© Hortonworks Inc. 2015 Apache Hadoop YARN 2015 Present and Future Vinod Kumar Vavilapalli vinodkv [at] apache.org @tshooter Page 1

Hadoop Summit Europe 2015 - YARN Present and Future
Jul 16, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

© Hortonworks Inc. 2015
Apache Hadoop YARN 2015
Present and Future
Vinod Kumar Vavilapalli
vinodkv [at] apache.org
@tshooter
Page 1

© Hortonworks Inc. 2015
Who am I?
• 7.75 Hadoop-years old
– Don’t fall for the job postings asking
for 10 years #Hadoop Experience yet
• Past
– 2007: Last thing at School – a two
node Tomcat cluster. Three months
later, first thing at job, brought down a
800 node cluster ;)
– Team that ran Hadoop @ Yahoo!
• Present: @Hortonworks
• Two hats
– Hortonworks: Hadoop MapReduce
and YARN Development lead
– Apache: Apache Hadoop PMC,
Apache Member
• Worked/working on
– YARN, Hadoop MapReduce,
HadoopOnDemand,
CapacityScheduler, Hadoop security
– Apache Ambari: Kickstarted the
project’s first release
– Stinger: High performance data
processing with Hadoop/Hive
• Lots of trouble shooting on
clusters (@tshooter)
• 99% + code in Apache, Hadoop
– Open Source
– Community driven
Page 2Architecting the Future of Big Data

© Hortonworks Inc. 2015
Agenda
• Apache Hadoop YARN : Overview
• Past
• Present
• Future
Page 3Architecting the Future of Big Data

© Hortonworks Inc. 2015
OverviewThe Why and the What
Architecting the Future of Big DataPage 4

© Hortonworks Inc. 2015
Why Hadoop YARN?
• Resource Management
• A messy problem
– Multiple apps, frameworks, their life-
cycles and evolution
• Varied expectations
– On isolation, capacity allocations,
scheduling
– Admin: “Best use of my cluster”
– Users: “Get me as much as possible,
as fast as possible”
• Tenancy
– “I am running this cluster for one
user”
– It almost never stops there
– Groups, Teams, Users
• Adhoc structures get bad real fast
• What’s different?
– Centered around Data
• ‘iIities
– Admission policies. Sharing. Security.
Elasticity. SLAs. ROI
Page 5Architecting the Future of Big Data
Data
?
Applications
Admins Users

© Hortonworks Inc. 2015
What is Hadoop YARN?
Page 6
HDFS (Scalable, Reliable Storage)
YARN (Cluster Resource Management)
Applications (Running Natively in Hadoop)
• Store all your data in one place … (HDFS)
• Interact with that data in multiple ways … (YARN Platform + Apps)
• Scale as you go, shared, multi-tenant, secure … (The Hadoop Stack)
Queues Admins/Users
Cluster Resources
Pipelines

© Hortonworks Inc. 2015
PastA quick history
Architecting the Future of Big DataPage 7
© Hortonworks Inc. 2015
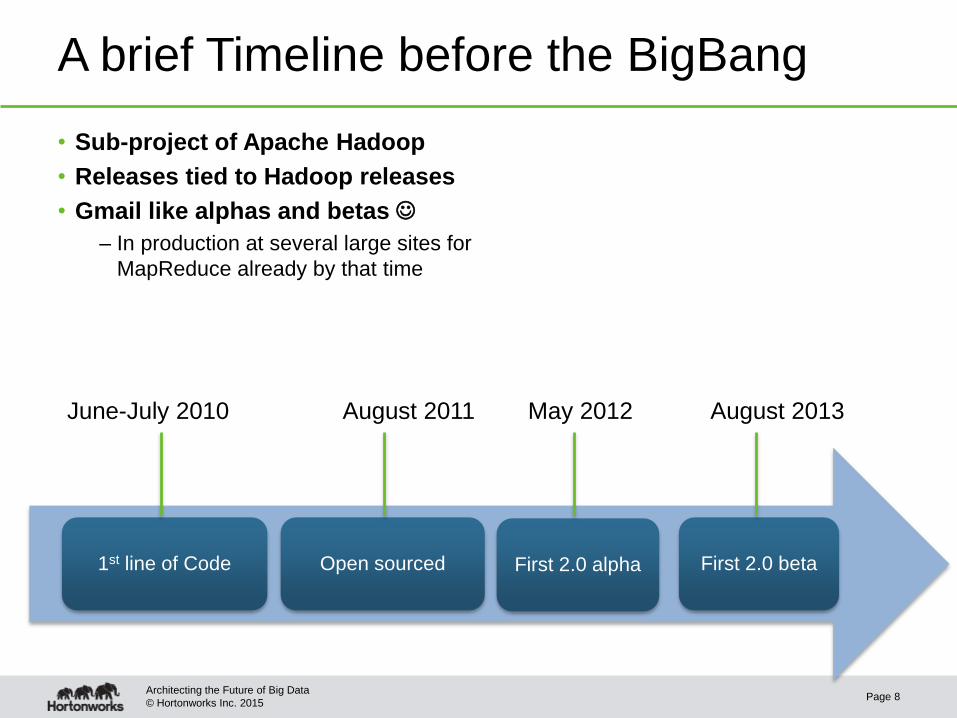
A brief Timeline before the BigBang
• Sub-project of Apache Hadoop
• Releases tied to Hadoop releases
• Gmail like alphas and betas
– In production at several large sites for
MapReduce already by that time
Page 8Architecting the Future of Big Data
1st line of Code Open sourced First 2.0 alpha First 2.0 beta
June-July 2010 August 2011 May 2012 August 2013

