International Journal of Image and Graphics Vol. 13, No. 4 (2013) 1350016 (21 pages) c World Scientific Publishing Company DOI: 10.1142/S0219467813500162 HANDHELD DEVICE-BASED CHARACTER RECOGNITION SYSTEM FOR CAMERA CAPTURED IMAGES AYATULLAH FARUK MOLLAH Department of Computer Science and Engineering Aliah University, Saltlake City, Kolkata 700064, India [email protected] SUBHADIP BASU ∗ and MITA NASIPURI † Department of Computer Science and Engineering Jadavpur University, Kolkata 700032, India ∗ [email protected] † [email protected] Received 18 May 2011 Accepted 6 November 2013 A novel character recognition system aimed at embedding into handheld devices is pre- sented. At first, text regions (TRs) are isolated from the camera captured image by seg- menting the image. Then, these TRs are rotated by the skew angles estimated for each of them by a self-developed fast skew correction technique. After that, the skew corrected regions are segmented and recognized. Using Tesseract as the plugged-in recognition engine, we have found a recognition accuracy of 93.51% for business card images. Rec- ognized results are then reorganized to get the original layout back. Experiments reveal that the proposed system is computationally efficient, required memory consumption is significantly low and therefore applicable on handheld devices. Keywords : Image segmentation; text recognition; business card reader; camera captured documents; handheld device; layout preservation. 1. Introduction With the increase of computing capabilities of handheld mobile devices, researchers have paid significant attention towards developing handheld device-based applica- tions. The application areas include image processing, pattern recognition, com- puter vision, image indexing and retrieval, mobile computing, multimedia, etc. In addition to computing capabilities, most of the handheld devices such as cell- phones, personal digital assistants (PDA) and wearable computers usually have built-in digital cameras. So, the idea of processing the captured image on the device itself opens a new pathway of research. Because of the non-contact nature of digi- tal cameras and portability of handheld devices, on-device camera-based document 1350016-1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
International Journal of Image and GraphicsVol. 13, No. 4 (2013) 1350016 (21 pages)c© World Scientific Publishing CompanyDOI: 10.1142/S0219467813500162
HANDHELD DEVICE-BASED CHARACTER RECOGNITIONSYSTEM FOR CAMERA CAPTURED IMAGES
AYATULLAH FARUK MOLLAH
Department of Computer Science and EngineeringAliah University, Saltlake City, Kolkata 700064, India
SUBHADIP BASU∗ and MITA NASIPURI†
Department of Computer Science and EngineeringJadavpur University, Kolkata 700032, India
∗[email protected]†[email protected]
Received 18 May 2011Accepted 6 November 2013
A novel character recognition system aimed at embedding into handheld devices is pre-sented. At first, text regions (TRs) are isolated from the camera captured image by seg-menting the image. Then, these TRs are rotated by the skew angles estimated for each ofthem by a self-developed fast skew correction technique. After that, the skew correctedregions are segmented and recognized. Using Tesseract as the plugged-in recognitionengine, we have found a recognition accuracy of 93.51% for business card images. Rec-ognized results are then reorganized to get the original layout back. Experiments revealthat the proposed system is computationally efficient, required memory consumption issignificantly low and therefore applicable on handheld devices.
Keywords: Image segmentation; text recognition; business card reader; camera captureddocuments; handheld device; layout preservation.
1. Introduction
With the increase of computing capabilities of handheld mobile devices, researchershave paid significant attention towards developing handheld device-based applica-tions. The application areas include image processing, pattern recognition, com-puter vision, image indexing and retrieval, mobile computing, multimedia, etc.In addition to computing capabilities, most of the handheld devices such as cell-phones, personal digital assistants (PDA) and wearable computers usually havebuilt-in digital cameras. So, the idea of processing the captured image on the deviceitself opens a new pathway of research. Because of the non-contact nature of digi-tal cameras and portability of handheld devices, on-device camera-based document
1350016-1

