Oracle BI & DWH Konferenz 2013 19./20. März 2013, Kassel Carsten Herbe metafinanz Informationssysteme GmbH Hadoop & SQL

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Oracle BI & DWH Konferenz 201319./20. März 2013, Kassel
Carsten Herbemetafinanz Informationssysteme GmbH
Hadoop & SQL

©
� Mehr als 8 Jahre DWH-Erfahrung
� Architekturen, Oracle DB & OWB
� Certified Hadoop Developer
mail [email protected]
phone +49 89 360531 5039
Data Quality (Profi-
ling & Cleansing)
Projekt-
Management
Big Data (Hadoop,
NoSQL)
Schulungen
(Oracle, DWH, Hadoop, etc.)
Performance
Tuning
DWH Architekturen
& Dimensionale Modellierung
Datenbanken
(Oracle, in-memory., spaltenorientiert)
ETL Prozesse &
Tools (OWB & SAS DI)
In unserer Business Line Business Intelligence & Risk gibt es fünf Bereiche: Risk, Insurance Reporting, Insurance Analytics, Customer Intelligence und Data Warehousing.
Data Warehousing
TechnologienLeistungen
Ihr Ansprechpartner
Wir unterstützen den kompletten Lebenszyklus von DWH-Projekten: von der Anforderungsanalyse bis zum Tuning bestehender ETL-Prozesse. Unser Team besteht aus Architekten, ETL-Entwicklern und Projektmanagern mit langjährigen Erfahrungen im DWH-Bereich.
TurningData into
Information
Carsten Herbe
Hadoop & SQL 20.03.2013 Seite 2

©©
Inhalt
Motivation Hadoop & SQL11
Hive22
Tabellen und Daten33
HiveQL44
Partitionierung66
Indexes & Explain Plans77
Hadoop & RDBMS88
Fazit99
User Defined Functions55
20.03.2013Hadoop & SQL Seite 3

©
Motivation Hadoop & SQL1

©
Hadoop besteht aus einem verteiltem Filesystem (HDFS) und einem Java-Framework zur parallelen Datenverarbeitung (MapReduce). Datenverarbeitung bedeutet Programmierung.
Überblick Hadoop
20.03.2013Hadoop & SQL Seite 5

©
Mit HIVE lässt sich SQL (mit ein paar Einschränkungen) auf einem Hadoop-Cluster nutzen. Voraussetzung sind natürlich entsprechend strukturierte Daten.
Hadoop & SQL
20.03.2013Hadoop & SQL Seite 6

©
Hive2

©
Hive Hadoop
Der Driver übersetzt HiveQL in MapReduce Jobs. Als (fat) Client dient CLI oder man nutzt den Thrift Server.
Hive Architektur
HiveQL(SQL)
CLI
ThriftDriver Job Tracker
metastore
/user/hive/warehouse
/...
20.03.2013Hadoop & SQL Seite 8

©
Tabellen und Daten3

©
Neben einigen primitiven Typen unterstützt Hive auch komplexe Datentypen:
Komplexe Datentypen
20.03.2013Hadoop & SQL Seite 10
STRUCT
� Zusammengesetzter Typ � z.B. bei einer Spalte c mit dem Datentyp
STRUCT {a INT; b INT}
wird mit dem Ausdruck c.a auf den Wert a zugegriffen
MAP� Key-Value-Paare
� Zugriff erfolgt bei Spalte x per X[‚element name‘]
ARRAYS� Zugriff erfolgt per zero-based Index
� z.B. bei einer Spalte c mit den Werten [‚a‘, ‚b‘, ‚c‘] gibt c[1] den Wert ‚b‘ zurück

©
Bei Managed Tables werden Daten und Metadaten von Hive verwaltet.
Managed Tables
Hadoop & SQL Seite 11
CREATE TABLE station_data_input (
stations_id STRING,
stations_hoehe STRING,
geograph_breite FLOAT,
geograph_laenge FLOAT,
von FLOAT,
bis FLOAT,
stationsname STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\;'
STORED AS TEXTFILE;
20.03.2013