© Hortonworks Inc. 2015
Apache Hadoop YARN releases
• 15 October, 2013
• The 1st GA release of Apache Hadoop 2.x
• YARN
– First stable and supported release of YARN
– Binary Compatibility for MapReduce applications built on Hadoop-1.x
– YARN level APIs solidified for the future
– Performance
– Scale from the get-go!
• Support for running Hadoop on Microsoft Windows
• Substantial amount of integration testing with rest of projects in the
ecosystem
Page 9Architecting the Future of Big Data
Apache Hadoop 2.2

© Hortonworks Inc. 2015
Releases (contd)
• 24 February, 2014
• First post GA release for the year 2014
• Number of bug-fixes, enhancements
• Alpha features in YARN
– ResourceManager Failover
– Application History
Page 10Architecting the Future of Big Data
Apache Hadoop 2.3

© Hortonworks Inc. 2015
Releases (contd)
• 07 April, 2014
• YARN
– ResourceManager Fail-over
– Preemption aided Scheduling
– Application History and Timeline Service V1
Page 11Architecting the Future of Big Data
Apache Hadoop 2.4

© Hortonworks Inc. 2015
Releases (contd)
• 11 August, 2014
• YARN
– YARN's REST APIs
– Submitting & killing applications.
– Timeline Service V1 Security
Page 12Architecting the Future of Big Data
Apache Hadoop 2.5

© Hortonworks Inc. 2015
Present
Architecting the Future of Big DataPage 13

© Hortonworks Inc. 2015
Apache Hadoop releases (contd)
• 18 November 2014
• Last major release at the time of this talk
• YARN
– Support for rolling upgrades
– Support for long running services
– Support for node labels
– Alpha/Beta features: Time-based resource reservations, running applications
natively in Docker containers
Page 14Architecting the Future of Big Data
Apache Hadoop 2.6

© Hortonworks Inc. 2015
Rolling UpgradesAt a click of a button
Architecting the Future of Big DataPage 15

© Hortonworks Inc. 2015
Work preserving ResourceManager restart
Page 16Architecting the Future of Big Data
• ResourceManager remembers some state
• Reconstructs the remaining from nodes and apps

© Hortonworks Inc. 2015
Work preserving NodeManager restart
Page 17Architecting the Future of Big Data
• NodeManager remembers state on each machine
• Reconnects to running containers

© Hortonworks Inc. 2015
ResourceManager Fail-over
• Active/Standby Mode
• Depends on fast-recovery
Page 18Architecting the Future of Big Data
ZooKeeper

© Hortonworks Inc. 2015
YARN Rolling Upgrades Workflow
Page 19Architecting the Future of Big Data
• Servers first
– Masters followed by Slaves
• Upgrade of Applications/Frameworks is decoupled!

© Hortonworks Inc. 2015
YARN Rolling Upgrades Snapshot
Page 20Architecting the Future of Big Data

© Hortonworks Inc. 2015
Stack Rolling Upgrades
Page 21Architecting the Future of Big Data
Rolling Updates Session by Sanjay Radia
Thursday April 16, 2015 11:45-12:25
@ Silver Hall

© Hortonworks Inc. 2015
Services on YARN
Architecting the Future of Big DataPage 22

© Hortonworks Inc. 2015
Long running services
• You could run them already before
2.6!
• Enhancements needed
– Logs
– Security
– Management/monitoring
– Sharing and Placement
– Discovery
• Resource sharing across
workload types
• Fault tolerance of long running
services
– Work preserving AM restart
– AM forgetting faults
• Service registry
• Project Slider:
http://slider.incubator.apache.org/
• HBase, Storm, Kafka already!
Page 23Architecting the Future of Big Data
“Bringing Long Running Services to Hadoop YARN”
by Steve Loughran
Thursday April 16, 2015 12:40-13:20
@ Copper Hall

© Hortonworks Inc. 2015
Cluster Management Features
Architecting the Future of Big DataPage 24

© Hortonworks Inc. 2015
Preemption aided Scheduling
• Admins
– “Make the best use of cluster resources”
• Users
– “Give me resources fast”
• Solution
– Elastic queues
– Loan idle capacities to others
– Take it back on demand
– Balance across queues: In
– Balance across users in a queue: WIP
Page 25Architecting the Future of Big Data

© Hortonworks Inc. 2015
Fine-grain isolation for multi-tenancy
• Memory
– Custom monitoring
– Inelastic Resource
• CPU
– Cgroups on Linux
– Elastic Resource
• Support on Windows
– WIP
Page 26Architecting the Future of Big Data

