, A-C. and Falsa�, B. Memory sharing predictor: The keyto a speculative coherent DSM. In Proc. 26th Intl. Symp. onComputer Architecture (ISCA), 1999.[14] Larus, J., Richards, B., and Viswanathan, G. LCM: memorysystem support for parallel language implementation. In Proc.Sixth Intl. Conf. on Architectural Support for ProgrammingLanguages and Operating Systems (ASPLOS), pages 208{218,1994.[15] Lenoski, D., Laudon, J., Gharachorloo, K., Weber, W., Gupta,A., Hennessy, J., Horowitz, M., and Lam, M. The StanfordDASH Multiprocessor. IEEE Computer, Mar 1992.[16] Olukotun, K., Hammond, L., and Willey, M. Improving theperformance of speculatively parallel applications on the HydraCMP. In Proc. ACM Intl. Conf. on Supercomputing (ICS),1999.[17] Oplinger, J. T., Heine, D. L., and Lam, M. S. In search ofspeculative thread-level parallelism. In Proc. Intl. Conf. onParallel Architectures and Compilation Techniques (PACT),Oct 1999.[18] Pai, V. S., Ranganathan, P., and Adve, S. V. The impact ofinstruction-level parallelism on multiprocessor performance andsimulation methodology. In Proc. 3rd Intl. Symp. on High-Performance Computer Architecture (HPCA), Feb 1997.[19] Sohi, G. S., Breach, S. E., and Vijaykumar, T. N. Multiscalarprocessors. In Proc. 22nd Intl. Symp. on Computer Architec-ture (ISCA), pages 414{425, June 1995.[20] Ste�an, J. G., Colohan, C. B., Zhai, A., and Mowry, T. C. Ascalable approach to thread-level speculation. In Proc. 27thIntl. Symp. on Computer Architecture (ISCA), 2000.[21] Ste�an, J.G. and Mowry, T. C. The potential for using thread-level data speculation to facilitate automatic parallelization. InProc. 4th Intl. Symp. on High-Performance Computer Archi-tecture (HPCA), Feb 1998.[22] Tremblay, M. MAJC: Microprocessor Architecture for JavaComputing. In Hot Chips, August 1999.[23] Verghese, B., Devine, S., Gupta, A., and Rosenblum, M. Oper-ating system support for improving data locality on CC-NUMAcompute servers. In Proc. 7th Intl. Conf. on ArchitecturalSupport for Programming Languages and Operating Systems(ASPLOS), 1996.[24] Zhang, Y., Rauchwerger, L., and Torrellas, J. Hardwarefor speculative run-time parallelization in distributed shared-memory multiprocessors. In Proc. 4th Intl. Symp. on High-Performance Computer Architecture (HPCA), Feb 1998.[25] Zhang, Y., Rauchwerger, L., and Torrellas, J. Hardwarefor speculative parallelization of partially-parallel loops inDSM multiprocessors. In Proc. 5th Intl. Symp. on High-Performance Computer Architecture (HPCA), Feb 1999.
Related Documents











