+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.ElephantScale.com [email protected] Bay Area ACM meetup (2015-02-23) © Elephant Scale, 2014

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

+Moving From Hadoop to
Spark
Sujee Maniyam
Founder / Principal @ www.ElephantScale.com
Bay Area ACM meetup (2015-02-23)
© Elephant Scale, 2014

+HI,
Featured in Hadoop Weekly #109

+About Me : Sujee Maniyam
n 15 years+ software development experience
n Consulting & Training in Big Data
n Author n “Hadoop illuminated” open source book n “HBase Design Patterns” coming soon
n Open Source contributor (including HBase) http://github.com/sujee
n Founder / Organizer of ‘Big Data Guru’ meetup http://www.meetup.com/BigDataGurus/
n http://sujee.net/
n Contact : [email protected]

+Hadoop in 20 Seconds
n ‘The’ Big data platform
n Very well field tested
n Scales to peta-bytes of data
n MapReduce : Batch oriented compute
© Elephant Scale, 2014
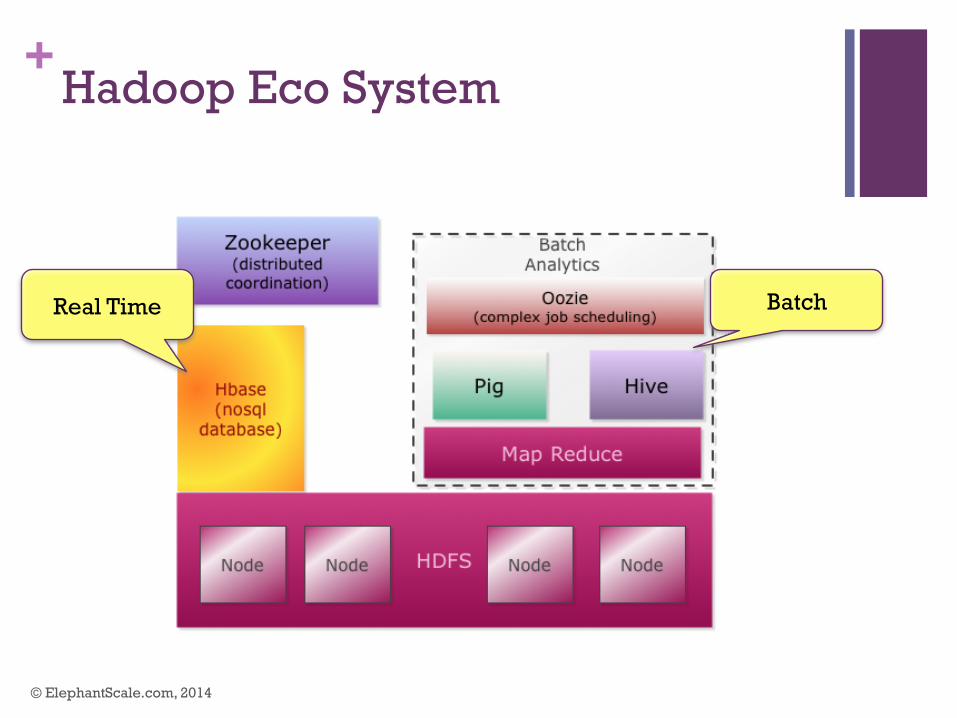
+Hadoop Eco System
© ElephantScale.com, 2014
Batch Real Time

+Hadoop Ecosystem
n HDFS n provides distributed storage
n Map Reduce n Provides distributed computing
n Pig n High level MapReduce
n Hive n SQL layer over Hadoop
n HBase n Nosql storage for realtime queries
© ElephantScale.com, 2014

+Spark in 20 Seconds
n Fast & Expressive Cluster computing engine
n Compatible with Hadoop
n Came out of Berkeley AMP Lab
n Now Apache project
n Version 1.2 just released (Dec 2014)
“First Big Data platform to integrate batch, streaming and interactive computations in a unified framework” – stratio.com
© Elephant Scale, 2014

+Spark Eco-System
© Elephant Scale, 2014
Spark Core
Spark SQL
Spark Streaming ML lib
Schema / sql Real Time
Machine Learning
Stand alone YARN MESOS Cluster
managers
GraphX
Graph processing
+Hypo-meter J
© Elephant Scale, 2014