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
analysis and recognition (CBDAR) applications are more useful than desktop-baseddocument analysis and recognition applications.
A potential example of on-device CBDAR applications is an automatic businesscard reader (BCR). It is meant for automatic population of textual informationfrom an image of a business card, also known as carte de visite or visiting card,to the phonebook of the cell-phone. However, design of a character recognitionsystem for camera captured document images on mobile devices involves a numberof challenges mentioned below.
Typically, optical character recognition (OCR) applications require 200–300dpiresolution images. For a business card image of standard size, digital camera with0.5 mega pixels resolution can give around 250 dpi images. Most of the present daycell-phones and other handheld devices have built-in digital cameras of more than0.5 mega pixels resolution. So, resolution is no more a considerable problem as itwas until last few years.
Although, resolution has reached to a satisfactory level, the image quality didnot. Due to the absence of sophisticated focusing system, image quality of cell-phonecameras is still unsatisfactory. This may not be explicitly visible for natural sceneimages captured by cell-phone cameras. But, degraded quality is quite visible whenplanar documents such as business cards are captured. So, the images capturedby such cameras are often found to be blurred, shadowed, unevenly illuminated,noisy, etc.
Besides these degradations, the acquired images often get distorted. Skew andperspective distortions are very common. Skew occurs when the axis of the cameraand that of the document are not parallel to each other. Perspective distortion isdue to perspective projection that occurs if the camera plane and the object planeare not mutually parallel.
The processing speed of mobile devices with built-in camera is another challenge.It starts with as low as few MHz to as high as 624MHz. The handset “Nokia6600” with an in-built VGA camera contains an ARM9 32-bit RISC CPU havinga processing speed of 104MHz.a The PDA “HP iPAQ 210” has Marvell PXA310type processor that can compute up to 624MHz.b Some mobile devices have dualprocessors too. For instance, “Nokia N95 8GB” has a “Dual ARM-11 332MHz”processors.c Processing speed of other mobile phones and PDAs are usually inbetween them.
Although, the computing power of mobile devices is gradually increasing, itmay not go beyond a certain limit mainly because of the following reasons. Usually,the higher the clock speed, the more is the generated heat. As most of the mobiledevices are handheld and kept closed to various parts of human body, amount
ahttp://www.gsmarena.com/nokia 6600-454.php.bhttp://h10010.www1.hp.com/wwpc/us/en/sm/WF06a/215348-215348-64929-314903-215384-3544499.html.chttp://www.gsmarena.com/nokia n95 8gb-2088.php.
1350016-2

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
of heat generated may be intolerable. Another reason is that the clock speed ofeven the desktop computing devices may reach a saturation stage. The clock speedmay not be made to increase anymore. However, overall computing speed can beincreased by the use of parallel processors. But, that is again a questionable issuefor mobile devices.
Energy is another important factor that limits the heavy computing becausepower consumption is proportional to CPU operations. However, in the presentscope of the work, it is not a serious problem at all since heavy computing has beenstrictly avoided here.
Memory is one of the important computing resources. Some algorithms requirehigh amount of memory. There are some algorithms that require a trade-off betweencomputation time and peak memory consumption. Higher memory consumptionreduces the computation time and the vice versa. Random access memory (RAM)which is frequently referred to as internal memory in case of mobile devices isusually in the range of 2–128MB. Among the mobile devices with high amount ofRAM, the following may be mentioned. The PDA “HP iPAQ 210” has a 128MBSDRAM (see footnote b). The cell-phone “Nokia N95 8GB” has a 128MB internalmemory.d This amount of memory is very low compared to desktop computers.
Another type of memory that contributes to faster operation of CPU is thecache memory. It resides within the CPU itself. Mobile devices have very low cachememory. So, caching which is responsible for faster operation is limited in case ofsuch devices.
Most modern general purpose architectures have one or more floating point units(FPU) with the CPU, which perform the floating point arithmetic operations.e
Older systems including mobile devices do not have such units. Therefore, floatingpoint operations that are frequently required in any real life scenario cannot bedirectly performed on such devices. However, these operations can be done withthe help of floating point emulators. But, it results in slower operation. Some morechallenges involved in mobile device based applications have been summarized byDunlop.1
Literature suggests lot of references on recognizing texts from images. Some ofthem are designed for low resourceful devices such as cell-phones, PDAs, etc. Asthe present work is solely for handheld mobile devices, we have restricted our studyto character recognition systems designed for low resourceful devices only. We haveidentified the following references2–10 in-line with our objective of the present work.
Pan et al.2 have presented a system for automatic Chinese business card recog-nition. Scanned binarized card images are taken as inputs. After de-skewing withHough transform, these images are segmented by a rule-based document geometricallayout analysis system developed by them for Chinese business cards. As Chinesebusiness cards often have English texts, language classification is required and it is
dhttp://www.nokia-asia.com/find-products/products/nokia-n95-8gb/technical-specifications.ehttp://en.wikipedia.org/wiki/Floating-point unit.
1350016-3

