GreaseVision: Rewriting the Rules of the Interface Siddhartha Datta [email protected] University of Oxford Konrad Kollnig [email protected] University of Oxford Nigel Shadbolt [email protected] University of Oxford ABSTRACT Digital harms can manifest across any interface. Key problems in addressing these harms include the high individuality of harms and the fast-changing nature of digital systems. As a result, we still lack a systematic approach to study harms and produce interventions for end-users. We put forward GreaseVision, a new framework that enables end-users to collaboratively develop interventions against harms in software using a no-code approach and recent advances in few-shot machine learning. The contribution of the framework and tool allow individual end-users to study their usage history and create personalized interventions. Our contribution also enables researchers to study the distribution of harms and interventions at scale. 1 INTRODUCTION The design of good user interfaces can be challenging. One usu- ally employs a range of qualitative methods, including interviews, surveys and user stories, paired with quantitative insights from analytics tools to understand user needs. In a fast changing world, however, with sometimes highly individual needs, traditional one- fits-all software development faces difficulty in keeping up with the pace of change and the breadth of user requirements. At the same time, the digital world is rife with a range of harms, ranging from dark patterns to hate speech and violence. Current mitigation strategies predominantly use legal tools to target the providers of social media platforms and other websites to combat these threats. While potentially potent, the use of legal remedies often struggles to capture the language of computer programs, which are written in code, and not in law. This paper is taking a step back to improve the user experience in the digital world. To achieve this, we put forward a new design philosophy for the development of software interfaces that serves its users. We call our technical prototype GreaseVision. Specifically, with our approach, we allow users to change problems about the software that they use by themselves. No prior programming knowl- edge is required; instead, we leverage recent advances in low-code programming to allow individuals avoid harmful UI aspects. As such, our work introduces a new way to fix flaws in code that does not rely on legal mechanisms, can be applied quickly, and can keep up with the fast-changing development cycle in the digital world. For the research community in human-computer interaction, our approach presents a new valuable resource for studying and improving interface design. Users can develop by themselves, but not necessarily just for themselves. Instead, users are able to share their interventions easily with others, thereby creating an online repository of widespread harms in apps and effective interventions against them. If one gathers all the different interventions that users develop for popular websites such as Facebook or Twitter, this would yield novel insights into the problems with current interface design. Contributions: Our work aims to contribute a novel interface modification framework, which we call GreaseVision. At a structural- level, our framework enables end-users to develop personalized interface modifications, either individually or collaboratively. This is supported by the use of screenome visualization, human-in-the- loop learning, and an overlay/hooks-enabled low-code development platform. Within the defined scopes, we enable the aggregation of distributionally-wide end-user digital harms (self-reflection for end-users, or analyzing the harms repository for researchers), to further enable the modification of user interfaces across a wide range of software systems, supported by the usage of visual over- lays, autonomously developed by users, and enhanced by scalable machine learning techniques. We publicly provide complete and re- producible implementation details to enable researchers to not only study harms and interventions, but other interface modification use cases as well. Structure: Having introduced the challenge of end-user inter- face modification in Section 1, we detail the landscape of problems and opportunities manifesting in digital harms and their interface modification methods in Section 2. We set the scope for the paper in Section 3, and share our proposed method – GreaseVision – in Section 4. We evaluate and discuss our method and findings in Sec- tion 5 and 6 respectively, and share final thoughts and conclusions in Section 7. 2 BACKGROUND 2.1 Motivation: Pervasiveness and Individuality of Digital Harms It is well-known that digital harms are widespread in our day-to- day technologies. Despite this, the academic literature around these harms is still developing, and it remains difficult to state exactly what the harms are that need to be addressed. Famously, Gray et al. [30] put forward a 5-class taxonomy to classify dark patterns within apps: interface interference (elements that manipulate the user interface to induce certain actions over other actions), nagging (elements that interrupt the user’s current task with out-of-focus tasks) forced action (elements that introduce sub-tasks forcefully before permitting a user to complete their desired task), obstruction (elements that introduce subtasks with the intention of dissuading a user from performing an operation in the desired mode), and sneaking (elements that conceal or delay information relevant to the user in performing a task). A challenge with such framework and taxonomies is to cap- ture and understand the material impacts of harms on individuals. Harms tend to be highly individual and vary in terms of how they manifest within users of digital systems. The harms landscape is also quickly changing with ever-changing digital systems. Defining the spectrum of harms is still an open problem, the range varying arXiv:2204.03731v1 [cs.HC] 7 Apr 2022

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

GreaseVision: Rewriting the Rules of the InterfaceSiddhartha Datta
[email protected] of Oxford
Konrad [email protected]
University of Oxford
Nigel [email protected]
University of Oxford
ABSTRACTDigital harms can manifest across any interface. Key problems inaddressing these harms include the high individuality of harms andthe fast-changing nature of digital systems. As a result, we still lacka systematic approach to study harms and produce interventionsfor end-users. We put forward GreaseVision, a new framework thatenables end-users to collaboratively develop interventions againstharms in software using a no-code approach and recent advancesin few-shot machine learning. The contribution of the frameworkand tool allow individual end-users to study their usage history andcreate personalized interventions. Our contribution also enablesresearchers to study the distribution of harms and interventions atscale.
1 INTRODUCTIONThe design of good user interfaces can be challenging. One usu-ally employs a range of qualitative methods, including interviews,surveys and user stories, paired with quantitative insights fromanalytics tools to understand user needs. In a fast changing world,however, with sometimes highly individual needs, traditional one-fits-all software development faces difficulty in keeping up withthe pace of change and the breadth of user requirements. At thesame time, the digital world is rife with a range of harms, rangingfrom dark patterns to hate speech and violence. Current mitigationstrategies predominantly use legal tools to target the providers ofsocial media platforms and other websites to combat these threats.While potentially potent, the use of legal remedies often strugglesto capture the language of computer programs, which are writtenin code, and not in law.
This paper is taking a step back to improve the user experiencein the digital world. To achieve this, we put forward a new designphilosophy for the development of software interfaces that servesits users. We call our technical prototype GreaseVision. Specifically,with our approach, we allow users to change problems about thesoftware that they use by themselves. No prior programming knowl-edge is required; instead, we leverage recent advances in low-codeprogramming to allow individuals avoid harmful UI aspects. Assuch, our work introduces a new way to fix flaws in code that doesnot rely on legal mechanisms, can be applied quickly, and can keepup with the fast-changing development cycle in the digital world.
For the research community in human-computer interaction,our approach presents a new valuable resource for studying andimproving interface design. Users can develop by themselves, butnot necessarily just for themselves. Instead, users are able to sharetheir interventions easily with others, thereby creating an onlinerepository of widespread harms in apps and effective interventionsagainst them. If one gathers all the different interventions thatusers develop for popular websites such as Facebook or Twitter,this would yield novel insights into the problems with currentinterface design.
Contributions: Our work aims to contribute a novel interfacemodification framework, whichwe callGreaseVision. At a structural-level, our framework enables end-users to develop personalizedinterface modifications, either individually or collaboratively. Thisis supported by the use of screenome visualization, human-in-the-loop learning, and an overlay/hooks-enabled low-code developmentplatform. Within the defined scopes, we enable the aggregationof distributionally-wide end-user digital harms (self-reflection forend-users, or analyzing the harms repository for researchers), tofurther enable the modification of user interfaces across a widerange of software systems, supported by the usage of visual over-lays, autonomously developed by users, and enhanced by scalablemachine learning techniques. We publicly provide complete and re-producible implementation details to enable researchers to not onlystudy harms and interventions, but other interface modificationuse cases as well.Structure: Having introduced the challenge of end-user inter-face modification in Section 1, we detail the landscape of problemsand opportunities manifesting in digital harms and their interfacemodification methods in Section 2. We set the scope for the paperin Section 3, and share our proposed method – GreaseVision – inSection 4. We evaluate and discuss our method and findings in Sec-tion 5 and 6 respectively, and share final thoughts and conclusionsin Section 7.
2 BACKGROUND2.1 Motivation: Pervasiveness and
Individuality of Digital HarmsIt is well-known that digital harms are widespread in our day-to-day technologies. Despite this, the academic literature around theseharms is still developing, and it remains difficult to state exactlywhat the harms are that need to be addressed. Famously, Gray etal. [30] put forward a 5-class taxonomy to classify dark patternswithin apps: interface interference (elements that manipulate theuser interface to induce certain actions over other actions), nagging(elements that interrupt the user’s current task with out-of-focustasks) forced action (elements that introduce sub-tasks forcefullybefore permitting a user to complete their desired task), obstruction(elements that introduce subtasks with the intention of dissuadinga user from performing an operation in the desired mode), andsneaking (elements that conceal or delay information relevant tothe user in performing a task).
A challenge with such framework and taxonomies is to cap-ture and understand the material impacts of harms on individuals.Harms tend to be highly individual and vary in terms of how theymanifest within users of digital systems. The harms landscape isalso quickly changing with ever-changing digital systems. Definingthe spectrum of harms is still an open problem, the range varying
arX
iv:2
204.
0373
1v1
[cs
.HC
] 7
Apr
202
2

Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt
Figure 1: Architecture of GreaseTerminator (left) and GreaseVision (right).
Interface Rendering InterventionsDevelopment
Server
Client
User Device & Screen
ScreenUnderlay
ScreenOverlay
inputframes
+ Selected Visual Interventions
outputframes
TextHook
MaskHook
ModelHook
(a) The high-level architecture of GreaseTerminator. Details are explained inSection 2.3 and 4.2.
Interface Rendering Interventions Development
Server
ClientWeb Application
User Database
User Virtual Machines & Containers
Fram
e tFram
e t+1
Fram
e t+2
…
Fram
e tFram
e t+1
Fram
e t+2
…
Raw Screen ImagesUpdated Screen Imagesaccess
render
inputcommands
overlay
generateaccess
Screenome Visualization
populatescreenome
annotate Masks, Modelsà (Personal) Interventions
activate interventions
Network Interventions
(b) The high-level architecture of GreaseVision, both as a summary of our technical infrastructure aswell as one of the collaborative HITL interventions development approach.
from heavily-biased content (e.g. disinformation, hate speech), self-harm (e.g. eating disorders, self-cutting, suicide), cyber crime (e.g.cyber-bullying, harassment, promotion of and recruitment for ex-treme causes (e.g. terrorist organizations), to demographic-specificexploitation (e.g. child-inappropriate content, social engineeringattacks) [39, 40, 67, 68, 89], for which we recommend the afore-mentioned cited literature. The last line of defense against manydigital harms is the user interface. This is why we are interested ininterface-emergent harms in this paper, and how to support individ-uals in developing their own strategies to cope with and overcomesuch harms.
2.2 Developments in Interface Modification &Re-rendering
Digital harms have long been acknowledged as a general prob-lem, and a range of technical interventions against digital harmsare developed. Interventions, also similarly called modificationsor patches, are changes to the software, which result in a changein (perceived) functionality and end-user usage. We review andcategorize key technical intervention methods for interface modi-fication by end-users, with cited examples specifically for digitalharms mitigation. While there also exist non-technical interven-tions, in particular legal remedies, it is beyond this work to givea full account of these different interventions against harms; auseful framework for such an analysis is provided by LawrenceLessig [53] who characterised the different regulatory forces in thedigital ecosystem.
Interface-code modifications [2, 5, 14, 15, 18, 22, 37, 43, 48,57, 59, 61, 70, 75, 87, 95] make changes to source code, either instal-lation code (to modify software before installation), or run-timecode (to modify software during usage). On desktop, this is donethrough browser extensions and has given rise to a large ecosystemof such extensions. Some of the most well-known interventionsare ad blockers, and tools that improve productivity online (e.g. byremoving the Facebook newsfeed [59]). On mobile, a prominentexample is AppGuard [5], a research project by Backes et al. thatallowed users to improve the privacy properties of apps on theirphone by making small, targeted modification to apps’ source code.Another popular mobile solution in the community is the app Lucky
Patcher [57] that allows to get paid apps for free, by removing thecode relating to payment functionality directly from the app code.
Some of these methods may require the highest level of privi-lege escalation to make modifications to the operating system andother programs/apps as a root user. On iOS, Cydia Substrate [22] isthe foundation for jailbreaking and further device modification. Asimilar system, called Xposed Framework [75], exists for Android.To alleviate the risks and challenges afflicted with privilege es-calation, VirtualXposed [87] create a virtual environment on theuser’s Android device with simulated privilege escalation. Userscan install apps into this virtual environment and apply tools ofother modification approaches that may require root access. Pro-tectMyPrivacy [2] for iOS and TaintDroid [18] for Android bothextend the functionality of the smartphone operating system withnew functionality for the analysis of apps’ privacy features. Ondesktops, code modifications tend not to be centred around a com-mon framework, but are more commonplace in general due to thetraditionally more permissive security model compared to mobile.Antivirus tools, copyright protections of games and the modding ofUI components are all often implemented through interface-codemodifications.
Interface-external modifications [4, 8, 24, 38, 46, 50, 52, 56,65] are the arguably most common way to change default inter-face behaviour. An end-user would install a program so as to affectother programs/apps. No change to the operating system or thetargeted programs/apps is made, so an uninstall of the programproviding the modification would revert the device to the originalstate. This approach is widely used to track duration of device usage,send notifications to the user during usage (e.g. timers, warnings),block certain actions on the user device, and other aspects. TheHabitLab [24] is a prominent example developed by Kovacs et al.at Stanford. This modification framework is open-source and main-tained by a community of developers, and provides interventionsfor both desktop and mobile devices.
Visual overlay modifications render graphics on an over-lay layer over any active interface instance, including browsers,apps/programs, videos, or any other interface in the operatingsystem. The modifications are visual, and do not change the func-tionality of the target interface. It may render sub-interfaces, labels,