+Spark Job Trends
© Elephant Scale, 2014

+Spark Benchmarks
© Elephant Scale, 2014
Source : stratio.com

+Spark Code / Activity
© Elephant Scale, 2014
Source : stratio.com

+Timeline : Hadoop & Spark
© Elephant Scale, 2014

+Hadoop Vs. Spark
© Elephant Scale, 2014
Hadoop Spark
Source : http://www.kwigger.com/mit-skifte-til-mac/

+Comparison With Hadoop
Hadoop Spark
Distributed Storage + Distributed Compute
Distributed Compute Only
MapReduce framework Generalized computation
Usually data on disk (HDFS) On disk / in memory
Not ideal for iterative work Great at Iterative workloads (machine learning ..etc)
Batch process - Upto 2x - 10x faster for data on disk - Upto 100x faster for data in memory
Compact code Java, Python, Scala supported
Shell for ad-hoc exploration © Elephant Scale, 2014

+Hadoop + Yarn : Universal OS for Distributed Compute
HDFS
YARN
Batch (mapreduce)
Streaming (storm, S4)
In-memory (spark)
Storage
Cluster Management
Applications
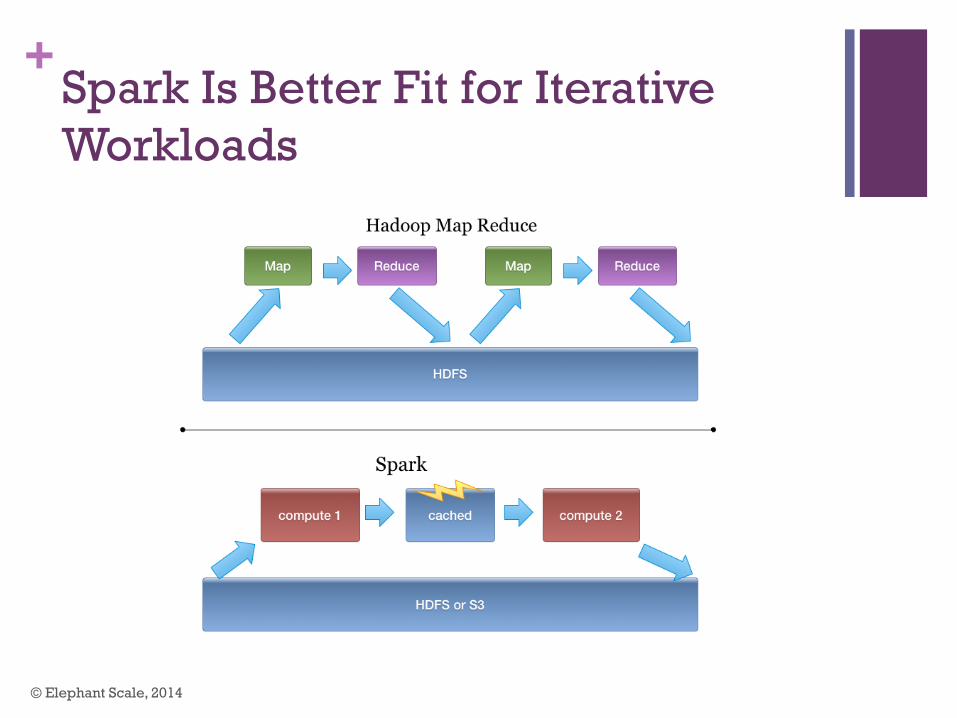
+Spark Is Better Fit for Iterative Workloads
© Elephant Scale, 2014

+Spark Programming Model
n More generic than MapReduce
© Elephant Scale, 2014

+Is Spark Replacing Hadoop?
n Spark runs on Hadoop / YARN n Complimentary
n Spark programming model is more flexible than MapReduce
n Spark is really great if data fits in memory (few hundred gigs),
n Spark is ‘storage agnostic’ (see next slide)
© Elephant Scale, 2014

+Spark & Pluggable Storage
Spark (compute engine)
HDFS Amazon
S3 Cassandra ???

+Spark & Hadoop
Use Case Other Spark
Batch processing Hadoop’s MapReduce (Java, Pig, Hive)
Spark RDDs (java / scala / python)
SQL querying Hadoop : Hive Spark SQL
Stream Processing / Real Time processing
Storm Kafka
Spark Streaming
Machine Learning Mahout Spark ML Lib
Real time lookups NoSQL (Hbase, Cassandra ..etc)
No Spark component. But Spark can query data in NoSQL stores
© Elephant Scale, 2014

+ Hadoop & Spark Future ???