©
Daten müssen in HIVE in Tabellen geladen werden. Dies geschieht über das LOAD DATA INPATH-Statement.
Laden von Daten� Zum Laden von Daten verwendet Hive das LOAD DATA INPATH-Statement.
Hierzu müssen die Daten bereits in HDFS vorliegen. Diese werden dann
kopiert.
Hadoop & SQL Seite 12
LOAD DATA INPATH "data/SingleFile/station-data"
INTO TABLE station_data_input;
LOAD DATA LOCAL INPATH "data/SingleFile/station-data"
INTO TABLE station_data_input;
� Wenn die Daten im lokalen Filesystem vorliegen (noch nicht in HDFS), können
sie über LOAD DATA LOCAL INPATH geladen werden. Die Daten werden
dann automatisch in HDFS abgelegt.
20.03.2013

©
Bei externen Tabellen bleiben die Daten an ihrem ursprünglichen Ort in HDFS liegen. In Hive werden nur die Metadaten verwaltet.
External Tables
Hadoop & SQL Seite 13
CREATE EXTERNAL TABLE station_data_input (
stations_id STRING,
stations_hoehe STRING,
geograph_breite FLOAT,
geograph_laenge FLOAT,
von FLOAT,
bis FLOAT,
stationsname STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\;'
LOCATION '/data/my_location';
20.03.2013

©
HiveQL4

©
Hive ist keine relationale Datenbank. Es gelten die gleichen Einschränkungen wie für das direkte Arbeiten mit Hadoop und HDFS. INSERT und SELECT werden in Teilen unterstützt.
HiveQL: SQL Funktionalität
INSERT
UPDATE
DELETE
MERGE
SELECT
UPDATE
DELETE
MERGE
INSERT
SELECT
20.03.2013Hadoop & SQL Seite 15

©
Es ist nur Bulk Insert (INSERT mit SELECT) möglich. Einzelsätze können nicht hinzugefügt werden.
INSERT� Die Syntax lautet hier (im Gegensatz zu z.B. Oracle)
Hadoop & SQL Seite 16
INSERT INTO TABLE targetTable SELECT ... FROM sourceTable;
INSERT OVERWRITE INTO TABLE targetTable
SELECT ... FROM sourceTable;
� MIT INSERT OVERWRITE werden bestehende Daten in der Tabelle ersetzt
20.03.2013

©
Sämtliche Join-Arten werden von Hive voll unterstützt. Die Join-Bedingung darf aber nur „gleich“ sein!
Selects & Joins� Unterstützt wird der normale INNER JOIN, LEFT OUTER JOIN, RIGHT
OUTER JOIN und FULL OUTER JOIN
� Weitere Join-Typen und Beispiele finden sich hier:
https://cwiki.apache.org/Hive/languagemanual-joins.html
Hadoop & SQL Seite 17
SELECT
s.stations_id,
s.stationsname,
w.windgeschwindigkeit
FROM station_data s
INNER JOIN weather_data w ON s.stations_id = w.stations_id
WHERE s.stations_id = 15000
;
20.03.2013

©
Sub-Selects müssen in Hive ein Alias haben, sonst funktioniert die Abfrage nicht.
Subselects
Hadoop & SQL Seite 18
SELECT
i.s,
i.l
FROM (
SELECT
trim(stationsname) AS s,
length(trim(stationsname)) AS l
FROM station_data
) i;
20.03.2013

©
ORBER BY: Besonderheit
Spalten in ORDER BY müssen auch selektiert werden, ansonsten endet das Parsen der Abfrage mit einem Fehler.
Hadoop & SQL Seite 19
SELECT
stations_id
FROM weather_data
ORDER BY mess_datum
;
SELECT
stations_id,
mess_datum
FROM weather_data
ORDER BY mess_datum
;
20.03.2013