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
done based on dimension, aspect ratio and topological relationship of the neighbor-ing connected components. Then, the components are recognized by two availablelanguage specific classifiers one for Chinese and the other for English. Preprocess-ing including binarization is the most time consuming operation in an OCR sys-tem. But, these modules are not included in their work. The recognition accuracyreported for English characters i.e. 91.20% is yet to be improved for satisfactoryapplications. Moreover, as camera captured business card images are worse thanscanned images of the same documents in many respects, the recognition accuracyreported by them will certainly decrease if the cards are captured by digital camerasembedded into handheld/mobile devices. The study of applicability of the presentedtechnique on handheld/mobile devices is also left.
Luo et al. of Motorolla China Research Center have reported two characterrecognition systems3,4 for business card images, one for Chinese scripts cards andthe other for Chinese–English mixed scripts cards. Although, the recognition ratesachieved are satisfactory, they did not account for complex layout, graphic back-ground and information extraction based on layout. Moreover, due to computingconstraints, they could not address the fact that the practical business card imagesare very often textured or background patterns are there, which makes segmentationand recognition very difficult.
Laine et al.5 developed a system to recognize only English capital letters printedin black against a white background. Practical documents, in most cases, will notbe written in black capital letters on white background. These documents oftenhave multi-font, multi-size and cursive texts on graphical/textured backgrounds. Inthe work of Koga et al.,6 the practical issues associated with Kanji OCR have beendiscussed and a recognition system has been presented for printed Japanese texts.It also translates them into English. Similar to the previous works, this too doesnot consider the complexity of the real captured documents.
Another prototype system for camera captured Chinese document recognitionhas been reported.7 Simple Japanese texts of uniform size and typed in well spacedmanner have been experimented and the results obtained have been reported.Mobile device-based recognition systems for assisting blind persons8,9 have beenreported. Shen et al.10 have presented a system for identifying digits from LEDdisplays and recognizing them.
As discussed above, research works carried out so far are either tested on simpleimages or the accuracy needs to be improved for practical purposes. Some of theworks reported above are prototype systems for camera captured images on mobiledevices. Designing an efficient on-device camera-based character recognition systemis still an open problem.
The present work is an attempt to meet the problem. In this paper, a characterrecognition system for mobile camera captured document images with the intent ofrunning it on low computing devices has been presented. The work has been dividedinto few stages. At the first stage, text regions (TRs) are identified by segmentingthe given document image. Next, these TRs are skew corrected, binarized and
1350016-4

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
segmented into text lines. At the last stage, segmented text lines are recognizedand the obtained results are reorganized to get the original layout back.
2. Present Work
Digital cameras embedded into most of the modern day cell-phones, PDAs and otherhandheld devices are capable of capturing color images. A color image consists ofcolor pixels each of which is represented by a combination of three basic colorcomponents viz. red (r), green (g) and blue (b). The range of values for all thesecolor components is 0–255. So, the corresponding gray scale value f(x, y) for eachpixel, which also lies between 0–255, may be obtained by using Eq. (1).
f(x, y) = 0.299× r(x, y) + 0.587× g(x, y) + 0.114× b(x, y). (1)
So, the gray scale image obtained from this transformation for all pixels can berepresented as a matrix of gray level intensities, IP×Q = [f(x, y)]P×Q where P andQ denote the number of rows i.e. the height of the image and the number of thecolumns i.e. the width of the image respectively, and f(x, y) ∈ GL. The set of allgray levels is referred to as GL = {0, 1, . . . , L− 1}, where L is the total number ofgray levels in the image. Such a gray level image is fed as input to the proposedcharacter recognition system.
The block diagram of the present character recognition system is shown in Fig. 1.The input gray level image is segmented into two types of regions — TRs andnon-text regions (NRs) as illustrated in Sec. 2.1. The NRs are removed and theTRs are de-skewed as discussed in Sec. 2.2. In Sec. 2.3, the text lines are segmented
Fig. 1. Block diagram of the present character recognition system.
1350016-5