+Why Move From Hadoop to Spark?
n Spark is ‘easier’ than Hadoop
n ‘friendlier’ for data scientists / analysts n Interactive shell
n fast development cycles
n adhoc exploration
n API supports multiple languages n Java, Scala, Python
n Great for small (Gigs) to medium (100s of Gigs) data
© Elephant Scale, 2014

+Spark : ‘Unified’ Stack
n Spark supports multiple programming models n Map reduce style batch processing
n Streaming / real time processing
n Querying via SQL
n Machine learning
n All modules are tightly integrated n Facilitates rich applications
n Spark can be only stack you need ! n No need to run multiple clusters
(Hadoop cluster, Storm cluster ..etc)
© Elephant Scale, 2014 Image: buymeposters.com

+Migrating From Hadoop à Spark
Functionality Hadoop Spark
Distributed Storage HDFS Cloud storage like Amazon S3 Or NFS mounts
SQL querying Hive Spark SQL
ETL work flow Pig - Spork : Pig on Spark
- Mix of Spark SQL ..etc
Machine Learning Mahout ML Lib
NoSQL DB Hbase ???
© Elephant Scale, 2014

+Moving From Hadoop à Spark
1. Data size
2. File System
3. SQL
4. ETL
5. Machine Learning
© Elephant Scale, 2014

+Hadoop To Spark
© ElephantScale.com, 2014
Batch
Real Time
Spark can help

+Big Data
© Elephant Scale, 2014

+Data Size : “You Don’t Have Big Data”
© Elephant Scale, 2014

+1) Data Size (T-shirt sizing)
© Elephant Scale, 2014 Image credit : blog.trumpi.co.za
10 G + 100 G +
1 TB + 100 TB + PB +
< few G
Hadoop
Spark

+1) Data Size
n Lot of Spark adoption at SMALL – MEDIUM scale n Good fit
n Data might fit in memory !!
n Hadoop may be overkill
n Applications n Iterative workloads (Machine learning ..etc)
n Streaming
n Hadoop is still preferred platform for TB + data
© Elephant Scale, 2014

+Next : 2) File System
© ElephantScale.com, 2014

+2) File System
n Hadoop = Storage + Compute Spark = Compute only Spark needs a distributed FS
n File system choices for Spark n HDFS - Hadoop File System
n Reliable n Good performance (data locality) n Field tested for PB of data
n S3 : Amazon n Reliable cloud storage n Huge scale
n NFS : Network File System (‘shared FS across machines)
© Elephant Scale, 2014

+Spark File Systems
© Elephant Scale, 2014

+File Systems For Spark
HDFS NFS Amazon S3
Data locality High (best)
Local enough None (ok)
Throughput High (best)
Medium (good)
Low (ok)
Latency Low (best)
Low High
Reliability Very High (replicated)
Low Very High
Cost Varies Varies $30 / TB / Month
© Elephant Scale, 2014

+File System Throughput Comparison (HDFS Vs. S3)
n Data : 10G + (11.3 G)
n Each file : ~1+ G ( x 10)
n 400 million records total
n Partition size : 128 M
n On HDFS & S3
n Cluster : n 8 Nodes on Amazon m3.xlarge (4 cpu , 15 G Mem, 40G SSD ) n Hadoop cluster , Latest Horton Works HDP v2.2 n Spark : on same 8 nodes, stand-alone, v 1.2
© Elephant Scale, 2014

+File System Throughput Comparison (HDFS Vs. S3)
val hdfs = sc.textFile("hdfs:///____/10G/")
val s3 = sc.textFile("s3n://______/10G/")
// count # records
hdfs.count() s3.count()
© Elephant Scale, 2014

+HDFS Vs. S3
© Elephant Scale, 2014

+HDFS Vs. S3 (lower is better)
© Elephant Scale, 2014

+HDFS Vs. S3 Conclusions
HDFS S3
Data locality à much higher throughput
Data is streamed à lower throughput
Need to maintain an Hadoop cluster
No Hadoop cluster to maintain à convenient
Large data sets (TB + ) Good use case: - Smallish data sets (few
gigs) - Load once and cache and
re-use
© Elephant Scale, 2014