GreaseVision
or other graphics on top of the foreground app. Prominent ex-amples are DetoxDroid [20], Gray-Switch [25], Google AccessibilitySuite [29], and GreaseTerminator [12].
We would like to establish early on that we pursue a visual over-lay modifications approach. Interventions should be rendered in theform of overlay graphics based on detected elements, rather thanimplementing program code changes natively, hence focused onchanging the interface rather than the functionality of the software.Interventions should be generalizable; they are not solely website-or app-oriented, but interface-oriented. Interventions do not tar-get specific apps, but general interface elements and patterns thatcould appear across different interface environments. To supportthe systemic requirements in Section 2.4, we require an interfacemodification approach that is (i) interface-agnostic and (ii) easy-to-use. To this extent, we build upon the work of GreaseTerminator[12], a framework optimized for these two requirements.
In response to the continued widespread presence of interface-based harms in digital systems, Datta et al. [12] developedGreaseTer-minator, a visual overlay modification method. This approach en-ables researchers to develop, deploy and study interventions againstinterface-based harms in apps. This is based on the observationthat it used to be difficult in the past for researchers to study theefficacy of different intervention designs against harms within mo-bile apps (most previous approaches focused on desktop browsers).GreaseTerminator provides a set of ‘hooks’ that serve as templatesfor researchers to develop interventions, which are then deployedand tested with study participants. GreaseTerminator interventionsusually come in the form of machine learning models that build onthe provided hooks, automatically detect harms within the smart-phone user interface at run-time, and choose appropriate inter-ventions (e.g. a visual overlay to hide harmful content, or contentwarnings). A visualisation of the GreaseTerminator approach isshown in Figure 1(a).
In addition to the contributions stated in Section 1, GreaseVisionis an improved visual overlay modification approach with respectto interface-agnosticity and ease of use. We discuss the technicalimprovements upon GreaseTerminator in Section 4.1, specificallylatency, device support, and interface-agnosticity. We discuss thespecific aspects of GreaseTerminator we adopt in GreaseVision inSection 4.2, specifically inter-operable hooks/overlay mechanisms.
2.3 Opportunities for Low-code Developmentin Interface Modification
Low-code development platforms have been defined, accordingto practitioners, to be (i) low-code (negligible programming skillrequired to reach endgoal, potentially drag-and-drop), (ii) visualprogramming (a visual approach to development, mostly reliant ona GUI, and "what-you-see-is-what-you-get"), and (iii) automated(unattended operations exist to minimize human involvement) [58].Low-code development platforms exist for varying stages of soft-ware creation, from frontend (e.g. App maker, Bubble.io, Webflow),to workflow (Airtable, Amazon Honeycode, Google Tables, UiPath,Zapier), to backend (e.g. Firevase, WordPress, flutterflow); noneexist for software modification of existing applications across in-terfaces. According to a review of StackOverflow and Reddit postsanalysed by Luo et al. [58], low-code development platforms are
cited by practitioners to be tools that enable faster development,lower the barrier to usage by non-technical people, improves ITgovernance compared to traditional programming, and even suitsteam development; one of the main limitations cited is that thecomplexity of the software created is constrained by the optionsoffered by the platform.
User studies have shown that users can self-identify malevolentharms and habits upon self-reflection and develop desires to in-tervene against them [9, 60]. Not only do end-users have a desireor interest in self-reflection, but there is indication that end-usershave a willingness to act. Statistics for content violation reportingfrom Meta show that in the Jan-Jun 2021 period, ∼ 42,200 and ∼5,300 in-app content violations were reported on Facebook andInstagram respectively [63] (in this report, the numbers are specificto violations in local law, so the actual number with respect tocommunity standard violatons would be much higher; the numbersalso include reporting by governments/courts and non-governmententities in addition to members of the public). Despite a willingnessto act, there are limited digital visualization or reflection tools thatenable flexible intervention development by end-users. There arevisualization or reflection tools on browser and mobile that allowfor reflection (e.g. device use time [4]), and there are separate anddisconnected tools for intervention (Section 2.2), but there are lim-ited offerings of flexible intervention development by end-users,where end-users can observe and analyze their problems whilegenerating corresponding fixes, which thus prematurely ends theloop for action upon regret/reflection. There is a disconnect be-tween the harms analysis ecosystem and interventions ecosystem.A barrier to binding these two ecosystems is the existence of low-code development platforms for end-users. While such tooling mayexist for specific use cases on specific interfaces (e.g. web/app/gamedevelopment) for mostly creationary purposes, there are limitedoptions available for modification purposes of existing software, theclosest alternative being extension ecosystems [27, 48]. Low-codedevelopment platforms are in essence "developer-less", removingdevelopers out of the software development/modification pipelineby reducing the barrier to development/modification through theuse of GUI-based features and negligible coding, to the extent thatan end-user can self-develop without expert knowledge.
Human-in-the-Loop (HITL) learning is the procedure of in-tegrating human knowledge and experience in the augmentationof machine learning models. It is commonly used to generate newdata from humans or annotate existing data by humans. Wallace etal. [88] constructed a HITL system of an interactive interface wherea human talks with a machine to generate more Q&A language andtrain/fine-tune Q&A models. Zhang et al. [98] proposed a HITLsystem for humans to provide data for entity extraction, includingrequiring humans to formulate regular expressions and highlighttext documents, and annotate and label data. For an extended lit-erature review, we refer the reader to Wu et al. [93]. Beyond labsettings, HITL has proven itself in wide deployment, where a widedistribution of users have indicated a willingness and ability to per-form tasks on a HITL annotation tool, reCAPTCHA, to access utilityand services. In 2010, Google reported over 100million reCAPTCHAinstances are displayed every day [28] to annotate different typesof data, such as deciphering text for OCR of books or street signs,or labelling objects in images such as traffic lights or vehicles.

Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt
Figure 2: Demonstration of hooks adapted in GreaseVision, based on the GreaseTerminator implementation.
(a) Occlusion of recommended items on Twitter(before left, after right)
(b) Occlusion of recommended items on Insta-gram (before left, after right)
(c) Text censoring (YouTube left, Reddit right) (d) Content moderation(Google Images, TikTok,YouTube, YouKu)
While HITL formulates the structure for human-AI collaborativemodel development,model fine-tuning and few-shot learningformulate the algorithmic methods of adapting models to changinginputs, environments, and contexts. Both adaptation approachesrequire the model to update its parameters with respect to the newinput distribution. For model fine-tuning, the developer re-trains apre-trained model on a new dataset. This is in contrast to training amodel from a random initialization. Model fine-tuning techniquesfor pre-trained foundation models, that already contain many ofthe pre-requisite subnetworks required for feature reuse and warm-started training on a smaller target dataset, have indicated robust-ness on downstream tasks [1, 23, 64]. If there is an extremely largenumber of input distributions and few samples per distribution(small datasets), few-shot learning is an approach where the devel-oper has separately trained a meta-model that learns how to changemodel parameters with respect to only a few samples. Few-shotlearning has demonstrated successful test-time adaptation in updat-ing model parameters with respect to limited test-time samples inboth image and text domains [11, 19, 47, 69]. Some overlapping tech-niques even exist between few-shot learning and fine-tuning, suchas constructing subspaces and optimizing with respect to intrinsicdimensions [3, 13, 78].
The raw data for harms and required interface changes reside inthe history of interactions between the user and the interface. In theScreenome project [71, 72], the investigators proposed the studyand analysis of the moment-by-moment changes on a person’sscreen, by capturing screenshots automatically and unobtrusivelyevery 𝑡 = 5 seconds while a device is on. This record of a user’sdigital experiences represented as a sequence of screens that theyview and interact with over time is denoted as a user’s screenome.Though not mobilized widely amongst users for their self-reflectionor personalized analysis, integrating screenomes into an interfacemodification framework can play the dual roles of visualizing raw(harms) data to users while manifesting as parseable input for visualoverlay modification frameworks.
3 SCOPEWe state early on the scope of our problem, solution, and evalua-tion. While further extension is possible, these scopes present therequired constraints needed to evaluate our contributions, and arenot intended as limitations. As the field of interface modificationis broad, we narrow our scope onto digital harms, and specify thelimits of its evaluation in Section 3.1. With respect to the challengesand opportunities shared in Section 2, and the bounds set in Sec-tion 3.1, we define in Section 3.2 the system requirements whichwe wish to instill into GreaseVision. With respect to the systemrequirements in Section 3.2, we discuss under this same context themethods that would optimally evaluate these system requirementsin Section 5.
3.1 Problem ScopeWhile the proposal for a collaborative low-code development sys-tem for end-users can have many use cases, such as customizingthemes or UI/UX modernization of legacy interfaces, we extend onthe developing literature on digital harms mitigation, in-line withprior work on interface re-rendering [12, 48]. Further on digitalharms, we propose a methodology for end-users to construct theirown interventions. We reference existing intervention designs thathave been previously-evaluated (e.g. user studies), hence we donot replicate these studies to evaluate our reproduced designs. Themethodology for constructing a wide range of existing interventiondesigns with overlay graphics rendering has been validated in theGreaseTerminator work [12]. The scope of types of interventiondevelopment is not under consideration when evaluating this HITLapproach. We focus on interface occlusion, as it has been indicatedin literature to be a sufficiently-strong source of interventions. Ithas been shown in the GreaseTerminator work that other inter-ventions can be crafted (e.g. screen-locking based on app usage),thus other output modalities such as interface augmentation (e.g.interpolating text or content from email or message apps over in-painted content rather than just inpainting with single colour, orinteraction flow detection with RICO dataset [16]) is feasible, butnot the focus of this work. Though we retain mask removal from