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
from the de-skewed TRs. Finally, these text lines are recognized and reassembledto preserve the original layout as illustrated in Secs. 2.4 and 2.5 respectively.
2.1. Image segmentation
Segmentation, in image processing and computer vision, refers to the process ofpartitioning an image into a number of regions Ri, i = 1, 2, . . . , n such that Ri ∩Rj = φ for all i �= j and
⋃ni=1 Ri = IP×Q. A region Ri is a set of pixels belonging to
a particular component. To generate such regions, the input image IP×Q is, at first,partitioned into m number of blocks Bi, i = 1, 2, . . . , m such that Bi ∩ Bj =φ andIP×Q =
⋃mi=1 Bi. A block Bi is a set of pixels represented as Bi = [f(x, y)]H×W
where H and W are the height and the width of the block respectively.Each such block is classified as part of either foreground or background based
on the intensity variation within it. After removal of background blocks, adjacentforeground blocks constitute isolated components called as regions Ri. The areaof a region is always a multiple of the area of the blocks. These regions are thenclassified as TR or NR using various characteristics features of textual and non-textual regions such as dimensions, aspect ratio, information pixel density, regionarea, coverage ratio, histogram, etc. A detail description of the technique has beenpublished in one of our prior work.11 Figure 2 shows a camera captured image andthe TRs extracted from it.
Usually text strokes are darker than the background in most document images.But, sometimes, it is observed that the text strokes are written with light colorson dark background. This type of text is referred to as reverse text whereas theformer one is called as normal text. The image segmentation technique11 discussedabove is meant for the normal text. Therefore, reversal of reverse TRs is required.It is called as reverse text correction. The following technique is developed for thispurpose.
(a) (b)
Fig. 2. Identifying TRs by image segmentation. (a) A business card image captured by a cell-phone camera and (b) isolated/identified TRs.
1350016-6
March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
(a) (b)
(c) (d)
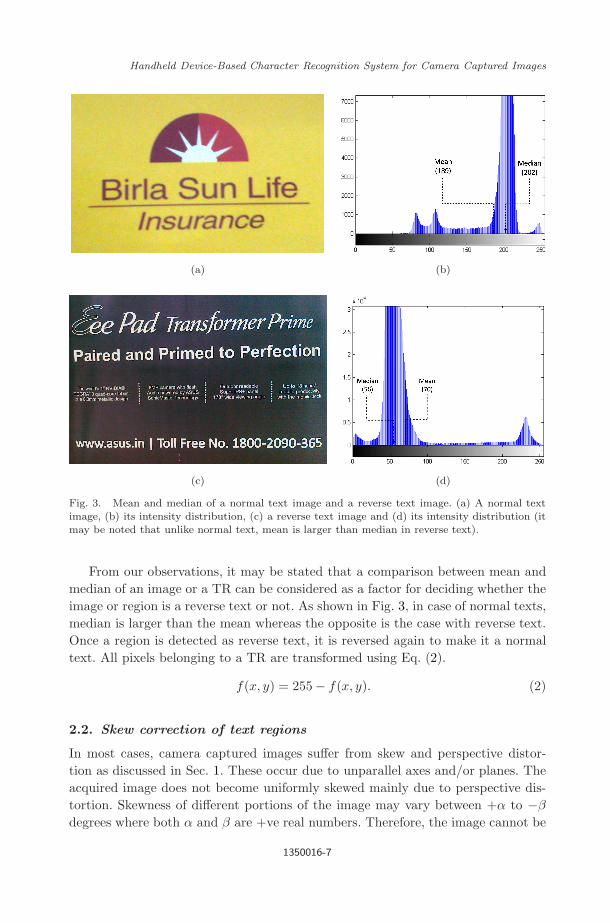
Fig. 3. Mean and median of a normal text image and a reverse text image. (a) A normal textimage, (b) its intensity distribution, (c) a reverse text image and (d) its intensity distribution (itmay be noted that unlike normal text, mean is larger than median in reverse text).
From our observations, it may be stated that a comparison between mean andmedian of an image or a TR can be considered as a factor for deciding whether theimage or region is a reverse text or not. As shown in Fig. 3, in case of normal texts,median is larger than the mean whereas the opposite is the case with reverse text.Once a region is detected as reverse text, it is reversed again to make it a normaltext. All pixels belonging to a TR are transformed using Eq. (2).
f(x, y) = 255− f(x, y). (2)
2.2. Skew correction of text regions
In most cases, camera captured images suffer from skew and perspective distor-tion as discussed in Sec. 1. These occur due to unparallel axes and/or planes. Theacquired image does not become uniformly skewed mainly due to perspective dis-tortion. Skewness of different portions of the image may vary between +α to −β
degrees where both α and β are +ve real numbers. Therefore, the image cannot be
1350016-7

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
de-skewed in a single step. On the other hand, the effect of perspective distortion isdistributed throughout the image. Its effect is hardly visible within a small region(e.g. the area of a character) of the image. At the same time, we see that the imagesegmentation module generates only a few TRs. So, these TRs are de-skewed usinga computationally efficient and fast skew correction technique designed in our workand published.12 A brief description is given here.
Every TR has two types of pixels — dark and gray. The dark pixels constitutethe texts and the gray pixels are background around the texts. For the four sidesof the virtual bounding rectangle of a TR, we can have four sets of values thatwill be called as profiles. If the length and breadth of the bounding rectangle areM and N respectively, then two profiles will have M number of values each andthe other two will have N number of values each. These values are the distances interms of pixel from a side to the first gray/black pixel of the TR. Among these fourprofiles, the one which is from the bottom side of the TR is taken into considerationfor estimating skew angle as shown in Fig. 4. This bottom profile is denoted as{hi, i = 1, 2, . . . , M}.
The mean (µ = 1M
∑Mi=1hi) and the mean deviation (τ = 1
M
∑Mi=1|µ − hi|) of
hi values are calculated. Then, the profile size is reduced by excluding some hi
values that are not within the range, µ± τ . The central idea behind this exclusionis that these elements hardly contribute to the actual skew of the TR. Now, fromthe remaining profile elements, we choose the leftmost h1, right-most h2 and themiddle one h3. The final skew angle is computed by averaging the three skew anglesobtained from the three pairs {h1, h3}, {h3, h2} and {h1, h2}. Once the skew anglefor a TR is estimated, it is rotated by the same.
2.3. Text region segmentation
Before segmenting a skew corrected TR into one or more text lines, it is binarizedusing a self-developed simple yet efficient binarization technique given in Algo-rithm 1. Basically, this is an improved version of Bernsen’s binarization method.13
In his method, the arithmetic mean of the maximum (Gmax) and the minimum(Gmin) gray levels around a pixel is taken as the threshold for binarizing the pixel.In the present algorithm, the eight immediate neighbors around the pixel subjectto binarization are also taken as deciding factors for binarization. This type ofapproach is especially useful to connect the disconnected foreground pixels of acharacter.
Fig. 4. Calculation of skew angle from bottom profile of a TR.
1350016-8