+Next : 3) SQL
© ElephantScale.com, 2014
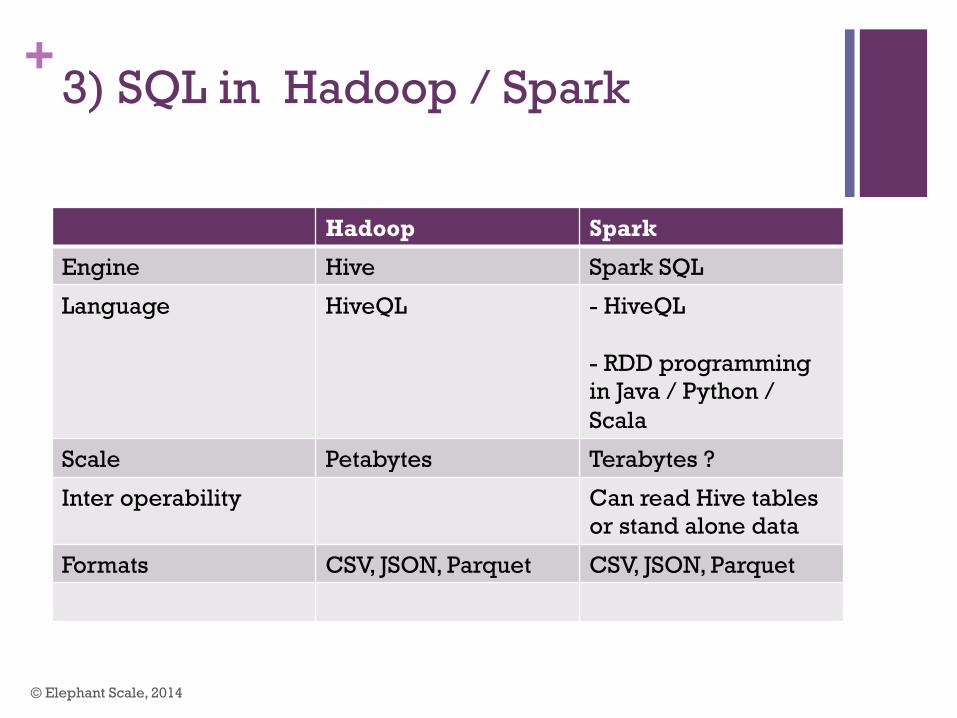
+3) SQL in Hadoop / Spark
Hadoop Spark
Engine Hive Spark SQL
Language HiveQL - HiveQL - RDD programming in Java / Python / Scala
Scale Petabytes Terabytes ?
Inter operability Can read Hive tables or stand alone data
Formats CSV, JSON, Parquet CSV, JSON, Parquet
© Elephant Scale, 2014

+SQL In Hadoop / Spark n Input Billing Records / CDR
n Query: Find top-10 customers
n Data Set n 10G + data n 400 million records n CSV Format
© Elephant Scale, 2014
Timestamp Customer_id Resource_id Qty cost
Milliseconds String Int Int int
1000 1 Phone 10 10c
1003 2 SMS 1 4c
1005 1 Data 3M 5c

+SQL In Hadoop / Spark
n Hive Table:
CREATE EXTERNAL TABLE billing ( ts BIGINT, customer_id INT, resource_id INT, qty INT, cost INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',’ stored as textfile LOCATION ’hdfs location' ;
n Hive Query (simple aggregate)
select customer_id, SUM(cost) as total from billing group by customer_id order by total DESC LIMIT 10;
© Elephant Scale, 2014
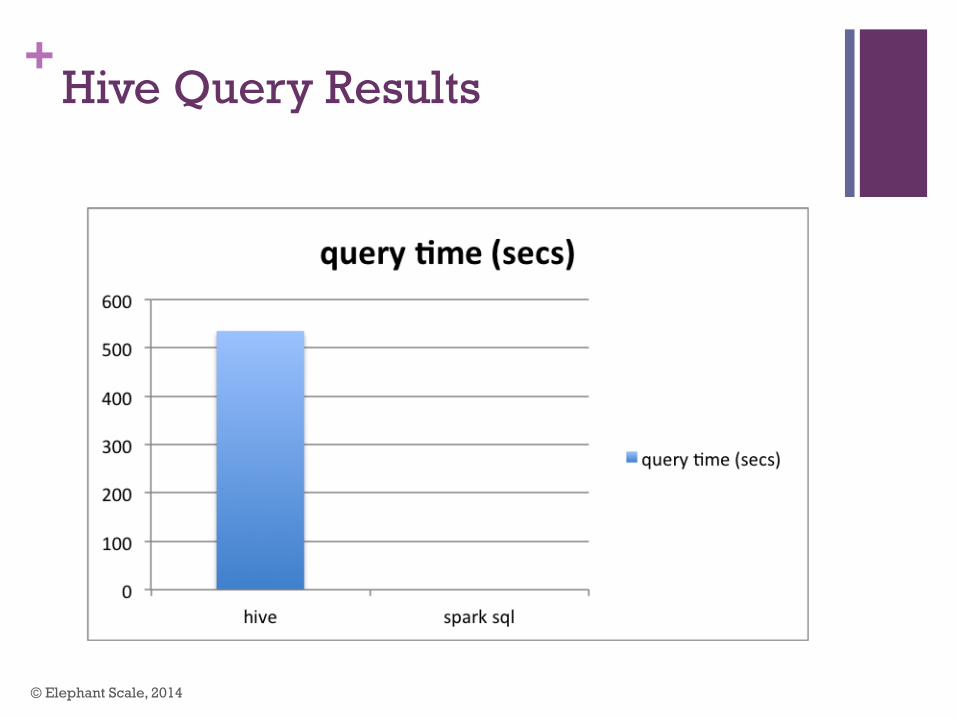
+Hive Query Results
© Elephant Scale, 2014