GreaseVision
GreaseTerminator and extend model hooks with fine-tuning andfew-shot learning, we provide evaluation results specifically on ele-ment removal and text censoring. Existing literature already reviewthat few-shot learning is feasible and scalable for multiple modali-ties, including text and images. Masks and text models are also theoptimal candidates of demonstrable few-shot learning and modelfine-tuning for this HITL setting. We do not evaluate the models ortraining regimes themselves; pre-trained and open-sourced mod-els are available online, and text classification (and hate speechdetection), out-of-distribution detection, model fine-tuning, andfew-shot learning are active research areas. As we do not deploythe tool widely amongst end-users, we do not provide analysis onthe distribution of harms and interventions from constructing aharms database/repository. We do not evaluate the user interfaceof the HITL annotation tool as the layout has been user-evaluatedand is considered a standard baseline interface in HITL [76].
3.2 System RequirementsThe goal of this paper shall be to construct a system/architecturethat is developer-less and solely user-driven in interface modifica-tions. In this system, users shall individually or collaboratively insmall networks develop changes to their target user interface. Thegoal is evaluated, with constraint to the scope of our study.
We derive the technical requirement (Requirement 1) and sys-temic requirement (Requirement 2) from our background in Section2. Section 2.1 shows that there is a wide harms landscape anddistribution afflicting users, but a disconnected interventions devel-opment process by developers. Section 2.2 and 2.3 shows that wecan potentially scale intervention development by making interven-tion development interface-agnostic and developer-less. We identifythat an individual end-user should be permitted to autonomouslypersonalize their digital interfaces against the wide distribution ofharms that can occur, despite the technical challenges an interven-tion developer and end-user faces regarding interface modification(e.g. changing code, escalating privilege, non-generalizable acrossversion and/or app changes). In parallel to these challenges, wefind opportunities for both the individual user and a network ofusers to benefit from HITL and model adaptation. Requirement 1is focused on the usability and feasibility of GreaseVision for anindividual user; Requirement 2 is focused of that for a network ofusers. Through Requirements 1 and 2, our work intends to bind theharms landscape to the intervention development process throughGreaseVision.
(1) Requirement 1:A complete feedback loop between user input(train-time) and interface re-render (test-time).
(2) Requirement 2: Prospects for scalability across the distri-bution of interface modifications (with respect to both harmslandscape and rendering landscape).
4 GREASEVISION4.1 System Architecture: Binding the Harms
Ecosystem to the Interventions EcosystemWe define the GreaseVision architecture, with which end-users (sys-tem administrators) interact with, as follows (Figure 1(b)): (i) theuser logs into the GreaseVision system to access amongst a set ofpersonal emulators and interventions (the system admin has provi-sioned a set of emulated devices, hosted on a server through a set ofvirtual machines or docker containers for each emulator/interface,and handling streaming of the emulators, handling pre-requisitesfor the emulators, handling data migrations, etc); (ii) the user selectstheir desired interventions and continues browsing on their inter-faces; (iii) after a time period, the user accesses their screenomeand annotates interface elements, graphics, or text that they wouldlike to generate interventions off of, which then re-populate thelist of interventions available to members in a network.
In our current implementation, the user accesses a web appli-cation (compatible with both desktop and mobile browsers). Withtheir login credentials, the database loads the corresponding map-ping of the user’s virtual machines/containers that are shown inthe interface selection page. The central server carries informa-tion on accessing a set of emulated devices (devices loaded locallyon the central server in our setup). Each emulator is rendered indocker containers or virtual machines where input commands canbe redirected. The database also loads the corresponding mappingof available interventions (generated by the user, or by the networkof users) in the interventions selection page. The database also loadsthe screenomes (images of all timestamped, browsed interfaces) inthe screenome visualization page. Primary input commands for bothdesktop and mobile are encoded, including keystroke entry (hard-ware keyboard, on-screen keyboard), mouse/touch input (scrolling,swiping, pinching, etc); input is locked to the coordinates of the dis-played screen image on the web app (to avoid stray/accidental inputcommands), and the coordinates correspond to each virtual ma-chine/container’s display coordinates. Screen images are capturedat a configurable framerate (we set it to 60FPS), and the images arestored under a directory mapped to the user. Generated masks andfine-tuned models are stored under an interventions directory andtheir intervention/file access is also locked by mapped users. Inter-ventions are applied sequentially upon a screen image to return aperturbed/new image, which then updates the screen image shownon the client web app.
The improvements of GreaseVision with respect to GreaseTermi-nator are two-fold: (i) improvements to the framework enablingend-user development and harms mitigation (discussed in detail inSections 4.2, 4.3, 5 and 6), and (ii) improvements to the technicalarchitecture (which we discuss in this section). Our distinctive andnon-trivial technical improvements to the GreaseTerminator archi-tecture fall under namely latency, device support, and interface-agnosticity. GreaseTerminator requires the end-user device to bethe host device, and overlays graphics on top. A downside of this isthe non-uniformity of network latency between users (e.g. depend-ing on the internet speed in their location) resulting in a potentialmismatch in rendered overlays and underlying interface. WithGreaseVision, we send a post-processed/re-rendered image once tothe end-user device’s browser (stream buffering) and do not need

Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt
Figure 3: Walkthrough of using GreaseVision-modified interfaces.
(a) User authentication: Secure gateway to theuser’s screenomes, personal devices, and inter-vention development suite.
(b) Interface & interventions selection: Listingsof all registered devices/emulators on server, aswell as interventions contributed by the usersor community using the tool in Figure 4.
(c) Interface access: Accessing a Linux desktop from an-other (Linux) desktop browser.
(d) Interface access: Ac-cessing anAndroid em-ulator from anotherAndroid host device.
to send any screen image from the host user device to a server,thus there is no risk of overlay-underlay mismatch and we evenreduce network latency by half. Images are relayed through anHTTPS connection, with a download/upload speed ∼ 250Mbps,and each image sent by the server amounting to ∼ 1Mb). The the-oretical latency per one-way transmission should be 1×1024×8bits
250×106bits/s= 0.033ms. With each user at most requiring server usage of oneNVIDIA GeForce RTX 2080, with reference to existing online bench-marks [42] the latency for 1 image (CNN) and text (LSTM) modelwould be 5.1ms and 4.8ms respectively. While the total theoreticallatency for GreaseTerminator is (2×0.033+5), that of GreaseVision is(0.033+5) = 5.03ms. Another downside of GreaseTerminator is that itrequires client-side software for each target platform. There wouldbe pre-requisite OS requirements for the end-user device, whereonly versions of GreaseTerminator developed for each OS can beoffered support (currently only for Android). GreaseVision streamsscreen images directly to a login-verified browser, allowing users toaccess desktop/mobile on any browser-supported device. Despitevariations in the streaming architecture between GreaseVision andGreaseTerminator, the interface modification framework (hooks andoverlays) are retained, hence interventions (even those developedby end-users) from GreaseVision are compatible in GreaseTermina-tor. In addition to improvements to the streaming architecture tofulfil interface-agnosticity, adapting the visual overlay modifica-tion framework into a collaborative HITL implementation furtherimproves the ease-of-use for all stakeholders in the ecosystem. End-users do not need to root their devices, find intervention tools oreven self-develop their own customized tools. We eliminate theneed for researchers to craft interventions (as users self-developautonomously) or develop their own custom experience samplingtools (as end-users/researchers can analyze digital experiences fromstored screenomes). We also eliminate the need for interventiondevelopers to learn a new technical framework or learn how to fine-tune models. Running emulators on docker containers and virtualmachines on a (single) host server is feasible, and thus allows for thebrowser stream to be accessible cross-device without restriction, e.g.access iOS emulator on Android device, or macOS virtual machine
on Windows device. Certain limitations are imposed on the cur-rent implementation, such as a lack of access to the device camera,audio, and haptics; however, these are not permanent issues, andengineered implementations exist where a virtual/emulated devicecan route and access the host device’s input/output sources [87].
4.2 Interface Modification & Re-renderingWe make use of the three hooks from GreaseTerminator (text, mask,and model hooks), and link it with the screenome visualizationtool. While in GreaseTerminator the hooks ease the interventiondevelopment process for intervention developers with previousprogramming knowledge, we further generalize the interventiondevelopment process for intervention developers to the extent thateven an end-user can craft their own interventions without de-veloper support nor expert knowledge. GreaseTerminator enablesintervention generation (via hooks) and interface re-rendering (viaoverlays). The added GreaseVision contribution of connecting thesecomponents with HITL learning and screenome visualization toreplace developers is what exemplifies end-user autonomy andscalability in personalized interventions.
The text hook enables modifying the text that is displayed onthe user’s device. It is implemented through character-level opticalcharacter recognition (OCR) that takes the screen image as an inputand returns a set of characters and their corresponding coordinates.The EAST text detection [100] model detects text in images andreturns a set of regions with text, then uses Tesseract [26] to ex-tract characters within each region containing text. The mask hookmatches the screen image against a target template of multipleimages. It is implemented withmulti-scale multi-template matchingby resizing an image multiple times and sampling different subim-ages to compare against each instance of mask in a masks directory(where each mask is a cropped screenshot of an interface element).We retain the default majority-pixel inpainting method for maskhooks (inpainting with the most common colour value in a screenimage or target masked region). As many mobile interfaces are stan-dardized or uniform from a design perspective compared to imagesfrom the natural world, this may work in many instances. The mask

GreaseVision
Figure 4: Screenome visualization page: The page offers the end-user the ability to traverse through the sequence of times-tamped screen images which compose their screenome. They can use bounding boxes to highlight GUI elements, images ortext. They can label these elements with specific encodings, such as mask- or text-.
hook could be connected to rendering functions such as highlight-ing the interface element with warning labels, or image inpainting(fill in the removed element pixels with newly generated pixelsfrom the background), or adding content/information (from otherapps) into the inpainted region. Developers can also tweak howthe mask hook is applied, for example using the multi-scale multi-template matching algorithm with contourized images (shapes,colour-independent) or coloured images depending on whetherthe mask contains (dynamic) sub-elements, or using few-shot deeplearning models if similar interface elements are non-uniform. Amodel hook loads any machine learning model to take any inputand generate any output. This allows for model embedding (i.e.model weights and architectures) to inform further overlay render-ing. We can connect models trained on specific tasks (e.g. personpose detection, emotion/sentiment analysis) to return output giventhe screen image (e.g. bounding box coordinates to filter), and thisoutput can then be passed to a pre-defined rendering function (e.g.draw filtering box).
Recent developments in few-shot learning and model fine-tuningcould potentially enable the scalability of interventions develop-ment through hooks and a low-code development platform.GreaseTer-minator mask hooks tend to only require a single cropped imageas input, and given the limited variability (or ease of re-croppingan updated interface design) of a specific GUI element on a givenapp, 1-shot of a GUI element is sufficient to detect it. Models usedby GreaseTerminator model hooks were expected to be either easilyaccessible from model zoos or model sharing platforms (e.g. Pa-persWithCode, Github, Kaggle, ModelZoo) or fine-tuned by inter-vention developers. Incorporating model fine-tuning and few-shotlearning mechanisms into the interface modification frameworkcan propagate new and personalized models/interventions for eachuser sub-group more efficiently without the need for a dedicated
intervention developer to manually collect the required data them-selves, if an open-ended input source is provided where an end-usercan simply capture and submit new inputs over time. It reduces thefeedback loop delay in deploying improved interfaces by removingall the development middlemen (including app/platform developersand external intervention developers).
4.3 Screenome Visualization & Low-codeDevelopment
An intersecting data source that enables both end-user self-reflection[9, 60] and interface re-rendering via overlay [12] is the screen his-tory or interface interaction history (denoted as screenome). Specif-ically, we can orchestrate a loop that receives input from usersand generates outputs for users. Through GreaseVision, end-userscan browse through their own screen history, and beyond self-analysis, they can constructively build interface modifications totackle specific needs.
Extending on the interface rendering approach of overlays andhook-based intervention development, a generalizable design pat-tern for GreaseTerminator-based interventions is observed, wherecurrent few-shot/fine-tuning techniques can reasonably approachmany digital harms, given appropriate extensions to the end-userdevelopment suite. In the current development suite (Figure 4),an end-user can inspect their screenomes across all GreaseVision-enabled interfaces (ranging from iOS, Android to desktops), andmake use of image segment highlighting techniques to annotateinterface patterns to detect (typically UI elements or image/text)and subsequently intervene against these interface patterns. Specif-ically, the interface images being stored and mapped to a useris shown in time-series sequence to the user. The user can gothrough the sequence of images to reflect on their browsing be-havior. The current implementation focuses on one-shot detectionof masks and fine-tuning of image and text classification models.

Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt
Figure 5: Removal of GUI elements (YouTube sharingmetrics/buttons) acrossmultiple target interfaces and operating systems.
(a) Element removal on emulated desktop (MacOS) (b) Element removal on emulatedAndroid
(c) Element removal on emulated iOS
When the user identifies a GUI element they do not wish to seeacross interfaces and apps, they highlight the region of the image,and annotate it as mask-<name-of-intervention>, and the maskhook will store a mask of intervention <name-of-intervention>,which will then populate a list of available interventions withthis option, and the user can choose to activate it during a brows-ing session. When a user identifies text (images) that they do notwish to see of similar variations, they can highlight the text (im-age) region, and annotate it as text-<name-of-intervention>(image-<name-of-intervention>). The text hook will extract thetext via OCR, and fine-tune a pretrained text classification modelspecifically for this type of text <name-of-intervention>. For im-ages, the highlighted region will be cropped as input to fine-tunea pretrained image classification model. The corresponding text(image) occlusion intervention (or extensibly other augmentationinterventions) will censor similar text (images) during the user’sbrowsing sessions if activated.
Extending on model few-shot training and fine-tuning, we canscale the accuracy of the models, not just through improvements tothese training methods, but also by improving the data collectiondynamics. More specifically, based on the spectrum of personal-ized and overlapping intervention needs for a distribution of users,we can leverage model-human and human-human collaborationto scale the generation of mask and model interventions. In thecase of mask hooks, end-users who encounter certain harmful GUIelements (perhaps due to exposure to specific apps or features priorto other users) can tag and share the mask intervention with otherusers collaboratively.
To collaboratively fine-tune models, users tag text based on ageneral intervention/category label, that is used to group text to-gether to form a mini-dataset to fine-tune the model. An exampleof this would be a network of users highlighting racist text theycome across in their screenomes that made them uncomfortableduring their browsing sessions, and tagging them as text-racist,which aggregates more sentences to fine-tune a text classification
model responsible for detecting/classifying text as racist or not, andsubsequently occluding the text for the network of users duringtheir live browsing sessions. The current premise is that users in anetwork know a ground-truth label of the category of the specifictext they wish to detect and occlude, and the crowd-sourced text ofeach of 𝑁 categories will yield corresponding 𝑁 fine-tuned models.Collaborative labelling scales the rate in which text of a specificcategory can be acquired, reducing the burden on a single userwhile also diversifying the fine-tune training set, while also prolif-erating the fine-tuned models across a network of users and notwasting effort re-training already fine-tuned models of other users(i.e. increasing scalability of crafting and usage of interventions). Aconcern with this assumption, is that the labelling of such inputs inthe real-world may not be standardized, and similar inputs may begrouped separately or dissimilar inputs may be grouped together, ifwe purely rely on network-based tagging. To mitigate this, possiblealgorithmic approaches to ensuring similar texts are grouped to-gether for fine-tuning, which in themselves are also active researchareas and should not be used to constrain the evaluation of oursystem, would be the use of in/out-of-distribution detection (e.g.computing the interference in loss convergence with respect to 2inputs coming from different categories, or using a similarity metric,in order to regroup contributed inputs into appropriate categories),or the use of ensemble models (e.g. preparing𝑀 different batchesof training sets to train 𝑀 different ensemble models, so that thedissimilarity between certain sentences do not afflict a single modelalone, and other models can validate a prediction). Additional exten-sions to the HITL interface could be the visualization of statisticsof existing interventions or newly-crafted interventions, such astracked accuracy of the models, the aleatoric/epistemic uncertaintyof an intervention (informing whether the intervention is sufferingfrom insufficient data or intrinsic ambiguity in the data) [77], orratings from other users.

GreaseVision
5 EVALUATIONWe describe the methods to evaluate our system against Section3.2’s requirements and share findings of this evaluation in Section5, and discuss the implications of these findings in Section 6. Weevaluate the architectural design rather than our extensible techni-cal implementation. With respect to Section 3.2 requirements, weevaluate the usability of (Req 1) the HITL component (usability for asingle user with respect to inputs/outputs; or "does our system helpgenerate interventions?"), and (Req 2) the collaborative component(improvement to usability for a single user when multiple users areinvolved; or "does our system scale with user numbers?").
We evaluate (Req 1) and (Req 2) with cognitive walkthroughsand scalability tests. We explain themethodology used to evaluateeach requirement, then we provide the raw data and informationretrieved, then provide findings from the data. Evaluating withwalkthrough demonstrations ("show and tell rather than use andtest") and performance benchmarking, while considering heuristicsusing a checklist approach, are all adopted evaluation strategies in-line with suggestions made by Ledo et al. [51]. We refer the readerto Strobelt et al. [81] for an example of literature that evaluates acollaborative HITL system based on Ledo et al. [51]’s principles.
5.1 Cognitive WalkthroughTo evaluate the HITL component, rather than evaluating the output(interventions), we will evaluate the HITL process. Qualitatively,we perform a cognitive walkthrough of the user experience to simu-late the cognitive process and explicit actions taken by an end-userduring usage of GreaseVision to access interfaces and craft inter-ventions. The evaluation of the development process with respectto development cognition and development actions is based onwork in cognitive walkthroughs [44, 74] and software engineeringethnographic studies [97]. While viewing their screenome, as thetime between when a user determines a set of pixels to be harm-ful and that of crafting a bounding box is negligible, rather thandemonstrating the ease of intervention development by time spent,we can quantitatively supplement with the number of variations ofinterventions generated (specifically element removal) (Table 1).
In our walkthrough, we as the authors/researchers presumethe role of an end-user. We state the walkthrough step in bold,data pertaining to the task in italics, and descriptive evaluation innormal font. To evaluate the process of constructing an interventionusing our proposed HITL system, based on the evaluation scopediscussed, we evaluate the completion of a set of required tasks basedon criteria from Parasuraman et al.’s [66] 4 types of automationapplications, which aim to measure the role of automation in theharms self-reflection and intervention self-development process.The four required tasks to be completed are:
(1) Information Acquisition: Could a user collect new data pointsto be used in intervention crafting?
(2) Information Analysis: Could a user analyze interface data toinform them of potential harms and interventions?
(3) Decision & Action Selection: Could a user act upon the ana-lyzed information about the harms they are exposed to, anddevelop interventions?
(4) Action Implementation: Could a user deploy the interventionin future browsing sessions?
User logs in (Figure 3a): The user enters their username andpassword. These credentials are stored in a database mapped to aspecific (set of) virtual machine(s) that contain the interfaces the userregistered for access. This is a standard step for any secured orpersonalized system, where a user is informed they are accessingdata and information that is tailored for their own usage.
User selects active interface and interventions (Figure 3b):The user is shown a set of available interventions, be it contributed bythemselves or other users in a network. They select their target inter-ventions, and select an interface to access during this session. Basedon their own configurations (e.g. GreaseVision set up locally on theirown computer, or specific virtual machines set up for the requiredinterfaces), users can view the set of interfaces that they can accessand use to facilitate their digital experiences. The interface is avail-able 24/7, retains all their personal data and storage, is recordingtheir screenome data for review, and accessible via a web browserfrom any other device/platform. They are less constrained by thehardware limitations of their personal device, and just need to en-sure the server of the interfaces has sufficient compute resources tohost the interface and run the interventions. The populated inter-ventions are also important to the user, as it is a marketplace andecosystem of personalized and shareable interventions. Users canpopulate interventions that they themselves can generate throughthe screenome visualization tool, or access interventions collab-oratively trained and contributed by multiple members in theirnetwork. The interventions are also modular enough that users arenot restricted to a specific combination of interventions, and areapplied sequentially onto the interface without mismatch in latencybetween the overlay and underlying interface. As the capabilities ofgenerating interventions (e.g. more hooks) and rendering interfaces(e.g. interface augmentation) become extended, so do their ability topersonalize their digital experience, and generate a distribution ofdigital experiences to match a similarly wide distribution of users.The autonomy to deploy interventions, with enhanced optionalitythrough community-contributed interventions, before usage of aninterface satisfies Task 4.
The user accesses the interface and browses (Figure 3c):The user begins usage of the interface through the browser from theirdesired host device, be it mobile or desktop. They enter input to thesystem, which is streamed to the virtual machine(s), and interventionsrender overlay graphics to make any required interface modifications.After the user has chosen their desired interventions, the user willenjoy an improved digital experience through the lack of exposureto certain digital elements, such as undesired text or GUI elements.The altered viewing experience satisfies both Task 1 and 4; not onlyis raw screen data being collected, but the screen is being alteredby deployed interventions in the wild. The user cannot be harmedby what they previously chose not to see, and what they do see butno longer wish to see in the future, they can annotate to remove infuture viewings in the screenome visualization tool. It is a cyclicalloop where users can redesign and self-improve their browsingexperiences through the use of unilateral or user-driven tools.
The user browses their screenome to generate interven-tions (Figure 4): After a browsing period, the user may opt tobrowse and view their personal screenome. They enter the screenomevisualization page to view recorded intervals of their browsing ac-tivity across all interfaces, and they can choose to annotate certain
Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt
Mask Min. masks Android app iOS app Mobile browser Desktop browserStories bar— Twitter 1 ✓ ✓ — —— Linkedin 1 ✓ ✓ — —— Instagram 1 ✓ ✓ — —Metrics/Sharing bar- Facebook 2 ✓ ✓ ✓ ✓
- Instagram 2 ✓ ✓ ✓ ✓
- Twitter 2 ✓ ✓ ✓ ✓
- YouTube 2 ✓ ✓ ✓ ✓
- TikTok 2 ✓ ✓ ✓ ✓
Recommended items- Twitter 2 ✓ ✓ ✓ ✓
- Facebook 2 ✓ ✓ ✓ ✓
Table 1: ✓ if element removal is successful, ✗ if elementremoval is unsuccessful, — if the element not availableon an interface.
0 20 40 60 80 100Timesteps
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Test
acc
urac
y
Baseline1 user, 5 sents/day5 users, 5 sents/day1 user, 10 sents/day5 users, 10 sents/day = 10 user, 5 sents/day10 user, 10 sents/day
Figure 6: Convergence of few-shot/fine-tuned models onsub-groups of hate speech
regions (image or text) to generate interventions to re-populate theinterventions available. The user is given autonomy in selectingand determining what aspects of the interface, be it the static appinterface of dynamic content provisioned, that they no longer wishto see in the future. Enabling the user to view their screenomeacross all used digital interfaces (extending to mobile and desktop)to self-reflect and analyze browsing or content patterns satisfiesTask 2. Though the screenome provides the user raw historicaldata, it may require additional processing (e.g. automated analysis,charts) to avoid information overload. Rather than waiting for afeedback loop for the app/platform developers or altruistic interven-tion developers to craft broad-spectrum interventions that may ormay not fit their personal needs, the end-user can enjoy a personal-ized loop of crafting and deploying interventions, almost instantlyfor certain interventions such as element masks. The user can entermetadata pertaining to each highlighted harm, and not only con-tribute to their own experience improvement, but also contributeto the improvement of others who may not have encountered orannotated the harm yet. By developing interventions based on theiranalysis, not only for themselves but potentially for other users,they could successfully achieve Task 3. Though previously-stated asout of scope, to further support Task 3, other potential interventionmodalities such as augmentation could also be contributed by a com-munity of professional intervention developers/researchers (whoredirect efforts from individual interventions towards enhancinglow-code development tools).
The four tasks, used to determine whether a complete feedbackloop between input collection/processing and interface renderingthrough HITL by a single user, could all be successfully completed,thus GreaseVision satisfies Requirement 1.
5.2 Scalability TestingTo evaluate the collaborative component, we measure the improve-ment to the user experience of a single user through the effortsof multiple users. We do not recruit a large number of real users,as it would bind our performance evaluation to the number ofusers available (which is additionally subject to constraints suchas the evaluation period, intervention quality control, diversity ofrecruited users). Instead, we evaluate through scalability testing
[62], a type of load testing that measures a system’s ability to scalewith respect to the number of users.
We simulate the usage of the system to evaluate the scalablegeneration of one-shot graphics (mask) detection, and scalable fine-tuning/few-shot training of (text) models, in order to evaluate thestrengths and weaknesses of the system’s scalability. We do notreplicate the scalability analysis on real users: the fine-tuning mech-anism is still the same, and the main variable (in common) is thesentences highlighted (and their assigned labels and metadata, aswell as the quality of the annotations), though error is expectedlyhigher in the real-world as the data may be sampled differentlyand of lower annotation quality. The primary utility of collabora-tion to an individual end-user is the scaled reduction of effort inintervention development. We evaluate this in terms of variety ofindividualized interventions (variations of masks), and the timesaved in constructing a single robust intervention (time needed toconstruct an accurate model intervention).
Breadth of interface-agnostic masks (Table 1): We inves-tigate the ease to annotate graphically-consistent GUI elementsfor few-shot detection. We sample elements to occlude that canexist across a variety of interfaces. We evaluate the occlusionof the stories bar (pre-dominantly only found on mobile devices,not desktop/browsers); some intervention tools exist on Android[12, 48, 61, 83] and iOS [82], though the tools are app- (and version-)specific. We evaluate the occlusion of like/share metrics; there aremainly desktop browser intervention tools [31–33, 36], and oneAndroid intervention tool [12]. We evaluate the occlusion of rec-ommendations; there are intervention tools that remove varyingextents of the interface on browsers (such as the entire newsfeed)[84, 90]. Existing implementations and interest in such interven-tions indicate some users have overlapping interests in tackling theremoval or occlusion of such GUI elements, though the implemen-tations may not exist across all interface platforms, and may notbe robust to version changes. For each intervention, we evaluateon a range of target (emulated) interfaces. We aim for the real-timeocclusion of the specific GUI element, and evaluate on native apps(for Android and iOS) and browsers (Android mobile browser, andLinux desktop browser).
For each of the GUI element cases, we make use of the screenomevisualization tool to annotate and tag the minimum number of