©
Hive unterstützt Queries mit GROUP BY und HAVING.
GROUP BY und HAVING
Hadoop & SQL Seite 20
SELECT
stations_id,
sum(sonnenscheindauer),
min(mess_datum),
max(mess_datum)
FROM weather_data
WHERE year(mess_datum) = 2007
GROUP BY stations_id
HAVING sum(sonnenscheindauer) > 100
;
20.03.2013

©
In Hive kann eine neue Tabelle mit dem Resultat einer SQL-Query erzeugt werden. Die Datentypen der Spalten werden hierbei automatisch bestimmt.
CTAS (Create Table As Select)
Hadoop & SQL Seite 21
CREATE TABLE station_data AS
SELECT
cast(trim(stations_id) as int) AS stations_id,
cast(trim(stations_hoehe) as int) AS stations_hoehe,
geograph_breite,
geograph_laenge,
von,
bis,
stationsname
FROM station_data_input;
20.03.2013

©
Correleated Subqueries werden nicht unterstütz.
Einschränkung: Correleated Subqueries
Hadoop & SQL Seite 22
SELECT * FROM station_data
WHERE stations_id IN (
SELECT stations_id FROM weather_data
WHERE stations_id = 15000
)
;
FAILED: ParseException line 3:22 cannot recognize input
near 'select' 'stations_id' 'from' in expression
specification
20.03.2013

©
User Defined Functions5

©
Mit User Defined Functions lässt sich die Funktionalität von HiveQL mittels Java erweitern.
User Defined Functions (UDF)
20.03.2013Hadoop & SQL Seite 24
User Defined Functions
� Argument: eine Zeile (d.h. ein oder mehrere Werte)� Rückgabe: ein einziger Wert� Bsp: round(), floor(), …
User Defined Aggregate Functions
� Argument: eine oder mehrere Zeilen (mit je einem oder mehreren Werten)
� Rückgabe: ein einziger Wert� Bsp: sum(), min(), …
User Defined Table Generating
Functions
� Argument: eine Liste von Werten� Rückgabe: eine oder mehrere Zeilen� Bsp:
SELECT explode(array(1,2,3)) FROM dual;
1
2
3
� Was nicht geht: SELECT stadt, explode(array(1,2,3)) FROM demo_tab;

©
Partitionierung6

©
Bei partitionierten Tabellen ist der Partition Key nicht explizit als Spalte zu definieren. Die Daten müssen manuell in die „richtige“ Partition geschrieben werden.
Partitionierte Tabellen: DDL
Hadoop & SQL Seite 26
CREATE TABLE demo_tab (
stadt STRING,
geograph_breite FLOAT,
...
)
PARITIONED BY (land);
20.03.2013

©
Die Daten müssen manuell in die „richtige“ Partition geschrieben werden. Für jede Partition wird ein eigenes Verzeichnis angelegt. Subpartitioning funktioniert analog.
Partitionierte Tabellen: Laden von Daten
Hadoop & SQL Seite 27
INSERT TABLE demo_tab PARTITION (land='DE')
SELECT ...
.../demo_tab/country=DE/...
.../demo_tab/country=US/...
20.03.2013

©
Abfragen auf partitionierte Tabellen funktionieren analog zu Oracle. Zusätzlich lässt sich Hive so konfigurieren, dass auf Partitionen eingeschränkt werden muss.
Partitionierte Tabellen: Abfragen
20.03.2013Hadoop & SQL Seite 28
SELECT * WHERE land='DE';
hive> set hive.mapred.mode=strict;
Strict Mode aktivieren:
SELECT t.city FROM demo_tab t;
FAILED: Error in semanctic analysis:
No partition predicate found for Alias "t" Table "demo_tab"
Abfragen ohne Einschränkung auf eine Partition führen im Strict Mode zu einem Fehler:
Abfragen von Daten einer Partition:

©
Bei dynamischer Partitionierung wird die letzte Spalte als Partition Key verwendet. Die Anzahl der Partitionen ist abhängig von der Anzahl der unterschiedlichen Werte!
Dynamische Partitionierung
20.03.2013Hadoop & SQL Seite 29
INSERT OVERWRITE TABLE demo_tab PARTITION (land)
SELECT ..., t.country
FROM demo_stg t;
hive> set hive.exec.dynamic.partition=true;
Dynamische Partitionierung muss explizit eingeschaltet werden:
hive> set hive.exec.dynamic.mode=nonstrict;
Per Default wird der Mode auf strict (Partitionen müssen eingeschränkt werden) gesetzt, um das Erzeugen von unnötig vielen Partitionen zu vermeiden. Dieser kann aber manuell ausgeschaltet werden:

©
Indexes & Explain Plans7

©
Neben den Compact und Bitmap Indextypen kann man eigene Custom Indexes durch Implementierung des entsprechenden Interfaces erstellen.
Index Typen
20.03.2013Hadoop & SQL Seite 31
Compact
Speichert für jede Ausprägung der indizierten Spalte(n) den Bucket und eine Liste von Block-Offsets der entsprechenden Zeilen:102 hdfs://…/000000_0 [1324,1140] 164 hdfs://…/000000_0 [2658,1508,3422,3615,1886,3036,2465,1693] 183 hdfs://…/000000_0 [3808,4572,4950,4757,4379,4186,3993,5143]
Bitmap• Speichert zu jeder Zeile für jede mögliche Ausprägung der indizierten
Spalte(n), ob die Spalte der Ausprägung entspricht (1) oder nicht (0)• Besonders effizient bei geringer Kardinalität (wenige mögliche
Ausprägungen)
Custom Eigene Indexstrukturen können in Java implementiert werden, indem man das vordefinierte Interface HiveIndexHandler implementiert

©
Aufbau und Verwendung von Indexes funktioniert (noch) nicht zuverlässig (Hadoop 2.0, Cloudera CDH4) .
Indexes
20.03.2013Hadoop & SQL Seite 32
CREATE TABLE demo_tab (
land STRING,
stadt STRING,
geograph_breite FLOAT,
...
);
CREATE INDEX demo_idx ON TABLE demo_tab (land)
AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
WITH DEFERRED REBUILD
IN TABLE demo_tab_idx;
ALTER INDEX demo_idx ON demo_tab REBUILD;

©
Mit EXPLAIN [EXTENDED] SELECT lässt sich der Ausführungsplan anzeigen, d.h. die verschiedenen MapReduce Jobs.
Explain Plan (1/2)
20.03.2013Hadoop & SQL Seite 33
EXPLAIN SELECT stations_id, COUNT(1) FROM station_data
WHERE stations_id BETWEEN 1000 AND 2000 GROUP BY stations_id;
[...]
Stage: Stage-1
Map Reduce
Alias -> Map Operator Tree:
[...]
predicate:
expr: stations_id BETWEEN 1000 AND 2000
type: boolean
Select Operator
expressions:
expr: stations_id
type: int
outputColumnNames: stations_id
Group By Operator aggregations:
expr: count(1)

©
Man erkennt die einzelnen Map- und Reduce-Phasen.
Explain Plan (2/2)
20.03.2013Hadoop & SQL Seite 34
Reduce Operator Tree:
Group By Operator
aggregations:
expr: count(VALUE._col0)
keys:
expr: KEY._col0
type: int
mode: mergepartial
outputColumnNames: _col0, _col1
Select Operator
expressions:
expr: _col0
type: int
expr: _col1
type: bigint
outputColumnNames: _col0, _col1
[...]