+Spark + Hive Table
n Spark code to access Hive table
import org.apache.spark.sql.hive.HiveContext
val hiveCtx = new org.apache.spark.sql.hive.HiveContext(sc)
val top10 = hiveCtx.sql("select customer_id, SUM(cost) as total from billing group by customer_id order by total DESC LIMIT 10")
top10.collect()
© Elephant Scale, 2014
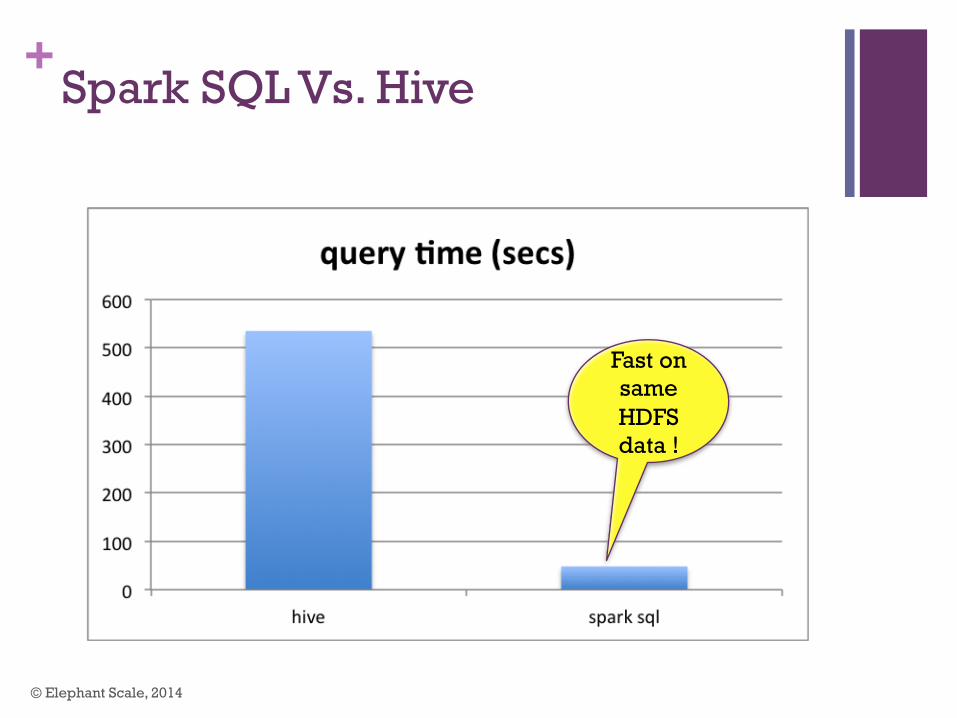
+Spark SQL Vs. Hive
© Elephant Scale, 2014
Fast on same HDFS data !