© Hortonworks Inc. 2015
Multi-resource scheduling
• Multi-dimensional bin-packing
– Application A says “I want 8GB RAM
and 2 CPUs”
– Application B says “I want 1GB RAM
and 10 CPUs”
• Today – memory & cpu
– Physical memory / virtual memory
– Cpu Cores – Virtual cores
• Scheduling constrained based on
the “bottleneck” resource
– Watch out for utilization drop on the
non-scarce resource
Page 27Architecting the Future of Big Data

© Hortonworks Inc. 2015
Node Labels
• Partitions
– Admin: “I have machines of different
types”
– Impact on capacity planning: “Hey,
we bought those Windows machines”
• Types
– Exclusive: “This is my Precious!”
– Non-exclusive: “I get binding
preference. Use it for others when
idle”
• Constraints
– “Take me to a machine running JDK
version 9”
– No impact on capacity planning
– WIP
Page 28Architecting the Future of Big Data
Default PartitionPartition B
Linux
Partition C
Windows
JDK 8 JDK 7 JDK 7

© Hortonworks Inc. 2015
Operational and Developer tooling
Architecting the Future of Big DataPage 29

© Hortonworks Inc. 2015
Application History and Timeline Service
• Before
– Few MR specific implementations:
History and web-UI
• Not just MR anymore!
• History
– “Why was my application slow?”
– “Where did my containers run?”
– MapReduce specific Job History
Server
– Need a generic solution beyond
ResourceManager Restart
• Run analytics on historical apps!
– “User with most resource utilization”
– “Largest application run”
• Application Timeline
– Framework specific event collection
and UIs
– “Show me the Counters for my
running MapReduce task”
– “Show me the slowest Storm stream
processing bolt while it is running”
• Present
– A LevelDB based implementation
– Integrated into MapReduce, Apache
Tez, Apache Hive
Page 30Architecting the Future of Big Data

© Hortonworks Inc. 2015
Other features
• Web Services
– No need for installed Hadoop Clients
– Submit an app
– Monitor / Kill it
• Multi-homing Environments
– Clients on a public networks
– Cluster traffic on a private network
– Fault tolerance
– Security
Page 31Architecting the Future of Big Data

© Hortonworks Inc. 2015
Future
Architecting the Future of Big DataPage 32

© Hortonworks Inc. 2015
Apache Hadoop releases (contd)
• Hadoop 2.7
– Likely April 19-24 week, 2014
– Moving to JDK 7 and beyond
• Future
Page 33Architecting the Future of Big Data
Apache Hadoop 2.7,
2.8 and beyond

© Hortonworks Inc. 2015
Future: Timeline Service Next Generation
• Next generation
– Today’s solution helped understand the space
– Limited scalability and availability
• Analyzing Hadoop Clusters is a big-data problem
– Don’t want to throw away the Hadoop application metadata
– Large scale
– Enable near real-time analysis: “Find me the user who is hammering the
FileSystem with rouge applications. Now.”
• Timeline data stored in HBase and accessible to queries
Page 34Architecting the Future of Big Data

© Hortonworks Inc. 2015
Future: Improved Usability
• Generic run-time information
– “What is my actual usage by the running container?”
– “How many rack local containers did I get”
– “How healthy is the scheduler”
– “Why is my application stuck? What limits did it hit?”
• With Timeline Service
– Why is my application slow?
– Why is my cluster slow?
– Why is my application failing?
– Why is my cluster down?
– What happened with my application? Succeeded?
– What happened in my clusters?
• Collect and use past data
– To schedule my application better
– To do better capacity planning
Page 35Architecting the Future of Big Data

© Hortonworks Inc. 2015
Future: Containerized Applications
• Running Containerized
Applications on YARN
• Docker
• Multiple use-cases
– Run my existing service on YARN
– Slider + Docker
– Run my existing MapReduce
application on YARN via a docker
image
Page 36Architecting the Future of Big Data
© Hortonworks Inc. 2015
Future: Scheduling
• Support priorities across
applications within the same
queue
• Policy Driven scheduling
– “I want app level fairness in queue A,
user level fairness in queue B, and
throughput focus in all other queues”
• Node anti-affinity
– “Do not run two copies of my service
daemon on the same machine”
• Gang scheduling
– “Run all of my app at once”
• Dynamic scheduling of containers
based on actual utilization
• Stabilized App Reservations
– “Create a reservation for my app with
X resources to run at 6AM tomorrow”
• Time based policies
– “10% cluster capacity for queue A
from 6-9AM, but 20% from 9-12AM”
• Prioritized queues
– Admin’s queue takes precedence
over everything else
• Lot more ..
Page 37Architecting the Future of Big Data

© Hortonworks Inc. 2015
Future: More Resource Types
• Node level Isolation and Cluster
level Scheduling
• Disks
– Space
– IOPS: Read/Write
• Network
– Incoming bandwidth
– Outgoing bandwidth
Page 38Architecting the Future of Big Data

© Hortonworks Inc. 2015
Thank you!
Page 39Architecting the Future of Big Data
Sandbox: Hadoop in a VM!
Questions Time!
Related Documents