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
Algorithm 1 Text region binarizationGmin ← Minimum intensity of a text regionGmax ← Maximum intensity of the text regionif intensity(x, y) < (Gmin + Gmax)/2 then
mark (x, y) as foregroundelse
if number of foreground neighbors > 4 thenmark (x, y) as foreground
elsemark (x, y) as background
end ifend if
After binarizing a TR, the horizontal histogram profile {fi, i = 1, 2, . . . , H} ofthe region as shown in Fig. 5 is analyzed for segmenting the region into text lines.Here fi denotes the number of black pixel along the ith row of the TR. Horizontalhistogram profile is a set of values that denote the number of black pixels alongeach row. At first, all possible line segments are determined by thresholding theprofile values. Line segments refer to the values of i for which the value of fi is lessthan the threshold. Thus, n such segments represent n − 1 text lines. After thatthe inter-segment distances are analyzed and some segments are rejected based onthe idea that the distance between two lines in terms of pixels will not be too smalland the inter-segment distances are likely to be equal. A detail description of themethod is given.14 Thus, the remaining segments give the text lines.
2.4. Recognition of text lines
Each individual text lines are passed to the recognition engine. Although, mo-bile devices have limited computing resources, the computation power is getting
(a) (b)
(c) (d)
Fig. 5. Use of horizontal histogram of TRs for their segmentation. (a) and (b) A skewed TR andits skew corrected view, (c) and (d) horizontal histogram plots of the skewed and the de-skewed TR.
1350016-9

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
increased gradually. Therefore, recognition engines like Tesseractf can be run onmobile devices. Tesseract is an open source (under Apache License 2.0) pluggableoffline OCR engine originally developed at Hewlett Packard from 1984 to 1994. Itwas first started as a PhD research project in HP Labs, Bristol.15 In 1995, it was sentto UNLV where it proved its worth against the then commercial engines. HewlettPackard and University of Nevada, Las Vegas, released it in 2005. Most of the workon Tesseract is sponsored by Google and it is released under the Apache license,version 2.0. Tesseract 2.03 which is used in the present work has been released inApril, 2008. Like any standard OCR engine, Tesseract is developed on top of thekey functional modules like line and word finder, word recognizer, static characterclassifier, linguistic analyzer and an adaptive classifier. However, Tesseract 2.03does not support document layout analysis, output formatting and graphical userinterface.
In the present work, Tesseract 2.03 has been plugged into our character recog-nition system and used for recognition of binarized text lines as shown in Fig. 6.It may be noted that the present system performs segmentation up to text lines.Character segmentation is done by Tesseract itself.
2.5. Post-processing
As mentioned earlier, Tesseract 2.03 does not support document layout analysisand output formatting. Therefore, the recognized text lines are post-processed toobtain the original layout. The spatial location of a text line in the original image isthe central basis of layout preservation. The recognized results for a given documentimage is represented as a virtual two-dimensional array. From the spatial locationof the text lines, the recognized characters are placed into the respective locationof the array.
However, collision may happen i.e. a character may be required to be insertedinto the array at a position which is not empty. Special care is ensured for collision
Fig. 6. Recognition of a binarized text line using Tesseract.
fhttp://code.google.com/p/tesseract-ocr.
1350016-10

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
(a)
(b)
Fig. 7. Recognition of skew corrected binarized image. (a) Skew corrected and binarized textlines of Fig. 2(a) and (b) recognized texts with preserved layout.
avoidance. By detecting collisions before it occurs, the characters of the recognizedtext line are relocated by finding the best position of the array in their neighbor-hood. Collision happens mainly because of different font sizes of different text lineswhereas the font size of the recognized texts is the same for all characters. In Fig. 7,A skew corrected binarized image and its recognized results with preserved layouthave been shown.
3. Experimental Results and Discussion
To evaluate the performance of the presented character recognition system, we haveexperimented on a dataset of 100 business card images of various types acquiredwith a cell-phone camera (Sony Ericsson K810i). The dataset contains both simpleand complex cards including complex backgrounds and logos. Some cards contain
1350016-11

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
multiple logos and some logos are combination of text and image. Most of theimages are skewed, perspectively distorted and degraded.
As low camera resolution is no more a serious problem, as it was in the last fewdecades, high resolution images (2048 × 1536 pixels) have been taken for experi-ments. However, the techniques presented in this paper are scalable in nature andtherefore can also be applied on business card images of various other resolutions.The performance of the proposed character recognition system has been evalu-ated in terms of image segmentation accuracy, skew correction accuracy and therecognition accuracy. Images of the obtained results show the efficiency of layoutpreservation.
3.1. Segmentation, skew correction and binarization accuracy
As discussed in Sec. 2.1, a segmented region Ri ∈ {TR, NR}. Based on the occur-rence of a region Ri in either or both ground truth and output images, it is classifiedas true positive (TP), false positive (FP), true negative (TN) and false negative(FN) as shown in Fig. 8. So, the definition for F-Measure (FM) in terms of recallrate (R) and precision rate (P ) can be given as Eq. (3)
FM =2×R× P
R + P, (3)
where R = TPTP+FN and P = TP
TP+FP . Here, TP, FP, TN and FN denote theirrespective counts. In an ideal situation i.e. when the output image is identicalwith the ground truth image, R, P and FM should be all 100%. In the presentexperiment, we have found an F-measure of 99.48%. This indicates that only afew TRs are improperly segmented. Detail experimentation and results have beengiven.11 Segmented TRs are then skew corrected and binarized. The skew correctiontechnique is very fast and satisfactorily accurate. The skew angle error is between±3◦ only.
Although, binarization is done after skew correction in the present work, bina-rization accuracy is calculated without skew correction. To quantify the binarization
Fig. 8. Interpretation based on occurrence in either/both ground truth and output.
1350016-12