+ SQL In Hadoop / Spark : Conclusions
n Spark can readily query Hive tables n Speed !
n Great for exploring / trying-out
n Fast iterative development
n Spark can load data natively n CSV
n JSON (Schema automatically inferred)
n Parquet (Schema automatically inferred)
© Elephant Scale, 2014
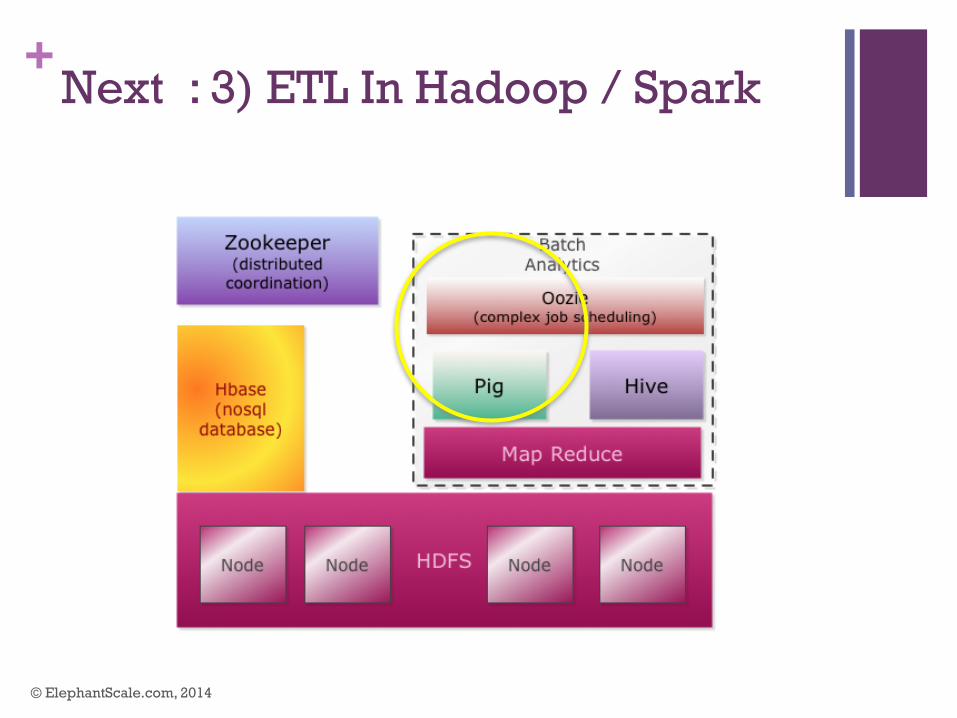
+Next : 3) ETL In Hadoop / Spark
© ElephantScale.com, 2014

+ETL?
© Elephant Scale, 2014
Data 1 Data 2 (clean)
Data 3
Data 4

+3) ETL on Hadoop / Spark
Hadoop Spark
ETL Tools Pig, Cascading, Oozie Native RDD programming (Scala, Java, Python)
Pig High level ETL workflow
Spork : Pig on Spark
Cascading High level Spark-scalding
© Elephant Scale, 2014

+ETL On Hadoop / Spark
n Pig n High level, expressive data flow language (Pig Latin) n Easier to program than Java Map Reduce n Used for ETL (data cleanup / data prep) n Spork : Run Pig on Spark
(as simple as $ pig -x spark …..) n https://github.com/sigmoidanalytics/spork
n Cascading n High level data flow declarations n Many sources (Cassandra / Accumulo / Solr) n Spark-Scalding n https://github.com/tresata/spark-scalding
© Elephant Scale, 2014

+ETL On Hadoop / Spark : Conclusions
n Try spork or spark-scalding n Code re-use
n Not re-writing from scratch
n Program RDDs directly n More flexible
n Multiple language support : Scala / Java / Python
n Simpler / faster in some cases
© Elephant Scale, 2014

+4) Machine Learning : Hadoop / Spark
Hadoop Spark
Tool Mahout MLLib
API Java Java / Scala / Python
Iterative Algorithms Slower Very fast (in memory)
In Memory processing
No YES
Efforts to port Mahout into Spark
Lots of momentum !
© Elephant Scale, 2014

+Spark Is Better Fit for Iterative Workloads
© Elephant Scale, 2014

+Spark Caching!
n Reading data from remote FS (S3) can be slow
n For small / medium data ( 10 – 100s of GB) use caching n Pay read penalty once
n Cache
n Then very high speed computes (in memory)
n Recommended for iterative work-loads
© Elephant Scale, 2014