GreaseVision
masks of the specific elements we wish to block across a set ofapps. There tend to be small variations in the design of the elementbetween browsers and mobile, hence we tend to require at least 1mask from each device type; Android and iOS apps tend to havesimilar enough GUI elements that a single mask can be reusedbetween them. We tabulate in Table 1 the successful generation andreal-time occlusion of all evaluated and applicable GUI elements.We append screenshots of the removal of recommended items fromthe Twitter and Instagram apps on Android (Figure 2(a,b)). Weappend screenshots of the demetrification (occlusion of like/sharebuttons and metrics) of YouTube across desktop browsers (MacOS)and mobile browsers (Android, iOS) (Figure 5).
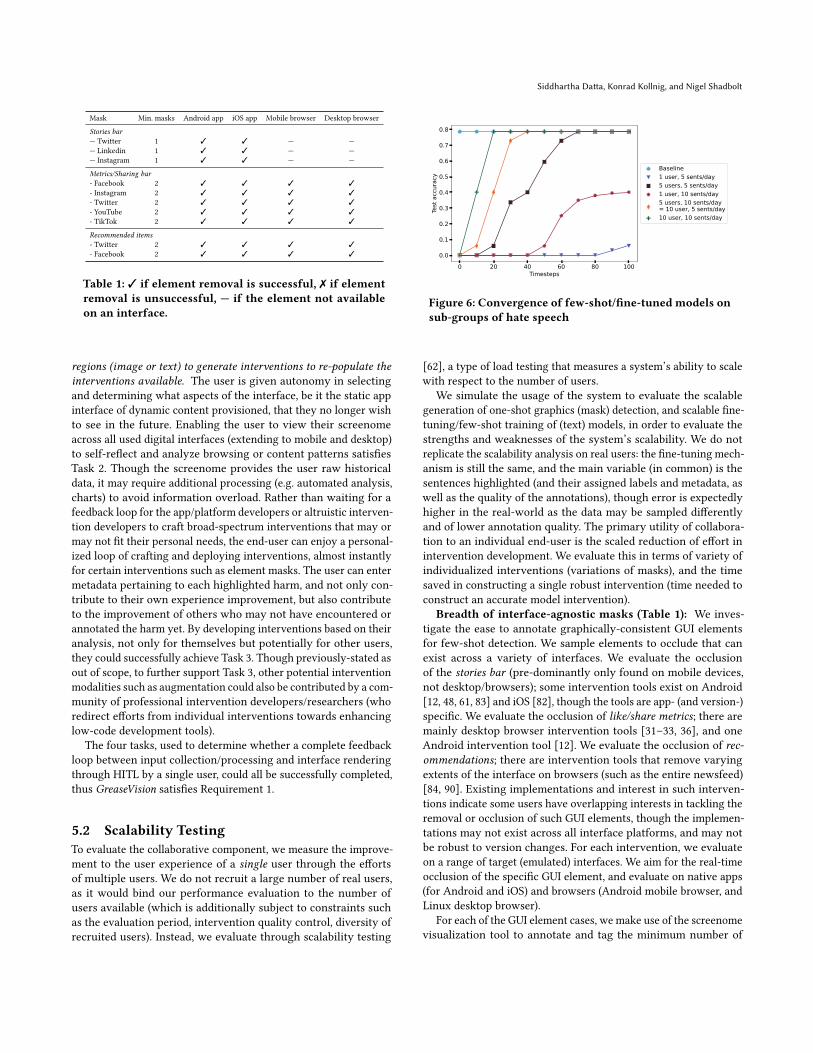
Convergence of few-shot/fine-tune trained textmodels (Fig-ure 6): We investigate the accuracy gains from fine-tuning pre-trained text models as a function of user numbers and annotatedsentence contributions. Specifically, we evaluate the text censor-ing of hate speech, where the primary form of mitigation is stillcommunity standard guidelines and platform moderation, with afew end-user tooling available [8, 12]. The premise of this empiri-cal evaluation is that we have a group of simualated users 𝑁 whoeach contribute 𝑁 inputs (sentences) of a specific target class (hatespeech, specifically against women) per timestep. With respect to abaseline, which is a pretrained model fine-tuned with all availablesentences against women from a hate speech dataset, we wish toobserve how the test accuracy of a model fine-tuned with𝑀 × 𝑁
sentences varies over time. Our source of hate speech for evalua-tion is the Dynamically Generated Hate Speech Dataset [86], whichcontains sentences of non-hate and hate labels, and also classi-fies hate-labelled data by the target victim of the text (e.g. women,muslim, jewish, black, disabled). As we expect the 𝑀 users tobe labelling a specific niche of hate speech to censor, we specifythe subset of hate speech of women (train set count: 1,652; test setcount: 187). We fine-tune a publicly-available, pre-trained RoBERTamodel [41, 55], which was trained on a large corpus of English data(Wikipedia [21], BookCorpus [101]). For each constant number ofusers𝑀 and constant sentence sampling rate 𝑁 , at each timestep 𝑡 ,𝑀 ×𝑁 ×𝑡 sentences are acquired of class hate against target women;there are a total of 1,652 train set sentences under these constraints(i.e. the max number of sentences that can be acquired before ithits the baseline accuracy), and to balance the class distribution, weretain all 15,184 train set non-hate sentences. We evaluate the testaccuracy of the fine-tuned model on all 187 test set women-targetedhate speech. We also vary𝑀 and 𝑁 to observe sensitivity of theseparameters to the convergence towards baseline test accuracy.
The rate of convergence of a finetuned model is quicker whenthe number of users and contributed sentences per timestep bothincrease, approximately when we reach at least 1,000 sentencesfor the women hate speech category. The difference in convergencerates indicate that a collaborative approach to training can scaleinterventions development, as opposed to training text classificationmodels from scratch and each user annotating text alone.
The empirical results for this section are stated in Table 1 andFigure 6. The data and evaluations from the scalability tests indicatethat the ease of mask generation and model fine-tuning, furthercatalyzed by performance improvements from more users, enablethe scalable generation of interventions and their associated harms,thus GreaseVision satisfies Requirement 2.
6 DISCUSSION6.1 What this means for understanding harms,
interventions, and interfacesSoftware is composed of interface/graphics and functionality. Tra-ditionally, the modification of software means changing sourcecode, but we have shown some of the first steps towards illusorymodifications, where we change the interface/graphics to change auser’s perception of the software, which then changes how they usethe software (i.e. perceived functionality change). Realistic func-tionality generation could be a next step, through further studyinto generative interfaces [17, 99], generalization of server-lessapp functionality (e.g. learning from RICO dataset), program in-duction/synthesis from GUI [6], and context-aware screen stateprediction [34] and human behavioural prediction [96].
In the software development life cycle, maintenance is usuallyperformed by the platform/software developers. Extension ecosys-tems extended upon this, by enabling intervention/patch developersto propose and share software patches, which may or may not beintegrated into the next version update of the software. The pro-posed paradigm offers the notion that end-users themselves cantakeover the maintenance and repair of their software, resulting infaster and needs-accurate version updates.
When users inspect andmodify elements of the software and con-tent, the resulting aggregated database of interface changes (harmsand their mapped interventions) can benefit users themselves, otherusers in the software’s ecosystem, software developers, and regula-tory bodies. The faster and public feedback cycle of what interfaceelements and content that varying portions of the user base like ordislike is informative for software regulation and policy-making,optimal software/interface design, optimal content moderation poli-cies, sustainable digital habits, logging of harms and perpetrators,logging of unsustainable design practices, and so on.
The collaborative nature of the proposed system reinforces thequality of interventions. The more users that share a specific need,the more data they contribute towards those interventions (e.g.tagging more elements or text). For niche users along the long-taildistribution, the interventions they craft are also of great impor-tance, as they ensure the availability of niche interventions forthemselves and other niche users that might have been previouslyignored by intervention/software developers.
Enhancements and extensions to the current system are possibletoo. Usage of app state exploration tools [10] and alternative GUIsegmentation and parsing tools [54, 92, 94] can improve technicalaspects of the implementation. Usage of end-user local desktopsas server, or loading personal devices instead of emulators or onlyusing browsers to access apps (most popular apps also exist aswebsites), can allow for secure and private access to devices with-out trusting a third-party server to manage an end-users personaldevices and data. Rating of user mechanisms, detection of out-of-distribution input samples, or ensembling techniques are algorith-mic techniques to handle the quality of collaborative interventionscontributed. Optimal intervention design may not be to pick oneextreme (end-users should develop their own interventions) orthe other (professional developers should develop interventionsfor end-users). We could balance the trade-offs to maximize thescalability of needs/harms and intervention design contributions

Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt
from end-users, against fine-tuning and development skill fromprofessional developers: end-users can define the requirementsof the initial prototype of interventions through the low-code de-velopment platform and circulate for usage in the network, andprofessional developers can refine the intervention implementationbased on criteria such as popularity of the intervention, amount ofdata contributed, and difficulty of re-development.
6.2 The new standard of end-user autonomyWe respond to the open call to action in Datta et al. [12] that asks forintervention development that increases autonomy for users whilereducing digital paternalism. Datta et al. argued that a risk of digitalpaternalismmanifests when interventions are developed by individ-uals other than those directly affected (e.g. researchers/developersbuilding interventions without a sound understanding of the actualunderlying challenges within an affected community). As a solutionto this potential risk, at best, the affected individuals should be ableto develop interventions against harms by themselves.
WhileGreaseTerminator aimed to strike a balance between auton-omy and paternalism [85] in regulating digital experiences, Grease-Vision aims to further increase end-user autonomy (and likewisereduce digital paternalism). We measure the extent of digital pater-nalism based on the extent in which an end-user delegates auton-omy over their device screen to an external party. The completetrust of interface design and functionality to the original app de-velopers is complete paternalism (negligible autonomy), given thatthe end-user is subject to the goals and decisions of the developer.The introduction of software modification frameworks for apps andbrowsers reduces paternalism slightly, in which the interventiondevelopers may account for the end-users’ best interests and goals,but it still requires trust from the end-user to the intervention de-veloper. The proposed developer-less intervention developmentframework enables users to develop their own interventions (with-out expert knowledge) with respect to their own personalized goals,inducing maximum autonomy. However, this autonomy would stillface constraints from the limitations of the development system,such as the generalizability of interface patterns, adverse networkdynamics (e.g. other end-users over-contribute malicious samplesto the few-shot learning models). With gradual improvements toimplementation, this framework could be an optimal path to anon-paternalistic, autonomy-maximizing software modificationframework.
While this tool will mostly be used in small-scale studies, andfurther development will be required towards large-scale deploy-ment, this first step towards end-user development for practicalpurposes highlights a potential tendency for the development land-scape to change, shifting away from tooling, access, and effortsfor/by professional developers, and more towards end-users. Ifother stakeholders oppose this movement, countermeasures maybe imposed, such as technical restrictions (e.g. restricting usageof emulators, screen-image awareness, dynamic GUI elements) orlegal restrictions (e.g. UI is copyrighted and not changeable).
6.3 Re-writing digital realitiesWith a system that allows for user-personalized, unilateral softwaremodification such that the distribution of user interfaces matchthe distribution of user preferences, it inductively follows that end-users can personalize and re-write their "digital realities" (and byextension, their reality as a whole).
It has been argued in various forms that a coherent mesh ex-ists between the physical reality and digital reality, the formerbeing the physical world/reality/environment in which end-usersexist and interact as physical human bodies, the latter being thedigital world/reality/environment in which end-users exist and in-teract as digital personas. This coherent mesh is argued to exist, asphenomena occurring in the physical world can leak/impact theend-user manifestation in the digital world, and vice versa phenom-ena occurring in the digital world can leak/impact the end-usermanifestation in the physical world. An example is the leaking ef-fects of online social networks onto the physical world: phenomenasuch as the viral propagation of content to large populations withor without filter, the large accessibility of other end-users aroundthe world without a constrained contact list, the minimal or circum-ventable regulation of content generation resulting in real-worldconsequences such as the wide-scale re-influencing and recruitmentof terrorists/extremists, wide-scale personalized influencing and bi-asing of niche populations for election rigging, or wide-scale socialbubble formation of extreme interest groups (e.g. "incel", "sigmamales", "furries") that lead to individuals exerting/manifesting theseopinions in real-life against other individuals (e.g. exerting thesepersonalities in the workplace or personal lives).
One of the downsides of limited end-user autonomy and person-alized interface rendering, is that the reality of the end-user hasbeen shaped by platforms and other developers, and subsequentlyother end-users in the social network. If we aggregated all the dataand information amassed on the Internet, this would form one con-crete, ultimate reality (metaphysical reality). However, rather thanenduring this information overload, each end-user is provisioned afiltered portion of this reality, with additional filters of perception(e.g. due to personalized preferences, goals/incentives of platformowners). As more of the physical world is driven by events takingplace in the digital world, one could argue that a large proportionof the metaphysical reality resides in the digital reality. While someexisting work on digital metaphysics [35, 73, 80] offers the proposi-tion that this digital world (and hence the physical world) may bedriven by programs (or automata) that potentially autonomouslyencode the rules of the physical world and may interact with otherprograms, the current state of affairs indicates that, regardless ofwhether programs may or may not be sentient, they do indeedhave an effect on the physical world through inputs and outputsmanifested by end-users. End-users are immersed in the digitalworld in their daily lives (users spent 161 minutes per day on mo-bile and desktop devices in 2018 [79]), are constantly tracked acrossplatforms and apps [7, 49] (i.e. providing inputs to the automatedprograms), and content generated by platforms, end-users or otherthird-parties are distributed and matched to end-users through rec-ommendation systems personalized with respect to tracked userdata [45] (with varying levels of regulation or moderation by human/ platform owners).

GreaseVision
Having argued in Section 4.2 that the proliferation of end-userinterface development/re-rendering systems like GreaseVision canenable end-users to re-design and re-render interfaces according totheir own preferences, objectives and goals (and potentially elimi-nating the goals/objectives of other network end-users, third par-ties, or software/platform developers), it follows that this enhancedend-user autonomy over their interfaces also grants end-users theability to re-write their digital realities. By encoding rules in thescreenome visualization page on what aspects of the interface toaugment or occlude, the end-user is dictating which aspects of themetaphysical (ultimate) reality that they wish to observe. This, inturn, may change the cognition and end-user perception in thelonger term. For example, we sample benevolent use cases in thismanuscript, in particular the reduction in harmful content to users.One could argue that the current digital reality is already personal-ized to end-user preferences and data, and whether marginal valueof an additional layer of end-user personalization exists. The ar-gument against this is that, though personalized to our personaldata, the interfaces and their content are dictated by systems thatmay not take into account our goals and objectives; they may haveour data, but they may not have our best interests. Conversely, bydictating our digital experiences, they have the ability to reversethe feedback loop: ideally the system should render what the userwould like to see, but instead what we observe is that the systemnudges the user into wanting to see what the system would likethem to see. With end-user interventions, at least the end-userhas an option of correcting for reverse-nudging, where the systemnudges the user rather than vice versa, and gives users the right tosee what they really would like to see. If we continue to extend thefunctionality of GreaseVision, we can enable the re-writing of thedigital reality (thus far indicated to be connected to the physicalworld). For example, we could develop interventions that re-renderthe digital interface as time-dependent, e.g. filtering or stylizing con-tent to be 1960s-based, to further evaluate benefits of reminiscencetherapy in aged patients facing dementia [91].
The progression for maximizing end-user autonomy and per-sonalizing digital realities can raise unexpected costs, and requirescareful consideration of what regulation for these realities mightlook like.While benevolent use cases exist, malevolent use cases canalso arise. For example, end-user intervention development couldbe abused to filter holistic information about the world and furtheringrain users into niche and perceptually-harmful bubbles, whichis already a harmful phenomenon manifesting in social networks.Since it has been argued thus far that changing one’s digital realitycan alter one’s cognition over time, the extreme personalization anddecentralization of user interface design and rendering can resultin adverse effects in the physical world if the personalization isunregulated. A parallel is observed in the Internet, where due to ex-treme decentralization of the underlying technology and protocols,pockets of the Internet exist in the dark web, and these unregulatedregions manifest discussions on murder, assassinations, rape, andother heinous dangers. While discussions take place online, real-world effects leak out, and countermeasures are regularly taken bylaw enforcement to curb this decentralization and anonymity. Like-wise, rather than curbing harmful content, end-users may in turnfilter specifically for harmful content and increase their exposure todangerous content that can result in harm to other individuals. For
example, certain end-users may choose to block beneficial content,and choose to occlude any content relating to the topic of "women"in general, which may result in the filtering of content pertain-ing to women’s health or systemic issues pertaining to women’srights, and over a long period of lacking exposure, may result inthe individual developing sexist worldviews and tendencies.
Hence, the next step needs to be a discussion and investigationon what alternative regulation on our digital realities need to looklike. End-user personalization through browser and app extensionecosystems are being developed and deployed, though the exten-sions/interventions are currently still constrained by interventiondevelopment by professional developers, hence this state of criti-cality is still averted thus far. Currently, it is the tech companies,the social networks (driven by wisdom of crowds and virality), andgovernments to some extent that are collectively fighting (some-times against each other) to regulate the platforms and software. Inthis manuscript, we have advocated for maximizing the goals andincentives of end-users and individual welfare, but we will need tothink carefully towards social welfare as well. Regulation by techcompanies may not be ideal given an intrinsic motivation towardsoptimizing viewership and profit, even at the cost of individual orsocial welfare. The effect of government regulation may vary byregion and may conflict with individual or social welfare as well,such as through enhanced interface-agnostic content censorship inoppressive regimes.
7 CONCLUSIONTo enable end-user autonomy over interface design, and the gener-ation and proliferation of a distribution of harms and interventionsto analyze and reflect upon, we contribute the novel interface modi-fication frameworkGreaseVision. End-users can reflect and annotatewith their digital browsing experiences, and collaboratively craftinterface interventions with our HITL and visual overlay mech-anisms. We hope GreaseVision will enable other researchers (andeventually end-users) to study harms and interventions, and otherinterface modification use cases.

Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt
REFERENCES[1] Samira Abnar, Mostafa Dehghani, Behnam Neyshabur, and Hanie Sedghi. 2022.
Exploring the Limits of Large Scale Pre-training. In International Conference onLearning Representations. https://openreview.net/forum?id=V3C8p78sDa
[2] Yuvraj Agarwal and Malcolm Hall. 2013. ProtectMyPrivacy: Detecting andMitigating Privacy Leaks on iOS Devices Using Crowdsourcing. In Proceedingof the 11th Annual International Conference on Mobile Systems, Applications, andServices - MobiSys ’13. ACM Press, Taipei, Taiwan, 97. https://doi.org/10.1145/2462456.2464460
[3] Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic Di-mensionality Explains the Effectiveness of Language Model Fine-Tuning. InProceedings of the 59th Annual Meeting of the Association for ComputationalLinguistics and the 11th International Joint Conference on Natural LanguageProcessing (Volume 1: Long Papers). Association for Computational Linguistics,Online, 7319–7328. https://doi.org/10.18653/v1/2021.acl-long.568
[4] Ionut Andone, Konrad Błaszkiewicz, Mark Eibes, Boris Trendafilov, ChristianMontag, and Alexander Markowetz. 2016. Menthal: A Framework for MobileData Collection and Analysis. In Proceedings of the 2016 ACM InternationalJoint Conference on Pervasive and Ubiquitous Computing: Adjunct (Heidelberg,Germany) (UbiComp ’16). Association for Computing Machinery, New York, NY,USA, 624–629. https://doi.org/10.1145/2968219.2971591
[5] Michael Backes, Sebastian Gerling, Christian Hammer, Matteo Maffei, andPhilipp von Styp-Rekowsky. 2014. AppGuard – Fine-Grained Policy Enforce-ment for Untrusted Android Applications. In Data Privacy Management andAutonomous Spontaneous Security, Joaquin Garcia-Alfaro, Georgios Lioudakis,Nora Cuppens-Boulahia, Simon Foley, and William M. Fitzgerald (Eds.). Lec-ture Notes in Computer Science, Vol. 8247. Springer Berlin Heidelberg, Berlin,Heidelberg, 213–231. https://doi.org/10.1007/978-3-642-54568-9_14
[6] Tony Beltramelli. 2018. Pix2code: Generating Code from a Graphical UserInterface Screenshot. In Proceedings of the ACM SIGCHI Symposium on Engi-neering Interactive Computing Systems (Paris, France) (EICS ’18). Associationfor Computing Machinery, New York, NY, USA, Article 3, 6 pages. https://doi.org/10.1145/3220134.3220135
[7] Reuben Binns, Ulrik Lyngs, Max Van Kleek, Jun Zhao, Timothy Libert, and NigelShadbolt. 2018. Third Party Tracking in the Mobile Ecosystem. In Proceedingsof the 10th ACM Conference on Web Science (Amsterdam, Netherlands) (WebSci’18). Association for Computing Machinery, New York, NY, USA, 23–31. https://doi.org/10.1145/3201064.3201089
[8] Inc Bodyguard. 2019. Bodyguard. https://www.bodyguard.ai/[9] Hyunsung Cho, DaEun Choi, Donghwi Kim, Wan Ju Kang, Eun Kyoung Choe,
and Sung-Ju Lee. 2021. Reflect, Not Regret: Understanding Regretful SmartphoneUse with App Feature-Level Analysis. Proc. ACM Hum.-Comput. Interact. 5,CSCW2, Article 456 (oct 2021), 36 pages. https://doi.org/10.1145/3479600
[10] Wontae Choi, George Necula, and Koushik Sen. 2013. Guided GUI Testing ofAndroid Apps with Minimal Restart and Approximate Learning. SIGPLAN Not.48, 10 (oct 2013), 623–640. https://doi.org/10.1145/2544173.2509552
[11] Siddhartha Datta. 2021. Learn2Weight: Weights Transfer Defense againstSimilar-domain Adversarial Attacks. https://openreview.net/forum?id=1-j4VLSHApJ
[12] Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt. 2021. Mind-proofingYour Phone: Navigating the Digital Minefield with GreaseTerminator. CoRRabs/2112.10699 (2021), 22 pages. arXiv:2112.10699 https://arxiv.org/abs/2112.10699
[13] Siddhartha Datta and Nigel Shadbolt. 2022. Low-Loss Subspace Compres-sion for Clean Gains against Multi-Agent Backdoor Attacks. arXiv preprintarXiv:2203.03692 (2022).
[14] Benjamin Davis and Hao Chen. 2013. RetroSkeleton: Retrofitting Android Apps.In Proceeding of the 11th Annual International Conference on Mobile Systems,Applications, and Services - MobiSys ’13. ACM Press, Taipei, Taiwan, 181. https://doi.org/10.1145/2462456.2464462
[15] Benjamin Davis, Ben S, Armen Khodaverdian, and Hao Chen. 2012. I-ARM-Droid: A rewriting framework for in-app reference monitors for android ap-plications. In In Proceedings of the Mobile Security Technologies 2012, MOST ’12.IEEE, New York, NY, United States, 1–9.
[16] Biplab Deka, Zifeng Huang, Chad Franzen, Joshua Hibschman, Daniel Afergan,Yang Li, Jeffrey Nichols, and Ranjitha Kumar. 2017. Rico: A Mobile App Datasetfor Building Data-Driven Design Applications. In Proceedings of the 30th AnnualACM Symposium on User Interface Software and Technology (Québec City, QC,Canada) (UIST ’17). Association for Computing Machinery, New York, NY, USA,845–854. https://doi.org/10.1145/3126594.3126651
[17] Peitong Duan, Casimir Wierzynski, and Lama Nachman. 2020. Optimizing UserInterface Layouts via Gradient Descent. Association for Computing Machinery,New York, NY, USA, 1–12. https://doi.org/10.1145/3313831.3376589
[18] William Enck, Peter Gilbert, Byung-Gon Chun, Landon P. Cox, Jaeyeon Jung,Patrick McDaniel, and Anmol N. Sheth. 2010. TaintDroid: An Information-Flow Tracking System for Realtime Privacy Monitoring on Smartphones. InProceedings of the 9th USENIX Conference on Operating Systems Design and
Implementation (OSDI’10). USENIX Association, Berkeley, CA, United States,393–407.
[19] Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. arXiv:1703.03400 [cs.LG]
[20] flxapps. 2021. DetoxDroid. https://github.com/flxapps/DetoxDroid[21] Wikimedia Foundation. [n.d.]. Wikimedia Downloads. https://dumps.wikimedia.
org[22] Jay Freeman. 2020. Cydia Substrate. http://www.cydiasubstrate.com/[23] Tomer Galanti, András György, and Marcus Hutter. 2022. On the Role of
Neural Collapse in Transfer Learning. In International Conference on LearningRepresentations. https://openreview.net/forum?id=SwIp410B6aQ
[24] Kovacs Geza. 2019. HabitLab: In-The-Wild Behavior Change Experiments atScale. Stanford Department of Computer Science (2019). https://stacks.stanford.edu/file/druid:qq438qv1791/Thesis-augmented.pdf
[25] Vegard IT GmbH. 2021. Gray-Switch. https://play.google.com/store/apps/details?id=com.vegardit.grayswitch
[26] Google. 2007. Tesseract. https://github.com/tesseract-ocr/tesseract[27] Google. 2010. Chrome Web Store. https://chrome.google.com/webstore/[28] Google. 2010. reCAPTCHA FAQ. https://web.archive.org/web/20100705103425/
http://www.google.com/recaptcha/faq[29] Google. 2021. Android Accessibility Suite. https://play.google.com/store/apps/
details?id=com.google.android.marvin.talkback[30] Colin M. Gray, Yubo Kou, Bryan Battles, Joseph Hoggatt, and Austin L. Toombs.
2018. The Dark (Patterns) Side of UX Design. In Proceedings of the 2018 CHIConference on Human Factors in Computing Systems (Montreal QC, Canada)(CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–14.https://doi.org/10.1145/3173574.3174108
[31] Benjamin Grosser. 2012. Facebook Demetricator. https://bengrosser.com/projects/facebook-demetricator/
[32] Benjamin Grosser. 2018. Twitter Demetricator. https://bengrosser.com/projects/twitter-demetricator/
[33] Benjamin Grosser. 2019. Instagram Demetricator. https://bengrosser.com/projects/instagram-demetricator/
[34] Zecheng He, Srinivas Sunkara, Xiaoxue Zang, Ying Xu, Lijuan Liu, NevanWichers, Gabriel Schubiner, Ruby B. Lee, and Jindong Chen. 2021. Actionbert:leveraging user actions for semantic understanding of user interfaces.
[35] Michael Henry Heim. 1993. The Metaphysics of Virtual Reality (1st ed.). OxfordUniversity Press, Inc., USA.
[36] hidelikes.com. 2022. Hide Likes. https://chrome.google.com/webstore/detail/hide-likes/ebamaffgiechnomghfojkmlkaipoadni
[37] Niklas Higi. 2020. apk-mitm. https://github.com/shroudedcode/apk-mitm/[38] Alexis Hiniker, Sungsoo (Ray) Hong, Tadayoshi Kohno, and Julie A. Kientz. 2016.
MyTime: Designing and Evaluating an Intervention for Smartphone Non-Use. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems(San Jose, California, USA) (CHI ’16). Association for Computing Machinery,New York, NY, USA, 4746–4757. https://doi.org/10.1145/2858036.2858403
[39] Government HM. 2019. Online Harms White Paper. Government Reporton Transparency Reporting (2019). https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/793360/Online_Harms_White_Paper.pdf
[40] Mahsa Honary, Beth Bell, Sarah Clinch, Julio Vega, Leo Kroll, Aaron Sefi, andRoisin McNaney. 2020. Shaping the Design of Smartphone-Based Interventionsfor Self-Harm. In Proceedings of the 2020 CHI Conference on Human Factors inComputing Systems (Honolulu, HI, USA) (CHI ’20). Association for ComputingMachinery, New York, NY, USA, 1–14. https://doi.org/10.1145/3313831.3376370
[41] HuggingFace. 2022. roberta-base. https://huggingface.co/roberta-base[42] Andrey Ignatov. 2021. AI-Benchmark. https://ai-benchmark.com/ranking_
deeplearning_detailed.html/[43] Jinseong Jeon, Kristopher K. Micinski, Jeffrey A. Vaughan, Ari Fogel, Nikhilesh
Reddy, Jeffrey S. Foster, and Todd Millstein. 2012. Dr. Android and Mr. Hide:Fine-Grained Permissions in Android Applications. In Proceedings of the SecondACM Workshop on Security and Privacy in Smartphones and Mobile Devices -SPSM ’12. ACM Press, Raleigh, North Carolina, USA, 3. https://doi.org/10.1145/2381934.2381938
[44] Bonnie E. John and Hilary Packer. 1995. Learning and Using the CognitiveWalkthrough Method: A Case Study Approach. In Proceedings of the SIGCHIConference on Human Factors in Computing Systems (Denver, Colorado, USA)(CHI ’95). ACM Press/Addison-Wesley Publishing Co., USA, 429–436. https://doi.org/10.1145/223904.223962
[45] Jussi Karlgren. 1990. An algebra for recommendations: Using reader data as abasis for measuring document proximity.
[46] Minsam Ko, Subin Yang, Joonwon Lee, Christian Heizmann, Jinyoung Jeong,Uichin Lee, Daehee Shin, Koji Yatani, Junehwa Song, and Kyong-Mee Chung.2015. NUGU: A Group-Based Intervention App for Improving Self-Regulationof Limiting Smartphone Use. In Proceedings of the 18th ACM Conference onComputer Supported Cooperative Work & Social Computing (Vancouver, BC,Canada) (CSCW ’15). Association for Computing Machinery, New York, NY,USA, 1235–1245. https://doi.org/10.1145/2675133.2675244