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
(a) (b)
(c) (d)
Fig. 9. Sample portions of some images (a) and (c) and their recognized results (b) and (d).
accuracy, similar method as discussed above has been adopted. Pixel-wise groundtruth images are compared with that of the output binarized images. Thus, we getthe counts of TP, FP, TN and FN. From these counts, we get an average recall rateof 93.52%, precision rate of 96.27% and FM of 94.88%.
After binarizing the skew corrected TRs, it is segmented into text lines. Theproposed TR segmentation method has been found to be effective enough to suc-cessfully segment all TRs in the present scope of experiment. It means that noinstance is found where two or more text lines have been extracted as a single textline or a single text line gets treated as more than one text lines. Besides havingskew corrected printed texts, soundness of the segmentation method makes TR seg-mentation so accurate. Figures 9(a) and 9(c) show heavily dense and skewed TRsthat have been successfully segmented into all possible text lines, and thereafterrecognized as shown in Figs. 9(b) and 9(d), respectively.
3.2. Recognition accuracy
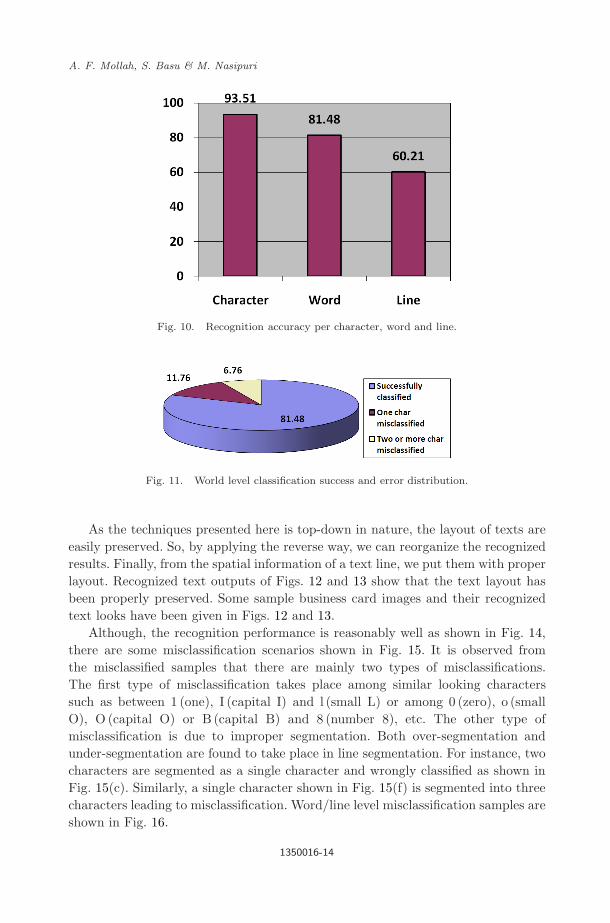
Recognition accuracy is evaluated at three levels — character level, world level andline level. Character level recognition accuracy is the number of successfully classi-fied characters divided by the total number of characters in the dataset. Accuraciesat these three levels are shown in Fig. 10.
It may be noted that special characters like dot, comma, parentheses, etc. havebeen classified. So, the number of classes supported by the recognition engine isvery large. A word is considered as misclassified if one or more of its characters aremisclassified. Similarly, a line is considered as misclassified if at least one character ofthat line gets misclassified. In Fig. 11, percentage of words having one misclassifiedcharacter and that of words having more than one misclassified characters are given.
1350016-13
March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
Fig. 10. Recognition accuracy per character, word and line.
Fig. 11. World level classification success and error distribution.
As the techniques presented here is top-down in nature, the layout of texts areeasily preserved. So, by applying the reverse way, we can reorganize the recognizedresults. Finally, from the spatial information of a text line, we put them with properlayout. Recognized text outputs of Figs. 12 and 13 show that the text layout hasbeen properly preserved. Some sample business card images and their recognizedtext looks have been given in Figs. 12 and 13.
Although, the recognition performance is reasonably well as shown in Fig. 14,there are some misclassification scenarios shown in Fig. 15. It is observed fromthe misclassified samples that there are mainly two types of misclassifications.The first type of misclassification takes place among similar looking characterssuch as between 1 (one), I (capital I) and l (small L) or among 0 (zero), o (smallO), O (capital O) or B (capital B) and 8 (number 8), etc. The other type ofmisclassification is due to improper segmentation. Both over-segmentation andunder-segmentation are found to take place in line segmentation. For instance, twocharacters are segmented as a single character and wrongly classified as shown inFig. 15(c). Similarly, a single character shown in Fig. 15(f) is segmented into threecharacters leading to misclassification. Word/line level misclassification samples areshown in Fig. 16.
1350016-14