+ Caching Demo!
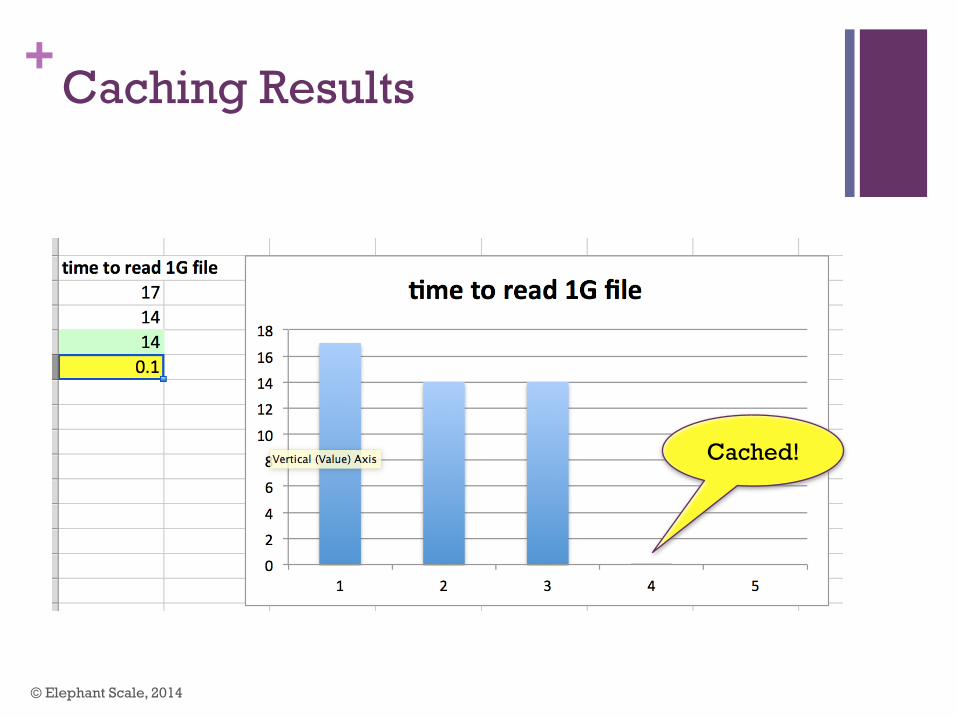
+Caching Results
© Elephant Scale, 2014
Cached!
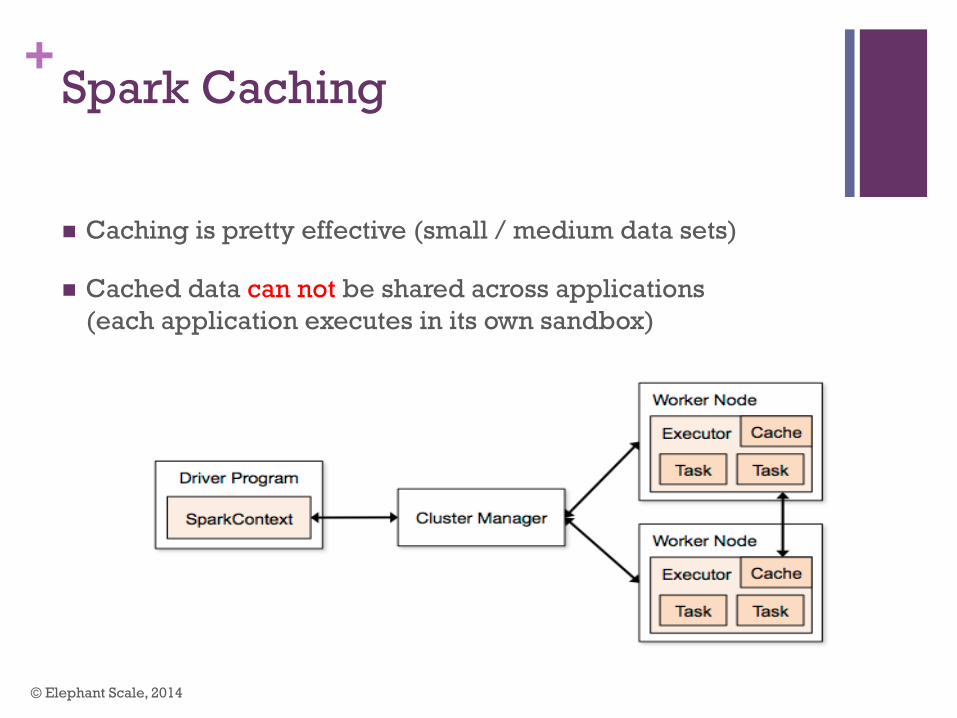
+Spark Caching
n Caching is pretty effective (small / medium data sets)
n Cached data can not be shared across applications (each application executes in its own sandbox)
© Elephant Scale, 2014