©
Hadoop & RDBMS8
©
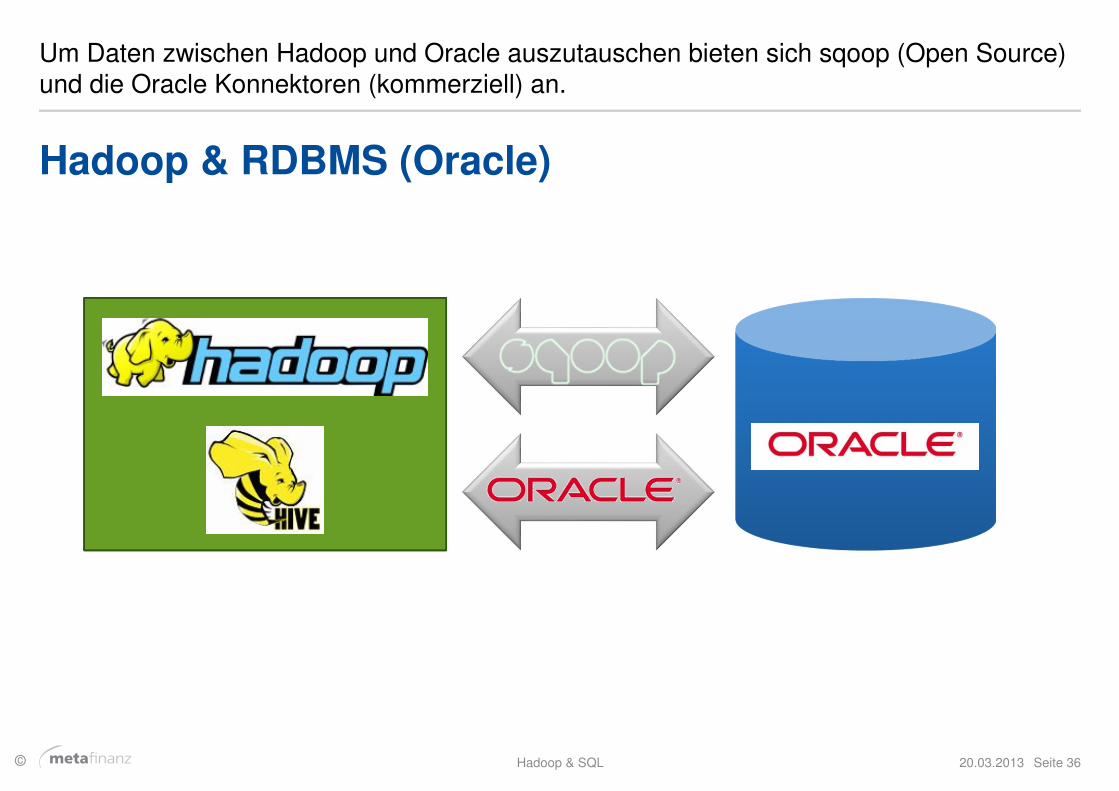
Um Daten zwischen Hadoop und Oracle auszutauschen bieten sich sqoop (Open Source) und die Oracle Konnektoren (kommerziell) an.
Hadoop & RDBMS (Oracle)
20.03.2013Hadoop & SQL Seite 36

©
CLI
browser
SqoopClient
Sqoop ist ein Tool zum Austauch von Daten zwischen Datenbanken und Hadoop. Es gibtJDBC-basierte Treiber für die gängigen Datenbanksysteme.
Sqoop Architektur
Hadoop & SQL Seite 37
Hadoop
SqoopServer
REST
UI
Connectors
Metadata
MetadataRepository
Map Task
ReduceTask
HDFS/HBase/Hive
EnterpriseData
Warehouse
Relational Database
DocumentBased
Systems
20.03.2013

©
Die Imports erfolgen als Map-Only Jobs.
Import nach HDFS
Hadoop & SQL Seite 38
Sqoop Job HDFS Storage
Hadoop Cluster
Map
Map
Map
Map
ORDERS
Sqoop Import
(2) Submit Map-Only Job
(1) GatherMetadata
20.03.2013

©
Export aus HDFS
Der Export aus HDFS erfolgt als Map-Only Jobs.
Hadoop & SQL Seite 39
Sqoop Job HDFS Storage
Hadoop Cluster
Map
Map
Map
Map
ORDERS
Sqoop Export
(2) Submit Map-Only Job
(1) GatherMetadata
20.03.2013