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
(a)
(b)
Fig. 12. Recognition from text/image mixed document. (a) A skewed business card image and(b) recognized texts with preserved layout.
3.3. Applicability on handheld devices
The applicability of the presented method on mobile devices is checked in termsof computational requirements. There are three major computational constraintsin the mobile devices. These are low computing power, less working memory andabsence of FPU responsible for floating point arithmetic operations.16–18 The meanprocessing time for a single card image is 0.85 s with respect to a moderately pow-erful notebook (DualCore T2370, 1.73GHz, 1GB RAM, 1MB L2 Cache). Thememory consumed is approximately thrice the image size i.e. for a three mega-pixelimage, the peak consumed memory is approximately 9MB. It is also worth noting
1350016-15

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
(a)
(b)
Fig. 13. Text recognition from graphical text documents. (a) A business card image with graph-ical background and (b) recognized texts with preserved layout.
that we have, in most of the cases, avoided floating point operations, although thesecould have been converted into integer ones.
3.4. Discussion
Overall performance of the proposed system is satisfactory. However, there are somelimitations. The system performs very poor in case of cursive texts. As no imageenhancement operators are used, the present system may not produce satisfactoryresults if the images are heavily degraded. In the present scope of experiments,
1350016-16

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
(a) Researcher (b) Distributor
(c) Independent (d) 700 071
(e) Fax: 2288 1990 (f) VIDEO STUDIO
Fig. 14. Successful scenarios in character recognition (sub-figure captions denote how the imagesare recognized).
(a) ‘o’ misclassified as ‘e’ (b) ‘o’ misclassified as ‘0’ (c) ‘rj’ misclassified as ‘n’
(d) ‘8’ misclassified as ‘B’ (e) ‘1’ misclassified as ‘I’ (f) ‘W’ misclassified as ‘\X/’
Fig. 15. Misclassification scenarios in character recognition (sub-figure captions denote how theimages are recognized).
1350016-17

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
(a) IITAIJAU
(b) News, ldd Mlm making
(c) mmlngent
Fig. 16. Word/line level misclassification samples (sub-figure captions denote how the images arerecognized).
images are neither captured with utmost care nor are they captured casually. Mod-erate care, as every user will do, is taken during capturing the images. Resultsobtained with the images captured with moderate care shows the effectiveness ofthe proposed system.
Regarding the binarization algorithm, one may think that, due to neighborhoodconsideration, false pixels can be categorized as true pixels. But, a higher preci-sion rate weakens the claim. In the present work, precision rate is higher than therecall rate. Although, the system is not implemented on any handheld device, itsapplicability has been studied by comparing its computational requirements withcomputational capabilities of those devices. The study gives the conjecture that themethod is applicable on mobile devices.
The graphical user interface (GUI) of such systems can be designed in such away that would support manual correction of the misclassified characters as onlyfew percentages of characters get misclassified. Although, the word level accuracyand thereby line level accuracy are significantly low, it can be slightly improved byincorporating dictionary based matches.
4. Conclusion
A novel character recognition system has been presented in this paper. Whiledesigning the system, computational constraints have been kept in mind. So, heavy
1350016-18

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
computation, bulk memory consumption and large number of floating point opera-tions have been strictly avoided. In spite of having some limitations, the characterrecognition system, presented in this paper, seem to be capable of serving the pur-pose of on-device image processing and recognition applications. Experiments withimage embedded text documents such as business card images show the effectivenessof the system.
Future research works include extracting necessary information such as name,contact number, email, etc. from the recognized results. Indexing and retrieval ofimages on handheld devices based on recognized texts is also a part of our futurework. Additionally, we plan to port the developed algorithms in Java-based androidplatforms and Xcode-based iOS platforms. Such efforts may open up new researchdirection especially in the areas of real-time text analytics, text extraction fromvideo, etc.
Acknowledgments
Authors are thankful to the Center for Microprocessor Application for TrainingEducation and Research (CMATER) and project on Storage Retrieval and Under-standing of Video for Multimedia (SRUVM) of the Department of Computer Scienceand Engineering, Jadavpur University for providing infrastructural support for theresearch work. We are also thankful to the School of Mobile Computing and Com-munication (SMCC) for providing the research fellowship to the first author whilecarrying out the research work.
References
1. M. D. Dunlop and S. A. Brewster, “The challenge of mobile devices for human com-puter interaction,” Personal and Ubiquitous Computing 6(4), 235–236 (2002).
2. W. Pan, J. Jin, G. Shi and Q. R. Wang, “A system for automatic Chinese businesscard recognition,” in Proc. ICDAR (2001), pp. 577–581.
3. X. P. Luo, J. Li and L. X. Zhen, “Design and implementation of a card reader basedon built-in camera,” in Proc. ICPR (2004), pp. 417–420.
4. X. P. Luo, L. X. Zhen, G. Peng, J. Li and B. H. Xiao, “Camera based mixed-lingualcard reader for mobile device,” in Proc. ICDAR (2005), pp. 665–669.
5. M. Laine and O. S. Nevalainen, “A standalone OCR system for mobile camera-phones,” in Proc. 17th IEEE International Symposium on Personal, Indoor andMobile Radio Communications (2006), pp. 1–5.
6. M. Koga, R. Mine, T. Kameyama, T. Takahashi, M. Yamazaki and T. Yamaguchi,“Camera-based Kanji OCR for Mobile-phones: Practical issues,” in Proc. Eighth Int.Conf. Document Analysis and Recognition (2005), pp. 635–639.
7. K. S. Bae, K. K. Kim, Y. G. Chung and W. P. Yu, “Character recognition systemfor cellular phone with camera,” in Proc. 29th Annual Int. Computer Software andApplications Conference (2005), pp. 539–544.
8. V. Gaudissart, S. Ferreira and C. Mancas-Thillou, “Mobile reading assistant for blindpeople,” in Proc. Speech and Computer (SPECOM), St. Petersburg, Russia (2004).
1350016-19