+Sharing Cached Data
n 1) ‘spark job server’ n Multiplexer
n All requests are executed through same ‘context’
n Provides web-service interface
n 2) Tachyon n Distributed In-memory file system
n Memory is the new disk!
n Out of AMP lab , Berkeley
n Early stages (very promising)
© Elephant Scale, 2014
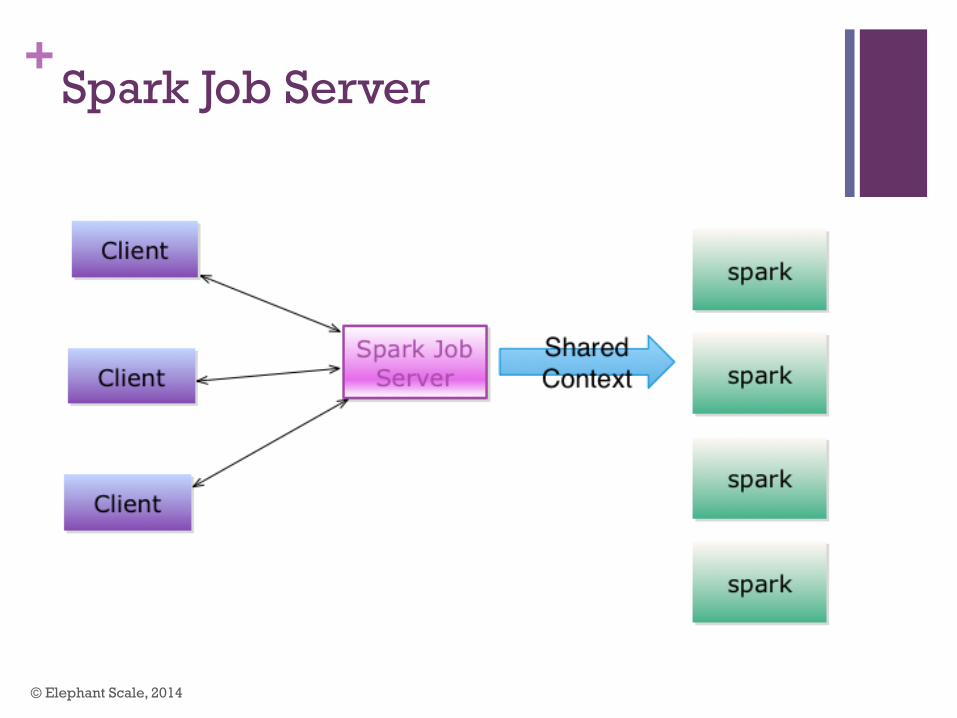
+Spark Job Server
© Elephant Scale, 2014

+Spark Job Server
n Open sourced from Ooyala
n ‘Spark as a Service’ – simple REST interface to launch jobs
n Sub-second latency !
n Pre-load jars for even faster spinup
n Share cached RDDs across requests (NamedRDD)
App1 : ctx.saveRDD(“my cached rdd”, rdd1)
App2: RDD rdd2 = ctx.loadRDD (“my cached rdd”)
n https://github.com/spark-jobserver/spark-jobserver
© Elephant Scale, 2014

+Tachyon + Spark
© Elephant Scale, 2014

+Next : New Big Data Applications With Spark
© Elephant Scale, 2014

+Big Data Applications : Now
n Analysis is done in batch mode (minutes / hours)
n Final results are stored in a real time data store like Cassandra / Hbase
n These results are displayed in a dashboard / web UI
n Doing interactive analysis ???? n Need special BI tools
© Elephant Scale, 2014

+With Spark…
n Load data set (Giga bytes) from S3 and cache it (one time)
n Super fast (sub-seconds) queries to data
n Response time : seconds (just like a web app !)
© Elephant Scale, 2014

+Lessons Learned
n Build sophisticated apps !
n Web-response-time (few seconds) !!
n In-depth analytics n Leverage existing libraries in Java / Scala / Python
n ‘data analytics as a service’
© Elephant Scale, 2014

+Final Thoughts
n Already on Hadoop? n Try Spark side-by-side n Process some data in HDFS n Try Spark SQL for Hive tables
n Contemplating Hadoop? n Try Spark (standalone) n Choose NFS or S3 file system
n Take advantage of caching n Iterative loads n Spark Job servers n Tachyon
n Build new class of ‘big / medium data’ apps
© Elephant Scale, 2014

+ Thanks !
Sujee Maniyam
[email protected] http://elephantscale.com
Expert consulting & training in Big Data
(Now offering Spark training)
Related Documents