GreaseVision
[47] Gregory Koch, Richard Zemel, and Ruslan Salakhutdinov. 2015. Siamese NeuralNetworks for One-shot Image Recognition.
[48] Konrad Kollnig, Siddhartha Datta, and Max Van Kleek. 2021. I Want My AppThat Way: Reclaiming Sovereignty Over Personal Devices. In Proceedings ofthe 2021 CHI Conference on Human Factors in Computing Systems Late-BreakingWorks (Yokohama, Japan). ACM Press, Yokohama, Japan. https://arxiv.org/abs/2102.11819
[49] Konrad Kollnig, Anastasia Shuba, Reuben Binns, Max Van Kleek, and NigelShadbolt. 2022. Are iPhones Really Better for Privacy? A Comparative Study ofiOS and Android Apps. Proceedings on Privacy Enhancing Technologies 2022, 2(2022), 6–24. https://doi.org/doi:10.2478/popets-2022-0033
[50] AV Tech Labs. 2019. Auto Logout. https://chrome.google.com/webstore/detail/auto-logout/affkccgnaoeohjnojjnpdalhpjhdiebh?hl=en
[51] David Ledo, Steven Houben, Jo Vermeulen, Nicolai Marquardt, Lora Oehlberg,and Saul Greenberg. 2018. Evaluation Strategies for HCI Toolkit Research.Association for Computing Machinery, New York, NY, USA, 1–17. https://doi.org/10.1145/3173574.3173610
[52] Heyoung Lee, Heejune Ahn, Samwook Choi, and Wanbok Choi. 2014. TheSAMS: Smartphone Addiction Management System and Verification. J. Med.Syst. 38, 1 (Jan. 2014), 1–10. https://doi.org/10.1007/s10916-013-0001-1
[53] Lawence Lessig. [n.d.]. Code 2.0 (1 ed.). Basic Books.[54] Toby Jia-Jun Li, Lindsay Popowski, Tom Mitchell, and Brad A Myers. 2021.
Screen2Vec: Semantic Embedding of GUI Screens and GUI Components. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan) (CHI ’21). Association for Computing Machinery, New York,NY, USA, Article 578, 15 pages. https://doi.org/10.1145/3411764.3445049
[55] Yinhan Liu,Myle Ott, NamanGoyal, Jingfei Du,Mandar Joshi, Danqi Chen, OmerLevy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: ARobustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019).arXiv:1907.11692 http://arxiv.org/abs/1907.11692
[56] Markus Löchtefeld, Matthias Böhmer, and Lyubomir Ganev. 2013. AppDetox:Helping UserswithMobile AppAddiction. In Proceedings of the 12th InternationalConference on Mobile and Ubiquitous Multimedia (Luleå, Sweden) (MUM ’13).Association for Computing Machinery, New York, NY, USA, Article 43, 2 pages.https://doi.org/10.1145/2541831.2541870
[57] LuckyPatcher. 2020. Lucky Patcher. https://www.luckypatchers.com/[58] Yajing Luo, Peng Liang, Chong Wang, Mojtaba Shahin, and Jing Zhan. 2021.
Characteristics and Challenges of Low-Code Development: The Practitioners’Perspective. Proceedings of the 15th ACM / IEEE International Symposium onEmpirical Software Engineering and Measurement (ESEM) (2021).
[59] Ulrik Lyngs, Kai Lukoff, Petr Slovak, William Seymour, Helena Webb, MarinaJirotka, Jun Zhao, Max Van Kleek, and Nigel Shadbolt. 2020. ’I Just Want to HackMyself to Not Get Distracted’: Evaluating Design Interventions for Self-Controlon Facebook. In Proceedings of the 2020 CHI Conference on Human Factors inComputing Systems. ACM, Honolulu HI USA, 1–15. https://doi.org/10.1145/3313831.3376672
[60] Ulrik Lyngs, Kai Lukoff, Petr Slovak, William Seymour, Helena Webb, MarinaJirotka, Jun Zhao, Max Van Kleek, and Nigel Shadbolt. 2020. ’I Just Want to HackMyself to Not Get Distracted’: Evaluating Design Interventions for Self-Control onFacebook. Association for Computing Machinery, New York, NY, USA, 1–15.https://doi.org/10.1145/3313831.3376672
[61] MaaarZ. 2019. InstaPrefs. https://forum.xda-developers.com/t/app-xposed-instaprefs-the-ultimate-instagram-utility.4005051/
[62] Joris Meerts and Dorothy Graham. 2010. The History of Software Testing.http://www.testingreferences.com/testinghistory.php
[63] Meta. 2022. Content Restrictions Based on Local Law. https://transparency.fb.com/data/content-restrictions/
[64] Behnam Neyshabur, Hanie Sedghi, and Chiyuan Zhang. 2020. What is beingtransferred in transfer learning?. In Advances in Neural Information ProcessingSystems, H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin (Eds.),Vol. 33. Curran Associates, Inc., 512–523. https://proceedings.neurips.cc/paper/2020/file/0607f4c705595b911a4f3e7a127b44e0-Paper.pdf
[65] Fabian Okeke, Michael Sobolev, Nicola Dell, and Deborah Estrin. 2018. GoodVibrations: Can a Digital Nudge Reduce Digital Overload?. In Proceedings ofthe 20th International Conference on Human-Computer Interaction with Mo-bile Devices and Services (Barcelona, Spain) (MobileHCI ’18). Association forComputing Machinery, New York, NY, USA, Article 4, 12 pages. https://doi.org/10.1145/3229434.3229463
[66] R. Parasuraman, T.B. Sheridan, and C.D. Wickens. 2000. A model for types andlevels of human interaction with automation. IEEE Transactions on Systems,Man, and Cybernetics - Part A: Systems and Humans 30, 3 (2000), 286–297. https://doi.org/10.1109/3468.844354
[67] Jessica Pater and Elizabeth Mynatt. 2017. Defining Digital Self-Harm. In Pro-ceedings of the 2017 ACM Conference on Computer Supported Cooperative Workand Social Computing (Portland, Oregon, USA) (CSCW ’17). Association forComputing Machinery, New York, NY, USA, 1501–1513. https://doi.org/10.1145/2998181.2998224
[68] Jessica A. Pater, Brooke Farrington, Alycia Brown, Lauren E. Reining, TammyToscos, and Elizabeth D. Mynatt. 2019. Exploring Indicators of Digital Self-Harmwith Eating Disorder Patients: A Case Study. Proc. ACM Hum.-Comput. Interact.3, CSCW, Article 84 (Nov. 2019), 26 pages. https://doi.org/10.1145/3359186
[69] Aniruddh Raghu, Maithra Raghu, Samy Bengio, and Oriol Vinyals. 2020. RapidLearning or Feature Reuse? Towards Understanding the Effectiveness of MAML.In International Conference on Learning Representations. https://openreview.net/forum?id=rkgMkCEtPB
[70] Siegfried Rasthofer, Steven Arzt, Enrico Lovat, and Eric Bodden. 2014. Droid-Force: Enforcing Complex, Data-Centric, System-Wide Policies in Android. In2014 Ninth International Conference on Availability, Reliability and Security. IEEE,Fribourg, Switzerland, 40–49. https://doi.org/10.1109/ARES.2014.13
[71] Byron Reeves, Nilam Ram, Thomas N. Robinson, James J. Cummings, C. LeeGiles, Jennifer Pan, Agnese Chiatti, Mj Cho, Katie Roehrick, Xiao Yang, AnupriyaGagneja, Miriam Brinberg, Daniel Muise, Yingdan Lu, Mufan Luo, AndrewFitzgerald, and Leo Yeykelis. 2021. Screenomics: A Framework to Capture andAnalyze Personal Life Experiences and the Ways that Technology Shapes Them.Human–Computer Interaction 36, 2 (2021), 150–201. https://doi.org/10.1080/07370024.2019.1578652 arXiv:https://doi.org/10.1080/07370024.2019.1578652PMID: 33867652.
[72] Byron Reeves, Thomas Robinson, and Nilam Ram. 2020. Time for the HumanScreenome Project. Nature 577, 7790 (16 Jan. 2020), 314–317. https://doi.org/10.1038/d41586-020-00032-5 Funding Information: The US National Institutes ofHealth (NIH) is Publisher Copyright: © 2020, Nature.
[73] Nicholas Rescher. 1991. G. W. Leibniz’s Monadology. Routledge.[74] John Rieman, Marita Franzke, and David Redmiles. 1995. Usability Eval-
uation with the Cognitive Walkthrough. In Conference Companion on Hu-man Factors in Computing Systems (Denver, Colorado, USA) (CHI ’95). As-sociation for Computing Machinery, New York, NY, USA, 387–388. https://doi.org/10.1145/223355.223735
[75] rovo89. 2020. Xposed Framework. https://xposed.info/[76] BryanC. Russell, Antonio Torralba, KevinP. Murphy, and WilliamT. Freeman.
2008. LabelMe: A Database and Web-Based Tool for Image Annotation. Interna-tional Journal of Computer Vision 77, 1-3 (2008), 157–173. https://doi.org/10.1007/s11263-007-0090-8
[77] Téo Sanchez, Baptiste Caramiaux, Pierre Thiel, and Wendy E. Mackay. 2022.Deep Learning Uncertainty in Machine Teaching. In 27th International Confer-ence on Intelligent User Interfaces (Helsinki, Finland) (IUI ’22). Association forComputing Machinery, New York, NY, USA, 173–190. https://doi.org/10.1145/3490099.3511117
[78] Christian Simon, Piotr Koniusz, Richard Nock, and Mehrtash Harandi. 2020.Adaptive Subspaces for Few-Shot Learning. In 2020 IEEE/CVF Conference onComputer Vision and Pattern Recognition (CVPR). 4135–4144. https://doi.org/10.1109/CVPR42600.2020.00419
[79] Statista. 2019. Daily time spent with the internet per capita worldwide from2011 to 2021, by device. https://www.statista.com/statistics/319732/daily-time-spent-online-device/
[80] Eric Steinhart. 1998. Digital Metaphysics. In The Digital Phoenix: How ComputersAre Changing Philosophy, Terrell Ward Bynum and James Moor (Eds.). Blackwell,117–134.
[81] Hendrik Strobelt, Jambay Kinley, Robert Krueger, Johanna Beyer, HanspeterPfister, and Alexander M. Rush. 2021. GenNI: Human-AI Collaboration forData-Backed Text Generation. IEEE Transactions on Visualization and ComputerGraphics (2021), 1–1. https://doi.org/10.1109/TVCG.2021.3114845
[82] Friendly App Studio. 2022. Friendly Social Browser. https://apps.apple.com/us/app/friendly-for-facebook/id400169658
[83] Happening Studios. 2021. Swipe for Facebook. https://play.google.com/store/apps/details?id=com.happening.studios.swipeforfacebookfree&hl=en_GB&gl=US
[84] unhook.app. 2022. Unhook - Remove YouTube Recommended Videos.https://chrome.google.com/webstore/detail/unhook-remove-youtube-rec/khncfooichmfjbepaaaebmommgaepoid?hl=en
[85] Donald Vandeveer. 2014. Paternalistic Intervention: The Moral Bounds on Benevo-lence. Princeton University Press. https://doi.org/doi:10.1515/9781400854066
[86] Bertie Vidgen, Tristan Thrush, Zeerak Waseem, and Douwe Kiela. 2021. Learn-ing from the Worst: Dynamically Generated Datasets to Improve Online HateDetection. In Proceedings of the 59th Annual Meeting of the Association for Com-putational Linguistics and the 11th International Joint Conference on NaturalLanguage Processing (Volume 1: Long Papers). Association for ComputationalLinguistics, Online, 1667–1682. https://doi.org/10.18653/v1/2021.acl-long.132
[87] VrtualApp. 2016. Virtual Xposed. https://virtualxposed.org/[88] EricWallace, Pedro Rodriguez, Shi Feng, Ikuya Yamada, and Jordan Boyd-Graber.
2019. Trick Me If You Can: Human-in-the-Loop Generation of Adversarial Exam-ples for Question Answering. Transactions of the Association for ComputationalLinguistics 7 (2019), 387–401. https://doi.org/10.1162/tacl_a_00279
[89] Yilin Wang, Jiliang Tang, Jundong Li, Baoxin Li, Yali Wan, Clayton Mellina,Neil O’Hare, and Yi Chang. 2017. Understanding and Discovering DeliberateSelf-Harm Content in Social Media. In Proceedings of the 26th International

Siddhartha Datta, Konrad Kollnig, and Nigel Shadbolt
Conference on World Wide Web (Perth, Australia) (WWW ’17). InternationalWorld Wide Web Conferences Steering Committee, Republic and Canton ofGeneva, CHE, 93–102. https://doi.org/10.1145/3038912.3052555
[90] Jordan West. 2012. News Feed Eradicator for Facebook. https://chrome.google.com/webstore/detail/news-feed-eradicator-for/fjcldmjmjhkklehbacihaiopjklihlgg?hl=en
[91] Bob Woods, Laura O’Philbin, Emma M Farrell, Aimee E Spector, and Martin Or-rell. 2018. Reminiscence therapy for dementia. Cochrane Database of SystematicReviews 3 (2018). https://doi.org/10.1002/14651858.CD001120.pub3
[92] Jason Wu, Xiaoyi Zhang, Jeff Nichols, and Jeffrey P Bigham. 2021. ScreenParsing: Towards Reverse Engineering of UI Models from Screenshots. In The34th Annual ACM Symposium on User Interface Software and Technology (VirtualEvent, USA) (UIST ’21). Association for Computing Machinery, New York, NY,USA, 470–483. https://doi.org/10.1145/3472749.3474763
[93] Xingjiao Wu, Luwei Xiao, Yixuan Sun, Junhang Zhang, Tianlong Ma, and LiangHe. 2021. A Survey of Human-in-the-loop for Machine Learning. https://doi.org/10.48550/ARXIV.2108.00941
[94] Mulong Xie, Sidong Feng, Zhenchang Xing, Jieshan Chen, and Chunyang Chen.2020. UIED: A Hybrid Tool for GUI Element Detection. In Proceedings of the 28thACM Joint Meeting on European Software Engineering Conference and Symposiumon the Foundations of Software Engineering (Virtual Event, USA) (ESEC/FSE2020). Association for Computing Machinery, New York, NY, USA, 1655–1659.https://doi.org/10.1145/3368089.3417940
[95] Rubin Xu, Hassen Saïdi, and Ross Anderson. 2012. Aurasium: Practi-cal Policy Enforcement for Android Applications. In 21st USENIX SecuritySymposium (USENIX Security 12). USENIX Association, Bellevue, WA, 539–552. https://www.usenix.org/conference/usenixsecurity12/technical-sessions/presentation/xu_rubin
[96] Xiao Yang, Nilam Ram, Thomas Robinson, and Byron Reeves. 2019. UsingScreenshots to Predict Task Switching on Smartphones. In Extended Abstractsof the 2019 CHI Conference on Human Factors in Computing Systems (Glasgow,
Scotland Uk) (CHI EA ’19). Association for Computing Machinery, New York,NY, USA, 1–6. https://doi.org/10.1145/3290607.3313089
[97] He Zhang, Xin Huang, Xin Zhou, HuangHuang, andMuhammadAli Babar. 2019.Ethnographic Research in Software Engineering: A Critical Review and Check-list. In Proceedings of the 2019 27th ACM Joint Meeting on European SoftwareEngineering Conference and Symposium on the Foundations of Software Engineer-ing (Tallinn, Estonia) (ESEC/FSE 2019). Association for Computing Machinery,New York, NY, USA, 659–670. https://doi.org/10.1145/3338906.3338976
[98] Shanshan Zhang, Lihong He, Eduard Dragut, and Slobodan Vucetic. 2019. Howto Invest My Time: Lessons from Human-in-the-Loop Entity Extraction. InProceedings of the 25th ACM SIGKDD International Conference on KnowledgeDiscovery & Data Mining (Anchorage, AK, USA) (KDD ’19). Association forComputing Machinery, New York, NY, USA, 2305–2313. https://doi.org/10.1145/3292500.3330773
[99] Tianming Zhao, Chunyang Chen, Yuanning Liu, and Xiaodong Zhu. 2021.GUIGAN: learning to generate GUI designs using generative adversarial net-works. In Proceedings - 2021 IEEE/ACM 43rd International Conference on Soft-ware Engineering, ICSE 2021 (Proceedings - International Conference on SoftwareEngineering), Arie van Deursen and Tao Xie (Eds.). IEEE, Institute of Elec-trical and Electronics Engineers, United States of America, 748–760. https://doi.org/10.1109/ICSE43902.2021.00074 Publisher Copyright: © 2021 IEEE.Copyright: Copyright 2021 Elsevier B.V., All rights reserved.; International Con-ference on Software Engineering 2021, ICSE 2021 ; Conference date: 25-05-2021Through 28-05-2021.
[100] Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He,and Jiajun Liang. 2017. EAST: An Efficient and Accurate Scene Text Detector.arXiv:1704.03155 [cs.CV]
[101] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun,Antonio Torralba, and Sanja Fidler. 2015. Aligning Books and Movies: TowardsStory-Like Visual Explanations by Watching Movies and Reading Books. In TheIEEE International Conference on Computer Vision (ICCV).
Related Documents