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
A. F. Mollah, S. Basu & M. Nasipuri
9. J. P. Peters, C. Mancas-Thillou and S. Ferreira, “Embedded reading device forblind people: A user-centred design,” in Proc. Emerging Technologies and Applica-tions for Imagery Pattern Recognition (AIPR 2004), Washington DC, USA (2004),pp. 217–222.
10. H. Shen and J. Coughlan, “Reading LCD/LED displays with a camera cell phone,”in Proc. of Computer Vision and Pattern Recognition Workshop (2006), pp. 119–124.
11. A. F. Mollah, S. Basu, M. Nasipuri and D. K. Basu, “Text/graphics separation forbusiness card images for mobile devices,” in Proc. Eighth IAPR Int. Workshop onGraphics Recognition (GREC09), France, July 2009, pp. 263–270.
12. A. F. Mollah, S. Basu, N. Das, R. Sarkar, M. Nasipuri and M. Kundu, “A fast skewcorrection technique for camera captured business card images,” in Proc. IEEE INDI-CON’09, Gandhinagar, India, December 18–20, 2009, pp. 629–632.
13. J. Bernsen, “Dynamic thresholding of grey-level images,” in Proc. Eighth Int. Conf.Pattern Recognition, Paris, 1986, pp. 1251–1255.
14. A. F. Mollah, S. Basu and M. Nasipuri, “Segmentation of camera captured busi-ness card images for mobile devices,” International Journal of Computer Science andApplications 1(1), 33–37 (2010).
15. R. W. Smith, “The Extraction and Recognition of Text from Multimedia DocumentImages,” Ph.D. Thesis, University of Bristol, November 1987.
16. S. Z. Zhou, S. O. Gilani and S. Winkler, “Open source OCR framework using mobiledevices,” in Proc. SPIE (2008).
17. V. Gaudissart, S. Ferreira, C. Thillou and B. Gosselin, “SYPOLE: A mobile assistantfor the blind,” in European Signal Processing Conference (EUSIPCO 2005) (2005).
18. H. K. Chethan and G. H. Kumar, “Graphics separation and skew correction for mobilecaptured documents and comparative analysis with existing methods,” InternationalJournal of Computer Applications 7(3), 42–47 (2010).
Ayatullah Faruk Mollah received his B.E. degree in Com-puter Science and Engineering from Jadavpur University,Kolkata, India in 2006. Then, he served as a Senior SoftwareEngineer in Atrenta (I) Pvt. Ltd., Noida, India for two years.Thereafter, he received his Ph.D.(Engg.) degree from JadavpurUniversity in 2013. He is presently serving as an Assistant Pro-fessor at Aliah University, Saltlake City, India. His researchinterests include image processing and pattern recognition onlow computing platforms.
Subhadip Basu received his B.E. degree in Computer Sci-ence and Engineering from Kuvempu University, Karnataka,India, in 1999. He received his Ph.D.(Engg.) degree thereafterfrom Jadavpur University (J.U.), Kolkata, India in 2006. Hejoined J.U. as an Assistant Professor (formerly senior lecturer)in 2006. His areas of current research interest are optical charac-ter recognition (OCR) of handwritten text, gesture recognition,realtime image processing.
1350016-20

March 26, 2014 10:11 WSPC/0219-4678 164-IJIG 1350016
Handheld Device-Based Character Recognition System for Camera Captured Images
Mita Nasipuri received her B.E.Tel.E., M.E.Tel.E. and Ph.D.(Engg.) degrees from Jadavpur University (J.U.), in 1979, 1981and 1990, respectively. Prof. Nasipuri is working as a facultymember of this university since 1987. Areas of her currentresearch interests include image processing, bio-informatics,pattern recognition and multimedia systems. She is a seniormember of the IEEE, USA, Fellow of I.E. (India) and W.A.S.T.,Kolkata, India.
1350016-21
Related Documents