©
Oracle Hadoop
Oracle Big Data Konnektoren ermöglichen die Analyse von HDFS Daten innerhalb der Datenbank.
Oracle Big Data Konnektoren
Job Tracker
datapump
delimited_text
ExternalTable
Table Loader forHadoop
SQL
DirectConnector for HDFS
20.03.2013Hadoop & SQL Seite 40

©
Oracle bietet eine Reihe von Konnektoren zur Integration der Oracle Datenbank mit Apache Hadoop.
Oracle Konnektoren
20.03.2013Hadoop & SQL Seite 41
Oracle Loader forHadoop
� Tool zum Laden von Daten aus dem HDFS in eine Oracle
Datenbank.
� Unterstützt Datapump Format => Performantes Laden
Oracle DirectConnector for HDFS
� Abfrage von Daten aus dem HDFS erfolgt mit Hilfe einer
Externen Tabelle direkt in der Oracle Datenbank.
� Join mit Oracle Tabellen möglich.
Oracle R Connector for Hadoop
� Package im statistischen Open-Source R Framework.
� Mapper und Reducer Funktionen können in R erstellt und
ausgeführt werden.
Oracle Data Integrator
Application Adapter for Hadoop
� Hadoop Integration in dem ODI
� Generiert optimierten HiveQL Code, der dann als
MapReduce Job umgesetzt wird� Erfordert ODI Lizenz

©
Fazit9

©
Hive ist kein Ersatz für eine relationale Datenbank, erleichtert aber die Arbeit mit (eher) strukturierten Daten in HDFS im Vergleich zu MapReduce.
Fazit HIVE
SQL(-like)� Leichter Einstieg in Hadoop für DB’ler� In vielen Fällen einfacher als MapReduce (Joins!)� SELECTs bis auf wenige Einschränkungen möglich� Aber nur (eher) strukturierte Daten
Nur BULK � Keine Einzelsätze� Kein UPDATE, MERGE, DELETE
Kein Realtime
� MapReduce hat Initialisierungsaufwand� Batch-orientierte Datenverarbeitung
20.03.2013Hadoop & SQL Seite 43

©
Hive arbeitet batch-orientiert. Für real-time Analysen bieten sich eher Tools wie Impala, Drill oder Hadapt an. Eine Alternative für batch-ETL wäre noch PIG.
Was es sonst noch so gibt …
SQLreal-timeAnalysen
� Cloudera Impala� Apache Drill� Hadapt� …
20.03.2013Hadoop & SQL Seite 44
PIG� Kein SQL!� Skriptbasiertes ETL in Hadoop� Alternative zu Hive
MapReduce� Mehr Freiheiten und Möglichkeiten …� … mehr Programmieraufwand und
Komplexität� Auch für unstrukturierte Daten

©
Wir bieten offene Kurse sowie maßgeschneiderte Schulung, welche speziell auf die Bedürfnisse unserer Kunden abgestimmt sind.
Schulungsangebot metafinanz
20.03.2013Hadoop & SQL Seite 45
Big Data mit Hadoop
Einführung Oracle in-memory Datenbank TimesTen
Data Warehousing & Dimensionale Modellierung
Oracle SQL Tuning
OWB Skripting mit OMB*Plus
Oracle Warehouse Builder 11.2 New Features
Einführung in Oracle: Architektur, SQL und PL/SQL
Mehr Information unter http://www.metafinanz.de/news/schulungen
All trainings are also available in English on request.
NEW 2013/Q2
Klassiker

©
Besuchen Sie auch unseren Info-Stand im Foyer!
Fragen? Jetzt …
Carsten HerbeHead of Data Warehousing
mail [email protected]
phone +49 89 360531 5039
… oder später?
20.03.2013Hadoop & SQL Seite 46

Data Warehousing & Big Data!
http://dwh.metafinanz.de
Besuchen Sie uns auch auf:
metafinanz Informationssysteme GmbH
Leopoldstraße 146D-80804 München
Phone: +49 89 360531 - 0Fax: +49 89 350531 - 5015
Email: [email protected]
www.metafinanz.de
Vielen Dank!
Related Documents











